
metadata
license: cc-by-4.0
model-index:
- name: piccolo-8x7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 69.62
name: normalized accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.98
name: normalized accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.13
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 64.17
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 79.87
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 72.02
name: accuracy
source:
url: >-
https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?query=macadeliccc/piccolo-8x7b
name: Open LLM Leaderboard
Piccolo-8x7b
In loving memory of my dog Klaus (Piccolo)
~ Piccolo (Italian): the little one ~

Based on mlabonne/NeuralBeagle-7b Quants are available here
Code Example
Inference and Evaluation colab available here
from transformers import AutoModelForCausalLM, AutoTokenizer
def generate_response(prompt):
"""
Generate a response from the model based on the input prompt.
Args:
prompt (str): Prompt for the model.
Returns:
str: The generated response from the model.
"""
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=256, eos_token_id=tokenizer.eos_token_id, pad_token_id=tokenizer.pad_token_id)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
model_id = "macadeliccc/piccolo-8x7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,load_in_4bit=True)
prompt = "What is the best way to train Cane Corsos?"
print("Response:")
print(generate_response(prompt), "\n")
The model is capable of quality code, math, and logical reasoning. Try whatever questions you think of.
Example output
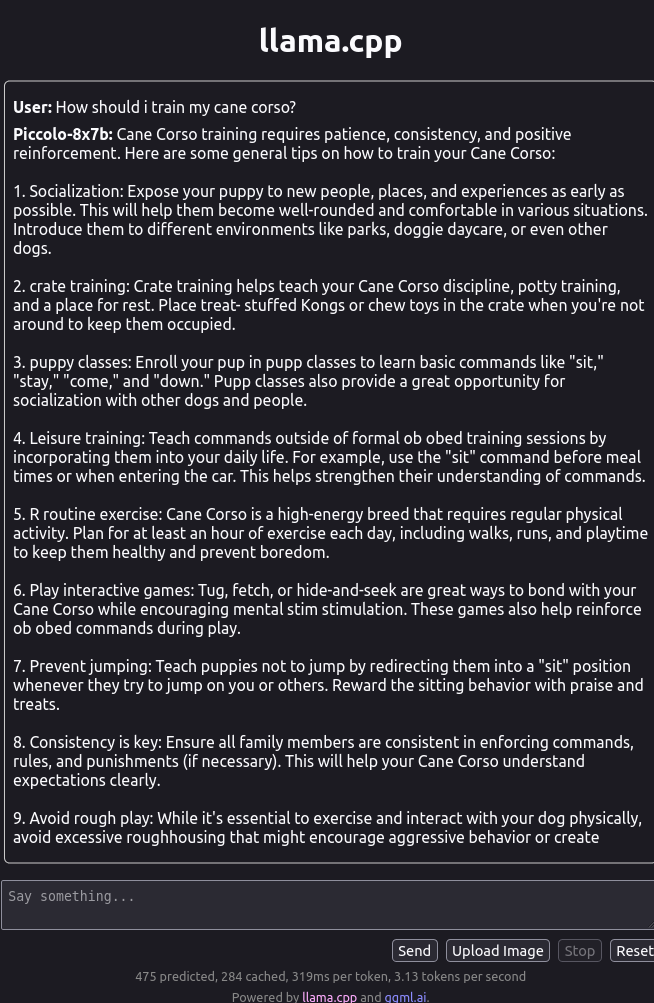
Evaluations

Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 72.80 |
| AI2 Reasoning Challenge (25-Shot) | 69.62 |
| HellaSwag (10-Shot) | 86.98 |
| MMLU (5-Shot) | 64.13 |
| TruthfulQA (0-shot) | 64.17 |
| Winogrande (5-shot) | 79.87 |
| GSM8k (5-shot) | 72.02 |