Pre-trained models for automatic speech recognition
In this section, we’ll cover how to use the pipeline() to leverage pre-trained models for speech recognition. In Unit 2,
we introduced the pipeline() as an easy way of running speech recognition tasks, with all pre- and post-processing handled under-the-hood
and the flexibility to quickly experiment with any pre-trained checkpoint on the Hugging Face Hub. In this Unit, we’ll go a
level deeper and explore the different attributes of speech recognition models and how we can use them to tackle a range
of different tasks.
As detailed in Unit 3, speech recognition model broadly fall into one of two categories:
- Connectionist Temporal Classification (CTC): encoder-only models with a linear classification (CTC) head on top
- Sequence-to-sequence (Seq2Seq): encoder-decoder models, with a cross-attention mechanism between the encoder and decoder
Prior to 2022, CTC was the more popular of the two architectures, with encoder-only models such as Wav2Vec2, HuBERT and XLSR achieving breakthoughs in the pre-training / fine-tuning paradigm for speech. Big corporations, such as Meta and Microsoft, pre-trained the encoder on vast amounts of unlabelled audio data for many days or weeks. Users could then take a pre-trained checkpoint, and fine-tune it with a CTC head on as little as 10 minutes of labelled speech data to achieve strong performance on a downstream speech recognition task.
However, CTC models have their shortcomings. Appending a simple linear layer to an encoder gives a small, fast overall model, but can be prone to phonetic spelling errors. We’ll demonstrate this for the Wav2Vec2 model below.
Probing CTC Models
Let’s load a small excerpt of the LibriSpeech ASR dataset to demonstrate Wav2Vec2’s speech transcription capabilities:
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
datasetOutput:
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})We can pick one of the 73 audio samples and inspect the audio sample as well as the transcription:
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Output:
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MINDAlright! Christmas and roast beef, sounds great! 🎄 Having chosen a data sample, we now load a fine-tuned checkpoint into
the pipeline(). For this, we’ll use the official Wav2Vec2 base checkpoint fine-tuned on
100 hours of LibriSpeech data:
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")Next, we’ll take an example from the dataset and pass its raw data to the pipeline. Since the pipeline consumes any
dictionary that we pass it (meaning it cannot be re-used), we’ll pass a copy of the data. This way, we can safely re-use
the same audio sample in the following examples:
pipe(sample["audio"].copy())Output:
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}We can see that the Wav2Vec2 model does a pretty good job at transcribing this sample - at a first glance it looks generally correct. Let’s put the target and prediction side-by-side and highlight the differences:
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MINDComparing the target text to the predicted transcription, we can see that all words sound correct, but some are not spelled accurately. For example:
- CHRISTMAUS vs. CHRISTMAS
- ROSE vs. ROAST
- SIMALYIS vs. SIMILES
This highlights the shortcoming of a CTC model. A CTC model is essentially an ‘acoustic-only’ model: it consists of an encoder which forms hidden-state representations from the audio inputs, and a linear layer which maps the hidden-states to characters:
This means that the system almost entirely bases its prediction on the acoustic input it was given (the phonetic sounds of the audio), and so has a tendency to transcribe the audio in a phonetic way (e.g. CHRISTMAUS). It gives less importance to the language modelling context of previous and successive letters, and so is prone to phonetic spelling errors. A more intelligent model would identify that CHRISTMAUS is not a valid word in the English vocabulary, and correct it to CHRISTMAS when making its predictions. We’re also missing two big features in our prediction - casing and punctuation - which limits the usefulness of the model’s transcriptions to real-world applications.
Graduation to Seq2Seq
Cue Seq2Seq models! As outlined in Unit 3, Seq2Seq models are formed of an encoder and decoder linked via a cross-attention mechanism. The encoder plays the same role as before, computing hidden-state representations of the audio inputs, while the decoder plays the role of a language model. The decoder processes the entire sequence of hidden-state representations from the encoder and generates the corresponding text transcriptions. With global context of the audio input, the decoder is able to use language modelling context as it makes its predictions, correcting for spelling mistakes on-the-fly and thus circumventing the issue of phonetic predictions.
There are two downsides to Seq2Seq models:
- They are inherently slower at decoding, since the decoding process happens one step at a time, rather than all at once
- They are more data hungry, requiring significantly more training data to reach convergence
In particular, the need for large amounts of training data has been a bottleneck in the advancement of Seq2Seq architectures for speech. Labelled speech data is difficult to come by, with the largest annotated datasets at the time clocking in at just 10,000 hours. This all changed in 2022 upon the release of Whisper. Whisper is a pre-trained model for speech recognition published in September 2022 by the authors Alec Radford et al. from OpenAI. Unlike its CTC predecessors, which were pre-trained entirely on un-labelled audio data, Whisper is pre-trained on a vast quantity of labelled audio-transcription data, 680,000 hours to be precise.
This is an order of magnitude more data than the un-labelled audio data used to train Wav2Vec 2.0 (60,000 hours). What is more, 117,000 hours of this pre-training data is multilingual (or “non-English”) data. This results in checkpoints that can be applied to over 96 languages, many of which are considered low-resource, meaning the language lacks a large corpus of data suitable for training.
When scaled to 680,000 hours of labelled pre-training data, Whisper models demonstrate a strong ability to generalise to many datasets and domains. The pre-trained checkpoints achieve competitive results to state-of-the-art pipe systems, with near 3% word error rate (WER) on the test-clean subset of LibriSpeech pipe and a new state-of-the-art on TED-LIUM with 4.7% WER (c.f. Table 8 of the Whisper paper).
Of particular importance is Whisper’s ability to handle long-form audio samples, its robustness to input noise and ability to predict cased and punctuated transcriptions. This makes it a viable candidate for real-world speech recognition systems.
The remainder of this section will show you how to use the pre-trained Whisper models for speech recognition using 🤗 Transformers. In many situations, the pre-trained Whisper checkpoints are extremely performant and give great results, thus we encourage you to try using the pre-trained checkpoints as a first step to solving any speech recognition problem. Through fine-tuning, the pre-trained checkpoints can be adapted for specific datasets and languages to further improve upon these results. We’ll demonstrate how to do this in the upcoming subsection on fine-tuning.
The Whisper checkpoints come in five configurations of varying model sizes. The smallest four are trained on either English-only or multilingual data. The largest checkpoint is multilingual only. All nine of the pre-trained checkpoints are available on the Hugging Face Hub. The checkpoints are summarised in the following table with links to the models on the Hub. “VRAM” denotes the required GPU memory to run the model with the minimum batch size of 1. “Rel Speed” is the relative speed of a checkpoint compared to the largest model. Based on this information, you can select a checkpoint that is best suited to your hardware.
| Size | Parameters | VRAM / GB | Rel Speed | English-only | Multilingual |
|---|---|---|---|---|---|
| tiny | 39 M | 1.4 | 32 | ✓ | ✓ |
| base | 74 M | 1.5 | 16 | ✓ | ✓ |
| small | 244 M | 2.3 | 6 | ✓ | ✓ |
| medium | 769 M | 4.2 | 2 | ✓ | ✓ |
| large | 1550 M | 7.5 | 1 | x | ✓ |
Let’s load the Whisper Base checkpoint, which is of comparable size to the
Wav2Vec2 checkpoint we used previously. Preempting our move to multilingual speech recognition, we’ll load the multilingual
variant of the base checkpoint. We’ll also load the model on the GPU if available, or CPU otherwise. The pipeline() will
subsequently take care of moving all inputs / outputs from the CPU to the GPU as required:
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)Great! Now let’s transcribe the audio as before. The only change we make is passing an extra argument, max_new_tokens,
which tells the model the maximum number of tokens to generate when making its prediction:
pipe(sample["audio"], max_new_tokens=256)Output:
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}Easy enough! The first thing you’ll notice is the presence of both casing and punctuation. Immediately this makes the transcription easier to read compared to the un-cased and un-punctuated transcription from Wav2Vec2. Let’s put the transcription side-by-side with the target:
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.Whisper has done a great job at correcting the phonetic errors we saw from Wav2Vec2 - both Christmas and roast are spelled correctly. We see that the model still struggles with SIMILES, being incorrectly transcribed as similarly, but this time the prediction is a valid word from the English vocabulary. Using a larger Whisper checkpoint can help further reduce transcription errors, at the expense of requiring more compute and a longer transcription time.
We’ve been promised a model that can handle 96 languages, so lets leave English speech recognition for now and go global 🌎! The Multilingual LibriSpeech (MLS) dataset is the multilingual equivalent of the LibriSpeech dataset, with labelled audio data in six languages. We’ll load one sample from the Spanish split of the MLS dataset, making use of streaming mode so that we don’t have to download the entire dataset:
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))Again, we’ll inspect the text transcription and take a listen to the audio segment:
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Output:
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha habladoThis is the target text that we’re aiming for with our Whisper transcription. Although we now know that we can probably do better this, since our model is also going to predict punctuation and casing, neither of which are present in the reference. Let’s forward the audio sample to the pipeline to get our text prediction. One thing to note is that the pipeline consumes the dictionary of audio inputs that we input, meaning the dictionary can’t be re-used. To circumvent this, we’ll pass a copy of the audio sample, so that we can re-use the same audio sample in the proceeding code examples:
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})Output:
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}Great - this looks very similar to our reference text (arguably better since it has punctuation and casing!). You’ll notice
that we forwarded the "task" as a generate key-word argument (generate kwarg). Setting the "task" to "transcribe"
forces Whisper to perform the task of speech recognition, where the audio is transcribed in the same language that the
speech was spoken in. Whisper is also capable of performing the closely related task of speech translation, where the
audio in Spanish can be translated to text in English. To achieve this, we set the "task" to "translate":
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})Output:
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}Now that we know we can toggle between speech recognition and speech translation, we can pick our task depending on our needs. Either we recognise from audio in language X to text in the same language X (e.g. Spanish audio to Spanish text), or we translate from audio in any language X to text in English (e.g. Spanish audio to English text).
To read more about how the "task" argument is used to control the properties of the generated text, refer to the
model card for the Whisper base model.
Long-Form Transcription and Timestamps
So far, we’ve focussed on transcribing short audio samples of less than 30 seconds. We mentioned that one of the appeals of Whisper was its ability to work on long audio samples. We’ll tackle this task here!
Let’s create a long audio file by concatenating sequential samples from the MLS dataset. Since the MLS dataset is curated by splitting long audiobook recordings into shorter segments, concatenating samples is one way of reconstructing longer audiobook passages. Consequently, the resulting audio should be coherent across the entire sample.
We’ll set our target audio length to 5 minutes, and stop concatenating samples once we hit this value:
import numpy as np
target_length_in_m = 5
# convert from minutes to seconds (* 60) to num samples (* sampling rate)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# iterate over our streaming dataset, concatenating samples until we hit our target
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# how did we do?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")Output:
Length of audio sample is 5.0 minutes 17.22 secondsAlright! 5 minutes and 17 seconds of audio to transcribe. There are two problems with forwarding this long audio sample directly to the model:
- Whisper is inherently designed to work with 30 second samples: anything shorter than 30s is padded to 30s with silence, anything longer than 30s is truncated to 30s by cutting of the extra audio, so if we pass our audio directly we’ll only get the transcription for the first 30s
- Memory in a transformer network scales with the sequence length squared: doubling the input length quadruples the memory requirement, so passing super long audio files is bound to lead to an out-of-memory (OOM) error
The way long-form transcription works in 🤗 Transformers is by chunking the input audio into smaller, more manageable segments. Each segment has a small amount of overlap with the previous one. This allows us to accurately stitch the segments back together at the boundaries, since we can find the overlap between segments and merge the transcriptions accordingly:
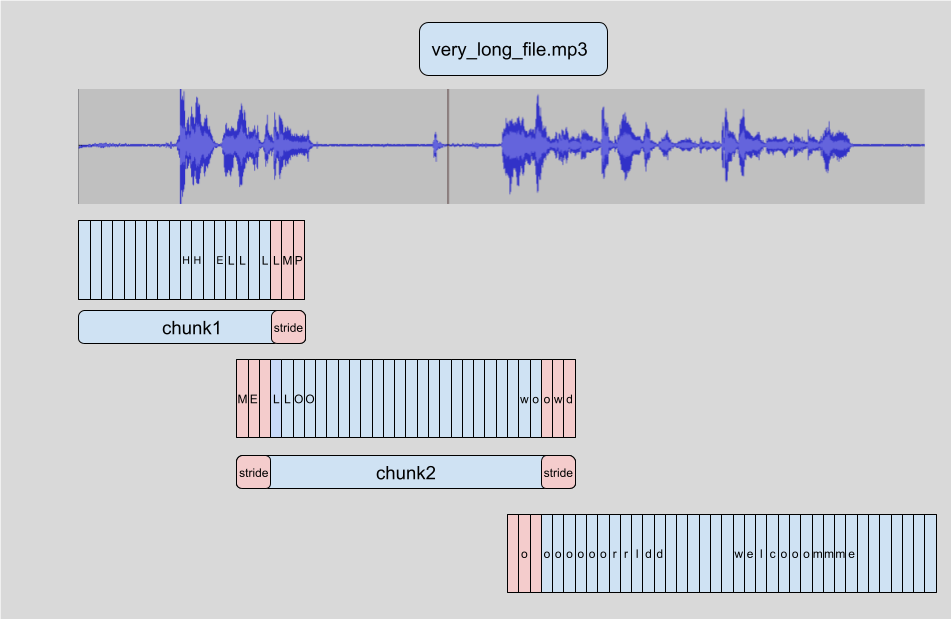
The advantage of chunking the samples is that we don’t need the result of chunk to transcribe the subsequent chunk. The stitching is done after we have transcribed all the chunks at the chunk boundaries, so it doesn’t matter which order we transcribe chunks in. The algorithm is entirely stateless, so we can even do chunk at the same time as chunk! This allows us to batch the chunks and run them through the model in parallel, providing a large computational speed-up compared to transcribing them sequentially. To read more about chunking in 🤗 Transformers, you can refer to this blog post.
To activate long-form transcriptions, we have to add one additional argument when we call the pipeline. This argument,
chunk_length_s, controls the length of the chunked segments in seconds. For Whisper, 30 second chunks are optimal,
since this matches the input length Whisper expects.
To activate batching, we need to pass the argument batch_size to the pipeline. Putting it all together, we can transcribe the
long audio sample with chunking and batching as follows:
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)Output:
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...We won’t print the entire output here since it’s pretty long (312 words total)! On a 16GB V100 GPU, you can expect the above line to take approximately 3.45 seconds to run, which is pretty good for a 317 second audio sample. On a CPU, expect closer to 30 seconds.
Whisper is also able to predict segment-level timestamps for the audio data. These timestamps indicate the start and end time for a short passage of audio, and are particularly useful for aligning a transcription with the input audio. Suppose we want to provide closed captions for a video - we need these timestamps to know which part of the transcription corresponds to a certain segment of video, in order to display the correct transcription for that time.
Activating timestamp prediction is straightforward, we just need to set the argument return_timestamps=True. Timestamps
are compatible with both the chunking and batching methods we used previously, so we can simply append the timestamp
argument to our previous call:
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]Output:
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...And voila! We have our predicted text as well as corresponding timestamps.
Summary
Whisper is a strong pre-trained model for speech recognition and translation. Compared to Wav2Vec2, it has higher
transcription accuracy, with outputs that contain punctuation and casing. It can be used to transcribe speech in English
as well as 96 other languages, both on short audio segments and longer ones through chunking. These attributes make it
a viable model for many speech recognition and translation tasks without the need for fine-tuning. The pipeline() method
provides an easy way of running inference in one-line API calls with control over the generated predictions.
While the Whisper model performs extremely well on many high-resource languages, it has lower transcription and translation accuracy on low-resource languages, i.e. those with less readily available training data. There is also varying performance across different accents and dialects of certain languages, including lower accuracy for speakers of different genders, races, ages or other demographic criteria (c.f. Whisper paper).
To boost the performance on low-resource languages, accents or dialects, we can take the pre-trained Whisper model and train it on a small corpus of appropriately selected data, in a process called fine-tuning. We’ll show that with as little as ten hours of additional data, we can improve the performance of the Whisper model by over 100% on a low-resource language. In the next section, we’ll cover the process behind selecting a dataset for fine-tuning.
< > Update on GitHub