
instance_id
stringlengths 10
57
| patch
stringlengths 261
37.7k
| repo
stringlengths 7
53
| base_commit
stringlengths 40
40
| hints_text
stringclasses 301
values | test_patch
stringlengths 212
2.22M
| problem_statement
stringlengths 23
37.7k
| version
int64 0
0
| environment_setup_commit
stringclasses 89
values | FAIL_TO_PASS
sequencelengths 1
4.94k
| PASS_TO_PASS
sequencelengths 0
7.82k
| meta
dict | created_at
unknown | license
stringclasses 8
values |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
vinitkumar__json2xml-119 | diff --git a/examples/booleanjson.json b/examples/booleanjson.json
new file mode 100644
index 0000000..a784c7b
--- /dev/null
+++ b/examples/booleanjson.json
@@ -0,0 +1,8 @@
+{
+ "boolean": true,
+ "boolean_dict_list": [
+ {"boolean_dict": {"boolean": true}},
+ {"boolean_dict": {"boolean": false}}
+ ],
+ "boolean_list": [true, false]
+}
diff --git a/json2xml/dicttoxml.py b/json2xml/dicttoxml.py
index d5e3f9f..489d55f 100755
--- a/json2xml/dicttoxml.py
+++ b/json2xml/dicttoxml.py
@@ -139,6 +139,13 @@ def convert(obj, ids, attr_type, item_func, cdata, item_wrap, parent="root"):
item_name = item_func(parent)
+ # since bool is also a subtype of number.Number and int, the check for bool
+ # never comes and hence we get wrong value for the xml type bool
+ # here, we just change order and check for bool first, because no other
+ # type other than bool can be true for bool check
+ if isinstance(obj, bool):
+ return convert_bool(item_name, obj, attr_type, cdata)
+
if isinstance(obj, (numbers.Number, str)):
return convert_kv(
key=item_name, val=obj, attr_type=attr_type, attr={}, cdata=cdata
@@ -153,9 +160,6 @@ def convert(obj, ids, attr_type, item_func, cdata, item_wrap, parent="root"):
cdata=cdata,
)
- if isinstance(obj, bool):
- return convert_bool(item_name, obj, attr_type, cdata)
-
if obj is None:
return convert_none(item_name, "", attr_type, cdata)
@@ -185,7 +189,14 @@ def convert_dict(obj, ids, parent, attr_type, item_func, cdata, item_wrap):
key, attr = make_valid_xml_name(key, attr)
- if isinstance(val, (numbers.Number, str)):
+ # since bool is also a subtype of number.Number and int, the check for bool
+ # never comes and hence we get wrong value for the xml type bool
+ # here, we just change order and check for bool first, because no other
+ # type other than bool can be true for bool check
+ if isinstance(val, bool):
+ addline(convert_bool(key, val, attr_type, attr, cdata))
+
+ elif isinstance(val, (numbers.Number, str)):
addline(
convert_kv(
key=key, val=val, attr_type=attr_type, attr=attr, cdata=cdata
@@ -203,9 +214,6 @@ def convert_dict(obj, ids, parent, attr_type, item_func, cdata, item_wrap):
)
)
- elif isinstance(val, bool):
- addline(convert_bool(key, val, attr_type, attr, cdata))
-
elif isinstance(val, dict):
if attr_type:
attr["type"] = get_xml_type(val)
| vinitkumar/json2xml | 4b2007ce4cc9998fbbecd0372ae33fdac4dd4195 | diff --git a/tests/test_json2xml.py b/tests/test_json2xml.py
index bbf7ae4..872ee32 100644
--- a/tests/test_json2xml.py
+++ b/tests/test_json2xml.py
@@ -176,3 +176,11 @@ class TestJson2xml(unittest.TestCase):
with pytest.raises(InvalidDataError) as pytest_wrapped_e:
json2xml.Json2xml(decoded).to_xml()
assert pytest_wrapped_e.type == InvalidDataError
+
+ def test_read_boolean_data_from_json(self):
+ """Test correct return for boolean types."""
+ data = readfromjson("examples/booleanjson.json")
+ result = json2xml.Json2xml(data).to_xml()
+ dict_from_xml = xmltodict.parse(result)
+ assert dict_from_xml["all"]["boolean"]["#text"] != 'True'
+ assert dict_from_xml["all"]["boolean"]["#text"] == 'true'
| Boolean types are not converted to their XML equivalents.
**Describe the bug**
When converting a JSON object with boolean type values, `Json2xml` is not converting the values to their XML equivalents. `Json2xml` should be exporting the values in the XML as the lowercase words `true` and `false` respectively. Instead, `Json2xml` is exporting them as Python boolean types using the capitalized words `True` and `False`.
**To Reproduce**
Steps to reproduce the behavior:
1. Given the following JSON object:
```json
{
"boolean": true,
"boolean_dict_list": [
{"boolean_dict": {"boolean": true}},
{"boolean_dict": {"boolean": false}}
],
"boolean_list": [true, false]
}
```
2. Calling the `Json2xml` conversion like so:
```python
xml = json2xml.Json2xml(sample_json, pretty=True).to_xml()
```
3. Produces the following XML:
```xml
<all>
<boolean type="bool">True</boolean>
<boolean_dict_list type="list">
<item type="dict">
<boolean_dict type="dict">
<boolean type="bool">True</boolean>
</boolean_dict>
</item>
<item type="dict">
<boolean_dict type="dict">
<boolean type="bool">False</boolean>
</boolean_dict>
</item>
</boolean_dict_list>
<item type="bool">True</item>
<item type="bool">False</item>
</all>
```
Notice all the boolean values are capitalized instead of being lowercase like they should be in XML and JSON. There also seems to be a problem with the `boolean_list` array, it is missing its parent tag.
**Expected behavior**
`Json2xml` should produce an XML string that looks like this:
```xml
<all>
<boolean type="bool">true</boolean>
<boolean_dict_list type="list">
<item type="dict">
<boolean_dict type="dict">
<boolean type="bool">true</boolean>
</boolean_dict>
</item>
<item type="dict">
<boolean_dict type="dict">
<boolean type="bool">false</boolean>
</boolean_dict>
</item>
</boolean_dict_list>
<boolean_list type="list">
<item type="bool">true</item>
<item type="bool">false</item>
</boolean_list>
</all>
```
**Additional context**
The problem with the capitalized boolean values is because of the following statements in the `json2xml.dicttoxml` module:
```python
def convert(obj, ids, attr_type, item_func, cdata, item_wrap, parent="root"):
"""Routes the elements of an object to the right function to convert them
based on their data type"""
LOG.info(f'Inside convert(). obj type is: "{type(obj).__name__}", obj="{str(obj)}"')
item_name = item_func(parent)
# Booleans are converted using this function because a Python boolean is a subclass of Number
if isinstance(obj, (numbers.Number, str)):
return convert_kv(
key=item_name, val=obj, attr_type=attr_type, attr={}, cdata=cdata
)
if hasattr(obj, "isoformat"):
return convert_kv(
key=item_name,
val=obj.isoformat(),
attr_type=attr_type,
attr={},
cdata=cdata,
)
# This is never evaluated because Python booleans are subclasses of Python integers
if isinstance(obj, bool):
return convert_bool(item_name, obj, attr_type, cdata)
```
Python booleans are subclasses of integers, so the boolean values are passed to `convert_kv` instead of `convert_bool` because an integer is also a `numbers.Number`. The following statements evaluate to `True` in Python:
```python
# Booleans are integers
isinstance(True, int)
# Booleans are numbers
isinstance(True, numbers.Number)
# Booleans are booleans
isinstance(True, bool)
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_json2xml.py::TestJson2xml::test_read_boolean_data_from_json"
] | [
"tests/test_json2xml.py::TestJson2xml::test_attrs",
"tests/test_json2xml.py::TestJson2xml::test_bad_data",
"tests/test_json2xml.py::TestJson2xml::test_custom_wrapper_and_indent",
"tests/test_json2xml.py::TestJson2xml::test_dict2xml_no_root",
"tests/test_json2xml.py::TestJson2xml::test_dict2xml_with_custom_root",
"tests/test_json2xml.py::TestJson2xml::test_dict2xml_with_root",
"tests/test_json2xml.py::TestJson2xml::test_dicttoxml_bug",
"tests/test_json2xml.py::TestJson2xml::test_empty_array",
"tests/test_json2xml.py::TestJson2xml::test_item_wrap",
"tests/test_json2xml.py::TestJson2xml::test_json_to_xml_conversion",
"tests/test_json2xml.py::TestJson2xml::test_no_item_wrap",
"tests/test_json2xml.py::TestJson2xml::test_no_wrapper",
"tests/test_json2xml.py::TestJson2xml::test_read_from_invalid_json",
"tests/test_json2xml.py::TestJson2xml::test_read_from_invalid_jsonstring",
"tests/test_json2xml.py::TestJson2xml::test_read_from_json",
"tests/test_json2xml.py::TestJson2xml::test_read_from_jsonstring",
"tests/test_json2xml.py::TestJson2xml::test_read_from_url",
"tests/test_json2xml.py::TestJson2xml::test_read_from_wrong_url"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-04-18T08:43:56Z" | apache-2.0 |
|
vitalik__django-ninja-133 | diff --git a/docs/src/tutorial/query/code010.py b/docs/src/tutorial/query/code010.py
index b60e90d..7150396 100644
--- a/docs/src/tutorial/query/code010.py
+++ b/docs/src/tutorial/query/code010.py
@@ -1,11 +1,16 @@
import datetime
-from ninja import Schema, Query
+from typing import List
+
+from pydantic import Field
+
+from ninja import Query, Schema
class Filters(Schema):
limit: int = 100
offset: int = None
query: str = None
+ category__in: List[str] = Field(None, alias="categories")
@api.get("/filter")
diff --git a/ninja/signature/details.py b/ninja/signature/details.py
index cca9b2a..488aa30 100644
--- a/ninja/signature/details.py
+++ b/ninja/signature/details.py
@@ -1,9 +1,20 @@
import inspect
from collections import defaultdict, namedtuple
-from typing import Any, Callable, Dict, List
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional
+
+try:
+ from typing import get_origin # type: ignore
+except ImportError: # pragma: no coverage
+
+ def get_origin(tp: Any) -> Optional[Any]:
+ return getattr(tp, "__origin__", None)
+
import pydantic
+if TYPE_CHECKING:
+ from pydantic.fields import ModelField # pragma: no cover
+
from ninja import params
from ninja.signature.utils import get_path_param_names, get_typed_signature
@@ -117,10 +128,19 @@ def is_pydantic_model(cls: Any) -> bool:
def is_collection_type(annotation: Any) -> bool:
# List[int] => __origin__ = list, __args__ = int
- origin = getattr(annotation, "__origin__", None)
+ origin = get_origin(annotation)
return origin in (List, list, set, tuple) # TODO: I gues we should handle only list
+def detect_pydantic_model_collection_fields(model: pydantic.BaseModel) -> List[str]:
+ def _list_field_name(field: "ModelField") -> Optional[str]:
+ if get_origin(field.outer_type_) in (List, list, tuple, set):
+ return str(field.alias)
+ return None
+
+ return list(filter(None, map(_list_field_name, model.__fields__.values())))
+
+
def detect_collection_fields(args: List[FuncParam]) -> List[str]:
"""
QueryDict has values that are always lists, so we need to help django ninja to understand
@@ -130,11 +150,6 @@ def detect_collection_fields(args: List[FuncParam]) -> List[str]:
result = [i.name for i in args if i.is_collection]
if len(args) == 1 and is_pydantic_model(args[0].annotation):
- # There is a special case - when query param of form param is only one and it's defined as pydantic model
- # In that case we need to detect collection
- # see #34 for more details about the issue
- for name, annotation in args[0].annotation.__annotations__.items():
- if is_collection_type(annotation):
- result.append(name)
+ result += detect_pydantic_model_collection_fields(args[0].annotation)
return result
| vitalik/django-ninja | b9c65dad17e9f67bad6440eae829da79b4efe667 | diff --git a/tests/test_docs/test_query.py b/tests/test_docs/test_query.py
index a7d055d..720ea95 100644
--- a/tests/test_docs/test_query.py
+++ b/tests/test_docs/test_query.py
@@ -63,16 +63,39 @@ def test_examples():
# Schema
assert client.get("/filter").json() == {
- "filters": {"limit": 100, "offset": None, "query": None}
+ "filters": {
+ "limit": 100,
+ "offset": None,
+ "query": None,
+ "category__in": None,
+ }
}
assert client.get("/filter?limit=10").json() == {
- "filters": {"limit": 10, "offset": None, "query": None}
+ "filters": {
+ "limit": 10,
+ "offset": None,
+ "query": None,
+ "category__in": None,
+ }
}
assert client.get("/filter?offset=10").json() == {
- "filters": {"limit": 100, "offset": 10, "query": None}
+ "filters": {"limit": 100, "offset": 10, "query": None, "category__in": None}
}
assert client.get("/filter?query=10").json() == {
- "filters": {"limit": 100, "offset": None, "query": "10"}
+ "filters": {
+ "limit": 100,
+ "offset": None,
+ "query": "10",
+ "category__in": None,
+ }
+ }
+ assert client.get("/filter?categories=a&categories=b").json() == {
+ "filters": {
+ "limit": 100,
+ "offset": None,
+ "query": None,
+ "category__in": ["a", "b"],
+ }
}
schema = api.get_openapi_schema("")
@@ -96,4 +119,14 @@ def test_examples():
"required": False,
"schema": {"title": "Query", "type": "string"},
},
+ {
+ "in": "query",
+ "name": "categories",
+ "required": False,
+ "schema": {
+ "title": "Categories",
+ "type": "array",
+ "items": {"type": "string"},
+ },
+ },
]
diff --git a/tests/test_lists.py b/tests/test_lists.py
index 71338cb..66b0ba9 100644
--- a/tests/test_lists.py
+++ b/tests/test_lists.py
@@ -1,7 +1,7 @@
import pytest
from typing import List
from ninja import Router, Query, Form, Schema
-from pydantic import BaseModel
+from pydantic import BaseModel, Field
from client import NinjaClient
@@ -12,7 +12,9 @@ router = Router()
@router.post("/list1")
def listview1(
- request, query: List[int] = Query(...), form: List[int] = Form(...),
+ request,
+ query: List[int] = Query(...),
+ form: List[int] = Form(...),
):
return {
"query": query,
@@ -22,7 +24,9 @@ def listview1(
@router.post("/list2")
def listview2(
- request, body: List[int], query: List[int] = Query(...),
+ request,
+ body: List[int],
+ query: List[int] = Query(...),
):
return {
"query": query,
@@ -52,11 +56,13 @@ def listviewdefault(request, body: List[int] = [1]):
class Filters(Schema):
tags: List[str] = []
+ other_tags: List[str] = Field([], alias="other_tags_alias")
@router.post("/list4")
def listview4(
- request, filters: Filters = Query(...),
+ request,
+ filters: Filters = Query(...),
):
return {
"filters": filters,
@@ -96,19 +102,19 @@ client = NinjaClient(router)
{"body": [1, 2]},
),
(
- "/list4?tags=a&tags=b",
+ "/list4?tags=a&tags=b&other_tags_alias=a&other_tags_alias=b",
{},
- {"filters": {"tags": ["a", "b"]}},
+ {"filters": {"tags": ["a", "b"], "other_tags": ["a", "b"]}},
),
(
- "/list4?tags=abc",
+ "/list4?tags=abc&other_tags_alias=abc",
{},
- {"filters": {"tags": ["abc"]}},
+ {"filters": {"tags": ["abc"], "other_tags": ["abc"]}},
),
(
"/list4",
{},
- {"filters": {"tags": []}},
+ {"filters": {"tags": [], "other_tags": []}},
),
]
# fmt: on
| Query parameters from Schema do not recognise lists with pydantic.Field alias
Using a schema to encapsulate GET requests with a `pydantic.Field` to handle `alias` will result in a 422 error.
```python
class Filters(Schema):
slug__in: typing.List[str] = pydantic.Field(
None,
alias="slugs",
)
@api.get("/filters/")
def test_filters(request, filters: Filters = Query(...)):
return filters.dict()
```
Expected response to http://127.0.0.1:8000/api/filters/?slugs=a&slugs=b
```python
{
"slug__in": [
"a",
"b"
]
}
```
Actual response to http://127.0.0.1:8000/api/filters/?slugs=a&slugs=b
```python
{
"detail": [
{
"loc": [
"query",
"filters",
"slugs"
],
"msg": "value is not a valid list",
"type": "type_error.list"
}
]
}
```
One work around is to *not* use aliases at all, but this is not ideal.
```python
class Filters(Schema):
slugs: typing.List[str] = pydantic.Field(None)
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_docs/test_query.py::test_examples",
"tests/test_lists.py::test_list[/list4?tags=a&tags=b&other_tags_alias=a&other_tags_alias=b-kwargs5-expected_response5]",
"tests/test_lists.py::test_list[/list4?tags=abc&other_tags_alias=abc-kwargs6-expected_response6]"
] | [
"tests/test_lists.py::test_list[/list1?query=1&query=2-kwargs0-expected_response0]",
"tests/test_lists.py::test_list[/list2?query=1&query=2-kwargs1-expected_response1]",
"tests/test_lists.py::test_list[/list3-kwargs2-expected_response2]",
"tests/test_lists.py::test_list[/list-default-kwargs3-expected_response3]",
"tests/test_lists.py::test_list[/list-default-kwargs4-expected_response4]",
"tests/test_lists.py::test_list[/list4-kwargs7-expected_response7]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-05-07T14:52:51Z" | mit |
|
vitalik__django-ninja-184 | diff --git a/docs/docs/tutorial/response-schema.md b/docs/docs/tutorial/response-schema.md
index f31ce32..7f1359b 100644
--- a/docs/docs/tutorial/response-schema.md
+++ b/docs/docs/tutorial/response-schema.md
@@ -286,3 +286,21 @@ Organization.update_forward_refs() # !!! this is important
def list_organizations(request):
...
```
+
+## Self-referencing schemes from `create_schema()`
+
+To be able to use the method `update_forward_refs()` from a schema generated via `create_schema()`,
+the "name" of the class needs to be in our namespace. In this case it is very important to pass
+the `name` parameter to `create_schema()`
+
+```Python hl_lines="3"
+UserSchema = create_schema(
+ User,
+ name='UserSchema', # !!! this is important for update_forward_refs()
+ fields=['id', 'username']
+ custom_fields=[
+ ('manager', 'UserSchema', None),
+ ]
+)
+UserSchema.update_forward_refs()
+```
diff --git a/ninja/operation.py b/ninja/operation.py
index 1956a61..f9718af 100644
--- a/ninja/operation.py
+++ b/ninja/operation.py
@@ -94,6 +94,10 @@ class Operation:
result = self.view_func(request, **values)
return self._result_to_response(request, result)
except Exception as e:
+ if isinstance(e, TypeError) and "required positional argument" in str(e):
+ msg = "Did you fail to use functools.wraps() in a decorator?"
+ msg = f"{e.args[0]}: {msg}" if e.args else msg
+ e.args = (msg,) + e.args[1:]
return self.api.on_exception(request, e)
def set_api_instance(self, api: "NinjaAPI", router: "Router") -> None:
| vitalik/django-ninja | efb29207ca764d34146cb59cfcb98f4cb3ebb94d | diff --git a/tests/test_app.py b/tests/test_app.py
index 5a2e4a5..307f0c5 100644
--- a/tests/test_app.py
+++ b/tests/test_app.py
@@ -63,11 +63,14 @@ def html(request):
def file_response(request):
tmp = NamedTemporaryFile(delete=False)
try:
- with open(tmp.name, 'wb') as f:
- f.write(b'this is a file')
- return FileResponse(open(tmp.name, 'rb'))
+ with open(tmp.name, "wb") as f:
+ f.write(b"this is a file")
+ return FileResponse(open(tmp.name, "rb"))
finally:
- os.remove(tmp.name)
+ try:
+ os.remove(tmp.name)
+ except PermissionError:
+ pass
@pytest.mark.parametrize(
@@ -109,4 +112,3 @@ def test_validates():
urls = api2.urls
finally:
os.environ["NINJA_SKIP_REGISTRY"] = "yes"
-
diff --git a/tests/test_wraps.py b/tests/test_wraps.py
new file mode 100644
index 0000000..b5800ed
--- /dev/null
+++ b/tests/test_wraps.py
@@ -0,0 +1,103 @@
+from functools import wraps
+import pytest
+from ninja import Router
+from ninja.testing import TestClient
+
+
+router = Router()
+client = TestClient(router)
+
+
+def a_good_test_wrapper(f):
+ """Validate that decorators using functools.wraps(), work as expected"""
+
+ @wraps(f)
+ def wrapper(*args, **kwargs):
+ return f(*args, **kwargs)
+
+ return wrapper
+
+
+def a_bad_test_wrapper(f):
+ """Validate that decorators failing to using functools.wraps(), fail"""
+
+ def wrapper(*args, **kwargs):
+ return f(*args, **kwargs)
+
+ return wrapper
+
+
[email protected]("/text")
+@a_good_test_wrapper
+def get_text(
+ request,
+):
+ return "Hello World"
+
+
[email protected]("/path/{item_id}")
+@a_good_test_wrapper
+def get_id(request, item_id):
+ return item_id
+
+
[email protected]("/query")
+@a_good_test_wrapper
+def get_query_type(request, query: int):
+ return f"foo bar {query}"
+
+
[email protected]("/path-query/{item_id}")
+@a_good_test_wrapper
+def get_id(request, item_id, query: int):
+ return f"foo bar {item_id} {query}"
+
+
[email protected]("/text-bad")
+@a_bad_test_wrapper
+def get_text(
+ request,
+):
+ return "Hello World"
+
+
[email protected]("/path-bad/{item_id}")
+@a_bad_test_wrapper
+def get_id(request, item_id):
+ return item_id
+
+
[email protected]("/query-bad")
+@a_bad_test_wrapper
+def get_query_type(request, query: int):
+ return f"foo bar {query}"
+
+
[email protected]("/path-query-bad/{item_id}")
+@a_bad_test_wrapper
+def get_id_bad(request, item_id, query: int):
+ return f"foo bar {item_id} {query}"
+
+
[email protected](
+ "path,expected_status,expected_response",
+ [
+ ("/text", 200, "Hello World"),
+ ("/path/id", 200, "id"),
+ ("/query?query=1", 200, "foo bar 1"),
+ ("/path-query/id?query=2", 200, "foo bar id 2"),
+ ("/text-bad", 200, "Hello World"), # no params so passes
+ ("/path-bad/id", None, TypeError),
+ ("/query-bad?query=1", None, TypeError),
+ ("/path-query-bad/id?query=2", None, TypeError),
+ ],
+)
+def test_get_path(path, expected_status, expected_response):
+ if isinstance(expected_response, str):
+ response = client.get(path)
+ assert response.status_code == expected_status
+ assert response.json() == expected_response
+ else:
+ match = r"Did you fail to use functools.wraps\(\) in a decorator\?"
+ with pytest.raises(expected_response, match=match):
+ client.get(path)
| Decorators
```
@api.get("/add")
@cache_page(60 * 15)
def add(request, a: int, b: int):
return {"result": a + b}
```
so currently this will not work due to inspection procedure...
I guess there must be some `@decorate` helper to allow to add custom decorators that will not conflict with arguments/annotations resolution
UPD:
looks like when `functools.wraps` is used it is possible to get to the original function declaration via `__wrapped__` attribute
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_wraps.py::test_get_path[/path-bad/id-None-TypeError]",
"tests/test_wraps.py::test_get_path[/query-bad?query=1-None-TypeError]",
"tests/test_wraps.py::test_get_path[/path-query-bad/id?query=2-None-TypeError]"
] | [
"tests/test_app.py::test_method[get-/-200-/-False]",
"tests/test_app.py::test_method[get-/get-200-this",
"tests/test_app.py::test_method[post-/post-200-this",
"tests/test_app.py::test_method[put-/put-200-this",
"tests/test_app.py::test_method[patch-/patch-200-this",
"tests/test_app.py::test_method[delete-/delete-200-this",
"tests/test_app.py::test_method[get-/multi-200-this",
"tests/test_app.py::test_method[post-/multi-200-this",
"tests/test_app.py::test_method[patch-/multi-405-Method",
"tests/test_app.py::test_method[get-/html-200-html-False]",
"tests/test_app.py::test_method[get-/file-200-this",
"tests/test_app.py::test_validates",
"tests/test_wraps.py::test_get_path[/text-200-Hello",
"tests/test_wraps.py::test_get_path[/path/id-200-id]",
"tests/test_wraps.py::test_get_path[/query?query=1-200-foo",
"tests/test_wraps.py::test_get_path[/path-query/id?query=2-200-foo",
"tests/test_wraps.py::test_get_path[/text-bad-200-Hello"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-27T17:00:09Z" | mit |
|
vitalik__django-ninja-185 | diff --git a/ninja/params_models.py b/ninja/params_models.py
index e8f8c7c..2ddabe6 100644
--- a/ninja/params_models.py
+++ b/ninja/params_models.py
@@ -48,6 +48,15 @@ class ParamModel(BaseModel, ABC):
varname = getattr(cls, "_single_attr", None)
if varname:
data = {varname: data}
+
+ mixed_attrs = getattr(cls, "_mixed_attrs", None)
+ if mixed_attrs:
+ for param_name, varname in mixed_attrs.items():
+ if varname not in data:
+ data[varname] = {}
+ if param_name in data:
+ data[varname][param_name] = data.pop(param_name)
+
# TODO: I guess if data is not dict - raise an HttpBadRequest
return cls(**data)
diff --git a/ninja/signature/details.py b/ninja/signature/details.py
index 6659a76..5e0d51f 100644
--- a/ninja/signature/details.py
+++ b/ninja/signature/details.py
@@ -34,9 +34,9 @@ class ViewSignature:
self.params = []
for name, arg in self.signature.parameters.items():
if name == "request":
- # TODO: maybe better assert that 1st param is request or check by type?
- # maybe even have attribute like `has_request`
- # so that users can ignroe passing request if not needed
+ # TODO: maybe better assert that 1st param is request or check by type?
+ # maybe even have attribute like `has_request`
+ # so that users can ignore passing request if not needed
continue
if arg.kind == arg.VAR_KEYWORD:
@@ -69,6 +69,23 @@ class ViewSignature:
if cls._in() == "body" or is_pydantic_model(args[0].annotation):
attrs["_single_attr"] = args[0].name
+ elif cls._in() == "query":
+ pydantic_models = [
+ arg for arg in args if is_pydantic_model(arg.annotation)
+ ]
+ if pydantic_models:
+ mixed_attrs = {}
+ for modeled_attr in pydantic_models:
+ for (
+ attr_name,
+ field,
+ ) in modeled_attr.annotation.__fields__.items():
+ mixed_attrs[attr_name] = modeled_attr.name
+ if hasattr(field, "alias"):
+ mixed_attrs[field.alias] = modeled_attr.name
+
+ attrs["_mixed_attrs"] = mixed_attrs
+
# adding annotations:
attrs["__annotations__"] = {i.name: i.annotation for i in args}
| vitalik/django-ninja | d1212693462a8753f187fecfd8b6686b35647ed6 | diff --git a/tests/test_query_schema.py b/tests/test_query_schema.py
index db37f0c..fca70c0 100644
--- a/tests/test_query_schema.py
+++ b/tests/test_query_schema.py
@@ -1,6 +1,7 @@
from datetime import datetime
from enum import IntEnum
+import pytest
from pydantic import Field
from ninja import NinjaAPI, Query, Schema, files
@@ -20,6 +21,11 @@ class Filter(Schema):
range: Range = Range.TWENTY
+class Data(Schema):
+ an_int: int = Field(alias="int", default=0)
+ a_float: float = Field(alias="float", default=1.5)
+
+
api = NinjaAPI()
@@ -28,6 +34,17 @@ def query_params_schema(request, filters: Filter = Query(...)):
return filters.dict()
[email protected]("/test-mixed")
+def query_params_mixed_schema(
+ request,
+ query1: int,
+ query2: int = 5,
+ filters: Filter = Query(...),
+ data: Data = Query(...),
+):
+ return dict(query1=query1, query2=query2, filters=filters.dict(), data=data.dict())
+
+
def test_request():
client = TestClient(api)
response = client.get("/test?from=1&to=2&range=20&foo=1&range2=50")
@@ -42,6 +59,42 @@ def test_request():
assert response.status_code == 422
+def test_request_mixed():
+ client = TestClient(api)
+ response = client.get(
+ "/test-mixed?from=1&to=2&range=20&foo=1&range2=50&query1=2&int=3&float=1.6"
+ )
+ print(response.json())
+ assert response.json() == {
+ "data": {"a_float": 1.6, "an_int": 3},
+ "filters": {
+ "from_datetime": "1970-01-01T00:00:01Z",
+ "range": 20,
+ "to_datetime": "1970-01-01T00:00:02Z",
+ },
+ "query1": 2,
+ "query2": 5,
+ }
+
+ response = client.get(
+ "/test-mixed?from=1&to=2&range=20&foo=1&range2=50&query1=2&query2=10"
+ )
+ print(response.json())
+ assert response.json() == {
+ "data": {"a_float": 1.5, "an_int": 0},
+ "filters": {
+ "from_datetime": "1970-01-01T00:00:01Z",
+ "range": 20,
+ "to_datetime": "1970-01-01T00:00:02Z",
+ },
+ "query1": 2,
+ "query2": 10,
+ }
+
+ response = client.get("/test-mixed?from=1&to=2")
+ assert response.status_code == 422
+
+
def test_schema():
schema = api.get_openapi_schema()
params = schema["paths"]["/api/test"]["get"]["parameters"]
| mixing query param bug
<img width="1089" alt="CleanShot 2021-07-21 at 15 23 44@2x" src="https://user-images.githubusercontent.com/95222/126487840-33ec0cf2-5978-4a1f-816e-73afe970561b.png">
this works
but this
<img width="1157" alt="CleanShot 2021-07-21 at 15 24 51@2x" src="https://user-images.githubusercontent.com/95222/126488014-853ee9bf-9574-49a4-b5a3-b11cc3ac9606.png">
not:
<img width="718" alt="CleanShot 2021-07-21 at 15 24 17@2x" src="https://user-images.githubusercontent.com/95222/126487860-88b282ff-2914-4d3d-8bb9-e1fa8552e178.png">
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_query_schema.py::test_request_mixed"
] | [
"tests/test_query_schema.py::test_request",
"tests/test_query_schema.py::test_schema"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_hyperlinks",
"has_media",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-28T00:21:42Z" | mit |
|
vitalik__django-ninja-187 | diff --git a/ninja/main.py b/ninja/main.py
index e4fbf7d..3ccf3c6 100644
--- a/ninja/main.py
+++ b/ninja/main.py
@@ -313,12 +313,13 @@ class NinjaAPI:
def urls(self) -> Tuple[Any, ...]:
self._validate()
return (
- self._get_urls(),
+ self._get_urls,
"ninja",
self.urls_namespace.split(":")[-1],
# ^ if api included into nested urls, we only care about last bit here
)
+ @property
def _get_urls(self) -> List[URLPattern]:
result = get_openapi_urls(self)
diff --git a/ninja/signature/details.py b/ninja/signature/details.py
index a680b72..632d187 100644
--- a/ninja/signature/details.py
+++ b/ninja/signature/details.py
@@ -129,17 +129,19 @@ class ViewSignature:
# 2) if param name is a part of the path parameter
elif name in self.path_params_names:
- assert arg.default == self.signature.empty, f"'{name}' is a path param"
+ assert (
+ arg.default == self.signature.empty
+ ), f"'{name}' is a path param, default not allowed"
param_source = params.Path(...)
- # 3) if param have no type annotation or annotation is not part of pydantic model:
+ # 3) if param is a collection or annotation is part of pydantic model:
elif is_collection or is_pydantic_model(annotation):
if arg.default == self.signature.empty:
param_source = params.Body(...)
else:
param_source = params.Body(arg.default)
- # 4) the last case is body param
+ # 4) the last case is query param
else:
if arg.default == self.signature.empty:
param_source = params.Query(...)
@@ -158,7 +160,12 @@ def is_pydantic_model(cls: Any) -> bool:
def is_collection_type(annotation: Any) -> bool:
origin = get_collection_origin(annotation)
- return origin in (List, list, set, tuple) # TODO: I gues we should handle only list
+ return origin in (
+ List,
+ list,
+ set,
+ tuple,
+ ) # TODO: I guess we should handle only list
def detect_pydantic_model_collection_fields(model: pydantic.BaseModel) -> List[str]:
diff --git a/ninja/signature/utils.py b/ninja/signature/utils.py
index 50e6827..fe46432 100644
--- a/ninja/signature/utils.py
+++ b/ninja/signature/utils.py
@@ -3,6 +3,8 @@ import inspect
import re
from typing import Any, Callable, Set
+from django.urls import register_converter
+from django.urls.converters import UUIDConverter
from pydantic.typing import ForwardRef, evaluate_forwardref
from ninja.types import DictStrAny
@@ -47,8 +49,8 @@ def make_forwardref(annotation: str, globalns: DictStrAny) -> Any:
def get_path_param_names(path: str) -> Set[str]:
- "turns path string like /foo/{var}/path/{another}/end to set ['var', 'another']"
- return {item.strip("{}") for item in re.findall("{[^}]*}", path)}
+ """turns path string like /foo/{var}/path/{int:another}/end to set {'var', 'another'}"""
+ return {item.strip("{}").split(":")[-1] for item in re.findall("{[^}]*}", path)}
def is_async(callable: Callable) -> bool:
@@ -62,3 +64,18 @@ def has_kwargs(call: Callable) -> bool:
if param.kind == param.VAR_KEYWORD:
return True
return False
+
+
+class NinjaUUIDConverter:
+ """Return a path converted UUID as a str instead of the standard UUID"""
+
+ regex = UUIDConverter.regex
+
+ def to_python(self, value: str) -> str:
+ return value
+
+ def to_url(self, value: Any) -> str:
+ return str(value)
+
+
+register_converter(NinjaUUIDConverter, "uuid")
| vitalik/django-ninja | 29d2b4741a1cd941384e650620ca81825d51efad | diff --git a/tests/main.py b/tests/main.py
index ab26e62..b2946df 100644
--- a/tests/main.py
+++ b/tests/main.py
@@ -1,3 +1,4 @@
+from uuid import UUID
from ninja import Router, Query, Path
@@ -131,6 +132,51 @@ def get_path_param_le_ge_int(request, item_id: int = Path(..., le=3, ge=1)):
return item_id
[email protected]("/path/param-django-str/{str:item_id}")
+def get_path_param_django_str(request, item_id):
+ return item_id
+
+
[email protected]("/path/param-django-int/{int:item_id}")
+def get_path_param_django_int(request, item_id:int):
+ assert isinstance(item_id, int)
+ return item_id
+
+
[email protected]("/path/param-django-int/not-an-int")
+def get_path_param_django_not_an_int(request):
+ """Verify that url resolution for get_path_param_django_int passes non-ints forward"""
+ return f"Found not-an-int"
+
+
[email protected]("/path/param-django-int-str/{int:item_id}")
+def get_path_param_django_int(request, item_id:str):
+ assert isinstance(item_id, str)
+ return item_id
+
+
[email protected]("/path/param-django-slug/{slug:item_id}")
+def get_path_param_django_slug(request, item_id):
+ return item_id
+
+
[email protected]("/path/param-django-uuid/{uuid:item_id}")
+def get_path_param_django_uuid(request, item_id: UUID):
+ assert isinstance(item_id, UUID)
+ return item_id
+
+
[email protected]("/path/param-django-uuid-str/{uuid:item_id}")
+def get_path_param_django_int(request, item_id):
+ assert isinstance(item_id, str)
+ return item_id
+
+
[email protected]("/path/param-django-path/{path:item_id}/after")
+def get_path_param_django_int(request, item_id):
+ return item_id
+
+
@router.get("/query")
def get_query(request, query):
return f"foo bar {query}"
@@ -175,3 +221,40 @@ def get_query_param_required(request, query=Query(...)):
@router.get("/query/param-required/int")
def get_query_param_required_type(request, query: int = Query(...)):
return f"foo bar {query}"
+
+
+class CustomPathConverter1:
+ regex = '[0-9]+'
+
+ def to_python(self, value) -> 'int':
+ """reverse the string and convert to int"""
+ return int(value[::-1])
+
+ def to_url(self, value):
+ return str(value)
+
+
+class CustomPathConverter2:
+ regex = "[0-9]+"
+
+ def to_python(self, value):
+ """reverse the string and convert to float like"""
+ return f"0.{value[::-1]}"
+
+ def to_url(self, value):
+ return str(value)
+
+
+from django.urls import register_converter
+register_converter(CustomPathConverter1, 'custom-int')
+register_converter(CustomPathConverter2, 'custom-float')
+
+
[email protected]("/path/param-django-custom-int/{custom-int:item_id}")
+def get_path_param_django_int(request, item_id: int):
+ return item_id
+
+
[email protected]("/path/param-django-custom-float/{custom-float:item_id}")
+def get_path_param_django_float(request, item_id:float):
+ return item_id
diff --git a/tests/test_path.py b/tests/test_path.py
index 4831587..0c44083 100644
--- a/tests/test_path.py
+++ b/tests/test_path.py
@@ -1,5 +1,6 @@
import pytest
from main import router
+from ninja import Router
from ninja.testing import TestClient
@@ -245,3 +246,69 @@ def test_get_path(path, expected_status, expected_response):
response = client.get(path)
assert response.status_code == expected_status
assert response.json() == expected_response
+
+
[email protected](
+ "path,expected_status,expected_response",
+ [
+ ("/path/param-django-str/42", 200, "42"),
+ ("/path/param-django-str/-1", 200, "-1"),
+ ("/path/param-django-str/foobar", 200, "foobar"),
+ ("/path/param-django-int/0", 200, 0),
+ ("/path/param-django-int/42", 200, 42),
+ ("/path/param-django-int/42.5", "Cannot resolve", Exception),
+ ("/path/param-django-int/-1", "Cannot resolve", Exception),
+ ("/path/param-django-int/True", "Cannot resolve", Exception),
+ ("/path/param-django-int/foobar", "Cannot resolve", Exception),
+ ("/path/param-django-int/not-an-int", 200, "Found not-an-int"),
+ ("/path/param-django-int-str/42", 200, '42'),
+ ("/path/param-django-int-str/42.5", "Cannot resolve", Exception),
+ (
+ "/path/param-django-slug/django-ninja-is-the-best",
+ 200,
+ "django-ninja-is-the-best",
+ ),
+ ("/path/param-django-slug/42.5", "Cannot resolve", Exception),
+ (
+ "/path/param-django-uuid/31ea378c-c052-4b4c-bf0b-679ce5cfcc2a",
+ 200,
+ "31ea378c-c052-4b4c-bf0b-679ce5cfcc2a",
+ ),
+ (
+ "/path/param-django-uuid/31ea378c-c052-4b4c-bf0b-679ce5cfcc2",
+ "Cannot resolve",
+ Exception,
+ ),
+ (
+ "/path/param-django-uuid-str/31ea378c-c052-4b4c-bf0b-679ce5cfcc2a",
+ 200,
+ "31ea378c-c052-4b4c-bf0b-679ce5cfcc2a",
+ ),
+ ("/path/param-django-path/some/path/things/after", 200, "some/path/things"),
+ ("/path/param-django-path/less/path/after", 200, "less/path"),
+ ("/path/param-django-path/plugh/after", 200, "plugh"),
+ ("/path/param-django-path//after", "Cannot resolve", Exception),
+ ("/path/param-django-custom-int/42", 200, 24),
+ ("/path/param-django-custom-int/x42", "Cannot resolve", Exception),
+ ("/path/param-django-custom-float/42", 200, 0.24),
+ ("/path/param-django-custom-float/x42", "Cannot resolve", Exception),
+ ],
+)
+def test_get_path_django(path, expected_status, expected_response):
+ if expected_response == Exception:
+ with pytest.raises(Exception, match=expected_status):
+ client.get(path)
+ else:
+ response = client.get(path)
+ assert response.status_code == expected_status
+ assert response.json() == expected_response
+
+
+def test_path_signature_asserts():
+ test_router = Router()
+
+ match = "'item_id' is a path param, default not allowed"
+ with pytest.raises(AssertionError, match=match):
+ @test_router.get("/path/{item_id}")
+ def get_path_item_id(request, item_id='1'):
+ pass
| Path param with converter(s)
Need to support Djaggo path converters
https://docs.djangoproject.com/en/3.1/topics/http/urls/#path-converters
basically this should work:
```Python
@api.get('/test-path/{path:page}')
def test_path(request, page):
return page
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_path.py::test_get_path_django[/path/param-django-str/42-200-42]",
"tests/test_path.py::test_get_path_django[/path/param-django-str/-1-200--1]",
"tests/test_path.py::test_get_path_django[/path/param-django-str/foobar-200-foobar]",
"tests/test_path.py::test_get_path_django[/path/param-django-int/0-200-0]",
"tests/test_path.py::test_get_path_django[/path/param-django-int/42-200-42]",
"tests/test_path.py::test_get_path_django[/path/param-django-int-str/42-200-42]",
"tests/test_path.py::test_get_path_django[/path/param-django-slug/django-ninja-is-the-best-200-django-ninja-is-the-best]",
"tests/test_path.py::test_get_path_django[/path/param-django-uuid/31ea378c-c052-4b4c-bf0b-679ce5cfcc2a-200-31ea378c-c052-4b4c-bf0b-679ce5cfcc2a]",
"tests/test_path.py::test_get_path_django[/path/param-django-uuid-str/31ea378c-c052-4b4c-bf0b-679ce5cfcc2a-200-31ea378c-c052-4b4c-bf0b-679ce5cfcc2a]",
"tests/test_path.py::test_get_path_django[/path/param-django-path/some/path/things/after-200-some/path/things]",
"tests/test_path.py::test_get_path_django[/path/param-django-path/less/path/after-200-less/path]",
"tests/test_path.py::test_get_path_django[/path/param-django-path/plugh/after-200-plugh]",
"tests/test_path.py::test_get_path_django[/path/param-django-custom-int/42-200-24]",
"tests/test_path.py::test_get_path_django[/path/param-django-custom-float/42-200-0.24]",
"tests/test_path.py::test_path_signature_asserts"
] | [
"tests/test_path.py::test_text_get",
"tests/test_path.py::test_get_path[/path/foobar-200-foobar]",
"tests/test_path.py::test_get_path[/path/str/foobar-200-foobar]",
"tests/test_path.py::test_get_path[/path/str/42-200-42]",
"tests/test_path.py::test_get_path[/path/str/True-200-True]",
"tests/test_path.py::test_get_path[/path/int/foobar-422-expected_response4]",
"tests/test_path.py::test_get_path[/path/int/True-422-expected_response5]",
"tests/test_path.py::test_get_path[/path/int/42-200-42]",
"tests/test_path.py::test_get_path[/path/int/42.5-422-expected_response7]",
"tests/test_path.py::test_get_path[/path/float/foobar-422-expected_response8]",
"tests/test_path.py::test_get_path[/path/float/True-422-expected_response9]",
"tests/test_path.py::test_get_path[/path/float/42-200-42]",
"tests/test_path.py::test_get_path[/path/float/42.5-200-42.5]",
"tests/test_path.py::test_get_path[/path/bool/foobar-422-expected_response12]",
"tests/test_path.py::test_get_path[/path/bool/True-200-True]",
"tests/test_path.py::test_get_path[/path/bool/42-422-expected_response14]",
"tests/test_path.py::test_get_path[/path/bool/42.5-422-expected_response15]",
"tests/test_path.py::test_get_path[/path/bool/1-200-True]",
"tests/test_path.py::test_get_path[/path/bool/0-200-False]",
"tests/test_path.py::test_get_path[/path/bool/true-200-True]",
"tests/test_path.py::test_get_path[/path/bool/False-200-False]",
"tests/test_path.py::test_get_path[/path/bool/false-200-False]",
"tests/test_path.py::test_get_path[/path/param/foo-200-foo]",
"tests/test_path.py::test_get_path[/path/param-required/foo-200-foo]",
"tests/test_path.py::test_get_path[/path/param-minlength/foo-200-foo]",
"tests/test_path.py::test_get_path[/path/param-minlength/fo-422-expected_response24]",
"tests/test_path.py::test_get_path[/path/param-maxlength/foo-200-foo]",
"tests/test_path.py::test_get_path[/path/param-maxlength/foobar-422-expected_response26]",
"tests/test_path.py::test_get_path[/path/param-min_maxlength/foo-200-foo]",
"tests/test_path.py::test_get_path[/path/param-min_maxlength/foobar-422-expected_response28]",
"tests/test_path.py::test_get_path[/path/param-min_maxlength/f-422-expected_response29]",
"tests/test_path.py::test_get_path[/path/param-gt/42-200-42]",
"tests/test_path.py::test_get_path[/path/param-gt/2-422-expected_response31]",
"tests/test_path.py::test_get_path[/path/param-gt0/0.05-200-0.05]",
"tests/test_path.py::test_get_path[/path/param-gt0/0-422-expected_response33]",
"tests/test_path.py::test_get_path[/path/param-ge/42-200-42]",
"tests/test_path.py::test_get_path[/path/param-ge/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-ge/2-422-expected_response36]",
"tests/test_path.py::test_get_path[/path/param-lt/42-422-expected_response37]",
"tests/test_path.py::test_get_path[/path/param-lt/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-lt0/-1-200--1]",
"tests/test_path.py::test_get_path[/path/param-lt0/0-422-expected_response40]",
"tests/test_path.py::test_get_path[/path/param-le/42-422-expected_response41]",
"tests/test_path.py::test_get_path[/path/param-le/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-le/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-lt-gt/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-lt-gt/4-422-expected_response45]",
"tests/test_path.py::test_get_path[/path/param-lt-gt/0-422-expected_response46]",
"tests/test_path.py::test_get_path[/path/param-le-ge/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-le-ge/1-200-1]",
"tests/test_path.py::test_get_path[/path/param-le-ge/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-le-ge/4-422-expected_response50]",
"tests/test_path.py::test_get_path[/path/param-lt-int/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-lt-int/42-422-expected_response52]",
"tests/test_path.py::test_get_path[/path/param-lt-int/2.7-422-expected_response53]",
"tests/test_path.py::test_get_path[/path/param-gt-int/42-200-42]",
"tests/test_path.py::test_get_path[/path/param-gt-int/2-422-expected_response55]",
"tests/test_path.py::test_get_path[/path/param-gt-int/2.7-422-expected_response56]",
"tests/test_path.py::test_get_path[/path/param-le-int/42-422-expected_response57]",
"tests/test_path.py::test_get_path[/path/param-le-int/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-le-int/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-le-int/2.7-422-expected_response60]",
"tests/test_path.py::test_get_path[/path/param-ge-int/42-200-42]",
"tests/test_path.py::test_get_path[/path/param-ge-int/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-ge-int/2-422-expected_response63]",
"tests/test_path.py::test_get_path[/path/param-ge-int/2.7-422-expected_response64]",
"tests/test_path.py::test_get_path[/path/param-lt-gt-int/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-lt-gt-int/4-422-expected_response66]",
"tests/test_path.py::test_get_path[/path/param-lt-gt-int/0-422-expected_response67]",
"tests/test_path.py::test_get_path[/path/param-lt-gt-int/2.7-422-expected_response68]",
"tests/test_path.py::test_get_path[/path/param-le-ge-int/2-200-2]",
"tests/test_path.py::test_get_path[/path/param-le-ge-int/1-200-1]",
"tests/test_path.py::test_get_path[/path/param-le-ge-int/3-200-3]",
"tests/test_path.py::test_get_path[/path/param-le-ge-int/4-422-expected_response72]",
"tests/test_path.py::test_get_path[/path/param-le-ge-int/2.7-422-expected_response73]",
"tests/test_path.py::test_get_path_django[/path/param-django-int/42.5-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-int/-1-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-int/True-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-int/foobar-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-int/not-an-int-200-Found",
"tests/test_path.py::test_get_path_django[/path/param-django-int-str/42.5-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-slug/42.5-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-uuid/31ea378c-c052-4b4c-bf0b-679ce5cfcc2-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-path/after-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-custom-int/x42-Cannot",
"tests/test_path.py::test_get_path_django[/path/param-django-custom-float/x42-Cannot"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-29T04:55:31Z" | mit |
|
vitalik__django-ninja-237 | diff --git a/ninja/openapi/schema.py b/ninja/openapi/schema.py
index 9232f18..795f0d1 100644
--- a/ninja/openapi/schema.py
+++ b/ninja/openapi/schema.py
@@ -230,12 +230,9 @@ class OpenAPISchema(dict):
if len(models) == 1:
model = models[0]
content_type = BODY_CONTENT_TYPES[model._param_source]
- if model._param_source == "file":
- schema, required = self._create_schema_from_model(
- model, remove_level=False
- )
- else:
- schema, required = self._create_schema_from_model(model)
+ schema, required = self._create_schema_from_model(
+ model, remove_level=model._param_source == "body"
+ )
else:
schema, content_type = self._create_multipart_schema_from_models(models)
required = True
| vitalik/django-ninja | 6e6e13ff1a44a855c0375049e949bf9935667edb | diff --git a/tests/test_openapi_schema.py b/tests/test_openapi_schema.py
index ba83386..537ba7a 100644
--- a/tests/test_openapi_schema.py
+++ b/tests/test_openapi_schema.py
@@ -62,6 +62,11 @@ def method_form(request, data: Payload = Form(...)):
return dict(i=data.i, f=data.f)
[email protected]("/test-form-single", response=Response)
+def method_form_single(request, data: float = Form(...)):
+ return dict(i=int(data), f=data)
+
+
@api.post("/test-form-body", response=Response)
def method_form_body(request, i: int = Form(10), s: str = Body("10")):
return dict(i=i, s=s)
@@ -358,6 +363,34 @@ def test_schema_form(schema):
}
+def test_schema_single(schema):
+ method_list = schema["paths"]["/api/test-form-single"]["post"]
+
+ assert method_list["requestBody"] == {
+ "content": {
+ "application/x-www-form-urlencoded": {
+ "schema": {
+ "properties": {"data": {"title": "Data", "type": "number"}},
+ "required": ["data"],
+ "title": "FormParams",
+ "type": "object",
+ }
+ }
+ },
+ "required": True,
+ }
+ assert method_list["responses"] == {
+ 200: {
+ "description": "OK",
+ "content": {
+ "application/json": {
+ "schema": {"$ref": "#/components/schemas/Response"}
+ }
+ },
+ }
+ }
+
+
def test_schema_form_body(schema):
method_list = schema["paths"]["/api/test-form-body"]["post"]
diff --git a/tests/test_wraps.py b/tests/test_wraps.py
index 69b0ee6..98fd0c4 100644
--- a/tests/test_wraps.py
+++ b/tests/test_wraps.py
@@ -1,4 +1,5 @@
from functools import wraps
+from unittest import mock
import pytest
@@ -60,10 +61,12 @@ def get_text_bad(request):
return "Hello World"
[email protected]("/path-bad/{item_id}")
-@a_bad_test_wrapper
-def get_id_bad(request, item_id):
- return item_id
+with mock.patch("ninja.signature.details.warnings.warn_explicit"):
+
+ @router.get("/path-bad/{item_id}")
+ @a_bad_test_wrapper
+ def get_id_bad(request, item_id):
+ return item_id
@router.get("/query-bad")
@@ -72,10 +75,12 @@ def get_query_type_bad(request, query: int):
return f"foo bar {query}"
[email protected]("/path-query-bad/{item_id}")
-@a_bad_test_wrapper
-def get_query_id_bad(request, item_id, query: int):
- return f"foo bar {item_id} {query}"
+with mock.patch("ninja.signature.details.warnings.warn_explicit"):
+
+ @router.get("/path-query-bad/{item_id}")
+ @a_bad_test_wrapper
+ def get_query_id_bad(request, item_id, query: int):
+ return f"foo bar {item_id} {query}"
@pytest.mark.parametrize(
| Schema doesn't render properly
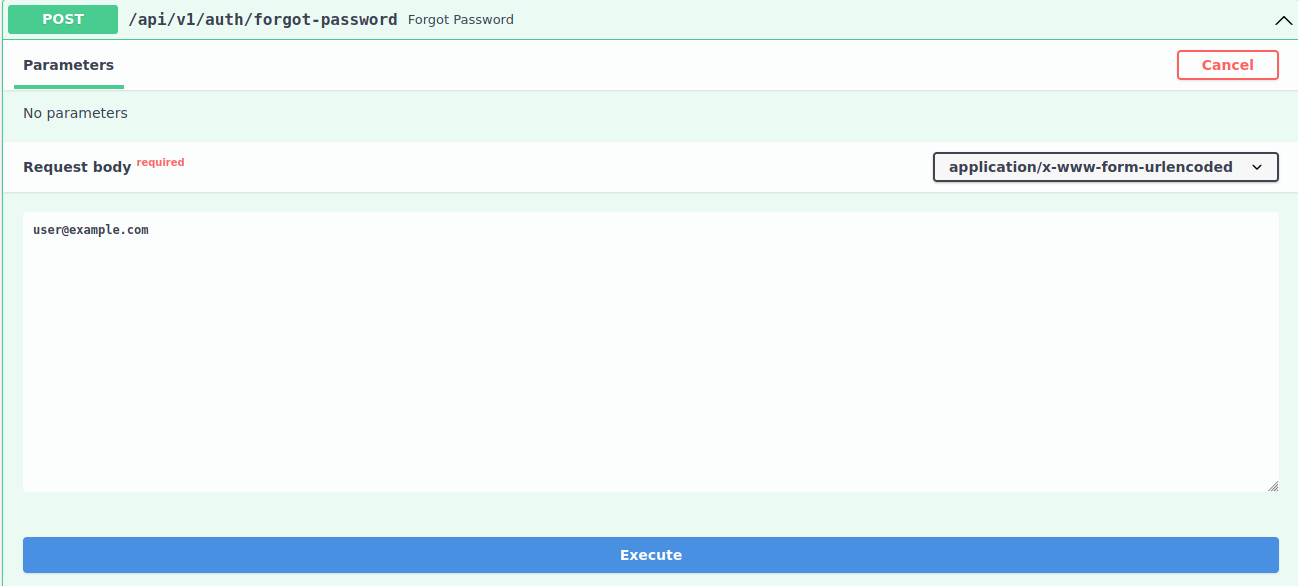
Code:
```python
def forgot_password(request: HttpRequest, email: EmailStr = Form(...)):
...
# And
def reset_password(
request: HttpRequest,
token: str,
password: constr(strip_whitespace=True, min_length=8) = Form(...),
):
...
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_openapi_schema.py::test_schema_single"
] | [
"tests/test_openapi_schema.py::test_schema_views",
"tests/test_openapi_schema.py::test_schema_views_no_INSTALLED_APPS",
"tests/test_openapi_schema.py::test_schema",
"tests/test_openapi_schema.py::test_schema_alias",
"tests/test_openapi_schema.py::test_schema_list",
"tests/test_openapi_schema.py::test_schema_body",
"tests/test_openapi_schema.py::test_schema_body_schema",
"tests/test_openapi_schema.py::test_schema_path",
"tests/test_openapi_schema.py::test_schema_form",
"tests/test_openapi_schema.py::test_schema_form_body",
"tests/test_openapi_schema.py::test_schema_form_file",
"tests/test_openapi_schema.py::test_schema_body_file",
"tests/test_openapi_schema.py::test_get_openapi_urls",
"tests/test_openapi_schema.py::test_unique_operation_ids",
"tests/test_wraps.py::test_get_path[/text-200-Hello",
"tests/test_wraps.py::test_get_path[/path/id-200-id]",
"tests/test_wraps.py::test_get_path[/query?query=1-200-foo",
"tests/test_wraps.py::test_get_path[/path-query/id?query=2-200-foo",
"tests/test_wraps.py::test_get_path[/text-bad-200-Hello",
"tests/test_wraps.py::test_get_path[/path-bad/id-None-TypeError]",
"tests/test_wraps.py::test_get_path[/query-bad?query=1-None-TypeError]",
"tests/test_wraps.py::test_get_path[/path-query-bad/id?query=2-None-TypeError]"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_hyperlinks",
"has_media"
],
"has_test_patch": true,
"is_lite": false
} | "2021-10-04T14:39:58Z" | mit |
|
vitalik__django-ninja-317 | diff --git a/docs/docs/tutorial/response-schema.md b/docs/docs/tutorial/response-schema.md
index fdfbc23..fecd511 100644
--- a/docs/docs/tutorial/response-schema.md
+++ b/docs/docs/tutorial/response-schema.md
@@ -90,7 +90,7 @@ class TaskSchema(Schema):
@api.get("/tasks", response=List[TaskSchema])
def tasks(request):
- queryset = Task.objects.all()
+ queryset = Task.objects.select_related("owner")
return list(queryset)
```
@@ -117,6 +117,59 @@ If you execute this operation, you should get a response like this:
]
```
+
+## Aliases
+
+Instead of a nested response, you may want to just flatten the response output.
+The Ninja `Schema` object extends Pydantic's `Field(..., alias="")` format to
+work with dotted responses.
+
+Using the models from above, let's make a schema that just includes the task
+owner's first name inline, and also uses `completed` rather than `is_completed`:
+
+```Python hl_lines="1 7-9"
+from ninja import Field, Schema
+
+
+class TaskSchema(Schema):
+ id: int
+ title: str
+ # The first Field param is the default, use ... for required fields.
+ completed: bool = Field(..., alias="is_completed)
+ owner_first_name: str = Field(None, alias="owner.first_name")
+```
+
+
+## Resolvers
+
+You can also create calculated fields via resolve methods based on the field
+name.
+
+The method must accept a single argument, which will be the object the schema
+is resolving against.
+
+When creating a resolver as a standard method, `self` gives you access to other
+validated and formatted attributes in the schema.
+
+```Python hl_lines="5 7-11"
+class TaskSchema(Schema):
+ id: int
+ title: str
+ is_completed: bool
+ owner: Optional[str]
+ lower_title: str
+
+ @staticmethod
+ def resolve_owner(obj):
+ if not obj.owner:
+ return
+ return f"{obj.owner.first_name} {obj.owner.last_name}"
+
+ def resolve_lower_title(self, obj):
+ return self.title.lower()
+```
+
+
## Returning querysets
In the previous example we specifically converted a queryset into a list (and executed the SQL query during evaluation).
diff --git a/ninja/orm/metaclass.py b/ninja/orm/metaclass.py
index 652b34c..1300238 100644
--- a/ninja/orm/metaclass.py
+++ b/ninja/orm/metaclass.py
@@ -1,16 +1,15 @@
from typing import no_type_check
from django.db.models import Model as DjangoModel
-from pydantic.main import ModelMetaclass
from ninja.errors import ConfigError
from ninja.orm.factory import create_schema
-from ninja.schema import Schema
+from ninja.schema import ResolverMetaclass, Schema
_is_modelschema_class_defined = False
-class ModelSchemaMetaclass(ModelMetaclass):
+class ModelSchemaMetaclass(ResolverMetaclass):
@no_type_check
def __new__(
mcs,
diff --git a/ninja/schema.py b/ninja/schema.py
index 73b762f..b86a722 100644
--- a/ninja/schema.py
+++ b/ninja/schema.py
@@ -1,9 +1,33 @@
-from typing import Any
+"""
+Since "Model" word would be very confusing when used in django context, this
+module basically makes an alias for it named "Schema" and adds extra whistles to
+be able to work with django querysets and managers.
+
+The schema is a bit smarter than a standard pydantic Model because it can handle
+dotted attributes and resolver methods. For example::
+
+
+ class UserSchema(User):
+ name: str
+ initials: str
+ boss: str = Field(None, alias="boss.first_name")
+
+ @staticmethod
+ def resolve_name(obj):
+ return f"{obj.first_name} {obj.last_name}"
+
+ def resolve_initials(self, obj):
+ return "".join(n[:1] for n in self.name.split())
+
+"""
+from operator import attrgetter
+from typing import Any, Callable, Dict, Type, TypeVar, Union, no_type_check
import pydantic
from django.db.models import Manager, QuerySet
from django.db.models.fields.files import FieldFile
from pydantic import BaseModel, Field, validator
+from pydantic.main import ModelMetaclass
from pydantic.utils import GetterDict
pydantic_version = list(map(int, pydantic.VERSION.split(".")[:2]))
@@ -11,16 +35,37 @@ assert pydantic_version >= [1, 6], "Pydantic 1.6+ required"
__all__ = ["BaseModel", "Field", "validator", "DjangoGetter", "Schema"]
-
-# Since "Model" word would be very confusing when used in django context
-# this module basically makes alias for it named "Schema"
-# and ads extra whistles to be able to work with django querysets and managers
+S = TypeVar("S", bound="Schema")
class DjangoGetter(GetterDict):
+ __slots__ = ("_obj", "_schema_cls")
+
+ def __init__(self, obj: Any, schema_cls: "Type[Schema]"):
+ self._obj = obj
+ self._schema_cls = schema_cls
+
+ def __getitem__(self, key: str) -> Any:
+ resolver = self._schema_cls._ninja_resolvers.get(key)
+ if resolver:
+ item = resolver(getter=self)
+ else:
+ try:
+ item = getattr(self._obj, key)
+ except AttributeError:
+ try:
+ item = attrgetter(key)(self._obj)
+ except AttributeError as e:
+ raise KeyError(key) from e
+ return self.format_result(item)
+
def get(self, key: Any, default: Any = None) -> Any:
- result = super().get(key, default)
+ try:
+ return self[key]
+ except KeyError:
+ return default
+ def format_result(self, result: Any) -> Any:
if isinstance(result, Manager):
return list(result.all())
@@ -35,7 +80,87 @@ class DjangoGetter(GetterDict):
return result
-class Schema(BaseModel):
+class Resolver:
+ __slots__ = ("_func", "_static")
+ _static: bool
+ _func: Any
+
+ def __init__(self, func: Union[Callable, staticmethod]):
+ if isinstance(func, staticmethod):
+ self._static = True
+ self._func = func.__func__
+ else:
+ self._static = False
+ self._func = func
+
+ def __call__(self, getter: DjangoGetter) -> Any:
+ if self._static:
+ return self._func(getter._obj)
+ return self._func(self._fake_instance(getter), getter._obj)
+
+ def _fake_instance(self, getter: DjangoGetter) -> "Schema":
+ """
+ Generate a partial schema instance that can be used as the ``self``
+ attribute of resolver functions.
+ """
+
+ class PartialSchema(Schema):
+ def __getattr__(self, key: str) -> Any:
+ value = getter[key]
+ field = getter._schema_cls.__fields__[key]
+ value = field.validate(value, values={}, loc=key, cls=None)[0]
+ return value
+
+ return PartialSchema()
+
+
+class ResolverMetaclass(ModelMetaclass):
+ _ninja_resolvers: Dict[str, Resolver]
+
+ @no_type_check
+ def __new__(cls, name, bases, namespace, **kwargs):
+ resolvers = {}
+
+ for base in reversed(bases):
+ base_resolvers = getattr(base, "_ninja_resolvers", None)
+ if base_resolvers:
+ resolvers.update(base_resolvers)
+ for attr, resolve_func in namespace.items():
+ if not attr.startswith("resolve_"):
+ continue
+ if (
+ not callable(resolve_func)
+ # A staticmethod isn't directly callable in Python <=3.9.
+ and not isinstance(resolve_func, staticmethod)
+ ):
+ continue
+ resolvers[attr[8:]] = Resolver(resolve_func)
+
+ result = super().__new__(cls, name, bases, namespace, **kwargs)
+ result._ninja_resolvers = resolvers
+ return result
+
+
+class Schema(BaseModel, metaclass=ResolverMetaclass):
class Config:
orm_mode = True
getter_dict = DjangoGetter
+
+ @classmethod
+ def from_orm(cls: Type[S], obj: Any) -> S:
+ getter_dict = cls.__config__.getter_dict
+ obj = (
+ # DjangoGetter also needs the class so it can find resolver methods.
+ getter_dict(obj, cls)
+ if issubclass(getter_dict, DjangoGetter)
+ else getter_dict(obj)
+ )
+ return super().from_orm(obj)
+
+ @classmethod
+ def _decompose_class(cls, obj: Any) -> GetterDict:
+ # This method has backported logic from Pydantic 1.9 and is no longer
+ # needed once that is the minimum version.
+ if isinstance(obj, GetterDict):
+ return obj
+ return super()._decompose_class(obj) # pragma: no cover
| vitalik/django-ninja | fc00cad403354637f59af01b7f4e6d38685a3fb3 | diff --git a/tests/test_schema.py b/tests/test_schema.py
index fa68982..0ae5d02 100644
--- a/tests/test_schema.py
+++ b/tests/test_schema.py
@@ -1,4 +1,4 @@
-from typing import List
+from typing import List, Optional
from unittest.mock import Mock
from django.db.models import Manager, QuerySet
@@ -34,11 +34,16 @@ class Tag:
self.title = title
-# mocking some user:
+# mocking some users:
+class Boss:
+ name = "Jane Jackson"
+
+
class User:
- name = "John"
+ name = "John Smith"
group_set = FakeManager([1, 2, 3])
avatar = ImageFieldFile(None, Mock(), name=None)
+ boss: Optional[Boss] = Boss()
@property
def tags(self):
@@ -57,11 +62,27 @@ class UserSchema(Schema):
avatar: str = None
+class UserWithBossSchema(UserSchema):
+ boss: Optional[str] = Field(None, alias="boss.name")
+ has_boss: bool
+
+ @staticmethod
+ def resolve_has_boss(obj):
+ return bool(obj.boss)
+
+
+class UserWithInitialsSchema(UserWithBossSchema):
+ initials: str
+
+ def resolve_initials(self, obj):
+ return "".join(n[:1] for n in self.name.split())
+
+
def test_schema():
user = User()
schema = UserSchema.from_orm(user)
assert schema.dict() == {
- "name": "John",
+ "name": "John Smith",
"groups": [1, 2, 3],
"tags": [{"id": "1", "title": "foo"}, {"id": "2", "title": "bar"}],
"avatar": None,
@@ -75,8 +96,47 @@ def test_schema_with_image():
user.avatar = ImageFieldFile(None, field, name="smile.jpg")
schema = UserSchema.from_orm(user)
assert schema.dict() == {
- "name": "John",
+ "name": "John Smith",
"groups": [1, 2, 3],
"tags": [{"id": "1", "title": "foo"}, {"id": "2", "title": "bar"}],
"avatar": "/smile.jpg",
}
+
+
+def test_with_boss_schema():
+ user = User()
+ schema = UserWithBossSchema.from_orm(user)
+ assert schema.dict() == {
+ "name": "John Smith",
+ "boss": "Jane Jackson",
+ "has_boss": True,
+ "groups": [1, 2, 3],
+ "tags": [{"id": "1", "title": "foo"}, {"id": "2", "title": "bar"}],
+ "avatar": None,
+ }
+
+ user_without_boss = User()
+ user_without_boss.boss = None
+ schema = UserWithBossSchema.from_orm(user_without_boss)
+ assert schema.dict() == {
+ "name": "John Smith",
+ "boss": None,
+ "has_boss": False,
+ "groups": [1, 2, 3],
+ "tags": [{"id": "1", "title": "foo"}, {"id": "2", "title": "bar"}],
+ "avatar": None,
+ }
+
+
+def test_with_initials_schema():
+ user = User()
+ schema = UserWithInitialsSchema.from_orm(user)
+ assert schema.dict() == {
+ "name": "John Smith",
+ "initials": "JS",
+ "boss": "Jane Jackson",
+ "has_boss": True,
+ "groups": [1, 2, 3],
+ "tags": [{"id": "1", "title": "foo"}, {"id": "2", "title": "bar"}],
+ "avatar": None,
+ }
| Foreign key field value instead of id without nesting schemas ?
Hi, is it possible to send a foreign key value without nesting the schemas ? Here's my scenario:
```python
class Department(models.Model):
id = models.IntegerField(primarty_key=True, editable=False)
dep = models.CharField(max_length=200, null=False,unique=True)
class Student(models.Model):
id = models.IntegerField(primarty_key=True, editable=False)
name = models.CharField(max_length=200, null=False)
dep = models.ForeignKey(Department, on_delete=models.CASCADE)
class DepartmentOut(Schema):
dep: str
class StudentOut(Schema):
id: int
name: str
dep: DepartmentOut
```
this will result in an output of:
```python
{
id: 1000,
name: 'Some name',
dep: {
dep: 'Some Text'
}
}
```
How can I show the dep string without a nested object called dep? Like the below shape of JSON:
```python
{
id: 1000,
name: 'Some name',
dep: 'Some Text'
}
```
I tried searching without any luck, thanks in advance. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_schema.py::test_with_boss_schema",
"tests/test_schema.py::test_with_initials_schema"
] | [
"tests/test_schema.py::test_schema",
"tests/test_schema.py::test_schema_with_image"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-01-09T03:40:27Z" | mit |
|
vitalik__django-ninja-336 | diff --git a/docs/docs/tutorial/temporal_response.md b/docs/docs/tutorial/temporal_response.md
new file mode 100644
index 0000000..e767441
--- /dev/null
+++ b/docs/docs/tutorial/temporal_response.md
@@ -0,0 +1,38 @@
+# Altering the Response
+
+Sometimes you'll want to change the response just before it gets served, for example, to add a header or alter a cookie.
+
+To do this, simply declare a function parameter with a type of `HttpResponse`:
+
+```Python
+from django.http import HttpRequest, HttpResponse
+
[email protected]("/cookie/")
+def feed_cookiemonster(request: HttpRequest, response: HttpResponse):
+ # Set a cookie.
+ response.set_cookie("cookie", "delicious")
+ # Set a header.
+ response["X-Cookiemonster"] = "blue"
+ return {"cookiemonster_happy": True}
+```
+
+
+## Temporal response object
+
+This response object is used for the base of all responses built by Django Ninja, including error responses. This object is *not* used if a Django `HttpResponse` object is returned directly by an operation.
+
+Obviously this response object won't contain the content yet, but it does have the `content_type` set (but you probably don't want to be changing it).
+
+The `status_code` will get overridden depending on the return value (200 by default, or the status code if a two-part tuple is returned).
+
+
+## Changing the base response object
+
+You can alter this temporal response object by overriding the `NinjaAPI.create_temporal_response` method.
+
+```Python
+ def create_temporal_response(self, request: HttpRequest) -> HttpResponse:
+ response = super().create_temporal_response(request)
+ # Do your magic here...
+ return response
+```
\ No newline at end of file
diff --git a/ninja/main.py b/ninja/main.py
index fbf540e..27ba4d6 100644
--- a/ninja/main.py
+++ b/ninja/main.py
@@ -335,13 +335,34 @@ class NinjaAPI:
return reverse(name)
def create_response(
- self, request: HttpRequest, data: Any, *, status: int = 200
+ self,
+ request: HttpRequest,
+ data: Any,
+ *,
+ status: int = None,
+ temporal_response: HttpResponse = None,
) -> HttpResponse:
+ if temporal_response:
+ status = temporal_response.status_code
+ assert status
+
content = self.renderer.render(request, data, response_status=status)
- content_type = "{}; charset={}".format(
- self.renderer.media_type, self.renderer.charset
- )
- return HttpResponse(content, status=status, content_type=content_type)
+
+ if temporal_response:
+ response = temporal_response
+ response.content = content
+ else:
+ response = HttpResponse(
+ content, status=status, content_type=self.get_content_type()
+ )
+
+ return response
+
+ def create_temporal_response(self, request: HttpRequest) -> HttpResponse:
+ return HttpResponse("", content_type=self.get_content_type())
+
+ def get_content_type(self) -> str:
+ return "{}; charset={}".format(self.renderer.media_type, self.renderer.charset)
def get_openapi_schema(self, path_prefix: Optional[str] = None) -> OpenAPISchema:
if path_prefix is None:
diff --git a/ninja/operation.py b/ninja/operation.py
index 2fa0935..dcdb955 100644
--- a/ninja/operation.py
+++ b/ninja/operation.py
@@ -94,9 +94,10 @@ class Operation:
if error:
return error
try:
- values = self._get_values(request, kw)
+ temporal_response = self.api.create_temporal_response(request)
+ values = self._get_values(request, kw, temporal_response)
result = self.view_func(request, **values)
- return self._result_to_response(request, result)
+ return self._result_to_response(request, result, temporal_response)
except Exception as e:
if isinstance(e, TypeError) and "required positional argument" in str(e):
msg = "Did you fail to use functools.wraps() in a decorator?"
@@ -151,7 +152,7 @@ class Operation:
return self.api.create_response(request, {"detail": "Unauthorized"}, status=401)
def _result_to_response(
- self, request: HttpRequest, result: Any
+ self, request: HttpRequest, result: Any, temporal_response: HttpResponse
) -> HttpResponseBase:
"""
The protocol for results
@@ -179,13 +180,16 @@ class Operation:
f"Schema for status {status} is not set in response {self.response_models.keys()}"
)
+ temporal_response.status_code = status
+
if response_model is NOT_SET:
- return self.api.create_response(request, result, status=status)
+ return self.api.create_response(
+ request, result, temporal_response=temporal_response
+ )
if response_model is None:
- return HttpResponse(status=status)
- # TODO: ^ maybe self.api.create_empty_response ?
- # return self.api.create_response(request, result, status=status)
+ # Empty response.
+ return temporal_response
resp_object = ResponseObject(result)
# ^ we need object because getter_dict seems work only with from_orm
@@ -195,9 +199,13 @@ class Operation:
exclude_defaults=self.exclude_defaults,
exclude_none=self.exclude_none,
)["response"]
- return self.api.create_response(request, result, status=status)
+ return self.api.create_response(
+ request, result, temporal_response=temporal_response
+ )
- def _get_values(self, request: HttpRequest, path_params: Any) -> DictStrAny:
+ def _get_values(
+ self, request: HttpRequest, path_params: Any, temporal_response: HttpResponse
+ ) -> DictStrAny:
values, errors = {}, []
for model in self.models:
try:
@@ -213,6 +221,8 @@ class Operation:
errors.extend(items)
if errors:
raise ValidationError(errors)
+ if self.signature.response_arg:
+ values[self.signature.response_arg] = temporal_response
return values
def _create_response_model_multiple(
@@ -244,9 +254,10 @@ class AsyncOperation(Operation):
if error:
return error
try:
- values = self._get_values(request, kw)
+ temporal_response = self.api.create_temporal_response(request)
+ values = self._get_values(request, kw, temporal_response)
result = await self.view_func(request, **values)
- return self._result_to_response(request, result)
+ return self._result_to_response(request, result, temporal_response)
except Exception as e:
return self.api.on_exception(request, e)
diff --git a/ninja/signature/details.py b/ninja/signature/details.py
index 4aea69d..a740684 100644
--- a/ninja/signature/details.py
+++ b/ninja/signature/details.py
@@ -1,9 +1,10 @@
import inspect
import warnings
from collections import defaultdict, namedtuple
-from typing import Any, Callable, Dict, Generator, List, Tuple, Union
+from typing import Any, Callable, Dict, Generator, List, Optional, Tuple, Union
import pydantic
+from django.http import HttpResponse
from ninja import UploadedFile, params
from ninja.compatibility.util import get_args, get_origin as get_collection_origin
@@ -28,6 +29,7 @@ class ViewSignature:
FLATTEN_PATH_SEP = (
"\x1e" # ASCII Record Separator. IE: not generally used in query names
)
+ response_arg: Optional[str] = None
def __init__(self, path: str, view_func: Callable) -> None:
self.view_func = view_func
@@ -54,6 +56,10 @@ class ViewSignature:
# Skipping *args
continue
+ if arg.annotation is HttpResponse:
+ self.response_arg = name
+ continue
+
func_param = self._get_param_type(name, arg)
self.params.append(func_param)
| vitalik/django-ninja | e9f369883f88517a551e304e1ee2e199cad0dd2d | diff --git a/ninja/testing/client.py b/ninja/testing/client.py
index a50db15..b471bfb 100644
--- a/ninja/testing/client.py
+++ b/ninja/testing/client.py
@@ -1,5 +1,6 @@
+from http import cookies
from json import dumps as json_dumps, loads as json_loads
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+from typing import Any, Callable, Dict, List, Optional, Tuple, Union, cast
from unittest.mock import Mock
from urllib.parse import urljoin
@@ -169,5 +170,10 @@ class NinjaResponse:
def __getitem__(self, key: str) -> Any:
return self._response[key]
+ @property
+ def cookies(self) -> cookies.SimpleCookie:
+ return cast(cookies.SimpleCookie, self._response.cookies)
+
def __getattr__(self, attr: str) -> Any:
return getattr(self._response, attr)
+
diff --git a/tests/test_response.py b/tests/test_response.py
index 0ec9ffe..7d2ae3d 100644
--- a/tests/test_response.py
+++ b/tests/test_response.py
@@ -1,6 +1,7 @@
from typing import List, Union
import pytest
+from django.http import HttpResponse
from pydantic import BaseModel, ValidationError
from ninja import Router
@@ -65,6 +66,25 @@ def check_union(request, q: int):
return "invalid"
[email protected]("/check_set_header")
+def check_set_header(request, response: HttpResponse):
+ response["Cache-Control"] = "no-cache"
+ return 1
+
+
[email protected]("/check_set_cookie")
+def check_set_cookie(request, set: bool, response: HttpResponse):
+ if set:
+ response.set_cookie("test", "me")
+ return 1
+
+
[email protected]("/check_del_cookie")
+def check_del_cookie(request, response: HttpResponse):
+ response.delete_cookie("test")
+ return 1
+
+
client = TestClient(router)
@@ -95,3 +115,28 @@ def test_validates():
with pytest.raises(ValidationError):
client.get("/check_union?q=2")
+
+
+def test_set_header():
+ response = client.get("/check_set_header")
+ assert response.status_code == 200
+ assert response.content == b"1"
+ assert response["Cache-Control"] == "no-cache"
+
+
+def test_set_cookie():
+ response = client.get("/check_set_cookie?set=0")
+ assert "test" not in response.cookies
+
+ response = client.get("/check_set_cookie?set=1")
+ cookie = response.cookies.get("test")
+ assert cookie
+ assert cookie.value == "me"
+
+
+def test_del_cookie():
+ response = client.get("/check_del_cookie")
+ cookie = response.cookies.get("test")
+ assert cookie
+ assert cookie["expires"] == "Thu, 01 Jan 1970 00:00:00 GMT"
+ assert cookie["max-age"] == 0
| Provide a way to specify response headers
Seems like currently [Operation._result_to_response](https://github.com/vitalik/django-ninja/blob/5a19d230cb451f1f3ab0e167460bc05f49a6554e/ninja/operation.py#L106-L135) do not expect response headers from view function result (if not already part of `HttpResponse` instance).
This makes passing response headers tedious task.
Maybe `django-ninja` should allow view handler to setup response headers,
1. Via [temporal Response instance](https://fastapi.tiangolo.com/advanced/response-headers/) as done in FastAPI
2. Or via [last tuple item](https://flask.palletsprojects.com/en/1.1.x/quickstart/#about-responses) as done in Flask
What do you think? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_response.py::test_responses[/check_int-1]",
"tests/test_response.py::test_responses[/check_model-expected_response1]",
"tests/test_response.py::test_responses[/check_list_model-expected_response2]",
"tests/test_response.py::test_responses[/check_model-expected_response3]",
"tests/test_response.py::test_responses[/check_model_alias-expected_response4]",
"tests/test_response.py::test_responses[/check_union?q=0-1]",
"tests/test_response.py::test_responses[/check_union?q=1-expected_response6]",
"tests/test_response.py::test_validates",
"tests/test_response.py::test_set_header",
"tests/test_response.py::test_set_cookie",
"tests/test_response.py::test_del_cookie"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-01-27T04:46:02Z" | mit |
|
vitalik__django-ninja-434 | diff --git a/ninja/signature/details.py b/ninja/signature/details.py
index 8ef6d56..3e91f8d 100644
--- a/ninja/signature/details.py
+++ b/ninja/signature/details.py
@@ -252,7 +252,11 @@ def is_collection_type(annotation: Any) -> bool:
origin = get_collection_origin(annotation)
types = (List, list, set, tuple)
if origin is None:
- return issubclass(annotation, types)
+ return (
+ isinstance(annotation, types)
+ if not isinstance(annotation, type)
+ else issubclass(annotation, types)
+ )
else:
return origin in types # TODO: I guess we should handle only list
| vitalik/django-ninja | 99281903cfd4db19fd462e875d87e6edace038fc | diff --git a/tests/test_signature_details.py b/tests/test_signature_details.py
new file mode 100644
index 0000000..c48f84f
--- /dev/null
+++ b/tests/test_signature_details.py
@@ -0,0 +1,48 @@
+import typing
+from sys import version_info
+
+import pytest
+
+from ninja.signature.details import is_collection_type
+
+
[email protected](
+ ("annotation", "expected"),
+ [
+ pytest.param(typing.List, True, id="true_for_typing_List"),
+ pytest.param(list, True, id="true_for_native_list"),
+ pytest.param(typing.Set, True, id="true_for_typing_Set"),
+ pytest.param(set, True, id="true_for_native_set"),
+ pytest.param(typing.Tuple, True, id="true_for_typing_Tuple"),
+ pytest.param(tuple, True, id="true_for_native_tuple"),
+ pytest.param(
+ type("Custom", (), {}),
+ False,
+ id="false_for_custom_type_without_typing_origin",
+ ),
+ pytest.param(
+ object(), False, id="false_for_custom_instance_without_typing_origin"
+ ),
+ pytest.param(
+ typing.NewType("SomethingNew", str),
+ False,
+ id="false_for_instance_without_typing_origin",
+ ),
+ # Can't mark with `pytest.mark.skipif` since we'd attempt to instantiate the
+ # parameterized value/type(e.g. `list[int]`). Which only works with Python >= 3.9)
+ *(
+ (
+ pytest.param(list[int], True, id="true_for_parameterized_native_list"),
+ pytest.param(set[int], True, id="true_for_parameterized_native_set"),
+ pytest.param(
+ tuple[int], True, id="true_for_parameterized_native_tuple"
+ ),
+ )
+ # TODO: Remove conditional once support for <=3.8 is dropped
+ if version_info >= (3, 9)
+ else ()
+ ),
+ ],
+)
+def test_is_collection_type_returns(annotation: typing.Any, expected: bool):
+ assert is_collection_type(annotation) is expected
| [BUG] Declaring path param as any kind of instance crashes (at `signature.details.is_collection_type`)
Declaring a path with parameters from e.g. `typing.NewType` raises a `TypingError` from `issubclass`. See relevant traceback below.
```
File "/app/venv/lib/python3.10/site-packages/ninja/router.py", line 238, in decorator
self.add_api_operation(
File "/app/venv/lib/python3.10/site-packages/ninja/router.py", line 285, in add_api_operation
path_view.add_operation(
File "/app/venv/lib/python3.10/site-packages/ninja/operation.py", line 289, in add_operation
operation = OperationClass(
File "/app/venv/lib/python3.10/site-packages/ninja/operation.py", line 240, in __init__
super().__init__(*args, **kwargs)
File "/app/venv/lib/python3.10/site-packages/ninja/operation.py", line 65, in __init__
self.signature = ViewSignature(self.path, self.view_func)
File "/app/venv/lib/python3.10/site-packages/ninja/signature/details.py", line 57, in __init__
func_param = self._get_param_type(name, arg)
File "/app/venv/lib/python3.10/site-packages/ninja/signature/details.py", line 202, in _get_param_type
is_collection = is_collection_type(annotation)
File "/app/venv/lib/python3.10/site-packages/ninja/signature/details.py", line 255, in is_collection_type
return issubclass(annotation, types)
File "/usr/local/lib/python3.10/typing.py", line 1157, in __subclasscheck__
return issubclass(cls, self.__origin__)
TypeError: issubclass() arg 1 must be a class
```
For background, I'm trying to use a custom Django path converter. Which feeds a complex type (based on `pydantic.BaseModel`) that has attributes typed via `typing.NewType`.
In any case, here's a minimal repro:
```python
from typing import NewType
from django.http import HttpRequest, HttpResponse
from ninja import NinjaAPI
Custom = NewType("Custom", str)
api = NinjaAPI()
@api.get("/endpoint/{custom:value}/")
def endpoint(request: HttpRequest, value: Custom) -> HttpResponse:
...
```
**Versions:**
- Python version: `3.10.4`
- Django version: `4.0.4`
- Django-Ninja version: `0.17.0`
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_signature_details.py::test_is_collection_type_returns[false_for_custom_instance_without_typing_origin]",
"tests/test_signature_details.py::test_is_collection_type_returns[false_for_instance_without_typing_origin]"
] | [
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_typing_List]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_native_list]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_typing_Set]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_native_set]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_typing_Tuple]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_native_tuple]",
"tests/test_signature_details.py::test_is_collection_type_returns[false_for_custom_type_without_typing_origin]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_parameterized_native_list]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_parameterized_native_set]",
"tests/test_signature_details.py::test_is_collection_type_returns[true_for_parameterized_native_tuple]"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2022-05-03T09:55:46Z" | mit |
|
vitalik__django-ninja-667 | diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index d9e7ff5..5374fc6 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -12,7 +12,7 @@ repos:
additional_dependencies: ["django-stubs", "pydantic"]
exclude: (tests|docs)/
- repo: https://github.com/psf/black
- rev: "22.3.0"
+ rev: "23.1.0"
hooks:
- id: black
exclude: docs/src/
diff --git a/ninja/main.py b/ninja/main.py
index fe70c1f..15ce90b 100644
--- a/ninja/main.py
+++ b/ninja/main.py
@@ -353,7 +353,7 @@ class NinjaAPI:
prefix = normalize_path("/".join((parent_prefix, prefix))).lstrip("/")
self._routers.extend(router.build_routers(prefix))
- router.set_api_instance(self)
+ router.set_api_instance(self, parent_router)
@property
def urls(self) -> Tuple[List[Union[URLResolver, URLPattern]], str, str]:
diff --git a/ninja/openapi/schema.py b/ninja/openapi/schema.py
index 022b51d..ce17241 100644
--- a/ninja/openapi/schema.py
+++ b/ninja/openapi/schema.py
@@ -179,7 +179,6 @@ class OpenAPISchema(dict):
by_alias: bool = True,
remove_level: bool = True,
) -> Tuple[DictStrAny, bool]:
-
if hasattr(model, "_flatten_map"):
schema = self._flatten_schema(model)
else:
@@ -242,7 +241,6 @@ class OpenAPISchema(dict):
result = {}
for status, model in operation.response_models.items():
-
if status == Ellipsis:
continue # it's not yet clear what it means if user wants to output any other code
diff --git a/ninja/params_models.py b/ninja/params_models.py
index 3c928fc..3714a87 100644
--- a/ninja/params_models.py
+++ b/ninja/params_models.py
@@ -163,7 +163,6 @@ class FileModel(ParamModel):
class _HttpRequest(HttpRequest):
-
body: bytes = b""
diff --git a/ninja/router.py b/ninja/router.py
index 2bfaa11..53bdec3 100644
--- a/ninja/router.py
+++ b/ninja/router.py
@@ -299,6 +299,8 @@ class Router:
self, api: "NinjaAPI", parent_router: Optional["Router"] = None
) -> None:
# TODO: check - parent_router seems not used
+ if self.auth is NOT_SET and parent_router and parent_router.auth:
+ self.auth = parent_router.auth
self.api = api
for path_view in self.path_operations.values():
path_view.set_api_instance(self.api, self)
diff --git a/ninja/security/http.py b/ninja/security/http.py
index 8deb1c4..6a67296 100644
--- a/ninja/security/http.py
+++ b/ninja/security/http.py
@@ -83,5 +83,7 @@ class HttpBasicAuth(HttpAuthBase, ABC): # TODO: maybe HttpBasicAuthBase
try:
username, password = b64decode(user_pass_encoded).decode().split(":", 1)
return unquote(username), unquote(password)
- except Exception as e: # dear contributors please do not change to valueerror - here can be multiple exceptions
+ except (
+ Exception
+ ) as e: # dear contributors please do not change to valueerror - here can be multiple exceptions
raise DecodeError("Invalid Authorization header") from e
| vitalik/django-ninja | 15d2401a3d926d07e0d817e8af8c9fb1846241e5 | diff --git a/tests/test_auth_inheritance_routers.py b/tests/test_auth_inheritance_routers.py
new file mode 100644
index 0000000..7457026
--- /dev/null
+++ b/tests/test_auth_inheritance_routers.py
@@ -0,0 +1,76 @@
+import pytest
+
+from ninja import NinjaAPI, Router
+from ninja.security import APIKeyQuery
+from ninja.testing import TestClient
+
+
+class Auth(APIKeyQuery):
+ def __init__(self, secret):
+ self.secret = secret
+ super().__init__()
+
+ def authenticate(self, request, key):
+ if key == self.secret:
+ return key
+
+
+api = NinjaAPI()
+
+r1 = Router()
+r2 = Router()
+r3 = Router()
+r4 = Router()
+
+api.add_router("/r1", r1, auth=Auth("r1_auth"))
+r1.add_router("/r2", r2)
+r2.add_router("/r3", r3)
+r3.add_router("/r4", r4, auth=Auth("r4_auth"))
+
+client = TestClient(api)
+
+
[email protected]("/")
+def op1(request):
+ return request.auth
+
+
[email protected]("/")
+def op2(request):
+ return request.auth
+
+
[email protected]("/")
+def op3(request):
+ return request.auth
+
+
[email protected]("/")
+def op4(request):
+ return request.auth
+
+
[email protected]("/op5", auth=Auth("op5_auth"))
+def op5(request):
+ return request.auth
+
+
[email protected](
+ "route, status_code",
+ [
+ ("/r1/", 401),
+ ("/r1/r2/", 401),
+ ("/r1/r2/r3/", 401),
+ ("/r1/r2/r3/r4/", 401),
+ ("/r1/r2/r3/op5", 401),
+ ("/r1/?key=r1_auth", 200),
+ ("/r1/r2/?key=r1_auth", 200),
+ ("/r1/r2/r3/?key=r1_auth", 200),
+ ("/r1/r2/r3/r4/?key=r4_auth", 200),
+ ("/r1/r2/r3/op5?key=op5_auth", 200),
+ ("/r1/r2/r3/r4/?key=r1_auth", 401),
+ ("/r1/r2/r3/op5?key=r1_auth", 401),
+ ],
+)
+def test_router_inheritance_auth(route, status_code):
+ assert client.get(route).status_code == status_code
diff --git a/tests/test_docs/test_body.py b/tests/test_docs/test_body.py
index c259424..a83ca3c 100644
--- a/tests/test_docs/test_body.py
+++ b/tests/test_docs/test_body.py
@@ -5,7 +5,6 @@ from ninja.testing import TestClient
def test_examples():
-
api = NinjaAPI()
with patch("builtins.api", api, create=True):
diff --git a/tests/test_docs/test_form.py b/tests/test_docs/test_form.py
index 0bc3597..315e0f2 100644
--- a/tests/test_docs/test_form.py
+++ b/tests/test_docs/test_form.py
@@ -5,7 +5,6 @@ from ninja.testing import TestClient
def test_examples():
-
api = NinjaAPI()
with patch("builtins.api", api, create=True):
diff --git a/tests/test_docs/test_path.py b/tests/test_docs/test_path.py
index fbd7cb1..1adba45 100644
--- a/tests/test_docs/test_path.py
+++ b/tests/test_docs/test_path.py
@@ -5,7 +5,6 @@ from ninja.testing import TestClient
def test_examples():
-
api = NinjaAPI()
with patch("builtins.api", api, create=True):
diff --git a/tests/test_docs/test_query.py b/tests/test_docs/test_query.py
index a4df178..a94b022 100644
--- a/tests/test_docs/test_query.py
+++ b/tests/test_docs/test_query.py
@@ -5,7 +5,6 @@ from ninja.testing import TestClient
def test_examples():
-
api = NinjaAPI()
with patch("builtins.api", api, create=True):
diff --git a/tests/test_export_openapi_schema.py b/tests/test_export_openapi_schema.py
index bf9fd96..0555e79 100644
--- a/tests/test_export_openapi_schema.py
+++ b/tests/test_export_openapi_schema.py
@@ -11,7 +11,6 @@ from ninja.management.commands.export_openapi_schema import Command as ExportCmd
def test_export_default():
-
output = StringIO()
call_command(ExportCmd(), stdout=output)
json.loads(output.getvalue()) # if no exception, then OK
diff --git a/tests/test_openapi_schema.py b/tests/test_openapi_schema.py
index b5507be..f0e6ab7 100644
--- a/tests/test_openapi_schema.py
+++ b/tests/test_openapi_schema.py
@@ -660,7 +660,6 @@ def test_union_payload_simple(schema):
def test_get_openapi_urls():
-
api = NinjaAPI(openapi_url=None)
paths = get_openapi_urls(api)
assert len(paths) == 0
@@ -677,7 +676,6 @@ def test_get_openapi_urls():
def test_unique_operation_ids():
-
api = NinjaAPI()
@api.get("/1")
diff --git a/tests/test_test_client.py b/tests/test_test_client.py
index c0114f9..f95080e 100644
--- a/tests/test_test_client.py
+++ b/tests/test_test_client.py
@@ -67,7 +67,6 @@ def test_django_2_2_plus_headers(version, has_headers):
class ClientTestSchema(Schema):
-
time: datetime
| Router does not support auth inheritance
**Describe the bug**
When you try adding a new router to an existing router, the leaf router doesn't inherit the top-level auth.
Consider the below example:
```py
from ninja import NinjaAPI, Router
from ninja.security import APIKeyQuery
api = NinjaAPI()
r1 = Router()
r2 = Router()
r3 = Router()
class Auth(APIKeyQuery):
def __init__(self, secret):
self.secret = secret
super().__init__()
def authenticate(self, request, key):
if key == self.secret:
return key
api.add_router("/r1", r1, auth=Auth("r1_auth"))
r1.add_router("/r2", r2)
r2.add_router("/r3", r3)
@r1.get("/")
def op1(request):
return request.auth
@r2.get("/")
def op2(request):
return request.auth
@r3.get("/")
def op3(request):
return request.auth
```
So the auth provided for router `r1` won't be present for any operations in routers `r2` and `r3` even though it comes under it.
This is only for routers though. If we add auth when we initialize `NinjaApi()` it propagates down to all routers and endpoints even if we provide the auth when initializing router r1 as `r1 = Router(auth=Auth("r1_auth"))`. Screenshot of the above code is shown below.
<img width="1453" alt="Screen Shot 2023-01-28 at 9 44 00 AM" src="https://user-images.githubusercontent.com/38973423/215273256-f2b43a14-153a-4e5b-9111-2aa779fc6a0c.png">
I think it's super helpful to include this in the documentation if we don't plan to support it as a dev can easily misinterpret it and in turn, pose a security threat to the app they are building.
**Versions (please complete the following information):**
- Python version: 3.9.12
- Django version: 4.1.5
- Django-Ninja version: 0.20.0
- Pydantic version: 1.10.4
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/?key=r1_auth-200]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/?key=r1_auth-200]"
] | [
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/r4/-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/op5-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/?key=r1_auth-200]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/r4/?key=r4_auth-200]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/op5?key=op5_auth-200]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/r4/?key=r1_auth-401]",
"tests/test_auth_inheritance_routers.py::test_router_inheritance_auth[/r1/r2/r3/op5?key=r1_auth-401]",
"tests/test_docs/test_body.py::test_examples",
"tests/test_docs/test_form.py::test_examples",
"tests/test_docs/test_path.py::test_examples",
"tests/test_docs/test_query.py::test_examples",
"tests/test_export_openapi_schema.py::test_export_default",
"tests/test_export_openapi_schema.py::test_export_indent",
"tests/test_export_openapi_schema.py::test_export_to_file",
"tests/test_export_openapi_schema.py::test_export_custom",
"tests/test_openapi_schema.py::test_schema_views",
"tests/test_openapi_schema.py::test_schema_views_no_INSTALLED_APPS",
"tests/test_openapi_schema.py::test_schema",
"tests/test_openapi_schema.py::test_schema_alias",
"tests/test_openapi_schema.py::test_schema_list",
"tests/test_openapi_schema.py::test_schema_body",
"tests/test_openapi_schema.py::test_schema_body_schema",
"tests/test_openapi_schema.py::test_schema_path",
"tests/test_openapi_schema.py::test_schema_form",
"tests/test_openapi_schema.py::test_schema_single",
"tests/test_openapi_schema.py::test_schema_form_body",
"tests/test_openapi_schema.py::test_schema_form_file",
"tests/test_openapi_schema.py::test_schema_body_file",
"tests/test_openapi_schema.py::test_schema_title_description",
"tests/test_openapi_schema.py::test_union_payload_type",
"tests/test_openapi_schema.py::test_union_payload_simple",
"tests/test_openapi_schema.py::test_get_openapi_urls",
"tests/test_openapi_schema.py::test_unique_operation_ids",
"tests/test_openapi_schema.py::test_docs_decorator",
"tests/test_openapi_schema.py::test_renderer_media_type",
"tests/test_test_client.py::test_sync_build_absolute_uri[/request/build_absolute_uri-HTTPStatus.OK-http:/testlocation/]",
"tests/test_test_client.py::test_sync_build_absolute_uri[/request/build_absolute_uri/location-HTTPStatus.OK-http:/testlocation/location]",
"tests/test_test_client.py::test_django_2_2_plus_headers[version0-False]",
"tests/test_test_client.py::test_django_2_2_plus_headers[version1-False]",
"tests/test_test_client.py::test_django_2_2_plus_headers[version2-True]",
"tests/test_test_client.py::test_django_2_2_plus_headers[version3-True]",
"tests/test_test_client.py::test_schema_as_data",
"tests/test_test_client.py::test_json_as_body"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-01-28T15:07:37Z" | mit |
|
vitalik__django-ninja-838 | diff --git a/ninja/errors.py b/ninja/errors.py
index 1be1dff..3c1056a 100644
--- a/ninja/errors.py
+++ b/ninja/errors.py
@@ -39,14 +39,18 @@ class ValidationError(Exception):
"""
def __init__(self, errors: List[DictStrAny]) -> None:
- super().__init__()
self.errors = errors
+ super().__init__(errors)
class HttpError(Exception):
def __init__(self, status_code: int, message: str) -> None:
self.status_code = status_code
- super().__init__(message)
+ self.message = message
+ super().__init__(status_code, message)
+
+ def __str__(self) -> str:
+ return self.message
def set_default_exc_handlers(api: "NinjaAPI") -> None:
| vitalik/django-ninja | 8be35e42a9dc2365e764a0fea0a0b868eeae312b | diff --git a/tests/test_errors.py b/tests/test_errors.py
new file mode 100644
index 0000000..b19c015
--- /dev/null
+++ b/tests/test_errors.py
@@ -0,0 +1,26 @@
+import pickle
+
+from ninja.errors import HttpError, ValidationError
+
+
+def test_validation_error_is_picklable_and_unpicklable():
+ error_to_serialize = ValidationError([{"testkey": "testvalue"}])
+
+ serialized = pickle.dumps(error_to_serialize)
+ assert serialized # Not empty
+
+ deserialized = pickle.loads(serialized)
+ assert isinstance(deserialized, ValidationError)
+ assert deserialized.errors == error_to_serialize.errors
+
+
+def test_http_error_is_picklable_and_unpicklable():
+ error_to_serialize = HttpError(500, "Test error")
+
+ serialized = pickle.dumps(error_to_serialize)
+ assert serialized # Not empty
+
+ deserialized = pickle.loads(serialized)
+ assert isinstance(deserialized, HttpError)
+ assert deserialized.status_code == error_to_serialize.status_code
+ assert deserialized.message == error_to_serialize.message
| [BUG] "ValidationError" and "HttpError" are not unpickable
**Describe the bug**
Hi.
It seems the `ValidationError` can be pickled but not un-pickled:
```python
import pickle
from ninja.errors import ValidationError
error = ValidationError(errors=[])
serialized = pickle.dumps(error) # OK
deserialized = pickle.loads(serialized) # NOK
```
It causes:
```
Traceback (most recent call last):
File "/home/delgan/test.py", line 6, in <module>
deserialized = pickle.loads(serialized)
^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: ValidationError.__init__() missing 1 required positional argument: 'errors'
```
This is actually a reccurent problem while inheriting Python `Exception`:
- [Cannot unpickle Exception subclass](https://stackoverflow.com/questions/41808912/cannot-unpickle-exception-subclass)
- [How to pickle inherited exceptions?](https://stackoverflow.com/questions/49715881/how-to-pickle-inherited-exceptions)
- [How to make a custom exception class with multiple init args pickleable](https://stackoverflow.com/questions/16244923/how-to-make-a-custom-exception-class-with-multiple-init-args-pickleable)
The fix requires to implement a `__reduce__` method for these classes.
The `multiprocessing` module makes extensive use of `pickle` protocol, and having objects that can't be de-serialized is source of unexpected errors (in my case, because the `Exception` is sent to a background processing thread for logging).
**Versions (please complete the following information):**
- Python version: 3.11.3
- Django version: 4.2.4
- Django-Ninja version: 0.22.2
- Pydantic version: 0.4.4
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_errors.py::test_validation_error_is_picklable_and_unpicklable",
"tests/test_errors.py::test_http_error_is_picklable_and_unpicklable"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-08-30T18:30:44Z" | mit |
|
vivisect__vivisect-447 | diff --git a/envi/archs/i386/emu.py b/envi/archs/i386/emu.py
index 658a6f7..02e9b6a 100755
--- a/envi/archs/i386/emu.py
+++ b/envi/archs/i386/emu.py
@@ -9,7 +9,7 @@ from envi.const import *
import envi.exc as e_exc
import envi.bits as e_bits
-from envi.archs.i386.opconst import PREFIX_REX_W
+from envi.archs.i386.opconst import PREFIX_REX_W, REP_OPCODES
from envi.archs.i386.regs import *
from envi.archs.i386.disasm import *
from envi.archs.i386 import i386Module
@@ -245,8 +245,9 @@ class IntelEmulator(i386RegisterContext, envi.Emulator):
if meth is None:
raise e_exc.UnsupportedInstruction(self, op)
+ # The behavior of the REP prefix is undefined when used with non-string instructions.
rep_prefix = op.prefixes & PREFIX_REP_MASK
- if rep_prefix and not self.getEmuOpt('i386:reponce'):
+ if rep_prefix and op.opcode in REP_OPCODES and not self.getEmuOpt('i386:reponce'):
# REP instructions (REP/REPNZ/REPZ/REPSIMD) get their own handlers
handler = self.__rep_prefix_handlers__.get(rep_prefix)
newpc = handler(meth, op)
@@ -273,9 +274,6 @@ class IntelEmulator(i386RegisterContext, envi.Emulator):
Then the instruction is repeated and ECX decremented until either
ECX reaches 0 or the ZF is cleared.
'''
- if op.mnem.startswith('nop'):
- return
-
ecx = emu.getRegister(REG_ECX)
emu.setFlag(EFLAGS_ZF, 1)
diff --git a/envi/archs/i386/opconst.py b/envi/archs/i386/opconst.py
index 9fc2db9..4f9add5 100644
--- a/envi/archs/i386/opconst.py
+++ b/envi/archs/i386/opconst.py
@@ -197,15 +197,24 @@ INS_OFLOW = INS_TRAPS | 0x08 # gen overflow trap
#/* INS_SYSTEM */
INS_HALT = INS_SYSTEM | 0x01 # halt machine
-INS_IN = INS_SYSTEM | 0x02 # input form port
+INS_IN = INS_SYSTEM | 0x02 # input from port
INS_OUT = INS_SYSTEM | 0x03 # output to port
INS_CPUID = INS_SYSTEM | 0x04 # iden
INS_NOP = INS_OTHER | 0x01
INS_BCDCONV = INS_OTHER | 0x02 # convert to/from BCD
INS_SZCONV = INS_OTHER | 0x03 # convert size of operand
-INS_CRYPT = INS_OTHER | 0x4 # AES-NI instruction support
+INS_CRYPT = INS_OTHER | 0x04 # AES-NI instruction support
+# string instructions that support REP prefix
+REP_OPCODES = (
+ INS_IN, # INS
+ INS_OUT, # OUTS
+ INS_STRMOV, # MOVS
+ INS_STRLOAD, # LODS
+ INS_STRSTOR, # STOS
+ INS_STRCMP # CMPS, SCAS
+ )
OP_R = 0x001
OP_W = 0x002
| vivisect/vivisect | e1f86b698704f37bebbe3996c7138d871c00652f | diff --git a/envi/tests/test_arch_i386_emu.py b/envi/tests/test_arch_i386_emu.py
index 273a29d..d8b26e7 100644
--- a/envi/tests/test_arch_i386_emu.py
+++ b/envi/tests/test_arch_i386_emu.py
@@ -108,7 +108,12 @@ i386Tests = [
# lea ecx,dword [esp + -973695896] (test SIB getOperAddr)
{'bytes': '8d8c246894f6c5',
'setup': ({'esp': 0x7fd0}, {}),
- 'tests': ({'ecx': 0xc5f71438}, {})}
+ 'tests': ({'ecx': 0xc5f71438}, {})},
+ # rep ret
+ # The behavior of the REP prefix is undefined when used with non-string instructions.
+ {'bytes': 'f3c3',
+ 'setup': ({'ecx': 0x1}, {'esp': b'\x00\x00\x00\x60'}),
+ 'tests': ({'ecx': 0x1, 'eip': 0x60000000}, {})}
]
| i386 rep emulation incorrect
The current emulator runs the rep prefix for every instruction.
Per the Intel manual: "The behavior of the REP prefix is undefined when used with non-string instructions."
Example assembly resulting in incorrect / slow emulation decrementing undefined `ecx` value.
```asm
.text:00402107 74 07 jz short loc_402110
.text:00402109 F3 C3 rep retn
```
References:
- https://repzret.org/p/repzret/
- https://stackoverflow.com/questions/10258918/what-happens-when-a-rep-prefix-is-attached-to-a-non-string-instruction | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"envi/tests/test_arch_i386_emu.py::i386EmulatorTests::test_i386_emulator"
] | [
"envi/tests/test_arch_i386_emu.py::i386EmulatorTests::test_i386_reps",
"envi/tests/test_arch_i386_emu.py::i386EmulatorTests::test_x86_OperAddrs"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-08-30T12:15:50Z" | apache-2.0 |
|
vogt4nick__dequindre-53 | diff --git a/.bumpversion.cfg b/.bumpversion.cfg
index a13f5ef..b6ca05f 100644
--- a/.bumpversion.cfg
+++ b/.bumpversion.cfg
@@ -1,5 +1,5 @@
[bumpversion]
-current_version = 0.5.0.dev0
+current_version = 0.5.0.dev1
commit = True
tag = False
parse = (?P<major>\d+)
diff --git a/dequindre/__init__.py b/dequindre/__init__.py
index ad99842..b8e0a67 100644
--- a/dequindre/__init__.py
+++ b/dequindre/__init__.py
@@ -16,7 +16,7 @@ from subprocess import check_output, CalledProcessError
from time import sleep
-__version__ = '0.5.0.dev0'
+__version__ = '0.5.0.dev1'
class CyclicGraphError(Exception):
@@ -360,8 +360,8 @@ class Dequindre:
return None
- def get_task_priorities(self) -> Dict[Task, int]:
- """Define priority level for each task
+ def get_task_schedules(self) -> Dict[Task, int]:
+ """Define schedule priority level for each task
Example:
make_tea -> pour_tea -> drink_tea will give the dict
@@ -388,8 +388,8 @@ class Dequindre:
return task_priority
- def get_priorities(self) -> Dict[int, Set[Task]]:
- """Define tasks for each priority level.
+ def get_schedules(self) -> Dict[int, Set[Task]]:
+ """Schedule tasks by priority level.
Example:
make_tea -> pour_tea -> drink_tea will give the dict
@@ -400,7 +400,7 @@ class Dequindre:
}
"""
priorities = defaultdict(set)
- task_priorities = self.get_task_priorities()
+ task_priorities = self.get_task_schedules()
for k, v in task_priorities.items():
priorities[v].add(k)
@@ -425,7 +425,7 @@ class Dequindre:
def run_tasks(self):
"""Run all tasks on the DAG"""
self.refresh_dag() # refresh just in case
- priorities = self.get_priorities()
+ priorities = self.get_schedules()
for k, tasks in priorities.items():
for task in tasks:
diff --git a/readme.md b/readme.md
index 6215e39..1e03959 100644
--- a/readme.md
+++ b/readme.md
@@ -37,7 +37,7 @@ Dequindre allows dynamic configuration with Python. By example, we may program t
>>>
>>> # run tasks
>>> dq = Dequindre(dag, check_conda=False)
->>> dq = dq.get_priorities()
+>>> dq = dq.get_schedules()
defaultdict(<class 'set'>, {
1: {Task(make_tea.py), Task(prep_infuser.py)},
2: {Task(boil_water.py)},
| vogt4nick/dequindre | 40465f0af55515c359f5e9965f38480df700149e | diff --git a/dequindre/tests/test_Dequindre.py b/dequindre/tests/test_Dequindre.py
index a48eb58..82b8b1c 100644
--- a/dequindre/tests/test_Dequindre.py
+++ b/dequindre/tests/test_Dequindre.py
@@ -68,7 +68,7 @@ def test__Dequindre_refresh_dag():
assert t == nt
-def test__Dequindre_get_task_priorities():
+def test__Dequindre_get_task_schedules():
A = Task('A.py', 'test-env')
B = Task('B.py', 'test-env')
C = Task('C.py', 'test-env')
@@ -78,7 +78,7 @@ def test__Dequindre_get_task_priorities():
dag.add_edges({A:B, B:C})
dq = Dequindre(dag)
- priorities = dq.get_task_priorities()
+ priorities = dq.get_task_schedules()
testable = {hash(k): v for k, v in priorities.items()}
assert testable == {
@@ -89,7 +89,7 @@ def test__Dequindre_get_task_priorities():
}
-def test__Dequindre_get_priorities():
+def test__Dequindre_get_schedules():
A = Task('A.py', 'test-env')
B = Task('B.py', 'test-env')
C = Task('C.py', 'test-env')
@@ -99,7 +99,7 @@ def test__Dequindre_get_priorities():
dag.add_edges({A:B, B:C})
dq = Dequindre(dag)
- priorities = dq.get_priorities()
+ priorities = dq.get_schedules()
testable = {}
# build a testable result dict
| Rework schedule methods
`Dequindre.get_task_priorities` and `Dequindre.get_priorities` is a little opaque.
### Proposal A
We rename `get_task_priorities` to `get_task_schedules`, and rename `get_priorities` to `get_schedules`. They'll return the same values, but the new names will be more obvious to users.
### Proposal B
We keep `get_task_priorities` and `get_priorities` as they are. We introduce `get_schedules` which returns an ordered list of when the tasks will be run at runtime.
Proposal A sounds best right now, but we should stew on it a bit before making a final decision. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"dequindre/tests/test_Dequindre.py::test__Dequindre_get_task_schedules",
"dequindre/tests/test_Dequindre.py::test__Dequindre_get_schedules"
] | [
"dequindre/tests/test_Dequindre.py::test__Dequindre_init_exceptions",
"dequindre/tests/test_Dequindre.py::test__Dequindre_init",
"dequindre/tests/test_Dequindre.py::test__Dequindre_repr",
"dequindre/tests/test_Dequindre.py::test__Dequindre_refresh_dag"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2019-02-24T15:37:49Z" | mit |
|
vprusso__toqito-26 | diff --git a/docs/channels.rst b/docs/channels.rst
index f0a73b7..22cc7f0 100644
--- a/docs/channels.rst
+++ b/docs/channels.rst
@@ -64,3 +64,4 @@ Properties of Quantum Channels
toqito.channel_props.is_herm_preserving
toqito.channel_props.is_positive
toqito.channel_props.is_unital
+ toqito.channel_props.choi_rank
diff --git a/toqito/channel_props/__init__.py b/toqito/channel_props/__init__.py
index 74eab7f..66750f4 100644
--- a/toqito/channel_props/__init__.py
+++ b/toqito/channel_props/__init__.py
@@ -3,3 +3,4 @@ from toqito.channel_props.is_herm_preserving import is_herm_preserving
from toqito.channel_props.is_completely_positive import is_completely_positive
from toqito.channel_props.is_positive import is_positive
from toqito.channel_props.is_unital import is_unital
+from toqito.channel_props.choi_rank import choi_rank
diff --git a/toqito/channel_props/choi_rank.py b/toqito/channel_props/choi_rank.py
new file mode 100644
index 0000000..dcc6b18
--- /dev/null
+++ b/toqito/channel_props/choi_rank.py
@@ -0,0 +1,89 @@
+"""Calculate the Choi rank of a channel."""
+from typing import List, Union
+
+import numpy as np
+from toqito.channel_ops import kraus_to_choi
+
+
+def choi_rank(phi: Union[np.ndarray, List[List[np.ndarray]]]) -> int:
+ r"""
+ Calculate the rank of the Choi representation of a quantum channel.
+
+ Examples
+ ==========
+
+ The transpose map can be written either in Choi representation (as a
+ SWAP operator) or in Kraus representation. If we choose the latter, it
+ will be given by the following matrices:
+
+ .. math::
+ \begin{equation}
+ \begin{aligned}
+ \frac{1}{\sqrt{2}}
+ \begin{pmatrix}
+ 0 & i \\ -i & 0
+ \end{pmatrix}, &\quad
+ \frac{1}{\sqrt{2}}
+ \begin{pmatrix}
+ 0 & 1 \\
+ 1 & 0
+ \end{pmatrix}, \\
+ \begin{pmatrix}
+ 1 & 0 \\
+ 0 & 0
+ \end{pmatrix}, &\quad
+ \begin{pmatrix}
+ 0 & 0 \\
+ 0 & 1
+ \end{pmatrix}.
+ \end{aligned}
+ \end{equation}
+
+ and can be generated in :code:`toqito` with the following list:
+
+ >>> import numpy as np
+ >>> kraus_1 = np.array([[1, 0], [0, 0]])
+ >>> kraus_2 = np.array([[1, 0], [0, 0]]).conj().T
+ >>> kraus_3 = np.array([[0, 1], [0, 0]])
+ >>> kraus_4 = np.array([[0, 1], [0, 0]]).conj().T
+ >>> kraus_5 = np.array([[0, 0], [1, 0]])
+ >>> kraus_6 = np.array([[0, 0], [1, 0]]).conj().T
+ >>> kraus_7 = np.array([[0, 0], [0, 1]])
+ >>> kraus_8 = np.array([[0, 0], [0, 1]]).conj().T
+ >>> kraus_ops = [
+ >>> [kraus_1, kraus_2],
+ >>> [kraus_3, kraus_4],
+ >>> [kraus_5, kraus_6],
+ >>> [kraus_7, kraus_8],
+ >>> ]
+
+ To calculate its Choi rank, we proceed in the following way:
+
+ >>> from toqito.channel_props import choi_rank
+ >>> choi_rank(kraus_ops)
+ 4
+
+ We can the verify the associated Choi representation (the SWAP gate)
+ gets the same Choi rank:
+
+ >>> choi_matrix = np.array([[1,0,0,0],[0,0,1,0],[0,1,0,0],[0,0,0,1]])
+ >>> choi_rank(choi_matrix)
+ 4
+
+ References
+ ==========
+
+ .. [WatDepo18] Watrous, John.
+ "The theory of quantum information."
+ Section: "2.2 Quantum Channels".
+ Cambridge University Press, 2018.
+
+ :param phi: Either a Choi matrix or a list of Kraus operators
+ :return: The Choi rank of the provided channel representation.
+ """
+ if isinstance(phi, list):
+ phi = kraus_to_choi(phi)
+ elif not isinstance(phi, np.ndarray):
+ raise ValueError("Not a valid Choi matrix.")
+
+ return np.linalg.matrix_rank(phi)
| vprusso/toqito | 530682340a703952061a520612468d5142efd7ca | diff --git a/tests/test_channel_props/test_choi_rank.py b/tests/test_channel_props/test_choi_rank.py
new file mode 100644
index 0000000..f6dddef
--- /dev/null
+++ b/tests/test_channel_props/test_choi_rank.py
@@ -0,0 +1,44 @@
+"""Tests for choi_rank."""
+import numpy as np
+import pytest
+
+from toqito.channel_props import choi_rank
+
+
+def test_choi_rank_list_kraus():
+ """Verify that a list of Kraus operators gives correct Choi rank"""
+ kraus_1 = np.array([[1, 0], [0, 0]])
+ kraus_2 = np.array([[1, 0], [0, 0]]).conj().T
+ kraus_3 = np.array([[0, 1], [0, 0]])
+ kraus_4 = np.array([[0, 1], [0, 0]]).conj().T
+ kraus_5 = np.array([[0, 0], [1, 0]])
+ kraus_6 = np.array([[0, 0], [1, 0]]).conj().T
+ kraus_7 = np.array([[0, 0], [0, 1]])
+ kraus_8 = np.array([[0, 0], [0, 1]]).conj().T
+
+ kraus_ops = [
+ [kraus_1, kraus_2],
+ [kraus_3, kraus_4],
+ [kraus_5, kraus_6],
+ [kraus_7, kraus_8],
+ ]
+ np.testing.assert_equal(choi_rank(kraus_ops), 4)
+
+
+def test_choi_rank_choi_matrix():
+ """Verify Choi matrix of the swap operator map gives correct Choi rank."""
+ choi_matrix = np.array([[1, 0, 0, 0], [0, 0, 1, 0],
+ [0, 1, 0, 0], [0, 0, 0, 1]])
+ np.testing.assert_equal(choi_rank(choi_matrix), 4)
+
+
+def test_choi_bad_input():
+ """Verify that a bad input (such as a string which still passes
+ with `numpy.linalg.matrix_rank`) raises an error"""
+ with pytest.raises(ValueError, match="Not a valid"):
+ bad_input = 'string'
+ choi_rank(bad_input)
+
+
+if __name__ == "__main__":
+ np.testing.run_module_suite()
| Feature: Choi rank
Write a function that calculates the "Choi rank".
Refer to page 79 of https://cs.uwaterloo.ca/~watrous/TQI/TQI.pdf for the definition of the Choi rank.
In short, the Choi rank is the rank of the Choi representation of a quantum channel. The input to the function should be either a set of Kraus operators or a Choi matrix. If the former, the Kraus operators should be converted to a Choi matrix. Calculating the matrix rank of the resulting Choi matrix would yield the desired "Choi rank".
This task would also require adding test coverage for the function along with ensuring it is included in the docs. Refer to the style guide and code contributing guidelines for more information. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_channel_props/test_choi_rank.py::test_choi_rank_list_kraus",
"tests/test_channel_props/test_choi_rank.py::test_choi_rank_choi_matrix",
"tests/test_channel_props/test_choi_rank.py::test_choi_bad_input"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-28T13:06:44Z" | mit |
|
vprusso__toqito-27 | diff --git a/docs/_autosummary/toqito.channel_props.is_trace_preserving.rst b/docs/_autosummary/toqito.channel_props.is_trace_preserving.rst
new file mode 100644
index 0000000..cb62066
--- /dev/null
+++ b/docs/_autosummary/toqito.channel_props.is_trace_preserving.rst
@@ -0,0 +1,6 @@
+toqito.channel\_props.is\_trace\_preserving
+==========================================
+
+.. currentmodule:: toqito.channel_props
+
+.. autofunction:: is_trace_preserving
diff --git a/toqito/channel_props/__init__.py b/toqito/channel_props/__init__.py
index 66750f4..c66cdc3 100644
--- a/toqito/channel_props/__init__.py
+++ b/toqito/channel_props/__init__.py
@@ -4,3 +4,4 @@ from toqito.channel_props.is_completely_positive import is_completely_positive
from toqito.channel_props.is_positive import is_positive
from toqito.channel_props.is_unital import is_unital
from toqito.channel_props.choi_rank import choi_rank
+from toqito.channel_props.is_trace_preserving import is_trace_preserving
diff --git a/toqito/channel_props/is_trace_preserving.py b/toqito/channel_props/is_trace_preserving.py
new file mode 100644
index 0000000..19db908
--- /dev/null
+++ b/toqito/channel_props/is_trace_preserving.py
@@ -0,0 +1,104 @@
+"""Is channel trace-preserving."""
+from typing import List, Union
+
+import numpy as np
+
+from toqito.matrix_props import is_identity
+from toqito.channels import partial_trace
+
+
+def is_trace_preserving(
+ phi: Union[np.ndarray, List[List[np.ndarray]]],
+ rtol: float = 1e-05,
+ atol: float = 1e-08,
+ sys: Union[int, List[int]] = 2,
+ dim: Union[List[int], np.ndarray] = None,
+) -> bool:
+ r"""
+ Determine whether the given channel is trace-preserving [WatH18]_.
+
+ A map :math:`\Phi \in \text{T} \left(\mathcal{X}, \mathcal{Y} \right)` is
+ *trace-preserving* if it holds that
+
+ .. math::
+ \text{Tr} \left( \Phi(X) \right) = \text{Tr}\left( X \right)
+
+ for every operator :math:`X \in \text{L}(\mathcal{X})`.
+
+ Given the corresponding Choi matrix of the channel, a neccessary and sufficient condition is
+
+ .. math::
+ \text{Tr}_{\mathcal{Y}} \left( J(\Phi) \right) = \mathbb{I}_{\mathcal{X}}
+
+ In case :code:`sys` is not specified, the default convention is that the Choi matrix
+ is the result of applying the map to the second subsystem of the standard maximally
+ entangled (unnormalized) state.
+
+ The dimensions of the subsystems are given by the vector :code:`dim`. By default,
+ both subsystems have equal dimension.
+
+ Alternatively, given a list of Kraus operators, a neccessary and sufficient condition is
+
+ .. math::
+ \sum_{a \in \Sigma} A_a^* B_a = \mathbb{I}_{\mathcal{X}}
+
+ Examples
+ ==========
+
+ The map :math:`\Phi` defined as
+
+ .. math::
+ \Phi(X) = X - U X U^*
+
+ is not trace-preserving, where
+
+ .. math::
+ U = \frac{1}{\sqrt{2}}
+ \begin{pmatrix}
+ 1 & 1 \\
+ -1 & 1
+ \end{pmatrix}.
+
+ >>> import numpy as np
+ >>> from toqito.channel_props import is_trace_preserving
+ >>> unitary_mat = np.array([[1, 1], [-1, 1]]) / np.sqrt(2)
+ >>> kraus_ops = [[np.identity(2), np.identity(2)], [unitary_mat, -unitary_mat]]
+ >>> is_trace_preserving(kraus_ops)
+ False
+
+ As another example, the depolarizing channel is trace-preserving.
+
+ >>> from toqito.channels import depolarizing
+ >>> from toqito.channel_props import is_trace_preserving
+ >>> choi_mat = depolarizing(2)
+ >>> is_trace_preserving(choi_mat)
+ True
+
+ References
+ ==========
+ .. [WatH18] Watrous, John.
+ "The theory of quantum information."
+ Section: "Linear maps of square operators".
+ Cambridge University Press, 2018.
+
+ :param phi: The channel provided as either a Choi matrix or a list of Kraus operators.
+ :param rtol: The relative tolerance parameter (default 1e-05).
+ :param atol: The absolute tolerance parameter (default 1e-08).
+ :param sys: Scalar or vector specifying the size of the subsystems.
+ :param dim: Dimension of the subsystems. If :code:`None`, all dimensions are assumed to be
+ equal.
+ :return: True if the channel is trace-preserving, and False otherwise.
+ """
+ # If the variable `phi` is provided as a list, we assume this is a list
+ # of Kraus operators.
+ if isinstance(phi, list):
+ phi_l = [A for A, _ in phi]
+ phi_r = [B for _, B in phi]
+
+ k_l = np.concatenate(phi_l, axis=0)
+ k_r = np.concatenate(phi_r, axis=0)
+
+ mat = k_l.conj().T @ k_r
+ else:
+ mat = partial_trace(input_mat=phi, sys=sys, dim=dim)
+ return is_identity(mat, rtol=rtol, atol=atol)
| vprusso/toqito | d9379fb267a8e77784b97820c3131522d384f54d | diff --git a/tests/test_channel_props/test_is_trace_preserving.py b/tests/test_channel_props/test_is_trace_preserving.py
new file mode 100644
index 0000000..de9f2b2
--- /dev/null
+++ b/tests/test_channel_props/test_is_trace_preserving.py
@@ -0,0 +1,22 @@
+"""Tests for is_trace_preserving."""
+import numpy as np
+
+from toqito.channel_props import is_trace_preserving
+from toqito.channels import depolarizing
+
+
+def test_is_trace_preserving_kraus_false():
+ """Verify non-trace preserving channel as Kraus ops as False."""
+ unitary_mat = np.array([[1, 1], [-1, 1]]) / np.sqrt(2)
+ kraus_ops = [[np.identity(2), np.identity(2)], [unitary_mat, -unitary_mat]]
+
+ np.testing.assert_equal(is_trace_preserving(kraus_ops), False)
+
+
+def test_is_trace_preserving_choi_true():
+ """Verify Choi matrix of the depolarizing map is trace preserving."""
+ np.testing.assert_equal(is_trace_preserving(depolarizing(2)), True)
+
+
+if __name__ == "__main__":
+ np.testing.run_module_suite()
| Feature: Is trace preserving
Given a channel specified by either its Choi matrix or its Kraus representation, determine if the channel is trace-preserving.
For the definition of what constitutes a channel to be trace-preserving, refer to Section 2.2.1 of https://cs.uwaterloo.ca/~watrous/TQI/TQI.pdf
This would involve creating `channel_props/is_trace_preserving.py` and adding the logic there. Refer to other files in the same directory, namely `is_completely_positive.py`, `is_herm_preserving.py`, etc. for ensuring consistency amongst the other related functions.
The function prototype would follow this form:
```
def is_trace_preserving(
phi: Union[np.ndarray, List[List[np.ndarray]]],
rtol: float = 1e-05,
atol: float = 1e-08,
) -> bool:
...
```
This task would also require adding test coverage for the function along with ensuring it is included in the docs. Refer to the style guide and code contributing guidelines for more information. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_channel_props/test_is_trace_preserving.py::test_is_trace_preserving_kraus_false",
"tests/test_channel_props/test_is_trace_preserving.py::test_is_trace_preserving_choi_true"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-28T13:52:11Z" | mit |
|
wagtail__wagtail-10469 | diff --git a/CHANGELOG.txt b/CHANGELOG.txt
index 0f001c1f76..f399c22696 100644
--- a/CHANGELOG.txt
+++ b/CHANGELOG.txt
@@ -11,6 +11,7 @@ Changelog
* Add oEmbed provider patterns for YouTube Shorts Shorts and YouTube Live URLs (valnuro, Fabien Le Frapper)
* Add initial implementation of `PagePermissionPolicy` (Sage Abdullah)
* Refactor `UserPagePermissionsProxy` and `PagePermissionTester` to use `PagePermissionPolicy` (Sage Abdullah)
+ * Add a predictable default ordering of the "Object/Other permissions" in the Group Editing view, allow this ordering to be customised (Daniel Kirkham)
* Fix: Prevent choosers from failing when initial value is an unrecognised ID, e.g. when moving a page from a location where `parent_page_types` would disallow it (Dan Braghis)
* Fix: Move comment notifications toggle to the comments side panel (Sage Abdullah)
* Fix: Remove comment button on InlinePanel fields (Sage Abdullah)
diff --git a/docs/extending/customising_group_views.md b/docs/extending/customising_group_views.md
index c3abae4070..3e56d16737 100644
--- a/docs/extending/customising_group_views.md
+++ b/docs/extending/customising_group_views.md
@@ -106,3 +106,29 @@ INSTALLED_APPS = [
...,
]
```
+
+(customising_group_views_permissions_order)=
+
+## Customising the group editor permissions ordering
+
+The order that object types appear in the group editor's "Object permissions" and "Other permissions" sections can be configured by registering that order in one or more `AppConfig` definitions. The order value is typically an integer between 0 and 999, although this is not enforced.
+
+```python
+from django.apps import AppConfig
+
+
+class MyProjectAdminAppConfig(AppConfig):
+ name = "myproject_admin"
+ verbose_name = "My Project Admin"
+
+ def ready(self):
+ from wagtail.users.permission_order import register
+
+ register("gadgets.SprocketType", order=150)
+ register("gadgets.ChainType", order=151)
+ register("site_settings.Settings", order=160)
+```
+
+A model class can also be passed to `register()`.
+
+Any object types that are not explicitly given an order will be sorted in alphabetical order by `app_label` and `model`, and listed after all of the object types _with_ a configured order.
diff --git a/docs/releases/5.1.md b/docs/releases/5.1.md
index a471821509..8f2156a73c 100644
--- a/docs/releases/5.1.md
+++ b/docs/releases/5.1.md
@@ -23,6 +23,7 @@ FieldPanels can now be marked as read-only with the `read_only=True` keyword arg
* Add oEmbed provider patterns for YouTube Shorts (e.g. [https://www.youtube.com/shorts/nX84KctJtG0](https://www.youtube.com/shorts/nX84KctJtG0)) and YouTube Live URLs (valnuro, Fabien Le Frapper)
* Add initial implementation of `PagePermissionPolicy` (Sage Abdullah)
* Refactor `UserPagePermissionsProxy` and `PagePermissionTester` to use `PagePermissionPolicy` (Sage Abdullah)
+ * Add a predictable default ordering of the "Object/Other permissions" in the Group Editing view, allow this [ordering to be customised](customising_group_views_permissions_order) (Daniel Kirkham)
### Bug fixes
@@ -120,3 +121,10 @@ If you use the `user_page_permissions` context variable or use the `UserPagePerm
The undocumented `get_pages_with_direct_explore_permission` and `get_explorable_root_page` functions in `wagtail.admin.navigation` are deprecated. They can be replaced with `PagePermissionPolicy().instances_with_direct_explore_permission(user)` and `PagePermissionPolicy().explorable_root_instance(user)`, respectively.
The undocumented `users_with_page_permission` function in `wagtail.admin.auth` is also deprecated. It can be replaced with `PagePermissionPolicy().users_with_permission_for_instance(action, page, include_superusers)`.
+
+### The default ordering of Group Editing Permissions models has changed
+
+The ordering for "Object permissions" and "Other permissions" now follows a predictable order equivalent do Django's default `Model` ordering.
+This will be different to the previous ordering which never intentionally implemented.
+
+This default ordering is now `["content_type__app_label", "content_type__model", "codename"]`, which can now be customised [](customising_group_views_permissions_order).
diff --git a/wagtail/users/permission_order.py b/wagtail/users/permission_order.py
new file mode 100644
index 0000000000..2314deff3f
--- /dev/null
+++ b/wagtail/users/permission_order.py
@@ -0,0 +1,17 @@
+from django.contrib.contenttypes.models import ContentType
+
+from wagtail.coreutils import resolve_model_string
+
+CONTENT_TYPE_ORDER = {}
+
+
+def register(model, **kwargs):
+ """
+ Registers order against the model content_type, used to
+ control the order the models and its permissions appear
+ in the groups object permission editor
+ """
+ order = kwargs.pop("order", None)
+ if order is not None:
+ content_type = ContentType.objects.get_for_model(resolve_model_string(model))
+ CONTENT_TYPE_ORDER[content_type.id] = order
diff --git a/wagtail/users/templatetags/wagtailusers_tags.py b/wagtail/users/templatetags/wagtailusers_tags.py
index 34b3f411a2..c188425ad0 100644
--- a/wagtail/users/templatetags/wagtailusers_tags.py
+++ b/wagtail/users/templatetags/wagtailusers_tags.py
@@ -4,6 +4,7 @@ import re
from django import template
from wagtail import hooks
+from wagtail.users.permission_order import CONTENT_TYPE_ORDER
register = template.Library()
@@ -38,8 +39,13 @@ def format_permissions(permission_bound_field):
"""
permissions = permission_bound_field.field._queryset
- # get a distinct list of the content types that these permissions relate to
- content_type_ids = set(permissions.values_list("content_type_id", flat=True))
+ # get a distinct and ordered list of the content types that these permissions relate to.
+ # relies on Permission model default ordering, dict.fromkeys() retaining that order
+ # from the queryset, and the stability of sorted().
+ content_type_ids = sorted(
+ dict.fromkeys(permissions.values_list("content_type_id", flat=True)),
+ key=lambda ct: CONTENT_TYPE_ORDER.get(ct, float("inf")),
+ )
# iterate over permission_bound_field to build a lookup of individual renderable
# checkbox objects
| wagtail/wagtail | f5187d1938b87391ae160116e4d00745787f3155 | diff --git a/wagtail/users/tests/test_admin_views.py b/wagtail/users/tests/test_admin_views.py
index d34b3fff86..37b7502212 100644
--- a/wagtail/users/tests/test_admin_views.py
+++ b/wagtail/users/tests/test_admin_views.py
@@ -24,6 +24,7 @@ from wagtail.models import (
from wagtail.test.utils import WagtailTestUtils
from wagtail.users.forms import UserCreationForm, UserEditForm
from wagtail.users.models import UserProfile
+from wagtail.users.permission_order import register as register_permission_order
from wagtail.users.views.groups import GroupViewSet
from wagtail.users.views.users import get_user_creation_form, get_user_edit_form
from wagtail.users.wagtail_hooks import get_group_viewset_cls
@@ -1947,6 +1948,71 @@ class TestGroupEditView(WagtailTestUtils, TestCase):
# Should not show inputs for publish permissions on models without DraftStateMixin
self.assertNotInHTML("Can publish advert", html)
+ def test_group_edit_loads_with_django_permissions_in_order(self):
+ # ensure objects are ordered as registered, followed by the default ordering
+
+ def object_position(object_perms):
+ # returns the list of objects in the object permsissions
+ # as provided by the format_permissions tag
+
+ def flatten(perm_set):
+ # iterates through perm_set dict, flattens the list if present
+ for v in perm_set.values():
+ if isinstance(v, list):
+ for e in v:
+ yield e
+ else:
+ yield v
+
+ return [
+ (
+ perm.content_type.app_label,
+ perm.content_type.model,
+ )
+ for perm_set in object_perms
+ for perm in [next(v for v in flatten(perm_set) if "perm" in v)["perm"]]
+ ]
+
+ # Set order on two objects, should appear first and second
+ register_permission_order("snippetstests.fancysnippet", order=100)
+ register_permission_order("snippetstests.standardsnippet", order=110)
+
+ response = self.get()
+ object_positions = object_position(response.context["object_perms"])
+ self.assertEqual(
+ object_positions[0],
+ ("snippetstests", "fancysnippet"),
+ msg="Configured object permission order is incorrect",
+ )
+ self.assertEqual(
+ object_positions[1],
+ ("snippetstests", "standardsnippet"),
+ msg="Configured object permission order is incorrect",
+ )
+
+ # Swap order of the objects
+ register_permission_order("snippetstests.standardsnippet", order=90)
+ response = self.get()
+ object_positions = object_position(response.context["object_perms"])
+
+ self.assertEqual(
+ object_positions[0],
+ ("snippetstests", "standardsnippet"),
+ msg="Configured object permission order is incorrect",
+ )
+ self.assertEqual(
+ object_positions[1],
+ ("snippetstests", "fancysnippet"),
+ msg="Configured object permission order is incorrect",
+ )
+
+ # Test remainder of objects are sorted
+ self.assertEqual(
+ object_positions[2:],
+ sorted(object_positions[2:]),
+ msg="Default object permission order is incorrect",
+ )
+
class TestGroupViewSet(TestCase):
def setUp(self):
| Order Object Permissions in the Group Editor
### Is your proposal related to a problem?
The Group Editor - at menu->Settings->Groups or /admin/groups/<<int:group>>/ - allows an administrator to control the permissions each member of the group receives. The "Object Permissions" section, which allows add, change, delete and other model permissions to be edited, are listed in an unmanaged order. The order appears to depend on the migration order, and depending on the development and deployment workflow, results in that ordering being different between development, staging and production deployments.
### Describe the solution you'd like
I would like a solution where the developer can control the order in which each Object type appears. Object permissions can then be placed in a logical order, such as placing related objects together. That order will then be consistent between deployments.
The solution should address objects defined by the developer and within Wagtail itself.
### Describe alternatives you've considered
There appears to be no practical solution to this problem.
### Additional context
I've developed a PR that addresses this, which I'll post shortly. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_creation_form_with_custom_form",
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_creation_form_with_default_form",
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_creation_form_with_invalid_form",
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_edit_form_with_custom_form",
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_edit_form_with_default_form",
"wagtail/users/tests/test_admin_views.py::TestUserFormHelpers::test_get_user_edit_form_with_invalid_form",
"wagtail/users/tests/test_admin_views.py::TestGroupViewSet::test_get_group_viewset_cls",
"wagtail/users/tests/test_admin_views.py::TestGroupViewSet::test_get_group_viewset_cls_custom_form_does_not_exist",
"wagtail/users/tests/test_admin_views.py::TestGroupViewSet::test_get_group_viewset_cls_custom_form_invalid_value",
"wagtail/users/tests/test_admin_views.py::TestGroupViewSet::test_get_group_viewset_cls_with_custom_form"
] | [] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-05-23T13:24:36Z" | bsd-3-clause |
|
wagtail__wagtail-10545 | diff --git a/CHANGELOG.txt b/CHANGELOG.txt
index 90ac8ed6e1..4c36a521dc 100644
--- a/CHANGELOG.txt
+++ b/CHANGELOG.txt
@@ -54,6 +54,7 @@ Changelog
* Maintenance: Upgrade Willow to v1.6.2 to support MIME type data without reliance on `imghdr` (Jake Howard)
* Maintenance: Replace `imghdr` with Willow's built-in MIME type detection (Jake Howard)
* Maintenance: Migrate all other `data-tippy` HTML attribute usage to the Stimulus data-*-value attributes for w-tooltip & w-dropdown (Subhajit Ghosh, LB (Ben) Johnston)
+ * Maintenance: Replace `@total_ordering` usage with comparison functions implementation (Virag Jain)
5.1.2 (xx.xx.20xx) - IN DEVELOPMENT
diff --git a/docs/releases/5.2.md b/docs/releases/5.2.md
index aa30a690fa..f411817951 100644
--- a/docs/releases/5.2.md
+++ b/docs/releases/5.2.md
@@ -73,6 +73,7 @@ depth: 1
* Upgrade Willow to v1.6.2 to support MIME type data without reliance on `imghdr` (Jake Howard)
* Replace `imghdr` with Willow's built-in MIME type detection (Jake Howard)
* Migrate all other `data-tippy` HTML attribute usage to the Stimulus data-*-value attributes for w-tooltip & w-dropdown (Subhajit Ghosh, LB (Ben) Johnston)
+ * Replace `@total_ordering` usage with comparison functions implementation (Virag Jain)
## Upgrade considerations - changes affecting all projects
diff --git a/wagtail/admin/search.py b/wagtail/admin/search.py
index 1c666549c2..6f5c338175 100644
--- a/wagtail/admin/search.py
+++ b/wagtail/admin/search.py
@@ -1,5 +1,3 @@
-from functools import total_ordering
-
from django.forms import Media, MediaDefiningClass
from django.forms.utils import flatatt
from django.template.loader import render_to_string
@@ -11,7 +9,6 @@ from wagtail import hooks
from wagtail.admin.forms.search import SearchForm
-@total_ordering
class SearchArea(metaclass=MediaDefiningClass):
template = "wagtailadmin/shared/search_area.html"
@@ -31,9 +28,28 @@ class SearchArea(metaclass=MediaDefiningClass):
self.attr_string = ""
def __lt__(self, other):
+ if not isinstance(other, SearchArea):
+ return NotImplemented
return (self.order, self.label) < (other.order, other.label)
+ def __le__(self, other):
+ if not isinstance(other, SearchArea):
+ return NotImplemented
+ return (self.order, self.label) <= (other.order, other.label)
+
+ def __gt__(self, other):
+ if not isinstance(other, SearchArea):
+ return NotImplemented
+ return (self.order, self.label) > (other.order, other.label)
+
+ def __ge__(self, other):
+ if not isinstance(other, SearchArea):
+ return NotImplemented
+ return (self.order, self.label) >= (other.order, other.label)
+
def __eq__(self, other):
+ if not isinstance(other, SearchArea):
+ return NotImplemented
return (self.order, self.label) == (other.order, other.label)
def is_shown(self, request):
diff --git a/wagtail/admin/widgets/button.py b/wagtail/admin/widgets/button.py
index 5f904f1926..7cc361dbbe 100644
--- a/wagtail/admin/widgets/button.py
+++ b/wagtail/admin/widgets/button.py
@@ -1,5 +1,3 @@
-from functools import total_ordering
-
from django.forms.utils import flatatt
from django.template.loader import render_to_string
from django.utils.functional import cached_property
@@ -8,7 +6,6 @@ from django.utils.html import format_html
from wagtail import hooks
-@total_ordering
class Button:
show = True
@@ -42,6 +39,21 @@ class Button:
return NotImplemented
return (self.priority, self.label) < (other.priority, other.label)
+ def __le__(self, other):
+ if not isinstance(other, Button):
+ return NotImplemented
+ return (self.priority, self.label) <= (other.priority, other.label)
+
+ def __gt__(self, other):
+ if not isinstance(other, Button):
+ return NotImplemented
+ return (self.priority, self.label) > (other.priority, other.label)
+
+ def __ge__(self, other):
+ if not isinstance(other, Button):
+ return NotImplemented
+ return (self.priority, self.label) >= (other.priority, other.label)
+
def __eq__(self, other):
if not isinstance(other, Button):
return NotImplemented
| wagtail/wagtail | ba9f7c898f6d9080daa6dd87100b96e8c6651355 | diff --git a/wagtail/admin/tests/test_admin_search.py b/wagtail/admin/tests/test_admin_search.py
index 2f5594ec69..c6e23092e3 100644
--- a/wagtail/admin/tests/test_admin_search.py
+++ b/wagtail/admin/tests/test_admin_search.py
@@ -3,10 +3,11 @@ Tests for the search box in the admin side menu, and the custom search hooks.
"""
from django.contrib.auth.models import Permission
from django.template import Context, Template
-from django.test import RequestFactory, TestCase
+from django.test import RequestFactory, SimpleTestCase, TestCase
from django.urls import reverse
from wagtail.admin.auth import user_has_any_page_permission
+from wagtail.admin.search import SearchArea
from wagtail.test.utils import WagtailTestUtils
@@ -107,3 +108,91 @@ class TestSearchAreaNoPagePermissions(BaseSearchAreaTestCase):
self.assertNotIn("Pages", rendered)
self.assertIn("My Search", rendered)
+
+
+class SearchAreaComparisonTestCase(SimpleTestCase):
+ """Tests the comparison functions."""
+
+ def setUp(self):
+ self.search_area1 = SearchArea("Label 1", "/url1", order=100)
+ self.search_area2 = SearchArea("Label 2", "/url2", order=200)
+ self.search_area3 = SearchArea("Label 1", "/url3", order=300)
+ self.search_area4 = SearchArea("Label 1", "/url1", order=100)
+
+ def test_eq(self):
+ # Same label and order, should be equal
+ self.assertTrue(self.search_area1 == self.search_area4)
+
+ # Different order, should not be equal
+ self.assertFalse(self.search_area1 == self.search_area2)
+
+ # Not a SearchArea, should not be equal
+ self.assertFalse(self.search_area1 == "Something")
+
+ def test_lt(self):
+ # Less order, should be True
+ self.assertTrue(self.search_area1 < self.search_area2)
+
+ # Same label, but less order, should be True
+ self.assertTrue(self.search_area1 < self.search_area3)
+
+ # Greater order, should be False
+ self.assertFalse(self.search_area2 < self.search_area1)
+
+ # Not a SearchArea, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.search_area1 < "Something"
+
+ def test_le(self):
+ # Less order, should be True
+ self.assertTrue(self.search_area1 <= self.search_area2)
+
+ # Same label, but less order, should be True
+ self.assertTrue(self.search_area1 <= self.search_area3)
+
+ # Same object, should be True
+ self.assertTrue(self.search_area1 <= self.search_area1)
+
+ # Same label and order, should be True
+ self.assertTrue(self.search_area1 <= self.search_area4)
+
+ # Greater order, should be False
+ self.assertFalse(self.search_area2 <= self.search_area1)
+
+ # Not a SearchArea, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.search_area1 <= "Something"
+
+ def test_gt(self):
+ # Greater order, should be True
+ self.assertTrue(self.search_area2 > self.search_area1)
+
+ # Same label, but greater order, should be True
+ self.assertTrue(self.search_area3 > self.search_area1)
+
+ # Less order, should be False
+ self.assertFalse(self.search_area1 > self.search_area2)
+
+ # Not a SearchArea, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.search_area1 > "Something"
+
+ def test_ge(self):
+ # Greater order, should be True
+ self.assertTrue(self.search_area2 >= self.search_area1)
+
+ # Same label, but greater order, should be True
+ self.assertTrue(self.search_area3 >= self.search_area1)
+
+ # Same object, should be True
+ self.assertTrue(self.search_area1 >= self.search_area1)
+
+ # Same label and order, should be True
+ self.assertTrue(self.search_area1 >= self.search_area4)
+
+ # Less order, should be False
+ self.assertFalse(self.search_area1 >= self.search_area2)
+
+ # Not a SearchArea, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.search_area1 >= "Something"
diff --git a/wagtail/admin/tests/test_buttons_hooks.py b/wagtail/admin/tests/test_buttons_hooks.py
index 04b8a39733..820b34816a 100644
--- a/wagtail/admin/tests/test_buttons_hooks.py
+++ b/wagtail/admin/tests/test_buttons_hooks.py
@@ -1,10 +1,11 @@
-from django.test import TestCase
+from django.test import SimpleTestCase, TestCase
from django.urls import reverse
from django.utils.http import urlencode
from wagtail import hooks
from wagtail.admin import widgets as wagtailadmin_widgets
from wagtail.admin.wagtail_hooks import page_header_buttons, page_listing_more_buttons
+from wagtail.admin.widgets.button import Button
from wagtail.models import Page
from wagtail.test.testapp.models import SimplePage
from wagtail.test.utils import WagtailTestUtils
@@ -293,3 +294,98 @@ class TestPageHeaderButtonsHooks(TestButtonsHooks):
unpublish_button = next(buttons)
full_url = unpublish_base_url + "?" + urlencode({"next": next_url})
self.assertEqual(unpublish_button.url, full_url)
+
+
+class ButtonComparisonTestCase(SimpleTestCase):
+ """Tests the comparison functions."""
+
+ def setUp(self):
+ self.button1 = Button(
+ "Label 1", "/url1", classes={"class1", "class2"}, priority=100
+ )
+ self.button2 = Button(
+ "Label 2", "/url2", classes={"class2", "class3"}, priority=200
+ )
+ self.button3 = Button(
+ "Label 1", "/url3", classes={"class1", "class2"}, priority=300
+ )
+ self.button4 = Button(
+ "Label 1", "/url1", classes={"class1", "class2"}, priority=100
+ )
+
+ def test_eq(self):
+ # Same properties, should be equal
+ self.assertTrue(self.button1 == self.button4)
+
+ # Different priority, should not be equal
+ self.assertFalse(self.button1 == self.button2)
+
+ # Different URL, should not be equal
+ self.assertFalse(self.button1 == self.button3)
+
+ # Not a Button, should not be equal
+ self.assertFalse(self.button1 == "Something")
+
+ def test_lt(self):
+ # Less priority, should be True
+ self.assertTrue(self.button1 < self.button2)
+
+ # Same label, but less priority, should be True
+ self.assertTrue(self.button1 < self.button3)
+
+ # Greater priority, should be False
+ self.assertFalse(self.button2 < self.button1)
+
+ # Not a Button, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.button1 < "Something"
+
+ def test_le(self):
+ # Less priority, should be True
+ self.assertTrue(self.button1 <= self.button2)
+
+ # Same label, but less priority, should be True
+ self.assertTrue(self.button1 <= self.button3)
+
+ # Same object, should be True
+ self.assertTrue(self.button1 <= self.button1)
+
+ # Same label and priority, should be True
+ self.assertTrue(self.button1 <= self.button4)
+
+ # Greater priority, should be False
+ self.assertFalse(self.button2 <= self.button1)
+
+ # Not a Button, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.button1 <= "Something"
+
+ def test_gt(self):
+ # Greater priority, should be True
+ self.assertTrue(self.button2 > self.button1)
+
+ # Same label, but greater priority, should be True
+ self.assertTrue(self.button3 > self.button1)
+
+ # Less priority, should be False
+ self.assertFalse(self.button1 > self.button2)
+
+ # Not a Button, should raise TypeError
+ with self.assertRaises(TypeError):
+ self.button1 > "Something"
+
+ def test_ge(self):
+ # Greater priority, should be True
+ self.assertTrue(self.button2 >= self.button1)
+
+ # Same label, but greater priority, should be True
+ self.assertTrue(self.button3 >= self.button1)
+
+ # Same object, should be True
+ self.assertTrue(self.button1 >= self.button1)
+
+ # Same label and priority, should be True
+ self.assertTrue(self.button1 >= self.button4)
+
+ # Less priority, should be False
+ self.assertFalse(self.button1 >= self.button2)
| Replace `total_ordering` usage with comparison functions implementation
### Is your proposal related to a problem?
We have two instances of `total_ordering` usage within the codebase:
https://github.com/wagtail/wagtail/blob/cd5200c8e1ac0d7299fd9c398b2b994606b3c7d2/wagtail/admin/search.py#L12-L13
https://github.com/wagtail/wagtail/blob/cd5200c8e1ac0d7299fd9c398b2b994606b3c7d2/wagtail/admin/widgets/button.py#L11-L12
Even though it's convenient, `total_ordering` is known to be slow. According to [Python's docs](https://docs.python.org/3/library/functools.html#functools.total_ordering):
> **Note**
> While this decorator makes it easy to create well behaved totally ordered types, it does come at the cost of slower execution and more complex stack traces for the derived comparison methods. If performance benchmarking indicates this is a bottleneck for a given application, implementing all six rich comparison methods instead is likely to provide an easy speed boost.
Django recently removed their usage of `total_ordering` in https://github.com/django/django/pull/16958/commits/ee36e101e8f8c0acde4bb148b738ab7034e902a0 (probably not all usages, I haven't checked).
### Describe the solution you'd like
<!--
Provide a clear and concise description of what you want to happen.
-->
Replace `total_ordering` with implementations of `__eq__()`, `__ne__()`, `__lt__()`, `__le__()`, `__gt__()`, and `__ge__()`.
### Describe alternatives you've considered
<!--
Let us know about other solutions you've tried or researched.
-->
Keep using `total_ordering`
### Additional context
I found this while fixing an incorrect import of `total_ordering` in #10525.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/admin/tests/test_admin_search.py::SearchAreaComparisonTestCase::test_eq",
"wagtail/admin/tests/test_admin_search.py::SearchAreaComparisonTestCase::test_ge",
"wagtail/admin/tests/test_admin_search.py::SearchAreaComparisonTestCase::test_gt",
"wagtail/admin/tests/test_admin_search.py::SearchAreaComparisonTestCase::test_le",
"wagtail/admin/tests/test_admin_search.py::SearchAreaComparisonTestCase::test_lt"
] | [
"wagtail/admin/tests/test_buttons_hooks.py::ButtonComparisonTestCase::test_eq",
"wagtail/admin/tests/test_buttons_hooks.py::ButtonComparisonTestCase::test_ge",
"wagtail/admin/tests/test_buttons_hooks.py::ButtonComparisonTestCase::test_gt",
"wagtail/admin/tests/test_buttons_hooks.py::ButtonComparisonTestCase::test_le",
"wagtail/admin/tests/test_buttons_hooks.py::ButtonComparisonTestCase::test_lt"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2023-06-11T17:53:30Z" | bsd-3-clause |
|
wagtail__wagtail-7427 | diff --git a/wagtail/embeds/finders/oembed.py b/wagtail/embeds/finders/oembed.py
index d2da0edf50..6151b5a1b2 100644
--- a/wagtail/embeds/finders/oembed.py
+++ b/wagtail/embeds/finders/oembed.py
@@ -87,8 +87,11 @@ class OEmbedFinder(EmbedFinder):
'html': html,
}
- cache_age = oembed.get('cache_age')
- if cache_age is not None:
+ try:
+ cache_age = int(oembed['cache_age'])
+ except (KeyError, TypeError, ValueError):
+ pass
+ else:
result['cache_until'] = timezone.now() + timedelta(seconds=cache_age)
return result
| wagtail/wagtail | 1efbfd49940206f22c6b4819cc1beb6fbc1c08a0 | diff --git a/wagtail/embeds/tests/test_embeds.py b/wagtail/embeds/tests/test_embeds.py
index ccabcc8c0b..d8c1a6cb57 100644
--- a/wagtail/embeds/tests/test_embeds.py
+++ b/wagtail/embeds/tests/test_embeds.py
@@ -490,6 +490,37 @@ class TestOembed(TestCase):
'cache_until': make_aware(datetime.datetime(2001, 2, 3, hour=1))
})
+ @patch('django.utils.timezone.now')
+ @patch('urllib.request.urlopen')
+ @patch('json.loads')
+ def test_oembed_cache_until_as_string(self, loads, urlopen, now):
+ urlopen.return_value = self.dummy_response
+ loads.return_value = {
+ 'type': 'something',
+ 'url': 'http://www.example.com',
+ 'title': 'test_title',
+ 'author_name': 'test_author',
+ 'provider_name': 'test_provider_name',
+ 'thumbnail_url': 'test_thumbail_url',
+ 'width': 'test_width',
+ 'height': 'test_height',
+ 'html': 'test_html',
+ 'cache_age': '3600'
+ }
+ now.return_value = make_aware(datetime.datetime(2001, 2, 3))
+ result = OEmbedFinder().find_embed("http://www.youtube.com/watch/")
+ self.assertEqual(result, {
+ 'type': 'something',
+ 'title': 'test_title',
+ 'author_name': 'test_author',
+ 'provider_name': 'test_provider_name',
+ 'thumbnail_url': 'test_thumbail_url',
+ 'width': 'test_width',
+ 'height': 'test_height',
+ 'html': 'test_html',
+ 'cache_until': make_aware(datetime.datetime(2001, 2, 3, hour=1))
+ })
+
def test_oembed_accepts_known_provider(self):
finder = OEmbedFinder(providers=[oembed_providers.youtube])
self.assertTrue(finder.accept("http://www.youtube.com/watch/"))
| Parsing cache_until field fails on Twitter embeds
Reported on Slack #support: Trying to embed a twitter link within a RichField paragraph triggers a 500 error.
```
ERROR 2021-08-08 19:41:11,207 log 2288 140316583144768 Internal Server Error: /cms/embeds/chooser/upload/
...
...
File "/home/asdf/asdffff/venv/lib/python3.7/site-packages/wagtail/embeds/finders/oembed.py", line 92, in find_embed
result['cache_until'] = timezone.now() + timedelta(seconds=cache_age)
TypeError: unsupported type for timedelta seconds component: str
```
The response returned by Twitter's oembed endpoint is:
```
{'url': 'https://twitter.com/elonmusk/status/1423659261452709893', 'author_name': 'Elon Musk', 'author_url': 'https://twitter.com/elonmusk', 'html': '<blockquote class="twitter-tweet"><p lang="en" dir="ltr">Starship Fully Stacked <a href="https://t.co/Fs88RNsmfH">pic.twitter.com/Fs88RNsmfH</a></p>— Elon Musk (@elonmusk) <a href="https://twitter.com/elonmusk/status/1423659261452709893?ref_src=twsrc%5Etfw">August 6, 2021</a></blockquote>\n<script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script>\n', 'width': 550, 'height': None, 'type': 'rich', 'cache_age': '3153600000', 'provider_name': 'Twitter', 'provider_url': 'https://twitter.com', 'version': '1.0'}
```
so it looks like we aren't handling `cache_age` being returned as a string rather than an int.
Checking `cache_age` was added in #7279, so this is most likely a 2.14 regression. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_cache_until_as_string"
] | [
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_defaults_to_oembed",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_find_facebook_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_find_instagram_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_embedly",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_oembed",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestEmbedHash::test_get_embed_hash",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_endpoint_with_format_param",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_accepts_known_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_cache_until",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_doesnt_accept_unknown_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_invalid_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_invalid_request",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_non_json_response",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_photo_request",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_failed_request",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_oembed_only_accepts_new_url_patterns",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_request_denied_401",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_request_not_found",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_failed_request",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_oembed_accepts_various_url_patterns",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_request_denied_401",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_request_not_found",
"wagtail/embeds/tests/test_embeds.py::TestEmbedTag::test_direct_call",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_clean_invalid_url",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_default",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_deserialize",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_serialize",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_value_from_form"
] | {
"failed_lite_validators": [
"has_hyperlinks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-08-11T17:02:47Z" | bsd-3-clause |
|
wagtail__wagtail-8006 | diff --git a/CHANGELOG.txt b/CHANGELOG.txt
index 6371280bcb..a8a8f7efe9 100644
--- a/CHANGELOG.txt
+++ b/CHANGELOG.txt
@@ -34,6 +34,7 @@ Changelog
* Remove `replace_text` management command (Sage Abdullah)
* Replace `data_json` `TextField` with `data` `JSONField` in `BaseLogEntry` (Sage Abdullah)
* Split up linting / formatting tasks in Makefile into client and server components (Hitansh Shah)
+ * Add support for embedding Instagram reels (Luis Nell)
* Fix: When using `simple_translations` ensure that the user is redirected to the page edit view when submitting for a single locale (Mitchel Cabuloy)
* Fix: When previewing unsaved changes to `Form` pages, ensure that all added fields are correctly shown in the preview (Joshua Munn)
* Fix: When Documents (e.g. PDFs) have been configured to be served inline via `WAGTAILDOCS_CONTENT_TYPES` & `WAGTAILDOCS_INLINE_CONTENT_TYPES` ensure that the filename is correctly set in the `Content-Disposition` header so that saving the files will use the correct filename (John-Scott Atlakson)
diff --git a/docs/releases/3.0.md b/docs/releases/3.0.md
index bed4be6735..3f198c7555 100644
--- a/docs/releases/3.0.md
+++ b/docs/releases/3.0.md
@@ -56,6 +56,7 @@ The panel types `StreamFieldPanel`, `RichTextFieldPanel`, `ImageChooserPanel`, `
* Update Jinja2 template support for Jinja2 3.x (Seb Brown)
* Add ability for `StreamField` to use `JSONField` to store data, rather than `TextField` (Sage Abdullah)
* Split up linting / formatting tasks in Makefile into client and server components (Hitansh Shah)
+ * Add support for embedding Instagram reels (Luis Nell)
### Bug fixes
@@ -156,3 +157,9 @@ When overriding the `get_form_class` method of a ModelAdmin `CreateView` or `Edi
`StreamField` now requires a `use_json_field` keyword argument that can be set to `True`/`False`. If set to `True`, the field will use `JSONField` as its internal type instead of `TextField`, which will change the data type used on the database and allow you to use `JSONField` lookups and transforms on the `StreamField`. If set to `False`, the field will keep its previous behaviour and no database changes will be made. If set to `None` (the default), the field will keep its previous behaviour and a warning (`RemovedInWagtail50Warning`) will appear.
After setting the keyword argument, make sure to generate and run the migrations for the models.
+
+### Removal of legacy `clean_name` on `AbstractFormField`
+
+- If you have a project migrating from pre 2.10 to this release and you are using the Wagtail form builder and you have existing form submissions you must first upgrade to at least 2.11. Then run migrations and run the application with your data to ensure that any existing form fields are correctly migrated.
+- In Wagtail 2.10 a `clean_name` field was added to form field models that extend `AbstractFormField` and this initially supported legacy migration of the [Unidecode](https://pypi.org/project/Unidecode/) label conversion.
+- Any new fields created since then will have used the [AnyAscii](https://pypi.org/project/anyascii/) conversion and Unidecode has been removed from the included packages.
diff --git a/setup.py b/setup.py
index 039b36031b..120ab0dbe9 100755
--- a/setup.py
+++ b/setup.py
@@ -49,7 +49,6 @@ testing_extras = [
"boto3>=1.16,<1.17",
"freezegun>=0.3.8",
"openpyxl>=2.6.4",
- "Unidecode>=0.04.14,<2.0",
"azure-mgmt-cdn>=5.1,<6.0",
"azure-mgmt-frontdoor>=0.3,<0.4",
"django-pattern-library>=0.7,<0.8",
diff --git a/wagtail/contrib/forms/models.py b/wagtail/contrib/forms/models.py
index 2b32cf20ca..f29e33dbb6 100644
--- a/wagtail/contrib/forms/models.py
+++ b/wagtail/contrib/forms/models.py
@@ -3,13 +3,10 @@ import json
import os
from django.conf import settings
-from django.core.checks import Info
-from django.core.exceptions import FieldError
from django.core.serializers.json import DjangoJSONEncoder
-from django.db import DatabaseError, models
+from django.db import models
from django.template.response import TemplateResponse
from django.utils.formats import date_format
-from django.utils.text import slugify
from django.utils.translation import gettext_lazy as _
from wagtail.admin.mail import send_mail
@@ -142,45 +139,6 @@ class AbstractFormField(Orderable):
super().save(*args, **kwargs)
- @classmethod
- def _migrate_legacy_clean_name(cls):
- """
- Ensure that existing data stored will be accessible via the legacy clean_name.
- When checks run, replace any blank clean_name values with the unidecode conversion.
- """
-
- try:
- objects = cls.objects.filter(clean_name__exact="")
- if objects.count() == 0:
- return None
-
- except (FieldError, DatabaseError):
- # attempting to query on clean_name before field has been added
- return None
-
- try:
- from unidecode import unidecode
- except ImportError as error:
- description = "You have form submission data that was created on an older version of Wagtail and requires the unidecode library to retrieve it correctly. Please install the unidecode package."
- raise Exception(description) from error
-
- for obj in objects:
- legacy_clean_name = str(slugify(str(unidecode(obj.label))))
- obj.clean_name = legacy_clean_name
- obj.save()
-
- return Info("Added `clean_name` on %s form field(s)" % objects.count(), obj=cls)
-
- @classmethod
- def check(cls, **kwargs):
- errors = super().check(**kwargs)
-
- messages = cls._migrate_legacy_clean_name()
- if messages:
- errors.append(messages)
-
- return errors
-
class Meta:
abstract = True
ordering = ["sort_order"]
diff --git a/wagtail/embeds/finders/instagram.py b/wagtail/embeds/finders/instagram.py
index f490cb685e..458248d1bc 100644
--- a/wagtail/embeds/finders/instagram.py
+++ b/wagtail/embeds/finders/instagram.py
@@ -24,6 +24,7 @@ class InstagramOEmbedFinder(EmbedFinder):
INSTAGRAM_URL_PATTERNS = [
r"^https?://(?:www\.)?instagram\.com/p/.+$",
r"^https?://(?:www\.)?instagram\.com/tv/.+$",
+ r"^https?://(?:www\.)?instagram\.com/reel/.+$",
]
def __init__(self, omitscript=False, app_id=None, app_secret=None):
diff --git a/wagtail/images/models.py b/wagtail/images/models.py
index 986b841f95..3c6103fae0 100644
--- a/wagtail/images/models.py
+++ b/wagtail/images/models.py
@@ -187,7 +187,7 @@ class AbstractImage(ImageFileMixin, CollectionMember, index.Indexed, models.Mode
folder_name = "original_images"
filename = self.file.field.storage.get_valid_name(filename)
- # do a unidecode in the filename and then
+ # convert the filename to simple ascii characters and then
# replace non-ascii characters in filename with _ , to sidestep issues with filesystem encoding
filename = "".join(
(i if ord(i) < 128 else "_") for i in string_to_ascii(filename)
| wagtail/wagtail | 97e781e31c3bb227970b174dc16fb7febb630571 | diff --git a/wagtail/contrib/forms/tests/test_models.py b/wagtail/contrib/forms/tests/test_models.py
index 4b2ad1bef7..d9567ca1b3 100644
--- a/wagtail/contrib/forms/tests/test_models.py
+++ b/wagtail/contrib/forms/tests/test_models.py
@@ -4,7 +4,6 @@ import unittest
from django import VERSION as DJANGO_VERSION
from django.core import mail
-from django.core.checks import Info
from django.test import TestCase, override_settings
from wagtail.contrib.forms.models import FormSubmission
@@ -19,7 +18,6 @@ from wagtail.test.testapp.models import (
CustomFormPageSubmission,
ExtendedFormField,
FormField,
- FormFieldWithCustomSubmission,
FormPageWithCustomFormBuilder,
JadeFormPage,
)
@@ -809,75 +807,3 @@ class TestNonHtmlExtension(TestCase):
self.assertEqual(
form_page.landing_page_template, "tests/form_page_landing.jade"
)
-
-
-class TestLegacyFormFieldCleanNameChecks(TestCase, WagtailTestUtils):
- fixtures = ["test.json"]
-
- def setUp(self):
- self.login(username="siteeditor", password="password")
- self.form_page = Page.objects.get(
- url_path="/home/contact-us-one-more-time/"
- ).specific
-
- def test_form_field_clean_name_update_on_checks(self):
- fields_before_checks = [
- (
- field.label,
- field.clean_name,
- )
- for field in FormFieldWithCustomSubmission.objects.all()
- ]
-
- self.assertEqual(
- fields_before_checks,
- [
- ("Your email", ""),
- ("Your message", ""),
- ("Your choices", ""),
- ],
- )
-
- # running checks should show an info message AND update blank clean_name values
-
- messages = FormFieldWithCustomSubmission.check()
-
- self.assertEqual(
- messages,
- [
- Info(
- "Added `clean_name` on 3 form field(s)",
- obj=FormFieldWithCustomSubmission,
- )
- ],
- )
-
- fields_after_checks = [
- (
- field.label,
- field.clean_name,
- )
- for field in FormFieldWithCustomSubmission.objects.all()
- ]
-
- self.assertEqual(
- fields_after_checks,
- [
- ("Your email", "your-email"), # kebab case, legacy format
- ("Your message", "your-message"),
- ("Your choices", "your-choices"),
- ],
- )
-
- # running checks again should return no messages as fields no longer need changing
- self.assertEqual(FormFieldWithCustomSubmission.check(), [])
-
- # creating a new field should use the non-legacy clean_name format
-
- field = FormFieldWithCustomSubmission.objects.create(
- page=self.form_page,
- label="Your FAVOURITE #number",
- field_type="number",
- )
-
- self.assertEqual(field.clean_name, "your_favourite_number")
diff --git a/wagtail/contrib/forms/tests/test_views.py b/wagtail/contrib/forms/tests/test_views.py
index 4491015781..9b06dfb062 100644
--- a/wagtail/contrib/forms/tests/test_views.py
+++ b/wagtail/contrib/forms/tests/test_views.py
@@ -5,7 +5,6 @@ from io import BytesIO
from django.conf import settings
from django.contrib.auth.models import AnonymousUser
-from django.core.checks import Info
from django.test import RequestFactory, TestCase, override_settings
from django.urls import reverse
from openpyxl import load_workbook
@@ -522,49 +521,6 @@ class TestFormsSubmissionsList(TestCase, WagtailTestUtils):
self.assertIn("this is a really old message", first_row_values)
-class TestFormsSubmissionsListLegacyFieldName(TestCase, WagtailTestUtils):
- fixtures = ["test.json"]
-
- def setUp(self):
- self.login(username="siteeditor", password="password")
- self.form_page = Page.objects.get(
- url_path="/home/contact-us-one-more-time/"
- ).specific
-
- # running checks should show an info message AND update blank clean_name values
-
- messages = FormFieldWithCustomSubmission.check()
-
- self.assertEqual(
- messages,
- [
- Info(
- "Added `clean_name` on 3 form field(s)",
- obj=FormFieldWithCustomSubmission,
- )
- ],
- )
-
- # check clean_name has been updated
- self.assertEqual(
- FormFieldWithCustomSubmission.objects.all()[0].clean_name, "your-email"
- )
-
- def test_list_submissions(self):
- response = self.client.get(
- reverse("wagtailforms:list_submissions", args=(self.form_page.id,))
- )
-
- # Check response
- self.assertEqual(response.status_code, 200)
- self.assertTemplateUsed(response, "wagtailforms/index_submissions.html")
- self.assertEqual(len(response.context["data_rows"]), 2)
-
- # check display of list values within form submissions
- self.assertContains(response, "[email protected]")
- self.assertContains(response, "[email protected]")
-
-
class TestFormsSubmissionsExport(TestCase, WagtailTestUtils):
def setUp(self):
# Create a form page
diff --git a/wagtail/embeds/tests/test_embeds.py b/wagtail/embeds/tests/test_embeds.py
index 40255d5602..5257dba19f 100644
--- a/wagtail/embeds/tests/test_embeds.py
+++ b/wagtail/embeds/tests/test_embeds.py
@@ -634,6 +634,16 @@ class TestInstagramOEmbed(TestCase):
"https://www.instagram.com/p/CHeRxmnDSYe/?utm_source=ig_embed"
)
)
+ self.assertTrue(
+ finder.accept(
+ "https://www.instagram.com/tv/CZMkxGaIXk3/?utm_source=ig_embed"
+ )
+ )
+ self.assertTrue(
+ finder.accept(
+ "https://www.instagram.com/reel/CZMs3O_I22w/?utm_source=ig_embed"
+ )
+ )
self.assertFalse(
finder.accept("https://instagr.am/p/CHeRxmnDSYe/?utm_source=ig_embed")
)
@@ -659,8 +669,6 @@ class TestInstagramOEmbed(TestCase):
)
# check that a request was made with the expected URL / authentication
request = urlopen.call_args[0][0]
- # check that a request was made with the expected URL / authentication
- request = urlopen.call_args[0][0]
self.assertEqual(
request.get_full_url(),
"https://graph.facebook.com/v11.0/instagram_oembed?url=https%3A%2F%2Finstagr.am%2Fp%2FCHeRxmnDSYe%2F&format=json",
diff --git a/wagtail/test/testapp/fixtures/test.json b/wagtail/test/testapp/fixtures/test.json
index 074a0b696f..65fb8028f4 100644
--- a/wagtail/test/testapp/fixtures/test.json
+++ b/wagtail/test/testapp/fixtures/test.json
@@ -487,7 +487,7 @@
"pk": 1,
"model": "tests.formfieldwithcustomsubmission",
"fields": {
- "clean_name": "",
+ "clean_name": "your_email",
"sort_order": 1,
"label": "Your email",
"field_type": "email",
@@ -502,7 +502,7 @@
"pk": 2,
"model": "tests.formfieldwithcustomsubmission",
"fields": {
- "clean_name": "",
+ "clean_name": "your_message",
"sort_order": 2,
"label": "Your message",
"field_type": "multiline",
@@ -517,7 +517,7 @@
"pk": 3,
"model": "tests.formfieldwithcustomsubmission",
"fields": {
- "clean_name": "",
+ "clean_name": "your_choices",
"sort_order": 3,
"label": "Your choices",
"field_type": "checkboxes",
| remove unidecode and legacy form field clean name
In Wagtail 2.10 the usage of unidecode was replaced with anyascii to ensure that the licenses used in Wagtail were compatible.
However, we still have not removed the legacy approach and the package.
After multiple subsequent releases, I think it is time to do this.
https://github.com/wagtail/wagtail/blob/7e6755ec625cf8a014f4218e0a65533a324ef5aa/wagtail/contrib/forms/models.py#L157
See https://github.com/wagtail/wagtail/issues/3311
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_oembed_only_accepts_new_url_patterns"
] | [
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_defaults_to_oembed",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_find_facebook_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_find_instagram_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_embedly",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_oembed",
"wagtail/embeds/tests/test_embeds.py::TestGetFinders::test_new_find_oembed_with_options",
"wagtail/embeds/tests/test_embeds.py::TestEmbedHash::test_get_embed_hash",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_endpoint_with_format_param",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_accepts_known_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_cache_until",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_cache_until_as_string",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_doesnt_accept_unknown_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_invalid_provider",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_invalid_request",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_non_json_response",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_photo_request",
"wagtail/embeds/tests/test_embeds.py::TestOembed::test_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_failed_request",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_request_denied_401",
"wagtail/embeds/tests/test_embeds.py::TestInstagramOEmbed::test_instagram_request_not_found",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_failed_request",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_oembed_accepts_various_url_patterns",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_oembed_return_values",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_request_denied_401",
"wagtail/embeds/tests/test_embeds.py::TestFacebookOEmbed::test_facebook_request_not_found",
"wagtail/embeds/tests/test_embeds.py::TestEmbedTag::test_call_from_template",
"wagtail/embeds/tests/test_embeds.py::TestEmbedTag::test_catches_embed_not_found",
"wagtail/embeds/tests/test_embeds.py::TestEmbedTag::test_direct_call",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_clean_invalid_url",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_clean_non_required",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_clean_required",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_default",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_deserialize",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_render",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_render_within_structblock",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_serialize",
"wagtail/embeds/tests/test_embeds.py::TestEmbedBlock::test_value_from_form"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-02-17T11:04:55Z" | bsd-3-clause |
|
wagtail__wagtail-8993 | diff --git a/CHANGELOG.txt b/CHANGELOG.txt
index 517cc23cf2..4b95ea22c3 100644
--- a/CHANGELOG.txt
+++ b/CHANGELOG.txt
@@ -163,6 +163,7 @@ Changelog
* Fix: Layout issues with reports (including form submissions listings) on md device widths (Akash Kumar Sen, LB (Ben) Johnston)
* Fix: Layout issue with page explorer's inner header item on small device widths (Akash Kumar Sen)
* Fix: Ensure that `BaseSiteSetting` / `BaseGenericSetting` objects can be pickled (Andy Babic)
+ * Fix: Ensure `DocumentChooserBlock` can be deconstructed for migrations (Matt Westcott)
3.0.1 (16.06.2022)
diff --git a/client/src/entrypoints/admin/page-editor.js b/client/src/entrypoints/admin/page-editor.js
index dd050952a9..da30ddbfff 100644
--- a/client/src/entrypoints/admin/page-editor.js
+++ b/client/src/entrypoints/admin/page-editor.js
@@ -94,7 +94,6 @@ function InlinePanel(opts) {
forms.each(function updateButtonStates(i) {
const isFirst = i === 0;
const isLast = i === forms.length - 1;
- console.log(isFirst, isLast);
$('[data-inline-panel-child-move-up]', this).prop('disabled', isFirst);
$('[data-inline-panel-child-move-down]', this).prop('disabled', isLast);
});
diff --git a/client/src/includes/breadcrumbs.js b/client/src/includes/breadcrumbs.js
index 6322500e8a..eb60b5cd31 100644
--- a/client/src/includes/breadcrumbs.js
+++ b/client/src/includes/breadcrumbs.js
@@ -15,6 +15,8 @@ export default function initCollapsibleBreadcrumbs() {
'[data-toggle-breadcrumbs]',
);
+ if (!breadcrumbsToggle) return;
+
const breadcrumbItems = breadcrumbsContainer.querySelectorAll(
'[data-breadcrumb-item]',
);
diff --git a/docs/extending/generic_views.md b/docs/extending/generic_views.md
index b003c33ee4..f506ab4164 100644
--- a/docs/extending/generic_views.md
+++ b/docs/extending/generic_views.md
@@ -96,6 +96,10 @@ The viewset also makes a StreamField chooser block class available, as the prope
from .views import person_chooser_viewset
PersonChooserBlock = person_chooser_viewset.block_class
+
+# When deconstructing a PersonChooserBlock instance for migrations, the module path
+# used in migrations should point back to this module
+PersonChooserBlock.__module__ = "myapp.blocks"
```
## Chooser viewsets for non-model datasources
diff --git a/docs/releases/4.0.md b/docs/releases/4.0.md
index a6d74c9ce5..4411cb18a1 100644
--- a/docs/releases/4.0.md
+++ b/docs/releases/4.0.md
@@ -220,6 +220,7 @@ The bulk of these enhancements have been from Paarth Agarwal, who has been doing
* Resolve layout issues with reports (including form submissions listings) on md device widths (Akash Kumar Sen, LB (Ben) Johnston)
* Resolve Layout issue with page explorer's inner header item on small device widths (Akash Kumar Sen)
* Ensure that `BaseSiteSetting` / `BaseGenericSetting` objects can be pickled (Andy Babic)
+ * Ensure `DocumentChooserBlock` can be deconstructed for migrations (Matt Westcott)
## Upgrade considerations
diff --git a/wagtail/documents/blocks.py b/wagtail/documents/blocks.py
index 291fa803ab..31af414252 100644
--- a/wagtail/documents/blocks.py
+++ b/wagtail/documents/blocks.py
@@ -1,3 +1,7 @@
from wagtail.documents.views.chooser import viewset as chooser_viewset
DocumentChooserBlock = chooser_viewset.block_class
+
+# When deconstructing a DocumentChooserBlock instance for migrations, the module path
+# used in migrations should point to this module
+DocumentChooserBlock.__module__ = "wagtail.documents.blocks"
| wagtail/wagtail | 5ff6922eb517015651b9012bd6534a912a50b449 | diff --git a/wagtail/documents/tests/test_blocks.py b/wagtail/documents/tests/test_blocks.py
new file mode 100644
index 0000000000..031dad9af1
--- /dev/null
+++ b/wagtail/documents/tests/test_blocks.py
@@ -0,0 +1,12 @@
+from django.test import TestCase
+
+from wagtail.documents.blocks import DocumentChooserBlock
+
+
+class TestDocumentChooserBlock(TestCase):
+ def test_deconstruct(self):
+ block = DocumentChooserBlock(required=False)
+ path, args, kwargs = block.deconstruct()
+ self.assertEqual(path, "wagtail.documents.blocks.DocumentChooserBlock")
+ self.assertEqual(args, ())
+ self.assertEqual(kwargs, {"required": False})
diff --git a/wagtail/images/tests/test_blocks.py b/wagtail/images/tests/test_blocks.py
index 904398e34c..bf8d537786 100644
--- a/wagtail/images/tests/test_blocks.py
+++ b/wagtail/images/tests/test_blocks.py
@@ -63,3 +63,10 @@ class TestImageChooserBlock(TestCase):
)
self.assertHTMLEqual(html, expected_html)
+
+ def test_deconstruct(self):
+ block = ImageChooserBlock(required=False)
+ path, args, kwargs = block.deconstruct()
+ self.assertEqual(path, "wagtail.images.blocks.ImageChooserBlock")
+ self.assertEqual(args, ())
+ self.assertEqual(kwargs, {"required": False})
diff --git a/wagtail/snippets/tests/test_snippets.py b/wagtail/snippets/tests/test_snippets.py
index c9cbcfb156..54c592d4e5 100644
--- a/wagtail/snippets/tests/test_snippets.py
+++ b/wagtail/snippets/tests/test_snippets.py
@@ -3174,6 +3174,13 @@ class TestSnippetChooserBlock(TestCase):
self.assertEqual(nonrequired_block.clean(test_advert), test_advert)
self.assertIsNone(nonrequired_block.clean(None))
+ def test_deconstruct(self):
+ block = SnippetChooserBlock(Advert, required=False)
+ path, args, kwargs = block.deconstruct()
+ self.assertEqual(path, "wagtail.snippets.blocks.SnippetChooserBlock")
+ self.assertEqual(args, (Advert,))
+ self.assertEqual(kwargs, {"required": False})
+
class TestAdminSnippetChooserWidget(TestCase, WagtailTestUtils):
def test_adapt(self):
| Breadcrumbs JavaScript error on root page listing / index (4.0 RC)
### Issue Summary
The breadcrumbs on the page listing under the root page is triggering a JavaScript error.
### Steps to Reproduce
1. Start a new project with `wagtail start myproject`
2. Load up the Wagtail admin
3. Navigate to the root page
4. Expected: No console errors
5. Actual: Console error triggers `Uncaught TypeError: breadcrumbsToggle is null` (note: error is not as clear in the compressed JS build).
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: no
### Technical details
- Python version: 3.9
- Django version: 4.0
- Wagtail version: 4.0 RC1
- Browser version: Firefox 103.0 (64-bit) on macOS 12.3
**Full error**
```
Uncaught TypeError: breadcrumbsToggle is null
initCollapsibleBreadcrumbs breadcrumbs.js:50
<anonymous> wagtailadmin.js:37
EventListener.handleEvent* wagtailadmin.js:30
js wagtailadmin.js:72
__webpack_require__ wagtailadmin.js:184
__webpack_exports__ wagtailadmin.js:348
O wagtailadmin.js:221
<anonymous> wagtailadmin.js:349
<anonymous> wagtailadmin.js:351
[breadcrumbs.js:50](webpack://wagtail/client/src/includes/breadcrumbs.js?b04c)
initCollapsibleBreadcrumbs breadcrumbs.js:50
<anonymous> wagtailadmin.js:37
(Async: EventListener.handleEvent)
<anonymous> wagtailadmin.js:30
js wagtailadmin.js:72
__webpack_require__ wagtailadmin.js:184
__webpack_exports__ wagtailadmin.js:348
O wagtailadmin.js:221
<anonymous> wagtailadmin.js:349
<anonymous> wagtailadmin.js:351
```
### Likely root cause
* `data-breadcrumbs-next` is still being rendered even though the root breadcrumbs are not collapsible
* https://github.com/wagtail/wagtail/blob/5ff6922eb517015651b9012bd6534a912a50b449/wagtail/admin/templates/wagtailadmin/pages/page_listing_header.html#L11
* https://github.com/wagtail/wagtail/blob/5ff6922eb517015651b9012bd6534a912a50b449/wagtail/admin/templates/wagtailadmin/shared/breadcrumbs.html#L11
* https://github.com/wagtail/wagtail/blob/5ff6922eb517015651b9012bd6534a912a50b449/client/src/includes/breadcrumbs.js#L14-L16
* Maybe when content is not collapsible we should not be adding the `data-breadcrumbs-next` so that the JS does not try to init the toggle at all OR maybe we should add extra logic to the JS so that it does not try to init the toggle if it is not present in the DOM. Preference would be to ensure the data attribute is not set when JS logic is not required.
### Screenshot
<img width="1557" alt="Screen Shot 2022-08-14 at 3 15 08 pm" src="https://user-images.githubusercontent.com/1396140/184523614-d44f9a69-a2b5-46cc-b638-eeb5e6435f28.png">
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/documents/tests/test_blocks.py::TestDocumentChooserBlock::test_deconstruct"
] | [
"wagtail/snippets/tests/test_snippets.py::TestSnippetRegistering::test_register_decorator",
"wagtail/snippets/tests/test_snippets.py::TestSnippetRegistering::test_register_function",
"wagtail/snippets/tests/test_snippets.py::TestSnippetOrdering::test_snippets_ordering",
"wagtail/snippets/tests/test_snippets.py::TestSnippetEditHandlers::test_fancy_edit_handler",
"wagtail/snippets/tests/test_snippets.py::TestSnippetEditHandlers::test_get_snippet_edit_handler",
"wagtail/snippets/tests/test_snippets.py::TestSnippetEditHandlers::test_standard_edit_handler",
"wagtail/snippets/tests/test_snippets.py::TestAdminSnippetChooserWidget::test_adapt",
"wagtail/snippets/tests/test_snippets.py::TestPanelConfigurationChecks::test_model_with_single_tabbed_panel_only"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-08-14T05:56:29Z" | bsd-3-clause |
|
wagtail__wagtail-9920 | diff --git a/wagtail/admin/templates/wagtailadmin/userbar/base.html b/wagtail/admin/templates/wagtailadmin/userbar/base.html
index ee3629e736..247652249d 100644
--- a/wagtail/admin/templates/wagtailadmin/userbar/base.html
+++ b/wagtail/admin/templates/wagtailadmin/userbar/base.html
@@ -51,7 +51,7 @@
</template>
<template id="w-a11y-result-selector-template">
<button class="w-a11y-result__selector" data-a11y-result-selector type="button">
- {% icon name="crosshairs" class_name="w-a11y-result__icon" %}
+ {% icon name="crosshairs" classname="w-a11y-result__icon" %}
<span data-a11y-result-selector-text></span>
</button>
</template>
diff --git a/wagtail/admin/templates/wagtailadmin/workflows/includes/workflow_content_types_checkbox.html b/wagtail/admin/templates/wagtailadmin/workflows/includes/workflow_content_types_checkbox.html
index 0005aaec1f..da943a5cde 100644
--- a/wagtail/admin/templates/wagtailadmin/workflows/includes/workflow_content_types_checkbox.html
+++ b/wagtail/admin/templates/wagtailadmin/workflows/includes/workflow_content_types_checkbox.html
@@ -3,7 +3,7 @@
{% for id, errors in errors_by_id.items %}
{% if id == widget.value %}
<div class="w-field__errors" data-field-errors>
- {% icon name="warning" class_name="w-field__errors-icon" %}
+ {% icon name="warning" classname="w-field__errors-icon" %}
<p class="error-message">
{% for error in errors %}{{ error.message }} {% endfor %}
</p>
diff --git a/wagtail/admin/templatetags/wagtailadmin_tags.py b/wagtail/admin/templatetags/wagtailadmin_tags.py
index fdb15c5d3c..a94d1a6f1e 100644
--- a/wagtail/admin/templatetags/wagtailadmin_tags.py
+++ b/wagtail/admin/templatetags/wagtailadmin_tags.py
@@ -764,8 +764,8 @@ def icon(name=None, classname=None, title=None, wrapped=False, class_name=None):
warn(
(
- "Icon template tag `class_name` has been renamed to `classname`, please adopt the new usage instead.",
- f'Replace `{{% icon ... class_name="{class_name}" %}}` with `{{% icon ... classname="{class_name}" %}}`',
+ "Icon template tag `class_name` has been renamed to `classname`, please adopt the new usage instead. "
+ f'Replace `{{% icon ... class_name="{class_name}" %}}` with `{{% icon ... classname="{class_name}" %}}`'
),
category=RemovedInWagtail50Warning,
)
| wagtail/wagtail | 357edf2914bfb7b1265011b1009f0d57ff9824f1 | diff --git a/wagtail/admin/tests/test_templatetags.py b/wagtail/admin/tests/test_templatetags.py
index 12aad1683a..a28c2f13ea 100644
--- a/wagtail/admin/tests/test_templatetags.py
+++ b/wagtail/admin/tests/test_templatetags.py
@@ -27,6 +27,7 @@ from wagtail.images.tests.utils import get_test_image_file
from wagtail.models import Locale
from wagtail.test.utils import WagtailTestUtils
from wagtail.users.models import UserProfile
+from wagtail.utils.deprecation import RemovedInWagtail50Warning
class TestAvatarTemplateTag(TestCase, WagtailTestUtils):
@@ -483,3 +484,62 @@ class ClassnamesTagTest(TestCase):
actual = Template(template).render(context)
self.assertEqual(expected.strip(), actual.strip())
+
+
+class IconTagTest(TestCase):
+ def test_basic(self):
+ template = """
+ {% load wagtailadmin_tags %}
+ {% icon "wagtail" %}
+ """
+
+ expected = """
+ <svg aria-hidden="true" class="icon icon-wagtail icon"><use href="#icon-wagtail"></svg>
+ """
+
+ self.assertHTMLEqual(expected, Template(template).render(Context()))
+
+ def test_with_classes_positional(self):
+ template = """
+ {% load wagtailadmin_tags %}
+ {% icon "cogs" "myclass" %}
+ """
+
+ expected = """
+ <svg aria-hidden="true" class="icon icon-cogs myclass"><use href="#icon-cogs"></svg>
+ """
+
+ self.assertHTMLEqual(expected, Template(template).render(Context()))
+
+ def test_with_classes_keyword(self):
+ template = """
+ {% load wagtailadmin_tags %}
+ {% icon "warning" classname="myclass" %}
+ """
+
+ expected = """
+ <svg aria-hidden="true" class="icon icon-warning myclass"><use href="#icon-warning"></svg>
+ """
+
+ self.assertHTMLEqual(expected, Template(template).render(Context()))
+
+ def test_with_classes_obsolete_keyword(self):
+ template = """
+ {% load wagtailadmin_tags %}
+ {% icon "doc-empty" class_name="myclass" %}
+ """
+
+ expected = """
+ <svg aria-hidden="true" class="icon icon-doc-empty myclass"><use href="#icon-doc-empty"></svg>
+ """
+
+ with self.assertWarnsMessage(
+ RemovedInWagtail50Warning,
+ (
+ "Icon template tag `class_name` has been renamed to `classname`, "
+ "please adopt the new usage instead. Replace "
+ '`{% icon ... class_name="myclass" %}` with '
+ '`{% icon ... classname="myclass" %}`'
+ ),
+ ):
+ self.assertHTMLEqual(expected, Template(template).render(Context()))
| Tests failing on latest `main`
<!--
Found a bug? Please fill out the sections below. 👍
-->
### Issue Summary
Some tests for the ~~legacy~~ moderation feature seems to be failing on latest `main` after #9817. Weirdly, they passed when the CI was run on the PR: https://github.com/wagtail/wagtail/actions/runs/3956994621
Will investigate later today.
<!--
A summary of the issue.
-->
### Steps to Reproduce
1. (for example) Start a new project with `wagtail start myproject`
2. Edit models.py as follows...
3. ...
Any other relevant information. For example, why do you consider this a bug and what did you expect to happen instead?
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: (yes / no)
### Technical details
- Python version: Run `python --version`.
- Django version: Look in your requirements.txt, or run `pip show django | grep Version`.
- Wagtail version: Look at the bottom of the Settings menu in the Wagtail admin, or run `pip show wagtail | grep Version:`.
- Browser version: You can use https://www.whatsmybrowser.org/ to find this out.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"wagtail/admin/tests/test_templatetags.py::IconTagTest::test_with_classes_obsolete_keyword"
] | [
"wagtail/admin/tests/test_templatetags.py::TestNotificationStaticTemplateTag::test_local_notification_static",
"wagtail/admin/tests/test_templatetags.py::TestNotificationStaticTemplateTag::test_local_notification_static_baseurl",
"wagtail/admin/tests/test_templatetags.py::TestNotificationStaticTemplateTag::test_remote_notification_static",
"wagtail/admin/tests/test_templatetags.py::TestVersionedStatic::test_versioned_static",
"wagtail/admin/tests/test_templatetags.py::TestVersionedStatic::test_versioned_static_absolute_path",
"wagtail/admin/tests/test_templatetags.py::TestVersionedStatic::test_versioned_static_url",
"wagtail/admin/tests/test_templatetags.py::TestVersionedStatic::test_versioned_static_version_string",
"wagtail/admin/tests/test_templatetags.py::TestTimesinceTags::test_human_readable_date",
"wagtail/admin/tests/test_templatetags.py::TestTimesinceTags::test_timesince_last_update_before_today_shows_timeago",
"wagtail/admin/tests/test_templatetags.py::TestTimesinceTags::test_timesince_last_update_today_shows_time",
"wagtail/admin/tests/test_templatetags.py::TestTimesinceTags::test_timesince_simple",
"wagtail/admin/tests/test_templatetags.py::TestComponentTag::test_component_escapes_unsafe_strings",
"wagtail/admin/tests/test_templatetags.py::TestComponentTag::test_error_on_rendering_non_component",
"wagtail/admin/tests/test_templatetags.py::TestComponentTag::test_passing_context_to_component",
"wagtail/admin/tests/test_templatetags.py::ComponentTest::test_kwargs_with_filters",
"wagtail/admin/tests/test_templatetags.py::ComponentTest::test_render_as_variable",
"wagtail/admin/tests/test_templatetags.py::ComponentTest::test_render_block_component",
"wagtail/admin/tests/test_templatetags.py::ComponentTest::test_render_nested",
"wagtail/admin/tests/test_templatetags.py::FragmentTagTest::test_basic",
"wagtail/admin/tests/test_templatetags.py::FragmentTagTest::test_syntax_error",
"wagtail/admin/tests/test_templatetags.py::FragmentTagTest::test_with_variables",
"wagtail/admin/tests/test_templatetags.py::ClassnamesTagTest::test_with_args_with_extra_whitespace",
"wagtail/admin/tests/test_templatetags.py::ClassnamesTagTest::test_with_falsy_args",
"wagtail/admin/tests/test_templatetags.py::ClassnamesTagTest::test_with_multiple_args",
"wagtail/admin/tests/test_templatetags.py::ClassnamesTagTest::test_with_single_arg",
"wagtail/admin/tests/test_templatetags.py::IconTagTest::test_basic",
"wagtail/admin/tests/test_templatetags.py::IconTagTest::test_with_classes_keyword",
"wagtail/admin/tests/test_templatetags.py::IconTagTest::test_with_classes_positional"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2023-01-19T18:04:11Z" | bsd-3-clause |
|
walles__px-50 | diff --git a/px/px_loginhistory.py b/px/px_loginhistory.py
index 57c3ff8..e03fa65 100644
--- a/px/px_loginhistory.py
+++ b/px/px_loginhistory.py
@@ -11,24 +11,26 @@ import dateutil.tz
LAST_USERNAME = "([^ ]+)"
LAST_DEVICE = "([^ ]+)"
LAST_ADDRESS = "([^ ]+)?"
+LAST_PID = "( \[[0-9]+\])?"
LAST_FROM = "(... ... .. ..:..)"
LAST_DASH = " [- ] "
LAST_TO = "[^(]*"
LAST_DURATION = "([0-9+:]+)"
LAST_RE = re.compile(
- LAST_USERNAME +
- " +" +
- LAST_DEVICE +
- " +" +
- LAST_ADDRESS +
- " +" +
- LAST_FROM +
- LAST_DASH +
- LAST_TO +
- " *(\(" +
- LAST_DURATION +
- "\))?"
+ LAST_USERNAME +
+ " +" +
+ LAST_DEVICE +
+ " +" +
+ LAST_ADDRESS +
+ LAST_PID +
+ " +" +
+ LAST_FROM +
+ LAST_DASH +
+ LAST_TO +
+ " *(\(" +
+ LAST_DURATION +
+ "\))?"
)
TIMEDELTA_RE = re.compile("(([0-9]+)\+)?([0-9][0-9]):([0-9][0-9])")
@@ -89,8 +91,8 @@ def get_users_at(timestamp, last_output=None, now=None):
username = match.group(1)
address = match.group(3)
- from_s = match.group(4)
- duration_s = match.group(6)
+ from_s = match.group(5)
+ duration_s = match.group(7)
if address:
username += " from " + address
| walles/px | 809f161662aa5df0108d154435cdc3186b35bb76 | diff --git a/tests/px_loginhistory_test.py b/tests/px_loginhistory_test.py
index 191e602..ffd5019 100644
--- a/tests/px_loginhistory_test.py
+++ b/tests/px_loginhistory_test.py
@@ -289,3 +289,14 @@ def test_to_timedelta(check_output):
assert px_loginhistory._to_timedelta("01:29") == datetime.timedelta(0, hours=1, minutes=29)
assert px_loginhistory._to_timedelta("4+01:29") == datetime.timedelta(4, hours=1, minutes=29)
assert px_loginhistory._to_timedelta("34+01:29") == datetime.timedelta(34, hours=1, minutes=29)
+
+
+def test_realworld_debian(check_output):
+ """
+ Regression test for https://github.com/walles/px/issues/48
+ """
+ now = datetime.datetime(2016, 12, 6, 9, 21, tzinfo=dateutil.tz.tzlocal())
+ testtime = datetime.datetime(2016, 10, 24, 15, 34, tzinfo=dateutil.tz.tzlocal())
+ lastline = "norbert pts/3 mosh [29846] Wed Oct 24 15:33 - 15:34 (00:01)"
+
+ assert set(["norbert from mosh"]) == get_users_at(lastline, now, testtime)
| Asked to report last line: mosh
Hi,
thanks for the very useful program. I just got the following message when running `px <PID-OF-MY-SESSION>`:
```
Users logged in when cinnamon-session(2417) started:
WARNING: Please report unmatched last line at https://github.com/walles/px/issues/new: <norbert pts/3 mosh [29846] Wed Oct 24 15:33 - 15:34 (00:01)>
WARNING: Please report unmatched last line at https://github.com/walles/px/issues/new: <norbert pts/1 mosh [14332] Tue Sep 11 15:28 - 15:29 (00:01)>
norbert from :0
```
This is on Debian/unstable, `px --version` returns `0.0.0`, and the Debian package version is `1.0.13-2`. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/px_loginhistory_test.py::test_realworld_debian"
] | [
"tests/px_loginhistory_test.py::test_get_users_at_range",
"tests/px_loginhistory_test.py::test_get_users_at_still_logged_in",
"tests/px_loginhistory_test.py::test_get_users_at_remote",
"tests/px_loginhistory_test.py::test_get_users_at_local_osx",
"tests/px_loginhistory_test.py::test_get_users_at_local_linux",
"tests/px_loginhistory_test.py::test_get_users_at_until_crash",
"tests/px_loginhistory_test.py::test_get_users_at_until_shutdown_osx",
"tests/px_loginhistory_test.py::test_get_users_at_until_shutdown_linux",
"tests/px_loginhistory_test.py::test_get_users_at_multiple",
"tests/px_loginhistory_test.py::test_get_users_at_pseudousers_osx",
"tests/px_loginhistory_test.py::test_get_users_at_pseudousers_linux",
"tests/px_loginhistory_test.py::test_get_users_at_gone_no_logout",
"tests/px_loginhistory_test.py::test_get_users_at_trailing_noise",
"tests/px_loginhistory_test.py::test_get_users_at_unexpected_last_output",
"tests/px_loginhistory_test.py::test_get_users_at_just_run_it",
"tests/px_loginhistory_test.py::test_to_timestamp",
"tests/px_loginhistory_test.py::test_to_timedelta"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2018-12-06T09:21:17Z" | mit |
|
wandera__1password-client-16 | diff --git a/onepassword/utils.py b/onepassword/utils.py
index f37313d..733612b 100644
--- a/onepassword/utils.py
+++ b/onepassword/utils.py
@@ -1,6 +1,10 @@
import os
import base64
from Crypto.Cipher import AES
+from Crypto.Util.Padding import pad
+
+
+BLOCK_SIZE = 32 # Bytes
def read_bash_return(cmd, single=True):
@@ -128,14 +132,14 @@ class BashProfile:
class Encryption:
def __init__(self, secret_key):
- self.secret_key = secret_key[0:32]
+ self.secret_key = secret_key[0:BLOCK_SIZE]
self.cipher = AES.new(self.secret_key, AES.MODE_ECB)
def decode(self, encoded):
- return self.cipher.decrypt(base64.b64decode(encoded)).decode('UTF-8').replace(" ", "")
+ return self.cipher.decrypt(base64.b64decode(encoded)).decode('UTF-8').replace("\x1f", "")
def encode(self, input_str):
- return base64.b64encode(self.cipher.encrypt(input_str.rjust(32)))
+ return base64.b64encode(self.cipher.encrypt(pad(input_str, BLOCK_SIZE)))
def bump_version():
| wandera/1password-client | 111638ee3e05762bb3008a6d31310afee1d22f1f | diff --git a/test/test_client.py b/test/test_client.py
index f27454d..281d14f 100644
--- a/test/test_client.py
+++ b/test/test_client.py
@@ -12,7 +12,7 @@ def set_up_one_password():
domain = "test"
email = "[email protected]"
secret = "test_secret"
- password = "test_password"
+ password = "a234567890b234567890c234567890d234567890e23"
account = "test"
with open('.bash_profile', 'w') as f:
f.write("OP_SESSION_test=fakelettersforsessionkey")
| Login fails: "Data must be aligned to block boundary in ECB mode"
Hi, logging into my 1password account fails with the ValueError message above:
`from onepassword import OnePassword
op = OnePassword()
1Password master password:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/homebrew/lib/python3.9/site-packages/onepassword/client.py", line 60, in __init__
self.encrypted_master_password, self.session_key = self.signin_wrapper(master_password=password)
File "/opt/homebrew/lib/python3.9/site-packages/onepassword/client.py", line 179, in signin_wrapper
encrypted_str = encrypt.encode(password)
File "/opt/homebrew/lib/python3.9/site-packages/onepassword/utils.py", line 173, in encode
return base64.b64encode(self.cipher.encrypt(input_str.rjust(32)))
File "/opt/homebrew/lib/python3.9/site-packages/Crypto/Cipher/_mode_ecb.py", line 141, in encrypt
raise ValueError("Data must be aligned to block boundary in ECB mode")
ValueError: Data must be aligned to block boundary in ECB mode`
Python 3.9.2, op 1.8.0, 1password-client 0.3.0
Best regards, Jan | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"test/test_client.py::TestClient::test_delete_document",
"test/test_client.py::TestClient::test_first_use",
"test/test_client.py::TestClient::test_get_document",
"test/test_client.py::TestClient::test_get_items",
"test/test_client.py::TestClient::test_get_uuid",
"test/test_client.py::TestClient::test_list_vaults",
"test/test_client.py::TestClient::test_put_document",
"test/test_client.py::TestClient::test_signin_wrapper",
"test/test_client.py::TestClient::test_signout",
"test/test_client.py::TestClient::test_update_document"
] | [] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2021-04-10T16:53:53Z" | mit |
|
warpnet__salt-lint-196 | diff --git a/saltlint/linter.py b/saltlint/linter.py
index 44951d9..83e12be 100644
--- a/saltlint/linter.py
+++ b/saltlint/linter.py
@@ -79,7 +79,8 @@ class RulesCollection(object):
self.config = config
def register(self, obj):
- self.rules.append(obj)
+ if not any(rule.id == obj.id for rule in self.rules):
+ self.rules.append(obj)
def __iter__(self):
return iter(self.rules)
diff --git a/saltlint/rules/JinjaVariableHasSpacesRule.py b/saltlint/rules/JinjaVariableHasSpacesRule.py
index a0c5fd8..0941753 100644
--- a/saltlint/rules/JinjaVariableHasSpacesRule.py
+++ b/saltlint/rules/JinjaVariableHasSpacesRule.py
@@ -15,7 +15,7 @@ class JinjaVariableHasSpacesRule(SaltLintRule):
tags = ['formatting', 'jinja']
version_added = 'v0.0.1'
- bracket_regex = re.compile(r"{{[^ \-\+]|{{[-\+][^ ]|[^ \-\+]}}|[^ ][-\+]}}")
+ bracket_regex = re.compile(r"{{[^ \-\+\d]|{{[-\+][^ ]|[^ \-\+\d]}}|[^ {][-\+\d]}}")
def match(self, file, line):
return self.bracket_regex.search(line)
| warpnet/salt-lint | b31433d5c8f2201c723a9c3be9b9034039a73d49 | diff --git a/tests/unit/TestJinjaVariableHasSpaces.py b/tests/unit/TestJinjaVariableHasSpaces.py
index a066818..1fd0448 100644
--- a/tests/unit/TestJinjaVariableHasSpaces.py
+++ b/tests/unit/TestJinjaVariableHasSpaces.py
@@ -18,7 +18,27 @@ BAD_VARIABLE_LINE = '''
{{-variable+}}
'''
-class TestLineTooLongRule(unittest.TestCase):
+BAD_VARIABLE_ENDING_IN_INTEGER = '''
+{{-variable0+}}
+'''
+
+BAD_VARIABLE_ENDING_IN_INTEGER_RIGHT = '''
+{{ variable0}}
+'''
+
+DOUBLE_QUOTED_INTEGER_IS_VALID = '''
+{{ "{{0}}" }}
+'''
+
+DOUBLE_QUOTED_INTEGER_TRAILING_SPACE_IS_INVALID = '''
+{{ "{{0}}"}}
+'''
+
+DOUBLE_QUOTED_INTEGER_LEADING_SPACE_IS_INVALID = '''
+{{"{{0}}" }}
+'''
+
+class TestJinjaVariableHasSpaces(unittest.TestCase):
collection = RulesCollection()
def setUp(self):
@@ -32,3 +52,23 @@ class TestLineTooLongRule(unittest.TestCase):
def test_statement_negative(self):
results = self.runner.run_state(BAD_VARIABLE_LINE)
self.assertEqual(1, len(results))
+
+ def test_double_quoted_integer(self):
+ results = self.runner.run_state(DOUBLE_QUOTED_INTEGER_IS_VALID)
+ self.assertEqual(0, len(results))
+
+ def test_double_quoted_integer_trailing_space_invalid(self):
+ results = self.runner.run_state(DOUBLE_QUOTED_INTEGER_TRAILING_SPACE_IS_INVALID)
+ self.assertEqual(1, len(results))
+
+ def test_double_quoted_integer_leading_space_invalid(self):
+ results = self.runner.run_state(DOUBLE_QUOTED_INTEGER_LEADING_SPACE_IS_INVALID)
+ self.assertEqual(1, len(results))
+
+ def test_variable_bad_ends_with_integer(self):
+ results = self.runner.run_state(BAD_VARIABLE_ENDING_IN_INTEGER)
+ self.assertEqual(1, len(results))
+
+ def test_variable_bad_ends_with_integer_right(self):
+ results = self.runner.run_state(BAD_VARIABLE_ENDING_IN_INTEGER_RIGHT)
+ self.assertEqual(1, len(results))
| String representing curly braces is incorrectly detected
**Describe the bug**
In a string with curly brace-notation for standard string formatting it is necessary to use double curly braces in order to output a pair of single curly braces.
The following snippet is an extract from a jinja file to format an ldap search pattern.
```jinja
{% set search_filter="(&({}={{0}})({}=CN={},{}))".format(string1, string2, string3, string4)) %}
```
The output should be (assuming the string contents are the same as the variable name) like so:
```python
search_filter="(&(string1={0})(string2=CN=string3,string4))"
```
However, salt-lint picks up the double braces as a jinja replacement. In this case, jinja will not replace, it formats the string as expected.
Quite a conundrum
**To Reproduce**
Use the string identified above in a `jinja` file and then run salt-lint.
**Expected behavior**
The string format to pass lint.
**Desktop (please complete the following information):**
any
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer_leading_space_invalid",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer_trailing_space_invalid",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_negative",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_variable_bad_ends_with_integer",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_variable_bad_ends_with_integer_right"
] | [
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_positive"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2020-10-08T10:34:31Z" | mit |
|
warpnet__salt-lint-206 | diff --git a/saltlint/rules/YamlHasOctalValueRule.py b/saltlint/rules/YamlHasOctalValueRule.py
index 7633f9f..d39477c 100644
--- a/saltlint/rules/YamlHasOctalValueRule.py
+++ b/saltlint/rules/YamlHasOctalValueRule.py
@@ -15,7 +15,7 @@ class YamlHasOctalValueRule(Rule):
tags = ['formatting']
version_added = 'v0.0.6'
- bracket_regex = re.compile(r"(?<=:)\s{0,}0[0-9]{1,}\s{0,}((?={#)|(?=#)|(?=$))")
+ bracket_regex = re.compile(r"^[^:]+:\s{0,}0[0-9]{1,}\s{0,}((?={#)|(?=#)|(?=$))")
def match(self, file, line):
return self.bracket_regex.search(line)
| warpnet/salt-lint | 978978e398e4240b533b35bd80bba1403ca5e684 | diff --git a/tests/unit/TestYamlHasOctalValueRule.py b/tests/unit/TestYamlHasOctalValueRule.py
index b756031..e03fc44 100644
--- a/tests/unit/TestYamlHasOctalValueRule.py
+++ b/tests/unit/TestYamlHasOctalValueRule.py
@@ -28,6 +28,12 @@ testdirectory02:
apache_disable_default_site:
apache_site.disabled:
- name: 000-default
+
+# MAC addresses shouldn't be matched, for more information see:
+# https://github.com/warpnet/salt-lint/issues/202
+infoblox_remove_record:
+ infoblox_host_record.absent:
+ - mac: 4c:f2:d3:1b:2e:05
'''
BAD_NUMBER_STATE = '''
| Some MAC addresses trigger rule 210
First of all, thank you for this tool!
**Describe the bug**
Some MAC addresses trigger rule 210.
This is the case then the two last characters are integers.
**To Reproduce**
```sls
valid: 00:e5:e5:aa:60:69
valid2: 09:41:a2:48:d1:6f
valid3: 4c:f2:d3:1b:2e:0d
invalid: 4c:f2:d3:1b:2e:05
```
**Expected behavior**
All of the above are valid (or all MAC addresses should be encapsulated).
```sh
pip3 show salt-lint
Name: salt-lint
Version: 0.4.2
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestYamlHasOctalValueRule.py::TestYamlHasOctalValueRule::test_statement_positive"
] | [
"tests/unit/TestYamlHasOctalValueRule.py::TestYamlHasOctalValueRule::test_statement_negative"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2020-11-28T20:20:21Z" | mit |
|
warpnet__salt-lint-207 | diff --git a/README.md b/README.md
index 5a02f7e..fbc3364 100644
--- a/README.md
+++ b/README.md
@@ -164,6 +164,10 @@ Optionally override the default file selection as follows:
## List of rules
+### Formatting
+
+Disable formatting checks using `-x formatting`
+
Rule | Description
:-:|:--
[201](https://github.com/warpnet/salt-lint/wiki/201) | Trailing whitespace
@@ -180,6 +184,25 @@ Rule | Description
[212](https://github.com/warpnet/salt-lint/wiki/212) | Most files should not contain irregular spaces
[213](https://github.com/warpnet/salt-lint/wiki/213) | SaltStack recommends using `cmd.run` together with `onchanges`, rather than `cmd.wait`
+### Jinja
+
+Disable jinja checks using `-x jinja`
+
+Rule | Description
+:-:|:--
+[202](https://github.com/warpnet/salt-lint/wiki/202) | Jinja statement should have spaces before and after: `{% statement %}`
+[206](https://github.com/warpnet/salt-lint/wiki/206) | Jinja variables should have spaces before and after `{{ var_name }}`
+[209](https://github.com/warpnet/salt-lint/wiki/209) | Jinja comment should have spaces before and after: `{# comment #}`
+[211](https://github.com/warpnet/salt-lint/wiki/211) | `pillar.get` or `grains.get` should be formatted differently
+
+### Deprecations
+
+Disable deprecation checks using `-x deprecation`
+
+Rule | Description
+:-:|:--
+[901](https://github.com/warpnet/salt-lint/wiki/901) | Using the `quiet` argument with `cmd.run` is deprecated. Use `output_loglevel: quiet`
+
## False Positives: Skipping Rules
Some rules are bit of a rule of thumb. To skip a specific rule for a specific task, inside your state add `# noqa [rule_id]` at the end of the line. You can skip multiple rules via a space-separated list. Example:
diff --git a/saltlint/rules/CmdRunQuietRule.py b/saltlint/rules/CmdRunQuietRule.py
new file mode 100644
index 0000000..5dd68ce
--- /dev/null
+++ b/saltlint/rules/CmdRunQuietRule.py
@@ -0,0 +1,39 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) 2020 Warpnet B.V.
+
+import re
+from saltlint.linter.rule import Rule
+from saltlint.utils import get_rule_skips_from_text
+
+class CmdRunQuietRule(Rule):
+ id = '901'
+ shortdesc = 'Using the quiet argument with cmd.run is deprecated. Use output_loglevel: quiet'
+ description = 'Using the quiet argument with cmd.run is deprecated. Use output_loglevel: quiet'
+
+ severity = 'HIGH'
+ tags = ['deprecation']
+ version_added = 'develop'
+
+ regex = re.compile(r"^.+\n^\s{2}cmd\.run:(?:\n.+)+\n^\s{4}- quiet\s?.*", re.MULTILINE)
+
+ def matchtext(self, file, text):
+ results = []
+
+ for match in re.finditer(self.regex, text):
+ # Get the location of the regex match
+ start = match.start()
+ end = match.end()
+
+ # Get the line number of the last character
+ lines = text[:end].splitlines()
+ line_no = len(lines)
+
+ # Skip result if noqa for this rule ID is found in section
+ section = text[start:end]
+ if self.id in get_rule_skips_from_text(section):
+ continue
+
+ # Append the match to the results
+ results.append((line_no, lines[-1], self.shortdesc))
+
+ return results
diff --git a/saltlint/utils.py b/saltlint/utils.py
index a0334b2..dbcdf23 100644
--- a/saltlint/utils.py
+++ b/saltlint/utils.py
@@ -31,3 +31,12 @@ def get_rule_skips_from_line(line):
noqa_text = line.split('# noqa')[1]
rule_id_list = noqa_text.split()
return rule_id_list
+
+
+def get_rule_skips_from_text(text):
+ rule_id_list = []
+ for line in text.splitlines():
+ rule_id_list.extend(get_rule_skips_from_line(line))
+
+ # Return a list of unique ids
+ return list(set(rule_id_list))
| warpnet/salt-lint | 56d5a889c467808135eecd6140fa9ad7b945ecd1 | diff --git a/tests/unit/TestCmdRunQuietRule.py b/tests/unit/TestCmdRunQuietRule.py
new file mode 100644
index 0000000..ffb4c55
--- /dev/null
+++ b/tests/unit/TestCmdRunQuietRule.py
@@ -0,0 +1,61 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) 2020 Warpnet B.V.
+
+import unittest
+
+from saltlint.linter.collection import RulesCollection
+from saltlint.rules.CmdRunQuietRule import CmdRunQuietRule
+from tests import RunFromText
+
+
+GOOD_QUIET_STATE = '''
+getpip:
+ cmd.run:
+ - name: /usr/bin/python /usr/local/sbin/get-pip.py
+ - unless: which pip
+ - require:
+ - pkg: python
+ - file: /usr/local/sbin/get-pip.py
+ - output_loglevel: quiet
+'''
+
+BAD_QUIET_STATE = '''
+getpip:
+ cmd.run:
+ - name: /usr/bin/python /usr/local/sbin/get-pip.py
+ - unless: which pip
+ - require:
+ - pkg: python
+ - file: /usr/local/sbin/get-pip.py
+ - quiet # This is the ninth line
+
+getpip2:
+ cmd.run:
+ - name: /usr/bin/python /usr/local/sbin/get-pip.py
+ - quiet
+
+getpip3:
+ cmd.run:
+ - name: /usr/bin/python /usr/local/sbin/get-pip.py
+ - quiet # noqa: 901
+'''
+
+class TestCmdRunQuietRule(unittest.TestCase):
+ collection = RulesCollection()
+
+ def setUp(self):
+ self.collection.register(CmdRunQuietRule())
+
+ def test_statement_positive(self):
+ runner = RunFromText(self.collection)
+ results = runner.run_state(GOOD_QUIET_STATE)
+ self.assertEqual(0, len(results))
+
+ def test_statement_negative(self):
+ runner = RunFromText(self.collection)
+ results = runner.run_state(BAD_QUIET_STATE)
+ self.assertEqual(2, len(results))
+
+ # Check line numbers of the results
+ self.assertEqual(9, results[0].linenumber)
+ self.assertEqual(14, results[1].linenumber)
| Feature Request: Check cmd state deprecation
### Preface
Kindly use the [check for state.cmd deprecation](https://github.com/roaldnefs/salt-lint/pull/37) as an example of adding a check. #37 has to be merged first.
### Description
Add the possibility to check for deprecation within the [cmd state](https://docs.saltstack.com/en/latest/ref/states/all/salt.states.cmd.html)
The following options have been deprecated:
* `cmd.run:quiet` (since _version 2014.1.0_)
The following options should be used:
* `cmd.run:output_loglevel: quiet`
Example(s) of an **improperly** configured state:
```code
getpip:
cmd.run:
- name: /usr/bin/python /usr/local/sbin/get-pip.py
- unless: which pip
- require:
- pkg: python
- file: /usr/local/sbin/get-pip.py
- reload_modules: True
- quiet
```
An example of **properly** configured state:
```code
getpip:
cmd.run:
- name: /usr/bin/python /usr/local/sbin/get-pip.py
- unless: which pip
- require:
- pkg: python
- file: /usr/local/sbin/get-pip.py
- reload_modules: True
- output_loglevel: quiet
```
### Fix requirements
A fix for this issue should (at least):
* Notify the user of using a deprecated option
* Notify the user since what version the option will be or has been deprecated
* A suggestion on what option to replace it with
* Contain unit tests for the check | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestCmdRunQuietRule.py::TestCmdRunQuietRule::test_statement_negative",
"tests/unit/TestCmdRunQuietRule.py::TestCmdRunQuietRule::test_statement_positive"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_issue_reference",
"has_added_files",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2020-11-28T22:20:13Z" | mit |
|
warpnet__salt-lint-213 | diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
index fc39d25..abf935e 100644
--- a/.github/workflows/lint.yml
+++ b/.github/workflows/lint.yml
@@ -20,7 +20,7 @@ jobs:
docker:
runs-on: ubuntu-latest
- steps:
+ steps:
- name: Checkout
uses: actions/checkout@v2
- name: dockerlint
@@ -57,7 +57,7 @@ jobs:
- name: Lint with codespell
run: |
pip install codespell
- codespell --skip="./.git*"
+ codespell --skip="./.git*,./saltlint/rules/FileManagedReplaceContentRule.py"
pylint:
runs-on: ubuntu-latest
diff --git a/README.md b/README.md
index 5c2f86e..81878e2 100644
--- a/README.md
+++ b/README.md
@@ -184,6 +184,7 @@ Rule | Description
[212](https://github.com/warpnet/salt-lint/wiki/212) | Most files should not contain irregular spaces
[213](https://github.com/warpnet/salt-lint/wiki/213) | SaltStack recommends using `cmd.run` together with `onchanges`, rather than `cmd.wait`
[214](https://github.com/warpnet/salt-lint/wiki/214) | SLS file with a period in the name (besides the suffix period) can not be referenced
+[215](https://github.com/warpnet/salt-lint/wiki/215) | Using `replace: False` is required when not specifying content
### Jinja
diff --git a/saltlint/rules/FileManagedReplaceContentRule.py b/saltlint/rules/FileManagedReplaceContentRule.py
new file mode 100644
index 0000000..5eca8c3
--- /dev/null
+++ b/saltlint/rules/FileManagedReplaceContentRule.py
@@ -0,0 +1,54 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) 2020 Warpnet B.V.
+
+import re
+from saltlint.linter.rule import Rule
+from saltlint.utils import get_rule_skips_from_text
+from saltlint.utils import LANGUAGE_SLS
+
+
+class FileManagedReplaceContentRule(Rule):
+ id = '215'
+ shortdesc = "Using 'replace: False' is required when not specifying content"
+ description = "Using 'replace: False' is required when not specifying content"
+
+ severity = 'HIGH'
+ languages = [LANGUAGE_SLS]
+ tags = ['formatting']
+ version_added = 'develop'
+
+ # Find the full file.managed state
+ regex = re.compile(r"^\s{2}file\.managed:.*(?:\n\s{4}.+)*", re.MULTILINE)
+ # Regex for finding the content source option
+ regex_options= re.compile(
+ r"^\s{4}-\s(?:source:|contents:|contents_pillar:|contents_grains:|replace:\s[F|f]alse).*$",
+ re.MULTILINE
+ )
+
+ def matchtext(self, file, text):
+ results = []
+
+ # Find all file.managed states in the specified sls file
+ for match in re.finditer(self.regex, text):
+ # Continue if the file.managed state includes a content source
+ # or replace is set to False
+ if re.search(self.regex_options, match.group(0)):
+ continue
+
+ # Get the location of the regex match
+ start = match.start()
+ end = match.end()
+
+ # Get the line number of the first character
+ lines = text[:start].splitlines()
+ line_no = len(lines) + 1
+
+ # Skip result if noqa for this rule ID is found in section
+ section = text[start:end]
+ if self.id in get_rule_skips_from_text(section):
+ continue
+
+ # Append the match to the results
+ results.append((line_no, section.splitlines()[0], self.shortdesc))
+
+ return results
diff --git a/saltlint/rules/JinjaCommentHasSpacesRule.py b/saltlint/rules/JinjaCommentHasSpacesRule.py
index 7c54719..cb93f30 100644
--- a/saltlint/rules/JinjaCommentHasSpacesRule.py
+++ b/saltlint/rules/JinjaCommentHasSpacesRule.py
@@ -10,8 +10,8 @@ from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
class JinjaCommentHasSpacesRule(Rule):
id = '209'
- shortdesc = 'Jinja comment should have spaces before and after: {# comment #}'
- description = 'Jinja comment should have spaces before and after: ``{# comment #}``'
+ shortdesc = "Jinja comment should have spaces before and after: '{# comment #}'"
+ description = "Jinja comment should have spaces before and after: '{# comment #}'"
severity = 'LOW'
languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
tags = ['formatting', 'jinja']
diff --git a/saltlint/rules/JinjaStatementHasSpacesRule.py b/saltlint/rules/JinjaStatementHasSpacesRule.py
index 59992e9..0ef024e 100644
--- a/saltlint/rules/JinjaStatementHasSpacesRule.py
+++ b/saltlint/rules/JinjaStatementHasSpacesRule.py
@@ -10,8 +10,8 @@ from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
class JinjaStatementHasSpacesRule(Rule):
id = '202'
- shortdesc = 'Jinja statement should have spaces before and after: {% statement %}'
- description = 'Jinja statement should have spaces before and after: ``{% statement %}``'
+ shortdesc = "Jinja statement should have spaces before and after: '{% statement %}'"
+ description = "Jinja statement should have spaces before and after: '{% statement %}'"
severity = 'LOW'
languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
tags = ['formatting', 'jinja']
diff --git a/saltlint/rules/JinjaVariableHasSpacesRule.py b/saltlint/rules/JinjaVariableHasSpacesRule.py
index 53fd0eb..946222b 100644
--- a/saltlint/rules/JinjaVariableHasSpacesRule.py
+++ b/saltlint/rules/JinjaVariableHasSpacesRule.py
@@ -10,8 +10,8 @@ from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
class JinjaVariableHasSpacesRule(Rule):
id = '206'
- shortdesc = 'Jinja variables should have spaces before and after: {{ var_name }}'
- description = 'Jinja variables should have spaces before and after: ``{{ var_name }}``'
+ shortdesc = "Jinja variables should have spaces before and after: '{{ var_name }}'"
+ description = "Jinja variables should have spaces before and after: '{{ var_name }}'"
severity = 'LOW'
languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
tags = ['formatting', 'jinja']
diff --git a/saltlint/rules/YamlHasOctalValueRule.py b/saltlint/rules/YamlHasOctalValueRule.py
index 57b4f82..2001e49 100644
--- a/saltlint/rules/YamlHasOctalValueRule.py
+++ b/saltlint/rules/YamlHasOctalValueRule.py
@@ -10,8 +10,8 @@ from saltlint.utils import LANGUAGE_SLS
class YamlHasOctalValueRule(Rule):
id = '210'
- shortdesc = 'Numbers that start with `0` should always be encapsulated in quotation marks'
- description = 'Numbers that start with `0` should always be encapsulated in quotation marks'
+ shortdesc = "Numbers that start with '0' should always be encapsulated in quotation marks"
+ description = "Numbers that start with '0' should always be encapsulated in quotation marks"
severity = 'HIGH'
languages = [LANGUAGE_SLS]
tags = ['formatting']
| warpnet/salt-lint | dc836e3a7f6cfe84544e39af9a0524aca59cd3fd | diff --git a/tests/unit/TestFileManagedReplaceContentRule.py b/tests/unit/TestFileManagedReplaceContentRule.py
new file mode 100644
index 0000000..76d453e
--- /dev/null
+++ b/tests/unit/TestFileManagedReplaceContentRule.py
@@ -0,0 +1,107 @@
+# -*- coding: utf-8 -*-
+# Copyright (c) 2020 Warpnet B.V.
+
+import unittest
+
+from saltlint.linter.collection import RulesCollection
+from saltlint.rules.FileManagedReplaceContentRule import FileManagedReplaceContentRule
+from tests import RunFromText
+
+
+GOOD_FILE_STATE = '''
+cis_grub.cfg:
+ file.managed:
+ - name: /boot/grub.cfg
+ - user: root
+ - group: root
+ - mode: '0700'
+ - source: salt://grub/files/grub.cfg
+
+cis_systemid_only_set_once:
+ file.managed:
+ - name: /tmp/systemid
+ - user: root
+ - group: root
+ - replace: False
+ - contents_grains: osmajorrelease
+
+user:
+ user.present:
+ - name: "salt-lint"
+ file.managed:
+ - name: /user/salt-lint/.bashrc
+ - user: root
+ - group: root
+ - mode: '0700'
+ - contents_pillar: bashrc
+
+cis_grub.cfg_managerights:
+ file.managed:
+ - name: /boot/grub.cfg
+ - user: root
+ - group: root
+ - mode: '0700'
+ - replace: False
+
+cis_grub_permissions:
+ file.managed:
+ - name: /boot/grub.cfg
+ - replace: false
+ - user: root
+ - group: root
+ - mode: '0700'
+'''
+
+BAD_FILE_STATE = '''
+cis_grub.cfg:
+ file.managed:
+ - name: /boot/grub.cfg
+ - user: root
+ - group: root
+ - mode: '0700'
+
+cis_systemid_only_set_once:
+ file.managed:
+ - name: /tmp/systemid
+ - user: root
+ - group: root
+ - replace: True
+
+user:
+ user.present:
+ - name: "salt-lint"
+ file.managed:
+ - name: /user/salt-lint/.bashrc
+ - user: root
+ - group: root
+ - mode: '0700'
+
+cis_grub_permissions:
+ file.managed: # noqa: 215
+ - name: /boot/grub.cfg
+ - user: root
+ - group: root
+ - mode: '0700'
+'''
+
+
+class TestFileManagedReplaceContentRule(unittest.TestCase):
+ collection = RulesCollection()
+
+ def setUp(self):
+ self.collection.register(FileManagedReplaceContentRule())
+
+ def test_statement_positive(self):
+ runner = RunFromText(self.collection)
+ results = runner.run_state(GOOD_FILE_STATE)
+ self.assertEqual(0, len(results))
+
+ def test_statement_negative(self):
+ runner = RunFromText(self.collection)
+ results = runner.run_state(BAD_FILE_STATE)
+ self.assertEqual(3, len(results))
+
+ # Check line numbers of the results
+ self.assertEqual(3, results[0].linenumber)
+ self.assertEqual(10, results[1].linenumber)
+ self.assertEqual(19, results[2].linenumber)
| Feature Request: Add rule for cron state validation
**Is your feature request related to a problem? Please describe.**
[`cron.{present,absent}`](https://docs.saltstack.com/en/master/ref/states/all/salt.states.cron.html#salt.states.cron.present) changes include some surprising gotchas, this is because the identifier defaults to the `- name:`
```bash
identifier
Custom-defined identifier for tracking the cron line for future crontab edits. This defaults to the state name
```
Require `- identifier:` to be present for `cron.{present,absent}` states which would avoid coupling action changing from identifier changing.
**Describe the solution you'd like**
Since name defines both identifier and action by default, I'd recommend that the linter would verify that `- identifier:` was present. It would also verify that the `- identifier:` does not use any jinja templating as it's ideal that the data is not changed external the declaration.
This would make changing the actions not create duplicate crons.
**Describe alternatives you've considered**
My personal opinion is that salt shouldn't be combining the identifier for uniqueness and the command you are running, but I feel that would be a fairly large and breaking api change.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestFileManagedReplaceContentRule.py::TestFileManagedReplaceContentRule::test_statement_negative",
"tests/unit/TestFileManagedReplaceContentRule.py::TestFileManagedReplaceContentRule::test_statement_positive"
] | [] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2020-12-04T14:11:04Z" | mit |
|
warpnet__salt-lint-231 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 2ff9c18..ba0a0f3 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -2,6 +2,9 @@
All notable changes in **salt-lint** are documented below.
## [Unreleased]
+### Fixed
+- Ensure all excluded paths from both the CLI and configuration are passed to the runner ([#231](https://github.com/warpnet/salt-lint/pull/231)).
+
## [0.5.0] (2021-01-17)
### Added
- Rule 213 to recommend using cmd.run together with onchanges ([#207](https://github.com/warpnet/salt-lint/pull/207)).
diff --git a/saltlint/linter/runner.py b/saltlint/linter/runner.py
index 752d0e6..5f62e4a 100644
--- a/saltlint/linter/runner.py
+++ b/saltlint/linter/runner.py
@@ -38,7 +38,8 @@ class Runner(object):
# These will be (potentially) relative paths
paths = [path.strip() for path in exclude_paths]
self.exclude_paths = paths + [os.path.abspath(path) for path in paths]
- self.exclude_paths = []
+ else:
+ self.exclude_paths = []
def is_excluded(self, file_path):
# Any will short-circuit as soon as something returns True, but will
| warpnet/salt-lint | ab17ad972c36ceb3d91ccae0bdabebadb040e324 | diff --git a/tests/unit/TestRunner.py b/tests/unit/TestRunner.py
index b1e8e02..0d0ceb2 100644
--- a/tests/unit/TestRunner.py
+++ b/tests/unit/TestRunner.py
@@ -4,6 +4,9 @@
import unittest
from saltlint.cli import run
+from saltlint.config import Configuration
+from saltlint.linter.runner import Runner
+
class TestRunner(unittest.TestCase):
@@ -18,3 +21,16 @@ class TestRunner(unittest.TestCase):
# expected.
args = ['tests/test-extension-success.sls']
self.assertEqual(run(args), 0)
+
+ def test_runner_exclude_paths(self):
+ """
+ Check if all the excluded paths from the configuration are passed to
+ the runner.
+ """
+ exclude_paths = ['first.sls', 'second.sls']
+ config = Configuration(dict(exclude_paths=exclude_paths))
+ runner = Runner([], 'init.sls', config)
+
+ self.assertTrue(
+ any(path in runner.exclude_paths for path in exclude_paths)
+ )
| --exclude does not seem to work since 0.5.0
In my CI I have :
``` bash
find . -name "*.jinja" -o -name "*sls" | xargs --no-run-if-empty salt-lint -x 204,205 --exclude ./common_syslog-ng.sls
```
So I was not notified on lint errors for `common_syslog-ng.sls` file, but since 0.5.0 version I get errors from this file.
If I set image tag to `0.4.2`, normal behaviour is back.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestRunner.py::TestRunner::test_runner_exclude_paths"
] | [
"tests/unit/TestRunner.py::TestRunner::test_runner_with_matches",
"tests/unit/TestRunner.py::TestRunner::test_runner_without_matches"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-19T18:24:18Z" | mit |
|
warpnet__salt-lint-236 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 82eff64..7d78e56 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -4,6 +4,7 @@ All notable changes in **salt-lint** are documented below.
## [Unreleased]
### Fixed
- Append the contents of the `CHANGELOG.md` file to the long description of the package instead of the duplicate `README.md` contents ([#234](https://github.com/warpnet/salt-lint/pull/234)).
+- Ignore Jinja specific rules in Jinja escaped blocks ([#236](https://github.com/warpnet/salt-lint/pull/236)).
## [0.5.1] (2021-01-19)
### Fixed
diff --git a/saltlint/linter/rule.py b/saltlint/linter/rule.py
index e006699..fc3fded 100644
--- a/saltlint/linter/rule.py
+++ b/saltlint/linter/rule.py
@@ -7,7 +7,7 @@ import six
from saltlint.utils import get_rule_skips_from_line, get_file_type
from saltlint.linter.match import Match
-from saltlint.utils import LANGUAGE_SLS
+from saltlint.utils import LANGUAGE_SLS, LANGUAGE_JINJA
class Rule(object):
@@ -89,6 +89,44 @@ class Rule(object):
return matches
+class JinjaRule(Rule):
+ languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
+ tags = ['formatting', 'jinja']
+
+ # Regex for matching all escaped Jinja blocks in the text
+ jinja_escape_regex = re.compile(
+ r"{%[+-]?\s?raw\s?[+-]?%}.*{%[+-]?\s?endraw\s?[+-]?%}",
+ re.DOTALL | re.MULTILINE
+ )
+
+ def matchlines(self, file, text):
+ """
+ Match the text line by line but ignore all escaped Jinja blocks, e.g.
+ content between {% raw %} and {% endraw %}.
+
+ Returns a list of Match objects.
+ """
+ escaped_text = text
+ # Replace escaped Jinja blocks with the same number of empty lines
+ for match in self.jinja_escape_regex.finditer(text):
+ start = match.start()
+ end = match.end()
+ # Get the number of newlines in the escaped match
+ lines = text[start:end].splitlines()
+ num_of_lines = len(lines) - 1
+
+ # Replace escaped Jinja block in the escaped text by newlines to
+ # keep all the line numbers consistent
+ pre_text = escaped_text[:start]
+ post_text = escaped_text[end:]
+ newlines = '\n' * num_of_lines
+ escaped_text = pre_text + newlines + post_text
+
+ # Call the matchlines() on the parent class with the escaped text
+ matches = super(JinjaRule, self).matchlines(file, escaped_text) # pylint: disable=R1725
+ return matches
+
+
class DeprecationRule(Rule):
id = None
state = None
diff --git a/saltlint/rules/JinjaCommentHasSpacesRule.py b/saltlint/rules/JinjaCommentHasSpacesRule.py
index cb93f30..ce61646 100644
--- a/saltlint/rules/JinjaCommentHasSpacesRule.py
+++ b/saltlint/rules/JinjaCommentHasSpacesRule.py
@@ -1,20 +1,17 @@
# -*- coding: utf-8 -*-
# Copyright (c) 2016 Will Thames and contributors
# Copyright (c) 2018 Ansible Project
-# Modified work Copyright (c) 2020 Warpnet B.V.
+# Modified work Copyright (c) 2020-2021 Warpnet B.V.
import re
-from saltlint.linter.rule import Rule
-from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
+from saltlint.linter.rule import JinjaRule
-class JinjaCommentHasSpacesRule(Rule):
+class JinjaCommentHasSpacesRule(JinjaRule):
id = '209'
shortdesc = "Jinja comment should have spaces before and after: '{# comment #}'"
description = "Jinja comment should have spaces before and after: '{# comment #}'"
severity = 'LOW'
- languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
- tags = ['formatting', 'jinja']
version_added = 'v0.0.5'
bracket_regex = re.compile(r"{#[^ \-\+]|{#[\-\+][^ ]|[^ \-\+]#}|[^ ][\-\+]#}")
diff --git a/saltlint/rules/JinjaPillarGrainsGetFormatRule.py b/saltlint/rules/JinjaPillarGrainsGetFormatRule.py
index accace3..8b53c5e 100644
--- a/saltlint/rules/JinjaPillarGrainsGetFormatRule.py
+++ b/saltlint/rules/JinjaPillarGrainsGetFormatRule.py
@@ -1,22 +1,19 @@
# -*- coding: utf-8 -*-
# Copyright (c) 2016 Will Thames and contributors
# Copyright (c) 2018 Ansible Project
-# Modified work Copyright (c) 2020 Warpnet B.V.
+# Modified work Copyright (c) 2020-2021 Warpnet B.V.
import re
-from saltlint.linter.rule import Rule
-from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
+from saltlint.linter.rule import JinjaRule
-class JinjaPillarGrainsGetFormatRule(Rule):
+class JinjaPillarGrainsGetFormatRule(JinjaRule):
id = '211'
shortdesc = 'pillar.get or grains.get should be formatted differently'
description = "pillar.get and grains.get should always be formatted " \
"like salt['pillar.get']('item'), grains['item1'] or " \
" pillar.get('item')"
severity = 'HIGH'
- languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
- tags = ['formatting', 'jinja']
version_added = 'v0.0.10'
bracket_regex = re.compile(r"{{( |\-|\+)?.(pillar|grains).get\[.+}}")
diff --git a/saltlint/rules/JinjaStatementHasSpacesRule.py b/saltlint/rules/JinjaStatementHasSpacesRule.py
index 0ef024e..696f591 100644
--- a/saltlint/rules/JinjaStatementHasSpacesRule.py
+++ b/saltlint/rules/JinjaStatementHasSpacesRule.py
@@ -1,20 +1,17 @@
# -*- coding: utf-8 -*-
# Copyright (c) 2016 Will Thames and contributors
# Copyright (c) 2018 Ansible Project
-# Modified work Copyright (c) 2020 Warpnet B.V.
+# Modified work Copyright (c) 2020-2021 Warpnet B.V.
import re
-from saltlint.linter.rule import Rule
-from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
+from saltlint.linter.rule import JinjaRule
-class JinjaStatementHasSpacesRule(Rule):
+class JinjaStatementHasSpacesRule(JinjaRule):
id = '202'
shortdesc = "Jinja statement should have spaces before and after: '{% statement %}'"
description = "Jinja statement should have spaces before and after: '{% statement %}'"
severity = 'LOW'
- languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
- tags = ['formatting', 'jinja']
version_added = 'v0.0.2'
bracket_regex = re.compile(r"{%[^ \-\+]|{%[\-\+][^ ]|[^ \-\+]%}|[^ ][\-\+]%}")
diff --git a/saltlint/rules/JinjaVariableHasSpacesRule.py b/saltlint/rules/JinjaVariableHasSpacesRule.py
index 946222b..03433b6 100644
--- a/saltlint/rules/JinjaVariableHasSpacesRule.py
+++ b/saltlint/rules/JinjaVariableHasSpacesRule.py
@@ -1,20 +1,17 @@
# -*- coding: utf-8 -*-
# Copyright (c) 2016 Will Thames and contributors
# Copyright (c) 2018 Ansible Project
-# Modified work Copyright (c) 2020 Warpnet B.V.
+# Modified work Copyright (c) 2020-2021 Warpnet B.V.
import re
-from saltlint.linter.rule import Rule
-from saltlint.utils import LANGUAGE_JINJA, LANGUAGE_SLS
+from saltlint.linter.rule import JinjaRule
-class JinjaVariableHasSpacesRule(Rule):
+class JinjaVariableHasSpacesRule(JinjaRule):
id = '206'
shortdesc = "Jinja variables should have spaces before and after: '{{ var_name }}'"
description = "Jinja variables should have spaces before and after: '{{ var_name }}'"
severity = 'LOW'
- languages = [LANGUAGE_SLS, LANGUAGE_JINJA]
- tags = ['formatting', 'jinja']
version_added = 'v0.0.1'
bracket_regex = re.compile(r"{{[^ \-\+\d]|{{[-\+][^ ]|[^ \-\+\d]}}|[^ {][-\+\d]}}")
| warpnet/salt-lint | 05dc6f2e1d3da6ffe7d6526bf88193cec6f09f51 | diff --git a/tests/unit/TestJinjaCommentHasSpaces.py b/tests/unit/TestJinjaCommentHasSpaces.py
index 60796fe..ea5e59e 100644
--- a/tests/unit/TestJinjaCommentHasSpaces.py
+++ b/tests/unit/TestJinjaCommentHasSpaces.py
@@ -12,6 +12,12 @@ from tests import RunFromText
GOOD_COMMENT_LINE = '''
{#- set example='good' +#}
+
+{% raw %}
+ # The following line should be ignored as it is placed in a Jinja escape
+ # block
+ {#-set example='bad'+#}
+{% endraw %}
'''
BAD_COMMENT_LINE = '''
diff --git a/tests/unit/TestJinjaStatementHasSpaces.py b/tests/unit/TestJinjaStatementHasSpaces.py
index 947a876..f1534f6 100644
--- a/tests/unit/TestJinjaStatementHasSpaces.py
+++ b/tests/unit/TestJinjaStatementHasSpaces.py
@@ -12,6 +12,12 @@ from tests import RunFromText
GOOD_STATEMENT_LINE = '''
{%- set example='good' +%}
+
+{% raw %}
+ # The following line should be ignored as it is placed in a Jinja escape
+ # block
+ {%-set example='bad'+%}
+{% endraw %}
'''
BAD_STATEMENT_LINE = '''
diff --git a/tests/unit/TestJinjaVariableHasSpaces.py b/tests/unit/TestJinjaVariableHasSpaces.py
index 301cb8d..4e53f33 100644
--- a/tests/unit/TestJinjaVariableHasSpaces.py
+++ b/tests/unit/TestJinjaVariableHasSpaces.py
@@ -1,7 +1,7 @@
# -*- coding: utf-8 -*-
# Copyright (c) 2013-2018 Will Thames <[email protected]>
# Copyright (c) 2018 Ansible by Red Hat
-# Modified work Copyright (c) 2020 Warpnet B.V.
+# Modified work Copyright (c) 2020-2021 Warpnet B.V.
import unittest
@@ -14,6 +14,19 @@ GOOD_VARIABLE_LINE = '''
{{- variable +}}
'''
+GOOD_VARIABLE_LINE_RAW = '''
+{% raw %}
+{{variable}}
+{% endraw %}
+'''
+
+BAD_VARIABLE_LINE_RAW = '''
+{% raw %}
+{{variable}}
+{% endraw %}
+{{variable}} # line 5
+'''
+
BAD_VARIABLE_LINE = '''
{{-variable+}}
'''
@@ -49,6 +62,19 @@ class TestJinjaVariableHasSpaces(unittest.TestCase):
results = self.runner.run_state(GOOD_VARIABLE_LINE)
self.assertEqual(0, len(results))
+ def test_statement_jinja_raw_positive(self):
+ """Check if Jinja looking variables between raw-blocks are ignored."""
+ results = self.runner.run_state(GOOD_VARIABLE_LINE_RAW)
+ self.assertEqual(0, len(results))
+
+ def test_statement_jinja_raw_negative(self):
+ """Check if Jinja looking variables between raw-blocks are ignored."""
+ results = self.runner.run_state(BAD_VARIABLE_LINE_RAW)
+ # Check if the correct number of matches are found
+ self.assertEqual(1, len(results))
+ # Check if the match occurred on the correct line
+ self.assertEqual(results[0].linenumber, 5)
+
def test_statement_negative(self):
results = self.runner.run_state(BAD_VARIABLE_LINE)
self.assertEqual(1, len(results))
| Errors 202, 206 and 209 triggered inside raw blocks {% raw %}/{% endraw %}
**Describe the bug**
While implementing CI using salt-lint on a Salt repo, I stumbled upon the following behavior, where errors were reported even inside raw blocks delimited by `{% raw %}`/`{% endraw %}`.
**To Reproduce**
```bash
cat > test.sls <<EOF
environments:
variables:
heketi:
{% raw %}
HEKETI_CLI_SERVER: \$(kubectl --kubeconfig=/etc/kubernetes/admin.conf get svc/heketi -n glusterfs --template "http://{{.spec.clusterIP}}:{{(index .spec.ports 0).port}}" 2>/dev/null || echo 'Go root!')
{% endraw %}
EOF
docker run --rm -v "$PWD":/data:ro -it warpnetbv/salt-lint:0.4.2 -x 204 test.sls
```
Result
```
[206] Jinja variables should have spaces before and after: {{ var_name }}
test.sls:5
HEKETI_CLI_SERVER: $(kubectl --kubeconfig=/etc/kubernetes/admin.conf get svc/heketi -n glusterfs --template "http://{{.spec.clusterIP}}:{{(index .spec.ports 0).port}}" 2>/dev/null || echo 'Go root!')
```
**Expected behavior**
Errors shouldn't be reported inside `raw` elements, or at least the ones about Jinja formatting (202, 206 and 209) should be ignored. Inside a raw block, we are not evaluating Jinja markup, so we don't care if some `{{` is not properly spaced (in fact, the raw block is meant to prevent errors during Jinja rendering by Salt as it would be interpreted as an undefined variable).
**Desktop:**
- OS: Debian 9 amd64
- Version 0.4.2
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/TestJinjaCommentHasSpaces.py::TestJinjaCommentHasSpaces::test_comment_positive",
"tests/unit/TestJinjaStatementHasSpaces.py::TestLineTooLongRule::test_statement_positive",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_jinja_raw_negative",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_jinja_raw_positive"
] | [
"tests/unit/TestJinjaCommentHasSpaces.py::TestJinjaCommentHasSpaces::test_comment_negative",
"tests/unit/TestJinjaStatementHasSpaces.py::TestLineTooLongRule::test_statement_negative",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer_leading_space_invalid",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_double_quoted_integer_trailing_space_invalid",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_negative",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_statement_positive",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_variable_bad_ends_with_integer",
"tests/unit/TestJinjaVariableHasSpaces.py::TestJinjaVariableHasSpaces::test_variable_bad_ends_with_integer_right"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-29T14:46:45Z" | mit |
|
wbond__asn1crypto-240 | diff --git a/asn1crypto/algos.py b/asn1crypto/algos.py
index fc25e4d..b7d406c 100644
--- a/asn1crypto/algos.py
+++ b/asn1crypto/algos.py
@@ -245,17 +245,29 @@ class SignedDigestAlgorithmId(ObjectIdentifier):
'1.2.840.10040.4.3': 'sha1_dsa',
'1.3.14.3.2.13': 'sha1_dsa',
'1.3.14.3.2.27': 'sha1_dsa',
+ # Source: NIST CSOR Algorithm Registrations
'2.16.840.1.101.3.4.3.1': 'sha224_dsa',
'2.16.840.1.101.3.4.3.2': 'sha256_dsa',
+ '2.16.840.1.101.3.4.3.3': 'sha384_dsa',
+ '2.16.840.1.101.3.4.3.4': 'sha512_dsa',
'1.2.840.10045.4.1': 'sha1_ecdsa',
'1.2.840.10045.4.3.1': 'sha224_ecdsa',
'1.2.840.10045.4.3.2': 'sha256_ecdsa',
'1.2.840.10045.4.3.3': 'sha384_ecdsa',
'1.2.840.10045.4.3.4': 'sha512_ecdsa',
+ # Source: NIST CSOR Algorithm Registrations
+ '2.16.840.1.101.3.4.3.5': 'sha3_224_dsa',
+ '2.16.840.1.101.3.4.3.6': 'sha3_256_dsa',
+ '2.16.840.1.101.3.4.3.7': 'sha3_384_dsa',
+ '2.16.840.1.101.3.4.3.8': 'sha3_512_dsa',
'2.16.840.1.101.3.4.3.9': 'sha3_224_ecdsa',
'2.16.840.1.101.3.4.3.10': 'sha3_256_ecdsa',
'2.16.840.1.101.3.4.3.11': 'sha3_384_ecdsa',
'2.16.840.1.101.3.4.3.12': 'sha3_512_ecdsa',
+ '2.16.840.1.101.3.4.3.13': 'sha3_224_rsa',
+ '2.16.840.1.101.3.4.3.14': 'sha3_256_rsa',
+ '2.16.840.1.101.3.4.3.15': 'sha3_384_rsa',
+ '2.16.840.1.101.3.4.3.16': 'sha3_512_rsa',
# For when the digest is specified elsewhere in a Sequence
'1.2.840.113549.1.1.1': 'rsassa_pkcs1v15',
'1.2.840.10040.4.1': 'dsa',
@@ -281,14 +293,25 @@ class SignedDigestAlgorithmId(ObjectIdentifier):
'sha256_dsa': '2.16.840.1.101.3.4.3.2',
'sha256_ecdsa': '1.2.840.10045.4.3.2',
'sha256_rsa': '1.2.840.113549.1.1.11',
+ 'sha384_dsa': '2.16.840.1.101.3.4.3.3',
'sha384_ecdsa': '1.2.840.10045.4.3.3',
'sha384_rsa': '1.2.840.113549.1.1.12',
+ 'sha512_dsa': '2.16.840.1.101.3.4.3.4',
'sha512_ecdsa': '1.2.840.10045.4.3.4',
'sha512_rsa': '1.2.840.113549.1.1.13',
+ # Source: NIST CSOR Algorithm Registrations
+ 'sha3_224_dsa': '2.16.840.1.101.3.4.3.5',
+ 'sha3_256_dsa': '2.16.840.1.101.3.4.3.6',
+ 'sha3_384_dsa': '2.16.840.1.101.3.4.3.7',
+ 'sha3_512_dsa': '2.16.840.1.101.3.4.3.8',
'sha3_224_ecdsa': '2.16.840.1.101.3.4.3.9',
'sha3_256_ecdsa': '2.16.840.1.101.3.4.3.10',
'sha3_384_ecdsa': '2.16.840.1.101.3.4.3.11',
'sha3_512_ecdsa': '2.16.840.1.101.3.4.3.12',
+ 'sha3_224_rsa': '2.16.840.1.101.3.4.3.13',
+ 'sha3_256_rsa': '2.16.840.1.101.3.4.3.14',
+ 'sha3_384_rsa': '2.16.840.1.101.3.4.3.15',
+ 'sha3_512_rsa': '2.16.840.1.101.3.4.3.16',
'ed25519': '1.3.101.112',
'ed448': '1.3.101.113',
}
@@ -323,11 +346,21 @@ class SignedDigestAlgorithm(_ForceNullParameters, Sequence):
'sha256_rsa': 'rsassa_pkcs1v15',
'sha384_rsa': 'rsassa_pkcs1v15',
'sha512_rsa': 'rsassa_pkcs1v15',
+ 'sha3_224_rsa': 'rsassa_pkcs1v15',
+ 'sha3_256_rsa': 'rsassa_pkcs1v15',
+ 'sha3_384_rsa': 'rsassa_pkcs1v15',
+ 'sha3_512_rsa': 'rsassa_pkcs1v15',
'rsassa_pkcs1v15': 'rsassa_pkcs1v15',
'rsassa_pss': 'rsassa_pss',
'sha1_dsa': 'dsa',
'sha224_dsa': 'dsa',
'sha256_dsa': 'dsa',
+ 'sha384_dsa': 'dsa',
+ 'sha512_dsa': 'dsa',
+ 'sha3_224_dsa': 'dsa',
+ 'sha3_256_dsa': 'dsa',
+ 'sha3_384_dsa': 'dsa',
+ 'sha3_512_dsa': 'dsa',
'dsa': 'dsa',
'sha1_ecdsa': 'ecdsa',
'sha224_ecdsa': 'ecdsa',
@@ -373,11 +406,25 @@ class SignedDigestAlgorithm(_ForceNullParameters, Sequence):
'sha1_dsa': 'sha1',
'sha224_dsa': 'sha224',
'sha256_dsa': 'sha256',
+ 'sha384_dsa': 'sha384',
+ 'sha512_dsa': 'sha512',
'sha1_ecdsa': 'sha1',
'sha224_ecdsa': 'sha224',
'sha256_ecdsa': 'sha256',
'sha384_ecdsa': 'sha384',
'sha512_ecdsa': 'sha512',
+ 'sha3_224_dsa': 'sha3_224',
+ 'sha3_256_dsa': 'sha3_256',
+ 'sha3_384_dsa': 'sha3_384',
+ 'sha3_512_dsa': 'sha3_512',
+ 'sha3_224_ecdsa': 'sha3_224',
+ 'sha3_256_ecdsa': 'sha3_256',
+ 'sha3_384_ecdsa': 'sha3_384',
+ 'sha3_512_ecdsa': 'sha3_512',
+ 'sha3_224_rsa': 'sha3_224',
+ 'sha3_256_rsa': 'sha3_256',
+ 'sha3_384_rsa': 'sha3_384',
+ 'sha3_512_rsa': 'sha3_512',
'ed25519': 'sha512',
'ed448': 'shake256',
}
diff --git a/asn1crypto/core.py b/asn1crypto/core.py
index 364c6b5..2edd4f3 100644
--- a/asn1crypto/core.py
+++ b/asn1crypto/core.py
@@ -166,6 +166,15 @@ def load(encoded_data, strict=False):
return Asn1Value.load(encoded_data, strict=strict)
+def unpickle_helper(asn1crypto_cls, der_bytes):
+ """
+ Helper function to integrate with pickle.
+
+ Note that this must be an importable top-level function.
+ """
+ return asn1crypto_cls.load(der_bytes)
+
+
class Asn1Value(object):
"""
The basis of all ASN.1 values
@@ -481,6 +490,12 @@ class Asn1Value(object):
return self.__repr__()
+ def __reduce__(self):
+ """
+ Permits pickling Asn1Value objects using their DER representation.
+ """
+ return unpickle_helper, (self.__class__, self.dump())
+
def _new_instance(self):
"""
Constructs a new copy of the current object, preserving any tagging
| wbond/asn1crypto | b5f03e6f9797c691a3b812a5bb1acade3a1f4eeb | diff --git a/tests/test_algos.py b/tests/test_algos.py
index 88e8cbf..064aad5 100644
--- a/tests/test_algos.py
+++ b/tests/test_algos.py
@@ -6,6 +6,8 @@ import sys
import os
from asn1crypto import algos, core
+
+from .unittest_data import data_decorator, data
from ._unittest_compat import patch
patch()
@@ -22,6 +24,7 @@ tests_root = os.path.dirname(__file__)
fixtures_dir = os.path.join(tests_root, 'fixtures')
+@data_decorator
class AlgoTests(unittest.TestCase):
def test_signed_digest_parameters(self):
@@ -78,3 +81,31 @@ class AlgoTests(unittest.TestCase):
params = algo["parameters"]
self.assertEqual(params["version"].native, 'v1-0')
self.assertEqual(params["rounds"].native, 42)
+
+ @staticmethod
+ def sha3_algo_pairs():
+ return [
+ ('sha3_224_dsa', 'sha3_224', 'dsa'),
+ ('sha3_256_dsa', 'sha3_256', 'dsa'),
+ ('sha3_384_dsa', 'sha3_384', 'dsa'),
+ ('sha3_512_dsa', 'sha3_512', 'dsa'),
+ ('sha3_224_ecdsa', 'sha3_224', 'ecdsa'),
+ ('sha3_256_ecdsa', 'sha3_256', 'ecdsa'),
+ ('sha3_384_ecdsa', 'sha3_384', 'ecdsa'),
+ ('sha3_512_ecdsa', 'sha3_512', 'ecdsa'),
+ ('sha3_224_rsa', 'sha3_224', 'rsa'),
+ ('sha3_256_rsa', 'sha3_256', 'rsa'),
+ ('sha3_384_rsa', 'sha3_384', 'rsa'),
+ ('sha3_512_rsa', 'sha3_512', 'rsa'),
+ ]
+
+ @data('sha3_algo_pairs', True)
+ def sha3_algos_round_trip(self, digest_alg, sig_alg):
+ alg_name = "%s_%s" % (digest_alg, sig_alg)
+ original = algos.SignedDigestAlgorithm({'algorithm': alg_name})
+ parsed = algos.SignedDigestAlgorithm.load(original.dump())
+ self.assertEqual(parsed.hash_algo, digest_alg)
+ self.assertEqual(
+ parsed.signature_algo,
+ 'rsassa_pkcs1v15' if sig_alg == 'rsa' else sig_alg
+ )
diff --git a/tests/test_core.py b/tests/test_core.py
index 7ac9196..fabb675 100644
--- a/tests/test_core.py
+++ b/tests/test_core.py
@@ -1,6 +1,7 @@
# coding: utf-8
from __future__ import unicode_literals, division, absolute_import, print_function
+import pickle
import unittest
import os
from datetime import datetime, timedelta
@@ -1375,3 +1376,11 @@ class CoreTests(unittest.TestCase):
with self.assertRaisesRegex(ValueError, "Second arc must be "):
core.ObjectIdentifier("0.40")
+
+ def test_pickle_integration(self):
+ orig = Seq({'id': '2.3.4', 'value': b"\xde\xad\xbe\xef"})
+ pickled_bytes = pickle.dumps(orig)
+ # ensure that our custom pickling implementation was used
+ self.assertIn(b"unpickle_helper", pickled_bytes)
+ unpickled = pickle.loads(pickled_bytes)
+ self.assertEqual(orig.native, unpickled.native)
| Can asn1crypto support pickle!
Whether asn1crypto supports serialization and deserialization with files. I found that it could not work normally after being serialized and saved to a file. It was not in the same memory twice.
[https://github.com/MatthiasValvekens/pyHanko/discussions/154](interrupted_signing) | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_224_dsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_224_ecdsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_224_rsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_256_dsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_256_ecdsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_256_rsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_384_dsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_384_ecdsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_384_rsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_512_dsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_512_ecdsa",
"tests/test_algos.py::AlgoTests::test_sha3_algos_round_trip_sha3_512_rsa",
"tests/test_core.py::CoreTests::test_pickle_integration"
] | [
"tests/test_algos.py::AlgoTests::test_ccm_parameters",
"tests/test_algos.py::AlgoTests::test_digest_parameters",
"tests/test_algos.py::AlgoTests::test_rc2_parameters",
"tests/test_algos.py::AlgoTests::test_rc5_parameters",
"tests/test_algos.py::AlgoTests::test_scrypt_parameters",
"tests/test_algos.py::AlgoTests::test_signed_digest_parameters",
"tests/test_core.py::CoreTests::test_add_to_end_sequence_value",
"tests/test_core.py::CoreTests::test_bit_string_1",
"tests/test_core.py::CoreTests::test_bit_string_2",
"tests/test_core.py::CoreTests::test_bit_string_3",
"tests/test_core.py::CoreTests::test_bit_string_4",
"tests/test_core.py::CoreTests::test_bit_string_errors_1",
"tests/test_core.py::CoreTests::test_bit_string_errors_2",
"tests/test_core.py::CoreTests::test_bit_string_errors_3",
"tests/test_core.py::CoreTests::test_bit_string_item_access",
"tests/test_core.py::CoreTests::test_bit_string_load_dump",
"tests/test_core.py::CoreTests::test_broken_object_identifier",
"tests/test_core.py::CoreTests::test_cast",
"tests/test_core.py::CoreTests::test_choice_dict_name",
"tests/test_core.py::CoreTests::test_choice_dump_header_native",
"tests/test_core.py::CoreTests::test_choice_parse_return",
"tests/test_core.py::CoreTests::test_choice_tuple_name",
"tests/test_core.py::CoreTests::test_compare_primitive_1",
"tests/test_core.py::CoreTests::test_compare_primitive_10",
"tests/test_core.py::CoreTests::test_compare_primitive_11",
"tests/test_core.py::CoreTests::test_compare_primitive_12",
"tests/test_core.py::CoreTests::test_compare_primitive_13",
"tests/test_core.py::CoreTests::test_compare_primitive_2",
"tests/test_core.py::CoreTests::test_compare_primitive_3",
"tests/test_core.py::CoreTests::test_compare_primitive_4",
"tests/test_core.py::CoreTests::test_compare_primitive_5",
"tests/test_core.py::CoreTests::test_compare_primitive_6",
"tests/test_core.py::CoreTests::test_compare_primitive_7",
"tests/test_core.py::CoreTests::test_compare_primitive_8",
"tests/test_core.py::CoreTests::test_compare_primitive_9",
"tests/test_core.py::CoreTests::test_concat",
"tests/test_core.py::CoreTests::test_copy",
"tests/test_core.py::CoreTests::test_copy_choice_mutate",
"tests/test_core.py::CoreTests::test_copy_indefinite",
"tests/test_core.py::CoreTests::test_copy_mutable",
"tests/test_core.py::CoreTests::test_delete_sequence_value",
"tests/test_core.py::CoreTests::test_dump_ber_indefinite",
"tests/test_core.py::CoreTests::test_dump_set",
"tests/test_core.py::CoreTests::test_dump_set_of",
"tests/test_core.py::CoreTests::test_explicit_application_tag",
"tests/test_core.py::CoreTests::test_explicit_application_tag_nested",
"tests/test_core.py::CoreTests::test_explicit_field_default",
"tests/test_core.py::CoreTests::test_explicit_header_field_choice",
"tests/test_core.py::CoreTests::test_explicit_tag_header",
"tests/test_core.py::CoreTests::test_fix_tagging_choice",
"tests/test_core.py::CoreTests::test_force_dump_unknown_sequence",
"tests/test_core.py::CoreTests::test_generalized_time_1",
"tests/test_core.py::CoreTests::test_generalized_time_10",
"tests/test_core.py::CoreTests::test_generalized_time_2",
"tests/test_core.py::CoreTests::test_generalized_time_3",
"tests/test_core.py::CoreTests::test_generalized_time_4",
"tests/test_core.py::CoreTests::test_generalized_time_5",
"tests/test_core.py::CoreTests::test_generalized_time_6",
"tests/test_core.py::CoreTests::test_generalized_time_7",
"tests/test_core.py::CoreTests::test_generalized_time_8",
"tests/test_core.py::CoreTests::test_generalized_time_9",
"tests/test_core.py::CoreTests::test_get_sequence_value",
"tests/test_core.py::CoreTests::test_indefinite_length_bit_string",
"tests/test_core.py::CoreTests::test_indefinite_length_integer_bit_string",
"tests/test_core.py::CoreTests::test_indefinite_length_integer_octet_string",
"tests/test_core.py::CoreTests::test_indefinite_length_octet_bit_string",
"tests/test_core.py::CoreTests::test_indefinite_length_octet_string",
"tests/test_core.py::CoreTests::test_indefinite_length_octet_string_2",
"tests/test_core.py::CoreTests::test_indefinite_length_parsable_octet_bit_string",
"tests/test_core.py::CoreTests::test_indefinite_length_parsable_octet_string",
"tests/test_core.py::CoreTests::test_indefinite_length_utf8string",
"tests/test_core.py::CoreTests::test_int_to_bit_tuple",
"tests/test_core.py::CoreTests::test_integer_1",
"tests/test_core.py::CoreTests::test_integer_2",
"tests/test_core.py::CoreTests::test_integer_3",
"tests/test_core.py::CoreTests::test_integer_4",
"tests/test_core.py::CoreTests::test_integer_5",
"tests/test_core.py::CoreTests::test_integer_6",
"tests/test_core.py::CoreTests::test_integer_7",
"tests/test_core.py::CoreTests::test_integer_8",
"tests/test_core.py::CoreTests::test_integer_9",
"tests/test_core.py::CoreTests::test_integer_bit_string",
"tests/test_core.py::CoreTests::test_integer_bit_string_errors_1",
"tests/test_core.py::CoreTests::test_integer_bit_string_errors_2",
"tests/test_core.py::CoreTests::test_integer_bit_string_errors_3",
"tests/test_core.py::CoreTests::test_integer_octet_string",
"tests/test_core.py::CoreTests::test_integer_octet_string_encoded_width",
"tests/test_core.py::CoreTests::test_large_tag_encode",
"tests/test_core.py::CoreTests::test_load",
"tests/test_core.py::CoreTests::test_load_invalid_choice",
"tests/test_core.py::CoreTests::test_load_wrong_type",
"tests/test_core.py::CoreTests::test_manual_construction",
"tests/test_core.py::CoreTests::test_mapped_bit_string_1",
"tests/test_core.py::CoreTests::test_mapped_bit_string_2",
"tests/test_core.py::CoreTests::test_mapped_bit_string_3",
"tests/test_core.py::CoreTests::test_mapped_bit_string_item_access",
"tests/test_core.py::CoreTests::test_mapped_bit_string_numeric",
"tests/test_core.py::CoreTests::test_mapped_bit_string_sparse",
"tests/test_core.py::CoreTests::test_mapped_bit_string_unset_bit",
"tests/test_core.py::CoreTests::test_nested_explicit_tag_choice",
"tests/test_core.py::CoreTests::test_nested_indefinite_length_octet_string",
"tests/test_core.py::CoreTests::test_object_identifier_1",
"tests/test_core.py::CoreTests::test_object_identifier_2",
"tests/test_core.py::CoreTests::test_object_identifier_3",
"tests/test_core.py::CoreTests::test_object_identifier_4",
"tests/test_core.py::CoreTests::test_object_identifier_5",
"tests/test_core.py::CoreTests::test_object_identifier_6",
"tests/test_core.py::CoreTests::test_object_identifier_7",
"tests/test_core.py::CoreTests::test_object_identifier_8",
"tests/test_core.py::CoreTests::test_octet_bit_string",
"tests/test_core.py::CoreTests::test_octet_bit_string_errors_1",
"tests/test_core.py::CoreTests::test_octet_bit_string_errors_2",
"tests/test_core.py::CoreTests::test_octet_bit_string_errors_3",
"tests/test_core.py::CoreTests::test_oid_dotted_native",
"tests/test_core.py::CoreTests::test_oid_map_unmap",
"tests/test_core.py::CoreTests::test_parse_broken_sequence_fields_repeatedly",
"tests/test_core.py::CoreTests::test_parse_broken_sequenceof_children_repeatedly",
"tests/test_core.py::CoreTests::test_parse_universal_type_1",
"tests/test_core.py::CoreTests::test_replace_sequence_value",
"tests/test_core.py::CoreTests::test_required_field",
"tests/test_core.py::CoreTests::test_retag",
"tests/test_core.py::CoreTests::test_sequece_choice_choice",
"tests/test_core.py::CoreTests::test_sequence_any_asn1value",
"tests/test_core.py::CoreTests::test_sequence_any_native_value",
"tests/test_core.py::CoreTests::test_sequence_choice_field_by_dict",
"tests/test_core.py::CoreTests::test_sequence_choice_field_by_tuple",
"tests/test_core.py::CoreTests::test_sequence_of_spec",
"tests/test_core.py::CoreTests::test_sequence_spec",
"tests/test_core.py::CoreTests::test_strict",
"tests/test_core.py::CoreTests::test_strict_choice",
"tests/test_core.py::CoreTests::test_strict_concat",
"tests/test_core.py::CoreTests::test_strict_on_class",
"tests/test_core.py::CoreTests::test_truncated_1",
"tests/test_core.py::CoreTests::test_truncated_2",
"tests/test_core.py::CoreTests::test_truncated_3",
"tests/test_core.py::CoreTests::test_untag",
"tests/test_core.py::CoreTests::test_utctime_1",
"tests/test_core.py::CoreTests::test_utctime_2",
"tests/test_core.py::CoreTests::test_utctime_3",
"tests/test_core.py::CoreTests::test_utctime_4",
"tests/test_core.py::CoreTests::test_utctime_copy",
"tests/test_core.py::CoreTests::test_utctime_errors",
"tests/test_core.py::CoreTests::test_wrong_asn1value",
"tests/test_core.py::CoreTests::test_wrong_asn1value2",
"tests/test_core.py::CoreTests::test_wrong_asn1value3",
"tests/test_core.py::CoreTests::test_wrong_asn1value4"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2022-09-26T20:49:53Z" | mit |
|
wbond__asn1crypto-271 | diff --git a/asn1crypto/x509.py b/asn1crypto/x509.py
index a67ab1a..38aa770 100644
--- a/asn1crypto/x509.py
+++ b/asn1crypto/x509.py
@@ -27,7 +27,7 @@ import unicodedata
from ._errors import unwrap
from ._iri import iri_to_uri, uri_to_iri
from ._ordereddict import OrderedDict
-from ._types import type_name, str_cls, bytes_to_list
+from ._types import type_name, str_cls, byte_cls, bytes_to_list
from .algos import AlgorithmIdentifier, AnyAlgorithmIdentifier, DigestAlgorithm, SignedDigestAlgorithm
from .core import (
Any,
@@ -708,7 +708,13 @@ class NameTypeAndValue(Sequence):
"""
if self._prepped is None:
- self._prepped = self._ldap_string_prep(self['value'].native)
+ native = self['value'].native
+ if isinstance(native, str_cls):
+ self._prepped = self._ldap_string_prep(native)
+ else:
+ if isinstance(native, byte_cls):
+ native = ' ' + native.decode('cp1252') + ' '
+ self._prepped = native
return self._prepped
def __ne__(self, other):
| wbond/asn1crypto | 1a7a5bacfbea25dddf9d6f10dc11c8b7a327db10 | diff --git a/tests/test_x509.py b/tests/test_x509.py
index c177fe6..43e0bea 100644
--- a/tests/test_x509.py
+++ b/tests/test_x509.py
@@ -485,6 +485,23 @@ class X509Tests(unittest.TestCase):
self.assertEqual("unique_identifier", complex_name.chosen[3][0]['type'].native)
self.assertIsInstance(complex_name.chosen[3][0]['value'], core.OctetBitString)
+ def test_name_hashable(self):
+ complex_name = x509.Name.build(
+ {
+ 'country_name': 'US',
+ 'tpm_manufacturer': 'Acme Co',
+ 'unique_identifier': b'\x04\x10\x03\x09',
+ 'email_address': '[email protected]'
+ }
+ )
+ self.assertEqual(
+ "country_name: us \x1e"
+ "email_address: [email protected] \x1e"
+ "tpm_manufacturer: acme co \x1e"
+ "unique_identifier: \x04\x10\x03\x09 ",
+ complex_name.hashable
+ )
+
def test_v1_cert(self):
cert = self._load_cert('chromium/ndn.ca.crt')
tbs_cert = cert['tbs_certificate']
| NameTypeAndValue of type "unique_indentifier" cannot be prepared
Loosely related to issue #228 and PR #241.
Note that the `NameTypeAndValue` class can hold a `unique_identifier` which is an `OctetBitString`:
https://github.com/wbond/asn1crypto/blob/af8a325794b3c1c96860746dbde4ad46218645fe/asn1crypto/x509.py#L652
https://github.com/wbond/asn1crypto/blob/af8a325794b3c1c96860746dbde4ad46218645fe/asn1crypto/x509.py#L677
However, the `prepped_value` property relies on the value being a unicode string:
https://github.com/wbond/asn1crypto/blob/af8a325794b3c1c96860746dbde4ad46218645fe/asn1crypto/x509.py#L700-L712
For this reason, attempting to hash a `Name` with a `RDNSequence` that includes a `unique_identifier` fails with the following error:
```python
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:1055: in hashable
return self.chosen.hashable
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:949: in hashable
return '\x1E'.join(rdn.hashable for rdn in self)
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:949: in <genexpr>
return '\x1E'.join(rdn.hashable for rdn in self)
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:856: in hashable
values = self._get_values(self)
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:925: in _get_values
for ntv in rdn:
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:931: in <listcomp>
[output.update([(ntv['type'].native, ntv.prepped_value)]) for ntv in rdn]
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:711: in prepped_value
self._prepped = self._ldap_string_prep(self['value'].native)
../../miniconda/envs/parsec/lib/python3.9/site-packages/asn1crypto/x509.py:749: in _ldap_string_prep
string = re.sub('[\u00ad\u1806\u034f\u180b-\u180d\ufe0f-\uff00\ufffc]+', '', string)
pattern = '[\xad᠆͏᠋-᠍️-\uff00]+', repl = '', string = b'test_ca', count = 0, flags = 0
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it's passed the Match object and must return
a replacement string to be used."""
> return _compile(pattern, flags).sub(repl, string, count)
E TypeError: cannot use a string pattern on a bytes-like object
../../miniconda/envs/parsec/lib/python3.9/re.py:210: TypeError
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_x509.py::X509Tests::test_name_hashable"
] | [
"tests/test_x509.py::X509Tests::test_authority_information_access_value_1",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_10",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_11",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_12",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_13",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_14",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_15",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_16",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_2",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_3",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_4",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_5",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_6",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_7",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_8",
"tests/test_x509.py::X509Tests::test_authority_information_access_value_9",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_1",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_10",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_11",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_12",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_13",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_14",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_15",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_16",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_2",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_3",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_4",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_5",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_6",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_7",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_8",
"tests/test_x509.py::X509Tests::test_authority_issuer_serial_9",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_1",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_10",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_11",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_12",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_13",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_14",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_15",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_16",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_2",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_3",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_4",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_5",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_6",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_7",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_8",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_9",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_1",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_10",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_11",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_12",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_13",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_14",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_15",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_16",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_2",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_3",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_4",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_5",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_6",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_7",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_8",
"tests/test_x509.py::X509Tests::test_authority_key_identifier_value_9",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_1",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_10",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_11",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_12",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_13",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_14",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_15",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_16",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_2",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_3",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_4",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_5",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_6",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_7",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_8",
"tests/test_x509.py::X509Tests::test_basic_constraints_value_9",
"tests/test_x509.py::X509Tests::test_build_name_printable",
"tests/test_x509.py::X509Tests::test_build_name_type_by_oid",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_1",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_10",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_11",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_12",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_13",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_14",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_15",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_16",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_2",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_3",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_4",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_5",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_6",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_7",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_8",
"tests/test_x509.py::X509Tests::test_certificate_policies_value_9",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_1",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_2",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_3",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_4",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_5",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_6",
"tests/test_x509.py::X509Tests::test_cms_hash_algo_7",
"tests/test_x509.py::X509Tests::test_compare_dnsname_1",
"tests/test_x509.py::X509Tests::test_compare_dnsname_2",
"tests/test_x509.py::X509Tests::test_compare_dnsname_3",
"tests/test_x509.py::X509Tests::test_compare_dnsname_4",
"tests/test_x509.py::X509Tests::test_compare_dnsname_5",
"tests/test_x509.py::X509Tests::test_compare_email_address_1",
"tests/test_x509.py::X509Tests::test_compare_email_address_2",
"tests/test_x509.py::X509Tests::test_compare_email_address_3",
"tests/test_x509.py::X509Tests::test_compare_email_address_4",
"tests/test_x509.py::X509Tests::test_compare_email_address_5",
"tests/test_x509.py::X509Tests::test_compare_email_address_6",
"tests/test_x509.py::X509Tests::test_compare_email_address_7",
"tests/test_x509.py::X509Tests::test_compare_email_address_8",
"tests/test_x509.py::X509Tests::test_compare_ip_address_1",
"tests/test_x509.py::X509Tests::test_compare_ip_address_2",
"tests/test_x509.py::X509Tests::test_compare_ip_address_3",
"tests/test_x509.py::X509Tests::test_compare_ip_address_4",
"tests/test_x509.py::X509Tests::test_compare_ip_address_5",
"tests/test_x509.py::X509Tests::test_compare_name_1",
"tests/test_x509.py::X509Tests::test_compare_name_2",
"tests/test_x509.py::X509Tests::test_compare_name_3",
"tests/test_x509.py::X509Tests::test_compare_name_4",
"tests/test_x509.py::X509Tests::test_compare_name_5",
"tests/test_x509.py::X509Tests::test_compare_name_6",
"tests/test_x509.py::X509Tests::test_compare_name_7",
"tests/test_x509.py::X509Tests::test_compare_uri_1",
"tests/test_x509.py::X509Tests::test_compare_uri_2",
"tests/test_x509.py::X509Tests::test_compare_uri_3",
"tests/test_x509.py::X509Tests::test_compare_uri_4",
"tests/test_x509.py::X509Tests::test_compare_uri_5",
"tests/test_x509.py::X509Tests::test_compare_uri_6",
"tests/test_x509.py::X509Tests::test_compare_uri_7",
"tests/test_x509.py::X509Tests::test_critical_extensions_1",
"tests/test_x509.py::X509Tests::test_critical_extensions_10",
"tests/test_x509.py::X509Tests::test_critical_extensions_11",
"tests/test_x509.py::X509Tests::test_critical_extensions_12",
"tests/test_x509.py::X509Tests::test_critical_extensions_13",
"tests/test_x509.py::X509Tests::test_critical_extensions_14",
"tests/test_x509.py::X509Tests::test_critical_extensions_15",
"tests/test_x509.py::X509Tests::test_critical_extensions_16",
"tests/test_x509.py::X509Tests::test_critical_extensions_2",
"tests/test_x509.py::X509Tests::test_critical_extensions_3",
"tests/test_x509.py::X509Tests::test_critical_extensions_4",
"tests/test_x509.py::X509Tests::test_critical_extensions_5",
"tests/test_x509.py::X509Tests::test_critical_extensions_6",
"tests/test_x509.py::X509Tests::test_critical_extensions_7",
"tests/test_x509.py::X509Tests::test_critical_extensions_8",
"tests/test_x509.py::X509Tests::test_critical_extensions_9",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_1",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_10",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_11",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_12",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_13",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_14",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_15",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_16",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_2",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_3",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_4",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_5",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_6",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_7",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_8",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_9",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_1",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_10",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_11",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_12",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_13",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_14",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_15",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_16",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_2",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_3",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_4",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_5",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_6",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_7",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_8",
"tests/test_x509.py::X509Tests::test_crl_distribution_points_value_9",
"tests/test_x509.py::X509Tests::test_dnsname",
"tests/test_x509.py::X509Tests::test_dnsname_begin_dot",
"tests/test_x509.py::X509Tests::test_dump_generalname",
"tests/test_x509.py::X509Tests::test_email_address",
"tests/test_x509.py::X509Tests::test_extended_datetime",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_1",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_10",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_11",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_12",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_13",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_14",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_15",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_16",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_2",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_3",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_4",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_5",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_6",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_7",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_8",
"tests/test_x509.py::X509Tests::test_extended_key_usage_value_9",
"tests/test_x509.py::X509Tests::test_indef_dnsname",
"tests/test_x509.py::X509Tests::test_indef_email_address",
"tests/test_x509.py::X509Tests::test_indef_uri",
"tests/test_x509.py::X509Tests::test_invalid_email_encoding",
"tests/test_x509.py::X509Tests::test_ip_address_1",
"tests/test_x509.py::X509Tests::test_ip_address_2",
"tests/test_x509.py::X509Tests::test_ip_address_3",
"tests/test_x509.py::X509Tests::test_ip_address_4",
"tests/test_x509.py::X509Tests::test_ip_address_5",
"tests/test_x509.py::X509Tests::test_ip_address_6",
"tests/test_x509.py::X509Tests::test_ip_address_7",
"tests/test_x509.py::X509Tests::test_iri_with_port",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_1",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_2",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_3",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_4",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_5",
"tests/test_x509.py::X509Tests::test_is_valid_domain_ip_6",
"tests/test_x509.py::X509Tests::test_issuer_serial_1",
"tests/test_x509.py::X509Tests::test_issuer_serial_10",
"tests/test_x509.py::X509Tests::test_issuer_serial_11",
"tests/test_x509.py::X509Tests::test_issuer_serial_12",
"tests/test_x509.py::X509Tests::test_issuer_serial_13",
"tests/test_x509.py::X509Tests::test_issuer_serial_14",
"tests/test_x509.py::X509Tests::test_issuer_serial_15",
"tests/test_x509.py::X509Tests::test_issuer_serial_16",
"tests/test_x509.py::X509Tests::test_issuer_serial_2",
"tests/test_x509.py::X509Tests::test_issuer_serial_3",
"tests/test_x509.py::X509Tests::test_issuer_serial_4",
"tests/test_x509.py::X509Tests::test_issuer_serial_5",
"tests/test_x509.py::X509Tests::test_issuer_serial_6",
"tests/test_x509.py::X509Tests::test_issuer_serial_7",
"tests/test_x509.py::X509Tests::test_issuer_serial_8",
"tests/test_x509.py::X509Tests::test_issuer_serial_9",
"tests/test_x509.py::X509Tests::test_key_identifier_1",
"tests/test_x509.py::X509Tests::test_key_identifier_10",
"tests/test_x509.py::X509Tests::test_key_identifier_11",
"tests/test_x509.py::X509Tests::test_key_identifier_12",
"tests/test_x509.py::X509Tests::test_key_identifier_13",
"tests/test_x509.py::X509Tests::test_key_identifier_14",
"tests/test_x509.py::X509Tests::test_key_identifier_15",
"tests/test_x509.py::X509Tests::test_key_identifier_16",
"tests/test_x509.py::X509Tests::test_key_identifier_2",
"tests/test_x509.py::X509Tests::test_key_identifier_3",
"tests/test_x509.py::X509Tests::test_key_identifier_4",
"tests/test_x509.py::X509Tests::test_key_identifier_5",
"tests/test_x509.py::X509Tests::test_key_identifier_6",
"tests/test_x509.py::X509Tests::test_key_identifier_7",
"tests/test_x509.py::X509Tests::test_key_identifier_8",
"tests/test_x509.py::X509Tests::test_key_identifier_9",
"tests/test_x509.py::X509Tests::test_key_identifier_value_1",
"tests/test_x509.py::X509Tests::test_key_identifier_value_10",
"tests/test_x509.py::X509Tests::test_key_identifier_value_11",
"tests/test_x509.py::X509Tests::test_key_identifier_value_12",
"tests/test_x509.py::X509Tests::test_key_identifier_value_13",
"tests/test_x509.py::X509Tests::test_key_identifier_value_14",
"tests/test_x509.py::X509Tests::test_key_identifier_value_15",
"tests/test_x509.py::X509Tests::test_key_identifier_value_16",
"tests/test_x509.py::X509Tests::test_key_identifier_value_2",
"tests/test_x509.py::X509Tests::test_key_identifier_value_3",
"tests/test_x509.py::X509Tests::test_key_identifier_value_4",
"tests/test_x509.py::X509Tests::test_key_identifier_value_5",
"tests/test_x509.py::X509Tests::test_key_identifier_value_6",
"tests/test_x509.py::X509Tests::test_key_identifier_value_7",
"tests/test_x509.py::X509Tests::test_key_identifier_value_8",
"tests/test_x509.py::X509Tests::test_key_identifier_value_9",
"tests/test_x509.py::X509Tests::test_key_usage_value_1",
"tests/test_x509.py::X509Tests::test_key_usage_value_10",
"tests/test_x509.py::X509Tests::test_key_usage_value_11",
"tests/test_x509.py::X509Tests::test_key_usage_value_12",
"tests/test_x509.py::X509Tests::test_key_usage_value_13",
"tests/test_x509.py::X509Tests::test_key_usage_value_14",
"tests/test_x509.py::X509Tests::test_key_usage_value_15",
"tests/test_x509.py::X509Tests::test_key_usage_value_16",
"tests/test_x509.py::X509Tests::test_key_usage_value_2",
"tests/test_x509.py::X509Tests::test_key_usage_value_3",
"tests/test_x509.py::X509Tests::test_key_usage_value_4",
"tests/test_x509.py::X509Tests::test_key_usage_value_5",
"tests/test_x509.py::X509Tests::test_key_usage_value_6",
"tests/test_x509.py::X509Tests::test_key_usage_value_7",
"tests/test_x509.py::X509Tests::test_key_usage_value_8",
"tests/test_x509.py::X509Tests::test_key_usage_value_9",
"tests/test_x509.py::X509Tests::test_name_constraints_value_1",
"tests/test_x509.py::X509Tests::test_name_constraints_value_10",
"tests/test_x509.py::X509Tests::test_name_constraints_value_11",
"tests/test_x509.py::X509Tests::test_name_constraints_value_12",
"tests/test_x509.py::X509Tests::test_name_constraints_value_13",
"tests/test_x509.py::X509Tests::test_name_constraints_value_14",
"tests/test_x509.py::X509Tests::test_name_constraints_value_15",
"tests/test_x509.py::X509Tests::test_name_constraints_value_16",
"tests/test_x509.py::X509Tests::test_name_constraints_value_2",
"tests/test_x509.py::X509Tests::test_name_constraints_value_3",
"tests/test_x509.py::X509Tests::test_name_constraints_value_4",
"tests/test_x509.py::X509Tests::test_name_constraints_value_5",
"tests/test_x509.py::X509Tests::test_name_constraints_value_6",
"tests/test_x509.py::X509Tests::test_name_constraints_value_7",
"tests/test_x509.py::X509Tests::test_name_constraints_value_8",
"tests/test_x509.py::X509Tests::test_name_constraints_value_9",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_1",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_10",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_11",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_12",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_13",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_14",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_15",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_2",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_3",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_4",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_5",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_6",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_7",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_8",
"tests/test_x509.py::X509Tests::test_name_is_rdn_squence_of_single_child_sets_9",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_1",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_10",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_11",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_12",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_13",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_14",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_15",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_16",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_2",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_3",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_4",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_5",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_6",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_7",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_8",
"tests/test_x509.py::X509Tests::test_ocsp_no_check_value_9",
"tests/test_x509.py::X509Tests::test_ocsp_urls_1",
"tests/test_x509.py::X509Tests::test_ocsp_urls_10",
"tests/test_x509.py::X509Tests::test_ocsp_urls_11",
"tests/test_x509.py::X509Tests::test_ocsp_urls_12",
"tests/test_x509.py::X509Tests::test_ocsp_urls_13",
"tests/test_x509.py::X509Tests::test_ocsp_urls_14",
"tests/test_x509.py::X509Tests::test_ocsp_urls_15",
"tests/test_x509.py::X509Tests::test_ocsp_urls_16",
"tests/test_x509.py::X509Tests::test_ocsp_urls_2",
"tests/test_x509.py::X509Tests::test_ocsp_urls_3",
"tests/test_x509.py::X509Tests::test_ocsp_urls_4",
"tests/test_x509.py::X509Tests::test_ocsp_urls_5",
"tests/test_x509.py::X509Tests::test_ocsp_urls_6",
"tests/test_x509.py::X509Tests::test_ocsp_urls_7",
"tests/test_x509.py::X509Tests::test_ocsp_urls_8",
"tests/test_x509.py::X509Tests::test_ocsp_urls_9",
"tests/test_x509.py::X509Tests::test_parse_certificate",
"tests/test_x509.py::X509Tests::test_parse_dsa_certificate",
"tests/test_x509.py::X509Tests::test_parse_dsa_certificate_inheritance",
"tests/test_x509.py::X509Tests::test_parse_ec_certificate",
"tests/test_x509.py::X509Tests::test_parse_ed25519_certificate",
"tests/test_x509.py::X509Tests::test_parse_ed448_certificate",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_1",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_10",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_11",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_12",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_13",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_14",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_15",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_16",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_2",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_3",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_4",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_5",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_6",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_7",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_8",
"tests/test_x509.py::X509Tests::test_policy_constraints_value_9",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_1",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_10",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_11",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_12",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_13",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_14",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_15",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_16",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_2",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_3",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_4",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_5",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_6",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_7",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_8",
"tests/test_x509.py::X509Tests::test_policy_mappings_value_9",
"tests/test_x509.py::X509Tests::test_private_key_usage_period_value_1",
"tests/test_x509.py::X509Tests::test_punycode_common_name",
"tests/test_x509.py::X509Tests::test_repeated_subject_fields",
"tests/test_x509.py::X509Tests::test_self_issued_1",
"tests/test_x509.py::X509Tests::test_self_issued_10",
"tests/test_x509.py::X509Tests::test_self_issued_11",
"tests/test_x509.py::X509Tests::test_self_issued_12",
"tests/test_x509.py::X509Tests::test_self_issued_13",
"tests/test_x509.py::X509Tests::test_self_issued_14",
"tests/test_x509.py::X509Tests::test_self_issued_15",
"tests/test_x509.py::X509Tests::test_self_issued_16",
"tests/test_x509.py::X509Tests::test_self_issued_2",
"tests/test_x509.py::X509Tests::test_self_issued_3",
"tests/test_x509.py::X509Tests::test_self_issued_4",
"tests/test_x509.py::X509Tests::test_self_issued_5",
"tests/test_x509.py::X509Tests::test_self_issued_6",
"tests/test_x509.py::X509Tests::test_self_issued_7",
"tests/test_x509.py::X509Tests::test_self_issued_8",
"tests/test_x509.py::X509Tests::test_self_issued_9",
"tests/test_x509.py::X509Tests::test_self_signed_1",
"tests/test_x509.py::X509Tests::test_self_signed_10",
"tests/test_x509.py::X509Tests::test_self_signed_11",
"tests/test_x509.py::X509Tests::test_self_signed_12",
"tests/test_x509.py::X509Tests::test_self_signed_13",
"tests/test_x509.py::X509Tests::test_self_signed_14",
"tests/test_x509.py::X509Tests::test_self_signed_15",
"tests/test_x509.py::X509Tests::test_self_signed_16",
"tests/test_x509.py::X509Tests::test_self_signed_2",
"tests/test_x509.py::X509Tests::test_self_signed_3",
"tests/test_x509.py::X509Tests::test_self_signed_4",
"tests/test_x509.py::X509Tests::test_self_signed_5",
"tests/test_x509.py::X509Tests::test_self_signed_6",
"tests/test_x509.py::X509Tests::test_self_signed_7",
"tests/test_x509.py::X509Tests::test_self_signed_8",
"tests/test_x509.py::X509Tests::test_self_signed_9",
"tests/test_x509.py::X509Tests::test_serial_number_1",
"tests/test_x509.py::X509Tests::test_serial_number_10",
"tests/test_x509.py::X509Tests::test_serial_number_11",
"tests/test_x509.py::X509Tests::test_serial_number_12",
"tests/test_x509.py::X509Tests::test_serial_number_13",
"tests/test_x509.py::X509Tests::test_serial_number_14",
"tests/test_x509.py::X509Tests::test_serial_number_15",
"tests/test_x509.py::X509Tests::test_serial_number_16",
"tests/test_x509.py::X509Tests::test_serial_number_2",
"tests/test_x509.py::X509Tests::test_serial_number_3",
"tests/test_x509.py::X509Tests::test_serial_number_4",
"tests/test_x509.py::X509Tests::test_serial_number_5",
"tests/test_x509.py::X509Tests::test_serial_number_6",
"tests/test_x509.py::X509Tests::test_serial_number_7",
"tests/test_x509.py::X509Tests::test_serial_number_8",
"tests/test_x509.py::X509Tests::test_serial_number_9",
"tests/test_x509.py::X509Tests::test_sha1_fingerprint",
"tests/test_x509.py::X509Tests::test_sha256_fingerprint",
"tests/test_x509.py::X509Tests::test_signature_algo_1",
"tests/test_x509.py::X509Tests::test_signature_algo_2",
"tests/test_x509.py::X509Tests::test_signature_algo_3",
"tests/test_x509.py::X509Tests::test_signature_algo_4",
"tests/test_x509.py::X509Tests::test_signature_algo_5",
"tests/test_x509.py::X509Tests::test_signature_algo_6",
"tests/test_x509.py::X509Tests::test_signature_algo_7",
"tests/test_x509.py::X509Tests::test_strict_teletex",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_1",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_10",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_11",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_12",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_13",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_14",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_15",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_16",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_2",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_3",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_4",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_5",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_6",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_7",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_8",
"tests/test_x509.py::X509Tests::test_subject_alt_name_value_9",
"tests/test_x509.py::X509Tests::test_subject_alt_name_variations",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_1",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_10",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_11",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_12",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_13",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_14",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_15",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_16",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_2",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_3",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_4",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_5",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_6",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_7",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_8",
"tests/test_x509.py::X509Tests::test_subject_directory_attributes_value_9",
"tests/test_x509.py::X509Tests::test_teletex_that_is_really_latin1",
"tests/test_x509.py::X509Tests::test_trusted_certificate",
"tests/test_x509.py::X509Tests::test_uri",
"tests/test_x509.py::X509Tests::test_uri_no_normalization",
"tests/test_x509.py::X509Tests::test_v1_cert",
"tests/test_x509.py::X509Tests::test_valid_domains_1",
"tests/test_x509.py::X509Tests::test_valid_domains_10",
"tests/test_x509.py::X509Tests::test_valid_domains_11",
"tests/test_x509.py::X509Tests::test_valid_domains_12",
"tests/test_x509.py::X509Tests::test_valid_domains_13",
"tests/test_x509.py::X509Tests::test_valid_domains_14",
"tests/test_x509.py::X509Tests::test_valid_domains_15",
"tests/test_x509.py::X509Tests::test_valid_domains_16",
"tests/test_x509.py::X509Tests::test_valid_domains_2",
"tests/test_x509.py::X509Tests::test_valid_domains_3",
"tests/test_x509.py::X509Tests::test_valid_domains_4",
"tests/test_x509.py::X509Tests::test_valid_domains_5",
"tests/test_x509.py::X509Tests::test_valid_domains_6",
"tests/test_x509.py::X509Tests::test_valid_domains_7",
"tests/test_x509.py::X509Tests::test_valid_domains_8",
"tests/test_x509.py::X509Tests::test_valid_domains_9",
"tests/test_x509.py::X509Tests::test_valid_ips_1",
"tests/test_x509.py::X509Tests::test_valid_ips_10",
"tests/test_x509.py::X509Tests::test_valid_ips_11",
"tests/test_x509.py::X509Tests::test_valid_ips_12",
"tests/test_x509.py::X509Tests::test_valid_ips_13",
"tests/test_x509.py::X509Tests::test_valid_ips_14",
"tests/test_x509.py::X509Tests::test_valid_ips_15",
"tests/test_x509.py::X509Tests::test_valid_ips_16",
"tests/test_x509.py::X509Tests::test_valid_ips_2",
"tests/test_x509.py::X509Tests::test_valid_ips_3",
"tests/test_x509.py::X509Tests::test_valid_ips_4",
"tests/test_x509.py::X509Tests::test_valid_ips_5",
"tests/test_x509.py::X509Tests::test_valid_ips_6",
"tests/test_x509.py::X509Tests::test_valid_ips_7",
"tests/test_x509.py::X509Tests::test_valid_ips_8",
"tests/test_x509.py::X509Tests::test_valid_ips_9",
"tests/test_x509.py::X509Tests::test_validity_after_before"
] | {
"failed_lite_validators": [
"has_issue_reference"
],
"has_test_patch": true,
"is_lite": false
} | "2023-11-03T11:44:20Z" | mit |
|
wearewhys__magnivore-12 | diff --git a/magnivore/Lexicon.py b/magnivore/Lexicon.py
index f9fa08d..84ae7a2 100644
--- a/magnivore/Lexicon.py
+++ b/magnivore/Lexicon.py
@@ -1,5 +1,6 @@
# -*- coding: utf-8 -*-
import re
+from decimal import Decimal
from functools import reduce
from .Tracker import Tracker
@@ -38,7 +39,8 @@ class Lexicon:
The factor rule multiplies the value by a factor.
"""
value = cls._dot_reduce(rule['from'], target)
- return value * rule['factor']
+ original_type = type(value)
+ return original_type(Decimal(value) * Decimal(rule['factor']))
@classmethod
def format(cls, rule, target):
| wearewhys/magnivore | be723f7f575376d0ce25b0590bd46dcc6f34ace8 | diff --git a/tests/unit/Lexicon.py b/tests/unit/Lexicon.py
index 4f8e888..f1c85d6 100644
--- a/tests/unit/Lexicon.py
+++ b/tests/unit/Lexicon.py
@@ -1,5 +1,6 @@
# -*- coding: utf-8 -*-
import re
+from decimal import Decimal
from unittest.mock import MagicMock
from magnivore.Lexicon import Lexicon
@@ -48,17 +49,20 @@ def test_lexicon_transform(target):
assert result == rule['transform'][target.temperature]
[email protected]('from_data, target', [
- ('value', MagicMock(value=100)),
- ('related.value', MagicMock(related=MagicMock(value=100)))
[email protected]('from_data, target, expected', [
+ ('value', MagicMock(value=100), 50),
+ ('value', MagicMock(value=Decimal(100)), Decimal(50)),
+ ('value', MagicMock(value=100.0), 50.0),
+ ('related.value', MagicMock(related=MagicMock(value=100)), 50)
])
-def test_lexicon_factor(from_data, target):
+def test_lexicon_factor(from_data, target, expected):
rule = {
'from': from_data,
'factor': 0.5
}
result = Lexicon.factor(rule, target)
- assert result == 50
+ assert result == expected
+ assert type(result) == type(expected)
@mark.parametrize('from_data, format, expected', [
| Lexicon.factor should check the type of the values
Lexicon.factor should check the values types or errors will happen | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/Lexicon.py::test_lexicon_factor[value-target0-50]",
"tests/unit/Lexicon.py::test_lexicon_factor[value-target1-expected1]",
"tests/unit/Lexicon.py::test_lexicon_factor[related.value-target3-50]"
] | [
"tests/unit/Lexicon.py::test_lexicon_basic",
"tests/unit/Lexicon.py::test_lexicon_basic_dot",
"tests/unit/Lexicon.py::test_lexicon_basic_dot_double",
"tests/unit/Lexicon.py::test_lexicon_basic_null[field]",
"tests/unit/Lexicon.py::test_lexicon_basic_null[table.field]",
"tests/unit/Lexicon.py::test_lexicon_basic_null[table.field.nested]",
"tests/unit/Lexicon.py::test_lexicon_transform[target0]",
"tests/unit/Lexicon.py::test_lexicon_transform[target1]",
"tests/unit/Lexicon.py::test_lexicon_factor[value-target2-50.0]",
"tests/unit/Lexicon.py::test_lexicon_format[birthyear-{}-0-0-1992-0-0]",
"tests/unit/Lexicon.py::test_lexicon_format[from_data1-{}-{}-0-1992-9-0]",
"tests/unit/Lexicon.py::test_lexicon_format_dot[rel.birthyear-{}-0-0-1992-0-0]",
"tests/unit/Lexicon.py::test_lexicon_format_dot[from_data1-{}-{}-0-1992-9-0]",
"tests/unit/Lexicon.py::test_lexicon_match",
"tests/unit/Lexicon.py::test_lexicon_match_none",
"tests/unit/Lexicon.py::test_lexicon_match_from",
"tests/unit/Lexicon.py::test_lexicon_match_dot",
"tests/unit/Lexicon.py::test_lexicon_match_from_none",
"tests/unit/Lexicon.py::test_lexicon_match_none_log",
"tests/unit/Lexicon.py::test_lexicon_sync",
"tests/unit/Lexicon.py::test_lexicon_sync_none",
"tests/unit/Lexicon.py::test_lexicon_static",
"tests/unit/Lexicon.py::test_lexicon_expression",
"tests/unit/Lexicon.py::test_lexicon_expression_dot",
"tests/unit/Lexicon.py::test_lexicon_expression_none"
] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2017-11-21T11:53:18Z" | apache-2.0 |
|
wearewhys__magnivore-14 | diff --git a/magnivore/Lexicon.py b/magnivore/Lexicon.py
index 84ae7a2..acf038b 100644
--- a/magnivore/Lexicon.py
+++ b/magnivore/Lexicon.py
@@ -2,6 +2,7 @@
import re
from decimal import Decimal
from functools import reduce
+from math import ceil, floor
from .Tracker import Tracker
@@ -40,7 +41,12 @@ class Lexicon:
"""
value = cls._dot_reduce(rule['from'], target)
original_type = type(value)
- return original_type(Decimal(value) * Decimal(rule['factor']))
+ result = Decimal(value) * Decimal(rule['factor'])
+ if 'round' in rule:
+ if rule['round'] == 'up':
+ return original_type(ceil(result))
+ return original_type(floor(result))
+ return original_type(result)
@classmethod
def format(cls, rule, target):
| wearewhys/magnivore | acf182faeb0cf80157ec5d7b448b355687dcbd94 | diff --git a/tests/unit/Lexicon.py b/tests/unit/Lexicon.py
index f1c85d6..3af833c 100644
--- a/tests/unit/Lexicon.py
+++ b/tests/unit/Lexicon.py
@@ -65,6 +65,19 @@ def test_lexicon_factor(from_data, target, expected):
assert type(result) == type(expected)
[email protected]('rounding, expected', [
+ ('down', 47),
+ ('up', 48)
+])
+def test_lexicon_factor_round(rounding, expected):
+ rule = {
+ 'from': 'value',
+ 'round': rounding,
+ 'factor': 0.5
+ }
+ assert Lexicon.factor(rule, MagicMock(value=95)) == expected
+
+
@mark.parametrize('from_data, format, expected', [
('birthyear', '{}-0-0', '1992-0-0'),
(['birthyear', 'birthmonth'], '{}-{}-0', '1992-9-0')
| Add possibility to specify whether to round up or down in factor | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/Lexicon.py::test_lexicon_factor_round[up-48]"
] | [
"tests/unit/Lexicon.py::test_lexicon_basic",
"tests/unit/Lexicon.py::test_lexicon_basic_dot",
"tests/unit/Lexicon.py::test_lexicon_basic_dot_double",
"tests/unit/Lexicon.py::test_lexicon_basic_null[field]",
"tests/unit/Lexicon.py::test_lexicon_basic_null[table.field]",
"tests/unit/Lexicon.py::test_lexicon_basic_null[table.field.nested]",
"tests/unit/Lexicon.py::test_lexicon_transform[target0]",
"tests/unit/Lexicon.py::test_lexicon_transform[target1]",
"tests/unit/Lexicon.py::test_lexicon_factor[value-target0-50]",
"tests/unit/Lexicon.py::test_lexicon_factor[value-target1-expected1]",
"tests/unit/Lexicon.py::test_lexicon_factor[value-target2-50.0]",
"tests/unit/Lexicon.py::test_lexicon_factor[related.value-target3-50]",
"tests/unit/Lexicon.py::test_lexicon_factor_round[down-47]",
"tests/unit/Lexicon.py::test_lexicon_format[birthyear-{}-0-0-1992-0-0]",
"tests/unit/Lexicon.py::test_lexicon_format[from_data1-{}-{}-0-1992-9-0]",
"tests/unit/Lexicon.py::test_lexicon_format_dot[rel.birthyear-{}-0-0-1992-0-0]",
"tests/unit/Lexicon.py::test_lexicon_format_dot[from_data1-{}-{}-0-1992-9-0]",
"tests/unit/Lexicon.py::test_lexicon_match",
"tests/unit/Lexicon.py::test_lexicon_match_none",
"tests/unit/Lexicon.py::test_lexicon_match_from",
"tests/unit/Lexicon.py::test_lexicon_match_dot",
"tests/unit/Lexicon.py::test_lexicon_match_from_none",
"tests/unit/Lexicon.py::test_lexicon_match_none_log",
"tests/unit/Lexicon.py::test_lexicon_sync",
"tests/unit/Lexicon.py::test_lexicon_sync_none",
"tests/unit/Lexicon.py::test_lexicon_static",
"tests/unit/Lexicon.py::test_lexicon_expression",
"tests/unit/Lexicon.py::test_lexicon_expression_dot",
"tests/unit/Lexicon.py::test_lexicon_expression_none"
] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2017-11-21T15:44:33Z" | apache-2.0 |
|
wearewhys__magnivore-9 | diff --git a/magnivore/Targets.py b/magnivore/Targets.py
index c2aa61c..27ce660 100644
--- a/magnivore/Targets.py
+++ b/magnivore/Targets.py
@@ -66,6 +66,16 @@ class Targets:
return query.join(model, 'LEFT OUTER', on=expression)
return query.join(model, on=expression)
+ def _apply_pick(self, query, join):
+ model = self.source_models[join['table']]
+ selects = []
+ for column, value in join['picks'].items():
+ if value is True:
+ selects.append(getattr(model, column))
+ elif value == 'sum':
+ selects.append(fn.Sum(getattr(model, column)))
+ return query.select(*selects)
+
def get(self, joins, limit=None, offset=0):
"""
Retrieves the targets for the given joins
@@ -76,6 +86,7 @@ class Targets:
aggregations = []
conditions = []
models = []
+ picks = []
for join in joins:
models.append(self.source_models[join['table']])
if 'conditions' in join:
@@ -84,7 +95,14 @@ class Targets:
if 'aggregation' in join:
aggregations.append(join)
- query = models[0].select(*models)
+ if 'picks' in join:
+ picks.append(join)
+
+ query = models[0]
+ if picks == []:
+ query = query.select(*models)
+ for pick in picks:
+ query = self._apply_pick(query, pick)
joins.pop(0)
for join in joins:
| wearewhys/magnivore | a9c896df3d054cb943a7f07540e04697952e0d62 | diff --git a/tests/unit/Targets.py b/tests/unit/Targets.py
index a0668e5..159af9c 100644
--- a/tests/unit/Targets.py
+++ b/tests/unit/Targets.py
@@ -193,6 +193,24 @@ def test_get_aggregations_eq(mocker, targets, joins, nodes, nodes_query):
assert nodes_query.join().group_by().having().execute.call_count == 1
+def test_get_picks(targets, joins, nodes, nodes_query):
+ joins[0]['picks'] = {
+ 'field': True
+ }
+ targets.get(joins)
+ nodes.select.assert_called_with(nodes.field)
+ assert nodes_query.join().execute.call_count == 1
+
+
+def test_get_picks_sum(targets, joins, nodes, nodes_query):
+ joins[0]['picks'] = {
+ 'field': 'sum'
+ }
+ targets.get(joins)
+ nodes.select.assert_called_with(fn.Sum(nodes.field))
+ assert nodes_query.join().execute.call_count == 1
+
+
def test_get_log_query(targets, joins, nodes_query, logger):
targets.get(joins)
calls = [call.logger.log('get-targets', nodes_query.join())]
| Add ability to specify selected columns
It should be possible to specify the columns to be selected in when retrieving items. This is necessary as it would allow to retrieve aggregated sets e.g. count queries | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/Targets.py::test_get_picks",
"tests/unit/Targets.py::test_get_picks_sum"
] | [
"tests/unit/Targets.py::test_get_targets_empty",
"tests/unit/Targets.py::test_get",
"tests/unit/Targets.py::test_get_triple_join",
"tests/unit/Targets.py::test_get_limit",
"tests/unit/Targets.py::test_get_limit_with_offset",
"tests/unit/Targets.py::test_get_switch",
"tests/unit/Targets.py::test_get_join_on",
"tests/unit/Targets.py::test_get_join_outer",
"tests/unit/Targets.py::test_get_conditions",
"tests/unit/Targets.py::test_get_conditions_greater[gt]",
"tests/unit/Targets.py::test_get_conditions_greater[lt]",
"tests/unit/Targets.py::test_get_conditions_greater[not]",
"tests/unit/Targets.py::test_get_conditions_in",
"tests/unit/Targets.py::test_get_conditions_isnull",
"tests/unit/Targets.py::test_get_aggregations",
"tests/unit/Targets.py::test_get_aggregations_eq",
"tests/unit/Targets.py::test_get_log_query",
"tests/unit/Targets.py::test_get_log_targets_count"
] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2017-11-20T15:44:17Z" | apache-2.0 |
|
weaveworks__grafanalib-301 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 808dfe3..20f0ccc 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -6,7 +6,7 @@ Changelog
===========
* Added Logs panel (https://grafana.com/docs/grafana/latest/panels/visualizations/logs-panel/)
-* ...
+* Added Cloudwatch metrics datasource (https://grafana.com/docs/grafana/latest/datasources/cloudwatch/)
Changes
-------
diff --git a/docs/api/grafanalib.rst b/docs/api/grafanalib.rst
index 4638337..7ac152a 100644
--- a/docs/api/grafanalib.rst
+++ b/docs/api/grafanalib.rst
@@ -4,6 +4,14 @@ grafanalib package
Submodules
----------
+grafanalib.cloudwatch module
+----------------------------
+
+.. automodule:: grafanalib.cloudwatch
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
grafanalib.core module
----------------------
@@ -20,6 +28,22 @@ grafanalib.elasticsearch module
:undoc-members:
:show-inheritance:
+grafanalib.formatunits module
+-----------------------------
+
+.. automodule:: grafanalib.formatunits
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+grafanalib.influxdb module
+--------------------------
+
+.. automodule:: grafanalib.influxdb
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
grafanalib.opentsdb module
--------------------------
@@ -60,7 +84,6 @@ grafanalib.zabbix module
:undoc-members:
:show-inheritance:
-
Module contents
---------------
diff --git a/grafanalib/cloudwatch.py b/grafanalib/cloudwatch.py
new file mode 100644
index 0000000..15f059d
--- /dev/null
+++ b/grafanalib/cloudwatch.py
@@ -0,0 +1,57 @@
+"""Helpers to create Cloudwatch-specific Grafana queries."""
+
+import attr
+
+from attr.validators import instance_of
+
+
[email protected]
+class CloudwatchMetricsTarget(object):
+ """
+ Generates Cloudwatch target JSON structure.
+
+ Grafana docs on using Cloudwatch:
+ https://grafana.com/docs/grafana/latest/datasources/cloudwatch/
+
+ AWS docs on Cloudwatch metrics:
+ https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/aws-services-cloudwatch-metrics.html
+
+ :param alias: legend alias
+ :param dimensions: Cloudwatch dimensions dict
+ :param expression: Cloudwatch Metric math expressions
+ :param id: unique id
+ :param matchExact: Only show metrics that exactly match all defined dimension names.
+ :param metricName: Cloudwatch metric name
+ :param namespace: Cloudwatch namespace
+ :param period: Cloudwatch data period
+ :param refId: target reference id
+ :param region: Cloudwatch region
+ :param statistics: Cloudwatch mathematic statistic
+ """
+ alias = attr.ib(default="")
+ dimensions = attr.ib(default={}, validator=instance_of(dict))
+ expression = attr.ib(default="")
+ id = attr.ib(default="")
+ matchExact = attr.ib(default=True, validator=instance_of(bool))
+ metricName = attr.ib(default="")
+ namespace = attr.ib(default="")
+ period = attr.ib(default="")
+ refId = attr.ib(default="")
+ region = attr.ib(default="default")
+ statistics = attr.ib(default=["Average"], validator=instance_of(list))
+
+ def to_json_data(self):
+
+ return {
+ "alias": self.alias,
+ "dimensions": self.dimensions,
+ "expression": self.expression,
+ "id": self.id,
+ "matchExact": self.matchExact,
+ "metricName": self.metricName,
+ "namespace": self.namespace,
+ "period": self.period,
+ "refId": self.refId,
+ "region": self.region,
+ "statistics": self.statistics
+ }
| weaveworks/grafanalib | e010c779d85f5ff28896ca94f549f92e4170b13e | diff --git a/grafanalib/tests/test_cloudwatch.py b/grafanalib/tests/test_cloudwatch.py
new file mode 100644
index 0000000..b9e91bb
--- /dev/null
+++ b/grafanalib/tests/test_cloudwatch.py
@@ -0,0 +1,25 @@
+"""Tests for Cloudwatch Datasource"""
+
+import grafanalib.core as G
+import grafanalib.cloudwatch as C
+from grafanalib import _gen
+from io import StringIO
+
+
+def test_serialization_cloudwatch_metrics_target():
+ """Serializing a graph doesn't explode."""
+ graph = G.Graph(
+ title="Lambda Duration",
+ dataSource="Cloudwatch data source",
+ targets=[
+ C.CloudwatchMetricsTarget(),
+ ],
+ id=1,
+ yAxes=G.YAxes(
+ G.YAxis(format=G.SHORT_FORMAT, label="ms"),
+ G.YAxis(format=G.SHORT_FORMAT),
+ ),
+ )
+ stream = StringIO()
+ _gen.write_dashboard(graph, stream)
+ assert stream.getvalue() != ''
| Cloudwatch datasources not supported due to Target class restrictions
There is no support for Cloudwatch since the Target class has restrictions. If you remove them, you'll be able to make Cloudwatch graphs. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"grafanalib/tests/test_cloudwatch.py::test_serialization_cloudwatch_metrics_target"
] | [] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-05T16:19:33Z" | apache-2.0 |
|
weaveworks__grafanalib-584 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 7b18f65..2da345a 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -2,7 +2,6 @@
Changelog
=========
-
0.x.x (?)
==================
@@ -11,6 +10,7 @@ Changelog
* Added Maximum option for Timeseries
* Added Number of decimals displays option for Timeseries* Added Bar_Chart_ panel support
* Extended SqlTarget to support parsing queries from files
+* Fix AlertCondition backwards compatibility (``useNewAlerts`` default to ``False``)
.. _Bar_Chart: basehttps://grafana.com/docs/grafana/latest/panels-visualizations/visualizations/bar-chart/
diff --git a/grafanalib/core.py b/grafanalib/core.py
index e10552a..aeb1cb3 100644
--- a/grafanalib/core.py
+++ b/grafanalib/core.py
@@ -1197,6 +1197,9 @@ class AlertCondition(object):
RTYPE_DIFF = 'diff'
RTYPE_PERCENT_DIFF = 'percent_diff'
RTYPE_COUNT_NON_NULL = 'count_non_null'
+ :param useNewAlerts: Whether or not the alert condition is used as part of the Grafana 8.x alerts.
+ Defaults to False for compatibility with old Grafana alerts, but automatically overridden to true
+ when used inside ``AlertExpression`` or ``AlertRulev8``
:param type: CTYPE_*
"""
@@ -1205,6 +1208,7 @@ class AlertCondition(object):
timeRange = attr.ib(default=None, validator=attr.validators.optional(attr.validators.instance_of(TimeRange)))
operator = attr.ib(default=OP_AND)
reducerType = attr.ib(default=RTYPE_LAST)
+ useNewAlerts = attr.ib(default=False)
type = attr.ib(default=CTYPE_QUERY, kw_only=True)
diff --git a/grafanalib/elasticsearch.py b/grafanalib/elasticsearch.py
index a01c531..9726983 100644
--- a/grafanalib/elasticsearch.py
+++ b/grafanalib/elasticsearch.py
@@ -2,7 +2,7 @@
import attr
import itertools
-from attr.validators import instance_of
+from attr.validators import in_, instance_of
from grafanalib.core import AlertCondition
DATE_HISTOGRAM_DEFAULT_FIELD = 'time_iso8601'
@@ -498,3 +498,49 @@ class PercentilesMetricAgg(object):
'inlineScript': self.inline,
'settings': self.settings,
}
+
+
[email protected]
+class RateMetricAgg(object):
+ """An aggregator that provides the rate of the values.
+ https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-metrics-rate-aggregation.html
+ :param field: name of elasticsearch field to provide the sum over
+ :param hide: show/hide the metric in the final panel display
+ :param id: id of the metric
+ :param unit: calendar interval to group by
+ supported calendar intervals
+ https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-datehistogram-aggregation.html#calendar_intervals
+ "minute"
+ "hour"
+ "day"
+ "week"
+ "month"
+ "quarter"
+ "year"
+ :param mode: sum or count the values
+ :param script: script to apply to the data, using '_value'
+ """
+
+ field = attr.ib(default="", validator=instance_of(str))
+ id = attr.ib(default=0, validator=instance_of(int))
+ hide = attr.ib(default=False, validator=instance_of(bool))
+ unit = attr.ib(default="", validator=instance_of(str))
+ mode = attr.ib(default="", validator=in_(["", "value_count", "sum"]))
+ script = attr.ib(default="", validator=instance_of(str))
+
+ def to_json_data(self):
+ self.settings = {}
+
+ if self.mode:
+ self.settings["mode"] = self.mode
+
+ if self.script:
+ self.settings["script"] = self.script
+
+ return {
+ "id": str(self.id),
+ "hide": self.hide,
+ "field": self.field,
+ "settings": self.settings,
+ "type": "rate",
+ }
| weaveworks/grafanalib | bfdae85a19048d2ea1f87c91b4b1207059807bbc | diff --git a/grafanalib/tests/test_core.py b/grafanalib/tests/test_core.py
index f8178e8..2b03610 100644
--- a/grafanalib/tests/test_core.py
+++ b/grafanalib/tests/test_core.py
@@ -954,6 +954,33 @@ def test_alertfilefasedfrovisioning():
assert data['groups'] == groups
+def test_alertCondition_useNewAlerts_default():
+ alert_condition = G.AlertCondition(
+ G.Target(refId="A"),
+ G.Evaluator('a', 'b'),
+ G.TimeRange('5', '6'),
+ 'd',
+ 'e'
+ )
+ data = alert_condition.to_json_data()
+ assert data['query']['model'] is not None
+ assert len(data['query']['params']) == 3
+
+
+def test_alertCondition_useNewAlerts_true():
+ alert_condition = G.AlertCondition(
+ G.Target(refId="A"),
+ G.Evaluator('a', 'b'),
+ G.TimeRange('5', '6'),
+ 'd',
+ 'e',
+ useNewAlerts=True
+ )
+ data = alert_condition.to_json_data()
+ assert 'model' not in data['query']
+ assert len(data['query']['params']) == 1
+
+
def test_worldmap():
data_source = 'dummy data source'
targets = ['dummy_prom_query']
| AlertCondition object missing useNewAlerts attribute
looking at https://github.com/weaveworks/grafanalib/blob/c9a77d481da8d76a91ad92efb1a155d6dae8a34d/grafanalib/core.py#L1192
and https://github.com/weaveworks/grafanalib/blob/c9a77d481da8d76a91ad92efb1a155d6dae8a34d/grafanalib/core.py#L1215 its possible to see there is use of self.useNewAlerts but AlertExpression don't have this attribute | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"grafanalib/tests/test_core.py::test_alertCondition_useNewAlerts_default",
"grafanalib/tests/test_core.py::test_alertCondition_useNewAlerts_true"
] | [
"grafanalib/tests/test_core.py::test_template_defaults",
"grafanalib/tests/test_core.py::test_custom_template_ok",
"grafanalib/tests/test_core.py::test_custom_template_dont_override_options",
"grafanalib/tests/test_core.py::test_table",
"grafanalib/tests/test_core.py::test_stat_no_repeat",
"grafanalib/tests/test_core.py::test_Text_exception_checks",
"grafanalib/tests/test_core.py::test_ePictBox",
"grafanalib/tests/test_core.py::test_ePictBox_custom_symbole_logic",
"grafanalib/tests/test_core.py::test_ePict",
"grafanalib/tests/test_core.py::test_Text",
"grafanalib/tests/test_core.py::test_DiscreteColorMappingItem_exception_checks",
"grafanalib/tests/test_core.py::test_DiscreteColorMappingItem",
"grafanalib/tests/test_core.py::test_Discrete_exceptions",
"grafanalib/tests/test_core.py::test_Discrete",
"grafanalib/tests/test_core.py::test_StatValueMappings_exception_checks",
"grafanalib/tests/test_core.py::test_StatValueMappings",
"grafanalib/tests/test_core.py::test_StatRangeMappings",
"grafanalib/tests/test_core.py::test_StatMapping",
"grafanalib/tests/test_core.py::test_stat_with_repeat",
"grafanalib/tests/test_core.py::test_single_stat",
"grafanalib/tests/test_core.py::test_dashboard_list",
"grafanalib/tests/test_core.py::test_logs_panel",
"grafanalib/tests/test_core.py::test_notification",
"grafanalib/tests/test_core.py::test_graph_panel",
"grafanalib/tests/test_core.py::test_panel_extra_json",
"grafanalib/tests/test_core.py::test_graph_panel_threshold",
"grafanalib/tests/test_core.py::test_graph_panel_alert",
"grafanalib/tests/test_core.py::test_graph_threshold",
"grafanalib/tests/test_core.py::test_graph_threshold_custom",
"grafanalib/tests/test_core.py::test_alert_list",
"grafanalib/tests/test_core.py::test_SeriesOverride_exception_checks",
"grafanalib/tests/test_core.py::test_SeriesOverride",
"grafanalib/tests/test_core.py::test_alert",
"grafanalib/tests/test_core.py::test_alertgroup",
"grafanalib/tests/test_core.py::test_alertrulev8",
"grafanalib/tests/test_core.py::test_alertrule_invalid_triggers",
"grafanalib/tests/test_core.py::test_alertrulev9",
"grafanalib/tests/test_core.py::test_alertexpression",
"grafanalib/tests/test_core.py::test_alertfilefasedfrovisioning",
"grafanalib/tests/test_core.py::test_worldmap",
"grafanalib/tests/test_core.py::test_stateTimeline",
"grafanalib/tests/test_core.py::test_timeseries",
"grafanalib/tests/test_core.py::test_timeseries_with_overrides",
"grafanalib/tests/test_core.py::test_news",
"grafanalib/tests/test_core.py::test_pieChartv2",
"grafanalib/tests/test_core.py::test_histogram",
"grafanalib/tests/test_core.py::test_ae3e_plotly",
"grafanalib/tests/test_core.py::test_barchart",
"grafanalib/tests/test_core.py::test_target_invalid",
"grafanalib/tests/test_core.py::test_sql_target",
"grafanalib/tests/test_core.py::test_sql_target_with_source_files"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-05-10T12:02:39Z" | apache-2.0 |
|
weaveworks__kubediff-82 | diff --git a/kubedifflib/_diff.py b/kubedifflib/_diff.py
index 03a6337..e51b8f6 100644
--- a/kubedifflib/_diff.py
+++ b/kubedifflib/_diff.py
@@ -21,6 +21,12 @@ from ._kube import (
iter_files,
)
+def mask(x):
+ """Turn a string into an equal-length string of asterisks"""
+ try:
+ return len(x) * '*'
+ except TypeError: # not a string - perhaps None - just return it as-is
+ return x
class Difference(object):
"""An observed difference."""
@@ -32,7 +38,7 @@ class Difference(object):
def to_text(self, kind=''):
if 'secret' in kind.lower() and len(self.args) == 2:
- message = self.message % ((len(self.args[0]) * '*'), (len(self.args[1]) * '*'))
+ message = self.message % (mask(self.args[0]), mask(self.args[1]))
else:
message = self.message % self.args
| weaveworks/kubediff | 42a6c302e06db06b5887e866e29d7d4a452a1d1e | diff --git a/kubedifflib/tests/test_diff.py b/kubedifflib/tests/test_diff.py
index fa5a683..575fffb 100644
--- a/kubedifflib/tests/test_diff.py
+++ b/kubedifflib/tests/test_diff.py
@@ -2,10 +2,10 @@ import copy
import random
-from hypothesis import given
+from hypothesis import given, example
from hypothesis.strategies import integers, lists, text, fixed_dictionaries, sampled_from, none, one_of
-from kubedifflib._diff import diff_lists, list_subtract
+from kubedifflib._diff import diff_lists, list_subtract, Difference
from kubedifflib._kube import KubeObject
@@ -137,3 +137,16 @@ def test_from_dict_kubernetes_list_type(data):
def test_from_dict_kubernetes_obj_type(data):
"""KubeObject.from_dict parses regular kubernetes objects."""
assert [kube_obj.data for kube_obj in KubeObject.from_dict(data)] == [data]
+
+@given(path=text(), kind=text())
+def test_difference_no_args(path, kind):
+ """Difference.to_text works as expected when no args passed."""
+ d = Difference("Message", path)
+ assert d.to_text(kind) == path + ": Message"
+
+@given(path=text(), kind=text(), arg1=text(), arg2=one_of(text(), none()))
+@example("somepath","Secret", "foo", None)
+def test_difference_two_args(path, kind, arg1, arg2):
+ """Difference.to_text works when two args passed, that may be 'none'."""
+ d = Difference("Message %s %s", path, arg1, arg2)
+ assert d.to_text(kind) != ""
| TypeError on SealedSecret
Reported in PR #78
error below for e.g. `SealedSecret.v1alpha1.bitnami.com`
```
Traceback (most recent call last):
File "/Users/po/src/kubediff/kubediff", line 48, in <module>
main()
File "/Users/po/src/kubediff/kubediff", line 42, in main
failed = check_files(args, printer, config)
File "/Users/po/src/kubediff/kubedifflib/_diff.py", line 246, in check_files
differences += check_file(printer, path, config)
File "/Users/po/src/kubediff/kubedifflib/_diff.py", line 174, in check_file
printer.diff(path, difference)
File "/Users/po/src/kubediff/kubedifflib/_diff.py", line 214, in diff
self._write('%s', difference.to_text(self._current.kind))
File "/Users/po/src/kubediff/kubedifflib/_diff.py", line 35, in to_text
message = self.message % ((len(self.args[0]) * '*'), (len(self.args[1]) * '*'))
TypeError: object of type 'NoneType' has no len()
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"kubedifflib/tests/test_diff.py::test_difference_two_args"
] | [
"kubedifflib/tests/test_diff.py::test_two_lists_of_same_size_generator",
"kubedifflib/tests/test_diff.py::test_diff_lists_doesnt_mutate_inputs",
"kubedifflib/tests/test_diff.py::test_from_dict_kubernetes_obj_type",
"kubedifflib/tests/test_diff.py::test_same_list_shuffled_is_not_different_nested",
"kubedifflib/tests/test_diff.py::test_from_dict_kubernetes_list_type",
"kubedifflib/tests/test_diff.py::test_list_subtract_recover",
"kubedifflib/tests/test_diff.py::test_difference_no_args",
"kubedifflib/tests/test_diff.py::test_same_list_shuffled_is_not_different",
"kubedifflib/tests/test_diff.py::test_list_subtract_same_list",
"kubedifflib/tests/test_diff.py::test_diff_lists_doesnt_mutate_inputs_nested_lists",
"kubedifflib/tests/test_diff.py::test_diff_lists_equal",
"kubedifflib/tests/test_diff.py::test_added_items_appear_in_diff"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2019-02-13T10:37:05Z" | apache-2.0 |
|
web2py__pydal-349 | diff --git a/pydal/dialects/base.py b/pydal/dialects/base.py
index 89e261f9..fb058fe2 100644
--- a/pydal/dialects/base.py
+++ b/pydal/dialects/base.py
@@ -399,7 +399,8 @@ class SQLDialect(CommonDialect):
return ''
def coalesce(self, first, second):
- expressions = [self.expand(first)]+[self.expand(e) for e in second]
+ expressions = [self.expand(first)] + \
+ [self.expand(val, first.type) for val in second]
return 'COALESCE(%s)' % ','.join(expressions)
def raw(self, val):
diff --git a/pydal/dialects/sqlite.py b/pydal/dialects/sqlite.py
index 0af56176..078d5c1a 100644
--- a/pydal/dialects/sqlite.py
+++ b/pydal/dialects/sqlite.py
@@ -28,6 +28,15 @@ class SQLiteDialect(SQLDialect):
return '(%s REGEXP %s)' % (
self.expand(first), self.expand(second, 'string'))
+ def select(self, fields, tables, where=None, groupby=None, having=None,
+ orderby=None, limitby=None, distinct=False, for_update=False):
+ if distinct and distinct is not True:
+ raise SyntaxError(
+ 'DISTINCT ON is not supported by SQLite')
+ return super(SQLiteDialect, self).select(
+ fields, tables, where, groupby, having, orderby, limitby, distinct,
+ for_update)
+
def truncate(self, table, mode=''):
tablename = table._tablename
return [
diff --git a/pydal/objects.py b/pydal/objects.py
index c159c181..59d6f471 100644
--- a/pydal/objects.py
+++ b/pydal/objects.py
@@ -1462,6 +1462,8 @@ class Field(Expression, Serializable):
return field
def store(self, file, filename=None, path=None):
+ # make sure filename is a str sequence
+ filename = "{}".format(filename)
if self.custom_store:
return self.custom_store(file, filename, path)
if isinstance(file, cgi.FieldStorage):
@@ -1474,7 +1476,8 @@ class Field(Expression, Serializable):
m = REGEX_STORE_PATTERN.search(filename)
extension = m and m.group('e') or 'txt'
uuid_key = self._db.uuid().replace('-', '')[-16:]
- encoded_filename = base64.b16encode(filename).lower()
+ encoded_filename = base64.b16encode(
+ filename.encode('utf-8')).lower().decode('utf-8')
newfilename = '%s.%s.%s.%s' % (
self._tablename, self.name, uuid_key, encoded_filename)
newfilename = newfilename[:(self.length - 1 - len(extension))] + \
@@ -1486,27 +1489,27 @@ class Field(Expression, Serializable):
blob_uploadfield_name: file.read()}
self_uploadfield.table.insert(**keys)
elif self_uploadfield is True:
- if path:
- pass
- elif self.uploadfolder:
- path = self.uploadfolder
- elif self.db._adapter.folder:
- path = pjoin(self.db._adapter.folder, '..', 'uploads')
- else:
- raise RuntimeError(
- "you must specify a Field(..., uploadfolder=...)")
- if self.uploadseparate:
- if self.uploadfs:
- raise RuntimeError("not supported")
- path = pjoin(path, "%s.%s" % (
- self._tablename, self.name), uuid_key[:2]
- )
- if not exists(path):
- os.makedirs(path)
- pathfilename = pjoin(path, newfilename)
if self.uploadfs:
dest_file = self.uploadfs.open(newfilename, 'wb')
else:
+ if path:
+ pass
+ elif self.uploadfolder:
+ path = self.uploadfolder
+ elif self.db._adapter.folder:
+ path = pjoin(self.db._adapter.folder, '..', 'uploads')
+ else:
+ raise RuntimeError(
+ "you must specify a Field(..., uploadfolder=...)")
+ if self.uploadseparate:
+ if self.uploadfs:
+ raise RuntimeError("not supported")
+ path = pjoin(path, "%s.%s" % (
+ self._tablename, self.name), uuid_key[:2]
+ )
+ if not exists(path):
+ os.makedirs(path)
+ pathfilename = pjoin(path, newfilename)
dest_file = open(pathfilename, 'wb')
try:
shutil.copyfileobj(file, dest_file)
@@ -1563,7 +1566,7 @@ class Field(Expression, Serializable):
return self.custom_retrieve_file_properties(name, path)
if m.group('name'):
try:
- filename = base64.b16decode(m.group('name'), True)
+ filename = base64.b16decode(m.group('name'), True).decode('utf-8')
filename = REGEX_CLEANUP_FN.sub('_', filename)
except (TypeError, AttributeError):
filename = name
diff --git a/setup.py b/setup.py
index f99ee9af..d4d69a06 100644
--- a/setup.py
+++ b/setup.py
@@ -38,7 +38,9 @@ setup(
maintainer_email='[email protected]',
description='a pure Python Database Abstraction Layer',
long_description=__doc__,
- packages=['pydal', 'pydal.adapters', 'pydal.helpers', 'pydal.contrib'],
+ packages=[
+ 'pydal', 'pydal.adapters', 'pydal.dialects', 'pydal.helpers',
+ 'pydal.parsers', 'pydal.representers', 'pydal.contrib'],
include_package_data=True,
zip_safe=False,
platforms='any',
| web2py/pydal | d59b588900f26e6e204fb119115efa91fe7db692 | diff --git a/tests/sql.py b/tests/sql.py
index 2573f3a3..c118e372 100644
--- a/tests/sql.py
+++ b/tests/sql.py
@@ -149,6 +149,74 @@ class TestFields(unittest.TestCase):
else:
isinstance(f.formatter(datetime.datetime.now()), str)
+ def testUploadField(self):
+ import tempfile
+
+ stream = tempfile.NamedTemporaryFile()
+ content = b"this is the stream content"
+ stream.write(content)
+ # rewind before inserting
+ stream.seek(0)
+
+
+ db = DAL(DEFAULT_URI, check_reserved=['all'])
+ db.define_table('tt', Field('fileobj', 'upload',
+ uploadfolder=tempfile.gettempdir(),
+ autodelete=True))
+ f_id = db.tt.insert(fileobj=stream)
+
+ row = db.tt[f_id]
+ (retr_name, retr_stream) = db.tt.fileobj.retrieve(row.fileobj)
+
+ # name should be the same
+ self.assertEqual(retr_name, os.path.basename(stream.name))
+ # content should be the same
+ retr_content = retr_stream.read()
+ self.assertEqual(retr_content, content)
+
+ # close streams!
+ retr_stream.close()
+
+ # delete
+ row.delete_record()
+
+ # drop
+ db.tt.drop()
+
+ # this part is triggered only if fs (AKA pyfilesystem) module is installed
+ try:
+ from fs.memoryfs import MemoryFS
+
+ # rewind before inserting
+ stream.seek(0)
+ db.define_table('tt', Field('fileobj', 'upload',
+ uploadfs=MemoryFS(),
+ autodelete=True))
+
+ f_id = db.tt.insert(fileobj=stream)
+
+ row = db.tt[f_id]
+ (retr_name, retr_stream) = db.tt.fileobj.retrieve(row.fileobj)
+
+ # name should be the same
+ self.assertEqual(retr_name, os.path.basename(stream.name))
+ # content should be the same
+ retr_content = retr_stream.read()
+ self.assertEqual(retr_content, content)
+
+ # close streams
+ retr_stream.close()
+ stream.close()
+
+ # delete
+ row.delete_record()
+
+ # drop
+ db.tt.drop()
+
+ except ImportError:
+ pass
+
def testRun(self):
"""Test all field types and their return values"""
db = DAL(DEFAULT_URI, check_reserved=['all'])
| coalesce() incorrectly expands constant values
When you pass string constant into coalesce, it will be expanded as identifier instead of string constant:
`db().select(db.table.str_field.coalesce('foo'))`
would expand into this:
`SELECT COALESCE(table.str_field,foo) FROM table`
but the expected behavior is this:
`SELECT COALESCE(table.str_field,'foo') FROM table` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/sql.py::TestFields::testUploadField"
] | [
"tests/sql.py::TestFields::testFieldFormatters",
"tests/sql.py::TestFields::testFieldLabels",
"tests/sql.py::TestFields::testFieldName",
"tests/sql.py::TestFields::testFieldTypes",
"tests/sql.py::TestFields::testRun",
"tests/sql.py::TestTables::testTableNames",
"tests/sql.py::TestAll::testSQLALL",
"tests/sql.py::TestTable::testTableAlias",
"tests/sql.py::TestTable::testTableCreation",
"tests/sql.py::TestTable::testTableInheritance",
"tests/sql.py::TestInsert::testRun",
"tests/sql.py::TestSelect::testCoalesce",
"tests/sql.py::TestSelect::testGroupByAndDistinct",
"tests/sql.py::TestSelect::testListInteger",
"tests/sql.py::TestSelect::testListReference",
"tests/sql.py::TestSelect::testListString",
"tests/sql.py::TestSelect::testRun",
"tests/sql.py::TestSelect::testTestQuery",
"tests/sql.py::TestAddMethod::testRun",
"tests/sql.py::TestBelongs::testRun",
"tests/sql.py::TestContains::testRun",
"tests/sql.py::TestLike::testEscaping",
"tests/sql.py::TestLike::testLikeInteger",
"tests/sql.py::TestLike::testRegexp",
"tests/sql.py::TestLike::testRun",
"tests/sql.py::TestLike::testStartsEndsWith",
"tests/sql.py::TestLike::testUpperLower",
"tests/sql.py::TestDatetime::testRun",
"tests/sql.py::TestExpressions::testOps",
"tests/sql.py::TestExpressions::testRun",
"tests/sql.py::TestExpressions::testSubstring",
"tests/sql.py::TestExpressions::testUpdate",
"tests/sql.py::TestJoin::testRun",
"tests/sql.py::TestMinMaxSumAvg::testRun",
"tests/sql.py::TestMigrations::testRun",
"tests/sql.py::TestReference::testRun",
"tests/sql.py::TestClientLevelOps::testRun",
"tests/sql.py::TestVirtualFields::testRun",
"tests/sql.py::TestComputedFields::testRun",
"tests/sql.py::TestCommonFilters::testRun",
"tests/sql.py::TestImportExportFields::testRun",
"tests/sql.py::TestImportExportUuidFields::testRun",
"tests/sql.py::TestDALDictImportExport::testRun",
"tests/sql.py::TestSelectAsDict::testSelect",
"tests/sql.py::TestRNameTable::testJoin",
"tests/sql.py::TestRNameTable::testSelect",
"tests/sql.py::TestRNameFields::testInsert",
"tests/sql.py::TestRNameFields::testJoin",
"tests/sql.py::TestRNameFields::testRun",
"tests/sql.py::TestRNameFields::testSelect",
"tests/sql.py::TestQuoting::testCase",
"tests/sql.py::TestQuoting::testPKFK",
"tests/sql.py::TestTableAndFieldCase::testme",
"tests/sql.py::TestQuotesByDefault::testme",
"tests/sql.py::TestGis::testGeometry",
"tests/sql.py::TestGis::testGeometryCase",
"tests/sql.py::TestGis::testGisMigration",
"tests/sql.py::TestSQLCustomType::testRun",
"tests/sql.py::TestLazy::testLazyGetter",
"tests/sql.py::TestLazy::testRowExtra",
"tests/sql.py::TestLazy::testRowNone",
"tests/sql.py::TestLazy::testRun",
"tests/sql.py::TestRedefine::testRun",
"tests/sql.py::TestUpdateInsert::testRun",
"tests/sql.py::TestBulkInsert::testRun",
"tests/sql.py::TestRecordVersioning::testRun",
"tests/sql.py::TestSerializers::testAsJson"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2016-04-21T22:23:30Z" | bsd-3-clause |
|
web2py__pydal-350 | diff --git a/pydal/dialects/sqlite.py b/pydal/dialects/sqlite.py
index 0af56176..078d5c1a 100644
--- a/pydal/dialects/sqlite.py
+++ b/pydal/dialects/sqlite.py
@@ -28,6 +28,15 @@ class SQLiteDialect(SQLDialect):
return '(%s REGEXP %s)' % (
self.expand(first), self.expand(second, 'string'))
+ def select(self, fields, tables, where=None, groupby=None, having=None,
+ orderby=None, limitby=None, distinct=False, for_update=False):
+ if distinct and distinct is not True:
+ raise SyntaxError(
+ 'DISTINCT ON is not supported by SQLite')
+ return super(SQLiteDialect, self).select(
+ fields, tables, where, groupby, having, orderby, limitby, distinct,
+ for_update)
+
def truncate(self, table, mode=''):
tablename = table._tablename
return [
diff --git a/pydal/objects.py b/pydal/objects.py
index c159c181..59d6f471 100644
--- a/pydal/objects.py
+++ b/pydal/objects.py
@@ -1462,6 +1462,8 @@ class Field(Expression, Serializable):
return field
def store(self, file, filename=None, path=None):
+ # make sure filename is a str sequence
+ filename = "{}".format(filename)
if self.custom_store:
return self.custom_store(file, filename, path)
if isinstance(file, cgi.FieldStorage):
@@ -1474,7 +1476,8 @@ class Field(Expression, Serializable):
m = REGEX_STORE_PATTERN.search(filename)
extension = m and m.group('e') or 'txt'
uuid_key = self._db.uuid().replace('-', '')[-16:]
- encoded_filename = base64.b16encode(filename).lower()
+ encoded_filename = base64.b16encode(
+ filename.encode('utf-8')).lower().decode('utf-8')
newfilename = '%s.%s.%s.%s' % (
self._tablename, self.name, uuid_key, encoded_filename)
newfilename = newfilename[:(self.length - 1 - len(extension))] + \
@@ -1486,27 +1489,27 @@ class Field(Expression, Serializable):
blob_uploadfield_name: file.read()}
self_uploadfield.table.insert(**keys)
elif self_uploadfield is True:
- if path:
- pass
- elif self.uploadfolder:
- path = self.uploadfolder
- elif self.db._adapter.folder:
- path = pjoin(self.db._adapter.folder, '..', 'uploads')
- else:
- raise RuntimeError(
- "you must specify a Field(..., uploadfolder=...)")
- if self.uploadseparate:
- if self.uploadfs:
- raise RuntimeError("not supported")
- path = pjoin(path, "%s.%s" % (
- self._tablename, self.name), uuid_key[:2]
- )
- if not exists(path):
- os.makedirs(path)
- pathfilename = pjoin(path, newfilename)
if self.uploadfs:
dest_file = self.uploadfs.open(newfilename, 'wb')
else:
+ if path:
+ pass
+ elif self.uploadfolder:
+ path = self.uploadfolder
+ elif self.db._adapter.folder:
+ path = pjoin(self.db._adapter.folder, '..', 'uploads')
+ else:
+ raise RuntimeError(
+ "you must specify a Field(..., uploadfolder=...)")
+ if self.uploadseparate:
+ if self.uploadfs:
+ raise RuntimeError("not supported")
+ path = pjoin(path, "%s.%s" % (
+ self._tablename, self.name), uuid_key[:2]
+ )
+ if not exists(path):
+ os.makedirs(path)
+ pathfilename = pjoin(path, newfilename)
dest_file = open(pathfilename, 'wb')
try:
shutil.copyfileobj(file, dest_file)
@@ -1563,7 +1566,7 @@ class Field(Expression, Serializable):
return self.custom_retrieve_file_properties(name, path)
if m.group('name'):
try:
- filename = base64.b16decode(m.group('name'), True)
+ filename = base64.b16decode(m.group('name'), True).decode('utf-8')
filename = REGEX_CLEANUP_FN.sub('_', filename)
except (TypeError, AttributeError):
filename = name
diff --git a/setup.py b/setup.py
index f99ee9af..d4d69a06 100644
--- a/setup.py
+++ b/setup.py
@@ -38,7 +38,9 @@ setup(
maintainer_email='[email protected]',
description='a pure Python Database Abstraction Layer',
long_description=__doc__,
- packages=['pydal', 'pydal.adapters', 'pydal.helpers', 'pydal.contrib'],
+ packages=[
+ 'pydal', 'pydal.adapters', 'pydal.dialects', 'pydal.helpers',
+ 'pydal.parsers', 'pydal.representers', 'pydal.contrib'],
include_package_data=True,
zip_safe=False,
platforms='any',
| web2py/pydal | d59b588900f26e6e204fb119115efa91fe7db692 | diff --git a/tests/sql.py b/tests/sql.py
index 2573f3a3..c118e372 100644
--- a/tests/sql.py
+++ b/tests/sql.py
@@ -149,6 +149,74 @@ class TestFields(unittest.TestCase):
else:
isinstance(f.formatter(datetime.datetime.now()), str)
+ def testUploadField(self):
+ import tempfile
+
+ stream = tempfile.NamedTemporaryFile()
+ content = b"this is the stream content"
+ stream.write(content)
+ # rewind before inserting
+ stream.seek(0)
+
+
+ db = DAL(DEFAULT_URI, check_reserved=['all'])
+ db.define_table('tt', Field('fileobj', 'upload',
+ uploadfolder=tempfile.gettempdir(),
+ autodelete=True))
+ f_id = db.tt.insert(fileobj=stream)
+
+ row = db.tt[f_id]
+ (retr_name, retr_stream) = db.tt.fileobj.retrieve(row.fileobj)
+
+ # name should be the same
+ self.assertEqual(retr_name, os.path.basename(stream.name))
+ # content should be the same
+ retr_content = retr_stream.read()
+ self.assertEqual(retr_content, content)
+
+ # close streams!
+ retr_stream.close()
+
+ # delete
+ row.delete_record()
+
+ # drop
+ db.tt.drop()
+
+ # this part is triggered only if fs (AKA pyfilesystem) module is installed
+ try:
+ from fs.memoryfs import MemoryFS
+
+ # rewind before inserting
+ stream.seek(0)
+ db.define_table('tt', Field('fileobj', 'upload',
+ uploadfs=MemoryFS(),
+ autodelete=True))
+
+ f_id = db.tt.insert(fileobj=stream)
+
+ row = db.tt[f_id]
+ (retr_name, retr_stream) = db.tt.fileobj.retrieve(row.fileobj)
+
+ # name should be the same
+ self.assertEqual(retr_name, os.path.basename(stream.name))
+ # content should be the same
+ retr_content = retr_stream.read()
+ self.assertEqual(retr_content, content)
+
+ # close streams
+ retr_stream.close()
+ stream.close()
+
+ # delete
+ row.delete_record()
+
+ # drop
+ db.tt.drop()
+
+ except ImportError:
+ pass
+
def testRun(self):
"""Test all field types and their return values"""
db = DAL(DEFAULT_URI, check_reserved=['all'])
| select(distinct=...) may produce faulty sql for sqlite
This one works:
```python
In [45]: db().select(db.player.country, distinct = True)
Out[45]: <Rows (40)>
In [46]: db._lastsql
Out[46]: 'SELECT DISTINCT player.country FROM player;'
```
But the other option given in the book does not:
```python
In [47]: db().select(db.player.country, distinct = db.player.country)
OperationalError: near "ON": syntax error
In [48]: db._lastsql
Out[48]: 'SELECT DISTINCT ON (player.country) player.country FROM player;'
```
I didn't test it with other DB engines since I don't currently have one installed.
Related to https://github.com/web2py/web2py/issues/1129 | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/sql.py::TestFields::testUploadField"
] | [
"tests/sql.py::TestFields::testFieldFormatters",
"tests/sql.py::TestFields::testFieldLabels",
"tests/sql.py::TestFields::testFieldName",
"tests/sql.py::TestFields::testFieldTypes",
"tests/sql.py::TestFields::testRun",
"tests/sql.py::TestTables::testTableNames",
"tests/sql.py::TestAll::testSQLALL",
"tests/sql.py::TestTable::testTableAlias",
"tests/sql.py::TestTable::testTableCreation",
"tests/sql.py::TestTable::testTableInheritance",
"tests/sql.py::TestInsert::testRun",
"tests/sql.py::TestSelect::testCoalesce",
"tests/sql.py::TestSelect::testGroupByAndDistinct",
"tests/sql.py::TestSelect::testListInteger",
"tests/sql.py::TestSelect::testListReference",
"tests/sql.py::TestSelect::testListString",
"tests/sql.py::TestSelect::testRun",
"tests/sql.py::TestSelect::testTestQuery",
"tests/sql.py::TestAddMethod::testRun",
"tests/sql.py::TestBelongs::testRun",
"tests/sql.py::TestContains::testRun",
"tests/sql.py::TestLike::testEscaping",
"tests/sql.py::TestLike::testLikeInteger",
"tests/sql.py::TestLike::testRegexp",
"tests/sql.py::TestLike::testRun",
"tests/sql.py::TestLike::testStartsEndsWith",
"tests/sql.py::TestLike::testUpperLower",
"tests/sql.py::TestDatetime::testRun",
"tests/sql.py::TestExpressions::testOps",
"tests/sql.py::TestExpressions::testRun",
"tests/sql.py::TestExpressions::testSubstring",
"tests/sql.py::TestExpressions::testUpdate",
"tests/sql.py::TestJoin::testRun",
"tests/sql.py::TestMinMaxSumAvg::testRun",
"tests/sql.py::TestMigrations::testRun",
"tests/sql.py::TestReference::testRun",
"tests/sql.py::TestClientLevelOps::testRun",
"tests/sql.py::TestVirtualFields::testRun",
"tests/sql.py::TestComputedFields::testRun",
"tests/sql.py::TestCommonFilters::testRun",
"tests/sql.py::TestImportExportFields::testRun",
"tests/sql.py::TestImportExportUuidFields::testRun",
"tests/sql.py::TestDALDictImportExport::testRun",
"tests/sql.py::TestSelectAsDict::testSelect",
"tests/sql.py::TestRNameTable::testJoin",
"tests/sql.py::TestRNameTable::testSelect",
"tests/sql.py::TestRNameFields::testInsert",
"tests/sql.py::TestRNameFields::testJoin",
"tests/sql.py::TestRNameFields::testRun",
"tests/sql.py::TestRNameFields::testSelect",
"tests/sql.py::TestQuoting::testCase",
"tests/sql.py::TestQuoting::testPKFK",
"tests/sql.py::TestTableAndFieldCase::testme",
"tests/sql.py::TestQuotesByDefault::testme",
"tests/sql.py::TestGis::testGeometry",
"tests/sql.py::TestGis::testGeometryCase",
"tests/sql.py::TestGis::testGisMigration",
"tests/sql.py::TestSQLCustomType::testRun",
"tests/sql.py::TestLazy::testLazyGetter",
"tests/sql.py::TestLazy::testRowExtra",
"tests/sql.py::TestLazy::testRowNone",
"tests/sql.py::TestLazy::testRun",
"tests/sql.py::TestRedefine::testRun",
"tests/sql.py::TestUpdateInsert::testRun",
"tests/sql.py::TestBulkInsert::testRun",
"tests/sql.py::TestRecordVersioning::testRun",
"tests/sql.py::TestSerializers::testAsJson"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2016-04-21T22:31:32Z" | bsd-3-clause |
|
websocket-client__websocket-client-929 | diff --git a/websocket/_url.py b/websocket/_url.py
index 259ce64..2141b02 100644
--- a/websocket/_url.py
+++ b/websocket/_url.py
@@ -137,7 +137,7 @@ def get_proxy_info(
Websocket server name.
is_secure: bool
Is the connection secure? (wss) looks for "https_proxy" in env
- before falling back to "http_proxy"
+ instead of "http_proxy"
proxy_host: str
http proxy host name.
proxy_port: str or int
@@ -158,15 +158,11 @@ def get_proxy_info(
auth = proxy_auth
return proxy_host, port, auth
- env_keys = ["http_proxy"]
- if is_secure:
- env_keys.insert(0, "https_proxy")
-
- for key in env_keys:
- value = os.environ.get(key, os.environ.get(key.upper(), "")).replace(" ", "")
- if value:
- proxy = urlparse(value)
- auth = (unquote(proxy.username), unquote(proxy.password)) if proxy.username else None
- return proxy.hostname, proxy.port, auth
+ env_key = "https_proxy" if is_secure else "http_proxy"
+ value = os.environ.get(env_key, os.environ.get(env_key.upper(), "")).replace(" ", "")
+ if value:
+ proxy = urlparse(value)
+ auth = (unquote(proxy.username), unquote(proxy.password)) if proxy.username else None
+ return proxy.hostname, proxy.port, auth
return None, 0, None
| websocket-client/websocket-client | bd506ad2e14749e1d31c07a1a6fca5644adb0ec4 | diff --git a/websocket/tests/test_url.py b/websocket/tests/test_url.py
index 6a210d5..a74dd76 100644
--- a/websocket/tests/test_url.py
+++ b/websocket/tests/test_url.py
@@ -254,6 +254,24 @@ def testProxyFromEnv(self):
os.environ["https_proxy"] = "http://localhost2:3128/"
self.assertEqual(get_proxy_info("echo.websocket.events", True), ("localhost2", 3128, None))
+ os.environ["http_proxy"] = ""
+ os.environ["https_proxy"] = "http://localhost2/"
+ self.assertEqual(get_proxy_info("echo.websocket.events", True), ("localhost2", None, None))
+ self.assertEqual(get_proxy_info("echo.websocket.events", False), (None, 0, None))
+ os.environ["http_proxy"] = ""
+ os.environ["https_proxy"] = "http://localhost2:3128/"
+ self.assertEqual(get_proxy_info("echo.websocket.events", True), ("localhost2", 3128, None))
+ self.assertEqual(get_proxy_info("echo.websocket.events", False), (None, 0, None))
+
+ os.environ["http_proxy"] = "http://localhost/"
+ os.environ["https_proxy"] = ""
+ self.assertEqual(get_proxy_info("echo.websocket.events", True), (None, 0, None))
+ self.assertEqual(get_proxy_info("echo.websocket.events", False), ("localhost", None, None))
+ os.environ["http_proxy"] = "http://localhost:3128/"
+ os.environ["https_proxy"] = ""
+ self.assertEqual(get_proxy_info("echo.websocket.events", True), (None, 0, None))
+ self.assertEqual(get_proxy_info("echo.websocket.events", False), ("localhost", 3128, None))
+
os.environ["http_proxy"] = "http://a:b@localhost/"
self.assertEqual(get_proxy_info("echo.websocket.events", False), ("localhost", None, ("a", "b")))
os.environ["http_proxy"] = "http://a:b@localhost:3128/"
| Environment variable HTTP_PROXY is used for HTTPS connections
The problem occurred in an environment where a proxy server is to be used for HTTP connections but not for HTTPS connections.
In this case `http_proxy` is set in the environment but `https_proxy` is not.
The problematic code is here:
https://github.com/websocket-client/websocket-client/blob/bd506ad2e14749e1d31c07a1a6fca5644adb0ec4/websocket/_url.py#L161-L163
In my opinion, only `https_proxy` should be used for secure connections.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"websocket/tests/test_url.py::ProxyInfoTest::testProxyFromEnv"
] | [
"websocket/tests/test_url.py::UrlTest::testParseUrl",
"websocket/tests/test_url.py::UrlTest::test_address_in_network",
"websocket/tests/test_url.py::IsNoProxyHostTest::testHostnameMatch",
"websocket/tests/test_url.py::IsNoProxyHostTest::testHostnameMatchDomain",
"websocket/tests/test_url.py::IsNoProxyHostTest::testIpAddress",
"websocket/tests/test_url.py::IsNoProxyHostTest::testIpAddressInRange",
"websocket/tests/test_url.py::IsNoProxyHostTest::testMatchAll",
"websocket/tests/test_url.py::ProxyInfoTest::testProxyFromArgs"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2023-07-10T09:14:17Z" | apache-2.0 |
|
wesleybowman__UTide-79 | diff --git a/utide/_reconstruct.py b/utide/_reconstruct.py
index ebb7723..e72c862 100644
--- a/utide/_reconstruct.py
+++ b/utide/_reconstruct.py
@@ -92,7 +92,7 @@ def _reconstruct(t, goodmask, coef, verbose, constit, min_SNR, min_PE):
# Determine constituents to include.
if constit is not None:
ind = [i for i, c in enumerate(coef['name']) if c in constit]
- elif min_SNR == 0 and min_PE == 0:
+ elif (min_SNR == 0 and min_PE == 0) or coef['aux']['opt']['nodiagn']:
ind = slice(None)
else:
if twodim:
diff --git a/utide/_solve.py b/utide/_solve.py
index 9ce79e5..0445c16 100644
--- a/utide/_solve.py
+++ b/utide/_solve.py
@@ -57,6 +57,7 @@ def _translate_opts(opts):
oldopts.linci = False
elif opts.conf_int == 'none':
oldopts.conf_int = False
+ oldopts.nodiagn = 1
else:
raise ValueError("'conf_int' must be 'linear', 'MC', or 'none'")
| wesleybowman/UTide | c5ac303aef3365c1a93cae7fddfc6a3672a50788 | diff --git a/tests/test_solve.py b/tests/test_solve.py
index 5295515..eaa507f 100644
--- a/tests/test_solve.py
+++ b/tests/test_solve.py
@@ -9,15 +9,18 @@ Smoke testing--just see if the system runs.
from __future__ import (absolute_import, division, print_function)
+import pytest
+
import numpy as np
from utide import reconstruct
from utide import solve
from utide._ut_constants import ut_constants
from utide.utilities import Bunch
-
-
-def test_roundtrip():
+# We omit the 'MC' case for now because with this test data, it
+# fails with 'numpy.linalg.LinAlgError: SVD did not converge'.
[email protected]('conf_int', ['linear', 'none'])
+def test_roundtrip(conf_int):
"""Minimal conversion from simple_utide_test."""
ts = 735604
duration = 35
@@ -44,7 +47,7 @@ def test_roundtrip():
'nodal': False,
'trend': False,
'method': 'ols',
- 'conf_int': 'linear',
+ 'conf_int': conf_int,
'Rayleigh_min': 0.95,
}
| solve failing when conf_int='none'
solve is failing when `conf_int='none'`.
For example, if I try changing `conf_int='linear'` to `conf_int='none'` in cell [5] of the [utide_uv_example.ipynb notebook](https://github.com/wesleybowman/UTide/blob/master/notebooks/utide_uv_example.ipynb), I get:
```python-traceback
solve: matrix prep ... solution ... diagnostics ...
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-10-359a0567fa71> in <module>
7 method='ols',
8 conf_int='none',
----> 9 Rayleigh_min=0.95,)
~/miniconda3/envs/pangeo/lib/python3.7/site-packages/utide/_solve.py in solve(t, u, v, lat, **opts)
198 compat_opts = _process_opts(opts, v is not None)
199
--> 200 coef = _solv1(t, u, v, lat, **compat_opts)
201
202 return coef
~/miniconda3/envs/pangeo/lib/python3.7/site-packages/utide/_solve.py in _solv1(tin, uin, vin, lat, **opts)
377 # Diagnostics.
378 if not opt['nodiagn']:
--> 379 coef, indPE = ut_diagn(coef, opt)
380
381 # Re-order constituents.
~/miniconda3/envs/pangeo/lib/python3.7/site-packages/utide/diagnostics.py in ut_diagn(coef, opt)
15
16 SNR = (coef['Lsmaj']**2 + coef['Lsmin']**2) / (
---> 17 (coef['Lsmaj_ci']/1.96)**2 +
18 (coef['Lsmin_ci']/1.96)**2)
19
KeyError: 'Lsmaj_ci'
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_solve.py::test_roundtrip[none]"
] | [
"tests/test_solve.py::test_roundtrip[linear]",
"tests/test_solve.py::test_masked_input",
"tests/test_solve.py::test_robust",
"tests/test_solve.py::test_MC"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2020-01-10T20:15:32Z" | mit |
|
wesleybowman__UTide-96 | diff --git a/utide/_solve.py b/utide/_solve.py
index 675f3d5..20ed0e8 100644
--- a/utide/_solve.py
+++ b/utide/_solve.py
@@ -5,10 +5,9 @@ Central module for calculating the tidal amplitudes, phases, etc.
import numpy as np
from ._time_conversion import _normalize_time
-from ._ut_constants import constit_index_dict
from .confidence import _confidence
from .constituent_selection import ut_cnstitsel
-from .diagnostics import ut_diagn
+from .diagnostics import _PE, _SNR, ut_diagn
from .ellipse_params import ut_cs2cep
from .harmonics import ut_E
from .robustfit import robustfit
@@ -17,6 +16,7 @@ from .utilities import Bunch
default_opts = {
"constit": "auto",
+ "order_constit": None,
"conf_int": "linear",
"method": "ols",
"trend": True,
@@ -37,6 +37,8 @@ def _process_opts(opts, is_2D):
newopts.update_values(strict=True, **opts)
# TODO: add more validations.
newopts.infer = validate_infer(newopts.infer, is_2D)
+ snr = newopts.conf_int != "none"
+ newopts.order_constit = validate_order_constit(newopts.order_constit, snr)
compat_opts = _translate_opts(newopts)
@@ -48,6 +50,7 @@ def _translate_opts(opts):
# Here or elsewhere, proper validation remains to be added.
oldopts = Bunch()
oldopts.cnstit = opts.constit
+ oldopts.ordercnstit = opts.order_constit
oldopts.infer = opts.infer # we will not use the matlab names, though
oldopts.conf_int = True
@@ -101,6 +104,22 @@ def validate_infer(infer, is_2D):
return infer
+def validate_order_constit(arg, have_snr):
+ available = ["PE", "frequency"]
+ if have_snr:
+ available.append("SNR")
+ if arg is None:
+ return "PE"
+ if isinstance(arg, str) and arg in available:
+ return arg
+ if not isinstance(arg, str) and np.iterable(arg):
+ return arg # TODO: add checking of its elements
+ raise ValueError(
+ f"order_constit must be one of {available} or"
+ f" a sequence of constituents, not '{arg}'",
+ )
+
+
def solve(t, u, v=None, lat=None, **opts):
"""
Calculate amplitude, phase, confidence intervals of tidal constituents.
@@ -122,7 +141,7 @@ def solve(t, u, v=None, lat=None, **opts):
standard library `datetime` proleptic Gregorian calendar,
starting with 1 at 00:00 on January 1 of year 1; this is
the 'datenum' used by Matplotlib.
- constit : {'auto', array_like}, optional
+ constit : {'auto', sequence}, optional
List of strings with standard letter abbreviations of
tidal constituents; or 'auto' to let the list be determined
based on the time span.
@@ -165,6 +184,14 @@ def solve(t, u, v=None, lat=None, **opts):
amp_ratios and phase_offsets have length N for a scalar
time series, or 2N for a vector series.
+ order_constit : {'PE', 'SNR', 'frequency', sequence}, optional
+ The default is 'PE' (percent energy) order, returning results ordered from
+ high energy to low.
+ The 'SNR' order is from high signal-to-noise ratio to low, and is
+ available only if `conf_int` is not 'none'. The
+ 'frequency' order is from low to high frequency. Alternatively, a
+ sequence of constituent names may be supplied, typically the same list as
+ given in the *constit* option.
MC_n : integer, optional
Not yet implemented.
robust_kw : dict, optional
@@ -370,7 +397,7 @@ def _solv1(tin, uin, vin, lat, **opts):
coef.theta = np.hstack((coef.theta, theta))
coef.g = np.hstack((coef.g, g))
- if opt["conf_int"] is True:
+ if opt["conf_int"]:
coef = _confidence(
coef,
cnstit,
@@ -392,63 +419,50 @@ def _solv1(tin, uin, vin, lat, **opts):
# Diagnostics.
if not opt["nodiagn"]:
- coef, indPE = ut_diagn(coef, opt)
+ coef = ut_diagn(coef)
+ # Adds a diagn dictionary, always sorted by energy.
+ # This doesn't seem very useful. Let's directly add the variables
+ # to the base coef structure. Then they can be sorted with everything
+ # else.
+ coef["PE"] = _PE(coef)
+ coef["SNR"] = _SNR(coef)
# Re-order constituents.
- if opt["ordercnstit"] is not None:
+ coef = _reorder(coef, opt)
+ # This might have added PE if it was not already present.
- if opt["ordercnstit"] == "frq":
- ind = coef["aux"]["frq"].argsort()
+ if opt["RunTimeDisp"]:
+ print("done.")
- elif opt["ordercnstit"] == "snr":
- if not opt["nodiagn"]:
- ind = coef["diagn"]["SNR"].argsort()[::-1]
- else:
- if opt["twodim"]:
- SNR = (coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2) / (
- (coef["Lsmaj_ci"] / 1.96) ** 2 + (coef["Lsmin_ci"] / 1.96) ** 2
- )
+ return coef
- else:
- SNR = (coef["A"] ** 2) / (coef["A_ci"] / 1.96) ** 2
- ind = SNR.argsort()[::-1]
+def _reorder(coef, opt):
+ if opt["ordercnstit"] == "PE":
+ # Default: order by decreasing energy.
+ if "PE" not in coef:
+ coef["PE"] = _PE(coef)
+ ind = coef["PE"].argsort()[::-1]
- else:
- ilist = [constit_index_dict[name] for name in opt["ordercnstit"]]
- ind = np.array(ilist, dtype=int)
+ elif opt["ordercnstit"] == "frequency":
+ ind = coef["aux"]["frq"].argsort()
- else: # Default: order by decreasing energy.
- if not opt["nodiagn"]:
- ind = indPE
- else:
- if opt["twodim"]:
- PE = np.sum(coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2)
- PE = 100 * (coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2) / PE
- else:
- PE = 100 * coef["A"] ** 2 / np.sum(coef["A"] ** 2)
-
- ind = PE.argsort()[::-1]
-
- reorderlist = ["g", "name"]
- if opt.twodim:
- reorderlist.extend(["Lsmaj", "Lsmin", "theta"])
- if opt.conf_int:
- reorderlist.extend(["Lsmaj_ci", "Lsmin_ci", "theta_ci", "g_ci"])
+ elif opt["ordercnstit"] == "SNR":
+ # If we are here, we should be guaranteed to have SNR already.
+ ind = coef["SNR"].argsort()[::-1]
else:
- reorderlist.append("A")
- if opt.conf_int:
- reorderlist.extend(["A_ci", "g_ci"])
+ namelist = list(coef["name"])
+ ilist = [namelist.index(name) for name in opt["ordercnstit"]]
+ ind = np.array(ilist, dtype=int)
+
+ arrays = "name PE SNR A A_ci g g_ci Lsmaj Lsmaj_ci Lsmin Lsmin_ci theta theta_ci"
+ reorderlist = [a for a in arrays.split() if a in coef]
for key in reorderlist:
coef[key] = coef[key][ind]
coef["aux"]["frq"] = coef["aux"]["frq"][ind]
coef["aux"]["lind"] = coef["aux"]["lind"][ind]
-
- if opt["RunTimeDisp"]:
- print("done.")
-
return coef
@@ -532,7 +546,7 @@ def _slvinit(tin, uin, vin, lat, **opts):
opt["rmin"] = 1
opt["method"] = "ols"
opt["tunrdn"] = 1
- opt["linci"] = 0
+ opt["linci"] = False
opt["white"] = 0
opt["nrlzn"] = 200
opt["lsfrqosmp"] = 1
diff --git a/utide/diagnostics.py b/utide/diagnostics.py
index bae848b..b6a250a 100644
--- a/utide/diagnostics.py
+++ b/utide/diagnostics.py
@@ -1,58 +1,44 @@
import numpy as np
-def ut_diagn(coef, opt):
-
- if opt["RunTimeDisp"]:
- print("diagnostics ... ", end="")
- coef["diagn"] = {}
+def _PE(coef):
+ """
+ Return the energy percentage for each constituent.
+ """
+ if "Lsmaj" in coef:
+ E = coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2
+ PE = (100 / np.sum(E)) * E
+ else:
+ PE = 100 * coef["A"] ** 2 / np.sum(coef["A"] ** 2)
+ return PE
- if opt["twodim"]:
- PE = np.sum(coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2)
- PE = 100 * (coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2) / PE
+def _SNR(coef):
+ """
+ Return the signal-to-noise ratio for each constituent.
+ """
+ if "Lsmaj" in coef:
SNR = (coef["Lsmaj"] ** 2 + coef["Lsmin"] ** 2) / (
(coef["Lsmaj_ci"] / 1.96) ** 2 + (coef["Lsmin_ci"] / 1.96) ** 2
)
-
else:
- PE = 100 * coef["A"] ** 2 / np.sum(coef["A"] ** 2)
SNR = (coef["A"] ** 2) / (coef["A_ci"] / 1.96) ** 2
+ return SNR
+
+def ut_diagn(coef):
+ """
+ Add to coef the names, PE, and SNR, *always* sorted by energy.
+
+ To be eliminated...
+ """
+ coef["diagn"] = {}
+ PE = _PE(coef)
+ SNR = _SNR(coef)
indPE = PE.argsort()[::-1]
coef["diagn"]["name"] = coef["name"][indPE]
coef["diagn"]["PE"] = PE[indPE]
coef["diagn"]["SNR"] = SNR[indPE]
- return coef, indPE
-
-
-# [~,indPE] = sort(PE,'descend');
-# coef.diagn.name = coef.name(indPE);
-# coef.diagn.PE = PE(indPE);
-# coef.diagn.SNR = SNR; % used in ut_diagntable; ordered by PE there
-# if opt.twodim
-# [coef.diagn,usnrc,vsnrc] = ut_diagntable(coef,cnstit,...
-# t,u,v,xmod,m,B,W,varMSM,Gall,Hall,elor,varcov_mCw,indPE);
-# else
-# [coef.diagn,usnrc,~] = ut_diagntable(coef,cnstit,...
-# t,u,[],xmod,m,B,W,varMSM,Gall,Hall,elor,varcov_mCw,indPE);
-# end
-# if opt.diagnplots
-# tmp = nan*ones(size(uin));
-# tmp(uvgd) = usnrc;
-# usnrc = tmp;
-# tmp = nan*ones(size(uin));
-# tmp(uvgd) = e;
-# e = tmp;
-# if opt.twodim
-# tmp = nan*ones(size(uin));
-# tmp(uvgd) = vsnrc;
-# vsnrc = tmp;
-# ut_diagnfigs(coef,indPE,tin,uin,vin,usnrc,vsnrc,e);
-# else
-# ut_diagnfigs(coef,indPE,tin,uin,[],usnrc,[],e);
-# end
-# end
-# end
+ return coef
| wesleybowman/UTide | 5f15bcb7ba4c724a7e680866272a676d0785f50f | diff --git a/tests/test_order_constit.py b/tests/test_order_constit.py
new file mode 100644
index 0000000..8c87e45
--- /dev/null
+++ b/tests/test_order_constit.py
@@ -0,0 +1,77 @@
+import numpy as np
+import pytest
+
+from utide import reconstruct, solve
+from utide._ut_constants import constit_index_dict, ut_constants
+
+
+ts = 735604
+duration = 35
+
+time = np.linspace(ts, ts + duration, 842)
+tref = (time[-1] + time[0]) / 2
+
+const = ut_constants.const
+
+amps = [1.0, 0.5, 0.6, 0.1]
+names = ["M2", "S2", "K1", "O1"]
+cpds = [24 * const.freq[constit_index_dict[name]] for name in names]
+sinusoids = []
+for amp, cpd in zip(amps, cpds):
+ arg = 2 * np.pi * (time - tref) * cpd
+ sinusoids.append(amp * np.cos(arg))
+tide = np.hstack(tuple(sinusoids)).sum(axis=0)
+
+np.random.seed(1234)
+noise = 1e-3 * np.random.randn(len(time))
+
+time_series = tide + noise
+
+opts0 = {
+ "constit": ["K1", "M2", "O1", "S2"],
+ "order_constit": "frequency",
+ "phase": "raw",
+ "nodal": False,
+ "trend": False,
+ "method": "ols",
+ "conf_int": "MC",
+ "Rayleigh_min": 0.95,
+}
+
+
[email protected]("conf_int", ["none", "linear", "MC"])
+def test_order(conf_int):
+
+ orders = [None, "PE", "frequency", opts0["constit"]]
+ if conf_int != "none":
+ orders.append("SNR")
+ elevs = []
+ ts_elevs = []
+ vels = []
+ ts_vels = []
+ for order in orders:
+ opts = opts0.copy()
+ opts["order_constit"] = order
+ opts["conf_int"] = conf_int
+ elevs.append(solve(time, time_series, lat=45, **opts))
+ vels.append(solve(time, time_series, time_series, lat=45, **opts))
+ ts_elevs.append(reconstruct(time, elevs[-1], min_SNR=0))
+ ts_vels.append(reconstruct(time, vels[-1], min_SNR=0))
+
+ # Are the reconstructions all the same?
+ for i in range(1, len(elevs)):
+ assert (ts_elevs[i].h == ts_elevs[0].h).all()
+ assert (ts_vels[i].u == ts_vels[0].u).all()
+ assert (ts_vels[i].v == ts_vels[0].v).all()
+
+ # Is None equivalent to "PE"? (Just a spot check.)
+ assert (elevs[0].name == elevs[1].name).all()
+ assert (elevs[0].A == elevs[1].A).all()
+
+
+def test_invalid_snr():
+ opts = opts0.copy()
+ opts["conf_int"] = "none"
+ opts["order_constit"] = "SNR"
+ with pytest.raises(ValueError):
+ solve(time, time_series, lat=45, **opts)
| Trying to reorder constituents as in ‘OrderCnstit’
As @rsignell-usgs mentioned in a previous issue, we are trying to analyze the tides at each grid cell in a numerical model solution. We run utide for each grid point but the order of the constituents can be different for each grid point. In the Matlab code, there is the option ‘OrderCnstit’ that allows passing a specified order of constituents when constit is not set to 'auto'. Is there a similar reordering for the python version? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_order_constit.py::test_order[none]",
"tests/test_order_constit.py::test_order[linear]",
"tests/test_order_constit.py::test_order[MC]",
"tests/test_order_constit.py::test_invalid_snr"
] | [] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-03-10T20:59:56Z" | mit |
|
wfondrie__mokapot-106 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 2a81e5f..27b7fe2 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,9 +1,11 @@
# Changelog for mokapot
## [Unreleased]
+
+## [v0.10.1] - 2023-09-11
### Breaking changes
- Mokapot now uses `numpy.random.Generator` instead of the deprecated `numpy.random.RandomState` API.
- New `rng` arguments have been added to functions and classes that rely on randomness in lieu of setting a global random seed with `np.random.seed()`. Thanks @sjust-seerbio!
+ New `rng` arguments have been added to functions and classes that rely on randomness in lieu of setting a global random seed with `np.random.seed()`. Thanks @sjust-seerbio! (#55)
### Changed
- Added linting with Ruff to tests and pre-commit hooks (along with others)!
@@ -11,15 +13,16 @@
### Fixed
- The PepXML reader, which broke due to a Pandas update.
- Potential bug if lowercase peptide sequences were used and protein-level confidence estimates were enabled
+- Multiprocessing led to the same training set being used for all splits (#104).
-## [0.9.1] - 2022-12-14
+## [v0.9.1] - 2022-12-14
### Changed
- Cross-validation classes are now detected by looking for inheritance from the `sklearn.model_selection._search.BaseSearchCV` class.
### Fixed
- Fixed backward compatibility issue for Python <3.10.
-## [0.9.0] - 2022-12-02
+## [v0.9.0] - 2022-12-02
### Added
- Support for plugins, allowing mokapot to use new models.
- Added a custom Docker image with optional dependencies.
@@ -31,11 +34,11 @@
- Updated GitHub Actions.
- Migrated to a full pyproject.toml setuptools build. Thanks @jspaezp!
-## [0.8.3] - 2022-07-20
+## [v0.8.3] - 2022-07-20
### Fixed
- Fixed the reported mokapot score when group FDR is used.
-## [0.8.2] - 2022-07-18
+## [v0.8.2] - 2022-07-18
### Added
- `mokapot.Model()` objects now recorded the CV fold that they were fit on.
This means that they can be provided to `mokapot.brew()` in any order
@@ -45,7 +48,7 @@
- Resolved issue where models were required to have an intercept term.
- The PepXML parser would sometimes try and log transform features with `0`'s, resulting in missing values.
-## [0.8.1] - 2022-06-24
+## [v0.8.1] - 2022-06-24
### Added
- Support for previously trained models in the `brew()` function and the CLI
@@ -56,7 +59,7 @@
`min_length-1`.
- Links to example datasets in the documentation.
-## [0.8.0] - 2022-03-11
+## [v0.8.0] - 2022-03-11
Thanks to @sambenfredj, @gessulat, @tkschmidt, and @MatthewThe for
PR #44, which made these things happen!
@@ -72,17 +75,17 @@ PR #44, which made these things happen!
- Parallelization within `mokapot.brew()` now uses `joblib`
instead of `concurrent.futures`.
-## [0.7.4] - 2021-09-03
+## [v0.7.4] - 2021-09-03
### Changed
- Improved documentation and added warnings for `--subset_max_train`. Thanks
@jspaezp!
-## [0.7.3] - 2021-07-20
+## [v0.7.3] - 2021-07-20
### Fixed
- Fixed bug where the `--keep_decoys` did not work with `--aggregate`. Also,
added tests to cover this. Thanks @jspaezp!
-## [0.7.2] - 2021-07-16
+## [v0.7.2] - 2021-07-16
### Added
- `--keep_decoys` option to the command line interface. Thanks @jspaezp!
- Notes about setting a random seed to the Python API documentation. (Issue #30)
@@ -96,12 +99,12 @@ PR #44, which made these things happen!
### Changed
- Updates to unit tests. Warnings are now treated as errors for system tests.
-## [0.7.1] - 2021-03-22
+## [v0.7.1] - 2021-03-22
### Changed
- Updated the build to align with
[PEP517](https://www.python.org/dev/peps/pep-0517/)
-## [0.7.0] - 2021-03-19
+## [v0.7.0] - 2021-03-19
### Added
- Support for downstream peptide and protein quantitation with
[FlashLFQ](https://github.com/smith-chem-wisc/FlashLFQ). This is accomplished
@@ -127,7 +130,7 @@ PR #44, which made these things happen!
`importlib.metadata` to the standard library, saving a few hundred
milliseconds.
-## [0.6.2] - 2021-03-12
+## [v0.6.2] - 2021-03-12
### Added
- Now checks to verify there are no debugging print statements in the code
base when linting.
@@ -135,7 +138,7 @@ PR #44, which made these things happen!
### Fixed
- Removed debugging print statements.
-## [0.6.1] - 2021-03-11
+## [v0.6.1] - 2021-03-11
### Fixed
- Parsing Percolator tab-delimited files with a "DefaultDirection" line.
- `Label` column is now converted to boolean during PIN file parsing.
@@ -143,7 +146,7 @@ PR #44, which made these things happen!
- Parsing modifications from pepXML files were indexed incorrectly on the
peptide string.
-## [0.6.0] - 2021-03-03
+## [v0.6.0] - 2021-03-03
### Added
- Support for parsing PSMs from PepXML input files.
- This changelog.
diff --git a/mokapot/brew.py b/mokapot/brew.py
index 86e06b3..c2c6ea9 100644
--- a/mokapot/brew.py
+++ b/mokapot/brew.py
@@ -106,9 +106,10 @@ def brew(psms, model=None, test_fdr=0.01, folds=3, max_workers=1, rng=None):
LOGGER.info("Splitting PSMs into %i folds...", folds)
test_idx = [p._split(folds) for p in psms]
train_sets = _make_train_sets(psms, test_idx)
+
if max_workers != 1:
# train_sets can't be a generator for joblib :(
- train_sets = list(train_sets)
+ train_sets = [copy.copy(d) for d in train_sets]
# If trained models are provided, use the them as-is.
try:
| wfondrie/mokapot | 2bc16136b94cddddec3decb222f89b796c18bdbb | diff --git a/tests/conftest.py b/tests/conftest.py
index c490a61..481d94e 100644
--- a/tests/conftest.py
+++ b/tests/conftest.py
@@ -1,12 +1,19 @@
"""
This file contains fixtures that are used at multiple points in the tests.
"""
+import logging
import pytest
import numpy as np
import pandas as pd
from mokapot import LinearPsmDataset
[email protected](autouse=True)
+def set_logging(caplog):
+ """Add logging to everything."""
+ caplog.set_level(level=logging.INFO, logger="mokapot")
+
+
@pytest.fixture(scope="session")
def psm_df_6():
"""A DataFrame containing 6 PSMs"""
@@ -34,6 +41,9 @@ def psm_df_1000(tmp_path):
"score": np.concatenate(
[rng.normal(3, size=200), rng.normal(size=300)]
),
+ "score2": np.concatenate(
+ [rng.normal(3, size=200), rng.normal(size=300)]
+ ),
"filename": "test.mzML",
"calcmass": rng.uniform(500, 2000, size=500),
"expmass": rng.uniform(500, 2000, size=500),
@@ -47,6 +57,7 @@ def psm_df_1000(tmp_path):
"group": rng.choice(2, size=500),
"peptide": [_random_peptide(5, rng) for _ in range(500)],
"score": rng.normal(size=500),
+ "score2": rng.normal(size=500),
"filename": "test.mzML",
"calcmass": rng.uniform(500, 2000, size=500),
"expmass": rng.uniform(500, 2000, size=500),
@@ -75,7 +86,7 @@ def psms(psm_df_1000):
target_column="target",
spectrum_columns="spectrum",
peptide_column="peptide",
- feature_columns="score",
+ feature_columns=["score", "score2"],
filename_column="filename",
scan_column="spectrum",
calcmass_column="calcmass",
diff --git a/tests/unit_tests/test_brew.py b/tests/unit_tests/test_brew.py
index 319626b..27d0495 100644
--- a/tests/unit_tests/test_brew.py
+++ b/tests/unit_tests/test_brew.py
@@ -44,7 +44,7 @@ def test_brew_joint(psms, svm):
def test_brew_folds(psms, svm):
"""Test that changing the number of folds works"""
- results, models = mokapot.brew(psms, svm, test_fdr=0.05, folds=4)
+ results, models = mokapot.brew(psms, svm, test_fdr=0.1, folds=4)
assert isinstance(results, mokapot.confidence.LinearConfidence)
assert len(models) == 4
@@ -92,7 +92,12 @@ def test_brew_test_fdr_error(psms, svm):
# @pytest.mark.skip(reason="Not currently working, at least on MacOS.")
def test_brew_multiprocess(psms, svm):
"""Test that multiprocessing doesn't yield an error"""
- mokapot.brew(psms, svm, test_fdr=0.05, max_workers=2)
+ _, models = mokapot.brew(psms, svm, test_fdr=0.05, max_workers=2)
+
+ # The models should not be the same:
+ assert_not_close(models[0].estimator.coef_, models[1].estimator.coef_)
+ assert_not_close(models[1].estimator.coef_, models[2].estimator.coef_)
+ assert_not_close(models[2].estimator.coef_, models[0].estimator.coef_)
def test_brew_trained_models(psms, svm):
@@ -131,3 +136,8 @@ def test_brew_using_non_trained_models_error(psms, svm):
"One or more of the provided models was not previously trained"
in str(err)
)
+
+
+def assert_not_close(x, y):
+ """Assert that two arrays are not equal"""
+ np.testing.assert_raises(AssertionError, np.testing.assert_allclose, x, y)
diff --git a/tests/unit_tests/test_confidence.py b/tests/unit_tests/test_confidence.py
index 34994f0..06f2d01 100644
--- a/tests/unit_tests/test_confidence.py
+++ b/tests/unit_tests/test_confidence.py
@@ -28,12 +28,12 @@ def test_one_group(psm_df_1000):
)
np.random.seed(42)
- grouped = psms.assign_confidence()
+ grouped = psms.assign_confidence(eval_fdr=0.05)
scores1 = grouped.group_confidence_estimates[0].psms["mokapot score"]
np.random.seed(42)
psms._group_column = None
- ungrouped = psms.assign_confidence()
+ ungrouped = psms.assign_confidence(eval_fdr=0.05)
scores2 = ungrouped.psms["mokapot score"]
pd.testing.assert_series_equal(scores1, scores2)
@@ -59,7 +59,7 @@ def test_pickle(psm_df_1000, tmp_path):
copy_data=True,
)
- results = psms.assign_confidence()
+ results = psms.assign_confidence(eval_fdr=0.05)
pkl_file = tmp_path / "results.pkl"
with pkl_file.open("wb+") as pkl_dat:
pickle.dump(results, pkl_dat)
diff --git a/tests/unit_tests/test_writer_flashlfq.py b/tests/unit_tests/test_writer_flashlfq.py
index 9aba9d7..8b468a1 100644
--- a/tests/unit_tests/test_writer_flashlfq.py
+++ b/tests/unit_tests/test_writer_flashlfq.py
@@ -8,7 +8,7 @@ import pandas as pd
def test_sanity(psms, tmp_path):
"""Run simple sanity checks"""
- conf = psms.assign_confidence()
+ conf = psms.assign_confidence(eval_fdr=0.05)
test1 = conf.to_flashlfq(tmp_path / "test1.txt")
mokapot.to_flashlfq(conf, tmp_path / "test2.txt")
test3 = mokapot.to_flashlfq([conf, conf], tmp_path / "test3.txt")
diff --git a/tests/unit_tests/test_writer_txt.py b/tests/unit_tests/test_writer_txt.py
index fea7f19..326cbae 100644
--- a/tests/unit_tests/test_writer_txt.py
+++ b/tests/unit_tests/test_writer_txt.py
@@ -8,7 +8,7 @@ import pandas as pd
def test_sanity(psms, tmp_path):
"""Run simple sanity checks"""
- conf = psms.assign_confidence()
+ conf = psms.assign_confidence(eval_fdr=0.05)
test1 = conf.to_txt(dest_dir=tmp_path, file_root="test1")
mokapot.to_txt(conf, dest_dir=tmp_path, file_root="test2")
test3 = mokapot.to_txt([conf, conf], dest_dir=tmp_path, file_root="test3")
| max_workers issue
The cross validation might not work as expected when using multiple threads.
```
(mokapot_test) mokapot -w 3 feature.pin
[INFO]
[INFO] === Analyzing Fold 1 ===
[INFO] === Analyzing Fold 2 ===
[INFO] === Analyzing Fold 3 ===
[INFO] Finding initial direction...
[INFO] Finding initial direction...
[INFO] Finding initial direction...
[INFO] - Selected feature score with 21657 PSMs at q<=0.01.
[INFO] - Selected feature score with 21657 PSMs at q<=0.01.
[INFO] - Selected feature score with 21657 PSMs at q<=0.01.
```
If I set **-w** as 3, it always has the same number of PSMs passed at a q-value 0.01 cutoff as shown above. When I set -w as 1, they are different. I also tried to print out the training data for each iteration, it looks like they are identical from different folds by looking at the first several rows. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit_tests/test_brew.py::test_brew_multiprocess"
] | [
"tests/unit_tests/test_brew.py::test_brew_simple",
"tests/unit_tests/test_brew.py::test_brew_random_forest",
"tests/unit_tests/test_brew.py::test_brew_joint",
"tests/unit_tests/test_brew.py::test_brew_folds",
"tests/unit_tests/test_brew.py::test_brew_seed",
"tests/unit_tests/test_brew.py::test_brew_test_fdr_error",
"tests/unit_tests/test_brew.py::test_brew_trained_models",
"tests/unit_tests/test_brew.py::test_brew_using_few_models_error",
"tests/unit_tests/test_brew.py::test_brew_using_non_trained_models_error",
"tests/unit_tests/test_confidence.py::test_one_group",
"tests/unit_tests/test_confidence.py::test_pickle",
"tests/unit_tests/test_writer_flashlfq.py::test_sanity",
"tests/unit_tests/test_writer_flashlfq.py::test_basic",
"tests/unit_tests/test_writer_flashlfq.py::test_with_missing",
"tests/unit_tests/test_writer_flashlfq.py::test_no_proteins",
"tests/unit_tests/test_writer_flashlfq.py::test_fasta_proteins",
"tests/unit_tests/test_writer_txt.py::test_sanity",
"tests/unit_tests/test_writer_txt.py::test_columns"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-09-11T16:56:06Z" | apache-2.0 |
|
wfondrie__mokapot-19 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 363da49..4bea464 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,11 @@
# Changelog for mokapot
+## [Unreleased]
+### Fixed
+- Parsing Percolator tab-delimited files with a "DefaultDirection" line.
+- `Label` column is now converted to boolean during PIN file parsing.
+ Previously, problems occurred if the `Label` column was of dtype `object`.
+
## [0.6.0] - 2021-03-03
### Added
- Support for parsing PSMs from PepXML input files.
diff --git a/mokapot/parsers/pin.py b/mokapot/parsers/pin.py
index 65e8e30..69567cd 100644
--- a/mokapot/parsers/pin.py
+++ b/mokapot/parsers/pin.py
@@ -87,14 +87,17 @@ def read_pin(pin_files, group_column=None, to_df=False, copy_data=False):
raise ValueError(f"More than one '{name}' column found.")
if not all([specid, peptides, proteins, labels, spectra]):
+ print([specid, peptides, proteins, labels, spectra])
raise ValueError(
"This PIN format is incompatible with mokapot. Please"
" verify that the required columns are present."
)
# Convert labels to the correct format.
+ print(pin_df[labels[0]])
+ pin_df[labels[0]] = pin_df[labels[0]].astype(int)
if any(pin_df[labels[0]] == -1):
- pin_df[labels[0]] = (pin_df[labels[0]] + 1) / 2
+ pin_df[labels[0]] = ((pin_df[labels[0]] + 1) / 2).astype(bool)
if to_df:
return pin_df
@@ -138,8 +141,14 @@ def read_percolator(perc_file):
with fopen(perc_file) as perc:
cols = perc.readline().rstrip().split("\t")
+ dir_line = perc.readline().rstrip().split("\t")[0]
+ if dir_line.lower() != "defaultdirection":
+ perc.seek(0)
+ _ = perc.readline()
+
psms = pd.concat((c for c in _parse_in_chunks(perc, cols)), copy=False)
+ print(psms.head())
return psms
| wfondrie/mokapot | 94d6b9eae7583f467349ff1bfa421a5ebe24fbd3 | diff --git a/tests/unit_tests/test_parser_pin.py b/tests/unit_tests/test_parser_pin.py
index e69de29..bae0fd3 100644
--- a/tests/unit_tests/test_parser_pin.py
+++ b/tests/unit_tests/test_parser_pin.py
@@ -0,0 +1,37 @@
+"""Test that parsing Percolator input files works correctly"""
+import pytest
+import mokapot
+import pandas as pd
+
+
[email protected]
+def std_pin(tmp_path):
+ """Create a standard pin file"""
+ out_file = tmp_path / "std_pin"
+ with open(str(out_file), "w+") as pin:
+ dat = (
+ "sPeCid\tLaBel\tpepTide\tsCore\tscanNR\tpRoteins\n"
+ "DefaultDirection\t-\t-\t-\t1\t-\t-\n"
+ "a\t1\tABC\t5\t2\tprotein1\tprotein2\n"
+ "b\t-1\tCBA\t10\t3\tdecoy_protein1\tdecoy_protein2"
+ )
+ pin.write(dat)
+
+ return out_file
+
+
+def test_pin_parsing(std_pin):
+ """Test pin parsing"""
+ df = mokapot.read_pin(std_pin, to_df=True)
+ assert df["LaBel"].dtype == "bool"
+ assert len(df) == 2
+ assert len(df[df["LaBel"]]) == 1
+ assert len(df[df["LaBel"]]) == 1
+
+ dat = mokapot.read_pin(std_pin)
+ pd.testing.assert_frame_equal(df.loc[:, ("sCore",)], dat.features)
+
+
+def test_pin_wo_dir():
+ """Test a PIN file without a DefaultDirection line"""
+ dat = mokapot.read_pin("data/scope2_FP97AA.pin")
| ValueError: No decoy PSMs were detected.
I have loaded a file in the required format (these are the first few lines and the names of the columns).
```
SpecId | Label | ScanNr | Peptide | Proteins
0 | 1 | 38422 | R.AEGSDVANAVLDGADC[Common Fixed:Carbamidomethy... | P14618
1 | 1 | 41542 | R.SNYLLNTTIAGVEEADVVLLVGTNPR.F | P28331
```
I am getting an error saying that there are no decoy PSMs, however, I know there are decoys. My label column has -1's in it. It loads the file in, but is not getting any further than that. I have looked through the documentation and can't seem to see what I could be missing. Any suggestions would be greatly appreciated. Thank you!
Here is the error that I am getting.
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-4-bc18f4fefa97> in <module>
----> 1 psms = mokapot.read_pin(file)
2 results, models = mokapot.brew(psms)
3 results.to_txt()
~/anaconda3/lib/python3.8/site-packages/mokapot/parsers.py in read_pin(pin_files, group_column, to_df, copy_data)
103 return pin_df
104
--> 105 return LinearPsmDataset(
106 psms=pin_df,
107 target_column=labels[0],
~/anaconda3/lib/python3.8/site-packages/mokapot/dataset.py in __init__(self, psms, target_column, spectrum_columns, peptide_column, protein_column, group_column, feature_columns, copy_data)
427 raise ValueError("No target PSMs were detected.")
428 if not num_decoys:
--> 429 raise ValueError("No decoy PSMs were detected.")
430 if not self.data.shape[0]:
431 raise ValueError("No PSMs were detected.")
ValueError: No decoy PSMs were detected.
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit_tests/test_parser_pin.py::test_pin_parsing"
] | [
"tests/unit_tests/test_parser_pin.py::test_pin_wo_dir"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-03-11T21:23:37Z" | apache-2.0 |
|
wfondrie__mokapot-65 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index 2030c9a..588e408 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -1,5 +1,9 @@
# Changelog for mokapot
+## [0.8.3] - 2022-07-20
+### Fixed
+- Fixed the reported mokapot score when group FDR is used.
+
## [0.8.2] - 2022-07-18
### Added
- `mokapot.Model()` objects now recored the CV fold that they were fit on.
diff --git a/mokapot/confidence.py b/mokapot/confidence.py
index c8935cb..e72cecd 100644
--- a/mokapot/confidence.py
+++ b/mokapot/confidence.py
@@ -63,9 +63,10 @@ class GroupedConfidence:
group_psms = copy.copy(psms)
self.group_column = group_psms._group_column
group_psms._group_column = None
- scores = scores * (desc * 2 - 1)
- # Do TDC
+ # Do TDC to eliminate multiples PSMs for a spectrum that may occur
+ # in different groups.
+ keep = "last" if desc else "first"
scores = (
pd.Series(scores, index=psms._data.index)
.sample(frac=1)
@@ -74,7 +75,7 @@ class GroupedConfidence:
idx = (
psms.data.loc[scores.index, :]
- .drop_duplicates(psms._spectrum_columns, keep="last")
+ .drop_duplicates(psms._spectrum_columns, keep=keep)
.index
)
@@ -84,9 +85,9 @@ class GroupedConfidence:
group_psms._data = None
tdc_winners = group_df.index.intersection(idx)
group_psms._data = group_df.loc[tdc_winners, :]
- group_scores = scores.loc[group_psms._data.index].values + 1
+ group_scores = scores.loc[group_psms._data.index].values
res = group_psms.assign_confidence(
- group_scores * (2 * desc - 1), desc=desc, eval_fdr=eval_fdr
+ group_scores, desc=desc, eval_fdr=eval_fdr
)
self._group_confidence_estimates[group] = res
| wfondrie/mokapot | 21680cc5b7136359c033bb0c7fc5d0f7b002c931 | diff --git a/tests/unit_tests/test_confidence.py b/tests/unit_tests/test_confidence.py
index e69de29..0be3fcd 100644
--- a/tests/unit_tests/test_confidence.py
+++ b/tests/unit_tests/test_confidence.py
@@ -0,0 +1,38 @@
+"""Test that Confidence classes are working correctly"""
+import pytest
+import numpy as np
+import pandas as pd
+from mokapot import LinearPsmDataset
+
+
+def test_one_group(psm_df_1000):
+ """Test that one group is equivalent to no group."""
+ psm_data, _ = psm_df_1000
+ psm_data["group"] = 0
+
+ psms = LinearPsmDataset(
+ psms=psm_data,
+ target_column="target",
+ spectrum_columns="spectrum",
+ peptide_column="peptide",
+ feature_columns="score",
+ filename_column="filename",
+ scan_column="spectrum",
+ calcmass_column="calcmass",
+ expmass_column="expmass",
+ rt_column="ret_time",
+ charge_column="charge",
+ group_column="group",
+ copy_data=True,
+ )
+
+ np.random.seed(42)
+ grouped = psms.assign_confidence()
+ scores1 = grouped.group_confidence_estimates[0].psms["mokapot score"]
+
+ np.random.seed(42)
+ psms._group_column = None
+ ungrouped = psms.assign_confidence()
+ scores2 = ungrouped.psms["mokapot score"]
+
+ pd.testing.assert_series_equal(scores1, scores2)
| [BUG] Different scores for LinearConfidence and GroupConfidence
`LinearConfidence` and `GroupedConfidence` give different scores, even when for `GroupedConfidence` all PSMs are part of a single group. I'm using a random forest, which should give scores between 0 and 1, but for `GroupedConfidence` the scores seem to range between 1 and 2 instead.
When using `LinearConfidence`:
```
import mokapot
from sklearn.ensemble import RandomForestClassifier
psms = mokapot.read_pin("phospho_rep1.pin")
moka_conf, _ = mokapot.brew(psms, mokapot.Model(RandomForestClassifier(random_state=1)))
moka_conf.psms["mokapot score"].describe()
```
Output:
```
count 42330.000000
mean 0.686944
std 0.435288
min 0.000000
25% 0.060000
50% 1.000000
75% 1.000000
max 1.000000
```
For simplicity, I use the constant `Charge1` column in the example PIN file as group for `GroupedConfidence`, i.e. all PSMs are part of the same group (`Charge1 == 0`):
```
import mokapot
from sklearn.ensemble import RandomForestClassifier
psms_grouped = mokapot.read_pin("phospho_rep1.pin", group_column="Charge1")
moka_conf_grouped, _ = mokapot.brew(psms_grouped, mokapot.Model(RandomForestClassifier(random_state=1)))
moka_conf_grouped.group_confidence_estimates[0].psms["mokapot score"].describe()
```
Output:
```
count 42330.000000
mean 1.687226
std 0.435448
min 1.000000
25% 1.060000
50% 2.000000
75% 2.000000
max 2.000000
```
Note how the scores seem to be almost identical except for being 1 more. I tried to figure out in the code what was happening, but didn't immediately find the problem.
This is with mokapot version 0.8.2. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit_tests/test_confidence.py::test_one_group"
] | [] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-07-20T16:47:04Z" | apache-2.0 |
|
whot__uji-17 | diff --git a/examples/example.yaml b/examples/example.yaml
index 666bcf1..9b144d6 100644
--- a/examples/example.yaml
+++ b/examples/example.yaml
@@ -36,7 +36,7 @@
# description: a longer description for human consumption
# tags: a dictionary of key: value that can be used to filter on
# value must not be a list/dict
-#
+#
# The test type is a description of a test that may produce log files.
# Allowed subkeys:
# extends: inherit all from the referenced section
@@ -47,6 +47,8 @@
# The value must be a list, even if it's just one entry
# Where the filter tag is missing, this test is assumed
# to be run only once.
+# If a value starts with ! it's a negative match, i.e.
+# the tag must NOT be present in the actor.
# tests: a list of instruction strings describing the tests to be
# performed.
# files: a list of files to collect
@@ -80,7 +82,7 @@ file:
#
# Since we support 'include:' statements, you could have files with all the
# hw you have defined in mice.yaml, keyboards.yaml, etc.
-
+
t450_keyboard:
type: actor
name: Lenovo T450s - AT Translated Keyboard
@@ -178,6 +180,15 @@ test_usb_hid:
tests:
- verify hid report descriptor parses with `hid-parse`
+# A test to run only on non-USB keyboards
+test_nonusb:
+ type: test
+ filter:
+ device: [keyboard]
+ bus: ["!USB"] # Note: YAML requires quotes
+ tests:
+ - "bus type for this keyboard is XXX"
+
# This is a test without a filter, so it will show up in the "Generic"
# section but not for any specific actor. Good for things you need to
# collect only once.
diff --git a/uji.py b/uji.py
index e5d0b6f..59bf2e4 100755
--- a/uji.py
+++ b/uji.py
@@ -736,8 +736,19 @@ class UjiNew(object):
for key, values in test.filters.items():
if key not in actor.tags:
break
- if ('__any__' not in values and
- actor.tags[key] not in values):
+
+ tag = actor.tags[key]
+
+ excluded = [v[1:] for v in values if v[0] == '!']
+ if tag in excluded:
+ break
+
+ required = [v for v in values if v[0] != '!']
+ if not required and excluded:
+ required = ['__any__']
+
+ if ('__any__' not in required and
+ actor.tags[key] not in required):
break
else:
dup = deepcopy(test)
| whot/uji | e7d0f65722caeeff5f5ab27d8aea0234a266c693 | diff --git a/tests/data/basic-tree.yaml b/tests/data/basic-tree.yaml
index 6e0e83a..61f3734 100644
--- a/tests/data/basic-tree.yaml
+++ b/tests/data/basic-tree.yaml
@@ -13,16 +13,16 @@ actor2:
# generic test
test1:
type: test
- test:
- - testcase0
+ tests:
+ - testcase1 (generic)
logs:
- files: [file1]
+ files: [file01-generic]
# generic test
test2:
type: test
logs:
- files: [file2]
+ files: [file02-generic]
# all actors but not generic
test3:
@@ -30,22 +30,38 @@ test3:
filter:
actor: [__any__]
tests:
- - testcase1
+ - testcase3 (all actors)
test4:
type: test
filter:
actor: [one]
tests:
- - testcase2
+ - testcase4 (actor one only)
logs:
- files: [file3]
+ files: [file04-actor-one]
test5:
type: test
filter:
actor: [two]
tests:
- - testcase3
+ - testcase5 (actor two only)
+ - testcase5.1 (actor two only)
+ - testcase5.2 (actor two only)
logs:
- files: [file4]
+ files: [file05-actor-two]
+
+test6:
+ type: test
+ filter:
+ actor: ["!two"]
+ tests:
+ - testcase6 (actor one only)
+
+test7:
+ type: test
+ filter:
+ actor: ["!one", "two"]
+ tests:
+ - testcase7 (actor two only)
diff --git a/tests/test_uji.py b/tests/test_uji.py
index d5381ad..c49040a 100644
--- a/tests/test_uji.py
+++ b/tests/test_uji.py
@@ -1,5 +1,7 @@
#!/usr/bin/env python3
+from typing import Optional
+
from click.testing import CliRunner
import pytest
import os
@@ -16,6 +18,22 @@ def datadir():
return Path(os.path.realpath(__file__)).parent / 'data'
+def find_in_section(markdown: str, section: str, string: str) -> Optional[str]:
+ prev_line = None
+ in_section = False
+ for line in markdown.split('\n'):
+ if prev_line is not None and prev_line == section and line == '-' * len(section):
+ in_section = True
+ elif in_section and line == '':
+ in_section = False
+ elif in_section:
+ if string in line:
+ return line
+ prev_line = line
+
+ return None
+
+
def test_uji_example(datadir):
args = ['new', os.fspath(Path(datadir) / 'example.yaml')]
runner = CliRunner()
@@ -49,12 +67,39 @@ def test_uji_tree(datadir):
assert 'actor2\n------\n' in markdown
assert 'Generic\n-------\n' in markdown
- # FIXME: check for the tests to be distributed across the actors
+ # check for the tests to be distributed across the actors
# correctly
+ assert find_in_section(markdown, 'Generic', 'testcase1')
+ assert find_in_section(markdown, 'Generic', 'file01')
+ assert find_in_section(markdown, 'Generic', 'file02')
+
+ assert find_in_section(markdown, 'actor1', 'testcase3')
+ assert find_in_section(markdown, 'actor2', 'testcase3')
+
+ assert find_in_section(markdown, 'actor1', 'testcase4')
+ assert find_in_section(markdown, 'actor1', 'file04')
+ assert not find_in_section(markdown, 'actor2', 'testcase4')
+ assert not find_in_section(markdown, 'actor2', 'file04')
+
+ assert not find_in_section(markdown, 'actor1', 'testcase5')
+ assert not find_in_section(markdown, 'actor1', 'testcase5.1')
+ assert not find_in_section(markdown, 'actor1', 'testcase5.2')
+ assert not find_in_section(markdown, 'actor1', 'file05')
+
+ assert find_in_section(markdown, 'actor2', 'testcase5')
+ assert find_in_section(markdown, 'actor2', 'testcase5.1')
+ assert find_in_section(markdown, 'actor2', 'testcase5.2')
+ assert find_in_section(markdown, 'actor2', 'file05')
+
+ assert find_in_section(markdown, 'actor1', 'testcase6'), markdown
+ assert not find_in_section(markdown, 'actor2', 'testcase6'), markdown
+
+ assert not find_in_section(markdown, 'actor1', 'testcase7'), markdown
+ assert find_in_section(markdown, 'actor2', 'testcase7'), markdown
# Check for the 'emtpy' files to be created
- assert (Path('testdir') / 'generic' / 'test1' / 'file1').exists()
- assert (Path('testdir') / 'generic' / 'test2' / 'file2').exists()
- assert (Path('testdir') / 'actor1' / 'test4' / 'file3').exists()
- assert (Path('testdir') / 'actor2' / 'test5' / 'file4').exists()
+ assert (Path('testdir') / 'generic' / 'test1' / 'file01-generic').exists()
+ assert (Path('testdir') / 'generic' / 'test2' / 'file02-generic').exists()
+ assert (Path('testdir') / 'actor1' / 'test4' / 'file04-actor-one').exists()
+ assert (Path('testdir') / 'actor2' / 'test5' / 'file05-actor-two').exists()
| Allow for specifying a "not" filter
Found this while using uji for the recent xserver CVEs: I needed a way to specify a test for actors that *don't* have a particular tag. e.g. `not rhel`.
Probably simple enough to add with `!` support. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_uji.py::test_uji_tree"
] | [
"tests/test_uji.py::test_uji_example"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-01-13T07:21:46Z" | mit |
|
willnx__iiqtools-27 | diff --git a/iiqtools/iiqtools_tar_to_zip.py b/iiqtools/iiqtools_tar_to_zip.py
index 9356238..2058091 100644
--- a/iiqtools/iiqtools_tar_to_zip.py
+++ b/iiqtools/iiqtools_tar_to_zip.py
@@ -10,7 +10,6 @@ the same, it's just a different compression format in InsightIQ 4.1.
import os
import re
import zlib
-import struct
import tarfile
import zipfile
import argparse
@@ -25,7 +24,7 @@ class BufferedZipFile(zipfile.ZipFile):
stream the contents into a new zip file.
"""
- def writebuffered(self, filename, file_handle):
+ def writebuffered(self, filename, file_handle, file_size):
"""Stream write data to the zip archive
:param filename: **Required** The name to give the data once added to the zip file
@@ -33,35 +32,39 @@ class BufferedZipFile(zipfile.ZipFile):
:param file_handle: **Required** The file-like object to read
:type file_handle: Anything that supports the `read <https://docs.python.org/2/tutorial/inputoutput.html#methods-of-file-objects>`_ method
+
+ :param file_size: **Required** The size of the file in bytes
+ :type file_size: Integer
"""
zinfo = zipfile.ZipInfo(filename=filename)
-
- zinfo.file_size = file_size = 0
+ zinfo.file_size = file_size
zinfo.flag_bits = 0x00
- zinfo.header_offset = self.fp.tell()
+ zinfo.header_offset = self.fp.tell() # Start of header bytes
self._writecheck(zinfo)
self._didModify = True
-
+ # Must overwrite CRC and sizes with correct data later
zinfo.CRC = CRC = 0
zinfo.compress_size = compress_size = 0
- self.fp.write(zinfo.FileHeader())
+ # Compressed size can be larger than uncompressed size
+ zip64 = self._allowZip64 and \
+ zinfo.file_size * 1.05 > zipfile.ZIP64_LIMIT
+ self.fp.write(zinfo.FileHeader(zip64))
if zinfo.compress_type == zipfile.ZIP_DEFLATED:
cmpr = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, zlib.DEFLATED, -15)
else:
cmpr = None
+ fsize = 0
while True:
buf = file_handle.read(1024 * 8)
if not buf:
break
-
- file_size = file_size + len(buf)
+ fsize = fsize + len(buf)
CRC = binascii.crc32(buf, CRC) & 0xffffffff
if cmpr:
buf = cmpr.compress(buf)
compress_size = compress_size + len(buf)
-
self.fp.write(buf)
if cmpr:
@@ -70,14 +73,19 @@ class BufferedZipFile(zipfile.ZipFile):
self.fp.write(buf)
zinfo.compress_size = compress_size
else:
- zinfo.compress_size = file_size
-
+ zinfo.compress_size = fsize
zinfo.CRC = CRC
- zinfo.file_size = file_size
-
- position = self.fp.tell()
- self.fp.seek(zinfo.header_offset + 14, 0)
- self.fp.write(struct.pack("<LLL", zinfo.CRC, zinfo.compress_size, zinfo.file_size))
+ zinfo.file_size = fsize
+ if not zip64 and self._allowZip64:
+ if fsize > zipfile.ZIP64_LIMIT:
+ raise RuntimeError('File size has increased during compressing')
+ if compress_size > zipfile.ZIP64_LIMIT:
+ raise RuntimeError('Compressed size larger than uncompressed size')
+ # Seek backwards and write file header (which will now include
+ # correct CRC and file sizes)
+ position = self.fp.tell() # Preserve current position in file
+ self.fp.seek(zinfo.header_offset, 0)
+ self.fp.write(zinfo.FileHeader(zip64))
self.fp.seek(position, 0)
self.filelist.append(zinfo)
self.NameToInfo[zinfo.filename] = zinfo
@@ -189,7 +197,7 @@ def main(the_cli_args):
log.info('Converting %s', the_file.name)
try:
filename = joinname(zip_export_dir, the_file.name)
- zip_export.writebuffered(filename=filename, file_handle=file_handle)
+ zip_export.writebuffered(filename=filename, file_handle=file_handle, file_size=the_file.size)
except (IOError, OSError) as doh:
log.error(doh)
log.error('Deleting zip file')
diff --git a/setup.py b/setup.py
index 504dd4b..2968bc9 100644
--- a/setup.py
+++ b/setup.py
@@ -9,7 +9,7 @@ setup(name="iiqtools",
author="Nicholas Willhite,",
author_email="[email protected]",
url='https://github.com/willnx/iiqtools',
- version='2.1.1',
+ version='2.1.2',
packages=find_packages(),
include_package_data=True,
scripts=['scripts/iiqtools_gather_info',
| willnx/iiqtools | 9633167b8232b4776d2ad4823fb6652507c08e8e | diff --git a/iiqtools_tests/test_iiqtools_tar_to_zip.py b/iiqtools_tests/test_iiqtools_tar_to_zip.py
index 797cadf..ec64b49 100644
--- a/iiqtools_tests/test_iiqtools_tar_to_zip.py
+++ b/iiqtools_tests/test_iiqtools_tar_to_zip.py
@@ -26,11 +26,10 @@ class TestBufferedZipFile(unittest.TestCase):
"""Runs after every tests case"""
os.remove(self.filepath)
- @patch.object(iiqtools_tar_to_zip, 'struct')
@patch.object(iiqtools_tar_to_zip, 'binascii')
- def test_basic(self, fake_binascii, fake_struct):
+ def test_basic(self, fake_binascii):
"""BufferedZipFile - writebuffered is callable"""
- self.zipfile.writebuffered(filename='foo', file_handle=self.fake_file)
+ self.zipfile.writebuffered(filename='foo', file_handle=self.fake_file, file_size=9000)
class TestCheckTar(unittest.TestCase):
| struct error export too large.
I am getting errors trying to convert to a zip. Looks like the export was too large.
```
[administrator@vcmcinsightiq tmp]$ /opt/rh/python27/root/usr/bin/iiqtools_tar_to_zip -s insightiq_export_1522783418.tar.gz -o /mnt/10.193.6.113/ifs/data/IIQ2/
2018-04-04 20:13:37,625 - INFO - Converting insightiq_export_1522783418.tar.gz to zip format
2018-04-04 20:34:32,536 - INFO - InsightIQ datastore tar export contained 2 files
2018-04-04 20:34:32,536 - INFO - Converting insightiq_export_1522783418/vcmc-12kisilon_00151b00007a2716ce4a1504000067458b6b_config.json
2018-04-04 20:34:32,560 - INFO - Converting insightiq_export_1522783418/vcmc-12kisilon_00151b00007a2716ce4a1504000067458b6b.dump
Traceback (most recent call last):
File "/opt/rh/python27/root/usr/bin/iiqtools_tar_to_zip", line 11, in <module>
sys.exit(main(sys.argv[1:]))
File "/opt/rh/python27/root/usr/lib/python2.7/site-packages/iiqtools/iiqtools_tar_to_zip.py", line 192, in main
zip_export.writebuffered(filename=filename, file_handle=file_handle)
File "/opt/rh/python27/root/usr/lib/python2.7/site-packages/iiqtools/iiqtools_tar_to_zip.py", line 80, in writebuffered
self.fp.write(struct.pack("<LLL", zinfo.CRC, zinfo.compress_size, zinfo.file_size))
struct.error: 'L' format requires 0 <= number <= 4294967295
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestBufferedZipFile::test_basic"
] | [
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestGetTimestampFromExport::test_absolute_path",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestParseCli::test_no_args",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestParseCli::test_returns_namespace",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestParseCli::test_missing_required",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestJoinname::test_absolute_path",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestJoinname::test_relative_path",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestCheckTar::test_not_a_file",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestCheckTar::test_bad_file_name",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestCheckTar::test_valid_tar",
"iiqtools_tests/test_iiqtools_tar_to_zip.py::TestCheckTar::test_not_a_tar"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2018-04-25T02:32:46Z" | mit |
|
wireservice__agate-637 | diff --git a/agate/aggregations/any.py b/agate/aggregations/any.py
index 70fa702..67a9651 100644
--- a/agate/aggregations/any.py
+++ b/agate/aggregations/any.py
@@ -32,7 +32,7 @@ class Any(Aggregation):
column = table.columns[self._column_name]
data = column.values()
- if isinstance(column.data_type, Boolean):
+ if isinstance(column.data_type, Boolean) and self._test is None:
return any(data)
return any(self._test(d) for d in data)
| wireservice/agate | 0d2671358cdea94c83bd8f28b5a6718a9326b033 | diff --git a/tests/test_aggregations.py b/tests/test_aggregations.py
index c3c8fbb..11eefe1 100644
--- a/tests/test_aggregations.py
+++ b/tests/test_aggregations.py
@@ -138,6 +138,7 @@ class TestBooleanAggregation(unittest.TestCase):
table = Table(rows, ['test'], [Boolean()])
Any('test').validate(table)
self.assertEqual(Any('test').run(table), False)
+ self.assertEqual(Any('test', lambda r: not r).run(table), True)
def test_all(self):
rows = [
| agate.All cannot test whether all data is False
If the column data type is boolean, test gets overwritten to search for True values.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_aggregations.py::TestBooleanAggregation::test_any"
] | [
"tests/test_aggregations.py::TestSimpleAggregation::test_all",
"tests/test_aggregations.py::TestSimpleAggregation::test_any",
"tests/test_aggregations.py::TestSimpleAggregation::test_count",
"tests/test_aggregations.py::TestSimpleAggregation::test_count_column",
"tests/test_aggregations.py::TestSimpleAggregation::test_count_value",
"tests/test_aggregations.py::TestSimpleAggregation::test_has_nulls",
"tests/test_aggregations.py::TestSimpleAggregation::test_summary",
"tests/test_aggregations.py::TestBooleanAggregation::test_all",
"tests/test_aggregations.py::TestDateTimeAggregation::test_max",
"tests/test_aggregations.py::TestDateTimeAggregation::test_min",
"tests/test_aggregations.py::TestNumberAggregation::test_deciles",
"tests/test_aggregations.py::TestNumberAggregation::test_iqr",
"tests/test_aggregations.py::TestNumberAggregation::test_mad",
"tests/test_aggregations.py::TestNumberAggregation::test_max",
"tests/test_aggregations.py::TestNumberAggregation::test_max_precision",
"tests/test_aggregations.py::TestNumberAggregation::test_mean",
"tests/test_aggregations.py::TestNumberAggregation::test_mean_with_nulls",
"tests/test_aggregations.py::TestNumberAggregation::test_median",
"tests/test_aggregations.py::TestNumberAggregation::test_min",
"tests/test_aggregations.py::TestNumberAggregation::test_mode",
"tests/test_aggregations.py::TestNumberAggregation::test_percentiles",
"tests/test_aggregations.py::TestNumberAggregation::test_percentiles_locate",
"tests/test_aggregations.py::TestNumberAggregation::test_population_stdev",
"tests/test_aggregations.py::TestNumberAggregation::test_population_variance",
"tests/test_aggregations.py::TestNumberAggregation::test_quartiles",
"tests/test_aggregations.py::TestNumberAggregation::test_quartiles_locate",
"tests/test_aggregations.py::TestNumberAggregation::test_quintiles",
"tests/test_aggregations.py::TestNumberAggregation::test_stdev",
"tests/test_aggregations.py::TestNumberAggregation::test_sum",
"tests/test_aggregations.py::TestNumberAggregation::test_variance",
"tests/test_aggregations.py::TestTextAggregation::test_max_length",
"tests/test_aggregations.py::TestTextAggregation::test_max_length_invalid"
] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2016-10-30T16:11:15Z" | mit |
|
wireservice__agate-638 | diff --git a/agate/aggregations/__init__.py b/agate/aggregations/__init__.py
index e4f40cc..cf82a30 100644
--- a/agate/aggregations/__init__.py
+++ b/agate/aggregations/__init__.py
@@ -21,6 +21,7 @@ from agate.aggregations.all import All # noqa
from agate.aggregations.any import Any # noqa
from agate.aggregations.count import Count # noqa
from agate.aggregations.deciles import Deciles # noqa
+from agate.aggregations.first import First # noqa
from agate.aggregations.has_nulls import HasNulls # noqa
from agate.aggregations.iqr import IQR # noqa
from agate.aggregations.mad import MAD # noqa
diff --git a/agate/aggregations/first.py b/agate/aggregations/first.py
new file mode 100644
index 0000000..37e1695
--- /dev/null
+++ b/agate/aggregations/first.py
@@ -0,0 +1,42 @@
+#!/usr/bin/env python
+
+from agate.aggregations.base import Aggregation
+from agate.data_types import Boolean
+
+
+class First(Aggregation):
+ """
+ Returns the first value that passes a test.
+
+ If the test is omitted, the aggregation will return the first value in the column.
+
+ If no values pass the test, the aggregation will raise an exception.
+
+ :param column_name:
+ The name of the column to check.
+ :param test:
+ A function that takes a value and returns `True` or `False`. Test may be
+ omitted when checking :class:`.Boolean` data.
+ """
+ def __init__(self, column_name, test=None):
+ self._column_name = column_name
+ self._test = test
+
+ def get_aggregate_data_type(self, table):
+ return table.columns[self._column_name].data_type
+
+ def validate(self, table):
+ column = table.columns[self._column_name]
+ data = column.values()
+
+ if self._test is not None and len([d for d in data if self._test(d)]) == 0:
+ raise ValueError('No values pass the given test.')
+
+ def run(self, table):
+ column = table.columns[self._column_name]
+ data = column.values()
+
+ if self._test is None:
+ return data[0]
+
+ return next((d for d in data if self._test(d)))
| wireservice/agate | 97cb37f673af480f74fef546ceefd3ba24aff93b | diff --git a/tests/test_aggregations.py b/tests/test_aggregations.py
index 11eefe1..e0dc625 100644
--- a/tests/test_aggregations.py
+++ b/tests/test_aggregations.py
@@ -67,6 +67,17 @@ class TestSimpleAggregation(unittest.TestCase):
self.assertEqual(All('one', lambda d: d != 5).run(self.table), True)
self.assertEqual(All('one', lambda d: d == 2).run(self.table), False)
+ def test_first(self):
+ with self.assertRaises(ValueError):
+ First('one', lambda d: d == 5).validate(self.table)
+
+ First('one', lambda d: d).validate(self.table)
+
+ self.assertIsInstance(First('one').get_aggregate_data_type(self.table), Number)
+ self.assertEqual(First('one').run(self.table), 1)
+ self.assertEqual(First('one', lambda d: d == 2).run(self.table), 2)
+ self.assertEqual(First('one', lambda d: not d).run(self.table), None)
+
def test_count(self):
rows = (
(1, 2, 'a'),
| agate.First aggregation
I end up doing this all the time:
```
def pick_first(c):
return c[0]
agate.Summary('Serial_Num', agate.Text(), pick_first)
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_aggregations.py::TestSimpleAggregation::test_first"
] | [
"tests/test_aggregations.py::TestSimpleAggregation::test_all",
"tests/test_aggregations.py::TestSimpleAggregation::test_any",
"tests/test_aggregations.py::TestSimpleAggregation::test_count",
"tests/test_aggregations.py::TestSimpleAggregation::test_count_column",
"tests/test_aggregations.py::TestSimpleAggregation::test_count_value",
"tests/test_aggregations.py::TestSimpleAggregation::test_has_nulls",
"tests/test_aggregations.py::TestSimpleAggregation::test_summary",
"tests/test_aggregations.py::TestBooleanAggregation::test_all",
"tests/test_aggregations.py::TestBooleanAggregation::test_any",
"tests/test_aggregations.py::TestDateTimeAggregation::test_max",
"tests/test_aggregations.py::TestDateTimeAggregation::test_min",
"tests/test_aggregations.py::TestNumberAggregation::test_deciles",
"tests/test_aggregations.py::TestNumberAggregation::test_iqr",
"tests/test_aggregations.py::TestNumberAggregation::test_mad",
"tests/test_aggregations.py::TestNumberAggregation::test_max",
"tests/test_aggregations.py::TestNumberAggregation::test_max_precision",
"tests/test_aggregations.py::TestNumberAggregation::test_mean",
"tests/test_aggregations.py::TestNumberAggregation::test_mean_with_nulls",
"tests/test_aggregations.py::TestNumberAggregation::test_median",
"tests/test_aggregations.py::TestNumberAggregation::test_min",
"tests/test_aggregations.py::TestNumberAggregation::test_mode",
"tests/test_aggregations.py::TestNumberAggregation::test_percentiles",
"tests/test_aggregations.py::TestNumberAggregation::test_percentiles_locate",
"tests/test_aggregations.py::TestNumberAggregation::test_population_stdev",
"tests/test_aggregations.py::TestNumberAggregation::test_population_variance",
"tests/test_aggregations.py::TestNumberAggregation::test_quartiles",
"tests/test_aggregations.py::TestNumberAggregation::test_quartiles_locate",
"tests/test_aggregations.py::TestNumberAggregation::test_quintiles",
"tests/test_aggregations.py::TestNumberAggregation::test_stdev",
"tests/test_aggregations.py::TestNumberAggregation::test_sum",
"tests/test_aggregations.py::TestNumberAggregation::test_variance",
"tests/test_aggregations.py::TestTextAggregation::test_max_length",
"tests/test_aggregations.py::TestTextAggregation::test_max_length_invalid"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_added_files",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2016-10-30T16:50:31Z" | mit |
|
wireservice__agate-excel-25 | diff --git a/agateexcel/table_xls.py b/agateexcel/table_xls.py
index 19612c6..9fb9c4a 100644
--- a/agateexcel/table_xls.py
+++ b/agateexcel/table_xls.py
@@ -83,6 +83,11 @@ def from_xls(cls, path, sheet=None, skip_lines=0, header=True, encoding_override
for i in range(len(columns[0])):
rows.append([c[i] for c in columns])
+ if 'column_names' in kwargs:
+ if not header:
+ column_names = kwargs.get('column_names', None)
+ del kwargs['column_names']
+
tables[sheet.name] = agate.Table(rows, column_names, **kwargs)
if multiple:
diff --git a/agateexcel/table_xlsx.py b/agateexcel/table_xlsx.py
index 87619e9..37afd71 100644
--- a/agateexcel/table_xlsx.py
+++ b/agateexcel/table_xlsx.py
@@ -82,6 +82,11 @@ def from_xlsx(cls, path, sheet=None, skip_lines=0, header=True, read_only=True,
rows.append(values)
+ if 'column_names' in kwargs:
+ if not header:
+ column_names = kwargs.get('column_names', None)
+ del kwargs['column_names']
+
tables[sheet.title] = agate.Table(rows, column_names, **kwargs)
f.close()
| wireservice/agate-excel | bb7474e2762099af5d6053e548341c460a47a758 | diff --git a/tests/test_table_xls.py b/tests/test_table_xls.py
index cc7b3e8..6d02d74 100644
--- a/tests/test_table_xls.py
+++ b/tests/test_table_xls.py
@@ -19,6 +19,10 @@ class TestXLS(agate.AgateTestCase):
'number', 'text', 'boolean', 'date', 'datetime',
]
+ self.user_provided_column_names = [
+ 'alt number', 'alt text', 'alt boolean', 'alt date', 'alt datetime',
+ ]
+
self.column_types = [
agate.Number(), agate.Text(), agate.Boolean(),
agate.Date(), agate.DateTime(),
@@ -26,6 +30,13 @@ class TestXLS(agate.AgateTestCase):
self.table = agate.Table(self.rows, self.column_names, self.column_types)
+ def test_from_xls_with_column_names(self):
+ table = agate.Table.from_xls('examples/test.xls', header=False, skip_lines=1, column_names=self.user_provided_column_names )
+
+ self.assertColumnNames(table, self.user_provided_column_names)
+ self.assertColumnTypes(table, [agate.Number, agate.Text, agate.Boolean, agate.Date, agate.DateTime])
+ self.assertRows(table, [r.values() for r in self.table.rows])
+
def test_from_xls(self):
table = agate.Table.from_xls('examples/test.xls')
diff --git a/tests/test_table_xlsx.py b/tests/test_table_xlsx.py
index 6dd4434..9b56b9b 100644
--- a/tests/test_table_xlsx.py
+++ b/tests/test_table_xlsx.py
@@ -19,6 +19,10 @@ class TestXLSX(agate.AgateTestCase):
'number', 'text', 'boolean', 'date', 'datetime',
]
+ self.user_provided_column_names = [
+ 'number', 'text', 'boolean', 'date', 'datetime',
+ ]
+
self.column_types = [
agate.Number(), agate.Text(), agate.Boolean(),
agate.Date(), agate.DateTime(),
@@ -26,6 +30,13 @@ class TestXLSX(agate.AgateTestCase):
self.table = agate.Table(self.rows, self.column_names, self.column_types)
+ def test_from_xlsx_with_column_names(self):
+ table = agate.Table.from_xlsx('examples/test.xlsx', header=False, skip_lines=1, column_names=self.user_provided_column_names)
+
+ self.assertColumnNames(table, self.user_provided_column_names)
+ self.assertColumnTypes(table, [agate.Number, agate.Text, agate.Boolean, agate.Date, agate.DateTime])
+ self.assertRows(table, [r.values() for r in self.table.rows])
+
def test_from_xlsx(self):
table = agate.Table.from_xlsx('examples/test.xlsx')
| Passing column_names to from_xls fails with TypeError
```
Traceback (most recent call last):
File "<stdin>", line 5, in <module>
File "/Users/jani.mikkonen/src/customers/vr/vr/venv/lib/python3.7/site-packages/agateexcel/table_xls.py", line 86, in from_xls
tables[sheet.name] = agate.Table(rows, column_names, **kwargs)
TypeError: __init__() got multiple values for argument 'column_names'
```
if column_names is present in kwargs, maybe remove column_names from there and copy it to the positional parameter passed to agate.Table() in https://github.com/wireservice/agate-excel/blob/master/agateexcel/table_xlsx.py#L85 & https://github.com/wireservice/agate-excel/blob/master/agateexcel/table_xls.py#L86 ?
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_table_xls.py::TestXLS::test_from_xls_with_column_names"
] | [
"tests/test_table_xls.py::TestXLS::test_ambiguous_date",
"tests/test_table_xls.py::TestXLS::test_empty",
"tests/test_table_xls.py::TestXLS::test_file_like",
"tests/test_table_xls.py::TestXLS::test_from_xls",
"tests/test_table_xls.py::TestXLS::test_header",
"tests/test_table_xls.py::TestXLS::test_numeric_column_name",
"tests/test_table_xls.py::TestXLS::test_sheet_index",
"tests/test_table_xls.py::TestXLS::test_sheet_multiple",
"tests/test_table_xls.py::TestXLS::test_sheet_name",
"tests/test_table_xls.py::TestXLS::test_skip_lines",
"tests/test_table_xls.py::TestXLS::test_zeros",
"tests/test_table_xlsx.py::TestXLSX::test_header"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2018-11-30T09:58:46Z" | mit |
|
wireservice__agate-sql-23 | diff --git a/agatesql/table.py b/agatesql/table.py
index c813f30..bad725d 100644
--- a/agatesql/table.py
+++ b/agatesql/table.py
@@ -11,7 +11,7 @@ import six
import agate
from sqlalchemy import Column, MetaData, Table, create_engine, dialects
from sqlalchemy.engine import Connection
-from sqlalchemy.types import BOOLEAN, DECIMAL, DATE, DATETIME, VARCHAR, Interval
+from sqlalchemy.types import BOOLEAN, DECIMAL, DATE, TIMESTAMP, VARCHAR, Interval
from sqlalchemy.dialects.oracle import INTERVAL as ORACLE_INTERVAL
from sqlalchemy.dialects.postgresql import INTERVAL as POSTGRES_INTERVAL
from sqlalchemy.schema import CreateTable
@@ -21,7 +21,7 @@ SQL_TYPE_MAP = {
agate.Boolean: BOOLEAN,
agate.Number: DECIMAL,
agate.Date: DATE,
- agate.DateTime: DATETIME,
+ agate.DateTime: TIMESTAMP,
agate.TimeDelta: None, # See below
agate.Text: VARCHAR
}
@@ -167,7 +167,10 @@ def make_sql_table(table, table_name, dialect=None, db_schema=None, constraints=
if isinstance(column.data_type, agate.Text):
sql_type_kwargs['length'] = table.aggregate(agate.MaxLength(column_name))
- sql_column_kwargs['nullable'] = table.aggregate(agate.HasNulls(column_name))
+ # Avoid errors due to NO_ZERO_DATE.
+ # @see http://dev.mysql.com/doc/refman/5.7/en/sql-mode.html#sqlmode_no_zero_date
+ if not isinstance(column.data_type, agate.DateTime):
+ sql_column_kwargs['nullable'] = table.aggregate(agate.HasNulls(column_name))
sql_table.append_column(make_sql_column(column_name, column, sql_type_kwargs, sql_column_kwargs))
| wireservice/agate-sql | 858bf8824d906a1acd160b239a13ccc17837dd2f | diff --git a/tests/test_agatesql.py b/tests/test_agatesql.py
index 46fdd1e..a270222 100644
--- a/tests/test_agatesql.py
+++ b/tests/test_agatesql.py
@@ -66,7 +66,7 @@ class TestSQL(agate.AgateTestCase):
self.assertIn('text VARCHAR(1) NOT NULL', statement)
self.assertIn('boolean BOOLEAN', statement)
self.assertIn('date DATE', statement)
- self.assertIn('datetime DATETIME', statement)
+ self.assertIn('datetime TIMESTAMP', statement)
def test_make_create_table_statement_no_constraints(self):
statement = self.table.to_sql_create_statement('test_table', constraints=False)
@@ -76,7 +76,7 @@ class TestSQL(agate.AgateTestCase):
self.assertIn('text VARCHAR', statement)
self.assertIn('boolean BOOLEAN', statement)
self.assertIn('date DATE', statement)
- self.assertIn('datetime DATETIME', statement)
+ self.assertIn('datetime TIMESTAMP', statement)
def test_make_create_table_statement_with_schema(self):
statement = self.table.to_sql_create_statement('test_table', db_schema='test_schema')
@@ -86,7 +86,7 @@ class TestSQL(agate.AgateTestCase):
self.assertIn('text VARCHAR(1) NOT NULL', statement)
self.assertIn('boolean BOOLEAN', statement)
self.assertIn('date DATE', statement)
- self.assertIn('datetime DATETIME', statement)
+ self.assertIn('datetime TIMESTAMP', statement)
def test_make_create_table_statement_with_dialects(self):
for dialect in ['mysql', 'postgresql', 'sqlite']:
| DateTime columns can not be stored as DATETIME in sqlite | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_agatesql.py::TestSQL::test_make_create_table_statement_no_constraints",
"tests/test_agatesql.py::TestSQL::test_make_create_table_statement_with_schema",
"tests/test_agatesql.py::TestSQL::test_to_sql_create_statement"
] | [
"tests/test_agatesql.py::TestSQL::test_make_create_table_statement_with_dialects"
] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2017-01-04T21:20:05Z" | mit |
|
wireservice__csvkit-1241 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index eebf5bb..0cf6ace 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -1,3 +1,10 @@
+2.0.0 - Unreleased
+------------------
+
+**BACKWARDS-INCOMPATIBLE CHANGES**
+
+* :doc:`/scripts/csvclean` now writes its output to standard output and its errors to standard error, instead of to ``basename_out.csv`` and ``basename_err.csv`` files. Consequently, it no longer supports a :code:`--dry-run` flag to output summary information like ``No errors.``, ``42 errors logged to basename_err.csv`` or ``42 rows were joined/reduced to 24 rows after eliminating expected internal line breaks.``.
+
1.5.0 - March 28, 2024
----------------------
diff --git a/csvkit/cleanup.py b/csvkit/cleanup.py
index aa8359c..818d268 100644
--- a/csvkit/cleanup.py
+++ b/csvkit/cleanup.py
@@ -5,8 +5,10 @@ from csvkit.exceptions import CSVTestException, LengthMismatchError
def join_rows(rows, joiner=' '):
"""
- Given a series of rows, return them as a single row where the inner edge cells are merged. By default joins with a
- single space character, but you can specify new-line, empty string, or anything else with the 'joiner' kwarg.
+ Given a series of rows, return them as a single row where the inner edge cells are merged.
+
+ :param joiner:
+ The separator between cells, a single space by default.
"""
rows = list(rows)
fixed_row = rows[0][:]
@@ -33,8 +35,6 @@ class RowChecker:
except StopIteration:
self.column_names = []
self.errors = []
- self.rows_joined = 0
- self.joins = 0
def checked_rows(self):
"""
@@ -69,9 +69,6 @@ class RowChecker:
break
if len(fixed_row) == length:
- self.rows_joined += len(joinable_row_errors)
- self.joins += 1
-
yield fixed_row
for fixed in joinable_row_errors:
diff --git a/csvkit/cli.py b/csvkit/cli.py
index f8c3ba4..6dabc6b 100644
--- a/csvkit/cli.py
+++ b/csvkit/cli.py
@@ -68,19 +68,26 @@ class CSVKitUtility:
epilog = ''
override_flags = ''
- def __init__(self, args=None, output_file=None):
+ def __init__(self, args=None, output_file=None, error_file=None):
"""
Perform argument processing and other setup for a CSVKitUtility.
"""
self._init_common_parser()
self.add_arguments()
self.args = self.argparser.parse_args(args)
+
# Output file is only set during testing.
if output_file is None:
self.output_file = sys.stdout
else:
self.output_file = output_file
+ # Error file is only set during testing.
+ if error_file is None:
+ self.error_file = sys.stderr
+ else:
+ self.error_file = error_file
+
self.reader_kwargs = self._extract_csv_reader_kwargs()
self.writer_kwargs = self._extract_csv_writer_kwargs()
diff --git a/csvkit/utilities/csvclean.py b/csvkit/utilities/csvclean.py
index 2dc0825..2b92bfd 100644
--- a/csvkit/utilities/csvclean.py
+++ b/csvkit/utilities/csvclean.py
@@ -1,7 +1,6 @@
#!/usr/bin/env python
import sys
-from os.path import splitext
import agate
@@ -14,9 +13,7 @@ class CSVClean(CSVKitUtility):
override_flags = ['L', 'blanks', 'date-format', 'datetime-format']
def add_arguments(self):
- self.argparser.add_argument(
- '-n', '--dry-run', dest='dryrun', action='store_true',
- help='Do not create output files. Information about what would have been done will be printed to STDERR.')
+ pass
def main(self):
if self.additional_input_expected():
@@ -24,65 +21,20 @@ class CSVClean(CSVKitUtility):
reader = agate.csv.reader(self.skip_lines(), **self.reader_kwargs)
- if self.args.dryrun:
- checker = RowChecker(reader)
+ checker = RowChecker(reader)
- for _row in checker.checked_rows():
- pass
+ output_writer = agate.csv.writer(self.output_file, **self.writer_kwargs)
+ output_writer.writerow(checker.column_names)
+ for row in checker.checked_rows():
+ output_writer.writerow(row)
- if checker.errors:
- for e in checker.errors:
- self.output_file.write('Line %i: %s\n' % (e.line_number, e.msg))
- else:
- self.output_file.write('No errors.\n')
+ if checker.errors:
+ error_writer = agate.csv.writer(self.error_file, **self.writer_kwargs)
+ error_writer.writerow(['line_number', 'msg'] + checker.column_names)
+ for error in checker.errors:
+ error_writer.writerow([error.line_number, error.msg] + error.row)
- if checker.joins:
- self.output_file.write('%i rows would have been joined/reduced to %i rows after eliminating expected '
- 'internal line breaks.\n' % (checker.rows_joined, checker.joins))
- else:
- if self.input_file == sys.stdin:
- base = 'stdin' # "<stdin>_out.csv" is invalid on Windows
- else:
- base = splitext(self.input_file.name)[0]
-
- with open(f'{base}_out.csv', 'w') as f:
- clean_writer = agate.csv.writer(f, **self.writer_kwargs)
-
- checker = RowChecker(reader)
- clean_writer.writerow(checker.column_names)
-
- for row in checker.checked_rows():
- clean_writer.writerow(row)
-
- if checker.errors:
- error_filename = f'{base}_err.csv'
-
- with open(error_filename, 'w') as f:
- error_writer = agate.csv.writer(f, **self.writer_kwargs)
-
- error_header = ['line_number', 'msg']
- error_header.extend(checker.column_names)
- error_writer.writerow(error_header)
-
- error_count = len(checker.errors)
-
- for e in checker.errors:
- error_writer.writerow(self._format_error_row(e))
-
- self.output_file.write('%i error%s logged to %s\n' % (
- error_count, '' if error_count == 1 else 's', error_filename))
- else:
- self.output_file.write('No errors.\n')
-
- if checker.joins:
- self.output_file.write('%i rows were joined/reduced to %i rows after eliminating expected internal '
- 'line breaks.\n' % (checker.rows_joined, checker.joins))
-
- def _format_error_row(self, error):
- row = [error.line_number, error.msg]
- row.extend(error.row)
-
- return row
+ sys.exit(1)
def launch_new_instance():
diff --git a/docs/scripts/csvclean.rst b/docs/scripts/csvclean.rst
index 0e3e16b..f94d6a2 100644
--- a/docs/scripts/csvclean.rst
+++ b/docs/scripts/csvclean.rst
@@ -18,13 +18,13 @@ Note that every csvkit tool does the following:
* changes the quote character to a double-quotation mark, if the character is set with the `--quotechar` (`-q`) option
* changes the character encoding to UTF-8, if the input encoding is set with the `--encoding` (`-e`) option
-Outputs [basename]_out.csv and [basename]_err.csv, the former containing all valid rows and the latter containing all error rows along with line numbers and descriptions:
+All valid rows are written to standard output, and all error rows along with line numbers and descriptions are written to standard error. If there are error rows, the exit code will be 1::
.. code-block:: none
usage: csvclean [-h] [-d DELIMITER] [-t] [-q QUOTECHAR] [-u {0,1,2,3}] [-b]
[-p ESCAPECHAR] [-z FIELD_SIZE_LIMIT] [-e ENCODING] [-S] [-H]
- [-K SKIP_LINES] [-v] [-l] [--zero] [-V] [-n]
+ [-K SKIP_LINES] [-v] [-l] [--zero] [-V]
[FILE]
Fix common errors in a CSV file.
@@ -35,8 +35,6 @@ Outputs [basename]_out.csv and [basename]_err.csv, the former containing all val
optional arguments:
-h, --help show this help message and exit
- -n, --dry-run Do not create output files. Information about what
- would have been done will be printed to STDERR.
See also: :doc:`../common_arguments`.
@@ -47,9 +45,13 @@ Test a file with known bad rows:
.. code-block:: console
- $ csvclean -n examples/bad.csv
- Line 1: Expected 3 columns, found 4 columns
- Line 2: Expected 3 columns, found 2 columns
+ $ csvclean examples/bad.csv 2> errors.csv
+ column_a,column_b,column_c
+ 0,mixed types.... uh oh,17
+ $ cat errors.csv
+ line_number,msg,column_a,column_b,column_c
+ 1,"Expected 3 columns, found 4 columns",1,27,,I'm too long!
+ 2,"Expected 3 columns, found 2 columns",,I'm too short!
To change the line ending from line feed (LF or ``\n``) to carriage return and line feed (CRLF or ``\r\n``) use:
| wireservice/csvkit | d00ea20b965548299f4724c6ef9f9a6bdb33e02d | diff --git a/tests/test_utilities/test_csvclean.py b/tests/test_utilities/test_csvclean.py
index 1d284c9..754f75a 100644
--- a/tests/test_utilities/test_csvclean.py
+++ b/tests/test_utilities/test_csvclean.py
@@ -3,6 +3,8 @@ import os
import sys
from unittest.mock import patch
+import agate
+
from csvkit.utilities.csvclean import CSVClean, launch_new_instance
from tests.utils import CSVKitTestCase, EmptyFileTests
@@ -15,98 +17,89 @@ class TestCSVClean(CSVKitTestCase, EmptyFileTests):
if os.path.isfile(output_file):
os.remove(output_file)
- def assertCleaned(self, basename, output_lines, error_lines, additional_args=[]):
- args = [f'examples/{basename}.csv'] + additional_args
+ def assertCleaned(self, args, output_rows, error_rows=[]):
output_file = io.StringIO()
+ error_file = io.StringIO()
- utility = CSVClean(args, output_file)
- utility.run()
+ utility = CSVClean(args, output_file, error_file)
- output_file.close()
+ if error_rows:
+ with self.assertRaises(SystemExit) as e:
+ utility.run()
+
+ self.assertEqual(e.exception.code, 1)
+ else:
+ utility.run()
+
+ output_file.seek(0)
+ error_file.seek(0)
- output_file = f'examples/{basename}_out.csv'
- error_file = f'examples/{basename}_err.csv'
-
- self.assertEqual(os.path.exists(output_file), bool(output_lines))
- self.assertEqual(os.path.exists(error_file), bool(error_lines))
-
- try:
- if output_lines:
- with open(output_file) as f:
- for line in output_lines:
- self.assertEqual(next(f), line)
- self.assertRaises(StopIteration, next, f)
- if error_lines:
- with open(error_file) as f:
- for line in error_lines:
- self.assertEqual(next(f), line)
- self.assertRaises(StopIteration, next, f)
- finally:
- if output_lines:
- os.remove(output_file)
- if error_lines:
- os.remove(error_file)
+ if output_rows:
+ reader = agate.csv.reader(output_file)
+ for row in output_rows:
+ self.assertEqual(next(reader), row)
+ self.assertRaises(StopIteration, next, reader)
+ if error_rows:
+ reader = agate.csv.reader(error_file)
+ for row in error_rows:
+ self.assertEqual(next(reader), row)
+ self.assertRaises(StopIteration, next, reader)
+
+ output_file.close()
+ error_file.close()
def test_launch_new_instance(self):
- with patch.object(sys, 'argv', [self.Utility.__name__.lower(), 'examples/bad.csv']):
+ with patch.object(sys, 'argv', [self.Utility.__name__.lower(), 'examples/dummy.csv']):
launch_new_instance()
def test_skip_lines(self):
- self.assertCleaned('bad_skip_lines', [
- 'column_a,column_b,column_c\n',
- '0,mixed types.... uh oh,17\n',
+ self.assertCleaned(['--skip-lines', '3', 'examples/bad_skip_lines.csv'], [
+ ['column_a', 'column_b', 'column_c'],
+ ['0', 'mixed types.... uh oh', '17'],
], [
- 'line_number,msg,column_a,column_b,column_c\n',
- '1,"Expected 3 columns, found 4 columns",1,27,,I\'m too long!\n',
- '2,"Expected 3 columns, found 2 columns",,I\'m too short!\n',
- ], ['--skip-lines', '3'])
+ ['line_number', 'msg', 'column_a', 'column_b', 'column_c'],
+ ['1', 'Expected 3 columns, found 4 columns', '1', '27', '', "I'm too long!"],
+ ['2', 'Expected 3 columns, found 2 columns', '', "I'm too short!"],
+ ])
def test_simple(self):
- self.assertCleaned('bad', [
- 'column_a,column_b,column_c\n',
- '0,mixed types.... uh oh,17\n',
+ self.assertCleaned(['examples/bad.csv'], [
+ ['column_a', 'column_b', 'column_c'],
+ ['0', 'mixed types.... uh oh', '17'],
], [
- 'line_number,msg,column_a,column_b,column_c\n',
- '1,"Expected 3 columns, found 4 columns",1,27,,I\'m too long!\n',
- '2,"Expected 3 columns, found 2 columns",,I\'m too short!\n',
+ ['line_number', 'msg', 'column_a', 'column_b', 'column_c'],
+ ['1', 'Expected 3 columns, found 4 columns', '1', '27', '', "I'm too long!"],
+ ['2', 'Expected 3 columns, found 2 columns', '', "I'm too short!"],
])
def test_no_header_row(self):
- self.assertCleaned('no_header_row', [
- '1,2,3\n',
+ self.assertCleaned(['examples/no_header_row.csv'], [
+ ['1', '2', '3'],
], [])
def test_removes_optional_quote_characters(self):
- self.assertCleaned('optional_quote_characters', [
- 'a,b,c\n',
- '1,2,3\n',
- ], [])
+ self.assertCleaned(['examples/optional_quote_characters.csv'], [
+ ['a', 'b', 'c'],
+ ['1', '2', '3'],
+ ])
def test_changes_line_endings(self):
- self.assertCleaned('mac_newlines', [
- 'a,b,c\n',
- '1,2,3\n',
- '"Once upon\n',
- 'a time",5,6\n',
- ], [])
+ self.assertCleaned(['examples/mac_newlines.csv'], [
+ ['a', 'b', 'c'],
+ ['1', '2', '3'],
+ ['Once upon\na time', '5', '6'],
+ ])
def test_changes_character_encoding(self):
- self.assertCleaned('test_latin1', [
- 'a,b,c\n',
- '1,2,3\n',
- '4,5,©\n',
- ], [], ['-e', 'latin1'])
+ self.assertCleaned(['-e', 'latin1', 'examples/test_latin1.csv'], [
+ ['a', 'b', 'c'],
+ ['1', '2', '3'],
+ ['4', '5', u'©'],
+ ])
def test_removes_bom(self):
- self.assertCleaned('test_utf8_bom', [
- 'foo,bar,baz\n',
- '1,2,3\n',
- '4,5,ʤ\n',
- ], [], [])
-
- def test_dry_run(self):
- output = self.get_output_as_io(['-n', 'examples/bad.csv'])
- self.assertFalse(os.path.exists('examples/bad_err.csv'))
- self.assertFalse(os.path.exists('examples/bad_out.csv'))
- self.assertEqual(next(output)[:6], 'Line 1')
- self.assertEqual(next(output)[:6], 'Line 2')
+ self.assertCleaned(['examples/test_utf8_bom.csv'], [
+ ['foo', 'bar', 'baz'],
+ ['1', '2', '3'],
+ ['4', '5', 'ʤ'],
+ ])
| csvclean: options for stdout and stderr
to output the fixed file on stdout and errors on stderr
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_changes_character_encoding",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_changes_line_endings",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_no_header_row",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_removes_bom",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_removes_optional_quote_characters",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_simple",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_skip_lines"
] | [
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_empty",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_launch_new_instance"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2024-04-27T22:19:01Z" | mit |
|
wireservice__csvkit-619 | diff --git a/CHANGELOG b/CHANGELOG
index a9645ce..fb00cfa 100644
--- a/CHANGELOG
+++ b/CHANGELOG
@@ -11,6 +11,7 @@ Backwards-incompatible changes:
* The --doublequote long flag is gone, and the -b short flag is now an alias for --no-doublequote.
* When using the --columns or --not-columns options, you must not have spaces around the comma-separated values, unless the column names contain spaces.
+* When sorting, null values are now greater than other values instead of less than.
* CSVKitReader, CSVKitWriter, CSVKitDictReader, and CSVKitDictWriter have been removed. Use agate.csv.reader, agate.csv.writer, agate.csv.DictReader and agate.csv.DictWriter.
* Drop Python 2.6 support.
@@ -39,8 +40,10 @@ Fixes:
* csvclean with standard input works on Windows.
* csvgrep returns the input file's line numbers if the --linenumbers flag is set.
* csvgrep can match multiline values.
+* csvgrep correctly operates on ragged rows.
* csvsql correctly escapes `%` characters in SQL queries.
* csvstack supports stacking a single file.
+* csvstat always reports frequencies.
* FilteringCSVReader's any_match argument works correctly.
* All tools handle empty files without error.
diff --git a/csvkit/grep.py b/csvkit/grep.py
index 975d111..58fc0ee 100644
--- a/csvkit/grep.py
+++ b/csvkit/grep.py
@@ -64,7 +64,11 @@ class FilteringCSVReader(six.Iterator):
def test_row(self, row):
for idx, test in self.patterns.items():
- result = test(row[idx])
+ try:
+ value = row[idx]
+ except IndexError:
+ value = ''
+ result = test(value)
if self.any_match:
if result:
return not self.inverse # True
diff --git a/csvkit/utilities/csvsort.py b/csvkit/utilities/csvsort.py
index 4d043b8..afe439a 100644
--- a/csvkit/utilities/csvsort.py
+++ b/csvkit/utilities/csvsort.py
@@ -35,7 +35,7 @@ class CSVSort(CSVKitUtility):
table = agate.Table.from_csv(self.input_file, sniff_limit=self.args.sniff_limit, header=not self.args.no_header_row, column_types=self.get_column_types(), **self.reader_kwargs)
column_ids = parse_column_identifiers(self.args.columns, table.column_names, column_offset=self.get_column_offset())
- table = table.order_by(lambda row: [(row[column_id] is not None, row[column_id]) for column_id in column_ids], reverse=self.args.reverse)
+ table = table.order_by(column_ids, reverse=self.args.reverse)
table.to_csv(self.output_file, **self.writer_kwargs)
diff --git a/csvkit/utilities/csvstat.py b/csvkit/utilities/csvstat.py
index e6b143c..56e8019 100644
--- a/csvkit/utilities/csvstat.py
+++ b/csvkit/utilities/csvstat.py
@@ -142,14 +142,13 @@ class CSVStat(CSVKitUtility):
self.output_file.write('\tUnique values: %i\n' % len(stats['unique']))
- if len(stats['unique']) != len(values):
- self.output_file.write('\t%i most frequent values:\n' % MAX_FREQ)
- for value, count in stats['freq']:
- self.output_file.write(('\t\t%s:\t%s\n' % (six.text_type(value), count)))
-
if c.type == six.text_type:
self.output_file.write('\tMax length: %i\n' % stats['len'])
+ self.output_file.write('\t%i most frequent values:\n' % MAX_FREQ)
+ for value, count in stats['freq']:
+ self.output_file.write(('\t\t%s:\t%s\n' % (six.text_type(value), count)))
+
if not operations:
self.output_file.write('\n')
self.output_file.write('Row count: %s\n' % tab.count_rows())
| wireservice/csvkit | 106006ba0a1893a7fb8dfb481f73ac242c4e5a30 | diff --git a/tests/test_grep.py b/tests/test_grep.py
index 4a293f0..ade3c9b 100644
--- a/tests/test_grep.py
+++ b/tests/test_grep.py
@@ -102,6 +102,16 @@ class TestGrep(unittest.TestCase):
except ColumnIdentifierError:
pass
+ def test_index_out_of_range(self):
+ fcr = FilteringCSVReader(iter(self.tab2), patterns={3: '0'})
+ self.assertEqual(self.tab2[0], next(fcr))
+ self.assertEqual(self.tab2[4], next(fcr))
+ try:
+ next(fcr)
+ self.fail("Should be no more rows left.")
+ except StopIteration:
+ pass
+
def test_any_match(self):
fcr = FilteringCSVReader(iter(self.tab2), patterns={'age': 'only', 0: '2'}, any_match=True)
self.assertEqual(self.tab2[0], next(fcr))
diff --git a/tests/test_utilities/test_csvsort.py b/tests/test_utilities/test_csvsort.py
index 796d11f..acd5512 100644
--- a/tests/test_utilities/test_csvsort.py
+++ b/tests/test_utilities/test_csvsort.py
@@ -29,7 +29,7 @@ class TestCSVSort(CSVKitTestCase, ColumnsTests, EmptyFileTests, NamesTests):
def test_sort_date(self):
reader = self.get_output_as_reader(['-c', '2', 'examples/testxls_converted.csv'])
- test_order = [u'text', u'This row has blanks', u'Unicode! Σ', u'Chicago Tribune', u'Chicago Sun-Times', u'Chicago Reader']
+ test_order = [u'text', u'Chicago Tribune', u'Chicago Sun-Times', u'Chicago Reader', u'This row has blanks', u'Unicode! Σ']
new_order = [six.text_type(r[0]) for r in reader]
self.assertEqual(test_order, new_order)
@@ -45,8 +45,8 @@ class TestCSVSort(CSVKitTestCase, ColumnsTests, EmptyFileTests, NamesTests):
new_order = [six.text_type(r[0]) for r in reader]
self.assertEqual(test_order, new_order)
- def test_sort_ints_and_nulls(self):
+ def test_sort_t_and_nulls(self):
reader = self.get_output_as_reader(['-c', '2', 'examples/sort_ints_nulls.csv'])
- test_order = ['b', '', '1', '2']
+ test_order = ['b', '1', '2', '']
new_order = [six.text_type(r[1]) for r in reader]
self.assertEqual(test_order, new_order)
| csvstat doen't give counts for some columns
csvstat is great, and usually gives a sense of the mode of the data, via a count of how many rows have the most frequent values:
<pre>
4. LAST_NAME
<type 'unicode'>
Nulls: True
Unique values: 307123
5 most frequent values:
SMITH: 28155
JOHNSON: 23713
MARTINEZ: 18465
MILLER: 16916
BROWN: 15428
Max length: 28
</pre>
But sometimes it doesn't, perhaps when there less than some predefined number of unique values:
<pre>
28. STATUS
<type 'unicode'>
Nulls: False
Values: Active, Inactive
</pre>
I'd like to get counts of the top 5 most frequent values for all columns, as long as there are any repeated values.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_grep.py::TestGrep::test_index_out_of_range",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_sort_date",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_sort_t_and_nulls"
] | [
"tests/test_grep.py::TestGrep::test_any_match",
"tests/test_grep.py::TestGrep::test_any_match_and_inverse",
"tests/test_grep.py::TestGrep::test_column_names_in_patterns",
"tests/test_grep.py::TestGrep::test_duplicate_column_ids_in_patterns",
"tests/test_grep.py::TestGrep::test_inverse",
"tests/test_grep.py::TestGrep::test_mixed_indices_and_column_names_in_patterns",
"tests/test_grep.py::TestGrep::test_multiline",
"tests/test_grep.py::TestGrep::test_no_header",
"tests/test_grep.py::TestGrep::test_pattern",
"tests/test_grep.py::TestGrep::test_regex",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_empty",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_invalid_column",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_invalid_options",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_launch_new_instance",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_names",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_no_header_row",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_no_inference",
"tests/test_utilities/test_csvsort.py::TestCSVSort::test_sort_string_reverse"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2016-06-08T19:25:29Z" | mit |
|
wireservice__csvkit-645 | diff --git a/CHANGELOG b/CHANGELOG
index 0929e08..b5b78f9 100644
--- a/CHANGELOG
+++ b/CHANGELOG
@@ -44,6 +44,7 @@ Fixes:
* csvgrep can match multiline values.
* csvgrep correctly operates on ragged rows.
* csvsql correctly escapes `%` characters in SQL queries.
+* csvsql adds standard input only if explicitly requested.
* csvstack supports stacking a single file.
* csvstat always reports frequencies.
* FilteringCSVReader's any_match argument works correctly.
diff --git a/csvkit/utilities/csvsql.py b/csvkit/utilities/csvsql.py
index 98c5e84..1da023e 100644
--- a/csvkit/utilities/csvsql.py
+++ b/csvkit/utilities/csvsql.py
@@ -11,7 +11,7 @@ from csvkit.cli import CSVKitUtility
class CSVSQL(CSVKitUtility):
- description = 'Generate SQL statements for one or more CSV files, create execute those statements directly on a database, and execute one or more SQL queries.'
+ description = 'Generate SQL statements for one or more CSV files, or execute those statements directly on a database, and execute one or more SQL queries.'
override_flags = ['l', 'f']
def add_arguments(self):
@@ -56,14 +56,6 @@ class CSVSQL(CSVKitUtility):
else:
table_names = []
- # If one or more filenames are specified, we need to add stdin ourselves (if available)
- if sys.stdin not in self.input_files:
- try:
- if not sys.stdin.isatty():
- self.input_files.insert(0, sys.stdin)
- except:
- pass
-
# Create an SQLite database in memory if no connection string is specified
if query and not connection_string:
connection_string = "sqlite:///:memory:"
diff --git a/docs/scripts/csvsql.rst b/docs/scripts/csvsql.rst
index 3a9b4b0..f2dd003 100644
--- a/docs/scripts/csvsql.rst
+++ b/docs/scripts/csvsql.rst
@@ -16,7 +16,7 @@ Generate SQL statements for a CSV file or execute those statements directly on a
[--blanks] [--no-inference] [--db-schema DB_SCHEMA]
[FILE [FILE ...]]
- Generate SQL statements for one or more CSV files, create execute those
+ Generate SQL statements for one or more CSV files, or execute those
statements directly on a database, and execute one or more SQL queries.
positional arguments:
| wireservice/csvkit | 70d641c60202c8c8d596d1bf90fb03b10a1a4614 | diff --git a/tests/test_utilities/test_csvsql.py b/tests/test_utilities/test_csvsql.py
index be7d54f..2135fad 100644
--- a/tests/test_utilities/test_csvsql.py
+++ b/tests/test_utilities/test_csvsql.py
@@ -67,7 +67,7 @@ class TestCSVSQL(CSVKitTestCase, EmptyFileTests):
input_file = six.StringIO("a,b,c\n1,2,3\n")
with stdin_as_string(input_file):
- sql = self.get_output(['examples/dummy.csv'])
+ sql = self.get_output(['-', 'examples/dummy.csv'])
self.assertTrue('CREATE TABLE stdin' in sql)
self.assertTrue('CREATE TABLE dummy' in sql)
| csvsql without tty always tries to read stdin
The following snip works from a terminal but fails in a non-interactive session (we hit it in Jenkins, but I'd guess it also fails in cron)
```
csvsql --table foo --query "select * from foo" foo.csv
```
You get a `StopIteration` exception because csvsql is trying to read from stdin, which has nothing coming (this line: https://github.com/wireservice/csvkit/blob/205175fb70745b80db19acd4c314ad6c774b7fc0/csvkit/utilities/csvsql.py#L57). There's a previous discussion of the issue at https://github.com/wireservice/csvkit/issues/342 and https://github.com/wireservice/csvkit/issues/627, but the linked commit doesn't solve the issue.
We're working around it by always sending something in to stdin when running from a job.
I think csvsql should require naming stdin with a "-" when you want to read from both files named as arguments and stdin. This is how `cat` works:
```
echo "foo" | cat /tmp/file.csv # just prints file.csv
echo "foo" | cat - /tmp/file.csv # prints foo, then file.csv
echo "foo" | cat /tmp/file.csv - # prints file.csv, then foo
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_create_table"
] | [
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_empty",
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_launch_new_instance",
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_no_header_row",
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_no_inference",
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_stdin",
"tests/test_utilities/test_csvsql.py::TestCSVSQL::test_stdin_and_filename"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2016-08-01T18:29:57Z" | mit |
|
wireservice__csvkit-755 | diff --git a/docs/scripts/csvclean.rst b/docs/scripts/csvclean.rst
index 281f2d0..8937495 100644
--- a/docs/scripts/csvclean.rst
+++ b/docs/scripts/csvclean.rst
@@ -5,7 +5,14 @@ csvclean
Description
===========
-Cleans a CSV file of common syntax errors. Outputs [basename]_out.csv and [basename]_err.csv, the former containing all valid rows and the latter containing all error rows along with line numbers and descriptions::
+Cleans a CSV file of common syntax errors:
+
+* reports rows that have a different number of columns than the header row
+* removes optional quote characters
+* changes the record delimiter to a line feed
+* changes the character encoding to UTF-8
+
+Outputs [basename]_out.csv and [basename]_err.csv, the former containing all valid rows and the latter containing all error rows along with line numbers and descriptions::
usage: csvclean [-h] [-d DELIMITER] [-t] [-q QUOTECHAR] [-u {0,1,2,3}] [-b]
[-p ESCAPECHAR] [-z MAXFIELDSIZE] [-e ENCODING] [-S] [-v] [-l]
diff --git a/examples/optional_quote_characters.csv b/examples/optional_quote_characters.csv
new file mode 100644
index 0000000..bf9fcfb
--- /dev/null
+++ b/examples/optional_quote_characters.csv
@@ -0,0 +1,2 @@
+a,b,c
+"1","2","3"
| wireservice/csvkit | f1180b3d674e7945bbcba336f541dc3597614918 | diff --git a/tests/test_utilities/test_csvclean.py b/tests/test_utilities/test_csvclean.py
index 808ec46..3b85ffb 100644
--- a/tests/test_utilities/test_csvclean.py
+++ b/tests/test_utilities/test_csvclean.py
@@ -1,4 +1,5 @@
#!/usr/bin/env python
+# -*- coding: utf-8 -*-
import os
import sys
@@ -17,12 +18,8 @@ from tests.utils import CSVKitTestCase, EmptyFileTests
class TestCSVClean(CSVKitTestCase, EmptyFileTests):
Utility = CSVClean
- def test_launch_new_instance(self):
- with patch.object(sys, 'argv', [self.Utility.__name__.lower(), 'examples/bad.csv']):
- launch_new_instance()
-
- def test_simple(self):
- args = ['examples/bad.csv']
+ def assertCleaned(self, basename, output_lines, error_lines, additional_args=[]):
+ args = ['examples/%s.csv' % basename] + additional_args
output_file = six.StringIO()
utility = CSVClean(args, output_file)
@@ -30,24 +27,64 @@ class TestCSVClean(CSVKitTestCase, EmptyFileTests):
output_file.close()
- self.assertTrue(os.path.exists('examples/bad_err.csv'))
- self.assertTrue(os.path.exists('examples/bad_out.csv'))
+ output_file = 'examples/%s_out.csv' % basename
+ error_file = 'examples/%s_err.csv' % basename
+
+ self.assertEqual(os.path.exists(output_file), bool(output_lines))
+ self.assertEqual(os.path.exists(error_file), bool(error_lines))
try:
- with open('examples/bad_err.csv') as f:
- next(f)
- self.assertEqual(next(f)[0], '1')
- self.assertEqual(next(f)[0], '2')
- self.assertRaises(StopIteration, next, f)
-
- with open('examples/bad_out.csv') as f:
- next(f)
- self.assertEqual(next(f)[0], '0')
- self.assertRaises(StopIteration, next, f)
+ if output_lines:
+ with open(output_file) as f:
+ for line in output_lines:
+ self.assertEqual(next(f), line)
+ self.assertRaises(StopIteration, next, f)
+ if error_lines:
+ with open(error_file) as f:
+ for line in error_lines:
+ self.assertEqual(next(f), line)
+ self.assertRaises(StopIteration, next, f)
finally:
- # Cleanup
- os.remove('examples/bad_err.csv')
- os.remove('examples/bad_out.csv')
+ if output_lines:
+ os.remove(output_file)
+ if error_lines:
+ os.remove(error_file)
+
+
+ def test_launch_new_instance(self):
+ with patch.object(sys, 'argv', [self.Utility.__name__.lower(), 'examples/bad.csv']):
+ launch_new_instance()
+
+ def test_simple(self):
+ self.assertCleaned('bad', [
+ 'column_a,column_b,column_c\n',
+ '0,mixed types.... uh oh,17\n',
+ ], [
+ 'line_number,msg,column_a,column_b,column_c\n',
+ '1,"Expected 3 columns, found 4 columns",1,27,,I\'m too long!\n',
+ '2,"Expected 3 columns, found 2 columns",,I\'m too short!\n',
+ ])
+
+ def test_removes_optional_quote_characters(self):
+ self.assertCleaned('optional_quote_characters', [
+ 'a,b,c\n',
+ '1,2,3\n',
+ ], [])
+
+ def test_changes_line_endings(self):
+ self.assertCleaned('mac_newlines', [
+ 'a,b,c\n',
+ '1,2,3\n',
+ '"Once upon\n',
+ 'a time",5,6\n',
+ ], [])
+
+ def test_changes_character_encoding(self):
+ self.assertCleaned('test_latin1', [
+ 'a,b,c\n',
+ '1,2,3\n',
+ '4,5,©\n',
+ ], [], ['-e', 'latin1'])
def test_dry_run(self):
output = self.get_output_as_io(['-n', 'examples/bad.csv'])
| csvclean documentation is poor
Great tool really, but the documentation is very poor. It should be interesting to explain each task done by csvclean:
- delete every unneeded quote
- recode from XXX charset to UTF-8
- replace X delimiter by a comma
- replace \r\n by \n
This last modification is ok for me as I can then grep the file without problem, but it is not compatible with the RFC (which recommand \r\n).
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_removes_optional_quote_characters"
] | [
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_changes_character_encoding",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_changes_line_endings",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_dry_run",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_empty",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_launch_new_instance",
"tests/test_utilities/test_csvclean.py::TestCSVClean::test_simple"
] | {
"failed_lite_validators": [
"has_added_files",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2017-01-17T05:17:22Z" | mit |
|
wireservice__csvkit-770 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 6ebf3be..06441ce 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -6,7 +6,8 @@ Improvements:
* Add a :code:`--version` (:code:`-V`) flag.
* :code:`-I` is the short option for :code:`--no-inference`.
* :doc:`/scripts/csvjoin` supports :code:`--snifflimit` and :code:`--no-inference`.
-* :doc:`/scripts/in2csv` now supports a :code:`--names` flag to print Excel sheet names.
+* :doc:`/scripts/csvstat` adds a :code:`--freq-count` option to set the maximum number of frequent values to display.
+* :doc:`/scripts/in2csv` adds a :code:`--names` flag to print Excel sheet names.
Fixes:
diff --git a/csvkit/utilities/csvstat.py b/csvkit/utilities/csvstat.py
index 2292e77..29908d2 100644
--- a/csvkit/utilities/csvstat.py
+++ b/csvkit/utilities/csvstat.py
@@ -13,9 +13,6 @@ from csvkit.cli import CSVKitUtility, parse_column_identifiers
NoneType = type(None)
-MAX_UNIQUE = 5
-MAX_FREQ = 5
-
OPERATIONS = OrderedDict([
('type', {
'aggregation': None,
@@ -97,8 +94,10 @@ class CSVStat(CSVKitUtility):
help='Only output the length of the longest values.')
self.argparser.add_argument('--freq', dest='freq_only', action='store_true',
help='Only output lists of frequent values.')
+ self.argparser.add_argument('--freq-count', dest='freq_count', type=int,
+ help='The maximum number of frequent values to display.')
self.argparser.add_argument('--count', dest='count_only', action='store_true',
- help='Only output total row count')
+ help='Only output total row count.')
self.argparser.add_argument('-y', '--snifflimit', dest='sniff_limit', type=int,
help='Limit CSV dialect sniffing to the specified number of bytes. Specify "0" to disable sniffing entirely.')
@@ -144,18 +143,23 @@ class CSVStat(CSVKitUtility):
self.get_column_offset()
)
+ kwargs = {}
+
+ if self.args.freq_count:
+ kwargs['freq_count'] = self.args.freq_count
+
# Output a single stat
if operations:
if len(column_ids) == 1:
- self.print_one(table, column_ids[0], operations[0], label=False)
+ self.print_one(table, column_ids[0], operations[0], label=False, **kwargs)
else:
for column_id in column_ids:
- self.print_one(table, column_id, operations[0])
+ self.print_one(table, column_id, operations[0], **kwargs)
else:
stats = {}
for column_id in column_ids:
- stats[column_id] = self.calculate_stats(table, column_id)
+ stats[column_id] = self.calculate_stats(table, column_id, **kwargs)
# Output as CSV
if self.args.csv_output:
@@ -164,7 +168,7 @@ class CSVStat(CSVKitUtility):
else:
self.print_stats(table, column_ids, stats)
- def print_one(self, table, column_id, operation, label=True):
+ def print_one(self, table, column_id, operation, label=True, **kwargs):
"""
Print data for a single statistic.
"""
@@ -178,7 +182,7 @@ class CSVStat(CSVKitUtility):
try:
if getter:
- stat = getter(table, column_id)
+ stat = getter(table, column_id, **kwargs)
else:
op = OPERATIONS[op_name]['aggregation']
stat = table.aggregate(op(column_id))
@@ -198,7 +202,7 @@ class CSVStat(CSVKitUtility):
else:
self.output_file.write(u'%s\n' % stat)
- def calculate_stats(self, table, column_id):
+ def calculate_stats(self, table, column_id, **kwargs):
"""
Calculate stats for all valid operations.
"""
@@ -212,7 +216,7 @@ class CSVStat(CSVKitUtility):
try:
if getter:
- stats[op_name] = getter(table, column_id)
+ stats[op_name] = getter(table, column_id, **kwargs)
else:
op = op_data['aggregation']
v = table.aggregate(op(column_id))
@@ -314,16 +318,16 @@ class CSVStat(CSVKitUtility):
writer.writerow(output_row)
-def get_type(table, column_id):
+def get_type(table, column_id, **kwargs):
return '%s' % table.columns[column_id].data_type.__class__.__name__
-def get_unique(table, column_id):
+def get_unique(table, column_id, **kwargs):
return len(table.columns[column_id].values_distinct())
-def get_freq(table, column_id):
- return table.pivot(column_id).order_by('Count', reverse=True).limit(MAX_FREQ)
+def get_freq(table, column_id, freq_count=5, **kwargs):
+ return table.pivot(column_id).order_by('Count', reverse=True).limit(freq_count)
def launch_new_instance():
| wireservice/csvkit | 7c26421a9f7f32318eb96b2649f62ab0192f2f33 | diff --git a/tests/test_utilities/test_csvstat.py b/tests/test_utilities/test_csvstat.py
index 2f9cec2..875c7dd 100644
--- a/tests/test_utilities/test_csvstat.py
+++ b/tests/test_utilities/test_csvstat.py
@@ -55,6 +55,14 @@ class TestCSVStat(CSVKitTestCase, ColumnsTests, EmptyFileTests, NamesTests):
self.assertIn('SALINE (59x)', output)
self.assertNotIn('MIAMI (56x)', output)
+
+ def test_freq_count(self):
+ output = self.get_output(['examples/realdata/ks_1033_data.csv', '--freq-count', '1'])
+
+ self.assertIn('WYANDOTTE (123x)', output)
+ self.assertNotIn('SALINE (59x)', output)
+ self.assertNotIn('MIAMI (56x)', output)
+
def test_csv(self):
output = self.get_output_as_io(['--csv', 'examples/realdata/ks_1033_data.csv'])
| csvstat: flag to specify how many frequent values to display
Csvstat is really a very useful tool, but it still could be better : the "frequent values" feature is apparently fixedly limited to 5 values. It would be great if this "5" value was only the default value, and could be altered by a new parameter, say "-f ".
For example : "csvstat -f 20 -c 3,7 --freq myfile.csv" would return the 20 most frequent values of colums 3 and 7. Today it (seems) impossible to exceed the limit of 5 values.
Best regards, thanks for this great kit.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_freq_count"
] | [
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_columns",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_count_only",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_csv",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_csv_columns",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_empty",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_encoding",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_freq_list",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_invalid_column",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_invalid_options",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_launch_new_instance",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_max_length",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_names",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_no_header_row",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_runs",
"tests/test_utilities/test_csvstat.py::TestCSVStat::test_unique"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2017-01-27T15:42:42Z" | mit |
|
wireservice__csvkit-776 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 8f1617b..9dc61c3 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -3,8 +3,9 @@
Improvements:
-* Add a :code:`--version` (:code:`-V`) flag.
+* Add a :code:`--version` flag.
* Add a :code:`--skip-lines` option to skip initial lines (e.g. comments, copyright notices, empty rows).
+* Add a :code:`--locale` option to set the locale of any formatted numbers.
* :code:`-I` is the short option for :code:`--no-inference`.
* :doc:`/scripts/csvjoin` supports :code:`--snifflimit` and :code:`--no-inference`.
* :doc:`/scripts/csvstat` adds a :code:`--freq-count` option to set the maximum number of frequent values to display.
diff --git a/csvkit/cli.py b/csvkit/cli.py
index cf52724..f69f961 100644
--- a/csvkit/cli.py
+++ b/csvkit/cli.py
@@ -159,7 +159,10 @@ class CSVKitUtility(object):
help='Maximum length of a single field in the input CSV file.')
if 'e' not in self.override_flags:
self.argparser.add_argument('-e', '--encoding', dest='encoding', default='utf-8',
- help='Specify the encoding the input CSV file.')
+ help='Specify the encoding of the input CSV file.')
+ if 'L' not in self.override_flags:
+ self.argparser.add_argument('-L', '--locale', dest='locale', default='en_US',
+ help='Specify the locale (en_US) of any formatted numbers.')
if 'S' not in self.override_flags:
self.argparser.add_argument('-S', '--skipinitialspace', dest='skipinitialspace', action='store_true',
help='Ignore whitespace immediately following the delimiter.')
@@ -283,7 +286,7 @@ class CSVKitUtility(object):
else:
return agate.TypeTester(types=[
agate.Boolean(),
- agate.Number(),
+ agate.Number(locale=self.args.locale),
agate.TimeDelta(),
agate.Date(),
agate.DateTime(),
diff --git a/csvkit/utilities/sql2csv.py b/csvkit/utilities/sql2csv.py
index 98bf911..1b56f52 100644
--- a/csvkit/utilities/sql2csv.py
+++ b/csvkit/utilities/sql2csv.py
@@ -10,7 +10,7 @@ from csvkit.cli import CSVKitUtility
class SQL2CSV(CSVKitUtility):
description = 'Execute an SQL query on a database and output the result to a CSV file.'
- override_flags = 'f,b,d,e,H,K,p,q,S,t,u,z,zero'.split(',')
+ override_flags = 'f,b,d,e,H,K,L,p,q,S,t,u,z,zero'.split(',')
def add_arguments(self):
self.argparser.add_argument('--db', dest='connection_string', default='sqlite://',
@@ -20,7 +20,7 @@ class SQL2CSV(CSVKitUtility):
self.argparser.add_argument('--query', default=None,
help="The SQL query to execute. If specified, it overrides FILE and STDIN.")
self.argparser.add_argument('-e', '--encoding', dest='encoding', default='utf-8',
- help='Specify the encoding the input query file.')
+ help='Specify the encoding of the input query file.')
self.argparser.add_argument('-H', '--no-header-row', dest='no_header_row', action='store_true',
help='Do not output column names.')
diff --git a/docs/common_arguments.rst b/docs/common_arguments.rst
index b4af001..337ac0a 100644
--- a/docs/common_arguments.rst
+++ b/docs/common_arguments.rst
@@ -24,7 +24,9 @@ All tools which accept CSV as input share a set of common command-line arguments
Maximum length of a single field in the input CSV
file.
-e ENCODING, --encoding ENCODING
- Specify the encoding the input CSV file.
+ Specify the encoding of the input CSV file.
+ -L LOCALE, --locale LOCALE
+ Specify the locale (en_US) of any formatted numbers.
-S, --skipinitialspace
Ignore whitespace immediately following the delimiter.
-H, --no-header-row Specify that the input CSV file has no header row.
diff --git a/docs/scripts/sql2csv.rst b/docs/scripts/sql2csv.rst
index 1ea81e2..bfd3439 100644
--- a/docs/scripts/sql2csv.rst
+++ b/docs/scripts/sql2csv.rst
@@ -30,7 +30,7 @@ Executes arbitrary commands against a SQL database and outputs the results as a
--query QUERY The SQL query to execute. If specified, it overrides
FILE and STDIN.
-e ENCODING, --encoding ENCODING
- Specify the encoding the input query file.
+ Specify the encoding of the input query file.
-H, --no-header-row Do not output column names.
Examples
| wireservice/csvkit | b69d7cd51f0e273564a3209d871bb9af3cfd7f42 | diff --git a/examples/test_locale.csv b/examples/test_locale.csv
new file mode 100644
index 0000000..4924ddc
--- /dev/null
+++ b/examples/test_locale.csv
@@ -0,0 +1,2 @@
+a,b,c
+"1,7","200.000.000",
diff --git a/examples/test_locale_converted.csv b/examples/test_locale_converted.csv
new file mode 100644
index 0000000..3cd0f59
--- /dev/null
+++ b/examples/test_locale_converted.csv
@@ -0,0 +1,2 @@
+a,b,c
+1.7,200000000,
diff --git a/tests/test_utilities/test_in2csv.py b/tests/test_utilities/test_in2csv.py
index 5bedf05..ce9382d 100644
--- a/tests/test_utilities/test_in2csv.py
+++ b/tests/test_utilities/test_in2csv.py
@@ -34,6 +34,9 @@ class TestIn2CSV(CSVKitTestCase, EmptyFileTests):
self.assertEqual(e.exception.code, 0)
+ def test_locale(self):
+ self.assertConverted('csv', 'examples/test_locale.csv', 'examples/test_locale_converted.csv', ['--locale', 'de_DE'])
+
def test_convert_csv(self):
self.assertConverted('csv', 'examples/testfixed_converted.csv', 'examples/testfixed_converted.csv')
| Parse non-US locale numbers
Sometimes numeric data contains thousands separators, typically ',', '_' or in Europe ','.
Also Europeans sometimes use ',' as the decimal point.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_locale"
] | [
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_csv",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_csv_with_skip_lines",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_geojson",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_json",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_ndjson",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_nested_json",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xls",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xls_with_sheet",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xls_with_skip_lines",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xlsx",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xlsx_with_sheet",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_convert_xlsx_with_skip_lines",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_csv_datetime_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_csv_no_headers",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_csv_no_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_empty",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_geojson_no_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_json_no_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_launch_new_instance",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_names_xls",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_names_xlsx",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_ndjson_no_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_version",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_xls_no_inference",
"tests/test_utilities/test_in2csv.py::TestIn2CSV::test_xlsx_no_inference"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2017-01-28T07:04:06Z" | mit |
|
wireservice__csvkit-800 | diff --git a/csvkit/utilities/csvstack.py b/csvkit/utilities/csvstack.py
index bf1c00b..39d544d 100644
--- a/csvkit/utilities/csvstack.py
+++ b/csvkit/utilities/csvstack.py
@@ -9,7 +9,7 @@ from csvkit.cli import CSVKitUtility, make_default_headers
class CSVStack(CSVKitUtility):
description = 'Stack up the rows from multiple CSV files, optionally adding a grouping value.'
- override_flags = ['f', 'K', 'L', 'date-format', 'datetime-format']
+ override_flags = ['f', 'L', 'date-format', 'datetime-format']
def add_arguments(self):
self.argparser.add_argument(metavar="FILE", nargs='+', dest='input_paths', default=['-'],
@@ -45,6 +45,14 @@ class CSVStack(CSVKitUtility):
output = agate.csv.writer(self.output_file, **self.writer_kwargs)
for i, f in enumerate(self.input_files):
+ if isinstance(self.args.skip_lines, int):
+ skip_lines = self.args.skip_lines
+ while skip_lines > 0:
+ f.readline()
+ skip_lines -= 1
+ else:
+ raise ValueError('skip_lines argument must be an int')
+
rows = agate.csv.reader(f, **self.reader_kwargs)
# If we have header rows, use them
| wireservice/csvkit | 3d9438e7ea5db34948ade66b0a4333736990c77a | diff --git a/tests/test_utilities/test_csvstack.py b/tests/test_utilities/test_csvstack.py
index abae02d..2921f2f 100644
--- a/tests/test_utilities/test_csvstack.py
+++ b/tests/test_utilities/test_csvstack.py
@@ -19,6 +19,13 @@ class TestCSVStack(CSVKitTestCase, EmptyFileTests):
with patch.object(sys, 'argv', [self.Utility.__name__.lower(), 'examples/dummy.csv']):
launch_new_instance()
+ def test_skip_lines(self):
+ self.assertRows(['--skip-lines', '3', 'examples/test_skip_lines.csv', 'examples/test_skip_lines.csv'], [
+ ['a', 'b', 'c'],
+ ['1', '2', '3'],
+ ['1', '2', '3'],
+ ])
+
def test_single_file_stack(self):
self.assertRows(['examples/dummy.csv'], [
['a', 'b', 'c'],
| csvstack to support --skip-lines
First , great library.
It was very handy in searching big csv files , i just needed to search a complete folder full of csv that each file has a header that should be ignored by using latest version 1.0.2 --skip-lines it was possible but file by file . i tried using csvstack but it did not recognise the parameter --skip-lines
```
Alis-Mac-mini:sonus shahbour$ csvgrep --skip-lines 1 -c 20 -r "^449" -H 20170219013000.1014D6F.ACT.gz | csvgrep -c 21 -r "^639" | csvcut -c 20,21
t,u
44971506961058,639398219637
44971504921587,639106889971
44971569097874,639291643991
44971568622691,639101981790
44971543461612,639495761895
44971502473650,639287415793
44971543544583,639183191196
44971569097874,639291643991
44971566267135,639293255451
44971507677524,639108700472
```
```
Alis-Mac-mini:sonus shahbour$ csvstack -H --skip-lines 1 * | csvgrep -c 20 -r "^449" | csvgrep -c 21 -r "^639" | csvcut -c 20,21
usage: csvstack [-h] [-d DELIMITER] [-t] [-q QUOTECHAR] [-u {0,1,2,3}] [-b]
[-p ESCAPECHAR] [-z FIELD_SIZE_LIMIT] [-e ENCODING] [-S] [-H]
[-v] [-l] [--zero] [-V] [-g GROUPS] [-n GROUP_NAME]
[--filenames]
FILE [FILE ...]
csvstack: error: unrecognized arguments: --skip-lines
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_skip_lines"
] | [
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_empty",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_explicit_grouping",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_filenames_grouping",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_launch_new_instance",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_multiple_file_stack",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_no_header_row",
"tests/test_utilities/test_csvstack.py::TestCSVStack::test_single_file_stack"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2017-02-24T20:00:49Z" | mit |
|
wireservice__csvkit-900 | diff --git a/.travis.yml b/.travis.yml
index ca53492..d5a2d31 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -7,10 +7,8 @@ python:
- "3.4"
- "3.5"
- "3.6"
- - "pypy-5.3.1"
install:
- if [[ $TRAVIS_PYTHON_VERSION == 3* ]]; then pip install -r requirements-py3.txt; else pip install -r requirements-py2.txt; fi
- - if [[ $TRAVIS_PYTHON_VERSION == "pypy-5.3.1" ]]; then pip install psycopg2cffi; else pip install psycopg2; fi
- pip install coveralls
before_script:
- psql -U postgres -c 'CREATE DATABASE dummy_test'
diff --git a/AUTHORS.rst b/AUTHORS.rst
index ce1a210..ad1e207 100644
--- a/AUTHORS.rst
+++ b/AUTHORS.rst
@@ -81,3 +81,4 @@ The following individuals have contributed code to csvkit:
* kjedamzik
* John Vandenberg
* Olivier Lacan
+* Adrien Delessert
diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index ea9460b..0cf8633 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -3,14 +3,19 @@
Improvements:
+* :doc:`/scripts/csvgrep` adds a :code:`--any-match` (:code:`-a`) flag to select rows where any column matches instead of all columns.
* :doc:`/scripts/csvjson` no longer emits a property if its value is null.
* :doc:`/scripts/in2csv` adds a :code:`--encoding-xls` option to specify the encoding of the input XLS file.
Fixes:
* :doc:`/scripts/csvgrep` accepts utf-8 arguments to the :code:`--match` and :code:`--regex` options in Python 2.
+* :doc:`/scripts/csvsql` sets a DECIMAL's precision and scale and a VARCHAR's length to avoid dialect-specific errors.
+* :doc:`/scripts/csvstack` no longer opens all files at once.
* :doc:`/scripts/in2csv` respects :code:`--no-header-row` when :code:`--no-inference` is set.
+csvkit is no longer tested on PyPy.
+
1.0.2 - April 28, 2017
----------------------
diff --git a/csvkit/utilities/csvgrep.py b/csvkit/utilities/csvgrep.py
index df18eb8..c0b080b 100644
--- a/csvkit/utilities/csvgrep.py
+++ b/csvkit/utilities/csvgrep.py
@@ -35,7 +35,8 @@ class CSVGrep(CSVKitUtility):
help='If specified, must be the path to a file. For each tested row, if any line in the file (stripped of line separators) is an exact match for the cell value, the row will pass.')
self.argparser.add_argument('-i', '--invert-match', dest='inverse', action='store_true',
help='If specified, select non-matching instead of matching rows.')
-
+ self.argparser.add_argument('-a', '--any-match', dest='any_match', action='store_true',
+ help='If specified, select rows where any column matches instead of all columns.')
def main(self):
if self.args.names_only:
self.print_column_names()
@@ -67,7 +68,7 @@ class CSVGrep(CSVKitUtility):
pattern = self.args.pattern
patterns = dict((column_id, pattern) for column_id in column_ids)
- filter_reader = FilteringCSVReader(rows, header=False, patterns=patterns, inverse=self.args.inverse)
+ filter_reader = FilteringCSVReader(rows, header=False, patterns=patterns, inverse=self.args.inverse, any_match=self.args.any_match)
output = agate.csv.writer(self.output_file, **writer_kwargs)
output.writerow(column_names)
diff --git a/csvkit/utilities/csvstack.py b/csvkit/utilities/csvstack.py
index 56e2051..cba10af 100644
--- a/csvkit/utilities/csvstack.py
+++ b/csvkit/utilities/csvstack.py
@@ -23,20 +23,15 @@ class CSVStack(CSVKitUtility):
help='Use the filename of each input file as its grouping value. When specified, -g will be ignored.')
def main(self):
- self.input_files = []
-
- for path in self.args.input_paths:
- self.input_files.append(self._open_input_file(path))
-
- if not self.input_files:
+ if not self.args.input_paths:
self.argparser.error('You must specify at least one file to stack.')
- if self.args.group_by_filenames:
- groups = [os.path.basename(f.name) for f in self.input_files]
- elif self.args.groups:
+ has_groups = self.args.group_by_filenames or self.args.groups
+
+ if self.args.groups and not self.args.group_by_filenames:
groups = self.args.groups.split(',')
- if len(groups) != len(self.input_files):
+ if len(groups) != len(self.args.input_paths):
self.argparser.error('The number of grouping values must be equal to the number of CSV files being stacked.')
else:
groups = None
@@ -45,7 +40,9 @@ class CSVStack(CSVKitUtility):
output = agate.csv.writer(self.output_file, **self.writer_kwargs)
- for i, f in enumerate(self.input_files):
+ for i, path in enumerate(self.args.input_paths):
+ f = self._open_input_file(path)
+
if isinstance(self.args.skip_lines, int):
skip_lines = self.args.skip_lines
while skip_lines > 0:
@@ -56,12 +53,18 @@ class CSVStack(CSVKitUtility):
rows = agate.csv.reader(f, **self.reader_kwargs)
+ if has_groups:
+ if groups:
+ group = groups[i]
+ else:
+ group = os.path.basename(f.name)
+
# If we have header rows, use them
if not self.args.no_header_row:
headers = next(rows, [])
if i == 0:
- if groups:
+ if has_groups:
headers.insert(0, group_name)
output.writerow(headers)
@@ -72,19 +75,19 @@ class CSVStack(CSVKitUtility):
headers = make_default_headers(len(row))
if i == 0:
- if groups:
+ if has_groups:
headers.insert(0, group_name)
output.writerow(headers)
- if groups:
- row.insert(0, groups[i])
+ if has_groups:
+ row.insert(0, group)
output.writerow(row)
for row in rows:
- if groups:
- row.insert(0, groups[i])
+ if has_groups:
+ row.insert(0, group)
output.writerow(row)
diff --git a/docs/scripts/csvgrep.rst b/docs/scripts/csvgrep.rst
index 7998053..d40b6d1 100644
--- a/docs/scripts/csvgrep.rst
+++ b/docs/scripts/csvgrep.rst
@@ -38,6 +38,8 @@ Filter tabular data to only those rows where certain columns contain a given val
row will pass.
-i, --invert-match If specified, select non-matching instead of matching
rows.
+ -a --any-match If specified, select rows where any column matches
+ instead of all columns.
See also: :doc:`../common_arguments`.
@@ -53,8 +55,7 @@ Search for the row relating to Illinois::
Search for rows relating to states with names beginning with the letter "I"::
csvgrep -c 1 -r "^I" examples/realdata/FY09_EDU_Recipients_by_State.csv
-
+
Search for rows that do not contain an empty state cell::
csvgrep -c 1 -r "^$" -i examples/realdata/FY09_EDU_Recipients_by_State.csv
-
| wireservice/csvkit | 8911438e05b83a78bbee778369e83f9defa1fac9 | diff --git a/tests/test_utilities/test_csvgrep.py b/tests/test_utilities/test_csvgrep.py
index 08b59d1..a4c8eb2 100644
--- a/tests/test_utilities/test_csvgrep.py
+++ b/tests/test_utilities/test_csvgrep.py
@@ -33,6 +33,12 @@ class TestCSVGrep(CSVKitTestCase, ColumnsTests, EmptyFileTests, NamesTests):
['1', '2', '3'],
])
+ def test_any_match(self):
+ self.assertRows(['-c', '1,2,3', '-a', '-m', '1', 'examples/dummy.csv'], [
+ ['a', 'b', 'c'],
+ ['1', '2', '3'],
+ ])
+
def test_match_utf8(self):
self.assertRows(['-c', '3', '-m', 'ʤ', 'examples/test_utf8.csv'], [
['foo', 'bar', 'baz'],
| csvstack [Errno 24] Too many open files
`csvstack` returns "[Errno 24] Too many open files" when many files are added for stacking. For example, `csvstack --filenames *.csv > stacked.csv`. It seems to be a Python error, but can `csvstack` use an intermediate file and close the previous ones?
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_any_match"
] | [
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_empty",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_invalid_column",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_invalid_options",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_invert_match",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_kwargs_with_line_numbers",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_launch_new_instance",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_match",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_match_utf8",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_match_with_line_numbers",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_names",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_no_match",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_re_match",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_re_match_utf8",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_skip_lines",
"tests/test_utilities/test_csvgrep.py::TestCSVGrep::test_string_match"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2017-10-26T00:15:59Z" | mit |
|
witchard__grole-21 | diff --git a/docs/tutorial.rst b/docs/tutorial.rst
index e7d4091..dd7d9af 100644
--- a/docs/tutorial.rst
+++ b/docs/tutorial.rst
@@ -51,7 +51,7 @@ Responding
In-built python types returned by registered request handlers are automatically converted into 200 OK HTTP responses. The following mappings apply:
* bytes: Sent directly with content type text/plain
-* string: Encoded as bytes and sent with content type text/plain
+* string: Encoded as bytes and sent with content type text/html
* others: Encoded as json and sent with content type application/json
Finer grained control of the response data can be achieved using :class:`ResponseBody` or one of it's children. These allow for overriding of the content type. The following are available:
diff --git a/grole.py b/grole.py
index d34ea4d..e8f6506 100755
--- a/grole.py
+++ b/grole.py
@@ -132,7 +132,7 @@ class ResponseString(ResponseBody):
"""
Response body from a string
"""
- def __init__(self, data='', content_type='text/plain'):
+ def __init__(self, data='', content_type='text/html'):
"""
Initialise object, data is the data to send
| witchard/grole | a766ad29789b27e75f388ef0f7ce8d999d52c4e4 | diff --git a/test/test_response.py b/test/test_response.py
index fb58ad8..967e050 100644
--- a/test/test_response.py
+++ b/test/test_response.py
@@ -106,5 +106,29 @@ class TestFile(unittest.TestCase):
self.assertEqual(writer.data, b'4\r\nfoo\n\r\n0\r\n\r\n')
+class TestAuto(unittest.TestCase):
+
+ def test_empty(self):
+ res = grole.Response()
+ self.assertTrue(isinstance(res.data, grole.ResponseBody))
+
+ def test_bytes(self):
+ res = grole.Response(b'foo')
+ self.assertTrue(isinstance(res.data, grole.ResponseBody))
+ self.assertEqual(res.data._data, b'foo')
+ self.assertEqual(res.data._headers['Content-Type'], 'text/plain')
+
+ def test_str(self):
+ res = grole.Response('foo')
+ self.assertTrue(isinstance(res.data, grole.ResponseString))
+ self.assertEqual(res.data._data, b'foo')
+ self.assertEqual(res.data._headers['Content-Type'], 'text/html')
+
+ def test_json(self):
+ res = grole.Response({'foo': 'bar'})
+ self.assertTrue(isinstance(res.data, grole.ResponseJSON))
+ self.assertEqual(res.data._data, b'{"foo": "bar"}')
+ self.assertEqual(res.data._headers['Content-Type'], 'application/json')
+
if __name__ == '__main__':
unittest.main()
| Change default content type for string to text/html
This feels like it makes more sense. Don't forget to update the doc! | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"test/test_response.py::TestAuto::test_str"
] | [
"test/test_response.py::TestHeader::test_header",
"test/test_response.py::TestBody::test_bytes",
"test/test_response.py::TestBody::test_data",
"test/test_response.py::TestBody::test_file",
"test/test_response.py::TestBody::test_headers",
"test/test_response.py::TestBody::test_json",
"test/test_response.py::TestBody::test_string",
"test/test_response.py::TestString::test_data",
"test/test_response.py::TestString::test_headers",
"test/test_response.py::TestJSON::test_data",
"test/test_response.py::TestJSON::test_headers",
"test/test_response.py::TestFile::test_data",
"test/test_response.py::TestFile::test_headers",
"test/test_response.py::TestAuto::test_bytes",
"test/test_response.py::TestAuto::test_empty",
"test/test_response.py::TestAuto::test_json"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2020-06-13T08:31:41Z" | mit |
|
wkeeling__selenium-wire-509 | diff --git a/README.rst b/README.rst
index 17e62f7..bb02330 100644
--- a/README.rst
+++ b/README.rst
@@ -694,21 +694,19 @@ If you wish to take advantage of this make sure you have undetected_chromedriver
pip install undetected-chromedriver
-Then you can select the version of undetected_chromedriver you want to use by importing ``Chrome`` and ``ChromeOptions`` from the appropriate package.
-
-For undetected_chromedriver version 1:
+Then in your code, import the ``seleniumwire.undetected_chromedriver`` package:
.. code:: python
- from seleniumwire.undetected_chromedriver import Chrome, ChromeOptions
-
-For undetected_chromedriver version 2:
+ import seleniumwire.undetected_chromedriver as uc
-.. code:: python
+ chrome_options = uc.ChromeOptions()
- from seleniumwire.undetected_chromedriver.v2 import Chrome, ChromeOptions
+ driver = uc.Chrome(
+ options=chrome_options,
+ seleniumwire_options={}
+ )
-See the `undetected_chromedriver docs <https://github.com/ultrafunkamsterdam/undetected-chromedriver>`_ for differences between the two versions.
Certificates
~~~~~~~~~~~~
diff --git a/seleniumwire/storage.py b/seleniumwire/storage.py
index 6d1cd66..1be95da 100644
--- a/seleniumwire/storage.py
+++ b/seleniumwire/storage.py
@@ -181,12 +181,9 @@ class RequestStorage:
request_dir = self._get_request_dir(request_id)
with open(os.path.join(request_dir, 'request'), 'rb') as req:
- try:
- request = pickle.load(req)
- except Exception:
- # Errors may sometimes occur with unpickling - e.g.
- # sometimes data hasn't been fully flushed to disk
- # by the OS by the time we come to unpickle it.
+ request = self._unpickle(req)
+
+ if request is None:
return None
ws_messages = self._ws_messages.get(request.id)
@@ -198,19 +195,37 @@ class RequestStorage:
try:
# Attach the response if there is one.
with open(os.path.join(request_dir, 'response'), 'rb') as res:
- response = pickle.load(res)
- request.response = response
-
- # The certificate data has been stored on the response but we make
- # it available on the request which is a more logical location.
- if hasattr(response, 'cert'):
- request.cert = response.cert
- del response.cert
+ response = self._unpickle(res)
+
+ if response is not None:
+ request.response = response
+
+ # The certificate data has been stored on the response but we make
+ # it available on the request which is a more logical location.
+ if hasattr(response, 'cert'):
+ request.cert = response.cert
+ del response.cert
except (FileNotFoundError, EOFError):
pass
return request
+ def _unpickle(self, f):
+ """Unpickle the object specified by the file f.
+
+ If unpickling fails return None.
+ """
+ try:
+ return pickle.load(f)
+ except Exception:
+ # Errors may sometimes occur with unpickling - e.g.
+ # sometimes data hasn't been fully flushed to disk
+ # by the OS by the time we come to unpickle it.
+ if log.isEnabledFor(logging.DEBUG):
+ log.exception('Error unpickling object')
+
+ return None
+
def load_last_request(self) -> Optional[Request]:
"""Load the last saved request.
@@ -240,8 +255,10 @@ class RequestStorage:
try:
with open(os.path.join(request_dir, 'har_entry'), 'rb') as f:
- entry = pickle.load(f)
- entries.append(entry)
+ entry = self._unpickle(f)
+
+ if entry is not None:
+ entries.append(entry)
except FileNotFoundError:
# HAR entries aren't necessarily saved with each request.
pass
diff --git a/seleniumwire/undetected_chromedriver/__init__.py b/seleniumwire/undetected_chromedriver/__init__.py
index a470664..8eaa1cd 100644
--- a/seleniumwire/undetected_chromedriver/__init__.py
+++ b/seleniumwire/undetected_chromedriver/__init__.py
@@ -1,12 +1,1 @@
-try:
- import undetected_chromedriver as uc
-except ImportError as e:
- raise ImportError(
- 'undetected_chromedriver not found. ' 'Install it with `pip install undetected_chromedriver`.'
- ) from e
-
-from seleniumwire.webdriver import Chrome
-
-uc._Chrome = Chrome
-Chrome = uc.Chrome
-ChromeOptions = uc.ChromeOptions # noqa: F811
+from .webdriver import Chrome, ChromeOptions
diff --git a/seleniumwire/undetected_chromedriver/v2.py b/seleniumwire/undetected_chromedriver/v2.py
index c4a42c9..e0c9dd0 100644
--- a/seleniumwire/undetected_chromedriver/v2.py
+++ b/seleniumwire/undetected_chromedriver/v2.py
@@ -1,58 +1,1 @@
-import logging
-
-import undetected_chromedriver.v2 as uc
-from selenium.webdriver import DesiredCapabilities
-
-from seleniumwire.inspect import InspectRequestsMixin
-from seleniumwire.utils import urlsafe_address
-from seleniumwire.webdriver import DriverCommonMixin
-
-log = logging.getLogger(__name__)
-
-
-class Chrome(InspectRequestsMixin, DriverCommonMixin, uc.Chrome):
- """Extends the undetected_chrome Chrome webdriver to provide additional
- methods for inspecting requests."""
-
- def __init__(self, *args, seleniumwire_options=None, **kwargs):
- """Initialise a new Chrome WebDriver instance.
-
- Args:
- seleniumwire_options: The seleniumwire options dictionary.
- """
- if seleniumwire_options is None:
- seleniumwire_options = {}
-
- config = self._setup_backend(seleniumwire_options)
-
- if seleniumwire_options.get('auto_config', True):
- capabilities = kwargs.get('desired_capabilities')
- if capabilities is None:
- capabilities = DesiredCapabilities.CHROME
- capabilities = capabilities.copy()
-
- capabilities.update(config)
-
- kwargs['desired_capabilities'] = capabilities
-
- try:
- chrome_options = kwargs['options']
- except KeyError:
- chrome_options = ChromeOptions()
-
- log.info('Using undetected_chromedriver.v2')
-
- # We need to point Chrome back to Selenium Wire since the executable
- # will be started separately by undetected_chromedriver.
- addr, port = urlsafe_address(self.backend.address())
- chrome_options.add_argument(f'--proxy-server={addr}:{port}')
- chrome_options.add_argument(
- f"--proxy-bypass-list={','.join(seleniumwire_options.get('exclude_hosts', ['<-loopback>']))}"
- )
-
- kwargs['options'] = chrome_options
-
- super().__init__(*args, **kwargs)
-
-
-ChromeOptions = uc.ChromeOptions # noqa: F811
+from .webdriver import Chrome, ChromeOptions # noqa: F401
diff --git a/seleniumwire/undetected_chromedriver/webdriver.py b/seleniumwire/undetected_chromedriver/webdriver.py
new file mode 100644
index 0000000..c261346
--- /dev/null
+++ b/seleniumwire/undetected_chromedriver/webdriver.py
@@ -0,0 +1,64 @@
+import logging
+
+from selenium.webdriver import DesiredCapabilities
+
+try:
+ import undetected_chromedriver as uc
+except ImportError as e:
+ raise ImportError(
+ 'undetected_chromedriver not found. ' 'Install it with `pip install undetected_chromedriver`.'
+ ) from e
+
+from seleniumwire.inspect import InspectRequestsMixin
+from seleniumwire.utils import urlsafe_address
+from seleniumwire.webdriver import DriverCommonMixin
+
+log = logging.getLogger(__name__)
+
+
+class Chrome(InspectRequestsMixin, DriverCommonMixin, uc.Chrome):
+ """Extends the undetected_chrome Chrome webdriver to provide additional
+ methods for inspecting requests."""
+
+ def __init__(self, *args, seleniumwire_options=None, **kwargs):
+ """Initialise a new Chrome WebDriver instance.
+
+ Args:
+ seleniumwire_options: The seleniumwire options dictionary.
+ """
+ if seleniumwire_options is None:
+ seleniumwire_options = {}
+
+ config = self._setup_backend(seleniumwire_options)
+
+ if seleniumwire_options.get('auto_config', True):
+ capabilities = kwargs.get('desired_capabilities')
+ if capabilities is None:
+ capabilities = DesiredCapabilities.CHROME
+ capabilities = capabilities.copy()
+
+ capabilities.update(config)
+
+ kwargs['desired_capabilities'] = capabilities
+
+ try:
+ chrome_options = kwargs['options']
+ except KeyError:
+ chrome_options = ChromeOptions()
+
+ log.info('Using undetected_chromedriver')
+
+ # We need to point Chrome back to Selenium Wire since the executable
+ # will be started separately by undetected_chromedriver.
+ addr, port = urlsafe_address(self.backend.address())
+ chrome_options.add_argument(f'--proxy-server={addr}:{port}')
+ chrome_options.add_argument(
+ f"--proxy-bypass-list={','.join(seleniumwire_options.get('exclude_hosts', ['<-loopback>']))}"
+ )
+
+ kwargs['options'] = chrome_options
+
+ super().__init__(*args, **kwargs)
+
+
+ChromeOptions = uc.ChromeOptions # noqa: F811
diff --git a/seleniumwire/webdriver.py b/seleniumwire/webdriver.py
index cb876e2..115a0ea 100644
--- a/seleniumwire/webdriver.py
+++ b/seleniumwire/webdriver.py
@@ -26,7 +26,7 @@ SELENIUM_V4 = parse_version(getattr(selenium, '__version__', '0')) >= parse_vers
class DriverCommonMixin:
- """Operations common to all webdriver types."""
+ """Attributes common to all webdriver types."""
def _setup_backend(self, seleniumwire_options: Dict[str, Any]) -> Dict[str, Any]:
"""Create the backend proxy server and return its configuration
@@ -121,7 +121,7 @@ class DriverCommonMixin:
class Firefox(InspectRequestsMixin, DriverCommonMixin, _Firefox):
- """Extends the Firefox webdriver to provide additional methods for inspecting requests."""
+ """Extend the Firefox webdriver to provide additional methods for inspecting requests."""
def __init__(self, *args, seleniumwire_options=None, **kwargs):
"""Initialise a new Firefox WebDriver instance.
@@ -174,7 +174,7 @@ class Firefox(InspectRequestsMixin, DriverCommonMixin, _Firefox):
class Chrome(InspectRequestsMixin, DriverCommonMixin, _Chrome):
- """Extends the Chrome webdriver to provide additional methods for inspecting requests."""
+ """Extend the Chrome webdriver to provide additional methods for inspecting requests."""
def __init__(self, *args, seleniumwire_options=None, **kwargs):
"""Initialise a new Chrome WebDriver instance.
@@ -207,7 +207,7 @@ class Chrome(InspectRequestsMixin, DriverCommonMixin, _Chrome):
class Safari(InspectRequestsMixin, DriverCommonMixin, _Safari):
- """Extends the Safari webdriver to provide additional methods for inspecting requests."""
+ """Extend the Safari webdriver to provide additional methods for inspecting requests."""
def __init__(self, seleniumwire_options=None, *args, **kwargs):
"""Initialise a new Safari WebDriver instance.
@@ -230,7 +230,7 @@ class Safari(InspectRequestsMixin, DriverCommonMixin, _Safari):
class Edge(InspectRequestsMixin, DriverCommonMixin, _Edge):
- """Extends the Edge webdriver to provide additional methods for inspecting requests."""
+ """Extend the Edge webdriver to provide additional methods for inspecting requests."""
def __init__(self, seleniumwire_options=None, *args, **kwargs):
"""Initialise a new Edge WebDriver instance.
@@ -253,7 +253,7 @@ class Edge(InspectRequestsMixin, DriverCommonMixin, _Edge):
class Remote(InspectRequestsMixin, DriverCommonMixin, _Remote):
- """Extends the Remote webdriver to provide additional methods for inspecting requests."""
+ """Extend the Remote webdriver to provide additional methods for inspecting requests."""
def __init__(self, *args, seleniumwire_options=None, **kwargs):
"""Initialise a new Firefox WebDriver instance.
diff --git a/setup.py b/setup.py
index 40a722f..013c914 100644
--- a/setup.py
+++ b/setup.py
@@ -61,7 +61,7 @@ setup(
'gunicorn',
'httpbin',
'isort',
- 'mitmproxy', # Needed for end2end tests
+ "mitmproxy>5.3.0; python_version>='3.8.0'", # Needed for end2end tests
'mypy',
'pre-commit',
'pytest',
| wkeeling/selenium-wire | 5a5a83c0189e0a10fbcf100d619148d6c1bc7dad | diff --git a/tests/seleniumwire/test_storage.py b/tests/seleniumwire/test_storage.py
index a31ab9b..67f83a8 100644
--- a/tests/seleniumwire/test_storage.py
+++ b/tests/seleniumwire/test_storage.py
@@ -212,6 +212,18 @@ class RequestStorageTest(TestCase):
self.assertIsNotNone(requests[0].response)
+ @patch('seleniumwire.storage.pickle')
+ def test_load_response_unpickle_error(self, mock_pickle):
+ request = self._create_request()
+ self.storage.save_request(request)
+ response = self._create_response()
+ self.storage.save_response(request.id, response)
+ mock_pickle.load.side_effect = [request, Exception]
+
+ requests = self.storage.load_requests()
+
+ self.assertIsNone(requests[0].response)
+
def test_load_last_request(self):
request_1 = self._create_request()
request_2 = self._create_request()
| importing uc from seleniumwire ignores proxy option
On newer versions of undetected chromedriver, I need to use this arg ``use_subprocess=True`` else I can't run it without getting a Runtime error. (https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/432) This argument seems to break the usage of proxies with selenium wire though.
```python
import seleniumwire.undetected_chromedriver.v2 as uc
from seleniumwire import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.headless = False
seleniumwire_options = {'proxy': {'https': 'type://host:port',}}
driver = uc.Chrome(options=chrome_options, seleniumwire_options=seleniumwire_options, use_subprocess=True)
driver.get('https://whatismyipaddress.com/')
```
Ignores passed proxy option and loads website without proxy. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_response_unpickle_error"
] | [
"tests/seleniumwire/test_storage.py::CreateTest::test_create_default_storage",
"tests/seleniumwire/test_storage.py::CreateTest::test_create_in_memory_storage",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_cleanup_does_not_remove_parent_folder",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_cleanup_removes_storage",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_clear_requests",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_find",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_find_similar_urls",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_get_home_dir",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_get_session_dir",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_initialise",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_initialise_clears_old_folders",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_iter_requests",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_last_request",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_last_request_none",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_request_cert_data",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_request_with_ws_messages",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_requests",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_requests_unpickle_error",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_load_response",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_har_entry",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_har_entry_no_request",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_request",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_request_with_body",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_response",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_response_no_request",
"tests/seleniumwire/test_storage.py::RequestStorageTest::test_save_response_with_body",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_cleanup",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_clear_requests",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_find",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_find_similar_urls",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_get_home_dir",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_iter_requests",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_load_last_request",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_load_last_request_none",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_load_request_with_ws_messages",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_load_requests",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_har_entry",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_har_entry_no_request",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_request",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_request_max_size",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_request_max_size_zero",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_response",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_response_cert_data",
"tests/seleniumwire/test_storage.py::InMemoryRequestStorageTest::test_save_response_no_request"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-02-16T20:12:56Z" | mit |
|
wookayin__expt-5 | diff --git a/expt/plot.py b/expt/plot.py
index 657d7e5..5a09b36 100644
--- a/expt/plot.py
+++ b/expt/plot.py
@@ -21,6 +21,11 @@ warnings.filterwarnings("ignore", category=UserWarning,
message='Creating legend with loc="best"')
# yapf: enable
+HypothesisSummaryFn = Callable[ # see HypothesisPlotter
+ [Hypothesis], pd.DataFrame]
+HypothesisSummaryErrFn = Callable[ # see HypothesisPlotter
+ [Hypothesis], Union[pd.DataFrame, Tuple[pd.DataFrame, pd.DataFrame]]]
+
class GridPlot:
"""Multi-plot grid subplots.
@@ -269,7 +274,8 @@ class HypothesisPlotter:
*args,
subplots=True,
err_style="runs",
- err_fn: Optional[Callable[[Hypothesis], pd.DataFrame]] = None,
+ err_fn: Optional[HypothesisSummaryFn] = None,
+ representative_fn: Optional[HypothesisSummaryErrFn] = None,
std_alpha=0.2,
runs_alpha=0.2,
n_samples=None,
@@ -309,13 +315,31 @@ class HypothesisPlotter:
(i) runs, unit_traces: Show individual runs/traces (see runs_alpha)
(ii) band, fill: Show as shaded area (see std_alpha)
(iii) None or False: do not display any errors
- - err_fn (Callable: Hypothesis -> pd.DataFrame):
- A strategy to compute the standard error or deviation. This should
- return the standard err results as a DataFrame, having the same
- column and index as the hypothesis.
- Defaults to "standard deviation.", i.e. `hypothoses.grouped.std()`.
- To use standard error, use `err_fn=lambda h: h.grouped.sem()`.
- - std_alpha (float): If not None, will show the 1-std range as a
+ - err_fn (Callable: Hypothesis -> pd.DataFrame | Tuple):
+ A strategy to compute the error range when err_style is band or fill.
+ Defaults to "standard deviation.", i.e. `hypothosis.grouped.std()`.
+ This function may return either:
+ (i) a single DataFrame, representing the standard error,
+ which must have the same column and index as the hypothesis; or
+ (ii) a tuple of two DataFrames, representing the error range
+ (lower, upper). Both DataFrames must also have the same
+ column and index as the hypothesis.
+ In the case of (i), we assume that a custom `representative_fn` is
+ NOT being used, but the representative value of the hypothesis is
+ the grouped mean of the Hypothesis, i.e., `hypothesis.mean()`.
+ (Example) To use standard error for the bands, you can use either
+ `err_fn=lambda h: h.grouped.sem()` or
+ `err_fn=lambda h: (h.grouped.mean() - h.grouped.sem(),
+ h.grouped.mean() + h.grouped.sem())`.
+ - representative_fn (Callable: Hypothesis -> pd.DataFrame):
+ A strategy to compute the representative value (usually drawn
+ in a thicker line) when plotting.
+ This function should return a DataFrame that has the same column
+ and index as the hypothesis.
+ Defaults to "sample mean.", i.e., `hypothesis.mean()`
+ For instance, to use median instead of mean, use
+ `representative_fn=lambda h: h.grouped.median()`
+ - std_alpha (float): If not None, will show the error band as a
shaded area. Defaults 0.2,
- runs_alpha (float): If not None, will draw an individual line
for each run. Defaults 0.2.
@@ -339,17 +363,50 @@ class HypothesisPlotter:
# nothing to draw (no rows)
raise ValueError("No data to plot, all runs have empty DataFrame.")
- mean, std = None, None
- _h_interpolated = None
+ def _representative_and_err(h: Hypothesis) -> Tuple[
+ pd.DataFrame, # representative (mean)
+ Tuple[pd.DataFrame, pd.DataFrame] # error band range (stderr)
+ ]: # yapf: disable
+ """Evaluate representative_fn and err_fn."""
- def _mean_and_err(h: Hypothesis): # type: ignore
- mean = h.grouped.mean()
+ representative = representative_fn(h) if representative_fn \
+ else h.grouped.mean() # noqa: E127
+ err_range: Tuple[pd.DataFrame, pd.DataFrame]
std = err_fn(h) if err_fn else h.grouped.std()
- return mean, std
+
+ # Condition check: when representative_fn is given,
+ # err_fn should return a range (i.e., tuple)
+ if representative_fn and err_fn and not isinstance(std, tuple):
+ raise ValueError(
+ "When representative_fn is given, err_fn must return a range "
+ "(tuple of pd.DataFrame) representing the lower and upper value "
+ "of the error band. Pass err_fn=None to use the default one, "
+ "or try: lambda h: (h.mean() + h.std(), h.mean() - h.std()). "
+ f"err_fn returned: {std}")
+
+ if isinstance(std, pd.DataFrame):
+ mean = h.grouped.mean()
+ err_range = (mean - std, mean + std)
+ return representative, err_range
+
+ elif (isinstance(std, tuple) and len(std) == 2 and
+ isinstance(std[0], pd.DataFrame) and
+ isinstance(std[1], pd.DataFrame)):
+ err_range = (std[0], std[1])
+ return representative, err_range # type: ignore
+
+ raise ValueError("err_fn must return either a tuple of "
+ "two DataFrames or a single DataFrame, but "
+ f"got {type(std)}")
+
+ NULL = pd.DataFrame()
+ representative = NULL
+ err = (NULL, NULL)
+ _h_interpolated = None
if 'x' not in kwargs:
# index (same across runs) being x value, so we can simply average
- mean, std = _mean_and_err(self._parent)
+ representative, err = _representative_and_err(self._parent)
else:
# might have different x values --- we need to interpolate.
# (i) check if the x-column is consistent?
@@ -363,31 +420,33 @@ class HypothesisPlotter:
"recommended.", UserWarning)
n_samples = 10000
else:
- mean, std = _mean_and_err(self._parent)
+ representative, err = _representative_and_err(self._parent)
if n_samples is not None:
# subsample by interpolation, then average.
_h_interpolated = self._parent.interpolate(
x_column=kwargs.get('x', None), n_samples=n_samples)
- mean, std = _mean_and_err(_h_interpolated)
+ representative, err = _representative_and_err(_h_interpolated)
# Now that the index of group-averaged dataframes are the x samples
# we interpolated on, we can let DataFrame.plot use them as index
if 'x' in kwargs:
del kwargs['x']
- if not isinstance(std, pd.DataFrame):
- raise TypeError(f"err_fn should return a pd.DataFrame, got {type(std)}")
+ if not isinstance(representative, pd.DataFrame):
+ raise TypeError("representative_fn should return a pd.DataFrame, "
+ f"but got {type(err)}")
# there might be many NaN values if each column is being logged
# at a different period. We fill in the missing values.
- mean = mean.interpolate() # type: ignore
- std = std.interpolate() # type: ignore
- assert mean is not None and std is not None
+ representative = representative.interpolate()
+ assert representative is not None
+ err = (err[0].interpolate(), err[1].interpolate())
+ assert err[0] is not None and err[1] is not None
# determine which columns to draw (i.e. y) before smoothing.
# should only include numerical values
- y: Iterable[str] = kwargs.get('y', None) or mean.columns
+ y: Iterable[str] = kwargs.get('y', None) or representative.columns
if isinstance(y, str):
y = [y]
if 'x' in kwargs:
@@ -397,24 +456,25 @@ class HypothesisPlotter:
# TODO(remove): this is hack to handle homogeneous column names
# over different hypotheses in a single of experiment, because it
# will end up adding dummy columns instead of ignoring unknowns.
- extra_y = set(y) - set(mean.columns)
+ extra_y = set(y) - set(representative.columns)
for yi in extra_y:
- mean[yi] = np.nan
+ representative[yi] = np.nan
def _should_include_column(col_name: str) -> bool:
if not col_name: # empty name
return False
# unknown column in the DataFrame
- assert mean is not None
- dtypes = mean.dtypes.to_dict() # type: ignore
+ assert representative is not None
+ dtypes = representative.dtypes.to_dict() # type: ignore
if col_name not in dtypes:
if ignore_unknown:
return False # just ignore, no error
else:
- raise ValueError(f"Unknown column name '{col_name}'. " +
- f"Available columns: {list(mean.columns)}; " +
- "Use ignore_unknown=True to ignore unknown columns.")
+ raise ValueError(
+ f"Unknown column name '{col_name}'. " +
+ f"Available columns: {list(representative.columns)}; " +
+ "Use ignore_unknown=True to ignore unknown columns.")
# include only numeric values (integer or float)
if not (dtypes[col_name].kind in ('i', 'f')):
@@ -424,8 +484,10 @@ class HypothesisPlotter:
y = [yi for yi in y if _should_include_column(yi)]
if rolling:
- mean = mean.rolling(rolling, min_periods=1, center=True).mean()
- std = std.rolling(rolling, min_periods=1, center=True).mean()
+ representative = representative.rolling(
+ rolling, min_periods=1, center=True).mean()
+ err = (err[0].rolling(rolling, min_periods=1, center=True).mean(),
+ err[1].rolling(rolling, min_periods=1, center=True).mean())
# suptitle: defaults to hypothesis name if ax/grid was not given
if suptitle is None and (ax is None and grid is None):
@@ -433,8 +495,8 @@ class HypothesisPlotter:
return self._do_plot(
y,
- mean, # type: ignore
- std, # type: ignore
+ representative, # type: ignore
+ err, # type: ignore
_h_interpolated=_h_interpolated,
n_samples=n_samples,
subplots=subplots,
@@ -465,8 +527,8 @@ class HypothesisPlotter:
def _do_plot(
self,
y: List[str],
- mean: pd.DataFrame,
- std: pd.DataFrame,
+ representative: pd.DataFrame, # usually mean
+ err_range: Tuple[pd.DataFrame, pd.DataFrame], # usually mean ± stderr
*,
_h_interpolated: Optional[Hypothesis] = None, # type: ignore
n_samples: Optional[int],
@@ -544,7 +606,7 @@ class HypothesisPlotter:
else:
kwargs['legend'] = bool(legend)
- axes = mean.plot(*args, subplots=subplots, ax=ax, **kwargs)
+ axes = representative.plot(*args, subplots=subplots, ax=ax, **kwargs)
if err_style not in self.KNOWN_ERR_STYLES:
raise ValueError(f"Unknown err_style '{err_style}', "
@@ -556,10 +618,10 @@ class HypothesisPlotter:
ax = cast(Axes, ax)
mean_line = ax.get_lines()[-1]
x = kwargs.get('x', None)
- x_values = mean[x].values if x else mean[yi].index
+ x_values = representative[x].values if x else representative[yi].index
ax.fill_between(x_values,
- (mean - std)[yi].values,
- (mean + std)[yi].values,
+ err_range[0][yi].values,
+ err_range[1][yi].values,
color=mean_line.get_color(),
alpha=std_alpha) # yapf: disable
@@ -623,8 +685,8 @@ class HypothesisHvPlotter(HypothesisPlotter):
def _do_plot(
self,
y: List[str],
- mean: pd.DataFrame,
- std: pd.DataFrame,
+ representative: pd.DataFrame,
+ err_range: Tuple[pd.DataFrame, pd.DataFrame], # usually mean ± stderr
*,
_h_interpolated: Optional[Hypothesis] = None,
n_samples: Optional[int],
@@ -642,7 +704,7 @@ class HypothesisHvPlotter(HypothesisPlotter):
args: List,
kwargs: Dict,
):
- if not hasattr(mean, 'hvplot'):
+ if not hasattr(representative, 'hvplot'):
import hvplot.pandas
if subplots:
@@ -650,7 +712,7 @@ class HypothesisHvPlotter(HypothesisPlotter):
# TODO implement various options for hvplot.
kwargs.update(dict(y=y))
- p = mean.hvplot(shared_axes=False, subplots=True, **kwargs)
+ p = representative.hvplot(shared_axes=False, subplots=True, **kwargs)
# Display a single legend without duplication
if legend and isinstance(p.data, dict):
@@ -674,9 +736,9 @@ class HypothesisHvPlotter(HypothesisPlotter):
raise NotImplementedError
if err_style in ('band', 'fill') and std_alpha:
- band_lower = mean - std
+ # TODO
+ band_lower, band_upper = err_range
band_lower['_facet'] = 'lower'
- band_upper = mean + std
band_upper['_facet'] = 'upper'
band = pd.concat([band_lower.add_suffix('.min'),
band_upper.add_suffix('.max')], axis=1) # yapf: disable
| wookayin/expt | 39cb29ab535082f8c209cf993708016245fe977a | diff --git a/expt/plot_test.py b/expt/plot_test.py
index f10c603..985f08d 100644
--- a/expt/plot_test.py
+++ b/expt/plot_test.py
@@ -1,7 +1,7 @@
"""Tests for expt.plot"""
import contextlib
import sys
-from typing import List, cast
+from typing import List, Tuple, cast
import matplotlib
import matplotlib.pyplot as plt
@@ -43,6 +43,7 @@ def matplotlib_rcparams(kwargs: dict):
# -----------------------------------------------------------------------------
# Fixtures
+# pylint: disable=redefined-outer-name
@pytest.fixture
@@ -247,8 +248,12 @@ class TestHypothesisPlot:
def test_error_range_custom_fn(self, hypothesis: Hypothesis):
"""Tests plot(err_fn=...)"""
+ # Case 1: err_fn returns a single DataFrame.
+ # ------------------------------------------
def err_fn(h: Hypothesis) -> pd.DataFrame:
- return cast(pd.DataFrame, h.grouped.std()).applymap(lambda x: 5000)
+ df: pd.DataFrame = h.grouped.mean()
+ df['loss'][:] = 5000
+ return df
# without interpolation
g = hypothesis.plot(x='step', y='loss', err_style='fill', err_fn=err_fn)
@@ -264,6 +269,52 @@ class TestHypothesisPlot:
x='step', y='loss', err_style='runs', n_samples=100,
err_fn=err_fn) # Note: with err_style='runs', err_fn is not useful..?
+ # Case 2: err_fn returns a tuple of two DataFrames.
+ # -------------------------------------------------
+ def err_fn2(h: Hypothesis) -> Tuple[pd.DataFrame, pd.DataFrame]:
+ df: pd.DataFrame = h.grouped.mean()
+ std: pd.DataFrame = h.grouped.sem()
+ return (df - std, df + std * 100000)
+
+ # without interpolation
+ g = hypothesis.plot(x='step', y='loss', err_style='fill', err_fn=err_fn2)
+ band = g['loss'].collections[0].get_paths()[0].vertices
+
+ # std is approximately 0.25 (0.25 * 100_000 ~= 25000)
+ assert -1 <= np.min(band[:, 1]) <= 0
+ assert 20000 <= np.max(band[:, 1]) <= 30000
+
+ def test_representative_custom_fn(self, hypothesis: Hypothesis):
+ """Tests plot(representative_fn=...)"""
+
+ def repr_fn(h: Hypothesis) -> pd.DataFrame:
+ # A dummy function that manipulates the representative value ('mean')
+ df: pd.DataFrame = h.grouped.mean()
+ df['loss'] = np.asarray(df.reset_index()['step']) * -1.0
+ return df
+
+ def _ensure_representative_curve(line):
+ assert line.get_alpha() is None
+ return line
+
+ # without interpolation
+ g = hypothesis.plot(x='step', y='loss', representative_fn=repr_fn)
+ line = _ensure_representative_curve(g['loss'].get_lines()[0])
+ np.testing.assert_array_equal(line.get_xdata() * -1, line.get_ydata())
+
+ # with interpolation
+ # yapf: disable
+ g = hypothesis.plot(x='step', y='loss', n_samples=100,
+ representative_fn=repr_fn, err_style='fill') # fill
+ line = _ensure_representative_curve(g['loss'].get_lines()[0])
+ np.testing.assert_array_equal(line.get_xdata() * -1, line.get_ydata())
+
+ g = hypothesis.plot(x='step', y='loss', n_samples=100,
+ representative_fn=repr_fn, err_style='runs') # runs
+ line = _ensure_representative_curve(g['loss'].get_lines()[0])
+ np.testing.assert_array_equal(line.get_xdata() * -1, line.get_ydata())
+ # yapf: enable
+
class TestExperimentPlot:
| Feature Request: Plotting the median
Hi @wookayin, I have been using the `expt` package to do plotting, and the experience has been great.
Any chance you could add support for plotting the **median**? I am trying to plot the human normalized score used in classical Atari literature, so it would be useful to plot the median instead of mean. As an example, the snippet below plots the mean
```python
# Costa: Note the data is not the same as Mnih et al., 2015
# Note the random agent score on Video Pinball is sometimes greater than the
# human score under other evaluation methods.
atari_human_normalized_scores = {
'Alien-v5': (227.8, 7127.7),
'Amidar-v5': (5.8, 1719.5),
'Assault-v5': (222.4, 742.0),
'Asterix-v5': (210.0, 8503.3),
'Asteroids-v5': (719.1, 47388.7),
'Atlantis-v5': (12850.0, 29028.1),
'BankHeist-v5': (14.2, 753.1),
'BattleZone-v5': (2360.0, 37187.5),
'BeamRider-v5': (363.9, 16926.5),
'Berzerk-v5': (123.7, 2630.4),
'Bowling-v5': (23.1, 160.7),
'Boxing-v5': (0.1, 12.1),
'Breakout-v5': (1.7, 30.5),
'Centipede-v5': (2090.9, 12017.0),
'ChopperCommand-v5': (811.0, 7387.8),
'CrazyClimber-v5': (10780.5, 35829.4),
'Defender-v5': (2874.5, 18688.9),
# 'DemonAttack-v5': (152.1, 1971.0),
# 'DoubleDunk-v5': (-18.6, -16.4),
# 'Enduro-v5': (0.0, 860.5),
# 'FishingDerby-v5': (-91.7, -38.7),
# 'Freeway-v5': (0.0, 29.6),
# 'Frostbite-v5': (65.2, 4334.7),
# 'Gopher-v5': (257.6, 2412.5),
# 'Gravitar-v5': (173.0, 3351.4),
# 'Hero-v5': (1027.0, 30826.4),
# 'IceHockey-v5': (-11.2, 0.9),
# 'Jamesbond-v5': (29.0, 302.8),
# 'Kangaroo-v5': (52.0, 3035.0),
# 'Krull-v5': (1598.0, 2665.5),
# 'KungFuMaster-v5': (258.5, 22736.3),
# 'MontezumaRevenge-v5': (0.0, 4753.3),
# 'MsPacman-v5': (307.3, 6951.6),
# 'NameThisGame-v5': (2292.3, 8049.0),
# 'Phoenix-v5': (761.4, 7242.6),
# 'Pitfall-v5': (-229.4, 6463.7),
# 'Pong-v5': (-20.7, 14.6),
# 'PrivateEye-v5': (24.9, 69571.3),
# 'Qbert-v5': (163.9, 13455.0),
# 'Riverraid-v5': (1338.5, 17118.0),
# 'RoadRunner-v5': (11.5, 7845.0),
# 'Robotank-v5': (2.2, 11.9),
# 'Seaquest-v5': (68.4, 42054.7),
# 'Skiing-v5': (-17098.1, -4336.9),
# 'Solaris-v5': (1236.3, 12326.7),
# 'SpaceInvaders-v5': (148.0, 1668.7),
# 'StarGunner-v5': (664.0, 10250.0),
# 'Surround-v5': (-10.0, 6.5),
# 'Tennis-v5': (-23.8, -8.3),
# 'TimePilot-v5': (3568.0, 5229.2),
# 'Tutankham-v5': (11.4, 167.6),
# 'UpNDown-v5': (533.4, 11693.2),
# 'Venture-v5': (0.0, 1187.5),
# 'VideoPinball-v5': (16256.9, 17667.9),
# 'WizardOfWor-v5': (563.5, 4756.5),
# 'YarsRevenge-v5': (3092.9, 54576.9),
# 'Zaxxon-v5': (32.5, 9173.3),
}
import enum
from matplotlib import axis
import numpy as np
import expt
from expt import Run, Hypothesis, Experiment
import pandas as pd
import matplotlib.pyplot as plt
import wandb
import wandb.apis.reports as wb # noqa
from expt.plot import GridPlot
def create_expt_runs(wandb_runs):
runs = []
for idx, run in enumerate(wandb_runs):
wandb_run = run.history()
if 'videos' in wandb_run:
wandb_run = wandb_run.drop(columns=['videos'], axis=1)
runs += [Run(f"seed{idx}", wandb_run)]
return runs
api = wandb.Api()
env_ids = atari_human_normalized_scores.keys()
NUM_FRAME_STACK = 4
runss = []
for env_id in env_ids:
api = wandb.Api()
wandb_runs = api.runs(
path="costa-huang/envpool-atari",
filters={'$and': [{'config.env_id.value': env_id}, {'config.exp_name.value': 'ppo_atari_envpool_xla_jax'}]}
)
expt_runs = create_expt_runs(wandb_runs)
# normalize scores and adjust x-axis from steps to frames
for expt_run in expt_runs:
expt_run.df["charts/avg_episodic_return"] = (
expt_run.df["charts/avg_episodic_return"] - atari_human_normalized_scores[env_id][0]) / \
(atari_human_normalized_scores[env_id][1] - atari_human_normalized_scores[env_id][0]
)
expt_run.df["global_step"] *= NUM_FRAME_STACK
runss.extend(expt_runs)
h = Hypothesis("CleanRL's PPO + Envpool", runss)
fig, ax = plt.subplots(figsize=(4, 4))
g = h.plot(x='global_step', y="charts/avg_episodic_return", rolling=50, n_samples=400, legend=False, err_fn=lambda h: h.grouped.sem(), err_style="fill",
suptitle="", ax=ax,)
ax.set_title("CleanRL's PPO + Envpool")
ax.yaxis.set_label_text("Human normalized score")
ax.xaxis.set_label_text("Frames")
plt.savefig("test.png", bbox_inches='tight')
```
<img width="401" alt="image" src="https://user-images.githubusercontent.com/5555347/179360171-1acfa6c0-55ea-48d5-8031-f03ae867ee55.png">
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"expt/plot_test.py::TestHypothesisPlot::test_error_range_custom_fn",
"expt/plot_test.py::TestHypothesisPlot::test_representative_custom_fn"
] | [
"expt/plot_test.py::TestGridPlot::test_layout",
"expt/plot_test.py::TestHypothesisPlot::test_grid_spec",
"expt/plot_test.py::TestHypothesisPlot::test_when_fig_axes_are_given",
"expt/plot_test.py::TestHypothesisPlot::test_suptitle",
"expt/plot_test.py::TestHypothesisPlot::test_single_hypothesis_legend",
"expt/plot_test.py::TestHypothesisPlot::test_error_range_averaging",
"expt/plot_test.py::TestExperimentPlot::test_gridplot_basic",
"expt/plot_test.py::TestExperimentPlot::test_when_fig_axes_are_given",
"expt/plot_test.py::TestExperimentPlot::test_suptitle",
"expt/plot_test.py::TestExperimentPlot::test_multi_hypothesis_legend",
"expt/plot_test.py::TestExperimentPlot::test_multi_hypothesis_legend_presets",
"expt/plot_test.py::TestExperimentPlot::test_color_kwargs"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-07-17T11:54:53Z" | mit |
|
wookayin__gpustat-28 | diff --git a/gpustat.py b/gpustat.py
index 4ec8a41..df936c4 100755
--- a/gpustat.py
+++ b/gpustat.py
@@ -113,6 +113,24 @@ class GPUStat(object):
v = self.entry['utilization.gpu']
return int(v) if v is not None else None
+ @property
+ def power_draw(self):
+ """
+ Returns the GPU power usage in Watts,
+ or None if the information is not available.
+ """
+ v = self.entry['power.draw']
+ return int(v) if v is not None else None
+
+ @property
+ def power_limit(self):
+ """
+ Returns the (enforced) GPU power limit in Watts,
+ or None if the information is not available.
+ """
+ v = self.entry['enforced.power.limit']
+ return int(v) if v is not None else None
+
@property
def processes(self):
"""
@@ -126,6 +144,7 @@ class GPUStat(object):
show_cmd=False,
show_user=False,
show_pid=False,
+ show_power=False,
gpuname_width=16,
term=Terminal(),
):
@@ -150,6 +169,8 @@ class GPUStat(object):
colors['CUser'] = term.bold_black # gray
colors['CUtil'] = _conditional(lambda: int(self.entry['utilization.gpu']) < 30,
term.green, term.bold_green)
+ colors['CPowU'] = term.bold_red
+ colors['CPowL'] = term.red
if not with_colors:
for k in list(colors.keys()):
@@ -160,10 +181,14 @@ class GPUStat(object):
else: return str(v)
# build one-line display information
- reps = ("%(C1)s[{entry[index]}]%(C0)s %(CName)s{entry[name]:{gpuname_width}}%(C0)s |" +
- "%(CTemp)s{entry[temperature.gpu]:>3}'C%(C0)s, %(CUtil)s{entry[utilization.gpu]:>3} %%%(C0)s | " +
- "%(C1)s%(CMemU)s{entry[memory.used]:>5}%(C0)s / %(CMemT)s{entry[memory.total]:>5}%(C0)s MB"
- ) % colors
+ # we want power use optional, but if deserves being grouped with temperature and utilization
+ reps = "%(C1)s[{entry[index]}]%(C0)s %(CName)s{entry[name]:{gpuname_width}}%(C0)s |" \
+ "%(CTemp)s{entry[temperature.gpu]:>3}'C%(C0)s, %(CUtil)s{entry[utilization.gpu]:>3} %%%(C0)s"
+
+ if show_power:
+ reps += ", %(CPowU)s{entry[power.draw]:>3}%(C0)s / %(CPowL)s{entry[enforced.power.limit]:>3}%(C0)s W"
+ reps += " | %(C1)s%(CMemU)s{entry[memory.used]:>5}%(C0)s / %(CMemT)s{entry[memory.total]:>5}%(C0)s MB"
+ reps = (reps) % colors
reps = reps.format(entry={k: _repr(v) for (k, v) in self.entry.items()},
gpuname_width=gpuname_width)
reps += " |"
@@ -252,6 +277,16 @@ class GPUStatCollection(object):
except N.NVMLError:
utilization = None # Not supported
+ try:
+ power = N.nvmlDeviceGetPowerUsage(handle)
+ except:
+ power = None
+
+ try:
+ power_limit = N.nvmlDeviceGetEnforcedPowerLimit(handle)
+ except:
+ power_limit = None
+
processes = []
try:
nv_comp_processes = N.nvmlDeviceGetComputeRunningProcesses(handle)
@@ -284,6 +319,8 @@ class GPUStatCollection(object):
'name': name,
'temperature.gpu': temperature,
'utilization.gpu': utilization.gpu if utilization else None,
+ 'power.draw': int(power / 1000) if power is not None else None,
+ 'enforced.power.limit': int(power_limit / 1000) if power is not None else None,
# Convert bytes into MBytes
'memory.used': int(memory.used / 1024 / 1024) if memory else None,
'memory.total': int(memory.total / 1024 / 1024) if memory else None,
@@ -323,7 +360,7 @@ class GPUStatCollection(object):
def print_formatted(self, fp=sys.stdout, force_color=False, no_color=False,
show_cmd=False, show_user=False, show_pid=False,
- gpuname_width=16,
+ show_power=False, gpuname_width=16,
):
# ANSI color configuration
if force_color and no_color:
@@ -355,6 +392,7 @@ class GPUStatCollection(object):
show_cmd=show_cmd,
show_user=show_user,
show_pid=show_pid,
+ show_power=show_power,
gpuname_width=gpuname_width,
term=t_color)
fp.write('\n')
@@ -430,6 +468,8 @@ def main():
help='Display username of running process')
parser.add_argument('-p', '--show-pid', action='store_true',
help='Display PID of running process')
+ parser.add_argument('-P', '--show-power', action='store_true',
+ help='Show GPU power usage (and limit)')
parser.add_argument('--gpuname-width', type=int, default=16,
help='The minimum column width of GPU names, defaults to 16')
parser.add_argument('--json', action='store_true', default=False,
| wookayin/gpustat | a38bc5fd11add4a8ab805f5b327020196ce558d0 | diff --git a/test_gpustat.py b/test_gpustat.py
index 0ac0279..4b81978 100644
--- a/test_gpustat.py
+++ b/test_gpustat.py
@@ -72,6 +72,18 @@ def _configure_mock(N, Process,
mock_handles[2]: 71,
}.get(handle, RuntimeError))
+ N.nvmlDeviceGetPowerUsage = _raise_ex(lambda handle: {
+ mock_handles[0]: 125000,
+ mock_handles[1]: 100000,
+ mock_handles[2]: 250000,
+ }.get(handle, RuntimeError))
+
+ N.nvmlDeviceGetEnforcedPowerLimit = _raise_ex(lambda handle: {
+ mock_handles[0]: 250000,
+ mock_handles[1]: 250000,
+ mock_handles[2]: 250000,
+ }.get(handle, RuntimeError))
+
mock_memory_t = namedtuple("Memory_t", ['total', 'used'])
N.nvmlDeviceGetMemoryInfo.side_effect = _raise_ex(lambda handle: {
mock_handles[0]: mock_memory_t(total=12883853312, used=8000*MB),
@@ -147,7 +159,7 @@ class TestGPUStat(unittest.TestCase):
gpustats = gpustat.new_query()
fp = StringIO()
- gpustats.print_formatted(fp=fp, no_color=False, show_user=True, show_cmd=True, show_pid=True)
+ gpustats.print_formatted(fp=fp, no_color=False, show_user=True, show_cmd=True, show_pid=True, show_power=True)
result = fp.getvalue()
print(result)
@@ -157,9 +169,9 @@ class TestGPUStat(unittest.TestCase):
unescaped = '\n'.join(unescaped.split('\n')[1:])
expected = """\
-[0] GeForce GTX TITAN 0 | 80'C, 76 % | 8000 / 12287 MB | user1:python/48448(4000M) user2:python/153223(4000M)
-[1] GeForce GTX TITAN 1 | 36'C, 0 % | 9000 / 12189 MB | user1:torch/192453(3000M) user3:caffe/194826(6000M)
-[2] GeForce GTX TITAN 2 | 71'C, ?? % | 0 / 12189 MB | (Not Supported)
+[0] GeForce GTX TITAN 0 | 80'C, 76 %, 125 / 250 W | 8000 / 12287 MB | user1:python/48448(4000M) user2:python/153223(4000M)
+[1] GeForce GTX TITAN 1 | 36'C, 0 %, 100 / 250 W | 9000 / 12189 MB | user1:torch/192453(3000M) user3:caffe/194826(6000M)
+[2] GeForce GTX TITAN 2 | 71'C, ?? %, 250 / 250 W | 0 / 12189 MB | (Not Supported)
"""
self.maxDiff = 4096
self.assertEqual(unescaped, expected)
| Power usage
Hi,
How to add power usage and efficiency information ? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"test_gpustat.py::TestGPUStat::test_new_query_mocked"
] | [
"test_gpustat.py::TestGPUStat::test_attributes_and_items",
"test_gpustat.py::TestGPUStat::test_new_query_mocked_nonexistent_pid"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2017-09-19T17:20:15Z" | mit |
|
wookayin__gpustat-63 | diff --git a/README.md b/README.md
index 4b9d24c..33bbad4 100644
--- a/README.md
+++ b/README.md
@@ -28,6 +28,7 @@ Options:
* `-u`, `--show-user` : Display username of the process owner
* `-c`, `--show-cmd` : Display the process name
* `-p`, `--show-pid` : Display PID of the process
+* `-F`, `--show-fan` : Display GPU fan speed
* `-P`, `--show-power` : Display GPU power usage and/or limit (`draw` or `draw,limit`)
* `--watch`, `-i`, `--interval` : Run in watch mode (equivalent to `watch gpustat`) if given. Denotes interval between updates. ([#41][gh-issue-41])
* `--json` : JSON Output (Experimental, [#10][gh-issue-10])
diff --git a/gpustat/__main__.py b/gpustat/__main__.py
index dab7954..8de332f 100644
--- a/gpustat/__main__.py
+++ b/gpustat/__main__.py
@@ -79,6 +79,8 @@ def main(*argv):
help='Display username of running process')
parser.add_argument('-p', '--show-pid', action='store_true',
help='Display PID of running process')
+ parser.add_argument('-F', '--show-fan', action='store_true',
+ help='Display GPU fan speed')
parser.add_argument('--json', action='store_true', default=False,
help='Print all the information in JSON format')
parser.add_argument('-v', '--version', action='version',
diff --git a/gpustat/core.py b/gpustat/core.py
index 85c85cf..dad85a3 100644
--- a/gpustat/core.py
+++ b/gpustat/core.py
@@ -107,6 +107,15 @@ class GPUStat(object):
v = self.entry['temperature.gpu']
return int(v) if v is not None else None
+ @property
+ def fan(self):
+ """
+ Returns the fan percentage of GPU as an integer,
+ or None if the information is not available.
+ """
+ v = self.entry['fan.speed']
+ return int(v) if v is not None else None
+
@property
def utilization(self):
"""
@@ -147,6 +156,7 @@ class GPUStat(object):
show_user=False,
show_pid=False,
show_power=None,
+ show_fan=None,
gpuname_width=16,
term=Terminal(),
):
@@ -165,6 +175,8 @@ class GPUStat(object):
colors['CName'] = term.blue
colors['CTemp'] = _conditional(lambda: self.temperature < 50,
term.red, term.bold_red)
+ colors['FSpeed'] = _conditional(lambda: self.fan < 50,
+ term.yellow, term.bold_yellow)
colors['CMemU'] = term.bold_yellow
colors['CMemT'] = term.yellow
colors['CMemP'] = term.yellow
@@ -189,8 +201,12 @@ class GPUStat(object):
# temperature and utilization
reps = "%(C1)s[{entry[index]}]%(C0)s " \
"%(CName)s{entry[name]:{gpuname_width}}%(C0)s |" \
- "%(CTemp)s{entry[temperature.gpu]:>3}'C%(C0)s, " \
- "%(CUtil)s{entry[utilization.gpu]:>3} %%%(C0)s"
+ "%(CTemp)s{entry[temperature.gpu]:>3}'C%(C0)s, "
+
+ if show_fan:
+ reps += "%(FSpeed)s{entry[fan.speed]:>3} %%%(C0)s, "
+
+ reps += "%(CUtil)s{entry[utilization.gpu]:>3} %%%(C0)s"
if show_power:
reps += ", %(CPowU)s{entry[power.draw]:>3}%(C0)s "
@@ -300,6 +316,11 @@ class GPUStatCollection(object):
except N.NVMLError:
temperature = None # Not supported
+ try:
+ fan_speed = N.nvmlDeviceGetFanSpeed(handle)
+ except N.NVMLError:
+ fan_speed = None # Not supported
+
try:
memory = N.nvmlDeviceGetMemoryInfo(handle) # in Bytes
except N.NVMLError:
@@ -354,6 +375,7 @@ class GPUStatCollection(object):
'uuid': uuid,
'name': name,
'temperature.gpu': temperature,
+ 'fan.speed': fan_speed,
'utilization.gpu': utilization.gpu if utilization else None,
'power.draw': power // 1000 if power is not None else None,
'enforced.power.limit': power_limit // 1000
@@ -403,7 +425,7 @@ class GPUStatCollection(object):
def print_formatted(self, fp=sys.stdout, force_color=False, no_color=False,
show_cmd=False, show_user=False, show_pid=False,
- show_power=None, gpuname_width=16,
+ show_power=None, show_fan=None, gpuname_width=16,
show_header=True,
eol_char=os.linesep,
**kwargs
@@ -453,6 +475,7 @@ class GPUStatCollection(object):
show_user=show_user,
show_pid=show_pid,
show_power=show_power,
+ show_fan=show_fan,
gpuname_width=gpuname_width,
term=t_color)
fp.write(eol_char)
| wookayin/gpustat | 28299cdcf55dd627fdd9800cf344988b43188ee8 | diff --git a/gpustat/test_gpustat.py b/gpustat/test_gpustat.py
index d41dd6b..088b6bd 100644
--- a/gpustat/test_gpustat.py
+++ b/gpustat/test_gpustat.py
@@ -81,6 +81,12 @@ def _configure_mock(N, Process,
mock_handles[2]: 71,
}.get(handle, RuntimeError))
+ N.nvmlDeviceGetFanSpeed = _raise_ex(lambda handle: {
+ mock_handles[0]: 16,
+ mock_handles[1]: 53,
+ mock_handles[2]: 100,
+ }.get(handle, RuntimeError))
+
N.nvmlDeviceGetPowerUsage = _raise_ex(lambda handle: {
mock_handles[0]: 125000,
mock_handles[1]: N.NVMLError_NotSupported(), # Not Supported
@@ -154,9 +160,9 @@ MOCK_EXPECTED_OUTPUT_DEFAULT = """\
""" # noqa: E501
MOCK_EXPECTED_OUTPUT_FULL = """\
-[0] GeForce GTX TITAN 0 | 80'C, 76 %, 125 / 250 W | 8000 / 12287 MB | user1:python/48448(4000M) user2:python/153223(4000M)
-[1] GeForce GTX TITAN 1 | 36'C, 0 %, ?? / 250 W | 9000 / 12189 MB | user1:torch/192453(3000M) user3:caffe/194826(6000M)
-[2] GeForce GTX TITAN 2 | 71'C, ?? %, 250 / ?? W | 0 / 12189 MB | (Not Supported)
+[0] GeForce GTX TITAN 0 | 80'C, 16 %, 76 %, 125 / 250 W | 8000 / 12287 MB | user1:python/48448(4000M) user2:python/153223(4000M)
+[1] GeForce GTX TITAN 1 | 36'C, 53 %, 0 %, ?? / 250 W | 9000 / 12189 MB | user1:torch/192453(3000M) user3:caffe/194826(6000M)
+[2] GeForce GTX TITAN 2 | 71'C, 100 %, ?? %, 250 / ?? W | 0 / 12189 MB | (Not Supported)
""" # noqa: E501
@@ -195,7 +201,7 @@ class TestGPUStat(unittest.TestCase):
fp = StringIO()
gpustats.print_formatted(
fp=fp, no_color=False, show_user=True,
- show_cmd=True, show_pid=True, show_power=True
+ show_cmd=True, show_pid=True, show_power=True, show_fan=True
)
result = fp.getvalue()
| Show fan speed
Command `nvidia-smi` shows also fan speed:
```bash
$ nvidia-smi
Wed Apr 3 14:09:10 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.37 Driver Version: 396.37 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... On | 00000000:03:00.0 On | N/A |
| 30% 42C P8 16W / 250W | 53MiB / 11177MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... On | 00000000:04:00.0 Off | N/A |
| 31% 43C P8 16W / 250W | 2MiB / 11178MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... On | 00000000:81:00.0 Off | N/A |
| 51% 68C P2 76W / 250W | 10781MiB / 11178MiB | 17% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... On | 00000000:82:00.0 Off | N/A |
| 29% 34C P8 16W / 250W | 2MiB / 11178MiB | 0% Default |
```
Could gpustat show this information too? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"gpustat/test_gpustat.py::TestGPUStat::test_new_query_mocked"
] | [
"gpustat/test_gpustat.py::TestGPUStat::test_args_endtoend",
"gpustat/test_gpustat.py::TestGPUStat::test_attributes_and_items",
"gpustat/test_gpustat.py::TestGPUStat::test_json_mocked",
"gpustat/test_gpustat.py::TestGPUStat::test_main",
"gpustat/test_gpustat.py::TestGPUStat::test_new_query_mocked_nonexistent_pid"
] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2019-04-18T19:26:46Z" | mit |
|
wright-group__WrightTools-1075 | diff --git a/CHANGELOG.md b/CHANGELOG.md
index cd3e6c7..b8410e9 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,6 +5,9 @@ The format is based on [Keep a Changelog](https://keepachangelog.com/).
## [Unreleased]
+### Fixed
+- `kit.fft`: fixed bug where Fourier coefficients were off by a scalar factor.
+
## [3.4.4]
### Added
diff --git a/WrightTools/kit/_array.py b/WrightTools/kit/_array.py
index a538aa9..3e3057c 100644
--- a/WrightTools/kit/_array.py
+++ b/WrightTools/kit/_array.py
@@ -8,6 +8,8 @@ import numpy as np
from .. import exceptions as wt_exceptions
+from typing import Tuple
+
# --- define --------------------------------------------------------------------------------------
@@ -120,35 +122,40 @@ def diff(xi, yi, order=1) -> np.ndarray:
return yi
-def fft(xi, yi, axis=0) -> tuple:
- """Take the 1D FFT of an N-dimensional array and return "sensible" properly shifted arrays.
+def fft(xi, yi, axis=0) -> Tuple[np.ndarray, np.ndarray]:
+ """Compute a discrete Fourier Transform along one axis of an N-dimensional
+ array and also compute the 1D frequency coordinates of the transform. The
+ Fourier coefficients and frequency coordinates are ordered so that the
+ coordinates are monotonic (i.e. uses `numpy.fft.fftshift`).
Parameters
----------
- xi : numpy.ndarray
- 1D array over which the points to be FFT'ed are defined
- yi : numpy.ndarray
- ND array with values to FFT
+ ti : 1D numpy.ndarray
+ Independent variable specifying data coordinates. Must be monotonic,
+ linearly spaced data. `ti.size` must be equal to `yi.shape[axis]`
+ yi : n-dimensional numpy.ndarray
+ Dependent variable. ND array with values to FFT.
axis : int
axis of yi to perform FFT over
Returns
-------
xi : 1D numpy.ndarray
- 1D array. Conjugate to input xi. Example: if input xi is in the time
- domain, output xi is in frequency domain.
- yi : ND numpy.ndarray
- FFT. Has the same shape as the input array (yi).
+ 1D array. Conjugate coordinates to input xi. Example: if input `xi`
+ is time coordinates, output `xi` is (cyclic) frequency coordinates.
+ yi : complex numpy.ndarray
+ Transformed data. Has the same shape as the input array (yi).
"""
# xi must be 1D
if xi.ndim != 1:
raise wt_exceptions.DimensionalityError(1, xi.ndim)
# xi must be evenly spaced
spacing = np.diff(xi)
- if not np.allclose(spacing, spacing.mean()):
+ spacing_mean = spacing.mean()
+ if not np.allclose(spacing, spacing_mean):
raise RuntimeError("WrightTools.kit.fft: argument xi must be evenly spaced")
# fft
- yi = np.fft.fft(yi, axis=axis)
+ yi = np.fft.fft(yi, axis=axis) * spacing_mean
d = (xi.max() - xi.min()) / (xi.size - 1)
xi = np.fft.fftfreq(xi.size, d=d)
# shift
| wright-group/WrightTools | 91554ccfe3a2b288e7277d52f34a0220412cc0cd | diff --git a/tests/kit/fft.py b/tests/kit/fft.py
index a03ab9c..5fb4973 100644
--- a/tests/kit/fft.py
+++ b/tests/kit/fft.py
@@ -14,12 +14,24 @@ import WrightTools as wt
# --- test ----------------------------------------------------------------------------------------
-def test_1_sin():
+def test_analytic_fft():
+ a = 1 - 1j
+ t = np.linspace(0, 10, 10000)
+ z = np.heaviside(t, 0.5) * np.exp(-a * t)
+ wi, zi = wt.kit.fft(t, z)
+ zi_analytical = 1 / (a + 1j * 2 * np.pi * wi)
+ assert np.allclose(zi.real, zi_analytical.real, atol=1e-3)
+ assert np.allclose(zi.imag, zi_analytical.imag, atol=1e-3)
+
+
+def test_plancherel():
t = np.linspace(-10, 10, 10000)
z = np.sin(2 * np.pi * t)
wi, zi = wt.kit.fft(t, z)
- freq = np.abs(wi[np.argmax(zi)])
- assert np.isclose(freq, 1, rtol=1e-3, atol=1e-3)
+ intensity_time = (z**2).sum() * (t[1] - t[0])
+ intensity_freq = (zi * zi.conjugate()).real.sum() * (wi[1] - wi[0])
+ rel_error = np.abs(intensity_time - intensity_freq) / (intensity_time + intensity_freq)
+ assert rel_error < 1e-12
def test_5_sines():
@@ -28,7 +40,7 @@ def test_5_sines():
z = np.sin(2 * np.pi * freqs[None, :] * t[:, None])
wi, zi = wt.kit.fft(t, z, axis=0)
freq = np.abs(wi[np.argmax(zi, axis=0)])
- assert np.all(np.isclose(freq, freqs, rtol=1e-3, atol=1e-3))
+ assert np.allclose(freq, freqs, rtol=1e-3, atol=1e-3)
def test_dimensionality_error():
| kit.fft: fourier coefficients ignore x-axis spacing
kit fft expands on np.fft.fft by accepting an x-axis as an argument to give convenient units for Fourier space. It neglects to use these units to calculate the Fourier transform itself (e.g. we calculate `array.sum()` instead of `array.sum() * dt`). Since our method we explicitly call for x-units, we should use their to calculate the Fourier coefficients as well.
This comes up when you want to relate spectral amplitudes to temporal features. e.g.
```
t = np.linspace(-10, 10, 10000)
z = np.sin(2 * np.pi * t)
wi, zi = wt.kit.fft(t, z)
intensity_time = (z**2).sum() * (t[1] - t[0])
intensity_freq = np.abs(zi).sum() * (wi[1] - wi[0])
```
By Parseval's (or Plancherel's) theorem, both `intensity_time` and `intensity_freq` should be equal to within calculation error. This is not currently the case. In general, all our FT coefficients are off by a constant that depends on the spacing between points. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/kit/fft.py::test_analytic_fft",
"tests/kit/fft.py::test_plancherel"
] | [
"tests/kit/fft.py::test_5_sines",
"tests/kit/fft.py::test_dimensionality_error",
"tests/kit/fft.py::test_even_spacing_error"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2022-06-10T22:12:55Z" | mit |
|
wright-group__WrightTools-534 | diff --git a/WrightTools/kit/_array.py b/WrightTools/kit/_array.py
index 66cfb11..16136f1 100644
--- a/WrightTools/kit/_array.py
+++ b/WrightTools/kit/_array.py
@@ -210,17 +210,10 @@ def remove_nans_1D(*args):
tuple
Tuple of 1D arrays in same order as given, with nan indicies removed.
"""
- # find all indicies to keep
- bads = np.array([])
- for arr in args:
- bad = np.array(np.where(np.isnan(arr))).flatten()
- bads = np.hstack((bad, bads))
- if hasattr(args, 'shape') and len(args.shape) == 1:
- goods = [i for i in np.arange(args.shape[0]) if i not in bads]
- else:
- goods = [i for i in np.arange(len(args[0])) if i not in bads]
- # apply
- return tuple(a[goods] for a in args)
+ vals = np.isnan(args[0])
+ for a in args:
+ vals |= np.isnan(a)
+ return tuple(np.array(a)[vals == False] for a in args)
def share_nans(*arrs):
| wright-group/WrightTools | a11e47d7786f63dcc595c8e9ccf121e73a16407b | diff --git a/tests/kit/remove_nans_1D.py b/tests/kit/remove_nans_1D.py
old mode 100644
new mode 100755
index 31d15ab..8c09a16
--- a/tests/kit/remove_nans_1D.py
+++ b/tests/kit/remove_nans_1D.py
@@ -1,3 +1,4 @@
+#! /usr/bin/env python3
"""Test remove_nans_1D."""
@@ -18,10 +19,20 @@ def test_simple():
assert wt.kit.remove_nans_1D(arr)[0].all() == np.arange(0, 6, dtype=float).all()
-def test_list():
+def test_multiple():
arrs = [np.random.random(21) for _ in range(5)]
arrs[0][0] = np.nan
arrs[1][-1] = np.nan
arrs = wt.kit.remove_nans_1D(*arrs)
for arr in arrs:
assert arr.size == 19
+
+
+def test_list():
+ assert np.all(wt.kit.remove_nans_1D([np.nan, 1, 2, 3])[0] == np.array([1, 2, 3]))
+
+
+if __name__ == "__main__":
+ test_simple()
+ test_multiple()
+ test_list()
| remove_nans_1D fails for list
```
>>> wt.kit.remove_nans_1D([np.nan, 1, 2, 2])
Traceback (most recent call last):
File "<input>", line 1, in <module>
wt.kit.remove_nans_1D([np.nan, 1, 2, 2])
File "/home/kyle/wright/WrightTools/WrightTools/kit/_array.py", line 223, in rem
ove_nans_1D
return tuple(a[goods] for a in args)
File "/home/kyle/wright/WrightTools/WrightTools/kit/_array.py", line 223, in <ge
nexpr>
return tuple(a[goods] for a in args)
TypeError: list indices must be integers or slices, not list
>>> wt.kit.remove_nans_1D(np.array([np.nan, 1, 2, 2]))
(array([1., 2., 2.]),)
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/kit/remove_nans_1D.py::test_list"
] | [
"tests/kit/remove_nans_1D.py::test_simple",
"tests/kit/remove_nans_1D.py::test_multiple"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2018-03-06T22:01:33Z" | mit |
|
wright-group__WrightTools-746 | diff --git a/WrightTools/kit/_array.py b/WrightTools/kit/_array.py
index dec8f19..e9ae20f 100644
--- a/WrightTools/kit/_array.py
+++ b/WrightTools/kit/_array.py
@@ -243,18 +243,52 @@ def share_nans(*arrs) -> tuple:
return tuple([a + nans for a in arrs])
-def smooth_1D(arr, n=10) -> np.ndarray:
- """Smooth 1D data by 'running average'.
+def smooth_1D(arr, n=10, smooth_type="flat") -> np.ndarray:
+ """Smooth 1D data using a window function.
+
+ Edge effects will be present.
Parameters
----------
- n : int
- number of points to average
+ arr : array_like
+ Input array, 1D.
+ n : int (optional)
+ Window length.
+ smooth_type : {'flat', 'hanning', 'hamming', 'bartlett', 'blackman'} (optional)
+ Type of window function to convolve data with.
+ 'flat' window will produce a moving average smoothing.
+
+ Returns
+ -------
+ array_like
+ Smoothed 1D array.
"""
- for i in range(n, len(arr) - n):
- window = arr[i - n : i + n].copy()
- arr[i] = window.mean()
- return arr
+
+ # check array input
+ if arr.ndim != 1:
+ raise wt_exceptions.DimensionalityError(1, arr.ndim)
+ if arr.size < n:
+ message = "Input array size must be larger than window size."
+ raise wt_exceptions.ValueError(message)
+ if n < 3:
+ return arr
+ # construct window array
+ if smooth_type == "flat":
+ w = np.ones(n, dtype=arr.dtype)
+ elif smooth_type == "hanning":
+ w = np.hanning(n)
+ elif smooth_type == "hamming":
+ w = np.hamming(n)
+ elif smooth_type == "bartlett":
+ w = np.bartlett(n)
+ elif smooth_type == "blackman":
+ w = np.blackman(n)
+ else:
+ message = "Given smooth_type, {0}, not available.".format(str(smooth_type))
+ raise wt_exceptions.ValueError(message)
+ # convolve reflected array with window function
+ out = np.convolve(w / w.sum(), arr, mode="same")
+ return out
def svd(a, i=None) -> tuple:
| wright-group/WrightTools | 4cf127e9d431265dad6f42c48b5be05bc36e3cb7 | diff --git a/tests/kit/smooth_1D.py b/tests/kit/smooth_1D.py
new file mode 100644
index 0000000..5e4e9b4
--- /dev/null
+++ b/tests/kit/smooth_1D.py
@@ -0,0 +1,35 @@
+"""Test kit.smooth_1D."""
+
+
+# --- import --------------------------------------------------------------------------------------
+
+
+import numpy as np
+
+import WrightTools as wt
+
+
+# --- test ----------------------------------------------------------------------------------------
+
+
+def test_basic_smoothing_functionality():
+ # create arrays
+ x = np.linspace(0, 10, 1000)
+ y = np.sin(x)
+ np.random.seed(seed=12)
+ r = np.random.rand(1000) - .5
+ yr = y + r
+ # iterate through window types
+ windows = ["flat", "hanning", "hamming", "bartlett", "blackman"]
+ for w in windows:
+ out = wt.kit.smooth_1D(yr, n=101, smooth_type=w)
+ check_arr = out - y
+ check_arr = check_arr[50:-50] # get rid of edge effects
+ assert np.allclose(check_arr, 0, rtol=.2, atol=.2)
+
+
+# --- run -----------------------------------------------------------------------------------------
+
+
+if __name__ == "__main__":
+ test_basic_smoothing_functionality()
| test kit.smooth_1D
write tests for `wt.kit.smooth_1D` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/kit/smooth_1D.py::test_basic_smoothing_functionality"
] | [] | {
"failed_lite_validators": [
"has_short_problem_statement"
],
"has_test_patch": true,
"is_lite": false
} | "2018-09-17T15:10:30Z" | mit |
|
wright-group__WrightTools-886 | diff --git a/WrightTools/data/_channel.py b/WrightTools/data/_channel.py
index 91a04ed..03d4973 100644
--- a/WrightTools/data/_channel.py
+++ b/WrightTools/data/_channel.py
@@ -152,14 +152,17 @@ class Channel(Dataset):
factor : number (optional)
Tolerance factor. Default is 3.
- replace : {'nan', 'mean', number} (optional)
+ replace : {'nan', 'mean', 'exclusive_mean', number} (optional)
Behavior of outlier replacement. Default is nan.
nan
Outliers are replaced by numpy nans.
mean
- Outliers are replaced by the mean of its neighborhood.
+ Outliers are replaced by the mean of its neighborhood, including itself.
+
+ exclusive_mean
+ Outilers are replaced by the mean of its neighborhood, not including itself.
number
Array becomes given number.
@@ -177,6 +180,7 @@ class Channel(Dataset):
warnings.warn("trim", category=wt_exceptions.EntireDatasetInMemoryWarning)
outliers = []
means = []
+ ex_means = []
# find outliers
for idx in np.ndindex(self.shape):
slices = []
@@ -186,26 +190,33 @@ class Channel(Dataset):
slices.append(slice(start, stop, 1))
neighbors = self[slices]
mean = np.nanmean(neighbors)
+ sum_ = np.nansum(neighbors)
limit = np.nanstd(neighbors) * factor
if np.abs(self[idx] - mean) > limit:
outliers.append(idx)
means.append(mean)
+ # Note, "- 1" is to exclude the point itself, which is not nan, in order
+ # to enter this if block, as `np.abs(nan - mean)` is nan, which would
+ # evaluate to False
+ ex_means.append((sum_ - self[idx]) / (np.sum(~np.isnan(neighbors)) - 1))
+
# replace outliers
i = tuple(zip(*outliers))
- if replace == "nan":
- arr = self[:]
- arr[i] = np.nan
- self[:] = arr
- elif replace == "mean":
- arr = self[:]
- arr[i] = means
- self[:] = arr
- elif isinstance(replace, numbers.Number):
- arr = self[:]
- arr[i] = replace
- self[:] = arr
- else:
- raise KeyError("replace must be one of {nan, mean} or some number")
+
+ if len(i) == 0:
+ if verbose:
+ print("No outliers found")
+ return []
+
+ replace = {"nan": np.nan, "mean": means, "exclusive_mean": ex_means}.get(replace, replace)
+
+ # This may someday be available in h5py directly, but seems that day is not yet.
+ # This is annoying because it is the only reason we hold the whole set in memory.
+ # KFS 2019-03-21
+ arr = self[:]
+ arr[i] = replace
+ self[:] = arr
+
# finish
if verbose:
print("%i outliers removed" % len(outliers))
| wright-group/WrightTools | dc02147913c603792e8a7c12228dc292334d8084 | diff --git a/tests/data/trim.py b/tests/data/trim.py
index 2a94167..f096904 100644
--- a/tests/data/trim.py
+++ b/tests/data/trim.py
@@ -32,18 +32,23 @@ def test_trim_2Dgauss():
d.create_channel("damaged1", arr2)
d.create_channel("damaged2", arr2)
d.create_channel("damaged3", arr2)
+ d.create_channel("damaged4", arr2)
d.transform("x", "y")
# trim
+ d.original.trim([2, 2], factor=2)
d.damaged1.trim([2, 2], factor=2)
d.damaged2.trim([2, 2], factor=2, replace="mean")
d.damaged3.trim([2, 2], factor=2, replace=0.5)
+ d.damaged4.trim([2, 2], factor=2, replace="exclusive_mean")
# now heal
d.create_channel("healed_linear", d.damaged1[:])
d.heal(channel="healed_linear", fill_value=0, method="linear")
# check
- assert np.allclose(d.original[:], d.healed_linear[:], rtol=1e-1, atol=1e-1)
- assert np.allclose(d.original[:], d.damaged2[:], rtol=1e-1, atol=9e-1)
- assert np.allclose(d.original[:], d.damaged3[:], rtol=1e-1, atol=5e-1)
+ np.testing.assert_allclose(d.original[:], d.original[:], rtol=1e-1, atol=1e-1)
+ np.testing.assert_allclose(d.original[:], d.healed_linear[:], rtol=1e-1, atol=1e-1)
+ np.testing.assert_allclose(d.original[:], d.damaged2[:], rtol=1e-1, atol=9e-1)
+ np.testing.assert_allclose(d.original[:], d.damaged3[:], rtol=1e-1, atol=5e-1)
+ np.testing.assert_allclose(d.original[:], d.damaged4[:], rtol=1e-1, atol=3e-1)
def test_trim_3Dgauss():
@@ -67,7 +72,7 @@ def test_trim_3Dgauss():
# trim
d.damaged.trim([2, 2, 2], factor=2, replace="mean")
# check
- assert np.allclose(d.original[:], d.damaged[:], rtol=1e-1, atol=9e-1)
+ np.testing.assert_allclose(d.original[:], d.damaged[:], rtol=1e-1, atol=9e-1)
if __name__ == "__main__":
| BUG: Trim writes channel to all NaNs when no outliers are present
Example code:
```
# import
import numpy as np
from matplotlib import pyplot as plt
import WrightTools as wt
# create arrays
x = np.linspace(-3, 3, 31)[:, None]
y = np.linspace(-3, 3, 31)[None, :]
arr = np.exp(-1 * (x ** 2 + y ** 2))
# create damaged array
arr2 = arr.copy()
arr2[15,15] = 20
# create data object
d = wt.data.Data()
d.create_variable("x", values=x)
d.create_variable("y", values=y)
d.create_channel("original", arr)
d.create_channel("damaged", arr2)
d.create_channel("trimmed", arr2)
d.create_channel("broken", arr)
d.transform("x", "y")
# now trim
d.trimmed.trim([2,2]) # this one works as expected
d.broken.trim([2,2]) # this one will write the channel to all NaNs
# create figure
fig, gs = wt.artists.create_figure(cols=[1, 1, 1, 1])
for i in range(4):
ax = plt.subplot(gs[i])
ax.pcolor(d, channel=i)
ax.set_title(d.channel_names[i])
# pretty up
ticks = [-2, 0, 2]
wt.artists.set_fig_labels(
xlabel=d.axes[0].label, ylabel=d.axes[1].label, xticks=ticks, yticks=ticks
)
```
stdout from execution is
```
1 outliers removed
0 outliers removed
/home/darien/source/WrightTools/WrightTools/_dataset.py:373: RuntimeWarning: All-NaN slice encountered
return np.nanmax(dataset[s])
/home/darien/source/WrightTools/WrightTools/_dataset.py:375: RuntimeWarning: All-NaN axis encountered
self.attrs["max"] = np.nanmax(list(self.chunkwise(f).values()))
```
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/data/trim.py::test_trim_2Dgauss"
] | [
"tests/data/trim.py::test_trim_3Dgauss"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media"
],
"has_test_patch": true,
"is_lite": false
} | "2019-03-21T16:59:48Z" | mit |
|
wright-group__WrightTools-938 | diff --git a/WrightTools/kit/_calculate.py b/WrightTools/kit/_calculate.py
index 50adda6..2aaa11e 100644
--- a/WrightTools/kit/_calculate.py
+++ b/WrightTools/kit/_calculate.py
@@ -137,8 +137,8 @@ def nm_width(center, width, units="wn") -> float:
number
Width in nm.
"""
- red = wt_units.converter(center - width / 2., units, "nm")
- blue = wt_units.converter(center + width / 2., units, "nm")
+ red = wt_units.converter(center - width / 2.0, units, "nm")
+ blue = wt_units.converter(center + width / 2.0, units, "nm")
return red - blue
@@ -162,4 +162,5 @@ def symmetric_sqrt(x, out=None):
"""
factor = np.sign(x)
out = np.sqrt(np.abs(x), out=out)
- return out * factor
+ out *= factor
+ return out
diff --git a/WrightTools/kit/_interpolate.py b/WrightTools/kit/_interpolate.py
index aaf5438..86667ea 100644
--- a/WrightTools/kit/_interpolate.py
+++ b/WrightTools/kit/_interpolate.py
@@ -21,7 +21,7 @@ __all__ = ["zoom2D", "Spline"]
# --- functions -----------------------------------------------------------------------------------
-def zoom2D(xi, yi, zi, xi_zoom=3., yi_zoom=3., order=3, mode="nearest", cval=0.):
+def zoom2D(xi, yi, zi, xi_zoom=3.0, yi_zoom=3.0, order=3, mode="nearest", cval=0.0):
"""Zoom a 2D array, with axes.
Parameters
diff --git a/WrightTools/kit/_timestamp.py b/WrightTools/kit/_timestamp.py
index 6ef2355..8a9c01e 100644
--- a/WrightTools/kit/_timestamp.py
+++ b/WrightTools/kit/_timestamp.py
@@ -159,7 +159,7 @@ class TimeStamp:
format_string = "%Y-%m-%dT%H:%M:%S.%f"
out = self.datetime.strftime(format_string)
# timezone
- if delta_sec == 0.:
+ if delta_sec == 0.0:
out += "Z"
else:
if delta_sec > 0:
| wright-group/WrightTools | e8966a3807c27c60ec23639601f4db276588d25f | diff --git a/tests/kit/symmetric_sqrt.py b/tests/kit/symmetric_sqrt.py
index 2cf5c93..55112d0 100644
--- a/tests/kit/symmetric_sqrt.py
+++ b/tests/kit/symmetric_sqrt.py
@@ -17,3 +17,11 @@ def test_numbers():
for number in numbers:
answer = wt.kit.symmetric_sqrt(number)
assert answer == np.sign(number) * np.sqrt(np.abs(number))
+
+
+def test_no_reallocation():
+ a = np.linspace(-9, 9, 3)
+ out = np.empty_like(a)
+ ret = wt.kit.symmetric_sqrt(a, out=out)
+ assert out is ret
+ assert np.allclose(ret, [-3, 0, 3])
| Symmetric square root does not correctly multiple by the sign factor when the output array is supplied
https://github.com/wright-group/WrightTools/blob/e875360573e8375f94ed4ed70a7d8dc02ab92bb5/WrightTools/kit/_calculate.py#L145-L165 | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/kit/symmetric_sqrt.py::test_no_reallocation"
] | [
"tests/kit/symmetric_sqrt.py::test_numbers"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2020-03-09T22:39:35Z" | mit |
|
wright-group__attune-122 | diff --git a/CHANGELOG.md b/CHANGELOG.md
new file mode 100644
index 0000000..28c3b65
--- /dev/null
+++ b/CHANGELOG.md
@@ -0,0 +1,17 @@
+# Changelog
+All notable changes to this project will be documented in this file.
+
+The format is based on [Keep a Changelog](https://keepachangelog.com/).
+
+## [Unreleased]
+
+### Fixed
+- Writing NDarrays to `instrument.json` files
+
+## [0.4.0]
+
+### Added
+- initial release after a major rewrite
+
+[Unreleased]: https://github.com/wright-group/attune/compare/0.4.0...master
+[0.4.0]: https://github.com/wright-group/attune/releases/tag/0.4.0
diff --git a/attune/_arrangement.py b/attune/_arrangement.py
index bab449f..d4d867e 100644
--- a/attune/_arrangement.py
+++ b/attune/_arrangement.py
@@ -31,8 +31,6 @@ class Arrangement:
k: Tune(**v) if isinstance(v, dict) else v for k, v in tunes.items()
}
self._ind_units: str = "nm"
- self._ind_max: float = min([t.ind_max for t in self._tunes.values()])
- self._ind_min: float = max([t.ind_min for t in self._tunes.values()])
def __repr__(self):
return f"Arrangement({repr(self.name)}, {repr(self.tunes)})"
@@ -81,11 +79,11 @@ class Arrangement:
@property
def ind_max(self):
- return self._ind_max
+ return min([t.ind_max for t in self._tunes.values()])
@property
def ind_min(self):
- return self._ind_min
+ return max([t.ind_min for t in self._tunes.values()])
@property
def name(self):
diff --git a/attune/_instrument.py b/attune/_instrument.py
index a3260eb..7bf50db 100644
--- a/attune/_instrument.py
+++ b/attune/_instrument.py
@@ -133,4 +133,11 @@ class Instrument(object):
def save(self, file):
"""Save the JSON representation into an open file."""
- json.dump(self.as_dict(), file)
+
+ class NdarrayEncoder(json.JSONEncoder):
+ def default(self, obj):
+ if hasattr(obj, "tolist"):
+ return obj.tolist()
+ return json.JSONEncoder.default(self, obj)
+
+ json.dump(self.as_dict(), file, cls=NdarrayEncoder)
diff --git a/attune/_tune.py b/attune/_tune.py
index 259e389..9e9e50c 100644
--- a/attune/_tune.py
+++ b/attune/_tune.py
@@ -31,8 +31,6 @@ class Tune:
dependent = np.asarray(dependent)
assert independent.size == dependent.size
assert independent.ndim == dependent.ndim == 1
- self._ind_max = max(independent)
- self._ind_min = min(independent)
self._ind_units = "nm"
self._dep_units = dep_units
self._interp = scipy.interpolate.interp1d(independent, dependent, fill_value="extrapolate")
@@ -79,11 +77,11 @@ class Tune:
@property
def ind_max(self):
- return self._ind_max
+ return self.independent.max()
@property
def ind_min(self):
- return self._ind_min
+ return self.independent.min()
@property
def ind_units(self):
| wright-group/attune | 4e98eec7d3a3e917fc1364a80e4b46017370f595 | diff --git a/tests/map.py b/tests/map.py
index d3d3887..351ca18 100644
--- a/tests/map.py
+++ b/tests/map.py
@@ -16,6 +16,8 @@ def test_map_ind_points():
inst1["test_map"]["test"](test_points), inst0["test_map"]["test"](test_points)
)
assert len(inst1["test_map"]["test"]) == 25
+ assert inst1["test_map"].ind_min == 1310
+ assert inst1["test_map"].ind_max == 1450
def test_map_ind_limits():
diff --git a/tests/store/test_store.py b/tests/store/test_store.py
index 97c32e7..8109c30 100644
--- a/tests/store/test_store.py
+++ b/tests/store/test_store.py
@@ -4,6 +4,7 @@ import shutil
import tempfile
import attune
+import numpy as np
import pytest
here = pathlib.Path(__file__).parent
@@ -46,3 +47,12 @@ def test_load_store():
instr = attune.load("test")
with pytest.warns(UserWarning, match="Attempted to store instrument equivalent"):
attune.store(instr)
+
+
+@temp_store
+def test_store_ndarray():
+ instr = attune.load("test")
+ instr = attune.map_ind_points(instr, "arr", "tune", np.linspace(0.25, 1, 5))
+ # Would raise here because it is trying to serialize the ndarray in metadata
+ # prior to bug fix
+ attune.store(instr)
| Incorrect ind_min and ind_max on arrangement after map
```
tune = attune.Tune(np.linspace(1300, 1400, 20), np.linspace(-5, 5, 20))
arr = attune.Arrangement("map", {"test": tune})
inst0 = attune.Instrument({"map": arr}, {"test": attune.Setable("tune")})
inst1 = attune.map_ind_points(inst0, "map", "test", np.linspace(1310, 1450, 25))
print(inst0(1373))
print(inst1(1373))
print(inst0["map"].ind_min, inst0["map"].ind_max)
print(inst1["map"].ind_min, inst1["map"].ind_max)
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/map.py::test_map_ind_points",
"tests/store/test_store.py::test_store_ndarray"
] | [
"tests/map.py::test_map_ind_limits",
"tests/store/test_store.py::test_normal_load_store",
"tests/store/test_store.py::test_load_old",
"tests/store/test_store.py::test_load_store"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2020-12-15T22:46:48Z" | mit |
|
wright-group__attune-123 | diff --git a/CHANGELOG.md b/CHANGELOG.md
new file mode 100644
index 0000000..28c3b65
--- /dev/null
+++ b/CHANGELOG.md
@@ -0,0 +1,17 @@
+# Changelog
+All notable changes to this project will be documented in this file.
+
+The format is based on [Keep a Changelog](https://keepachangelog.com/).
+
+## [Unreleased]
+
+### Fixed
+- Writing NDarrays to `instrument.json` files
+
+## [0.4.0]
+
+### Added
+- initial release after a major rewrite
+
+[Unreleased]: https://github.com/wright-group/attune/compare/0.4.0...master
+[0.4.0]: https://github.com/wright-group/attune/releases/tag/0.4.0
diff --git a/attune/_arrangement.py b/attune/_arrangement.py
index bab449f..d4d867e 100644
--- a/attune/_arrangement.py
+++ b/attune/_arrangement.py
@@ -31,8 +31,6 @@ class Arrangement:
k: Tune(**v) if isinstance(v, dict) else v for k, v in tunes.items()
}
self._ind_units: str = "nm"
- self._ind_max: float = min([t.ind_max for t in self._tunes.values()])
- self._ind_min: float = max([t.ind_min for t in self._tunes.values()])
def __repr__(self):
return f"Arrangement({repr(self.name)}, {repr(self.tunes)})"
@@ -81,11 +79,11 @@ class Arrangement:
@property
def ind_max(self):
- return self._ind_max
+ return min([t.ind_max for t in self._tunes.values()])
@property
def ind_min(self):
- return self._ind_min
+ return max([t.ind_min for t in self._tunes.values()])
@property
def name(self):
diff --git a/attune/_instrument.py b/attune/_instrument.py
index a3260eb..39b8ae6 100644
--- a/attune/_instrument.py
+++ b/attune/_instrument.py
@@ -15,7 +15,7 @@ class Instrument(object):
def __init__(
self,
arrangements: Dict["str", Union[Arrangement, dict]],
- setables: Dict["str", Union[Setable, dict]],
+ setables: Dict["str", Optional[Union[Setable, dict]]] = None,
*,
name: Optional[str] = None,
transition: Optional[Union[Transition, dict]] = None,
@@ -25,6 +25,8 @@ class Instrument(object):
self._arrangements: Dict["str", Arrangement] = {
k: Arrangement(**v) if isinstance(v, dict) else v for k, v in arrangements.items()
}
+ if setables is None:
+ setables = {}
self._setables: Dict["str", Setable] = {
k: Setable(**v) if isinstance(v, dict) else v for k, v in setables.items()
}
@@ -77,20 +79,20 @@ class Instrument(object):
raise ValueError("There are multiple valid arrangements! You must specify one.")
# call arrangement
setable_positions = {}
+ setables = self._setables.copy()
todo = [(ind_value, tune) for tune in arrangement.tunes.items()]
while todo:
v, t = todo.pop(0)
tune_name, tune = t
- if tune_name in self._setables:
- assert tune_name not in setable_positions
- setable_positions[tune_name] = tune(v)
- elif tune_name in self._arrangements:
+ if tune_name in self._arrangements:
new = [
(tune(v), subtune) for subtune in self._arrangements[tune_name].tunes.items()
]
todo += new
else:
- raise ValueError(f"Unrecognized name {tune_name}")
+ assert tune_name not in setable_positions
+ setable_positions[tune_name] = tune(v)
+ setables[tune_name] = Setable(tune_name)
# finish
note = Note(
setables=self._setables,
@@ -133,4 +135,11 @@ class Instrument(object):
def save(self, file):
"""Save the JSON representation into an open file."""
- json.dump(self.as_dict(), file)
+
+ class NdarrayEncoder(json.JSONEncoder):
+ def default(self, obj):
+ if hasattr(obj, "tolist"):
+ return obj.tolist()
+ return json.JSONEncoder.default(self, obj)
+
+ json.dump(self.as_dict(), file, cls=NdarrayEncoder)
diff --git a/attune/_tune.py b/attune/_tune.py
index 259e389..9e9e50c 100644
--- a/attune/_tune.py
+++ b/attune/_tune.py
@@ -31,8 +31,6 @@ class Tune:
dependent = np.asarray(dependent)
assert independent.size == dependent.size
assert independent.ndim == dependent.ndim == 1
- self._ind_max = max(independent)
- self._ind_min = min(independent)
self._ind_units = "nm"
self._dep_units = dep_units
self._interp = scipy.interpolate.interp1d(independent, dependent, fill_value="extrapolate")
@@ -79,11 +77,11 @@ class Tune:
@property
def ind_max(self):
- return self._ind_max
+ return self.independent.max()
@property
def ind_min(self):
- return self._ind_min
+ return self.independent.min()
@property
def ind_units(self):
| wright-group/attune | 4e98eec7d3a3e917fc1364a80e4b46017370f595 | diff --git a/tests/instrument/test_call.py b/tests/instrument/test_call.py
index 9ae5426..ba2c911 100644
--- a/tests/instrument/test_call.py
+++ b/tests/instrument/test_call.py
@@ -30,3 +30,12 @@ def test_nested():
second = attune.Arrangement("second", {"first": tune1})
inst = attune.Instrument({"first": first, "second": second}, {"tune": attune.Setable("tune")})
assert math.isclose(inst(0.75, "second")["tune"], 0.25)
+
+
+def test_implicit_setable():
+ tune = attune.Tune([0, 1], [0, 1])
+ tune1 = attune.Tune([0.5, 1.5], [0, 1])
+ first = attune.Arrangement("first", {"tune": tune})
+ second = attune.Arrangement("second", {"first": tune1})
+ inst = attune.Instrument({"first": first, "second": second})
+ assert math.isclose(inst(0.75, "second")["tune"], 0.25)
diff --git a/tests/map.py b/tests/map.py
index d3d3887..351ca18 100644
--- a/tests/map.py
+++ b/tests/map.py
@@ -16,6 +16,8 @@ def test_map_ind_points():
inst1["test_map"]["test"](test_points), inst0["test_map"]["test"](test_points)
)
assert len(inst1["test_map"]["test"]) == 25
+ assert inst1["test_map"].ind_min == 1310
+ assert inst1["test_map"].ind_max == 1450
def test_map_ind_limits():
diff --git a/tests/store/test_store.py b/tests/store/test_store.py
index 97c32e7..8109c30 100644
--- a/tests/store/test_store.py
+++ b/tests/store/test_store.py
@@ -4,6 +4,7 @@ import shutil
import tempfile
import attune
+import numpy as np
import pytest
here = pathlib.Path(__file__).parent
@@ -46,3 +47,12 @@ def test_load_store():
instr = attune.load("test")
with pytest.warns(UserWarning, match="Attempted to store instrument equivalent"):
attune.store(instr)
+
+
+@temp_store
+def test_store_ndarray():
+ instr = attune.load("test")
+ instr = attune.map_ind_points(instr, "arr", "tune", np.linspace(0.25, 1, 5))
+ # Would raise here because it is trying to serialize the ndarray in metadata
+ # prior to bug fix
+ attune.store(instr)
| Settables robustness
Setables are not really anything other than a string for their name at this point... which raises the question: do they need to exist at all
Currently if there is a tune that is not an arrangement or setable `__call__` fails.
I think it should fall back to assuming it is a setable if it is not an arrangement
We made setables objects such that they can have null positions (for arrangements which do not use them), but that has not been implemented.
I propose that we make setables completely optional, and basically unused until we have such null behavior. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/instrument/test_call.py::test_implicit_setable",
"tests/map.py::test_map_ind_points",
"tests/store/test_store.py::test_store_ndarray"
] | [
"tests/instrument/test_call.py::test_overlap",
"tests/instrument/test_call.py::test_nested",
"tests/map.py::test_map_ind_limits",
"tests/store/test_store.py::test_normal_load_store",
"tests/store/test_store.py::test_load_old",
"tests/store/test_store.py::test_load_store"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2020-12-15T22:53:36Z" | mit |
|
wtbarnes__fiasco-223 | diff --git a/fiasco/ions.py b/fiasco/ions.py
index 3a97dd5..6dd30db 100644
--- a/fiasco/ions.py
+++ b/fiasco/ions.py
@@ -6,7 +6,7 @@ import astropy.units as u
import numpy as np
from functools import cached_property
-from scipy.interpolate import interp1d, splev, splrep
+from scipy.interpolate import interp1d, PchipInterpolator, splev, splrep
from scipy.ndimage import map_coordinates
from fiasco import proton_electron_ratio
@@ -173,18 +173,34 @@ Using Datasets:
ionization equilibrium outside of this temperature range, it is better to use the ionization
and recombination rates.
+ Note
+ ----
+ The cubic interpolation is performed in log-log spaceusing a Piecewise Cubic Hermite
+ Interpolating Polynomial with `~scipy.interpolate.PchipInterpolator`. This helps to
+ ensure smoothness while reducing oscillations in the interpolated ionization fractions.
+
See Also
--------
fiasco.Element.equilibrium_ionization
"""
- f = interp1d(self._ioneq[self._dset_names['ioneq_filename']]['temperature'].to('MK').value,
- self._ioneq[self._dset_names['ioneq_filename']]['ionization_fraction'],
- kind='linear',
- bounds_error=False,
- fill_value=np.nan)
- ioneq = f(self.temperature.to('MK').value)
- isfinite = np.isfinite(ioneq)
- ioneq[isfinite] = np.where(ioneq[isfinite] < 0., 0., ioneq[isfinite])
+ temperature = self.temperature.to_value('K')
+ temperature_data = self._ioneq[self._dset_names['ioneq_filename']]['temperature'].to_value('K')
+ ioneq_data = self._ioneq[self._dset_names['ioneq_filename']]['ionization_fraction'].value
+ # Perform PCHIP interpolation in log-space on only the non-zero ionization fractions.
+ # See https://github.com/wtbarnes/fiasco/pull/223 for additional discussion.
+ is_nonzero = ioneq_data > 0.0
+ f_interp = PchipInterpolator(np.log10(temperature_data[is_nonzero]),
+ np.log10(ioneq_data[is_nonzero]),
+ extrapolate=False)
+ ioneq = f_interp(np.log10(temperature))
+ ioneq = 10**ioneq
+ # This sets all entries that would have interpolated to zero ionization fraction to zero
+ ioneq = np.where(np.isnan(ioneq), 0.0, ioneq)
+ # Set entries that are truly out of bounds of the original temperature data back to NaN
+ out_of_bounds = np.logical_or(temperature<temperature_data.min(), temperature>temperature_data.max())
+ ioneq = np.where(out_of_bounds, np.nan, ioneq)
+ is_finite = np.isfinite(ioneq)
+ ioneq[is_finite] = np.where(ioneq[is_finite] < 0., 0., ioneq[is_finite])
return u.Quantity(ioneq)
@property
@@ -339,6 +355,7 @@ Using Datasets:
See Also
--------
+ proton_collision_deexcitation_rate
electron_collision_excitation_rate
"""
# Create scaled temperature--these are not stored in the file
@@ -389,6 +406,7 @@ Using Datasets:
def level_populations(self,
density: u.cm**(-3),
include_protons=True,
+ include_level_resolved_rate_correction=True,
couple_density_to_temperature=False) -> u.dimensionless_unscaled:
"""
Energy level populations as a function of temperature and density.
@@ -507,10 +525,136 @@ Using Datasets:
# positivity
np.fabs(pop, out=pop)
np.divide(pop, pop.sum(axis=1)[:, np.newaxis], out=pop)
+ # Apply ionization/recombination correction
+ if include_level_resolved_rate_correction:
+ correction = self._population_correction(pop, d, c_matrix)
+ pop *= correction
+ np.divide(pop, pop.sum(axis=1)[:, np.newaxis], out=pop)
populations[:, i, :] = pop
return u.Quantity(populations)
+ def _level_resolved_rates_interpolation(self, temperature_table, rate_table,
+ extrapolate_above=False,
+ extrapolate_below=False):
+ # NOTE: According to CHIANTI Technical Report No. 20, Section 5,
+ # the interpolation of the level resolved recombination,
+ # the rates should be zero below the temperature range and above
+ # the temperature range, the last two points should be used to perform
+ # a linear extrapolation. For the ionization rates, the rates should be
+ # zero above the temperature range and below the temperature range, the
+ # last two points should be used. Thus, we need to perform two interpolations
+ # for each level.
+ # NOTE: In the CHIANTI IDL code, the interpolation is done using a cubic spline.
+ # Here, the rates are interpolated using a Piecewise Cubic Hermite Interpolating
+ # Polynomial (PCHIP) which balances smoothness and also reduces the oscillations
+ # that occur with higher order spline fits. This is needed mostly due to the wide
+ # range over which this data is fit.
+ temperature = self.temperature.to_value('K')
+ rates = []
+ for t, r in zip(temperature_table.to_value('K'), rate_table.to_value('cm3 s-1')):
+ rate_interp = PchipInterpolator(t, r, extrapolate=False)(temperature)
+ # NOTE: Anything outside of the temperature range will be set to NaN by the
+ # interpolation but we want these to be 0.
+ rate_interp = np.where(np.isnan(rate_interp), 0, rate_interp)
+ if extrapolate_above:
+ f_extrapolate = interp1d(t[-2:], r[-2:], kind='linear', fill_value='extrapolate')
+ i_extrapolate = np.where(temperature > t[-1])
+ rate_interp[i_extrapolate] = f_extrapolate(temperature[i_extrapolate])
+ if extrapolate_below:
+ f_extrapolate = interp1d(t[:2], r[:2], kind='linear', fill_value='extrapolate')
+ i_extrapolate = np.where(temperature < t[0])
+ rate_interp[i_extrapolate] = f_extrapolate(temperature[i_extrapolate])
+ rates.append(rate_interp)
+ # NOTE: Take transpose to maintain consistent ordering of temperature in the leading
+ # dimension and levels in the last dimension
+ rates = u.Quantity(rates, 'cm3 s-1').T
+ # NOTE: The linear extrapolation at either end may return rates < 0 so we set these
+ # to zero.
+ rates = np.where(rates<0, 0, rates)
+ return rates
+
+ @cached_property
+ @needs_dataset('cilvl')
+ @u.quantity_input
+ def _level_resolved_ionization_rate(self):
+ ionization_rates = self._level_resolved_rates_interpolation(
+ self._cilvl['temperature'],
+ self._cilvl['ionization_rate'],
+ extrapolate_below=True,
+ extrapolate_above=False,
+ )
+ return self._cilvl['upper_level'], ionization_rates
+
+ @cached_property
+ @needs_dataset('reclvl')
+ @u.quantity_input
+ def _level_resolved_recombination_rate(self):
+ recombination_rates = self._level_resolved_rates_interpolation(
+ self._reclvl['temperature'],
+ self._reclvl['recombination_rate'],
+ extrapolate_below=False,
+ extrapolate_above=True,
+ )
+ return self._reclvl['upper_level'], recombination_rates
+
+ @u.quantity_input
+ def _population_correction(self, population, density, rate_matrix):
+ """
+ Correct level population to account for ionization and
+ recombination processes.
+
+ Parameters
+ ----------
+ population: `np.ndarray`
+ density: `~astropy.units.Quantity`
+ rate_matrix: `~astropy.units.Quantity`
+
+ Returns
+ -------
+ correction: `np.ndarray`
+ Correction factor to multiply populations by
+ """
+ # NOTE: These are done in separate try/except blocks because some ions have just a cilvl file,
+ # some have just a reclvl file, and some have both.
+ # NOTE: Ioneq values for surrounding ions are retrieved afterwards because first and last ions do
+ # not have previous or next ions but also do not have reclvl or cilvl files.
+ # NOTE: stripping the units off and adding them at the end because of some strange astropy
+ # Quantity behavior that does not allow for adding these two compatible shapes together.
+ numerator = np.zeros(population.shape)
+ try:
+ upper_level_ionization, ionization_rate = self._level_resolved_ionization_rate
+ ioneq_previous = self.previous_ion().ioneq.value[:, np.newaxis]
+ numerator[:, upper_level_ionization-1] += (ionization_rate * ioneq_previous).to_value('cm3 s-1')
+ except MissingDatasetException:
+ pass
+ try:
+ upper_level_recombination, recombination_rate = self._level_resolved_recombination_rate
+ ioneq_next = self.next_ion().ioneq.value[:, np.newaxis]
+ numerator[:, upper_level_recombination-1] += (recombination_rate * ioneq_next).to_value('cm3 s-1')
+ except MissingDatasetException:
+ pass
+ numerator *= density.to_value('cm-3')
+
+ c = rate_matrix.to_value('s-1').copy()
+ # This excludes processes that depopulate the level
+ i_diag, j_diag = np.diag_indices(c.shape[1])
+ c[:, i_diag, j_diag] = 0.0
+ # Sum of the population-weighted excitations from lower levels
+ # and cascades from higher levels
+ denominator = np.einsum('ijk,ik->ij', c, population)
+ denominator *= self.ioneq.value[:, np.newaxis]
+ # Set any zero entries to NaN to avoid divide by zero warnings
+ denominator = np.where(denominator==0.0, np.nan, denominator)
+
+ ratio = numerator / denominator
+ # Set ratio to zero where denominator is zero. This also covers the
+ # case of out-of-bounds ionization fractions (which will be NaN)
+ ratio = np.where(np.isfinite(ratio), ratio, 0.0)
+ # NOTE: Correction should not affect the ground state populations
+ ratio[:, 0] = 0.0
+ return 1.0 + ratio
+
@needs_dataset('abundance', 'elvlc')
@u.quantity_input
def contribution_function(self, density: u.cm**(-3), **kwargs) -> u.cm**3 * u.erg / u.s:
| wtbarnes/fiasco | c674d97fc88262d1ad2afe29edafadb8e24674bb | diff --git a/fiasco/conftest.py b/fiasco/conftest.py
index ce8c437..15519c7 100644
--- a/fiasco/conftest.py
+++ b/fiasco/conftest.py
@@ -84,6 +84,11 @@ TEST_FILES = {
'fe_27.rrparams': '75383b0f1b167f862cfd26bbadd2a029',
'fe_10.psplups': 'dd34363f6daa81dbf106fbeb211b457d',
'fe_10.elvlc': 'f221d4c7167336556d57378ac368afc1',
+ 'fe_20.elvlc': 'bbddcf958dd41311ea24bf177c2b62de',
+ 'fe_20.wgfa': 'c991c30b98b03c9152ba5a2c71877149',
+ 'fe_20.scups': 'f0e375cad2ec8296efb2abcb8f02705e',
+ 'fe_20.cilvl': 'b71833c51a03c7073f1657ce60afcdbb',
+ 'fe_20.reclvl': 'cf28869709acef521fb6a1c9a2b59530',
}
diff --git a/fiasco/tests/idl/test_idl_ioneq.py b/fiasco/tests/idl/test_idl_ioneq.py
index 6061370..ac542c8 100644
--- a/fiasco/tests/idl/test_idl_ioneq.py
+++ b/fiasco/tests/idl/test_idl_ioneq.py
@@ -32,6 +32,7 @@ def ioneq_from_idl(idl_env, ascii_dbase_root):
'C 2',
'C 3',
'Ca 2',
+ 'Fe 20',
])
def test_ioneq_from_idl(ion_name, ioneq_from_idl, hdf5_dbase_root):
temperature = 10**ioneq_from_idl['ioneq_logt'] * u.K
diff --git a/fiasco/tests/test_collections.py b/fiasco/tests/test_collections.py
index ae8575b..507ae1f 100644
--- a/fiasco/tests/test_collections.py
+++ b/fiasco/tests/test_collections.py
@@ -93,16 +93,18 @@ def test_length(collection):
def test_free_free(another_collection, wavelength):
ff = another_collection.free_free(wavelength)
assert ff.shape == temperature.shape + wavelength.shape if wavelength.shape else (1,)
- index = 50 if wavelength.shape else 0
- assert u.allclose(ff[50, index], 3.19877384e-35 * u.Unit('erg cm3 s-1 Angstrom-1'))
+ index_w = 50 if wavelength.shape else 0
+ index_t = 24 # This is approximately where the ioneq for Fe V peaks
+ assert u.allclose(ff[index_t, index_w], 3.2914969734961024e-42 * u.Unit('erg cm3 s-1 Angstrom-1'))
@pytest.mark.parametrize('wavelength', [wavelength, wavelength[50]])
def test_free_bound(another_collection, wavelength):
fb = another_collection.free_bound(wavelength)
assert fb.shape == temperature.shape + wavelength.shape if wavelength.shape else (1,)
- index = 50 if wavelength.shape else 0
- assert u.allclose(fb[50, index], 3.2653516e-29 * u.Unit('erg cm3 s-1 Angstrom-1'))
+ index_w = 50 if wavelength.shape else 0
+ index_t = 24 # This is approximately where the ioneq for Fe V peaks
+ assert u.allclose(fb[index_t, index_w], 1.1573022245197259e-35 * u.Unit('erg cm3 s-1 Angstrom-1'))
def test_radiative_los(collection):
diff --git a/fiasco/tests/test_ion.py b/fiasco/tests/test_ion.py
index 04abc5d..fa7ea95 100644
--- a/fiasco/tests/test_ion.py
+++ b/fiasco/tests/test_ion.py
@@ -32,6 +32,13 @@ def c6(hdf5_dbase_root):
return fiasco.Ion('C VI', temperature, hdf5_dbase_root=hdf5_dbase_root)
[email protected]
+def fe20(hdf5_dbase_root):
+ # NOTE: This ion was added because it has reclvl and cilvl files which
+ # we need to test the level-resolved rate correction factor
+ return fiasco.Ion('Fe XX', temperature, hdf5_dbase_root=hdf5_dbase_root)
+
+
def test_new_instance(ion):
abundance_filename = ion._instance_kwargs['abundance_filename']
new_ion = ion._new_instance()
@@ -99,15 +106,7 @@ def test_scalar_temperature(hdf5_dbase_root):
t_data = ion._ioneq[ion._dset_names['ioneq_filename']]['temperature']
ioneq_data = ion._ioneq[ion._dset_names['ioneq_filename']]['ionization_fraction']
i_t = np.where(t_data == ion.temperature)
- np.testing.assert_allclose(ioneq, ioneq_data[i_t])
-
-
-def test_scalar_density(hdf5_dbase_root):
- ion = fiasco.Ion('H 1', temperature, hdf5_dbase_root=hdf5_dbase_root)
- pop = ion.level_populations(1e8 * u.cm**-3)
- assert pop.shape == ion.temperature.shape + (1,) + ion._elvlc['level'].shape
- # This value has not been checked for correctness
- np.testing.assert_allclose(pop[0, 0, 0], 0.9965048292729177)
+ assert u.allclose(ioneq, ioneq_data[i_t])
def test_no_elvlc_raises_index_error(hdf5_dbase_root):
@@ -116,13 +115,21 @@ def test_no_elvlc_raises_index_error(hdf5_dbase_root):
def test_ioneq(ion):
- assert ion.ioneq.shape == temperature.shape
t_data = ion._ioneq[ion._dset_names['ioneq_filename']]['temperature']
ioneq_data = ion._ioneq[ion._dset_names['ioneq_filename']]['ionization_fraction']
- i_t = np.where(t_data == ion.temperature[0])
- # Essentially test that we've done the interpolation to the data correctly
- # for a single value
- np.testing.assert_allclose(ion.ioneq[0], ioneq_data[i_t])
+ ion_at_nodes = ion._new_instance(temperature=t_data)
+ assert u.allclose(ion_at_nodes.ioneq, ioneq_data, rtol=1e-6)
+
+
+def test_ioneq_positive(ion):
+ assert np.all(ion.ioneq >= 0)
+
+
+def test_ioneq_out_bounds_is_nan(ion):
+ t_data = ion._ioneq[ion._dset_names['ioneq_filename']]['temperature']
+ t_out_of_bounds = t_data[[0,-1]] + [-100, 1e6] * u.K
+ ion_out_of_bounds = ion._new_instance(temperature=t_out_of_bounds)
+ assert np.isnan(ion_out_of_bounds.ioneq).all()
def test_formation_temeprature(ion):
@@ -132,7 +139,7 @@ def test_formation_temeprature(ion):
def test_abundance(ion):
assert ion.abundance.dtype == np.dtype('float64')
# This value has not been tested for correctness
- np.testing.assert_allclose(ion.abundance, 0.0001258925411794166)
+ assert u.allclose(ion.abundance, 0.0001258925411794166)
def test_proton_collision(fe10):
@@ -164,6 +171,15 @@ def test_missing_ip(hdf5_dbase_root):
_ = ion.ip
+def test_level_populations(ion):
+ pop = ion.level_populations(1e8 * u.cm**-3)
+ assert pop.shape == ion.temperature.shape + (1,) + ion._elvlc['level'].shape
+ # This value has not been checked for correctness
+ assert u.allclose(pop[0, 0, 0], 0.011643747849652244)
+ # Check that the total populations are normalized to 1 for all temperatures
+ assert u.allclose(pop.squeeze().sum(axis=1), 1, atol=None, rtol=1e-15)
+
+
def test_contribution_function(ion):
cont_func = ion.contribution_function(1e7 * u.cm**-3)
assert cont_func.shape == ion.temperature.shape + (1, ) + ion._wgfa['wavelength'].shape
@@ -204,6 +220,39 @@ def test_coupling_unequal_dimensions_exception(ion):
_ = ion.level_populations([1e7, 1e8]*u.cm**(-3), couple_density_to_temperature=True)
[email protected]
+def pops_with_correction(fe20):
+ return fe20.level_populations(1e9*u.cm**(-3)).squeeze()
+
+
[email protected]
+def pops_no_correction(fe20):
+ return fe20.level_populations(1e9*u.cm**(-3),
+ include_level_resolved_rate_correction=False).squeeze()
+
+
+def test_level_populations_normalized(pops_no_correction, pops_with_correction):
+ assert u.allclose(pops_with_correction.sum(axis=1), 1, atol=None, rtol=1e-15)
+ assert u.allclose(pops_no_correction.sum(axis=1), 1, atol=None, rtol=1e-15)
+
+
+def test_level_populations_correction(fe20, pops_no_correction, pops_with_correction):
+ # Test level-resolved correction applied to correct levels
+ i_corrected = np.unique(np.concatenate([fe20._cilvl['upper_level'], fe20._reclvl['upper_level']]))
+ i_corrected -= 1
+ # This tests that, for at least some portion of the temperature axis, the populations are
+ # significantly different for each corrected level
+ pops_equal = u.isclose(pops_with_correction[:, i_corrected], pops_no_correction[:, i_corrected],
+ atol=0.0, rtol=1e-5)
+ assert ~np.all(np.all(pops_equal, axis=0))
+ # All other levels should be unchanged (with some tolerance for renormalization)
+ is_uncorrected = np.ones(pops_no_correction.shape[-1], dtype=bool)
+ is_uncorrected[i_corrected] = False
+ i_uncorrected = np.where(is_uncorrected)
+ assert u.allclose(pops_with_correction[:, i_uncorrected], pops_no_correction[:, i_uncorrected],
+ atol=0.0, rtol=1e-5)
+
+
def test_emissivity(ion):
emm = ion.emissivity(1e7 * u.cm**-3)
assert emm.shape == ion.temperature.shape + (1, ) + ion._wgfa['wavelength'].shape
| Add correction for ionization and recombination in level populations calculation
There should be a correction for ionization and recombination processes in the level population calculation. Currently, this is not included. See [section 2.3 of Landi et al. (2006)](http://adsabs.harvard.edu/abs/2006ApJS..162..261L) for more details as well as [section 6 of Dere et al. (2009)](http://adsabs.harvard.edu/abs/2009A%26A...498..915D). | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"fiasco/tests/test_collections.py::test_free_free[wavelength0]",
"fiasco/tests/test_collections.py::test_free_free[wavelength1]",
"fiasco/tests/test_collections.py::test_free_bound[wavelength0]",
"fiasco/tests/test_collections.py::test_free_bound[wavelength1]",
"fiasco/tests/test_ion.py::test_level_populations_normalized",
"fiasco/tests/test_ion.py::test_level_populations_correction"
] | [
"fiasco/tests/test_collections.py::test_create_collection_from_ions",
"fiasco/tests/test_collections.py::test_create_collection_from_elements",
"fiasco/tests/test_collections.py::test_create_collection_from_mixture",
"fiasco/tests/test_collections.py::test_create_collection_from_collection",
"fiasco/tests/test_collections.py::test_getitem",
"fiasco/tests/test_collections.py::test_contains",
"fiasco/tests/test_collections.py::test_length",
"fiasco/tests/test_collections.py::test_radiative_los",
"fiasco/tests/test_collections.py::test_spectrum",
"fiasco/tests/test_collections.py::test_spectrum_no_valid_ions",
"fiasco/tests/test_collections.py::test_unequal_temperatures_raise_value_error",
"fiasco/tests/test_collections.py::test_create_with_wrong_type_raise_type_error",
"fiasco/tests/test_collections.py::test_collections_repr",
"fiasco/tests/test_ion.py::test_new_instance",
"fiasco/tests/test_ion.py::test_level_indexing",
"fiasco/tests/test_ion.py::test_level",
"fiasco/tests/test_ion.py::test_repr",
"fiasco/tests/test_ion.py::test_repr_scalar_temp",
"fiasco/tests/test_ion.py::test_ion_properties",
"fiasco/tests/test_ion.py::test_level_properties",
"fiasco/tests/test_ion.py::test_scalar_temperature",
"fiasco/tests/test_ion.py::test_no_elvlc_raises_index_error",
"fiasco/tests/test_ion.py::test_ioneq",
"fiasco/tests/test_ion.py::test_ioneq_positive",
"fiasco/tests/test_ion.py::test_ioneq_out_bounds_is_nan",
"fiasco/tests/test_ion.py::test_formation_temeprature",
"fiasco/tests/test_ion.py::test_abundance",
"fiasco/tests/test_ion.py::test_proton_collision",
"fiasco/tests/test_ion.py::test_missing_abundance",
"fiasco/tests/test_ion.py::test_ip",
"fiasco/tests/test_ion.py::test_missing_ip",
"fiasco/tests/test_ion.py::test_level_populations",
"fiasco/tests/test_ion.py::test_contribution_function",
"fiasco/tests/test_ion.py::test_emissivity_shape",
"fiasco/tests/test_ion.py::test_coupling_unequal_dimensions_exception",
"fiasco/tests/test_ion.py::test_emissivity",
"fiasco/tests/test_ion.py::test_intensity[em0]",
"fiasco/tests/test_ion.py::test_intensity[em1]",
"fiasco/tests/test_ion.py::test_intensity[em2]",
"fiasco/tests/test_ion.py::test_excitation_autoionization_rate",
"fiasco/tests/test_ion.py::test_dielectronic_recombination_rate",
"fiasco/tests/test_ion.py::test_free_free",
"fiasco/tests/test_ion.py::test_free_bound",
"fiasco/tests/test_ion.py::test_add_ions",
"fiasco/tests/test_ion.py::test_radd_ions",
"fiasco/tests/test_ion.py::test_transitions",
"fiasco/tests/test_ion.py::test_create_ion_without_units_raises_units_error",
"fiasco/tests/test_ion.py::test_create_ion_with_wrong_units_raises_unit_conversion_error",
"fiasco/tests/test_ion.py::test_indexing_no_levels",
"fiasco/tests/test_ion.py::test_repr_no_levels",
"fiasco/tests/test_ion.py::test_next_ion",
"fiasco/tests/test_ion.py::test_previous_ion"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-02-24T00:25:39Z" | bsd-3-clause |
|
wwkimball__yamlpath-155 | diff --git a/CHANGES b/CHANGES
index 1e09b97..afa9061 100644
--- a/CHANGES
+++ b/CHANGES
@@ -1,3 +1,8 @@
+3.6.4
+Bug Fixes:
+* Refactored single-star wildcard segment (*) handling to enable filtering
+ matches when subsequent segments exist; this fixes Issue #154.
+
3.6.3
Bug Fixes:
* The eyaml-rotate-keys command-line tool failed to preserve block-style EYAML
diff --git a/yamlpath/__init__.py b/yamlpath/__init__.py
index 17f456c..a47c822 100644
--- a/yamlpath/__init__.py
+++ b/yamlpath/__init__.py
@@ -1,6 +1,6 @@
"""Core YAML Path classes."""
# Establish the version number common to all components
-__version__ = "3.6.3"
+__version__ = "3.6.4"
from yamlpath.yamlpath import YAMLPath
from yamlpath.processor import Processor
diff --git a/yamlpath/enums/pathsegmenttypes.py b/yamlpath/enums/pathsegmenttypes.py
index 489d9e0..4c9a402 100644
--- a/yamlpath/enums/pathsegmenttypes.py
+++ b/yamlpath/enums/pathsegmenttypes.py
@@ -36,6 +36,9 @@ class PathSegmentTypes(Enum):
Traverses the document tree deeply. If there is a next segment, it
must match or no data is matched. When there is no next segment, every
leaf node matches.
+
+ `MATCH_ALL`
+ Matches every immediate child node.
"""
ANCHOR = auto()
@@ -45,3 +48,4 @@ class PathSegmentTypes(Enum):
SEARCH = auto()
TRAVERSE = auto()
KEYWORD_SEARCH = auto()
+ MATCH_ALL = auto()
diff --git a/yamlpath/processor.py b/yamlpath/processor.py
index 7c97027..38e301c 100644
--- a/yamlpath/processor.py
+++ b/yamlpath/processor.py
@@ -839,6 +839,11 @@ class Processor:
node_coords = self._get_nodes_by_index(
data, yaml_path, segment_index,
translated_path=translated_path, ancestry=ancestry)
+ elif segment_type == PathSegmentTypes.MATCH_ALL:
+ node_coords = self._get_nodes_by_match_all(
+ data, yaml_path, segment_index, parent=parent,
+ parentref=parentref, translated_path=translated_path,
+ ancestry=ancestry)
elif segment_type == PathSegmentTypes.ANCHOR:
node_coords = self._get_nodes_by_anchor(
data, yaml_path, segment_index,
@@ -1894,6 +1899,244 @@ class Processor:
data=node_coord)
yield node_coord
+ def _get_nodes_by_match_all_unfiltered(
+ self, data: Any, yaml_path: YAMLPath, segment_index: int, **kwargs: Any
+ ) -> Generator[Any, None, None]:
+ """
+ Yield every immediate, non-leaf child node.
+
+ Parameters:
+ 1. data (ruamel.yaml data) The parsed YAML data to process
+ 2. yaml_path (yamlpath.Path) The YAML Path being processed
+ 3. segment_index (int) Segment index of the YAML Path to process
+
+ Keyword Arguments:
+ * parent (ruamel.yaml node) The parent node from which this query
+ originates
+ * parentref (Any) The Index or Key of data within parent
+ * translated_path (YAMLPath) YAML Path indicating precisely which node
+ is being evaluated
+ * ancestry (List[AncestryEntry]) Stack of ancestors preceding the
+ present node under evaluation
+
+ Returns: (Generator[Any, None, None]) Each node coordinate as they are
+ matched.
+ """
+ dbg_prefix="Processor::_get_nodes_by_match_all_unfiltered: "
+ parent: Any = kwargs.pop("parent", None)
+ parentref: Any = kwargs.pop("parentref", None)
+ translated_path: YAMLPath = kwargs.pop("translated_path", YAMLPath(""))
+ ancestry: List[AncestryEntry] = kwargs.pop("ancestry", [])
+ segments = yaml_path.escaped
+ pathseg: PathSegment = segments[segment_index]
+
+ self.logger.debug(
+ "Gathering ALL immediate children in the tree at parentref,"
+ f" {parentref}, in data:",
+ prefix=dbg_prefix, data=data)
+
+ if isinstance(data, (CommentedMap, dict)):
+ self.logger.debug(
+ "Iterating over all keys to find ANY matches in data:",
+ prefix=dbg_prefix, data=data)
+ for key, val in data.items():
+ next_translated_path = (
+ translated_path + YAMLPath.escape_path_section(
+ key, translated_path.seperator))
+ next_ancestry = ancestry + [(data, key)]
+ self.logger.debug(
+ f"Yielding dict value at key, {key} from data:",
+ prefix=dbg_prefix, data={'VAL': val, 'OF_DATA': data})
+ yield NodeCoords(val, data, key, next_translated_path,
+ next_ancestry, pathseg)
+ return
+
+ if isinstance(data, (CommentedSeq, list)):
+ for idx, ele in enumerate(data):
+ next_translated_path = translated_path + f"[{idx}]"
+ next_ancestry = ancestry + [(data, idx)]
+ self.logger.debug(
+ f"Yielding list element at index, {idx}:",
+ prefix=dbg_prefix, data=ele)
+ yield NodeCoords(ele, data, idx, next_translated_path,
+ next_ancestry, pathseg)
+ return
+
+ if isinstance(data, (CommentedSet, set)):
+ for ele in data:
+ next_translated_path = (
+ translated_path + YAMLPath.escape_path_section(
+ ele, translated_path.seperator))
+ self.logger.debug(
+ "Yielding set element:",
+ prefix=dbg_prefix, data=ele)
+ yield NodeCoords(
+ ele, parent, ele, next_translated_path, ancestry, pathseg)
+ return
+
+ self.logger.debug(
+ "NOT yielding Scalar node (* excludes scalars):",
+ prefix=dbg_prefix, data=data)
+ return
+
+ def _get_nodes_by_match_all_filtered(
+ self, data: Any, yaml_path: YAMLPath, segment_index: int, **kwargs: Any
+ ) -> Generator[Any, None, None]:
+ """
+ Yield immediate child nodes whose children match additional filters.
+
+ Parameters:
+ 1. data (ruamel.yaml data) The parsed YAML data to process
+ 2. yaml_path (yamlpath.Path) The YAML Path being processed
+ 3. segment_index (int) Segment index of the YAML Path to process
+
+ Keyword Arguments:
+ * parent (ruamel.yaml node) The parent node from which this query
+ originates
+ * parentref (Any) The Index or Key of data within parent
+ * translated_path (YAMLPath) YAML Path indicating precisely which node
+ is being evaluated
+ * ancestry (List[AncestryEntry]) Stack of ancestors preceding the
+ present node under evaluation
+
+ Returns: (Generator[Any, None, None]) Each node coordinate as they are
+ matched.
+ """
+ dbg_prefix="Processor::_get_nodes_by_match_all_filtered: "
+ parentref: Any = kwargs.pop("parentref", None)
+ translated_path: YAMLPath = kwargs.pop("translated_path", YAMLPath(""))
+ ancestry: List[AncestryEntry] = kwargs.pop("ancestry", [])
+ segments = yaml_path.escaped
+ pathseg: PathSegment = segments[segment_index]
+ next_segment_idx: int = segment_index + 1
+
+ self.logger.debug(
+ "FILTERING children in the tree at parentref,"
+ f" {parentref}, of data:",
+ prefix=dbg_prefix, data=data)
+
+ # There is a filter on this segment. Return nodes from the present
+ # data if-and-only-if any of their immediate children will match the
+ # filter. Do not return the child nodes; the caller will continue to
+ # process subsequent path segments to yield them.
+ if isinstance(data, dict):
+ self.logger.debug(
+ "Iterating over all keys to find ANY matches in data:",
+ prefix=dbg_prefix, data=data)
+ for key, val in data.items():
+ next_translated_path = (
+ translated_path + YAMLPath.escape_path_section(
+ key, translated_path.seperator))
+ next_ancestry = ancestry + [(data, key)]
+ for filtered_nc in self._get_nodes_by_path_segment(
+ val, yaml_path, next_segment_idx, parent=data,
+ parentref=key, translated_path=next_translated_path,
+ ancestry=next_ancestry
+ ):
+ self.logger.debug(
+ "Ignoring yielded child node coordinate to yield its"
+ " successfully matched, filtered dict val parent for"
+ f" key, {key}:"
+ , prefix=dbg_prefix
+ , data={
+ 'VAL': val
+ , 'OF_DATA': data
+ , 'IGNORING': filtered_nc
+ })
+ yield NodeCoords(
+ val, data, key, next_translated_path, next_ancestry,
+ pathseg
+ )
+ break # because we need only the matching parent
+ return
+
+ if isinstance(data, list):
+ for idx, ele in enumerate(data):
+ self.logger.debug(
+ f"Recursing into INDEX '{idx}' at ref '{parentref}' for"
+ " next-segment matches...", prefix=dbg_prefix)
+ next_translated_path = translated_path + f"[{idx}]"
+ next_ancestry = ancestry + [(data, idx)]
+ for filtered_nc in self._get_nodes_by_path_segment(
+ ele, yaml_path, next_segment_idx, parent=data,
+ parentref=idx, translated_path=next_translated_path,
+ ancestry=next_ancestry
+ ):
+ self.logger.debug(
+ "Ignoring yielded child node coordinate to yield its"
+ " successfully matched, filtered list ele parent for"
+ f" idx, {idx}:"
+ , prefix=dbg_prefix
+ , data={
+ 'ELE': ele
+ , 'OF_DATA': data
+ , 'IGNORING': filtered_nc
+ })
+ yield NodeCoords(
+ ele, data, idx, next_translated_path, next_ancestry,
+ pathseg
+ )
+ break # because we need only the matching parent
+ return
+
+ def _get_nodes_by_match_all(
+ self, data: Any, yaml_path: YAMLPath, segment_index: int, **kwargs: Any
+ ) -> Generator[Any, None, None]:
+ """
+ Yield every immediate child node.
+
+ Parameters:
+ 1. data (ruamel.yaml data) The parsed YAML data to process
+ 2. yaml_path (yamlpath.Path) The YAML Path being processed
+ 3. segment_index (int) Segment index of the YAML Path to process
+
+ Keyword Arguments:
+ * parent (ruamel.yaml node) The parent node from which this query
+ originates
+ * parentref (Any) The Index or Key of data within parent
+ * translated_path (YAMLPath) YAML Path indicating precisely which node
+ is being evaluated
+ * ancestry (List[AncestryEntry]) Stack of ancestors preceding the
+ present node under evaluation
+
+ Returns: (Generator[Any, None, None]) Each node coordinate as they are
+ matched.
+ """
+ dbg_prefix="Processor::_get_nodes_by_match_all: "
+ parent: Any = kwargs.pop("parent", None)
+ parentref: Any = kwargs.pop("parentref", None)
+ translated_path: YAMLPath = kwargs.pop("translated_path", YAMLPath(""))
+ ancestry: List[AncestryEntry] = kwargs.pop("ancestry", [])
+
+ segments = yaml_path.escaped
+ next_segment_idx: int = segment_index + 1
+ filter_results = next_segment_idx < len(segments)
+
+ self.logger.debug(
+ "Processing either FILTERED or UNFILTERED nodes from data:"
+ , prefix=dbg_prefix, data=data)
+
+ if filter_results:
+ # Of data, yield every node which has children matching next seg
+ all_coords = self._get_nodes_by_match_all_filtered(
+ data, yaml_path, segment_index,
+ parent=parent, parentref=parentref,
+ translated_path=translated_path, ancestry=ancestry
+ )
+ else:
+ # Of data, yield every node
+ all_coords = self._get_nodes_by_match_all_unfiltered(
+ data, yaml_path, segment_index,
+ parent=parent, parentref=parentref,
+ translated_path=translated_path, ancestry=ancestry
+ )
+
+ for all_coord in all_coords:
+ self.logger.debug(
+ "Yielding matched child node of source data:"
+ , prefix=dbg_prefix, data={'NODE': all_coord, 'DATA': data})
+ yield all_coord
+
def _get_required_nodes(
self, data: Any, yaml_path: YAMLPath, depth: int = 0, **kwargs: Any
) -> Generator[NodeCoords, None, None]:
diff --git a/yamlpath/yamlpath.py b/yamlpath/yamlpath.py
index 759bafd..132e8e1 100644
--- a/yamlpath/yamlpath.py
+++ b/yamlpath/yamlpath.py
@@ -798,10 +798,9 @@ class YAMLPath:
segment_len = len(segment_id)
if splat_count == 1:
if segment_len == 1:
- # /*/ -> [.=~/.*/]
- coal_type = PathSegmentTypes.SEARCH
- coal_value = SearchTerms(
- False, PathSearchMethods.REGEX, ".", ".*")
+ # /*/ -> MATCH_ALL
+ coal_type = PathSegmentTypes.MATCH_ALL
+ coal_value = None
elif splat_pos == 0:
# /*text/ -> [.$text]
coal_type = PathSegmentTypes.SEARCH
@@ -877,6 +876,10 @@ class YAMLPath:
)
elif segment_type == PathSegmentTypes.INDEX:
ppath += "[{}]".format(segment_attrs)
+ elif segment_type == PathSegmentTypes.MATCH_ALL:
+ if add_sep:
+ ppath += pathsep
+ ppath += "*"
elif segment_type == PathSegmentTypes.ANCHOR:
if add_sep:
ppath += "[&{}]".format(segment_attrs)
@@ -886,17 +889,7 @@ class YAMLPath:
ppath += str(segment_attrs)
elif (segment_type == PathSegmentTypes.SEARCH
and isinstance(segment_attrs, SearchTerms)):
- terms: SearchTerms = segment_attrs
- if (terms.method == PathSearchMethods.REGEX
- and terms.attribute == "."
- and terms.term == ".*"
- and not terms.inverted
- ):
- if add_sep:
- ppath += pathsep
- ppath += "*"
- else:
- ppath += str(segment_attrs)
+ ppath += str(segment_attrs)
elif segment_type == PathSegmentTypes.COLLECTOR:
ppath += str(segment_attrs)
elif segment_type == PathSegmentTypes.TRAVERSE:
| wwkimball/yamlpath | d2b693ca756638122697288ea25cc02310b00842 | diff --git a/tests/test_processor.py b/tests/test_processor.py
index a205d18..34e6ebd 100644
--- a/tests/test_processor.py
+++ b/tests/test_processor.py
@@ -82,7 +82,11 @@ class Test_Processor():
("/array_of_hashes/**", [1, "one", 2, "two"], True, None),
("products_hash.*[dimensions.weight==4].(availability.start.date)+(availability.stop.date)", [[date(2020, 8, 1), date(2020, 9, 25)], [date(2020, 1, 1), date(2020, 1, 1)]], True, None),
("products_array[dimensions.weight==4].product", ["doohickey", "widget"], True, None),
- ("(products_hash.*.dimensions.weight)[max()][parent(2)].dimensions.weight", [10], True, None)
+ ("(products_hash.*.dimensions.weight)[max()][parent(2)].dimensions.weight", [10], True, None),
+ ("/Locations/*/*", ["ny", "bstn"], True, None),
+ ("/AoH_Locations/*/*/*", ["nyc", "bo"], True, None),
+ ("/Weird_AoH_Locations/*/*/*", ["nyc", "bstn"], True, None),
+ ("/Set_Locations/*/*", ["New York", "Boston"], True, None),
])
def test_get_nodes(self, quiet_logger, yamlpath, results, mustexist, default):
yamldata = """---
@@ -222,7 +226,35 @@ products_array:
height: 10
depth: 1
weight: 4
+
###############################################################################
+# For wildcard matching (#154)
+Locations:
+ United States:
+ New York: ny
+ Boston: bstn
+ Canada: cnd
+
+AoH_Locations:
+ - United States: us
+ New York:
+ New York City: nyc
+ Massachussets:
+ Boston: bo
+ - Canada: ca
+
+# Weird Array-of-Hashes
+Weird_AoH_Locations:
+ - United States:
+ New York: nyc
+ Boston: bstn
+ - Canada: cnd
+
+Set_Locations:
+ United States: !!set
+ ? New York
+ ? Boston
+ Canada:
"""
yaml = YAML()
processor = Processor(quiet_logger, yaml.load(yamldata))
| Unexpected nodes returned for grandchild query /Locations/*/*
## Operating System
1. Name/Distribution: Windows 10 Home
2. Version: 10.0.19043 Build 19043
## Version of Python and packages in use at the time of the issue.
1. [Distribution](https://wiki.python.org/moin/PythonDistributions): CPython (for Windows) from python.org
2. Python Version: 3.7
3. Version of yamlpath installed: 3.6.3
4. Version of ruamel.yaml installed: 0.17.10
## Minimum sample of YAML (or compatible) data necessary to trigger the issue
```yaml
---
Locations:
United States:
New York:
Boston:
Canada:
```
## Complete steps to reproduce the issue when triggered via:
1. Command-Line Tools (yaml-get, yaml-set, or eyaml-rotate-keys): Precise command-line arguments which trigger the defect.
2. Libraries (yamlpath.*): Minimum amount of code necessary to trigger the defect.
#I thought that a complete unittest might be the most helpful way to demonstrate my issue. Please let me know if another format would be more helpful.
```python
import unittest
import yamlpath
from yamlpath.wrappers import ConsolePrinter
from yamlpath.common import Parsers
from yamlpath import Processor
from yamlpath.exceptions.yamlpathexception import YAMLPathException
from types import SimpleNamespace
class IssueReportTest(unittest.TestCase):
def setUp(self):
pass
def tearDown(self):
pass
def test_retrieveGrandChildren_OnlyGrandChildrenAreReturned(self):
yamlTagHierarchy = '''---
Locations:
United States:
New York:
Boston:
Canada:
'''
logging_args = SimpleNamespace(quiet=True, verbose=False, debug=False)
self._log = ConsolePrinter(logging_args)
self._editor = Parsers.get_yaml_editor()
(yaml_data, doc_loaded) = Parsers.get_yaml_data(self._editor, self._log, yamlTagHierarchy, literal=True)
self._processor = Processor(self._log, yaml_data)
nodes = list(self._processor.get_nodes("/Locations/*/*"))
self.assertEqual(nodes[0].parentref, "New York")
self.assertEqual(nodes[1].parentref, "Boston")
self.assertEqual(len(nodes), 2, f"Node '{nodes[2].parentref}' should not be part of this list, or?")
```
## Expected Outcome
When I try to select a specific level of descendant nodes using child and wildcard operators I expect to receive only nodes at the requested level. For example, in the above sample I expect "/Locations/*/*" to return "New York" and "Boston" (grandchildren of "Locations")
## Actual Outcome
If another branch of the yaml tree ends above the requested level, the query returns the last leaf on that branch. The above example returns "Canada" in addition to "New York" and "Boston", which is surprising to me as "Canada" is merely a child of "Location", while "New York" and "Boston" are grandchildren. I haven't been able to identify an easy way to distinguish the child from the grandchild nodes.
## Thank you
Thanks so much for considering this. I was thrilled to find yamlpath for a hobby project and really appreciate the library. I hope that I'm actually reporting a real issue rather than flaunting my ignorance of how the wildcard operator should work.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_processor.py::Test_Processor::test_get_nodes[/Locations/*/*-results38-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/AoH_Locations/*/*/*-results39-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/Weird_AoH_Locations/*/*/*-results40-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/Set_Locations/*/*-results41-True-None]"
] | [
"tests/test_processor.py::Test_Processor::test_get_none_data_nodes",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[&aliasAnchorOne]-results0-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[&newAlias]-results1-False-Not",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[0]-results2-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases.0-results3-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(array_of_hashes.name)+(rollback_hashes.on_condition.failure.name)-results4-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/array_of_hashes/name-results5-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[1:2]-results6-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[1:1]-results7-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[bravo:charlie]-results8-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/&arrayOfHashes/1/step-results9-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[&arrayOfHashes[step=1].name-results10-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.!=][.=1.1]-results11-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.!=][.>1.1][.<3.3]-results12-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[.^Hey]-results13-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[.$Value]-results14-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[aliases[.%Value]-results15-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[&arrayOfHashes[step>1].name-results16-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[&arrayOfHashes[step<2].name-results17-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.>charlie]-results18-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.>=charlie]-results19-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.<bravo]-results20-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.<=bravo]-results21-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[.=~/^\\\\w{6,}$/]-results22-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[squads[alpha=1.1]-results23-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(&arrayOfHashes.step)+(/rollback_hashes/on_condition/failure/step)-(disabled_steps)-results24-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(&arrayOfHashes.step)+((/rollback_hashes/on_condition/failure/step)-(disabled_steps))-results25-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(disabled_steps)+(&arrayOfHashes.step)-results26-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(&arrayOfHashes.step)+(disabled_steps)[1]-results27-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[((&arrayOfHashes.step)[1])[0]-results28-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[does.not.previously.exist[7]-results29-False-Huzzah!]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/number_keys/1-results30-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[**.[.^Hey]-results31-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/**/Hey*-results32-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[lots_of_names.**.name-results33-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[/array_of_hashes/**-results34-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[products_hash.*[dimensions.weight==4].(availability.start.date)+(availability.stop.date)-results35-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[products_array[dimensions.weight==4].product-results36-True-None]",
"tests/test_processor.py::Test_Processor::test_get_nodes[(products_hash.*.dimensions.weight)[max()][parent(2)].dimensions.weight-results37-True-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends-results0-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends.*bb-results1-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends[A:S]-results2-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends[2]-results3-Array",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends[&bl_anchor]-results4-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends([A:M])+([T:Z])-results5-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-baseball_legends([A:Z])-([S:Z])-results6-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[True-**-results7-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends-results8-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends.*bb-results9-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends[A:S]-results10-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends[2]-results11-Array",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends[&bl_anchor]-results12-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends([A:M])+([T:Z])-results13-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends([A:Z])-([S:Z])-results14-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-**-results15-None]",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends(rbi)+(errate)-results16-Cannot",
"tests/test_processor.py::Test_Processor::test_get_from_sets[False-baseball_legends.Ted\\\\",
"tests/test_processor.py::Test_Processor::test_change_values_in_sets[aliases[&bl_anchor]-REPLACEMENT-**.&bl_anchor-2]",
"tests/test_processor.py::Test_Processor::test_change_values_in_sets[baseball_legends.Sammy\\\\",
"tests/test_processor.py::Test_Processor::test_delete_from_sets[**[&bl_anchor]-old_deleted_nodes0-new_flat_data0]",
"tests/test_processor.py::Test_Processor::test_delete_from_sets[/baseball_legends/Ken\\\\",
"tests/test_processor.py::Test_Processor::test_enforce_pathsep",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[abc-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/ints/[.=4F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/ints/[.>4F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/ints/[.<4F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/ints/[.>=4F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/ints/[.<=4F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/floats/[.=4.F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/floats/[.>4.F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/floats/[.<4.F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/floats/[.>=4.F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[/floats/[.<=4.F]-True]",
"tests/test_processor.py::Test_Processor::test_get_impossible_nodes_error[abc.**-True]",
"tests/test_processor.py::Test_Processor::test_illegal_traversal_recursion",
"tests/test_processor.py::Test_Processor::test_set_value_in_empty_data",
"tests/test_processor.py::Test_Processor::test_set_value_in_none_data",
"tests/test_processor.py::Test_Processor::test_set_value[aliases[&testAnchor]-Updated",
"tests/test_processor.py::Test_Processor::test_set_value[yamlpath1-New",
"tests/test_processor.py::Test_Processor::test_set_value[/top_array/2-42-1-False-YAMLValueFormats.INT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[/top_hash/positive_float-0.009-1-True-YAMLValueFormats.FLOAT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[/top_hash/negative_float--0.009-1-True-YAMLValueFormats.FLOAT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[/top_hash/positive_float--2.71828-1-True-YAMLValueFormats.FLOAT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[/top_hash/negative_float-5283.4-1-True-YAMLValueFormats.FLOAT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[/null_value-No",
"tests/test_processor.py::Test_Processor::test_set_value[(top_array[0])+(top_hash.negative_float)+(/null_value)-REPLACEMENT-3-True-YAMLValueFormats.DEFAULT-/]",
"tests/test_processor.py::Test_Processor::test_set_value[(((top_array[0])+(top_hash.negative_float))+(/null_value))-REPLACEMENT-3-False-YAMLValueFormats.DEFAULT-/]",
"tests/test_processor.py::Test_Processor::test_cannot_set_nonexistent_required_node_error",
"tests/test_processor.py::Test_Processor::test_none_data_to_get_nodes_by_path_segment",
"tests/test_processor.py::Test_Processor::test_bad_segment_index_for_get_nodes_by_path_segment",
"tests/test_processor.py::Test_Processor::test_get_nodes_by_unknown_path_segment_error",
"tests/test_processor.py::Test_Processor::test_non_int_slice_error",
"tests/test_processor.py::Test_Processor::test_non_int_array_index_error",
"tests/test_processor.py::Test_Processor::test_nonexistant_path_search_method_error",
"tests/test_processor.py::Test_Processor::test_adjoined_collectors_error",
"tests/test_processor.py::Test_Processor::test_no_attrs_to_arrays_error",
"tests/test_processor.py::Test_Processor::test_no_index_to_hashes_error",
"tests/test_processor.py::Test_Processor::test_get_nodes_array_impossible_type_error",
"tests/test_processor.py::Test_Processor::test_no_attrs_to_scalars_errors",
"tests/test_processor.py::Test_Processor::test_key_anchor_changes[/anchorKeys[&keyOne]-Set",
"tests/test_processor.py::Test_Processor::test_key_anchor_changes[/hash[&keyTwo]-Confirm-1-True-YAMLValueFormats.DEFAULT-.]",
"tests/test_processor.py::Test_Processor::test_key_anchor_changes[/anchorKeys[&recursiveAnchorKey]-Recurse",
"tests/test_processor.py::Test_Processor::test_key_anchor_changes[/hash[&recursiveAnchorKey]-Recurse",
"tests/test_processor.py::Test_Processor::test_key_anchor_children",
"tests/test_processor.py::Test_Processor::test_cannot_add_novel_alias_keys",
"tests/test_processor.py::Test_Processor::test_set_nonunique_values[number-5280-verifications0]",
"tests/test_processor.py::Test_Processor::test_set_nonunique_values[aliases[&alias_number]-5280-verifications1]",
"tests/test_processor.py::Test_Processor::test_set_nonunique_values[bool-False-verifications2]",
"tests/test_processor.py::Test_Processor::test_set_nonunique_values[aliases[&alias_bool]-False-verifications3]",
"tests/test_processor.py::Test_Processor::test_get_singular_collectors[(temps[.",
"tests/test_processor.py::Test_Processor::test_scalar_collectors[(/list1)",
"tests/test_processor.py::Test_Processor::test_scalar_collectors[(/list2)",
"tests/test_processor.py::Test_Processor::test_scalar_collectors[((/list1)",
"tests/test_processor.py::Test_Processor::test_scalar_collectors[(((/list1)",
"tests/test_processor.py::Test_Processor::test_collector_math[(hash.*)-(array[1])-results0]",
"tests/test_processor.py::Test_Processor::test_collector_math[(hash)-(hoh.two.*)-results1]",
"tests/test_processor.py::Test_Processor::test_collector_math[(aoa)-(hoa.two)-results2]",
"tests/test_processor.py::Test_Processor::test_collector_math[(aoh)-(aoh[max(key1)])-results3]",
"tests/test_processor.py::Test_Processor::test_get_every_data_type",
"tests/test_processor.py::Test_Processor::test_delete_nodes[delete_yamlpath0-/-old_deleted_nodes0-new_flat_data0]",
"tests/test_processor.py::Test_Processor::test_delete_nodes[records[1]-.-old_deleted_nodes1-new_flat_data1]",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_delete",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_gather_and_alias",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_alias",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_gather_and_ymk",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_ymk",
"tests/test_processor.py::Test_Processor::test_null_docs_have_nothing_to_tag",
"tests/test_processor.py::Test_Processor::test_anchor_nodes[alias_path0-anchor_path0--/]",
"tests/test_processor.py::Test_Processor::test_anchor_nodes[a_hash.a_key-some_key--.]",
"tests/test_processor.py::Test_Processor::test_ymk_nodes[target-source--.-validations0]",
"tests/test_processor.py::Test_Processor::test_ymk_nodes[change_path1-ymk_path1--.-validations1]",
"tests/test_processor.py::Test_Processor::test_ymk_nodes[/target-/source--/-validations2]",
"tests/test_processor.py::Test_Processor::test_ymk_nodes[target-source-custom_name-.-validations3]",
"tests/test_processor.py::Test_Processor::test_tag_nodes[yaml_path0-!taggidy-/]",
"tests/test_processor.py::Test_Processor::test_tag_nodes[key-taggidy-.]",
"tests/test_processor.py::Test_Processor::test_rename_dict_key[yaml_path0-renamed_key-old_data0-new_data0]",
"tests/test_processor.py::Test_Processor::test_rename_dict_key_cannot_overwrite[yaml_path0-renamed_key-old_data0]",
"tests/test_processor.py::Test_Processor::test_traverse_with_null",
"tests/test_processor.py::Test_Processor::test_yaml_merge_keys_access[reuse1.key12-results0]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_keys_access[reuse1.&alias_name1.key12-results1]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_keys_access[reuse1[&alias_name1].key12-results2]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/list*[has_child(&anchored_value)][name()]-results0]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/list*[!has_child(&anchored_value)][name()]-results1]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[has_child(&anchored_hash)][name()]-results2]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[!has_child(&anchored_hash)][name()]-results3]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[has_child(&anchored_key)][name()]-results4]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[!has_child(&anchored_key)][name()]-results5]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[has_child(&anchored_value)][name()]-results6]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/hash*[!has_child(&anchored_value)][name()]-results7]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/aoh[has_child(&anchored_hash)]/intent-results8]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/aoh[!has_child(&anchored_hash)]/intent-results9]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/aoa/*[has_child(&anchored_value)][name()]-results10]",
"tests/test_processor.py::Test_Processor::test_yaml_merge_key_queries[/aoa/*[!has_child(&anchored_value)][name()]-results11]",
"tests/test_processor.py::Test_Processor::test_wiki_array_element_searches[temperature[.",
"tests/test_processor.py::Test_Processor::test_wiki_collectors[consoles[.",
"tests/test_processor.py::Test_Processor::test_wiki_collector_math[(/standard/setup/action)",
"tests/test_processor.py::Test_Processor::test_wiki_collector_math[(/standard[.!='']/action)",
"tests/test_processor.py::Test_Processor::test_wiki_collector_math[(/standard[.!='']/id)",
"tests/test_processor.py::Test_Processor::test_wiki_collector_order_of_ops[(/list1)",
"tests/test_processor.py::Test_Processor::test_wiki_collector_order_of_ops[(/list2)",
"tests/test_processor.py::Test_Processor::test_wiki_collector_order_of_ops[((/list1)",
"tests/test_processor.py::Test_Processor::test_wiki_search_array_of_hashes[warriors[power_level",
"tests/test_processor.py::Test_Processor::test_wiki_search_key_names[contrast_ct[.",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[hash_of_hashes.*[!has_child(child_two)]-results0]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/array_of_hashes/*[!has_child(child_two)]-results1]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/hash_of_hashes/*[!has_child(child_two)][name()]-results2]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[array_of_hashes.*[!has_child(child_two)].id-results3]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/array_of_arrays/*[!has_child(value2.1)]-results4]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[array_of_arrays[*!=value2.1]-results5]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[array_of_arrays.*[!has_child(value2.1)][name()]-results6]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/array_of_arrays[*!=value2.1][name()]-results7]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[(/array_of_arrays/*[!has_child(value2.1)][name()])[0]-results8]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[(array_of_arrays[*!=value2.1][name()])[0]-results9]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[(array_of_arrays.*[!has_child(value2.1)][name()])[-1]-results10]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[(/array_of_arrays[*!=value2.1][name()])[-1]-results11]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/simple_array[has_child(value1.1)]-results12]",
"tests/test_processor.py::Test_Processor::test_wiki_has_child[/simple_array[!has_child(value1.3)]-results13]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[max(price)]-results0]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[max(price)]-results1]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[max(price)]/price-results2]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[max(price)]/price-results3]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[max(price)]/product-results4]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[max(price)][name()]-results5]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[prices_array[max()]-results6]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_aoh[max(price)]-results7]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_hash[max(price)]-results8]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_array[max()]-results9]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bare[max()]-results10]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[(prices_aoh[!max(price)])[max(price)]-results11]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[(prices_hash[!max(price)])[max(price)]-results12]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[(prices_aoh)-(prices_aoh[max(price)])[max(price)]-results13]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[(prices_hash)-(prices_hash[max(price)]).*[max(price)]-results14]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[((prices_aoh[!max(price)])[max(price)])[0]-results15]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[((prices_hash[!max(price)])[max(price)])[0]-results16]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[((prices_aoh[!max(price)])[max(price)])[0].price-results17]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[((prices_hash[!max(price)])[max(price)])[0].price-results18]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[min(price)]-results19]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[min(price)]-results20]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[min(price)]/price-results21]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[min(price)]/price-results22]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_aoh[min(price)]/product-results23]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[/prices_hash[min(price)][name()]-results24]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[prices_array[min()]-results25]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_aoh[min(price)]-results26]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_hash[min(price)]-results27]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bad_prices_array[min()]-results28]",
"tests/test_processor.py::Test_Processor::test_wiki_min_max[bare[min()]-results29]",
"tests/test_processor.py::Test_Processor::test_wiki_parent[**.Opal[parent()][name()]-results0]",
"tests/test_processor.py::Test_Processor::test_wiki_parent[minerals.*.*.mohs_hardness[.>7][parent(2)][name()]-results1]",
"tests/test_processor.py::Test_Processor::test_wiki_parent[minerals.*.*.[mohs_hardness[1]>7][name()]-results2]",
"tests/test_processor.py::Test_Processor::test_wiki_parent[minerals.*.*(([mohs_hardness[0]>=4])-([mohs_hardness[1]>5]))[name()]-results3]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-12-06T19:50:45Z" | isc |
|
wwkimball__yamlpath-225 | diff --git a/yamlpath/merger/mergerconfig.py b/yamlpath/merger/mergerconfig.py
index cafc0c3..394abac 100644
--- a/yamlpath/merger/mergerconfig.py
+++ b/yamlpath/merger/mergerconfig.py
@@ -4,7 +4,7 @@ Implement MergerConfig.
Copyright 2020, 2021 William W. Kimball, Jr. MBA MSIS
"""
import configparser
-from typing import Any, Dict, Union
+from typing import Any, Dict, Optional
from argparse import Namespace
from yamlpath.exceptions import YAMLPathException
@@ -24,23 +24,35 @@ from yamlpath.wrappers import ConsolePrinter, NodeCoords
class MergerConfig:
"""Config file processor for the Merger."""
- def __init__(self, logger: ConsolePrinter, args: Namespace) -> None:
+ def __init__(
+ self,
+ logger: ConsolePrinter,
+ args: Namespace,
+ **kwargs: Any,
+ ) -> None:
"""
Instantiate this class into an object.
Parameters:
1. logger (ConsolePrinter) Instance of ConsoleWriter or subclass
2. args (dict) Default options for merge rules
+ 3. kwargs (dict) Overrides for config values
Returns: N/A
"""
self.log = logger
self.args = args
- self.config: Union[None, configparser.ConfigParser] = None
+ self.config: Optional[configparser.ConfigParser] = None
self.rules: Dict[NodeCoords, str] = {}
self.keys: Dict[NodeCoords, str] = {}
+ config_overrides: Dict[str, Any] = {}
+
+ if "keys" in kwargs:
+ config_overrides["keys"] = kwargs.pop("keys")
+ if "rules" in kwargs:
+ config_overrides["rules"] = kwargs.pop("rules")
- self._load_config()
+ self._load_config(config_overrides)
def anchor_merge_mode(self) -> AnchorConflictResolutions:
"""
@@ -322,7 +334,7 @@ class MergerConfig:
"... NODE:", data=node_coord,
prefix="MergerConfig::_prepare_user_rules: ")
- def _load_config(self) -> None:
+ def _load_config(self, config_overrides: Dict[str, Any]) -> None:
"""Load the external configuration file."""
config = configparser.ConfigParser()
@@ -334,8 +346,15 @@ class MergerConfig:
if config_file:
config.read(config_file)
- if config.sections():
- self.config = config
+
+ if "keys" in config_overrides:
+ config["keys"] = config_overrides["keys"]
+
+ if "rules" in config_overrides:
+ config["rules"] = config_overrides["rules"]
+
+ if config.sections():
+ self.config = config
def _get_config_for(self, node_coord: NodeCoords, section: dict) -> str:
"""
| wwkimball/yamlpath | a80a36c73912ca69ba388ef2f05369c3243bc1c5 | diff --git a/tests/test_merger_mergerconfig.py b/tests/test_merger_mergerconfig.py
index 96aaf93..a40196f 100644
--- a/tests/test_merger_mergerconfig.py
+++ b/tests/test_merger_mergerconfig.py
@@ -20,6 +20,7 @@ from tests.conftest import (
create_temp_yaml_file
)
+
class Test_merger_MergerConfig():
"""Tests for the MergerConfig class."""
@@ -207,6 +208,83 @@ class Test_merger_MergerConfig():
assert mc.hash_merge_mode(
NodeCoords(node, parent, parentref)) == mode
+ @pytest.mark.parametrize("ini_rule, override_rule, mode", [
+ ("left", "right", HashMergeOpts.RIGHT),
+ ("right", "deep", HashMergeOpts.DEEP),
+ ("deep", "left", HashMergeOpts.LEFT),
+ ])
+ def test_hash_merge_mode_override_rule_overrides_ini_rule(
+ self, quiet_logger, tmp_path_factory, ini_rule, override_rule, mode
+ ):
+ config_file = create_temp_yaml_file(tmp_path_factory, """
+ [rules]
+ /hash = {}
+ """.format(ini_rule))
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(quiet_logger, SimpleNamespace(config=config_file), rules={"/hash": override_rule})
+ mc.prepare(lhs_data)
+
+ node = lhs_data["hash"]
+ parent = lhs_data
+ parentref = "hash"
+
+ assert mc.hash_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
+
+ @pytest.mark.parametrize("arg_rule, override_rule, mode", [
+ ("left", "right", HashMergeOpts.RIGHT),
+ ("right", "deep", HashMergeOpts.DEEP),
+ ("deep", "left", HashMergeOpts.LEFT),
+ ])
+ def test_hash_merge_mode_override_rule_overrides_arg_rule(
+ self, quiet_logger, tmp_path_factory, arg_rule, override_rule, mode
+ ):
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(quiet_logger, SimpleNamespace(hashes=arg_rule), rules={"/hash": override_rule})
+ mc.prepare(lhs_data)
+
+ node = lhs_data["hash"]
+ parent = lhs_data
+ parentref = "hash"
+
+ assert mc.hash_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
###
# array_merge_mode
@@ -311,6 +389,93 @@ class Test_merger_MergerConfig():
assert mc.array_merge_mode(
NodeCoords(node, parent, parentref)) == mode
+ @pytest.mark.parametrize("ini_rule, override_rule, mode", [
+ ("left", "right", ArrayMergeOpts.RIGHT),
+ ("right", "unique", ArrayMergeOpts.UNIQUE),
+ ("unique", "all", ArrayMergeOpts.ALL),
+ ("all", "left", ArrayMergeOpts.LEFT),
+ ])
+ def test_array_merge_mode_override_rule_overrides_ini_rule(
+ self, quiet_logger, tmp_path_factory, ini_rule, override_rule, mode
+ ):
+ config_file = create_temp_yaml_file(tmp_path_factory, """
+ [rules]
+ /hash/merge_targets/subarray = {}
+ """.format(ini_rule))
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(
+ quiet_logger,
+ SimpleNamespace(config=config_file),
+ rules={"/hash/merge_targets/subarray": override_rule}
+ )
+ mc.prepare(lhs_data)
+
+ node = lhs_data["hash"]["merge_targets"]["subarray"]
+ parent = lhs_data["hash"]["merge_targets"]
+ parentref = "subarray"
+
+ assert mc.array_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
+
+ @pytest.mark.parametrize("arg_rule, override_rule, mode", [
+ ("left", "right", ArrayMergeOpts.RIGHT),
+ ("right", "unique", ArrayMergeOpts.UNIQUE),
+ ("unique", "all", ArrayMergeOpts.ALL),
+ ("all", "left", ArrayMergeOpts.LEFT),
+ ])
+ def test_array_merge_mode_override_rule_overrides_arg_rule(
+ self, quiet_logger, tmp_path_factory, arg_rule, override_rule, mode
+ ):
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(
+ quiet_logger,
+ SimpleNamespace(arrays=arg_rule),
+ rules={"/hash/merge_targets/subarray": override_rule}
+ )
+ mc.prepare(lhs_data)
+
+ node = lhs_data["hash"]["merge_targets"]["subarray"]
+ parent = lhs_data["hash"]["merge_targets"]
+ parentref = "subarray"
+
+ assert mc.array_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
###
# aoh_merge_mode
@@ -419,6 +584,95 @@ class Test_merger_MergerConfig():
assert mc.aoh_merge_mode(
NodeCoords(node, parent, parentref)) == mode
+ @pytest.mark.parametrize("ini_rule, override_rule, mode", [
+ ("deep", "left", AoHMergeOpts.LEFT),
+ ("left", "right", AoHMergeOpts.RIGHT),
+ ("right", "unique", AoHMergeOpts.UNIQUE),
+ ("unique", "all", AoHMergeOpts.ALL),
+ ("all", "deep", AoHMergeOpts.DEEP),
+ ])
+ def test_array_merge_mode_override_rule_overrides_ini_rule(
+ self, quiet_logger, tmp_path_factory, ini_rule, override_rule, mode
+ ):
+ config_file = create_temp_yaml_file(tmp_path_factory, """
+ [rules]
+ /array_of_hashes = {}
+ """.format(ini_rule))
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(
+ quiet_logger,
+ SimpleNamespace(config=config_file),
+ rules={"/array_of_hashes": override_rule}
+ )
+ mc.prepare(lhs_data)
+
+ node = lhs_data["array_of_hashes"]
+ parent = lhs_data
+ parentref = "array_of_hashes"
+
+ assert mc.aoh_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
+
+ @pytest.mark.parametrize("arg_rule, override_rule, mode", [
+ ("deep", "left", AoHMergeOpts.LEFT),
+ ("left", "right", AoHMergeOpts.RIGHT),
+ ("right", "unique", AoHMergeOpts.UNIQUE),
+ ("unique", "all", AoHMergeOpts.ALL),
+ ("all", "deep", AoHMergeOpts.DEEP),
+ ])
+ def test_array_merge_mode_override_rule_overrides_arg_rule(
+ self, quiet_logger, tmp_path_factory, arg_rule, override_rule, mode
+ ):
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(
+ quiet_logger,
+ SimpleNamespace(aoh=arg_rule),
+ rules={"/array_of_hashes": override_rule}
+ )
+ mc.prepare(lhs_data)
+
+ node = lhs_data["array_of_hashes"]
+ parent = lhs_data
+ parentref = "array_of_hashes"
+
+ assert mc.aoh_merge_mode(
+ NodeCoords(node, parent, parentref)) == mode
###
# aoh_merge_key
@@ -526,6 +780,40 @@ class Test_merger_MergerConfig():
assert mc.aoh_merge_key(
NodeCoords(node, parent, parentref), record) == "prop"
+ def test_aoh_merge_key_override_rule_overrides_ini(self, quiet_logger, tmp_path_factory):
+ config_file = create_temp_yaml_file(tmp_path_factory, """
+ [keys]
+ /array_of_hashes = name
+ """)
+ lhs_yaml_file = create_temp_yaml_file(tmp_path_factory, """---
+ hash:
+ lhs_exclusive: lhs value 1
+ merge_targets:
+ subkey: lhs value 2
+ subarray:
+ - one
+ - two
+ array_of_hashes:
+ - name: LHS Record 1
+ id: 1
+ prop: LHS value AoH 1
+ - name: LHS Record 2
+ id: 2
+ prop: LHS value AoH 2
+ """)
+ lhs_yaml = get_yaml_editor()
+ (lhs_data, lhs_loaded) = get_yaml_data(lhs_yaml, quiet_logger, lhs_yaml_file)
+
+ mc = MergerConfig(quiet_logger, SimpleNamespace(config=config_file), keys={"/array_of_hashes": "id"})
+ mc.prepare(lhs_data)
+
+ node = lhs_data["array_of_hashes"]
+ parent = lhs_data
+ parentref = "array_of_hashes"
+ record = node[0]
+
+ assert mc.aoh_merge_key(
+ NodeCoords(node, parent, parentref), record) == "id"
###
# set_merge_mode
| Difficulty using MergerConfig
Hey, first off, thanks for the awesome library. This project solves a huge recurring problem for me when trying to parse config files. I plan to use this in a lot of projects moving forward.
From my experience, it seems like this project is CLI-first rather than API-first. This makes the library a huge pain to integrate into other projects. For example, I'm trying to make a CLI program that merges some YAML files, overwriting only specific nodes. It seems like the only way to specify these exceptions using this project is to write out a config file with a list of rules (which in my case changes on every run). This adds unnecessary complexity as I should be able to just pass these options to the `MergerConfig` class directly.
Additionally, the YAML path rules I'm writing into the config include the `:` character, which `ConfigParse` likes to convert to `=`. Then the code in `MergerConfig` assumes that the `=` symbol is part of the value, not the key. I've solve this problem by using the following nasty hack:
```python
old_init = configparser.ConfigParser.__init__
def new_init(self):
old_init(self, delimiters="=")
configparser.ConfigParser.__init__ = new_init
```
Both of these problems can be solved by allowing rules, defaults, and key to be specified in the class constructor, and only loading from a config file in the event these values are absent. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_ini_rule[left-right-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_ini_rule[right-deep-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_ini_rule[deep-left-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_arg_rule[left-right-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_arg_rule[right-deep-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_override_rule_overrides_arg_rule[deep-left-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_ini_rule[deep-left-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_ini_rule[left-right-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_ini_rule[right-unique-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_ini_rule[unique-all-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_ini_rule[all-deep-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_arg_rule[deep-left-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_arg_rule[left-right-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_arg_rule[right-unique-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_arg_rule[unique-all-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_override_rule_overrides_arg_rule[all-deep-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_key_override_rule_overrides_ini"
] | [
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_get_insertion_point_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_get_insertion_point_cli",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_get_document_format",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_get_multidoc_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_get_multidoc_mode_cli",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli[left-AnchorConflictResolutions.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli[rename-AnchorConflictResolutions.RENAME]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli[right-AnchorConflictResolutions.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli[stop-AnchorConflictResolutions.STOP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_ini[left-AnchorConflictResolutions.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_ini[rename-AnchorConflictResolutions.RENAME]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_ini[right-AnchorConflictResolutions.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_ini[stop-AnchorConflictResolutions.STOP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli_overrides_ini[left-stop-AnchorConflictResolutions.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli_overrides_ini[rename-stop-AnchorConflictResolutions.RENAME]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli_overrides_ini[right-stop-AnchorConflictResolutions.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_anchor_merge_mode_cli_overrides_ini[stop-rename-AnchorConflictResolutions.STOP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli[deep-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli[left-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli[right-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini[deep-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini[left-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini[right-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli_overrides_ini_defaults[deep-left-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli_overrides_ini_defaults[left-right-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_cli_overrides_ini_defaults[right-deep-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini_rule_overrides_cli[deep-left-right-HashMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini_rule_overrides_cli[left-right-deep-HashMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_hash_merge_mode_ini_rule_overrides_cli[right-deep-left-HashMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli[all-ArrayMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli[left-ArrayMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli[right-ArrayMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli[unique-ArrayMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini[all-ArrayMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini[left-ArrayMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini[right-ArrayMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini[unique-ArrayMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli_overrides_ini_defaults[all-left-ArrayMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli_overrides_ini_defaults[left-right-ArrayMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli_overrides_ini_defaults[right-unique-ArrayMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_cli_overrides_ini_defaults[unique-all-ArrayMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini_rule_overrides_cli[all-left-right-ArrayMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini_rule_overrides_cli[left-right-unique-ArrayMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini_rule_overrides_cli[right-unique-all-ArrayMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_array_merge_mode_ini_rule_overrides_cli[unique-all-left-ArrayMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli[all-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli[deep-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli[left-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli[right-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli[unique-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini[all-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini[deep-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini[left-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini[right-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini[unique-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli_overrides_ini_defaults[all-deep-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli_overrides_ini_defaults[deep-left-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli_overrides_ini_defaults[left-right-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli_overrides_ini_defaults[right-unique-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_cli_overrides_ini_defaults[unique-all-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini_rule_overrides_cli[all-deep-left-AoHMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini_rule_overrides_cli[deep-left-right-AoHMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini_rule_overrides_cli[left-right-unique-AoHMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini_rule_overrides_cli[right-unique-all-AoHMergeOpts.ALL]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_mode_ini_rule_overrides_cli[unique-all-deep-AoHMergeOpts.DEEP]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_key_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_key_ini",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_aoh_merge_key_ini_inferred_parent",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_default",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli[left-SetMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli[right-SetMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli[unique-SetMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini[left-SetMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini[right-SetMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini[unique-SetMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli_overrides_ini_defaults[left-right-SetMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli_overrides_ini_defaults[right-unique-SetMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_cli_overrides_ini_defaults[unique-all-SetMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini_rule_overrides_cli[left-right-unique-SetMergeOpts.UNIQUE]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini_rule_overrides_cli[right-unique-left-SetMergeOpts.LEFT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_set_merge_mode_ini_rule_overrides_cli[unique-left-right-SetMergeOpts.RIGHT]",
"tests/test_merger_mergerconfig.py::Test_merger_MergerConfig::test_warn_when_rules_matches_zero_nodes"
] | {
"failed_lite_validators": [
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-10-23T01:40:37Z" | isc |
|
xCDAT__xcdat-226 | diff --git a/xcdat/spatial.py b/xcdat/spatial.py
index 97d2b55..65c0581 100644
--- a/xcdat/spatial.py
+++ b/xcdat/spatial.py
@@ -17,18 +17,13 @@ import numpy as np
import xarray as xr
from dask.array.core import Array
-from xcdat.axis import (
- GENERIC_AXIS_MAP,
- GenericAxis,
- _align_lon_bounds_to_360,
- _get_prime_meridian_index,
-)
+from xcdat.axis import _align_lon_bounds_to_360, _get_prime_meridian_index
from xcdat.dataset import get_data_var
#: Type alias for a dictionary of axis keys mapped to their bounds.
AxisWeights = Dict[Hashable, xr.DataArray]
#: Type alias for supported spatial axis keys.
-SpatialAxis = Literal["lat", "lon"]
+SpatialAxis = Literal["X", "Y"]
SPATIAL_AXES: Tuple[SpatialAxis, ...] = get_args(SpatialAxis)
#: Type alias for a tuple of floats/ints for the regional selection bounds.
RegionAxisBounds = Tuple[float, float]
@@ -44,13 +39,13 @@ class SpatialAccessor:
def average(
self,
data_var: str,
- axis: Union[List[SpatialAxis], SpatialAxis] = ["lat", "lon"],
+ axis: List[SpatialAxis] = ["X", "Y"],
weights: Union[Literal["generate"], xr.DataArray] = "generate",
lat_bounds: Optional[RegionAxisBounds] = None,
lon_bounds: Optional[RegionAxisBounds] = None,
) -> xr.Dataset:
"""
- Calculate the spatial average for a rectilinear grid over a (optional)
+ Calculates the spatial average for a rectilinear grid over an optionally
specified regional domain.
Operations include:
@@ -62,14 +57,21 @@ class SpatialAccessor:
- Adjust weights to conform to the specified regional boundary.
- Compute spatial weighted average.
+ This method requires that the dataset's coordinates have the 'axis'
+ attribute set to the keys in ``axis``. For example, the latitude
+ coordinates should have its 'axis' attribute set to 'Y' (which is also
+ CF-compliant). This 'axis' attribute is used to retrieve the related
+ coordinates via `cf_xarray`. Refer to this method's examples for more
+ information.
+
Parameters
----------
data_var: str
The name of the data variable inside the dataset to spatially
average.
- axis : Union[List[SpatialAxis], SpatialAxis]
- List of axis dimensions or single axis dimension to average over.
- For example, ["lat", "lon"] or "lat", by default ["lat", "lon"].
+ axis : List[SpatialAxis]
+ List of axis dimensions to average over, by default ["X", "Y"].
+ Valid axis keys include "X" and "Y".
weights : Union[Literal["generate"], xr.DataArray], optional
If "generate", then weights are generated. Otherwise, pass a
DataArray containing the regional weights used for weighted
@@ -104,30 +106,36 @@ class SpatialAccessor:
>>> import xcdat
- Open a dataset and limit to a single variable:
+ Check the 'axis' attribute is set on the required coordinates:
+
+ >>> ds.lat.attrs["axis"]
+ >>> Y
+ >>>
+ >>> ds.lon.attrs["axis"]
+ >>> X
+
+ Set the 'axis' attribute for the required coordinates if it isn't:
- >>> ds = xcdat.open_dataset("path/to/file.nc", var="tas")
+ >>> ds.lat.attrs["axis"] = "Y"
+ >>> ds.lon.attrs["axis"] = "X"
Call spatial averaging method:
- >>> # First option
>>> ds.spatial.average(...)
- >>> # Second option
- >>> ds.xcdat.average(...)
Get global average time series:
- >>> ts_global = ds.spatial.average("tas", axis=["lat", "lon"])["tas"]
+ >>> ts_global = ds.spatial.average("tas", axis=["X", "Y"])["tas"]
Get time series in Nino 3.4 domain:
- >>> ts_n34 = ds.spatial.average("ts", axis=["lat", "lon"],
+ >>> ts_n34 = ds.spatial.average("ts", axis=["X", "Y"],
>>> lat_bounds=(-5, 5),
>>> lon_bounds=(-170, -120))["ts"]
Get zonal mean time series:
- >>> ts_zonal = ds.spatial.average("tas", axis=['lon'])["tas"]
+ >>> ts_zonal = ds.spatial.average("tas", axis=["X"])["tas"]
Using custom weights for averaging:
@@ -138,18 +146,18 @@ class SpatialAccessor:
>>> dims=["lat", "lon"],
>>> )
>>>
- >>> ts_global = ds.spatial.average("tas", axis=["lat","lon"],
+ >>> ts_global = ds.spatial.average("tas", axis=["X", "Y"],
>>> weights=weights)["tas"]
"""
dataset = self._dataset.copy()
dv = get_data_var(dataset, data_var)
- axis = self._validate_axis(dv, axis)
+ self._validate_axis_arg(axis)
if isinstance(weights, str) and weights == "generate":
if lat_bounds is not None:
- self._validate_region_bounds("lat", lat_bounds)
+ self._validate_region_bounds("Y", lat_bounds)
if lon_bounds is not None:
- self._validate_region_bounds("lon", lon_bounds)
+ self._validate_region_bounds("X", lon_bounds)
dv_weights = self._get_weights(axis, lat_bounds, lon_bounds)
elif isinstance(weights, xr.DataArray):
dv_weights = weights
@@ -158,51 +166,39 @@ class SpatialAccessor:
dataset[dv.name] = self._averager(dv, axis, dv_weights)
return dataset
- def _validate_axis(
- self, data_var: xr.DataArray, axis: Union[List[SpatialAxis], SpatialAxis]
- ) -> List[SpatialAxis]:
- """Validates if ``axis`` arg is supported and exists in the data var.
+ def _validate_axis_arg(self, axis: List[SpatialAxis]):
+ """
+ Validates that the ``axis`` dimension(s) exists in the dataset.
Parameters
----------
- data_var : xr.DataArray
- The data variable.
- axis : Union[List[SpatialAxis], SpatialAxis]
- List of axis dimensions or single axis dimension to average over.
-
- Returns
- -------
- List[SpatialAxis]
- List of axis dimensions or single axis dimension to average over.
+ axis : List[SpatialAxis]
+ List of axis dimensions to average over.
Raises
------
ValueError
- If any key in ``axis`` is not supported for spatial averaging.
+ If a key in ``axis`` is not a supported value.
KeyError
- If any key in ``axis`` does not exist in the ``data_var``.
+ If the dataset does not have coordinates for the ``axis`` dimension,
+ or the `axis` attribute is not set for those coordinates.
"""
- if isinstance(axis, str):
- axis = [axis]
-
for key in axis:
if key not in SPATIAL_AXES:
raise ValueError(
- "Incorrect `axis` argument. Supported axes include: "
+ "Incorrect `axis` argument value. Supported values include: "
f"{', '.join(SPATIAL_AXES)}."
)
- generic_axis_key = GENERIC_AXIS_MAP[key]
try:
- data_var.cf.axes[generic_axis_key]
+ self._dataset.cf.axes[key]
except KeyError:
raise KeyError(
- f"The data variable '{data_var.name}' is missing the '{axis}' "
- "dimension, which is required for spatial averaging."
+ f"A '{key}' axis dimension was not found in the dataset. Make sure "
+ f"the dataset has '{key}' axis coordinates and the coordinates' "
+ f"'axis' attribute is set to '{key}'."
)
- return axis
-
def _validate_domain_bounds(self, domain_bounds: xr.DataArray):
"""Validates the ``domain_bounds`` arg based on a set of criteria.
@@ -244,7 +240,7 @@ class SpatialAccessor:
TypeError
If the ``bounds`` upper bound is not a float or integer.
ValueError
- If the ``axis`` is "lat" and the ``bounds`` lower value is larger
+ If the ``axis`` is "Y" and the ``bounds`` lower value is larger
than the upper value.
"""
if not isinstance(bounds, tuple):
@@ -269,12 +265,12 @@ class SpatialAccessor:
f"The regional {axis} upper bound is not a float or an integer."
)
- # For latitude, require that the upper bound be larger than the lower
- # bound. Note that this does not apply to longitude (since it is
- # a circular axis).
- if axis == "lat" and lower >= upper:
+ # For the "Y" axis (latitude), require that the upper bound be larger
+ # than the lower bound. Note that this does not apply to the "X" axis
+ # (longitude) since it is circular.
+ if axis == "Y" and lower >= upper:
raise ValueError(
- f"The regional {axis} lower bound is greater than the upper. "
+ "The regional latitude lower bound is greater than the upper. "
"Pass a tuple with the format (lower, upper)."
)
@@ -299,9 +295,8 @@ class SpatialAccessor:
Parameters
----------
- axis : Union[List[SpatialAxis], SpatialAxis]
- List of axis dimensions or single axis dimension to average over.
- For example, ["lat", "lon"] or "lat".
+ axis : List[SpatialAxis]
+ List of axis dimensions to average over.
lat_bounds : Optional[RegionAxisBounds]
Tuple of latitude boundaries for regional selection.
lon_bounds : Optional[RegionAxisBounds]
@@ -326,17 +321,18 @@ class SpatialAccessor:
{"domain": xr.DataArray, "region": Optional[RegionAxisBounds]},
)
axis_bounds: Dict[SpatialAxis, Bounds] = {
- "lat": {
- "domain": self._dataset.bounds.get_bounds("lat").copy(),
- "region": lat_bounds,
- },
- "lon": {
+ "X": {
"domain": self._dataset.bounds.get_bounds("lon").copy(),
"region": lon_bounds,
},
+ "Y": {
+ "domain": self._dataset.bounds.get_bounds("lat").copy(),
+ "region": lat_bounds,
+ },
}
axis_weights: AxisWeights = {}
+
for key in axis:
d_bounds = axis_bounds[key]["domain"]
self._validate_domain_bounds(d_bounds)
@@ -347,9 +343,9 @@ class SpatialAccessor:
if r_bounds is not None:
r_bounds = np.array(r_bounds, dtype="float")
- if key == "lon":
+ if key == "X":
weights = self._get_longitude_weights(d_bounds, r_bounds)
- elif key == "lat":
+ elif key == "Y":
weights = self._get_latitude_weights(d_bounds, r_bounds)
weights.attrs = d_bounds.attrs
@@ -357,6 +353,7 @@ class SpatialAccessor:
axis_weights[key] = weights
weights = self._combine_weights(axis_weights)
+
return weights
def _get_longitude_weights(
@@ -386,9 +383,9 @@ class SpatialAccessor:
Parameters
----------
domain_bounds : xr.DataArray
- The array of bounds for the latitude domain.
+ The array of bounds for the longitude domain.
region_bounds : Optional[np.ndarray]
- The array of bounds for latitude regional selection.
+ The array of bounds for longitude regional selection.
Returns
-------
@@ -655,14 +652,22 @@ class SpatialAccessor:
If the axis dimension sizes between ``weights`` and ``data_var``
are misaligned.
"""
- # Check that the supplied weights include lat and lon dimensions.
- lat_key = data_var.cf.axes["Y"][0]
- lon_key = data_var.cf.axes["X"][0]
-
- if "lat" in axis and lat_key not in weights.dims:
- raise KeyError(f"Check weights DataArray includes {lat_key} dimension.")
- if "lon" in axis and lon_key not in weights.dims:
- raise KeyError(f"Check weights DataArray includes {lon_key} dimension.")
+ # Check that the supplied weights include x and y dimensions.
+ x_key = data_var.cf.axes["X"][0]
+ y_key = data_var.cf.axes["Y"][0]
+
+ if "X" in axis and x_key not in weights.dims:
+ raise KeyError(
+ "The weights DataArray either does not include an X axis, "
+ "or the X axis coordinates does not have the 'axis' attribute "
+ "set to 'X'."
+ )
+ if "Y" in axis and y_key not in weights.dims:
+ raise KeyError(
+ "The weights DataArray either does not include an Y axis, "
+ "or the Y axis coordinates does not have the 'axis' attribute "
+ "set to 'Y'."
+ )
# Check the weight dim sizes equal data var dim sizes.
dim_sizes = {key: data_var.sizes[key] for key in weights.sizes.keys()}
@@ -692,8 +697,7 @@ class SpatialAccessor:
data_var : xr.DataArray
Data variable inside a Dataset.
axis : List[SpatialAxis]
- List of axis dimensions or single axis dimension to average over.
- For example, ["lat", "lon"] or "lat".
+ List of axis dimensions to average over.
weights : xr.DataArray
A DataArray containing the region area weights for averaging.
``weights`` must include the same spatial axis dimensions and have
@@ -710,34 +714,8 @@ class SpatialAccessor:
Missing values are replaced with 0 using ``weights.fillna(0)``.
"""
weights = weights.fillna(0)
- with xr.set_options(keep_attrs=True):
- weighted_mean = data_var.cf.weighted(weights).mean(
- self._get_generic_axis_keys(axis)
- )
- return weighted_mean
- def _get_generic_axis_keys(self, axis: List[SpatialAxis]) -> List[GenericAxis]:
- """Converts supported axis keys to their generic CF representations.
-
- Since xCDAT's spatial averaging accepts the CF short version of axes
- keys, attempting to index a Dataset/DataArray on the short key through
- cf_xarray might fail for cases where the long key is used instead (e.g.,
- "latitude" instead of "lat"). This method handles this edge case by
- converting the list of axis keys to their generic representations (e.g.,
- "Y" instead of "lat") for indexing operations.
-
- Parameters
- ----------
- axis_keys : List[SpatialAxis]
- List of axis dimension(s) to average over.
-
- Returns
- -------
- List[GenericAxis]
- List of axis dimension(s) to average over.
- """
- generic_axis_keys = []
- for key in axis:
- generic_axis_keys.append(GENERIC_AXIS_MAP[key])
+ with xr.set_options(keep_attrs=True):
+ weighted_mean = data_var.cf.weighted(weights).mean(axis)
- return generic_axis_keys
+ return weighted_mean
diff --git a/xcdat/temporal.py b/xcdat/temporal.py
index 702b15e..ad13d93 100644
--- a/xcdat/temporal.py
+++ b/xcdat/temporal.py
@@ -106,8 +106,9 @@ class TemporalAccessor:
dataset.cf["T"]
except KeyError:
raise KeyError(
- "This dataset does not have a time dimension, which is required for "
- "using the methods in the TemporalAccessor class."
+ "A 'T' axis dimension was not found in the dataset. Make sure the "
+ "dataset has time axis coordinates and its 'axis' attribute is set to "
+ "'T'."
)
self._dataset: xr.Dataset = dataset
@@ -210,6 +211,15 @@ class TemporalAccessor:
>>> import xcdat
+ Check the 'axis' attribute is set on the time coordinates:
+
+ >>> ds.time.attrs["axis"]
+ >>> T
+
+ Set the 'axis' attribute for the time coordinates if it isn't:
+
+ >>> ds.time.attrs["axis"] = "T"
+
Call ``average()`` method:
>>> ds.temporal.average(...)
| xCDAT/xcdat | 4e582e54e564d6d69339b2218027c6cd1affd957 | diff --git a/tests/test_spatial.py b/tests/test_spatial.py
index dd0f9fb..49e01b8 100644
--- a/tests/test_spatial.py
+++ b/tests/test_spatial.py
@@ -41,7 +41,7 @@ class TestAverage:
with pytest.raises(KeyError):
self.ds.spatial.average(
"not_a_data_var",
- axis=["lat", "incorrect_axis"],
+ axis=["Y", "incorrect_axis"],
)
def test_spatial_average_for_lat_and_lon_region_using_custom_weights(self):
@@ -53,7 +53,7 @@ class TestAverage:
dims=["lat", "lon"],
)
result = ds.spatial.average(
- axis=["lat", "lon"],
+ axis=["X", "Y"],
lat_bounds=(-5.0, 5),
lon_bounds=(-170, -120.1),
weights=weights,
@@ -72,7 +72,7 @@ class TestAverage:
def test_spatial_average_for_lat_and_lon_region(self):
ds = self.ds.copy()
result = ds.spatial.average(
- "ts", axis=["lat", "lon"], lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
+ "ts", axis=["X", "Y"], lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
)
expected = self.ds.copy()
@@ -89,7 +89,7 @@ class TestAverage:
# Specifying axis as a str instead of list of str.
result = ds.spatial.average(
- "ts", axis="lat", lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
+ "ts", axis=["Y"], lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
)
expected = self.ds.copy()
@@ -109,7 +109,7 @@ class TestAverage:
# Specifying axis as a str instead of list of str.
result = ds.spatial.average(
- "ts", axis="lat", lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
+ "ts", axis=["Y"], lat_bounds=(-5.0, 5), lon_bounds=(-170, -120.1)
)
expected = self.ds.copy()
@@ -124,32 +124,26 @@ class TestAverage:
assert result.identical(expected)
-class TestValidateAxis:
+class TestValidateAxisArg:
@pytest.fixture(autouse=True)
def setup(self):
self.ds = generate_dataset(cf_compliant=True, has_bounds=True)
def test_raises_error_if_axis_list_contains_unsupported_axis(self):
with pytest.raises(ValueError):
- self.ds.spatial._validate_axis(self.ds.ts, axis=["lat", "incorrect_axis"])
+ self.ds.spatial._validate_axis_arg(axis=["Y", "incorrect_axis"])
def test_raises_error_if_lat_axis_does_not_exist(self):
ds = self.ds.copy()
- ds["ts"] = xr.DataArray(data=None, coords={"lon": ds.lon}, dims=["lon"])
+ ds.lat.attrs["axis"] = None
with pytest.raises(KeyError):
- ds.spatial._validate_axis(ds.ts, axis=["lat", "lon"])
+ ds.spatial._validate_axis_arg(axis=["X", "Y"])
def test_raises_error_if_lon_axis_does_not_exist(self):
ds = self.ds.copy()
- ds["ts"] = xr.DataArray(data=None, coords={"lat": ds.lat}, dims=["lat"])
+ ds.lon.attrs["axis"] = None
with pytest.raises(KeyError):
- ds.spatial._validate_axis(ds.ts, axis=["lat", "lon"])
-
- def test_returns_list_of_str_if_axis_is_a_single_supported_str_input(self):
- result = self.ds.spatial._validate_axis(self.ds.ts, axis="lat")
- expected = ["lat"]
-
- assert result == expected
+ ds.spatial._validate_axis_arg(axis=["X", "Y"])
class TestValidateRegionBounds:
@@ -178,18 +172,18 @@ class TestValidateRegionBounds:
def test_raises_error_if_lower_bound_is_not_a_float_or_int(self):
with pytest.raises(TypeError):
- self.ds.spatial._validate_region_bounds("lat", ("invalid", 1))
+ self.ds.spatial._validate_region_bounds("Y", ("invalid", 1))
def test_raises_error_if_upper_bound_is_not_a_float_or_int(self):
with pytest.raises(TypeError):
- self.ds.spatial._validate_region_bounds("lon", (1, "invalid"))
+ self.ds.spatial._validate_region_bounds("X", (1, "invalid"))
def test_raises_error_if_lower_lat_bound_is_bigger_than_upper(self):
with pytest.raises(ValueError):
- self.ds.spatial._validate_region_bounds("lat", (2, 1))
+ self.ds.spatial._validate_region_bounds("Y", (2, 1))
def test_does_not_raise_error_if_lon_lower_bound_is_larger_than_upper(self):
- self.ds.spatial._validate_region_bounds("lon", (2, 1))
+ self.ds.spatial._validate_region_bounds("X", (2, 1))
class TestValidateWeights:
@@ -209,7 +203,7 @@ class TestValidateWeights:
coords={"lat": self.ds.lat, "lon": self.ds.lon},
dims=["lat", "lon"],
)
- self.ds.spatial._validate_weights(self.ds["ts"], axis="lat", weights=weights)
+ self.ds.spatial._validate_weights(self.ds["ts"], axis=["Y"], weights=weights)
def test_error_is_raised_when_lat_axis_is_specified_but_lat_is_not_in_weights_dims(
self,
@@ -219,7 +213,7 @@ class TestValidateWeights:
)
with pytest.raises(KeyError):
self.ds.spatial._validate_weights(
- self.ds["ts"], axis=["lon", "lat"], weights=weights
+ self.ds["ts"], axis=["X", "Y"], weights=weights
)
def test_error_is_raised_when_lon_axis_is_specified_but_lon_is_not_in_weights_dims(
@@ -230,7 +224,7 @@ class TestValidateWeights:
)
with pytest.raises(KeyError):
self.ds.spatial._validate_weights(
- self.ds["ts"], axis=["lon", "lat"], weights=weights
+ self.ds["ts"], axis=["X", "Y"], weights=weights
)
def test_error_is_raised_when_weights_lat_and_lon_dims_dont_align_with_data_var_dims(
@@ -247,7 +241,7 @@ class TestValidateWeights:
with pytest.raises(ValueError):
self.ds.spatial._validate_weights(
- self.ds["ts"], axis=["lat", "lon"], weights=weights
+ self.ds["ts"], axis=["X", "Y"], weights=weights
)
@@ -404,7 +398,7 @@ class TestGetWeights:
def test_weights_for_region_in_lat_and_lon_domains(self):
result = self.ds.spatial._get_weights(
- axis=["lat", "lon"], lat_bounds=(-5, 5), lon_bounds=(-170, -120)
+ axis=["Y", "X"], lat_bounds=(-5, 5), lon_bounds=(-170, -120)
)
expected = xr.DataArray(
data=np.array(
@@ -423,7 +417,7 @@ class TestGetWeights:
def test_area_weights_for_region_in_lat_domain(self):
result = self.ds.spatial._get_weights(
- axis=["lat", "lon"], lat_bounds=(-5, 5), lon_bounds=None
+ axis=["Y", "X"], lat_bounds=(-5, 5), lon_bounds=None
)
expected = xr.DataArray(
data=np.array(
@@ -454,7 +448,7 @@ class TestGetWeights:
dims=["lat", "lon"],
)
result = self.ds.spatial._get_weights(
- axis=["lat", "lon"], lat_bounds=None, lon_bounds=(-170, -120)
+ axis=["Y", "X"], lat_bounds=None, lon_bounds=(-170, -120)
)
xr.testing.assert_allclose(result, expected)
@@ -828,7 +822,7 @@ class TestAverager:
dims=["lat", "lon"],
)
- result = ds.spatial._averager(ds.ts, axis=["lat", "lon"], weights=weights)
+ result = ds.spatial._averager(ds.ts, axis=["X", "Y"], weights=weights)
expected = xr.DataArray(
name="ts", data=np.ones(15), coords={"time": ds.time}, dims=["time"]
)
@@ -843,7 +837,7 @@ class TestAverager:
dims=["lat"],
)
- result = self.ds.spatial._averager(self.ds.ts, axis=["lat"], weights=weights)
+ result = self.ds.spatial._averager(self.ds.ts, axis=["Y"], weights=weights)
expected = xr.DataArray(
name="ts",
data=np.ones((15, 4)),
@@ -861,7 +855,7 @@ class TestAverager:
dims=["lon"],
)
- result = self.ds.spatial._averager(self.ds.ts, axis=["lon"], weights=weights)
+ result = self.ds.spatial._averager(self.ds.ts, axis=["X"], weights=weights)
expected = xr.DataArray(
name="ts",
data=np.ones((15, 4)),
@@ -878,22 +872,9 @@ class TestAverager:
dims=["lat", "lon"],
)
- result = self.ds.spatial._averager(
- self.ds.ts, axis=["lat", "lon"], weights=weights
- )
+ result = self.ds.spatial._averager(self.ds.ts, axis=["X", "Y"], weights=weights)
expected = xr.DataArray(
name="ts", data=np.ones(15), coords={"time": self.ds.time}, dims=["time"]
)
assert result.identical(expected)
-
-
-class TestGetGenericAxisKeys:
- @pytest.fixture(autouse=True)
- def setup(self):
- self.ds = generate_dataset(cf_compliant=True, has_bounds=True)
-
- def test_generic_keys(self):
- result = self.ds.spatial._get_generic_axis_keys(["lat", "lon"])
- expected = ["Y", "X"]
- assert result == expected
| [FEATURE]: Update supported spatial `axis` arg keys generic format
### Is your feature request related to a problem?
The valid `axis` arg values of `"lat"` and `"lon"` do not follow the axis naming convention that we adopted with our APIs.
https://github.com/XCDAT/xcdat/blob/79c488ea890febc422fe2e38b85c4e9dc7c72565/xcdat/spatial.py#L47
We implemented a mapping system for axis and coordinates names to their generic axis name.
https://github.com/XCDAT/xcdat/blob/79c488ea890febc422fe2e38b85c4e9dc7c72565/xcdat/axis.py#L14-L25
### Describe the solution you'd like
1. Update valid `axis` arg values from `"lat"` and `"lon"` to `"Y"`/`"y"` and `"X"`/`"x"`
3. Convert the `axis` arg value to `.upper()`
4. Map the `axis` arg to the dimension/coordinates in the `xr.Dataset`
5. Update `KeyError` if the CF `axis` attribute is not set for the X and Y axis coordinates
* Related to https://github.com/XCDAT/xcdat/issues/166#issuecomment-1099382979
> We can probably improve the KeyError so that it says something like:
> KeyError: "Could not find an X and/or Y axis for spatial averaging. Make sure the data variable 'tas' has X and Y axis coordinates and the 'axis' attribute is set for both."
* A reusable convenience function/method might be useful for checking if the `axis` attribute is set for the desired axis in the Dataset. If it isn't, then raise a `KeyError`. `cf_xarray` already throws an error if we try something like `ds.cf["X"]` when the `"X"` axis attr is not set, but the error is ambiguous.
### Describe alternatives you've considered
### Additional context
* `cdutil.averager()`'s `axis` arg accepts lowercase generic axis names (`"x"`, `"y"`, `"t"`, etc.)
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_spatial.py::TestAverage::test_spatial_average_for_lat_and_lon_region_using_custom_weights",
"tests/test_spatial.py::TestAverage::test_spatial_average_for_lat_and_lon_region",
"tests/test_spatial.py::TestAverage::test_spatial_average_for_lat_region",
"tests/test_spatial.py::TestAverage::test_chunked_spatial_average_for_lat_region",
"tests/test_spatial.py::TestValidateAxisArg::test_raises_error_if_axis_list_contains_unsupported_axis",
"tests/test_spatial.py::TestValidateAxisArg::test_raises_error_if_lat_axis_does_not_exist",
"tests/test_spatial.py::TestValidateAxisArg::test_raises_error_if_lon_axis_does_not_exist",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_lower_lat_bound_is_bigger_than_upper",
"tests/test_spatial.py::TestGetWeights::test_weights_for_region_in_lat_and_lon_domains",
"tests/test_spatial.py::TestGetWeights::test_area_weights_for_region_in_lat_domain",
"tests/test_spatial.py::TestGetWeights::test_weights_for_region_in_lon_domain"
] | [
"tests/test_spatial.py::TestSpatialAccessor::test__init__",
"tests/test_spatial.py::TestSpatialAccessor::test_decorator_call",
"tests/test_spatial.py::TestAverage::test_raises_error_if_data_var_not_in_dataset",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_bounds_type_is_not_a_tuple",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_there_are_0_elements_in_the_bounds",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_there_are_more_than_two_elements_in_the_bounds",
"tests/test_spatial.py::TestValidateRegionBounds::test_does_not_raise_error_if_lower_and_upper_bounds_are_floats_or_ints",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_lower_bound_is_not_a_float_or_int",
"tests/test_spatial.py::TestValidateRegionBounds::test_raises_error_if_upper_bound_is_not_a_float_or_int",
"tests/test_spatial.py::TestValidateRegionBounds::test_does_not_raise_error_if_lon_lower_bound_is_larger_than_upper",
"tests/test_spatial.py::TestSwapLonAxis::test_raises_error_with_incorrect_orientation_to_swap_to",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_chunked_domain_dataarray_from_180_to_360",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_chunked_domain_dataarray_from_360_to_180",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_domain_dataarray_from_180_to_360",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_domain_dataarray_from_360_to_180",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_region_ndarray_from_180_to_360",
"tests/test_spatial.py::TestSwapLonAxis::test_swap_region_ndarray_from_360_to_180",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_for_region_in_lon_domain",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_for_region_in_lon_domain_with_both_spanning_p_meridian",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_for_region_in_lon_domain_with_domain_spanning_p_meridian",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_for_region_in_lon_domain_with_region_spanning_p_meridian",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_all_longitudes_for_equal_region_bounds",
"tests/test_spatial.py::TestGetLongitudeWeights::test_weights_for_equal_region_bounds_representing_entire_lon_domain",
"tests/test_spatial.py::TestGetLatitudeWeights::test_weights_for_region_in_lat_domain",
"tests/test_spatial.py::TestValidateDomainBounds::test_raises_error_if_low_bounds_exceeds_high_bound",
"tests/test_spatial.py::TestCalculateWeights::test_returns_weights_as_the_absolute_difference_of_upper_and_lower_bounds",
"tests/test_spatial.py::TestScaleDimToRegion::test_scales_chunked_lat_bounds_when_not_wrapping_around_prime_meridian",
"tests/test_spatial.py::TestScaleDimToRegion::test_scales_chunked_lon_bounds_when_not_wrapping_around_prime_meridian",
"tests/test_spatial.py::TestScaleDimToRegion::test_scales_lat_bounds_when_not_wrapping_around_prime_meridian",
"tests/test_spatial.py::TestScaleDimToRegion::test_scales_lon_bounds_when_not_wrapping_around_prime_meridian",
"tests/test_spatial.py::TestScaleDimToRegion::test_scales_lon_bounds_when_wrapping_around_prime_meridian",
"tests/test_spatial.py::TestCombineWeights::test_weights_for_single_axis_are_identical",
"tests/test_spatial.py::TestCombineWeights::test_weights_for_multiple_axis_is_the_product_of_matrix_multiplication",
"tests/test_spatial.py::TestAverager::test_chunked_weighted_avg_over_lat_and_lon_axes",
"tests/test_spatial.py::TestAverager::test_weighted_avg_over_lat_axis",
"tests/test_spatial.py::TestAverager::test_weighted_avg_over_lon_axis",
"tests/test_spatial.py::TestAverager::test_weighted_avg_over_lat_and_lon_axis"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-04-25T23:03:09Z" | apache-2.0 |
|
xCDAT__xcdat-241 | diff --git a/xcdat/bounds.py b/xcdat/bounds.py
index 0d81742..0b011fe 100644
--- a/xcdat/bounds.py
+++ b/xcdat/bounds.py
@@ -1,9 +1,12 @@
"""Bounds module for functions related to coordinate bounds."""
import collections
+import warnings
from typing import Dict, List, Literal, Optional
import cf_xarray as cfxr # noqa: F401
+import cftime
import numpy as np
+import pandas as pd
import xarray as xr
from xcdat.axis import GENERIC_AXIS_MAP
@@ -253,13 +256,32 @@ class BoundsAccessor:
diffs = da_coord.diff(dim).values
# Add beginning and end points to account for lower and upper bounds.
+ # np.array of string values with `dtype="timedelta64[ns]"`
diffs = np.insert(diffs, 0, diffs[0])
diffs = np.append(diffs, diffs[-1])
- # Get lower and upper bounds by using the width relative to nearest point.
+ # In xarray and xCDAT, time coordinates with non-CF compliant calendars
+ # (360-day, noleap) and/or units ("months", "years") are decoded using
+ # `cftime` objects instead of `datetime` objects. `cftime` objects only
+ # support arithmetic using `timedelta` objects, so the values of `diffs`
+ # must be casted from `dtype="timedelta64[ns]"` to `timedelta`.
+ if da_coord.name in ("T", "time") and issubclass(
+ type(da_coord.values[0]), cftime.datetime
+ ):
+ diffs = pd.to_timedelta(diffs)
+
+ # FIXME: These lines produces the warning: `PerformanceWarning:
+ # Adding/subtracting object-dtype array to TimedeltaArray not
+ # vectorized` after converting diffs to `timedelta`. I (Tom) was not
+ # able to find an alternative, vectorized solution at the time of this
+ # implementation.
+ with warnings.catch_warnings():
+ warnings.simplefilter("ignore", category=pd.errors.PerformanceWarning)
+ # Get lower and upper bounds by using the width relative to nearest point.
+ lower_bounds = da_coord - diffs[:-1] * width
+ upper_bounds = da_coord + diffs[1:] * (1 - width)
+
# Transpose both bound arrays into a 2D array.
- lower_bounds = da_coord - diffs[:-1] * width
- upper_bounds = da_coord + diffs[1:] * (1 - width)
bounds = np.array([lower_bounds, upper_bounds]).transpose()
# Clip latitude bounds at (-90, 90)
diff --git a/xcdat/dataset.py b/xcdat/dataset.py
index eddc9bb..0c7e3c5 100644
--- a/xcdat/dataset.py
+++ b/xcdat/dataset.py
@@ -457,7 +457,7 @@ def _postprocess_dataset(
if center_times:
if dataset.cf.dims.get("T") is not None:
- dataset = dataset.temporal.center_times(dataset)
+ dataset = dataset.temporal.center_times()
else:
raise ValueError("This dataset does not have a time coordinates to center.")
diff --git a/xcdat/temporal.py b/xcdat/temporal.py
index 20baec6..4a6078c 100644
--- a/xcdat/temporal.py
+++ b/xcdat/temporal.py
@@ -677,7 +677,7 @@ class TemporalAccessor:
return ds_departs
- def center_times(self, dataset: xr.Dataset) -> xr.Dataset:
+ def center_times(self) -> xr.Dataset:
"""Centers the time coordinates using the midpoint between time bounds.
Time coordinates can be recorded using different intervals, including
@@ -695,12 +695,9 @@ class TemporalAccessor:
xr.Dataset
The Dataset with centered time coordinates.
"""
- ds = dataset.copy()
-
- if hasattr(self, "_time_bounds") is False:
- self._time_bounds = ds.bounds.get_bounds("time")
+ ds = self._dataset.copy()
+ time_bounds = ds.bounds.get_bounds("time")
- time_bounds = self._time_bounds.copy()
lower_bounds, upper_bounds = (time_bounds[:, 0].data, time_bounds[:, 1].data)
bounds_diffs: np.timedelta64 = (upper_bounds - lower_bounds) / 2
bounds_mids: np.ndarray = lower_bounds + bounds_diffs
@@ -842,7 +839,7 @@ class TemporalAccessor:
ds = self._dataset.copy()
if self._center_times:
- ds = self.center_times(ds)
+ ds = self.center_times()
if (
self._freq == "season"
@@ -1393,14 +1390,14 @@ class TemporalAccessor:
self._time_bounds[:, 1] - self._time_bounds[:, 0]
)
- # Must be convert dtype from timedelta64[ns] to float64, specifically
- # when chunking DataArrays using Dask. Otherwise, the numpy warning
- # below is thrown: `DeprecationWarning: The `dtype` and `signature`
- # arguments to ufuncs only select the general DType and not details such
- # as the byte order or time unit (with rare exceptions see release
- # notes). To avoid this warning please use the scalar types
- # `np.float64`, or string notation.`
+ # Must be cast dtype from "timedelta64[ns]" to "float64", specifically
+ # when using Dask arrays. Otherwise, the numpy warning below is thrown:
+ # `DeprecationWarning: The `dtype` and `signature` arguments to ufuncs
+ # only select the general DType and not details such as the byte order
+ # or time unit (with rare exceptions see release notes). To avoid this
+ # warning please use the scalar types `np.float64`, or string notation.`
time_lengths = time_lengths.astype(np.float64)
+
grouped_time_lengths = self._group_data(time_lengths)
weights: xr.DataArray = grouped_time_lengths / grouped_time_lengths.sum() # type: ignore
| xCDAT/xcdat | 112eb58f797821f14af2934b7b2551b39912c291 | diff --git a/tests/test_bounds.py b/tests/test_bounds.py
index 2c1bfcb..92698ba 100644
--- a/tests/test_bounds.py
+++ b/tests/test_bounds.py
@@ -1,3 +1,4 @@
+import cftime
import numpy as np
import pytest
import xarray as xr
@@ -115,7 +116,7 @@ class TestAddBounds:
with pytest.raises(ValueError):
ds.bounds.add_bounds("lat")
- def test__add_bounds_raises_errors_for_data_dim_and_length(self):
+ def test_add_bounds_raises_errors_for_data_dim_and_length(self):
# Multidimensional
lat = xr.DataArray(
data=np.array([[0, 1, 2], [3, 4, 5]]),
@@ -132,23 +133,23 @@ class TestAddBounds:
# If coords dimensions does not equal 1.
with pytest.raises(ValueError):
- ds.bounds._add_bounds("lat")
+ ds.bounds.add_bounds("lat")
# If coords are length of <=1.
with pytest.raises(ValueError):
- ds.bounds._add_bounds("lon")
+ ds.bounds.add_bounds("lon")
- def test__add_bounds_returns_dataset_with_bounds_added(self):
+ def test_add_bounds_for_dataset_with_coords_as_datetime_objects(self):
ds = self.ds.copy()
- ds = ds.bounds._add_bounds("lat")
- assert ds.lat_bnds.equals(lat_bnds)
- assert ds.lat_bnds.is_generated == "True"
+ result = ds.bounds.add_bounds("lat")
+ assert result.lat_bnds.equals(lat_bnds)
+ assert result.lat_bnds.is_generated == "True"
- ds = ds.bounds._add_bounds("lon")
- assert ds.lon_bnds.equals(lon_bnds)
- assert ds.lon_bnds.is_generated == "True"
+ result = result.bounds.add_bounds("lon")
+ assert result.lon_bnds.equals(lon_bnds)
+ assert result.lon_bnds.is_generated == "True"
- ds = ds.bounds._add_bounds("time")
+ result = ds.bounds.add_bounds("time")
# NOTE: The algorithm for generating time bounds doesn't extend the
# upper bound into the next month.
expected_time_bnds = xr.DataArray(
@@ -173,16 +174,61 @@ class TestAddBounds:
],
dtype="datetime64[ns]",
),
- coords={"time": ds.time},
+ coords={"time": ds.time.assign_attrs({"bounds": "time_bnds"})},
+ dims=["time", "bnds"],
+ attrs={"is_generated": "True"},
+ )
+
+ assert result.time_bnds.identical(expected_time_bnds)
+
+ def test_returns_bounds_for_dataset_with_coords_as_cftime_objects(self):
+ ds = self.ds.copy()
+ ds = ds.drop_dims("time")
+ ds["time"] = xr.DataArray(
+ name="time",
+ data=np.array(
+ [
+ cftime.DatetimeNoLeap(1850, 1, 1),
+ cftime.DatetimeNoLeap(1850, 2, 1),
+ cftime.DatetimeNoLeap(1850, 3, 1),
+ ],
+ ),
+ dims=["time"],
+ attrs={
+ "axis": "T",
+ "long_name": "time",
+ "standard_name": "time",
+ },
+ )
+
+ result = ds.bounds.add_bounds("time")
+ expected_time_bnds = xr.DataArray(
+ name="time_bnds",
+ data=np.array(
+ [
+ [
+ cftime.DatetimeNoLeap(1849, 12, 16, 12),
+ cftime.DatetimeNoLeap(1850, 1, 16, 12),
+ ],
+ [
+ cftime.DatetimeNoLeap(1850, 1, 16, 12),
+ cftime.DatetimeNoLeap(1850, 2, 15, 0),
+ ],
+ [
+ cftime.DatetimeNoLeap(1850, 2, 15, 0),
+ cftime.DatetimeNoLeap(1850, 3, 15, 0),
+ ],
+ ],
+ ),
+ coords={"time": ds.time.assign_attrs({"bounds": "time_bnds"})},
dims=["time", "bnds"],
- attrs=ds.time_bnds.attrs,
+ attrs={"is_generated": "True"},
)
- assert ds.time_bnds.equals(expected_time_bnds)
- assert ds.time_bnds.is_generated == "True"
+ assert result.time_bnds.identical(expected_time_bnds)
-class TestGetCoord:
+class Test_GetCoord:
@pytest.fixture(autouse=True)
def setup(self):
self.ds = generate_dataset(cf_compliant=True, has_bounds=False)
diff --git a/tests/test_dataset.py b/tests/test_dataset.py
index 4ca3438..d8e8c4d 100644
--- a/tests/test_dataset.py
+++ b/tests/test_dataset.py
@@ -264,7 +264,7 @@ class TestOpenMfDataset:
assert result.identical(expected)
-class TestHasCFCompliantTime:
+class Test_HasCFCompliantTime:
@pytest.fixture(autouse=True)
def setUp(self, tmp_path):
# Create temporary directory to save files.
@@ -668,7 +668,7 @@ class TestDecodeNonCFTimeUnits:
assert result.time_bnds.encoding == expected.time_bnds.encoding
-class TestPostProcessDataset:
+class Test_PostProcessDataset:
@pytest.fixture(autouse=True)
def setup(self):
self.ds = generate_dataset(cf_compliant=True, has_bounds=True)
@@ -868,7 +868,7 @@ class TestPostProcessDataset:
_postprocess_dataset(ds, lon_orient=(0, 360))
-class TestKeepSingleVar:
+class Test_KeepSingleVar:
@pytest.fixture(autouse=True)
def setup(self):
self.ds = generate_dataset(cf_compliant=True, has_bounds=True)
@@ -909,7 +909,7 @@ class TestKeepSingleVar:
assert ds.get("time_bnds") is not None
-class TestPreProcessNonCFDataset:
+class Test_PreProcessNonCFDataset:
@pytest.fixture(autouse=True)
def setup(self):
self.ds = generate_dataset(cf_compliant=False, has_bounds=True)
@@ -944,7 +944,7 @@ class TestPreProcessNonCFDataset:
assert result.identical(expected)
-class TestSplitTimeUnitsAttr:
+class Test_SplitTimeUnitsAttr:
def test_raises_error_if_units_attr_is_none(self):
with pytest.raises(KeyError):
_split_time_units_attr(None) # type: ignore
diff --git a/tests/test_temporal.py b/tests/test_temporal.py
index 15f4c48..a5d5ef2 100644
--- a/tests/test_temporal.py
+++ b/tests/test_temporal.py
@@ -64,7 +64,7 @@ class TestAverage:
attrs={"is_generated": "True"},
)
ds["ts"] = xr.DataArray(
- data=np.array([[[2]], [[1]], [[1]], [[1]], [[2]]]),
+ data=np.array([[[2]], [[np.nan]], [[1]], [[1]], [[2]]]),
coords={"lat": ds.lat, "lon": ds.lon, "time": ds.time},
dims=["time", "lat", "lon"],
)
@@ -74,7 +74,7 @@ class TestAverage:
expected = ds.copy()
expected = expected.drop_dims("time")
expected["ts"] = xr.DataArray(
- data=np.array([[1.4]]),
+ data=np.array([[1.5]]),
coords={"lat": expected.lat, "lon": expected.lon},
dims=["lat", "lon"],
attrs={
@@ -93,7 +93,7 @@ class TestAverage:
expected = ds.copy()
expected = expected.drop_dims("time")
expected["ts"] = xr.DataArray(
- data=np.array([[1.4]]),
+ data=np.array([[1.5]]),
coords={"lat": expected.lat, "lon": expected.lon},
dims=["lat", "lon"],
attrs={
@@ -120,7 +120,7 @@ class TestAverage:
"2000-02-01T00:00:00.000000000",
"2000-03-01T00:00:00.000000000",
"2000-04-01T00:00:00.000000000",
- "2000-05-01T00:00:00.000000000",
+ "2001-02-01T00:00:00.000000000",
],
dtype="datetime64[ns]",
),
@@ -142,7 +142,7 @@ class TestAverage:
["2000-02-01T00:00:00.000000000", "2000-03-01T00:00:00.000000000"],
["2000-03-01T00:00:00.000000000", "2000-04-01T00:00:00.000000000"],
["2000-04-01T00:00:00.000000000", "2000-05-01T00:00:00.000000000"],
- ["2000-05-01T00:00:00.000000000", "2000-06-01T00:00:00.000000000"],
+ ["2001-01-01T00:00:00.000000000", "2000-03-01T00:00:00.000000000"],
],
dtype="datetime64[ns]",
),
@@ -151,7 +151,7 @@ class TestAverage:
attrs={"is_generated": "True"},
)
ds["ts"] = xr.DataArray(
- data=np.array([[[2]], [[1]], [[1]], [[1]], [[1]]]),
+ data=np.array([[[2]], [[np.nan]], [[1]], [[1]], [[1]]]),
coords={"lat": ds.lat, "lon": ds.lon, "time": ds.time},
dims=["time", "lat", "lon"],
)
@@ -161,7 +161,7 @@ class TestAverage:
expected = ds.copy()
expected = expected.drop_dims("time")
expected["ts"] = xr.DataArray(
- data=np.array([[1.2]]),
+ data=np.array([[1.24362357]]),
coords={"lat": expected.lat, "lon": expected.lon},
dims=["lat", "lon"],
attrs={
@@ -173,14 +173,14 @@ class TestAverage:
},
)
- assert result.identical(expected)
+ xr.testing.assert_allclose(result, expected)
# Test unweighted averages
result = ds.temporal.average("ts", weighted=False)
expected = ds.copy()
expected = expected.drop_dims("time")
expected["ts"] = xr.DataArray(
- data=np.array([[1.2]]),
+ data=np.array([[1.25]]),
coords={"lat": expected.lat, "lon": expected.lon},
dims=["lat", "lon"],
attrs={
@@ -191,7 +191,7 @@ class TestAverage:
"center_times": "False",
},
)
- assert result.identical(expected)
+ xr.testing.assert_allclose(result, expected)
def test_averages_for_daily_time_series(self):
ds = xr.Dataset(
@@ -826,6 +826,57 @@ class TestGroupAverage:
assert result.identical(expected)
+ def test_weighted_monthly_averages_with_masked_data(self):
+ ds = self.ds.copy()
+ ds["ts"] = xr.DataArray(
+ data=np.array(
+ [[[2.0]], [[np.nan]], [[1.0]], [[1.0]], [[2.0]]], dtype="float64"
+ ),
+ coords={"time": self.ds.time, "lat": self.ds.lat, "lon": self.ds.lon},
+ dims=["time", "lat", "lon"],
+ )
+
+ result = ds.temporal.group_average("ts", "month")
+ expected = ds.copy()
+ expected = expected.drop_dims("time")
+ expected["ts"] = xr.DataArray(
+ name="ts",
+ data=np.array([[[2.0]], [[0.0]], [[1.0]], [[1.0]], [[2.0]]]),
+ coords={
+ "lat": expected.lat,
+ "lon": expected.lon,
+ "time": xr.DataArray(
+ data=np.array(
+ [
+ "2000-01-01T00:00:00.000000000",
+ "2000-03-01T00:00:00.000000000",
+ "2000-06-01T00:00:00.000000000",
+ "2000-09-01T00:00:00.000000000",
+ "2001-02-01T00:00:00.000000000",
+ ],
+ dtype="datetime64[ns]",
+ ),
+ dims=["time"],
+ attrs={
+ "axis": "T",
+ "long_name": "time",
+ "standard_name": "time",
+ "bounds": "time_bnds",
+ },
+ ),
+ },
+ dims=["time", "lat", "lon"],
+ attrs={
+ "operation": "temporal_avg",
+ "mode": "group_average",
+ "freq": "month",
+ "weighted": "True",
+ "center_times": "False",
+ },
+ )
+
+ assert result.identical(expected)
+
def test_weighted_daily_averages(self):
ds = self.ds.copy()
@@ -1584,7 +1635,7 @@ class TestCenterTimes:
ds = ds.drop_dims("time")
with pytest.raises(KeyError):
- ds.temporal.center_times(ds)
+ ds.temporal.center_times()
def test_gets_time_as_the_midpoint_between_time_bounds(self):
ds = self.ds.copy()
@@ -1658,7 +1709,7 @@ class TestCenterTimes:
time_bounds["time"] = expected.time
expected["time_bnds"] = time_bounds
- result = ds.temporal.center_times(ds)
+ result = ds.temporal.center_times()
assert result.identical(expected)
| [Bug]: `add_bounds()` breaks when time coordinates are in `cftime` objects instead of `datetime`
### Bug Report Criteria
- [X] Bug is not related to a data quality issue(s) beyond the scope of xCDAT
- [X] Bug is not related to core xarray APIs (please open an issue in the xarray repo if it is)
### What happened?
`cftime` datetime objects are used to represent time coordinates for non-cf compliant calendars (360-day, noleap) and units ("months", "years"). Unlike `datetime` datetime objects, `cftime` datetime objects (e.g., `cftime.Datetime`, `cftime.DatetimeNoLeap`) don't support arithmetic involving `timedelta64[ns]`, ints, floats, etc.
In the formula to calculate the lower and upper bounds for each coordinate point, a subtraction and addition operation is performed respectively (example below). The `diffs` array consists of `timedelta64[ns]`, so it breaks (refer to MCV example and log outputs).
https://github.com/xCDAT/xcdat/blob/112eb58f797821f14af2934b7b2551b39912c291/xcdat/bounds.py#L255-L263
Instead of subtracting `diffs` as a `np.array` of strings with a dtype of `timedelta64[ns]`, we have to subtract using `timedelta` objects. This can be achieved by using `pd.to_timedelta(diffs)`.
```python
# Add beginning and end points to account for lower and upper bounds.
# np.array of string values with dtype "timedelta64[ns]""
diffs = np.insert(diffs, 0, diffs[0])
diffs = np.append(diffs, diffs[-1])
# In xarray and xCDAT, `cftime` objects are used to represent time
# coordinates for non-Cf compliant calendars (360-day, noleap) and
# units ("months", "years"), instead of `datetime` objects. `cftime`
# objects only support arithmetic using `timedelta`` objects, so
# the values of `diffs` must be casted to `timedelta`.
# FIXME: This line produces the warning: python3.9/site-packages/pandas
# /core/arrays/datetimelike.py:1189: PerformanceWarning:
# Adding/subtracting object-dtype array to TimedeltaArray not
# vectorized.warnings.warn(
diffs = pd.to_timedelta(diffs)
```
Related issue: https://github.com/Unidata/cftime/issues/198
### What did you expect to happen?
Bounds are generated regardless of the datetime object type used to represent time coordinates
### Minimal Complete Verifiable Example
```python
import xcdat
dataset_links = [
"https://esgf-data2.llnl.gov/thredds/dodsC/user_pub_work/E3SM/1_0/amip_1850_aeroF/1deg_atm_60-30km_ocean/atmos/180x360/time-series/mon/ens2/v3/TS_187001_189412.nc",
"https://esgf-data2.llnl.gov/thredds/dodsC/user_pub_work/E3SM/1_0/amip_1850_aeroF/1deg_atm_60-30km_ocean/atmos/180x360/time-series/mon/ens2/v3/TS_189501_191912.nc",
]
ds = xcdat.open_mfdataset(dataset_links)
# Drop the existing time bounds to demonstrate adding new bounds
ds = ds.drop_vars("time_bnds")
# Breaks here dataset_links = [
"https://esgf-data2.llnl.gov/thredds/dodsC/user_pub_work/E3SM/1_0/amip_1850_aeroF/1deg_atm_60-30km_ocean/atmos/180x360/time-series/mon/ens2/v3/TS_187001_189412.nc",
"https://esgf-data2.llnl.gov/thredds/dodsC/user_pub_work/E3SM/1_0/amip_1850_aeroF/1deg_atm_60-30km_ocean/atmos/180x360/time-series/mon/ens2/v3/TS_189501_191912.nc",
]
ds = ds.bounds.add_bounds("time")
```
### Relevant log output
```python
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/vo13/miniconda3/envs/xcdat_dev/lib/python3.9/site-packages/IPython/core/interactiveshell.py", line 3397, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "/tmp/ipykernel_9974/1848296045.py", line 1, in <cell line: 1>
ds_new.bounds.add_bounds("time")
File "/home/vo13/XCDAT/xcdat/xcdat/bounds.py", line 207, in add_bounds
dataset = self._add_bounds(axis, width)
File "/home/vo13/XCDAT/xcdat/xcdat/bounds.py", line 262, in _add_bounds
lower_bounds = da_coord - diffs[:-1] * width
File "/home/vo13/miniconda3/envs/xcdat_dev/lib/python3.9/site-packages/xarray/core/_typed_ops.py", line 209, in __sub__
return self._binary_op(other, operator.sub)
File "/home/vo13/miniconda3/envs/xcdat_dev/lib/python3.9/site-packages/xarray/core/dataarray.py", line 3098, in _binary_op
f(self.variable, other_variable)
File "/home/vo13/miniconda3/envs/xcdat_dev/lib/python3.9/site-packages/xarray/core/_typed_ops.py", line 399, in __sub__
return self._binary_op(other, operator.sub)
File "/home/vo13/miniconda3/envs/xcdat_dev/lib/python3.9/site-packages/xarray/core/variable.py", line 2467, in _binary_op
f(self_data, other_data) if not reflexive else f(other_data, self_data)
numpy.core._exceptions._UFuncBinaryResolutionError: ufunc 'subtract' cannot use operands with types dtype('O') and dtype('<m8[ns]')
```
### Anything else we need to know?
Related code:
https://github.com/Unidata/cftime/blob/dc75368cd02bbcd1352dbecfef10404a58683f94/src/cftime/_cftime.pyx#L1020-L1021
https://github.com/Unidata/cftime/blob/dc75368cd02bbcd1352dbecfef10404a58683f94/src/cftime/_cftime.pyx#L439-L472
### Environment
INSTALLED VERSIONS
------------------
commit: None
python: 3.9.12 | packaged by conda-forge | (main, Mar 24 2022, 23:22:55)
[GCC 10.3.0]
python-bits: 64
OS: Linux
OS-release: 3.10.0-1160.45.1.el7.x86_64
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: 1.12.1
libnetcdf: 4.8.1
xarray: 2022.3.0
pandas: 1.4.1
numpy: 1.22.3
scipy: 1.8.1
netCDF4: 1.5.8
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: None
cftime: 1.6.0
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: 1.3.2
dask: 2022.03.0
distributed: 2022.3.0
matplotlib: 3.5.1
cartopy: 0.20.1
seaborn: None
numbagg: None
fsspec: 2022.3.0
cupy: None
pint: None
sparse: None
setuptools: 61.2.0
pip: 22.0.4
conda: None
pytest: 7.1.1
IPython: 8.3.0
sphinx: 4.4.0
INSTALLED VERSIONS
------------------
commit: None
python: 3.9.12 | packaged by conda-forge | (main, Mar 24 2022, 23:22:55)
[GCC 10.3.0]
python-bits: 64
OS: Linux
OS-release: 3.10.0-1160.45.1.el7.x86_64
machine: x86_64
processor: x86_64
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
libhdf5: 1.12.1
libnetcdf: 4.8.1
xarray: 2022.3.0
pandas: 1.4.1
numpy: 1.22.3
scipy: 1.8.1
netCDF4: 1.5.8
pydap: None
h5netcdf: None
h5py: None
Nio: None
zarr: None
cftime: 1.6.0
nc_time_axis: None
PseudoNetCDF: None
rasterio: None
cfgrib: None
iris: None
bottleneck: 1.3.2
dask: 2022.03.0
distributed: 2022.3.0
matplotlib: 3.5.1
cartopy: 0.20.1
seaborn: None
numbagg: None
fsspec: 2022.3.0
cupy: None
pint: None
sparse: None
setuptools: 61.2.0
pip: 22.0.4
conda: None
pytest: 7.1.1
IPython: 8.3.0
sphinx: 4.4.0
None
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_bounds.py::TestAddBounds::test_returns_bounds_for_dataset_with_coords_as_cftime_objects",
"tests/test_temporal.py::TestCenterTimes::test_gets_time_as_the_midpoint_between_time_bounds"
] | [
"tests/test_bounds.py::TestBoundsAccessor::test__init__",
"tests/test_bounds.py::TestBoundsAccessor::test_decorator_call",
"tests/test_bounds.py::TestBoundsAccessor::test_map_property_returns_map_of_axis_and_coordinate_keys_to_bounds_dataarray",
"tests/test_bounds.py::TestBoundsAccessor::test_keys_property_returns_a_list_of_sorted_bounds_keys",
"tests/test_bounds.py::TestAddMissingBounds::test_adds_bounds_in_dataset",
"tests/test_bounds.py::TestAddMissingBounds::test_does_not_fill_bounds_for_coord_of_len_less_than_2",
"tests/test_bounds.py::TestGetBounds::test_raises_error_when_bounds_dont_exist",
"tests/test_bounds.py::TestGetBounds::test_getting_existing_bounds_in_dataset",
"tests/test_bounds.py::TestGetBounds::test_get_nonexistent_bounds_in_dataset",
"tests/test_bounds.py::TestGetBounds::test_raises_error_with_incorrect_coord_arg",
"tests/test_bounds.py::TestAddBounds::test_add_bounds_raises_error_if_bounds_exist",
"tests/test_bounds.py::TestAddBounds::test_add_bounds_raises_errors_for_data_dim_and_length",
"tests/test_bounds.py::TestAddBounds::test_add_bounds_for_dataset_with_coords_as_datetime_objects",
"tests/test_bounds.py::Test_GetCoord::test_gets_coords",
"tests/test_bounds.py::Test_GetCoord::test_raises_error_if_coord_does_not_exist",
"tests/test_dataset.py::TestOpenDataset::test_non_cf_compliant_time_is_not_decoded",
"tests/test_dataset.py::TestOpenDataset::test_non_cf_compliant_time_is_decoded",
"tests/test_dataset.py::TestOpenDataset::test_preserves_lat_and_lon_bounds_if_they_exist",
"tests/test_dataset.py::TestOpenDataset::test_keeps_specified_var",
"tests/test_dataset.py::TestOpenMfDataset::test_non_cf_compliant_time_is_not_decoded",
"tests/test_dataset.py::TestOpenMfDataset::test_non_cf_compliant_time_is_decoded",
"tests/test_dataset.py::TestOpenMfDataset::test_keeps_specified_var",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_non_cf_compliant_time",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_no_time_axis",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_glob_cf_compliant_time",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_list_cf_compliant_time",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_cf_compliant_time_with_string_path",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_cf_compliant_time_with_pathlib_path",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_cf_compliant_time_with_list_of_list_of_strings",
"tests/test_dataset.py::Test_HasCFCompliantTime::test_cf_compliant_time_with_list_of_list_of_pathlib_paths",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_raises_error_if_function_is_called_on_already_decoded_cf_compliant_dataset",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_months_with_a_reference_date_at_the_start_of_the_month",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_months_with_a_reference_date_at_the_middle_of_the_month",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_months_with_a_reference_date_at_the_end_of_the_month",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_months_with_a_reference_date_on_a_leap_year",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_years_with_a_reference_date_at_the_middle_of_the_year",
"tests/test_dataset.py::TestDecodeNonCFTimeUnits::test_decodes_years_with_a_reference_date_on_a_leap_year",
"tests/test_dataset.py::Test_PostProcessDataset::test_keeps_specified_var",
"tests/test_dataset.py::Test_PostProcessDataset::test_centers_time",
"tests/test_dataset.py::Test_PostProcessDataset::test_raises_error_if_dataset_has_no_time_coords_but_center_times_is_true",
"tests/test_dataset.py::Test_PostProcessDataset::test_adds_missing_lat_and_lon_bounds",
"tests/test_dataset.py::Test_PostProcessDataset::test_orients_longitude_bounds_from_180_to_360_and_sorts_with_prime_meridian_cell",
"tests/test_dataset.py::Test_PostProcessDataset::test_raises_error_if_dataset_has_no_longitude_coords_but_lon_orient_is_specified",
"tests/test_dataset.py::Test_KeepSingleVar::tests_raises_error_if_only_bounds_data_variables_exist",
"tests/test_dataset.py::Test_KeepSingleVar::test_raises_error_if_specified_data_var_does_not_exist",
"tests/test_dataset.py::Test_KeepSingleVar::test_raises_error_if_specified_data_var_is_a_bounds_var",
"tests/test_dataset.py::Test_KeepSingleVar::test_returns_dataset_with_specified_data_var",
"tests/test_dataset.py::Test_KeepSingleVar::test_bounds_always_persist",
"tests/test_dataset.py::Test_PreProcessNonCFDataset::test_user_specified_callable_results_in_subsetting_dataset_on_time_slice",
"tests/test_dataset.py::Test_SplitTimeUnitsAttr::test_raises_error_if_units_attr_is_none",
"tests/test_dataset.py::Test_SplitTimeUnitsAttr::test_splits_units_attr_to_unit_and_reference_date",
"tests/test_temporal.py::TestTemporalAccessor::test__init__",
"tests/test_temporal.py::TestTemporalAccessor::test_decorator",
"tests/test_temporal.py::TestAverage::test_averages_for_yearly_time_series",
"tests/test_temporal.py::TestAverage::test_averages_for_monthly_time_series",
"tests/test_temporal.py::TestAverage::test_averages_for_daily_time_series",
"tests/test_temporal.py::TestAverage::test_averages_for_hourly_time_series",
"tests/test_temporal.py::TestGroupAverage::test_weighted_annual_averages",
"tests/test_temporal.py::TestGroupAverage::test_weighted_annual_averages_with_chunking",
"tests/test_temporal.py::TestGroupAverage::test_weighted_seasonal_averages_with_DJF_and_drop_incomplete_seasons",
"tests/test_temporal.py::TestGroupAverage::test_weighted_seasonal_averages_with_DJF_without_dropping_incomplete_seasons",
"tests/test_temporal.py::TestGroupAverage::test_weighted_seasonal_averages_with_JFD",
"tests/test_temporal.py::TestGroupAverage::test_weighted_custom_seasonal_averages",
"tests/test_temporal.py::TestGroupAverage::test_raises_error_with_incorrect_custom_seasons_argument",
"tests/test_temporal.py::TestGroupAverage::test_weighted_monthly_averages",
"tests/test_temporal.py::TestGroupAverage::test_weighted_monthly_averages_with_masked_data",
"tests/test_temporal.py::TestGroupAverage::test_weighted_daily_averages",
"tests/test_temporal.py::TestGroupAverage::test_weighted_daily_averages_and_center_times",
"tests/test_temporal.py::TestGroupAverage::test_weighted_hourly_averages",
"tests/test_temporal.py::TestClimatology::test_weighted_seasonal_climatology_with_DJF",
"tests/test_temporal.py::TestClimatology::test_chunked_weighted_seasonal_climatology_with_DJF",
"tests/test_temporal.py::TestClimatology::test_weighted_seasonal_climatology_with_JFD",
"tests/test_temporal.py::TestClimatology::test_weighted_custom_seasonal_climatology",
"tests/test_temporal.py::TestClimatology::test_weighted_monthly_climatology",
"tests/test_temporal.py::TestClimatology::test_unweighted_monthly_climatology",
"tests/test_temporal.py::TestClimatology::test_weighted_daily_climatology",
"tests/test_temporal.py::TestClimatology::test_unweighted_daily_climatology",
"tests/test_temporal.py::TestDepartures::test_weighted_seasonal_departures_with_DJF",
"tests/test_temporal.py::TestDepartures::test_unweighted_seasonal_departures_with_DJF",
"tests/test_temporal.py::TestDepartures::test_unweighted_seasonal_departures_with_JFD",
"tests/test_temporal.py::TestCenterTimes::test_raises_error_if_time_dimension_does_not_exist_in_dataset",
"tests/test_temporal.py::Test_SetObjAttrs::test_raises_error_if_operation_is_not_supported",
"tests/test_temporal.py::Test_SetObjAttrs::test_raises_error_if_freq_arg_is_not_supported_by_operation",
"tests/test_temporal.py::Test_SetObjAttrs::test_does_not_raise_error_if_freq_arg_is_supported_by_operation",
"tests/test_temporal.py::Test_SetObjAttrs::test_raises_error_if_season_config_key_is_not_supported",
"tests/test_temporal.py::Test_SetObjAttrs::test_raises_error_if_december_mode_is_not_supported",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForAverageMode::test_weights_for_yearly_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForAverageMode::test_weights_for_monthly_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_yearly_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_monthly_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_seasonal_averages_with_DJF_and_drop_incomplete_seasons",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_seasonal_averages_with_JFD",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_custom_season_time_series_weights",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_daily_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForGroupAverageMode::test_weights_for_hourly_averages",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForClimatologyMode::test_weights_for_seasonal_climatology_with_DJF",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForClimatologyMode::test_weights_for_seasonal_climatology_with_JFD",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForClimatologyMode::test_weights_for_annual_climatology",
"tests/test_temporal.py::Test_GetWeights::TestWeightsForClimatologyMode::test_weights_for_daily_climatology"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-05-26T23:39:23Z" | apache-2.0 |
|
xCDAT__xcdat-257 | diff --git a/xcdat/axis.py b/xcdat/axis.py
index 55eac02..5d1a256 100644
--- a/xcdat/axis.py
+++ b/xcdat/axis.py
@@ -100,22 +100,22 @@ def swap_lon_axis(
The Dataset with swapped lon axes orientation.
"""
ds = dataset.copy()
- lon: xr.DataArray = dataset.bounds._get_coords("lon").copy()
+ lon: xr.DataArray = _get_coord_var(ds, "X").copy()
lon_bounds: xr.DataArray = dataset.bounds.get_bounds("lon").copy()
with xr.set_options(keep_attrs=True):
if to == (-180, 180):
- lon = ((lon + 180) % 360) - 180
- lon_bounds = ((lon_bounds + 180) % 360) - 180
- ds = _reassign_lon(ds, lon, lon_bounds)
+ new_lon = ((lon + 180) % 360) - 180
+ new_lon_bounds = ((lon_bounds + 180) % 360) - 180
+ ds = _reassign_lon(ds, new_lon, new_lon_bounds)
elif to == (0, 360):
- lon = lon % 360
- lon_bounds = lon_bounds % 360
- ds = _reassign_lon(ds, lon, lon_bounds)
+ new_lon = lon % 360
+ new_lon_bounds = lon_bounds % 360
+ ds = _reassign_lon(ds, new_lon, new_lon_bounds)
# Handle cases where a prime meridian cell exists, which can occur
# after swapping to (0, 360).
- p_meridian_index = _get_prime_meridian_index(lon_bounds)
+ p_meridian_index = _get_prime_meridian_index(new_lon_bounds)
if p_meridian_index is not None:
ds = _align_lon_to_360(ds, p_meridian_index)
else:
@@ -124,8 +124,13 @@ def swap_lon_axis(
"orientations."
)
+ # If the swapped axis orientation is the same as the existing axis
+ # orientation, return the original Dataset.
+ if new_lon.identical(lon):
+ return dataset
+
if sort_ascending:
- ds = ds.sortby(lon.name, ascending=True)
+ ds = ds.sortby(new_lon.name, ascending=True)
return ds
| xCDAT/xcdat | 092854ac8327ebce6d9581e773a7f837f6dbc170 | diff --git a/tests/test_axis.py b/tests/test_axis.py
index 1263ed8..abf0943 100644
--- a/tests/test_axis.py
+++ b/tests/test_axis.py
@@ -143,6 +143,32 @@ class TestSwapLonAxis:
with pytest.raises(ValueError):
swap_lon_axis(ds_180, to=(0, 360))
+ def test_does_not_swap_if_desired_orientation_is_the_same_as_the_existing_orientation(
+ self,
+ ):
+ ds_360 = xr.Dataset(
+ coords={
+ "lon": xr.DataArray(
+ name="lon",
+ data=np.array([60, 150, 271]),
+ dims=["lon"],
+ attrs={"units": "degrees_east", "axis": "X", "bounds": "lon_bnds"},
+ )
+ },
+ data_vars={
+ "lon_bnds": xr.DataArray(
+ name="lon_bnds",
+ data=np.array([[0, 120], [120, 181], [181, 360]]),
+ dims=["lon", "bnds"],
+ attrs={"is_generated": "True"},
+ )
+ },
+ )
+
+ result = swap_lon_axis(ds_360, to=(0, 360))
+
+ assert result.identical(ds_360)
+
def test_swap_from_360_to_180_and_sorts(self):
ds_360 = xr.Dataset(
coords={
| [Bug]: Converting the longitude axis orientation to the same system results in odd behaviors
### What happened?
> As a side note, there is some weird behavior here: the longitude axis goes from size 360 to 361 (and one set of lon_bnds
> goes from 0 to 0). I'm not sure if this is specific to converting from one longitude coordinate system to the same system
> (something people wouldn't normally do) or a more generic issue. This doesn't happen when converting to (-180, 180).
> — @pochedls from https://github.com/xCDAT/xcdat/pull/239#issuecomment-1146235781
### What did you expect to happen?
The coordinates and coordinate bounds should remain the same if attempting to convert to the same axis system.
Solution: Detect that the desired axis system is the same as the existing system, so use a `pass` statement to ignore.
### Minimal Complete Verifiable Example
_No response_
### Relevant log output
_No response_
### Anything else we need to know?
_No response_
### Environment
`main` branch of xcdat | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_axis.py::TestSwapLonAxis::test_does_not_swap_if_desired_orientation_is_the_same_as_the_existing_orientation"
] | [
"tests/test_axis.py::TestCenterTimes::test_raises_error_if_time_coord_var_does_not_exist_in_dataset",
"tests/test_axis.py::TestCenterTimes::test_raises_error_if_time_bounds_does_not_exist_in_the_dataset",
"tests/test_axis.py::TestCenterTimes::test_gets_time_as_the_midpoint_between_time_bounds",
"tests/test_axis.py::TestSwapLonAxis::test_raises_error_with_incorrect_lon_orientation_for_swapping",
"tests/test_axis.py::TestSwapLonAxis::test_raises_error_if_lon_bounds_contains_more_than_one_prime_meridian_cell",
"tests/test_axis.py::TestSwapLonAxis::test_swap_from_360_to_180_and_sorts",
"tests/test_axis.py::TestSwapLonAxis::test_swap_from_180_to_360_and_sorts_with_prime_meridian_cell_in_lon_bnds"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2022-06-10T23:02:55Z" | apache-2.0 |
|
xarg__kuku-4 | diff --git a/kuku/dump.py b/kuku/dump.py
index b9366c0..614fec6 100644
--- a/kuku/dump.py
+++ b/kuku/dump.py
@@ -48,11 +48,13 @@ def dump(rendering: Rendering) -> str:
template_output = []
template_header = "# Source: {}\n".format(template_path)
for k8s_object in k8s_objects:
- # Override the default to_dict method so we can update the k8s keys
if not k8s_object:
+ if k8s_object is None:
+ continue
raise ValueError(
"Template '{}' returned {} object".format(template_path, k8s_object)
)
+ # Override the default to_dict method so we can update the k8s keys
k8s_object.to_dict = MethodType(_camelized_to_dict, k8s_object)
k8s_object = k8s_object.to_dict()
| xarg/kuku | be65d1b83cc3725cf7fbce16069559bd2e5cef93 | diff --git a/kuku/tests/test_dump.py b/kuku/tests/test_dump.py
index e69de29..0ccafa8 100644
--- a/kuku/tests/test_dump.py
+++ b/kuku/tests/test_dump.py
@@ -0,0 +1,6 @@
+from kuku.dump import dump
+
+
+def test_dump_with_none_object():
+ output = dump({"dir1": [None, ]})
+ assert output == "# Source: dir1\n"
| Feature request: ability to enable/disable whole K8s resource
I want to do something like this:
```python
def template(context):
if not context["deployment"]["enabled"]:
return
context_name = context["name"]
labels = {"app": context_name}
...
```
This fails with
```
Traceback (most recent call last):
File ".../bin/kuku", line 10, in <module>
sys.exit(cli())
File ".../kuku/cli.py", line 59, in cli
output = dump(rendering)
File ".../kuku/dump.py", line 54, in dump
"Template '{}' returned {} object".format(template_path, k8s_object)
ValueError: Template 'deployment/k8s/templates/cronjob.py' returned None object
```
I am going to submit a PR that is going to skip the serialization/dumping of the `k8s_object` if it's `None` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"kuku/tests/test_dump.py::test_dump_with_none_object"
] | [] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2019-10-03T16:13:45Z" | apache-2.0 |
|
xarray-contrib__xskillscore-230 | diff --git a/.github/workflows/lint.yml b/.github/workflows/lint.yml
index 1be599e..8c0f2fe 100644
--- a/.github/workflows/lint.yml
+++ b/.github/workflows/lint.yml
@@ -13,6 +13,6 @@ jobs:
- name: Set up Python
uses: actions/setup-python@v2
with:
- python-version: 3.6
+ python-version: 3.8
- name: Lint via pre-commit checks
uses: pre-commit/[email protected]
diff --git a/.github/workflows/xskillscore_installs.yml b/.github/workflows/xskillscore_installs.yml
index 68dfc61..4dc3d9d 100644
--- a/.github/workflows/xskillscore_installs.yml
+++ b/.github/workflows/xskillscore_installs.yml
@@ -17,7 +17,7 @@ jobs:
- name: Setup python
uses: actions/setup-python@v2
with:
- python-version: 3.6
+ python-version: 3.8
- name: Install dependencies
run: |
python -m pip install --upgrade pip
diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index e0b8757..211bb5b 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -34,6 +34,8 @@ Internal Changes
- Added Python 3.7 and Python 3.8 to the CI. Use the latest version of Python 3
for development. (:issue:`21`, :pr:`189`). `Aaron Spring`_
- Lint with the latest black. (:issue:`179`, :pr:`191`). `Ray Bell`_
+- Update mape algorithm from scikit-learn v0.24.0 and test against it.
+ (:issue:`160`, :pr:`230`) `Ray Bell`_
xskillscore v0.0.18 (2020-09-23)
diff --git a/ci/doc.yml b/ci/doc.yml
index afbdf91..ee45765 100644
--- a/ci/doc.yml
+++ b/ci/doc.yml
@@ -2,7 +2,7 @@ name: xskillscore-docs
channels:
- conda-forge
dependencies:
- - python=3.6
+ - python=3.8
- bottleneck
- doc8
- importlib_metadata
diff --git a/xskillscore/core/deterministic.py b/xskillscore/core/deterministic.py
index aafe46a..a8958eb 100644
--- a/xskillscore/core/deterministic.py
+++ b/xskillscore/core/deterministic.py
@@ -1046,12 +1046,13 @@ def mape(a, b, dim=None, weights=None, skipna=False, keep_attrs=False):
.. math::
\\mathrm{MAPE} = \\frac{1}{n} \\sum_{i=1}^{n}
\\frac{\\vert a_{i} - b_{i} \\vert}
- {\\vert a_{i} \\vert}
+ {max(\epsilon, \\vert a_{i} \\vert)}
.. note::
The percent error is calculated in reference to ``a``. Percent
error is reported as decimal percent. I.e., a value of 1 is
- 100%.
+ 100%. :math:`\epsilon` is an arbitrary small yet strictly positive
+ number to avoid undefined results when ``a`` is zero.
Parameters
----------
@@ -1078,6 +1079,10 @@ def mape(a, b, dim=None, weights=None, skipna=False, keep_attrs=False):
xarray.Dataset or xarray.DataArray
Mean Absolute Percentage Error.
+ See Also
+ --------
+ sklearn.metrics.mean_absolute_percentage_error
+
References
----------
https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
diff --git a/xskillscore/core/np_deterministic.py b/xskillscore/core/np_deterministic.py
index e6fb19a..ae736ac 100644
--- a/xskillscore/core/np_deterministic.py
+++ b/xskillscore/core/np_deterministic.py
@@ -652,7 +652,7 @@ def _mape(a, b, weights, axis, skipna):
.. math::
\\mathrm{MAPE} = \\frac{1}{n} \\sum_{i=1}^{n}
\\frac{\\vert a_{i} - b_{i} \\vert}
- {\\vert a_{i} \\vert}
+ {max(\epsilon, \\vert a_{i} \\vert)}
Parameters
----------
@@ -679,6 +679,13 @@ def _mape(a, b, weights, axis, skipna):
Percent error is reported as decimal percent. I.e., a value of
1 is 100%.
+ \epsilon is an arbitrary small yet strictly positive number to avoid
+ undefined results when ``a`` is zero.
+
+ See Also
+ --------
+ sklearn.metrics.mean_absolute_percentage_error
+
References
----------
https://en.wikipedia.org/wiki/Mean_absolute_percentage_error
@@ -687,8 +694,8 @@ def _mape(a, b, weights, axis, skipna):
if skipna:
a, b, weights = _match_nans(a, b, weights)
weights = _check_weights(weights)
- # replace divided by 0 with nan
- mape = np.absolute(a - b) / np.absolute(np.where(a != 0, a, np.nan))
+ epsilon = np.finfo(np.float64).eps
+ mape = np.absolute(a - b) / np.maximum(np.absolute(a), epsilon)
if weights is not None:
return sumfunc(mape * weights, axis=axis) / sumfunc(weights, axis=axis)
else:
| xarray-contrib/xskillscore | 6783decc906adeefca05ef54f04461c326634677 | diff --git a/.github/workflows/xskillscore_testing.yml b/.github/workflows/xskillscore_testing.yml
index 4ed6d27..0508ea9 100644
--- a/.github/workflows/xskillscore_testing.yml
+++ b/.github/workflows/xskillscore_testing.yml
@@ -60,7 +60,7 @@ jobs:
channels: conda-forge
mamba-version: '*'
activate-environment: xskillscore-docs-notebooks
- python-version: 3.6
+ python-version: 3.8
- name: Set up conda environment
run: |
mamba env update -f ci/docs_notebooks.yml
diff --git a/xskillscore/tests/conftest.py b/xskillscore/tests/conftest.py
index 059f3e2..9998ae9 100644
--- a/xskillscore/tests/conftest.py
+++ b/xskillscore/tests/conftest.py
@@ -68,6 +68,13 @@ def b_nan(b):
return b.copy().where(b < 0.5)
+# with zeros
[email protected]
+def a_with_zeros(a):
+ """Zeros"""
+ return a.copy().where(a < 0.5, 0)
+
+
# dask
@pytest.fixture
def a_dask(a):
@@ -116,6 +123,12 @@ def b_1d_nan(a_1d_nan):
return b
[email protected]
+def a_1d_with_zeros(a_with_zeros):
+ """Timeseries of a with zeros"""
+ return a_with_zeros.isel(lon=0, lat=0, drop=True)
+
+
# weights
@pytest.fixture
def weights(a):
diff --git a/xskillscore/tests/test_metric_results_accurate.py b/xskillscore/tests/test_metric_results_accurate.py
index a00e3d4..54f1481 100644
--- a/xskillscore/tests/test_metric_results_accurate.py
+++ b/xskillscore/tests/test_metric_results_accurate.py
@@ -2,7 +2,12 @@ import numpy as np
import pytest
import sklearn.metrics
from scipy.stats import pearsonr, spearmanr
-from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
+from sklearn.metrics import (
+ mean_absolute_error,
+ mean_absolute_percentage_error,
+ mean_squared_error,
+ r2_score,
+)
import xskillscore as xs
from xskillscore.core.deterministic import (
@@ -23,6 +28,11 @@ xs_skl_metrics = [
(r2, r2_score),
(mse, mean_squared_error),
(mae, mean_absolute_error),
+ (mape, mean_absolute_percentage_error),
+]
+
+xs_skl_metrics_with_zeros = [
+ (mape, mean_absolute_percentage_error),
]
xs_scipy_metrics = [
@@ -34,7 +44,6 @@ xs_scipy_metrics = [
xs_np_metrics = [
- (mape, lambda x, y: np.mean(np.abs((x - y) / x))),
(me, lambda x, y: np.mean(x - y)),
(smape, lambda x, y: 1 / len(x) * np.sum(np.abs(y - x) / (np.abs(x) + np.abs(y)))),
]
@@ -69,6 +78,15 @@ def test_xs_same_as_skl_same_name(a_1d, b_1d, request):
assert np.allclose(actual, expected)
[email protected]("xs_skl_metrics", xs_skl_metrics_with_zeros)
+def test_xs_same_as_skl_with_zeros(a_1d_with_zeros, b_1d, xs_skl_metrics):
+ """Tests xskillscore metric is same as scikit-learn metric."""
+ xs_metric, skl_metric = xs_skl_metrics
+ actual = xs_metric(a_1d_with_zeros, b_1d, "time")
+ expected = skl_metric(a_1d_with_zeros, b_1d)
+ assert np.allclose(actual, expected)
+
+
@pytest.mark.parametrize("xs_scipy_metrics", xs_scipy_metrics)
def test_xs_same_as_scipy(a_1d, b_1d, xs_scipy_metrics):
"""Tests xskillscore metric is same as scipy metric."""
| Add MAPE in See Also and in testing from sklearn
`sklearn` has MAPE now in their master branch (https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/metrics/_regression.py#L197). Once released, we can test against this and put it in "See Also" for MAPE. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl_with_zeros[xs_skl_metrics0]"
] | [
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl[xs_skl_metrics0]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl[xs_skl_metrics1]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl[xs_skl_metrics2]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl[xs_skl_metrics3]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_skl_rmse[False]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_scipy[xs_scipy_metrics0]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_scipy[xs_scipy_metrics1]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_scipy[xs_scipy_metrics2]",
"xskillscore/tests/test_metric_results_accurate.py::test_xs_same_as_scipy[xs_scipy_metrics3]",
"xskillscore/tests/test_metric_results_accurate.py::test_mape_same_as_numpy[xs_np_metrics0]",
"xskillscore/tests/test_metric_results_accurate.py::test_mape_same_as_numpy[xs_np_metrics1]"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-01-05T03:58:59Z" | apache-2.0 |
|
xarray-contrib__xskillscore-339 | diff --git a/CHANGELOG.rst b/CHANGELOG.rst
index 4a955fd..40f2270 100644
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -5,6 +5,11 @@ Changelog History
xskillscore v0.0.23 (2021-xx-xx)
--------------------------------
+Internal Changes
+~~~~~~~~~~~~~~~~
+- :py:func:`~xskillscore.resampling.resample_iterations_idx` do not break when ``dim`` is
+ not coordinate. (:issue:`303`, :pr:`339`) `Aaron Spring`_
+
xskillscore v0.0.22 (2021-06-29)
--------------------------------
diff --git a/xskillscore/core/resampling.py b/xskillscore/core/resampling.py
index e4f1096..5481029 100644
--- a/xskillscore/core/resampling.py
+++ b/xskillscore/core/resampling.py
@@ -107,6 +107,8 @@ def resample_iterations(forecast, iterations, dim="member", dim_max=None, replac
forecast_smp.append(forecast.isel({dim: idx}).assign_coords({dim: new_dim}))
forecast_smp = xr.concat(forecast_smp, dim="iteration", **CONCAT_KWARGS)
forecast_smp["iteration"] = np.arange(iterations)
+ if dim not in forecast.coords:
+ del forecast_smp.coords[dim]
return forecast_smp.transpose(..., "iteration")
@@ -172,7 +174,12 @@ def resample_iterations_idx(
for interannual-to-decadal predictions experiments. Climate Dynamics, 40(1–2),
245–272. https://doi.org/10/f4jjvf
"""
- # equivalent to above
+ if dim not in forecast.coords:
+ forecast.coords[dim] = np.arange(0, forecast[dim].size)
+ dim_coord_set = True
+ else:
+ dim_coord_set = False
+
select_dim_items = forecast[dim].size
new_dim = forecast[dim]
@@ -205,4 +212,6 @@ def resample_iterations_idx(
# return only dim_max members
if dim_max is not None and dim_max <= forecast[dim].size:
forecast_smp = forecast_smp.isel({dim: slice(None, dim_max)})
+ if dim_coord_set:
+ del forecast_smp.coords[dim]
return forecast_smp
| xarray-contrib/xskillscore | ef0c0fd34add126eb88a0334b3da348b9eef971b | diff --git a/xskillscore/tests/test_resampling.py b/xskillscore/tests/test_resampling.py
index 6d09fe3..572a55c 100644
--- a/xskillscore/tests/test_resampling.py
+++ b/xskillscore/tests/test_resampling.py
@@ -154,3 +154,14 @@ def test_resample_inputs(a_1d, func, input, chunk, replace):
assert is_dask_collection(actual) if chunk else not is_dask_collection(actual)
# input type preserved
assert type(actual) == type(a_1d)
+
+
[email protected]("func", resample_iterations_funcs)
+def test_resample_dim_no_coord(func):
+ """resample_iterations doesnt fail when no dim coords"""
+ da = xr.DataArray(
+ np.random.rand(100, 3, 3),
+ coords=[("time", np.arange(100)), ("x", np.arange(3)), ("y", np.arange(3))],
+ )
+ del da.coords["time"]
+ assert "time" not in func(da, 2, dim="time").coords
| raise error if forecast doesn't contain coords in resample_iterations_idx
`a = xr.DataArray(np.random.rand(1000, 3, 3), dims=['time', 'x', 'y'])`
doesn't work in
`xs.resample_iterations_idx(a, 500, 'time')`
```
xr.DataArray(
np.random.rand(1000, 3, 3),
coords=[("time", np.arange(1000)), ("x", np.arange(3)), ("y", np.arange(3))],
)
```
does.
Taken from https://github.com/xarray-contrib/xskillscore/pull/302#issuecomment-832863346 | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xskillscore/tests/test_resampling.py::test_resample_dim_no_coord[resample_iterations]",
"xskillscore/tests/test_resampling.py::test_resample_dim_no_coord[resample_iterations_idx]"
] | [
"xskillscore/tests/test_resampling.py::test_resampling_roughly_identical_mean",
"xskillscore/tests/test_resampling.py::test_gen_idx_replace[True]",
"xskillscore/tests/test_resampling.py::test_gen_idx_replace[False]",
"xskillscore/tests/test_resampling.py::test_resample_replace_False_once_same_mean[resample_iterations]",
"xskillscore/tests/test_resampling.py::test_resample_replace_False_once_same_mean[resample_iterations_idx]",
"xskillscore/tests/test_resampling.py::test_resample_dim_max[None-resample_iterations]",
"xskillscore/tests/test_resampling.py::test_resample_dim_max[None-resample_iterations_idx]",
"xskillscore/tests/test_resampling.py::test_resample_dim_max[5-resample_iterations]",
"xskillscore/tests/test_resampling.py::test_resample_dim_max[5-resample_iterations_idx]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-Dataset-True-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-Dataset-True-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-Dataset-False-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-Dataset-False-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-multidim",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-DataArray-True-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-DataArray-True-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-DataArray-False-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations-DataArray-False-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-Dataset-True-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-Dataset-True-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-Dataset-False-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-Dataset-False-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-multidim",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-DataArray-True-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-DataArray-True-False]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-DataArray-False-True]",
"xskillscore/tests/test_resampling.py::test_resample_inputs[resample_iterations_idx-DataArray-False-False]"
] | {
"failed_lite_validators": [
"has_short_problem_statement",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-24T22:26:25Z" | apache-2.0 |
|
xgcm__xhistogram-17 | diff --git a/xhistogram/core.py b/xhistogram/core.py
index c14f977..9f992c2 100644
--- a/xhistogram/core.py
+++ b/xhistogram/core.py
@@ -88,7 +88,6 @@ def _histogram_2d_vectorized(*args, bins=None, weights=None, density=False,
"""Calculate the histogram independently on each row of a 2D array"""
N_inputs = len(args)
- bins = _ensure_bins_is_a_list_of_arrays(bins, N_inputs)
a0 = args[0]
# consistency checks for inputa
@@ -128,7 +127,9 @@ def _histogram_2d_vectorized(*args, bins=None, weights=None, density=False,
# just throw out everything outside of the bins, as np.histogram does
# TODO: make this optional?
slices = (slice(None),) + (N_inputs * (slice(1, -1),))
- return bin_counts[slices]
+ bin_counts = bin_counts[slices]
+
+ return bin_counts
def histogram(*args, bins=None, axis=None, weights=None, density=False,
@@ -242,9 +243,29 @@ def histogram(*args, bins=None, axis=None, weights=None, density=False,
else:
weights_reshaped = None
- h = _histogram_2d_vectorized(*all_args_reshaped, bins=bins,
- weights=weights_reshaped,
- density=density, block_size=block_size)
+ n_inputs = len(all_args_reshaped)
+ bins = _ensure_bins_is_a_list_of_arrays(bins, n_inputs)
+
+ bin_counts = _histogram_2d_vectorized(*all_args_reshaped, bins=bins,
+ weights=weights_reshaped,
+ density=density,
+ block_size=block_size)
+
+ if density:
+ # Normalise by dividing by bin counts and areas such that all the
+ # histogram data integrated over all dimensions = 1
+ bin_widths = [np.diff(b) for b in bins]
+ if n_inputs == 1:
+ bin_areas = bin_widths[0]
+ elif n_inputs == 2:
+ bin_areas = np.outer(*bin_widths)
+ else:
+ # Slower, but N-dimensional logic
+ bin_areas = np.prod(np.ix_(*bin_widths))
+
+ h = bin_counts / bin_areas / bin_counts.sum()
+ else:
+ h = bin_counts
if h.shape[0] == 1:
assert do_full_array
diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index c4d41d8..8b9af1f 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -126,7 +126,7 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
axis = None
h_data = _histogram(*args_data, weights=weights_data, bins=bins, axis=axis,
- block_size=block_size)
+ density=density, block_size=block_size)
# create output dims
new_dims = [a.name + bin_dim_suffix for a in args[:N_args]]
@@ -155,6 +155,12 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
da_out = xr.DataArray(h_data, dims=output_dims, coords=all_coords,
name=output_name)
+
+ if density:
+ # correct for overcounting the bins which weren't histogrammed along
+ n_bins_bystander_dims = da_out.isel(**{bd: 0 for bd in new_dims}).size
+ da_out = da_out * n_bins_bystander_dims
+
return da_out
# we need weights to be passed through apply_func's alignment algorithm,
| xgcm/xhistogram | c53fea67ab8ed4cb47dac625301454433c9eab09 | diff --git a/xhistogram/test/test_core.py b/xhistogram/test/test_core.py
index 1ba4f88..a5b0a05 100644
--- a/xhistogram/test/test_core.py
+++ b/xhistogram/test/test_core.py
@@ -27,6 +27,33 @@ def test_histogram_results_1d(block_size):
np.testing.assert_array_equal(hist, h_na)
[email protected]('block_size', [None, 1, 2])
+def test_histogram_results_1d_density(block_size):
+ nrows, ncols = 5, 20
+ data = np.random.randn(nrows, ncols)
+ bins = np.linspace(-4, 4, 10)
+
+ h = histogram(data, bins=bins, axis=1, block_size=block_size, density=True)
+ assert h.shape == (nrows, len(bins)-1)
+
+ # make sure we get the same thing as histogram
+ hist, _ = np.histogram(data, bins=bins, density=True)
+ np.testing.assert_allclose(hist, h.sum(axis=0))
+
+ # check integral is 1
+ widths = np.diff(bins)
+ integral = np.sum(hist * widths)
+ np.testing.assert_allclose(integral, 1.0)
+
+ # now try with no axis
+ h_na = histogram(data, bins=bins, block_size=block_size, density=True)
+ np.testing.assert_array_equal(hist, h_na)
+
+ # check integral is 1
+ integral = np.sum(h_na * widths)
+ np.testing.assert_allclose(integral, 1.0)
+
+
@pytest.mark.parametrize('block_size', [None, 1, 2])
def test_histogram_results_1d_weighted(block_size):
nrows, ncols = 5, 20
@@ -52,7 +79,6 @@ def test_histogram_results_1d_weighted_broadcasting(block_size):
np.testing.assert_array_equal(2*h, h_w)
-
def test_histogram_results_2d():
nrows, ncols = 5, 20
data_a = np.random.randn(nrows, ncols)
@@ -70,6 +96,61 @@ def test_histogram_results_2d():
np.testing.assert_array_equal(hist, h)
+def test_histogram_results_2d_density():
+ nrows, ncols = 5, 20
+ data_a = np.random.randn(nrows, ncols)
+ data_b = np.random.randn(nrows, ncols)
+ nbins_a = 9
+ bins_a = np.linspace(-4, 4, nbins_a + 1)
+ nbins_b = 10
+ bins_b = np.linspace(-4, 4, nbins_b + 1)
+
+ h = histogram(data_a, data_b, bins=[bins_a, bins_b], density=True)
+ assert h.shape == (nbins_a, nbins_b)
+
+ hist, _, _ = np.histogram2d(data_a.ravel(), data_b.ravel(),
+ bins=[bins_a, bins_b], density=True)
+ np.testing.assert_allclose(hist, h)
+
+ # check integral is 1
+ widths_a = np.diff(bins_a)
+ widths_b = np.diff(bins_b)
+ areas = np.outer(widths_a, widths_b)
+ integral = np.sum(hist * areas)
+ np.testing.assert_allclose(integral, 1.0)
+
+
+def test_histogram_results_3d_density():
+ nrows, ncols = 5, 20
+ data_a = np.random.randn(nrows, ncols)
+ data_b = np.random.randn(nrows, ncols)
+ data_c = np.random.randn(nrows, ncols)
+ nbins_a = 9
+ bins_a = np.linspace(-4, 4, nbins_a + 1)
+ nbins_b = 10
+ bins_b = np.linspace(-4, 4, nbins_b + 1)
+ nbins_c = 9
+ bins_c = np.linspace(-4, 4, nbins_c + 1)
+
+ h = histogram(data_a, data_b, data_c, bins=[bins_a, bins_b, bins_c],
+ density=True)
+
+ assert h.shape == (nbins_a, nbins_b, nbins_c)
+
+ hist, _ = np.histogramdd((data_a.ravel(), data_b.ravel(), data_c.ravel()),
+ bins=[bins_a, bins_b, bins_c], density=True)
+
+ np.testing.assert_allclose(hist, h)
+
+ # check integral is 1
+ widths_a = np.diff(bins_a)
+ widths_b = np.diff(bins_b)
+ widths_c = np.diff(bins_c)
+ areas = np.einsum('i,j,k', widths_a, widths_b, widths_c)
+ integral = np.sum(hist * areas)
+ np.testing.assert_allclose(integral, 1.0)
+
+
@pytest.mark.parametrize('block_size', [None, 5, 'auto'])
@pytest.mark.parametrize('use_dask', [False, True])
def test_histogram_shape(use_dask, block_size):
diff --git a/xhistogram/test/test_xarray.py b/xhistogram/test/test_xarray.py
index 0018f0d..7be7449 100644
--- a/xhistogram/test/test_xarray.py
+++ b/xhistogram/test/test_xarray.py
@@ -59,6 +59,32 @@ def test_histogram_ones(ones, ndims):
_check_result(h, d)
[email protected]('ndims', [1, 2, 3, 4])
+def test_histogram_ones_density(ones, ndims):
+ dims = ones.dims
+ if ones.ndim < ndims:
+ pytest.skip(
+ "Don't need to test when number of dimension combinations "
+ "exceeds the number of array dimensions")
+
+ # everything should be in the middle bin (index 1)
+ bins = np.array([0, 0.9, 1.1, 2])
+ bin_area = 0.2
+
+ def _check_result(h_density, d):
+ other_dims = [dim for dim in ones.dims if dim not in d]
+ if len(other_dims) > 0:
+ assert set(other_dims) <= set(h_density.dims)
+
+ # check that all integrals over pdfs at different locations are = 1
+ h_integrals = (h_density * bin_area).sum(dim='ones_bin')
+ np.testing.assert_allclose(h_integrals.values, 1.0)
+
+ for d in combinations(dims, ndims):
+ h_density = histogram(ones, bins=[bins], dim=d, density=True)
+ _check_result(h_density, d)
+
+
# TODO: refactor this test to use better fixtures
# (it currently has a ton of loops)
@pytest.mark.parametrize('ndims', [1, 2, 3, 4])
| Support for density=True keyword
Numpy histogram has the `density` keyword, which normalized the outputs by the bin spacing.
https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.html
We can easily support this in xhistogram, but it has to .be plugged in. Just opening this issue to make a note of it. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_core.py::test_histogram_results_1d_density[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_density[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_density[2]",
"xhistogram/test/test_core.py::test_histogram_results_2d_density",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[1D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[2D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[2D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[3D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[3D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[3D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[4D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[4D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[4D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones_density[4D-4]"
] | [
"xhistogram/test/test_core.py::test_histogram_results_1d[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[auto]",
"xhistogram/test/test_core.py::test_histogram_results_2d",
"xhistogram/test/test_core.py::test_histogram_shape[False-None]",
"xhistogram/test/test_core.py::test_histogram_shape[False-5]",
"xhistogram/test/test_core.py::test_histogram_shape[False-auto]",
"xhistogram/test/test_core.py::test_histogram_shape[True-None]",
"xhistogram/test/test_core.py::test_histogram_shape[True-5]",
"xhistogram/test/test_core.py::test_histogram_shape[True-auto]",
"xhistogram/test/test_xarray.py::test_histogram_ones[1D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[2D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[2D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-4]",
"xhistogram/test/test_xarray.py::test_weights[1D-1]",
"xhistogram/test/test_xarray.py::test_weights[2D-1]",
"xhistogram/test/test_xarray.py::test_weights[2D-2]",
"xhistogram/test/test_xarray.py::test_weights[3D-1]",
"xhistogram/test/test_xarray.py::test_weights[3D-2]",
"xhistogram/test/test_xarray.py::test_weights[3D-3]",
"xhistogram/test/test_xarray.py::test_weights[4D-1]",
"xhistogram/test/test_xarray.py::test_weights[4D-2]",
"xhistogram/test/test_xarray.py::test_weights[4D-3]",
"xhistogram/test/test_xarray.py::test_weights[4D-4]",
"xhistogram/test/test_xarray.py::test_dims_and_coords"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2020-02-12T15:42:06Z" | mit |
|
xgcm__xhistogram-20 | diff --git a/doc/contributing.rst b/doc/contributing.rst
index cc351d3..80841b5 100644
--- a/doc/contributing.rst
+++ b/doc/contributing.rst
@@ -8,6 +8,12 @@ GitHub repo: `https://github.com/xgcm/xhistogram <https://github.com/xgcm/xhisto
Release History
---------------
+v0.1.?
+~~~~~
+
+- Aligned definition of `bins` with `numpy.histogram` (:pr:`???`)
+ By `Dougie Squire <https://github.com/dougiesquire>`_.
+
v0.1.1
~~~~~~
diff --git a/xhistogram/core.py b/xhistogram/core.py
index 9f992c2..559d1a2 100644
--- a/xhistogram/core.py
+++ b/xhistogram/core.py
@@ -107,6 +107,15 @@ def _histogram_2d_vectorized(*args, bins=None, weights=None, density=False,
# https://github.com/numpy/numpy/blob/9c98662ee2f7daca3f9fae9d5144a9a8d3cabe8c/numpy/lib/histograms.py#L864-L882
# for now we stick with `digitize` because it's easy to understand how it works
+ # Add small increment to the last bin edge to make the final bin right-edge inclusive
+ # Note, this is the approach taken by sklearn, e.g.
+ # https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/calibration.py#L592
+ # but a better approach would be to use something like _search_sorted_inclusive() in
+ # numpy histogram. This is an additional motivation for moving to searchsorted
+ bins = [np.concatenate((
+ b[:-1],
+ b[-1:] + 1e-8)) for b in bins]
+
# the maximum possible value of of digitize is nbins
# for right=False:
# - 0 corresponds to a < b[0]
@@ -154,6 +163,9 @@ def histogram(*args, bins=None, axis=None, weights=None, density=False,
* A combination [int, array] or [array, int], where int
is the number of bins and array is the bin edges.
+ When bin edges are specified, all but the last (righthand-most) bin include
+ the left edge and exclude the right edge. The last bin includes both edges.
+
A ``TypeError`` will be raised if ``args`` contains dask arrays and
``bins`` are not specified explicitly as a list of arrays.
axis : None or int or tuple of ints, optional
diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index cd9b65f..2dc8ba9 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -31,6 +31,9 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
* A combination [int, array] or [array, int], where int
is the number of bins and array is the bin edges.
+ When bin edges are specified, all but the last (righthand-most) bin include
+ the left edge and exclude the right edge. The last bin includes both edges.
+
A ``TypeError`` will be raised if ``args`` contains dask arrays and
``bins`` are not specified explicitly as a list of arrays.
dim : tuple of strings, optional
| xgcm/xhistogram | 4ae9f0a5afd50bf2c143828e6114bfcbbcce905b | diff --git a/xhistogram/test/test_core.py b/xhistogram/test/test_core.py
index a5b0a05..e4802fb 100644
--- a/xhistogram/test/test_core.py
+++ b/xhistogram/test/test_core.py
@@ -79,6 +79,27 @@ def test_histogram_results_1d_weighted_broadcasting(block_size):
np.testing.assert_array_equal(2*h, h_w)
[email protected]('block_size', [None, 1, 2])
+def test_histogram_right_edge(block_size):
+ """Test that last bin is both left- and right-edge inclusive as it
+ is for numpy.histogram
+ """
+ nrows, ncols = 5, 20
+ data = np.ones((nrows, ncols))
+ bins = np.array([0, 0.5, 1]) # All data at rightmost edge
+
+ h = histogram(data, bins=bins, axis=1, block_size=block_size)
+ assert h.shape == (nrows, len(bins)-1)
+
+ # make sure we get the same thing as histogram (all data in the last bin)
+ hist, _ = np.histogram(data, bins=bins)
+ np.testing.assert_array_equal(hist, h.sum(axis=0))
+
+ # now try with no axis
+ h_na = histogram(data, bins=bins, block_size=block_size)
+ np.testing.assert_array_equal(hist, h_na)
+
+
def test_histogram_results_2d():
nrows, ncols = 5, 20
data_a = np.random.randn(nrows, ncols)
| Align definition of `bins` with numpy.histogram
When bin edges are specified in `numpy.histogram`, the last bin is closed on both sides. From the `numpy` docs (https://numpy.org/doc/stable/reference/generated/numpy.histogram.html):
> All but the last (righthand-most) bin is half-open. In other words, if bins is:
>
> [1, 2, 3, 4]
> then the first bin is [1, 2) (including 1, but excluding 2) and the second [2, 3). The last bin, however, is [3, 4], which includes 4.
This is not the case for `xhistogram`, e.g.:
```python
import numpy as np
import xarray as xr
from xhistogram.xarray import histogram as xhist
data = np.ones(10)
da = xr.DataArray(data, coords=[range(10)], dims=['x']).rename('test')
bins = np.array([0, 0.5, 1])
print(f'xhistogram: {xhist(da, bins=[bins]).values}')
print(f'numpy histogram: {np.histogram(data, bins=bins)[0]}')
```
```
xhistogram: [0 0]
numpy histogram: [ 0 10]
```
Could we make it the case? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_core.py::test_histogram_right_edge[None]",
"xhistogram/test/test_core.py::test_histogram_right_edge[1]",
"xhistogram/test/test_core.py::test_histogram_right_edge[2]"
] | [
"xhistogram/test/test_core.py::test_histogram_results_1d[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_density[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_density[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_density[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[auto]",
"xhistogram/test/test_core.py::test_histogram_results_2d",
"xhistogram/test/test_core.py::test_histogram_results_2d_density",
"xhistogram/test/test_core.py::test_histogram_shape[False-None]",
"xhistogram/test/test_core.py::test_histogram_shape[False-5]",
"xhistogram/test/test_core.py::test_histogram_shape[False-auto]",
"xhistogram/test/test_core.py::test_histogram_shape[True-None]",
"xhistogram/test/test_core.py::test_histogram_shape[True-5]",
"xhistogram/test/test_core.py::test_histogram_shape[True-auto]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2020-09-18T06:19:48Z" | mit |
|
xgcm__xhistogram-45 | diff --git a/doc/contributing.rst b/doc/contributing.rst
index 67aa942..e2a8407 100644
--- a/doc/contributing.rst
+++ b/doc/contributing.rst
@@ -140,6 +140,13 @@ Preparing Pull Requests
Release History
---------------
+v0.2.1 (not yet released)
+~~~~~~~~~~~~~~~~~~~~~~~~~
+- Implemented various options for users for providing bins to
+ xhistogram that mimic the numpy histogram API. This included
+ adding a range argument to the xhistogram API :issue:`13`.
+ By `Dougie Squire <https://github.com/dougiesquire>`_.
+
v0.2.0
~~~~~~
diff --git a/xhistogram/core.py b/xhistogram/core.py
index 9275e3b..3470506 100644
--- a/xhistogram/core.py
+++ b/xhistogram/core.py
@@ -3,8 +3,10 @@ Numpy API for xhistogram.
"""
+import dask
import numpy as np
from functools import reduce
+from collections.abc import Iterable
from .duck_array_ops import (
digitize,
bincount,
@@ -13,16 +15,45 @@ from .duck_array_ops import (
concatenate,
broadcast_arrays,
)
-import warnings
+# range is a keyword so save the builtin so they can use it.
+_range = range
-def _ensure_bins_is_a_list_of_arrays(bins, N_expected):
+
+def _ensure_correctly_formatted_bins(bins, N_expected):
+ # TODO: This could be done better / more robustly
+ if bins is None:
+ raise ValueError("bins must be provided")
+ if isinstance(bins, (int, str, np.ndarray)):
+ bins = N_expected * [bins]
if len(bins) == N_expected:
return bins
- elif N_expected == 1:
- return [bins]
else:
- raise ValueError("Can't figure out what to do with bins.")
+ raise ValueError(
+ "The number of bin definitions doesn't match the number of args"
+ )
+
+
+def _ensure_correctly_formatted_range(range_, N_expected):
+ # TODO: This could be done better / more robustly
+ def _iterable_nested(x):
+ return all(isinstance(i, Iterable) for i in x)
+
+ if range_ is not None:
+ if (len(range_) == 2) & (not _iterable_nested(range_)):
+ return N_expected * [range_]
+ elif N_expected == len(range_):
+ if all(len(x) == 2 for x in range_):
+ return range_
+ else:
+ raise ValueError(
+ "range should be provided as (lower_range, upper_range). In the "
+ + "case of multiple args, range should be a list of such tuples"
+ )
+ else:
+ raise ValueError("The number of ranges doesn't match the number of args")
+ else:
+ return N_expected * [range_]
def _bincount_2d(bin_indices, weights, N, hist_shapes):
@@ -148,7 +179,13 @@ def _histogram_2d_vectorized(
def histogram(
- *args, bins=None, axis=None, weights=None, density=False, block_size="auto"
+ *args,
+ bins=None,
+ range=None,
+ axis=None,
+ weights=None,
+ density=False,
+ block_size="auto",
):
"""Histogram applied along specified axis / axes.
@@ -158,23 +195,38 @@ def histogram(
Input data. The number of input arguments determines the dimensonality
of the histogram. For example, two arguments prodocue a 2D histogram.
All args must have the same size.
- bins : int or array_like or a list of ints or arrays, optional
+ bins : int, str or numpy array or a list of ints, strs and/or arrays, optional
If a list, there should be one entry for each item in ``args``.
- The bin specification:
+ The bin specifications are as follows:
- * If int, the number of bins for all arguments in ``args``.
- * If array_like, the bin edges for all arguments in ``args``.
- * If a list of ints, the number of bins for every argument in ``args``.
- * If a list arrays, the bin edges for each argument in ``args``
- (required format for Dask inputs).
- * A combination [int, array] or [array, int], where int
- is the number of bins and array is the bin edges.
+ * If int; the number of bins for all arguments in ``args``.
+ * If str; the method used to automatically calculate the optimal bin width
+ for all arguments in ``args``, as defined by numpy `histogram_bin_edges`.
+ * If numpy array; the bin edges for all arguments in ``args``.
+ * If a list of ints, strs and/or arrays; the bin specification as
+ above for every argument in ``args``.
When bin edges are specified, all but the last (righthand-most) bin include
the left edge and exclude the right edge. The last bin includes both edges.
- A ``TypeError`` will be raised if ``args`` contains dask arrays and
- ``bins`` are not specified explicitly as a list of arrays.
+ A TypeError will be raised if args contains dask arrays and bins are not
+ specified explicitly as an array or list of arrays. This is because other
+ bin specifications trigger computation.
+ range : (float, float) or a list of (float, float), optional
+ If a list, there should be one entry for each item in ``args``.
+ The range specifications are as follows:
+
+ * If (float, float); the lower and upper range(s) of the bins for all
+ arguments in ``args``. Values outside the range are ignored. The first
+ element of the range must be less than or equal to the second. `range`
+ affects the automatic bin computation as well. In this case, while bin
+ width is computed to be optimal based on the actual data within `range`,
+ the bin count will fill the entire range including portions containing
+ no data.
+ * If a list of (float, float); the ranges as above for every argument in
+ ``args``.
+ * If not provided, range is simply ``(arg.min(), arg.max())`` for each
+ arg.
axis : None or int or tuple of ints, optional
Axis or axes along which the histogram is computed. The default is to
compute the histogram of the flattened array
@@ -203,25 +255,19 @@ def histogram(
-------
hist : array
The values of the histogram.
+ bin_edges : list of arrays
+ Return the bin edges for each input array.
See Also
--------
numpy.histogram, numpy.bincount, numpy.digitize
"""
- # Future warning for https://github.com/xgcm/xhistogram/pull/45
- warnings.warn(
- "Future versions of xhistogram.core.histogram will return a "
- + "tuple containing arrays of the the histogram bins and the "
- + "histogram values, rather than just an array of the histogram "
- + "values. This API change will only affect users of "
- + "xhistogram.core. Users of xhistogram.xarray can ignore this "
- + "message.",
- FutureWarning,
- )
-
a0 = args[0]
ndim = a0.ndim
+ n_inputs = len(args)
+
+ is_dask_array = any([dask.is_dask_collection(a) for a in args])
if axis is not None:
axis = np.atleast_1d(axis)
@@ -236,11 +282,11 @@ def histogram(
axis_normed.append(ax_positive)
axis = np.atleast_1d(axis_normed)
- do_full_array = (axis is None) or (set(axis) == set(range(a0.ndim)))
+ do_full_array = (axis is None) or (set(axis) == set(_range(a0.ndim)))
if do_full_array:
kept_axes_shape = None
else:
- kept_axes_shape = tuple([a0.shape[i] for i in range(a0.ndim) if i not in axis])
+ kept_axes_shape = tuple([a0.shape[i] for i in _range(a0.ndim) if i not in axis])
all_args = list(args)
if weights is not None:
@@ -254,7 +300,7 @@ def histogram(
# reshape the array to 2D
# axis 0: preserved axis after histogram
# axis 1: calculate histogram along this axis
- new_pos = tuple(range(-len(axis), 0))
+ new_pos = tuple(_range(-len(axis), 0))
c = np.moveaxis(a, axis, new_pos)
split_idx = c.ndim - len(axis)
dims_0 = c.shape[:split_idx]
@@ -272,8 +318,23 @@ def histogram(
else:
weights_reshaped = None
- n_inputs = len(all_args_reshaped)
- bins = _ensure_bins_is_a_list_of_arrays(bins, n_inputs)
+ # Some sanity checks and format bins and range correctly
+ bins = _ensure_correctly_formatted_bins(bins, n_inputs)
+ range = _ensure_correctly_formatted_range(range, n_inputs)
+
+ # histogram_bin_edges trigges computation on dask arrays. It would be possible
+ # to write a version of this that doesn't trigger when `range` is provided, but
+ # for now let's just use np.histogram_bin_edges
+ if is_dask_array:
+ if not all([isinstance(b, np.ndarray) for b in bins]):
+ raise TypeError(
+ "When using dask arrays, bins must be provided as numpy array(s) of edges"
+ )
+ else:
+ bins = [
+ np.histogram_bin_edges(a, b, r, weights_reshaped)
+ for a, b, r in zip(all_args_reshaped, bins, range)
+ ]
bin_counts = _histogram_2d_vectorized(
*all_args_reshaped,
@@ -306,4 +367,4 @@ def histogram(
final_shape = kept_axes_shape + h.shape[1:]
h = reshape(h, final_shape)
- return h
+ return h, bins
diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index 8c5e944..aea7a1f 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -3,22 +3,23 @@ Xarray API for xhistogram.
"""
import xarray as xr
-import numpy as np
from collections import OrderedDict
from .core import histogram as _histogram
-import warnings
+
+# range is a keyword so save the builtin so they can use it.
+_range = range
def histogram(
*args,
bins=None,
+ range=None,
dim=None,
weights=None,
density=False,
block_size="auto",
keep_coords=False,
- bin_dim_suffix="_bin",
- bin_edge_suffix="_bin_edge"
+ bin_dim_suffix="_bin"
):
"""Histogram applied along specified dimensions.
@@ -28,23 +29,38 @@ def histogram(
Input data. The number of input arguments determines the dimensonality of
the histogram. For example, two arguments prodocue a 2D histogram. All
args must be aligned and have the same dimensions.
- bins : int or array_like or a list of ints or arrays, optional
+ bins : int, str or numpy array or a list of ints, strs and/or arrays, optional
If a list, there should be one entry for each item in ``args``.
- The bin specification:
+ The bin specifications are as follows:
- * If int, the number of bins for all arguments in ``args``.
- * If array_like, the bin edges for all arguments in ``args``.
- * If a list of ints, the number of bins for every argument in ``args``.
- * If a list arrays, the bin edges for each argument in ``args``
- (required format for Dask inputs).
- * A combination [int, array] or [array, int], where int
- is the number of bins and array is the bin edges.
+ * If int; the number of bins for all arguments in ``args``.
+ * If str; the method used to automatically calculate the optimal bin width
+ for all arguments in ``args``, as defined by numpy `histogram_bin_edges`.
+ * If numpy array; the bin edges for all arguments in ``args``.
+ * If a list of ints, strs and/or arrays; the bin specification as
+ above for every argument in ``args``.
When bin edges are specified, all but the last (righthand-most) bin include
the left edge and exclude the right edge. The last bin includes both edges.
- A ``TypeError`` will be raised if ``args`` contains dask arrays and
- ``bins`` are not specified explicitly as a list of arrays.
+ A TypeError will be raised if args contains dask arrays and bins are not
+ specified explicitly as an array or list of arrays. This is because other
+ bin specifications trigger computation.
+ range : (float, float) or a list of (float, float), optional
+ If a list, there should be one entry for each item in ``args``.
+ The range specifications are as follows:
+
+ * If (float, float); the lower and upper range(s) of the bins for all
+ arguments in ``args``. Values outside the range are ignored. The first
+ element of the range must be less than or equal to the second. `range`
+ affects the automatic bin computation as well. In this case, while bin
+ width is computed to be optimal based on the actual data within `range`,
+ the bin count will fill the entire range including portions containing
+ no data.
+ * If a list of (float, float); the ranges as above for every argument in
+ ``args``.
+ * If not provided, range is simply ``(arg.min(), arg.max())`` for each
+ arg.
dim : tuple of strings, optional
Dimensions over which which the histogram is computed. The default is to
compute the histogram of the flattened array.
@@ -72,11 +88,15 @@ def histogram(
chunks (dask inputs) or an experimental built-in heuristic (numpy inputs).
keep_coords : bool, optional
If ``True``, keep all coordinates. Default: ``False``
+ bin_dim_suffix : str, optional
+ Suffix to append to input arg names to define names of output bin
+ dimensions
Returns
-------
- hist : array
- The values of the histogram.
+ hist : xarray.DataArray
+ The values of the histogram. For each bin, the midpoint of the bin edges
+ is given along the bin coordinates.
"""
@@ -85,12 +105,6 @@ def histogram(
# TODO: allow list of weights as well
N_weights = 1 if weights is not None else 0
- # some sanity checks
- # TODO: replace this with a more robust function
- assert len(bins) == N_args
- for bin in bins:
- assert isinstance(bin, np.ndarray), "all bins must be numpy arrays"
-
for a in args:
# TODO: make this a more robust check
assert a.name is not None, "all arrays must have a name"
@@ -140,21 +154,15 @@ def histogram(
dims_to_keep = []
axis = None
- # Allow future warning for https://github.com/xgcm/xhistogram/pull/45
- with warnings.catch_warnings():
- warnings.filterwarnings(
- "ignore",
- message="Future versions of xhistogram\\.core\\.histogram will return",
- category=FutureWarning,
- )
- h_data = _histogram(
- *args_data,
- weights=weights_data,
- bins=bins,
- axis=axis,
- density=density,
- block_size=block_size
- )
+ h_data, bins = _histogram(
+ *args_data,
+ weights=weights_data,
+ bins=bins,
+ range=range,
+ axis=axis,
+ density=density,
+ block_size=block_size
+ )
# create output dims
new_dims = [a.name + bin_dim_suffix for a in args[:N_args]]
@@ -195,7 +203,7 @@ def histogram(
# this feels like a hack
# def _histogram_wrapped(*args, **kwargs):
# alist = list(args)
- # weights = [alist.pop() for n in range(N_weights)]
+ # weights = [alist.pop() for n in _range(N_weights)]
# if N_weights == 0:
# weights = None
# elif N_weights == 1:
| xgcm/xhistogram | c62cf9fdfae95fe52638448dddaee797c3fc283f | diff --git a/xhistogram/test/test_core.py b/xhistogram/test/test_core.py
index eef22dd..e0df0ee 100644
--- a/xhistogram/test/test_core.py
+++ b/xhistogram/test/test_core.py
@@ -3,40 +3,61 @@ import numpy as np
from itertools import combinations
import dask.array as dsa
-from ..core import histogram
+from ..core import (
+ histogram,
+ _ensure_correctly_formatted_bins,
+ _ensure_correctly_formatted_range,
+)
from .fixtures import empty_dask_array
import pytest
+bins_int = 10
+bins_str = "auto"
+bins_arr = np.linspace(-4, 4, 10)
+range_ = (0, 1)
+
+
@pytest.mark.parametrize("density", [False, True])
@pytest.mark.parametrize("block_size", [None, 1, 2])
@pytest.mark.parametrize("axis", [1, None])
-def test_histogram_results_1d(block_size, density, axis):
[email protected]("bins", [10, np.linspace(-4, 4, 10), "auto"])
[email protected]("range_", [None, (-4, 4)])
+def test_histogram_results_1d(block_size, density, axis, bins, range_):
nrows, ncols = 5, 20
# Setting the random seed here prevents np.testing.assert_allclose
# from failing beow. We should investigate this further.
np.random.seed(2)
data = np.random.randn(nrows, ncols)
- bins = np.linspace(-4, 4, 10)
- h = histogram(data, bins=bins, axis=axis, block_size=block_size, density=density)
+ h, bin_edges = histogram(
+ data, bins=bins, range=range_, axis=axis, block_size=block_size, density=density
+ )
- expected_shape = (nrows, len(bins) - 1) if axis == 1 else (len(bins) - 1,)
+ expected_shape = (
+ (nrows, len(bin_edges[0]) - 1) if axis == 1 else (len(bin_edges[0]) - 1,)
+ )
assert h.shape == expected_shape
# make sure we get the same thing as numpy.histogram
if axis:
+ bins_np = np.histogram_bin_edges(
+ data, bins=bins, range=range_
+ ) # Use same bins for all slices below
expected = np.stack(
- [np.histogram(data[i], bins=bins, density=density)[0] for i in range(nrows)]
+ [
+ np.histogram(data[i], bins=bins_np, range=range_, density=density)[0]
+ for i in range(nrows)
+ ]
)
else:
- expected = np.histogram(data, bins=bins, density=density)[0]
+ expected = np.histogram(data, bins=bins, range=range_, density=density)[0]
norm = nrows if (density and axis) else 1
np.testing.assert_allclose(h, expected / norm)
if density:
- widths = np.diff(bins)
+ widths = np.diff(bin_edges)
integral = np.sum(h * widths)
np.testing.assert_allclose(integral, 1.0)
@@ -46,9 +67,9 @@ def test_histogram_results_1d_weighted(block_size):
nrows, ncols = 5, 20
data = np.random.randn(nrows, ncols)
bins = np.linspace(-4, 4, 10)
- h = histogram(data, bins=bins, axis=1, block_size=block_size)
+ h, _ = histogram(data, bins=bins, axis=1, block_size=block_size)
weights = 2 * np.ones_like(data)
- h_w = histogram(data, bins=bins, axis=1, weights=weights, block_size=block_size)
+ h_w, _ = histogram(data, bins=bins, axis=1, weights=weights, block_size=block_size)
np.testing.assert_array_equal(2 * h, h_w)
@@ -58,9 +79,9 @@ def test_histogram_results_1d_weighted_broadcasting(block_size):
nrows, ncols = 5, 20
data = np.random.randn(nrows, ncols)
bins = np.linspace(-4, 4, 10)
- h = histogram(data, bins=bins, axis=1, block_size=block_size)
+ h, _ = histogram(data, bins=bins, axis=1, block_size=block_size)
weights = 2 * np.ones((1, ncols))
- h_w = histogram(data, bins=bins, axis=1, weights=weights, block_size=block_size)
+ h_w, _ = histogram(data, bins=bins, axis=1, weights=weights, block_size=block_size)
np.testing.assert_array_equal(2 * h, h_w)
@@ -73,7 +94,7 @@ def test_histogram_right_edge(block_size):
data = np.ones((nrows, ncols))
bins = np.array([0, 0.5, 1]) # All data at rightmost edge
- h = histogram(data, bins=bins, axis=1, block_size=block_size)
+ h, _ = histogram(data, bins=bins, axis=1, block_size=block_size)
assert h.shape == (nrows, len(bins) - 1)
# make sure we get the same thing as histogram (all data in the last bin)
@@ -81,7 +102,7 @@ def test_histogram_right_edge(block_size):
np.testing.assert_array_equal(hist, h.sum(axis=0))
# now try with no axis
- h_na = histogram(data, bins=bins, block_size=block_size)
+ h_na, _ = histogram(data, bins=bins, block_size=block_size)
np.testing.assert_array_equal(hist, h_na)
@@ -94,7 +115,7 @@ def test_histogram_results_2d():
nbins_b = 10
bins_b = np.linspace(-4, 4, nbins_b + 1)
- h = histogram(data_a, data_b, bins=[bins_a, bins_b])
+ h, _ = histogram(data_a, data_b, bins=[bins_a, bins_b])
assert h.shape == (nbins_a, nbins_b)
hist, _, _ = np.histogram2d(data_a.ravel(), data_b.ravel(), bins=[bins_a, bins_b])
@@ -110,7 +131,7 @@ def test_histogram_results_2d_density():
nbins_b = 10
bins_b = np.linspace(-4, 4, nbins_b + 1)
- h = histogram(data_a, data_b, bins=[bins_a, bins_b], density=True)
+ h, _ = histogram(data_a, data_b, bins=[bins_a, bins_b], density=True)
assert h.shape == (nbins_a, nbins_b)
hist, _, _ = np.histogram2d(
@@ -138,7 +159,9 @@ def test_histogram_results_3d_density():
nbins_c = 9
bins_c = np.linspace(-4, 4, nbins_c + 1)
- h = histogram(data_a, data_b, data_c, bins=[bins_a, bins_b, bins_c], density=True)
+ h, _ = histogram(
+ data_a, data_b, data_c, bins=[bins_a, bins_b, bins_c], density=True
+ )
assert h.shape == (nbins_a, nbins_b, nbins_c)
@@ -173,18 +196,18 @@ def test_histogram_shape(use_dask, block_size):
bins = np.linspace(-4, 4, 27)
# no axis
- c = histogram(b, bins=bins, block_size=block_size)
+ c, _ = histogram(b, bins=bins, block_size=block_size)
assert c.shape == (len(bins) - 1,)
# same thing
for axis in [(0, 1, 2, 3), (0, 1, 3, 2), (3, 2, 1, 0), (3, 2, 0, 1)]:
- c = histogram(b, bins=bins, axis=axis)
+ c, _ = histogram(b, bins=bins, axis=axis)
assert c.shape == (len(bins) - 1,)
if use_dask:
assert isinstance(c, dsa.Array)
# scalar axis (check positive and negative)
for axis in list(range(4)) + list(range(-1, -5, -1)):
- c = histogram(b, bins=bins, axis=axis, block_size=block_size)
+ c, _ = histogram(b, bins=bins, axis=axis, block_size=block_size)
shape = list(b.shape)
del shape[axis]
expected_shape = tuple(shape) + (len(bins) - 1,)
@@ -195,10 +218,70 @@ def test_histogram_shape(use_dask, block_size):
# two axes
for i, j in combinations(range(4), 2):
axis = (i, j)
- c = histogram(b, bins=bins, axis=axis, block_size=block_size)
+ c, _ = histogram(b, bins=bins, axis=axis, block_size=block_size)
shape = list(b.shape)
partial_shape = [shape[k] for k in range(b.ndim) if k not in axis]
expected_shape = tuple(partial_shape) + (len(bins) - 1,)
assert c.shape == expected_shape
if use_dask:
assert isinstance(c, dsa.Array)
+
+
+def test_histogram_dask():
+ """ Test that fails with dask arrays and inappropriate bins"""
+ shape = 10, 15, 12, 20
+ b = empty_dask_array(shape, chunks=(1,) + shape[1:])
+ histogram(b, bins=bins_arr) # Should work when bins is all numpy arrays
+ with pytest.raises(TypeError): # Should fail otherwise
+ histogram(b, bins=bins_int)
+ histogram(b, bins=bins_str)
+ histogram(b, b, bins=[bins_arr, bins_int])
+
+
[email protected](
+ "in_out",
+ [
+ (bins_int, 1, [bins_int]), # ( bins_in, n_args, bins_out )
+ (bins_str, 1, [bins_str]),
+ (bins_arr, 1, [bins_arr]),
+ ([bins_int], 1, [bins_int]),
+ (bins_int, 2, 2 * [bins_int]),
+ (bins_str, 2, 2 * [bins_str]),
+ (bins_arr, 2, 2 * [bins_arr]),
+ ([bins_int, bins_str, bins_arr], 3, [bins_int, bins_str, bins_arr]),
+ ([bins_arr], 2, None),
+ (None, 1, None),
+ ([bins_arr, bins_arr], 1, None),
+ ],
+)
+def test_ensure_correctly_formatted_bins(in_out):
+ """ Test the helper function _ensure_correctly_formatted_bins"""
+ bins_in, n, bins_expected = in_out
+ if bins_expected is not None:
+ bins = _ensure_correctly_formatted_bins(bins_in, n)
+ assert bins == bins_expected
+ else:
+ with pytest.raises((ValueError, TypeError)):
+ _ensure_correctly_formatted_bins(bins_in, n)
+
+
[email protected](
+ "in_out",
+ [
+ (range_, 1, [range_]), # ( range_in, n_args, range_out )
+ (range_, 2, [range_, range_]),
+ ([range_, range_], 2, [range_, range_]),
+ ([(range_[0],)], 1, None),
+ ([range_], 2, None),
+ ([range_, range_], 1, None),
+ ],
+)
+def test_ensure_correctly_formatted_range(in_out):
+ """ Test the helper function _ensure_correctly_formatted_range"""
+ range_in, n, range_expected = in_out
+ if range_expected is not None:
+ range_ = _ensure_correctly_formatted_range(range_in, n)
+ assert range_ == range_expected
+ else:
+ with pytest.raises(ValueError):
+ _ensure_correctly_formatted_range(range_in, n)
| Bins argument of type int doesn't work
Currently the documentation suggests that one can pass an int `xhist(bins=...)` similarly to that of numpy, but it doesn't work and looks like it isn't tested for in the pytest suite.
```python
import numpy as np
import xarray as xr
# Demo data
A = np.arange(100)
da = xr.DataArray(A, dims='time').rename('test')
```
Case 1:
`xhist(da, bins=10)`
```python-traceback
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-48-1c6580238521> in <module>
----> 1 xhist(da, bins=10)
~/miniconda3/envs/analysis/lib/python3.6/site-packages/xhistogram/xarray.py in histogram(bins, dim, weights, density, block_size, bin_dim_suffix, bin_edge_suffix, *args)
72 # some sanity checks
73 # TODO: replace this with a more robust function
---> 74 assert len(bins)==N_args
75 for bin in bins:
76 assert isinstance(bin, np.ndarray), 'all bins must be numpy arrays'
TypeError: object of type 'int' has no len()
```
Case 2:
`xhist(da, bins=[10])`
```python-traceback
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-49-85ba491a8442> in <module>
----> 1 xhist(da, bins=[10])
~/miniconda3/envs/analysis/lib/python3.6/site-packages/xhistogram/xarray.py in histogram(bins, dim, weights, density, block_size, bin_dim_suffix, bin_edge_suffix, *args)
74 assert len(bins)==N_args
75 for bin in bins:
---> 76 assert isinstance(bin, np.ndarray), 'all bins must be numpy arrays'
77
78 for a in args:
AssertionError: all bins must be numpy arrays
```
Case 3:
`xhist(da, bins=[np.array(10)])`
```python-traceback
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-50-394f2e7f4bcc> in <module>
----> 1 xhist(da, bins=[np.array(10)])
~/miniconda3/envs/analysis/lib/python3.6/site-packages/xhistogram/xarray.py in histogram(bins, dim, weights, density, block_size, bin_dim_suffix, bin_edge_suffix, *args)
127
128 h_data = _histogram(*args_data, weights=weights_data, bins=bins, axis=axis,
--> 129 block_size=block_size)
130
131 # create output dims
~/miniconda3/envs/analysis/lib/python3.6/site-packages/xhistogram/core.py in histogram(bins, axis, weights, density, block_size, *args)
245 h = _histogram_2d_vectorized(*all_args_reshaped, bins=bins,
246 weights=weights_reshaped,
--> 247 density=density, block_size=block_size)
248
249 if h.shape[0] == 1:
~/miniconda3/envs/analysis/lib/python3.6/site-packages/xhistogram/core.py in _histogram_2d_vectorized(bins, weights, density, right, block_size, *args)
95 for a, b in zip(args, bins):
96 assert a.ndim == 2
---> 97 assert b.ndim == 1
98 assert a.shape == a0.shape
99 if weights is not None:
AssertionError:
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[None-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[range_1-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[auto]",
"xhistogram/test/test_core.py::test_histogram_right_edge[None]",
"xhistogram/test/test_core.py::test_histogram_right_edge[1]",
"xhistogram/test/test_core.py::test_histogram_right_edge[2]",
"xhistogram/test/test_core.py::test_histogram_results_2d",
"xhistogram/test/test_core.py::test_histogram_results_2d_density",
"xhistogram/test/test_core.py::test_histogram_shape[False-None]",
"xhistogram/test/test_core.py::test_histogram_shape[False-5]",
"xhistogram/test/test_core.py::test_histogram_shape[False-auto]",
"xhistogram/test/test_core.py::test_histogram_shape[True-None]",
"xhistogram/test/test_core.py::test_histogram_shape[True-5]",
"xhistogram/test/test_core.py::test_histogram_shape[True-auto]",
"xhistogram/test/test_core.py::test_histogram_dask",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out5]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out6]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out7]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out8]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out9]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out10]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out5]"
] | [] | {
"failed_lite_validators": [
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-04-12T04:35:02Z" | mit |
|
xgcm__xhistogram-52 | diff --git a/doc/contributing.rst b/doc/contributing.rst
index 5dac01f..aa787a4 100644
--- a/doc/contributing.rst
+++ b/doc/contributing.rst
@@ -140,8 +140,12 @@ Preparing Pull Requests
Release History
---------------
+
v0.2.1 (not yet released)
~~~~~~~~~~~~~~~~~~~~~~~~~
+
+- Fixed bug with density calculation when NaNs are present :issue:`51`.
+ By `Dougie Squire <https://github.com/dougiesquire>`_.
- Implemented various options for users for providing bins to
xhistogram that mimic the numpy histogram API. This included
adding a range argument to the xhistogram API :issue:`13`.
diff --git a/xhistogram/core.py b/xhistogram/core.py
index c13dda9..48f31c9 100644
--- a/xhistogram/core.py
+++ b/xhistogram/core.py
@@ -436,7 +436,13 @@ def histogram(
# Slower, but N-dimensional logic
bin_areas = np.prod(np.ix_(*bin_widths))
- h = bin_counts / bin_areas / bin_counts.sum()
+ # Sum over the last n_inputs axes, which correspond to the bins. All other axes
+ # are "bystander" axes. Sums must be done independently for each bystander axes
+ # so that nans are dealt with correctly (#51)
+ bin_axes = tuple(_range(-n_inputs, 0))
+ bin_count_sums = bin_counts.sum(axis=bin_axes)
+ bin_count_sums_shape = bin_count_sums.shape + len(bin_axes) * (1,)
+ h = bin_counts / bin_areas / reshape(bin_count_sums, bin_count_sums_shape)
else:
h = bin_counts
diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index a587abc..922fc26 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -197,11 +197,6 @@ def histogram(
da_out = xr.DataArray(h_data, dims=output_dims, coords=all_coords, name=output_name)
- if density:
- # correct for overcounting the bins which weren't histogrammed along
- n_bins_bystander_dims = da_out.isel(**{bd: 0 for bd in new_dims}).size
- da_out = da_out * n_bins_bystander_dims
-
return da_out
# we need weights to be passed through apply_func's alignment algorithm,
| xgcm/xhistogram | 8a6765ac25c749961a32b209e54d47ed483651fc | diff --git a/xhistogram/test/test_core.py b/xhistogram/test/test_core.py
index f6ebcc3..3a692c6 100644
--- a/xhistogram/test/test_core.py
+++ b/xhistogram/test/test_core.py
@@ -24,12 +24,17 @@ range_ = (0, 1)
@pytest.mark.parametrize("axis", [1, None])
@pytest.mark.parametrize("bins", [10, np.linspace(-4, 4, 10), "auto"])
@pytest.mark.parametrize("range_", [None, (-4, 4)])
-def test_histogram_results_1d(block_size, density, axis, bins, range_):
[email protected]("add_nans", [False, True])
+def test_histogram_results_1d(block_size, density, axis, bins, range_, add_nans):
nrows, ncols = 5, 20
# Setting the random seed here prevents np.testing.assert_allclose
# from failing beow. We should investigate this further.
np.random.seed(2)
data = np.random.randn(nrows, ncols)
+ if add_nans:
+ N_nans = 20
+ data.ravel()[np.random.choice(data.size, N_nans, replace=False)] = np.nan
+ bins = np.linspace(-4, 4, 10)
h, bin_edges = histogram(
data, bins=bins, range=range_, axis=axis, block_size=block_size, density=density
@@ -53,12 +58,11 @@ def test_histogram_results_1d(block_size, density, axis, bins, range_):
)
else:
expected = np.histogram(data, bins=bins, range=range_, density=density)[0]
- norm = nrows if (density and axis) else 1
- np.testing.assert_allclose(h, expected / norm)
+ np.testing.assert_allclose(h, expected)
if density:
- widths = np.diff(bin_edges)
- integral = np.sum(h * widths)
+ widths = np.diff(bins)
+ integral = np.sum(h * widths, axis)
np.testing.assert_allclose(integral, 1.0)
@@ -150,10 +154,15 @@ def test_histogram_results_2d_broadcasting(dask):
np.testing.assert_array_equal(hist, h)
-def test_histogram_results_2d_density():
[email protected]("add_nans", [False, True])
+def test_histogram_results_2d_density(add_nans):
nrows, ncols = 5, 20
data_a = np.random.randn(nrows, ncols)
data_b = np.random.randn(nrows, ncols)
+ if add_nans:
+ N_nans = 20
+ data_a.ravel()[np.random.choice(data_a.size, N_nans, replace=False)] = np.nan
+ data_b.ravel()[np.random.choice(data_b.size, N_nans, replace=False)] = np.nan
nbins_a = 9
bins_a = np.linspace(-4, 4, nbins_a + 1)
nbins_b = 10
@@ -175,11 +184,17 @@ def test_histogram_results_2d_density():
np.testing.assert_allclose(integral, 1.0)
-def test_histogram_results_3d_density():
[email protected]("add_nans", [False, True])
+def test_histogram_results_3d_density(add_nans):
nrows, ncols = 5, 20
data_a = np.random.randn(nrows, ncols)
data_b = np.random.randn(nrows, ncols)
data_c = np.random.randn(nrows, ncols)
+ if add_nans:
+ N_nans = 20
+ data_a.ravel()[np.random.choice(data_a.size, N_nans, replace=False)] = np.nan
+ data_b.ravel()[np.random.choice(data_b.size, N_nans, replace=False)] = np.nan
+ data_c.ravel()[np.random.choice(data_c.size, N_nans, replace=False)] = np.nan
nbins_a = 9
bins_a = np.linspace(-4, 4, nbins_a + 1)
nbins_b = 10
| Bug with density calculation when NaNs are present
There is a bug in the way histograms are normalised to densities that manifests when there are NaNs in the input data:
```python
import numpy as np
import xarray as xr
import matplotlib.pyplot as plt
from xhistogram.xarray import histogram
data = np.random.normal(size=(10,2))
# Add some nans
N_nans = 6
data.ravel()[np.random.choice(data.size, N_nans, replace=False)] = np.nan
bins = np.linspace(-5,5,5)
bin_centers = 0.5 * (bins[:-1] + bins[1:])
# np.histogram -----
h, _ = np.histogram(data[:,0], bins, density=True)
plt.plot(bin_centers, h, label='numpy histogram')
# xhistogram -----
da = xr.DataArray(
data, dims=['s', 'x'],
coords=[range(data.shape[0]),
range(data.shape[1])]).rename('test')
h2 = histogram(da, bins=[bins], dim=['s'], density=True)
plt.plot(bin_centers, h2[0,:], linestyle='--', label='xhistogram')
plt.legend()
plt.xlabel('bins')
plt.ylabel('pdf')
```
<img width="399" alt="Screen Shot 2021-05-05 at 8 31 17 pm" src="https://user-images.githubusercontent.com/42455466/117128520-df907d00-ade0-11eb-9452-641c2b779633.png">
This bug comes about when there are dimensions that are not being histogram'd ("bystander" dimensions). Currently we sum over all axis to estimate the area/volume of our histogram and then account bystander dimensions [as a secondary step](https://github.com/xgcm/xhistogram/blob/master/xhistogram/xarray.py#L180). However, this can produce incorrect results when NaNs are present because there may be a different number of NaNs along each bystander dimension. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-2-True]"
] | [
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[auto]",
"xhistogram/test/test_core.py::test_histogram_right_edge[None]",
"xhistogram/test/test_core.py::test_histogram_right_edge[1]",
"xhistogram/test/test_core.py::test_histogram_right_edge[2]",
"xhistogram/test/test_core.py::test_histogram_results_2d",
"xhistogram/test/test_core.py::test_histogram_results_2d_broadcasting[False]",
"xhistogram/test/test_core.py::test_histogram_results_2d_broadcasting[True]",
"xhistogram/test/test_core.py::test_histogram_results_2d_density[False]",
"xhistogram/test/test_core.py::test_histogram_results_2d_density[True]",
"xhistogram/test/test_core.py::test_histogram_shape[False-None]",
"xhistogram/test/test_core.py::test_histogram_shape[False-5]",
"xhistogram/test/test_core.py::test_histogram_shape[False-auto]",
"xhistogram/test/test_core.py::test_histogram_shape[True-None]",
"xhistogram/test/test_core.py::test_histogram_shape[True-5]",
"xhistogram/test/test_core.py::test_histogram_shape[True-auto]",
"xhistogram/test/test_core.py::test_histogram_dask",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out5]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out6]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out7]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out8]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out9]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out10]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out5]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-05-05T10:39:31Z" | mit |
|
xgcm__xhistogram-77 | diff --git a/doc/contributing.rst b/doc/contributing.rst
index 9ccbb9e..fd4ba77 100644
--- a/doc/contributing.rst
+++ b/doc/contributing.rst
@@ -141,17 +141,17 @@ Release History
---------------
v0.3.2 (not released)
-~~~~~~~~~~~~~~~~~~~~~~~~
+~~~~~~~~~~~~~~~~~~~~~~~~~
-- Fix bug producing TypeError when weights is provided with
+- Fix bug producing TypeError when `weights` is provided with
`keep_coords=True` :issue:`78`. By
`Dougie Squire <https://github.com/dougiesquire>`_.
-- Raise TypeError when weights is a dask array and bin edges are
+- Raise TypeError when `weights` is a dask array and bin edges are
not explicitly provided :issue:`12`. By
`Dougie Squire <https://github.com/dougiesquire>`_.
v0.3.1
-~~~~~~~~~~~~~~~~~~~~~~~~
+~~~~~~~~~~~~~~~~~~~~~~~~~
- Add DOI badge and CITATION.cff. By
`Julius Busecke <https://github.com/jbusecke>`_.
diff --git a/setup.py b/setup.py
index 4481b45..532192a 100644
--- a/setup.py
+++ b/setup.py
@@ -20,7 +20,7 @@ CLASSIFIERS = [
"Topic :: Scientific/Engineering",
]
-INSTALL_REQUIRES = ["xarray>=0.12.0", "dask[array]", "numpy>=1.17"]
+INSTALL_REQUIRES = ["xarray>=0.12.0", "dask[array]>=2.3.0", "numpy>=1.17"]
PYTHON_REQUIRES = ">=3.7"
DESCRIPTION = "Fast, flexible, label-aware histograms for numpy and xarray"
diff --git a/xhistogram/core.py b/xhistogram/core.py
index 04cef56..181325f 100644
--- a/xhistogram/core.py
+++ b/xhistogram/core.py
@@ -278,9 +278,9 @@ def histogram(
When bin edges are specified, all but the last (righthand-most) bin include
the left edge and exclude the right edge. The last bin includes both edges.
- A TypeError will be raised if args contains dask arrays and bins are not
- specified explicitly as an array or list of arrays. This is because other
- bin specifications trigger computation.
+ A TypeError will be raised if args or weights contains dask arrays and bins
+ are not specified explicitly as an array or list of arrays. This is because
+ other bin specifications trigger computation.
range : (float, float) or a list of (float, float), optional
If a list, there should be one entry for each item in ``args``.
The range specifications are as follows:
@@ -336,7 +336,7 @@ def histogram(
ndim = a0.ndim
n_inputs = len(args)
- is_dask_array = any([dask.is_dask_collection(a) for a in args])
+ is_dask_array = any([dask.is_dask_collection(a) for a in list(args) + [weights]])
if axis is not None:
axis = np.atleast_1d(axis)
diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index f1b7976..975aa9b 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -43,9 +43,9 @@ def histogram(
When bin edges are specified, all but the last (righthand-most) bin include
the left edge and exclude the right edge. The last bin includes both edges.
- A TypeError will be raised if args contains dask arrays and bins are not
- specified explicitly as an array or list of arrays. This is because other
- bin specifications trigger computation.
+ A TypeError will be raised if args or weights contains dask arrays and bins
+ are not specified explicitly as an array or list of arrays. This is because
+ other bin specifications trigger computation.
range : (float, float) or a list of (float, float), optional
If a list, there should be one entry for each item in ``args``.
The range specifications are as follows:
| xgcm/xhistogram | 44a78384e9c6c7d14caed51d013311ec5753b3f1 | diff --git a/xhistogram/test/test_core.py b/xhistogram/test/test_core.py
index db0bf99..0868dff 100644
--- a/xhistogram/test/test_core.py
+++ b/xhistogram/test/test_core.py
@@ -9,10 +9,12 @@ from ..core import (
_ensure_correctly_formatted_bins,
_ensure_correctly_formatted_range,
)
-from .fixtures import empty_dask_array
+from .fixtures import empty_dask_array, example_dataarray
import pytest
+import contextlib
+
bins_int = 10
bins_str = "auto"
@@ -271,15 +273,44 @@ def test_histogram_shape(use_dask, block_size):
assert isinstance(c, dsa.Array)
-def test_histogram_dask():
- """Test that fails with dask arrays and inappropriate bins"""
[email protected]("arg_type", ["dask", "numpy"])
[email protected]("weights_type", ["dask", "numpy", None])
[email protected]("bins_type", ["int", "str", "numpy"])
+def test_histogram_dask(arg_type, weights_type, bins_type):
+ """Test that a TypeError is raised with dask arrays and inappropriate bins"""
shape = 10, 15, 12, 20
- b = empty_dask_array(shape, chunks=(1,) + shape[1:])
- histogram(b, bins=bins_arr) # Should work when bins is all numpy arrays
- with pytest.raises(TypeError): # Should fail otherwise
- histogram(b, bins=bins_int)
- histogram(b, bins=bins_str)
- histogram(b, b, bins=[bins_arr, bins_int])
+
+ if arg_type == "dask":
+ arg = empty_dask_array(shape)
+ else:
+ arg = example_dataarray(shape)
+
+ if weights_type == "dask":
+ weights = empty_dask_array(shape)
+ elif weights_type == "numpy":
+ weights = example_dataarray(shape)
+ else:
+ weights = None
+
+ if bins_type == "int":
+ bins = bins_int
+ elif bins_type == "str":
+ bins = bins_str
+ else:
+ bins = bins_arr
+
+ # TypeError should be returned when
+ # 1. args or weights is a dask array and bins is not a numpy array, or
+ # 2. bins is a string and weights is a numpy array
+ cond_1 = ((arg_type == "dask") | (weights_type == "dask")) & (bins_type != "numpy")
+ cond_2 = (weights_type == "numpy") & (bins_type == "str")
+ should_TypeError = cond_1 | cond_2
+
+ with contextlib.ExitStack() as stack:
+ if should_TypeError:
+ stack.enter_context(pytest.raises(TypeError))
+ histogram(arg, bins=bins, weights=weights)
+ histogram(arg, arg, bins=[bins, bins], weights=weights)
@pytest.mark.parametrize(
| numpy / dask verison compatibility bug
There is a bug in xhistogram with numpy version >= 1.17 and dask version < 2.3
```python
import xarray as xr
import numpy as np
from xhistogram.xarray import histogram
nt, nx = 100, 30
da = xr.DataArray(np.random.randn(nt, nx), dims=['time', 'x'],
name='foo').chunk({'time': 1})
bins = np.linspace(-4, 4, 20)
h = histogram(da, bins=[bins], dim=['x'])
```
This should be lazy. However, as reported by @stb2145 in https://github.com/pangeo-data/pangeo/issues/690, certain numpy / dask combination produce the warning
```
/srv/conda/envs/notebook/lib/python3.7/site-packages/dask/array/core.py:1263: FutureWarning: The `numpy.moveaxis` function is not implemented by Dask array. You may want to use the da.map_blocks function or something similar to silence this warning. Your code may stop working in a future release.
FutureWarning,
```
and evaluates eagerly.
In https://github.com/pangeo-data/pangeo/issues/690 we found a workaround involving setting the environment variable `NUMPY_EXPERIMENTAL_ARRAY_FUNCTION=0`. However, in the meantime, the root issues was fixed in dask (https://github.com/dask/dask/issues/2559).
We can avoid this bug by requiring dask >= 2.3.0 as a dependency for xhistogram. I guess that's the easiest way to go. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_core.py::test_histogram_dask[int-dask-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[str-dask-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-dask-numpy]"
] | [
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-None-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[False-range_1-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-None-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-10-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-bins1-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-1-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-None-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-None-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-1-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-1-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-2-False]",
"xhistogram/test/test_core.py::test_histogram_results_1d[True-range_1-auto-None-2-True]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[None]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[1]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[2]",
"xhistogram/test/test_core.py::test_histogram_results_1d_weighted_broadcasting[auto]",
"xhistogram/test/test_core.py::test_histogram_right_edge[None]",
"xhistogram/test/test_core.py::test_histogram_right_edge[1]",
"xhistogram/test/test_core.py::test_histogram_right_edge[2]",
"xhistogram/test/test_core.py::test_histogram_results_2d",
"xhistogram/test/test_core.py::test_histogram_results_2d_broadcasting[False]",
"xhistogram/test/test_core.py::test_histogram_results_2d_broadcasting[True]",
"xhistogram/test/test_core.py::test_histogram_results_2d_density[False]",
"xhistogram/test/test_core.py::test_histogram_results_2d_density[True]",
"xhistogram/test/test_core.py::test_histogram_shape[False-None]",
"xhistogram/test/test_core.py::test_histogram_shape[False-5]",
"xhistogram/test/test_core.py::test_histogram_shape[False-auto]",
"xhistogram/test/test_core.py::test_histogram_shape[True-None]",
"xhistogram/test/test_core.py::test_histogram_shape[True-5]",
"xhistogram/test/test_core.py::test_histogram_shape[True-auto]",
"xhistogram/test/test_core.py::test_histogram_dask[int-dask-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[int-numpy-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[int-numpy-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[int-None-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[int-None-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[str-dask-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[str-numpy-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[str-numpy-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[str-None-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[str-None-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-dask-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-numpy-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-numpy-numpy]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-None-dask]",
"xhistogram/test/test_core.py::test_histogram_dask[numpy-None-numpy]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out5]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out6]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out7]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out8]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out9]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_bins[in_out10]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out0]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out1]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out2]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out3]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out4]",
"xhistogram/test/test_core.py::test_ensure_correctly_formatted_range[in_out5]",
"xhistogram/test/test_core.py::test_histogram_results_datetime[False-None]",
"xhistogram/test/test_core.py::test_histogram_results_datetime[False-1]",
"xhistogram/test/test_core.py::test_histogram_results_datetime[False-2]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-07-21T06:59:51Z" | mit |
|
xgcm__xhistogram-8 | diff --git a/xhistogram/xarray.py b/xhistogram/xarray.py
index 230a44c..c4d41d8 100644
--- a/xhistogram/xarray.py
+++ b/xhistogram/xarray.py
@@ -4,6 +4,7 @@ Xarray API for xhistogram.
import xarray as xr
import numpy as np
+from collections import OrderedDict
from .core import histogram as _histogram
@@ -95,11 +96,11 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
# roll our own broadcasting
# now manually expand the arrays
- all_dims = set([d for a in args for d in a.dims])
- all_dims_ordered = list(all_dims)
+ all_dims = [d for a in args for d in a.dims]
+ all_dims_ordered = list(OrderedDict.fromkeys(all_dims))
args_expanded = []
for a in args:
- expand_keys = all_dims - set(a.dims)
+ expand_keys = [d for d in all_dims_ordered if d not in a.dims]
a_expanded = a.expand_dims({k: 1 for k in expand_keys})
args_expanded.append(a_expanded)
@@ -118,7 +119,7 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
weights_data = None
if dim is not None:
- dims_to_keep = [d for d in a_dims if d not in dim]
+ dims_to_keep = [d for d in all_dims_ordered if d not in dim]
axis = [args_transposed[0].get_axis_num(d) for d in dim]
else:
dims_to_keep = []
@@ -129,11 +130,19 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
# create output dims
new_dims = [a.name + bin_dim_suffix for a in args[:N_args]]
- bin_centers = [0.5*(bin[:-1] + bin[1:]) for bin in bins]
- coords = {name: ((name,), bin_center, a.attrs)
- for name, bin_center, a in zip(new_dims, bin_centers, args)}
output_dims = dims_to_keep + new_dims
+ # create new coords
+ bin_centers = [0.5*(bin[:-1] + bin[1:]) for bin in bins]
+ new_coords = {name: ((name,), bin_center, a.attrs)
+ for name, bin_center, a in zip(new_dims, bin_centers, args)}
+
+ old_coords = {name: a0[name]
+ for name in dims_to_keep if name in a0.coords}
+ all_coords = {}
+ all_coords.update(old_coords)
+ all_coords.update(new_coords)
+
# CF conventions tell us how to specify cell boundaries
# http://cfconventions.org/Data/cf-conventions/cf-conventions-1.7/cf-conventions.html#cell-boundaries
# However, they require introduction of an additional dimension.
@@ -143,7 +152,8 @@ def histogram(*args, bins=None, dim=None, weights=None, density=False,
for name, bin_edge, a in zip(edge_dims, bins, args)}
output_name = '_'.join(['histogram'] + [a.name for a in args[:N_args]])
- da_out = xr.DataArray(h_data, dims=output_dims, coords=coords,
+
+ da_out = xr.DataArray(h_data, dims=output_dims, coords=all_coords,
name=output_name)
return da_out
| xgcm/xhistogram | a636393e1d10d2f8609967869c6ce028d3d9ba41 | diff --git a/xhistogram/test/test_xarray.py b/xhistogram/test/test_xarray.py
index 9b46dd4..0018f0d 100644
--- a/xhistogram/test/test_xarray.py
+++ b/xhistogram/test/test_xarray.py
@@ -94,3 +94,31 @@ def test_weights(ones, ndims):
for d in combinations(dims, nc+1):
h = histogram(ones, weights=weights, bins=[bins], dim=d)
_check_result(h, d)
+
+
+# test for issue #5
+def test_dims_and_coords():
+ time_axis = np.arange(4)
+ depth_axis = np.arange(10)
+ X_axis = np.arange(30)
+ Y_axis = np.arange(30)
+
+ dat1 = np.random.randint(low=0, high=100,
+ size=(len(time_axis), len(depth_axis),
+ len(X_axis), len(Y_axis)))
+ array1 = xr.DataArray(dat1, coords=[time_axis,depth_axis,X_axis,Y_axis],
+ dims=['time', 'depth', 'X', 'Y'], name='one')
+
+ dat2 = np.random.randint(low=0, high=50,
+ size=(len(time_axis), len(depth_axis),
+ len(X_axis), len(Y_axis)))
+ array2 = xr.DataArray(dat2, coords=[time_axis,depth_axis,X_axis,Y_axis],
+ dims=['time','depth','X','Y'], name='two')
+
+ bins1 = np.linspace(0, 100, 50)
+ bins2 = np.linspace(0,50,25)
+
+ result = histogram(array1,array2,dim = ['X','Y'] , bins=[bins1,bins2])
+ assert result.dims == ('time', 'depth', 'one_bin', 'two_bin')
+ assert result.time.identical(array1.time)
+ assert result.depth.identical(array2.depth)
| axes not used for making hist got shifted
Say we have two xarray.DataArrays with dims (t:4, z:10, x:100, y:100). If we make histagram based on dimensions x and y, what we have in the result is (t:10, z:4, x_bin, y_bin). The t and z get exchanged.
```python
import numpy as np
import xarray as xr
from xhistogram.xarray import histogram
# create data for testing
time_axis = range(4)
depth_axis = range(10)
X_axis = range(30)
Y_axis = range(30)
dat1 = np.random.randint(low = 0, high = 100,size=(len(time_axis),len(depth_axis),len(X_axis),len(Y_axis)))
array1 = xr.DataArray(dat1, coords = [time_axis,depth_axis,X_axis,Y_axis], dims = ['time','depth','X','Y'])
dat2 = np.random.randint(low = 0, high = 50,size=(len(time_axis),len(depth_axis),len(X_axis),len(Y_axis)))
array2 = xr.DataArray(dat2, coords = [time_axis,depth_axis,X_axis,Y_axis], dims = ['time','depth','X','Y'])
# create bins and rename arrays
bins1 = np.linspace(0, 100, 50)
bins2 = np.linspace(0,50,25)
array1 = array1.rename('one')
array2 = array2.rename('two')
result= histogram(array1,array2,dim = ['X','Y'] , bins=[bins1,bins2])
```
The dimensions of result is (time: 10, depth: 4, one_bin: 49, two_bin: 24) instead of (time: 4, depth: 10, one_bin: 49, two_bin: 24). Is this a bug of the code or just my misusing of the function? | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"xhistogram/test/test_xarray.py::test_dims_and_coords"
] | [
"xhistogram/test/test_xarray.py::test_histogram_ones[1D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[2D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[2D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[3D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-1]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-2]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-3]",
"xhistogram/test/test_xarray.py::test_histogram_ones[4D-4]",
"xhistogram/test/test_xarray.py::test_weights[1D-1]",
"xhistogram/test/test_xarray.py::test_weights[2D-1]",
"xhistogram/test/test_xarray.py::test_weights[2D-2]",
"xhistogram/test/test_xarray.py::test_weights[3D-1]",
"xhistogram/test/test_xarray.py::test_weights[3D-2]",
"xhistogram/test/test_xarray.py::test_weights[3D-3]",
"xhistogram/test/test_xarray.py::test_weights[4D-1]",
"xhistogram/test/test_xarray.py::test_weights[4D-2]",
"xhistogram/test/test_xarray.py::test_weights[4D-3]",
"xhistogram/test/test_xarray.py::test_weights[4D-4]"
] | {
"failed_lite_validators": [
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2019-08-02T14:17:03Z" | mit |
|
xlab-si__xopera-opera-116 | diff --git a/docs/index.rst b/docs/index.rst
index db233d6..f7328c8 100644
--- a/docs/index.rst
+++ b/docs/index.rst
@@ -12,6 +12,8 @@ The following documentation explains the usage of xOpera TOSCA orchestrator. Wan
installation
examples
documentation
+ saas
+
..
Indices and tables
==================
diff --git a/docs/saas.rst b/docs/saas.rst
new file mode 100644
index 0000000..1080af4
--- /dev/null
+++ b/docs/saas.rst
@@ -0,0 +1,74 @@
+.. _SaaS:
+
+***********
+xOpera SaaS
+***********
+
+The Software as a Service edition of xOpera is available at https://xopera-radon.xlab.si/ui/_.
+
+It is a multi-user multi-platform multi-deployment multifunctional service offering all capabilities of the
+console-based ``opera``, providing all of its functionalities.
+
+Please read the warnings below, as you accept some inherent risks when using xOpera-SaaS
+
+Using the browser version is straightforward.
+
+Using the xOpera SaaS API through ``curl``::
+
+ csar_base64="$(base64 --wrap 0 test.csar)"
+ api="https://xopera-radon.xlab.si/api"
+ secret_base64="$(echo 'hello!' | base64 -)"
+
+ your_username=YOUR_USERNAME
+ your_password=YOUR_PASSWORD
+
+ # login process (would be automated by browser)
+ alias cookiecurl="curl -sSL --cookie-jar cookiejar.txt --cookie cookiejar.txt"
+ response="$(cookiecurl $api/credential)"
+ redirect_url="$(echo $response | xmllint --html --xpath "string(//form[@id='kc-form-login']/@action)" - 2>/dev/null)"
+ cookiecurl "$redirect_url" -d "username=$your_username" -d "password=$your_password" -d credentialId=""
+
+ # normal usage
+ cookiecurl "$api/credential"
+ cookiecurl "$api/credential" -XPOST -d "{\"name\": \"credential1\", \"path\": \"/tmp/credential.txt\", \"contents\": \"$secret_base64\"}"
+ cookiecurl "$api/credential"
+ cookiecurl "$api/credential/1"
+ cookiecurl "$api/workspace"
+ cookiecurl "$api/workspace" -XPOST -d '{"name": "workspace1"}'
+ cookiecurl "$api/workspace/1/credential/1" -XPUT
+ cookiecurl "$api/workspace/1/credential"
+ cookiecurl "$api/credential/1"
+ cookiecurl "$api/workspace/1"
+ cookiecurl "$api/workspace/1/project" -XPOST -d "{\"name\": \"myproject\", \"csar\": \"$csar_base64\"}"
+ cookiecurl "$api/workspace/1/project"
+ cookiecurl "$api/workspace/1"
+ cookiecurl "$api/workspace/1/project/1/creationStatus"
+ cookiecurl "$api/workspace/1/project/1/debugPackage"
+
+ # interaction with the project (identical to xopera-api), instructions copied from there
+ project_url="$api/workspace/1/project/1"
+ cookiecurl "$project_url/status"
+ cookiecurl "$project_url/validate" -XPOST -H "Content-Type: application/json" -d @inputs-request.json
+ cookiecurl "$project_url/deploy" -XPOST -H "Content-Type: application/json" -d @inputs-request.json
+ cookiecurl "$project_url/status" | jq
+ cookiecurl "$project_url/outputs"
+ cookiecurl "$project_url/undeploy" -XPOST
+
+For further interaction with each project, see
+`the xopera-api specification <https://github.com/xlab-si/xopera-api/blob/master/openapi-spec.yml>`_
+
+
+====================================================
+Warnings about your credentials and general security
+====================================================
+
+Your credentials - not for xOpera-SaaS, but those you add for services you access in CSARs etc - are stored in
+plaintext on the server xOpera-SaaS is running on.
+All assigned workspaces have access to them, as they have control of the filesystem, therefore all users with access
+to the workspace also have access to them.
+You need to use caution with the credentials you submit.
+
+If you request xOpera-SaaS server administrators to help you or access your project, they will also be in a position
+to access the credentials.
+Whenever possible, use temporary credentials with limited access to the smallest required set of capabilities
+to improve you security.
diff --git a/examples/attribute_mapping/service.yaml b/examples/attribute_mapping/service.yaml
index cfd8b1d..61b7370 100644
--- a/examples/attribute_mapping/service.yaml
+++ b/examples/attribute_mapping/service.yaml
@@ -20,7 +20,7 @@ node_types:
operations:
create:
inputs:
- id: { default: { get_property: [ SELF, enrolment_number ] } }
+ id: { default: { get_property: [ SELF, enrolment_number ] }, type: integer }
outputs:
student_id: [ SELF, student_id ]
implementation: playbooks/create-student.yaml
@@ -51,8 +51,10 @@ relationship_types:
inputs:
student_id:
default: { get_attribute: [ TARGET, student_id ] }
+ type: string
student_ids:
default: { get_attribute: [ SOURCE, student_ids ] }
+ type: list
outputs:
new_list: [ SOURCE, student_ids ]
implementation: playbooks/teacher-teaches-student--preconfigure-source.yaml
diff --git a/examples/nginx_openstack/library/nginx/server/types.yaml b/examples/nginx_openstack/library/nginx/server/types.yaml
index 845e467..45a73e6 100644
--- a/examples/nginx_openstack/library/nginx/server/types.yaml
+++ b/examples/nginx_openstack/library/nginx/server/types.yaml
@@ -22,7 +22,6 @@ node_types:
implementation:
primary: playbooks/uninstall.yaml
-
relationship_types:
my.relationships.NginxSiteHosting:
derived_from: tosca.relationships.HostedOn
@@ -33,5 +32,6 @@ relationship_types:
inputs:
marker:
default: { get_attribute: [ TARGET, host, id ] }
+ type: string
implementation:
primary: playbooks/reload.yaml
diff --git a/examples/nginx_openstack/library/openstack/vm/types.yaml b/examples/nginx_openstack/library/openstack/vm/types.yaml
index df58465..31411e7 100644
--- a/examples/nginx_openstack/library/openstack/vm/types.yaml
+++ b/examples/nginx_openstack/library/openstack/vm/types.yaml
@@ -34,15 +34,16 @@ node_types:
operations:
create:
inputs:
- vm_name: { default: { get_property: [ SELF, name ] } }
- image: { default: { get_property: [ SELF, image ] } }
- flavor: { default: { get_property: [ SELF, flavor ] } }
- network: { default: { get_property: [ SELF, network ] } }
- key_name: { default: { get_property: [ SELF, key_name ] } }
+ vm_name: { default: { get_property: [ SELF, name ] }, type: string }
+ image: { default: { get_property: [ SELF, image ] }, type: string }
+ flavor: { default: { get_property: [ SELF, flavor ] }, type: string }
+ network: { default: { get_property: [ SELF, network ] }, type: string }
+ key_name: { default: { get_property: [ SELF, key_name ] }, type: string }
security_groups:
- default: { get_property: [ SELF, security_groups ] }
+ default: { get_property: [ SELF, security_groups ] }
+ type: string
implementation: playbooks/create.yaml
delete:
inputs:
- id: { default: { get_attribute: [ SELF, id ] } }
+ id: { default: { get_attribute: [ SELF, id ] }, type: string }
implementation: playbooks/delete.yaml
diff --git a/examples/policy_triggers/service.yaml b/examples/policy_triggers/service.yaml
index a8addc9..a131c56 100644
--- a/examples/policy_triggers/service.yaml
+++ b/examples/policy_triggers/service.yaml
@@ -34,7 +34,7 @@ interface_types:
operations:
scale_down:
inputs:
- adjustment: { default: { get_property: [ SELF, name ] } }
+ adjustment: { default: 1, type: integer }
description: Operation for scaling down.
implementation: playbooks/scale_down.yaml
@@ -43,7 +43,7 @@ interface_types:
operations:
scale_up:
inputs:
- adjustment: { default: { get_property: [ SELF, name ] } }
+ adjustment: { default: 1, type: integer }
description: Operation for scaling up.
implementation: playbooks/scale_up.yaml
@@ -83,8 +83,8 @@ policy_types:
condition:
- not:
- and:
- - available_instances: [ { greater: 42 } ]
- - available_space: [ { greater: 1000 } ]
+ - available_instances: [ { greater_than: 42 } ]
+ - available_space: [ { greater_than: 1000 } ]
action:
- call_operation:
operation: radon.interfaces.scaling.ScaleDown.scale_down
@@ -116,8 +116,8 @@ policy_types:
condition:
- not:
- and:
- - available_instances: [ { greater: 42 } ]
- - available_space: [ { greater: 1000 } ]
+ - available_instances: [ { greater_than: 42 } ]
+ - available_space: [ { greater_than: 1000 } ]
action:
- call_operation:
operation: radon.interfaces.scaling.ScaleUp.scale_up
@@ -160,52 +160,46 @@ topology_template:
key_name: my_key
requirements:
- host: workstation
- capabilities:
- host_capability:
- properties:
- num_cpus: 1
- disk_size: 10 GB
- mem_size: 4096 MB
policies:
- scale_down:
- type: radon.policies.scaling.ScaleDown
- properties:
- cpu_upper_bound: 90
- adjustment: 1
+ - scale_down:
+ type: radon.policies.scaling.ScaleDown
+ properties:
+ cpu_upper_bound: 90
+ adjustment: 1
- scale_up:
- type: radon.policies.scaling.ScaleUp
- properties:
- cpu_upper_bound: 90
- adjustment: 1
+ - scale_up:
+ type: radon.policies.scaling.ScaleUp
+ properties:
+ cpu_upper_bound: 90
+ adjustment: 1
- autoscale:
- type: radon.policies.scaling.AutoScale
- properties:
- min_size: 3
- max_size: 7
- targets: [ openstack_vm ]
- triggers:
- radon.triggers.scaling:
- description: A trigger for autoscaling
- event: auto_scale_trigger
- schedule:
- start_time: 2020-04-08T21:59:43.10-06:00
- end_time: 2022-04-08T21:59:43.10-06:00
- target_filter:
- node: openstack_vm
- requirement: workstation
- capability: host_capability
- condition:
- constraint:
- - not:
- - and:
- - available_instances: [ { greater: 42 } ]
- - available_space: [ { greater: 1000 } ]
- period: 60 sec
- evaluations: 2
- method: average
- action:
- - call_operation: radon.interfaces.scaling.AutoScale.retrieve_info
- - call_operation: radon.interfaces.scaling.AutoScale.autoscale
+ - autoscale:
+ type: radon.policies.scaling.AutoScale
+ properties:
+ min_size: 3
+ max_size: 7
+ targets: [ openstack_vm ]
+ triggers:
+ radon.triggers.scaling:
+ description: A trigger for autoscaling
+ event: auto_scale_trigger
+ schedule:
+ start_time: 2020-04-08T21:59:43.10-06:00
+ end_time: 2022-04-08T21:59:43.10-06:00
+ target_filter:
+ node: openstack_vm
+ requirement: workstation
+ capability: host_capability
+ condition:
+ constraint:
+ - not:
+ - and:
+ - available_instances: [ { greater_than: 42 } ]
+ - available_space: [ { greater_than: 1000 } ]
+ period: 60 sec
+ evaluations: 2
+ method: average
+ action:
+ - call_operation: radon.interfaces.scaling.AutoScale.retrieve_info
+ - call_operation: radon.interfaces.scaling.AutoScale.autoscale
diff --git a/src/opera/parser/tosca/v_1_3/topology_template.py b/src/opera/parser/tosca/v_1_3/topology_template.py
index ce17793..a973590 100644
--- a/src/opera/parser/tosca/v_1_3/topology_template.py
+++ b/src/opera/parser/tosca/v_1_3/topology_template.py
@@ -3,6 +3,7 @@ from opera.template.topology import Topology
from ..entity import Entity
from ..map import Map
+from ..list import List
from ..string import String
from .group_definition import GroupDefinition
@@ -19,7 +20,7 @@ class TopologyTemplate(Entity):
node_templates=Map(NodeTemplate),
relationship_templates=Map(RelationshipTemplate),
groups=Map(GroupDefinition),
- policies=Map(PolicyDefinition),
+ policies=List(Map(PolicyDefinition)),
outputs=Map(ParameterDefinition),
# TODO(@tadeboro): substitution_mappings and workflows
)
| xlab-si/xopera-opera | 0eabdc0c7305979c897772fb5c935a5755fb903d | diff --git a/tests/integration/misc-tosca-types/service-template.yaml b/tests/integration/misc-tosca-types/service-template.yaml
index 610c071..27818b0 100644
--- a/tests/integration/misc-tosca-types/service-template.yaml
+++ b/tests/integration/misc-tosca-types/service-template.yaml
@@ -105,11 +105,11 @@ topology_template:
members: [ my-workstation1, my-workstation2 ]
policies:
- test:
- type: daily_test_policies.test
- properties:
- test_id: *test
- targets: [ hello, setter, workstation_group ]
+ - test:
+ type: daily_test_policies.test
+ properties:
+ test_id: *test
+ targets: [ hello, setter, workstation_group ]
outputs:
output_prop:
diff --git a/tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py b/tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py
index 6ffaa6c..9423610 100644
--- a/tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py
+++ b/tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py
@@ -20,8 +20,8 @@ class TestParse:
my_group:
type: group.type
policies:
- my_policy:
- type: policy.type
+ - my_policy:
+ type: policy.type
outputs:
my_output:
type: string
| Policies in service templates should be serialized as a list
## Description
This issue describe the inconsistency spotted in opera's TOSCA YAML v1.3 parser. [Section 3.9 of TOSCA Simple Profile in YAML v1.3](https://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.3/os/TOSCA-Simple-Profile-YAML-v1.3-os.html#_Toc26969450) states that `policies` keyname within the `topology_template` should be represented as an optional list of TOSCA policy definitions that apply to the topology template.
So, the syntax for TOSCA policies here should look like this:
```yaml
topology_template:
node_templates:
# left off for brevity
policies:
- policy1:
type: tosca.policies.placement
# left off for brevity
- policy2:
type: tosca.policies.placement
# left off for brevity
- policy3:
type: tosca.policies.placement
# left off for brevity
```
When we try to use that syntax and deploy it with opera, we get an error (`Expected map.`), saying that opera expected a YAML dictionary/map for the `policies` keyname. And by looking into opera's parser we soon realize that policies are not serialized as a list, but rather as a map which is in contradiction with the TOSCA standard and it needs to be fixed.
## Steps
To fix the issue in the TOSCA parser, we should modify the content in `src/opera/parser/tosca/v_1_3/topology_template.py` and also fix any tests or examples that use the wrong synax.
## Current behaviour
Right now opera treats policies in `topology_template` as YAML maps.
## Expected results
Opera's TOSCA parser should serialize policies as YAML lists.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py::TestParse::test_full"
] | [
"tests/unit/opera/parser/tosca/v_1_3/test_topology_template.py::TestParse::test_minimal"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2020-10-19T11:34:43Z" | apache-2.0 |
|
xlab-si__xopera-opera-207 | diff --git a/.gitignore b/.gitignore
index b67d06d..226bf78 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,13 +1,89 @@
+# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
+*$py.class
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
eggs/
.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+share/python-wheels/
*.egg-info/
+.installed.cfg
*.egg
-dist/
+MANIFEST
-venv/
-.venv/
+# PyInstaller
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.nox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+*.py,cover
+.hypothesis/
.pytest_cache/
+cover/
+
+# PyBuilder
+.pybuilder/
+target/
+
+# pyenv
+.python-version
+
+# pipenv
+Pipfile.lock
+
+# Environments
+.env
+.venv
+.venv*
+env/
+venv/
+venv*
+ENV/
+env.bak/
+venv.bak/
+
+# mypy
.mypy_cache/
+.dmypy.json
+dmypy.json
+
+# packages
+*.7z
+*.dmg
+*.gz
+*.iso
+*.jar
+*.rar
+*.tar
+*.tar.gz
+*.zip
+*.log.*
+*.csar
+
+# default opera storage folder
+.opera
diff --git a/examples/policy_triggers/service.yaml b/examples/policy_triggers/service.yaml
index 858e329..77c027f 100644
--- a/examples/policy_triggers/service.yaml
+++ b/examples/policy_triggers/service.yaml
@@ -33,6 +33,10 @@ node_types:
type: radon.interfaces.scaling.ScaleDown
autoscaling:
type: radon.interfaces.scaling.AutoScale
+ requirements:
+ - host:
+ capability: tosca.capabilities.Compute
+ relationship: tosca.relationships.HostedOn
interface_types:
radon.interfaces.scaling.ScaleDown:
diff --git a/src/opera/parser/tosca/v_1_3/node_template.py b/src/opera/parser/tosca/v_1_3/node_template.py
index f2d7040..823844c 100644
--- a/src/opera/parser/tosca/v_1_3/node_template.py
+++ b/src/opera/parser/tosca/v_1_3/node_template.py
@@ -86,4 +86,7 @@ class NodeTemplate(CollectorMixin, Entity):
)
)
+ if undeclared_requirements:
+ self.abort("Undeclared requirements: {}.".format(", ".join(undeclared_requirements)), self.loc)
+
return requirements
| xlab-si/xopera-opera | 442ff83960f03ba4507a078394a6447f22edf648 | diff --git a/tests/integration/concurrency/service.yaml b/tests/integration/concurrency/service.yaml
index 6934ddd..7e13804 100644
--- a/tests/integration/concurrency/service.yaml
+++ b/tests/integration/concurrency/service.yaml
@@ -134,7 +134,7 @@ topology_template:
time: "1"
requirements:
- host: my-workstation
- - dependency1: hello-1
- - dependency2: hello-2
- - dependency7: hello-7
- - dependency13: hello-13
+ - dependency: hello-1
+ - dependency: hello-2
+ - dependency: hello-7
+ - dependency: hello-13
diff --git a/tests/integration/misc_tosca_types/modules/node_types/test/test.yaml b/tests/integration/misc_tosca_types/modules/node_types/test/test.yaml
index cc1c473..3ad3b9a 100644
--- a/tests/integration/misc_tosca_types/modules/node_types/test/test.yaml
+++ b/tests/integration/misc_tosca_types/modules/node_types/test/test.yaml
@@ -40,10 +40,7 @@ node_types:
test_capability:
type: daily_test.capabilities.test
requirements:
- - host1:
+ - host:
capability: tosca.capabilities.Compute
relationship: daily_test.relationships.test
- - host2:
- capability: tosca.capabilities.Compute
- relationship: daily_test.relationships.interfaces
...
diff --git a/tests/unit/opera/parser/test_tosca.py b/tests/unit/opera/parser/test_tosca.py
index a81f803..b472187 100644
--- a/tests/unit/opera/parser/test_tosca.py
+++ b/tests/unit/opera/parser/test_tosca.py
@@ -316,3 +316,29 @@ class TestExecute:
ast = tosca.load(tmp_path, name)
with pytest.raises(ParseError, match="Missing a required property: property3"):
ast.get_template({})
+
+ def test_undeclared_requirements(self, tmp_path, yaml_text):
+ name = pathlib.PurePath("template.yaml")
+ (tmp_path / name).write_text(yaml_text(
+ # language=yaml
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ topology_template:
+ node_templates:
+ node_1:
+ type: tosca.nodes.SoftwareComponent
+ node_2:
+ type: tosca.nodes.SoftwareComponent
+ requirements:
+ - dependency: node_1
+ node_3:
+ type: tosca.nodes.SoftwareComponent
+ requirements:
+ - dependency_not_defined1: node_1
+ """
+ ))
+ storage = Storage(tmp_path / pathlib.Path(".opera"))
+ storage.write("template.yaml", "root_file")
+ ast = tosca.load(tmp_path, name)
+ with pytest.raises(ParseError, match="Undeclared requirements: dependency_not_defined1"):
+ ast.get_template({})
| Repair the concurrency deployment integration test
## Description
With this issue, we want to repair the concurrency integration test showing the right interdependency of nodes done in the original test and changed in a [subsequent commit](https://github.com/xlab-si/xopera-opera/commit/a803058071405f02c5be16eedc9ec172175625d1#diff-26bd1afdf3f59f80a604bac88b4519fd737e2fb182b745882653ec3b300224cbR137).
In the test the node dependency for node `hello-14` should be used as defined in [TOSCA 1.3 5.9.1.3 Definition](https://docs.oasis-open.org/tosca/TOSCA-Simple-Profile-YAML/v1.3/csprd01/TOSCA-Simple-Profile-YAML-v1.3-csprd01.html#_Toc9262333) `tosca.nodes.Root` where the `dependency` requirement has an UNBOUNDED max. limit of occurrences.
## Steps
Running the test in the current version of the test with this code for node `hello-14` executes without returning an error and produces the output not intended by the initial version of the test:
``` YAML
hello-14:
type: hello_type
properties:
time: "1"
requirements:
- host: my-workstation
- dependency1: hello-1
- dependency2: hello-2
- dependency7: hello-7
- dependency13: hello-13
```
## Current behavior
Currently, opera executes the test without taking into account the undefined `dependency1` requirement in which will be addressed in a separate issue.
When defining dependencies for node `hello-14` as in the initially intended test:
``` YAML
hello-14:
type: hello_type
properties:
time: "1"
requirements:
- host: my-workstation
- dependency: hello-1
- dependency: hello-2
- dependency: hello-7
- dependency: hello-13
```
opera produces the correct outputs.
## Expected results
The execution of the corrected test should produce this output:
```
[Worker_0] Deploying my-workstation_0
[Worker_0] Deployment of my-workstation_0 complete
[Worker_0] Deploying hello-1_0
[Worker_0] Executing create on hello-1_0
[Worker_2] Deploying hello-2_0
[Worker_3] Deploying hello-3_0
[Worker_4] Deploying hello-4_0
[Worker_5] Deploying hello-8_0
[Worker_6] Deploying hello-9_0
[Worker_7] Deploying hello-10_0
[Worker_4] Executing create on hello-4_0
[Worker_2] Executing create on hello-2_0
[Worker_5] Executing create on hello-8_0
[Worker_3] Executing create on hello-3_0
[Worker_6] Executing create on hello-9_0
[Worker_7] Executing create on hello-10_0
[Worker_4] Executing start on hello-4_0
[Worker_3] Executing start on hello-3_0
[Worker_6] Executing start on hello-9_0
[Worker_7] Executing start on hello-10_0
[Worker_3] Deployment of hello-3_0 complete
[Worker_1] Deploying hello-12_0
[Worker_1] Executing create on hello-12_0
[Worker_4] Deployment of hello-4_0 complete
[Worker_3] Deploying hello-13_0
[Worker_3] Executing create on hello-13_0
[Worker_6] Deployment of hello-9_0 complete
[Worker_5] Executing start on hello-8_0
[Worker_2] Executing start on hello-2_0
[Worker_0] Executing start on hello-1_0
[Worker_1] Executing start on hello-12_0
[Worker_7] Deployment of hello-10_0 complete
[Worker_3] Executing start on hello-13_0
[Worker_1] Deployment of hello-12_0 complete
[Worker_3] Deployment of hello-13_0 complete
[Worker_2] Deployment of hello-2_0 complete
[Worker_0] Deployment of hello-1_0 complete
[Worker_8] Deploying hello-5_0
[Worker_4] Deploying hello-11_0
[Worker_5] Deployment of hello-8_0 complete
[Worker_4] Executing create on hello-11_0
[Worker_8] Executing create on hello-5_0
[Worker_4] Executing start on hello-11_0
[Worker_8] Executing start on hello-5_0
[Worker_8] Deployment of hello-5_0 complete
[Worker_4] Deployment of hello-11_0 complete
[Worker_4] Deploying hello-6_0
[Worker_4] Executing create on hello-6_0
[Worker_4] Executing start on hello-6_0
[Worker_4] Deployment of hello-6_0 complete
[Worker_6] Deploying hello-7_0
[Worker_6] Executing create on hello-7_0
[Worker_6] Executing start on hello-7_0
[Worker_6] Deployment of hello-7_0 complete
[Worker_7] Deploying hello-14_0
[Worker_7] Executing create on hello-14_0
[Worker_7] Executing start on hello-14_0
[Worker_7] Deployment of hello-14_0 complete
``` | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/opera/parser/test_tosca.py::TestExecute::test_undeclared_requirements"
] | [
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_load_minimal_document",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_empty_document_is_invalid",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ0]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ1]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ2]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ3]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ4]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ5]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ6]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ7]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ0]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ1]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ2]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ3]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ4]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ5]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ6]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ7]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_loads_template_part",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_load_from_csar_subfolder",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_duplicate_import",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_imports_from_multiple_levels",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_merge_topology_template",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_merge_duplicate_node_templates_invalid",
"tests/unit/opera/parser/test_tosca.py::TestExecute::test_undefined_required_properties1",
"tests/unit/opera/parser/test_tosca.py::TestExecute::test_undefined_required_properties2",
"tests/unit/opera/parser/test_tosca.py::TestExecute::test_undefined_required_properties3"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_many_modified_files",
"has_pytest_match_arg"
],
"has_test_patch": true,
"is_lite": false
} | "2021-05-12T14:12:15Z" | apache-2.0 |
|
xlab-si__xopera-opera-52 | diff --git a/src/opera/parser/tosca/v_1_3/topology_template.py b/src/opera/parser/tosca/v_1_3/topology_template.py
index 1af5075..ce17793 100644
--- a/src/opera/parser/tosca/v_1_3/topology_template.py
+++ b/src/opera/parser/tosca/v_1_3/topology_template.py
@@ -64,3 +64,20 @@ class TopologyTemplate(Entity):
),
) for name, definition in self.get("outputs", {}).items()
}
+
+ def merge(self, other):
+ for key in (
+ "inputs",
+ "node_templates",
+ "data_types",
+ "relationship_templates",
+ "groups",
+ "policies",
+ "outputs"
+ ):
+ if key not in other.data:
+ continue
+ if key in self.data:
+ self.data[key].merge(other.data[key])
+ else:
+ self.data[key] = other.data[key]
| xlab-si/xopera-opera | ffe72a4dce9ac24f33304582577fed7b56ae34cd | diff --git a/tests/unit/opera/parser/test_tosca.py b/tests/unit/opera/parser/test_tosca.py
index 88741eb..15607c7 100644
--- a/tests/unit/opera/parser/test_tosca.py
+++ b/tests/unit/opera/parser/test_tosca.py
@@ -140,3 +140,68 @@ class TestLoad:
))
tosca.load(tmp_path, name)
+
+ def test_merge_topology_template(self, tmp_path, yaml_text):
+ name = pathlib.PurePath("template.yaml")
+ (tmp_path / name).write_text(yaml_text(
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ imports:
+ - merge.yaml
+ topology_template:
+ inputs:
+ some-input:
+ type: string
+ node_templates:
+ my_node:
+ type: tosca.nodes.SoftwareComponent
+ """
+ ))
+ (tmp_path / "merge.yaml").write_text(yaml_text(
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ topology_template:
+ inputs:
+ other-input:
+ type: string
+ node_templates:
+ other_node:
+ type: tosca.nodes.SoftwareComponent
+ """
+ ))
+ tosca.load(tmp_path, name)
+
+ def test_merge_duplicate_node_templates_invalid(self, tmp_path, yaml_text):
+ name = pathlib.PurePath("template.yaml")
+ (tmp_path / name).write_text(yaml_text(
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ imports:
+ - merge1.yaml
+ - merge2.yaml
+ topology_template:
+ node_templates:
+ my_node:
+ type: tosca.nodes.SoftwareComponent
+ """
+ ))
+ (tmp_path / "merge1.yaml").write_text(yaml_text(
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ topology_template:
+ node_templates:
+ other_node:
+ type: tosca.nodes.SoftwareComponent
+ """
+ ))
+ (tmp_path / "merge2.yaml").write_text(yaml_text(
+ """
+ tosca_definitions_version: tosca_simple_yaml_1_3
+ topology_template:
+ node_templates:
+ other_node:
+ type: tosca.nodes.SoftwareComponent
+ """
+ ))
+ with pytest.raises(ParseError):
+ tosca.load(tmp_path, name)
\ No newline at end of file
| node_templates section defined in imported service templates
## Description
In some cases, it would be useful to import a service template that already contains some node_templates defined. For example, in a situation, when a service template describing existing infastruture that cannot be modified externally (e.g. HPC nodes) is automatically generated by some service and later imported into other templates.
## Prerequisites
- `opera` installed
- A valid TOSCA Service Template file `service.yaml` that contains an import definition of another valid TOSCA Service Template file with **topology_template** and **node_templates** sections defined.
## Steps
- User runs deploy `opera deploy service.yaml`
## Current behaviour
- xOpera returns an error `Duplicate keys 'node_templates' found in service.yml`
## Expected behavior
- Service template is deployed without error.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_merge_topology_template"
] | [
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_load_minimal_document",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_empty_document_is_invalid",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ0]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ1]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ2]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ3]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ4]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ5]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ6]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_stdlib_is_present[typ7]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ0]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ1]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ2]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ3]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ4]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ5]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ6]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_custom_type_is_present[typ7]",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_loads_template_part",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_load_from_csar_subfolder",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_duplicate_import",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_imports_from_multiple_levels",
"tests/unit/opera/parser/test_tosca.py::TestLoad::test_merge_duplicate_node_templates_invalid"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2020-06-03T12:47:35Z" | apache-2.0 |
|
xlab-si__xopera-opera-76 | diff --git a/src/opera/parser/yaml/constructor.py b/src/opera/parser/yaml/constructor.py
index 464b4fa..154526a 100644
--- a/src/opera/parser/yaml/constructor.py
+++ b/src/opera/parser/yaml/constructor.py
@@ -1,4 +1,5 @@
from yaml.constructor import BaseConstructor, ConstructorError
+from collections import Counter
from opera.parser.utils.location import Location
@@ -56,6 +57,14 @@ class Constructor(BaseConstructor):
data = Node({}, self._pos(node))
yield data
data.value.update(self.construct_mapping(node))
+ counts = Counter(n.bare for n in data.value)
+ duplicates = [k for k, v in counts.items() if v > 1]
+ if duplicates:
+ raise ConstructorError(
+ None, None,
+ "Duplicate map names: {}".format(', '.join(duplicates)),
+ node.start_mark,
+ )
def construct_undefined(self, node):
raise ConstructorError(
| xlab-si/xopera-opera | 5437501466c3a18ef4a5c53cb6ce35ae9f726fe7 | diff --git a/tests/unit/opera/parser/yaml/test_constructor.py b/tests/unit/opera/parser/yaml/test_constructor.py
index cec2c01..ee88892 100644
--- a/tests/unit/opera/parser/yaml/test_constructor.py
+++ b/tests/unit/opera/parser/yaml/test_constructor.py
@@ -3,6 +3,7 @@ import math
import pytest
from yaml.error import Mark
from yaml.nodes import MappingNode, ScalarNode, SequenceNode
+from yaml.constructor import ConstructorError
from opera.parser.yaml.constructor import Constructor
@@ -138,3 +139,19 @@ class TestNull:
assert res.loc.line == 9
assert res.loc.column == 9
assert res.loc.stream_name == "map"
+
+ def test_construct_map_duplicate(self):
+ mark = Mark(None, None, 8, 8, None, None)
+ children = [
+ (
+ ScalarNode("tag:yaml.org,2002:str", "node1", start_mark=mark),
+ ScalarNode("tag:yaml.org,2002:str", "node1", start_mark=mark),
+ ),
+ (
+ ScalarNode("tag:yaml.org,2002:str", "node1", start_mark=mark),
+ ScalarNode("tag:yaml.org,2002:str", "node1", start_mark=mark),
+ )
+ ]
+ node = MappingNode("tag:yaml.org,2002:map", children, start_mark=mark)
+ with pytest.raises(ConstructorError):
+ res, = Constructor("map").construct_yaml_map(node)
| Duplicate node_template names
## Description
If a service template has 2 node template with same node template names defined, one of them is omitted, and template execution proceeds without error. According to section **3.1.3.1 Additional Requirements**
> Duplicate Template names within a Service Template’s Topology Template SHALL be considered an error.
## Prerequisites
- `opera` installed
- `service.yaml` TOSCA Service Template containing 2 node templates with same name.
```
tosca_definitions_version: tosca_simple_yaml_1_3
topology_template:
node_templates:
node_1:
type: tosca.nodes.SoftwareComponent
node_1:
type: tosca.nodes.SoftwareComponent
```
## Steps
- User runs deploy `opera deploy service.yaml`
## Current behavior
- xOpera proceeds with deployment.
## Expected behavior
- xOpera returns a parser error. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_map_duplicate"
] | [
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_null[NULL]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_null[Null]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_null[null]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_null[~]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_null[]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[True-True]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[true-True]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[TRUE-True]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[False-False]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[false-False]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_bool_true[FALSE-False]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[1-1]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0-0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[100-100]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[987654-987654]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[-100--100]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[+100-100]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[00005-5]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[054-54]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0o1-1]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0o0-0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0o100-64]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0o765-501]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0o0000015-13]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0x1-1]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0x0-0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0x100-256]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0x90abc-592572]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_int[0xAaBbFdE-179027934]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+.inf-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-.inf--inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[.inf-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+.Inf-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-.Inf--inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[.Inf-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+.INF-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-.INF--inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[.INF-inf]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+.987-0.987]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-.765--0.765]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[.0987-0.0987]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+.6e-3-0.0006]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-.5E+2--50.0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[.4E32-4e+31]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+1.3-1.3]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-2.4--2.4]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[3.5-3.5]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+1.3E-3-0.0013]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-2.42e+5--242000.0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[3.5e7-35000000.0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[+13E-3-0.013]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[-2e+5--200000.0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_no_nan[3E7-30000000.0]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_nan_only[.nan]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_nan_only[.NaN]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_float_nan_only[.NAN]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[abc]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[1.2.3]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[NaN]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[INF]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[.NAn]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[\\n]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[\\t]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[1",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[https://url]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[:bare]",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_str[multi\\n",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_seq",
"tests/unit/opera/parser/yaml/test_constructor.py::TestNull::test_construct_map"
] | {
"failed_lite_validators": [],
"has_test_patch": true,
"is_lite": true
} | "2020-07-22T09:51:34Z" | apache-2.0 |
|
xlwings__jsondiff-64 | diff --git a/.github/workflows/pr_check.yml b/.github/workflows/pr_check.yml
index aafc4f9..41155fb 100644
--- a/.github/workflows/pr_check.yml
+++ b/.github/workflows/pr_check.yml
@@ -19,7 +19,7 @@ jobs:
python-version: ${{ matrix.python-version }}
- name: Install Dependencies
run: |
- pip install -r dev-requirements.txt
+ pip install .[test]
- name: Run Tests
run: |
python -m pytest
diff --git a/dev-requirements.txt b/dev-requirements.txt
deleted file mode 100644
index 9a54149..0000000
--- a/dev-requirements.txt
+++ /dev/null
@@ -1,2 +0,0 @@
-hypothesis
-pytest
diff --git a/jsondiff/__init__.py b/jsondiff/__init__.py
index e2920c4..a3fdcc2 100644
--- a/jsondiff/__init__.py
+++ b/jsondiff/__init__.py
@@ -84,7 +84,7 @@ class CompactJsonDiffSyntax(object):
def emit_list_diff(self, a, b, s, inserted, changed, deleted):
if s == 0.0:
return {replace: b} if isinstance(b, dict) else b
- elif s == 1.0:
+ elif s == 1.0 and not (inserted or changed or deleted):
return {}
else:
d = changed
@@ -97,7 +97,7 @@ class CompactJsonDiffSyntax(object):
def emit_dict_diff(self, a, b, s, added, changed, removed):
if s == 0.0:
return {replace: b} if isinstance(b, dict) else b
- elif s == 1.0:
+ elif s == 1.0 and not (added or changed or removed):
return {}
else:
changed.update(added)
@@ -171,9 +171,9 @@ class ExplicitJsonDiffSyntax(object):
return d
def emit_list_diff(self, a, b, s, inserted, changed, deleted):
- if s == 0.0:
+ if s == 0.0 and not (inserted or changed or deleted):
return b
- elif s == 1.0:
+ elif s == 1.0 and not (inserted or changed or deleted):
return {}
else:
d = changed
@@ -184,9 +184,9 @@ class ExplicitJsonDiffSyntax(object):
return d
def emit_dict_diff(self, a, b, s, added, changed, removed):
- if s == 0.0:
+ if s == 0.0 and not (added or changed or removed):
return b
- elif s == 1.0:
+ elif s == 1.0 and not (added or changed or removed):
return {}
else:
d = {}
@@ -218,9 +218,9 @@ class SymmetricJsonDiffSyntax(object):
return d
def emit_list_diff(self, a, b, s, inserted, changed, deleted):
- if s == 0.0:
+ if s == 0.0 and not (inserted or changed or deleted):
return [a, b]
- elif s == 1.0:
+ elif s == 1.0 and not (inserted or changed or deleted):
return {}
else:
d = changed
@@ -231,9 +231,9 @@ class SymmetricJsonDiffSyntax(object):
return d
def emit_dict_diff(self, a, b, s, added, changed, removed):
- if s == 0.0:
+ if s == 0.0 and not (added or changed or removed):
return [a, b]
- elif s == 1.0:
+ elif s == 1.0 and not (added or changed or removed):
return {}
else:
d = changed
diff --git a/pyproject.toml b/pyproject.toml
new file mode 100644
index 0000000..3f46156
--- /dev/null
+++ b/pyproject.toml
@@ -0,0 +1,39 @@
+[build-system]
+requires = ["setuptools>=43.0.0", "wheel"]
+build-backend = "setuptools.build_meta"
+
+[project]
+name = "jsondiff"
+description = "Diff JSON and JSON-like structures in Python"
+dynamic = ["version"]
+readme = "README.rst"
+license= {file = "LICENSE" }
+requires-python = ">=3.8"
+authors = [
+ { name = "Zoomer Analytics LLC", email = "[email protected]"}
+]
+keywords = ['json', 'diff', 'diffing', 'difference', 'patch', 'delta', 'dict', 'LCS']
+classifiers = [
+ 'License :: OSI Approved :: MIT License',
+ 'Programming Language :: Python :: 3',
+]
+
+[project.optional-dependencies]
+test = [
+ "hypothesis",
+ "pytest"
+]
+
+[project.urls]
+"Homepage" = "https://github.com/xlwings/jsondiff"
+"Bug Tracker" = "https://github.com/xlwings/jsondiff/issues"
+
+[project.scripts]
+jdiff = "jsondiff.cli:main"
+
+[tool.setuptools.packages.find]
+include = ["jsondiff*"]
+exclude = ["tests*"]
+
+[tool.setuptools.dynamic]
+version = {attr = "jsondiff.__version__"}
diff --git a/setup.py b/setup.py
index 08a30dc..bf508c8 100644
--- a/setup.py
+++ b/setup.py
@@ -1,26 +1,4 @@
-import os
-import re
-from setuptools import setup, find_packages
+# Maintained for legacy compatibility
+from setuptools import setup
-with open(os.path.join(os.path.dirname(__file__), 'jsondiff', '__init__.py')) as f:
- version = re.compile(r".*__version__ = '(.*?)'", re.S).match(f.read()).group(1)
-
-setup(
- name='jsondiff',
- packages=find_packages(exclude=['tests']),
- version=version,
- description='Diff JSON and JSON-like structures in Python',
- author='Zoomer Analytics LLC',
- author_email='[email protected]',
- url='https://github.com/ZoomerAnalytics/jsondiff',
- keywords=['json', 'diff', 'diffing', 'difference', 'patch', 'delta', 'dict', 'LCS'],
- classifiers=[
- 'License :: OSI Approved :: MIT License',
- 'Programming Language :: Python :: 3',
- ],
- entry_points={
- 'console_scripts': [
- 'jdiff=jsondiff.cli:main'
- ]
- }
-)
+setup()
| xlwings/jsondiff | aa55a7f2fbce6d24f44e863ffc4db132d03b62ab | diff --git a/tests/test_jsondiff.py b/tests/test_jsondiff.py
index 8328ee9..2cbbc66 100644
--- a/tests/test_jsondiff.py
+++ b/tests/test_jsondiff.py
@@ -1,5 +1,6 @@
import sys
import unittest
+import pytest
from jsondiff import diff, replace, add, discard, insert, delete, update, JsonDiffer
@@ -134,3 +135,30 @@ class JsonDiffTests(unittest.TestCase):
self.fail('cannot diff long arrays')
finally:
sys.setrecursionlimit(r)
+
+
[email protected](
+ ("a", "b", "syntax", "expected"),
+ [
+ pytest.param([], [{"a": True}], "explicit", {insert: [(0, {"a": True})]},
+ id="issue59_"),
+ pytest.param([{"a": True}], [], "explicit", {delete: [0]},
+ id="issue59_"),
+ pytest.param([], [{"a": True}], "compact", [{"a": True}],
+ id="issue59_"),
+ pytest.param([{"a": True}], [], "compact", [],
+ id="issue59_"),
+ pytest.param([], [{"a": True}], "symmetric", {insert: [(0, {"a": True})]},
+ id="issue59_"),
+ pytest.param([{"a": True}], [], "symmetric", {delete: [(0, {"a": True})]},
+ id="issue59_"),
+ pytest.param({1: 2}, {5: 3}, "symmetric", {delete: {1: 2}, insert: {5: 3}},
+ id="issue36_"),
+ pytest.param({1: 2}, {5: 3}, "compact", {replace: {5: 3}},
+ id="issue36_"),
+ ],
+)
+class TestSpecificIssue:
+ def test_issue(self, a, b, syntax, expected):
+ actual = diff(a, b, syntax=syntax)
+ assert actual == expected
| No difference label if one of JSON is empty
Hi,
I did some tests with the library and I have a case scenario where one of the compared JSON is empty: { }. I am using syntax='explicit' and the diff returns me exactly the JSON that is not the one empty. My problem is that I would like it to return me something like:
```js
{
insert: ...
}
```
The "insert" tag is quite important during my parsing. | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_5]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_1]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_4]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_0]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue36_0]"
] | [
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue36_1]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_2]",
"tests/test_jsondiff.py::TestSpecificIssue::test_issue[issue59_3]",
"tests/test_jsondiff.py::JsonDiffTests::test_long_arrays",
"tests/test_jsondiff.py::JsonDiffTests::test_explicit_syntax",
"tests/test_jsondiff.py::JsonDiffTests::test_compact_syntax",
"tests/test_jsondiff.py::JsonDiffTests::test_dump",
"tests/test_jsondiff.py::JsonDiffTests::test_symmetric_syntax",
"tests/test_jsondiff.py::JsonDiffTests::test_a",
"tests/test_jsondiff.py::JsonDiffTests::test_marshal"
] | {
"failed_lite_validators": [
"has_added_files",
"has_removed_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2023-06-04T02:09:09Z" | mit |
|
xonsh__xonsh-3772 | diff --git a/news/simple-variables.rst b/news/simple-variables.rst
index 3b1d6478..0592b11f 100644
--- a/news/simple-variables.rst
+++ b/news/simple-variables.rst
@@ -1,7 +1,7 @@
**Added:**
* Xonsh now supports bash-style variable assignments preceding
- subprocess commands (e.g. ``$FOO = "bar" bash -c r"echo $FOO"``).
+ subprocess commands (e.g. ``$FOO="bar" bash -c r"echo $FOO"``).
**Changed:**
diff --git a/xonsh/parsers/base.py b/xonsh/parsers/base.py
index 2b6ce18e..63d7a82d 100644
--- a/xonsh/parsers/base.py
+++ b/xonsh/parsers/base.py
@@ -3325,11 +3325,7 @@ class BaseParser(object):
p[0] = ast.Str(s=p1.value, lineno=p1.lineno, col_offset=p1.lexpos)
def p_envvar_assign_left(self, p):
- """envvar_assign_left : dollar_name_tok EQUALS
- | dollar_name_tok WS EQUALS
- | dollar_name_tok EQUALS WS
- | dollar_name_tok WS EQUALS WS
- """
+ """envvar_assign_left : dollar_name_tok EQUALS"""
p[0] = p[1]
def p_envvar_assign(self, p):
| xonsh/xonsh | f23e9195a0ac174e0db953b8e6604863858f8e88 | diff --git a/tests/test_parser.py b/tests/test_parser.py
index 53f5a4cd..67de9208 100644
--- a/tests/test_parser.py
+++ b/tests/test_parser.py
@@ -2240,6 +2240,10 @@ def test_bang_ls_envvar_listval():
check_xonsh_ast({"WAKKA": [".", "."]}, "!(ls $WAKKA)", False)
+def test_bang_envvar_args():
+ check_xonsh_ast({"LS": "ls"}, "!($LS .)", False)
+
+
def test_question():
check_xonsh_ast({}, "range?")
@@ -2502,7 +2506,7 @@ def test_ls_quotes_3_space():
def test_leading_envvar_assignment():
- check_xonsh_ast({}, "![$FOO= 'foo' $BAR =2 echo r'$BAR']", False)
+ check_xonsh_ast({}, "![$FOO='foo' $BAR=2 echo r'$BAR']", False)
def test_echo_comma():
| conda init error
Hi! Xonsh is super cool! I'm happy every time I'm writing xonshrc!
Today I tried to install master and got an error with conda init:
```bash
pip install -U git+https://github.com/xonsh/xonsh
xonfig
+------------------+----------------------+
| xonsh | 0.9.21.dev31 |
| Git SHA | d42b4140 |
```
```
cat ~/.xonshrc
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
import sys as _sys
from types import ModuleType as _ModuleType
_mod = _ModuleType("xontrib.conda",
"Autogenerated from $(/opt/miniconda/bin/conda shell.xonsh hook)")
__xonsh__.execer.exec($("/opt/miniconda/bin/conda" "shell.xonsh" "hook"),
glbs=_mod.__dict__,
filename="$(/opt/miniconda/bin/conda shell.xonsh hook)")
_sys.modules["xontrib.conda"] = _mod
del _sys, _mod, _ModuleType
# <<< conda initialize <<<
```
```
xonsh
Traceback (most recent call last):
File "/opt/miniconda/lib/python3.8/site-packages/xonsh/proc.py", line 1737, in wait
r = self.f(self.args, stdin, stdout, stderr, spec, spec.stack)
File "/opt/miniconda/lib/python3.8/site-packages/xonsh/proc.py", line 1232, in proxy_two
return f(args, stdin)
File "/opt/miniconda/lib/python3.8/site-packages/xonsh/aliases.py", line 583, in source_alias
print_color(
File "/opt/miniconda/lib/python3.8/site-packages/xonsh/tools.py", line 1768, in print_color
builtins.__xonsh__.shell.shell.print_color(string, **kwargs)
AttributeError: 'NoneType' object has no attribute 'shell'
xonsh>
```
How I can fix this?
Thanks!
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_parser.py::test_bang_envvar_args"
] | [
"tests/test_parser.py::test_int_literal",
"tests/test_parser.py::test_int_literal_underscore",
"tests/test_parser.py::test_float_literal",
"tests/test_parser.py::test_float_literal_underscore",
"tests/test_parser.py::test_imag_literal",
"tests/test_parser.py::test_float_imag_literal",
"tests/test_parser.py::test_complex",
"tests/test_parser.py::test_str_literal",
"tests/test_parser.py::test_bytes_literal",
"tests/test_parser.py::test_raw_literal",
"tests/test_parser.py::test_f_literal",
"tests/test_parser.py::test_fstring_adaptor[f\"$HOME\"-$HOME]",
"tests/test_parser.py::test_fstring_adaptor[f\"{0}",
"tests/test_parser.py::test_fstring_adaptor[f\"{'$HOME'}\"-$HOME]",
"tests/test_parser.py::test_raw_bytes_literal",
"tests/test_parser.py::test_unary_plus",
"tests/test_parser.py::test_unary_minus",
"tests/test_parser.py::test_unary_invert",
"tests/test_parser.py::test_binop_plus",
"tests/test_parser.py::test_binop_minus",
"tests/test_parser.py::test_binop_times",
"tests/test_parser.py::test_binop_matmult",
"tests/test_parser.py::test_binop_div",
"tests/test_parser.py::test_binop_mod",
"tests/test_parser.py::test_binop_floordiv",
"tests/test_parser.py::test_binop_pow",
"tests/test_parser.py::test_plus_pow",
"tests/test_parser.py::test_plus_plus",
"tests/test_parser.py::test_plus_minus",
"tests/test_parser.py::test_minus_plus",
"tests/test_parser.py::test_minus_minus",
"tests/test_parser.py::test_minus_plus_minus",
"tests/test_parser.py::test_times_plus",
"tests/test_parser.py::test_plus_times",
"tests/test_parser.py::test_times_times",
"tests/test_parser.py::test_times_div",
"tests/test_parser.py::test_times_div_mod",
"tests/test_parser.py::test_times_div_mod_floor",
"tests/test_parser.py::test_str_str",
"tests/test_parser.py::test_str_str_str",
"tests/test_parser.py::test_str_plus_str",
"tests/test_parser.py::test_str_times_int",
"tests/test_parser.py::test_int_times_str",
"tests/test_parser.py::test_group_plus_times",
"tests/test_parser.py::test_plus_group_times",
"tests/test_parser.py::test_group",
"tests/test_parser.py::test_lt",
"tests/test_parser.py::test_gt",
"tests/test_parser.py::test_eq",
"tests/test_parser.py::test_le",
"tests/test_parser.py::test_ge",
"tests/test_parser.py::test_ne",
"tests/test_parser.py::test_in",
"tests/test_parser.py::test_is",
"tests/test_parser.py::test_not_in",
"tests/test_parser.py::test_is_not",
"tests/test_parser.py::test_lt_lt",
"tests/test_parser.py::test_lt_lt_lt",
"tests/test_parser.py::test_not",
"tests/test_parser.py::test_or",
"tests/test_parser.py::test_or_or",
"tests/test_parser.py::test_and",
"tests/test_parser.py::test_and_and",
"tests/test_parser.py::test_and_or",
"tests/test_parser.py::test_or_and",
"tests/test_parser.py::test_group_and_and",
"tests/test_parser.py::test_group_and_or",
"tests/test_parser.py::test_if_else_expr",
"tests/test_parser.py::test_if_else_expr_expr",
"tests/test_parser.py::test_str_idx",
"tests/test_parser.py::test_str_slice",
"tests/test_parser.py::test_str_step",
"tests/test_parser.py::test_str_slice_all",
"tests/test_parser.py::test_str_slice_upper",
"tests/test_parser.py::test_str_slice_lower",
"tests/test_parser.py::test_str_slice_other",
"tests/test_parser.py::test_str_slice_lower_other",
"tests/test_parser.py::test_str_slice_upper_other",
"tests/test_parser.py::test_list_empty",
"tests/test_parser.py::test_list_one",
"tests/test_parser.py::test_list_one_comma",
"tests/test_parser.py::test_list_two",
"tests/test_parser.py::test_list_three",
"tests/test_parser.py::test_list_three_comma",
"tests/test_parser.py::test_list_one_nested",
"tests/test_parser.py::test_list_list_four_nested",
"tests/test_parser.py::test_list_tuple_three_nested",
"tests/test_parser.py::test_list_set_tuple_three_nested",
"tests/test_parser.py::test_list_tuple_one_nested",
"tests/test_parser.py::test_tuple_tuple_one_nested",
"tests/test_parser.py::test_dict_list_one_nested",
"tests/test_parser.py::test_dict_list_one_nested_comma",
"tests/test_parser.py::test_dict_tuple_one_nested",
"tests/test_parser.py::test_dict_tuple_one_nested_comma",
"tests/test_parser.py::test_dict_list_two_nested",
"tests/test_parser.py::test_set_tuple_one_nested",
"tests/test_parser.py::test_set_tuple_two_nested",
"tests/test_parser.py::test_tuple_empty",
"tests/test_parser.py::test_tuple_one_bare",
"tests/test_parser.py::test_tuple_two_bare",
"tests/test_parser.py::test_tuple_three_bare",
"tests/test_parser.py::test_tuple_three_bare_comma",
"tests/test_parser.py::test_tuple_one_comma",
"tests/test_parser.py::test_tuple_two",
"tests/test_parser.py::test_tuple_three",
"tests/test_parser.py::test_tuple_three_comma",
"tests/test_parser.py::test_bare_tuple_of_tuples",
"tests/test_parser.py::test_set_one",
"tests/test_parser.py::test_set_one_comma",
"tests/test_parser.py::test_set_two",
"tests/test_parser.py::test_set_two_comma",
"tests/test_parser.py::test_set_three",
"tests/test_parser.py::test_dict_empty",
"tests/test_parser.py::test_dict_one",
"tests/test_parser.py::test_dict_one_comma",
"tests/test_parser.py::test_dict_two",
"tests/test_parser.py::test_dict_two_comma",
"tests/test_parser.py::test_dict_three",
"tests/test_parser.py::test_dict_from_dict_two_xy",
"tests/test_parser.py::test_dict_from_dict_two_x_first",
"tests/test_parser.py::test_dict_from_dict_two_x_second",
"tests/test_parser.py::test_unpack_range_tuple",
"tests/test_parser.py::test_unpack_range_tuple_4",
"tests/test_parser.py::test_unpack_range_tuple_parens",
"tests/test_parser.py::test_unpack_range_tuple_parens_4",
"tests/test_parser.py::test_unpack_range_list",
"tests/test_parser.py::test_unpack_range_list_4",
"tests/test_parser.py::test_unpack_range_set",
"tests/test_parser.py::test_unpack_range_set_4",
"tests/test_parser.py::test_true",
"tests/test_parser.py::test_false",
"tests/test_parser.py::test_none",
"tests/test_parser.py::test_elipssis",
"tests/test_parser.py::test_not_implemented_name",
"tests/test_parser.py::test_genexpr",
"tests/test_parser.py::test_genexpr_if",
"tests/test_parser.py::test_genexpr_if_and",
"tests/test_parser.py::test_dbl_genexpr",
"tests/test_parser.py::test_genexpr_if_genexpr",
"tests/test_parser.py::test_genexpr_if_genexpr_if",
"tests/test_parser.py::test_listcomp",
"tests/test_parser.py::test_listcomp_if",
"tests/test_parser.py::test_listcomp_if_and",
"tests/test_parser.py::test_listcomp_multi_if",
"tests/test_parser.py::test_dbl_listcomp",
"tests/test_parser.py::test_listcomp_if_listcomp",
"tests/test_parser.py::test_listcomp_if_listcomp_if",
"tests/test_parser.py::test_setcomp",
"tests/test_parser.py::test_setcomp_if",
"tests/test_parser.py::test_setcomp_if_and",
"tests/test_parser.py::test_dbl_setcomp",
"tests/test_parser.py::test_setcomp_if_setcomp",
"tests/test_parser.py::test_setcomp_if_setcomp_if",
"tests/test_parser.py::test_dictcomp",
"tests/test_parser.py::test_dictcomp_unpack_parens",
"tests/test_parser.py::test_dictcomp_unpack_no_parens",
"tests/test_parser.py::test_dictcomp_if",
"tests/test_parser.py::test_dictcomp_if_and",
"tests/test_parser.py::test_dbl_dictcomp",
"tests/test_parser.py::test_dictcomp_if_dictcomp",
"tests/test_parser.py::test_dictcomp_if_dictcomp_if",
"tests/test_parser.py::test_lambda",
"tests/test_parser.py::test_lambda_x",
"tests/test_parser.py::test_lambda_kwx",
"tests/test_parser.py::test_lambda_x_y",
"tests/test_parser.py::test_lambda_x_y_z",
"tests/test_parser.py::test_lambda_x_kwy",
"tests/test_parser.py::test_lambda_kwx_kwy",
"tests/test_parser.py::test_lambda_kwx_kwy_kwz",
"tests/test_parser.py::test_lambda_x_comma",
"tests/test_parser.py::test_lambda_x_y_comma",
"tests/test_parser.py::test_lambda_x_y_z_comma",
"tests/test_parser.py::test_lambda_x_kwy_comma",
"tests/test_parser.py::test_lambda_kwx_kwy_comma",
"tests/test_parser.py::test_lambda_kwx_kwy_kwz_comma",
"tests/test_parser.py::test_lambda_args",
"tests/test_parser.py::test_lambda_args_x",
"tests/test_parser.py::test_lambda_args_x_y",
"tests/test_parser.py::test_lambda_args_x_kwy",
"tests/test_parser.py::test_lambda_args_kwx_y",
"tests/test_parser.py::test_lambda_args_kwx_kwy",
"tests/test_parser.py::test_lambda_x_args",
"tests/test_parser.py::test_lambda_x_args_y",
"tests/test_parser.py::test_lambda_x_args_y_z",
"tests/test_parser.py::test_lambda_kwargs",
"tests/test_parser.py::test_lambda_x_kwargs",
"tests/test_parser.py::test_lambda_x_y_kwargs",
"tests/test_parser.py::test_lambda_x_kwy_kwargs",
"tests/test_parser.py::test_lambda_args_kwargs",
"tests/test_parser.py::test_lambda_x_args_kwargs",
"tests/test_parser.py::test_lambda_x_y_args_kwargs",
"tests/test_parser.py::test_lambda_kwx_args_kwargs",
"tests/test_parser.py::test_lambda_x_kwy_args_kwargs",
"tests/test_parser.py::test_lambda_x_args_y_kwargs",
"tests/test_parser.py::test_lambda_x_args_kwy_kwargs",
"tests/test_parser.py::test_lambda_args_y_kwargs",
"tests/test_parser.py::test_lambda_star_x",
"tests/test_parser.py::test_lambda_star_x_y",
"tests/test_parser.py::test_lambda_star_x_kwargs",
"tests/test_parser.py::test_lambda_star_kwx_kwargs",
"tests/test_parser.py::test_lambda_x_star_y",
"tests/test_parser.py::test_lambda_x_y_star_z",
"tests/test_parser.py::test_lambda_x_kwy_star_y",
"tests/test_parser.py::test_lambda_x_kwy_star_kwy",
"tests/test_parser.py::test_lambda_x_star_y_kwargs",
"tests/test_parser.py::test_lambda_x_divide_y_star_z_kwargs",
"tests/test_parser.py::test_call_range",
"tests/test_parser.py::test_call_range_comma",
"tests/test_parser.py::test_call_range_x_y",
"tests/test_parser.py::test_call_range_x_y_comma",
"tests/test_parser.py::test_call_range_x_y_z",
"tests/test_parser.py::test_call_dict_kwx",
"tests/test_parser.py::test_call_dict_kwx_comma",
"tests/test_parser.py::test_call_dict_kwx_kwy",
"tests/test_parser.py::test_call_tuple_gen",
"tests/test_parser.py::test_call_tuple_genifs",
"tests/test_parser.py::test_call_range_star",
"tests/test_parser.py::test_call_range_x_star",
"tests/test_parser.py::test_call_int",
"tests/test_parser.py::test_call_int_base_dict",
"tests/test_parser.py::test_call_dict_kwargs",
"tests/test_parser.py::test_call_list_many_star_args",
"tests/test_parser.py::test_call_list_many_starstar_args",
"tests/test_parser.py::test_call_list_many_star_and_starstar_args",
"tests/test_parser.py::test_call_alot",
"tests/test_parser.py::test_call_alot_next",
"tests/test_parser.py::test_call_alot_next_next",
"tests/test_parser.py::test_getattr",
"tests/test_parser.py::test_getattr_getattr",
"tests/test_parser.py::test_dict_tuple_key",
"tests/test_parser.py::test_pipe_op",
"tests/test_parser.py::test_pipe_op_two",
"tests/test_parser.py::test_pipe_op_three",
"tests/test_parser.py::test_xor_op",
"tests/test_parser.py::test_xor_op_two",
"tests/test_parser.py::test_xor_op_three",
"tests/test_parser.py::test_xor_pipe",
"tests/test_parser.py::test_amp_op",
"tests/test_parser.py::test_amp_op_two",
"tests/test_parser.py::test_amp_op_three",
"tests/test_parser.py::test_lshift_op",
"tests/test_parser.py::test_lshift_op_two",
"tests/test_parser.py::test_lshift_op_three",
"tests/test_parser.py::test_rshift_op",
"tests/test_parser.py::test_rshift_op_two",
"tests/test_parser.py::test_rshift_op_three",
"tests/test_parser.py::test_named_expr",
"tests/test_parser.py::test_named_expr_list",
"tests/test_parser.py::test_equals",
"tests/test_parser.py::test_equals_semi",
"tests/test_parser.py::test_x_y_equals_semi",
"tests/test_parser.py::test_equals_two",
"tests/test_parser.py::test_equals_two_semi",
"tests/test_parser.py::test_equals_three",
"tests/test_parser.py::test_equals_three_semi",
"tests/test_parser.py::test_plus_eq",
"tests/test_parser.py::test_sub_eq",
"tests/test_parser.py::test_times_eq",
"tests/test_parser.py::test_matmult_eq",
"tests/test_parser.py::test_div_eq",
"tests/test_parser.py::test_floordiv_eq",
"tests/test_parser.py::test_pow_eq",
"tests/test_parser.py::test_mod_eq",
"tests/test_parser.py::test_xor_eq",
"tests/test_parser.py::test_ampersand_eq",
"tests/test_parser.py::test_bitor_eq",
"tests/test_parser.py::test_lshift_eq",
"tests/test_parser.py::test_rshift_eq",
"tests/test_parser.py::test_bare_unpack",
"tests/test_parser.py::test_lhand_group_unpack",
"tests/test_parser.py::test_rhand_group_unpack",
"tests/test_parser.py::test_grouped_unpack",
"tests/test_parser.py::test_double_grouped_unpack",
"tests/test_parser.py::test_double_ungrouped_unpack",
"tests/test_parser.py::test_stary_eq",
"tests/test_parser.py::test_stary_x",
"tests/test_parser.py::test_tuple_x_stary",
"tests/test_parser.py::test_list_x_stary",
"tests/test_parser.py::test_bare_x_stary",
"tests/test_parser.py::test_bare_x_stary_z",
"tests/test_parser.py::test_equals_list",
"tests/test_parser.py::test_equals_dict",
"tests/test_parser.py::test_equals_attr",
"tests/test_parser.py::test_equals_annotation",
"tests/test_parser.py::test_dict_keys",
"tests/test_parser.py::test_assert_msg",
"tests/test_parser.py::test_assert",
"tests/test_parser.py::test_pass",
"tests/test_parser.py::test_del",
"tests/test_parser.py::test_del_comma",
"tests/test_parser.py::test_del_two",
"tests/test_parser.py::test_del_two_comma",
"tests/test_parser.py::test_del_with_parens",
"tests/test_parser.py::test_raise",
"tests/test_parser.py::test_raise_x",
"tests/test_parser.py::test_raise_x_from",
"tests/test_parser.py::test_import_x",
"tests/test_parser.py::test_import_xy",
"tests/test_parser.py::test_import_xyz",
"tests/test_parser.py::test_from_x_import_y",
"tests/test_parser.py::test_from_dot_import_y",
"tests/test_parser.py::test_from_dotx_import_y",
"tests/test_parser.py::test_from_dotdotx_import_y",
"tests/test_parser.py::test_from_dotdotdotx_import_y",
"tests/test_parser.py::test_from_dotdotdotdotx_import_y",
"tests/test_parser.py::test_from_import_x_y",
"tests/test_parser.py::test_from_import_x_y_z",
"tests/test_parser.py::test_from_dot_import_x_y",
"tests/test_parser.py::test_from_dot_import_x_y_z",
"tests/test_parser.py::test_from_dot_import_group_x_y",
"tests/test_parser.py::test_import_x_as_y",
"tests/test_parser.py::test_import_xy_as_z",
"tests/test_parser.py::test_import_x_y_as_z",
"tests/test_parser.py::test_import_x_as_y_z",
"tests/test_parser.py::test_import_x_as_y_z_as_a",
"tests/test_parser.py::test_from_dot_import_x_as_y",
"tests/test_parser.py::test_from_x_import_star",
"tests/test_parser.py::test_from_x_import_group_x_y_z",
"tests/test_parser.py::test_from_x_import_group_x_y_z_comma",
"tests/test_parser.py::test_from_x_import_y_as_z",
"tests/test_parser.py::test_from_x_import_y_as_z_a_as_b",
"tests/test_parser.py::test_from_dotx_import_y_as_z_a_as_b_c_as_d",
"tests/test_parser.py::test_continue",
"tests/test_parser.py::test_break",
"tests/test_parser.py::test_global",
"tests/test_parser.py::test_global_xy",
"tests/test_parser.py::test_nonlocal_x",
"tests/test_parser.py::test_nonlocal_xy",
"tests/test_parser.py::test_yield",
"tests/test_parser.py::test_yield_x",
"tests/test_parser.py::test_yield_x_comma",
"tests/test_parser.py::test_yield_x_y",
"tests/test_parser.py::test_return_x_starexpr",
"tests/test_parser.py::test_yield_from_x",
"tests/test_parser.py::test_return",
"tests/test_parser.py::test_return_x",
"tests/test_parser.py::test_return_x_comma",
"tests/test_parser.py::test_return_x_y",
"tests/test_parser.py::test_if_true",
"tests/test_parser.py::test_if_true_twolines",
"tests/test_parser.py::test_if_true_twolines_deindent",
"tests/test_parser.py::test_if_true_else",
"tests/test_parser.py::test_if_true_x",
"tests/test_parser.py::test_if_switch",
"tests/test_parser.py::test_if_switch_elif1_else",
"tests/test_parser.py::test_if_switch_elif2_else",
"tests/test_parser.py::test_if_nested",
"tests/test_parser.py::test_while",
"tests/test_parser.py::test_while_else",
"tests/test_parser.py::test_for",
"tests/test_parser.py::test_for_zip",
"tests/test_parser.py::test_for_idx",
"tests/test_parser.py::test_for_zip_idx",
"tests/test_parser.py::test_for_attr",
"tests/test_parser.py::test_for_zip_attr",
"tests/test_parser.py::test_for_else",
"tests/test_parser.py::test_async_for",
"tests/test_parser.py::test_with",
"tests/test_parser.py::test_with_as",
"tests/test_parser.py::test_with_xy",
"tests/test_parser.py::test_with_x_as_y_z",
"tests/test_parser.py::test_with_x_as_y_a_as_b",
"tests/test_parser.py::test_with_in_func",
"tests/test_parser.py::test_async_with",
"tests/test_parser.py::test_try",
"tests/test_parser.py::test_try_except_t",
"tests/test_parser.py::test_try_except_t_as_e",
"tests/test_parser.py::test_try_except_t_u",
"tests/test_parser.py::test_try_except_t_u_as_e",
"tests/test_parser.py::test_try_except_t_except_u",
"tests/test_parser.py::test_try_except_else",
"tests/test_parser.py::test_try_except_finally",
"tests/test_parser.py::test_try_except_else_finally",
"tests/test_parser.py::test_try_finally",
"tests/test_parser.py::test_func",
"tests/test_parser.py::test_func_ret",
"tests/test_parser.py::test_func_ret_42",
"tests/test_parser.py::test_func_ret_42_65",
"tests/test_parser.py::test_func_rarrow",
"tests/test_parser.py::test_func_x",
"tests/test_parser.py::test_func_kwx",
"tests/test_parser.py::test_func_x_y",
"tests/test_parser.py::test_func_x_y_z",
"tests/test_parser.py::test_func_x_kwy",
"tests/test_parser.py::test_func_kwx_kwy",
"tests/test_parser.py::test_func_kwx_kwy_kwz",
"tests/test_parser.py::test_func_x_comma",
"tests/test_parser.py::test_func_x_y_comma",
"tests/test_parser.py::test_func_x_y_z_comma",
"tests/test_parser.py::test_func_x_kwy_comma",
"tests/test_parser.py::test_func_kwx_kwy_comma",
"tests/test_parser.py::test_func_kwx_kwy_kwz_comma",
"tests/test_parser.py::test_func_args",
"tests/test_parser.py::test_func_args_x",
"tests/test_parser.py::test_func_args_x_y",
"tests/test_parser.py::test_func_args_x_kwy",
"tests/test_parser.py::test_func_args_kwx_y",
"tests/test_parser.py::test_func_args_kwx_kwy",
"tests/test_parser.py::test_func_x_args",
"tests/test_parser.py::test_func_x_args_y",
"tests/test_parser.py::test_func_x_args_y_z",
"tests/test_parser.py::test_func_kwargs",
"tests/test_parser.py::test_func_x_kwargs",
"tests/test_parser.py::test_func_x_y_kwargs",
"tests/test_parser.py::test_func_x_kwy_kwargs",
"tests/test_parser.py::test_func_args_kwargs",
"tests/test_parser.py::test_func_x_args_kwargs",
"tests/test_parser.py::test_func_x_y_args_kwargs",
"tests/test_parser.py::test_func_kwx_args_kwargs",
"tests/test_parser.py::test_func_x_kwy_args_kwargs",
"tests/test_parser.py::test_func_x_args_y_kwargs",
"tests/test_parser.py::test_func_x_args_kwy_kwargs",
"tests/test_parser.py::test_func_args_y_kwargs",
"tests/test_parser.py::test_func_star_x",
"tests/test_parser.py::test_func_star_x_y",
"tests/test_parser.py::test_func_star_x_kwargs",
"tests/test_parser.py::test_func_star_kwx_kwargs",
"tests/test_parser.py::test_func_x_star_y",
"tests/test_parser.py::test_func_x_y_star_z",
"tests/test_parser.py::test_func_x_kwy_star_y",
"tests/test_parser.py::test_func_x_kwy_star_kwy",
"tests/test_parser.py::test_func_x_star_y_kwargs",
"tests/test_parser.py::test_func_x_divide",
"tests/test_parser.py::test_func_x_divide_y_star_z_kwargs",
"tests/test_parser.py::test_func_tx",
"tests/test_parser.py::test_func_txy",
"tests/test_parser.py::test_class",
"tests/test_parser.py::test_class_obj",
"tests/test_parser.py::test_class_int_flt",
"tests/test_parser.py::test_class_obj_kw",
"tests/test_parser.py::test_decorator",
"tests/test_parser.py::test_decorator_2",
"tests/test_parser.py::test_decorator_call",
"tests/test_parser.py::test_decorator_call_args",
"tests/test_parser.py::test_decorator_dot_call_args",
"tests/test_parser.py::test_decorator_dot_dot_call_args",
"tests/test_parser.py::test_broken_prompt_func",
"tests/test_parser.py::test_class_with_methods",
"tests/test_parser.py::test_nested_functions",
"tests/test_parser.py::test_function_blank_line",
"tests/test_parser.py::test_async_func",
"tests/test_parser.py::test_async_decorator",
"tests/test_parser.py::test_async_await",
"tests/test_parser.py::test_named_expr_args",
"tests/test_parser.py::test_named_expr_if",
"tests/test_parser.py::test_named_expr_elif",
"tests/test_parser.py::test_named_expr_while",
"tests/test_parser.py::test_path_literal",
"tests/test_parser.py::test_path_fstring_literal",
"tests/test_parser.py::test_dollar_name",
"tests/test_parser.py::test_dollar_py",
"tests/test_parser.py::test_dollar_py_test",
"tests/test_parser.py::test_dollar_py_recursive_name",
"tests/test_parser.py::test_dollar_py_test_recursive_name",
"tests/test_parser.py::test_dollar_py_test_recursive_test",
"tests/test_parser.py::test_dollar_name_set",
"tests/test_parser.py::test_dollar_py_set",
"tests/test_parser.py::test_dollar_sub",
"tests/test_parser.py::test_dollar_sub_space",
"tests/test_parser.py::test_ls_dot",
"tests/test_parser.py::test_lambda_in_atparens",
"tests/test_parser.py::test_generator_in_atparens",
"tests/test_parser.py::test_bare_tuple_in_atparens",
"tests/test_parser.py::test_nested_madness",
"tests/test_parser.py::test_atparens_intoken",
"tests/test_parser.py::test_ls_dot_nesting",
"tests/test_parser.py::test_ls_dot_nesting_var",
"tests/test_parser.py::test_ls_dot_str",
"tests/test_parser.py::test_ls_nest_ls",
"tests/test_parser.py::test_ls_nest_ls_dashl",
"tests/test_parser.py::test_ls_envvar_strval",
"tests/test_parser.py::test_ls_envvar_listval",
"tests/test_parser.py::test_bang_sub",
"tests/test_parser.py::test_bang_sub_space",
"tests/test_parser.py::test_bang_ls_dot",
"tests/test_parser.py::test_bang_ls_dot_nesting",
"tests/test_parser.py::test_bang_ls_dot_nesting_var",
"tests/test_parser.py::test_bang_ls_dot_str",
"tests/test_parser.py::test_bang_ls_nest_ls",
"tests/test_parser.py::test_bang_ls_nest_ls_dashl",
"tests/test_parser.py::test_bang_ls_envvar_strval",
"tests/test_parser.py::test_bang_ls_envvar_listval",
"tests/test_parser.py::test_question",
"tests/test_parser.py::test_dobquestion",
"tests/test_parser.py::test_question_chain",
"tests/test_parser.py::test_ls_regex",
"tests/test_parser.py::test_backtick",
"tests/test_parser.py::test_ls_regex_octothorpe",
"tests/test_parser.py::test_ls_explicitregex",
"tests/test_parser.py::test_rbacktick",
"tests/test_parser.py::test_ls_explicitregex_octothorpe",
"tests/test_parser.py::test_ls_glob",
"tests/test_parser.py::test_gbacktick",
"tests/test_parser.py::test_pbacktrick",
"tests/test_parser.py::test_pgbacktick",
"tests/test_parser.py::test_prbacktick",
"tests/test_parser.py::test_ls_glob_octothorpe",
"tests/test_parser.py::test_ls_customsearch",
"tests/test_parser.py::test_custombacktick",
"tests/test_parser.py::test_ls_customsearch_octothorpe",
"tests/test_parser.py::test_injection",
"tests/test_parser.py::test_rhs_nested_injection",
"tests/test_parser.py::test_merged_injection",
"tests/test_parser.py::test_backtick_octothorpe",
"tests/test_parser.py::test_uncaptured_sub",
"tests/test_parser.py::test_hiddenobj_sub",
"tests/test_parser.py::test_slash_envarv_echo",
"tests/test_parser.py::test_echo_double_eq",
"tests/test_parser.py::test_bang_two_cmds_one_pipe",
"tests/test_parser.py::test_bang_three_cmds_two_pipes",
"tests/test_parser.py::test_bang_one_cmd_write",
"tests/test_parser.py::test_bang_one_cmd_append",
"tests/test_parser.py::test_bang_two_cmds_write",
"tests/test_parser.py::test_bang_two_cmds_append",
"tests/test_parser.py::test_bang_cmd_background",
"tests/test_parser.py::test_bang_cmd_background_nospace",
"tests/test_parser.py::test_bang_git_quotes_no_space",
"tests/test_parser.py::test_bang_git_quotes_space",
"tests/test_parser.py::test_bang_git_two_quotes_space",
"tests/test_parser.py::test_bang_git_two_quotes_space_space",
"tests/test_parser.py::test_bang_ls_quotes_3_space",
"tests/test_parser.py::test_two_cmds_one_pipe",
"tests/test_parser.py::test_three_cmds_two_pipes",
"tests/test_parser.py::test_two_cmds_one_and_brackets",
"tests/test_parser.py::test_three_cmds_two_ands",
"tests/test_parser.py::test_two_cmds_one_doubleamps",
"tests/test_parser.py::test_three_cmds_two_doubleamps",
"tests/test_parser.py::test_two_cmds_one_or",
"tests/test_parser.py::test_three_cmds_two_ors",
"tests/test_parser.py::test_two_cmds_one_doublepipe",
"tests/test_parser.py::test_three_cmds_two_doublepipe",
"tests/test_parser.py::test_one_cmd_write",
"tests/test_parser.py::test_one_cmd_append",
"tests/test_parser.py::test_two_cmds_write",
"tests/test_parser.py::test_two_cmds_append",
"tests/test_parser.py::test_cmd_background",
"tests/test_parser.py::test_cmd_background_nospace",
"tests/test_parser.py::test_git_quotes_no_space",
"tests/test_parser.py::test_git_quotes_space",
"tests/test_parser.py::test_git_two_quotes_space",
"tests/test_parser.py::test_git_two_quotes_space_space",
"tests/test_parser.py::test_ls_quotes_3_space",
"tests/test_parser.py::test_echo_comma",
"tests/test_parser.py::test_echo_internal_comma",
"tests/test_parser.py::test_comment_only",
"tests/test_parser.py::test_echo_slash_question",
"tests/test_parser.py::test_bad_quotes",
"tests/test_parser.py::test_redirect",
"tests/test_parser.py::test_use_subshell[![(cat)]]",
"tests/test_parser.py::test_use_subshell[![(cat;)]]",
"tests/test_parser.py::test_use_subshell[![(cd",
"tests/test_parser.py::test_use_subshell[![(echo",
"tests/test_parser.py::test_use_subshell[![(if",
"tests/test_parser.py::test_redirect_abspath[$[cat",
"tests/test_parser.py::test_redirect_abspath[$[(cat)",
"tests/test_parser.py::test_redirect_abspath[$[<",
"tests/test_parser.py::test_redirect_abspath[![<",
"tests/test_parser.py::test_redirect_output[]",
"tests/test_parser.py::test_redirect_output[o]",
"tests/test_parser.py::test_redirect_output[out]",
"tests/test_parser.py::test_redirect_output[1]",
"tests/test_parser.py::test_redirect_error[e]",
"tests/test_parser.py::test_redirect_error[err]",
"tests/test_parser.py::test_redirect_error[2]",
"tests/test_parser.py::test_redirect_all[a]",
"tests/test_parser.py::test_redirect_all[all]",
"tests/test_parser.py::test_redirect_all[&]",
"tests/test_parser.py::test_redirect_error_to_output[-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>&1]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>&2]",
"tests/test_parser.py::test_macro_call_empty",
"tests/test_parser.py::test_macro_call_one_arg[x]",
"tests/test_parser.py::test_macro_call_one_arg[True]",
"tests/test_parser.py::test_macro_call_one_arg[None]",
"tests/test_parser.py::test_macro_call_one_arg[import",
"tests/test_parser.py::test_macro_call_one_arg[x=10]",
"tests/test_parser.py::test_macro_call_one_arg[\"oh",
"tests/test_parser.py::test_macro_call_one_arg[...]",
"tests/test_parser.py::test_macro_call_one_arg[",
"tests/test_parser.py::test_macro_call_one_arg[if",
"tests/test_parser.py::test_macro_call_one_arg[{x:",
"tests/test_parser.py::test_macro_call_one_arg[{1,",
"tests/test_parser.py::test_macro_call_one_arg[(x,y)]",
"tests/test_parser.py::test_macro_call_one_arg[(x,",
"tests/test_parser.py::test_macro_call_one_arg[((x,",
"tests/test_parser.py::test_macro_call_one_arg[g()]",
"tests/test_parser.py::test_macro_call_one_arg[range(10)]",
"tests/test_parser.py::test_macro_call_one_arg[range(1,",
"tests/test_parser.py::test_macro_call_one_arg[()]",
"tests/test_parser.py::test_macro_call_one_arg[{}]",
"tests/test_parser.py::test_macro_call_one_arg[[]]",
"tests/test_parser.py::test_macro_call_one_arg[[1,",
"tests/test_parser.py::test_macro_call_one_arg[@(x)]",
"tests/test_parser.py::test_macro_call_one_arg[!(ls",
"tests/test_parser.py::test_macro_call_one_arg[![ls",
"tests/test_parser.py::test_macro_call_one_arg[$(ls",
"tests/test_parser.py::test_macro_call_one_arg[${x",
"tests/test_parser.py::test_macro_call_one_arg[$[ls",
"tests/test_parser.py::test_macro_call_one_arg[@$(which",
"tests/test_parser.py::test_macro_call_two_args[x-True]",
"tests/test_parser.py::test_macro_call_two_args[x-import",
"tests/test_parser.py::test_macro_call_two_args[x-\"oh",
"tests/test_parser.py::test_macro_call_two_args[x-",
"tests/test_parser.py::test_macro_call_two_args[x-{x:",
"tests/test_parser.py::test_macro_call_two_args[x-{1,",
"tests/test_parser.py::test_macro_call_two_args[x-(x,",
"tests/test_parser.py::test_macro_call_two_args[x-g()]",
"tests/test_parser.py::test_macro_call_two_args[x-range(1,",
"tests/test_parser.py::test_macro_call_two_args[x-{}]",
"tests/test_parser.py::test_macro_call_two_args[x-[1,",
"tests/test_parser.py::test_macro_call_two_args[x-!(ls",
"tests/test_parser.py::test_macro_call_two_args[x-$(ls",
"tests/test_parser.py::test_macro_call_two_args[x-$[ls",
"tests/test_parser.py::test_macro_call_two_args[None-True]",
"tests/test_parser.py::test_macro_call_two_args[None-import",
"tests/test_parser.py::test_macro_call_two_args[None-\"oh",
"tests/test_parser.py::test_macro_call_two_args[None-",
"tests/test_parser.py::test_macro_call_two_args[None-{x:",
"tests/test_parser.py::test_macro_call_two_args[None-{1,",
"tests/test_parser.py::test_macro_call_two_args[None-(x,",
"tests/test_parser.py::test_macro_call_two_args[None-g()]",
"tests/test_parser.py::test_macro_call_two_args[None-range(1,",
"tests/test_parser.py::test_macro_call_two_args[None-{}]",
"tests/test_parser.py::test_macro_call_two_args[None-[1,",
"tests/test_parser.py::test_macro_call_two_args[None-!(ls",
"tests/test_parser.py::test_macro_call_two_args[None-$(ls",
"tests/test_parser.py::test_macro_call_two_args[None-$[ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-True]",
"tests/test_parser.py::test_macro_call_two_args[x=10-import",
"tests/test_parser.py::test_macro_call_two_args[x=10-\"oh",
"tests/test_parser.py::test_macro_call_two_args[x=10-",
"tests/test_parser.py::test_macro_call_two_args[x=10-{x:",
"tests/test_parser.py::test_macro_call_two_args[x=10-{1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-(x,",
"tests/test_parser.py::test_macro_call_two_args[x=10-g()]",
"tests/test_parser.py::test_macro_call_two_args[x=10-range(1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-{}]",
"tests/test_parser.py::test_macro_call_two_args[x=10-[1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-!(ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-$(ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-$[ls",
"tests/test_parser.py::test_macro_call_two_args[...-True]",
"tests/test_parser.py::test_macro_call_two_args[...-import",
"tests/test_parser.py::test_macro_call_two_args[...-\"oh",
"tests/test_parser.py::test_macro_call_two_args[...-",
"tests/test_parser.py::test_macro_call_two_args[...-{x:",
"tests/test_parser.py::test_macro_call_two_args[...-{1,",
"tests/test_parser.py::test_macro_call_two_args[...-(x,",
"tests/test_parser.py::test_macro_call_two_args[...-g()]",
"tests/test_parser.py::test_macro_call_two_args[...-range(1,",
"tests/test_parser.py::test_macro_call_two_args[...-{}]",
"tests/test_parser.py::test_macro_call_two_args[...-[1,",
"tests/test_parser.py::test_macro_call_two_args[...-!(ls",
"tests/test_parser.py::test_macro_call_two_args[...-$(ls",
"tests/test_parser.py::test_macro_call_two_args[...-$[ls",
"tests/test_parser.py::test_macro_call_two_args[if",
"tests/test_parser.py::test_macro_call_two_args[{x:",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-True]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-import",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{x:",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-(x,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-g()]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{}]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-[1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[((x,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-True]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-import",
"tests/test_parser.py::test_macro_call_two_args[range(10)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[range(10)-",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{x:",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-(x,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-g()]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{}]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-[1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[range(10)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[range(10)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[()-True]",
"tests/test_parser.py::test_macro_call_two_args[()-import",
"tests/test_parser.py::test_macro_call_two_args[()-\"oh",
"tests/test_parser.py::test_macro_call_two_args[()-",
"tests/test_parser.py::test_macro_call_two_args[()-{x:",
"tests/test_parser.py::test_macro_call_two_args[()-{1,",
"tests/test_parser.py::test_macro_call_two_args[()-(x,",
"tests/test_parser.py::test_macro_call_two_args[()-g()]",
"tests/test_parser.py::test_macro_call_two_args[()-range(1,",
"tests/test_parser.py::test_macro_call_two_args[()-{}]",
"tests/test_parser.py::test_macro_call_two_args[()-[1,",
"tests/test_parser.py::test_macro_call_two_args[()-!(ls",
"tests/test_parser.py::test_macro_call_two_args[()-$(ls",
"tests/test_parser.py::test_macro_call_two_args[()-$[ls",
"tests/test_parser.py::test_macro_call_two_args[[]-True]",
"tests/test_parser.py::test_macro_call_two_args[[]-import",
"tests/test_parser.py::test_macro_call_two_args[[]-\"oh",
"tests/test_parser.py::test_macro_call_two_args[[]-",
"tests/test_parser.py::test_macro_call_two_args[[]-{x:",
"tests/test_parser.py::test_macro_call_two_args[[]-{1,",
"tests/test_parser.py::test_macro_call_two_args[[]-(x,",
"tests/test_parser.py::test_macro_call_two_args[[]-g()]",
"tests/test_parser.py::test_macro_call_two_args[[]-range(1,",
"tests/test_parser.py::test_macro_call_two_args[[]-{}]",
"tests/test_parser.py::test_macro_call_two_args[[]-[1,",
"tests/test_parser.py::test_macro_call_two_args[[]-!(ls",
"tests/test_parser.py::test_macro_call_two_args[[]-$(ls",
"tests/test_parser.py::test_macro_call_two_args[[]-$[ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-True]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-import",
"tests/test_parser.py::test_macro_call_two_args[@(x)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[@(x)-",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{x:",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-(x,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-g()]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{}]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-[1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[![ls",
"tests/test_parser.py::test_macro_call_two_args[${x",
"tests/test_parser.py::test_macro_call_two_args[@$(which",
"tests/test_parser.py::test_macro_call_three_args[x-True-None]",
"tests/test_parser.py::test_macro_call_three_args[x-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-True-if",
"tests/test_parser.py::test_macro_call_three_args[x-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-True-${x",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[x-",
"tests/test_parser.py::test_macro_call_three_args[x-{x:",
"tests/test_parser.py::test_macro_call_three_args[x-(x,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[x-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[x-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-{}-if",
"tests/test_parser.py::test_macro_call_three_args[x-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[x-$(ls",
"tests/test_parser.py::test_macro_call_three_args[x-@$(which",
"tests/test_parser.py::test_macro_call_three_args[import",
"tests/test_parser.py::test_macro_call_three_args[...-True-None]",
"tests/test_parser.py::test_macro_call_three_args[...-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-True-if",
"tests/test_parser.py::test_macro_call_three_args[...-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-True-${x",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[...-",
"tests/test_parser.py::test_macro_call_three_args[...-{x:",
"tests/test_parser.py::test_macro_call_three_args[...-(x,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[...-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[...-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-{}-if",
"tests/test_parser.py::test_macro_call_three_args[...-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[...-$(ls",
"tests/test_parser.py::test_macro_call_three_args[...-@$(which",
"tests/test_parser.py::test_macro_call_three_args[{x:",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{x:",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-(x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-$(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@$(which",
"tests/test_parser.py::test_macro_call_three_args[g()-True-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-True-if",
"tests/test_parser.py::test_macro_call_three_args[g()-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-True-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-",
"tests/test_parser.py::test_macro_call_three_args[g()-{x:",
"tests/test_parser.py::test_macro_call_three_args[g()-(x,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-if",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-$(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-@$(which",
"tests/test_parser.py::test_macro_call_three_args[()-True-None]",
"tests/test_parser.py::test_macro_call_three_args[()-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-True-if",
"tests/test_parser.py::test_macro_call_three_args[()-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-True-${x",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[()-",
"tests/test_parser.py::test_macro_call_three_args[()-{x:",
"tests/test_parser.py::test_macro_call_three_args[()-(x,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[()-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[()-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-{}-if",
"tests/test_parser.py::test_macro_call_three_args[()-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[()-$(ls",
"tests/test_parser.py::test_macro_call_three_args[()-@$(which",
"tests/test_parser.py::test_macro_call_three_args[[1,",
"tests/test_parser.py::test_macro_call_three_args[![ls",
"tests/test_parser.py::test_macro_call_three_args[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing[x]",
"tests/test_parser.py::test_macro_call_one_trailing[True]",
"tests/test_parser.py::test_macro_call_one_trailing[None]",
"tests/test_parser.py::test_macro_call_one_trailing[import",
"tests/test_parser.py::test_macro_call_one_trailing[x=10]",
"tests/test_parser.py::test_macro_call_one_trailing[\"oh",
"tests/test_parser.py::test_macro_call_one_trailing[...]",
"tests/test_parser.py::test_macro_call_one_trailing[",
"tests/test_parser.py::test_macro_call_one_trailing[if",
"tests/test_parser.py::test_macro_call_one_trailing[{x:",
"tests/test_parser.py::test_macro_call_one_trailing[{1,",
"tests/test_parser.py::test_macro_call_one_trailing[(x,y)]",
"tests/test_parser.py::test_macro_call_one_trailing[(x,",
"tests/test_parser.py::test_macro_call_one_trailing[((x,",
"tests/test_parser.py::test_macro_call_one_trailing[g()]",
"tests/test_parser.py::test_macro_call_one_trailing[range(10)]",
"tests/test_parser.py::test_macro_call_one_trailing[range(1,",
"tests/test_parser.py::test_macro_call_one_trailing[()]",
"tests/test_parser.py::test_macro_call_one_trailing[{}]",
"tests/test_parser.py::test_macro_call_one_trailing[[]]",
"tests/test_parser.py::test_macro_call_one_trailing[[1,",
"tests/test_parser.py::test_macro_call_one_trailing[@(x)]",
"tests/test_parser.py::test_macro_call_one_trailing[!(ls",
"tests/test_parser.py::test_macro_call_one_trailing[![ls",
"tests/test_parser.py::test_macro_call_one_trailing[$(ls",
"tests/test_parser.py::test_macro_call_one_trailing[${x",
"tests/test_parser.py::test_macro_call_one_trailing[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing[@$(which",
"tests/test_parser.py::test_macro_call_one_trailing_space[x]",
"tests/test_parser.py::test_macro_call_one_trailing_space[True]",
"tests/test_parser.py::test_macro_call_one_trailing_space[None]",
"tests/test_parser.py::test_macro_call_one_trailing_space[import",
"tests/test_parser.py::test_macro_call_one_trailing_space[x=10]",
"tests/test_parser.py::test_macro_call_one_trailing_space[\"oh",
"tests/test_parser.py::test_macro_call_one_trailing_space[...]",
"tests/test_parser.py::test_macro_call_one_trailing_space[",
"tests/test_parser.py::test_macro_call_one_trailing_space[if",
"tests/test_parser.py::test_macro_call_one_trailing_space[{x:",
"tests/test_parser.py::test_macro_call_one_trailing_space[{1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[(x,y)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[(x,",
"tests/test_parser.py::test_macro_call_one_trailing_space[((x,",
"tests/test_parser.py::test_macro_call_one_trailing_space[g()]",
"tests/test_parser.py::test_macro_call_one_trailing_space[range(10)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[range(1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[()]",
"tests/test_parser.py::test_macro_call_one_trailing_space[{}]",
"tests/test_parser.py::test_macro_call_one_trailing_space[[]]",
"tests/test_parser.py::test_macro_call_one_trailing_space[[1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[@(x)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[!(ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[![ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[$(ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[${x",
"tests/test_parser.py::test_macro_call_one_trailing_space[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[@$(which",
"tests/test_parser.py::test_empty_subprocbang[echo!-!(-)]",
"tests/test_parser.py::test_empty_subprocbang[echo!-$(-)]",
"tests/test_parser.py::test_empty_subprocbang[echo!-![-]]",
"tests/test_parser.py::test_empty_subprocbang[echo!-$[-]]",
"tests/test_parser.py::test_empty_subprocbang[echo",
"tests/test_parser.py::test_single_subprocbang[echo!x-!(-)]",
"tests/test_parser.py::test_single_subprocbang[echo!x-$(-)]",
"tests/test_parser.py::test_single_subprocbang[echo!x-![-]]",
"tests/test_parser.py::test_single_subprocbang[echo!x-$[-]]",
"tests/test_parser.py::test_single_subprocbang[echo",
"tests/test_parser.py::test_arg_single_subprocbang[echo",
"tests/test_parser.py::test_arg_single_subprocbang_nested[echo",
"tests/test_parser.py::test_many_subprocbang[echo!x",
"tests/test_parser.py::test_many_subprocbang[echo",
"tests/test_parser.py::test_many_subprocbang[timeit!",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-$[-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-$[-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-$[-]]",
"tests/test_parser.py::test_withbang_single_suite[pass\\n]",
"tests/test_parser.py::test_withbang_single_suite[x",
"tests/test_parser.py::test_withbang_single_suite[export",
"tests/test_parser.py::test_withbang_single_suite[with",
"tests/test_parser.py::test_withbang_as_single_suite[pass\\n]",
"tests/test_parser.py::test_withbang_as_single_suite[x",
"tests/test_parser.py::test_withbang_as_single_suite[export",
"tests/test_parser.py::test_withbang_as_single_suite[with",
"tests/test_parser.py::test_withbang_single_suite_trailing[pass\\n]",
"tests/test_parser.py::test_withbang_single_suite_trailing[x",
"tests/test_parser.py::test_withbang_single_suite_trailing[export",
"tests/test_parser.py::test_withbang_single_suite_trailing[with",
"tests/test_parser.py::test_withbang_single_simple[pass]",
"tests/test_parser.py::test_withbang_single_simple[x",
"tests/test_parser.py::test_withbang_single_simple[export",
"tests/test_parser.py::test_withbang_single_simple[[1,\\n",
"tests/test_parser.py::test_withbang_single_simple_opt[pass]",
"tests/test_parser.py::test_withbang_single_simple_opt[x",
"tests/test_parser.py::test_withbang_single_simple_opt[export",
"tests/test_parser.py::test_withbang_single_simple_opt[[1,\\n",
"tests/test_parser.py::test_withbang_as_many_suite[pass\\n]",
"tests/test_parser.py::test_withbang_as_many_suite[x",
"tests/test_parser.py::test_withbang_as_many_suite[export",
"tests/test_parser.py::test_withbang_as_many_suite[with",
"tests/test_parser.py::test_subproc_raw_str_literal",
"tests/test_parser.py::test_syntax_error_del_literal",
"tests/test_parser.py::test_syntax_error_del_constant",
"tests/test_parser.py::test_syntax_error_del_emptytuple",
"tests/test_parser.py::test_syntax_error_del_call",
"tests/test_parser.py::test_syntax_error_del_lambda",
"tests/test_parser.py::test_syntax_error_del_ifexp",
"tests/test_parser.py::test_syntax_error_del_comps[[i",
"tests/test_parser.py::test_syntax_error_del_comps[{i",
"tests/test_parser.py::test_syntax_error_del_comps[(i",
"tests/test_parser.py::test_syntax_error_del_comps[{k:v",
"tests/test_parser.py::test_syntax_error_del_ops[x",
"tests/test_parser.py::test_syntax_error_del_ops[-x]",
"tests/test_parser.py::test_syntax_error_del_cmp[x",
"tests/test_parser.py::test_syntax_error_lonely_del",
"tests/test_parser.py::test_syntax_error_assign_literal",
"tests/test_parser.py::test_syntax_error_assign_constant",
"tests/test_parser.py::test_syntax_error_assign_emptytuple",
"tests/test_parser.py::test_syntax_error_assign_call",
"tests/test_parser.py::test_syntax_error_assign_lambda",
"tests/test_parser.py::test_syntax_error_assign_ifexp",
"tests/test_parser.py::test_syntax_error_assign_comps[[i",
"tests/test_parser.py::test_syntax_error_assign_comps[{i",
"tests/test_parser.py::test_syntax_error_assign_comps[(i",
"tests/test_parser.py::test_syntax_error_assign_comps[{k:v",
"tests/test_parser.py::test_syntax_error_assign_ops[x",
"tests/test_parser.py::test_syntax_error_assign_ops[-x]",
"tests/test_parser.py::test_syntax_error_assign_cmp[x",
"tests/test_parser.py::test_syntax_error_augassign_literal",
"tests/test_parser.py::test_syntax_error_augassign_constant",
"tests/test_parser.py::test_syntax_error_augassign_emptytuple",
"tests/test_parser.py::test_syntax_error_augassign_call",
"tests/test_parser.py::test_syntax_error_augassign_lambda",
"tests/test_parser.py::test_syntax_error_augassign_ifexp",
"tests/test_parser.py::test_syntax_error_augassign_comps[[i",
"tests/test_parser.py::test_syntax_error_augassign_comps[{i",
"tests/test_parser.py::test_syntax_error_augassign_comps[(i",
"tests/test_parser.py::test_syntax_error_augassign_comps[{k:v",
"tests/test_parser.py::test_syntax_error_augassign_ops[x",
"tests/test_parser.py::test_syntax_error_augassign_ops[-x]",
"tests/test_parser.py::test_syntax_error_augassign_cmp[x",
"tests/test_parser.py::test_syntax_error_bar_kwonlyargs",
"tests/test_parser.py::test_syntax_error_bar_posonlyargs",
"tests/test_parser.py::test_syntax_error_bar_posonlyargs_no_comma",
"tests/test_parser.py::test_syntax_error_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_posonly_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_lambda_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_lambda_posonly_nondefault_follows_default"
] | {
"failed_lite_validators": [
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2020-09-16T12:58:56Z" | bsd-2-clause |
|
xonsh__xonsh-4218 | diff --git a/news/fix_aliases_infinite_loop.rst b/news/fix_aliases_infinite_loop.rst
new file mode 100644
index 00000000..60a5ab32
--- /dev/null
+++ b/news/fix_aliases_infinite_loop.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* Ability to call the tool by the name from callable alias with the same name without the infinite loop error.
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/procs/proxies.py b/xonsh/procs/proxies.py
index 4e9b100b..d9a5ff74 100644
--- a/xonsh/procs/proxies.py
+++ b/xonsh/procs/proxies.py
@@ -500,10 +500,16 @@ class ProcProxyThread(threading.Thread):
sp_stderr = sys.stderr
# run the function itself
try:
+ alias_stack = builtins.__xonsh__.env.get("__ALIAS_STACK", "")
+ if self.env.get("__ALIAS_NAME"):
+ alias_stack += ":" + self.env["__ALIAS_NAME"]
+
with STDOUT_DISPATCHER.register(sp_stdout), STDERR_DISPATCHER.register(
sp_stderr
), xt.redirect_stdout(STDOUT_DISPATCHER), xt.redirect_stderr(
STDERR_DISPATCHER
+ ), builtins.__xonsh__.env.swap(
+ __ALIAS_STACK=alias_stack
):
r = self.f(self.args, sp_stdin, sp_stdout, sp_stderr, spec, spec.stack)
except SystemExit as e:
diff --git a/xonsh/procs/specs.py b/xonsh/procs/specs.py
index 845c4e52..384edf71 100644
--- a/xonsh/procs/specs.py
+++ b/xonsh/procs/specs.py
@@ -355,6 +355,8 @@ class SubprocSpec:
# pure attrs
self.args = list(cmd)
self.alias = None
+ self.alias_name = None
+ self.alias_stack = builtins.__xonsh__.env.get("__ALIAS_STACK", "").split(":")
self.binary_loc = None
self.is_proxy = False
self.background = False
@@ -442,6 +444,7 @@ class SubprocSpec:
kwargs = {n: getattr(self, n) for n in self.kwnames}
self.prep_env(kwargs)
if callable(self.alias):
+ kwargs["env"]["__ALIAS_NAME"] = self.alias_name
p = self.cls(self.alias, self.cmd, **kwargs)
else:
self.prep_preexec_fn(kwargs, pipeline_group=pipeline_group)
@@ -589,17 +592,29 @@ class SubprocSpec:
def resolve_alias(self):
"""Sets alias in command, if applicable."""
cmd0 = self.cmd[0]
+
+ if cmd0 in self.alias_stack:
+ # Disabling the alias resolving to prevent infinite loop in call stack
+ # and futher using binary_loc to resolve the alias name.
+ self.alias = None
+ return
+
if callable(cmd0):
alias = cmd0
else:
alias = builtins.aliases.get(cmd0, None)
+ if alias is not None:
+ self.alias_name = cmd0
self.alias = alias
def resolve_binary_loc(self):
"""Sets the binary location"""
alias = self.alias
if alias is None:
- binary_loc = xenv.locate_binary(self.cmd[0])
+ cmd0 = self.cmd[0]
+ binary_loc = xenv.locate_binary(cmd0)
+ if binary_loc == cmd0 and cmd0 in self.alias_stack:
+ raise Exception(f'Recursive calls to "{cmd0}" alias.')
elif callable(alias):
binary_loc = None
else:
| xonsh/xonsh | 4dc08232e615a75a524fbf96f17402a7a5b353a5 | diff --git a/tests/test_integrations.py b/tests/test_integrations.py
index 9ade1fa8..fb125d28 100644
--- a/tests/test_integrations.py
+++ b/tests/test_integrations.py
@@ -472,15 +472,57 @@ a
),
]
+UNIX_TESTS = [
+ # testing alias stack: lambda function
+ (
+ """
+def _echo():
+ echo hello
+
+aliases['echo'] = _echo
+echo
+""",
+ "hello\n",
+ 0,
+ ),
+ # testing alias stack: ExecAlias
+ (
+ """
+aliases['echo'] = "echo @('hello')"
+echo
+""",
+ "hello\n",
+ 0,
+ ),
+ # testing alias stack: callable alias (ExecAlias) + no binary location + infinite loop
+ (
+ """
+aliases['first'] = "second @(1)"
+aliases['second'] = "first @(1)"
+first
+""",
+ lambda out: 'Recursive calls to "first" alias.' in out,
+ 0,
+ ),
+]
@skip_if_no_xonsh
@pytest.mark.parametrize("case", ALL_PLATFORMS)
def test_script(case):
script, exp_out, exp_rtn = case
out, err, rtn = run_xonsh(script)
- assert exp_out == out
+ if callable(exp_out):
+ assert exp_out(out)
+ else:
+ assert exp_out == out
assert exp_rtn == rtn
+@skip_if_no_xonsh
+@skip_if_on_windows
[email protected]("case", UNIX_TESTS)
+def test_unix_tests(case):
+ test_script(case)
+
ALL_PLATFORMS_STDERR = [
# test redirecting a function alias
| Infinite alias call
I'm trying to override 'ls' command to display dotfiles in my $DOTFILES directory.
This code goes into an endless loop because _ls function calls ls command and it calls _ls function.
```python
def _ls():
if $(pwd).rstrip(os.linesep) == $DOTFILES:
ls -Ga
else:
ls -G
aliases['ls'] = _ls
```
## xonfig
<details>
```
+------------------+---------------------+
| xonsh | 0.8.10 |
| Git SHA | 2cb42bdb |
| Commit Date | Feb 6 16:49:16 2019 |
| Python | 3.6.4 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | 2.0.7 |
| shell type | prompt_toolkit2 |
| pygments | 2.3.1 |
| on posix | True |
| on linux | False |
| on darwin | True |
| on windows | False |
| on cygwin | False |
| on msys2 | False |
| is superuser | False |
| default encoding | utf-8 |
| xonsh encoding | utf-8 |
| encoding errors | surrogateescape |
+------------------+---------------------+
```
</details>
## Current Behavior
<!--- Tell us what happens instead of the expected behavior -->
<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error
To enter debug mode, set the environment variableNSH_DEBUG=1` _before_ starting `xonsh`. `XO
On Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->
When I input "ls" command, the terminal freezes.
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_integrations.py::test_script[case21]",
"tests/test_integrations.py::test_unix_tests[case0]"
] | [
"tests/test_integrations.py::test_script[case0]",
"tests/test_integrations.py::test_script[case1]",
"tests/test_integrations.py::test_script[case2]",
"tests/test_integrations.py::test_script[case3]",
"tests/test_integrations.py::test_script[case4]",
"tests/test_integrations.py::test_script[case5]",
"tests/test_integrations.py::test_script[case6]",
"tests/test_integrations.py::test_script[case7]",
"tests/test_integrations.py::test_script[case8]",
"tests/test_integrations.py::test_script[case9]",
"tests/test_integrations.py::test_script[case10]",
"tests/test_integrations.py::test_script[case11]",
"tests/test_integrations.py::test_script[case12]",
"tests/test_integrations.py::test_script[case13]",
"tests/test_integrations.py::test_script[case14]",
"tests/test_integrations.py::test_script[case15]",
"tests/test_integrations.py::test_script[case16]",
"tests/test_integrations.py::test_script[case17]",
"tests/test_integrations.py::test_script[case18]",
"tests/test_integrations.py::test_script[case19]",
"tests/test_integrations.py::test_script[case20]",
"tests/test_integrations.py::test_unix_tests[case1]",
"tests/test_integrations.py::test_unix_tests[case2]",
"tests/test_integrations.py::test_script_stderr[case0]",
"tests/test_integrations.py::test_single_command_no_windows[pwd-None-<lambda>]",
"tests/test_integrations.py::test_single_command_no_windows[echo",
"tests/test_integrations.py::test_single_command_no_windows[ls",
"tests/test_integrations.py::test_single_command_no_windows[$FOO='foo'",
"tests/test_integrations.py::test_eof_syntax_error",
"tests/test_integrations.py::test_open_quote_syntax_error",
"tests/test_integrations.py::test_printfile",
"tests/test_integrations.py::test_printname",
"tests/test_integrations.py::test_sourcefile",
"tests/test_integrations.py::test_subshells[\\nwith",
"tests/test_integrations.py::test_redirect_out_to_file[pwd-<lambda>]",
"tests/test_integrations.py::test_pipe_between_subprocs[cat",
"tests/test_integrations.py::test_negative_exit_codes_fail",
"tests/test_integrations.py::test_ampersand_argument[echo",
"tests/test_integrations.py::test_single_command_return_code[sys.exit(0)-0]",
"tests/test_integrations.py::test_single_command_return_code[sys.exit(100)-100]",
"tests/test_integrations.py::test_single_command_return_code[sh",
"tests/test_integrations.py::test_argv0"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-04-03T15:43:05Z" | bsd-2-clause |
|
xonsh__xonsh-4221 | diff --git a/news/subproc_captured_print_stderr.rst b/news/subproc_captured_print_stderr.rst
new file mode 100644
index 00000000..0227acf6
--- /dev/null
+++ b/news/subproc_captured_print_stderr.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* Added XONSH_SUBPROC_CAPTURED_PRINT_STDERR environment variable to hide unwanted printing the stderr when using captured object.
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/environ.py b/xonsh/environ.py
index 3e499128..f1fa33b3 100644
--- a/xonsh/environ.py
+++ b/xonsh/environ.py
@@ -857,6 +857,10 @@ class GeneralSetting(Xettings):
"should cause an end to execution. This is less useful at a terminal. "
"The error that is raised is a ``subprocess.CalledProcessError``.",
)
+ XONSH_SUBPROC_CAPTURED_PRINT_STDERR = Var.with_default(
+ True,
+ "If ``True`` the stderr from captured subproc will be printed automatically.",
+ )
TERM = Var.no_default(
"str",
"TERM is sometimes set by the terminal emulator. This is used (when "
diff --git a/xonsh/procs/pipelines.py b/xonsh/procs/pipelines.py
index cfa5ad5d..351252d2 100644
--- a/xonsh/procs/pipelines.py
+++ b/xonsh/procs/pipelines.py
@@ -396,12 +396,16 @@ class CommandPipeline:
if self.stderr_postfix:
b += self.stderr_postfix
stderr_has_buffer = hasattr(sys.stderr, "buffer")
- # write bytes to std stream
- if stderr_has_buffer:
- sys.stderr.buffer.write(b)
- else:
- sys.stderr.write(b.decode(encoding=enc, errors=err))
- sys.stderr.flush()
+ show_stderr = self.captured != "object" or env.get(
+ "XONSH_SUBPROC_CAPTURED_PRINT_STDERR", True
+ )
+ if show_stderr:
+ # write bytes to std stream
+ if stderr_has_buffer:
+ sys.stderr.buffer.write(b)
+ else:
+ sys.stderr.write(b.decode(encoding=enc, errors=err))
+ sys.stderr.flush()
# save the raw bytes
self._raw_error = b
# do some munging of the line before we save it to the attr
| xonsh/xonsh | 16884fc605d185c0ae0a84e36cf762595aafc2e1 | diff --git a/tests/test_integrations.py b/tests/test_integrations.py
index de96da1c..e9b05e07 100644
--- a/tests/test_integrations.py
+++ b/tests/test_integrations.py
@@ -174,6 +174,22 @@ print(x.returncode)
"hallo on err\n1\n",
0,
),
+ # test captured streaming alias without stderr
+ (
+ """
+def _test_stream(args, stdin, stdout, stderr):
+ print('hallo on err', file=stderr)
+ print('hallo on out', file=stdout)
+ return 1
+
+aliases['test-stream'] = _test_stream
+with __xonsh__.env.swap(XONSH_SUBPROC_CAPTURED_PRINT_STDERR=False):
+ x = !(test-stream)
+ print(x.returncode)
+""",
+ "1\n",
+ 0,
+ ),
# test piping aliases
(
"""
| Captured object shows unwanted stderr
Hi!
Captured object shows unwanted stderr i.e. before object repr:
```python
cd /tmp
echo @("""
import sys
print('out', file=sys.stdout)
print('err', file=sys.stderr)
""") > ttt.py
r=!(python ttt.py) # No stdout, no stderr - good
!(python ttt.py) # stderr before object repr - bad
# err
# CommandPipeline(
# stdin=<_io.BytesIO object at 0x7f4c48b3c900>,
# stdout=<_io.BytesIO object at 0x7f4c48b3cdb0>,
# stderr=<_io.BytesIO object at 0x7f4c48b3c680>,
# pid=6314,
# returncode=0,
# args=['python', 'ttt.py'],
# alias=None,
# stdin_redirect=['<stdin>', 'r'],
# stdout_redirect=[10, 'wb'],
# stderr_redirect=[12, 'w'],
# timestamps=[1608146243.7313583, 1608146243.761544],
# executed_cmd=['python', 'ttt.py'],
# input='',
# output='out\n',
# errors='err\n'
# )
# Prepared by xontrib-hist-format
```
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_integrations.py::test_script[case6]"
] | [
"tests/test_integrations.py::test_script[case0]",
"tests/test_integrations.py::test_script[case1]",
"tests/test_integrations.py::test_script[case2]",
"tests/test_integrations.py::test_script[case3]",
"tests/test_integrations.py::test_script[case4]",
"tests/test_integrations.py::test_script[case7]",
"tests/test_integrations.py::test_script[case8]",
"tests/test_integrations.py::test_script[case9]",
"tests/test_integrations.py::test_script[case10]",
"tests/test_integrations.py::test_script[case11]",
"tests/test_integrations.py::test_script[case12]",
"tests/test_integrations.py::test_script[case13]",
"tests/test_integrations.py::test_script[case14]",
"tests/test_integrations.py::test_script[case15]",
"tests/test_integrations.py::test_script[case16]",
"tests/test_integrations.py::test_script[case17]",
"tests/test_integrations.py::test_script[case18]",
"tests/test_integrations.py::test_script[case19]",
"tests/test_integrations.py::test_script[case20]",
"tests/test_integrations.py::test_script[case21]",
"tests/test_integrations.py::test_script_stderr[case0]",
"tests/test_integrations.py::test_single_command_no_windows[pwd-None-<lambda>]",
"tests/test_integrations.py::test_single_command_no_windows[echo",
"tests/test_integrations.py::test_single_command_no_windows[ls",
"tests/test_integrations.py::test_single_command_no_windows[$FOO='foo'",
"tests/test_integrations.py::test_eof_syntax_error",
"tests/test_integrations.py::test_open_quote_syntax_error",
"tests/test_integrations.py::test_printfile",
"tests/test_integrations.py::test_printname",
"tests/test_integrations.py::test_sourcefile",
"tests/test_integrations.py::test_subshells[\\nwith",
"tests/test_integrations.py::test_redirect_out_to_file[pwd-<lambda>]",
"tests/test_integrations.py::test_pipe_between_subprocs[cat",
"tests/test_integrations.py::test_negative_exit_codes_fail",
"tests/test_integrations.py::test_ampersand_argument[echo",
"tests/test_integrations.py::test_single_command_return_code[sys.exit(0)-0]",
"tests/test_integrations.py::test_single_command_return_code[sys.exit(100)-100]",
"tests/test_integrations.py::test_single_command_return_code[sh",
"tests/test_integrations.py::test_argv0"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-04-04T10:20:17Z" | bsd-2-clause |
|
xonsh__xonsh-4400 | diff --git a/news/fix-jedi-path-completion.rst b/news/fix-jedi-path-completion.rst
new file mode 100644
index 00000000..8757b89d
--- /dev/null
+++ b/news/fix-jedi-path-completion.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* <news item>
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* ``Jedi`` completer doesn't complete paths with ``~``.
+
+**Security:**
+
+* <news item>
diff --git a/xontrib/jedi.py b/xontrib/jedi.py
index 1d860b82..49d99138 100644
--- a/xontrib/jedi.py
+++ b/xontrib/jedi.py
@@ -65,8 +65,8 @@ def complete_jedi(context: CompletionContext):
# if we're completing a possible command and the prefix contains a valid path, don't complete.
if context.command:
- path_parts = os.path.split(context.command.prefix)
- if len(path_parts) > 1 and os.path.isdir(os.path.join(*path_parts[:-1])):
+ path_dir = os.path.dirname(context.command.prefix)
+ if path_dir and os.path.isdir(os.path.expanduser(path_dir)):
return None
filter_func = get_filter_function()
| xonsh/xonsh | 65913462438ffe869efabd2ec5f7137ef85efaef | diff --git a/tests/xontribs/test_jedi.py b/tests/xontribs/test_jedi.py
index 0681e7fb..166ef200 100644
--- a/tests/xontribs/test_jedi.py
+++ b/tests/xontribs/test_jedi.py
@@ -253,6 +253,7 @@ def test_special_tokens(jedi_xontrib):
@skip_if_on_windows
def test_no_command_path_completion(jedi_xontrib, completion_context_parse):
assert jedi_xontrib.complete_jedi(completion_context_parse("./", 2)) is None
+ assert jedi_xontrib.complete_jedi(completion_context_parse("~/", 2)) is None
assert jedi_xontrib.complete_jedi(completion_context_parse("./e", 3)) is None
assert jedi_xontrib.complete_jedi(completion_context_parse("/usr/bin/", 9)) is None
assert (
| bare path completion
<!--- Provide a general summary of the issue in the Title above -->
<!--- If you have a question along the lines of "How do I do this Bash command in xonsh"
please first look over the Bash to Xonsh translation guide: https://xon.sh/bash_to_xsh.html
If you don't find an answer there, please do open an issue! -->
## xonfig
<details>
```
+------------------+----------------------+
| xonsh | 0.9.27 |
| Git SHA | bc3b4962 |
| Commit Date | Jun 11 12:27:29 2021 |
| Python | 3.9.5 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | 3.0.19 |
| shell type | prompt_toolkit |
| history backend | sqlite |
| pygments | 2.9.0 |
| on posix | True |
| on linux | True |
| distro | manjaro |
| on wsl | False |
| on darwin | False |
| on windows | False |
| on cygwin | False |
| on msys2 | False |
| is superuser | False |
| default encoding | utf-8 |
| xonsh encoding | utf-8 |
| encoding errors | surrogateescape |
| on jupyter | False |
| jupyter kernel | None |
| xontrib 1 | abbrevs |
| xontrib 2 | argcomplete |
| xontrib 3 | avox_poetry |
| xontrib 4 | back2dir |
| xontrib 5 | broot |
| xontrib 6 | cmd_done |
| xontrib 7 | commands |
| xontrib 8 | fzf-widgets |
| xontrib 9 | hist_navigator |
| xontrib 10 | jedi |
| xontrib 11 | powerline3 |
| xontrib 12 | prompt_ret_code |
| xontrib 13 | vox |
| xontrib 14 | voxapi |
+------------------+----------------------+
```
</details>
## Expected Behavior
<!--- Tell us what should happen -->
upon typing just the path, xonsh `cd` into that. auto-completion for this is not working.
## Current Behavior
<!--- Tell us what happens instead of the expected behavior -->
<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error
To enter debug mode, set the environment variable `XONSH_DEBUG=1` _before_ starting `xonsh`.
On Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->
### Traceback (if applicable)
<details>
```
traceback
```
</details>
## Steps to Reproduce
<!--- Please try to write out a minimal reproducible snippet to trigger the bug, it will help us fix it! -->
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/xontribs/test_jedi.py::test_no_command_path_completion"
] | [
"tests/xontribs/test_jedi.py::test_completer_added",
"tests/xontribs/test_jedi.py::test_jedi_api[new-context0]",
"tests/xontribs/test_jedi.py::test_jedi_api[old-context0]",
"tests/xontribs/test_jedi.py::test_multiline",
"tests/xontribs/test_jedi.py::test_rich_completions[completion0-xx]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion1-xx]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion2-from_bytes]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion3-imag]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion4-bytes=]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion5-bytes=]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion6-collections]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion7-NameError]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion8-\"name\"]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion9-passwd\"]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion10-class]",
"tests/xontribs/test_jedi.py::test_special_tokens"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_media",
"has_added_files"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-28T21:13:37Z" | bsd-2-clause |
|
xonsh__xonsh-4401 | diff --git a/docs/keyboard_shortcuts.rst b/docs/keyboard_shortcuts.rst
index 5131a273..45ef7401 100644
--- a/docs/keyboard_shortcuts.rst
+++ b/docs/keyboard_shortcuts.rst
@@ -31,4 +31,6 @@ Xonsh comes pre-baked with a few keyboard shortcuts. The following is only avail
- Cut highlighted section
* - Ctrl-V *[Beta]*
- Paste clipboard contents
+ * - Ctrl-Right
+ - Complete a single auto-suggestion word
diff --git a/news/auto-suggest-word-alias.rst b/news/auto-suggest-word-alias.rst
new file mode 100644
index 00000000..045f4ea0
--- /dev/null
+++ b/news/auto-suggest-word-alias.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* Add ``CTRL-Right`` key binding to complete a single auto-suggestion word.
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/news/fix-jedi-path-completion.rst b/news/fix-jedi-path-completion.rst
new file mode 100644
index 00000000..8757b89d
--- /dev/null
+++ b/news/fix-jedi-path-completion.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* <news item>
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* ``Jedi`` completer doesn't complete paths with ``~``.
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/ptk_shell/key_bindings.py b/xonsh/ptk_shell/key_bindings.py
index 941c9d46..84598a44 100644
--- a/xonsh/ptk_shell/key_bindings.py
+++ b/xonsh/ptk_shell/key_bindings.py
@@ -208,9 +208,14 @@ def wrap_selection(buffer, left, right=None):
buffer.selection_state = selection_state
-def load_xonsh_bindings() -> KeyBindingsBase:
+def load_xonsh_bindings(ptk_bindings: KeyBindingsBase) -> KeyBindingsBase:
"""
Load custom key bindings.
+
+ Parameters
+ ----------
+ ptk_bindings :
+ The default prompt toolkit bindings. We need these to add aliases to them.
"""
key_bindings = KeyBindings()
handle = key_bindings.add
@@ -389,4 +394,12 @@ def load_xonsh_bindings() -> KeyBindingsBase:
buff.cut_selection()
get_by_name("yank").call(event)
+ def create_alias(new_keys, original_keys):
+ bindings = ptk_bindings.get_bindings_for_keys(tuple(original_keys))
+ for original_binding in bindings:
+ handle(*new_keys, filter=original_binding.filter)(original_binding.handler)
+
+ # Complete a single auto-suggestion word
+ create_alias([Keys.ControlRight], ["escape", "f"])
+
return key_bindings
diff --git a/xonsh/ptk_shell/shell.py b/xonsh/ptk_shell/shell.py
index f61ea789..459c0bab 100644
--- a/xonsh/ptk_shell/shell.py
+++ b/xonsh/ptk_shell/shell.py
@@ -207,7 +207,8 @@ class PromptToolkitShell(BaseShell):
self.prompt_formatter = PTKPromptFormatter(self.prompter)
self.pt_completer = PromptToolkitCompleter(self.completer, self.ctx, self)
- self.key_bindings = load_xonsh_bindings()
+ ptk_bindings = self.prompter.app.key_bindings
+ self.key_bindings = load_xonsh_bindings(ptk_bindings)
self._overrides_deprecation_warning_shown = False
# Store original `_history_matches` in case we need to restore it
diff --git a/xontrib/jedi.py b/xontrib/jedi.py
index 1d860b82..49d99138 100644
--- a/xontrib/jedi.py
+++ b/xontrib/jedi.py
@@ -65,8 +65,8 @@ def complete_jedi(context: CompletionContext):
# if we're completing a possible command and the prefix contains a valid path, don't complete.
if context.command:
- path_parts = os.path.split(context.command.prefix)
- if len(path_parts) > 1 and os.path.isdir(os.path.join(*path_parts[:-1])):
+ path_dir = os.path.dirname(context.command.prefix)
+ if path_dir and os.path.isdir(os.path.expanduser(path_dir)):
return None
filter_func = get_filter_function()
| xonsh/xonsh | 65913462438ffe869efabd2ec5f7137ef85efaef | diff --git a/tests/xontribs/test_jedi.py b/tests/xontribs/test_jedi.py
index 0681e7fb..166ef200 100644
--- a/tests/xontribs/test_jedi.py
+++ b/tests/xontribs/test_jedi.py
@@ -253,6 +253,7 @@ def test_special_tokens(jedi_xontrib):
@skip_if_on_windows
def test_no_command_path_completion(jedi_xontrib, completion_context_parse):
assert jedi_xontrib.complete_jedi(completion_context_parse("./", 2)) is None
+ assert jedi_xontrib.complete_jedi(completion_context_parse("~/", 2)) is None
assert jedi_xontrib.complete_jedi(completion_context_parse("./e", 3)) is None
assert jedi_xontrib.complete_jedi(completion_context_parse("/usr/bin/", 9)) is None
assert (
| fish-like partial suggestion completion
Xonsh already supports the fish-like suggestion completion, which is great. I.e., on a greyed suggestion, typing the right arrow completes with the full suggestion.
One thing I miss though is the fish partial suggestion completion. In fish, if I am right, when a suggestion is provided, typing "alt + right_arrow" completes the suggestion only until the next separator. Great to use parts of a suggestion only.
Any way a partial suggestion completion with alt + right_arrow is either already available, or could be added? :) . | 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/xontribs/test_jedi.py::test_no_command_path_completion"
] | [
"tests/xontribs/test_jedi.py::test_completer_added",
"tests/xontribs/test_jedi.py::test_jedi_api[new-context0]",
"tests/xontribs/test_jedi.py::test_jedi_api[old-context0]",
"tests/xontribs/test_jedi.py::test_multiline",
"tests/xontribs/test_jedi.py::test_rich_completions[completion0-xx]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion1-xx]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion2-from_bytes]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion3-imag]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion4-bytes=]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion5-bytes=]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion6-collections]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion7-NameError]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion8-\"name\"]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion9-passwd\"]",
"tests/xontribs/test_jedi.py::test_rich_completions[completion10-class]",
"tests/xontribs/test_jedi.py::test_special_tokens"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2021-07-28T22:30:26Z" | bsd-2-clause |
|
xonsh__xonsh-4673 | diff --git a/news/vox-add-prompt-arg.rst b/news/vox-add-prompt-arg.rst
new file mode 100644
index 00000000..e811eb6b
--- /dev/null
+++ b/news/vox-add-prompt-arg.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* vox new/create accepts a new ``--prompt`` argument, which is passed through to ``python -m venv``
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/news/vox-respect-prompt.rst b/news/vox-respect-prompt.rst
new file mode 100644
index 00000000..8837b7f9
--- /dev/null
+++ b/news/vox-respect-prompt.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* ``prompt.env.env_name`` is now aware of the "prompt" key in ``pyvenv.cfg`` - search order from first to last is: ``$VIRTUAL_ENV_PROMPT``, ``pyvenv.cfg``, ``$VIRTUAL_ENV``, $``CONDA_DEFAULT_ENV``
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/prompt/env.py b/xonsh/prompt/env.py
index fa6a9142..2edfd17c 100644
--- a/xonsh/prompt/env.py
+++ b/xonsh/prompt/env.py
@@ -1,42 +1,70 @@
"""Prompt formatter for virtualenv and others"""
-
-import os
+import functools
+import re
+from pathlib import Path
+from typing import Optional
from xonsh.built_ins import XSH
-def find_env_name():
- """Finds the current environment name from $VIRTUAL_ENV or
- $CONDA_DEFAULT_ENV if that is set.
+def find_env_name() -> Optional[str]:
+ """Find current environment name from available sources.
+
+ If ``$VIRTUAL_ENV`` is set, it is determined from the prompt setting in
+ ``<venv>/pyvenv.cfg`` or from the folder name of the environment.
+
+ Otherwise - if it is set - from ``$CONDA_DEFAULT_ENV``.
+ """
+ virtual_env = XSH.env.get("VIRTUAL_ENV")
+ if virtual_env:
+ name = _determine_env_name(virtual_env)
+ if name:
+ return name
+ conda_default_env = XSH.env.get("CONDA_DEFAULT_ENV")
+ if conda_default_env:
+ return conda_default_env
+
+
+def env_name() -> str:
+ """Build env_name based on different sources. Respect order of precedence.
+
+ Name from VIRTUAL_ENV_PROMPT will be used as-is.
+ Names from other sources are surrounded with ``{env_prefix}`` and
+ ``{env_postfix}`` fields.
"""
- env_path = XSH.env.get("VIRTUAL_ENV", "")
- if env_path:
- env_name = os.path.basename(env_path)
- else:
- env_name = XSH.env.get("CONDA_DEFAULT_ENV", "")
- return env_name
+ if XSH.env.get("VIRTUAL_ENV_DISABLE_PROMPT"):
+ return ""
+ virtual_env_prompt = XSH.env.get("VIRTUAL_ENV_PROMPT")
+ if virtual_env_prompt:
+ return virtual_env_prompt
+ found_envname = find_env_name()
+ return _surround_env_name(found_envname) if found_envname else ""
+
[email protected]_cache(maxsize=5)
+def _determine_env_name(virtual_env: str) -> str:
+ """Use prompt setting from pyvenv.cfg or basename of virtual_env.
-def env_name():
- """Returns the current env_name if it non-empty, surrounded by the
- ``{env_prefix}`` and ``{env_postfix}`` fields.
+ Tries to be resilient to subtle changes in whitespace and quoting in the
+ configuration file format as it adheres to no clear standard.
"""
- env_name = find_env_name()
- if XSH.env.get("VIRTUAL_ENV_DISABLE_PROMPT") or not env_name:
- # env name prompt printing disabled, or no environment; just return
- return
-
- venv_prompt = XSH.env.get("VIRTUAL_ENV_PROMPT")
- if venv_prompt is not None:
- return venv_prompt
- else:
- pf = XSH.shell.prompt_formatter
- pre = pf._get_field_value("env_prefix")
- post = pf._get_field_value("env_postfix")
- return pre + env_name + post
-
-
-def vte_new_tab_cwd():
+ venv_path = Path(virtual_env)
+ pyvenv_cfg = venv_path / "pyvenv.cfg"
+ if pyvenv_cfg.is_file():
+ match = re.search(r"prompt\s*=\s*(.*)", pyvenv_cfg.read_text())
+ if match:
+ return match.group(1).strip().lstrip("'\"").rstrip("'\"")
+ return venv_path.name
+
+
+def _surround_env_name(name: str) -> str:
+ pf = XSH.shell.prompt_formatter
+ pre = pf._get_field_value("env_prefix")
+ post = pf._get_field_value("env_postfix")
+ return f"{pre}{name}{post}"
+
+
+def vte_new_tab_cwd() -> None:
"""This prints an escape sequence that tells VTE terminals the hostname
and pwd. This should not be needed in most cases, but sometimes is for
certain Linux terminals that do not read the PWD from the environment
diff --git a/xontrib/vox.py b/xontrib/vox.py
index 3d5dac12..2a994f59 100644
--- a/xontrib/vox.py
+++ b/xontrib/vox.py
@@ -87,6 +87,7 @@ class VoxHandler(xcli.ArgParserAlias):
packages: xcli.Annotated[tp.Sequence[str], xcli.Arg(nargs="*")] = (),
requirements: xcli.Annotated[tp.Sequence[str], xcli.Arg(action="append")] = (),
link_project_dir=False,
+ prompt: "str|None" = None,
):
"""Create a virtual environment in $VIRTUALENV_HOME with python3's ``venv``.
@@ -114,6 +115,8 @@ class VoxHandler(xcli.ArgParserAlias):
The argument value is passed to ``pip -r`` to be installed.
link_project_dir: -l, --link, --link-project
Associate the current directory with the new environment.
+ prompt: --prompt
+ Provides an alternative prompt prefix for this environment.
"""
print("Creating environment...")
@@ -128,6 +131,7 @@ class VoxHandler(xcli.ArgParserAlias):
symlinks=symlinks,
with_pip=(not without_pip),
interpreter=interpreter,
+ prompt=prompt,
)
if link_project_dir:
self.project_set(name)
diff --git a/xontrib/voxapi.py b/xontrib/voxapi.py
index b74dd1b7..c844c91e 100644
--- a/xontrib/voxapi.py
+++ b/xontrib/voxapi.py
@@ -139,6 +139,7 @@ class Vox(collections.abc.Mapping):
system_site_packages=False,
symlinks=False,
with_pip=True,
+ prompt=None,
):
"""Create a virtual environment in $VIRTUALENV_HOME with python3's ``venv``.
@@ -157,8 +158,9 @@ class Vox(collections.abc.Mapping):
environment.
with_pip : bool
If True, ensure pip is installed in the virtual environment. (Default is True)
+ prompt: str
+ Provides an alternative prompt prefix for this environment.
"""
-
if interpreter is None:
interpreter = _get_vox_default_interpreter()
print(f"Using Interpreter: {interpreter}")
@@ -176,7 +178,14 @@ class Vox(collections.abc.Mapping):
)
)
- self._create(env_path, interpreter, system_site_packages, symlinks, with_pip)
+ self._create(
+ env_path,
+ interpreter,
+ system_site_packages,
+ symlinks,
+ with_pip,
+ prompt=prompt,
+ )
events.vox_on_create.fire(name=name)
def upgrade(self, name, symlinks=False, with_pip=True, interpreter=None):
@@ -219,6 +228,9 @@ class Vox(collections.abc.Mapping):
"symlinks": symlinks,
"with_pip": with_pip,
}
+ prompt = cfgops.get("prompt")
+ if prompt:
+ flags["prompt"] = prompt.lstrip("'\"").rstrip("'\"")
# END things we shouldn't be doing.
# Ok, do what we came here to do.
@@ -233,6 +245,7 @@ class Vox(collections.abc.Mapping):
symlinks=False,
with_pip=True,
upgrade=False,
+ prompt=None,
):
version_output = sp.check_output(
[interpreter, "--version"], stderr=sp.STDOUT, text=True
@@ -255,8 +268,10 @@ class Vox(collections.abc.Mapping):
with_pip,
upgrade,
]
- cmd = [arg for arg in cmd if arg] # remove empty args
+ if prompt and module == "venv":
+ cmd.extend(["--prompt", prompt])
+ cmd = [arg for arg in cmd if arg] # remove empty args
logging.debug(cmd)
return_code = sp.call(cmd)
| xonsh/xonsh | 5268dd80031fe321b4d1811c2c818ff3236aba5a | diff --git a/tests/prompt/test_base.py b/tests/prompt/test_base.py
index 40976a8c..a9994aeb 100644
--- a/tests/prompt/test_base.py
+++ b/tests/prompt/test_base.py
@@ -1,7 +1,9 @@
+import functools
from unittest.mock import Mock
import pytest
+from xonsh.prompt import env as prompt_env
from xonsh.prompt.base import PROMPT_FIELDS, PromptFormatter
@@ -118,10 +120,10 @@ def test_format_prompt_with_various_prepost(formatter, xession, live_fields, pre
xession.env["VIRTUAL_ENV"] = "env"
- live_fields.update({"env_prefix": pre, "env_postfix": post})
-
+ lf_copy = dict(live_fields) # live_fields fixture is not idempotent!
+ lf_copy.update({"env_prefix": pre, "env_postfix": post})
exp = pre + "env" + post
- assert formatter("{env_name}", fields=live_fields) == exp
+ assert formatter("{env_name}", fields=lf_copy) == exp
def test_noenv_with_disable_set(formatter, xession, live_fields):
@@ -132,6 +134,98 @@ def test_noenv_with_disable_set(formatter, xession, live_fields):
assert formatter("{env_name}", fields=live_fields) == exp
+class TestPromptFromVenvCfg:
+ WANTED = "wanted"
+ CONFIGS = [
+ f"prompt = '{WANTED}'",
+ f'prompt = "{WANTED}"',
+ f'\t prompt = "{WANTED}" ',
+ f"prompt \t= {WANTED} ",
+ "nothing = here",
+ ]
+ CONFIGS.extend([f"other = fluff\n{t}\nmore = fluff" for t in CONFIGS])
+
+ @pytest.mark.parametrize("text", CONFIGS)
+ def test_determine_env_name_from_cfg(self, monkeypatch, tmp_path, text):
+ monkeypatch.setattr(prompt_env, "_surround_env_name", lambda x: x)
+ (tmp_path / "pyvenv.cfg").write_text(text)
+ wanted = self.WANTED if self.WANTED in text else tmp_path.name
+ assert prompt_env._determine_env_name(tmp_path) == wanted
+
+
+class TestEnvNamePrompt:
+ def test_no_prompt(self, formatter, live_fields):
+ assert formatter("{env_name}", fields=live_fields) == ""
+
+ def test_search_order(self, monkeypatch, tmp_path, formatter, xession, live_fields):
+ xession.shell.prompt_formatter = formatter
+
+ first = "first"
+ second = "second"
+ third = "third"
+ fourth = "fourth"
+
+ pyvenv_cfg = tmp_path / third / "pyvenv.cfg"
+ pyvenv_cfg.parent.mkdir()
+ pyvenv_cfg.write_text(f"prompt={second}")
+
+ fmt = functools.partial(formatter, "{env_name}", fields=live_fields)
+ xession.env.update(
+ dict(
+ VIRTUAL_ENV_PROMPT=first,
+ VIRTUAL_ENV=str(pyvenv_cfg.parent),
+ CONDA_DEFAULT_ENV=fourth,
+ )
+ )
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 0
+ assert fmt() == first
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 1
+ assert fmt() == ""
+
+ del xession.env["VIRTUAL_ENV_PROMPT"]
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 0
+ assert fmt() == f"({second}) "
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 1
+ assert fmt() == ""
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 0
+ pyvenv_cfg.unlink()
+ # In the interest of speed the calls are cached, but if the user
+ # fiddles with environments this will bite them. I will not do anythin
+ prompt_env._determine_env_name.cache_clear()
+ assert fmt() == f"({third}) "
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 1
+ assert fmt() == ""
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 0
+ del xession.env["VIRTUAL_ENV"]
+ assert fmt() == f"({fourth}) "
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 1
+ assert fmt() == ""
+
+ xession.env["VIRTUAL_ENV_DISABLE_PROMPT"] = 0
+ del xession.env["CONDA_DEFAULT_ENV"]
+ assert fmt() == ""
+
+ @pytest.mark.xfail(reason="caching introduces stale values")
+ def test_env_name_updates_on_filesystem_change(self, tmp_path):
+ """Due to cache, user might get stale value.
+
+ if user fiddles with env folder or the config, they might get a stale
+ value from the cache.
+ """
+ cfg = tmp_path / "pyvenv.cfg"
+ cfg.write_text("prompt=fromfile")
+ assert prompt_env._determine_env_name(cfg.parent) == "fromfile"
+ cfg.unlink()
+ assert prompt_env._determine_env_name(cfg.parent) == cfg.parent.name
+
+
@pytest.mark.parametrize("disable", [0, 1])
def test_custom_env_overrides_default(formatter, xession, live_fields, disable):
xession.shell.prompt_formatter = formatter
diff --git a/tests/test_vox.py b/tests/test_vox.py
index 741e170c..7379d2d4 100644
--- a/tests/test_vox.py
+++ b/tests/test_vox.py
@@ -368,6 +368,7 @@ _VOX_RM_OPTS = {"-f", "--force"}.union(_HELP_OPTS)
"--requirements",
"-t",
"--temp",
+ "--prompt",
}
),
),
| make promp.env.env_name venv --prompt aware (set in pyvenv.cfg)
## xonfig
<details>
```
> xonfig
<xonsh-code>:1:0 - xonfig
<xonsh-code>:1:0 + ![xonfig]
+------------------+----------------------+
| xonsh | 0.11.0 |
| Git SHA | adfa60ea |
| Commit Date | Feb 11 14:53:00 2022 |
| Python | 3.9.7 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | None |
| shell type | readline |
| history backend | json |
| pygments | 2.11.2 |
| on posix | True |
| on linux | True |
| distro | unknown |
| on wsl | False |
| on darwin | False |
| on windows | False |
| on cygwin | False |
| on msys2 | False |
| is superuser | False |
| default encoding | utf-8 |
| xonsh encoding | utf-8 |
| encoding errors | surrogateescape |
| on jupyter | False |
| jupyter kernel | None |
| xontrib 1 | coreutils |
| xontrib 2 | vox |
| xontrib 3 | voxapi |
| RC file 1 | /home/ob/.xonshrc |
+------------------+----------------------+
```
</details>
## Expected Behavior
When activating a venv via `vox activate` the name should be set to the value of `prompt` key in `pyvenv.cfg` if present (file and key) - see https://docs.python.org/3/library/venv.html.
## Current Behavior
The prompt is always set to name of venv directory independent of prompt settings.
## Steps to Reproduce
```shell
$ python -m venv --prompt "MY SPECIAL PROMPT" .venv
$ cat .venv/pyvenv.cfg | grep prompt
prompt = 'MY SPECIAL PROMPT'
vox activate ./.venv
```
new prompt looks like this:
`[17:58:10] (.venv) ob@ob1 ~/oss/xonsh dropthedot|✓`
but should look like this:
`[17:58:10] (MY SPECIAL PROMPT) ob@ob1 ~/oss/xonsh dropthedot|✓`
## Also add `--prompt` to `vox new`?
If this is done, maybe a good idea would be to also add `--prompt` to `vox new` to make this possible on creation (also in the interest of symmetry), but it seems like the common pattern for many xonsh users is to have virtualenvs in `~/.virtualenv` with the venv folder name being the same as the project, therefore automatically having a meaningful prompt, so this does not seem to be an urgently wanted feature for most.
I want to prepare a PR for the "passive" part of the functionality, but could also have a stab at adding `--prompt` to `vox new` at a later date. My main itch would be to respect `prompt` from already existing venvs first.
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_vox.py::test_vox_completer[vox"
] | [
"tests/prompt/test_base.py::test_format_prompt[my",
"tests/prompt/test_base.py::test_format_prompt[{f}",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{a_number:{0:^3}}cats-",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{current_job:{}",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{none:{}",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{none:{}}--fields0]",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{{{a_string:{{{}}}}}}-{{cats}}-fields0]",
"tests/prompt/test_base.py::test_format_prompt_with_format_spec[{{{none:{{{}}}}}}-{}-fields0]",
"tests/prompt/test_base.py::test_format_prompt_with_broken_template",
"tests/prompt/test_base.py::test_format_prompt_with_broken_template_in_func[{user]",
"tests/prompt/test_base.py::test_format_prompt_with_broken_template_in_func[{{user]",
"tests/prompt/test_base.py::test_format_prompt_with_broken_template_in_func[{{user}]",
"tests/prompt/test_base.py::test_format_prompt_with_broken_template_in_func[{user}{hostname]",
"tests/prompt/test_base.py::test_format_prompt_with_invalid_func",
"tests/prompt/test_base.py::test_format_prompt_with_func_that_raises",
"tests/prompt/test_base.py::test_format_prompt_with_no_env",
"tests/prompt/test_base.py::test_format_prompt_with_various_envs[env]",
"tests/prompt/test_base.py::test_format_prompt_with_various_envs[foo]",
"tests/prompt/test_base.py::test_format_prompt_with_various_envs[bar]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[)-(]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[)-[[]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[)-]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[)-",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[]]-(]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[]]-[[]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[]]-]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[]]-",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[-(]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[-[[]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[-]",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[-",
"tests/prompt/test_base.py::test_format_prompt_with_various_prepost[",
"tests/prompt/test_base.py::test_noenv_with_disable_set",
"tests/prompt/test_base.py::TestEnvNamePrompt::test_no_prompt",
"tests/prompt/test_base.py::test_custom_env_overrides_default[0]",
"tests/prompt/test_base.py::test_custom_env_overrides_default[1]",
"tests/prompt/test_base.py::test_promptformatter_cache",
"tests/prompt/test_base.py::test_promptformatter_clears_cache",
"tests/test_vox.py::test_vox_completer[vox-positionals0-opts0]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-02-19T14:43:54Z" | bsd-2-clause |
|
xonsh__xonsh-4715 | diff --git a/news/fix-globbing-path-containing-regex.rst b/news/fix-globbing-path-containing-regex.rst
new file mode 100644
index 00000000..30e06e20
--- /dev/null
+++ b/news/fix-globbing-path-containing-regex.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* <news item>
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* Fixed regex globbing for file paths that contain special regex characters (e.g. "test*1/model")
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/built_ins.py b/xonsh/built_ins.py
index 737347ce..cd83ef8b 100644
--- a/xonsh/built_ins.py
+++ b/xonsh/built_ins.py
@@ -20,7 +20,7 @@ from ast import AST
from xonsh.inspectors import Inspector
from xonsh.lazyasd import lazyobject
-from xonsh.platform import ON_POSIX, ON_WINDOWS
+from xonsh.platform import ON_POSIX
from xonsh.tools import (
XonshCalledProcessError,
XonshError,
@@ -92,12 +92,7 @@ def reglob(path, parts=None, i=None):
base = ""
elif len(parts) > 1:
i += 1
- regex = os.path.join(base, parts[i])
- if ON_WINDOWS:
- # currently unable to access regex backslash sequences
- # on Windows due to paths using \.
- regex = regex.replace("\\", "\\\\")
- regex = re.compile(regex)
+ regex = re.compile(parts[i])
files = os.listdir(subdir)
files.sort()
paths = []
@@ -105,12 +100,12 @@ def reglob(path, parts=None, i=None):
if i1 == len(parts):
for f in files:
p = os.path.join(base, f)
- if regex.fullmatch(p) is not None:
+ if regex.fullmatch(f) is not None:
paths.append(p)
else:
for f in files:
p = os.path.join(base, f)
- if regex.fullmatch(p) is None or not os.path.isdir(p):
+ if regex.fullmatch(f) is None or not os.path.isdir(p):
continue
paths += reglob(p, parts=parts, i=i1)
return paths
diff --git a/xonsh/dirstack.py b/xonsh/dirstack.py
index b73a1ac8..91ffb925 100644
--- a/xonsh/dirstack.py
+++ b/xonsh/dirstack.py
@@ -20,6 +20,7 @@ _unc_tempDrives: tp.Dict[str, str] = {}
""" drive: sharePath for temp drive letters we create for UNC mapping"""
[email protected]_type_check
def _unc_check_enabled() -> bool:
r"""Check whether CMD.EXE is enforcing no-UNC-as-working-directory check.
| xonsh/xonsh | f0d77b28e86292e3404c883541d15ff51207bfa3 | diff --git a/requirements/tests.txt b/requirements/tests.txt
index fc49411f..fea8a4d2 100644
--- a/requirements/tests.txt
+++ b/requirements/tests.txt
@@ -18,9 +18,7 @@ pre-commit
pyte>=0.8.0
# types related
-# mypy==0.931
-git+git://github.com/python/mypy.git@9b3147701f054bf8ef42bd96e33153b05976a5e1
-# TODO: replace above with mypy==0.940 once its released
+mypy==0.940
types-ujson
# ensure tests run with the amalgamated (==production) xonsh
diff --git a/tests/test_builtins.py b/tests/test_builtins.py
index bf0c5b6b..ab5a2d1f 100644
--- a/tests/test_builtins.py
+++ b/tests/test_builtins.py
@@ -1,8 +1,10 @@
"""Tests the xonsh builtins."""
import os
import re
+import shutil
import types
from ast import AST, Expression, Interactive, Module
+from pathlib import Path
import pytest
@@ -85,6 +87,41 @@ def test_repath_HOME_PATH_var_brace(home_env):
assert exp == obs[0]
+# helper
+def check_repath(path, pattern):
+ base_testdir = Path("re_testdir")
+ testdir = base_testdir / path
+ testdir.mkdir(parents=True)
+ try:
+ obs = regexsearch(str(base_testdir / pattern))
+ assert [str(testdir)] == obs
+ finally:
+ shutil.rmtree(base_testdir)
+
+
+@skip_if_on_windows
[email protected](
+ "path, pattern",
+ [
+ ("test*1/model", ".*/model"),
+ ("hello/test*1/model", "hello/.*/model"),
+ ],
+)
+def test_repath_containing_asterisk(path, pattern):
+ check_repath(path, pattern)
+
+
[email protected](
+ "path, pattern",
+ [
+ ("test+a/model", ".*/model"),
+ ("hello/test+1/model", "hello/.*/model"),
+ ],
+)
+def test_repath_containing_plus_sign(path, pattern):
+ check_repath(path, pattern)
+
+
def test_helper_int(home_env):
helper(int, "int")
| Regex globbing broken for path including active regex characters
Paths including active regex characters such as `test+a/model` are not matched by regex globbing:
```xonsh
mkdir -p test/model
mkdir -p test+a/model
mkdir -p test*1/model
for d in `.*/model`:
print(d)
```
Gives the following output
```output
test/model
```
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_builtins.py::test_repath_containing_asterisk[test*1/model-.*/model]",
"tests/test_builtins.py::test_repath_containing_asterisk[hello/test*1/model-hello/.*/model]",
"tests/test_builtins.py::test_repath_containing_plus_sign[test+a/model-.*/model]",
"tests/test_builtins.py::test_repath_containing_plus_sign[hello/test+1/model-hello/.*/model]"
] | [
"tests/test_builtins.py::test_repath_backslash",
"tests/test_builtins.py::test_repath_HOME_PATH_itself",
"tests/test_builtins.py::test_repath_HOME_PATH_contents",
"tests/test_builtins.py::test_repath_HOME_PATH_var",
"tests/test_builtins.py::test_repath_HOME_PATH_var_brace",
"tests/test_builtins.py::test_helper_int",
"tests/test_builtins.py::test_helper_helper",
"tests/test_builtins.py::test_helper_env",
"tests/test_builtins.py::test_superhelper_int",
"tests/test_builtins.py::test_superhelper_helper",
"tests/test_builtins.py::test_superhelper_env",
"tests/test_builtins.py::test_ensure_list_of_strs[exp0-yo]",
"tests/test_builtins.py::test_ensure_list_of_strs[exp1-inp1]",
"tests/test_builtins.py::test_ensure_list_of_strs[exp2-42]",
"tests/test_builtins.py::test_ensure_list_of_strs[exp3-inp3]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp0-yo]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp1-inp1]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp2-42]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp3-inp3]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp4-<lambda>]",
"tests/test_builtins.py::test_list_of_strs_or_callables[exp5-inp5]",
"tests/test_builtins.py::test_list_of_list_of_strs_outer_product[inp0-exp0]",
"tests/test_builtins.py::test_list_of_list_of_strs_outer_product[inp1-exp1]",
"tests/test_builtins.py::test_list_of_list_of_strs_outer_product[inp2-exp2]",
"tests/test_builtins.py::test_expand_path[~]",
"tests/test_builtins.py::test_expand_path[~/]",
"tests/test_builtins.py::test_expand_path[x=~/place]",
"tests/test_builtins.py::test_expand_path[x=one:~/place]",
"tests/test_builtins.py::test_expand_path[x=one:~/place:~/yo]",
"tests/test_builtins.py::test_expand_path[x=~/one:~/place:~/yo]",
"tests/test_builtins.py::test_convert_macro_arg_str[str0]",
"tests/test_builtins.py::test_convert_macro_arg_str[s]",
"tests/test_builtins.py::test_convert_macro_arg_str[S]",
"tests/test_builtins.py::test_convert_macro_arg_str[str1]",
"tests/test_builtins.py::test_convert_macro_arg_str[string]",
"tests/test_builtins.py::test_convert_macro_arg_ast[AST]",
"tests/test_builtins.py::test_convert_macro_arg_ast[a]",
"tests/test_builtins.py::test_convert_macro_arg_ast[Ast]",
"tests/test_builtins.py::test_convert_macro_arg_code[code0]",
"tests/test_builtins.py::test_convert_macro_arg_code[compile0]",
"tests/test_builtins.py::test_convert_macro_arg_code[c]",
"tests/test_builtins.py::test_convert_macro_arg_code[code1]",
"tests/test_builtins.py::test_convert_macro_arg_code[compile1]",
"tests/test_builtins.py::test_convert_macro_arg_eval[eval0]",
"tests/test_builtins.py::test_convert_macro_arg_eval[v]",
"tests/test_builtins.py::test_convert_macro_arg_eval[eval1]",
"tests/test_builtins.py::test_convert_macro_arg_exec[exec0]",
"tests/test_builtins.py::test_convert_macro_arg_exec[x]",
"tests/test_builtins.py::test_convert_macro_arg_exec[exec1]",
"tests/test_builtins.py::test_convert_macro_arg_type[type0]",
"tests/test_builtins.py::test_convert_macro_arg_type[t]",
"tests/test_builtins.py::test_convert_macro_arg_type[type1]",
"tests/test_builtins.py::test_in_macro_call",
"tests/test_builtins.py::test_call_macro_str[x]",
"tests/test_builtins.py::test_call_macro_str[42]",
"tests/test_builtins.py::test_call_macro_str[x",
"tests/test_builtins.py::test_call_macro_ast[x]",
"tests/test_builtins.py::test_call_macro_ast[42]",
"tests/test_builtins.py::test_call_macro_ast[x",
"tests/test_builtins.py::test_call_macro_code[x]",
"tests/test_builtins.py::test_call_macro_code[42]",
"tests/test_builtins.py::test_call_macro_code[x",
"tests/test_builtins.py::test_call_macro_eval[x]",
"tests/test_builtins.py::test_call_macro_eval[42]",
"tests/test_builtins.py::test_call_macro_eval[x",
"tests/test_builtins.py::test_call_macro_exec[if",
"tests/test_builtins.py::test_call_macro_raw_arg[x]",
"tests/test_builtins.py::test_call_macro_raw_arg[42]",
"tests/test_builtins.py::test_call_macro_raw_arg[x",
"tests/test_builtins.py::test_call_macro_raw_kwarg[x]",
"tests/test_builtins.py::test_call_macro_raw_kwarg[42]",
"tests/test_builtins.py::test_call_macro_raw_kwarg[x",
"tests/test_builtins.py::test_call_macro_raw_kwargs[x]",
"tests/test_builtins.py::test_call_macro_raw_kwargs[42]",
"tests/test_builtins.py::test_call_macro_raw_kwargs[x",
"tests/test_builtins.py::test_call_macro_ast_eval_expr",
"tests/test_builtins.py::test_call_macro_ast_single_expr",
"tests/test_builtins.py::test_call_macro_ast_exec_expr",
"tests/test_builtins.py::test_call_macro_ast_eval_statement",
"tests/test_builtins.py::test_call_macro_ast_single_statement",
"tests/test_builtins.py::test_call_macro_ast_exec_statement",
"tests/test_builtins.py::test_enter_macro"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-03-14T18:35:12Z" | bsd-2-clause |
|
xonsh__xonsh-4835 | diff --git a/docs/tutorial.rst b/docs/tutorial.rst
index 0cc3de3b..41945aef 100644
--- a/docs/tutorial.rst
+++ b/docs/tutorial.rst
@@ -1054,6 +1054,23 @@ mode or subprocess mode) by using the ``g````:
5
+Formatted Glob Literals
+-----------------------
+
+Using the ``f`` modifier with either regex or normal globbing makes
+the glob pattern behave like a formatted string literal. This can be used to
+substitute variables and other expressions into the glob pattern:
+
+.. code-block:: xonshcon
+
+ >>> touch a aa aaa aba abba aab aabb abcba
+ >>> mypattern = 'ab'
+ >>> print(f`{mypattern[0]}+`)
+ ['a', 'aa', 'aaa']
+ >>> print(gf`{mypattern}*`)
+ ['aba', 'abba', 'abcba']
+
+
Custom Path Searches
--------------------
diff --git a/news/feat-f-glob-strings.rst b/news/feat-f-glob-strings.rst
new file mode 100644
index 00000000..7c1d02a3
--- /dev/null
+++ b/news/feat-f-glob-strings.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* Support for f-glob strings (e.g. ``fg`{prefix}*```)
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* <news item>
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/parsers/base.py b/xonsh/parsers/base.py
index ab20d244..7208ddf6 100644
--- a/xonsh/parsers/base.py
+++ b/xonsh/parsers/base.py
@@ -124,31 +124,6 @@ def xonsh_superhelp(x, lineno=None, col=None):
return xonsh_call("__xonsh__.superhelp", [x], lineno=lineno, col=col)
-def xonsh_pathsearch(pattern, pymode=False, lineno=None, col=None):
- """Creates the AST node for calling the __xonsh__.pathsearch() function.
- The pymode argument indicate if it is called from subproc or python mode"""
- pymode = ast.NameConstant(value=pymode, lineno=lineno, col_offset=col)
- searchfunc, pattern = RE_SEARCHPATH.match(pattern).groups()
- pattern = ast.Str(s=pattern, lineno=lineno, col_offset=col)
- pathobj = False
- if searchfunc.startswith("@"):
- func = searchfunc[1:]
- elif "g" in searchfunc:
- func = "__xonsh__.globsearch"
- pathobj = "p" in searchfunc
- else:
- func = "__xonsh__.regexsearch"
- pathobj = "p" in searchfunc
- func = load_attribute_chain(func, lineno=lineno, col=col)
- pathobj = ast.NameConstant(value=pathobj, lineno=lineno, col_offset=col)
- return xonsh_call(
- "__xonsh__.pathsearch",
- args=[func, pattern, pymode, pathobj],
- lineno=lineno,
- col=col,
- )
-
-
def load_ctx(x):
"""Recursively sets ctx to ast.Load()"""
if not hasattr(x, "ctx"):
@@ -658,6 +633,44 @@ class BaseParser:
def _parse_error(self, msg, loc):
raise_parse_error(msg, loc, self._source, self.lines)
+ def xonsh_pathsearch(self, pattern, pymode=False, lineno=None, col=None):
+ """Creates the AST node for calling the __xonsh__.pathsearch() function.
+ The pymode argument indicate if it is called from subproc or python mode"""
+ pymode = ast.NameConstant(value=pymode, lineno=lineno, col_offset=col)
+ searchfunc, pattern = RE_SEARCHPATH.match(pattern).groups()
+ if not searchfunc.startswith("@") and "f" in searchfunc:
+ pattern_as_str = f"f'''{pattern}'''"
+ try:
+ pattern = pyparse(pattern_as_str).body[0].value
+ except SyntaxError:
+ pattern = None
+ if pattern is None:
+ try:
+ pattern = FStringAdaptor(
+ pattern_as_str, "f", filename=self.lexer.fname
+ ).run()
+ except SyntaxError as e:
+ self._set_error(str(e), self.currloc(lineno=lineno, column=col))
+ else:
+ pattern = ast.Str(s=pattern, lineno=lineno, col_offset=col)
+ pathobj = False
+ if searchfunc.startswith("@"):
+ func = searchfunc[1:]
+ elif "g" in searchfunc:
+ func = "__xonsh__.globsearch"
+ pathobj = "p" in searchfunc
+ else:
+ func = "__xonsh__.regexsearch"
+ pathobj = "p" in searchfunc
+ func = load_attribute_chain(func, lineno=lineno, col=col)
+ pathobj = ast.NameConstant(value=pathobj, lineno=lineno, col_offset=col)
+ return xonsh_call(
+ "__xonsh__.pathsearch",
+ args=[func, pattern, pymode, pathobj],
+ lineno=lineno,
+ col=col,
+ )
+
#
# Precedence of operators
#
@@ -2413,7 +2426,9 @@ class BaseParser:
def p_atom_pathsearch(self, p):
"""atom : SEARCHPATH"""
- p[0] = xonsh_pathsearch(p[1], pymode=True, lineno=self.lineno, col=self.col)
+ p[0] = self.xonsh_pathsearch(
+ p[1], pymode=True, lineno=self.lineno, col=self.col
+ )
# introduce seemingly superfluous symbol 'atom_dname' to enable reuse it in other places
def p_atom_dname_indirection(self, p):
@@ -3352,7 +3367,7 @@ class BaseParser:
def p_subproc_atom_re(self, p):
"""subproc_atom : SEARCHPATH"""
- p0 = xonsh_pathsearch(p[1], pymode=False, lineno=self.lineno, col=self.col)
+ p0 = self.xonsh_pathsearch(p[1], pymode=False, lineno=self.lineno, col=self.col)
p0._cliarg_action = "extend"
p[0] = p0
diff --git a/xonsh/tokenize.py b/xonsh/tokenize.py
index 609bbb5b..045b47e7 100644
--- a/xonsh/tokenize.py
+++ b/xonsh/tokenize.py
@@ -305,7 +305,7 @@ String = group(
)
# Xonsh-specific Syntax
-SearchPath = r"((?:[rgp]+|@\w*)?)`([^\n`\\]*(?:\\.[^\n`\\]*)*)`"
+SearchPath = r"((?:[rgpf]+|@\w*)?)`([^\n`\\]*(?:\\.[^\n`\\]*)*)`"
# Because of leftmost-then-longest match semantics, be sure to put the
# longest operators first (e.g., if = came before ==, == would get
| xonsh/xonsh | 0ddc05e82e3c91130f61173618925619e44cda7e | diff --git a/tests/test_parser.py b/tests/test_parser.py
index 400b6c96..05ce324f 100644
--- a/tests/test_parser.py
+++ b/tests/test_parser.py
@@ -2376,8 +2376,11 @@ def test_ls_regex(check_xonsh_ast):
check_xonsh_ast({}, "$(ls `[Ff]+i*LE` -l)", False)
-def test_backtick(check_xonsh_ast):
- check_xonsh_ast({}, "print(`.*`)", False)
[email protected]("p", ["", "p"])
[email protected]("f", ["", "f"])
[email protected]("glob_type", ["", "r", "g"])
+def test_backtick(p, f, glob_type, check_xonsh_ast):
+ check_xonsh_ast({}, f"print({p}{f}{glob_type}`.*`)", False)
def test_ls_regex_octothorpe(check_xonsh_ast):
@@ -2388,10 +2391,6 @@ def test_ls_explicitregex(check_xonsh_ast):
check_xonsh_ast({}, "$(ls r`[Ff]+i*LE` -l)", False)
-def test_rbacktick(check_xonsh_ast):
- check_xonsh_ast({}, "print(r`.*`)", False)
-
-
def test_ls_explicitregex_octothorpe(check_xonsh_ast):
check_xonsh_ast({}, "$(ls r`#[Ff]+i*LE` -l)", False)
@@ -2400,22 +2399,6 @@ def test_ls_glob(check_xonsh_ast):
check_xonsh_ast({}, "$(ls g`[Ff]+i*LE` -l)", False)
-def test_gbacktick(check_xonsh_ast):
- check_xonsh_ast({}, "print(g`.*`)", False)
-
-
-def test_pbacktrick(check_xonsh_ast):
- check_xonsh_ast({}, "print(p`.*`)", False)
-
-
-def test_pgbacktick(check_xonsh_ast):
- check_xonsh_ast({}, "print(pg`.*`)", False)
-
-
-def test_prbacktick(check_xonsh_ast):
- check_xonsh_ast({}, "print(pr`.*`)", False)
-
-
def test_ls_glob_octothorpe(check_xonsh_ast):
check_xonsh_ast({}, "$(ls g`#[Ff]+i*LE` -l)", False)
| Feat: add f-glob strings
In Xonsh we have augmented string literals with `p`-strings (that return a Path object) and glob strings g`...` (that return a list of results). It would seem that we want glob strings to behave similarly to normal strings, and so there is a case to be made for supporting `f`-strings in this context.
An example:
```xonsh
>>> ls
file-a file-b
>>> prefix = "file"
>>> echo fg`{prefix}*`
file-a file-b
```
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_parser.py::test_backtick[-f-]",
"tests/test_parser.py::test_backtick[-f-p]",
"tests/test_parser.py::test_backtick[r-f-]",
"tests/test_parser.py::test_backtick[r-f-p]",
"tests/test_parser.py::test_backtick[g-f-]",
"tests/test_parser.py::test_backtick[g-f-p]"
] | [
"tests/test_parser.py::test_int_literal",
"tests/test_parser.py::test_int_literal_underscore",
"tests/test_parser.py::test_float_literal",
"tests/test_parser.py::test_float_literal_underscore",
"tests/test_parser.py::test_imag_literal",
"tests/test_parser.py::test_float_imag_literal",
"tests/test_parser.py::test_complex",
"tests/test_parser.py::test_str_literal",
"tests/test_parser.py::test_bytes_literal",
"tests/test_parser.py::test_raw_literal",
"tests/test_parser.py::test_f_literal",
"tests/test_parser.py::test_f_env_var",
"tests/test_parser.py::test_fstring_adaptor[f\"$HOME\"-$HOME]",
"tests/test_parser.py::test_fstring_adaptor[f\"{0}",
"tests/test_parser.py::test_fstring_adaptor[f\"{$HOME}\"-/foo/bar]",
"tests/test_parser.py::test_fstring_adaptor[f\"{",
"tests/test_parser.py::test_fstring_adaptor[f\"{'$HOME'}\"-$HOME]",
"tests/test_parser.py::test_fstring_adaptor[f\"$HOME",
"tests/test_parser.py::test_fstring_adaptor[f\"{${'HOME'}}\"-/foo/bar]",
"tests/test_parser.py::test_fstring_adaptor[f'{${$FOO+$BAR}}'-/foo/bar]",
"tests/test_parser.py::test_fstring_adaptor[f\"${$FOO}{$BAR}={f'{$HOME}'}\"-$HOME=/foo/bar]",
"tests/test_parser.py::test_fstring_adaptor[f\"\"\"foo\\n{f\"_{$HOME}_\"}\\nbar\"\"\"-foo\\n_/foo/bar_\\nbar]",
"tests/test_parser.py::test_fstring_adaptor[f\"\"\"foo\\n{f\"_{${'HOME'}}_\"}\\nbar\"\"\"-foo\\n_/foo/bar_\\nbar]",
"tests/test_parser.py::test_fstring_adaptor[f\"\"\"foo\\n{f\"_{${",
"tests/test_parser.py::test_fstring_adaptor[f'{$HOME=}'-$HOME='/foo/bar']",
"tests/test_parser.py::test_raw_bytes_literal",
"tests/test_parser.py::test_unary_plus",
"tests/test_parser.py::test_unary_minus",
"tests/test_parser.py::test_unary_invert",
"tests/test_parser.py::test_binop_plus",
"tests/test_parser.py::test_binop_minus",
"tests/test_parser.py::test_binop_times",
"tests/test_parser.py::test_binop_matmult",
"tests/test_parser.py::test_binop_div",
"tests/test_parser.py::test_binop_mod",
"tests/test_parser.py::test_binop_floordiv",
"tests/test_parser.py::test_binop_pow",
"tests/test_parser.py::test_plus_pow",
"tests/test_parser.py::test_plus_plus",
"tests/test_parser.py::test_plus_minus",
"tests/test_parser.py::test_minus_plus",
"tests/test_parser.py::test_minus_minus",
"tests/test_parser.py::test_minus_plus_minus",
"tests/test_parser.py::test_times_plus",
"tests/test_parser.py::test_plus_times",
"tests/test_parser.py::test_times_times",
"tests/test_parser.py::test_times_div",
"tests/test_parser.py::test_times_div_mod",
"tests/test_parser.py::test_times_div_mod_floor",
"tests/test_parser.py::test_str_str",
"tests/test_parser.py::test_str_str_str",
"tests/test_parser.py::test_str_plus_str",
"tests/test_parser.py::test_str_times_int",
"tests/test_parser.py::test_int_times_str",
"tests/test_parser.py::test_group_plus_times",
"tests/test_parser.py::test_plus_group_times",
"tests/test_parser.py::test_group",
"tests/test_parser.py::test_lt",
"tests/test_parser.py::test_gt",
"tests/test_parser.py::test_eq",
"tests/test_parser.py::test_le",
"tests/test_parser.py::test_ge",
"tests/test_parser.py::test_ne",
"tests/test_parser.py::test_in",
"tests/test_parser.py::test_is",
"tests/test_parser.py::test_not_in",
"tests/test_parser.py::test_is_not",
"tests/test_parser.py::test_lt_lt",
"tests/test_parser.py::test_lt_lt_lt",
"tests/test_parser.py::test_not",
"tests/test_parser.py::test_or",
"tests/test_parser.py::test_or_or",
"tests/test_parser.py::test_and",
"tests/test_parser.py::test_and_and",
"tests/test_parser.py::test_and_or",
"tests/test_parser.py::test_or_and",
"tests/test_parser.py::test_group_and_and",
"tests/test_parser.py::test_group_and_or",
"tests/test_parser.py::test_if_else_expr",
"tests/test_parser.py::test_if_else_expr_expr",
"tests/test_parser.py::test_subscription_syntaxes",
"tests/test_parser.py::test_subscription_special_syntaxes",
"tests/test_parser.py::test_str_idx",
"tests/test_parser.py::test_str_slice",
"tests/test_parser.py::test_str_step",
"tests/test_parser.py::test_str_slice_all",
"tests/test_parser.py::test_str_slice_upper",
"tests/test_parser.py::test_str_slice_lower",
"tests/test_parser.py::test_str_slice_other",
"tests/test_parser.py::test_str_slice_lower_other",
"tests/test_parser.py::test_str_slice_upper_other",
"tests/test_parser.py::test_str_2slice",
"tests/test_parser.py::test_str_2step",
"tests/test_parser.py::test_str_2slice_all",
"tests/test_parser.py::test_str_2slice_upper",
"tests/test_parser.py::test_str_2slice_lower",
"tests/test_parser.py::test_str_2slice_lowerupper",
"tests/test_parser.py::test_str_2slice_other",
"tests/test_parser.py::test_str_2slice_lower_other",
"tests/test_parser.py::test_str_2slice_upper_other",
"tests/test_parser.py::test_str_3slice",
"tests/test_parser.py::test_str_3step",
"tests/test_parser.py::test_str_3slice_all",
"tests/test_parser.py::test_str_3slice_upper",
"tests/test_parser.py::test_str_3slice_lower",
"tests/test_parser.py::test_str_3slice_lowerlowerupper",
"tests/test_parser.py::test_str_3slice_lowerupperlower",
"tests/test_parser.py::test_str_3slice_lowerupperupper",
"tests/test_parser.py::test_str_3slice_upperlowerlower",
"tests/test_parser.py::test_str_3slice_upperlowerupper",
"tests/test_parser.py::test_str_3slice_upperupperlower",
"tests/test_parser.py::test_str_3slice_other",
"tests/test_parser.py::test_str_3slice_lower_other",
"tests/test_parser.py::test_str_3slice_upper_other",
"tests/test_parser.py::test_str_slice_true",
"tests/test_parser.py::test_str_true_slice",
"tests/test_parser.py::test_list_empty",
"tests/test_parser.py::test_list_one",
"tests/test_parser.py::test_list_one_comma",
"tests/test_parser.py::test_list_two",
"tests/test_parser.py::test_list_three",
"tests/test_parser.py::test_list_three_comma",
"tests/test_parser.py::test_list_one_nested",
"tests/test_parser.py::test_list_list_four_nested",
"tests/test_parser.py::test_list_tuple_three_nested",
"tests/test_parser.py::test_list_set_tuple_three_nested",
"tests/test_parser.py::test_list_tuple_one_nested",
"tests/test_parser.py::test_tuple_tuple_one_nested",
"tests/test_parser.py::test_dict_list_one_nested",
"tests/test_parser.py::test_dict_list_one_nested_comma",
"tests/test_parser.py::test_dict_tuple_one_nested",
"tests/test_parser.py::test_dict_tuple_one_nested_comma",
"tests/test_parser.py::test_dict_list_two_nested",
"tests/test_parser.py::test_set_tuple_one_nested",
"tests/test_parser.py::test_set_tuple_two_nested",
"tests/test_parser.py::test_tuple_empty",
"tests/test_parser.py::test_tuple_one_bare",
"tests/test_parser.py::test_tuple_two_bare",
"tests/test_parser.py::test_tuple_three_bare",
"tests/test_parser.py::test_tuple_three_bare_comma",
"tests/test_parser.py::test_tuple_one_comma",
"tests/test_parser.py::test_tuple_two",
"tests/test_parser.py::test_tuple_three",
"tests/test_parser.py::test_tuple_three_comma",
"tests/test_parser.py::test_bare_tuple_of_tuples",
"tests/test_parser.py::test_set_one",
"tests/test_parser.py::test_set_one_comma",
"tests/test_parser.py::test_set_two",
"tests/test_parser.py::test_set_two_comma",
"tests/test_parser.py::test_set_three",
"tests/test_parser.py::test_dict_empty",
"tests/test_parser.py::test_dict_one",
"tests/test_parser.py::test_dict_one_comma",
"tests/test_parser.py::test_dict_two",
"tests/test_parser.py::test_dict_two_comma",
"tests/test_parser.py::test_dict_three",
"tests/test_parser.py::test_dict_from_dict_one",
"tests/test_parser.py::test_dict_from_dict_one_comma",
"tests/test_parser.py::test_dict_from_dict_two_xy",
"tests/test_parser.py::test_dict_from_dict_two_x_first",
"tests/test_parser.py::test_dict_from_dict_two_x_second",
"tests/test_parser.py::test_dict_from_dict_two_x_none",
"tests/test_parser.py::test_dict_from_dict_three_xyz[True-True-True]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[True-True-False]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[True-False-True]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[True-False-False]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[False-True-True]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[False-True-False]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[False-False-True]",
"tests/test_parser.py::test_dict_from_dict_three_xyz[False-False-False]",
"tests/test_parser.py::test_unpack_range_tuple",
"tests/test_parser.py::test_unpack_range_tuple_4",
"tests/test_parser.py::test_unpack_range_tuple_parens",
"tests/test_parser.py::test_unpack_range_tuple_parens_4",
"tests/test_parser.py::test_unpack_range_list",
"tests/test_parser.py::test_unpack_range_list_4",
"tests/test_parser.py::test_unpack_range_set",
"tests/test_parser.py::test_unpack_range_set_4",
"tests/test_parser.py::test_true",
"tests/test_parser.py::test_false",
"tests/test_parser.py::test_none",
"tests/test_parser.py::test_elipssis",
"tests/test_parser.py::test_not_implemented_name",
"tests/test_parser.py::test_genexpr",
"tests/test_parser.py::test_genexpr_if",
"tests/test_parser.py::test_genexpr_if_and",
"tests/test_parser.py::test_dbl_genexpr",
"tests/test_parser.py::test_genexpr_if_genexpr",
"tests/test_parser.py::test_genexpr_if_genexpr_if",
"tests/test_parser.py::test_listcomp",
"tests/test_parser.py::test_listcomp_if",
"tests/test_parser.py::test_listcomp_if_and",
"tests/test_parser.py::test_listcomp_multi_if",
"tests/test_parser.py::test_dbl_listcomp",
"tests/test_parser.py::test_listcomp_if_listcomp",
"tests/test_parser.py::test_listcomp_if_listcomp_if",
"tests/test_parser.py::test_setcomp",
"tests/test_parser.py::test_setcomp_if",
"tests/test_parser.py::test_setcomp_if_and",
"tests/test_parser.py::test_dbl_setcomp",
"tests/test_parser.py::test_setcomp_if_setcomp",
"tests/test_parser.py::test_setcomp_if_setcomp_if",
"tests/test_parser.py::test_dictcomp",
"tests/test_parser.py::test_dictcomp_unpack_parens",
"tests/test_parser.py::test_dictcomp_unpack_no_parens",
"tests/test_parser.py::test_dictcomp_if",
"tests/test_parser.py::test_dictcomp_if_and",
"tests/test_parser.py::test_dbl_dictcomp",
"tests/test_parser.py::test_dictcomp_if_dictcomp",
"tests/test_parser.py::test_dictcomp_if_dictcomp_if",
"tests/test_parser.py::test_lambda",
"tests/test_parser.py::test_lambda_x",
"tests/test_parser.py::test_lambda_kwx",
"tests/test_parser.py::test_lambda_x_y",
"tests/test_parser.py::test_lambda_x_y_z",
"tests/test_parser.py::test_lambda_x_kwy",
"tests/test_parser.py::test_lambda_kwx_kwy",
"tests/test_parser.py::test_lambda_kwx_kwy_kwz",
"tests/test_parser.py::test_lambda_x_comma",
"tests/test_parser.py::test_lambda_x_y_comma",
"tests/test_parser.py::test_lambda_x_y_z_comma",
"tests/test_parser.py::test_lambda_x_kwy_comma",
"tests/test_parser.py::test_lambda_kwx_kwy_comma",
"tests/test_parser.py::test_lambda_kwx_kwy_kwz_comma",
"tests/test_parser.py::test_lambda_args",
"tests/test_parser.py::test_lambda_args_x",
"tests/test_parser.py::test_lambda_args_x_y",
"tests/test_parser.py::test_lambda_args_x_kwy",
"tests/test_parser.py::test_lambda_args_kwx_y",
"tests/test_parser.py::test_lambda_args_kwx_kwy",
"tests/test_parser.py::test_lambda_x_args",
"tests/test_parser.py::test_lambda_x_args_y",
"tests/test_parser.py::test_lambda_x_args_y_z",
"tests/test_parser.py::test_lambda_kwargs",
"tests/test_parser.py::test_lambda_x_kwargs",
"tests/test_parser.py::test_lambda_x_y_kwargs",
"tests/test_parser.py::test_lambda_x_kwy_kwargs",
"tests/test_parser.py::test_lambda_args_kwargs",
"tests/test_parser.py::test_lambda_x_args_kwargs",
"tests/test_parser.py::test_lambda_x_y_args_kwargs",
"tests/test_parser.py::test_lambda_kwx_args_kwargs",
"tests/test_parser.py::test_lambda_x_kwy_args_kwargs",
"tests/test_parser.py::test_lambda_x_args_y_kwargs",
"tests/test_parser.py::test_lambda_x_args_kwy_kwargs",
"tests/test_parser.py::test_lambda_args_y_kwargs",
"tests/test_parser.py::test_lambda_star_x",
"tests/test_parser.py::test_lambda_star_x_y",
"tests/test_parser.py::test_lambda_star_x_kwargs",
"tests/test_parser.py::test_lambda_star_kwx_kwargs",
"tests/test_parser.py::test_lambda_x_star_y",
"tests/test_parser.py::test_lambda_x_y_star_z",
"tests/test_parser.py::test_lambda_x_kwy_star_y",
"tests/test_parser.py::test_lambda_x_kwy_star_kwy",
"tests/test_parser.py::test_lambda_x_star_y_kwargs",
"tests/test_parser.py::test_lambda_x_divide_y_star_z_kwargs",
"tests/test_parser.py::test_call_range",
"tests/test_parser.py::test_call_range_comma",
"tests/test_parser.py::test_call_range_x_y",
"tests/test_parser.py::test_call_range_x_y_comma",
"tests/test_parser.py::test_call_range_x_y_z",
"tests/test_parser.py::test_call_dict_kwx",
"tests/test_parser.py::test_call_dict_kwx_comma",
"tests/test_parser.py::test_call_dict_kwx_kwy",
"tests/test_parser.py::test_call_tuple_gen",
"tests/test_parser.py::test_call_tuple_genifs",
"tests/test_parser.py::test_call_range_star",
"tests/test_parser.py::test_call_range_x_star",
"tests/test_parser.py::test_call_int",
"tests/test_parser.py::test_call_int_base_dict",
"tests/test_parser.py::test_call_dict_kwargs",
"tests/test_parser.py::test_call_list_many_star_args",
"tests/test_parser.py::test_call_list_many_starstar_args",
"tests/test_parser.py::test_call_list_many_star_and_starstar_args",
"tests/test_parser.py::test_call_alot",
"tests/test_parser.py::test_call_alot_next",
"tests/test_parser.py::test_call_alot_next_next",
"tests/test_parser.py::test_getattr",
"tests/test_parser.py::test_getattr_getattr",
"tests/test_parser.py::test_dict_tuple_key",
"tests/test_parser.py::test_dict_tuple_key_get",
"tests/test_parser.py::test_dict_tuple_key_get_3",
"tests/test_parser.py::test_pipe_op",
"tests/test_parser.py::test_pipe_op_two",
"tests/test_parser.py::test_pipe_op_three",
"tests/test_parser.py::test_xor_op",
"tests/test_parser.py::test_xor_op_two",
"tests/test_parser.py::test_xor_op_three",
"tests/test_parser.py::test_xor_pipe",
"tests/test_parser.py::test_amp_op",
"tests/test_parser.py::test_amp_op_two",
"tests/test_parser.py::test_amp_op_three",
"tests/test_parser.py::test_lshift_op",
"tests/test_parser.py::test_lshift_op_two",
"tests/test_parser.py::test_lshift_op_three",
"tests/test_parser.py::test_rshift_op",
"tests/test_parser.py::test_rshift_op_two",
"tests/test_parser.py::test_rshift_op_three",
"tests/test_parser.py::test_named_expr",
"tests/test_parser.py::test_named_expr_list",
"tests/test_parser.py::test_equals",
"tests/test_parser.py::test_equals_semi",
"tests/test_parser.py::test_x_y_equals_semi",
"tests/test_parser.py::test_equals_two",
"tests/test_parser.py::test_equals_two_semi",
"tests/test_parser.py::test_equals_three",
"tests/test_parser.py::test_equals_three_semi",
"tests/test_parser.py::test_plus_eq",
"tests/test_parser.py::test_sub_eq",
"tests/test_parser.py::test_times_eq",
"tests/test_parser.py::test_matmult_eq",
"tests/test_parser.py::test_div_eq",
"tests/test_parser.py::test_floordiv_eq",
"tests/test_parser.py::test_pow_eq",
"tests/test_parser.py::test_mod_eq",
"tests/test_parser.py::test_xor_eq",
"tests/test_parser.py::test_ampersand_eq",
"tests/test_parser.py::test_bitor_eq",
"tests/test_parser.py::test_lshift_eq",
"tests/test_parser.py::test_rshift_eq",
"tests/test_parser.py::test_bare_unpack",
"tests/test_parser.py::test_lhand_group_unpack",
"tests/test_parser.py::test_rhand_group_unpack",
"tests/test_parser.py::test_grouped_unpack",
"tests/test_parser.py::test_double_grouped_unpack",
"tests/test_parser.py::test_double_ungrouped_unpack",
"tests/test_parser.py::test_stary_eq",
"tests/test_parser.py::test_stary_x",
"tests/test_parser.py::test_tuple_x_stary",
"tests/test_parser.py::test_list_x_stary",
"tests/test_parser.py::test_bare_x_stary",
"tests/test_parser.py::test_bare_x_stary_z",
"tests/test_parser.py::test_equals_list",
"tests/test_parser.py::test_equals_dict",
"tests/test_parser.py::test_equals_attr",
"tests/test_parser.py::test_equals_annotation",
"tests/test_parser.py::test_equals_annotation_empty",
"tests/test_parser.py::test_dict_keys",
"tests/test_parser.py::test_assert_msg",
"tests/test_parser.py::test_assert",
"tests/test_parser.py::test_pass",
"tests/test_parser.py::test_del",
"tests/test_parser.py::test_del_comma",
"tests/test_parser.py::test_del_two",
"tests/test_parser.py::test_del_two_comma",
"tests/test_parser.py::test_del_with_parens",
"tests/test_parser.py::test_raise",
"tests/test_parser.py::test_raise_x",
"tests/test_parser.py::test_raise_x_from",
"tests/test_parser.py::test_import_x",
"tests/test_parser.py::test_import_xy",
"tests/test_parser.py::test_import_xyz",
"tests/test_parser.py::test_from_x_import_y",
"tests/test_parser.py::test_from_dot_import_y",
"tests/test_parser.py::test_from_dotx_import_y",
"tests/test_parser.py::test_from_dotdotx_import_y",
"tests/test_parser.py::test_from_dotdotdotx_import_y",
"tests/test_parser.py::test_from_dotdotdotdotx_import_y",
"tests/test_parser.py::test_from_import_x_y",
"tests/test_parser.py::test_from_import_x_y_z",
"tests/test_parser.py::test_from_dot_import_x_y",
"tests/test_parser.py::test_from_dot_import_x_y_z",
"tests/test_parser.py::test_from_dot_import_group_x_y",
"tests/test_parser.py::test_import_x_as_y",
"tests/test_parser.py::test_import_xy_as_z",
"tests/test_parser.py::test_import_x_y_as_z",
"tests/test_parser.py::test_import_x_as_y_z",
"tests/test_parser.py::test_import_x_as_y_z_as_a",
"tests/test_parser.py::test_from_dot_import_x_as_y",
"tests/test_parser.py::test_from_x_import_star",
"tests/test_parser.py::test_from_x_import_group_x_y_z",
"tests/test_parser.py::test_from_x_import_group_x_y_z_comma",
"tests/test_parser.py::test_from_x_import_y_as_z",
"tests/test_parser.py::test_from_x_import_y_as_z_a_as_b",
"tests/test_parser.py::test_from_dotx_import_y_as_z_a_as_b_c_as_d",
"tests/test_parser.py::test_continue",
"tests/test_parser.py::test_break",
"tests/test_parser.py::test_global",
"tests/test_parser.py::test_global_xy",
"tests/test_parser.py::test_nonlocal_x",
"tests/test_parser.py::test_nonlocal_xy",
"tests/test_parser.py::test_yield",
"tests/test_parser.py::test_yield_x",
"tests/test_parser.py::test_yield_x_comma",
"tests/test_parser.py::test_yield_x_y",
"tests/test_parser.py::test_yield_x_starexpr",
"tests/test_parser.py::test_yield_from_x",
"tests/test_parser.py::test_return",
"tests/test_parser.py::test_return_x",
"tests/test_parser.py::test_return_x_comma",
"tests/test_parser.py::test_return_x_y",
"tests/test_parser.py::test_return_x_starexpr",
"tests/test_parser.py::test_if_true",
"tests/test_parser.py::test_if_true_twolines",
"tests/test_parser.py::test_if_true_twolines_deindent",
"tests/test_parser.py::test_if_true_else",
"tests/test_parser.py::test_if_true_x",
"tests/test_parser.py::test_if_switch",
"tests/test_parser.py::test_if_switch_elif1_else",
"tests/test_parser.py::test_if_switch_elif2_else",
"tests/test_parser.py::test_if_nested",
"tests/test_parser.py::test_while",
"tests/test_parser.py::test_while_else",
"tests/test_parser.py::test_for",
"tests/test_parser.py::test_for_zip",
"tests/test_parser.py::test_for_idx",
"tests/test_parser.py::test_for_zip_idx",
"tests/test_parser.py::test_for_attr",
"tests/test_parser.py::test_for_zip_attr",
"tests/test_parser.py::test_for_else",
"tests/test_parser.py::test_async_for",
"tests/test_parser.py::test_with",
"tests/test_parser.py::test_with_as",
"tests/test_parser.py::test_with_xy",
"tests/test_parser.py::test_with_x_as_y_z",
"tests/test_parser.py::test_with_x_as_y_a_as_b",
"tests/test_parser.py::test_with_in_func",
"tests/test_parser.py::test_async_with",
"tests/test_parser.py::test_try",
"tests/test_parser.py::test_try_except_t",
"tests/test_parser.py::test_try_except_t_as_e",
"tests/test_parser.py::test_try_except_t_u",
"tests/test_parser.py::test_try_except_t_u_as_e",
"tests/test_parser.py::test_try_except_t_except_u",
"tests/test_parser.py::test_try_except_else",
"tests/test_parser.py::test_try_except_finally",
"tests/test_parser.py::test_try_except_else_finally",
"tests/test_parser.py::test_try_finally",
"tests/test_parser.py::test_func",
"tests/test_parser.py::test_func_ret",
"tests/test_parser.py::test_func_ret_42",
"tests/test_parser.py::test_func_ret_42_65",
"tests/test_parser.py::test_func_rarrow",
"tests/test_parser.py::test_func_x",
"tests/test_parser.py::test_func_kwx",
"tests/test_parser.py::test_func_x_y",
"tests/test_parser.py::test_func_x_y_z",
"tests/test_parser.py::test_func_x_kwy",
"tests/test_parser.py::test_func_kwx_kwy",
"tests/test_parser.py::test_func_kwx_kwy_kwz",
"tests/test_parser.py::test_func_x_comma",
"tests/test_parser.py::test_func_x_y_comma",
"tests/test_parser.py::test_func_x_y_z_comma",
"tests/test_parser.py::test_func_x_kwy_comma",
"tests/test_parser.py::test_func_kwx_kwy_comma",
"tests/test_parser.py::test_func_kwx_kwy_kwz_comma",
"tests/test_parser.py::test_func_args",
"tests/test_parser.py::test_func_args_x",
"tests/test_parser.py::test_func_args_x_y",
"tests/test_parser.py::test_func_args_x_kwy",
"tests/test_parser.py::test_func_args_kwx_y",
"tests/test_parser.py::test_func_args_kwx_kwy",
"tests/test_parser.py::test_func_x_args",
"tests/test_parser.py::test_func_x_args_y",
"tests/test_parser.py::test_func_x_args_y_z",
"tests/test_parser.py::test_func_kwargs",
"tests/test_parser.py::test_func_x_kwargs",
"tests/test_parser.py::test_func_x_y_kwargs",
"tests/test_parser.py::test_func_x_kwy_kwargs",
"tests/test_parser.py::test_func_args_kwargs",
"tests/test_parser.py::test_func_x_args_kwargs",
"tests/test_parser.py::test_func_x_y_args_kwargs",
"tests/test_parser.py::test_func_kwx_args_kwargs",
"tests/test_parser.py::test_func_x_kwy_args_kwargs",
"tests/test_parser.py::test_func_x_args_y_kwargs",
"tests/test_parser.py::test_func_x_args_kwy_kwargs",
"tests/test_parser.py::test_func_args_y_kwargs",
"tests/test_parser.py::test_func_star_x",
"tests/test_parser.py::test_func_star_x_y",
"tests/test_parser.py::test_func_star_x_kwargs",
"tests/test_parser.py::test_func_star_kwx_kwargs",
"tests/test_parser.py::test_func_x_star_y",
"tests/test_parser.py::test_func_x_y_star_z",
"tests/test_parser.py::test_func_x_kwy_star_y",
"tests/test_parser.py::test_func_x_kwy_star_kwy",
"tests/test_parser.py::test_func_x_star_y_kwargs",
"tests/test_parser.py::test_func_x_divide",
"tests/test_parser.py::test_func_x_divide_y_star_z_kwargs",
"tests/test_parser.py::test_func_tx",
"tests/test_parser.py::test_func_txy",
"tests/test_parser.py::test_class",
"tests/test_parser.py::test_class_obj",
"tests/test_parser.py::test_class_int_flt",
"tests/test_parser.py::test_class_obj_kw",
"tests/test_parser.py::test_decorator",
"tests/test_parser.py::test_decorator_2",
"tests/test_parser.py::test_decorator_call",
"tests/test_parser.py::test_decorator_call_args",
"tests/test_parser.py::test_decorator_dot_call_args",
"tests/test_parser.py::test_decorator_dot_dot_call_args",
"tests/test_parser.py::test_broken_prompt_func",
"tests/test_parser.py::test_class_with_methods",
"tests/test_parser.py::test_nested_functions",
"tests/test_parser.py::test_function_blank_line",
"tests/test_parser.py::test_async_func",
"tests/test_parser.py::test_async_decorator",
"tests/test_parser.py::test_async_await",
"tests/test_parser.py::test_named_expr_args",
"tests/test_parser.py::test_named_expr_if",
"tests/test_parser.py::test_named_expr_elif",
"tests/test_parser.py::test_named_expr_while",
"tests/test_parser.py::test_path_literal",
"tests/test_parser.py::test_path_fstring_literal",
"tests/test_parser.py::test_dollar_name",
"tests/test_parser.py::test_dollar_py",
"tests/test_parser.py::test_dollar_py_test",
"tests/test_parser.py::test_dollar_py_recursive_name",
"tests/test_parser.py::test_dollar_py_test_recursive_name",
"tests/test_parser.py::test_dollar_py_test_recursive_test",
"tests/test_parser.py::test_dollar_name_set",
"tests/test_parser.py::test_dollar_py_set",
"tests/test_parser.py::test_dollar_sub",
"tests/test_parser.py::test_dollar_sub_space[$(ls",
"tests/test_parser.py::test_dollar_sub_space[$(",
"tests/test_parser.py::test_ls_dot",
"tests/test_parser.py::test_lambda_in_atparens",
"tests/test_parser.py::test_generator_in_atparens",
"tests/test_parser.py::test_bare_tuple_in_atparens",
"tests/test_parser.py::test_nested_madness",
"tests/test_parser.py::test_atparens_intoken",
"tests/test_parser.py::test_ls_dot_nesting",
"tests/test_parser.py::test_ls_dot_nesting_var",
"tests/test_parser.py::test_ls_dot_str",
"tests/test_parser.py::test_ls_nest_ls",
"tests/test_parser.py::test_ls_nest_ls_dashl",
"tests/test_parser.py::test_ls_envvar_strval",
"tests/test_parser.py::test_ls_envvar_listval",
"tests/test_parser.py::test_bang_sub",
"tests/test_parser.py::test_bang_sub_space[!(ls",
"tests/test_parser.py::test_bang_sub_space[!(",
"tests/test_parser.py::test_bang_ls_dot",
"tests/test_parser.py::test_bang_ls_dot_nesting",
"tests/test_parser.py::test_bang_ls_dot_nesting_var",
"tests/test_parser.py::test_bang_ls_dot_str",
"tests/test_parser.py::test_bang_ls_nest_ls",
"tests/test_parser.py::test_bang_ls_nest_ls_dashl",
"tests/test_parser.py::test_bang_ls_envvar_strval",
"tests/test_parser.py::test_bang_ls_envvar_listval",
"tests/test_parser.py::test_bang_envvar_args",
"tests/test_parser.py::test_question",
"tests/test_parser.py::test_dobquestion",
"tests/test_parser.py::test_question_chain",
"tests/test_parser.py::test_ls_regex",
"tests/test_parser.py::test_backtick[--]",
"tests/test_parser.py::test_backtick[--p]",
"tests/test_parser.py::test_backtick[r--]",
"tests/test_parser.py::test_backtick[r--p]",
"tests/test_parser.py::test_backtick[g--]",
"tests/test_parser.py::test_backtick[g--p]",
"tests/test_parser.py::test_ls_regex_octothorpe",
"tests/test_parser.py::test_ls_explicitregex",
"tests/test_parser.py::test_ls_explicitregex_octothorpe",
"tests/test_parser.py::test_ls_glob",
"tests/test_parser.py::test_ls_glob_octothorpe",
"tests/test_parser.py::test_ls_customsearch",
"tests/test_parser.py::test_custombacktick",
"tests/test_parser.py::test_ls_customsearch_octothorpe",
"tests/test_parser.py::test_injection",
"tests/test_parser.py::test_rhs_nested_injection",
"tests/test_parser.py::test_merged_injection",
"tests/test_parser.py::test_backtick_octothorpe",
"tests/test_parser.py::test_uncaptured_sub",
"tests/test_parser.py::test_hiddenobj_sub",
"tests/test_parser.py::test_slash_envarv_echo",
"tests/test_parser.py::test_echo_double_eq",
"tests/test_parser.py::test_bang_two_cmds_one_pipe",
"tests/test_parser.py::test_bang_three_cmds_two_pipes",
"tests/test_parser.py::test_bang_one_cmd_write",
"tests/test_parser.py::test_bang_one_cmd_append",
"tests/test_parser.py::test_bang_two_cmds_write",
"tests/test_parser.py::test_bang_two_cmds_append",
"tests/test_parser.py::test_bang_cmd_background",
"tests/test_parser.py::test_bang_cmd_background_nospace",
"tests/test_parser.py::test_bang_git_quotes_no_space",
"tests/test_parser.py::test_bang_git_quotes_space",
"tests/test_parser.py::test_bang_git_two_quotes_space",
"tests/test_parser.py::test_bang_git_two_quotes_space_space",
"tests/test_parser.py::test_bang_ls_quotes_3_space",
"tests/test_parser.py::test_two_cmds_one_pipe",
"tests/test_parser.py::test_three_cmds_two_pipes",
"tests/test_parser.py::test_two_cmds_one_and_brackets",
"tests/test_parser.py::test_three_cmds_two_ands",
"tests/test_parser.py::test_two_cmds_one_doubleamps",
"tests/test_parser.py::test_three_cmds_two_doubleamps",
"tests/test_parser.py::test_two_cmds_one_or",
"tests/test_parser.py::test_three_cmds_two_ors",
"tests/test_parser.py::test_two_cmds_one_doublepipe",
"tests/test_parser.py::test_three_cmds_two_doublepipe",
"tests/test_parser.py::test_one_cmd_write",
"tests/test_parser.py::test_one_cmd_append",
"tests/test_parser.py::test_two_cmds_write",
"tests/test_parser.py::test_two_cmds_append",
"tests/test_parser.py::test_cmd_background",
"tests/test_parser.py::test_cmd_background_nospace",
"tests/test_parser.py::test_git_quotes_no_space",
"tests/test_parser.py::test_git_quotes_space",
"tests/test_parser.py::test_git_two_quotes_space",
"tests/test_parser.py::test_git_two_quotes_space_space",
"tests/test_parser.py::test_ls_quotes_3_space",
"tests/test_parser.py::test_leading_envvar_assignment",
"tests/test_parser.py::test_echo_comma",
"tests/test_parser.py::test_echo_internal_comma",
"tests/test_parser.py::test_comment_only",
"tests/test_parser.py::test_echo_slash_question",
"tests/test_parser.py::test_bad_quotes",
"tests/test_parser.py::test_redirect",
"tests/test_parser.py::test_use_subshell[![(cat)]]",
"tests/test_parser.py::test_use_subshell[![(cat;)]]",
"tests/test_parser.py::test_use_subshell[![(cd",
"tests/test_parser.py::test_use_subshell[![(echo",
"tests/test_parser.py::test_use_subshell[![(if",
"tests/test_parser.py::test_redirect_abspath[$[cat",
"tests/test_parser.py::test_redirect_abspath[$[(cat)",
"tests/test_parser.py::test_redirect_abspath[$[<",
"tests/test_parser.py::test_redirect_abspath[![<",
"tests/test_parser.py::test_redirect_output[]",
"tests/test_parser.py::test_redirect_output[o]",
"tests/test_parser.py::test_redirect_output[out]",
"tests/test_parser.py::test_redirect_output[1]",
"tests/test_parser.py::test_redirect_error[e]",
"tests/test_parser.py::test_redirect_error[err]",
"tests/test_parser.py::test_redirect_error[2]",
"tests/test_parser.py::test_redirect_all[a]",
"tests/test_parser.py::test_redirect_all[all]",
"tests/test_parser.py::test_redirect_all[&]",
"tests/test_parser.py::test_redirect_error_to_output[-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[o-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[o-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[out-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[out-2>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>out]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>1]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>out]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>o]",
"tests/test_parser.py::test_redirect_error_to_output[1-err>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-e>&1]",
"tests/test_parser.py::test_redirect_error_to_output[1-2>&1]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[e-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[e-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[e-1>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[err-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[err-1>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>err]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>2]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>err]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>e]",
"tests/test_parser.py::test_redirect_output_to_error[2-out>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-o>&2]",
"tests/test_parser.py::test_redirect_output_to_error[2-1>&2]",
"tests/test_parser.py::test_macro_call_empty",
"tests/test_parser.py::test_macro_call_one_arg[x]",
"tests/test_parser.py::test_macro_call_one_arg[True]",
"tests/test_parser.py::test_macro_call_one_arg[None]",
"tests/test_parser.py::test_macro_call_one_arg[import",
"tests/test_parser.py::test_macro_call_one_arg[x=10]",
"tests/test_parser.py::test_macro_call_one_arg[\"oh",
"tests/test_parser.py::test_macro_call_one_arg[...]",
"tests/test_parser.py::test_macro_call_one_arg[",
"tests/test_parser.py::test_macro_call_one_arg[if",
"tests/test_parser.py::test_macro_call_one_arg[{x:",
"tests/test_parser.py::test_macro_call_one_arg[{1,",
"tests/test_parser.py::test_macro_call_one_arg[(x,y)]",
"tests/test_parser.py::test_macro_call_one_arg[(x,",
"tests/test_parser.py::test_macro_call_one_arg[((x,",
"tests/test_parser.py::test_macro_call_one_arg[g()]",
"tests/test_parser.py::test_macro_call_one_arg[range(10)]",
"tests/test_parser.py::test_macro_call_one_arg[range(1,",
"tests/test_parser.py::test_macro_call_one_arg[()]",
"tests/test_parser.py::test_macro_call_one_arg[{}]",
"tests/test_parser.py::test_macro_call_one_arg[[]]",
"tests/test_parser.py::test_macro_call_one_arg[[1,",
"tests/test_parser.py::test_macro_call_one_arg[@(x)]",
"tests/test_parser.py::test_macro_call_one_arg[!(ls",
"tests/test_parser.py::test_macro_call_one_arg[![ls",
"tests/test_parser.py::test_macro_call_one_arg[$(ls",
"tests/test_parser.py::test_macro_call_one_arg[${x",
"tests/test_parser.py::test_macro_call_one_arg[$[ls",
"tests/test_parser.py::test_macro_call_one_arg[@$(which",
"tests/test_parser.py::test_macro_call_two_args[x-True]",
"tests/test_parser.py::test_macro_call_two_args[x-import",
"tests/test_parser.py::test_macro_call_two_args[x-\"oh",
"tests/test_parser.py::test_macro_call_two_args[x-",
"tests/test_parser.py::test_macro_call_two_args[x-{x:",
"tests/test_parser.py::test_macro_call_two_args[x-{1,",
"tests/test_parser.py::test_macro_call_two_args[x-(x,",
"tests/test_parser.py::test_macro_call_two_args[x-g()]",
"tests/test_parser.py::test_macro_call_two_args[x-range(1,",
"tests/test_parser.py::test_macro_call_two_args[x-{}]",
"tests/test_parser.py::test_macro_call_two_args[x-[1,",
"tests/test_parser.py::test_macro_call_two_args[x-!(ls",
"tests/test_parser.py::test_macro_call_two_args[x-$(ls",
"tests/test_parser.py::test_macro_call_two_args[x-$[ls",
"tests/test_parser.py::test_macro_call_two_args[None-True]",
"tests/test_parser.py::test_macro_call_two_args[None-import",
"tests/test_parser.py::test_macro_call_two_args[None-\"oh",
"tests/test_parser.py::test_macro_call_two_args[None-",
"tests/test_parser.py::test_macro_call_two_args[None-{x:",
"tests/test_parser.py::test_macro_call_two_args[None-{1,",
"tests/test_parser.py::test_macro_call_two_args[None-(x,",
"tests/test_parser.py::test_macro_call_two_args[None-g()]",
"tests/test_parser.py::test_macro_call_two_args[None-range(1,",
"tests/test_parser.py::test_macro_call_two_args[None-{}]",
"tests/test_parser.py::test_macro_call_two_args[None-[1,",
"tests/test_parser.py::test_macro_call_two_args[None-!(ls",
"tests/test_parser.py::test_macro_call_two_args[None-$(ls",
"tests/test_parser.py::test_macro_call_two_args[None-$[ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-True]",
"tests/test_parser.py::test_macro_call_two_args[x=10-import",
"tests/test_parser.py::test_macro_call_two_args[x=10-\"oh",
"tests/test_parser.py::test_macro_call_two_args[x=10-",
"tests/test_parser.py::test_macro_call_two_args[x=10-{x:",
"tests/test_parser.py::test_macro_call_two_args[x=10-{1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-(x,",
"tests/test_parser.py::test_macro_call_two_args[x=10-g()]",
"tests/test_parser.py::test_macro_call_two_args[x=10-range(1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-{}]",
"tests/test_parser.py::test_macro_call_two_args[x=10-[1,",
"tests/test_parser.py::test_macro_call_two_args[x=10-!(ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-$(ls",
"tests/test_parser.py::test_macro_call_two_args[x=10-$[ls",
"tests/test_parser.py::test_macro_call_two_args[...-True]",
"tests/test_parser.py::test_macro_call_two_args[...-import",
"tests/test_parser.py::test_macro_call_two_args[...-\"oh",
"tests/test_parser.py::test_macro_call_two_args[...-",
"tests/test_parser.py::test_macro_call_two_args[...-{x:",
"tests/test_parser.py::test_macro_call_two_args[...-{1,",
"tests/test_parser.py::test_macro_call_two_args[...-(x,",
"tests/test_parser.py::test_macro_call_two_args[...-g()]",
"tests/test_parser.py::test_macro_call_two_args[...-range(1,",
"tests/test_parser.py::test_macro_call_two_args[...-{}]",
"tests/test_parser.py::test_macro_call_two_args[...-[1,",
"tests/test_parser.py::test_macro_call_two_args[...-!(ls",
"tests/test_parser.py::test_macro_call_two_args[...-$(ls",
"tests/test_parser.py::test_macro_call_two_args[...-$[ls",
"tests/test_parser.py::test_macro_call_two_args[if",
"tests/test_parser.py::test_macro_call_two_args[{x:",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-True]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-import",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{x:",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-(x,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-g()]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-{}]",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-[1,",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[(x,y)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[((x,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-True]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-import",
"tests/test_parser.py::test_macro_call_two_args[range(10)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[range(10)-",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{x:",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-(x,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-g()]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-{}]",
"tests/test_parser.py::test_macro_call_two_args[range(10)-[1,",
"tests/test_parser.py::test_macro_call_two_args[range(10)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[range(10)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[range(10)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[()-True]",
"tests/test_parser.py::test_macro_call_two_args[()-import",
"tests/test_parser.py::test_macro_call_two_args[()-\"oh",
"tests/test_parser.py::test_macro_call_two_args[()-",
"tests/test_parser.py::test_macro_call_two_args[()-{x:",
"tests/test_parser.py::test_macro_call_two_args[()-{1,",
"tests/test_parser.py::test_macro_call_two_args[()-(x,",
"tests/test_parser.py::test_macro_call_two_args[()-g()]",
"tests/test_parser.py::test_macro_call_two_args[()-range(1,",
"tests/test_parser.py::test_macro_call_two_args[()-{}]",
"tests/test_parser.py::test_macro_call_two_args[()-[1,",
"tests/test_parser.py::test_macro_call_two_args[()-!(ls",
"tests/test_parser.py::test_macro_call_two_args[()-$(ls",
"tests/test_parser.py::test_macro_call_two_args[()-$[ls",
"tests/test_parser.py::test_macro_call_two_args[[]-True]",
"tests/test_parser.py::test_macro_call_two_args[[]-import",
"tests/test_parser.py::test_macro_call_two_args[[]-\"oh",
"tests/test_parser.py::test_macro_call_two_args[[]-",
"tests/test_parser.py::test_macro_call_two_args[[]-{x:",
"tests/test_parser.py::test_macro_call_two_args[[]-{1,",
"tests/test_parser.py::test_macro_call_two_args[[]-(x,",
"tests/test_parser.py::test_macro_call_two_args[[]-g()]",
"tests/test_parser.py::test_macro_call_two_args[[]-range(1,",
"tests/test_parser.py::test_macro_call_two_args[[]-{}]",
"tests/test_parser.py::test_macro_call_two_args[[]-[1,",
"tests/test_parser.py::test_macro_call_two_args[[]-!(ls",
"tests/test_parser.py::test_macro_call_two_args[[]-$(ls",
"tests/test_parser.py::test_macro_call_two_args[[]-$[ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-True]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-import",
"tests/test_parser.py::test_macro_call_two_args[@(x)-\"oh",
"tests/test_parser.py::test_macro_call_two_args[@(x)-",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{x:",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-(x,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-g()]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-range(1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-{}]",
"tests/test_parser.py::test_macro_call_two_args[@(x)-[1,",
"tests/test_parser.py::test_macro_call_two_args[@(x)-!(ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-$(ls",
"tests/test_parser.py::test_macro_call_two_args[@(x)-$[ls",
"tests/test_parser.py::test_macro_call_two_args[![ls",
"tests/test_parser.py::test_macro_call_two_args[${x",
"tests/test_parser.py::test_macro_call_two_args[@$(which",
"tests/test_parser.py::test_macro_call_three_args[x-True-None]",
"tests/test_parser.py::test_macro_call_three_args[x-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-True-if",
"tests/test_parser.py::test_macro_call_three_args[x-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-True-${x",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[x-",
"tests/test_parser.py::test_macro_call_three_args[x-{x:",
"tests/test_parser.py::test_macro_call_three_args[x-(x,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[x-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[x-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-{}-if",
"tests/test_parser.py::test_macro_call_three_args[x-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[x-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[x-$(ls",
"tests/test_parser.py::test_macro_call_three_args[x-@$(which",
"tests/test_parser.py::test_macro_call_three_args[import",
"tests/test_parser.py::test_macro_call_three_args[...-True-None]",
"tests/test_parser.py::test_macro_call_three_args[...-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-True-if",
"tests/test_parser.py::test_macro_call_three_args[...-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-True-${x",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[...-",
"tests/test_parser.py::test_macro_call_three_args[...-{x:",
"tests/test_parser.py::test_macro_call_three_args[...-(x,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[...-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[...-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-{}-if",
"tests/test_parser.py::test_macro_call_three_args[...-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[...-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[...-$(ls",
"tests/test_parser.py::test_macro_call_three_args[...-@$(which",
"tests/test_parser.py::test_macro_call_three_args[{x:",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-True-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{x:",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-(x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-$(ls",
"tests/test_parser.py::test_macro_call_three_args[(x,y)-@$(which",
"tests/test_parser.py::test_macro_call_three_args[g()-True-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-True-if",
"tests/test_parser.py::test_macro_call_three_args[g()-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-True-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-",
"tests/test_parser.py::test_macro_call_three_args[g()-{x:",
"tests/test_parser.py::test_macro_call_three_args[g()-(x,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-if",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[g()-$(ls",
"tests/test_parser.py::test_macro_call_three_args[g()-@$(which",
"tests/test_parser.py::test_macro_call_three_args[()-True-None]",
"tests/test_parser.py::test_macro_call_three_args[()-True-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-True-if",
"tests/test_parser.py::test_macro_call_three_args[()-True-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-True-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-True-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-True-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-True-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-True-${x",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-None]",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-if",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-x=10-${x",
"tests/test_parser.py::test_macro_call_three_args[()-",
"tests/test_parser.py::test_macro_call_three_args[()-{x:",
"tests/test_parser.py::test_macro_call_three_args[()-(x,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-None]",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-if",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-range(10)-${x",
"tests/test_parser.py::test_macro_call_three_args[()-{}-None]",
"tests/test_parser.py::test_macro_call_three_args[()-{}-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-{}-if",
"tests/test_parser.py::test_macro_call_three_args[()-{}-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-{}-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-{}-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-{}-${x",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-None]",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-\"oh",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-if",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-{1,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-((x,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-range(1,",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-[]]",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-!(ls",
"tests/test_parser.py::test_macro_call_three_args[()-@(x)-${x",
"tests/test_parser.py::test_macro_call_three_args[()-$(ls",
"tests/test_parser.py::test_macro_call_three_args[()-@$(which",
"tests/test_parser.py::test_macro_call_three_args[[1,",
"tests/test_parser.py::test_macro_call_three_args[![ls",
"tests/test_parser.py::test_macro_call_three_args[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing[x]",
"tests/test_parser.py::test_macro_call_one_trailing[True]",
"tests/test_parser.py::test_macro_call_one_trailing[None]",
"tests/test_parser.py::test_macro_call_one_trailing[import",
"tests/test_parser.py::test_macro_call_one_trailing[x=10]",
"tests/test_parser.py::test_macro_call_one_trailing[\"oh",
"tests/test_parser.py::test_macro_call_one_trailing[...]",
"tests/test_parser.py::test_macro_call_one_trailing[",
"tests/test_parser.py::test_macro_call_one_trailing[if",
"tests/test_parser.py::test_macro_call_one_trailing[{x:",
"tests/test_parser.py::test_macro_call_one_trailing[{1,",
"tests/test_parser.py::test_macro_call_one_trailing[(x,y)]",
"tests/test_parser.py::test_macro_call_one_trailing[(x,",
"tests/test_parser.py::test_macro_call_one_trailing[((x,",
"tests/test_parser.py::test_macro_call_one_trailing[g()]",
"tests/test_parser.py::test_macro_call_one_trailing[range(10)]",
"tests/test_parser.py::test_macro_call_one_trailing[range(1,",
"tests/test_parser.py::test_macro_call_one_trailing[()]",
"tests/test_parser.py::test_macro_call_one_trailing[{}]",
"tests/test_parser.py::test_macro_call_one_trailing[[]]",
"tests/test_parser.py::test_macro_call_one_trailing[[1,",
"tests/test_parser.py::test_macro_call_one_trailing[@(x)]",
"tests/test_parser.py::test_macro_call_one_trailing[!(ls",
"tests/test_parser.py::test_macro_call_one_trailing[![ls",
"tests/test_parser.py::test_macro_call_one_trailing[$(ls",
"tests/test_parser.py::test_macro_call_one_trailing[${x",
"tests/test_parser.py::test_macro_call_one_trailing[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing[@$(which",
"tests/test_parser.py::test_macro_call_one_trailing_space[x]",
"tests/test_parser.py::test_macro_call_one_trailing_space[True]",
"tests/test_parser.py::test_macro_call_one_trailing_space[None]",
"tests/test_parser.py::test_macro_call_one_trailing_space[import",
"tests/test_parser.py::test_macro_call_one_trailing_space[x=10]",
"tests/test_parser.py::test_macro_call_one_trailing_space[\"oh",
"tests/test_parser.py::test_macro_call_one_trailing_space[...]",
"tests/test_parser.py::test_macro_call_one_trailing_space[",
"tests/test_parser.py::test_macro_call_one_trailing_space[if",
"tests/test_parser.py::test_macro_call_one_trailing_space[{x:",
"tests/test_parser.py::test_macro_call_one_trailing_space[{1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[(x,y)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[(x,",
"tests/test_parser.py::test_macro_call_one_trailing_space[((x,",
"tests/test_parser.py::test_macro_call_one_trailing_space[g()]",
"tests/test_parser.py::test_macro_call_one_trailing_space[range(10)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[range(1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[()]",
"tests/test_parser.py::test_macro_call_one_trailing_space[{}]",
"tests/test_parser.py::test_macro_call_one_trailing_space[[]]",
"tests/test_parser.py::test_macro_call_one_trailing_space[[1,",
"tests/test_parser.py::test_macro_call_one_trailing_space[@(x)]",
"tests/test_parser.py::test_macro_call_one_trailing_space[!(ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[![ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[$(ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[${x",
"tests/test_parser.py::test_macro_call_one_trailing_space[$[ls",
"tests/test_parser.py::test_macro_call_one_trailing_space[@$(which",
"tests/test_parser.py::test_empty_subprocbang[echo!-!(-)]",
"tests/test_parser.py::test_empty_subprocbang[echo!-$(-)]",
"tests/test_parser.py::test_empty_subprocbang[echo!-![-]]",
"tests/test_parser.py::test_empty_subprocbang[echo!-$[-]]",
"tests/test_parser.py::test_empty_subprocbang[echo",
"tests/test_parser.py::test_single_subprocbang[echo!x-!(-)]",
"tests/test_parser.py::test_single_subprocbang[echo!x-$(-)]",
"tests/test_parser.py::test_single_subprocbang[echo!x-![-]]",
"tests/test_parser.py::test_single_subprocbang[echo!x-$[-]]",
"tests/test_parser.py::test_single_subprocbang[echo",
"tests/test_parser.py::test_arg_single_subprocbang[echo",
"tests/test_parser.py::test_arg_single_subprocbang_nested[echo",
"tests/test_parser.py::test_many_subprocbang[echo!x",
"tests/test_parser.py::test_many_subprocbang[echo",
"tests/test_parser.py::test_many_subprocbang[timeit!",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!!!-$[-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!!(ls)-$[-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-!(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-$(-)]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-![-]]",
"tests/test_parser.py::test_many_subprocbang[timeit!\"!)\"-$[-]]",
"tests/test_parser.py::test_withbang_single_suite[pass\\n]",
"tests/test_parser.py::test_withbang_single_suite[x",
"tests/test_parser.py::test_withbang_single_suite[export",
"tests/test_parser.py::test_withbang_single_suite[with",
"tests/test_parser.py::test_withbang_as_single_suite[pass\\n]",
"tests/test_parser.py::test_withbang_as_single_suite[x",
"tests/test_parser.py::test_withbang_as_single_suite[export",
"tests/test_parser.py::test_withbang_as_single_suite[with",
"tests/test_parser.py::test_withbang_single_suite_trailing[pass\\n]",
"tests/test_parser.py::test_withbang_single_suite_trailing[x",
"tests/test_parser.py::test_withbang_single_suite_trailing[export",
"tests/test_parser.py::test_withbang_single_suite_trailing[with",
"tests/test_parser.py::test_withbang_single_simple[pass]",
"tests/test_parser.py::test_withbang_single_simple[x",
"tests/test_parser.py::test_withbang_single_simple[export",
"tests/test_parser.py::test_withbang_single_simple[[1,\\n",
"tests/test_parser.py::test_withbang_single_simple_opt[pass]",
"tests/test_parser.py::test_withbang_single_simple_opt[x",
"tests/test_parser.py::test_withbang_single_simple_opt[export",
"tests/test_parser.py::test_withbang_single_simple_opt[[1,\\n",
"tests/test_parser.py::test_withbang_as_many_suite[pass\\n]",
"tests/test_parser.py::test_withbang_as_many_suite[x",
"tests/test_parser.py::test_withbang_as_many_suite[export",
"tests/test_parser.py::test_withbang_as_many_suite[with",
"tests/test_parser.py::test_subproc_raw_str_literal",
"tests/test_parser.py::test_syntax_error_del_literal",
"tests/test_parser.py::test_syntax_error_del_constant",
"tests/test_parser.py::test_syntax_error_del_emptytuple",
"tests/test_parser.py::test_syntax_error_del_call",
"tests/test_parser.py::test_syntax_error_del_lambda",
"tests/test_parser.py::test_syntax_error_del_ifexp",
"tests/test_parser.py::test_syntax_error_del_comps[[i",
"tests/test_parser.py::test_syntax_error_del_comps[{i",
"tests/test_parser.py::test_syntax_error_del_comps[(i",
"tests/test_parser.py::test_syntax_error_del_comps[{k:v",
"tests/test_parser.py::test_syntax_error_del_ops[x",
"tests/test_parser.py::test_syntax_error_del_ops[-x]",
"tests/test_parser.py::test_syntax_error_del_cmp[x",
"tests/test_parser.py::test_syntax_error_lonely_del",
"tests/test_parser.py::test_syntax_error_assign_literal",
"tests/test_parser.py::test_syntax_error_assign_constant",
"tests/test_parser.py::test_syntax_error_assign_emptytuple",
"tests/test_parser.py::test_syntax_error_assign_call",
"tests/test_parser.py::test_syntax_error_assign_lambda",
"tests/test_parser.py::test_syntax_error_assign_ifexp",
"tests/test_parser.py::test_syntax_error_assign_comps[[i",
"tests/test_parser.py::test_syntax_error_assign_comps[{i",
"tests/test_parser.py::test_syntax_error_assign_comps[(i",
"tests/test_parser.py::test_syntax_error_assign_comps[{k:v",
"tests/test_parser.py::test_syntax_error_assign_ops[x",
"tests/test_parser.py::test_syntax_error_assign_ops[-x]",
"tests/test_parser.py::test_syntax_error_assign_cmp[x",
"tests/test_parser.py::test_syntax_error_augassign_literal",
"tests/test_parser.py::test_syntax_error_augassign_constant",
"tests/test_parser.py::test_syntax_error_augassign_emptytuple",
"tests/test_parser.py::test_syntax_error_augassign_call",
"tests/test_parser.py::test_syntax_error_augassign_lambda",
"tests/test_parser.py::test_syntax_error_augassign_ifexp",
"tests/test_parser.py::test_syntax_error_augassign_comps[[i",
"tests/test_parser.py::test_syntax_error_augassign_comps[{i",
"tests/test_parser.py::test_syntax_error_augassign_comps[(i",
"tests/test_parser.py::test_syntax_error_augassign_comps[{k:v",
"tests/test_parser.py::test_syntax_error_augassign_ops[x",
"tests/test_parser.py::test_syntax_error_augassign_ops[-x]",
"tests/test_parser.py::test_syntax_error_augassign_cmp[x",
"tests/test_parser.py::test_syntax_error_bar_kwonlyargs",
"tests/test_parser.py::test_syntax_error_bar_posonlyargs",
"tests/test_parser.py::test_syntax_error_bar_posonlyargs_no_comma",
"tests/test_parser.py::test_syntax_error_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_posonly_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_lambda_nondefault_follows_default",
"tests/test_parser.py::test_syntax_error_lambda_posonly_nondefault_follows_default",
"tests/test_parser.py::test_get_repo_url",
"tests/test_parser.py::test_match_and_case_are_not_keywords"
] | {
"failed_lite_validators": [
"has_added_files",
"has_many_modified_files",
"has_many_hunks"
],
"has_test_patch": true,
"is_lite": false
} | "2022-06-11T16:34:14Z" | bsd-2-clause |
|
xonsh__xonsh-4860 | diff --git a/news/xonshlexer-fix.rst b/news/xonshlexer-fix.rst
new file mode 100644
index 00000000..9207589a
--- /dev/null
+++ b/news/xonshlexer-fix.rst
@@ -0,0 +1,23 @@
+**Added:**
+
+* <news item>
+
+**Changed:**
+
+* <news item>
+
+**Deprecated:**
+
+* <news item>
+
+**Removed:**
+
+* <news item>
+
+**Fixed:**
+
+* Fixed error caused by unintialized Xonsh session env when using Xonsh as a library just for its Pygments lexer plugin.
+
+**Security:**
+
+* <news item>
diff --git a/xonsh/pyghooks.py b/xonsh/pyghooks.py
index 8c18f285..021c0406 100644
--- a/xonsh/pyghooks.py
+++ b/xonsh/pyghooks.py
@@ -1644,7 +1644,7 @@ class XonshLexer(Python3Lexer):
def __init__(self, *args, **kwargs):
# If the lexer is loaded as a pygment plugin, we have to mock
# __xonsh__.env and __xonsh__.commands_cache
- if not hasattr(XSH, "env"):
+ if getattr(XSH, "env", None) is None:
XSH.env = {}
if ON_WINDOWS:
pathext = os_environ.get("PATHEXT", [".EXE", ".BAT", ".CMD"])
| xonsh/xonsh | 52a12aaf858dc58af773da05bac6007fc525f381 | diff --git a/tests/test_pyghooks.py b/tests/test_pyghooks.py
index f6fc5e5a..48ec4d1b 100644
--- a/tests/test_pyghooks.py
+++ b/tests/test_pyghooks.py
@@ -9,8 +9,10 @@ import pytest
from xonsh.environ import LsColors
from xonsh.platform import ON_WINDOWS
from xonsh.pyghooks import (
+ XSH,
Color,
Token,
+ XonshLexer,
XonshStyle,
code_by_name,
color_file,
@@ -388,3 +390,15 @@ def test_register_custom_pygments_style(name, styles, refrules):
for rule, color in refrules.items():
assert rule in style.styles
assert style.styles[rule] == color
+
+
+def test_can_use_xonsh_lexer_without_xession(xession, monkeypatch):
+ # When Xonsh is used as a library and simply for its lexer plugin, the
+ # xession's env can be unset, so test that it can yield tokens without
+ # that env being set.
+ monkeypatch.setattr(xession, "env", None)
+
+ assert XSH.env is None
+ lexer = XonshLexer()
+ assert XSH.env is not None
+ list(lexer.get_tokens_unprocessed(" some text"))
| Error when using Xonsh pygments lexer (pyghooks.XonshLexer) outside of a console session
## xonfig
No actual `xonfig` here - using `xonsh` 0.12.6 as a library
## Expected Behavior
I should be able to use the `XonshLexer` to highlight code using Pygments even if I'm not in a Xonsh console session.
## Current Behavior
When I use the Xonsh lexer in [Pelican](https://blog.getpelican.com/), I get a KeyError because the `XSH.env` dictionary hasn't been initialized, and a check within `pyghooks.XonshLexer` that tries to guard against this doesn't work exactly as it should.
### Traceback (if applicable)
The following happens when I try to generate my Pelican static site that uses the `XonshLexer` to highlight Xonsh code:
<details>
```
| Traceback (most recent call last):
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pelican/generators.py", line 616, in generate_context
| article = self.readers.read_file(
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pelican/readers.py", line 573, in read_file
| content, reader_metadata = reader.read(path)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pelican/readers.py", line 337, in read
| content = self._md.convert(text)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/markdown/core.py", line 267, in convert
| newRoot = treeprocessor.run(root)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/markdown/extensions/codehilite.py", line 224, in run
| placeholder = self.md.htmlStash.store(code.hilite())
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/markdown/extensions/codehilite.py", line 122, in hilite
| return highlight(self.src, lexer, formatter)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/__init__.py", line 84, in highlight
| return format(lex(code, lexer), formatter, outfile)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/__init__.py", line 63, in format
| formatter.format(tokens, realoutfile)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatter.py", line 95, in format
| return self.format_unencoded(tokensource, outfile)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatters/html.py", line 879, in format_unencoded
| for t, piece in source:
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatters/html.py", line 710, in _wrap_div
| for tup in inner:
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatters/html.py", line 728, in _wrap_pre
| for tup in inner:
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatters/html.py", line 734, in _wrap_code
| for tup in inner:
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/formatters/html.py", line 753, in _format_lines
| for ttype, value in tokensource:
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/pygments/lexer.py", line 188, in streamer
| for _, t, v in self.get_tokens_unprocessed(text):
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/xonsh/pyghooks.py", line 1747, in get_tokens_unprocessed
| cmd_is_autocd = _command_is_autocd(cmd)
| File "/Users/eddiepeters/source/website/.venv/lib/python3.9/site-packages/xonsh/pyghooks.py", line 1611, in _command_is_autocd
| if not XSH.env.get("AUTO_CD", False):
| AttributeError: 'NoneType' object has no attribute 'get'
```
Note that `XSH.env.get("AUTO_CD", False)` does not allow for the non-existence of `XSH.env`.
</details>
Fix:
The problem is that the `XSH.env` property sometimes exists but is not yet initialized as a dictionary.
I believe the following line: https://github.com/xonsh/xonsh/blob/52a12aaf858dc58af773da05bac6007fc525f381/xonsh/pyghooks.py#L1647
Just needs to be changed to:
`if getattr(XSH, "env", None) is None:`
## For community
⬇️ **Please click the 👍 reaction instead of leaving a `+1` or 👍 comment**
| 0 | 2401580b6f41fe72f1360493ee46e8a842bd04ba | [
"tests/test_pyghooks.py::test_can_use_xonsh_lexer_without_xession"
] | [
"tests/test_pyghooks.py::test_color_name_to_pygments_code[RESET-noinherit]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[RED-ansired]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BACKGROUND_RED-bg:ansired]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BACKGROUND_INTENSE_RED-bg:ansibrightred]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[UNDERLINE_RED-underline",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_UNDERLINE_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[UNDERLINE_BOLD_RED-underline",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_FAINT_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_SLOWBLINK_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_FASTBLINK_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_INVERT_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_CONCEAL_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BOLD_STRIKETHROUGH_RED-bold",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[#000-#000]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[#000000-#000000]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BACKGROUND_#000-bg:#000]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BACKGROUND_#000000-bg:#000000]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[BG#000-bg:#000]",
"tests/test_pyghooks.py::test_color_name_to_pygments_code[bg#000000-bg:#000000]",
"tests/test_pyghooks.py::test_code_by_name[RESET-noinherit]",
"tests/test_pyghooks.py::test_code_by_name[RED-ansired]",
"tests/test_pyghooks.py::test_code_by_name[BACKGROUND_RED-bg:ansired]",
"tests/test_pyghooks.py::test_code_by_name[BACKGROUND_INTENSE_RED-bg:ansibrightred]",
"tests/test_pyghooks.py::test_code_by_name[BOLD_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[UNDERLINE_RED-underline",
"tests/test_pyghooks.py::test_code_by_name[BOLD_UNDERLINE_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[UNDERLINE_BOLD_RED-underline",
"tests/test_pyghooks.py::test_code_by_name[BOLD_FAINT_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[BOLD_SLOWBLINK_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[BOLD_FASTBLINK_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[BOLD_INVERT_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[BOLD_CONCEAL_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[BOLD_STRIKETHROUGH_RED-bold",
"tests/test_pyghooks.py::test_code_by_name[#000-#000]",
"tests/test_pyghooks.py::test_code_by_name[#000000-#000000]",
"tests/test_pyghooks.py::test_code_by_name[BACKGROUND_#000-bg:#000]",
"tests/test_pyghooks.py::test_code_by_name[BACKGROUND_#000000-bg:#000000]",
"tests/test_pyghooks.py::test_code_by_name[BG#000-bg:#000]",
"tests/test_pyghooks.py::test_code_by_name[bg#000000-bg:#000000]",
"tests/test_pyghooks.py::test_color_token_by_name[in_tuple0-exp_ct0-noinherit]",
"tests/test_pyghooks.py::test_color_token_by_name[in_tuple1-exp_ct1-ansigreen]",
"tests/test_pyghooks.py::test_color_token_by_name[in_tuple2-exp_ct2-bold",
"tests/test_pyghooks.py::test_color_token_by_name[in_tuple3-exp_ct3-bg:ansiblack",
"tests/test_pyghooks.py::test_XonshStyle_init_file_color_tokens",
"tests/test_pyghooks.py::test_colorize_file[fi-regular]",
"tests/test_pyghooks.py::test_colorize_file[di-simple_dir]",
"tests/test_pyghooks.py::test_colorize_file[ln-sym_link]",
"tests/test_pyghooks.py::test_colorize_file[pi-pipe]",
"tests/test_pyghooks.py::test_colorize_file[or-orphan]",
"tests/test_pyghooks.py::test_colorize_file[su-set_uid]",
"tests/test_pyghooks.py::test_colorize_file[sg-set_gid]",
"tests/test_pyghooks.py::test_colorize_file[tw-sticky_ow_dir]",
"tests/test_pyghooks.py::test_colorize_file[ow-other_writable_dir]",
"tests/test_pyghooks.py::test_colorize_file[st-sticky_dir]",
"tests/test_pyghooks.py::test_colorize_file[ex-executable]",
"tests/test_pyghooks.py::test_colorize_file[*.emf-foo.emf]",
"tests/test_pyghooks.py::test_colorize_file[*.zip-foo.zip]",
"tests/test_pyghooks.py::test_colorize_file[*.ogg-foo.ogg]",
"tests/test_pyghooks.py::test_colorize_file[mh-hard_link]",
"tests/test_pyghooks.py::test_colorize_file_symlink[fi-regular]",
"tests/test_pyghooks.py::test_colorize_file_symlink[di-simple_dir]",
"tests/test_pyghooks.py::test_colorize_file_symlink[ln-sym_link]",
"tests/test_pyghooks.py::test_colorize_file_symlink[pi-pipe]",
"tests/test_pyghooks.py::test_colorize_file_symlink[or-orphan]",
"tests/test_pyghooks.py::test_colorize_file_symlink[su-set_uid]",
"tests/test_pyghooks.py::test_colorize_file_symlink[sg-set_gid]",
"tests/test_pyghooks.py::test_colorize_file_symlink[tw-sticky_ow_dir]",
"tests/test_pyghooks.py::test_colorize_file_symlink[ow-other_writable_dir]",
"tests/test_pyghooks.py::test_colorize_file_symlink[st-sticky_dir]",
"tests/test_pyghooks.py::test_colorize_file_symlink[ex-executable]",
"tests/test_pyghooks.py::test_colorize_file_symlink[*.emf-foo.emf]",
"tests/test_pyghooks.py::test_colorize_file_symlink[*.zip-foo.zip]",
"tests/test_pyghooks.py::test_colorize_file_symlink[*.ogg-foo.ogg]",
"tests/test_pyghooks.py::test_colorize_file_symlink[mh-hard_link]",
"tests/test_pyghooks.py::test_colorize_file_ca",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test1-styles0-refrules0]",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test2-styles1-refrules1]",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test3-styles2-refrules2]",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test4-styles3-refrules3]",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test5-styles4-refrules4]",
"tests/test_pyghooks.py::test_register_custom_pygments_style[test6-styles5-refrules5]"
] | {
"failed_lite_validators": [
"has_hyperlinks",
"has_added_files"
],
"has_test_patch": true,
"is_lite": false
} | "2022-06-30T02:33:05Z" | bsd-2-clause |