

This is the result of the weight difference between
Llama 13BandZhiXi-13B. You can click here to learn more.
Knowledgable Large Language Model Framework.
With the rapid development of deep learning technology, large language models such as ChatGPT have made substantial strides in the realm of natural language processing. However, these expansive models still encounter several challenges in acquiring and comprehending knowledge, including the difficulty of updating knowledge and potential knowledge discrepancies and biases, collectively known as knowledge fallacies. The KnowLM project endeavors to tackle these issues by launching an open-source large-scale knowledgable language model framework and releasing corresponding models.
The project's initial phase introduced a knowledge extraction LLM based on LLaMA, dubbed ZhiXi (智析, which means intelligent analysis of data for knowledge extraction). To integrate the capacity of Chinese understanding into the language models without compromising their inherent knowledge, we firstly (1) use Chinese corpora for the full-scale pre-training with LLaMA (13B), augment the language model's understanding of Chinese and improve its knowledge richness while retaining its original English and code capacities; Then (2) we fine-tune the model obtained from the first step with an instruction dataset, thus bolstering the language model's understanding of human instructions for knowledge extraction.
- ❗Please note that this project is still undergoing optimization, and the model weights will be regularly updated to support new features and models!
The features of this project are as follows:
- Centered on knowledge and large models, a full-scale pre-training of the large model, such as LLaMA, is conducted using the built Chinese&English pre-training corpus.
- Based on the technology of KG2Instructions, the knowledge extraction tasks, including NER, RE, and IE, are optimized and can be completed using human instructions.
- Using the built Chinese instruction dataset (approximately 1400K), LoRA fine-tuning is used to enhance the model's understanding of human instructions.
- The weights of the pre-training model and LoRA's instruction fine-tuning are open-sourced.
- The full-scale pre-training code (providing conversion, construction, and loading of large corpora) and LoRA instruction fine-tuning code are open-sourced (support multi-machine multi-GPU).
All weights have been uploaded to HuggingFace🤗. It should be noted that all the following effects are based on ZhiXi-13B-Diff. If you have downloaded ZhiXi-13B-Diff-fp16, there may be some variations in the effects.
| Model Name | Train Method | Weight Type | Size | Download Link | Notes |
|---|---|---|---|---|---|
| ZhiXi-13B-Diff | Full Pretraining | Differential Weights | 48GB | HuggingFace GoogleDrive |
Restoring the pre-trained weights (i.e. ZhiXi-13B) needs to match the weights of LLaMA-13B, please refer to here for specific instructions. |
| ZhiXi-13B-Diff-fp16 | Full Pretraining | Differential Weights(fp16) | 24GB | HuggingFace Google Drive |
The main difference with ZhiXi-13B-Diff is the adoption of the fp16 format for storage, which reduces memory usage. However, it may result in slight differences in the weights obtained from our actual training, which can slightly impact performance. For specific usage instructions, please refer to here for specific instructions. |
| ZhiXi-13B-LoRA | LoRA Instruction-tuning | LoRA Weights | 251MB | HuggingFace GoogleDrive |
It needs to be used with ZhiXi-13B. For specific instructions, please refer to here. |
| ZhiXi-7B Series | Coming soon | Coming soon | Coming soon | Coming soon | Coming soon |
NEWS
- [June 2023] The project name has been changed from CaMA to KnowLM.
- [June 2023] Release the first version of pre-trained weights and the LoRA weights.
Contents
1. Quick Start
1.1 Environment Configuration
conda create -n knowlm python=3.9 -y
conda activate knowlm
pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 torchaudio==0.12.0 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
1.2 Pretraining model weight acquisition and restoration
❗❗❗ Note that in terms of hardware, performing step 2.2, which involves merging LLaMA-13B with KnowLM-13B-Diff, requires approximately 100GB of RAM, with no demand for VRAM (this is due to the memory overhead caused by our merging strategy. For your convenience, we have provided the fp16 weights at this link: https://huggingface.co./zjunlp/zhixi-13b-diff-fp16. fp16 weights require less memory but may slightly impact performance. We will improve our merging approach in future updates, and we are currently developing a 7B model as well, so stay tuned). For step 2.4, which involves inference using ZhiXi, a minimum of 26GB of VRAM is required.
1. Download LLaMA 13B and KnowLM-13B-Diff
Please click here to apply for the official pre-training weights of LLaMA from meta. In this case, we are using the 13B version of the model, so you only need to download the 13B version. Once downloaded, the file directory will be as follows:
|-- 13B
| |-- checklist.chk
| |-- consolidated.00.pth
| |-- consolidated.01.pth
| |-- params.json
|-- llama.sh
|-- tokenizer.model
|-- tokenizer_checklist.chk
You can use the following command to download the KnowLM-13B-Diff file (assuming it is saved in the ./knowlm-diff folder):
python tools/download.py --specify --repo_name openkg/knowlm-13b-diff --download_path ./knowlm-diff
:exclamation:Noted. If the download is interrupted, please repeat the command mentioned above. HuggingFace provides the functionality of resumable downloads, allowing you to resume the download from where it was interrupted.
2. Use the conversion script provided by huggingface
To convert the original LLaMA-13B model into the HuggingFace format, you can use the provided script file by HuggingFace, which can be found here. Below is the command to run the script (assuming the downloaded original files(LLaMA-13B) are located in ./ and you want the converted files to be stored in ./converted):
python convert_llama_weights_to_hf.py --input_dir ./ --model_size 13B --output_dir ./converted
3. Restore KnowLM 13B
Use the script we provided, located at ./tools/weight_diff.py, execute the following command, and you will get the complete KnowLM weight:
python tools/weight_diff.py recover --path_raw ./converted --path_diff ./knowlm-diff --path_tuned ./knowlm --check_integrity_naively False
The final complete KnowLM weights are saved in the ./knowlm folder.
1.3 Instruction tuning LoRA weight acquisition
Use the script file we provided, located at ./tools/download.py, execute the following command to get the LoRA weight (assuming the saved path is located at ./LoRA):
python tools/download.py --download_path ./lora --specify --repo_name openkg/knowlm-13b-lora
The final complete weights are saved in the ./lora folder.
1.4 Model Usage Guide
1. Usage of Pretraining Model
We offer two methods: the first one is command-line interaction, and the second one is web-based interaction, which provides greater flexibility.
Use the following command to enter command-line interaction:
python examples/generate_finetune.py --base_model ./knowlm --interactiveThe disadvantage is the inability to dynamically change decoding parameters.
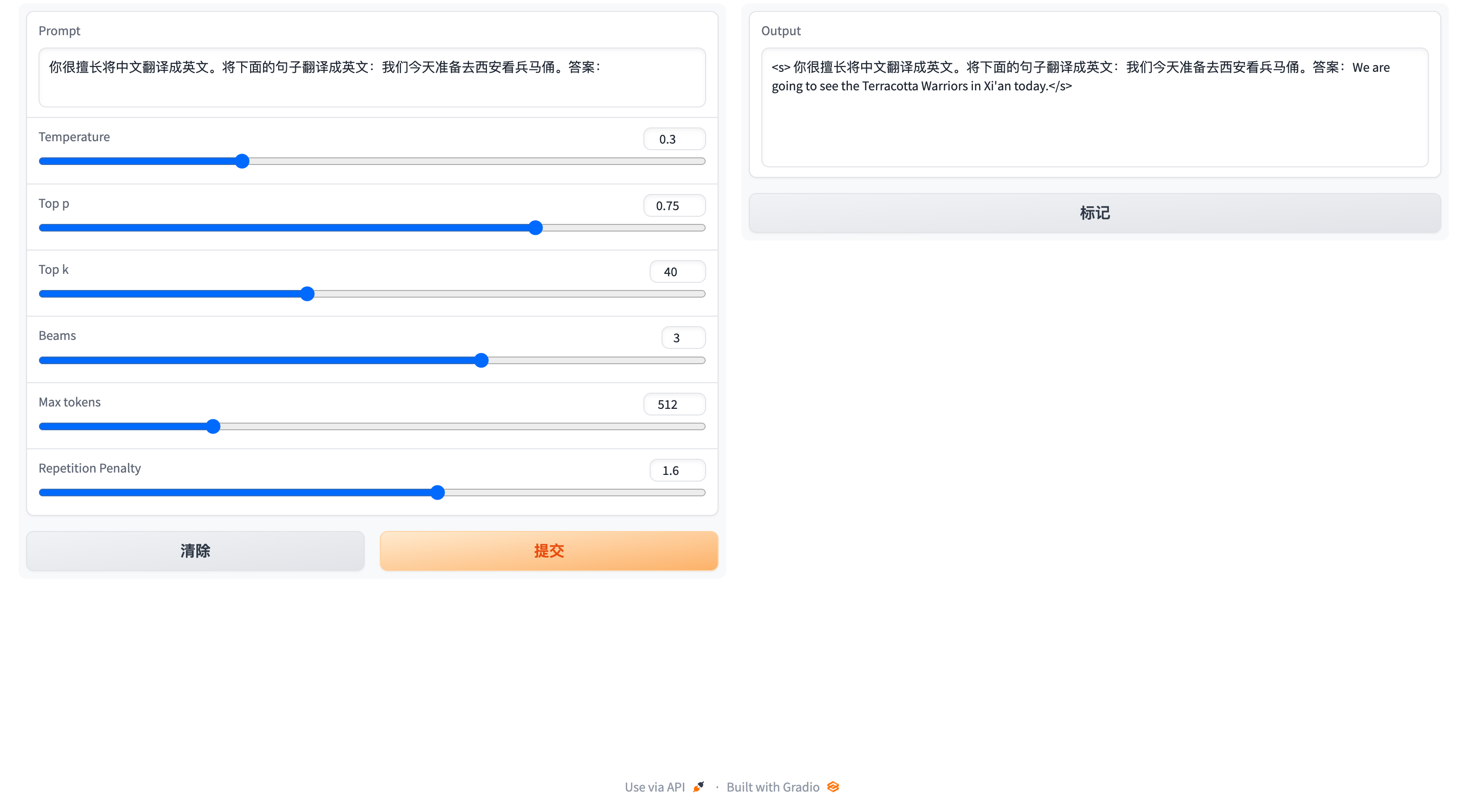
Use the following command to enter web-based interaction:
python examples/generate_finetune_web.py --base_model ./knowlmHere is a screenshot of the web-based interaction:
2. Usage of Instruction tuning Model
Here, we provide a web-based interaction method. Use the following command to access the web:
python examples/generate_lora_web.py --base_model ./knowlm --lora_weights ./lora
Here is a screenshot of the web-based interaction:
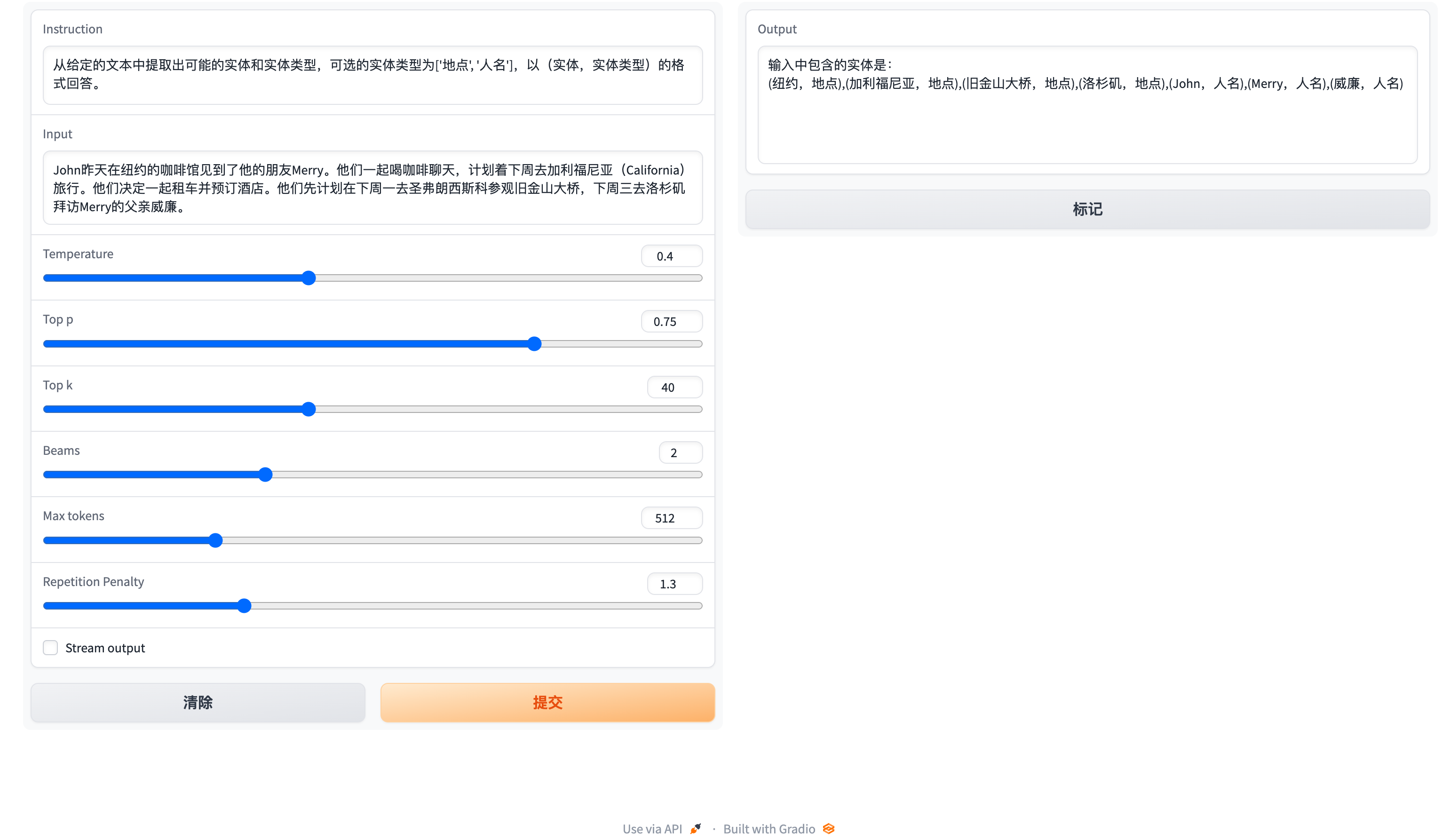
The instruction is a required parameter, while input is an optional parameter. For general tasks (such as the examples provided in section 1.3), you can directly enter the input in the instruction field. For information extraction tasks (as shown in the example in section 1.2), please enter the instruction in the instruction field and the sentence to be extracted in the input field. We provide an information extraction prompt in section 2.5.
If you want to perform batch testing, please modify the examples/generate_lora.py file and update the examples and hyperparameters in the variable cases.
1.5 Information Extraction Prompt
For information extraction tasks such as named entity recognition (NER), event extraction (EE), and relation extraction (RE), we provide some prompts for ease of use. You can refer to this link for examples. Of course, you can also try using your own prompts.
Here is a case where KnowLM-13B-LoRA is used to accomplish the instruction-based knowledge graph construction task in CCKS2023.
2. Training Details
The following figures illustrates the entire training process and dataset construction. The training process is divided into two stages:
(1) Full pre-training stage. The purpose of this stage is to enhance the model's Chinese language proficiency and knowledge base.
(2) Instruction tuning stage using LoRA. This stage enables the model to understand human instructions and generate appropriate responses.

2.1 Dataset Construction (Pretraining)
In order to enhance the model's understanding of Chinese while preserving its original code and English language capabilities, we did not expand the vocabulary. Instead, we collected Chinese corpora, English corpora, and code corpora. The Chinese corpora were sourced from Baidu Baike, Wudao, and Chinese Wikipedia. The English dataset was sampled from the original English corpus of LLaMA, with the exception of the Wikipedia data. The original paper's English Wikipedia data was up until August 2022, and we additionally crawled data from September 2022 to February 2023, covering a total of six months. As for the code dataset, due to the low-quality code in the Pile dataset, we crawled code data from GitHub and LeetCode. A portion of the data was used for pre-training, while another portion was used for fine-tuning with instructions.
For the crawled datasets mentioned above, we employed a heuristic approach to filter out harmful content. Additionally, we removed duplicate data.
2.2 Training Process (Pretraining)
Detailed data processing code, training code, complete training scripts, and detailed training results can be found in ./pretrain.
Before training, we need to tokenize the data. We set the maximum length of a single sample to 1024, while most documents are much longer than this. Therefore, we need to partition these documents. We designed a greedy algorithm to split the documents, with the goal of ensuring that each sample consists of complete sentences and minimizing the number of segments while maximizing the length of each sample. Additionally, due to the diversity of data sources, we developed a comprehensive data preprocessing tool that can process and merge data from various sources. Finally, considering the large amount of data, loading it directly into memory would impose excessive hardware pressure. Therefore, we referred to DeepSpeed-Megatron and used the mmap method to process and load the data. This involves loading the indices into memory and accessing the corresponding data on disk when needed.
Finally, we performed pre-training on 5.5 million Chinese samples, 1.5 million English samples, and 0.9 million code samples. We utilized the transformers' Trainer in conjunction with Deepspeed ZeRO3 (it was observed that strategy ZeRO2 had slower speeds in a multi-node, multi-GPU setup). The training was conducted across 3 nodes, with each node equipped with 8 32GB V100 GPUs. The table below showcases our training speeds:
| Parameter | Values |
|---|---|
| micro batch size | 20 |
| gradient accumulation | 3 |
| global batch size | 20*3*24=1440 |
| Time-consuming of a step | 260s |
2.3 Dataset Construction (Instruction tuning)
In addition to incorporating general capabilities such as reasoning and coding, we have also introduced additional information extraction abilities, including NER (Named Entity Recognition), IE (Information Extraction), and EE (Event Extraction), into the current homogeneous models. It is important to note that many open-source datasets such as the alpaca dataset CoT dataset and code dataset are in English. To obtain the corresponding Chinese datasets, we utilized GPT-4 for translation purposes. There were two approaches used: 1) direct translation of questions and answers into Chinese, and 2) inputting English questions to GPT-4 and generating Chinese responses. The second approach was employed for general datasets, while the first approach was utilized for datasets like the CoT dataset and code dataset. These datasets are readily available online.
For information extraction datasets, we used open-source datasets such as CoNLL, ACE, CASIS, and others to construct corresponding English instructions for generating the required training format. For the Chinese part, for NER and EE tasks, we utilized open-source datasets such as DualEE, PEOPLE DAILY, and others, and then created corresponding Chinese instructions to synthesize the required training format. As for the RE task, we built a dataset called KG2Instruction. Specifically, we used Chinese Wikipedia data and BERT for Chinese entity recognition. We then aligned the recognized entities with the Wikipedia index. Due to potential ambiguity (i.e., a Chinese entity may have multiple indexes, such as apple referring to both a fruit and a company), we devised a strategy to disambiguate the entities. Subsequently, we used a distantly supervised method to generate possible triplets and applied predefined rules to filter out illegal or incorrect triplets. Finally, with the help of crowdsourcing, we refined the obtained triplets. Following that, we constructed corresponding Chinese instructions to generate the required training format.
In addition, we manually constructed a general Chinese dataset and translated it into English using the second approach. Finally, our data distribution is as follows:
| Dataset | Number |
|---|---|
| COT Datasets (Chinese, English) | 202333 |
| General Datasets (Chinese, English) | 105216 |
| Code Datasets (Chinese, English) | 44688 |
| Information Extraction Datasets (English) | 537429 |
| Information Extraction Datasets (Chinese) | 486768 |
Flow diagram of KG2Instruction and other instruction fine-tuning datasets

2.4 Training Process (Instruction tuning)
Currently, most instruction tuning scripts using LoRA are based on alpaca-lora, so we will not go into detail here. Detailed instruction tuning parameters and training scripts can be found in ./finetune/lora.
3. Limitations
Due to time constraints, hardware limitations, and technical reasons, our model has limitations, including but not limited to:
Our intruction tuning process does not involve full tuning. Instead, we use the LoRA approach for instruction tuning.
Our model does not currently support multi-turn conversations.
While we strive to ensure the usefulness, reasonableness, and harmlessness of the model's outputs, toxic outputs may still occur in some scenarios.
The pretraining is not exhaustive. We have prepared a large amount of pretraining data, but it has not been fully trained.
······
4. TODO List
- Instruction tuning using full tuning instead of LoRA version is being trained and will be released soon.
- New instruction tuning weights using LoRA will be updated shortly.
- New models (Llama-7b, Falcon-7b) are being trained (We have limited GPUs!).
- New abilities such as molecule and protein generation with Mol-Instructions, a large-scale biomolecules instruction dataset for large language models.
- supporting llama.cpp
- ......
5. FAQ
Question: What should I do if the model encounters � during decoding?
Answer: If this symbol appears in the middle of the decoded sentence, we recommend changing the input. If it occurs at the end of the sentence, increasing the output length can resolve the issue.
Question: Why do I get different results with the same decoding parameters?
Answer: It is possible that you have enabled
do_sample=True. It could also be due to the order of execution. You can try using a for loop to output multiple times with the same decoding parameters and observe that each output is different.Question: Why is the extraction or answer quality not good?
Answer: Please try changing the decoding parameters.
6. Others
6.1 Contributors
Ningyu Zhang, Haofen Wang, Xiang Chen, Jintian Zhang, Xiaozhuan Liang, Zhen Bi, Honghao Gui, Jing Chen, Runnan Fang, Xiaohan Wang, Shengyu Mao, Shuofei Qiao, Yixin Ou, Lei Li, Yunzhi Yao, Peng Wang, Siyuan Cheng, Bozhong Tian, Mengru Wang, Zhoubo Li, Yinuo Jiang, Yuqi Zhu, Hongbin Ye, Zekun Xi, Xinrong Li, Huajun Chen
6.2 Citation
If you use our repository, please cite the following related papers:
@article{deepke-llm,
author = {Ningyu Zhang, Jintian Zhang, Xiaohan Wang, Honghao Gui, Yinuo Jiang, Xiang Chen, Shengyu Mao, Shuofei Qiao, Zhen Bi, Jing Chen, Xiaozhuan Liang, Yixin Ou, Ruinan Fang, Zekun Xi, Xin Xu, Liankuan Tao, Lei Li, Peng Wang, Zhoubo Li, Guozhou Zheng, Huajun Chen},
title = {DeepKE-LLM: A Large Language Model Based Knowledge Extraction Toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/}},
}
6.3 Acknowledgment
We are very grateful to the following open source projects for their help:
- Downloads last month
- 18