
A model for solving the problem of missing words in search queries. The model uses the context of the query to generate possible words that could be missing.
## don't forget
# pip install protobuf sentencepiece
from transformers import pipeline
unmasker = pipeline("fill-mask", model="fkrasnov2/COLD2", device="cuda")
unmasker("электроника зарядка [MASK] USB")
[{'score': 0.3712620437145233,
'token': 1131,
'token_str': 'автомобильная',
'sequence': 'электроника зарядка автомобильная usb'},
{'score': 0.12239563465118408,
'token': 7436,
'token_str': 'быстрая',
'sequence': 'электроника зарядка быстрая usb'},
{'score': 0.046715956181287766,
'token': 5819,
'token_str': 'проводная',
'sequence': 'электроника зарядка проводная usb'},
{'score': 0.031308457255363464,
'token': 635,
'token_str': 'универсальная',
'sequence': 'электроника зарядка универсальная usb'},
{'score': 0.02941182069480419,
'token': 2371,
'token_str': 'адаптер',
'sequence': 'электроника зарядка адаптер usb'}]
Coupled prepositions can be used to improve tokenization.
unmasker("одежда женское [MASK] для_праздника")
[{'score': 0.9355553984642029,
'token': 503,
'token_str': 'платье',
'sequence': 'одежда женское платье для_праздника'},
{'score': 0.011321154423058033,
'token': 615,
'token_str': 'кольцо',
'sequence': 'одежда женское кольцо для_праздника'},
{'score': 0.008672593161463737,
'token': 993,
'token_str': 'украшение',
'sequence': 'одежда женское украшение для_праздника'},
{'score': 0.0038903721142560244,
'token': 27100,
'token_str': 'пончо',
'sequence': 'одежда женское пончо для_праздника'},
{'score': 0.003703165566548705,
'token': 453,
'token_str': 'белье',
'sequence': 'одежда женское белье для_праздника'}]
For transformers.js, it turned out that the ONNX version of the model was required.
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("fkrasnov2/COLD2")
model = ORTModelForMaskedLM.from_pretrained("fkrasnov2/COLD2", file_name='model.onnx')
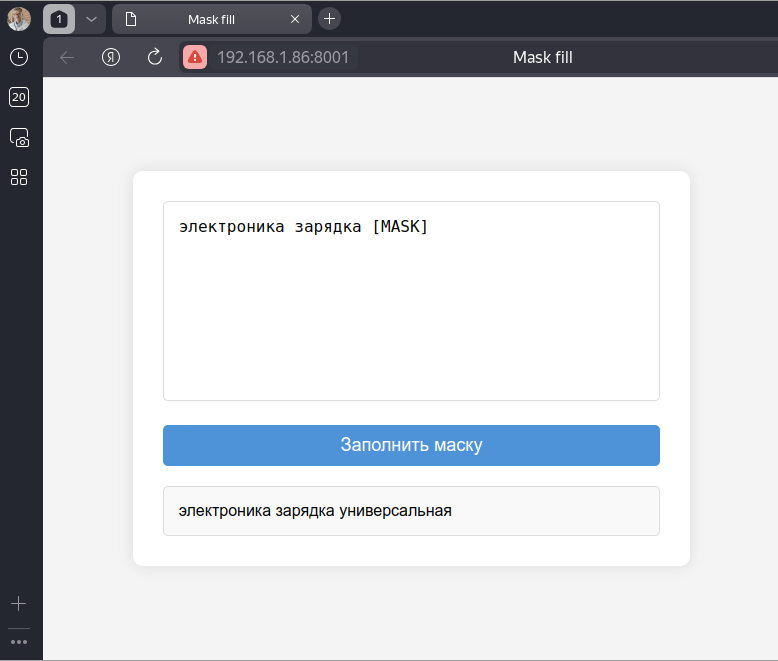
You can also run and use the model straight from your browser.
index.html
<!DOCTYPE html>
<html lang="ru">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Mask fill</title>
<link rel="stylesheet" href="styles.css">
<script src="main.js" type="module" defer></script>
</head>
<body>
<div class="container">
<textarea id="long-text-input" placeholder="Enter search query with [MASK]"></textarea>
<button id="generate-button">
Заполнить маску
</button>
<div id="output-div"></div>
</div>
</body>
</html>
main.js
import { pipeline } from 'https://cdn.jsdelivr.net/npm/@huggingface/[email protected]';
const longTextInput = document.getElementById('long-text-input');
const output = document.getElementById('output-div');
const generateButton = document.getElementById('generate-button');
const pipe = await pipeline(
'fill-mask', // task
'fkrasnov2/COLD2' // model
);
generateButton.addEventListener('click', async () => {
const input = longTextInput.value;
const result = await pipe(input);
output.innerHTML = result[0].sequence;
output.style.display = 'block';
});
- Downloads last month
- 48
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.