
id
stringlengths 36
36
| status
stringclasses 1
value | inserted_at
timestamp[us] | updated_at
timestamp[us] | _server_id
stringlengths 36
36
| title
stringlengths 11
142
| authors
stringlengths 3
297
| filename
stringlengths 5
62
| content
stringlengths 2
64.1k
| content_class.responses
sequencelengths 1
1
| content_class.responses.users
sequencelengths 1
1
| content_class.responses.status
sequencelengths 1
1
| content_class.suggestion
sequencelengths 1
4
| content_class.suggestion.agent
null | content_class.suggestion.score
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
0a213c9b-9637-437b-b443-ee77a81eea0f | completed | 2025-01-16T03:09:11.596466 | 2025-01-19T17:17:19.097914 | e1b38558-cec3-44a1-9d97-1de32f3bde1c | Generating Human-level Text with Contrastive Search in Transformers 🤗 | GMFTBY | introducing-csearch.md | ****
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
### 1. Introduction:
Natural language generation (i.e. text generation) is one of the core tasks in natural language processing (NLP). In this blog, we introduce the current state-of-the-art decoding method, ___Contrastive Search___, for neural text generation. Contrastive search is originally proposed in _"A Contrastive Framework for Neural Text Generation"_ <a href='#references'>[1]</a> ([[Paper]](https://arxiv.org/abs/2202.06417)[[Official Implementation]](https://github.com/yxuansu/SimCTG)) at NeurIPS 2022. Moreover, in this follow-up work, _"Contrastive Search Is What You Need For Neural Text Generation"_ <a href='#references'>[2]</a> ([[Paper]](https://arxiv.org/abs/2210.14140) [[Official Implementation]](https://github.com/yxuansu/Contrastive_Search_Is_What_You_Need)), the authors further demonstrate that contrastive search can generate human-level text using **off-the-shelf** language models across **16** languages.
**[Remark]** For users who are not familiar with text generation, please refer more details to [this blog post](https://huggingface.co./blog/how-to-generate).
****
<span id='demo'/>
### 2. Hugging Face 🤗 Demo of Contrastive Search:
Contrastive Search is now available on 🤗 `transformers`, both on PyTorch and TensorFlow. You can interact with the examples shown in this blog post using your framework of choice in [this Colab notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb), which is linked at the top. We have also built this awesome [demo](https://huggingface.co./spaces/joaogante/contrastive_search_generation) which directly compares contrastive search with other popular decoding methods (e.g. beam search, top-k sampling <a href='#references'>[3]</a>, and nucleus sampling <a href='#references'>[4]</a>).
****
<span id='installation'/>
### 3. Environment Installation:
Before running the experiments in the following sections, please install the update-to-date version of `transformers` as
```yaml
pip install torch
pip install "transformers==4.24.0"
```
****
<span id='problems_of_decoding_methods'/>
### 4. Problems of Existing Decoding Methods:
Decoding methods can be divided into two categories: (i) deterministic methods and (ii) stochastic methods. Let's discuss both!
<span id='deterministic_methods'/>
#### 4.1. Deterministic Methods:
Deterministic methods, e.g. greedy search and beam search, generate text by selecting the text continuation with the highest likelihood measured by the language model. However, as widely discussed in previous studies <a href='#references'>[3]</a><a href='#references'>[4]</a>, deterministic methods often lead to the problem of _model degeneration_, i.e., the generated text is unnatural and contains undesirable repetitions.
Below, let's see an example of generated text from greedy search using GPT-2 model.
```python
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
output = model.generate(input_ids, max_length=128)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
<details open>
<summary><b>Model Output:</b></summary>
```
Output: | [
[
"llm",
"transformers",
"research",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"text_generation",
"research"
] | null | null |
197170c8-6576-4b49-9006-bb14c11f8aaa | completed | 2025-01-16T03:09:11.596478 | 2025-01-19T18:53:16.009848 | cf29eb3f-9b2f-4fe7-9053-02f895c59df9 | Summer at Hugging Face | huggingface | summer-at-huggingface.md | Summer is now officially over and these last few months have been quite busy at Hugging Face. From new features in the Hub to research and Open Source development, our team has been working hard to empower the community through open and collaborative technology.
In this blog post you'll catch up on everything that happened at Hugging Face in June, July and August!

This post covers a wide range of areas our team has been working on, so don't hesitate to skip to the parts that interest you the most 🤗
1. [New Features](#new-features)
2. [Community](#community)
3. [Open Source](#open-source)
4. [Solutions](#solutions)
5. [Research](#research)
## New Features
In the last few months, the Hub went from 10,000 public model repositories to over 16,000 models! Kudos to our community for sharing so many amazing models with the world. And beyond the numbers, we have a ton of cool new features to share with you!
### Spaces Beta ([hf.co/spaces](/spaces))
Spaces is a simple and free solution to host Machine Learning demo applications directly on your user profile or your organization [hf.co](http://hf.co/) profile. We support two awesome SDKs that let you build cool apps easily in Python: [Gradio](https://gradio.app/) and [Streamlit](https://streamlit.io/). In a matter of minutes you can deploy an app and share it with the community! 🚀
Spaces lets you [set up secrets](/docs/hub/spaces-overview#managing-secrets), permits [custom requirements](/docs/hub/spaces-dependencies), and can even be managed [directly from GitHub repos](/docs/hub/spaces-github-actions). You can sign up for the beta at [hf.co/spaces](/spaces). Here are some of our favorites!
- Create recipes with the help of [Chef Transformer](/spaces/flax-community/chef-transformer)
- Transcribe speech to text with [HuBERT](https://huggingface.co./spaces/osanseviero/HUBERT)
- Do segmentation in a video with the [DINO model](/spaces/nateraw/dino-clips)
- Use [Paint Transformer](/spaces/akhaliq/PaintTransformer) to make paintings from a given picture
- Or you can just explore any of the over [100 existing Spaces](/spaces)!

### Share Some Love
You can now like any model, dataset, or Space on [http://huggingface.co](http://huggingface.co/), meaning you can share some love with the community ❤️. You can also keep an eye on who's liking what by clicking on the likes box 👀. Go ahead and like your own repos, we're not judging 😉.

### TensorBoard Integration
In late June, we launched a TensorBoard integration for all our models. If there are TensorBoard traces in the repo, an automatic, free TensorBoard instance is launched for you. This works with both public and private repositories and for any library that has TensorBoard traces!

### Metrics
In July, we added the ability to list evaluation metrics in model repos by adding them to their model card📈. If you add an evaluation metric under the `model-index` section of your model card, it will be displayed proudly in your model repo.

If that wasn't enough, these metrics will be automatically linked to the corresponding [Papers With Code](https://paperswithcode.com/) leaderboard. That means as soon as you share your model on the Hub, you can compare your results side-by-side with others in the community. 💪
Check out [this repo](https://huggingface.co./nateraw/vit-base-beans-demo) as an example, paying close attention to `model-index` section of its [model card](https://huggingface.co./nateraw/vit-base-beans-demo/blob/main/README.md#L12-L25) to see how you can do this yourself and find the metrics in Papers with Code [automatically](https://paperswithcode.com/sota/image-classification-on-beans).
### New Widgets
The Hub has 18 widgets that allow users to try out models directly in the browser.
With our latest integrations to Sentence Transformers, we also introduced two new widgets: feature extraction and sentence similarity.
The latest **audio classification** widget enables many cool use cases: language identification, [street sound detection](https://huggingface.co./speechbrain/urbansound8k_ecapa) 🚨, [command recognition](https://huggingface.co./speechbrain/google_speech_command_xvector), [speaker identification](https://huggingface.co./speechbrain/spkrec-xvect-voxceleb), and more! You can try this out with `transformers` and `speechbrain` models today! 🔊 (Beware, when you try some of the models, you might need to bark out loud)
You can try our early demo of [structured data classification](https://huggingface.co./julien-c/wine-quality) with Scikit-learn. And finally, we also introduced new widgets for image-related models: **text to image**, **image classification**, and **object detection**. Try image classification with Google's ViT model [here](https://huggingface.co./google/vit-base-patch16-224) and object detection with Facebook AI's DETR model [here](https://huggingface.co./facebook/detr-resnet-50)!

### More Features
That's not everything that has happened in the Hub. We've introduced new and improved [documentation](https://huggingface.co./docs/hub/main) of the Hub. We also introduced two widely requested features: users can now transfer/rename repositories and directly upload new files to the Hub.

## Community
### Hugging Face Course
In June, we launched the first part of our [free online course](https://huggingface.co./course/chapter1)! The course teaches you everything about the 🤗 Ecosystem: Transformers, Tokenizers, Datasets, Accelerate, and the Hub. You can also find links to the course lessons in the official documentation of our libraries. The live sessions for all chapters can be found on our [YouTube channel](https://www.youtube.com/playlist?list=PLo2EIpI_JMQuQ8StH9RwKXwJVqLTDxwwy). Stay tuned for the next part of the course which we'll be launching later this year!

### JAX/FLAX Sprint
In July we hosted our biggest [community event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) ever with almost 800 participants! In this event co-organized with the JAX/Flax and Google Cloud teams, compute-intensive NLP, Computer Vision, and Speech projects were made accessible to a wider audience of engineers and researchers by providing free TPUv3s. The participants created over 170 models, 22 datasets, and 38 Spaces demos 🤯. You can explore all the amazing demos and projects [here](https://huggingface.co./flax-community).
There were talks around JAX/Flax, Transformers, large-scale language modeling, and more! You can find all recordings [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects#talks).
We're really excited to share the work of the 3 winning teams!
1. [Dall-e mini](https://huggingface.co./spaces/flax-community/dalle-mini). DALL·E mini is a model that generates images from any prompt you give! DALL·E mini is 27 times smaller than the original DALL·E and still has impressive results.

2. [DietNerf](https://huggingface.co./spaces/flax-community/DietNerf-Demo). DietNerf is a 3D neural view synthesis model designed for few-shot learning of 3D scene reconstruction using 2D views. This is the first Open Source implementation of the "[Putting Nerf on a Diet](https://arxiv.org/abs/2104.00677)" paper.

3. [CLIP RSIC](https://huggingface.co./spaces/sujitpal/clip-rsicd-demo). CLIP RSIC is a CLIP model fine-tuned on remote sensing image data to enable zero-shot satellite image classification and captioning. This project demonstrates how effective fine-tuned CLIP models can be for specialized domains.

Apart from these very cool projects, we're excited about how these community events enable training large and multi-modal models for multiple languages. For example, we saw the first ever Open Source big LMs for some low-resource languages like [Swahili](https://huggingface.co./models?language=sw), [Polish](https://huggingface.co./flax-community/papuGaPT2) and [Marathi](https://huggingface.co./spaces/flax-community/roberta-base-mr).
## Bonus
On top of everything we just shared, our team has been doing lots of other things. Here are just some of them:
- 📖 This 3-part [video series](https://www.youtube.com/watch?time_continue=6&v=qmN1fJ7Fdmo&feature=emb_title&ab_channel=NilsR) shows the theory on how to train state-of-the-art sentence embedding models.
- We presented at PyTorch Community Voices and participated in a QA ([video](https://www.youtube.com/watch?v=wE3bk7JaH4E&ab_channel=PyTorch)).
- Hugging Face has collaborated with [NLP in Spanish](https://twitter.com/NLP_en_ES) and [SpainAI](https://twitter.com/Spain_AI_) in a Spanish [course](https://www.youtube.com/playlist?list=PLBILcz47fTtPspj9QDm2E0oHLe1p67tMz) that teaches concepts and state-of-the art architectures as well as their applications through use cases.
- We presented at [MLOps World Demo Days](https://www.youtube.com/watch?v=lWahHp5vpVg).
## Open Source
### New in Transformers
Summer has been an exciting time for 🤗 Transformers! The library reached 50,000 stars, 30 million total downloads, and almost 1000 contributors! 🤩
So what's new? JAX/Flax is now the 3rd supported framework with over [5000](https://huggingface.co./models?library=jax&sort=downloads) models in the Hub! You can find actively maintained [examples](https://github.com/huggingface/transformers/tree/master/examples/flax) for different tasks such as text classification. We're also working hard on improving our TensorFlow support: all our [examples](https://github.com/huggingface/transformers/tree/master/examples/tensorflow) have been reworked to be more robust, TensorFlow idiomatic, and clearer. This includes examples such as summarization, translation, and named entity recognition.
You can now easily publish your model to the Hub, including automatically authored model cards, evaluation metrics, and TensorBoard instances. There is also increased support for exporting models to ONNX with the new [`transformers.onnx` module](https://huggingface.co./transformers/serialization.html?highlight=onnx).
```bash
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
```
The last 4 releases introduced many new cool models!
- [DETR](https://huggingface.co./transformers/model_doc/detr.html) can do fast end-to-end object detection and image segmentation. Check out some of our community [tutorials](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR)!

- [ByT5](https://huggingface.co./transformers/model_doc/byt5.html) is the first tokenizer-free model in the Hub! You can find all available checkpoints [here](https://huggingface.co./models?search=byt5).
- [CANINE](https://huggingface.co./transformers/model_doc/canine.html) is another tokenizer-free encoder-only model by Google AI, operating directly at the character level. You can find all (multilingual) checkpoints [here](https://huggingface.co./models?search=canine).
- [HuBERT](https://huggingface.co./transformers/model_doc/hubert.html?highlight=hubert) shows exciting results for downstream audio tasks such as [command classification](https://huggingface.co./superb/hubert-base-superb-ks) and [emotion recognition](https://huggingface.co./superb/hubert-base-superb-er). Check the models [here](https://huggingface.co./models?filter=hubert).
- [LayoutLMv2](https://huggingface.co./transformers/model_doc/layoutlmv2.html) and [LayoutXLM](https://huggingface.co./transformers/model_doc/layoutxlm.html?highlight=layoutxlm) are two incredible models capable of parsing document images (like PDFs) by incorporating text, layout, and visual information. We built a [Space demo](https://huggingface.co./spaces/nielsr/LayoutLMv2-FUNSD) so you can directly try it out! Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2).

- [BEiT](https://huggingface.co./transformers/model_doc/beit.html) by Microsoft Research makes self-supervised Vision Transformers outperform supervised ones, using a clever pre-training objective inspired by BERT.
- [RemBERT](https://huggingface.co./transformers/model_doc/rembert.html?), a large multilingual Transformer that outperforms XLM-R (and mT5 with a similar number of parameters) in zero-shot transfer.
- [Splinter](https://huggingface.co./transformers/model_doc/splinter.html) which can be used for few-shot question answering. Given only 128 examples, Splinter is able to reach ~73% F1 on SQuAD, outperforming MLM-based models by 24 points!
The Hub is now integrated into `transformers`, with the ability to push to the Hub configuration, model, and tokenizer files without leaving the Python runtime! The `Trainer` can now push directly to the Hub every time a checkpoint is saved:

### New in Datasets
You can find 1400 public datasets in [https://huggingface.co./datasets](https://huggingface.co./datasets) thanks to the awesome contributions from all our community. 💯
The support for `datasets` keeps growing: it can be used in JAX, process parquet files, use remote files, and has wider support for other domains such as Automatic Speech Recognition and Image Classification.
Users can also directly host and share their datasets to the community simply by uploading their data files in a repository on the Dataset Hub.

What are the new datasets highlights? Microsoft CodeXGlue [datasets](https://huggingface.co./datasets?search=code_x_glue) for multiple coding tasks (code completion, generation, search, etc), huge datasets such as [C4](https://huggingface.co./datasets/c4) and [MC4](https://huggingface.co./datasets/mc4), and many more such as [RussianSuperGLUE](https://huggingface.co./datasets/russian_super_glue) and [DISFL-QA](https://huggingface.co./datasets/disfl_qa).
### Welcoming new Libraries to the Hub
Apart from having deep integration with `transformers`-based models, the Hub is also building great partnerships with Open Source ML libraries to provide free model hosting and versioning. We've been achieving this with our [huggingface_hub](https://github.com/huggingface/huggingface_hub) Open-Source library as well as new Hub [documentation](https://huggingface.co./docs/hub/main).
All spaCy canonical pipelines can now be found in the official spaCy [organization](https://huggingface.co./spacy), and any user can share their pipelines with a single command `python -m spacy huggingface-hub`. To read more about it, head to [https://huggingface.co./blog/spacy](https://huggingface.co./blog/spacy). You can try all canonical spaCy models directly in the Hub in the demo [Space](https://huggingface.co./spaces/spacy/pipeline-visualizer)!

Another exciting integration is Sentence Transformers. You can read more about it in the [blog announcement](https://huggingface.co./blog/sentence-transformers-in-the-hub): you can find over 200 [models](https://huggingface.co./models?library=sentence-transformers) in the Hub, easily share your models with the rest of the community and reuse models from the community.
But that's not all! You can now find over 100 Adapter Transformers in the Hub and try out Speechbrain models with widgets directly in the browser for different tasks such as audio classification. If you're interested in our collaborations to integrate new ML libraries to the Hub, you can read more about them [here](https://huggingface.co./docs/hub/libraries).

## Solutions
### **Coming soon: Infinity**
Transformers latency down to 1ms? 🤯🤯🤯
We have been working on a really sleek solution to achieve unmatched efficiency for state-of-the-art Transformer models, for companies to deploy in their own infrastructure.
- Infinity comes as a single-container and can be deployed in any production environment.
- It can achieve 1ms latency for BERT-like models on GPU and 4-10ms on CPU 🤯🤯🤯
- Infinity meets the highest security requirements and can be integrated into your system without the need for internet access. You have control over all incoming and outgoing traffic.
⚠️ Join us for a [live announcement and demo on Sep 28](https://app.livestorm.co/hugging-face/hugging-face-infinity-launch?type=detailed), where we will be showcasing Infinity for the first time in public!
### **NEW: Hardware Acceleration**
Hugging Face is [partnering with leading AI hardware accelerators](http://hf.co/hardware) such as Intel, Qualcomm and GraphCore to make state-of-the-art production performance accessible and extend training capabilities on SOTA hardware. As the first step in this journey, we [introduced a new Open Source library](https://huggingface.co./blog/hardware-partners-program): 🤗 Optimum - the ML optimization toolkit for production performance 🏎. Learn more in this [blog post](https://huggingface.co./blog/graphcore).
### **NEW: Inference on SageMaker**
We launched a [new integration with AWS](https://huggingface.co./blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) to make it easier than ever to deploy 🤗 Transformers in SageMaker 🔥. Pick up the code snippet right from the 🤗 Hub model page! Learn more about how to leverage transformers in SageMaker in our [docs](https://huggingface.co./docs/sagemaker/inference) or check out these [video tutorials](https://youtube.com/playlist?list=PLo2EIpI_JMQtPhGR5Eo2Ab0_Vb89XfhDJ).
For questions reach out to us on the forum: [https://discuss.huggingface.co/c/sagemaker/17](https://discuss.huggingface.co/c/sagemaker/17)

### **NEW: AutoNLP In Your Browser**
We released a new [AutoNLP](https://huggingface.co./autonlp) experience: a web interface to train models straight from your browser! Now all it takes is a few clicks to train, evaluate and deploy **🤗** Transformers models on your own data. [Try it out](https://ui.autonlp.huggingface.co/) - NO CODE needed!

### Inference API
**Webinar**:
We hosted a [live webinar](https://youtu.be/p055U0dnEos) to show how to add Machine Learning capabilities with just a few lines of code. We also built a VSCode extension that leverages the Hugging Face Inference API to generate comments describing Python code.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/p055U0dnEos"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face** + **Zapier Demo**
20,000+ Machine Learning models connected to 3,000+ apps? 🤯 By leveraging the [Inference API](https://huggingface.co./landing/inference-api/startups), you can now easily connect models right into apps like Gmail, Slack, Twitter, and more. In this demo video, we created a zap that uses this [code snippet](https://gist.github.com/feconroses/3476a91dc524fdb930a726b3894a1d08) to analyze your Twitter mentions and alerts you on Slack about the negative ones.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/sjfpOJ4KA78"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face + Google Sheets Demo**
With the [Inference API](https://huggingface.co./landing/inference-api/startups), you can easily use zero-shot classification right into your spreadsheets in Google Sheets. Just [add this script](https://gist.github.com/feconroses/302474ddd3f3c466dc069ecf16bb09d7) in Tools -> Script Editor:
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/-A-X3aUYkDs"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Few-shot learning in practice**
We wrote a [blog post](https://huggingface.co./blog/few-shot-learning-gpt-neo-and-inference-api) about what Few-Shot Learning is and explores how GPT-Neo and 🤗 Accelerated Inference API are used to generate your own predictions.
### **Expert Acceleration Program**
Check out out the brand [new home for the Expert Acceleration Program](https://huggingface.co./landing/premium-support); you can now get direct, premium support from our Machine Learning experts and build better ML solutions, faster.
## Research
At BigScience we held our first live event (since the kick off) in July BigScience Episode #1. Our second event BigScience Episode #2 was held on September 20th, 2021 with technical talks and updates by the BigScience working groups and invited talks by Jade Abbott (Masakhane), Percy Liang (Stanford CRFM), Stella Biderman (EleutherAI) and more. We have completed the first large-scale training on Jean Zay, a 13B English only decoder model (you can find the details [here](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr1-13B-base/chronicles.md)), and we're currently deciding on the architecture of the second model. The organization working group has filed the application for the second half of the compute budget: Jean Zay V100 : 2,500,000 GPU hours. 🚀
In June, we shared the result of our collaboration with the Yandex research team: [DeDLOC](https://arxiv.org/abs/2106.10207), a method to collaboratively train your large neural networks, i.e. without using an HPC cluster, but with various accessible resources such as Google Colaboratory or Kaggle notebooks, personal computers or preemptible VMs. Thanks to this method, we were able to train [sahajBERT](https://huggingface.co./neuropark/sahajBERT), a Bengali language model, with 40 volunteers! And our model competes with the state of the art, and even is [the best for the downstream task of classification](https://huggingface.co./neuropark/sahajBERT-NCC) on Soham News Article Classification dataset. You can read more about it in this [blog](https://huggingface.co./blog/collaborative-training) post. This is a fascinating line of research because it would make model pre-training much more accessible (financially speaking)!
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/v8ShbLasRF8"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
In June our [paper](https://arxiv.org/abs/2103.08493), How Many Data Points is a Prompt Worth?, got a Best Paper award at NAACL! In it, we reconcile and compare traditional and prompting approaches to adapt pre-trained models, finding that human-written prompts are worth up to thousands of supervised data points on new tasks. You can also read its blog [post](https://huggingface.co./blog/how_many_data_points/).

We're looking forward to EMNLP this year where we have four accepted papers!
- Our [paper](https://arxiv.org/abs/2109.02846) "[Datasets: A Community Library for Natural Language Processing](https://arxiv.org/abs/2109.02846)" documents the Hugging Face Datasets project that has over 300 contributors. This community project gives easy access to hundreds of datasets to researchers. It has facilitated new use cases of cross-dataset NLP, and has advanced features for tasks like indexing and streaming large datasets.
- Our collaboration with researchers from TU Darmstadt lead to another paper accepted at the conference (["Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning"](https://arxiv.org/abs/2109.04144)). In this paper, we show that prompt-based fine-tuned language models (which achieve strong performance in few-shot setups) still suffer from learning surface heuristics (sometimes called *dataset biases*), a pitfall that zero-shot models don't exhibit.
- Our submission "[Block Pruning For Faster Transformers](https://arxiv.org/abs/2109.04838v1)" has also been accepted as a long paper. In this paper, we show how to use block sparsity to obtain both fast and small Transformer models. Our experiments yield models which are 2.4x faster and 74% smaller than BERT on SQuAD.
## Last words
😎 🔥 Summer was fun! So many things have happened! We hope you enjoyed reading this blog post and looking forward to share the new projects we're working on. See you in the winter! ❄️ | [
[
"research",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"research",
"tools"
] | null | null |
0aa257a0-36cf-4e1a-86cb-37aa082bbe21 | completed | 2025-01-16T03:09:11.596484 | 2025-01-16T15:16:02.250253 | 2a3cd58c-3c34-481a-94fb-43fe7e41b67e | AudioLDM 2, but faster ⚡️ | sanchit-gandhi | audioldm2.md | <a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
AudioLDM 2 was proposed in [AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining](https://arxiv.org/abs/2308.05734)
by Haohe Liu et al. AudioLDM 2 takes a text prompt as input and predicts the corresponding audio. It can generate realistic
sound effects, human speech and music.
While the generated audios are of high quality, running inference with the original implementation is very slow: a 10
second audio sample takes upwards of 30 seconds to generate. This is due to a combination of factors, including a deep
multi-stage modelling approach, large checkpoint sizes, and un-optimised code.
In this blog post, we showcase how to use AudioLDM 2 in the Hugging Face 🧨 Diffusers library, exploring a range of code
optimisations such as half-precision, flash attention, and compilation, and model optimisations such as scheduler choice
and negative prompting, to reduce the inference time by over **10 times**, with minimal degradation in quality of the
output audio. The blog post is also accompanied by a more streamlined [Colab notebook](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb),
that contains all the code but fewer explanations.
Read to the end to find out how to generate a 10 second audio sample in just 1 second!
## Model overview
Inspired by [Stable Diffusion](https://huggingface.co./docs/diffusers/api/pipelines/stable_diffusion/overview), AudioLDM 2
is a text-to-audio _latent diffusion model (LDM)_ that learns continuous audio representations from text embeddings.
The overall generation process is summarised as follows:
1. Given a text input \\(\boldsymbol{x}\\), two text encoder models are used to compute the text embeddings: the text-branch of [CLAP](https://huggingface.co./docs/transformers/main/en/model_doc/clap), and the text-encoder of [Flan-T5](https://huggingface.co./docs/transformers/main/en/model_doc/flan-t5)
$$
\boldsymbol{E}_{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_{2} = \text{T5}\left(\boldsymbol{x}\right)
$$
The CLAP text embeddings are trained to be aligned with the embeddings of the corresponding audio sample, whereas the Flan-T5 embeddings give a better representation of the semantics of the text.
2. These text embeddings are projected to a shared embedding space through individual linear projections:
$$
\boldsymbol{P}_{1} = \boldsymbol{W}_{\text{CLAP}} \boldsymbol{E}_{1}; \quad \boldsymbol{P}_{2} = \boldsymbol{W}_{\text{T5}}\boldsymbol{E}_{2}
$$
In the `diffusers` implementation, these projections are defined by the [AudioLDM2ProjectionModel](https://huggingface.co./docs/diffusers/api/pipelines/audioldm2/AudioLDM2ProjectionModel).
3. A [GPT2](https://huggingface.co./docs/transformers/main/en/model_doc/gpt2) language model (LM) is used to auto-regressively generate a sequence of \\(N\\) new embedding vectors, conditional on the projected CLAP and Flan-T5 embeddings:
$$
\tilde{\boldsymbol{E}}_{i} = \text{GPT2}\left(\boldsymbol{P}_{1}, \boldsymbol{P}_{2}, \tilde{\boldsymbol{E}}_{1:i-1}\right) \qquad \text{for } i=1,\dots,N
$$
4. The generated embedding vectors \\(\tilde{\boldsymbol{E}}_{1:N}\\) and Flan-T5 text embeddings \\(\boldsymbol{E}_{2}\\) are used as cross-attention conditioning in the LDM, which *de-noises*
a random latent via a reverse diffusion process. The LDM is run in the reverse diffusion process for a total of \\(T\\) inference steps:
$$
\boldsymbol{z}_{t} = \text{LDM}\left(\boldsymbol{z}_{t-1} | \tilde{\boldsymbol{E}}_{1:N}, \boldsymbol{E}_{2}\right) \qquad \text{for } t = 1, \dots, T
$$
where the initial latent variable \\(\boldsymbol{z}_{0}\\) is drawn from a normal distribution \\(\mathcal{N} \left(\boldsymbol{0}, \boldsymbol{I} \right)\\).
The [UNet](https://huggingface.co./docs/diffusers/api/pipelines/audioldm2/AudioLDM2UNet2DConditionModel) of the LDM is unique in
the sense that it takes **two** sets of cross-attention embeddings, \\(\tilde{\boldsymbol{E}}_{1:N}\\) from the GPT2 language model and \\(\boldsymbol{E}_{2}\\)
from Flan-T5, as opposed to one cross-attention conditioning as in most other LDMs.
5. The final de-noised latents \\(\boldsymbol{z}_{T}\\) are passed to the VAE decoder to recover the Mel spectrogram \\(\boldsymbol{s}\\):
$$
\boldsymbol{s} = \text{VAE}_{\text{dec}} \left(\boldsymbol{z}_{T}\right)
$$
6. The Mel spectrogram is passed to the vocoder to obtain the output audio waveform \\(\mathbf{y}\\):
$$
\boldsymbol{y} = \text{Vocoder}\left(\boldsymbol{s}\right)
$$
The diagram below demonstrates how a text input is passed through the text conditioning models, with the two prompt embeddings used as cross-conditioning in the LDM:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/audioldm2.png?raw=true" width="600"/>
</p>
For full details on how the AudioLDM 2 model is trained, the reader is referred to the [AudioLDM 2 paper](https://arxiv.org/abs/2308.05734).
Hugging Face 🧨 Diffusers provides an end-to-end inference pipeline class [`AudioLDM2Pipeline`](https://huggingface.co./docs/diffusers/main/en/api/pipelines/audioldm2) that wraps this multi-stage generation process into a single callable object, enabling you to generate audio samples from text in just a few lines of code.
AudioLDM 2 comes in three variants. Two of these checkpoints are applicable to the general task of text-to-audio generation. The third checkpoint is trained exclusively on text-to-music generation. See the table below for details on the three official checkpoints, which can all be found on the [Hugging Face Hub](https://huggingface.co./models?search=cvssp/audioldm2):
| Checkpoint | Task | Model Size | Training Data / h |
| | [
[
"audio",
"research",
"implementation",
"optimization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"audio",
"implementation",
"optimization",
"research"
] | null | null |
52178b63-05af-4cfc-bdaf-453b268b7ffd | completed | 2025-01-16T03:09:11.596489 | 2025-01-19T19:13:35.377297 | 856ae484-db41-42df-980a-515a295dcb74 | Using Machine Learning to Aid Survivors and Race through Time | merve, adirik | using-ml-for-disasters.md | On February 6, 2023, earthquakes measuring 7.7 and 7.6 hit South Eastern Turkey, affecting 10 cities and resulting in more than 42,000 deaths and 120,000 injured as of February 21.
A few hours after the earthquake, a group of programmers started a Discord server to roll out an application called *afetharita*, literally meaning, *disaster map*. This application would serve search & rescue teams and volunteers to find survivors and bring them help. The need for such an app arose when survivors posted screenshots of texts with their addresses and what they needed (including rescue) on social media. Some survivors also tweeted what they needed so their relatives knew they were alive and that they need rescue. Needing to extract information from these tweets, we developed various applications to turn them into structured data and raced against time in developing and deploying these apps.
When I got invited to the discord server, there was quite a lot of chaos regarding how we (volunteers) would operate and what we would do. We decided to collaboratively train models so we needed a model and dataset registry. We opened a Hugging Face organization account and collaborated through pull requests as to build ML-based applications to receive and process information.

We had been told by volunteers in other teams that there's a need for an application to post screenshots, extract information from the screenshots, structure it and write the structured information to the database. We started developing an application that would take a given image, extract the text first, and from text, extract a name, telephone number, and address and write these informations to a database that would be handed to authorities. After experimenting with various open-source OCR tools, we started using `easyocr` for OCR part and `Gradio` for building an interface for this application. We were asked to build a standalone application for OCR as well so we opened endpoints from the interface. The text output from OCR is parsed using transformers-based fine-tuned NER model.

To collaborate and improve the application, we hosted it on Hugging Face Spaces and we've received a GPU grant to keep the application up and running. Hugging Face Hub team has set us up a CI bot for us to have an ephemeral environment, so we could see how a pull request would affect the Space, and it helped us during pull request reviews.
Later on, we were given labeled content from various channels (e.g. twitter, discord) with raw tweets of survivors' calls for help, along with the addresses and personal information extracted from them. We started experimenting both with few-shot prompting of closed-source models and fine-tuning our own token classification model from transformers. We’ve used [bert-base-turkish-cased](https://huggingface.co./dbmdz/bert-base-turkish-cased) as a base model for token classification and came up with the first address extraction model.

The model was later used in `afetharita` to extract addresses. The parsed addresses would be sent to a geocoding API to obtain longitude and latitude, and the geolocation would then be displayed on the front-end map. For inference, we have used Inference API, which is an API that hosts model for inference and is automatically enabled when the model is pushed to Hugging Face Hub. Using Inference API for serving has saved us from pulling the model, writing an app, building a docker image, setting up CI/CD, and deploying the model to a cloud instance, where it would be extra overhead work for the DevOps and cloud teams as well. Hugging Face teams have provided us with more replicas so that there would be no downtime and the application would be robust against a lot of traffic.

Later on, we were asked if we could extract what earthquake survivors need from a given tweet. We were given data with multiple labels for multiple needs in a given tweet, and these needs could be shelter, food, or logistics, as it was freezing cold over there. We’ve started experimenting first with zero-shot experimentations with open-source NLI models on Hugging Face Hub and few-shot experimentations with closed-source generative model endpoints. We have tried [xlm-roberta-large-xnli](https://huggingface.co./joeddav/xlm-roberta-large-xnli) and [convbert-base-turkish-mc4-cased-allnli_tr](https://huggingface.co./emrecan/convbert-base-turkish-mc4-cased-allnli_tr). NLI models were particularly useful as we could directly infer with candidate labels and change the labels as data drift occurs, whereas generative models could have made up labels and cause mismatches when giving responses to the backend. We initially didn’t have labeled data so anything would work.
In the end, we decided to fine-tune our own model as it would take roughly three minutes to fine-tune BERT’s text classification head on a single GPU. We had a labelling effort to develop the dataset to train this model. We logged our experiments in the model card’s metadata so we could later come up with a leaderboard to keep track of which model should be deployed to production. For base model, we have tried [bert-base-turkish-uncased](https://huggingface.co./loodos/bert-base-turkish-uncased) and [bert-base-turkish-128k-cased](https://huggingface.co./dbmdz/bert-base-turkish-128k-cased) and realized they perform better than [bert-base-turkish-cased](https://huggingface.co./dbmdz/bert-base-turkish-cased). You can find our leaderboard [here](https://huggingface.co./spaces/deprem-ml/intent-leaderboard).

Considering the task at hand and the imbalance of our data classes, we focused on eliminating false negatives and created a Space to benchmark the recall and F1-scores of all models. To do this, we added the metadata tag `deprem-clf-v1` to all relevant model repos and used this tag to automatically retrieve the logged F1 and recall scores and rank models. We had a separate benchmark set to avoid leakage to the train set and consistently benchmark our models. We also benchmarked each model to identify the best threshold per label for deployment.
We wanted our NER model to be evaluated and crowd-sourced the effort because the data labelers were working to give us better and updated intent datasets. To evaluate the NER model, we’ve set up a labeling interface using `Argilla` and `Gradio`, where people could input a tweet and flag the output as correct/incorrect/ambiguous.

Later, the dataset was deduplicated and used to benchmark our further experiments.
Another team under machine learning has worked with generative models (behind a gated API) to get the specific needs (as labels were too broad) as free text and pass the text as an additional context to each posting. For this, they’ve done prompt engineering and wrapped the API endpoints as a separate API, and deployed them on the cloud. We found that using few-shot prompting with LLMs helps adjust to fine-grained needs in the presence of rapidly developing data drift, as the only thing we need to adjust is the prompt and we do not need any labeled data for this.
These models are currently being used in production to create the points in the heat map below so that volunteers and search and rescue teams can bring the needs to survivors.

We’ve realized that if it wasn’t for Hugging Face Hub and the ecosystem, we wouldn’t be able to collaborate, prototype, and deploy this fast. Below is our MLOps pipeline for address recognition and intent classification models.

There are tens of volunteers behind this application and its individual components, who worked with no sleep to get these out in such a short time.
## Remote Sensing Applications
Other teams worked on remote sensing applications to assess the damage to buildings and infrastructure in an effort to direct search and rescue operations. The lack of electricity and stable mobile networks during the first 48 hours of the earthquake, combined with collapsed roads, made it extremely difficult to assess the extent of the damage and where help was needed. The search and rescue operations were also heavily affected by false reports of collapsed and damaged buildings due to the difficulties in communication and transportation.
To address these issues and create open source tools that can be leveraged in the future, we started by collecting pre and post-earthquake satellite images of the affected zones from Planet Labs, Maxar and Copernicus Open Access Hub.

Our initial approach was to rapidly label satellite images for object detection and instance segmentation, with a single category for "buildings". The aim was to evaluate the extent of damage by comparing the number of surviving buildings in pre- and post-earthquake images collected from the same area. In order to make it easier to train models, we started by cropping 1080x1080 satellite images into smaller 640x640 chunks. Next, we fine-tuned [YOLOv5](https://huggingface.co./spaces/deprem-ml/deprem_satellite_test), YOLOv8 and EfficientNet models for building detection and a [SegFormer](https://huggingface.co./spaces/deprem-ml/deprem_satellite_semantic_whu) model for semantic segmentation of buildings, and deployed these apps as Hugging Face Spaces.

Once again, dozens of volunteers worked on labeling, preparing data, and training models. In addition to individual volunteers, companies like [Co-One](https://co-one.co/) volunteered to label satellite data with more detailed annotations for buildings and infrastructure, including *no damage*, *destroyed*, *damaged*, *damaged facility,* and *undamaged facility* labels. Our current objective is to release an extensive open-source dataset that can expedite search and rescue operations worldwide in the future.

## Wrapping Up
For this extreme use case, we had to move fast and optimize over classification metrics where even one percent improvement mattered. There were many ethical discussions in the progress, as even picking the metric to optimize over was an ethical question. We have seen how open-source machine learning and democratization enables individuals to build life-saving applications.
We are thankful for the community behind Hugging Face for releasing these models and datasets, and team at Hugging Face for their infrastructure and MLOps support. | [
[
"data",
"implementation",
"community",
"text_classification"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"text_classification",
"community",
"implementation"
] | null | null |
5fa1a269-bacb-410c-9a09-5be50175f97a | completed | 2025-01-16T03:09:11.596494 | 2025-01-19T19:12:11.142761 | 610edbad-fe3c-493c-a9e9-3d95a5b4d895 | An Introduction to Q-Learning Part 1 | ThomasSimonini | deep-rl-q-part1.md | <h2>Unit 2, part 1 of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co./deep-rl-course/unit1/introduction](https://huggingface.co./deep-rl-course/unit2/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co./deep-rl-course/unit0/introduction)*
<img src="assets/70_deep_rl_q_part1/thumbnail.gif" alt="Thumbnail"/> | [
[
"research",
"implementation",
"tutorial",
"robotics"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tutorial",
"implementation",
"research",
"robotics"
] | null | null |
ac3dbcb1-7a08-4028-b08c-071553560797 | completed | 2025-01-16T03:09:11.596499 | 2025-01-19T18:56:46.042767 | 78d5ff5e-e703-418c-860b-5237090c90b5 | Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub | davanstrien | huggylingo.md | **tl;dr**: We're using machine learning to detect the language of Hub datasets with no language metadata, and [librarian-bots](https://huggingface.co./librarian-bots) to make pull requests to add this metadata.
The Hugging Face Hub has become the repository where the community shares machine learning models, datasets, and applications. As the number of datasets grows, metadata becomes increasingly important as a tool for finding the right resource for your use case.
In this blog post, I'm excited to share some early experiments which seek to use machine learning to improve the metadata for datasets hosted on the Hugging Face Hub.
### Language metadata for datasets on the Hub
There are currently ~50K public datasets on the Hugging Face Hub. Metadata about the language used in a dataset can be specified using a [YAML](https://en.wikipedia.org/wiki/YAML) field at the top of the [dataset card](https://huggingface.co./docs/datasets/upload_dataset#create-a-dataset-card).
All public datasets specify 1,716 unique languages via a language tag in their metadata. Note that some of them will be the result of languages being specified in different ways i.e. `en` vs `eng` vs `english` vs `English`.
For example, the [IMDB dataset](https://huggingface.co./datasets/imdb) specifies `en` in the YAML metadata (indicating English):

* Section of the YAML metadata for the IMDB dataset*
It is perhaps unsurprising that English is by far the most common language for datasets on the Hub, with around 19% of datasets on the Hub listing their language as `en` (not including any variations of `en`, so the actual percentage is likely much higher).

*The frequency and percentage frequency for datasets on the Hugging Face Hub*
What does the distribution of languages look like if we exclude English? We can see that there is a grouping of a few dominant languages and after that there is a pretty smooth fall in the frequencies at which languages appear.

*Distribution of language tags for datasets on the hub excluding English*
However, there is a major caveat to this. Most datasets (around 87%) do not specify any language at all!

*The percent of datasets which have language metadata. True indicates language metadata is specified, False means no language data is listed. No card data means that there isn't any metadata or it couldn't be loaded by the `huggingface_hub` Python library.*
#### Why is language metadata important?
Language metadata can be a vital tool for finding relevant datasets. The Hugging Face Hub allows you to filter datasets by language. For example, if we want to find datasets with Dutch language we can use [a filter](https://huggingface.co./datasets?language=language:nl&sort=trending) on the Hub to include only datasets with Dutch data.
Currently this filter returns 184 datasets. However, there are datasets on the Hub which include Dutch but don't specify this in the metadata. These datasets become more difficult to find, particularly as the number of datasets on the Hub grows.
Many people want to be able to find datasets for a particular language. One of the major barriers to training good open source LLMs for a particular language is a lack of high quality training data.
If we switch to the task of finding relevant machine learning models, knowing what languages were included in the training data for a model can help us find models for the language we are interested in. This relies on the dataset specifying this information.
Finally, knowing what languages are represented on the Hub (and which are not), helps us understand the language biases of the Hub and helps inform community efforts to address gaps in particular languages.
### Predicting the languages of datasets using machine learning
We’ve already seen that many of the datasets on the Hugging Face Hub haven’t included metadata for the language used. However, since these datasets are already shared openly, perhaps we can look at the dataset and try to identify the language using machine learning.
#### Getting the data
One way we could access some examples from a dataset is by using the datasets library to download the datasets i.e.
```python
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")
```
However, for some of the datasets on the Hub, we might be keen not to download the whole dataset. We could instead try to load a sample of the dataset. However, depending on how the dataset was created, we might still end up downloading more data than we’d need onto the machine we’re working on.
Luckily, many datasets on the Hub are available via the [dataset viewer API](https://huggingface.co./docs/datasets-server/index). It allows us to access datasets hosted on the Hub without downloading the dataset locally. The API powers the dataset viewer you will see for many datasets hosted on the Hub.
For this first experiment with predicting language for datasets, we define a list of column names and data types likely to contain textual content i.e. `text` or `prompt` column names and `string` features are likely to be relevant `image` is not. This means we can avoid predicting the language for datasets where language information is less relevant, for example, image classification datasets. We use the dataset viewer API to get 20 rows of text data to pass to a machine learning model (we could modify this to take more or fewer examples from the dataset).
This approach means that for the majority of datasets on the Hub we can quickly request the contents of likely text columns for the first 20 rows in a dataset.
#### Predicting the language of a dataset
Once we have some examples of text from a dataset, we need to predict the language. There are various options here, but for this work, we used the [facebook/fasttext-language-identification](https://huggingface.co./facebook/fasttext-language-identification) fastText model created by [Meta](https://huggingface.co./facebook) as part of the [No Language Left Behind](https://ai.facebook.com/research/no-language-left-behind/) work. This model can detect 217 languages which will likely represent the majority of languages for datasets hosted on the Hub.
We pass 20 examples to the model representing rows from a dataset. This results in 20 individual language predictions (one per row) for each dataset.
Once we have these predictions, we do some additional filtering to determine if we will accept the predictions as a metadata suggestion. This roughly consists of:
- Grouping the predictions for each dataset by language: some datasets return predictions for multiple languages. We group these predictions by the language predicted i.e. if a dataset returns predictions for English and Dutch, we group the English and Dutch predictions together.
- For datasets with multiple languages predicted, we count how many predictions we have for each language. If a language is predicted less than 20% of the time, we discard this prediction. i.e. if we have 18 predictions for English and only 2 for Dutch we discard the Dutch predictions.
- We calculate the mean score for all predictions for a language. If the mean score associated with a languages prediction is below 80% we discard this prediction.
Once we’ve done this filtering, we have a further step of deciding how to use these predictions. The fastText language prediction model returns predictions as an [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) code (an international standard for language codes) along with a script type. i.e. `kor_Hang` is the ISO 693-3 language code for Korean (kor) + Hangul script (Hang) a [ISO 15924](https://en.wikipedia.org/wiki/ISO_15924) code representing the script of a language.
We discard the script information since this isn't currently captured consistently as metadata on the Hub and, where possible, we convert the language prediction returned by the model from [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) to [ISO 639-1](https://en.wikipedia.org/wiki/ISO_639-1) language codes. This is largely done because these language codes have better support in the Hub UI for navigating datasets.
For some ISO 639-3 codes, there is no ISO 639-1 equivalent. For these cases we manually specify a mapping if we deem it to make sense, for example Standard Arabic (`arb`) is mapped to Arabic (`ar`). Where an obvious mapping is not possible, we currently don't suggest metadata for this dataset. In future iterations of this work we may take a different approach. It is important to recognise this approach does come with downsides, since it reduces the diversity of languages which might be suggested and also relies on subjective judgments about what languages can be mapped to others.
But the process doesn't stop here. After all, what use is predicting the language of the datasets if we can't share that information with the rest of the community?
### Using Librarian-Bot to Update Metadata
To ensure this valuable language metadata is incorporated back into the Hub, we turn to Librarian-Bot! Librarian-Bot takes the language predictions generated by Meta's [facebook/fasttext-language-identification](https://huggingface.co./facebook/fasttext-language-identification) fastText model and opens pull requests to add this information to the metadata of each respective dataset.
This automated system not only updates the datasets with language information, but also does it swiftly and efficiently, without requiring manual work from humans. Once these pull requests are approved and merged, the language metadata becomes available for all users, significantly enhancing the usability of the Hugging Face Hub. You can keep track of what the librarian-bot is doing [here](https://huggingface.co./librarian-bot/activity/community)!
#### Next steps
As the number of datasets on the Hub grows, metadata becomes increasingly important. Language metadata, in particular, can be incredibly valuable for identifying the correct dataset for your use case.
With the assistance of the dataset viewer API and the [Librarian-Bots](https://huggingface.co./librarian-bots), we can update our dataset metadata at a scale that wouldn't be possible manually. As a result, we're enriching the Hub and making it an even more powerful tool for data scientists, linguists, and AI enthusiasts around the world.
As the machine learning librarian at Hugging Face, I continue exploring opportunities for automatic metadata enrichment for machine learning artefacts hosted on the Hub. Feel free to reach out (daniel at thiswebsite dot co) if you have ideas or want to collaborate on this effort! | [
[
"data",
"implementation",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"tools",
"community",
"implementation"
] | null | null |
eca4dc4b-ba79-4050-b063-1534ef96f331 | completed | 2025-01-16T03:09:11.596505 | 2025-01-19T17:19:01.245026 | 75481bad-44e8-49d0-8964-692927239a80 | Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU | edbeeching, ybelkada, lvwerra, smangrul, lewtun, kashif | trl-peft.md | We are excited to officially release the integration of `trl` with `peft` to make Large Language Model (LLM) fine-tuning with Reinforcement Learning more accessible to anyone! In this post, we explain why this is a competitive alternative to existing fine-tuning approaches.
Note `peft` is a general tool that can be applied to many ML use-cases but it’s particularly interesting for RLHF as this method is especially memory-hungry!
If you want to directly deep dive into the code, check out the example scripts directly on the [documentation page of TRL](https://huggingface.co./docs/trl/main/en/sentiment_tuning_peft).
## Introduction
### LLMs & RLHF
LLMs combined with RLHF (Reinforcement Learning with Human Feedback) seems to be the next go-to approach for building very powerful AI systems such as ChatGPT.
Training a language model with RLHF typically involves the following three steps:
1- Fine-tune a pretrained LLM on a specific domain or corpus of instructions and human demonstrations
2- Collect a human annotated dataset and train a reward model
3- Further fine-tune the LLM from step 1 with the reward model and this dataset using RL (e.g. PPO)
|  |
|:--:|
| <b>Overview of ChatGPT's training protocol, from the data collection to the RL part. Source: <a href="https://openai.com/blog/chatgpt" rel="noopener" target="_blank" >OpenAI's ChatGPT blogpost</a> </b>|
The choice of the base LLM is quite crucial here. At this time of writing, the “best” open-source LLM that can be used “out-of-the-box” for many tasks are instruction finetuned LLMs. Notable models being: [BLOOMZ](https://huggingface.co./bigscience/bloomz), [Flan-T5](https://huggingface.co./google/flan-t5-xxl), [Flan-UL2](https://huggingface.co./google/flan-ul2), and [OPT-IML](https://huggingface.co./facebook/opt-iml-max-30b). The downside of these models is their size. To get a decent model, you need at least to play with 10B+ scale models which would require up to 40GB GPU memory in full precision, just to fit the model on a single GPU device without doing any training at all!
### What is TRL?
The `trl` library aims at making the RL step much easier and more flexible so that anyone can fine-tune their LM using RL on their custom dataset and training setup. Among many other applications, you can use this algorithm to fine-tune a model to generate [positive movie reviews](https://huggingface.co./docs/trl/sentiment_tuning), do [controlled generation](https://github.com/lvwerra/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb) or [make the model less toxic](https://huggingface.co./docs/trl/detoxifying_a_lm).
Using `trl` you can run one of the most popular Deep RL algorithms, [PPO](https://huggingface.co./deep-rl-course/unit8/introduction?fw=pt), in a distributed manner or on a single device! We leverage `accelerate` from the Hugging Face ecosystem to make this possible, so that any user can scale up the experiments up to an interesting scale.
Fine-tuning a language model with RL follows roughly the protocol detailed below. This requires having 2 copies of the original model; to avoid the active model deviating too much from its original behavior / distribution you need to compute the logits of the reference model at each optimization step. This adds a hard constraint on the optimization process as you need always at least two copies of the model per GPU device. If the model grows in size, it becomes more and more tricky to fit the setup on a single GPU.
|  |
|:--:|
| <b>Overview of the PPO training setup in TRL.</b>|
In `trl` you can also use shared layers between reference and active models to avoid entire copies. A concrete example of this feature is showcased in the detoxification example.
### Training at scale
Training at scale can be challenging. The first challenge is fitting the model and its optimizer states on the available GPU devices. The amount of GPU memory a single parameter takes depends on its “precision” (or more specifically `dtype`). The most common `dtype` being `float32` (32-bit), `float16`, and `bfloat16` (16-bit). More recently “exotic” precisions are supported out-of-the-box for training and inference (with certain conditions and constraints) such as `int8` (8-bit). In a nutshell, to load a model on a GPU device each billion parameters costs 4GB in float32 precision, 2GB in float16, and 1GB in int8. If you would like to learn more about this topic, have a look at this blogpost which dives deeper: [https://huggingface.co./blog/hf-bitsandbytes-integration](https://huggingface.co./blog/hf-bitsandbytes-integration).
If you use an AdamW optimizer each parameter needs 8 bytes (e.g. if your model has 1B parameters, the full AdamW optimizer of the model would require 8GB GPU memory - [source](https://huggingface.co./docs/transformers/v4.20.1/en/perf_train_gpu_one)).
Many techniques have been adopted to tackle these challenges at scale. The most familiar paradigms are Pipeline Parallelism, Tensor Parallelism, and Data Parallelism.
|  |
|:--:|
| <b>Image Credits to <a href="https://towardsdatascience.com/distributed-parallel-training-data-parallelism-and-model-parallelism-ec2d234e3214" rel="noopener" target="_blank" >this blogpost</a> </b>|
With data parallelism the same model is hosted in parallel on several machines and each instance is fed a different data batch. This is the most straight forward parallelism strategy essentially replicating the single-GPU case and is already supported by `trl`. With Pipeline and Tensor Parallelism the model itself is distributed across machines: in Pipeline Parallelism the model is split layer-wise, whereas Tensor Parallelism splits tensor operations across GPUs (e.g. matrix multiplications). With these Model Parallelism strategies, you need to shard the model weights across many devices which requires you to define a communication protocol of the activations and gradients across processes. This is not trivial to implement and might need the adoption of some frameworks such as [`Megatron-DeepSpeed`](https://github.com/microsoft/Megatron-DeepSpeed) or [`Nemo`](https://github.com/NVIDIA/NeMo). It is also important to highlight other tools that are essential for scaling LLM training such as Adaptive activation checkpointing and fused kernels. Further reading about parallelism paradigms can be found [here](https://huggingface.co./docs/transformers/v4.17.0/en/parallelism).
Therefore, we asked ourselves the following question: how far can we go with just data parallelism? Can we use existing tools to fit super-large training processes (including active model, reference model and optimizer states) in a single device? The answer appears to be yes. The main ingredients are: adapters and 8bit matrix multiplication! Let us cover these topics in the following sections:
### 8-bit matrix multiplication
Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper LLM.int8() and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8.
|  |
|:--:|
| <b>Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper [LLM.int8()](https://arxiv.org/abs/2208.07339) and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8. </b>|
In a nutshell, you can reduce the size of a full-precision model by 4 (thus, by 2 for half-precision models) if you use 8-bit matrix multiplication.
### Low rank adaptation and PEFT
In 2021, a paper called LoRA: Low-Rank Adaption of Large Language Models demonstrated that fine tuning of large language models can be performed by freezing the pretrained weights and creating low rank versions of the query and value layers attention matrices. These low rank matrices have far fewer parameters than the original model, enabling fine-tuning with far less GPU memory. The authors demonstrate that fine-tuning of low-rank adapters achieved comparable results to fine-tuning the full pretrained model.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
This technique allows the fine tuning of LLMs using a fraction of the memory requirements. There are, however, some downsides. The forward and backward pass is approximately twice as slow, due to the additional matrix multiplications in the adapter layers.
### What is PEFT?
[Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft), is a Hugging Face library, created to support the creation and fine tuning of adapter layers on LLMs.`peft` is seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
The library supports many state of the art models and has an extensive set of examples, including:
- Causal language modeling
- Conditional generation
- Image classification
- 8-bit int8 training
- Low Rank adaption of Dreambooth models
- Semantic segmentation
- Sequence classification
- Token classification
The library is still under extensive and active development, with many upcoming features to be announced in the coming months.
## Fine-tuning 20B parameter models with Low Rank Adapters
Now that the prerequisites are out of the way, let us go through the entire pipeline step by step, and explain with figures how you can fine-tune a 20B parameter LLM with RL using the tools mentioned above on a single 24GB GPU!
### Step 1: Load your active model in 8-bit precision
|  |
|:--:|
| <b> Loading a model in 8-bit precision can save up to 4x memory compared to full precision model</b>|
A “free-lunch” memory reduction of a LLM using `transformers` is to load your model in 8-bit precision using the method described in LLM.int8. This can be performed by simply adding the flag `load_in_8bit=True` when calling the `from_pretrained` method (you can read more about that [here](https://huggingface.co./docs/transformers/main/en/main_classes/quantization)).
As stated in the previous section, a “hack” to compute the amount of GPU memory you should need to load your model is to think in terms of “billions of parameters”. As one byte needs 8 bits, you need 4GB per billion parameters for a full-precision model (32bit = 4bytes), 2GB per billion parameters for a half-precision model, and 1GB per billion parameters for an int8 model.
So in the first place, let’s just load the active model in 8-bit. Let’s see what we need to do for the second step!
### Step 2: Add extra trainable adapters using `peft`
|  |
|:--:|
| <b> You easily add adapters on a frozen 8-bit model thus reducing the memory requirements of the optimizer states, by training a small fraction of parameters</b>|
The second step is to load adapters inside the model and make these adapters trainable. This enables a drastic reduction of the number of trainable weights that are needed for the active model. This step leverages `peft` library and can be performed with a few lines of code. Note that once the adapters are trained, you can easily push them to the Hub to use them later.
### Step 3: Use the same model to get the reference and active logits
|  |
|:--:|
| <b> You can easily disable and enable adapters using the `peft` API.</b>|
Since adapters can be deactivated, we can use the same model to get the reference and active logits for PPO, without having to create two copies of the same model! This leverages a feature in `peft` library, which is the `disable_adapters` context manager.
### Overview of the training scripts:
We will now describe how we trained a 20B parameter [gpt-neox model](https://huggingface.co./EleutherAI/gpt-neox-20b) using `transformers`, `peft` and `trl`. The end goal of this example was to fine-tune a LLM to generate positive movie reviews in a memory constrained settting. Similar steps could be applied for other tasks, such as dialogue models.
Overall there were three key steps and training scripts:
1. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/clm_finetune_peft_imdb.py)** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
2. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py)** - Merging of the adapter layers into the base model’s weights and storing these on the hub.
3. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py)** - Sentiment fine-tuning of a Low Rank Adapter to create positive reviews.
We tested these steps on a 24GB NVIDIA 4090 GPU. While it is possible to perform the entire training run on a 24 GB GPU, the full training runs were untaken on a single A100 on the 🤗 reseach cluster.
The first step in the training process was fine-tuning on the pretrained model. Typically this would require several high-end 80GB A100 GPUs, so we chose to train a low rank adapter. We treated this as a Causal Language modeling setting and trained for one epoch of examples from the [imdb](https://huggingface.co./datasets/imdb) dataset, which features movie reviews and labels indicating whether they are of positive or negative sentiment.
|  |
|:--:|
| <b> Training loss during one epoch of training of a gpt-neox-20b model for one epoch on the imdb dataset</b>|
In order to take the adapted model and perform further finetuning with RL, we first needed to combine the adapted weights, this was achieved by loading the pretrained model and adapter in 16-bit floating point and summary with weight matrices (with the appropriate scaling applied).
Finally, we could then fine-tune another low-rank adapter, on top of the frozen imdb-finetuned model. We use an [imdb sentiment classifier](https://huggingface.co./lvwerra/distilbert-imdb) to provide the rewards for the RL algorithm.
|  |
|:--:|
| <b> Mean of rewards when RL fine-tuning of a peft adapted 20B parameter model to generate positive movie reviews.</b>|
The full Weights and Biases report is available for this experiment [here](https://wandb.ai/edbeeching/trl/runs/l8e7uwm6?workspace=user-edbeeching), if you want to check out more plots and text generations.
## Conclusion
We have implemented a new functionality in `trl` that allows users to fine-tune large language models using RLHF at a reasonable cost by leveraging the `peft` and `bitsandbytes` libraries. We demonstrated that fine-tuning `gpt-neo-x` (40GB in `bfloat16`!) on a 24GB consumer GPU is possible, and we expect that this integration will be widely used by the community to fine-tune larger models utilizing RLHF and share great artifacts.
We have identified some interesting directions for the next steps to push the limits of this integration
- *How this will scale in the multi-GPU setting?* We’ll mainly explore how this integration will scale with respect to the number of GPUs, whether it is possible to apply Data Parallelism out-of-the-box or if it’ll require some new feature adoption on any of the involved libraries.
- *What tools can we leverage to increase training speed?* We have observed that the main downside of this integration is the overall training speed. In the future we would be keen to explore the possible directions to make the training much faster.
## References
- parallelism paradigms: [https://huggingface.co./docs/transformers/v4.17.0/en/parallelism](https://huggingface.co./docs/transformers/v4.17.0/en/parallelism)
- 8-bit integration in `transformers`: [https://huggingface.co./blog/hf-bitsandbytes-integration](https://huggingface.co./blog/hf-bitsandbytes-integration)
- LLM.int8 paper: [https://arxiv.org/abs/2208.07339](https://arxiv.org/abs/2208.07339)
- Gradient checkpoiting explained: [https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html) | [
[
"llm",
"implementation",
"optimization",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"optimization",
"implementation"
] | null | null |
a088f3f4-c23f-4fdc-ad2a-a47f3d29513d | completed | 2025-01-16T03:09:11.596510 | 2025-01-16T13:37:27.071081 | 0d628f09-c7fd-4bee-b1eb-3eef74d61ba7 | Introducing Community Tools on HuggingChat | nsarrazin | community-tools.md | <video alt="demo.mp4" controls autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/demo.webm" type="video/webm">
</video>
</div>
Today we’re releasing our latest feature on HuggingChat: Community Tools! This lets you turn any Space that you love on HuggingFace into a tool that can be used by models directly from HuggingChat.
With this feature, we’re also expanding the modalities available in HuggingChat. You can now use community tools to understand images, generate videos, or answer with a text-to-speech model. The possibilities are endless and anyone can create tools using Spaces on Hugging Face! Explore existing tools [here](https://huggingface.co./chat/tools).
In this post we’re going to look at a few use cases for creating community tools:
1. [Turning a community Space into a tool](#turning-a-community-Space-into-a-tool)
2. [Creating a custom tool yourself](#creating-a-custom-tool-yourself)
3. [Enhance your assistants with community tools](#enhance-your-assistants-with-community-tools)
4. [Create a RAG tool on your own documents](#create-a-rag-tool-on-your-own-documents)
## Turning a community Space into a tool
You can turn anyone’s public Space into a tool. This is handy for using the latest models directly in HuggingChat. Let’s use [DamarJati/FLUX.1-RealismLora](https://huggingface.co./spaces/DamarJati/FLUX.1-RealismLora) as an example here.
Start by [creating a new tool](https://huggingface.co./chat/tools/new) and filling in the fields. As soon as you input the Space URL into the _Hugging Face Space URL_ field you’ll see the available functions and parameters get filled automatically.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-step-1.png"/>
</div>
There are some fields that need to be filled in correctly in order to ensure optimal tool performance.
- **Tool Description:** The description is passed to the LLM to explain what the tool can do. Keep it short and describe what the tool can be used for.
- **AI Function Name:** The tools are represented as code functions. This is your tool’s function name. Keep it short, unique and self-explanatory.
- **Arguments:** These are the tool parameters the LLM can fill-in. They can be:
- **Required:** The model must fill in a value to use this tool. This required the parameter to be described properly.
- **Optional:** There is a default value provided but the model can override it if needed.
- **Fixed:** The value is fixed when creating the tool and can’t be changed by the model.
You can always look at other tools’ definition to better understand how to create tools. [(example)](https://huggingface.co./chat/tools/000000000000000000000001/edit)
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-step-2.png"/>
</div>
Now that our tool is created, we can enable it and start using it with tools compatible models!
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-step-3.png"/>
</div>
## **Creating a custom tool yourself**
Using existing Spaces can cover a lot of use cases but if you can write basic python then you can just as easily create custom tools for yourself. Let’s do a simple example of a dice roll tool since LLMs are quite bad at picking random numbers by themselves.
Start by creating a [new Gradio Space](https://huggingface.co./new-space?sdk=gradio) on Hugging Face. The _CPU Basic_ free tier works fine for this. Your Space will have to be public in order to be used inside HuggingChat.
Create a simple [`app.py`](http://app.py) app inside your pace repo, in the case of our roll dice example that could be:
```python
import gradio as gr
import random
def roll_dice(sides=6):
return random.randint(1, sides)
demo = gr.Interface(
fn=roll_dice,
inputs=gr.Number(value=6, label="Number of Sides"),
outputs="text",
title="Dice Roller",
description="Enter the number of sides for the dice and get the roll result."
)
demo.launch()
```
If you’re not familiar with Gradio, it’s very easy to get started creating interfaces, you can find the docs [here](https://www.gradio.app/docs/gradio/interface).
> [!TIP]
> You can have multiple functions inside a single Space to make it easier to manage your tools.
Once you’re done, push the changes and when your Space is deployed you can create a community tool for it in HuggingChat just like we did previously.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-custom.png"/>
</div>
## Enhance your assistants with Community Tools
You can activate tools directly by going to [the tools page](https://huggingface.co./chat/tools) and picking the ones you like or you can also package tools in an assistant.
When [creating an assistant](https://huggingface.co./chat/settings/assistants/new) using a model that is compatible with tool calling you will now have the option to select tools. Search for the name of the tools and add up to 3 different tools. In our case, let’s create a Game Master assistant that has access to image generation and dice rolling tools.
> [!TIP]
> You can use the system instructions field to tell the model when to use the tools.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-assistant.png"/>
</div>
## Create a RAG tool on your own documents
To go along with the release we created a simple RAG tool that you can easily copy to ask questions about your documents directly from HuggingChat. Start by duplicating [this Space](https://huggingface.co./spaces/nsarrazin/rag-tool-template) into your own account. You can then drop files you want to be parsed in the `sources/` folder of that Space.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-rag-1.png"/>
</div>
Once the Space is started up you can easily create a tool out of it on HuggingChat like we’ve covered previously.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/community-tools/tools-rag-2.png"/>
</div>
### Share your feedback with us
With the release of Community Tools we hope you’ll be able to enhance your chats with multimodal content and custom tools. The feature is still experimental so if you see Spaces that are not supported or tools that don’t work, please share them with us in [the feedback thread](https://huggingface.co./spaces/huggingchat/chat-ui/discussions/569)! | [
[
"llm",
"community",
"tools",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"multi_modal",
"tools",
"community"
] | null | null |
b25a0601-3cb5-4c03-b633-02076d5e996c | completed | 2025-01-16T03:09:11.596515 | 2025-01-19T18:47:18.194704 | 36fdb6a0-4590-4b76-88a3-eab56d05d512 | WWDC 24: Running Mistral 7B with Core ML | pcuenq, FL33TW00D-HF, reach-vb, osanseviero | mistral-coreml.md | WWDC’ 24 is the moment Apple officially unveiled Apple Intelligence and
reiterated their commitment to efficient, private, and on-device AI.
During the keynote and the sessions that followed, they demonstrated
Apple Intelligence, which powers a huge array of AI-enhanced features
that show practical uses for everyday tasks. These are not
\*AI-for-the-sake-of-AI\* shiny demos. These are time-saving,
appropriate (and fun!) helpers that are deeply integrated with apps and
the OS, that also offer developers a number of ways to include these
features within their own apps.
Apple Intelligence features can only work this well
because of the vertically integrated software stack that harnesses
Apple Silicon's capabilities to the fullest. Apple also offers a platform for developers to run models on-device, known as
Core ML. This software stack allows you to run ML models across all 3
compute units (CPU, GPU & Neural Engine) available on Apple Silicon hardware.
In this blog post, we’ll be exploring some of the best new Core ML
features to replicate the Mistral 7B example Apple showcased in the
WWDC’24 [Deploy machine learning and AI models on-device with Core
ML](https://developer.apple.com/videos/play/wwdc2024/10161/)
session, where they use a fork of
[swift-transformers](https://github.com/huggingface/swift-transformers)
to run a state-of-the-art LLM on a Mac. This is a high-quality model
with more than 7 billion parameters that pushes the capabilities of
consumer hardware today. You can also check out WWDC’24 [Bring your
machine learning and AI models to Apple
silicon](https://developer.apple.com/videos/play/wwdc2024/10159/)
session, where part of the Mistral 7B conversion process is shown.
Let’s see what steps to take to run it as efficiently as possible, and
learn the new tools available in iOS 18 & macOS Sequoia.
This is what we’ll be building today:
<video controls title="Mistral 7B running with Core ML">
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/mistral-coreml/swift-chat.mp4" type="video/mp4">
Video: Mistral 7B running with Core ML.
</video>
## TL;DR
By the end of this blog post, you will have learnt all the new goodies
accompanying the latest macOS release AND you will have successfully run
a 7B parameter model using less than 4GB of memory on your Mac.
Step 1: Clone the `preview` branch of the `swift-transformers` repo: git clone -b preview [`https://github.com/huggingface/swift-transformers`](https://github.com/huggingface/swift-transformers)
Step 2: Download the converted Core ML models from [`this Hugging Face repo`](https://huggingface.co./apple/mistral-coreml)
Step 3: Run inference using Swift: `swift run transformers "Best recommendations for a place to visit in Paris in August 2024:" --max-length 200 Mistral7B-CoreML/StatefulMistralInstructInt4.mlpackage`
## Best new Core ML features from WWDC’ 24
Here are some of the most impactful Core ML features from WWDC’ 24 we
will use to run Mistral 7B on a Mac.
### Swift Tensor
The first feature we want to highlight is an entirely new Swift type to
work with ML tensors. These are multi-dimensional data structures every
ML framework uses. Python developers working on ML are familiar with
`numpy` arrays or `torch` tensors, which provide convenient,
high-level interfaces to manipulate these large multi-dimensional
matrices easily. The new [`MLTensor`](https://developer.apple.com/documentation/coreml/MLTensor) type provides a high-level
abstraction that mimics the ones available in Python frameworks, greatly
simplifying working with tensor data in Swift.
Core ML already had multi-dimensional data types in the form of
[MLMultiArray](https://developer.apple.com/documentation/coreml/mlmultiarray)
and
[MLShapedArray](https://developer.apple.com/documentation/coreml/mlshapedarray).
However, they were only meant for data storage and simple operations
like wrapping your data and sending it as input to a Core ML model, or
unwrapping results from a Core ML model. However, *manipulating* tensor
data with these APIs is difficult. Only a few primitive operations are
provided, and you may have to write your own by accessing the underlying
storage as an opaque pointer to number data. This is time-consuming and
error-prone.
The new `Tensor` type provides a high-level abstraction that mimics
the ones available in Python frameworks, greatly simplifying working
with tensor data in Swift. Consider a language model like the one we
want to port to Core ML. Language models take in an input sequence of
tokens, and they output an estimation of the probabilities of all the
tokens in the vocabulary, meaning that tokens with a high probability
have a high chance of being plausible continuations of the input. The
application’s job is to select the best next token to append to the
sequence based on those probabilities. `Tensor` type makes it easy to
handle these operations without custom code.
[When we released swift-transformers](https://huggingface.co./blog/swift-coreml-llm),
we wrote a lot of code (later extended by the community, thanks! ❤️) to
help with input preparations (convert words to tokens) and output
post-processing. For example, check out [our softmax operation](https://github.com/huggingface/swift-transformers/blob/main/Sources/TensorUtils/Math.swift#L103)
using Accelerate. All this can be removed when using `MLTensor`, as
`softmax` is provided out of the box!
### Stateful Buffers
Before WWDC’ 24, a Core ML model was essentially a pure stateless
function where you provide inputs and return some outputs. However,
sometimes you need to keep a state that depends on previous
computations. The functional programming method for maintaining state is
to add an additional input/output pair. So, based on your inputs and
state, the model computes the output and the new state. There is nothing
wrong with this approach, and in fact, that’s the way high-performance
frameworks like JAX work.
However, there are practical limitations: the stateful data needs to be
sent to the model as an input and retrieved as an output every time you
call the model. If the stateful data is large, then all this going back
and forth increases overhead and slows things down. This is particularly
important for LLMs because you have to run many iterations to generate a
sequence. The performance bottleneck is usually your computer’s memory
bandwidth (i.e., how fast you can move things to your GPU and back).
Stateful models solve this problem by reserving a block of memory for
state data and keeping it on the GPU so you don’t have to send and
receive it every time you use the model.
Stateful buffers were introduced [in this WWDC’ 24 session](https://developer.apple.com/videos/play/wwdc2024/10161/?time=510)
using a toy example that is easy to understand but not representative of
practical uses with big models such as LLMs. An LLM performance trick
for transformers-based models is key-value caching (known as
kv-caching). As shown in the following illustration, it avoids costly
matrix multiplications in the crucial attention block by caching the
result of previous operations performed in previous steps. We won’t go
into details, but the takeaways are: kv-cache dramatically increases
performance, and it requires a large block of memory that is the perfect
candidate for using stateful buffers. Here is a [coremltools user guide](https://apple.github.io/coremltools/docs-guides/source/stateful-models.html)
update about stateful models.

### New Quantization Techniques
In WWDC 23, we explored a very cool technique called palletization, and
we showed how it could help bring text-to-image models, [such as Stable
Diffusion](https://huggingface.co./blog/fast-diffusers-coreml), to Macs and iPhones.
Whilst these techniques allow you to reduce the size considerably, if
pushed too far, the impact on quality is drastic. Bigger models suffer
more from this, as the weight data has an extensive dynamic range.
Trying to create a small lookup table (LUT) that captures all possible
values becomes increasingly difficult. The solution introduced in WWDC
24 is to focus on a smaller portion of the data at a time, and create
multiple lookup tables for different areas of the same tensor.

These methods (block-wise quantization) allow us to compress models to
as low as 4-bit precision. Instead of using 4 bytes (the size of a
`float32` number) to represent each model parameter, we can get away
with half a byte (a nibble) for each. This is an 8-fold reduction in
model size (minus some overhead to account for the block-wise
quantization tables), or 4 times smaller when compared to `float16`
precision.
### Multifunction Support
We won’t use this feature for this example but we wanted to mention it
here as it was introduced at WWDC 24, and we will be showcasing it in
some upcoming work. Multifunction support essentially allows you to
package LoRA adapters into generative models to use the same model (with
a small set of additional parameters, called adapters) for different
tasks. LoRA is the preferred community technique for large model
fine-tuning. In diffusion models, for example, you can use LoRA to
generate images with different styles, such as photorealistic or
cartoonish. We believe LoRA is part of the solution that powers Apple’s
Genmoji implementation. For language models, LoRA adapters can be used
to adapt a generic LLM to specific tasks or domains.
To read more about LoRA, you can check [this post.](https://huggingface.co./blog/lora)
To read more about Multifunction, you can check out Apple coremltools
user guide [here](https://apple.github.io/coremltools/docs-guides/source/multifunction-models.html).
## Converting Mistral 7B to Core ML
The single most important component for running a large language model
efficiently is the kv-cache. As mentioned above, this is a great
candidate for [the new stateful model feature](https://apple.github.io/coremltools/docs-guides/source/stateful-models.html)
released at WWDC’ 24. Models in the transformers library already use
efficient attention implementations that rely heavily on kv-caching.
However, the default implementations are optimized for Nvidia GPUs, and
this hardware has a different set of constraints than Apple Silicon
does. In the case of Core ML, we need to pre-allocate the full cache
buffer beforehand and ensure that each time we call the model, we update
the buffer in place. This avoids inefficient memory allocations and
tensor concatenations and is also a requirement for Core ML stateful
buffers.
To achieve this goal, we have to use a different attention
implementation that considers these factors. This requires modifying the
transformers modeling code for the Mistral architecture, and it’s done
in [this fragment of code](https://github.com/huggingface/swift-transformers/blob/21b015691624ad103470370f0f255eb660579511/Examples/Mistral7B/export.py#L121).
Note: If you want to follow along and replicate the conversion (or
convert another Mistral-based model, like a different fine-tune), you
can use [this script](https://github.com/huggingface/swift-transformers/blob/preview/Examples/Mistral7B/export.py)
to run all the conversion steps.
### Tracing & Conversion
The first step is to load the model. We’ll use the patched
implementation with the in-place cache method.
```python
MODEL_ID = "mistralai/Mistral-7B-Instruct-v0.3"
torch_model = StatefulMistralForCausalLM(MODEL_ID)
torch_model.eval()
```
Before running Core ML conversion, we need to trace the model with
example inputs. This process records the tensor operations performed on
those inputs, and the traced graph will be translated to Core ML
operations during conversion. We use sample inputs to trace the model;
we don’t need real data.
```python
input_ids = torch.zeros((1, 2), dtype=torch.int32)
causal_mask = torch.zeros((1, 1, 2, 5), dtype=torch.float32)
traced_model = torch.jit.trace(torch_model, [input_ids, causal_mask])
```
The input to a language model is a sequence of tokens of varying length.
We’ll allow the input to grow from a single token to a maximum context
length of 2048. We can use
[coremltools](https://github.com/apple/coremltools) range
dimensions to specify these bounds.
```python
query_length = ct.RangeDim(lower_bound=1, upper_bound=2048, default=1)
end_step_dim = ct.RangeDim(lower_bound=1, upper_bound=2048, default=1)
inputs = [
ct.TensorType(shape=(1, query_length), dtype=np.int32, name="inputIds"),
ct.TensorType(shape=(1, 1, query_length, end_step_dim), dtype=np.float16, name="causalMask"),
]
outputs = [ct.TensorType(dtype=np.float16, name="logits")]
```
In addition to the sequence tokens (called `inputIds` in the example
above), there’s another input called `causalMask`, which specifies the
tokens the model needs to pay attention to. This is mostly used when
generating multiple sequences at the same time using batching. Check out
how these inputs are used in an [example runner
here](https://github.com/huggingface/swift-transformers/blob/21b015691624ad103470370f0f255eb660579511/Examples/Mistral7B/generate.py#L29-L42).
In this situation, all the input sequences inside a batch must have the
same length, so we use padding tokens and the causal mask to tell the
model that the padding tokens are not to be considered as inputs.
### State Preparation
The PyTorch modeling code uses `keyCache` and `valueCache` as the
names of the cache buffers to hold the kv-cache. Those blocks are
allocated for the maximum context length (2048). We use `coremltools`'
new
[StateType](https://apple.github.io/coremltools/source/coremltools.converters.mil.input_types.html#statetype)
to specify that those blocks must be converted to a stateful Core ML
buffer during conversion.
```python
# Specify kv-cache states by using `StateType`.
states = [
ct.StateType(
wrapped_type=ct.TensorType(shape=torch_model.kv_cache_shape, dtype=np.float16),
name="keyCache",
),
ct.StateType(
wrapped_type=ct.TensorType(shape=torch_model.kv_cache_shape, dtype=np.float16),
name="valueCache",
),
]
```
### Core ML Conversion
To convert the model to Core ML, we need to specify the input and output
types, as well as the states. The converted model will use `float16`
precision because that’s what we specified for the input data. We also
need to indicate the minimum deployment target as iOS18, as that’s where
these features are available. (We can also use `macOS15`, which refers
to the same conversion target.)
```python
mlmodel_fp16 = ct.convert(
traced_model,
inputs=inputs,
states=states,
outputs=outputs,
minimum_deployment_target=ct.target.iOS18,
skip_model_load=True,
)
```
### Model Compression
Using the new block-size quantization strategies described above, we use
4-bit linear quantization with block size 32. This will greatly reduce
model size and make the model run faster. Even though computation will
still be performed in `float16`, weights are transferred in 4-bit mode
and decompressed on the fly, which is more efficient than transferring a
large amount of 16-bit weights.
The quantization parameters are configured as follows:
```python
op_config = ct.optimize.coreml.OpLinearQuantizerConfig(
mode="linear_symmetric",
dtype="int4",
granularity="per_block",
block_size=32,
)
config = ct.optimize.coreml.OptimizationConfig(global_config=op_config)
```
Let’s use that configuration to quantize the model. The following line
will take a few minutes to run:
```python
mlmodel_int4 = ct.optimize.coreml.linear_quantize_weights(mlmodel_fp16, config=config)
mlmodel_int4.save("StatefulMistral7BInstructInt4.mlpackage")
```
There’s a final step after conversion and quantization are done. We need
to include a piece of additional metadata that indicates the model
identifier we used (`mistralai/Mistral-7B-Instruct-v0.3`). The Swift
code will use this to download the tokenizer files from the Hub.
Tokenization is converting text data to the numerical representations
used by models, and it’s different for every model.
```python
mlmodel_int4._spec.description.metadata.userDefined.update({
"co.huggingface.exporters.name": MODEL_ID
})
```
The generated model is a `mlpackage` of about 3.8G, compared with the
14G that a `float16` conversion would produce. [You can find it
here on the
Hub.](https://huggingface.co./apple/mistral-coreml/tree/main)
## Running Mistral 7B with Swift
If you followed the steps above or downloaded the model from the Hub,
you can run it locally using the `preview` branch of
`swift-transformers`. Apple engineers contributed it to the project,
including the following important features:
- Full `Tensor` support, which greatly simplifies pre- and
post-processing tasks, and allows us to delete many lines of
low-level, confusing and fragile code.
- Support for the Swift counterpart of the Stateful API.
Since adopting these features is a breaking change and requires iOS 18
or macOS 15, we’ll keep them in a `preview` branch for now.
To run the model from the command line, please first clone the `preview`
branch from the GitHub repo:
```bash
git clone -b preview https://github.com/huggingface/swift-transformers
```
And then run the CLI to test the model:
```bash
#to run in release mode, pass -c release
swift run transformers "Best recommendations for a place to visit in Paris in August 2024:" --max-length 128 Examples/Mistral7B/StatefulMistral7BInstructInt4.mlpackage
```
For easier testing, you can also use `swift-chat`, a simple app we
wrote to show how to integrate the `swift-transformers` package
inside. You have to use the `preview` branch as well. An example of
`swift-chat` running the converted Mistral model was shown at the
beginning of this post.
## Running Mistral 7B with Python
For those of you who are more familiar with Python, it’s just as easy!
```bash
python3 generate.py Examples/Mistral7B/StatefulMistral7BInstructInt4.mlpackage --prompt "Best recommendations for a place to visit in Paris in August 2024:"
```
coremltools makes it just as easy to run Core ML models with Python.
## What's Next?
We are extremely excited about the progress in [Core ML](https://developer.apple.com/documentation/coreml/) and
[coremltools](https://github.com/apple/coremltools) this year,
and we are looking forward to seeing lots of third-party apps leveraging
ML models to solve real tasks people need. On our side, we are committed
to making this as easy as possible so developers can concentrate on
creating cool apps. There are a few things on our drawing board:
- The model updates presented here are excellent for GPUs on Mac
computers. Core ML can use the Neural Engine, which is particularly
efficient on iPhones. Getting the most performance out of the Neural
Engine requires some additional adaptations, which we plan to carry
out on a few example models. This work will be based on the
learnings discussed in this [2022 (and still very relevant) article by Apple](https://machinelearning.apple.com/research/neural-engine-transformers).
We won’t run Mistral 7B on iPhone, but there are several smaller
models, like Apple’s OpenELM or DCLM that make for great
candidates to explore!
- The code presented here is highly experimental. As summer goes on,
we plan to adopt these methods and incorporate them into
`exporters`, a Python tool designed to convert transformers models
to Core ML. Hopefully, you’ll soon be able to convert many
interesting model architectures very easily.
- We’ll keep working on the `preview` branch of
`swift-transformers` to incorporate new features or API changes as
they are released. If you are interested, keep an eye on it!
## How can you help?
The tools released by Apple in WWDC help us on our long-term goal to
make AI easy and accessible to all, and we’d love to see where you can
take them. The example we showed is experimental, but you can use it to
convert any Mistral fine-tune to Core ML – please let us know if you do!
If you want to try other model architectures, please feel free to open
issues or PRs to the `preview` branch of `swift-transformers` –
we’ll try to help you get going!
There’s never been a better time than today to apply your creativity to
solve problems that interest you! Go try things, have fun, and tell us
how we can help. | [
[
"llm",
"implementation",
"tools",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"efficient_computing",
"tools"
] | null | null |
983d2135-7643-4756-b369-5c28486006bc | completed | 2025-01-16T03:09:11.596520 | 2025-01-19T18:56:00.102128 | f7768400-9023-4f32-9a59-6d316b5a2845 | 'Accelerated Inference with Optimum and Transformers Pipelines' | philschmid | optimum-inference.md | > Inference has landed in Optimum with support for Hugging Face Transformers pipelines, including text-generation using ONNX Runtime.
The adoption of BERT and Transformers continues to grow. Transformer-based models are now not only achieving state-of-the-art performance in Natural Language Processing but also for Computer Vision, Speech, and Time-Series. 💬 🖼 🎤 ⏳
Companies are now moving from the experimentation and research phase to the production phase in order to use Transformer models for large-scale workloads. But by default BERT and its friends are relatively slow, big, and complex models compared to traditional Machine Learning algorithms.
To solve this challenge, we created [Optimum](https://huggingface.co./blog/hardware-partners-program) – an extension of [Hugging Face Transformers](https://github.com/huggingface/transformers) to accelerate the training and inference of Transformer models like BERT.
In this blog post, you'll learn:
- [1. What is Optimum? An ELI5](#1-what-is-optimum-an-eli5)
- [2. New Optimum inference and pipeline features](#2-new-optimum-inference-and-pipeline-features)
- [3. End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization)
- [4. Current Limitations](#4-current-limitations)
- [5. Optimum Inference FAQ](#5-optimum-inference-faq)
- [6. What’s next?](#6-whats-next)
Let's get started! 🚀
## 1. What is Optimum? An ELI5
[Hugging Face Optimum](https://github.com/huggingface/optimum) is an open-source library and an extension of [Hugging Face Transformers](https://github.com/huggingface/transformers), that provides a unified API of performance optimization tools to achieve maximum efficiency to train and run models on accelerated hardware, including toolkits for optimized performance on [Graphcore IPU](https://github.com/huggingface/optimum-graphcore) and [Habana Gaudi](https://github.com/huggingface/optimum-habana). Optimum can be used for accelerated training, quantization, graph optimization, and now inference as well with support for [transformers pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#pipelines).
## 2. New Optimum inference and pipeline features
With [release](https://github.com/huggingface/optimum/releases/tag/v1.2.0) of Optimum 1.2, we are adding support for [inference](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort) and [transformers pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#pipelines). This allows Optimum users to leverage the same API they are used to from transformers with the power of accelerated runtimes, like [ONNX Runtime](https://onnxruntime.ai/).
**Switching from Transformers to Optimum Inference**
The [Optimum Inference models](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort) are API compatible with Hugging Face Transformers models. This means you can just replace your `AutoModelForXxx` class with the corresponding `ORTModelForXxx` class in Optimum. For example, this is how you can use a question answering model in Optimum:
```diff
from transformers import AutoTokenizer, pipeline
-from transformers import AutoModelForQuestionAnswering
+from optimum.onnxruntime import ORTModelForQuestionAnswering
-model = AutoModelForQuestionAnswering.from_pretrained("deepset/roberta-base-squad2") # pytorch checkpoint
+model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2") # onnx checkpoint
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
question = "What's my name?"
context = "My name is Philipp and I live in Nuremberg."
pred = optimum_qa(question, context)
```
In the first release, we added [support for ONNX Runtime](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort) but there is more to come!
These new `ORTModelForXX` can now be used with the [transformers pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#pipelines). They are also fully integrated into the [Hugging Face Hub](https://huggingface.co./models) to push and pull optimized checkpoints from the community. In addition to this, you can use the [ORTQuantizer](https://huggingface.co./docs/optimum/main/en/onnxruntime/quantization) and [ORTOptimizer](https://huggingface.co./docs/optimum/main/en/onnxruntime/optimization) to first quantize and optimize your model and then run inference on it.
Check out [End-to-End Tutorial on accelerating RoBERTa for question-answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization) for more details.
## 3. End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization
In this End-to-End tutorial on accelerating RoBERTa for question-answering, you will learn how to:
1. Install `Optimum` for ONNX Runtime
2. Convert a Hugging Face `Transformers` model to ONNX for inference
3. Use the `ORTOptimizer` to optimize the model
4. Use the `ORTQuantizer` to apply dynamic quantization
5. Run accelerated inference using Transformers pipelines
6. Evaluate the performance and speed
Let’s get started 🚀
*This tutorial was created and run on an `m5.xlarge` AWS EC2 Instance.*
### 3.1 Install `Optimum` for Onnxruntime
Our first step is to install `Optimum` with the `onnxruntime` utilities.
```bash
pip install "optimum[onnxruntime]==1.2.0"
```
This will install all required packages for us including `transformers`, `torch`, and `onnxruntime`. If you are going to use a GPU you can install optimum with `pip install optimum[onnxruntime-gpu]`.
### 3.2 Convert a Hugging Face `Transformers` model to ONNX for inference**
Before we can start optimizing we need to convert our vanilla `transformers` model to the `onnx` format. To do this we will use the new [ORTModelForQuestionAnswering](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort#optimum.onnxruntime.ORTModelForQuestionAnswering) class calling the `from_pretrained()` method with the `from_transformers` attribute. The model we are using is the [deepset/roberta-base-squad2](https://huggingface.co./deepset/roberta-base-squad2) a fine-tuned RoBERTa model on the SQUAD2 dataset achieving an F1 score of `82.91` and as the feature (task) `question-answering`.
```python
from pathlib import Path
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
model_id = "deepset/roberta-base-squad2"
onnx_path = Path("onnx")
task = "question-answering"
# load vanilla transformers and convert to onnx
model = ORTModelForQuestionAnswering.from_pretrained(model_id, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# save onnx checkpoint and tokenizer
model.save_pretrained(onnx_path)
tokenizer.save_pretrained(onnx_path)
# test the model with using transformers pipeline, with handle_impossible_answer for squad_v2
optimum_qa = pipeline(task, model=model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
We successfully converted our vanilla transformers to `onnx` and used the model with the `transformers.pipelines` to run the first prediction. Now let's optimize it. 🏎
If you want to learn more about exporting transformers model check-out the documentation: [Export 🤗 Transformers Models](https://huggingface.co./docs/transformers/main/en/serialization)
### 3.3 Use the `ORTOptimizer` to optimize the model
After we saved our onnx checkpoint to `onnx/` we can now use the `ORTOptimizer` to apply graph optimization such as operator fusion and constant folding to accelerate latency and inference.
```python
from optimum.onnxruntime import ORTOptimizer
from optimum.onnxruntime.configuration import OptimizationConfig
# create ORTOptimizer and define optimization configuration
optimizer = ORTOptimizer.from_pretrained(model_id, feature=task)
optimization_config = OptimizationConfig(optimization_level=99) # enable all optimizations
# apply the optimization configuration to the model
optimizer.export(
onnx_model_path=onnx_path / "model.onnx",
onnx_optimized_model_output_path=onnx_path / "model-optimized.onnx",
optimization_config=optimization_config,
)
```
To test performance we can use the `ORTModelForQuestionAnswering` class again and provide an additional `file_name` parameter to load our optimized model. **(This also works for models available on the hub).**
```python
from optimum.onnxruntime import ORTModelForQuestionAnswering
# load quantized model
opt_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-optimized.onnx")
# test the quantized model with using transformers pipeline
opt_optimum_qa = pipeline(task, model=opt_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = opt_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
We will evaluate the performance changes in step [3.6 Evaluate the performance and speed](#36-evaluate-the-performance-and-speed) in detail.
### 3.4 Use the `ORTQuantizer` to apply dynamic quantization
After we have optimized our model we can accelerate it even more by quantizing it using the `ORTQuantizer`. The `ORTOptimizer` can be used to apply dynamic quantization to decrease the size of the model size and accelerate latency and inference.
*We use the `avx512_vnni` since the instance is powered by an intel cascade-lake CPU supporting avx512.*
```python
from optimum.onnxruntime import ORTQuantizer
from optimum.onnxruntime.configuration import AutoQuantizationConfig
# create ORTQuantizer and define quantization configuration
quantizer = ORTQuantizer.from_pretrained(model_id, feature=task)
qconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=True)
# apply the quantization configuration to the model
quantizer.export(
onnx_model_path=onnx_path / "model-optimized.onnx",
onnx_quantized_model_output_path=onnx_path / "model-quantized.onnx",
quantization_config=qconfig,
)
```
We can now compare this model size as well as some latency performance
```python
import os
# get model file size
size = os.path.getsize(onnx_path / "model.onnx")/(1024*1024)
print(f"Vanilla Onnx Model file size: {size:.2f} MB")
size = os.path.getsize(onnx_path / "model-quantized.onnx")/(1024*1024)
print(f"Quantized Onnx Model file size: {size:.2f} MB")
# Vanilla Onnx Model file size: 473.31 MB
# Quantized Onnx Model file size: 291.77 MB
```
<figure class="image table text-center m-0 w-full">
<img src="assets/66_optimum_inference/model_size.png" alt="Model size comparison"/>
</figure>
We decreased the size of our model by almost 50% from 473MB to 291MB. To run inference we can use the `ORTModelForQuestionAnswering` class again and provide an additional `file_name` parameter to load our quantized model. **(This also works for models available on the hub).**
```python
# load quantized model
quantized_model = ORTModelForQuestionAnswering.from_pretrained(onnx_path, file_name="model-quantized.onnx")
# test the quantized model with using transformers pipeline
quantized_optimum_qa = pipeline(task, model=quantized_model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = quantized_optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9246969819068909, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
Nice! The model predicted the same answer.
### 3.5 Run accelerated inference using Transformers pipelines
[Optimum](https://huggingface.co./docs/optimum/main/en/pipelines#optimizing-with-ortoptimizer) has built-in support for [transformers pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#pipelines). This allows us to leverage the same API that we know from using PyTorch and TensorFlow models. We have already used this feature in steps 3.2,3.3 & 3.4 to test our converted and optimized models. At the time of writing this, we are supporting [ONNX Runtime](https://onnxruntime.ai/) with more to come in the future. An example of how to use the [transformers pipelines](https://huggingface.co./docs/transformers/main/en/main_classes/pipelines#pipelines) can be found below.
```python
from transformers import AutoTokenizer, pipeline
from optimum.onnxruntime import ORTModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained(onnx_path)
model = ORTModelForQuestionAnswering.from_pretrained(onnx_path)
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
In addition to this we added a `pipelines` API to Optimum to guarantee more safety for your accelerated models. Meaning if you are trying to use `optimum.pipelines` with an unsupported model or task you will see an error. You can use `optimum.pipelines` as a replacement for `transformers.pipelines`.
```python
from transformers import AutoTokenizer
from optimum.onnxruntime import ORTModelForQuestionAnswering
from optimum.pipelines import pipeline
tokenizer = AutoTokenizer.from_pretrained(onnx_path)
model = ORTModelForQuestionAnswering.from_pretrained(onnx_path)
optimum_qa = pipeline("question-answering", model=model, tokenizer=tokenizer, handle_impossible_answer=True)
prediction = optimum_qa(question="What's my name?", context="My name is Philipp and I live in Nuremberg.")
print(prediction)
# {'score': 0.9041663408279419, 'start': 11, 'end': 18, 'answer': 'Philipp'}
```
### 3.6 Evaluate the performance and speed
During this [End-to-End tutorial on accelerating RoBERTa for Question-Answering including quantization and optimization](#3-end-to-end-tutorial-on-accelerating-roberta-for-question-answering-including-quantization-and-optimization), we created 3 different models. A vanilla converted model, an optimized model, and a quantized model.
As the last step of the tutorial, we want to take a detailed look at the performance and accuracy of our model. Applying optimization techniques, like graph optimizations or quantization not only impact performance (latency) those also might have an impact on the accuracy of the model. So accelerating your model comes with a trade-off.
Let's evaluate our models. Our transformers model [deepset/roberta-base-squad2](https://huggingface.co./deepset/roberta-base-squad2) was fine-tuned on the SQUAD2 dataset. This will be the dataset we use to evaluate our models.
```python
from datasets import load_metric,load_dataset
metric = load_metric("squad_v2")
dataset = load_dataset("squad_v2")["validation"]
print(f"length of dataset {len(dataset)}")
#length of dataset 11873
```
We can now leverage the [map](https://huggingface.co./docs/datasets/v2.1.0/en/process#map) function of [datasets](https://huggingface.co./docs/datasets/index) to iterate over the validation set of squad 2 and run prediction for each data point. Therefore we write a `evaluate` helper method which uses our pipelines and applies some transformation to work with the [squad v2 metric.](https://huggingface.co./metrics/squad_v2)
*This can take quite a while (1.5h)*
```python
def evaluate(example):
default = optimum_qa(question=example["question"], context=example["context"])
optimized = opt_optimum_qa(question=example["question"], context=example["context"])
quantized = quantized_optimum_qa(question=example["question"], context=example["context"])
return {
'reference': {'id': example['id'], 'answers': example['answers']},
'default': {'id': example['id'],'prediction_text': default['answer'], 'no_answer_probability': 0.},
'optimized': {'id': example['id'],'prediction_text': optimized['answer'], 'no_answer_probability': 0.},
'quantized': {'id': example['id'],'prediction_text': quantized['answer'], 'no_answer_probability': 0.},
}
result = dataset.map(evaluate)
# COMMENT IN to run evaluation on 2000 subset of the dataset
# result = dataset.shuffle().select(range(2000)).map(evaluate)
```
Now lets compare the results
```python
default_acc = metric.compute(predictions=result["default"], references=result["reference"])
optimized = metric.compute(predictions=result["optimized"], references=result["reference"])
quantized = metric.compute(predictions=result["quantized"], references=result["reference"])
print(f"vanilla model: exact={default_acc['exact']}% f1={default_acc['f1']}%")
print(f"optimized model: exact={optimized['exact']}% f1={optimized['f1']}%")
print(f"quantized model: exact={quantized['exact']}% f1={quantized['f1']}%")
# vanilla model: exact=79.07858165585783% f1=82.14970024570314%
# optimized model: exact=79.07858165585783% f1=82.14970024570314%
# quantized model: exact=78.75010528088941% f1=81.82526107204629%
```
Our optimized & quantized model achieved an exact match of `78.75%` and an f1 score of `81.83%` which is `99.61%` of the original accuracy. Achieving `99%` of the original model is very good especially since we used dynamic quantization.
Okay, let's test the performance (latency) of our optimized and quantized model.
But first, let’s extend our context and question to a more meaningful sequence length of 128.
```python
context="Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science. In the past I designed and implemented cloud-native machine learning architectures for fin-tech and insurance companies. I found my passion for cloud concepts and machine learning 5 years ago. Since then I never stopped learning. Currently, I am focusing myself in the area NLP and how to leverage models like BERT, Roberta, T5, ViT, and GPT2 to generate business value."
question="As what is Philipp working?"
```
To keep it simple, we are going to use a python loop and calculate the avg/mean latency for our vanilla model and for the optimized and quantized model.
```python
from time import perf_counter
import numpy as np
def measure_latency(pipe):
latencies = []
# warm up
for _ in range(10):
_ = pipe(question=question, context=context)
# Timed run
for _ in range(100):
start_time = perf_counter()
_ = pipe(question=question, context=context)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
return f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}"
print(f"Vanilla model {measure_latency(optimum_qa)}")
print(f"Optimized & Quantized model {measure_latency(quantized_optimum_qa)}")
# Vanilla model Average latency (ms) - 117.61 +\- 8.48
# Optimized & Quantized model Average latency (ms) - 64.94 +\- 3.65
```
<figure class="image table text-center m-0 w-full">
<img src="assets/66_optimum_inference/results.png" alt="Latency & F1 results"/>
</figure>
We managed to accelerate our model latency from `117.61ms` to `64.94ms` or roughly 2x while keeping `99.61%` of the accuracy. Something we should keep in mind is that we used a mid-performant CPU instance with 2 physical cores. By switching to GPU or a more performant CPU instance, e.g. [ice-lake powered you can decrease the latency number down to a few milliseconds.](https://huggingface.co./blog/bert-cpu-scaling-part-2#more-efficient-ai-processing-on-latest-intel-ice-lake-cpus)
## 4. Current Limitations
We just started supporting inference in [https://github.com/huggingface/optimum](https://github.com/huggingface/optimum) so we would like to share current limitations as well. All of those limitations are on the roadmap and will be resolved in the near future.
- **Remote Models > 2GB:** Currently, only models smaller than 2GB can be loaded from the [Hugging Face Hub](https://hf.co/). We are working on adding support for models > 2GB / multi-file models.
- **Seq2Seq tasks/model:** We don’t have support for seq2seq tasks, like summarization and models like T5 mostly due to the limitation of the single model support. But we are actively working to solve it, to provide you with the same experience you are familiar with in transformers.
- **Past key values:** Generation models like GPT-2 use something called past key values which are precomputed key-value pairs of the attention blocks and can be used to speed up decoding. Currently the ORTModelForCausalLM is not using past key values.
- **No cache:** Currently when loading an optimized model (*.onnx), it will not be cached locally.
## 5. Optimum Inference FAQ
**Which tasks are supported?**
You can find a list of all supported tasks in the [documentation](https://huggingface.co./docs/optimum/main/en/pipelines). Currently support pipelines tasks are `feature-extraction`, `text-classification`, `token-classification`, `question-answering`, `zero-shot-classification`, `text-generation`
**Which models are supported?**
Any model that can be exported with [transformers.onnx](https://huggingface.co./docs/transformers/serialization) and has a supported task can be used, this includes among others BERT, ALBERT, GPT2, RoBERTa, XLM-RoBERTa, DistilBERT ....
**Which runtimes are supported?**
Currently, ONNX Runtime is supported. We are working on adding more in the future. [Let us know](https://discuss.huggingface.co/c/optimum/59) if you are interested in a specific runtime.
**How can I use Optimum with Transformers?**
You can find an example and instructions in our [documentation](https://huggingface.co./docs/optimum/main/en/pipelines#transformers-pipeline-usage).
**How can I use GPUs?**
To be able to use GPUs you simply need to install `optimum[onnxruntine-gpu]` which will install the required GPU providers and use them by default.
**How can I use a quantized and optimized model with pipelines?**
You can load the optimized or quantized model using the new [ORTModelForXXX](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort) classes using the [from_pretrained](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort#optimum.onnxruntime.ORTModelForQuestionAnswering.forward.example) method. You can learn more about it in our [documentation](https://huggingface.co./docs/optimum/main/en/onnxruntime/modeling_ort#optimum-inference-with-onnx-runtime).
## 6. What’s next?
What’s next for Optimum you ask? A lot of things. We are focused on making Optimum the reference open-source toolkit to work with transformers for acceleration & optimization. To be able to achieve this we will solve the current limitations, improve the documentation, create more content and examples and push the limits for accelerating and optimizing transformers.
Some important features on the roadmap for Optimum amongst the [current limitations](#4-current-limitations) are:
- Support for speech models (Wav2vec2) and speech tasks (automatic speech recognition)
- Support for vision models (ViT) and vision tasks (image classification)
- Improve performance by adding support for [OrtValue](https://onnxruntime.ai/docs/api/python/api_summary.html#ortvalue) and [IOBinding](https://onnxruntime.ai/docs/api/python/api_summary.html#iobinding)
- Easier ways to evaluate accelerated models
- Add support for other runtimes and providers like TensorRT and AWS-Neuron | [
[
"transformers",
"mlops",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"optimization",
"mlops",
"efficient_computing"
] | null | null |
50e2ac92-1f20-4978-954f-94723a36c5b4 | completed | 2025-01-16T03:09:11.596524 | 2025-01-16T13:35:38.376430 | 424f2271-0d14-470f-958a-dd2d5f6e8f4c | Director of Machine Learning Insights [Part 3: Finance Edition] | britneymuller | ml-director-insights-3.md | _If you're interested in building ML solutions faster visit [hf.co/support](https://huggingface.co./support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series, Finance Edition! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co./blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co./blog/ml-director-insights-2)
Machine Learning Directors within finance face the unique challenges of navigating legacy systems, deploying interpretable models, and maintaining customer trust, all while being highly regulated (with lots of government oversight). Each of these challenges requires deep industry knowledge and technical expertise to pilot effectively. The following experts from U.S. Bank, the Royal Bank of Canada, Moody's Analytics and ex Research Scientist at Bloomberg AI all help uncover unique gems within the Machine Learning x Finance sector.
You’ll hear from a juniors Greek National Tennis Champion, a published author with over 100+ patents, and a cycle polo player who regularly played at the world’s oldest polo club (the Calcutta Polo Club). All turned financial ML experts.
🚀 Buckle up Goose, here are the top insights from financial ML Mavericks:
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Ioannis-Bakagiannis.jpeg"></a>
### [Ioannis Bakagiannis](https://www.linkedin.com/in/bakagiannisioannis//) - Director of Machine Learning, Marketing Science at [RBC](https://www.rbcroyalbank.com/personal.html)
**Background:** Passionate Machine Learning Expert with experience in delivering scalable, production-grade, and state-of-the-art Machine Learning solutions. Ioannis is also the Host of [Bak Up Podcast](https://www.youtube.com/channel/UCHK-YMcyzw2TwKonKoFtiug) and seeks to make an impact on the world through AI.
**Fun Fact:** Ioannis was a juniors Greek national tennis champion.🏆
**RBC:** The world’s leading organizations look to RBC Capital Markets as an innovative, trusted partner in capital markets, banking and finance.
#### **1. How has ML made a positive impact on finance?**
We all know that ML is a disrupting force in all industries while continuously creating new business opportunities. Many financial products have been created or altered due to ML such as personalized insurance and targeted marketing.
Disruptions and profit are great but my favorite financial impact has been the ML-initiated conversation around trust in financial decision making.
In the past, financial decisions like loan approval, rate determination, portfolio management, etc. have all been done by humans with relevant expertise. Essentially, people trusted “other people” or “experts” for financial decisions (and often without question).
When ML attempted to automate that decision-making process, people asked, “Why should we trust a model?”. Models appeared to be black boxes of doom coming to replace honest working people. But that argument has initiated the conversation of trust in financial decision-making and ethics, regardless of who or what is involved.
As an industry, we are still defining this conversation but with more transparency, thanks to ML in finance.
#### **2. What are the biggest ML challenges within finance?**
I can’t speak for companies but established financial institutions experience one continuous struggle, like all long-lived organizations: Legacy Systems.
Financial organizations have been around for a while and they have evolved over time but today they have found themselves somehow as ‘tech companies’. Such organizations need to be part of cutting-edge technologies so they can compete with newcomer rivals but at the same time maintain the robustness that makes our financial world work.
This internal battle is skewed by the risk appetite of the institutions. Financial risk increases linearly (usually) with the scale of the solution you provide since we are talking about money. But on top of that, there are other forms of risk that a system failure will incur such as Regulatory and Reputational risk. This compounded risk along with the complexity of migrating a huge, mature system to a new tech stack is, at least in my opinion, the biggest challenge in adopting cutting-edge technologies such as ML.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
ML, even with all its recent attention, is still a relatively new field in software engineering. The deployment of ML applications is often not a well-defined process. The artist/engineer can deliver an ML application but the world around it is still not familiar with the technical process. At that intersection of technical and non-technical worlds, I have seen the most “mistakes”.
It is hard to optimize for the right Business and ML KPIs and define the right objective function or the desired labels. I have seen applications go to waste due to undesired prediction windows or because they predict the wrong labels.
The worst outcome comes when the misalignment is not uncovered in the development step and makes it into production.
Then applications can create unwanted user behavior or simply measure/predict the wrong thing. Unfortunately, we tend to equip the ML teams with tools and computing but not with solid processes and communication buffers. And mistakes at the beginning of an ill-defined process grow with every step.
#### **4. What excites you most about the future of ML?**
It is difficult not to get excited with everything new that comes out of ML. The field changes so frequently that it’s refreshing.
Currently, we are good at solving individual problems: computer vision, the next word prediction, data point generation, etc, but we haven’t been able to address multiple problems at the same time. I’m excited to see how we can model such behaviors in mathematical expressions that currently seem to contradict each other. Hope we get there soon!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Debanjan-Mahata.jpeg"></a>
### [Debanjan Mahata](https://www.linkedin.com/in/debanjanmahata/) - Director of AI & ML at [Moody's Analytics](https://www.moodysanalytics.com/) / Ex Research Scientist @ Bloomberg AI
**Background:** Debanjan is Director of Machine Learning in the AI Team at Moody's Analytics and also serves as an Adjunct Faculty at IIIT-Delhi, India. He is an active researcher and is currently interested in various information extraction problems and domain adaptation techniques in NLP. He has a track record of formulating and applying machine learning to various use cases. He actively participates in the program committee of different top tier conference venues in machine learning.
**Fun Fact:** Debanjan played cycle polo at the world's oldest polo club (the Calcutta Polo Club) when he was a kid.
**Moody's Analytics:** Provides financial intelligence and analytical tools supporting our clients’ growth, efficiency and risk management objectives.
#### **1. How has ML made a positive impact on finance?**
Machine learning (ML) has made a significant positive impact in the finance industry in many ways. For example, it has helped in combating financial crimes and identifying fraudulent transactions. Machine learning has been a crucial tool in applications such as Know Your Customer (KYC) screening and Anti Money Laundering (AML). With an increase in AML fines by financial institutions worldwide, ever changing realm of sanctions, and greater complexity in money laundering, banks are increasing their investments in KYC and AML technologies, many of which are powered by ML. ML is revolutionizing multiple facets of this sector, especially bringing huge efficiency gains by automating various processes and assisting analysts to do their jobs more efficiently and accurately.
One of the key useful traits of ML is that it can learn from and find hidden patterns in large volumes of data. With a focus on digitization, the financial sector is producing digital data more than ever, which makes it challenging for humans to comprehend, process and make decisions. ML is enabling humans in making sense of the data, glean information from them, and make well-informed decisions. At Moody's Analytics, we are using ML and helping our clients to better manage risk and meet business and industry demands.
#### **2. What are the biggest ML challenges within finance?**
1. Reducing the False Positives without impacting the True Positives - A number of applications using ML in the regtech space rely on alerts. With strict regulatory measures and big financial implications of a wrong decision, human investigations can be time consuming and demanding. ML certainly helps in these scenarios in assisting human analysts to arrive at the right decisions. But if a ML system results in a lot of False Positives, it makes an analysts' job harder. Coming up with the right balance is an important challenge for ML in finance.
2. Gap between ML in basic research and education and ML in finance - Due to the regulated nature of the finance industry, we see limited exchange of ideas, data, and resources between the basic research and the finance sector, in the area of ML. There are few exceptions of course. This has led to scarcity of developing ML research that cater to the needs of the finance industry. I think more efforts must be made to decrease this gap. Otherwise, it will be increasingly challenging for the finance industry to leverage the latest ML advances.
3. Legacy infrastructure and databases - Many financial institutions still carry legacy infrastructure with them which makes it challenging for applying modern ML technologies and especially to integrate them. The finance industry would benefit from borrowing key ideas, culture and best practices from the tech industry when it comes to developing new infrastructure and enabling the ML professionals to innovate and make more impact. There are certainly challenges related to operationalizing ML across the industry.
4. Data and model governance - More data and model governance efforts need to be made in this sector. As we collect more and more data there should be more increase in the efforts to collect high quality data and the right data. Extra precautions need to be taken when ML models are involved in decisioning. Proper model governance measures and frameworks needs to be developed for different financial applications. A big challenge in this space is the lack of tools and technologies to operationalize data and model governance that are often needed for ML systems operating in this sector. More efforts should also be made in understanding bias in the data that train the models and how to make it a common practice to mitigate them in the overall process. Ensuring auditability, model and data lineage has been challenging for ML teams.
5. Explainability and Interpretability - Developing models which are highly accurate as well as interpretable and explainable is a big challenge. Modern deep learning models often outperform more traditional models; however, they lack explainability and interpretability. Most of the applications in finance demands explainability. Adopting the latest developments in this area and ensuring the development of interpretable models with explainable predictions have been a challenge.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
- Not understanding the data well and the raw predictions made by the ML models trained on them.
- Not analyzing failed efforts and learning from them.
- Not understanding the end application and how it will be used.
- Trying complex techniques when simpler solutions might suffice.
#### **4. What excites you most about the future of ML?**
I am really blown away by how modern ML models have been learning rich representations of text, audio, images, videos, code and so on using self-supervised learning on large amounts of data. The future is certainly multi-modal and there has been consistent progress in understanding multi-modal content through the lens of ML. I think this is going to play a crucial role in the near future and I am excited by it and looking forward to being a part of these advances.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Soumitri-Kolavennu.jpeg"></a>
### [Soumitri Kolavennu](https://www.linkedin.com/in/soumitri-kolavennu-2b47376/) - Artificial Intelligence Leader - Enterprise Analytics & AI at [U.S. Bank](https://www.usbank.com/index.html)
**Background:** Soumitri Kolavennu is a SVP and head of AI research in U.S. Bank’s enterprise analytics and AI organization. He is currently focused on deep learning based NLP, vision & audio analytics, graph neural networks, sensor/knowledge fusion, time-series data with application to automation, information extraction, fraud detection and anti-money laundering in financial systems.
Previously, he held the position of Fellows Leader & Senior Fellow, while working at Honeywell International Inc. where he had worked on IoT and control systems applied to smart home, smart cities, industrial and automotive systems.
**Fun Fact:** Soumitri is a prolific inventor with 100+ issued U.S. patents in varied fields including control systems, Internet of Things, wireless networking, optimization, turbocharging, speech recognition, machine learning and AI. He also has around 30 publications, [authored a book](https://www.elsevier.com/books/industrial-wireless-sensor-networks/budampati/978-1-78242-230-3), book chapters and was elected member of NIST’s smart grid committee.
**U.S. Bank:** The largest regional bank in the United States, U.S. Bank blends its relationship teams, branches and ATM networks with digital tools that allow customers to bank when, where and how they prefer.
#### **1. How has ML made a positive impact on finance?**
Machine learning and artificial intelligence have made a profound and positive impact on finance in general and banking in particular. There are many applications in banking where many factors (features) are to be considered when making a decision and ML has traditionally helped in this respect. For example, the credit score we all universally rely on is derived from a machine learning algorithm.
Over the years ML has interestingly also helped remove human bias from decisions and provided a consistent algorithmic approach to decisions. For example, in credit card/loan underwriting and mortgages, modern AI techniques can take more factors (free form text, behavioral trends, social and financial interactions) into account for decisions while also detecting fraud.
#### **2. What are the biggest ML challenges within finance?**
The finance and banking industry brings a lot of challenges due to the nature of the industry. First of all, it is a highly regulated industry with government oversight in many aspects. The data that is often used is very personal and identifiable data (social security numbers, bank statements, tax records, etc). Hence there is a lot of care taken to create machine learning and AI models that are private and unbiased. Many government regulations require any models to be explainable. For example, if a loan is denied, there is a fundamental need to explain why it is denied.
The data on the other hand, which may be scarce in other industries is abundant in the financial industry. (Mortgage records have to be kept for 30 years for example). The current trend for digitization of data and the explosion of more sophisticated AI/ML techniques has created a unique opportunity for the application of these advances.
#### **3. What’s a common mistake you see people make trying to integrate ML into financial applications?**
One of the most common mistakes people make is to use a model or a technique without understanding the underlying working principles, advantages, and shortcomings of the model. People tend to think of AI/ML models as a ‘black box’. In finance, it is especially important to understand the model and to be able to explain its’ output. Another mistake is not comprehensively testing the model on a representative input space. Model performance, validation, inference capacities, and model monitoring (retraining intervals) are all important to consider when choosing a model.
#### **4. What excites you most about the future of ML?**
Now is a great time to be in applied ML and AI. The techniques in AI/ML are certainly refining if not redefining many scientific disciplines. I am very excited about how all the developments that are currently underway will reshape the future.
When I first started working in NLP, I was in awe of the ability of neural networks/language models to generate a number or vector (which we now call embeddings) that represents a word, a sentence with the associated grammar, or even a paragraph. We are constantly in search of more and more appropriate and contextual embeddings.
We have advanced far beyond a “simple” embedding for a text to “multimodal” embeddings that are even more awe-inspiring to me. I am most excited and look forward to generating and playing with these new embeddings enabling more exciting applications in the future. | [
[
"mlops",
"community",
"security",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"deployment",
"security"
] | null | null |
30f70a51-48fb-4bdf-8381-f16ea9405210 | completed | 2025-01-16T03:09:11.596529 | 2025-01-16T14:20:04.631115 | eedc35a6-eb11-42fc-9ff4-6f17332bb13b | Introducing ConTextual: How well can your Multimodal model jointly reason over text and image in text-rich scenes? | rohan598, hbXNov, kaiweichang, violetpeng, clefourrier | leaderboard-contextual.md | Models are becoming quite good at understanding text on its own, but what about text in images, which gives important contextual information? For example, navigating a map, or understanding a meme? The ability to reason about the interactions between the text and visual context in images can power many real-world applications, such as AI assistants, or tools to assist the visually impaired.
We refer to these tasks as "context-sensitive text-rich visual reasoning tasks".
At the moment, most evaluations of instruction-tuned large multimodal models (LMMs) focus on testing how well models can respond to human instructions posed as questions or imperative sentences (“Count this”, “List that”, etc) over images... but not how well they understand context-sensitive text-rich scenes!
That’s why we (researchers from University of California Los Angeles) created ConTextual, a Context-sensitive Text-rich visuaL reasoning dataset for evaluating LMMs. We also released a leaderboard, so that the community can see for themselves which models are the best at this task.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="ucla-contextual/contextual_leaderboard"></gradio-app>
For an in-depth dive, you can also check these additional resources: [paper](https://arxiv.org/abs/2401.13311), [code](https://github.com/rohan598/ConTextual), [dataset](https://huggingface.co./datasets/ucla-contextual/contextual_all), [validation dataset](https://huggingface.co./datasets/ucla-contextual/contextual_val), and [leaderboard](https://huggingface.co./spaces/ucla-contextual/contextual_leaderboard).
## What is ConTextual
ConTextual is a Context-sensitive Text-rich visual reasoning dataset consisting of 506 challenging instructions for LMM evaluation. We create a diverse set of instructions on text-rich images with the constraint that they should require context-sensitive joint reasoning over the textual and visual cues in the image.
It covers 8 real-world visual scenarios - Time Reading, Shopping, Navigation, Abstract Scenes, Mobile Application, Webpages, Infographics and Miscellaneous Natural Scenes. (See the figure for a sample of each dataset).

Each sample consists of:
- A text-rich image
- A human-written instruction (question or imperative task)
- A human-written reference response
The dataset is released in two forms:
- (a) a validation set of 100 instances from the complete dataset with instructions, images, and reference answers to the instructions.
- (b) a test dataset with instructions and images only.
The leaderboard contains model results both on the validation and test datasets (the information is also present in the paper). The development set allows the practitioners to test and iterate on their approaches easily. The evaluation sandbox is present in our github.
## Experiments
For our initial experiments, our benchmark assessed the performance of 13 models. We divided them into three categories:
- **Augmented LLM approach**: GPT4 + visual information in the form of OCR of the image and/or dense image captions;
- **Closed-Source LMMs**: GPT4V(ision) and Gemini-Vision-Pro;
- **Open-Source LMMs**: LLaVA-v1.5-13B, ShareGPT4V-7B, Instruct-Blip-Vicuna-7B, mPlugOwl-v2-7B, Bliva-Vicuna-7B, Qwen-VL-7B and Idefics-9B.
Our dataset includes a reference response for each instruction, allowing us to test various automatic evaluation methods. For evaluation, we use an LLM-as-a-judge approach, and prompt GPT-4 with the instruction, reference response, and predicted response. The model has to return whether the predicted response is acceptable or not. (GPT4 was chosen as it correlated the most with human judgement in our experiments.)
Let's look at some examples!
[Example 1](https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/leaderboards-on-the-hub/contextual-qualitative-ex-1.png)
In this instance, GPT-4V provides an incorrect response to the instruction, despite its logical reasoning. The use of green indicates responses that match the reference, while red highlights errors in the responses. Additionally, a Summarized Reasoning is provided to outline the rationale used by GPT-4V to arrive at its answer.
[Example 2](https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/leaderboards-on-the-hub/contextual-qualitative-ex-2.png)
In this example, GPT-4V correctly responds to the instruction. However, ShareGPT-4V-7B (best performing open-source LMM) and GPT-4 w/ Layout-aware OCR + Caption (Augmented LLM) produce a wrong response, due to lack of joint reasoning over text and image.
You’ll find more examples like this in the Appendix section of our [paper](https://arxiv.org/abs/2401.13311)!
## Key Takeaways!
While working on this, we found that:
- Modern LMMs (proprietary and open models) struggle to perform on ConTextual dataset while humans are good at it, hinting at the possibility of model improvement to enhance reasoning over text-rich images, a domain with significant real-world applications.
- Proprietary LMMs perform poorly in infographics reasoning that involves time reading, indicating a gap in their capabilities compared to humans. Notably, GPT-4V, the best performing model, surpasses humans in abstract reasoning, potentially due to exposure to memes and quotes data, but struggles in time-related tasks where humans excel.
- For open-source models such as LLaVA-1.5-13B and ShareGPT-4V-7B, there is a strong gap between the domains on which they achieve acceptable human ratings (abstract and natural scene contexts) and the other domains ((time-reading, infographics, navigation, shopping, web, and mobile usage). It's therefore likely that many of the domains we cover in our samples are out-of-distribution for these models. Open-source models should therefore aim to increase the diversity in their training data.
- Augmenting an LMMs with a Large Language Model, which receives visual information converted into text via OCR or captions, performs notably badly, with an human approval rate of 17.2%. Our samples need a combination of precise visual perception along with fine-grained nuanced vision-language alignment to be solved.
Our analysis suggests promising next steps include:
- developing enhanced image encoders,
- creating highly accurate image descriptions,
- facilitating fine-grained vision-language alignment to improve the model's perception and mitigate the occurrence of hallucinations.
This, in turn, will lead to more effective context-sensitive text-rich visual reasoning.
## What’s next?
We’d love to evaluate your models too, to help collectively advance the state of vision language models! To submit, please follow our guidelines below.
We hope that this benchmark will help in developing nuanced vision-language alignment techniques and welcome any kind of collaboration! You can contact us here: [Rohan]([email protected]) and [Hritik]([email protected]), and know more about the team here: [Rohan](https://web.cs.ucla.edu/~rwadhawan7/), [Hritik](https://sites.google.com/view/hbansal), [Kai-Wei Chang](https://web.cs.ucla.edu/~kwchang/), [Nanyun (Violet) Peng](https://vnpeng.net/).
## How to Submit?
We are accepting submissions for both the test and validation sets. Please, follow the corresponding procedure below.
### Validation Set Submission
To submit your validation results to the leaderboard, you can run our auto-evaluation code (Evaluation Pipeline with GPT4), following [these instructions](https://github.com/rohan598/ConTextual?tab=readme-ov-file#-evaluation-pipeline-gpt-4).
We expect submissions to be json format as shown below:
```json
{"model_name": {"img_url": "The boolean score of your model on the image, 1 for success and 0 for failure"}}
```
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is either 0 or 1 (int)
There should be 100 predictions, corresponding to the 100 urls of the val set.
To make the submission please go to the [leaderboard](https://huggingface.co./spaces/ucla-contextual/contextual_leaderboard) hosted on HuggingFace and fill up the Submission form.
### Test Set Submission
Once you are happy with your validation results, you can send your model predictions to [Rohan]([email protected]) and [Hritik]([email protected]).
Please include in your email:
- A name for your model.
- Organization (affiliation).
- (Optionally) GitHub repo or paper link.
We expect submissions to be json format similar to val set as shown below:
```json
{"model_name": {"img_url": "predicted response"}}
```
- Replace model name with your model name (string)
- Replace img_url with img_url of the instance (string)
- Value for an img url is the predicted response for that instance (string)
There should be 506 predictions, corresponding to the 506 urls of the test set. | [
[
"computer_vision",
"data",
"research",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"multi_modal",
"computer_vision",
"data",
"research"
] | null | null |
60ea712b-af5d-4b14-83e4-3aa5ed5bbc2a | completed | 2025-01-16T03:09:11.596534 | 2025-01-19T18:52:37.634347 | 2c18b3d7-1314-448f-9f4c-110c45a8043b | 'Introducing Snowball Fight ☃️, our first ML-Agents environment' | ThomasSimonini | snowball-fight.md | We're excited to share our **first custom Deep Reinforcement Learning environment**: Snowball Fight 1vs1 🎉.

Snowball Fight is a game made with Unity ML-Agents, where you shoot snowballs against a Deep Reinforcement Learning agent. The game is [**hosted on Hugging Face Spaces**](https://hf.co/spaces/launch).
👉 [You can play it online here](https://huggingface.co./spaces/ThomasSimonini/SnowballFight)
In this post, we'll cover **the ecosystem we are working on for Deep Reinforcement Learning researchers and enthusiasts that use Unity ML-Agents**.
## Unity ML-Agents at Hugging Face
The [Unity Machine Learning Agents Toolkit](https://github.com/Unity-Technologies/ml-agents) is an open source library that allows you to build games and simulations with Unity game engine to **serve as environments for training intelligent agents**.
With this first step, our goal is to build an ecosystem on Hugging Face for Deep Reinforcement Learning researchers and enthusiasts that uses ML-Agents, with three features.
1. **Building and sharing custom environments.** We are developing and sharing exciting environments to experiment with new problems: snowball fights, racing, puzzles... All of them will be open source and hosted on the Hugging Face's Hub.
2. **Allowing you to easily host your environments, save models and share them** on the Hugging Face Hub. We have already published the Snowball Fight training environment [here](https://huggingface.co./ThomasSimonini/ML-Agents-SnowballFight-1vs1), but there will be more to come!
3. **You can now easily host your demos on Spaces** and showcase your results quickly with the rest of the ecosystem.
## Be part of the conversation: join our discord server!
If you're using ML-Agents or interested in Deep Reinforcement Learning and want to be part of the conversation, **[you can join our discord server](https://discord.gg/YRAq8fMnUG)**. We just added two channels (and we'll add more in the future):
- Deep Reinforcement Learning
- ML-Agents
[Our discord](https://discord.gg/YRAq8fMnUG) is the place where you can exchange about Hugging Face, NLP, Deep RL, and more! It's also in this discord that we'll announce all our new environments and features in the future.
## What's next?
In the coming weeks and months, we will be extending the ecosystem by:
- Writing some **technical tutorials on ML-Agents**.
- Working on a **Snowball Fight 2vs2 version**, where the agents will collaborate in teams using [MA-POCA, a new Deep Reinforcement Learning algorithm](https://blog.unity.com/technology/ml-agents-plays-dodgeball) that trains cooperative behaviors in a team.

- And we're building **new custom environments that will be hosted in Hugging Face**.
## Conclusion
We're excited to see what you're working on with ML-Agents and how we can build features and tools **that help you to empower your work**.
Don't forget to [join our discord server](https://discord.gg/YRAq8fMnUG) to be alerted of the new features. | [
[
"implementation",
"tutorial",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"tutorial",
"tools",
"community"
] | null | null |
dc4146ff-a5ae-4981-a59e-e2b99dde5842 | completed | 2025-01-16T03:09:11.596539 | 2025-01-19T17:16:26.000532 | d0b64336-795d-4f68-aa7a-2763d3823106 | Hugging Face partners with Wiz Research to Improve AI Security | JJoe206, GuillaumeSalouHF, michellehbn, XciD, mcpotato, Narsil, julien-c | hugging-face-wiz-security-blog.md | We are pleased to announce that we are partnering with Wiz with the goal of improving security across our platform and the AI/ML ecosystem at large.
Wiz researchers [collaborated with Hugging Face on the security of our platform and shared their findings](https://www.wiz.io/blog/wiz-and-hugging-face-address-risks-to-ai-infrastructure). Wiz is a cloud security company that helps their customers build and maintain software in a secure manner. Along with the publication of this research, we are taking the opportunity to highlight some related Hugging Face security improvements.
Hugging Face has recently integrated Wiz for Vulnerability Management, a continuous and proactive process to keep our platform free of security vulnerabilities. In addition, we are using Wiz for Cloud Security Posture Management (CSPM), which allows us to configure our cloud environment securely, and monitor to ensure it remains secure.
One of our favorite Wiz features is a holistic view of Vulnerabilities, from storage to compute to network. We run multiple Kubernetes (k8s) clusters and have resources across multiple regions and cloud providers, so it is extremely helpful to have a central report in a single location with the full context graph for each vulnerability. We’ve also built on top of their tooling, to automatically remediate detected issues in our products, most notably in Spaces.
As part of the joint work, Wiz’s security research team identified shortcomings of our sandboxed compute environments by running arbitrary code within the system thanks to pickle. As you read this blog and the Wiz security research paper, it is important to remember that we have resolved all issues related to the exploit and continue to remain diligent in our Threat Detection and Incident Response process.
## Hugging Face Security
At Hugging Face we take security seriously, as AI rapidly evolves, new threat vectors seemingly pop up every day. Even as Hugging Face announces multiple partnerships and business relationships with the largest names in tech, we remain committed to allow our users and the AI community to responsibly experiment with and operationalize AI/ML systems and technologies. We are dedicated to securing our platform as well as democratizing AI/ML, such that the community can contribute to and be a part of this paradigm shifting event that will impact us all. We are writing this blog to reaffirm our commitment to protecting our users and customers from security threats. Below we will also discuss Hugging Face’s philosophy regarding our support of the controversial pickle files as well as discuss the shared responsibility of moving away from the pickle format.
There are many other exciting security improvements and announcements coming in the near future. The publications will not only discuss the security risks to the Hugging Face platform community, but also cover systemic security risks of AI as well as best practices for mitigation. We remain committed to making our products, our infrastructure, and the AI community secure, stay tuned for followup security blog posts and whitepapers.
## Open Source Security Collaboration and Tools for the Community
We highly value transparency and collaboration with the community and this includes participation in the identification and disclosure of vulnerabilities, collaborating on resolving security issues, and security tooling. Below are examples of our security wins born from collaboration, which help the entire AI community lower their security risk:
- Picklescan was built in partnership with Microsoft; Matthieu Maitre started the project and given we had our own internal version of the same tool, we joined forces and contributed to picklescan. Refer to the following documentation page if you are curious to know more on how it works:
https://huggingface.co./docs/hub/en/security-pickle
- Safetensors, which was developed by Nicolas Patry, is a secure alternative to pickle files. Safetensors has been audited by Trail of Bits on a collaborative initiative with EuletherAI & Stability AI.
https://huggingface.co./docs/safetensors/en/index
- We have a robust bug bounty program, with many amazing researchers from all around the world. Researchers who have identified a security vuln may inquire about joining our program through [email protected]
- Malware Scanning: https://huggingface.co./docs/hub/en/security-malware
- Secrets Scanning: https://huggingface.co./docs/hub/security-secrets
- As previously mentioned, we’re also collaborating with Wiz to lower Platform security risks
- We are starting a series of security publications which address security issues facing the AI/ML community.
## Security Best Practices for Open Source AI/ML users
AI/ML has introduced new vectors of attack, but for many of these attacks mitigants are long standing and well known. Security professionals should ensure that they apply relevant security controls to AI resources and models. In addition, below are some resources and best practices when working with open source software and models:
- Know the contributor: Only use models from trusted sources and pay attention to commit signing. https://huggingface.co./docs/hub/en/security-gpg
- Don’t use pickle files in production environments
- Use Safetensors: https://huggingface.co./docs/safetensors/en/index
- Review the OWASP top 10: https://owasp.org/www-project-top-ten/
- Enable MFA on your Hugging Face accounts
- Establish a Secure Development Lifecycle, which includes code review by a security professional or engineer with appropriate security training
Test models in non-production and virtualized test/dev environments
## Pickle Files - The Insecure Elephant in the Room
Pickle files have been at the core of most of the research done by Wiz and other recent publications by security researchers about Hugging Face. Pickle files have long been considered to have security risks associated with them, see our doc files for more information: https://huggingface.co./docs/hub/en/security-pickle
Despite these known security flaws, the AI/ML community still frequently uses pickles (or similarly trivially exploitable formats). Many of these use cases are low risk or for test purposes making the familiarity and ease of use of pickle files more attractive than the secure alternative.
As the open source AI platform, we are left with the following options:
- Ban pickle files entirely
- Do nothing about pickle files
- Finding a middle ground that both allows for pickle use as well as reasonably and practicably mitigating the risks associated with pickle files
We have chosen option 3, the middle ground for now. This option is a burden on our engineering and security teams and we have put in significant effort to mitigate the risks while allowing the AI community to use tools they choose. Some of the key mitigants we have implemented to the risks related to pickle include:
- Creating clear documentation outlining the risks
- Developing automated scanning tools
- Using scanning tools and labeling models with security vulnerabilities with clear warnings
- We have even provided a secure solution to use in lieu of pickle (Safetensors)
- We have also made Safetensors a first class citizen on our platform to protect the community members who may not understand the risks
- In addition to the above, we have also had to significantly segment and enhance security of the areas in which models are used to account for potential vulnerabilities within them
We intend to continue to be the leader in protecting and securing the AI Community. Part of this will be monitoring and addressing risks related to pickle files. Sunsetting support of pickle is also not out of the question either, however, we do our best to balance the impact on the community as part of a decision like this.
An important note that the upstream open source communities as well as large tech and security firms, have been largely silent on contributing to solutions here and left Hugging Face to both define philosophy and invest heavily in developing and implementing mitigating controls to ensure the solution is both acceptable and practicable.
## Closing remarks
I spoke extensively to Nicolas Patry, the creator of Safetensors in writing this blog post and he requested that I add a call to action to the AI open source community and AI enthusiasts:
- Pro-actively start replacing your pickle files with Safetensors. As mentioned earlier, pickle contains inherent security flaws and may be unsupported in the near future.
- Keep opening issues/PRs upstream about security to your favorite libraries to push secure defaults as much as possible upstream.
The AI industry is rapidly changing and new attack vectors / exploits are being identified all the time. Huggingface has a one of a kind community and we partner heavily with you to help us maintain a secure platform.
Please remember to responsibly disclose security vulns/bugs through the appropriate channels to avoid potential legal liability and violation of laws.
Want to join the discussion? Reach out to us as [email protected] or follow us on Linkedin/Twitter. | [
[
"mlops",
"security",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"security",
"mlops",
"integration",
"tools"
] | null | null |
1e0395c5-c432-42c5-800e-b056e9c019a7 | completed | 2025-01-16T03:09:11.596544 | 2025-01-19T19:14:03.622956 | 8cf5389a-1902-4178-9637-4460c855df75 | FineVideo: behind the scenes | mfarre, andito, lewtun, lvwerra, pcuenq, thomwolf | fine-video.md | <img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/finevideo/logo.png" alt="FineVideo logo" style="width: 50%;"><br>
</center>
Open video datasets are scarce and therefore slowing down the development of open-source video AI. For this reason we built [FineVideo](https://huggingface.co./spaces/HuggingFaceFV/FineVideo-Explorer), a dataset with 43k videos that span 3.4k hours and are annotated with rich descriptions, narrative details, scene splits, and QA pairs.
FineVideo contains a highly diverse collection of videos and metadata which makes it a good ingredient to train models to understand video content, train diffusion models to generate videos from a text description or train computer vision models using its structured data as input.
Wait, you haven’t seen FineVideo yet? take a look at it through the [dataset explorer page](https://huggingface.co./spaces/HuggingFaceFV/FineVideo-Explorer).
<center>
<br>
<a href="https://huggingface.co./spaces/HuggingFaceFV/FineVideo-Explorer">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/finevideo/finevideo.gif" alt="FineVideo Explorer" style="width: 60%;">
</a>
<br><br>
</center>
## Table of Contents
- [Table of Contents](#table-of-contents)
- [About this blog post](#about-this-blog-post)
- [Building the Raw dataset](#building-the-raw-dataset)
- [Filtering YouTube-Commons](#filtering-youtube-commons)
- [Downloading the videos](#downloading-the-videos)
- [Keeping dynamic content](#keeping-dynamic-content)
- [Word density filtering](#word-density-filtering)
- [Visual dynamism filtering](#visual-dynamism-filtering)
- [Video Categorization](#video-categorization)
- [Custom built Taxonomy](#custom-built-taxonomy)
- [Content annotation](#content-annotation)
- [Feedback loop taxonomy - content annotation](#feedback-loop-taxonomy | [
[
"computer_vision",
"data",
"research",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"data",
"research",
"image_generation"
] | null | null |
bbce0d19-709f-4d5d-b682-c9a3b88aaef1 | completed | 2025-01-16T03:09:11.596548 | 2025-01-19T19:05:26.224754 | a61bb58b-3696-4a59-8721-bfc1e1f3a2ac | A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes | ybelkada, timdettmers | hf-bitsandbytes-integration.md | 
## Introduction
Language models are becoming larger all the time. At the time of this writing, PaLM has 540B parameters, OPT, GPT-3, and BLOOM have around 176B parameters, and we are trending towards even larger models. Below is a diagram showing the size of some recent language models.

Therefore, these models are hard to run on easily accessible devices. For example, just to do inference on BLOOM-176B, you would need to have 8x 80GB A100 GPUs (~$15k each). To fine-tune BLOOM-176B, you'd need 72 of these GPUs! Much larger models, like PaLM would require even more resources.
Because these huge models require so many GPUs to run, we need to find ways to reduce these requirements while preserving the model's performance. Various technologies have been developed that try to shrink the model size, you may have heard of quantization and distillation, and there are many others.
After completing the training of BLOOM-176B, we at HuggingFace and BigScience were looking for ways to make this big model easier to run on less GPUs. Through our BigScience community we were made aware of research on Int8 inference that does not degrade predictive performance of large models and reduces the memory footprint of large models by a factor or 2x. Soon we started collaboring on this research which ended with a full integration into Hugging Face `transformers`. With this blog post, we offer LLM.int8() integration for all Hugging Face models which we explain in more detail below. If you want to read more about our research, you can read our paper, [LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://arxiv.org/abs/2208.07339).
This article focuses on giving a high-level overview of this quantization technology, outlining the difficulties in incorporating it into the `transformers` library, and drawing up the long-term goals of this partnership.
Here you will learn what exactly make a large model use so much memory? What makes BLOOM 350GB? Let's begin by gradually going over a few basic premises.
## Common data types used in Machine Learning
We start with the basic understanding of different floating point data types, which are also referred to as "precision" in the context of Machine Learning.
The size of a model is determined by the number of its parameters, and their precision, typically one of float32, float16 or bfloat16 (image below from: https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/).

Float32 (FP32) stands for the standardized IEEE 32-bit floating point representation. With this data type it is possible to represent a wide range of floating numbers. In FP32, 8 bits are reserved for the "exponent", 23 bits for the "mantissa" and 1 bit for the sign of the number. In addition to that, most of the hardware supports FP32 operations and instructions.
In the float16 (FP16) data type, 5 bits are reserved for the exponent and 10 bits are reserved for the mantissa. This makes the representable range of FP16 numbers much lower than FP32. This exposes FP16 numbers to the risk of overflowing (trying to represent a number that is very large) and underflowing (representing a number that is very small).
For example, if you do `10k * 10k` you end up with `100M` which is not possible to represent in FP16, as the largest number possible is `64k`. And thus you'd end up with `NaN` (Not a Number) result and if you have sequential computation like in neural networks, all the prior work is destroyed.
Usually, loss scaling is used to overcome this issue, but it doesn't always work well.
A new format, bfloat16 (BF16), was created to avoid these constraints. In BF16, 8 bits are reserved for the exponent (which is the same as in FP32) and 7 bits are reserved for the fraction.
This means that in BF16 we can retain the same dynamic range as FP32. But we lose 3 bits of precision with respect to FP16. Now there is absolutely no problem with huge numbers, but the precision is worse than FP16 here.
In the Ampere architecture, NVIDIA also introduced [TensorFloat-32](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) (TF32) precision format, combining the dynamic range of BF16 and precision of FP16 to only use 19 bits. It's currently only used internally during certain operations.
In the machine learning jargon FP32 is called full precision (4 bytes), while BF16 and FP16 are referred to as half-precision (2 bytes).
On top of that, the int8 (INT8) data type consists of an 8-bit representation that can store 2^8 different values (between [0, 255] or [-128, 127] for signed integers).
While, ideally the training and inference should be done in FP32, it is two times slower than FP16/BF16 and therefore a mixed precision approach is used where the weights are held in FP32 as a precise "main weights" reference, while computation in a forward and backward pass are done for FP16/BF16 to enhance training speed. The FP16/BF16 gradients are then used to update the FP32 main weights.
During training, the main weights are always stored in FP32, but in practice, the half-precision weights often provide similar quality during inference as their FP32 counterpart -- a precise reference of the model is only needed when it receives multiple gradient updates. This means we can use the half-precision weights and use half the GPUs to accomplish the same outcome.

To calculate the model size in bytes, one multiplies the number of parameters by the size of the chosen precision in bytes. For example, if we use the bfloat16 version of the BLOOM-176B model, we have `176*10**9 x 2 bytes = 352GB`! As discussed earlier, this is quite a challenge to fit into a few GPUs.
But what if we can store those weights with less memory using a different data type? A methodology called quantization has been used widely in Deep Learning.
## Introduction to model quantization
Experimentially, we have discovered that instead of using the 4-byte FP32 precision, we can get an almost identical inference outcome with 2-byte BF16/FP16 half-precision, which halves the model size. It'd be amazing to cut it further, but the inference quality outcome starts to drop dramatically at lower precision.
To remediate that, we introduce 8-bit quantization. This method uses a quarter precision, thus needing only 1/4th of the model size! But it's not done by just dropping another half of the bits.
Quantization is done by essentially “rounding” from one data type to another. For example, if one data type has the range 0..9 and another 0..4, then the value “4” in the first data type would be rounded to “2” in the second data type. However, if we have the value “3” in the first data type, it lies between 1 and 2 of the second data type, then we would usually round to “2”. This shows that both values “4” and “3” of the first data type have the same value “2” in the second data type. This highlights that quantization is a noisy process that can lead to information loss, a sort of lossy compression.
The two most common 8-bit quantization techniques are zero-point quantization and absolute maximum (absmax) quantization. Zero-point quantization and absmax quantization map the floating point values into more compact int8 (1 byte) values. First, these methods normalize the input by scaling it by a quantization constant.
For example, in zero-point quantization, if my range is -1.0…1.0 and I want to quantize into the range -127…127, I want to scale by the factor of 127 and then round it into the 8-bit precision. To retrieve the original value, you would need to divide the int8 value by that same quantization factor of 127. For example, the value 0.3 would be scaled to `0.3*127 = 38.1`. Through rounding, we get the value of 38. If we reverse this, we get `38/127=0.2992` – we have a quantization error of 0.008 in this example. These seemingly tiny errors tend to accumulate and grow as they get propagated through the model’s layers and result in performance degradation.

(Image taken from: [this blogpost](https://intellabs.github.io/distiller/algo_quantization.html) )
Now let's look at the details of absmax quantization. To calculate the mapping between the fp16 number and its corresponding int8 number in absmax quantization, you have to first divide by the absolute maximum value of the tensor and then multiply by the total range of the data type.
For example, let's assume you want to apply absmax quantization in a vector that contains `[1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4]`. You extract the absolute maximum of it, which is `5.4` in this case. Int8 has a range of `[-127, 127]`, so we divide 127 by `5.4` and obtain `23.5` for the scaling factor. Therefore multiplying the original vector by it gives the quantized vector `[28, -12, -101, 28, -73, 19, 56, 127]`.

To retrieve the latest, one can just divide in full precision the int8 number with the quantization factor, but since the result above is "rounded" some precision will be lost.

For an unsigned int8, we would subtract the minimum and scale by the absolute maximum. This is close to what zero-point quantization does. It's is similar to a min-max scaling but the latter maintains the value scales in such a way that the value “0” is always represented by an integer without any quantization error.
These tricks can be combined in several ways, for example, row-wise or vector-wise quantization, when it comes to matrix multiplication for more accurate results. Looking at the matrix multiplication, A\*B=C, instead of regular quantization that normalize by a absolute maximum value per tensor, vector-wise quantization finds the absolute maximum of each row of A and each column of B. Then we normalize A and B by dividing these vectors. We then multiply A\*B to get C. Finally, to get back the FP16 values, we denormalize by computing the outer product of the absolute maximum vector of A and B. More details on this technique can be found in the [LLM.int8() paper](https://arxiv.org/abs/2208.07339) or in the [blog post about quantization and emergent features](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/) on Tim's blog.
While these basic techniques enable us to quanitize Deep Learning models, they usually lead to a drop in accuracy for larger models. The LLM.int8() implementation that we integrated into Hugging Face Transformers and Accelerate libraries is the first technique that does not degrade performance even for large models with 176B parameters, such as BLOOM.
## A gentle summary of LLM.int8(): zero degradation matrix multiplication for Large Language Models
In LLM.int8(), we have demonstrated that it is crucial to comprehend the scale-dependent emergent properties of transformers in order to understand why traditional quantization fails for large models. We demonstrate that performance deterioration is caused by outlier features, which we explain in the next section. The LLM.int8() algorithm itself can be explain as follows.
In essence, LLM.int8() seeks to complete the matrix multiplication computation in three steps:
1. From the input hidden states, extract the outliers (i.e. values that are larger than a certain threshold) by column.
2. Perform the matrix multiplication of the outliers in FP16 and the non-outliers in int8.
3. Dequantize the non-outlier results and add both outlier and non-outlier results together to receive the full result in FP16.
These steps can be summarized in the following animation:

### The importance of outlier features
A value that is outside the range of some numbers' global distribution is generally referred to as an outlier. Outlier detection has been widely used and covered in the current literature, and having prior knowledge of the distribution of your features helps with the task of outlier detection. More specifically, we have observed that classic quantization at scale fails for transformer-based models >6B parameters. While large outlier features are also present in smaller models, we observe that a certain threshold these outliers from highly systematic patterns across transformers which are present in every layer of the transformer. For more details on these phenomena see the [LLM.int8() paper](https://arxiv.org/abs/2208.07339) and [emergent features blog post](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/).
As mentioned earlier, 8-bit precision is extremely constrained, therefore quantizing a vector with several big values can produce wildly erroneous results. Additionally, because of a built-in characteristic of the transformer-based architecture that links all the elements together, these errors tend to compound as they get propagated across multiple layers. Therefore, mixed-precision decomposition has been developed to facilitate efficient quantization with such extreme outliers. It is discussed next.
### Inside the MatMul
Once the hidden states are computed we extract the outliers using a custom threshold and we decompose the matrix into two parts as explained above. We found that extracting all outliers with magnitude 6 or greater in this way recoveres full inference performance. The outlier part is done in fp16 so it is a classic matrix multiplication, whereas the 8-bit matrix multiplication is done by quantizing the weights and hidden states into 8-bit precision using vector-wise quantization -- that is, row-wise quantization for the hidden state and column-wise quantization for the weight matrix.
After this step, the results are dequantized and returned in half-precision in order to add them to the first matrix multiplication.

### What does 0 degradation mean?
How can we properly evaluate the performance degradation of this method? How much quality do we lose in terms of generation when using 8-bit models?
We ran several common benchmarks with the 8-bit and native models using lm-eval-harness and reported the results.
For OPT-175B:
| benchmarks | - | - | - | - | difference - value |
| | [
[
"llm",
"transformers",
"quantization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"quantization",
"efficient_computing"
] | null | null |
380169ec-ae90-4d8b-9da1-ea75c58eb98a | completed | 2025-01-16T03:09:11.596553 | 2025-01-19T17:20:10.874596 | e9d414fd-96a0-4c64-a377-7df86898576e | From DeepSpeed to FSDP and Back Again with Hugging Face Accelerate | mirinflim, aldopareja, muellerzr, stas | deepspeed-to-fsdp-and-back.md | There are two popular implementations of the [ZeRO Redundancy Optimizer (Zero)](https://arxiv.org/abs/1910.02054) algorithm in the community, one from [DeepSpeed](https://github.com/microsoft/DeepSpeed) and the other from [PyTorch](https://pytorch.org/docs/stable/fsdp.html). Hugging Face [Accelerate](https://huggingface.co./docs/accelerate/en/index) exposes both these frameworks for the end users to train/tune their models. This blog highlights the differences between how these backends are exposed through Accelerate. To enable users to seamlessly switch between these backends, we [upstreamed a precision-related change](https://github.com/huggingface/accelerate/issues/2624) and a [concept guide](https://huggingface.co./docs/accelerate/concept_guides/fsdp_and_deepspeed).
## Are FSDP and DeepSpeed Interchangeable?
Recently, we tried running a training pipeline with DeepSpeed and PyTorch FSDP. We noticed that the results obtained differed. The specific model was Mistral-7B base and it was loaded in half-precision (`bfloat16`). While the DeepSpeed (blue) loss had converged well, the FSDP (orange) loss was not decreasing, as can be seen in Figure 1.

We hypothesized that the learning rate may need scaling by the number of GPUs and bumped up the learning rate by 4x since we were using 4 GPUs. Then, we saw the following loss behavior, shown in Figure 2.

It looked like the desired behavior had been achieved by scaling the FSDP learning rate by the number of GPUs! However, when we tried a different learning rate (`1e-5`) without scaling, we observed similar loss and gradient norm characteristics for both frameworks, shown in Figure 3.

## Precision Matters
Inside the `DeepSpeed` codebase, specifically in the implementation of
`DeepSpeedZeroOptimizer_Stage3` (as the name implies, what handles doing Stage 3 optimizer sharding), we noticed that the `trainable_param_groups`, the parameter groups being trained on, pass through an
internal `_setup_for_real_optimizer` function call, which calls another function called `_create_fp32_partitions`.
As the `fp32` in the name suggests, `DeepSpeed` was performing upcasting internally, and it always keeps its master weights in `fp32` by design. This upcasting to full precision meant that the optimizer could converge at learning rates that it would not converge in lower precision. The earlier observations were artifacts of this precision difference.
In FSDP, before the model and optimizer parameters are distributed across GPUs, they are first "flattened" to a one-dimensional tensor. FSDP and DeepSpeed use different `dtype`s for these "flattened" parameters which has ramifications for PyTorch optimizers. Table 1 outlines the processes for both frameworks; the "Local" column indicates the process occurring per-GPU, therefore the memory overhead from upcasting is amortized by the number of GPUs.
| **Process** | **Local?** | **Framework** | **Details** |
| | [
[
"llm",
"implementation",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"optimization",
"efficient_computing"
] | null | null |
d10f91ee-b197-48d8-8323-fce1a831e7c2 | completed | 2025-01-16T03:09:11.596559 | 2025-01-16T14:19:42.649662 | d04b3284-b1a0-489e-8ed5-19fbbf330391 | The Falcon has landed in the Hugging Face ecosystem | lvwerra, ybelkada, smangrul, lewtun, olivierdehaene, pcuenq, philschmid, osanseviero | falcon.md | Falcon is a new family of state-of-the-art language models created by the [Technology Innovation Institute](https://www.tii.ae/) in Abu Dhabi, and released under the Apache 2.0 license. **Notably, [Falcon-40B](https://huggingface.co./tiiuae/falcon-40b) is the first “truly open” model with capabilities rivaling many current closed-source models**. This is fantastic news for practitioners, enthusiasts, and industry, as it opens the door for many exciting use cases.
*Note: Few months after this release, the Falcon team released a larger model of [180 billion parameters](https://huggingface.co./blog/falcon-180b).*
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 5px;">
September 2023 Update: <a href="https://huggingface.co./blog/falcon-180b">Falcon 180B</a> has just been released! It's currently the largest openly available model, and rivals proprietary models like PaLM-2.
</div>
In this blog, we will be taking a deep dive into the Falcon models: first discussing what makes them unique and then **showcasing how easy it is to build on top of them (inference, quantization, finetuning, and more) with tools from the Hugging Face ecosystem**.
## Table of Contents
- [The Falcon models](#the-falcon-models)
- [Demo](#demo)
- [Inference](#inference)
- [Evaluation](#evaluation)
- [Fine-tuning with PEFT](#fine-tuning-with-peft)
- [Conclusion](#conclusion)
## The Falcon models
The Falcon family is composed of two base models: [Falcon-40B](https://huggingface.co./tiiuae/falcon-40b) and its little brother [Falcon-7B](https://huggingface.co./tiiuae/falcon-7b). **The 40B parameter model was at the top of the [Open LLM Leaderboard](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard) at the time of its release, while the 7B model was the best in its weight class**.
*Note: the performance scores shown in the table below have been updated to account for the new methodology introduced in November 2023, which added new benchmarks. More details in [this post](https://huggingface.co./blog/open-llm-leaderboard-drop)*.
Falcon-40B requires ~90GB of GPU memory — that’s a lot, but still less than LLaMA-65B, which Falcon outperforms. On the other hand, Falcon-7B only needs ~15GB, making inference and finetuning accessible even on consumer hardware. *(Later in this blog, we will discuss how we can leverage quantization to make Falcon-40B accessible even on cheaper GPUs!)*
TII has also made available instruct versions of the models, [Falcon-7B-Instruct](https://huggingface.co./tiiuae/falcon-7b-instruct) and [Falcon-40B-Instruct](https://huggingface.co./tiiuae/falcon-40b-instruct). These experimental variants have been finetuned on instructions and conversational data; they thus lend better to popular assistant-style tasks. **If you are just looking to quickly play with the models they are your best shot.** It’s also possible to build your own custom instruct version, based on the plethora of datasets built by the community—keep reading for a step-by-step tutorial!
Falcon-7B and Falcon-40B have been trained on 1.5 trillion and 1 trillion tokens respectively, in line with modern models optimising for inference. **The key ingredient for the high quality of the Falcon models is their training data, predominantly based (>80%) on [RefinedWeb](https://arxiv.org/abs/2306.01116) — a novel massive web dataset based on CommonCrawl**. Instead of gathering scattered curated sources, TII has focused on scaling and improving the quality of web data, leveraging large-scale deduplication and strict filtering to match the quality of other corpora. The Falcon models still include some curated sources in their training (such as conversational data from Reddit), but significantly less so than has been common for state-of-the-art LLMs like GPT-3 or PaLM. The best part? TII has publicly released a 600 billion tokens extract of [RefinedWeb](https://huggingface.co./datasets/tiiuae/falcon-refinedweb) for the community to use in their own LLMs!
Another interesting feature of the Falcon models is their use of [**multiquery attention**](https://arxiv.org/abs/1911.02150). The vanilla multihead attention scheme has one query, key, and value per head; multiquery instead shares one key and value across all heads.
|  |
|:--:|
| <b>Multi-Query Attention shares keys and value embeddings across attention heads. Courtesy Harm de Vries. </b>|
This trick doesn’t significantly influence pretraining, but it greatly [improves the scalability of inference](https://arxiv.org/abs/2211.05102): indeed, **the K,V-cache kept during autoregressive decoding is now significantly smaller** (10-100 times depending on the specific of the architecture), reducing memory costs and enabling novel optimizations such as statefulness.
| Model | License | Commercial use? | Pretraining length [tokens] | Pretraining compute [PF-days] | Leaderboard score | K,V-cache size for a 2.048 context |
| | [
[
"llm",
"text_generation",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"text_generation",
"integration"
] | null | null |
db225413-9783-4fb0-8c47-0a117fe13e7f | completed | 2025-01-16T03:09:11.596564 | 2025-01-19T18:58:30.829170 | 1db28411-9192-4a88-abb4-18f2150c12e1 | “Llama 3.2 in Keras” | martin-gorner | keras-llama-32.md | This is going to be the shortest blog post ever.
> **Question**: *Llama 3.2 landed two weeks ago on Hugging Face / Transformers. When will it be available in Keras?*
> **Answer**: *It has been working from day 1 😀. There is nothing to wait for.*
Yes, Keras Llama3 can be loaded from any standard (i.e. safetensors) Hugging Face checkpoint, including the 3.2 checkpoints. If a conversion is required, it happens on the fly. Try this:
```py
!pip install keras_hub
from keras_hub import models.Llama3CausalLM
model = Llama3CausalLM.from_preset("hf://meta-llama/Llama-3.2-1B-Instruct", dtype="bfloat16")
model.generate("Hi there!")
```
#### Here is a [Colab](https://colab.research.google.com/drive/1cnAUQbDfM8lErQ8MD2x9Mo5sfKIqIxEh) to try this out. Enjoy! 🤗 | [
[
"llm",
"transformers",
"implementation",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"implementation",
"text_generation"
] | null | null |
0399e580-ca29-4087-b248-99ae428b26b9 | completed | 2025-01-16T03:09:11.596568 | 2025-01-19T18:50:38.292574 | d198f081-35d4-4644-8434-6fdefba3abbe | We Raised $100 Million for Open & Collaborative Machine Learning 🚀 | huggingface | series-c.md | Today we have some exciting news to share! Hugging Face has raised $100 Million in Series C funding 🔥🔥🔥 led by Lux Capital with major participations from Sequoia, Coatue and support of existing investors Addition, a_capital, SV Angel, Betaworks, AIX Ventures, Kevin Durant, Rich Kleiman from Thirty Five Ventures, Olivier Pomel (co-founder & CEO at Datadog) and more.
<figure class="image table text-center m-0 w-full">
<img src="/blog/assets/65_series_c/thumbnail.jpg" alt="Series C"/>
</figure>
We've come a long way since we first open sourced [PyTorch BERT](https://twitter.com/Thom_Wolf/status/1068637731281088513) in 2018 and are just getting started! 🙌
Machine learning is becoming the default way to build technology. When you think about your average day, machine learning is everywhere: from your Zoom background, to searching on Google, to ordering an Uber or writing an email with auto-complete --it's all machine learning.
Hugging Face is now the fastest growing community & most used platform for machine learning! With 100,000 pre-trained models & 10,000 datasets hosted on the platform for NLP, computer vision, speech, time-series, biology, reinforcement learning, chemistry and more, the [Hugging Face Hub](https://huggingface.co./models) has become the Home of Machine Learning to create, collaborate, and deploy state-of-the-art models.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/home-of-machine-learning.png" alt="The Home of Machine Learning"/>
</figure>
Over 10,000 companies are now using Hugging Face to build technology with machine learning. Their Machine Learning scientists, Data scientists and Machine Learning engineers have saved countless hours while accelerating their machine learning roadmaps with the help of our [products](https://huggingface.co./platform) and [services](https://huggingface.co./support).
We want to have a positive impact on the AI field. We think the direction of more responsible AI is through openly sharing models, datasets, training procedures, evaluation metrics and working together to solve issues. We believe open source and open science bring trust, robustness, reproducibility, and continuous innovation. With this in mind, we are leading [BigScience](https://bigscience.huggingface.co/), a collaborative workshop around the study and creation of very large language models gathering more than 1,000 researchers of all backgrounds and disciplines. We are now training the [world's largest open source multilingual language model](https://twitter.com/BigScienceLLM) 🌸
⚠️ But there’s still a huge amount of work left to do.
At Hugging Face, we know that Machine Learning has some important limitations and challenges that need to be tackled now like biases, privacy, and energy consumption. With openness, transparency & collaboration, we can foster responsible & inclusive progress, understanding & accountability to mitigate these challenges.
Thanks to the new funding, we’ll be doubling down on research, open-source, products and responsible democratization of AI.
<figure class="image table text-center m-0 w-full">
<img src="assets/65_series_c/team.png" alt="The Home of Machine Learning"/>
</figure>
It's been a hell of a ride to grow from 30 to 120+ team members in the past 12 months. We were super lucky to have been joined by incredibly talented (and fun!) teammates like [Dr. Margaret Mitchell](https://www.bloomberg.com/news/articles/2021-08-24/fired-at-google-after-critical-work-ai-researcher-mitchell-to-join-hugging-face) and the [Gradio team](https://gradio.app/joining-huggingface/), and we don't plan to stop here. We're [hiring for every position](https://apply.workable.com/huggingface) you can think of for every level of seniority. We are a remote-friendly, decentralized organization with transparency and value-inspired decision making by default.
Huge thanks to every contributor in our amazing community and team, our customers, partners, and investors for helping us reach this point. We couldn't have done it without you, and we can't wait to work together with you on what's next. Your contributions are key to helping build a better future where AI is founded on open source, open science, ethics and collaboration. | [
[
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"transformers",
"mlops",
"tools"
] | null | null |
75fadfc0-b76e-4fb9-8034-4bd8cab0e9e9 | completed | 2025-01-16T03:09:11.596573 | 2025-01-19T17:14:25.824573 | 460a79ea-0c5a-483a-8fde-490b7985ed2a | Diffusers welcomes Stable Diffusion 3.5 Large | YiYiXu, a-r-r-o-w, dn6, sayakpaul, linoyts, multimodalart, OzzyGT, ariG23498 | sd3-5.md | Stable Diffusion 3.5 is the improved variant of its predecessor, [Stable Diffusion 3](https://huggingface.co./blog/sd3).
As of today, the models are available on the Hugging Face Hub and can be used with 🧨 Diffusers.
The release comes with [two checkpoints](https://huggingface.co./collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838):
- A large (8B) model
- A large (8B) timestep-distilled model enabling few-step inference
In this post, we will focus on how to use Stable Diffusion 3.5 (SD3.5) with Diffusers, covering both inference and training.
## Table Of Contents
- [Architectural changes](#architectural-changes)
- [Using SD3.5 with Diffusers](#using-sd35-with-diffusers)
- [Performing inference with quantization](#running-inference-with-quantization)
- [Training LoRAs with quantization](#training-loras-with-sd35-large-with-quantization)
- [Using single-file loading](#using-single-file-loading-with-the-stable-diffusion-35-transformer)
- [Important links](#important-links)
## Architectural changes
The transformer architecture of SD3.5 (large) is very similar to SD3 (medium), with the following changes:
- QK normalization: For training large transformer models, [QK normalization](https://research.google/blog/scaling-vision-transformers-to-22-billion-parameters/) has now become a standard, and SD3.5 Large is no exception.
- Dual attention layers: Instead of using single attention layers for each stream of modality in the MMDiT blocks, SD3.5 uses double attention layers.
The rest of the details in terms of the text encoders, VAE, and noise scheduler stay exactly the same as in SD3 Medium. For more on SD3, we recommend checking out the [original paper](https://arxiv.org/abs/2403.03206).
## Using SD3.5 with Diffusers
Make sure you install the latest version of diffusers:
```bash
pip install -U diffusers
```
As the model is gated, before using it with diffusers, you first need to go to the [Stable Diffusion 3.5 Large Hugging Face page](link), fill in the form and accept the gate.
Once you are in, you need to log in so that your system knows you’ve accepted the gate. Use the command below to log in:
```bash
huggingface-cli login
```
The following snippet will download the 8B parameter version of SD3.5 in `torch.bfloat16` precision.
This is the format used in the original checkpoint published by Stability AI, and is the recommended way to run inference.
```python
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large", torch_dtype=torch.bfloat16
).to("cuda")
image = pipe(
prompt="a photo of a cat holding a sign that says hello world",
negative_prompt="",
num_inference_steps=40,
height=1024,
width=1024,
guidance_scale=4.5,
).images[0]
image.save("sd3_hello_world.png")
```

The release also comes with a **“timestep-distilled”** model that eliminates classifier-free guidance and lets us generate images in fewer steps (typically in 4-8 steps).
```python
import torch
from diffusers import StableDiffusion3Pipeline
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large-turbo", torch_dtype=torch.bfloat16
).to("cuda")
image = pipe(
prompt="a photo of a cat holding a sign that says hello world",
num_inference_steps=4,
height=1024,
width=1024,
guidance_scale=1.0,
).images[0]
image.save("sd3_hello_world.png")
```

All the examples shown in our [SD3 blog post](https://huggingface.co./blog/sd3) and the [official Diffusers documentation](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_3) should already work with SD3.5.
In particular, both of those resources dive deep into optimizing the memory requirements to run inference.
Since SD3.5 Large is significantly larger than SD3 Medium, memory optimization becomes crucial to allow inference on consumer interfaces.
## Running inference with quantization
Diffusers natively support working with [`bitsandbytes`](https://github.com/bitsandbytes-foundation/bitsandbytes) quantization, which otimizes memory even more.
First, make sure to install all the libraries necessary:
```bash
pip install -Uq git+https://github.com/huggingface/transformers@main
pip install -Uq bitsandbytes
```
Then load the transformer in [“NF4” precision](https://huggingface.co./blog/4bit-transformers-bitsandbytes):
```python
from diffusers import BitsAndBytesConfig, SD3Transformer2DModel
import torch
model_id = "stabilityai/stable-diffusion-3.5-large"
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = SD3Transformer2DModel.from_pretrained(
model_id,
subfolder="transformer",
quantization_config=nf4_config,
torch_dtype=torch.bfloat16
)
```
And now, we’re ready to run inference:
```python
from diffusers import StableDiffusion3Pipeline
pipeline = StableDiffusion3Pipeline.from_pretrained(
model_id,
transformer=model_nf4,
torch_dtype=torch.bfloat16
)
pipeline.enable_model_cpu_offload()
prompt = "A whimsical and creative image depicting a hybrid creature that is a mix of a waffle and a hippopotamus, basking in a river of melted butter amidst a breakfast-themed landscape. It features the distinctive, bulky body shape of a hippo. However, instead of the usual grey skin, the creature's body resembles a golden-brown, crispy waffle fresh off the griddle. The skin is textured with the familiar grid pattern of a waffle, each square filled with a glistening sheen of syrup. The environment combines the natural habitat of a hippo with elements of a breakfast table setting, a river of warm, melted butter, with oversized utensils or plates peeking out from the lush, pancake-like foliage in the background, a towering pepper mill standing in for a tree. As the sun rises in this fantastical world, it casts a warm, buttery glow over the scene. The creature, content in its butter river, lets out a yawn. Nearby, a flock of birds take flight"
image = pipeline(
prompt=prompt,
negative_prompt="",
num_inference_steps=28,
guidance_scale=4.5,
max_sequence_length=512,
).images[0]
image.save("whimsical.png")
```

You can control other knobs in the `BitsAndBytesConfig`. Refer to the [documentation](https://huggingface.co./docs/diffusers/main/en/quantization/bitsandbytes) for details.
It is also possible to directly load a model quantized with the same `nf4_config` as above.
This is particularly helpful for machines with low RAM. Refer to [this Colab Notebook](https://colab.research.google.com/drive/1nK5hOCPY3RoGi0yqddscGdKvo1r-rHqE?usp=sharing) for an end-to-end example.
## Training LoRAs with SD3.5 Large with quantization
Thanks to libraries like `bitsandbytes` and `peft`, it is possible to fine-tune large models like SD3.5 Large on consumer GPU cards having 24GBs of VRAM. It is already possible to leverage our existing [SD3 training script](https://huggingface.co./blog/sd3#dreambooth-and-lora-fine-tuning) for training LoRAs.
The below training command already works:
```bash
accelerate launch train_dreambooth_lora_sd3.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-3.5-large" \
--dataset_name="Norod78/Yarn-art-style" \
--output_dir="yart_art_sd3-5_lora" \
--mixed_precision="bf16" \
--instance_prompt="Frog, yarn art style" \
--caption_column="text"\
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=4e-4 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=700 \
--rank=16 \
--seed="0" \
--push_to_hub
```
However, to make it work with quantization, we need to tweak a couple of knobs. Below, we provide pointers on how to do that:
- We initialize `transformer` either with a quantization config or load a quantized checkpoint directly.
- Then, we prepare it by using the `prepare_model_for_kbit_training()` from `peft`.
- The rest of the process remains the same, thanks to `peft`'s strong support for `bitsandbytes`!
Refer to [this example](https://gist.github.com/sayakpaul/05afd428bc089b47af7c016e42004527) script for a fuller example.
## Using single-file loading with the Stable Diffusion 3.5 Transformer
You can load the Stable Diffusion 3.5 Transformer model using the original checkpoint files published by Stability AI with the `from_single_file` method:
```python
import torch
from diffusers import SD3Transformer2DModel, StableDiffusion3Pipeline
transformer = SD3Transformer2DModel.from_single_file(
"https://huggingface.co./stabilityai/stable-diffusion-3.5-large-turbo/blob/main/sd3.5_large.safetensors",
torch_dtype=torch.bfloat16,
)
pipe = StableDiffusion3Pipeline.from_pretrained(
"stabilityai/stable-diffusion-3.5-large",
transformer=transformer,
torch_dtype=torch.bfloat16,
)
pipe.enable_model_cpu_offload()
image = pipe("a cat holding a sign that says hello world").images[0]
image.save("sd35.png")
```
### Important links
- Stable Diffusion 3.5 Large [collection](https://huggingface.co./collections/stabilityai/stable-diffusion-35-671785cca799084f71fa2838) on the Hub
- Official Diffusers [documentation](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/stable_diffusion_3) for Stable Diffusion 3.5
- [Colab Notebook](https://colab.research.google.com/drive/1nK5hOCPY3RoGi0yqddscGdKvo1r-rHqE?usp=sharing) to run inference with quantization
- [Training LoRAs](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sd3.md)
- Stable Diffusion 3 [paper](https://arxiv.org/abs/2403.03206)
- Stable Diffusion 3 [blog post](https://huggingface.co./blog/sd3)
_Acknowledgements: [Daniel Frank](https://www.pexels.com/@fr3nks/) for the background photo used in the thumbnail of this blog post. Thanks to [Pedro Cuenca](https://huggingface.co./pcuenq) and [Tom Aarsen](https://huggingface.co./tomaarsen) for their reviews on the post draft._ | [
[
"implementation",
"tools",
"image_generation",
"quantization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"implementation",
"quantization",
"tools"
] | null | null |
82e1f959-23e3-4ff8-bd7e-015178801a37 | completed | 2025-01-16T03:09:11.596578 | 2025-01-16T03:24:34.265644 | ed175201-79cd-436c-9aee-1fa4567db098 | Welcome spaCy to the Hugging Face Hub | osanseviero, ines | spacy.md | [spaCy](https://github.com/explosion/spaCy) is a popular library for advanced Natural Language Processing used widely across industry. spaCy makes it easy to use and train pipelines for tasks like named entity recognition, text classification, part of speech tagging and more, and lets you build powerful applications to process and analyze large volumes of text.
Hugging Face makes it really easy to share your spaCy pipelines with the community! With a single command, you can upload any pipeline package, with a pretty model card and all required metadata auto-generated for you. The inference API currently supports NER out-of-the-box, and you can try out your pipeline interactively in your browser. You'll also get a live URL for your package that you can `pip install` from anywhere for a smooth path from prototype all the way to production!
### Finding models
Over 60 canonical models can be found in the [spaCy](https://hf.co/spacy) org. These models are from the [latest 3.1 release](https://explosion.ai/blog/spacy-v3-1), so you can try the latest realesed models right now! On top of this, you can find all spaCy models from the community here https://huggingface.co./models?filter=spacy.
### Widgets
This integration includes support for NER widgets, so all models with a NER component will have this out of the box! Coming soon there will be support for text classification and POS.
<div><a class="text-xs block mb-3 text-gray-300" href="/spacy/en_core_web_sm"><code>spacy/en_core_web_sm</code></a>
<div class="SVELTE_HYDRATER " data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"spacy","autoArchitecture":"AutoModel","branch":"main","cardData":{"tags":["spacy","token-classification"],"language":["en"],"license":"MIT","model-index":[{"name":"en_core_web_sm","results":[{"tasks":{"name":"NER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.8424355924},{"name":"Recall","type":"recall","value":0.8335336538},{"name":"F Score","type":"f_score","value":0.8379609817}]}},{"tasks":{"name":"POS","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9720712187}]}},{"tasks":{"name":"SENTER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.9074955788},{"name":"Recall","type":"recall","value":0.8801372122},{"name":"F Score","type":"f_score","value":0.893607046}]}},{"tasks":{"name":"UNLABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}},{"tasks":{"name":"LABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}}]}]},"cardSource":true,"id":"spacy/en_core_web_sm","pipeline_tag":"token-classification","library_name":"spacy","modelId":"spacy/en_core_web_sm","private":false,"siblings":[{"rfilename":".gitattributes"},{"rfilename":"LICENSE"},{"rfilename":"LICENSES_SOURCES"},{"rfilename":"README.md"},{"rfilename":"accuracy.json"},{"rfilename":"config.cfg"},{"rfilename":"en_core_web_sm-any-py3-none-any.whl"},{"rfilename":"meta.json"},{"rfilename":"tokenizer"},{"rfilename":"attribute_ruler/patterns"},{"rfilename":"lemmatizer/lookups/lookups.bin"},{"rfilename":"ner/cfg"},{"rfilename":"ner/model"},{"rfilename":"ner/moves"},{"rfilename":"vocab/lookups.bin"},{"rfilename":"vocab/strings.json"},{"rfilename":"vocab/vectors"}],"tags":["en","spacy","token-classification","license:mit","model-index"],"tag_objs":[{"id":"token-classification","label":"Token Classification","type":"pipeline_tag"},{"id":"spacy","label":"spaCy","type":"library"},{"id":"en","label":"en","type":"language"},{"id":"license:mit","label":"mit","type":"license"},{"id":"model-index","label":"model-index","type":"other"}],"widgetData":[{"text":"My name is Wolfgang and I live in Berlin"},{"text":"My name is Sarah and I live in London"},{"text":"My name is Clara and I live in Berkeley, California."}]},"shouldUpdateUrl":true}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full
"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="/docs"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center text-sm text-gray-500 mb-1.5"><div class="inline-flex items-center"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 18 18"><path d="M11.075 10.1875H12.1625V11.275H11.075V10.1875Z"></path><path d="M15.425 9.10004H16.5125V10.1875H15.425V9.10004Z"></path><path d="M7.8125 3.66254H8.9V4.75004H7.8125V3.66254Z"></path><path d="M8.90001 12.3625H6.72501V9.09998C6.72472 8.81165 6.61005 8.5352 6.40617 8.33132C6.20228 8.12744 5.92584 8.01277 5.63751 8.01248H2.37501C2.08667 8.01277 1.81023 8.12744 1.60635 8.33132C1.40246 8.5352 1.28779 8.81165 1.28751 9.09998V12.3625C1.28779 12.6508 1.40246 12.9273 1.60635 13.1311C1.81023 13.335 2.08667 13.4497 2.37501 13.45H5.63751V15.625C5.63779 15.9133 5.75246 16.1898 5.95635 16.3936C6.16023 16.5975 6.43667 16.7122 6.72501 16.7125H8.90001C9.18834 16.7122 9.46478 16.5975 9.66867 16.3936C9.87255 16.1898 9.98722 15.9133 9.98751 15.625V13.45C9.98722 13.1616 9.87255 12.8852 9.66867 12.6813C9.46478 12.4774 9.18834 12.3628 8.90001 12.3625V12.3625ZM2.37501 12.3625V9.09998H5.63751V12.3625H2.37501ZM6.72501 15.625V13.45H8.90001V15.625H6.72501Z"></path><path d="M15.425 16.7125H13.25C12.9617 16.7122 12.6852 16.5976 12.4813 16.3937C12.2775 16.1898 12.1628 15.9134 12.1625 15.625V13.45C12.1628 13.1617 12.2775 12.8852 12.4813 12.6814C12.6852 12.4775 12.9617 12.3628 13.25 12.3625H15.425C15.7133 12.3628 15.9898 12.4775 16.1937 12.6814C16.3976 12.8852 16.5122 13.1617 16.5125 13.45V15.625C16.5122 15.9134 16.3976 16.1898 16.1937 16.3937C15.9898 16.5976 15.7133 16.7122 15.425 16.7125ZM13.25 13.45V15.625H15.425V13.45H13.25Z"></path><path d="M15.425 1.48752H12.1625C11.8742 1.48781 11.5977 1.60247 11.3938 1.80636C11.19 2.01024 11.0753 2.28668 11.075 2.57502V5.83752H9.98751C9.69917 5.83781 9.42273 5.95247 9.21885 6.15636C9.01496 6.36024 8.9003 6.63668 8.90001 6.92502V8.01252C8.9003 8.30085 9.01496 8.5773 9.21885 8.78118C9.42273 8.98506 9.69917 9.09973 9.98751 9.10002H11.075C11.3633 9.09973 11.6398 8.98506 11.8437 8.78118C12.0476 8.5773 12.1622 8.30085 12.1625 8.01252V6.92502H15.425C15.7133 6.92473 15.9898 6.81006 16.1937 6.60618C16.3976 6.4023 16.5122 6.12585 16.5125 5.83752V2.57502C16.5122 2.28668 16.3976 2.01024 16.1937 1.80636C15.9898 1.60247 15.7133 1.48781 15.425 1.48752ZM9.98751 8.01252V6.92502H11.075V8.01252H9.98751ZM12.1625 5.83752V2.57502H15.425V5.83752H12.1625Z"></path><path d="M4.55001 5.83752H2.37501C2.08667 5.83723 1.81023 5.72256 1.60635 5.51868C1.40246 5.3148 1.28779 5.03835 1.28751 4.75002V2.57502C1.28779 2.28668 1.40246 2.01024 1.60635 1.80636C1.81023 1.60247 2.08667 1.48781 2.37501 1.48752H4.55001C4.83834 1.48781 5.11478 1.60247 5.31867 1.80636C5.52255 2.01024 5.63722 2.28668 5.63751 2.57502V4.75002C5.63722 5.03835 5.52255 5.3148 5.31867 5.51868C5.11478 5.72256 4.83834 5.83723 4.55001 5.83752V5.83752ZM2.37501 2.57502V4.75002H4.55001V2.57502H2.37501Z"></path></svg> <span>Token Classification</span></div> <div class="ml-auto"></div></div> <form><div class="flex h-10"><input class="form-input-alt flex-1 rounded-r-none " placeholder="Your sentence here..." required="" type="text"> <button class="btn-widget w-24 h-10 px-5 rounded-l-none border-l-0 " type="submit">Compute</button></div></form> <div class="mt-1.5"><div class="text-gray-400 text-xs">This model is currently loaded and running on the Inference API.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
### Using existing models
All models from the Hub can be directly installed using `pip install`.
```bash
pip install https://huggingface.co./spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl
```
```python
# Using spacy.load().
import spacy
nlp = spacy.load("en_core_web_sm")
# Importing as module.
import en_core_web_sm
nlp = en_core_web_sm.load()
```
When you open a repository, you can click `Use in spaCy` and you will be given a working snippet that you can use to install and load the model!


You can even make HTTP requests to call the models from the Inference API, which is useful in production settings. Here is an example of a simple request:
```bash
curl -X POST --data '{"inputs": "Hello, this is Omar"}' https://api-inference.huggingface.co/models/spacy/en_core_web_sm
>>> [{"entity_group":"PERSON","word":"Omar","start":15,"end":19,"score":1.0}]
```
And for larger-scale use cases, you can click "Deploy > Accelerated Inference" and see how to do this with Python.
### Sharing your models
But probably the coolest feature is that now you can very easily share your models with the `spacy-huggingface-hub` [library](https://github.com/explosion/spacy-huggingface-hub), which extends the `spaCy` CLI with a new command, `huggingface-hub push`.
```bash
huggingface-cli login
python -m spacy package ./en_ner_fashion ./output --build wheel
cd ./output/en_ner_fashion-0.0.0/dist
python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl
```
In just a minute, you can get your packaged model in the Hub, try it out directly in the browser, and share it with the rest of the community. All the required metadata will be uploaded for you and you even get a cool model card.
Try it out and share your models with the community!
## Would you like to integrate your library to the Hub?
This integration is possible thanks to the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library which has all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co./docs/hub/models-adding-libraries) for you! | [
[
"mlops",
"tools",
"text_classification",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tools",
"integration",
"mlops",
"text_classification"
] | null | null |
c3c5a622-c871-4e44-bc41-d8e0d47ec529 | completed | 2025-01-16T03:09:11.596583 | 2025-01-16T03:13:00.690622 | 6cee1ddc-b173-402c-851b-4b955c8700b0 | Hugging Face + PyCharm | rocketknight1 | pycharm-integration.md | It’s a Tuesday morning. As a Transformers maintainer, I’m doing the same thing I do most weekday mornings: Opening [PyCharm](https://jb.gg/get-pycharm-hf), loading up the Transformers codebase and gazing lovingly at the [chat template documentation](https://huggingface.co./docs/transformers/main/chat_templating) while ignoring the 50 user issues I was pinged on that day. But this time, something feels different:

Something is… wait\! Computer\! Enhance\!

Is that..?

Those user issues are definitely not getting responses today. Let’s talk about the Hugging Face integration in PyCharm.
## The Hugging Face Is Inside Your House
I could introduce this integration by just listing features, but that’s boring and there’s [documentation](https://www.jetbrains.com/help/pycharm/hugging-face.html) for that. Instead, let’s walk through how we’d use it all in practice. Let’s say I’m writing a Python app, and I decide I want the app to be able to chat with users. Not just text chat, though – we want the users to be able to paste in images too, and for the app to naturally chat about them as well.
If you’re not super-familiar with the current state-of-the-art in machine learning, this might seem like a terrifying demand, but don’t fear. Simply right click in your code, and select “Insert HF Model”. You’ll get a dialog box:

Chatting with both images and text is called “image-text-to-text”: the user can supply images and text, and the model outputs text. Scroll down on the left until you find it. By default, the model list will be sorted by Likes – but remember, older models often have a lot of likes built up even if they’re not really the state of the art anymore. We can check how old models are by seeing the date they were last updated, just under the model name. Let’s pick something that’s both recent and popular: `microsoft/Phi-3.5-vision-instruct`.
You can select “Use Model” for some model categories to automatically paste some basic code into your notebook, but what often works better is to scroll through the Model Card on the right and grab any sample code. You can see the full model card to the right of the dialog box, exactly as it's shown on Hugging Face Hub. Let’s do that and paste it into our code!

Your office cybersecurity person might complain about you copying a chunk of random text from the internet and running it without even reading all of it, but if that happens just call them a nerd and continue regardless. And behold: We now have a working model that can happily chat about images - in this case, it reads and comments on screenshots of a Microsoft slide deck. Feel free to play around with this example. Try your own chat, or your own images. Once you get it working, simply wrap this code into a class and it’s ready to go in your app. We just got state of the art open-source machine learning in ten minutes without even opening a web browser.
> [!TIP]
> These models can be large! If you’re getting memory errors, try using a GPU with more memory, or try reducing the 20 in the sample code. You can also remove device_map="cuda" to put the model in CPU memory instead, at the cost of speed.
## Instant Model Cards
Next, let’s change perspective in our little scenario. Now let’s say you’re not the author of this code - you’re a coworker who has to review it. Maybe you’re the cybersecurity person from earlier, who’s still upset about the “nerd” comment. You look at this code snippet, and you have no idea what you’re seeing. Don’t panic - just hover over the model name, and the entire model card instantly appears. You can quickly verify the origin of this model, and what its intended uses are.
(This is also extremely helpful if you work on something else and completely forget everything about the code you wrote two weeks ago)

## The Local Model Cache
You might notice that the model has to be downloaded the first time you run this code, but after that, it’s loaded much more quickly. The model has been stored in your local cache. Remember the mysterious little 🤗 icon from earlier? Simply click it, and you’ll get a listing of everything in your cache:

This is a neat way to find the models you’re working with right now, and also to clear them out and save some disk space once you don’t need them anymore. It’s also very helpful for the two-week amnesia scenario - if you can’t remember the model you were using back then, it’s probably in here. Remember, though, that most useful, production-ready models in 2024 are going to be >1GB, so your cache can fill up fast!
## Python in the age of AI
At Hugging Face, we tend to think of open-source AI as being a natural extension of the open-source philosophy: Open software solves problems for developers and users, creating new abilities for them to integrate into their code, and open models do the same. There is a tendency to be blinded by complexity, and to focus too much on the implementation details because they’re all so novel and exciting, but models exist to **do stuff for you.** If you abstract away the details of architecture and training, they’re fundamentally **functions** - tools in your code that will transform a certain kind of input into a certain kind of output.
These features are thus a natural fit. Just as IDEs already pull up function signatures and docstrings for you, they can also pull up sample code and model cards for trained models. Integrations like these make it easy to reach over and import a chat or image recognition model as conveniently as you would import any other library. We think it’s obvious that this is what the future of code will look like, and we hope that you find these features useful!
**[Download PyCharm](https://jb.gg/get-pycharm-hf) to give the Hugging Face integration a try.**
*[HF integration is a [Pycharm Professional](https://blog.jetbrains.com/pycharm/2024/08/pycharm-2024-2/#hugging-face-integration-pro) feature.]*
**Get a free 3-month PyCharm subscription using the PyCharm4HF code [here](http://jetbrains.com/store/redeem/).** | [
[
"transformers",
"implementation",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"tools",
"integration",
"implementation"
] | null | null |
6e47fe36-d2ec-42e9-b266-839d83ab8d9d | completed | 2025-01-16T03:09:11.596587 | 2025-01-19T19:01:41.440900 | a76d9ad2-fdb7-4490-9e31-5ff31c5a56e4 | Welcome to the Falcon 3 Family of Open Models! | FalconLLM | falcon3.md | We introduce Falcon3, a family of decoder-only large language models under 10 billion parameters, developed by
[Technology Innovation Institute (TII)](https://www.tii.ae/ai-and-digital-science) in Abu Dhabi. By pushing the
boundaries of performance and training efficiency, this release reflects our ongoing commitment to advancing open
and accessible large foundation models.
Falcon3 represents a natural evolution from previous releases, emphasizing expanding the models' science, math, and code capabilities.
This iteration includes five base models:
1. [Falcon3-1B-Base](https://huggingface.co./tiiuae/Falcon3-1B-Base)
2. [Falcon3-3B-Base](https://huggingface.co./tiiuae/Falcon3-3B-Base)
3. [Falcon3-Mamba-7B-Base](https://huggingface.co./tiiuae/Falcon3-Mamba-7B-Base)
4. [Falcon3-7B-Base](https://huggingface.co./tiiuae/Falcon3-7B-Base)
5. [Falcon3-10B-Base](https://huggingface.co./tiiuae/Falcon3-10B-Base)
In developing these models, we incorporated several key innovations aimed at improving the models' performances while reducing training costs:
- **One pre-training for transformer-based models:** We conducted a single large-scale pretraining run on the 7B model, using 1024 H100 GPU chips, leveraging 14 trillion tokens featuring web, code, STEM, and curated high-quality and multilingual data.
- **Depth up-scaling for improved reasoning:** Building on recent studies on the effects of model depth, we upscaled the 7B model to a 10B parameters model by duplicating the redundant layers and continuing pre-training with 2 trillion tokens of high-quality data. This yielded Falcon3-10B-Base which achieves state-of-the-art zero-shot and few-shot performance for models under 13B parameters.
- **Knowledge distillation for better tiny models:** To provide compact and efficient alternatives, we developed Falcon3-1B-Base and Falcon3-3B-Base by leveraging pruning and knowledge distillation techniques, using less than 100GT of curated high-quality data, thereby redefining pre-training efficiency.
- **Pure SSM:** We have further enhanced [Falcon Mamba 7B](https://huggingface.co./tiiuae/falcon-mamba-7b) by training on an additional 1.5 trillion tokens of high-quality data, resulting in Falcon3-Mamba-7B-Base. Notably, the updated model offers significantly improved reasoning and mathematical capabilities.
- **Other variants:** All models in the Falcon3 family are available in variants such as Instruct, GGUF, GPTQ-Int4, GPTQ-Int8, AWQ, and 1.58-bit, offering flexibility for a wide range of applications.
## Key Highlights
Falcon3 featured the limits within the small and medium scales of large language models by demonstrating high performance on common benchmarks:
- [Falcon3-1B-Base](https://huggingface.co./tiiuae/Falcon3-1B-Base) surpasses SmolLM2-1.7B and is on par with gemma-2-2b.
- [Falcon3-3B-Base](https://huggingface.co./tiiuae/Falcon3-3B-Base) outperforms larger models like Llama-3.1-8B and Minitron-4B-Base, highlighting the benefits of pre-training with knowledge distillation.
- [Falcon3-7B-Base](https://huggingface.co./tiiuae/Falcon3-7B-Base) demonstrates top performance, on par with Qwen2.5-7B, among models under the 9B scale.
- [Falcon3-10B-Base](https://huggingface.co./tiiuae/Falcon3-10B-Base) stands as the state-of-the-art achieving strong results in the under-13B category.
- All the transformer-based Falcon3 models are compatible with [Llama](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/) architecture allowing better integration in the AI ecosystem.
- [Falcon3-Mamba-7B](https://huggingface.co./tiiuae/Falcon3-Mamba-7B-Base) continues to lead as the top-performing State Space Language Model (SSLM), matching or even surpassing leading transformer-based LLMs at the 7B scale, along with support for a longer 32K context length. Having the same architecture as the original [Falcon Mamba 7B](https://huggingface.co./tiiuae/falcon-mamba-7b), users can integrate Falcon3-Mamba-7B seamlessly without any additional effort.
- The instruct versions of our collection of base models further show remarkable performance across various benchmarks with Falcon3-7B-Instruct and Falcon3-10B-Instruct outperforming all instruct models under the 13B scale on the open leaderboard.
## Enhanced Capabilities
We evaluated models with our internal evaluation pipeline (based on [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness)) and we report raw scores.
Our evaluations highlight key areas where the Falcon3 family of models excel, reflecting the emphasis on enhancing performance in scientific domains, reasoning, and general knowledge capabilities:
- **Math Capabilities:** Falcon3-10B-Base achieves 22.9 on MATH-Lvl5 and 83.0 on GSM8K, showcasing enhanced reasoning in complex math-focused tasks.
- **Coding Capabilities:** Falcon3-10B-Base achieves 73.8 on MBPP, while Falcon3-10B-Instruct scores 45.8 on Multipl-E, reflecting their abilities to generalize across programming-related tasks.
- **Extended Context Length**: Models in the Falcon3 family support up to 32k tokens (except the 1B supporting up to 8k context), with functional improvements such as scoring 86.3 on BFCL (Falcon3-10B-Instruct).
- **Improved Reasoning:** Falcon3-7B-Base and Falcon3-10B-Base achieve 51.0 and 59.7 on BBH, reflecting enhanced reasoning capabilities, with the 10B model showing improved reasoning performance over the 7B.
- **Scientific Knowledge Expansion:** Performance on MMLU benchmarks demonstrates advances in specialized knowledge, with scores of 67.4/39.2 (MMLU/MMLU-PRO) for Falcon3-7B-Base and 73.1/42.5 (MMLU/MMLU-PRO) for Falcon3-10B-Base respectively.
## Models' Specs and Benchmark Results
Detailed specifications of the Falcon3 family of models are summarized in the following table. The architecture of [Falcon3-7B-Base](https://huggingface.co./tiiuae/Falcon3-7B-Base)
is characterized by a head dimension of 256 which yields high throughput when using [FlashAttention-3](https://arxiv.org/abs/2407.08608) as it is optimized for this dimension. These decoder-only models span 18 to 40 layers for the transformer-based ones, and 64 layers for the mamba one, all models share the SwiGLU activation function, with vocabulary size of 131K tokens (65Kfor Mamba-7B). The Falcon3-7B-Base is trained on the largest amount of data ensuring comprehensive coverage of concepts and knowledge, the other variants require way less data.
<br/><br/>
<!--  -->
<div style="text-align: center;" align="center">
<img src="https://huggingface.co./datasets/tiiuae/documentation-images/resolve/main/general/Falcon3-specs.png" alt="Training efficiency" width="750">
</div>
<br/><br/>
The table below highlights the performances of Falcon3-7B-Base and Falcon3-10B-Base on key benchmarks showing competitive performances in general, math, reasoning, and common sense understanding domains.
Feel free to take a look at models' cards where we provide additional evaluation results (e.g. MT-Bench, Alpaca, etc).
<br/><br/>
<!--  -->
<div style="text-align: center;" align="center">
<img src="https://huggingface.co./datasets/tiiuae/documentation-images/resolve/main/general/medium-base-models.png" alt="Training efficiency" width="800">
</div>
<br/><br/>
The instruct models also demonstrate competitive and super performances with equivalent and small-size models as highlighted in the tables below.
### Instruct models
Falcon3-1B-Instruct and Falcon3-3B-Instruct achieve robust performance across the evaluated benchmarks. Specifically, Falcon3-1B attains competitive results in IFEval (54.4), MUSR (40.7), and SciQ (86.8), while Falcon3-3B exhibits further gains—particularly in MMLU-PRO (29.7) and MATH (19.9)—demonstrating clear scaling effects. Although they do not surpass all competing models on every metric, Falcon models show strong performances in reasoning and common-sense understanding relative to both Qwen and Llama.
In our internal evaluation pipeline:
- We use [lm-evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness).
- We report **raw scores** obtained by applying chat template **without fewshot_as_multiturn** (unlike Llama3.1).
- We use same batch-size across all models.
<br/><br/>
<!--  -->
<div style="text-align: left;" align="center">
<img src="https://huggingface.co./datasets/tiiuae/documentation-images/resolve/main/general/small-instruct-models.png" alt="Training efficiency" width="800">
</div>
<br/><br/>
Furthermore, Falcon3-7B and Falcon3-10B show robust performance across the evaluated benchmarks. Falcon3-7B achieves competitive scores on reasoning (Arc Challenge: 65.9, MUSR: 46.4) and math (GSM8K: 79.1), while Falcon3-10B demonstrates further improvements, notably in GSM8K (83.1) and IFEval (78), indicating clear scaling benefits.
<br/><br/>
<!--  -->
<div style="text-align: left;" align="center">
<img src="https://huggingface.co./datasets/tiiuae/documentation-images/resolve/main/general/medium-instruct-models.png" alt="Training efficiency" width="800">
</div>
<br/><br/>
## Open Source Commitment
In line with our mission to foster AI accessibility and collaboration, all models in the Falcon3 family are released under the [**Falcon LLM license**](https://falconllm.tii.ae/falcon-terms-and-conditions.html). We hope the AI community finds these models valuable for research, application development, and further experimentation. Falcon3 is not a culmination but a continuation of our efforts to create more capable, efficient, specialized foundation models. In January 2025, we will further release other models of the Falcon3 family featuring enhanced multi-modal capabilities including image, video, and audio support, as well as a full technical report covering our methodologies. We welcome feedback and collaboration from the community as we continue to refine and advance these technologies.
## Useful links
- Access to our models (including GGUF and 1.58bit models) of this series through [the Falcon3 HuggingFace collection](https://huggingface.co./collections/tiiuae/falcon3-67605ae03578be86e4e87026).
- Feel free to join [our discord server](https://discord.gg/fwXpMyGc) if you have any questions or to interact with our researchers and developers.
- Check out the [Falcon-LLM License link](https://falconllm.tii.ae/falcon-terms-and-conditions.html) for more details about the license.
- Refer to the official [Open LLM Leaderboard](https://huggingface.co./spaces/open-llm-leaderboard/open_llm_leaderboard#/) for HF evaluations of our models.
## Acknowledgments
We warmly thank the following people for their smooth support and integration within the ecosystem.
- [Alina Lozovskaya](https://huggingface.co./alozowski) and [Clementine Fourrier](https://huggingface.co./clefourrier) for helping us evaluate the model on the HF leaderboard.
- [Cyril Vallez](https://huggingface.co./cyrilvallez) and [Arthur Zucker](https://huggingface.co./ArthurZ) for the transformers documentation integration.
- [Vaibhav Srivastav](https://huggingface.co./reach-vb) and [Aritra Roy Gosthipaty](https://huggingface.co./ariG23498) for his help reviewing this blogpost.
- [Georgi Gerganov](https://github.com/ggerganov) for his help in integrating an important fix to make Falcon3 series models work in [llama.cpp](https://github.com/ggerganov/llama.cpp).
- [Awni Hannun](https://github.com/awni) for helping us review necessary changes in order to integrate Falcon3 series into MLX ecosystem.
- [BitNet.cpp team](https://github.com/microsoft/BitNet) for helping us integrating 1.58bit variants of Falcon3 models into BitNet.
## Citation
If the Falcon3 family of models were helpful to your work, feel free to give us a cite.
```
@misc{Falcon3,
title = {The Falcon 3 Family of Open Models},
url = {https://huggingface.co./blog/falcon3},
author = {Falcon-LLM Team},
month = {December},
year = {2024}
}
``` | [
[
"llm",
"research",
"benchmarks",
"optimization"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"optimization",
"benchmarks"
] | null | null |
ca28583b-3256-4e7c-9181-6a4e44f18c19 | completed | 2025-01-16T03:09:11.596592 | 2025-01-19T19:16:07.889133 | 94a4983f-722c-44a4-b7a6-27c270ca5c5b | Introducing Idefics2: A Powerful 8B Vision-Language Model for the community | Leyo, HugoLaurencon, VictorSanh | idefics2.md | <img src="https://huggingface.co./HuggingFaceM4/idefics-80b/resolve/main/assets/IDEFICS.png" alt="Idefics-Obelics logo" width="250" height="250">
</p>
# Introducing Idefics2: A Powerful 8B Vision-Language Model for the community
We are excited to release [Idefics2](https://huggingface.co./HuggingFaceM4/idefics2-8b), a general multimodal model that takes as input arbitrary sequences of texts and images, and generates text responses. It can answer questions about images, describe visual content, create stories grounded in multiple images, extract information from documents, and perform basic arithmetic operations. \
Idefics2 improves upon [Idefics1](https://huggingface.co./blog/idefics): with 8B parameters, an open license (Apache 2.0), and enhanced OCR (Optical Character Recognition) capabilities, Idefics2 is a strong foundation for the community working on multimodality. Its performance on Visual Question Answering benchmarks is top of its class size, and competes with much larger models such as [LLava-Next-34B](https://huggingface.co./liuhaotian/llava-v1.6-34b) and [MM1-30B-chat](https://huggingface.co./papers/2403.09611). \
Idefics2 is also integrated in 🤗 Transformers from the get-go and therefore is straightforward to finetune for many multimodal applications. You can try out the [models](https://huggingface.co./HuggingFaceM4/idefics2-8b) on the Hub right now!
<p align="left">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/idefics2/Idefics2_eval_barchart.png?download=true" width="900" alt="The Cauldron"/>
</p>
| <nobr>Model</nobr> | <nobr>Open <br>weights</nobr> | <nobr>Size</nobr> | <nobr># tokens <br>per image</nobr> | <nobr>MMMU <br>(val/test)</nobr> | <nobr>MathVista <br>(testmini)</nobr> | <nobr>TextVQA <br>(val)</nobr> | <nobr>MMBench <br>(test)</nobr> | <nobr>VQAv2 <br>(test-dev)</nobr> | <nobr>DocVQA <br>(test)</nobr> |
| | [
[
"llm",
"computer_vision",
"benchmarks",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"computer_vision",
"multi_modal",
"benchmarks"
] | null | null |
ead12205-b314-4ed9-9322-264abbf49faf | completed | 2025-01-16T03:09:11.596596 | 2025-01-16T13:36:59.266086 | 251b7d66-19ce-4698-a93b-39c3d8615fcf | Multivariate Probabilistic Time Series Forecasting with Informer | elisim, nielsr, kashif | informer.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multivariate_informer.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
A few months ago we introduced the [Time Series Transformer](https://huggingface.co./blog/time-series-transformers), which is the vanilla Transformer ([Vaswani et al., 2017](https://arxiv.org/abs/1706.03762)) applied to forecasting, and showed an example for the **univariate** probabilistic forecasting task (i.e. predicting each time series' 1-d distribution individually). In this post we introduce the _Informer_ model ([Zhou, Haoyi, et al., 2021](https://arxiv.org/abs/2012.07436)), AAAI21 best paper which is [now available](https://huggingface.co./docs/transformers/main/en/model_doc/informer) in 🤗 Transformers. We will show how to use the Informer model for the **multivariate** probabilistic forecasting task, i.e., predicting the distribution of a future **vector** of time-series target values. Note that this will also work for the vanilla Time Series Transformer model.
## Multivariate Probabilistic Time Series Forecasting
As far as the modeling aspect of probabilistic forecasting is concerned, the Transformer/Informer will require no change when dealing with multivariate time series. In both the univariate and multivariate setting, the model will receive a sequence of vectors and thus the only change is on the output or emission side.
Modeling the full joint conditional distribution of high dimensional data can get computationally expensive and thus methods resort to some approximation of the distribution, the easiest being to model the data as an independent distribution from the same family, or some low-rank approximation to the full covariance, etc. Here we will just resort to the independent (or diagonal) emissions which are supported for the families of distributions we have implemented [here](https://huggingface.co./docs/transformers/main/en/internal/time_series_utils).
## Informer - Under The Hood
Based on the vanilla Transformer ([Vaswani et al., 2017](https://arxiv.org/abs/1706.03762)), Informer employs two major improvements. To understand these improvements, let's recall the drawbacks of the vanilla Transformer:
1. **Quadratic computation of canonical self-attention:** The vanilla Transformer has a computational complexity of \\(O(T^2 D)\\) where \\(T\\) is the time series length and \\(D\\) is the dimension of the hidden states. For long sequence time-series forecasting (also known as the _LSTF problem_), this might be really computationally expensive. To solve this problem, Informer employs a new self-attention mechanism called _ProbSparse_ attention, which has \\(O(T \log T)\\) time and space complexity.
1. **Memory bottleneck when stacking layers:** When stacking \\(N\\) encoder/decoder layers, the vanilla Transformer has a memory usage of \\(O(N T^2)\\), which limits the model's capacity for long sequences. Informer uses a _Distilling_ operation, for reducing the input size between layers into its half slice. By doing so, it reduces the whole memory usage to be \\(O(N\cdot T \log T)\\).
As you can see, the motivation for the Informer model is similar to Longformer ([Beltagy et el., 2020](https://arxiv.org/abs/2004.05150)), Sparse Transformer ([Child et al., 2019](https://arxiv.org/abs/1904.10509)) and other NLP papers for reducing the quadratic complexity of the self-attention mechanism **when the input sequence is long**. Now, let's dive into _ProbSparse_ attention and the _Distilling_ operation with code examples.
### ProbSparse Attention
The main idea of ProbSparse is that the canonical self-attention scores form a long-tail distribution, where the "active" queries lie in the "head" scores and "lazy" queries lie in the "tail" area. By "active" query we mean a query \\(q_i\\) such that the dot-product \\(\langle q_i,k_i \rangle\\) **contributes** to the major attention, whereas a "lazy" query forms a dot-product which generates **trivial** attention. Here, \\(q_i\\) and \\(k_i\\) are the \\(i\\)-th rows in \\(Q\\) and \\(K\\) attention matrices respectively.
|  |
|:--:|
| Vanilla self attention vs ProbSparse attention from [Autoformer (Wu, Haixu, et al., 2021)](https://wuhaixu2016.github.io/pdf/NeurIPS2021_Autoformer.pdf) |
Given the idea of "active" and "lazy" queries, the ProbSparse attention selects the "active" queries, and creates a reduced query matrix \\(Q_{reduced}\\) which is used to calculate the attention weights in \\(O(T \log T)\\). Let's see this more in detail with a code example.
Recall the canonical self-attention formula:
$$
\textrm{Attention}(Q, K, V) = \textrm{softmax}(\frac{QK^T}{\sqrt{d_k}} )V
$$
Where \\(Q\in \mathbb{R}^{L_Q \times d}\\), \\(K\in \mathbb{R}^{L_K \times d}\\) and \\(V\in \mathbb{R}^{L_V \times d}\\). Note that in practice, the input length of queries and keys are typically equivalent in the self-attention computation, i.e. \\(L_Q = L_K = T\\) where \\(T\\) is the time series length. Therefore, the \\(QK^T\\) multiplication takes \\(O(T^2 \cdot d)\\) computational complexity. In ProbSparse attention, our goal is to create a new \\(Q_{reduce}\\) matrix and define:
$$
\textrm{ProbSparseAttention}(Q, K, V) = \textrm{softmax}(\frac{Q_{reduce}K^T}{\sqrt{d_k}} )V
$$
where the \\(Q_{reduce}\\) matrix only selects the Top \\(u\\) "active" queries. Here, \\(u = c \cdot \log L_Q\\) and \\(c\\) called the _sampling factor_ hyperparameter for the ProbSparse attention. Since \\(Q_{reduce}\\) selects only the Top \\(u\\) queries, its size is \\(c\cdot \log L_Q \times d\\), so the multiplication \\(Q_{reduce}K^T\\) takes only \\(O(L_K \log L_Q) = O(T \log T)\\).
This is good! But how can we select the \\(u\\) "active" queries to create \\(Q_{reduce}\\)? Let's define the _Query Sparsity Measurement_.
#### Query Sparsity Measurement
Query Sparsity Measurement \\(M(q_i, K)\\) is used for selecting the \\(u\\) "active" queries \\(q_i\\) in \\(Q\\) to create \\(Q_{reduce}\\). In theory, the dominant \\(\langle q_i,k_i \rangle\\) pairs encourage the "active" \\(q_i\\)'s probability distribution **away** from the uniform distribution as can be seen in the figure below. Hence, the [KL divergence](https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence) between the actual queries distribution and the uniform distribution is used to define the sparsity measurement.
|  |
|:--:|
| The illustration of ProbSparse Attention from official [repository](https://github.com/zhouhaoyi/Informer2020)|
In practice, the measurement is defined as:
$$
M(q_i, K) = \max_j \frac{q_ik_j^T}{\sqrt{d}}-\frac{1}{L_k} \sum_{j=1}^{L_k}\frac{q_ik_j^T}{\sqrt{d}}
$$
The important thing to understand here is when \\(M(q_i, K)\\) is larger, the query \\(q_i\\) should be in \\(Q_{reduce}\\) and vice versa.
But how can we calculate the term \\(q_ik_j^T\\) in non-quadratic time? Recall that most of the dot-product \\(\langle q_i,k_i \rangle\\) generate either way the trivial attention (i.e. long-tail distribution property), so it is enough to randomly sample a subset of keys from \\(K\\), which will be called `K_sample` in the code.
Now, we are ready to see the code of `probsparse_attention`:
```python
from torch import nn
import math
def probsparse_attention(query_states, key_states, value_states, sampling_factor=5):
"""
Compute the probsparse self-attention.
Input shape: Batch x Time x Channel
Note the additional `sampling_factor` input.
"""
# get input sizes with logs
L_K = key_states.size(1)
L_Q = query_states.size(1)
log_L_K = np.ceil(np.log1p(L_K)).astype("int").item()
log_L_Q = np.ceil(np.log1p(L_Q)).astype("int").item()
# calculate a subset of samples to slice from K and create Q_K_sample
U_part = min(sampling_factor * L_Q * log_L_K, L_K)
# create Q_K_sample (the q_i * k_j^T term in the sparsity measurement)
index_sample = torch.randint(0, L_K, (U_part,))
K_sample = key_states[:, index_sample, :]
Q_K_sample = torch.bmm(query_states, K_sample.transpose(1, 2))
# calculate the query sparsity measurement with Q_K_sample
M = Q_K_sample.max(dim=-1)[0] - torch.div(Q_K_sample.sum(dim=-1), L_K)
# calculate u to find the Top-u queries under the sparsity measurement
u = min(sampling_factor * log_L_Q, L_Q)
M_top = M.topk(u, sorted=False)[1]
# calculate Q_reduce as query_states[:, M_top]
dim_for_slice = torch.arange(query_states.size(0)).unsqueeze(-1)
Q_reduce = query_states[dim_for_slice, M_top] # size: c*log_L_Q x channel
# and now, same as the canonical
d_k = query_states.size(-1)
attn_scores = torch.bmm(Q_reduce, key_states.transpose(-2, -1)) # Q_reduce x K^T
attn_scores = attn_scores / math.sqrt(d_k)
attn_probs = nn.functional.softmax(attn_scores, dim=-1)
attn_output = torch.bmm(attn_probs, value_states)
return attn_output, attn_scores
```
Note that in the implementation, \\(U_{part}\\) contain \\(L_Q\\) in the calculation, for stability issues (see [this disccusion](https://discuss.huggingface.co/t/probsparse-attention-in-informer/34428) for more information).
We did it! Please be aware that this is only a partial implementation of the `probsparse_attention`, and the full implementation can be found in 🤗 Transformers.
### Distilling
Because of the ProbSparse self-attention, the encoder’s feature map has some redundancy that can be removed. Therefore,
the distilling operation is used to reduce the input size between encoder layers into its half slice, thus in theory removing this redundancy. In practice, Informer's "distilling" operation just adds 1D convolution layers with max pooling between each of the encoder layers. Let \\(X_n\\) be the output of the \\(n\\)-th encoder layer, the distilling operation is then defined as:
$$
X_{n+1} = \textrm{MaxPool} ( \textrm{ELU}(\textrm{Conv1d}(X_n))
$$
Let's see this in code:
```python
from torch import nn
# ConvLayer is a class with forward pass applying ELU and MaxPool1d
def informer_encoder_forward(x_input, num_encoder_layers=3, distil=True):
# Initialize the convolution layers
if distil:
conv_layers = nn.ModuleList([ConvLayer() for _ in range(num_encoder_layers - 1)])
conv_layers.append(None)
else:
conv_layers = [None] * num_encoder_layers
# Apply conv_layer between each encoder_layer
for encoder_layer, conv_layer in zip(encoder_layers, conv_layers):
output = encoder_layer(x_input)
if conv_layer is not None:
output = conv_layer(loutput)
return output
```
By reducing the input of each layer by two, we get a memory usage of \\(O(N\cdot T \log T)\\) instead of \\(O(N\cdot T^2)\\) where \\(N\\) is the number of encoder/decoder layers. This is what we wanted!
The Informer model in [now available](https://huggingface.co./docs/transformers/main/en/model_doc/informer) in the 🤗 Transformers library, and simply called `InformerModel`. In the sections below, we will show how to train this model on a custom multivariate time-series dataset.
## Set-up Environment
First, let's install the necessary libraries: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate and [GluonTS](https://github.com/awslabs/gluonts).
As we will show, GluonTS will be used for transforming the data to create features as well as for creating appropriate training, validation and test batches.
```python
!pip install -q transformers datasets evaluate accelerate gluonts ujson
```
## Load Dataset
In this blog post, we'll use the `traffic_hourly` dataset, which is available on the [Hugging Face Hub](https://huggingface.co./datasets/monash_tsf). This dataset contains the San Francisco Traffic dataset used by [Lai et al. (2017)](https://arxiv.org/abs/1703.07015). It contains 862 hourly time series showing the road occupancy rates in the range \\([0, 1]\\) on the San Francisco Bay area freeways from 2015 to 2016.
This dataset is part of the [Monash Time Series Forecasting](https://forecastingdata.org/) repository, a collection of time series datasets from a number of domains. It can be viewed as the [GLUE benchmark](https://gluebenchmark.com/) of time series forecasting.
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "traffic_hourly")
```
As can be seen, the dataset contains 3 splits: train, validation and test.
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 862
})
})
```
Each example contains a few keys, of which `start` and `target` are the most important ones. Let us have a look at the first time series in the dataset:
```python
train_example = dataset["train"][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The `start` simply indicates the start of the time series (as a datetime), and the `target` contains the actual values of the time series.
The `start` will be useful to add time related features to the time series values, as extra input to the model (such as "month of year"). Since we know the frequency of the data is `hourly`, we know for instance that the second value has the timestamp `2015-01-01 01:00:01`, `2015-01-01 02:00:01`, etc.
```python
print(train_example["start"])
print(len(train_example["target"]))
>>> 2015-01-01 00:00:01
17448
```
The validation set contains the same data as the training set, just for a `prediction_length` longer amount of time. This allows us to validate the model's predictions against the ground truth.
The test set is again one `prediction_length` longer data compared to the validation set (or some multiple of `prediction_length` longer data compared to the training set for testing on multiple rolling windows).
```python
validation_example = dataset["validation"][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The initial values are exactly the same as the corresponding training example. However, this example has `prediction_length=48` (48 hours, or 2 days) additional values compared to the training example. Let us verify it.
```python
freq = "1H"
prediction_length = 48
assert len(train_example["target"]) + prediction_length == len(
dataset["validation"][0]["target"]
)
```
Let's visualize this:
```python
import matplotlib.pyplot as plt
num_of_samples = 150
figure, axes = plt.subplots()
axes.plot(train_example["target"][-num_of_samples:], color="blue")
axes.plot(
validation_example["target"][-num_of_samples - prediction_length :],
color="red",
alpha=0.5,
)
plt.show()
```

Let's split up the data:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## Update `start` to `pd.Period`
The first thing we'll do is convert the `start` feature of each time series to a pandas `Period` index using the data's `freq`:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
We now use `datasets`' [`set_transform`](https://huggingface.co./docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) functionality to do this on-the-fly in place:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
Now, let's convert the dataset into a multivariate time series using the `MultivariateGrouper` from GluonTS. This grouper will convert the individual 1-dimensional time series into a single 2D matrix.
```python
from gluonts.dataset.multivariate_grouper import MultivariateGrouper
num_of_variates = len(train_dataset)
train_grouper = MultivariateGrouper(max_target_dim=num_of_variates)
test_grouper = MultivariateGrouper(
max_target_dim=num_of_variates,
num_test_dates=len(test_dataset) // num_of_variates, # number of rolling test windows
)
multi_variate_train_dataset = train_grouper(train_dataset)
multi_variate_test_dataset = test_grouper(test_dataset)
```
Note that the target is now 2-dimensional, where the first dimension is the number of variates (number of time series) and the second is the time series values (time dimension):
```python
multi_variate_train_example = multi_variate_train_dataset[0]
print("multi_variate_train_example["target"].shape =", multi_variate_train_example["target"].shape)
>>> multi_variate_train_example["target"].shape = (862, 17448)
```
## Define the Model
Next, let's instantiate a model. The model will be trained from scratch, hence we won't use the `from_pretrained` method here, but rather randomly initialize the model from a [`config`](https://huggingface.co./docs/transformers/main/en/model_doc/informer#transformers.InformerConfig).
We specify a couple of additional parameters to the model:
- `prediction_length` (in our case, `48` hours): this is the horizon that the decoder of the Informer will learn to predict for;
- `context_length`: the model will set the `context_length` (input of the encoder) equal to the `prediction_length`, if no `context_length` is specified;
- `lags` for a given frequency: these specify an efficient "look back" mechanism, where we concatenate values from the past to the current values as additional features, e.g. for a `Daily` frequency we might consider a look back of `[1, 7, 30, ...]` or for `Minute` data we might consider `[1, 30, 60, 60*24, ...]` etc.;
- the number of time features: in our case, this will be `5` as we'll add `HourOfDay`, `DayOfWeek`, ..., and `Age` features (see below).
Let us check the default lags provided by GluonTS for the given frequency ("hourly"):
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 23, 24, 25, 47, 48, 49, 71, 72, 73, 95, 96, 97, 119, 120,
121, 143, 144, 145, 167, 168, 169, 335, 336, 337, 503, 504, 505, 671, 672, 673, 719, 720, 721]
```
This means that this would look back up to 721 hours (~30 days) for each time step, as additional features. However, the resulting feature vector would end up being of size `len(lags_sequence)*num_of_variates` which for our case will be 34480! This is not going to work so we will use our own sensible lags.
Let us also check the default time features which GluonTS provides us:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function hour_of_day at 0x7f3809539240>, <function day_of_week at 0x7f3809539360>, <function day_of_month at 0x7f3809539480>, <function day_of_year at 0x7f38095395a0>]
```
In this case, there are four additional features, namely "hour of day", "day of week", "day of month" and "day of year". This means that for each time step, we'll add these features as a scalar values. For example, consider the timestamp `2015-01-01 01:00:01`. The four additional features will be:
```python
from pandas.core.arrays.period import period_array
timestamp = pd.Period("2015-01-01 01:00:01", freq=freq)
timestamp_as_index = pd.PeriodIndex(data=period_array([timestamp]))
additional_features = [
(time_feature.__name__, time_feature(timestamp_as_index))
for time_feature in time_features
]
print(dict(additional_features))
>>> {'hour_of_day': array([-0.45652174]), 'day_of_week': array([0.]), 'day_of_month': array([-0.5]), 'day_of_year': array([-0.5])}
```
Note that hours and days are encoded as values between `[-0.5, 0.5]` from GluonTS. For more information about `time_features`, please see [this](https://github.com/awslabs/gluonts/blob/dev/src/gluonts/time_feature/_base.py). Besides those 4 features, we'll also add an "age" feature as we'll see later on in the data transformations.
We now have everything to define the model:
```python
from transformers import InformerConfig, InformerForPrediction
config = InformerConfig(
# in the multivariate setting, input_size is the number of variates in the time series per time step
input_size=num_of_variates,
# prediction length:
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags value copied from 1 week before:
lags_sequence=[1, 24 * 7],
# we'll add 5 time features ("hour_of_day", ..., and "age"):
num_time_features=len(time_features) + 1,
# informer params:
dropout=0.1,
encoder_layers=6,
decoder_layers=4,
# project input from num_of_variates*len(lags_sequence)+num_time_features to:
d_model=64,
)
model = InformerForPrediction(config)
```
By default, the model uses a diagonal Student-t distribution (but this is [configurable](https://huggingface.co./docs/transformers/main/en/internal/time_series_utils)):
```python
model.config.distribution_output
>>> 'student_t'
```
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
Again, we'll use the GluonTS library for this. We define a `Chain` of transformations (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
```python
from gluonts.time_feature import TimeFeature
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
The transformations below are annotated with comments, to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
# create list of fields to remove later
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in the life the value of the time series is
# sort of running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the model due to time- and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create DataLoaders
Next, it's time to create the DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from all the possible transformed time series, 1 in our case)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=multi_variate_train_dataset,
batch_size=256,
num_batches_per_epoch=100,
num_workers=2,
)
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=multi_variate_test_dataset,
batch_size=32,
)
```
Let's check the first batch:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 264, 5]) torch.FloatTensor
past_values torch.Size([256, 264, 862]) torch.FloatTensor
past_observed_mask torch.Size([256, 264, 862]) torch.FloatTensor
future_time_features torch.Size([256, 48, 5]) torch.FloatTensor
future_values torch.Size([256, 48, 862]) torch.FloatTensor
future_observed_mask torch.Size([256, 48, 862]) torch.FloatTensor
```
As can be seen, we don't feed `input_ids` and `attention_mask` to the encoder (as would be the case for NLP models), but rather `past_values`, along with `past_observed_mask`, `past_time_features` and `static_real_features`.
The decoder inputs consist of `future_values`, `future_observed_mask` and `future_time_features`. The `future_values` can be seen as the equivalent of `decoder_input_ids` in NLP.
We refer to the [docs](https://huggingface.co./docs/transformers/main/en/model_doc/informer#transformers.InformerModel.forward.past_values) for a detailed explanation for each of them.
## Forward Pass
Let's perform a single forward pass with the batch we just created:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: -1071.5718994140625
```
Note that the model is returning a loss. This is possible as the decoder automatically shifts the `future_values` one position to the right in order to have the labels. This allows computing a loss between the predicted values and the labels. The loss is the negative log-likelihood of the predicted distribution with respect to the ground truth values and tends to negative infinity.
Also note that the decoder uses a causal mask to not look into the future as the values it needs to predict are in the `future_values` tensor.
## Train the Model
It's time to train the model! We'll use a standard PyTorch training loop.
We will use the 🤗 [Accelerate](https://huggingface.co./docs/accelerate/index) library here, which automatically places the model, optimizer and dataloader on the appropriate `device`.
```python
from accelerate import Accelerator
from torch.optim import AdamW
epochs = 25
loss_history = []
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(epochs):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
loss_history.append(loss.item())
if idx % 100 == 0:
print(loss.item())
>>> -1081.978515625
...
-2877.723876953125
```
```python
# view training
loss_history = np.array(loss_history).reshape(-1)
x = range(loss_history.shape[0])
plt.figure(figsize=(10, 5))
plt.plot(x, loss_history, label="train")
plt.title("Loss", fontsize=15)
plt.legend(loc="upper right")
plt.xlabel("iteration")
plt.ylabel("nll")
plt.show()
```

## Inference
At inference time, it's recommended to use the `generate()` method for autoregressive generation, similar to NLP models.
Forecasting involves getting data from the test instance sampler, which will sample the very last `context_length` sized window of values from each time series in the dataset, and pass it to the model. Note that we pass `future_time_features`, which are known ahead of time, to the decoder.
The model will autoregressively sample a certain number of values from the predicted distribution and pass them back to the decoder to return the prediction outputs:
```python
model.eval()
forecasts_ = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts_.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`, `input_size`).
In this case, we get `100` possible values for the next `48` hours for each of the `862` time series (for each example in the batch which is of size `1` since we only have a single multivariate time series):
```python
forecasts_[0].shape
>>> (1, 100, 48, 862)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset (just in case there are more time series in the test set):
```python
forecasts = np.vstack(forecasts_)
print(forecasts.shape)
>>> (1, 100, 48, 862)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. For that, we'll use the 🤗 [Evaluate](https://huggingface.co./docs/evaluate/index) library, which includes the [MASE](https://huggingface.co./spaces/evaluate-metric/mase) and [sMAPE](https://huggingface.co./spaces/evaluate-metric/smape) metrics.
We calculate both metrics for each time series variate in the dataset:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1).squeeze(0).T
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq),
)
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.1913437728068093
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.5322665081607634
```
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.2)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```

To plot the prediction for any time series variate with respect the ground truth test data we define the following helper:
```python
import matplotlib.dates as mdates
def plot(ts_index, mv_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=multi_variate_test_dataset[ts_index][FieldName.START],
periods=len(multi_variate_test_dataset[ts_index][FieldName.TARGET]),
freq=multi_variate_test_dataset[ts_index][FieldName.START].freq,
).to_timestamp()
ax.xaxis.set_minor_locator(mdates.HourLocator())
ax.plot(
index[-2 * prediction_length :],
multi_variate_test_dataset[ts_index]["target"][mv_index, -2 * prediction_length :],
label="actual",
)
ax.plot(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(axis=0),
label="mean",
)
ax.fill_between(
index[-prediction_length:],
forecasts[ts_index, ..., mv_index].mean(0)
- forecasts[ts_index, ..., mv_index].std(axis=0),
forecasts[ts_index, ..., mv_index].mean(0)
+ forecasts[ts_index, ..., mv_index].std(axis=0),
alpha=0.2,
interpolate=True,
label="+/- 1-std",
)
ax.legend()
fig.autofmt_xdate()
```
For example:
```python
plot(0, 344)
```

## Conclusion
How do we compare against other models? The [Monash Time Series Repository](https://forecastingdata.org/#results) has a comparison table of test set MASE metrics which we can add to:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| Transformer (uni.) | **Informer (mv. our)**|
|: | [
[
"transformers",
"research",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"implementation",
"tutorial"
] | null | null |
ec26104e-9e16-4838-a835-20569685fb8b | completed | 2025-01-16T03:09:11.596601 | 2025-01-19T18:47:03.806107 | ed537acd-a36c-4e04-b05f-3ef8e8159ac8 | Snorkel AI x Hugging Face: unlock foundation models for enterprises | Violette | snorkel-case-study.md | _This article is a cross-post from an originally published post on April 6, 2023 [in Snorkel's blog](https://snorkel.ai/snorkel-hugging-face-unlock-foundation-models-for-enterprise/), by Friea Berg ._
As OpenAI releases [GPT-4](https://openai.com/research/gpt-4) and Google debuts [Bard](https://gizmodo.com/google-bard-chatgpt-ai-rival-released-1850248162) in beta, enterprises around the world are excited to leverage the power of foundation models. As that excitement builds, so does the realization that most companies and organizations are not equipped to properly take advantage of foundation models.
Foundation models pose a unique set of challenges for enterprises. Their larger-than-ever size makes them difficult and expensive for companies to host themselves, and using off-the-shelf FMs for production use cases could mean poor performance or substantial governance and compliance risks.
Snorkel AI bridges the gap between foundation models and practical enterprise use cases and has [yielded impressive results](https://snorkel.ai/how-pixability-uses-foundation-models-to-accelerate-nlp-application-development-by-months/) for AI innovators like Pixability. We’re teaming with [Hugging Face](https://huggingface.co./), best known for its enormous repository of ready-to-use open-source models, to provide enterprises with even more flexibility and choice as they develop AI applications.
## Foundation models in Snorkel Flow
The Snorkel Flow development platform enables users to [adapt foundation models](https://snorkel.ai/snorkel-flow/foundation-model-development/) for their specific use cases. Application development begins by inspecting the predictions of a selected foundation model “out of the box” on their data. These predictions become an initial version of training labels for those data points. Snorkel Flow helps users to identify error modes in that model and correct them efficiently via [programmatic labeling](https://snorkel.ai/programmatic-labeling/), which can include updating training labels with heuristics or [prompts](https://snorkel.ai/combining-foundation-models-with-weak-supervision/). The base foundation model can then be fine-tuned on the updated labels and evaluated once again, with this iterative “detect and correct” process continuing until the adapted foundation model is sufficiently high quality to deploy.
Hugging Face helps enable this powerful development process by making more than 150,000 open-source models immediately available from a single source. Many of those models are specialized on domain-specific data, like the BioBERT and SciBERT models used to demonstrate [how ML can be used to spot adverse drug events](https://snorkel.ai/adverse-drug-events-how-to-spot-them-with-machine-learning/). One – or better yet, [multiple](https://snorkel.ai/combining-foundation-models-with-weak-supervision/) – specialized base models can give users a jump-start on initial predictions, prompts for improving labels, or fine-tuning a final model for deployment.
## How does Hugging Face help?
Snorkel AI’s partnership with Hugging Face supercharges Snorkel Flow’s foundation model capabilities. Initially we only made a small number of foundation models available. Each one required a dedicated service, making it prohibitively expensive and difficult for us to offer enterprises the flexibility to capitalize on the rapidly growing variety of models available. Adopting Hugging Face’s Inference Endpoint service enabled us to expand the number of foundation models our users could tap into while keeping costs manageable.
Hugging Face’s service allows users to create a model API in a few clicks and begin using it immediately. Crucially, the new service has “pause and resume” capabilities that allow us to activate a model API when a client needs it, and put it to sleep when they don’t.
"We were pleasantly surprised to see how straightforward Hugging Face Inference Endpoint service was to set up.. All the configuration options were pretty self-explanatory, but we also had access to all the options we needed in terms of what cloud to run on, what security level we needed, etc."
– Snorkel CTO and Co-founder Braden Hancock
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/woblG7iZPSw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
## How does this help Snorkel customers?
Few enterprises have the resources to train their own foundation models from scratch. While many may have the in-house expertise to fine-tune their own version of a foundation model, they may struggle to gather the volume of data needed for that task. Snorkel’s data-centric platform for developing foundation models and alignment with leading industry innovators like Hugging Face help put the power of foundation models at our users’ fingertips.
#### "With Snorkel AI and Hugging Face Inference Endpoints, companies will accelerate their data-centric AI applications with open source at the core. Machine Learning is becoming the default way of building technology, and building from open source allows companies to build the right solution for their use case and take control of the experience they offer to their customers. We are excited to see Snorkel AI enable automated data labeling for the enterprise building from open-source Hugging Face models and Inference Endpoints, our machine learning production service.”
Clement Delangue, co-founder and CEO, Hugging Face
## Conclusion
Together, Snorkel and Hugging Face make it easier than ever for large companies, government agencies, and AI innovators to get value from foundation models. The ability to use Hugging Face’s comprehensive hub of foundation models means that users can pick the models that best align with their business needs without having to invest in the resources required to train them. This integration is a significant step forward in making foundation models more accessible to enterprises around the world.
_If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co./inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_ | [
[
"llm",
"mlops",
"fine_tuning",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"fine_tuning",
"integration"
] | null | null |
608268cd-3c9b-43d9-a582-3619495a852e | completed | 2025-01-16T03:09:11.596605 | 2025-01-19T17:19:38.831161 | 0be3243f-36b5-48ab-9bbe-6519991455d4 | Large Language Models: A New Moore's Law? | juliensimon | large-language-models.md | A few days ago, Microsoft and NVIDIA [introduced](https://www.microsoft.com/en-us/research/blog/using-deepspeed-and-megatron-to-train-megatron-turing-nlg-530b-the-worlds-largest-and-most-powerful-generative-language-model/) Megatron-Turing NLG 530B, a Transformer-based model hailed as "*the world’s largest and most powerful generative language model*."
This is an impressive show of Machine Learning engineering, no doubt about it. Yet, should we be excited about this mega-model trend? I, for one, am not. Here's why.
<kbd>
<img src="assets/33_large_language_models/01_model_size.jpg">
</kbd>
### This is your Brain on Deep Learning
Researchers estimate that the human brain contains an average of [86 billion neurons](https://pubmed.ncbi.nlm.nih.gov/19226510/) and 100 trillion synapses. It's safe to assume that not all of them are dedicated to language either. Interestingly, GPT-4 is [expected](https://www.wired.com/story/cerebras-chip-cluster-neural-networks-ai/) to have about 100 trillion parameters... As crude as this analogy is, shouldn't we wonder whether building language models that are about the size of the human brain is the best long-term approach?
Of course, our brain is a marvelous device, produced by millions of years of evolution, while Deep Learning models are only a few decades old. Still, our intuition should tell us that something doesn't compute (pun intended).
### Deep Learning, Deep Pockets?
As you would expect, training a 530-billion parameter model on humongous text datasets requires a fair bit of infrastructure. In fact, Microsoft and NVIDIA used hundreds of DGX A100 multi-GPU servers. At $199,000 a piece, and factoring in networking equipment, hosting costs, etc., anyone looking to replicate this experiment would have to spend close to $100 million dollars. Want fries with that?
Seriously, which organizations have business use cases that would justify spending $100 million on Deep Learning infrastructure? Or even $10 million? Very few. So who are these models for, really?
### That Warm Feeling is your GPU Cluster
For all its engineering brilliance, training Deep Learning models on GPUs is a brute force technique. According to the spec sheet, each DGX server can consume up to 6.5 kilowatts. Of course, you'll need at least as much cooling power in your datacenter (or your server closet). Unless you're the Starks and need to keep Winterfell warm in winter, that's another problem you'll have to deal with.
In addition, as public awareness grows on climate and social responsibility issues, organizations need to account for their carbon footprint. According to this 2019 [study](https://arxiv.org/pdf/1906.02243.pdf) from the University of Massachusetts, "*training BERT on GPU is roughly equivalent to a trans-American flight*".
BERT-Large has 340 million parameters. One can only extrapolate what the footprint of Megatron-Turing could be... People who know me wouldn't call me a bleeding-heart environmentalist. Still, some numbers are hard to ignore.
### So?
Am I excited by Megatron-Turing NLG 530B and whatever beast is coming next? No. Do I think that the (relatively small) benchmark improvement is worth the added cost, complexity and carbon footprint? No. Do I think that building and promoting these huge models is helping organizations understand and adopt Machine Learning ? No.
I'm left wondering what's the point of it all. Science for the sake of science? Good old marketing? Technological supremacy? Probably a bit of each. I'll leave them to it, then.
Instead, let me focus on pragmatic and actionable techniques that you can all use to build high quality Machine Learning solutions.
### Use Pretrained Models
In the vast majority of cases, you won't need a custom model architecture. Maybe you'll *want* a custom one (which is a different thing), but there be dragons. Experts only!
A good starting point is to look for [models](https://huggingface.co./models) that have been pretrained for the task you're trying to solve (say, [summarizing English text](https://huggingface.co./models?language=en&pipeline_tag=summarization&sort=downloads)).
Then, you should quickly try out a few models to predict your own data. If metrics tell you that one works well enough, you're done! If you need a little more accuracy, you should consider fine-tuning the model (more on this in a minute).
### Use Smaller Models
When evaluating models, you should pick the smallest one that can deliver the accuracy you need. It will predict faster and require fewer hardware resources for training and inference. Frugality goes a long way.
It's nothing new either. Computer Vision practitioners will remember when [SqueezeNet](https://arxiv.org/abs/1602.07360) came out in 2017, achieving a 50x reduction in model size compared to [AlexNet](https://papers.nips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html), while meeting or exceeding its accuracy. How clever that was!
Downsizing efforts are also under way in the Natural Language Processing community, using transfer learning techniques such as [knowledge distillation](https://en.wikipedia.org/wiki/Knowledge_distillation). [DistilBERT](https://arxiv.org/abs/1910.01108) is perhaps its most widely known achievement. Compared to the original BERT model, it retains 97% of language understanding while being 40% smaller and 60% faster. You can try it [here](https://huggingface.co./distilbert-base-uncased). The same approach has been applied to other models, such as Facebook's [BART](https://arxiv.org/abs/1910.13461), and you can try DistilBART [here](https://huggingface.co./models?search=distilbart).
Recent models from the [Big Science](https://bigscience.huggingface.co/) project are also very impressive. As visible in this graph included in the [research paper](https://arxiv.org/abs/2110.08207), their T0 model outperforms GPT-3 on many tasks while being 16x smaller.
<kbd>
<img src="assets/33_large_language_models/02_t0.png">
</kbd>
You can try T0 [here](https://huggingface.co./bigscience/T0pp). This is the kind of research we need more of!
### Fine-Tune Models
If you need to specialize a model, there should be very few reasons to train it from scratch. Instead, you should fine-tune it, that is to say train it only for a few epochs on your own data. If you're short on data, maybe of one these [datasets](https://huggingface.co./datasets) can get you started.
You guessed it, that's another way to do transfer learning, and it'll help you save on everything!
* Less data to collect, store, clean and annotate,
* Faster experiments and iterations,
* Fewer resources required in production.
In other words: save time, save money, save hardware resources, save the world!
If you need a tutorial, the Hugging Face [course](https://huggingface.co./course) will get you started in no time.
### Use Cloud-Based Infrastructure
Like them or not, cloud companies know how to build efficient infrastructure. Sustainability studies show that cloud-based infrastructure is more energy and carbon efficient than the alternative: see [AWS](https://sustainability.aboutamazon.com/environment/the-cloud), [Azure](https://azure.microsoft.com/en-us/global-infrastructure/sustainability), and [Google](https://cloud.google.com/sustainability). Earth.org [says](https://earth.org/environmental-impact-of-cloud-computing/) that while cloud infrastructure is not perfect, "[*it's] more energy efficient than the alternative and facilitates environmentally beneficial services and economic growth.*"
Cloud certainly has a lot going for it when it comes to ease of use, flexibility and pay as you go. It's also a little greener than you probably thought. If you're short on GPUs, why not try fine-tune your Hugging Face models on [Amazon SageMaker](https://aws.amazon.com/sagemaker/), AWS' managed service for Machine Learning? We've got [plenty of examples](https://huggingface.co./docs/sagemaker/train) for you.
### Optimize Your Models
From compilers to virtual machines, software engineers have long used tools that automatically optimize their code for whatever hardware they're running on.
However, the Machine Learning community is still struggling with this topic, and for good reason. Optimizing models for size and speed is a devilishly complex task, which involves techniques such as:
* Specialized hardware that speeds up training ([Graphcore](https://www.graphcore.ai/), [Habana](https://habana.ai/)) and inference ([Google TPU](https://cloud.google.com/tpu), [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/)).
* Pruning: remove model parameters that have little or no impact on the predicted outcome.
* Fusion: merge model layers (say, convolution and activation).
* Quantization: storing model parameters in smaller values (say, 8 bits instead of 32 bits)
Fortunately, automated tools are starting to appear, such as the [Optimum](https://huggingface.co./hardware) open source library, and [Infinity](https://huggingface.co./infinity), a containerized solution that delivers Transformers accuracy at 1-millisecond latency.
### Conclusion
Large language model size has been increasing 10x every year for the last few years. This is starting to look like another [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law).
We've been there before, and we should know that this road leads to diminishing returns, higher cost, more complexity, and new risks. Exponentials tend not to end well. Remember [Meltdown and Spectre](https://meltdownattack.com/)? Do we want to find out what that looks like for AI?
Instead of chasing trillion-parameter models (place your bets), wouldn't all be better off if we built practical and efficient solutions that all developers can use to solve real-world problems?
*Interested in how Hugging Face can help your organization build and deploy production-grade Machine Learning solutions? Get in touch at [[email protected]](mailto:[email protected]) (no recruiters, no sales pitches, please).* | [
[
"llm",
"transformers",
"research",
"benchmarks"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"research",
"benchmarks"
] | null | null |
488b9673-0ab9-45c0-aa41-1e072b565327 | completed | 2025-01-16T03:09:11.596610 | 2025-01-16T03:18:19.457050 | 41826805-eb69-4c6a-b92b-6e4cd2c6f9f1 | Accelerate 1.0.0 | muellerzr, marcsun13, BenjaminB | accelerate-v1.md | ## What is Accelerate today?
3.5 years ago, [Accelerate](https://github.com/huggingface/accelerate) was a simple framework aimed at making training on multi-GPU and TPU systems easier
by having a low-level abstraction that simplified a *raw* PyTorch training loop:
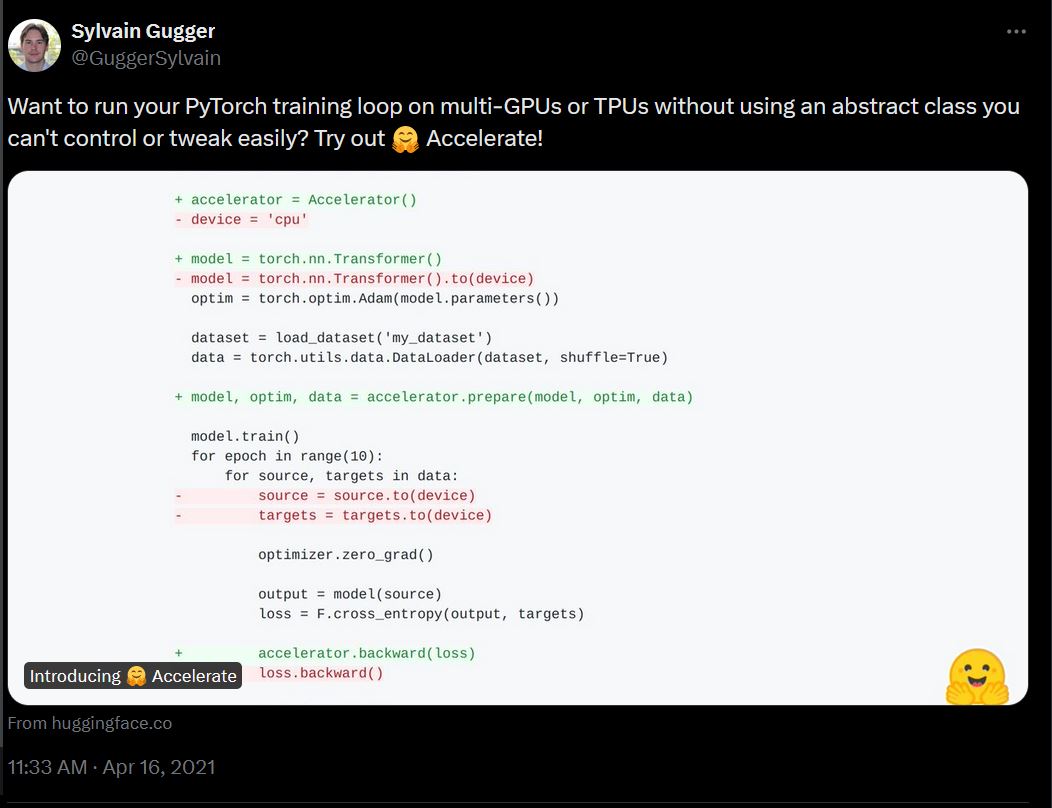
Since then, Accelerate has expanded into a multi-faceted library aimed at tackling many common problems with
large-scale training and large models in an age where 405 billion parameters (Llama) are the new language model size. This involves:
* [A flexible low-level training API](https://huggingface.co./docs/accelerate/basic_tutorials/migration), allowing for training on six different hardware accelerators (CPU, GPU, TPU, XPU, NPU, MLU) while maintaining 99% of your original training loop
* An easy-to-use [command-line interface](https://huggingface.co./docs/accelerate/basic_tutorials/launch) aimed at configuring and running scripts across different hardware configurations
* The birthplace of [Big Model Inference](https://huggingface.co./docs/accelerate/usage_guides/big_modeling) or `device_map="auto"`, allowing users to not only perform inference on LLMs with multi-devices but now also aiding in training LLMs on small compute through techniques like parameter-efficient fine-tuning (PEFT)
These three facets have allowed Accelerate to become the foundation of **nearly every package at Hugging Face**, including `transformers`, `diffusers`, `peft`, `trl`, and more!
As the package has been stable for nearly a year, we're excited to announce that, as of today, we've published **the first release candidates for Accelerate 1.0.0**!
This blog will detail:
1. Why did we decide to do 1.0?
2. What is the future for Accelerate, and where do we see PyTorch as a whole going?
3. What are the breaking changes and deprecations that occurred, and how can you migrate over easily?
## Why 1.0?
The plans to release 1.0.0 have been in the works for over a year. The API has been roughly at a point where we wanted,
centering on the `Accelerator` side, simplifying much of the configuration and making it more extensible. However, we knew
there were a few missing pieces before we could call the "base" of `Accelerate` "feature complete":
* Integrating FP8 support of both MS-AMP and `TransformersEngine` (read more [here](https://github.com/huggingface/accelerate/tree/main/benchmarks/fp8/transformer_engine) and [here](https://github.com/huggingface/accelerate/tree/main/benchmarks/fp8/ms_amp))
* Supporting orchestration of multiple models when using DeepSpeed ([Experimental](https://huggingface.co./docs/accelerate/usage_guides/deepspeed_multiple_model))
* `torch.compile` support for the big model inference API (requires `torch>=2.5`)
* Integrating `torch.distributed.pipelining` as an [alternative distributed inference mechanic](https://huggingface.co./docs/accelerate/main/en/usage_guides/distributed_inference#memory-efficient-pipeline-parallelism-experimental)
* Integrating `torchdata.StatefulDataLoader` as an [alternative dataloader mechanic](https://github.com/huggingface/accelerate/blob/main/examples/by_feature/checkpointing.py)
With the changes made for 1.0, accelerate is prepared to tackle new tech integrations while keeping the user-facing API stable.
## The future of Accelerate
Now that 1.0 is almost done, we can focus on new techniques coming out throughout the community and find integration paths into Accelerate, as we foresee some radical changes in the PyTorch ecosystem very soon:
* As part of the multiple-model DeepSpeed support, we found that while generally how DeepSpeed is currently *could* work, some heavy changes to the overall API may eventually be needed as we work to support simple wrappings to prepare models for any multiple-model training scenario.
* With [torchao](https://github.com/pytorch/ao) and [torchtitan](https://github.com/pytorch/torchtitan) picking up steam, they hint at the future of PyTorch as a whole. Aiming at more native support for FP8 training, a new distributed sharding API, and support for a new version of FSDP, FSDPv2, we predict that much of the internals and general usage API of Accelerate will need to change (hopefully not too drastic) to meet these needs as the frameworks slowly become more stable.
* Riding on `torchao`/FP8, many new frameworks are bringing in different ideas and implementations on how to make FP8 training work and be stable (`transformer_engine`, `torchao`, `MS-AMP`, `nanotron`, to name a few). Our aim with Accelerate is to house each of these implementations in one place with easy configurations to let users explore and test out each one as they please, intending to find the ones that wind up being the most stable and flexible. It's a rapidly accelerating (no pun intended) field of research, especially with NVIDIA's FP4 training support on the way, and we want to make sure that not only can we support each of these methods but aim to provide **solid benchmarks for each** to show their tendencies out-of-the-box (with minimal tweaking) compared to native BF16 training
We're incredibly excited about the future of distributed training in the PyTorch ecosystem, and we want to make sure that Accelerate is there every step of the way, providing a lower barrier to entry for these new techniques. By doing so, we hope the community will continue experimenting and learning together as we find the best methods for training and scaling larger models on more complex computing systems.
## How to try it out
To try the first release candidate for Accelerate today, please use one of the following methods:
* pip:
```bash
pip install --pre accelerate
```
* Docker:
```bash
docker pull huggingface/accelerate:gpu-release-1.0.0rc1
```
Valid release tags are:
* `gpu-release-1.0.0rc1`
* `cpu-release-1.0.0rc1`
* `gpu-fp8-transformerengine-release-1.0.0rc1`
* `gpu-deepspeed-release-1.0.0rc1`
## Migration assistance
Below are the full details for all deprecations that are being enacted as part of this release:
* Passing in `dispatch_batches`, `split_batches`, `even_batches`, and `use_seedable_sampler` to the `Accelerator()` should now be handled by creating an `accelerate.utils.DataLoaderConfiguration()` and passing this to the `Accelerator()` instead (`Accelerator(dataloader_config=DataLoaderConfiguration(...))`)
* `Accelerator().use_fp16` and `AcceleratorState().use_fp16` have been removed; this should be replaced by checking `accelerator.mixed_precision == "fp16"`
* `Accelerator().autocast()` no longer accepts a `cache_enabled` argument. Instead, an `AutocastKwargs()` instance should be used which handles this flag (among others) passing it to the `Accelerator` (`Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)])`)
* `accelerate.utils.is_tpu_available` should be replaced with `accelerate.utils.is_torch_xla_available`
* `accelerate.utils.modeling.shard_checkpoint` should be replaced with `split_torch_state_dict_into_shards` from the `huggingface_hub` library
* `accelerate.tqdm.tqdm()` no longer accepts `True`/`False` as the first argument, and instead, `main_process_only` should be passed in as a named argument
* `ACCELERATE_DISABLE_RICH` is no longer a valid environmental variable, and instead, one should manually enable `rich` traceback by setting `ACCELERATE_ENABLE_RICH=1`
* The FSDP setting `fsdp_backward_prefetch_policy` has been replaced with `fsdp_backward_prefetch`
## Closing thoughts
Thank you so much for using Accelerate; it's been amazing watching a small idea turn into over 100 million downloads and nearly 300,000 **daily** downloads over the last few years.
With this release candidate, we hope to give the community an opportunity to try it out and migrate to 1.0 before the official release.
Please stay tuned for more information by keeping an eye on the [github](https://github.com/huggingface/accelerate) and on [socials](https://x.com/TheZachMueller)! | [
[
"mlops",
"implementation",
"tools",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"implementation",
"tools",
"efficient_computing"
] | null | null |
992838c7-dbf4-4792-a0df-4a056d31eec3 | completed | 2025-01-16T03:09:11.596615 | 2025-01-19T19:07:17.431831 | 24bd8194-7a2f-404d-844f-5f14e1121765 | Llama 2 on Amazon SageMaker a Benchmark | philschmid | llama-sagemaker-benchmark.md | 
Deploying large language models (LLMs) and other generative AI models can be challenging due to their computational requirements and latency needs. To provide useful recommendations to companies looking to deploy Llama 2 on Amazon SageMaker with the [Hugging Face LLM Inference Container](https://huggingface.co./blog/sagemaker-huggingface-llm), we created a comprehensive benchmark analyzing over 60 different deployment configurations for Llama 2.
In this benchmark, we evaluated varying sizes of Llama 2 on a range of Amazon EC2 instance types with different load levels. Our goal was to measure latency (ms per token), and throughput (tokens per second) to find the optimal deployment strategies for three common use cases:
- Most Cost-Effective Deployment: For users looking for good performance at low cost
- Best Latency Deployment: Minimizing latency for real-time services
- Best Throughput Deployment: Maximizing tokens processed per second
To keep this benchmark fair, transparent, and reproducible, we share all of the assets, code, and data we used and collected:
- [GitHub Repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container)
- [Raw Data](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker)
- [Spreadsheet with processed data](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit?usp=sharing)
We hope to enable customers to use LLMs and Llama 2 efficiently and optimally for their use case. Before we get into the benchmark and data, let's look at the technologies and methods we used.
- [Llama 2 on Amazon SageMaker a Benchmark](#llama-2-on-amazon-sagemaker-a-benchmark)
- [What is the Hugging Face LLM Inference Container?](#what-is-the-hugging-face-llm-inference-container)
- [What is Llama 2?](#what-is-llama-2)
- [What is GPTQ?](#what-is-gptq)
- [Benchmark](#benchmark)
- [Recommendations \& Insights](#recommendations--insights)
- [Most Cost-Effective Deployment](#most-cost-effective-deployment)
- [Best Throughput Deployment](#best-throughput-deployment)
- [Best Latency Deployment](#best-latency-deployment)
- [Conclusions](#conclusions)
### What is the Hugging Face LLM Inference Container?
[Hugging Face LLM DLC](https://huggingface.co./blog/sagemaker-huggingface-llm) is a purpose-built Inference Container to easily deploy LLMs in a secure and managed environment. The DLC is powered by [Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference), an open-source, purpose-built solution for deploying and serving LLMs. TGI enables high-performance text generation using Tensor Parallelism and dynamic batching for the most popular open-source LLMs, including StarCoder, BLOOM, GPT-NeoX, Falcon, Llama, and T5. VMware, IBM, Grammarly, Open-Assistant, Uber, Scale AI, and many more already use Text Generation Inference.
### What is Llama 2?
Llama 2 is a family of LLMs from Meta, trained on 2 trillion tokens. Llama 2 comes in three sizes - 7B, 13B, and 70B parameters - and introduces key improvements like longer context length, commercial licensing, and optimized chat abilities through reinforcement learning compared to Llama (1). If you want to learn more about Llama 2 check out this [blog post](https://huggingface.co./blog/llama2).
### What is GPTQ?
GPTQ is a post-training quantziation method to compress LLMs, like GPT. GPTQ compresses GPT (decoder) models by reducing the number of bits needed to store each weight in the model, from 32 bits down to just 3-4 bits. This means the model takes up much less memory and can run on less Hardware, e.g. Single GPU for 13B Llama2 models. GPTQ analyzes each layer of the model separately and approximates the weights to preserve the overall accuracy. If you want to learn more and how to use it, check out [Optimize open LLMs using GPTQ and Hugging Face Optimum](https://www.philschmid.de/gptq-llama).
## Benchmark
To benchmark the real-world performance of Llama 2, we tested 3 model sizes (7B, 13B, 70B parameters) on four different instance types with four different load levels, resulting in 60 different configurations:
- Models: We evaluated all currently available model sizes, including 7B, 13B, and 70B.
- Concurrent Requests: We tested configurations with 1, 5, 10, and 20 concurrent requests to determine the performance on different usage scenarios.
- Instance Types: We evaluated different GPU instances, including g5.2xlarge, g5.12xlarge, g5.48xlarge powered by NVIDIA A10G GPUs, and p4d.24xlarge powered by NVIDIA A100 40GB GPU.
- Quantization: We compared performance with and without quantization. We used GPTQ 4-bit as a quantization technique.
As metrics, we used Throughput and Latency defined as:
- Throughput (tokens/sec): Number of tokens being generated per second.
- Latency (ms/token): Time it takes to generate a single token
We used those to evaluate the performance of Llama across the different setups to understand the benefits and tradeoffs. If you want to run the benchmark yourself, we created a [Github repository](https://github.com/philschmid/text-generation-inference-tests/tree/master/sagemaker_llm_container).
You can find the full data of the benchmark in the [Amazon SageMaker Benchmark: TGI 1.0.3 Llama 2](https://docs.google.com/spreadsheets/d/1PBjw6aG3gPaoxd53vp7ZtCdPngExi2vWPC0kPZXaKlw/edit#gid=0) sheet. The raw data is available on [GitHub](https://github.com/philschmid/text-generation-inference-tests/tree/master/results/sagemaker).
If you are interested in all of the details, we recommend you to dive deep into the provided raw data.
## Recommendations & Insights
Based on the benchmark, we provide specific recommendations for optimal LLM deployment depending on your priorities between cost, throughput, and latency for all Llama 2 model sizes.
*Note: The recommendations are based on the configuration we tested. In the future, other environments or hardware offerings, such as Inferentia2, may be even more cost-efficient.*
### Most Cost-Effective Deployment
The most cost-effective configuration focuses on the right balance between performance (latency and throughput) and cost. Maximizing the output per dollar spent is the goal. We looked at the performance during 5 concurrent requests. We can see that GPTQ offers the best cost-effectiveness, allowing customers to deploy Llama 2 13B on a single GPU.
| Model | Quantization | Instance | concurrent requests | Latency (ms/token) median | Throughput (tokens/second) | On-demand cost ($/h) in us-west-2 | Time to generate 1 M tokens (minutes) | cost to generate 1M tokens ($) |
| | [
[
"llm",
"mlops",
"benchmarks",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"benchmarks",
"deployment"
] | null | null |
c9a6cb4c-3a0a-4950-994d-dcc6fb6e4779 | completed | 2025-01-16T03:09:11.596619 | 2025-01-18T14:43:09.300412 | d250c16f-88c7-49e5-aab6-5815c12a5fba | Zero-shot image-to-text generation with BLIP-2 | MariaK, JunnanLi | blip-2.md | This guide introduces [BLIP-2](https://huggingface.co./docs/transformers/main/en/model_doc/blip-2) from Salesforce Research
that enables a suite of state-of-the-art visual-language models that are now available in [🤗 Transformers](https://huggingface.co./transformers).
We'll show you how to use it for image captioning, prompted image captioning, visual question-answering, and chat-based prompting.
## Table of contents
1. [Introduction](#introduction)
2. [What's under the hood in BLIP-2?](#whats-under-the-hood-in-blip-2)
3. [Using BLIP-2 with Hugging Face Transformers](#using-blip-2-with-hugging-face-transformers)
1. [Image Captioning](#image-captioning)
2. [Prompted image captioning](#prompted-image-captioning)
3. [Visual question answering](#visual-question-answering)
4. [Chat-based prompting](#chat-based-prompting)
4. [Conclusion](#conclusion)
5. [Acknowledgments](#acknowledgments)
## Introduction
Recent years have seen rapid advancements in computer vision and natural language processing. Still, many real-world
problems are inherently multimodal - they involve several distinct forms of data, such as images and text.
Visual-language models face the challenge of combining modalities so that they can open the door to a wide range of
applications. Some of the image-to-text tasks that visual language models can tackle include image captioning, image-text
retrieval, and visual question answering. Image captioning can aid the visually impaired, create useful product descriptions,
identify inappropriate content beyond text, and more. Image-text retrieval can be applied in multimodal search, as well
as in applications such as autonomous driving. Visual question-answering can aid in education, enable multimodal chatbots,
and assist in various domain-specific information retrieval applications.
Modern computer vision and natural language models have become more capable; however, they have also significantly
grown in size compared to their predecessors. While pre-training a single-modality model is resource-consuming and expensive,
the cost of end-to-end vision-and-language pre-training has become increasingly prohibitive.
[BLIP-2](https://arxiv.org/pdf/2301.12597.pdf) tackles this challenge by introducing a new visual-language pre-training paradigm that can potentially leverage
any combination of pre-trained vision encoder and LLM without having to pre-train the whole architecture end to end.
This enables achieving state-of-the-art results on multiple visual-language tasks while significantly reducing the number
of trainable parameters and pre-training costs. Moreover, this approach paves the way for a multimodal ChatGPT-like model.
## What's under the hood in BLIP-2?
BLIP-2 bridges the modality gap between vision and language models by adding a lightweight Querying Transformer (Q-Former)
between an off-the-shelf frozen pre-trained image encoder and a frozen large language model. Q-Former is the only
trainable part of BLIP-2; both the image encoder and language model remain frozen.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/blip-2/q-former-1.png" alt="Overview of BLIP-2's framework" width=500>
</p>
Q-Former is a transformer model that consists of two submodules that share the same self-attention layers:
* an image transformer that interacts with the frozen image encoder for visual feature extraction
* a text transformer that can function as both a text encoder and a text decoder
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/blip-2/q-former-2.png" alt="Q-Former architecture" width=500>
</p>
The image transformer extracts a fixed number of output features from the image encoder, independent of input image resolution,
and receives learnable query embeddings as input. The queries can additionally interact with the text through the same self-attention layers.
Q-Former is pre-trained in two stages. In the first stage, the image encoder is frozen, and Q-Former is trained with three losses:
* Image-text contrastive loss: pairwise similarity between each query output and text output's CLS token is calculated, and the highest one is picked. Query embeddings and text don't “see” each other.
* Image-grounded text generation: queries can attend to each other but not to the text tokens, and text has a causal mask and can attend to all of the queries.
* Image-text matching loss: queries and text can see others, and a logit is obtained to indicate whether the text matches the image or not. To obtain negative examples, hard negative mining is used.
In the second pre-training stage, the query embeddings now have the relevant visual information to the text as it has
passed through an information bottleneck. These embeddings are now used as a visual prefix to the input to the LLM. This
pre-training phase effectively involves an image-ground text generation task using the causal LM loss.
As a visual encoder, BLIP-2 uses ViT, and for an LLM, the paper authors used OPT and Flan T5 models. You can find
pre-trained checkpoints for both OPT and Flan T5 on [Hugging Face Hub](https://huggingface.co./models?other=blip-2).
However, as mentioned before, the introduced pre-training approach allows combining any visual backbone with any LLM.
## Using BLIP-2 with Hugging Face Transformers
Using Hugging Face Transformers, you can easily download and run a pre-trained BLIP-2 model on your images. Make sure to use a GPU environment with high RAM if you'd like to follow along with the examples in this blog post.
Let's start by installing Transformers. As this model has been added to Transformers very recently, we need to install Transformers from the source:
```bash
pip install git+https://github.com/huggingface/transformers.git
```
Next, we'll need an input image. Every week The New Yorker runs a [cartoon captioning contest](https://www.newyorker.com/cartoons/contest#thisweek)
among its readers, so let's take one of these cartoons to put BLIP-2 to the test.
```
import requests
from PIL import Image
url = 'https://media.newyorker.com/cartoons/63dc6847be24a6a76d90eb99/master/w_1160,c_limit/230213_a26611_838.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
display(image.resize((596, 437)))
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/blip-2/cartoon.jpeg" alt="New Yorker Cartoon" width=500>
</p>
We have an input image. Now we need a pre-trained BLIP-2 model and corresponding preprocessor to prepare the inputs. You
can find the list of all available pre-trained checkpoints on [Hugging Face Hub](https://huggingface.co./models?other=blip-2).
Here, we'll load a BLIP-2 checkpoint that leverages the pre-trained OPT model by Meta AI, which has 2.7 billion parameters.
```
from transformers import AutoProcessor, Blip2ForConditionalGeneration
import torch
processor = AutoProcessor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16)
```
Notice that BLIP-2 is a rare case where you cannot load the model with Auto API (e.g. AutoModelForXXX), and you need to
explicitly use `Blip2ForConditionalGeneration`. However, you can use `AutoProcessor` to fetch the appropriate processor
class - `Blip2Processor` in this case.
Let's use GPU to make text generation faster:
```
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
```
### Image Captioning
Let's find out if BLIP-2 can caption a New Yorker cartoon in a zero-shot manner. To caption an image, we do not have to
provide any text prompt to the model, only the preprocessed input image. Without any text prompt, the model will start
generating text from the BOS (beginning-of-sequence) token thus creating a caption.
```
inputs = processor(image, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
```
```
"two cartoon monsters sitting around a campfire"
```
This is an impressively accurate description for a model that wasn't trained on New Yorker style cartoons!
### Prompted image captioning
We can extend image captioning by providing a text prompt, which the model will continue given the image.
```
prompt = "this is a cartoon of"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
```
```
"two monsters sitting around a campfire"
```
```
prompt = "they look like they are"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=20)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
```
```
"having a good time"
```
### Visual question answering
For visual question answering the prompt has to follow a specific format:
"Question: {} Answer:"
```
prompt = "Question: What is a dinosaur holding? Answer:"
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
```
```
"A torch"
```
### Chat-based prompting
Finally, we can create a ChatGPT-like interface by concatenating each generated response to the conversation. We prompt
the model with some text (like "What is a dinosaur holding?"), the model generates an answer for it "a torch"), which we
can concatenate to the conversation. Then we do it again, building up the context.
However, make sure that the context does not exceed 512 tokens, as this is the context length of the language models used by BLIP-2 (OPT and T5).
```
context = [
("What is a dinosaur holding?", "a torch"),
("Where are they?", "In the woods.")
]
question = "What for?"
template = "Question: {} Answer: {}."
prompt = " ".join([template.format(context[i][0], context[i][1]) for i in range(len(context))]) + " Question: " + question + " Answer:"
print(prompt)
```
```
Question: What is a dinosaur holding? Answer: a torch. Question: Where are they? Answer: In the woods.. Question: What for? Answer:
```
```
inputs = processor(image, text=prompt, return_tensors="pt").to(device, torch.float16)
generated_ids = model.generate(**inputs, max_new_tokens=10)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
```
```
To light a fire.
```
## Conclusion
BLIP-2 is a zero-shot visual-language model that can be used for multiple image-to-text tasks with image and image and
text prompts. It is an effective and efficient approach that can be applied to image understanding in numerous scenarios,
especially when examples are scarce.
The model bridges the gap between vision and natural language modalities by adding a transformer between pre-trained models.
The new pre-training paradigm allows this model to keep up with the advances in both individual modalities.
If you'd like to learn how to fine-tune BLIP-2 models for various vision-language tasks, check out [LAVIS library by Salesforce](https://github.com/salesforce/LAVIS)
that offers comprehensive support for model training.
To see BLIP-2 in action, try its demo on [Hugging Face Spaces](https://huggingface.co./spaces/Salesforce/BLIP2).
## Acknowledgments
Many thanks to the Salesforce Research team for working on BLIP-2, Niels Rogge for adding BLIP-2 to 🤗 Transformers, and
to Omar Sanseviero for reviewing this blog post. | [
[
"computer_vision",
"transformers",
"tutorial",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"multi_modal",
"tutorial"
] | null | null |
ce87297e-70cc-4570-8035-8ca7adb1aef7 | completed | 2025-01-16T03:09:11.596624 | 2025-01-19T19:11:33.633246 | 5aef1272-8fd0-40ef-8743-bb324636f5c3 | Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA | ybelkada, timdettmers, artidoro, sgugger, smangrul | 4bit-transformers-bitsandbytes.md | LLMs are known to be large, and running or training them in consumer hardware is a huge challenge for users and accessibility.
Our [LLM.int8 blogpost](https://huggingface.co./blog/hf-bitsandbytes-integration) showed how the techniques in the [LLM.int8 paper](https://arxiv.org/abs/2208.07339) were integrated in transformers using the `bitsandbytes` library.
As we strive to make models even more accessible to anyone, we decided to collaborate with bitsandbytes again to allow users to run models in 4-bit precision. This includes a large majority of HF models, in any modality (text, vision, multi-modal, etc.). Users can also train adapters on top of 4bit models leveraging tools from the Hugging Face ecosystem. This is a new method introduced today in the QLoRA paper by Dettmers et al. The abstract of the paper is as follows:
> We present QLoRA, an efficient finetuning approach that reduces memory usage enough to finetune a 65B parameter model on a single 48GB GPU while preserving full 16-bit finetuning task performance. QLoRA backpropagates gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters~(LoRA). Our best model family, which we name Guanaco, outperforms all previous openly released models on the Vicuna benchmark, reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of finetuning on a single GPU. QLoRA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) double quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) paged optimizers to manage memory spikes. We use QLoRA to finetune more than 1,000 models, providing a detailed analysis of instruction following and chatbot performance across 8 instruction datasets, multiple model types (LLaMA, T5), and model scales that would be infeasible to run with regular finetuning (e.g. 33B and 65B parameter models). Our results show that QLoRA finetuning on a small high-quality dataset leads to state-of-the-art results, even when using smaller models than the previous SoTA. We provide a detailed analysis of chatbot performance based on both human and GPT-4 evaluations showing that GPT-4 evaluations are a cheap and reasonable alternative to human evaluation. Furthermore, we find that current chatbot benchmarks are not trustworthy to accurately evaluate the performance levels of chatbots. A lemon-picked analysis demonstrates where Guanaco fails compared to ChatGPT. We release all of our models and code, including CUDA kernels for 4-bit training.
## Resources
This blogpost and release come with several resources to get started with 4bit models and QLoRA:
- [Original paper](https://arxiv.org/abs/2305.14314)
- [Basic usage Google Colab notebook](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing) - This notebook shows how to use 4bit models in inference with all their variants, and how to run GPT-neo-X (a 20B parameter model) on a free Google Colab instance 🤯
- [Fine tuning Google Colab notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) - This notebook shows how to fine-tune a 4bit model on a downstream task using the Hugging Face ecosystem. We show that it is possible to fine tune GPT-neo-X 20B on a Google Colab instance!
- [Original repository for replicating the paper's results](https://github.com/artidoro/qlora)
- [Guanaco 33b playground](https://huggingface.co./spaces/uwnlp/guanaco-playground-tgi) - or check the playground section below
## Introduction
If you are not familiar with model precisions and the most common data types (float16, float32, bfloat16, int8), we advise you to carefully read the introduction in [our first blogpost](https://huggingface.co./blog/hf-bitsandbytes-integration) that goes over the details of these concepts in simple terms with visualizations.
For more information we recommend reading the fundamentals of floating point representation through [this wikibook document](https://en.wikibooks.org/wiki/A-level_Computing/AQA/Paper_2/Fundamentals_of_data_representation/Floating_point_numbers#:~:text=In%20decimal%2C%20very%20large%20numbers,be%20used%20for%20binary%20numbers.).
The recent QLoRA paper explores different data types, 4-bit Float and 4-bit NormalFloat. We will discuss here the 4-bit Float data type since it is easier to understand.
FP8 and FP4 stand for Floating Point 8-bit and 4-bit precision, respectively. They are part of the minifloats family of floating point values (among other precisions, the minifloats family also includes bfloat16 and float16).
Let’s first have a look at how to represent floating point values in FP8 format, then understand how the FP4 format looks like.
### FP8 format
As discussed in our previous blogpost, a floating point contains n-bits, with each bit falling into a specific category that is responsible for representing a component of the number (sign, mantissa and exponent). These represent the following.
The FP8 (floating point 8) format has been first introduced in the paper [“FP8 for Deep Learning”](https://arxiv.org/pdf/2209.05433.pdf) with two different FP8 encodings: E4M3 (4-bit exponent and 3-bit mantissa) and E5M2 (5-bit exponent and 2-bit mantissa).
|  |
|:--:|
| <b>Overview of Floating Point 8 (FP8) format. Source: Original content from [`sgugger`](https://huggingface.co./sgugger) </b>|
Although the precision is substantially reduced by reducing the number of bits from 32 to 8, both versions can be used in a variety of situations. Currently one could use [Transformer Engine library](https://github.com/NVIDIA/TransformerEngine) that is also integrated with HF ecosystem through accelerate.
The potential floating points that can be represented in the E4M3 format are in the range -448 to 448, whereas in the E5M2 format, as the number of bits of the exponent increases, the range increases to -57344 to 57344 - but with a loss of precision because the number of possible representations remains constant.
It has been empirically proven that the E4M3 is best suited for the forward pass, and the second version is best suited for the backward computation
### FP4 precision in a few words
The sign bit represents the sign (+/-), the exponent bits a base two to the power of the integer represented by the bits (e.g. `2^{010} = 2^{2} = 4`), and the fraction or mantissa is the sum of powers of negative two which are “active” for each bit that is “1”. If a bit is “0” the fraction remains unchanged for that power of `2^-i` where i is the position of the bit in the bit-sequence. For example, for mantissa bits 1010 we have `(0 + 2^-1 + 0 + 2^-3) = (0.5 + 0.125) = 0.625`. To get a value, we add *1* to the fraction and multiply all results together, for example, with 2 exponent bits and one mantissa bit the representations 1101 would be:
`-1 * 2^(2) * (1 + 2^-1) = -1 * 4 * 1.5 = -6`
For FP4 there is no fixed format and as such one can try combinations of different mantissa/exponent combinations. In general, 3 exponent bits do a bit better in most cases. But sometimes 2 exponent bits and a mantissa bit yield better performance.
## QLoRA paper, a new way of democratizing quantized large transformer models
In few words, QLoRA reduces the memory usage of LLM finetuning without performance tradeoffs compared to standard 16-bit model finetuning. This method enables 33B model finetuning on a single 24GB GPU and 65B model finetuning on a single 46GB GPU.
More specifically, QLoRA uses 4-bit quantization to compress a pretrained language model. The LM parameters are then frozen and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters. During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the [original LoRA paper](https://arxiv.org/abs/2106.09685).
QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference.
QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the [OpenAssistant dataset (OASST1)](https://huggingface.co./datasets/OpenAssistant/oasst1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning.
For a more detailed reading, we recommend you read the [QLoRA paper](https://arxiv.org/abs/2305.14314).
## How to use it in transformers?
In this section let us introduce the transformers integration of this method, how to use it and which models can be effectively quantized.
### Getting started
As a quickstart, load a model in 4bit by (at the time of this writing) installing accelerate and transformers from source, and make sure you have installed the latest version of bitsandbytes library (0.39.0).
```bash
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
```
### Quickstart
The basic way to load a model in 4bit is to pass the argument `load_in_4bit=True` when calling the `from_pretrained` method by providing a device map (pass `"auto"` to get a device map that will be automatically inferred).
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_4bit=True, device_map="auto")
...
```
That's all you need!
As a general rule, we recommend users to not manually set a device once the model has been loaded with `device_map`. So any device assignment call to the model, or to any model’s submodules should be avoided after that line - unless you know what you are doing.
Keep in mind that loading a quantized model will automatically cast other model's submodules into `float16` dtype. You can change this behavior, (if for example you want to have the layer norms in `float32`), by passing `torch_dtype=dtype` to the `from_pretrained` method.
### Advanced usage
You can play with different variants of 4bit quantization such as NF4 (normalized float 4 (default)) or pure FP4 quantization. Based on theoretical considerations and empirical results from the paper, we recommend using NF4 quantization for better performance.
Other options include `bnb_4bit_use_double_quant` which uses a second quantization after the first one to save an additional 0.4 bits per parameter. And finally, the compute type. While 4-bit bitsandbytes stores weights in 4-bits, the computation still happens in 16 or 32-bit and here any combination can be chosen (float16, bfloat16, float32 etc).
The matrix multiplication and training will be faster if one uses a 16-bit compute dtype (default torch.float32). One should leverage the recent `BitsAndBytesConfig` from transformers to change these parameters. An example to load a model in 4bit using NF4 quantization below with double quantization with the compute dtype bfloat16 for faster training:
```python
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
```
#### Changing the compute dtype
As mentioned above, you can also change the compute dtype of the quantized model by just changing the `bnb_4bit_compute_dtype` argument in `BitsAndBytesConfig`.
```python
import torch
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
```
#### Nested quantization
For enabling nested quantization, you can use the `bnb_4bit_use_double_quant` argument in `BitsAndBytesConfig`. This will enable a second quantization after the first one to save an additional 0.4 bits per parameter. We also use this feature in the training Google colab notebook.
```python
from transformers import BitsAndBytesConfig
double_quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
)
model_double_quant = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=double_quant_config)
```
And of course, as mentioned in the beginning of the section, all of these components are composable. You can combine all these parameters together to find the optimial use case for you. A rule of thumb is: use double quant if you have problems with memory, use NF4 for higher precision, and use a 16-bit dtype for faster finetuning. For instance in the [inference demo](https://colab.research.google.com/drive/1ge2F1QSK8Q7h0hn3YKuBCOAS0bK8E0wf?usp=sharing), we use nested quantization, bfloat16 compute dtype and NF4 quantization to fit gpt-neo-x-20b (40GB) entirely in 4bit in a single 16GB GPU.
### Common questions
In this section, we will also address some common questions anyone could have regarding this integration.
#### Does FP4 quantization have any hardware requirements?
Note that this method is only compatible with GPUs, hence it is not possible to quantize models in 4bit on a CPU. Among GPUs, there should not be any hardware requirement about this method, therefore any GPU could be used to run the 4bit quantization as long as you have CUDA>=11.2 installed.
Keep also in mind that the computation is not done in 4bit, the weights and activations are compressed to that format and the computation is still kept in the desired or native dtype.
#### What are the supported models?
Similarly as the integration of LLM.int8 presented in [this blogpost](https://huggingface.co./blog/hf-bitsandbytes-integration) the integration heavily relies on the `accelerate` library. Therefore, any model that supports accelerate loading (i.e. the `device_map` argument when calling `from_pretrained`) should be quantizable in 4bit. Note also that this is totally agnostic to modalities, as long as the models can be loaded with the `device_map` argument, it is possible to quantize them.
For text models, at this time of writing, this would include most used architectures such as Llama, OPT, GPT-Neo, GPT-NeoX for text models, Blip2 for multimodal models, and so on.
At this time of writing, the models that support accelerate are:
```python
[
'bigbird_pegasus', 'blip_2', 'bloom', 'bridgetower', 'codegen', 'deit', 'esm',
'gpt2', 'gpt_bigcode', 'gpt_neo', 'gpt_neox', 'gpt_neox_japanese', 'gptj', 'gptsan_japanese',
'lilt', 'llama', 'longformer', 'longt5', 'luke', 'm2m_100', 'mbart', 'mega', 'mt5', 'nllb_moe',
'open_llama', 'opt', 'owlvit', 'plbart', 'roberta', 'roberta_prelayernorm', 'rwkv', 'switch_transformers',
't5', 'vilt', 'vit', 'vit_hybrid', 'whisper', 'xglm', 'xlm_roberta'
]
```
Note that if your favorite model is not there, you can open a Pull Request or raise an issue in transformers to add the support of accelerate loading for that architecture.
#### Can we train 4bit/8bit models?
It is not possible to perform pure 4bit training on these models. However, you can train these models by leveraging parameter efficient fine tuning methods (PEFT) and train for example adapters on top of them. That is what is done in the paper and is officially supported by the PEFT library from Hugging Face. We also provide a [training notebook](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) and recommend users to check the [QLoRA repository](https://github.com/artidoro/qlora) if they are interested in replicating the results from the paper.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
#### What other consequences are there?
This integration can open up several positive consequences to the community and AI research as it can affect multiple use cases and possible applications.
In RLHF (Reinforcement Learning with Human Feedback) it is possible to load a single base model, in 4bit and train multiple adapters on top of it, one for the reward modeling, and another for the value policy training. A more detailed blogpost and announcement will be made soon about this use case.
We have also made some benchmarks on the impact of this quantization method on training large models on consumer hardware. We have run several experiments on finetuning 2 different architectures, Llama 7B (15GB in fp16) and Llama 13B (27GB in fp16) on an NVIDIA T4 (16GB) and here are the results
| Model name | Half precision model size (in GB) | Hardware type / total VRAM | quantization method (CD=compute dtype / GC=gradient checkpointing / NQ=nested quantization) | batch_size | gradient accumulation steps | optimizer | seq_len | Result |
| | [
[
"llm",
"quantization",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"quantization",
"fine_tuning",
"efficient_computing"
] | null | null |
f4c8d960-300f-431a-af1e-18d1f4104126 | completed | 2025-01-16T03:09:11.596629 | 2025-01-19T17:20:13.912207 | 086a73d6-f929-4ee5-8774-7c395c71e573 | Introducing Decision Transformers on Hugging Face 🤗 | edbeeching, ThomasSimonini | decision-transformers.md | At Hugging Face, we are contributing to the ecosystem for Deep Reinforcement Learning researchers and enthusiasts. Recently, we have integrated Deep RL frameworks such as [Stable-Baselines3](https://github.com/DLR-RM/stable-baselines3).
And today we are happy to announce that we integrated the [Decision Transformer](https://arxiv.org/abs/2106.01345), an Offline Reinforcement Learning method, into the 🤗 transformers library and the Hugging Face Hub. We have some exciting plans for improving accessibility in the field of Deep RL and we are looking forward to sharing them with you over the coming weeks and months.
- [What is Offline Reinforcement Learning?](#what-is-offline-reinforcement-learning?)
- [Introducing Decision Transformers](#introducing-decision-transformers)
- [Using the Decision Transformer in 🤗 Transformers](#using-the-decision-transformer-in--transformers)
- [Conclusion](#conclusion)
- [What's next?](#whats-next)
- [References](#references)
## What is Offline Reinforcement Learning?
Deep Reinforcement Learning (RL) is a framework to build decision-making agents. These agents aim to learn optimal behavior (policy) by interacting with the environment through trial and error and receiving rewards as unique feedback.
The agent’s goal is to maximize **its cumulative reward, called return.** Because RL is based on the reward hypothesis: **all goals can be described as the maximization of the expected cumulative reward.**
Deep Reinforcement Learning agents **learn with batches of experience.** The question is, how do they collect it?:

*A comparison between Reinforcement Learning in an Online and Offline setting, figure taken from [this post](https://offline-rl.github.io/)*
In online reinforcement learning, **the agent gathers data directly**: it collects a batch of experience by interacting with the environment. Then, it uses this experience immediately (or via some replay buffer) to learn from it (update its policy).
But this implies that either you train your agent directly in the real world or have a simulator. If you don’t have one, you need to build it, which can be very complex (how to reflect the complex reality of the real world in an environment?), expensive, and insecure since if the simulator has flaws, the agent will exploit them if they provide a competitive advantage.
On the other hand, in offline reinforcement learning, the agent only uses data collected from other agents or human demonstrations. **It does not interact with the environment**.
The process is as follows:
1. Create a dataset using one or more policies and/or human interactions.
2. Run offline RL on this dataset to learn a policy
This method has one drawback: the counterfactual queries problem. What do we do if our agent decides to do something for which we don’t have the data? For instance, turning right on an intersection but we don’t have this trajectory.
There’s already exists some solutions on this topic, but if you want to know more about offline reinforcement learning you can watch [this video](https://www.youtube.com/watch?v=k08N5a0gG0A)
## Introducing Decision Transformers
The Decision Transformer model was introduced by [“Decision Transformer: Reinforcement Learning via Sequence Modeling” by Chen L. et al](https://arxiv.org/abs/2106.01345). It abstracts Reinforcement Learning as a **conditional-sequence modeling problem**.
The main idea is that instead of training a policy using RL methods, such as fitting a value function, that will tell us what action to take to maximize the return (cumulative reward), we use a sequence modeling algorithm (Transformer) that, given a desired return, past states, and actions, will generate future actions to achieve this desired return. It’s an autoregressive model conditioned on the desired return, past states, and actions to generate future actions that achieve the desired return.
This is a complete shift in the Reinforcement Learning paradigm since we use generative trajectory modeling (modeling the joint distribution of the sequence of states, actions, and rewards) to replace conventional RL algorithms. It means that in Decision Transformers, we don’t maximize the return but rather generate a series of future actions that achieve the desired return.
The process goes this way:
1. We feed the last K timesteps into the Decision Transformer with 3 inputs:
- Return-to-go
- State
- Action
2. The tokens are embedded either with a linear layer if the state is a vector or CNN encoder if it’s frames.
3. The inputs are processed by a GPT-2 model which predicts future actions via autoregressive modeling.

*Decision Transformer architecture. States, actions, and returns are fed into modality specific linear embeddings and a positional episodic timestep encoding is added. Tokens are fed into a GPT architecture which predicts actions autoregressively using a causal self-attention mask. Figure from [1].*
## Using the Decision Transformer in 🤗 Transformers
The Decision Transformer model is now available as part of the 🤗 transformers library. In addition, we share [nine pre-trained model checkpoints for continuous control tasks in the Gym environment](https://huggingface.co./models?other=gym-continous-control).
<figure class="image table text-center m-0 w-full">
<video
alt="WalkerEd-expert"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/58_decision-transformers/walker2d-expert.mp4" type="video/mp4">
</video>
</figure>
*An “expert” Decision Transformers model, learned using offline RL in the Gym Walker2d environment.*
### Install the package
`````python
pip install git+https://github.com/huggingface/transformers
`````
### Loading the model
Using the Decision Transformer is relatively easy, but as it is an autoregressive model, some care has to be taken in order to prepare the model’s inputs at each time-step. We have prepared both a [Python script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/decision_transformer/run_decision_transformer.py) and a [Colab notebook](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing) that demonstrates how to use this model.
Loading a pretrained Decision Transformer is simple in the 🤗 transformers library:
`````python
from transformers import DecisionTransformerModel
model_name = "edbeeching/decision-transformer-gym-hopper-expert"
model = DecisionTransformerModel.from_pretrained(model_name)
``````
### Creating the environment
We provide pretrained checkpoints for the Gym Hopper, Walker2D and Halfcheetah. Checkpoints for Atari environments will soon be available.
`````python
import gym
env = gym.make("Hopper-v3")
state_dim = env.observation_space.shape[0] # state size
act_dim = env.action_space.shape[0] # action size
``````
### Autoregressive prediction function
The model performs an [autoregressive prediction](https://en.wikipedia.org/wiki/Autoregressive_model); that is to say that predictions made at the current time-step **t** are sequentially conditioned on the outputs from previous time-steps. This function is quite meaty, so we will aim to explain it in the comments.
`````python
# Function that gets an action from the model using autoregressive prediction
# with a window of the previous 20 timesteps.
def get_action(model, states, actions, rewards, returns_to_go, timesteps):
# This implementation does not condition on past rewards
states = states.reshape(1, -1, model.config.state_dim)
actions = actions.reshape(1, -1, model.config.act_dim)
returns_to_go = returns_to_go.reshape(1, -1, 1)
timesteps = timesteps.reshape(1, -1)
# The prediction is conditioned on up to 20 previous time-steps
states = states[:, -model.config.max_length :]
actions = actions[:, -model.config.max_length :]
returns_to_go = returns_to_go[:, -model.config.max_length :]
timesteps = timesteps[:, -model.config.max_length :]
# pad all tokens to sequence length, this is required if we process batches
padding = model.config.max_length - states.shape[1]
attention_mask = torch.cat([torch.zeros(padding), torch.ones(states.shape[1])])
attention_mask = attention_mask.to(dtype=torch.long).reshape(1, -1)
states = torch.cat([torch.zeros((1, padding, state_dim)), states], dim=1).float()
actions = torch.cat([torch.zeros((1, padding, act_dim)), actions], dim=1).float()
returns_to_go = torch.cat([torch.zeros((1, padding, 1)), returns_to_go], dim=1).float()
timesteps = torch.cat([torch.zeros((1, padding), dtype=torch.long), timesteps], dim=1)
# perform the prediction
state_preds, action_preds, return_preds = model(
states=states,
actions=actions,
rewards=rewards,
returns_to_go=returns_to_go,
timesteps=timesteps,
attention_mask=attention_mask,
return_dict=False,)
return action_preds[0, -1]
``````
### Evaluating the model
In order to evaluate the model, we need some additional information; the mean and standard deviation of the states that were used during training. Fortunately, these are available for each of the checkpoint’s [model card](https://huggingface.co./edbeeching/decision-transformer-gym-hopper-expert) on the Hugging Face Hub!
We also need a target return for the model. This is the power of return conditioned Offline Reinforcement Learning: we can use the target return to control the performance of the policy. This could be really powerful in a multiplayer setting, where we would like to adjust the performance of an opponent bot to be at a suitable difficulty for the player. The authors show a great plot of this in their paper!

*Sampled (evaluation) returns accumulated by Decision Transformer when conditioned on
the specified target (desired) returns. Top: Atari. Bottom: D4RL medium-replay datasets. Figure from [1].*
``````python
TARGET_RETURN = 3.6 # This was normalized during training
MAX_EPISODE_LENGTH = 1000
state_mean = np.array(
[1.3490015, -0.11208222, -0.5506444, -0.13188992, -0.00378754, 2.6071432,
0.02322114, -0.01626922, -0.06840388, -0.05183131, 0.04272673,])
state_std = np.array(
[0.15980862, 0.0446214, 0.14307782, 0.17629202, 0.5912333, 0.5899924,
1.5405099, 0.8152689, 2.0173461, 2.4107876, 5.8440027,])
state_mean = torch.from_numpy(state_mean)
state_std = torch.from_numpy(state_std)
state = env.reset()
target_return = torch.tensor(TARGET_RETURN).float().reshape(1, 1)
states = torch.from_numpy(state).reshape(1, state_dim).float()
actions = torch.zeros((0, act_dim)).float()
rewards = torch.zeros(0).float()
timesteps = torch.tensor(0).reshape(1, 1).long()
# take steps in the environment
for t in range(max_ep_len):
# add zeros for actions as input for the current time-step
actions = torch.cat([actions, torch.zeros((1, act_dim))], dim=0)
rewards = torch.cat([rewards, torch.zeros(1)])
# predicting the action to take
action = get_action(model,
(states - state_mean) / state_std,
actions,
rewards,
target_return,
timesteps)
actions[-1] = action
action = action.detach().numpy()
# interact with the environment based on this action
state, reward, done, _ = env.step(action)
cur_state = torch.from_numpy(state).reshape(1, state_dim)
states = torch.cat([states, cur_state], dim=0)
rewards[-1] = reward
pred_return = target_return[0, -1] - (reward / scale)
target_return = torch.cat([target_return, pred_return.reshape(1, 1)], dim=1)
timesteps = torch.cat([timesteps, torch.ones((1, 1)).long() * (t + 1)], dim=1)
if done:
break
``````
You will find a more detailed example, with the creation of videos of the agent in our [Colab notebook](https://colab.research.google.com/drive/1K3UuajwoPY1MzRKNkONNRS3gS5DxZ-qF?usp=sharing).
## Conclusion
In addition to Decision Transformers, we want to support more use cases and tools from the Deep Reinforcement Learning community. Therefore, it would be great to hear your feedback on the Decision Transformer model, and more generally anything we can build with you that would be useful for RL. Feel free to **[reach out to us](mailto:[email protected])**.
## What’s next?
In the coming weeks and months, we plan on supporting other tools from the ecosystem:
- Integrating **[RL-baselines3-zoo](https://github.com/DLR-RM/rl-baselines3-zoo)**
- Uploading **[RL-trained-agents models](https://github.com/DLR-RM/rl-trained-agents)** into the Hub: a big collection of pre-trained Reinforcement Learning agents using stable-baselines3
- Integrating other Deep Reinforcement Learning libraries
- Implementing Convolutional Decision Transformers For Atari
- And more to come 🥳
The best way to keep in touch is to **[join our discord server](https://discord.gg/YRAq8fMnUG)** to exchange with us and with the community.
## References
[1] Chen, Lili, et al. "Decision transformer: Reinforcement learning via sequence modeling." *Advances in neural information processing systems* 34 (2021).
[2] Agarwal, Rishabh, Dale Schuurmans, and Mohammad Norouzi. "An optimistic perspective on offline reinforcement learning." *International Conference on Machine Learning*. PMLR, 2020.
### Acknowledgements
We would like to thank the paper’s first authors, Kevin Lu and Lili Chen, for their constructive conversations. | [
[
"transformers",
"research",
"implementation",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"implementation",
"integration"
] | null | null |
ba7394b3-4140-4f4c-8eab-d7ae678e57f6 | completed | 2025-01-16T03:09:11.596633 | 2025-01-16T15:08:42.586377 | 5ca861bf-8a4c-42fb-ac30-36745d9c0223 | Mixture of Experts Explained | osanseviero, lewtun, philschmid, smangrul, ybelkada, pcuenq | moe.md | With the release of Mixtral 8x7B ([announcement](https://mistral.ai/news/mixtral-of-experts/), [model card](https://huggingface.co./mistralai/Mixtral-8x7B-v0.1)), a class of transformer has become the hottest topic in the open AI community: Mixture of Experts, or MoEs for short. In this blog post, we take a look at the building blocks of MoEs, how they’re trained, and the tradeoffs to consider when serving them for inference.
Let’s dive in!
## Table of Contents
- [What is a Mixture of Experts?](#what-is-a-mixture-of-experts-moe)
- [A Brief History of MoEs](#a-brief-history-of-moes)
- [What is Sparsity?](#what-is-sparsity)
- [Load Balancing tokens for MoEs](#load-balancing-tokens-for-moes)
- [MoEs and Transformers](#moes-and-transformers)
- [Switch Transformers](#switch-transformers)
- [Stabilizing training with router Z-loss](#stabilizing-training-with-router-z-loss)
- [What does an expert learn?](#what-does-an-expert-learn)
- [How does scaling the number of experts impact pretraining?](#how-does-scaling-the-number-of-experts-impact-pretraining)
- [Fine-tuning MoEs](#fine-tuning-moes)
- [When to use sparse MoEs vs dense models?](#when-to-use-sparse-moes-vs-dense-models)
- [Making MoEs go brrr](#making-moes-go-brrr)
- [Expert Parallelism](#parallelism)
- [Capacity Factor and Communication costs](#capacity-factor-and-communication-costs)
- [Serving Techniques](#serving-techniques)
- [Efficient Training](#more-on-efficient-training)
- [Open Source MoEs](#open-source-moes)
- [Exciting directions of work](#exciting-directions-of-work)
- [Some resources](#some-resources)
## TL;DR
MoEs:
- Are **pretrained much faster** vs. dense models
- Have **faster inference** compared to a model with the same number of parameters
- Require **high VRAM** as all experts are loaded in memory
- Face many **challenges in fine-tuning**, but [recent work](https://arxiv.org/pdf/2305.14705.pdf) with MoE **instruction-tuning is promising**
Let’s dive in!
## What is a Mixture of Experts (MoE)?
The scale of a model is one of the most important axes for better model quality. Given a fixed computing budget, training a larger model for fewer steps is better than training a smaller model for more steps.
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
So, what exactly is a MoE? In the context of transformer models, a MoE consists of two main elements:
- **Sparse MoE layers** are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 8), where each expert is a neural network. In practice, the experts are FFNs, but they can also be more complex networks or even a MoE itself, leading to hierarchical MoEs!
- A **gate network or router**, that determines which tokens are sent to which expert. For example, in the image below, the token “More” is sent to the second expert, and the token "Parameters” is sent to the first network. As we’ll explore later, we can send a token to more than one expert. How to route a token to an expert is one of the big decisions when working with MoEs - the router is composed of learned parameters and is pretrained at the same time as the rest of the network.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/00_switch_transformer.png" alt="Switch Layer">
<figcaption>MoE layer from the [Switch Transformers paper](https://arxiv.org/abs/2101.03961)</figcaption>
</figure>
So, to recap, in MoEs we replace every FFN layer of the transformer model with an MoE layer, which is composed of a gate network and a certain number of experts.
Although MoEs provide benefits like efficient pretraining and faster inference compared to dense models, they also come with challenges:
- **Training:** MoEs enable significantly more compute-efficient pretraining, but they’ve historically struggled to generalize during fine-tuning, leading to overfitting.
- **Inference:** Although a MoE might have many parameters, only some of them are used during inference. This leads to much faster inference compared to a dense model with the same number of parameters. However, all parameters need to be loaded in RAM, so memory requirements are high. For example, given a MoE like Mixtral 8x7B, we’ll need to have enough VRAM to hold a dense 47B parameter model. Why 47B parameters and not 8 x 7B = 56B? That’s because in MoE models, only the FFN layers are treated as individual experts, and the rest of the model parameters are shared. At the same time, assuming just two experts are being used per token, the inference speed (FLOPs) is like using a 12B model (as opposed to a 14B model), because it computes 2x7B matrix multiplications, but with some layers shared (more on this soon).
Now that we have a rough idea of what a MoE is, let’s take a look at the research developments that led to their invention.
## A Brief History of MoEs
The roots of MoEs come from the 1991 paper [Adaptive Mixture of Local Experts](https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf). The idea, akin to ensemble methods, was to have a supervised procedure for a system composed of separate networks, each handling a different subset of the training cases. Each separate network, or expert, specializes in a different region of the input space. How is the expert chosen? A gating network determines the weights for each expert. During training, both the expert and the gating are trained.
Between 2010-2015, two different research areas contributed to later MoE advancement:
- **Experts as components**: In the traditional MoE setup, the whole system comprises a gating network and multiple experts. MoEs as the whole model have been explored in SVMs, Gaussian Processes, and other methods. The work by [Eigen, Ranzato, and Ilya](https://arxiv.org/abs/1312.4314) explored MoEs as components of deeper networks. This allows having MoEs as layers in a multilayer network, making it possible for the model to be both large and efficient simultaneously.
- **Conditional Computation**: Traditional networks process all input data through every layer. In this period, Yoshua Bengio researched approaches to dynamically activate or deactivate components based on the input token.
These works led to exploring a mixture of experts in the context of NLP. Concretely, [Shazeer et al.](https://arxiv.org/abs/1701.06538) (2017, with “et al.” including Geoffrey Hinton and Jeff Dean, [Google’s Chuck Norris](https://www.informatika.bg/jeffdean)) scaled this idea to a 137B LSTM (the de-facto NLP architecture back then, created by Schmidhuber) by introducing sparsity, allowing to keep very fast inference even at high scale. This work focused on translation but faced many challenges, such as high communication costs and training instabilities.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/01_moe_layer.png" alt="MoE layer in LSTM">
<figcaption>MoE layer from the Outrageously Large Neural Network paper</figcaption>
</figure>
MoEs have allowed training multi-trillion parameter models, such as the open-sourced 1.6T parameters Switch Transformers, among others. MoEs have also been explored in Computer Vision, but this blog post will focus on the NLP domain.
## What is Sparsity?
Sparsity uses the idea of conditional computation. While in dense models all the parameters are used for all the inputs, sparsity allows us to only run some parts of the whole system.
Let’s dive deeper into Shazeer's exploration of MoEs for translation. The idea of conditional computation (parts of the network are active on a per-example basis) allows one to scale the size of the model without increasing the computation, and hence, this led to thousands of experts being used in each MoE layer.
This setup introduces some challenges. For example, although large batch sizes are usually better for performance, batch sizes in MOEs are effectively reduced as data flows through the active experts. For example, if our batched input consists of 10 tokens, **five tokens might end in one expert, and the other five tokens might end in five different experts, leading to uneven batch sizes and underutilization**. The [Making MoEs go brrr](#making-moes-go-brrr) section below will discuss other challenges and solutions.
How can we solve this? A learned gating network (G) decides which experts (E) to send a part of the input:
$$
y = \sum_{i=1}^{n} G(x)_i E_i(x)
$$
In this setup, all experts are run for all inputs - it’s a weighted multiplication. But, what happens if G is 0? If that’s the case, there’s no need to compute the respective expert operations and hence we save compute. What’s a typical gating function? In the most traditional setup, we just use a simple network with a softmax function. The network will learn which expert to send the input.
$$
G_\sigma(x) = \text{Softmax}(x \cdot W_g)
$$
Shazeer’s work also explored other gating mechanisms, such as Noisy Top-k Gating. This gating approach introduces some (tunable) noise and then keeps the top k values. That is:
1. We add some noise
$$
H(x)_i = (x \cdot W_{\text{g}})_i + \text{StandardNormal()} \cdot \text{Softplus}((x \cdot W_{\text{noise}})_i)
$$
2. We only pick the top k
$$
\text{KeepTopK}(v, k)_i = \begin{cases}
v_i & \text{if } v_i \text{ is in the top } k \text{ elements of } v, \\
-\infty & \text{otherwise.}
\end{cases}
$$
3. We apply the softmax.
$$
G(x) = \text{Softmax}(\text{KeepTopK}(H(x), k))
$$
This sparsity introduces some interesting properties. By using a low enough k (e.g. one or two), we can train and run inference much faster than if many experts were activated. Why not just select the top expert? The initial conjecture was that routing to more than one expert was needed to have the gate learn how to route to different experts, so at least two experts had to be picked. The [Switch Transformers](#switch-transformers) section revisits this decision.
Why do we add noise? That’s for load balancing!
## Load balancing tokens for MoEs
As discussed before, if all our tokens are sent to just a few popular experts, that will make training inefficient. In a normal MoE training, the gating network converges to mostly activate the same few experts. This self-reinforces as favored experts are trained quicker and hence selected more. To mitigate this, an **auxiliary loss** is added to encourage giving all experts equal importance. This loss ensures that all experts receive a roughly equal number of training examples. The following sections will also explore the concept of expert capacity, which introduces a threshold of how many tokens can be processed by an expert. In `transformers`, the auxiliary loss is exposed via the `aux_loss` parameter.
## MoEs and Transformers
Transformers are a very clear case that scaling up the number of parameters improves the performance, so it’s not surprising that Google explored this with [GShard](https://arxiv.org/abs/2006.16668), which explores scaling up transformers beyond 600 billion parameters.
GShard replaces every other FFN layer with an MoE layer using top-2 gating in both the encoder and the decoder. The next image shows how this looks like for the encoder part. This setup is quite beneficial for large-scale computing: when we scale to multiple devices, the MoE layer is shared across devices while all the other layers are replicated. This is further discussed in the [“Making MoEs go brrr”](#making-moes-go-brrr) section.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/02_moe_block.png" alt="MoE Transformer Encoder">
<figcaption>MoE Transformer Encoder from the GShard Paper</figcaption>
</figure>
To maintain a balanced load and efficiency at scale, the GShard authors introduced a couple of changes in addition to an auxiliary loss similar to the one discussed in the previous section:
- **Random routing**: in a top-2 setup, we always pick the top expert, but the second expert is picked with probability proportional to its weight.
- **Expert capacity**: we can set a threshold of how many tokens can be processed by one expert. If both experts are at capacity, the token is considered overflowed, and it’s sent to the next layer via residual connections (or dropped entirely in other projects). This concept will become one of the most important concepts for MoEs. Why is expert capacity needed? Since all tensor shapes are statically determined at compilation time, but we cannot know how many tokens will go to each expert ahead of time, we need to fix the capacity factor.
The GShard paper has contributions by expressing parallel computation patterns that work well for MoEs, but discussing that is outside the scope of this blog post.
**Note:** when we run inference, only some experts will be triggered. At the same time, there are shared computations, such as self-attention, which is applied for all tokens. That’s why when we talk of a 47B model of 8 experts, we can run with the compute of a 12B dense model. If we use top-2, 14B parameters would be used. But given that the attention operations are shared (among others), the actual number of used parameters is 12B.
## Switch Transformers
Although MoEs showed a lot of promise, they struggle with training and fine-tuning instabilities. [Switch Transformers](https://arxiv.org/abs/2101.03961) is a very exciting work that deep dives into these topics. The authors even released a [1.6 trillion parameters MoE on Hugging Face](https://huggingface.co./google/switch-c-2048) with 2048 experts, which you can run with transformers. Switch Transformers achieved a 4x pre-train speed-up over T5-XXL.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/03_switch_layer.png" alt="Switch Transformer Layer">
<figcaption>Switch Transformer Layer of the Switch Transformer paper</figcaption>
</figure>
Just as in GShard, the authors replaced the FFN layers with a MoE layer. The Switch Transformers paper proposes a Switch Transformer layer that receives two inputs (two different tokens) and has four experts.
Contrary to the initial idea of using at least two experts, Switch Transformers uses a simplified single-expert strategy. The effects of this approach are:
- The router computation is reduced
- The batch size of each expert can be at least halved
- Communication costs are reduced
- Quality is preserved
Switch Transformers also explores the concept of expert capacity.
$$
\text{Expert Capacity} = \left(\frac{\text{tokens per batch}}{\text{number of experts}}\right) \times \text{capacity factor}
$$
The capacity suggested above evenly divides the number of tokens in the batch across the number of experts. If we use a capacity factor greater than 1, we provide a buffer for when tokens are not perfectly balanced. Increasing the capacity will lead to more expensive inter-device communication, so it’s a trade-off to keep in mind. In particular, Switch Transformers perform well at low capacity factors (1-1.25)
Switch Transformer authors also revisit and simplify the load balancing loss mentioned in the sections. For each Switch layer, the auxiliary loss is added to the total model loss during training. This loss encourages uniform routing and can be weighted using a hyperparameter.
The authors also experiment with selective precision, such as training the experts with `bfloat16` while using full precision for the rest of the computations. Lower precision reduces communication costs between processors, computation costs, and memory for storing tensors. The initial experiments, in which both the experts and the gate networks were trained in `bfloat16`, yielded more unstable training. This was, in particular, due to the router computation: as the router has an exponentiation function, having higher precision is important. To mitigate the instabilities, full precision was used for the routing as well.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/04_switch_table.png" alt="Table shows that selective precision does not degrade quality.">
<figcaption>Using selective precision does not degrade quality and enables faster models</figcaption>
</figure>
This [notebook](https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing) showcases fine-tuning Switch Transformers for summarization, but we suggest first reviewing the [fine-tuning section](#fine-tuning-moes).
Switch Transformers uses an encoder-decoder setup in which they did a MoE counterpart of T5. The [GLaM](https://arxiv.org/abs/2112.06905) paper explores pushing up the scale of these models by training a model matching GPT-3 quality using 1/3 of the energy (yes, thanks to the lower amount of computing needed to train a MoE, they can reduce the carbon footprint by up to an order of magnitude). The authors focused on decoder-only models and few-shot and one-shot evaluation rather than fine-tuning. They used Top-2 routing and much larger capacity factors. In addition, they explored the capacity factor as a metric one can change during training and evaluation depending on how much computing one wants to use.
## Stabilizing training with router Z-loss
The balancing loss previously discussed can lead to instability issues. We can use many methods to stabilize sparse models at the expense of quality. For example, introducing dropout improves stability but leads to loss of model quality. On the other hand, adding more multiplicative components improves quality but decreases stability.
Router z-loss, introduced in [ST-MoE](https://arxiv.org/abs/2202.08906), significantly improves training stability without quality degradation by penalizing large logits entering the gating network. Since this loss encourages absolute magnitude of values to be smaller, roundoff errors are reduced, which can be quite impactful for exponential functions such as the gating. We recommend reviewing the paper for details.
## What does an expert learn?
The ST-MoE authors observed that encoder experts specialize in a group of tokens or shallow concepts. For example, we might end with a punctuation expert, a proper noun expert, etc. On the other hand, the decoder experts have less specialization. The authors also trained in a multilingual setup. Although one could imagine each expert specializing in a language, the opposite happens: due to token routing and load balancing, there is no single expert specialized in any given language.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/05_experts_learning.png" alt="Experts specialize in some token groups">
<figcaption>Table from the ST-MoE paper showing which token groups were sent to which expert.</figcaption>
</figure>
## How does scaling the number of experts impact pretraining?
More experts lead to improved sample efficiency and faster speedup, but these are diminishing gains (especially after 256 or 512), and more VRAM will be needed for inference. The properties studied in Switch Transformers at large scale were consistent at small scale, even with 2, 4, or 8 experts per layer.
## Fine-tuning MoEs
> Mixtral is supported with version 4.36.0 of transformers. You can install it with `pip install transformers==4.36.0 --upgrade`
The overfitting dynamics are very different between dense and sparse models. Sparse models are more prone to overfitting, so we can explore higher regularization (e.g. dropout) within the experts themselves (e.g. we can have one dropout rate for the dense layers and another, higher, dropout for the sparse layers).
One question is whether to use the auxiliary loss for fine-tuning. The ST-MoE authors experimented with turning off the auxiliary loss, and the quality was not significantly impacted, even when up to 11% of the tokens were dropped. Token dropping might be a form of regularization that helps prevent overfitting.
Switch Transformers observed that at a fixed pretrain perplexity, the sparse model does worse than the dense counterpart in downstream tasks, especially on reasoning-heavy tasks such as SuperGLUE. On the other hand, for knowledge-heavy tasks such as TriviaQA, the sparse model performs disproportionately well. The authors also observed that a fewer number of experts helped at fine-tuning. Another observation that confirmed the generalization issue is that the model did worse in smaller tasks but did well in larger tasks.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/06_superglue_curves.png" alt="Fine-tuning learning curves">
<figcaption>In the small task (left), we can see clear overfitting as the sparse model does much worse in the validation set. In the larger task (right), the MoE performs well. This image is from the ST-MoE paper.</figcaption>
</figure>
One could experiment with freezing all non-expert weights. That is, we'll only update the MoE layers. This leads to a huge performance drop. We could try the opposite: freezing only the parameters in MoE layers, which worked almost as well as updating all parameters. This can help speed up and reduce memory for fine-tuning. This can be somewhat counter-intuitive as 80% of the parameters are in the MoE layers (in the ST-MoE project). Their hypothesis for that architecture is that, as expert layers only occur every 1/4 layers, and each token sees at most two experts per layer, updating the MoE parameters affects much fewer layers than updating other parameters.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/07_superglue_bars.png" alt="Only updating the non MoE layers works well in fine-tuning">
<figcaption>By only freezing the MoE layers, we can speed up the training while preserving the quality. This image is from the ST-MoE paper.</figcaption>
</figure>
One last part to consider when fine-tuning sparse MoEs is that they have different fine-tuning hyperparameter setups - e.g., sparse models tend to benefit more from smaller batch sizes and higher learning rates.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/08_superglue_dense_vs_sparse.png" alt="Table comparing fine-tuning batch size and learning rate between dense and sparse models.">
<figcaption>Sparse models fine-tuned quality improves with higher learning rates and smaller batch sizes. This image is from the ST-MoE paper.</figcaption>
</figure>
At this point, you might be a bit sad that people have struggled to fine-tune MoEs. Excitingly, a recent paper, [MoEs Meets Instruction Tuning](https://arxiv.org/pdf/2305.14705.pdf) (July 2023), performs experiments doing:
- Single task fine-tuning
- Multi-task instruction-tuning
- Multi-task instruction-tuning followed by single-task fine-tuning
When the authors fine-tuned the MoE and the T5 equivalent, the T5 equivalent was better. When the authors fine-tuned the Flan T5 (T5 instruct equivalent) MoE, the MoE performed significantly better. Not only this, the improvement of the Flan-MoE over the MoE was larger than Flan T5 over T5, indicating that MoEs might benefit much more from instruction tuning than dense models. MoEs benefit more from a higher number of tasks. Unlike the previous discussion suggesting to turn off the auxiliary loss function, the loss actually prevents overfitting.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/09_fine_tune_evals.png" alt="MoEs benefit even more from instruct tuning than dense models">
<figcaption>Sparse models benefit more from instruct-tuning compared to dense models. This image is from the MoEs Meets Instruction Tuning paper</figcaption>
</figure>
## When to use sparse MoEs vs dense models?
Experts are useful for high throughput scenarios with many machines. Given a fixed compute budget for pretraining, a sparse model will be more optimal. For low throughput scenarios with little VRAM, a dense model will be better.
**Note:** one cannot directly compare the number of parameters between sparse and dense models, as both represent significantly different things.
## Making MoEs go brrr
The initial MoE work presented MoE layers as a branching setup, leading to slow computation as GPUs are not designed for it and leading to network bandwidth becoming a bottleneck as the devices need to send info to others. This section will discuss some existing work to make pretraining and inference with these models more practical. MoEs go brrrrr.
### Parallelism
Let’s do a brief review of parallelism:
- **Data parallelism:** the same weights are replicated across all cores, and the data is partitioned across cores.
- **Model parallelism:** the model is partitioned across cores, and the data is replicated across cores.
- **Model and data parallelism:** we can partition the model and the data across cores. Note that different cores process different batches of data.
- **Expert parallelism**: experts are placed on different workers. If combined with data parallelism, each core has a different expert and the data is partitioned across all cores
With expert parallelism, experts are placed on different workers, and each worker takes a different batch of training samples. For non-MoE layers, expert parallelism behaves the same as data parallelism. For MoE layers, tokens in the sequence are sent to workers where the desired experts reside.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/10_parallelism.png" alt="Image illustrating model, expert, and data prallelism">
<figcaption>Illustration from the Switch Transformers paper showing how data and models are split over cores with different parallelism techniques.</figcaption>
</figure>
### Capacity Factor and communication costs
Increasing the capacity factor (CF) increases the quality but increases communication costs and memory of activations. If all-to-all communications are slow, using a smaller capacity factor is better. A good starting point is using top-2 routing with 1.25 capacity factor and having one expert per core. During evaluation, the capacity factor can be changed to reduce compute.
### Serving techniques
> You can deploy [mistralai/Mixtral-8x7B-Instruct-v0.1](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000) to Inference Endpoints.
A big downside of MoEs is the large number of parameters. For local use cases, one might want to use a smaller model. Let's quickly discuss a few techniques that can help with serving:
* The Switch Transformers authors did early distillation experiments. By distilling a MoE back to its dense counterpart, they could keep 30-40% of the sparsity gains. Distillation, hence, provides the benefits of faster pretaining and using a smaller model in production.
* Recent approaches modify the routing to route full sentences or tasks to an expert, permitting extracting sub-networks for serving.
* Aggregation of Experts (MoE): this technique merges the weights of the experts, hence reducing the number of parameters at inference time.
### More on efficient training
FasterMoE (March 2022) analyzes the performance of MoEs in highly efficient distributed systems and analyzes the theoretical limit of different parallelism strategies, as well as techniques to skew expert popularity, fine-grained schedules of communication that reduce latency, and an adjusted topology-aware gate that picks experts based on the lowest latency, leading to a 17x speedup.
Megablocks (Nov 2022) explores efficient sparse pretraining by providing new GPU kernels that can handle the dynamism present in MoEs. Their proposal never drops tokens and maps efficiently to modern hardware, leading to significant speedups. What’s the trick? Traditional MoEs use batched matrix multiplication, which assumes all experts have the same shape and the same number of tokens. In contrast, Megablocks expresses MoE layers as block-sparse operations that can accommodate imbalanced assignment.
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/moe/11_expert_matmuls.png" alt="Matrix multiplication optimized for block-sparse operations.">
<figcaption>Block-sparse matrix multiplication for differently sized experts and number of tokens (from [MegaBlocks](https://arxiv.org/abs/2211.15841)).</figcaption>
</figure>
## Open Source MoEs
There are nowadays several open source projects to train MoEs:
- Megablocks: https://github.com/stanford-futuredata/megablocks
- Fairseq: https://github.com/facebookresearch/fairseq/tree/main/examples/moe_lm
- OpenMoE: https://github.com/XueFuzhao/OpenMoE
In the realm of released open access MoEs, you can check:
- [Switch Transformers (Google)](https://huggingface.co./collections/google/switch-transformers-release-6548c35c6507968374b56d1f): Collection of T5-based MoEs going from 8 to 2048 experts. The largest model has 1.6 trillion parameters.
- [NLLB MoE (Meta)](https://huggingface.co./facebook/nllb-moe-54b): A MoE variant of the NLLB translation model.
- [OpenMoE](https://huggingface.co./fuzhao): A community effort that has released Llama-based MoEs.
- [Mixtral 8x7B (Mistral)](https://huggingface.co./mistralai): A high-quality MoE that outperforms Llama 2 70B and has much faster inference. A instruct-tuned model is also released. Read more about it in [the announcement blog post](https://mistral.ai/news/mixtral-of-experts/).
## Exciting directions of work
Further experiments on **distilling** a sparse MoE back to a dense model with less parameters but similar number of parameters.
Another area will be quantization of MoEs. [QMoE](https://arxiv.org/abs/2310.16795) (Oct. 2023) is a good step in this direction by quantizing the MoEs to less than 1 bit per parameter, hence compressing the 1.6T Switch Transformer which uses 3.2TB accelerator to just 160GB.
So, TL;DR, some interesting areas to explore:
* Distilling Mixtral into a dense model
* Explore model merging techniques of the experts and their impact in inference time
* Perform extreme quantization techniques of Mixtral
## Some resources
- [Adaptive Mixture of Local Experts (1991)](https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf)
- [Learning Factored Representations in a Deep Mixture of Experts (2013)](https://arxiv.org/abs/1312.4314)
- [Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer (2017)](https://arxiv.org/abs/1701.06538)
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (Jun 2020)](https://arxiv.org/abs/2006.16668)
- [GLaM: Efficient Scaling of Language Models with Mixture-of-Experts (Dec 2021)](https://arxiv.org/abs/2112.06905)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity (Jan 2022)](https://arxiv.org/abs/2101.03961)
- [ST-MoE: Designing Stable and Transferable Sparse Expert Models (Feb 2022)](https://arxiv.org/abs/2202.08906)
- [FasterMoE: modeling and optimizing training of large-scale dynamic pre-trained models(April 2022)](https://dl.acm.org/doi/10.1145/3503221.3508418)
- [MegaBlocks: Efficient Sparse Training with Mixture-of-Experts (Nov 2022)](https://arxiv.org/abs/2211.15841)
- [Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models (May 2023)](https://arxiv.org/abs/2305.14705)
- [Mixtral-8x7B-v0.1](https://huggingface.co./mistralai/Mixtral-8x7B-v0.1), [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co./mistralai/Mixtral-8x7B-Instruct-v0.1).
## Citation
```bibtex
@misc {sanseviero2023moe,
author = { Omar Sanseviero and
Lewis Tunstall and
Philipp Schmid and
Sourab Mangrulkar and
Younes Belkada and
Pedro Cuenca
},
title = { Mixture of Experts Explained },
year = 2023,
url = { https://huggingface.co./blog/moe },
publisher = { Hugging Face Blog }
}
```
```
Sanseviero, et al., "Mixture of Experts Explained", Hugging Face Blog, 2023.
``` | [
[
"llm",
"transformers",
"research",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"research",
"efficient_computing"
] | null | null |
1d9c8753-0474-4a21-8c16-b24a9159c0cc | completed | 2025-01-16T03:09:11.596638 | 2025-01-16T03:16:09.482883 | 9dce912a-d6df-43bd-81d6-bbb6ba1dbb98 | Student Ambassador Program’s call for applications is open! | Violette | ambassadors.md | As an open-source company democratizing machine learning, Hugging Face believes it is essential to **[teach](https://huggingface.co./blog/education)** open-source ML to people from all backgrounds worldwide. **We aim to teach machine learning to 5 million people by 2023**.
Are you studying machine learning and/or already evangelizing your community with ML? Do you want to be a part of our ML democratization efforts and show your campus community how to build ML models with Hugging Face?
**If yes, we want to support you in your journey by opening our first Student Ambassador Program 🤗 🥳**
If you want to:
* help your peers in their machine learning journey,
* learn and use free, open-source technologies,
* contribute to a thriving ecosystem,
* and you're keen on fostering communities while sharing [our community values](https://huggingface2.notion.site/huggingface2/Hugging-Face-Code-of-Conduct-45eeeafa9ef44c5e888a2952619fdfa8),
The Student Ambassador Program is an excellent opportunity for you. You have until June 13, 2022, to [apply](https://docs.google.com/forms/d/e/1FAIpQLScY9kTi-TjZipRFRviluRCwSjFf3CCsMbKedzO1tq2S0wtbNQ/viewform?usp=sf_link)!
<br />
**What are the benefits of being part of the Program?** 🤩
Selected ambassadors will benefit from resources and support:
🎎 Network of peers with whom ambassadors can collaborate.
🧑🏻💻 Workshops and support from the Hugging Face team!
🤗 Insight into the latest projects, features, and more!
🎁 Merchandise and assets.
✨ Being officially recognized as a Hugging Face’s Ambassador
<br />
**Eligibility Requirements for Students**
- Validate your student status
- Have taken at least one machine learning/data science course (online courses are considered as well)
- Be enrolled in an accredited college or university
- Be a user of the Hugging Face Hub and/or the Hugging Face’s libraries
- Acknowledge the [Code of Conduct](https://huggingface2.notion.site/huggingface2/Hugging-Face-Code-of-Conduct-45eeeafa9ef44c5e888a2952619fdfa8). Community is at the center of the Hugging Face ecosystem. Because of that, we strictly adhere to our [Code of conduct](https://huggingface2.notion.site/huggingface2/Hugging-Face-Code-of-Conduct-45eeeafa9ef44c5e888a2952619fdfa8). If any ambassador infringes it or behaves inadequately, they will be excluded from the Program.
**[Apply here](https://docs.google.com/forms/d/e/1FAIpQLScY9kTi-TjZipRFRviluRCwSjFf3CCsMbKedzO1tq2S0wtbNQ/viewform?usp=sf_link) to become an ambassador!**
**Timeline:**
- Deadline for the end of the [application](https://docs.google.com/forms/d/e/1FAIpQLScY9kTi-TjZipRFRviluRCwSjFf3CCsMbKedzO1tq2S0wtbNQ/viewform?usp=sf_link) is June 13.
- The Program will start on June 30, 2022.
- The Program will end on December 31, 2022. | [
[
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"tutorial",
"tools"
] | null | null |
9ae187e6-93f3-4d0e-8486-95366b64faf9 | completed | 2025-01-16T03:09:11.596643 | 2025-01-19T18:57:46.921387 | 34e9cff4-7c2c-4efd-8a2e-12d1c616a0ee | Welcome Llama 3 - Meta's new open LLM | philschmid, osanseviero, pcuenq, ybelkada, lvwerra | llama3.md | ## Introduction
Meta’s Llama 3, the next iteration of the open-access Llama family, is now released and available at Hugging Face. It's great to see Meta continuing its commitment to open AI, and we’re excited to fully support the launch with comprehensive integration in the Hugging Face ecosystem.
Llama 3 comes in two sizes: 8B for efficient deployment and development on consumer-size GPU, and 70B for large-scale AI native applications. Both come in base and instruction-tuned variants. In addition to the 4 models, a new version of Llama Guard was fine-tuned on Llama 3 8B and is released as Llama Guard 2 (safety fine-tune).
We’ve collaborated with Meta to ensure the best integration into the Hugging Face ecosystem. You can find all 5 open-access models (2 base models, 2 fine-tuned & Llama Guard) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co./meta-llama), with their model cards and licenses
- 🤗 Transformers integration
- [Hugging Chat integration for Meta Llama 3 70b](https://huggingface.co./chat/models/meta-llama/Meta-Llama-3-70B-instruct)
- Inference Integration into Inference Endpoints, Google Cloud & Amazon SageMaker
- An example of fine-tuning Llama 3 8B on a single GPU with 🤗 TRL
## Table of contents
- [What’s new with Llama 3?](#whats-new-with-llama-3)
- [Llama 3 evaluation](#llama-3-evaluation)
- [How to prompt Llama 3](#how-to-prompt-llama-3)
- [Demo](#demo)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Inference Integrations](#inference-integrations)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Additional Resources](#additional-resources)
- [Acknowledgments](#acknowledgments)
## What’s new with Llama 3?
The Llama 3 release introduces 4 new open LLM models by Meta based on the Llama 2 architecture. They come in two sizes: 8B and 70B parameters, each with base (pre-trained) and instruct-tuned versions. All the variants can be run on various types of consumer hardware and have a context length of 8K tokens.
- [Meta-Llama-3-8b](https://huggingface.co./meta-llama/Meta-Llama-3-8B): Base 8B model
- [Meta-Llama-3-8b-instruct](https://huggingface.co./meta-llama/Meta-Llama-3-8B-Instruct): Instruct fine-tuned version of the base 8b model
- [Meta-Llama-3-70b](https://huggingface.co./meta-llama/Meta-Llama-3-70B): Base 70B model
- [Meta-Llama-3-70b-instruct](https://huggingface.co./meta-llama/Meta-Llama-3-70B-instruct): Instruct fine-tuned version of the base 70b model
In addition to these 4 base models, Llama Guard 2 was also released. Fine-tuned on Llama 3 8B, it’s the latest iteration in the Llama Guard family. Llama Guard 2, built for production use cases, is designed to classify LLM inputs (prompts) as well as LLM responses in order to detect content that would be considered unsafe in a risk taxonomy.
A big change in Llama 3 compared to Llama 2 is the use of a new tokenizer that expands the vocabulary size to 128,256 (from 32K tokens in the previous version). This larger vocabulary can encode text more efficiently (both for input and output) and potentially yield stronger multilingualism. This comes at a cost, though: the embedding input and output matrices are larger, which accounts for a good portion of the parameter count increase of the small model: it goes from 7B in Llama 2 to 8B in Llama 3. In addition, the 8B version of the model now uses Grouped-Query Attention (GQA), which is an efficient representation that should help with longer contexts.
The Llama 3 models were trained ~8x more data on over 15 trillion tokens on a new mix of publicly available online data on two clusters with 24,000 GPUs. We don’t know the exact details of the training mix, and we can only guess that bigger and more careful data curation was a big factor in the improved performance. Llama 3 Instruct has been optimized for dialogue applications and was trained on over 10 Million human-annotated data samples with combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO).
Regarding the licensing terms, Llama 3 comes with a permissive license that allows redistribution, fine-tuning, and derivative works. The requirement for explicit attribution is new in the Llama 3 license and was not present in Llama 2. Derived models, for instance, need to include "Llama 3" at the beginning of their name, and you also need to mention "Built with Meta Llama 3" in derivative works or services. For full details, please make sure to read the [official license](https://huggingface.co./meta-llama/Meta-Llama-3-70B/blob/main/LICENSE).
## Llama 3 evaluation
Here, you can see a list of models and their [Open LLM Leaderboard](https://huggingface.co./spaces/open-llm-leaderboard/open_llm_leaderboard) scores. This is not a comprehensive list and we encourage you to look at the full leaderboard. Note that the LLM Leaderboard is specially useful to evaluate pre-trained models, as there are other benchmarks specific to conversational models.
| Model | License | Pretraining length [tokens] | Leaderboard score |
| | [
[
"llm",
"transformers",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"integration",
"fine_tuning"
] | null | null |
2a7a2005-e129-4207-84db-a5a671465d45 | completed | 2025-01-16T03:09:11.596647 | 2025-01-16T03:09:34.249551 | 71665a78-7e56-4ce7-9938-f76521001c62 | Train a Sentence Embedding Model with 1B Training Pairs | asi | 1b-sentence-embeddings.md | **Sentence embedding** is a method that maps sentences to vectors of real numbers. Ideally, these vectors would capture the semantic of a sentence and be highly generic. Such representations could then be used for many downstream applications such as clustering, text mining, or question answering.
We developed state-of-the-art sentence embedding models as part of the project ["Train the Best Sentence Embedding Model Ever with 1B Training Pairs"](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). This project took place during the [Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by Hugging Face. We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as guidance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks!
## Training methodology
### Model
Unlike words, we can not define a finite set of sentences. Sentence embedding methods, therefore, compose inner words to compute the final representation. For example, SentenceBert model ([Reimers and Gurevych, 2019](https://aclanthology.org/D19-1410.pdf)) uses Transformer, the cornerstone of many NLP applications, followed by a pooling operation over the contextualized word vectors. (c.f. Figure below.)

### Multiple Negative Ranking Loss
The parameters from the composition module are usually learned using a self-supervised objective. For the project, we used a contrastive training method illustrated in the figure below. We constitute a dataset with sentence pairs \\( (a_i, p_i) \\) such that sentences from the pair have a close meaning. For example, we consider pairs such as (query, answer-passage), (question, duplicate_question),(paper title, cited paper title). Our model is then trained to map pairs \\( (a_i , p_i) \\) to close vectors while assigning unmatched pairs \\( (a_i , p_j), i \neq j \\) to distant vectors in the embedding space. This training method is also called training with in-batch negatives, InfoNCE or NTXentLoss.

Formally, given a batch of training samples, the model optimises the following [loss function](https://github.com/UKPLab/sentence-transformers/blob/master/sentence_transformers/losses/MultipleNegativesRankingLoss.py):
$$-\frac{1}{n}\sum_{i=1}^n\frac{exp(sim(a_i, p_i))}{\sum_j exp(sim(a_i, p_j))}$$
An illustrative example can be seen below. The model first embeds each sentence from every pair in the batch. Then, we compute a similarity matrix between every possible pair \\( (a_i, p_j) \\). We then compare the similarity matrix with the ground truth, which indicates the original pairs. Finally, we perform the comparison using the cross entropy loss.
Intuitively, the model should assign high similarity to the sentences « How many people live in Berlin? » and « Around 3.5 million people live in Berlin » and low similarity to other negative answers such as « The capital of France is Paris » as detailed in the Figure below.

In the loss equation, `sim` indicates a similarity function between \\( (a, p) \\). The similarity function could be either the Cosine-Similarity or the Dot-Product operator. Both methods have their pros and cons summarized below ([Thakur et al., 2021](https://arxiv.org/abs/2104.08663), [Bachrach et al., 2014](https://dl.acm.org/doi/10.1145/2645710.2645741)):
| Cosine-similarity | Dot-product |
| | [
[
"transformers",
"research",
"implementation",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"implementation",
"community"
] | null | null |
9137872d-10b4-4cb1-bb2e-3d9b3c39b181 | completed | 2025-01-16T03:09:11.596652 | 2025-01-16T03:11:30.360152 | 3e4da615-9a97-4ee1-89d3-bf29a182f540 | Director of Machine Learning Insights [Part 4] | nan | ml-director-insights-4.md | _If you're interested in building ML solutions faster visit: [hf.co/support](https://huggingface.co./support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_3) today!_
👋 Welcome back to our Director of ML Insights Series! If you missed earlier Editions you can find them here:
- [Director of Machine Learning Insights [Part 1]](https://huggingface.co./blog/ml-director-insights)
- [Director of Machine Learning Insights [Part 2 : SaaS Edition]](https://huggingface.co./blog/ml-director-insights-2)
- [Director of Machine Learning Insights [Part 3 : Finance Edition]](https://huggingface.co./blog/ml-director-insights-3)
🚀 In this fourth installment, you’ll hear what the following top Machine Learning Directors say about Machine Learning’s impact on their respective industries: Javier Mansilla, Shaun Gittens, Samuel Franklin, and Evan Castle. —All are currently Directors of Machine Learning with rich field insights.
_Disclaimer: All views are from individuals and not from any past or current employers._
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Javier.png"></a>
### [Javier Mansilla](https://www.linkedin.com/in/javimansilla/?originalSubdomain=ar) - Director of Machine Learning, Marketing Science at [Mercado Libre](https://mercadolibre.com/)
**Background:** Seasoned entrepreneur and leader, Javier was co-founder and CTO of Machinalis, a high-end company building Machine Learning since 2010 (yes, before the breakthrough of neural nets). When Machinalis was acquired by Mercado Libre, that small team evolved to enable Machine Learning as a capability for a tech giant with more than 10k devs, impacting the lives of almost 100 million direct users. Daily, Javier leads not only the tech and product roadmap of their Machine Learning Platform (NASDAQ MELI), but also their users' tracking system, the AB Testing framework, and the open-source office. Javier is an active member & contributor of [Python-Argentina non-profit PyAr](https://www.python.org.ar/), he loves hanging out with family and friends, python, biking, football, carpentry, and slow-paced holidays in nature!
**Fun Fact:** I love reading science fiction, and my idea of retirement includes resuming the teenage dream of writing short stories.📚
**Mercado Libre:** The biggest company in Latam and the eCommerce & fintech omnipresent solution for the continent
#### **1. How has ML made a positive impact on e-commerce?**
I would say that ML made the impossible possible in specific cases like fraud prevention and optimized processes and flows in ways we couldn't have imagined in a vast majority of other areas.
In the middle, there are applications where ML enabled a next-level of UX that otherwise would be very expensive (but maybe possible). For example, the discovery and serendipity added to users' journey navigating between listings and offers.
We ran search, recommendations, ads, credit-scoring, moderations, forecasting of several key aspects, logistics, and a lot more core units with Machine Learning optimizing at least one of its fundamental metrics.
We even use ML to optimize the way we reserve and use infrastructure.
#### **2. What are the biggest ML challenges within e-commerce?**
Besides all the technical challenges ahead (for instance, more and more real timeless and personalization), the biggest challenge is the always present focus on the end-user.
E-commerce is scaling its share of the market year after year, and Machine Learning is always a probabilistic approach that doesn't provide 100% perfection. We need to be careful to keep optimizing our products while still paying attention to the long tail and the experience of each individual person.
Finally, a growing challenge is coordinating and fostering data (inputs and outputs) co-existence in a multi-channel and multi-business world—marketplace, logistics, credits, insurance, payments on brick-and-mortar stores, etc.
#### **3. A common mistake you see people make trying to integrate ML into e-commerce?**
The most common mistakes are related to using the wrong tool for the wrong problem.
For instance, starting complex instead of with the simplest baseline possible. For instance not measuring the with/without machine learning impact. For instance, investing in tech without having a clear clue of the boundaries of the expected gain.
Last but not least: thinking only in the short term, forgetting about the hidden impacts, technical debts, maintenance, and so on.
#### **4. What excites you most about the future of ML?**
Talking from the perspective of being on the trench crafting technology with our bare hands like we used to do ten years ago, definitely what I like the most is to see that we as an industry are solving most of the slow, repetitive and boring pieces of the challenge.
It’s of course an ever-moving target, and new difficulties arise.
But we are getting better at incorporating mature tools and practices that will lead to shorter cycles of model-building which, at the end of the day, reduces time to market.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Shaun.png"></a>
### [Shaun Gittens](https://www.linkedin.com/in/shaungittens/) - Director of Machine Learning at [MasterPeace Solutions](https://www.masterpeaceltd.com/)
**Background:** Dr. Shaun Gittens is the Director of the Machine Learning Capability of MasterPeace Solutions, Ltd., a company specializing in providing advanced technology and mission-critical cyber services to its clients. In this role, he is:
1. Growing the core of machine learning experts and practitioners at the company.
2. Increasing the knowledge of bleeding-edge machine learning practices among its existing employees.
3. Ensuring the delivery of effective machine learning solutions and consulting support not only to the company’s clientele but also to the start-up companies currently being nurtured from within MasterPeace.
Before joining MasterPeace, Dr. Gittens served as Principal Data Scientist for the Applied Technology Group, LLC. He built his career on training and deploying machine learning solutions on distributed big data and streaming platforms such as Apache Hadoop, Apache Spark, and Apache Storm. As a postdoctoral fellow at Auburn University, he investigated effective methods for visualizing the knowledge gained from trained non-linear machine-learned models.
**Fun Fact:** Addicted to playing tennis & Huge anime fan. 🎾
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on Engineering?**
Engineering is vast in its applications and can encompass a great many areas. That said, more recently, we are seeing ML affect a range of engineering facets addressing obvious fields such as robotics and automobile engineering to not-so-obvious fields such as chemical and civil engineering. ML is so broad in its application that merely the very existence of training data consisting of prior recorded labor processes is all required to attempt to have ML affect your bottom line. In essence, we are in an age where ML has significantly impacted the automation of all sorts of previously human-only-operated engineering processes.
#### **2. What are the biggest ML challenges within Engineering?**
1. The biggest challenges come with the operationalization and deployment of ML-trained solutions in a manner in which human operations can be replaced with minimal consequences. We’re seeing it now with fully self-driving automobiles. It’s challenging to automate processes with little to no fear of jeopardizing humans or processes that humans rely on. One of the most significant examples of this phenomenon that concerns me is ML and Bias. It is a reality that ML models trained on data containing, even if unaware, prejudiced decision-making can reproduce said bias in operation. Bias needs to be put front and center in the attempt to incorporate ML into engineering such that systemic racism isn’t propagated into future technological advances to then cause harm to disadvantaged populations. ML systems trained on data emanating from biased processes are doomed to repeat them, mainly if those training the ML solutions aren’t acutely aware of all forms of data present in the process to be automated.
2. Another critical challenge regarding ML in engineering is that the field is mainly categorized by the need for problem-solving, which often requires creativity. As of now, few great cases exist today of ML agents being truly “creative” and capable of “thinking out-of-the-box” since current ML solutions tend to result merely from a search through all possible solutions. In my humble opinion, though a great many solutions can be found via these methods, ML will have somewhat of a ceiling in engineering until the former can consistently demonstrate creativity in a variety of problem spaces. That said, that ceiling is still pretty high, and there is much left to be accomplished in ML applications in engineering.
#### **3. What’s a common mistake you see people make when trying to integrate ML into Engineering?**
Using an overpowered ML technique on a small problem dataset is one common mistake I see people making in integrating ML into Engineering. Deep Learning, for example, is moving AI and ML to heights unimagined in such a short period, but it may not be one’s best method for solving a problem, depending on your problem space. Often more straightforward methods work just as well or better when working with small training datasets on limited hardware.
Also, not setting up an effective CI/CD (continuous integration/ continuous deployment) structure for your ML solution is another mistake I see. Very often, a once-trained model won’t suffice not only because data changes over time but resources and personnel do as well. Today’s ML practitioner needs to:
1. secure consistent flow of data as it changes and continuously retrain new models to keep it accurate and useful,
2. ensure the structure is in place to allow for seamless replacement of older models by newly trained models while,
3. allowing for minimal disruption to the consumer of the ML model outputs.
#### **4. What excites you most about the future of ML?**
The future of ML continues to be exciting and seemingly every month there are advances reported in the field that even wow the experts to this day. As 1) ML techniques improve and become more accessible to established practitioners and novices alike, 2) everyday hardware becomes faster, 3) power consumption becomes less problematic for miniaturized edge devices, and 4) memory limitations diminish over time, the ceiling for ML in Engineering will be bright for years to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/Samuel.png
"></a>
### [Samuel Franklin](https://www.linkedin.com/in/samuelcfranklin/) - Senior Director of Data Science & ML Engineering at [Pluralsight](https://www.pluralsight.com/)
**Background:** Samuel is a senior Data Science and ML Engineering leader at Pluralsight with a Ph.D. in cognitive science. He leads talented teams of Data Scientists and ML Engineers building intelligent services that power Pluralsight’s Skills platform.
Outside the virtual office, Dr. Franklin teaches Data Science and Machine Learning seminars for Emory University. He also serves as Chairman of the Board of Directors for the Atlanta Humane Society.
**Fun Fact:** I live in a log cabin on top of a mountain in the Appalachian range.
**Pluralsight:** We are a technology workforce development company and our Skills platform is used by 70% of the Fortune 500 to help their employees build business-critical tech skills.
#### **1. How has ML made a positive impact on Education?**
Online, on-demand educational content has made lifelong learning more accessible than ever for billions of people globally. Decades of cognitive research show that the relevance, format, and sequence of educational content significantly impact students’ success. Advances in deep learning content search and recommendation algorithms have greatly improved our ability to create customized, efficient learning paths at-scale that can adapt to individual student’s needs over time.
#### **2. What are the biggest ML challenges within Education?**
I see MLOps technology as a key opportunity area for improving ML across industries. The state of MLOps technology today reminds me of the Container Orchestration Wars circa 2015-16. There are competing visions for the ML Train-Deploy-Monitor stack, each evangelized by enthusiastic communities and supported by large organizations. If a predominant vision eventually emerges, then consensus on MLOps engineering patterns could follow, reducing the decision-making complexity that currently creates friction for ML teams.
#### **3. What’s a common mistake you see people make trying to integrate ML into existing products?**
There are two critical mistakes that I’ve seen organizations of all sizes make when getting started with ML. The first mistake is underestimating the importance of investing in senior leaders with substantial hands-on ML experience. ML strategy and operations leadership benefits from a depth of technical expertise beyond what is typically found in the BI / Analytics domain or provided by educational programs that offer a limited introduction to the field. The second mistake is waiting too long to design, test, and implement production deployment pipelines. Effective prototype models can languish in repos for months – even years – while waiting on ML pipeline development. This can impose significant opportunity costs on an organization and frustrate ML teams to the point of increasing attrition risk.
#### **4. What excites you most about the future of ML?**
I’m excited about the opportunity to mentor the next generation of ML leaders. My career began when cloud computing platforms were just getting started and ML tooling was much less mature than it is now. It was exciting to explore different engineering patterns for ML experimentation and deployment, since established best practices were rare. But, that exploration included learning too many technical and people leadership lessons the hard way. Sharing those lessons with the next generation of ML leaders will help empower them to advance the field farther and faster than what we’ve seen over the past 10+ years.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/78_ml_director_insights/evan.png"></a>
### [Evan Castle](https://www.linkedin.com/in/evan-castle-ai/) - Director of ML, Product Marketing, Elastic Stack at [Elastic](www.elastic.co)
**Background:** Over a decade of leadership experience in the intersection of data science, product, and strategy. Evan worked in various industries, from building risk models at Fortune 100s like Capital One to launching ML products at Sisense and Elastic.
**Fun Fact:** Met Paul McCarthy. 🎤
**MasterPeace Solutions:** MasterPeace Solutions has emerged as one of the fastest-growing advanced technology companies in the Mid-Atlantic region. The company designs and develops software, systems, solutions and products to solve some of the most pressing challenges facing the Intelligence Community.
#### **1. How has ML made a positive impact on SaaS?**
Machine learning has become truly operational in SaaS, powering multiple uses from personalization, semantic and image search, recommendations to anomaly detection, and a ton of other business scenarios. The real impact is that ML comes baked right into more and more applications. It's becoming an expectation and more often than not it's invisible to end users.
For example, at Elastic we invested in ML for anomaly detection, optimized for endpoint security and SIEM. It delivers some heavy firepower out of the box with an amalgamation of different techniques like time series decomposition, clustering, correlation analysis, and Bayesian distribution modeling. The big benefit for security analysts is threat detection is automated in many different ways. So anomalies are quickly bubbled up related to temporal deviations, unusual geographic locations, statistical rarity, and many other factors. That's the huge positive impact of integrating ML.
#### **2. What are the biggest ML challenges within SaaS?**
To maximize the benefits of ML there is a double challenge of delivering value to users that are new to machine learning and also to seasoned data scientists. There's obviously a huge difference in demands for these two folks. If an ML capability is a total black box it's likely to be too rigid or simple to have a real impact. On the other hand, if you solely deliver a developer toolkit it's only useful if you have a data science team in-house. Striking the right balance is about making sure ML is open enough for the data science team to have transparency and control over models and also packing in battle-tested models that are easy to configure and deploy without being a pro.
#### **3. What’s a common mistake you see people make trying to integrate ML into SaaS?**
To get it right, any integrated model has to work at scale, which means support for massive data sets while ensuring results are still performant and accurate. Let's illustrate this with a real example. There has been a surge in interest in vector search. All sorts of things can be represented in vectors from text, and images to events. Vectors can be used to capture similarities between content and are great for things like search relevance and recommendations. The challenge is developing algorithms that can compare vectors taking into account trade-offs in speed, complexity, and cost.
At Elastic, we spent a lot of time evaluating and benchmarking the performance of models for vector search. We decided on an approach for the approximate nearest neighbor (ANN) algorithm called Hierarchical Navigable Small World graphs (HNSW), which basically maps vectors into a
graph based on their similarity to each other. HNSW delivers an order of magnitude increase in speed and accuracy across a variety of ANN-benchmarks. This is just one example of non-trivial decisions more and more product and engineering teams need to take to successfully integrate ML into their products.
#### **4. What excites you most about the future of ML?**
Machine learning will become as simple as ordering online. The big advances in NLP especially have made ML more human by understanding context, intent, and meaning. I think we are in an era of foundational models that will blossom into many interesting directions. At Elastic we are thrilled with our own integration to Hugging Face and excited to already see how our customers are leveraging NLP for observability, security, and search. | [
[
"mlops",
"research",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"community",
"research"
] | null | null |
c00774a4-22d5-42ea-a121-7767e9540db3 | completed | 2025-01-16T03:09:11.596656 | 2025-01-19T17:13:02.587985 | 8b711142-942e-4659-a612-f55d8d0a868d | Controlling Language Model Generation with NVIDIA's LogitsProcessorZoo | ariG23498, aerdem4 | logits-processor-zoo.md | Generating text with language models often involves selecting the next token based on a distribution of probabilities.
A straightforward approach like **greedy search** selects the most probable token, but this can result in generic or repetitive outputs.
To add diversity and control, more advanced **decoding strategies**, such as beam search, nucleus sampling, and top-k sampling, are widely used.
These strategies, supported by the [🤗 Transformers library](https://huggingface.co./docs/transformers/en/generation_strategies),
give us flexibility in shaping the model's outputs.
But what if we wanted to go a step further and **control the text generation process itself** by directly modifying the probability distribution?
That’s where **logit processing** comes into play. Hugging Face's [LogitsProcessor API](https://huggingface.co./docs/transformers/en/internal/generation_utils#logitsprocessor)
lets you customize the prediction scores of the language model head, providing granular control over model behavior.
The 🤗 Transformers library not only offers a rich set of built-in logits processors but also empowers the community
to create and share custom processors tailored to unique use cases.
Enter NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo/tree/main) — a collection of powerful, modular logits processors
designed for specific tasks such as controlling sequence lengths, enforcing key phrases, or guiding multiple-choice answers.
Fully compatible with Hugging Face's [`generate`](https://huggingface.co./docs/transformers/v4.47.1/en/main_classes/text_generation#transformers.GenerationMixin.generate)
method, NVIDIA’s library serves as an excellent example of community-driven innovation in logits processing.
In this post, we’ll explore how NVIDIA’s LogitsProcessorZoo enhances and expands on existing capabilities, diving deep into its features and demonstrating how it can refine your AI workflows.
## What Are Logits in Language Models?
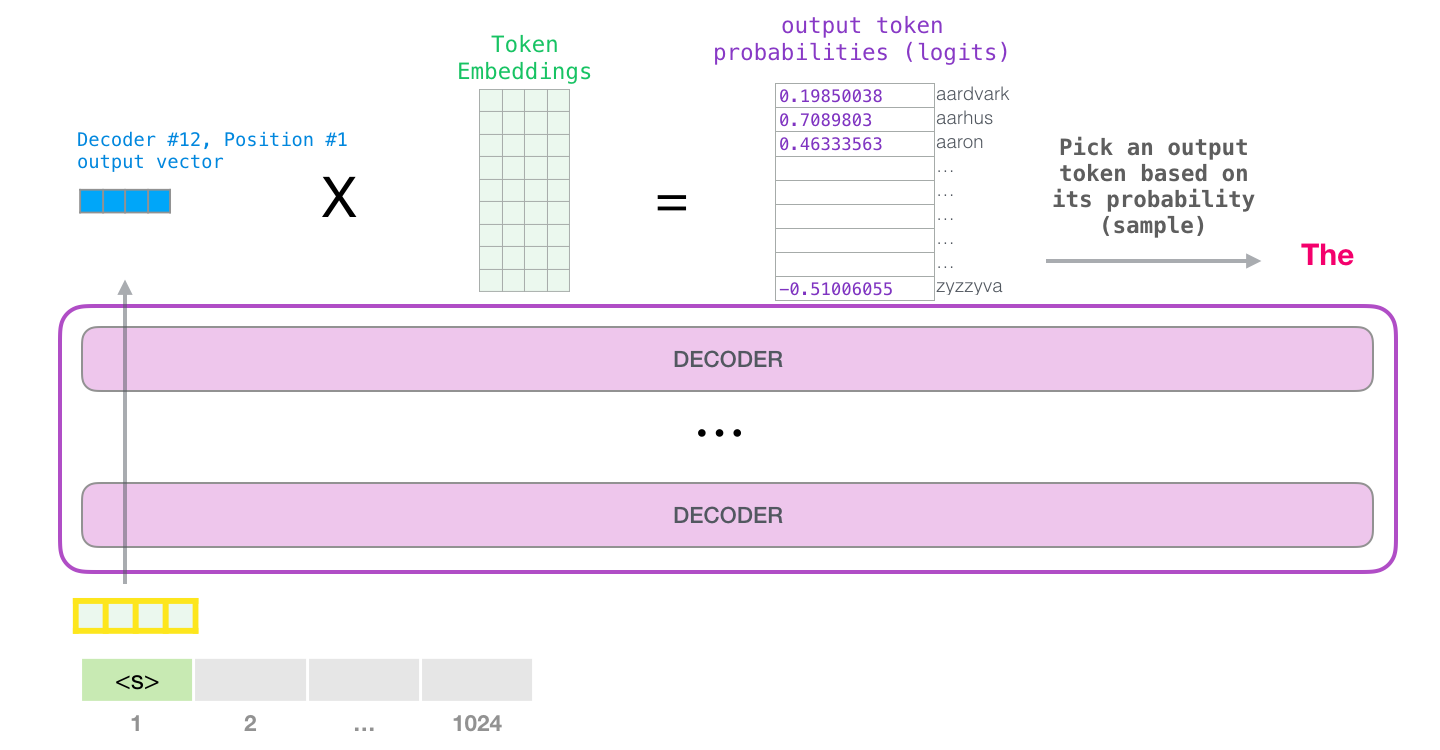
Taken from: https://jalammar.github.io/illustrated-gpt2/
Logits are the raw, unnormalized scores generated by language models for each token in their vocabulary. These scores are transformed into probabilities via the **softmax** function, guiding the model in selecting the next token.
Here's an example of how logits fit into the generation process:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load a model and tokenizer
model_name = "meta-llama/Llama-3.2-1B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
# Input text
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Get logits
with torch.inference_mode():
outputs = model(**inputs)
logits = outputs.logits
# Logits for the last token
last_token_logits = logits[:, -1, :]
```
These logits represent the model's confidence for each potential next word. Using softmax, we can turn them into probabilities and decode them into the generated text:
```python
# Prediction for the next token
next_token_probs = torch.nn.functional.softmax(last_token_logits, dim=-1)
# Decode logits to generate text
predicted_token_ids = torch.argmax(next_token_probs, dim=-1)
generated_text = tokenizer.batch_decode(predicted_token_ids, skip_special_tokens=True)
print("Generated Text:", generated_text[0])
>>> Generated Text: Paris
```
While this pipeline demonstrates how raw logits can be transformed into text, it's worth noting that 🤗 Transformers streamlines this process.
For instance, the [`generate()`](https://huggingface.co./docs/transformers/en/main_classes/text_generation) method automatically handles these
transformations, including applying the softmax function and sampling from the probability distribution.
However, raw logits may be undesirable for common tasks like sampling or imposing task-specific constraints. For more details on handling logits
effectively during generation, refer to Hugging Face's [generation blog post](https://huggingface.co./blog/how-to-generate).
This is where **logit processing** becomes indispensable to tailor the output to specific needs.
## Why Process Logits?
Raw logits often fall short when controlling output behavior. For example:
- **Lack of constraints:** They might not adhere to required formats, grammar rules, or predefined structures.
- **Overgeneralization:** The model could prioritize generic responses instead of specific, high-quality outputs.
- **Task misalignment:** Sequences may end too early, be overly verbose, or miss critical details.
Logit processing enables us to tweak the model's behavior by modifying these raw scores before generation.
## NVIDIA's LogitsProcessorZoo
NVIDIA's [LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo) simplifies post-processing of logits with modular components tailored for specific tasks.
Let's explore its features and see how to use them. To follow along, head over to
[the notebook](https://huggingface.co./datasets/ariG23498/quick-notebooks/blob/main/nvidia-logits-processor-zoo.ipynb) and experiment with the logits processors.
Install the library using:
```bash
pip install logits-processor-zoo
```
To demonstrate the processors, we'll create a simple `LLMRunner` class that initializes a model and tokenizer,
exposing a `generate_response` method. We will then provide different processors to the `generate_response` method and see them in action.
```python
# Adapted from: https://github.com/NVIDIA/logits-processor-zoo/blob/main/example_notebooks/transformers/utils.py
class LLMRunner:
def __init__(self, model_name="meta-llama/Llama-3.2-1B-Instruct"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
)
def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000):
if logits_processor_list is None:
logits_processor_list = []
for prompt in prompts:
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
inputs = self.tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(self.model.device)
outputs = self.model.generate(
**inputs,
max_new_tokens=max_tokens,
min_new_tokens=1,
logits_processor=LogitsProcessorList(logits_processor_list),
)
gen_output = self.tokenizer.batch_decode(
outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Extract only the generated output after the original input length
generated_text = gen_output[0][
len(
self.tokenizer.decode(
inputs["input_ids"][0], skip_special_tokens=True
)
) :
].strip()
print(f"Prompt: {prompt}")
print()
print(f"LLM response:\n{generated_text}")
runner = LLMRunner()
```
### 1. GenLengthLogitsProcessor
Control the length of generated sequences by adjusting the likelihood of the end-of-sequence (EOS) token.
This processor is particularly useful in scenarios where the desired length of generated text plays a
crucial role, such as generating concise summaries, restricting verbose outputs, or tailoring responses
to specific use cases. For instance, it can help ensure that a chatbot provides short and meaningful
responses while maintaining grammatical integrity by completing sentences when required.
```py
example_prompts =[
"Tell me a story about a kid lost in forest."
]
# generate short response
print(runner.generate_response(
example_prompts,
[GenLengthLogitsProcessor(runner.tokenizer, boost_factor=0.1, p=2, complete_sentences=True)]
))
```
> LLM response:
Once upon a time, in a dense forest, there lived a young boy named Timmy. Timmy was on a family camping trip with his parents and little sister, Emma. They had been walking for hours, and the dense trees seemed to close in around them. As the sun began to set, Timmy realized he had wandered away from his family.
At first, Timmy didn't panic. He thought about calling out for his parents and Emma, but his voice was hoarse from singing campfire songs. He looked around, but the trees seemed to stretch on forever, making it impossible to see any familiar landmarks. As the darkness grew thicker, Timmy's fear began to creep in.
```py
# generate long response
print(runner.generate_response(
example_prompts,
[GenLengthLogitsProcessor(runner.tokenizer, boost_factor=-10.0, p=0, complete_sentences=False)]
))
```
> LLM response:
Once upon a time, in a dense and vibrant forest, there lived a young boy named Max. Max was an adventurous and curious 8-year-old who loved exploring the outdoors. One sunny afternoon, while wandering through the forest, he stumbled upon a narrow path he had never seen before.
Excited by the discovery, Max decided to follow the path and see where it would lead. The forest was teeming with life, and the sunlight filtering through the trees created a magical atmosphere. Max walked for about 20 minutes, his eyes scanning the surroundings for any signs of civilization.
As the sun began to set, casting a warm orange glow over the forest, Max realized he was lost. He had no phone, no wallet, and no way to communicate with his family. Panic started to set in, and Max began to feel scared and alone.
Panicked, Max started to run through the forest, his heart racing and his legs trembling. He stumbled upon a clearing and saw a faint light in the distance. As he approached, he saw a small cabin in the center of the clearing. Smoke was rising from the chimney, and Max could hear the sound of someone singing a gentle tune.
...
In the examples above, we have used the `GenLengthLogitsProcessor` to both shorten and lengthen the
response generated by the model.
### 2. CiteFromPromptLogitsProcessor
Boost or diminish tokens from the prompt to encourage similar outputs.
This is particularly valuable in tasks requiring context retention, such as answering questions based
on a passage, generating summaries with specific details, or producing consistent outputs in dialogue systems.
For example, in the given code snippet where a user review is analyzed, this processor ensures the
model generates a response closely tied to the review's content, such as emphasizing opinions about
the product's price.
```py
example_prompts =[
"""
A user review: very soft, colorful, expensive but deserves its price, stylish.
What is the user's opinion about the product's price?
""",
]
# Cite from the Prompt
print(runner.generate_response(
example_prompts,
[CiteFromPromptLogitsProcessor(runner.tokenizer, example_prompts, boost_factor=5.0)],
max_tokens=50,
))
```
> LLM response:
Based on the user review, the user's opinion about the product's price is: the user is very satisfied, but the price is expensive, but the product is stylish, soft, and colorful, which is the price the user is willing to pay
Notice how the generation cites the input prompt.
### 3. ForceLastPhraseLogitsProcessor
Force the model to include a specific phrase before ending its output.
This processor is especially useful in structured content generation scenarios where consistency or
adherence to a specific format is crucial. It is ideal for tasks like generating citations,
formal reports, or outputs requiring specific phrasing to maintain a professional or organized presentation.
```py
example_prompts = [
"""
Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur
Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise.
Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon.
Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise.
It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May.
It is featured in various manga and is owned by protagonist Red in Pokémon Adventures.
What is Bulbasaur?
""",
]
phrase = "\n\nReferences:"
batch_size = len(example_prompts)
print(runner.generate_response(
example_prompts,
[ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)]
))
```
> LLM response:
According to the information retrieved from the Wikipedia article, Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, and it has been featured in various forms of media, including:
- As a starter Pokémon in the first generation of Pokémon games, including Pokémon Red and Blue.
- As a main character in the Pokémon anime, where it is one of Ash Ketchum's first Pokémon.
- As a character in the Pokémon manga, where it is owned by protagonist Red.
- As a character in various other Pokémon media, such as spin-off games and related merchandise.
Bulbasaur is also a central character in the Pokémon franchise, often appearing alongside other Pokémon and being a key part of the Pokémon world.
References:
- https://en.wikipedia.org/wiki/Bulbasaur
```py
phrase = "\n\nThanks for trying our RAG application! If you have more questions about"
print(runner.generate_response(example_prompts,
[ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)]
))
```
> LLM response:
Bulbasaur is a fictional Pokémon species in the Pokémon franchise. It is a Grass and Poison-type Pokémon, characterized by its distinctive appearance.
Thanks for trying our RAG application! If you have more questions about Bulbasaur, feel free to ask.
With each generation we were able to add the `phrase` string right before the end of the generation.
### 4. MultipleChoiceLogitsProcessor
Guide the model to answer multiple-choice questions by selecting one of the given options.
This processor is particularly useful in tasks requiring strict adherence to a structured answer format,
such as quizzes, surveys, or decision-making support systems.
```py
example_prompts = [
"""
I am getting a lot of calls during the day. What is more important for me to consider when I buy a new phone?
0. Camera
1. Battery
2. Operating System
3. Screen Resolution
Answer:
""",
]
mclp = MultipleChoiceLogitsProcessor(
runner.tokenizer,
choices=["0", "1", "2", "3"],
delimiter="."
)
print(runner.generate_response(example_prompts, [mclp], max_tokens=1))
```
> LLM response:
1
Here our model does not generate anything other than the choice. This is an immensely helpful attribute while
working with agents or using models for multiple choice questions.
## Wrapping Up
Whether you are generating concise summaries, crafting chatbot responses, or solving structured tasks like multiple-choice questions, logit processors provide the flexibility to control outputs effectively. This makes them invaluable for scenarios where precision, adherence to constraints, or task-specific behavior is critical.
If you're interested in exploring more about how to control generation with logit processors, here are some resources to get started:
- [How to Generate Text with Transformers](https://huggingface.co./blog/how-to-generate) – A beginner-friendly guide to understanding text generation in 🤗 Transformers.
- [Hugging Face: Generation Strategies](https://huggingface.co./docs/transformers/en/generation_strategies) – Learn about decoding strategies like greedy search, beam search, and top-k sampling.
- [Hugging Face: LogitsProcessor API](https://huggingface.co./docs/transformers/en/internal/generation_utils#logitsprocessor) – Dive deeper into how logits processing works in 🤗 Transformers and how to create custom logits processors.
- [NVIDIA's LogitsProcessorZoo](https://github.com/NVIDIA/logits-processor-zoo) – Explore the full range of logits processors available in NVIDIA’s library with examples and use cases.
With NVIDIA's LogitsProcessorZoo and Hugging Face's tools, you have a robust ecosystem to take your language model applications to the next level. Experiment with these libraries, build custom solutions, and share your creations with the community to push the boundaries of what's possible with generative AI. | [
[
"llm",
"transformers",
"implementation",
"tutorial",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"text_generation",
"implementation"
] | null | null |
d0b6acb1-80ed-4481-8e31-2f71a44d492a | completed | 2025-01-16T03:09:11.596661 | 2025-01-19T19:03:46.763567 | 47cb5779-ebdc-4388-8479-499c3efc964e | Tool Use, Unified | rocketknight1 | unified-tool-use.md | There is now a **unified tool use API** across several popular families of models. This API means the same code is portable - few or no model-specific changes are needed to use tools in chats with [Mistral](https://huggingface.co./mistralai), [Cohere](https://huggingface.co./CohereForAI), [NousResearch](https://huggingface.co./NousResearch) or [Llama](https://huggingface.co./collections/meta-llama/llama-31-669fc079a0c406a149a5738f) models. In addition, Transformers now includes helper functionality to make tool calling even easier, as well as [complete documentation](https://huggingface.co./docs/transformers/main/chat_templating#advanced-tool-use--function-calling) and [examples](https://github.com/huggingface/blog/blob/main/notebooks/unified-tool-calling.ipynb) for the entire tool use process. Support for even more models will be added in the near future.
## Introduction
Tool use is a curious feature – everyone thinks it’s great, but most people haven’t tried it themselves. Conceptually, it’s very straightforward: you give some tools (callable functions) to your LLM, and it can decide to call them to help it respond to user queries. Maybe you give it a calculator so it doesn’t have to rely on its internal, unreliable arithmetic abilities. Maybe you let it search the web or view your calendar, or you give it (read-only!) access to a company database so it can pull up information or search technical documentation.
Tool use overcomes a lot of the core limitations of LLMs. Many LLMs are fluent and loquacious but often imprecise with calculations and facts and hazy on specific details of more niche topics. They don’t know anything that happened after their training cutoff date. They are generalists; they arrive into the conversation with no idea of you or your workplace beyond what you give them in the system message. Tools provide them with access to structured, specific, relevant, and up-to-date information that can help a lot in making them into genuinely helpful partners rather than just fascinating novelty.
The problems arise, however, when you actually try to implement tool use. Documentation is often sparse, inconsistent, and even contradictory - and this is true for both closed-source APIs as well as open-access models! Although tool use is simple in theory, it frequently becomes a nightmare in practice: How do you pass tools to the model? How do you ensure the tool prompts match the formats it was trained with? When the model calls a tool, how do you incorporate that into the chat? If you’ve tried to implement tool use before, you’ve probably found that these questions are surprisingly tricky and that the documentation wasn’t always complete and helpful.
Worse, different models can have wildly different implementations of tool use. Even at the most basic level of defining the available tools, some providers expect JSON schemas, while others expect Python function headers. Even among the ones that expect JSON schemas, small details often differ and create big API incompatibilities. This creates a lot of friction and generally just deepens user confusion. So, what can we do about all of this?
## Chat Templating
Devoted fans of the Hugging Face Cinematic Universe will remember that the open-source community faced a similar challenge in the past with **chat models**. Chat models use control tokens like `<|start_of_user_turn|>` or `<|end_of_message|>` to let the model know what’s going on in the chat, but different models were trained with totally different control tokens, which meant that users needed to write specific formatting code for each model they wanted to use. This was a huge headache at the time.
Our solution to this was **chat templates** - essentially, models would come with a tiny [Jinja](https://jinja.palletsprojects.com/en/3.1.x/) template, which would render chats with the right format and control tokens for each model. Chat templates meant that users could write chats in a universal, model-agnostic format, trusting in the Jinja templates to handle any model-specific formatting required.
The obvious approach to supporting tool use, then, was to extend chat templates to support tools as well. And that’s exactly what we did, but tools created many new challenges for the templating system. Let’s go through those challenges and how we solved them. In the process, hopefully, you’ll gain a deeper understanding of how the system works and how you can make it work for you.
## Passing tools to a chat template
Our first criterion when designing the tool use API was that it should be intuitive to define tools and pass them to the chat template. We found that most users wrote their tool functions first and then figured out how to generate tool definitions from them and pass those to the model. This led to an obvious approach: What if users could simply pass functions directly to the chat template and let it generate tool definitions for them?
The problem here, though, is that “passing functions” is a very language-specific thing to do, and lots of people access chat models through [JavaScript](https://huggingface.co./docs/transformers.js/en/index) or [Rust](https://huggingface.co./docs/text-generation-inference/en/index) instead of Python. So, we found a compromise that we think offers the best of both worlds: **Chat templates expect tools to be defined as JSON schema, but if you pass Python functions to the template instead, they will be automatically converted to JSON schema for you.** This results in a nice, clean API:
```python
def get_current_temperature(location: str):
"""
Gets the temperature at a given location.
Args:
location: The location to get the temperature for
"""
return 22.0 # bug: Sometimes the temperature is not 22. low priority
tools = [get_current_temperature]
chat = [
{"role": "user", "content": "Hey, what's the weather like in Paris right now?"}
]
tool_prompt = tokenizer.apply_chat_template(
chat,
tools=tools,
add_generation_prompt=True,
return_tensors="pt"
)
```
Internally, the `get_current_temperature` function will be expanded into a complete JSON schema. If you want to see the generated schema, you can use the `get_json_schema` function:
```python
>>> from transformers.utils import get_json_schema
>>> get_json_schema(get_current_weather)
{
"type": "function",
"function": {
"name": "get_current_temperature",
"description": "Gets the temperature at a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The location to get the temperature for"
}
},
"required": [
"location"
]
}
}
}
```
If you prefer manual control or you’re coding in a language other than Python, you can pass JSON schemas like these directly to the template. However, when you’re working in Python, you can avoid handling JSON schema directly. All you need to do is define your tool functions with clear **names,** accurate **type hints**, and complete **docstrings,** including **argument docstrings,** since all of these will be used to generate the JSON schema that will be read by the template. Much of this is good Python practice anyway, and if you follow it, then you’ll find that no extra work is required - your functions are already usable as tools!
Remember: accurate JSON schemas, whether generated from docstrings and type hints or specified manually, are crucial for the model to understand how to use your tools. The model will never see the code inside your functions, but it will see the JSON schemas. The cleaner and more accurate they are, the better!
## Adding tool calls to the chat
One detail that is often overlooked by users (and model documentation 😬) is that when a model calls a tool, this actually requires **two** messages to be added to the chat history. The first message is the assistant **calling** the tool, and the second is the **tool response,** the output of the called function.
Both tool calls and tool responses are necessary - remember that the model only knows what’s in the chat history, and it will not be able to make sense of a tool response if it can’t also see the call it made and the arguments it passed to get that response. “22” on its own is not very informative, but it’s very helpful if you know that the message preceding it was `get_current_temperature("Paris, France")`.
This is one of the areas that can be extremely divergent between different providers, but the standard we settled on is that **tool calls are a field of assistant messages,** like so:
```python
message = {
"role": "assistant",
"tool_calls": [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"arguments": {
"location": "Paris, France"
}
}
}
]
}
chat.append(message)
```
## Adding tool responses to the chat
Tool responses are much simpler, especially when tools only return a single string or number.
```python
message = {
"role": "tool",
"name": "get_current_temperature",
"content": "22.0"
}
chat.append(message)
```
## Tool use in action
Let’s take the code we have so far and build a complete example of tool-calling. If you want to use tools in your own projects, we recommend playing around with the code here - try running it yourself, adding or removing tools, swapping models, and tweaking details to get a feel for the system. That familiarity will make things much easier when the time comes to implement tool use in your software! To make that easier, this example is [available as a notebook](https://github.com/huggingface/blog/blob/main/notebooks/unified-tool-calling.ipynb) as well.
First, let’s set up our model. We’ll use `Hermes-2-Pro-Llama-3-8B` because it’s small, capable, ungated, and it supports tool calling. You may get better results on complex tasks if you use a larger model, though!
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "NousResearch/Hermes-2-Pro-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
```
Next, we’ll set up our tool and the chat we want to use. Let’s use the `get_current_temperature` example from above:
```python
def get_current_temperature(location: str):
"""
Gets the temperature at a given location.
Args:
location: The location to get the temperature for, in the format "city, country"
"""
return 22.0 # bug: Sometimes the temperature is not 22. low priority to fix tho
tools = [get_current_temperature]
chat = [
{"role": "user", "content": "Hey, what's the weather like in Paris right now?"}
]
tool_prompt = tokenizer.apply_chat_template(
chat,
tools=tools,
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
)
tool_prompt = tool_prompt.to(model.device)
```
Now we’re ready to generate the model’s response to the user query, given the tools it has access to:
```python
out = model.generate(**tool_prompt, max_new_tokens=128)
generated_text = out[0, tool_prompt['input_ids'].shape[1]:]
print(tokenizer.decode(generated_text))
```
and we get:
```python
<tool_call>
{"arguments": {"location": "Paris, France"}, "name": "get_current_temperature"}
</tool_call><|im_end|>
```
The model has requested a tool! Note how it correctly inferred that it should pass the argument “Paris, France” rather than just “Paris”, because that is the format recommended by the function docstring.
The model does not really have programmatic access to the tools, though - like all language models, it just generates text. It's up to you as the programmer to take the model's request and call the function. First, though, let’s add the model's tool request to the chat.
Note that this step can require a little bit of manual processing - although you should always add the request to the chat in the format below, the text of the tool call request, such as the `<tool_call>` tags, may differ between models. Usually, it's quite intuitive, but bear in mind you may need a little bit of model-specific `json.loads()` or `re.search()` when trying this in your own code!
```python
message = {
"role": "assistant",
"tool_calls": [
{
"type": "function",
"function": {
"name": "get_current_temperature",
"arguments": {"location": "Paris, France"}
}
}
]
}
chat.append(message)
```
Now, we actually call the tool in our Python code, and we add its response to the chat:
```python
message = {
"role": "tool",
"name": "get_current_temperature",
"content": "22.0"
}
chat.append(message)
```
And finally, just as we did before, we format the updated chat and pass it to the model, so that it can use the tool response in conversation:
```python
tool_prompt = tokenizer.apply_chat_template(
chat,
tools=tools,
return_tensors="pt",
return_dict=True,
add_generation_prompt=True,
)
tool_prompt = tool_prompt.to(model.device)
out = model.generate(**tool_prompt, max_new_tokens=128)
generated_text = out[0, tool_prompt['input_ids'].shape[1]:]
print(tokenizer.decode(generated_text))
```
And we get the final response to the user, built using information from the intermediate tool calling step:
```html
The current temperature in Paris is 22.0 degrees Celsius. Enjoy your day!<|im_end|>
```
## The regrettable disunity of response formats
While reading this example, you may have noticed that even though chat templates can hide model-specific differences when converting from chats and tool definitions to formatted text, the same isn’t true in reverse. When the model emits a tool call, it will do so in its own format, so you’ll need to parse it out manually for now before adding it to the chat in the universal format. Thankfully, most of the formats are pretty intuitive, so this should only be a couple of lines of `json.loads()` or, at worst, a simple `re.search()` to create the tool call dict you need.
Still, this is the biggest part of the process that remains "un-unified." We have some ideas on how to fix it, but they’re not quite ready for prime time yet. “Let us cook,” as the kids say.
## Conclusion
Despite the minor caveat above, we think this is a big improvement from the previous situation, where tool use was scattered, confusing, and poorly documented. We hope this makes it a lot easier for open-source developers to include tool use in their projects, augmenting powerful LLMs with a range of tools that add amazing new capabilities. From smaller models like [Hermes-2-Pro-8B](https://huggingface.co./NousResearch/Hermes-2-Pro-Llama-3-8B) to the giant state-of-the-art behemoths like [Mistral-Large](https://huggingface.co./mistralai/Mistral-Large-Instruct-2407), [Command-R-Plus](https://huggingface.co./CohereForAI/c4ai-command-r-plus) or [Llama-3.1-405B](https://huggingface.co./meta-llama/Meta-Llama-3.1-405B-Instruct), many of the LLMs at the cutting edge now support tool use. We think tools will be an integral part of the next wave of LLM products, and we hope these changes make it easier for you to use them in your own projects. Good luck! | [
[
"llm",
"transformers",
"implementation",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"tools",
"implementation"
] | null | null |
626be6f9-2ba4-4126-a7b2-47136499f3fa | completed | 2025-01-16T03:09:11.596666 | 2025-01-16T15:08:57.516698 | cf1aa208-72c9-4cd6-b39a-33e53e433237 | ControlNet in 🧨 Diffusers | sayakpaul, yiyixu, patrickvonplaten | controlnet.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Ever since Stable Diffusion took the world by storm, people have been looking for ways to have more control over the results of the generation process. ControlNet provides a minimal interface allowing users to customize the generation process up to a great extent. With [ControlNet](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet), users can easily condition the generation with different spatial contexts such as a depth map, a segmentation map, a scribble, keypoints, and so on!
We can turn a cartoon drawing into a realistic photo with incredible coherence.
<table>
<tr style="text-align: center;">
<th>Realistic Lofi Girl</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/lofi.jpg" width=300 /></td>
</tr>
</table>
Or even use it as your interior designer.
<table>
<tr style="text-align: center;">
<th>Before</th>
<th>After</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/house_depth.png" width=300/></td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/house_after.jpeg" width=300/></td>
</tr>
</table>
You can turn your sketch scribble into an artistic drawing.
<table>
<tr style="text-align: center;">
<th>Before</th>
<th>After</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/drawing_before.png" width=300/></td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/drawing_after.jpeg" width=300/></td>
</tr>
</table>
Also, make some of the famous logos coming to life.
<table>
<tr style="text-align: center;">
<th>Before</th>
<th>After</th>
</tr>
<tr>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/starbucks_logo.jpeg" width=300/></td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/starbucks_after.png" width=300/></td>
</tr>
</table>
With ControlNet, the sky is the limit 🌠
In this blog post, we first introduce the [`StableDiffusionControlNetPipeline`](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet) and then show how it can be applied for various control conditionings. Let’s get controlling!
## ControlNet: TL;DR
ControlNet was introduced in [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) by Lvmin Zhang and Maneesh Agrawala.
It introduces a framework that allows for supporting various spatial contexts that can serve as additional conditionings to Diffusion models such as Stable Diffusion.
The diffusers implementation is adapted from the original [source code](https://github.com/lllyasviel/ControlNet/).
Training ControlNet is comprised of the following steps:
1. Cloning the pre-trained parameters of a Diffusion model, such as Stable Diffusion's latent UNet, (referred to as “trainable copy”) while also maintaining the pre-trained parameters separately (”locked copy”). It is done so that the locked parameter copy can preserve the vast knowledge learned from a large dataset, whereas the trainable copy is employed to learn task-specific aspects.
2. The trainable and locked copies of the parameters are connected via “zero convolution” layers (see [here](https://github.com/lllyasviel/ControlNet#controlnet) for more information) which are optimized as a part of the ControlNet framework. This is a training trick to preserve the semantics already learned by frozen model as the new conditions are trained.
Pictorially, training a ControlNet looks like so:
<p align="center">
<img src="https://github.com/lllyasviel/ControlNet/raw/main/github_page/sd.png" alt="controlnet-structure"><br>
<em>The diagram is taken from <a href=https://github.com/lllyasviel/ControlNet/blob/main/github_page/sd.png>here</a>.</em>
</p>
A sample from the training set for ControlNet-like training looks like this (additional conditioning is via edge maps):
<table>
<tr style="text-align: center;">
<th>Prompt</th>
<th>Original Image</th>
<th>Conditioning</th>
</tr>
<tr style="text-align: center;">
<td style="vertical-align: middle">"bird"</td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/original_bird.png" width=200/></td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/canny_map.png" width=200/></td>
</tr>
</table>
Similarly, if we were to condition ControlNet with semantic segmentation maps, a training sample would be like so:
<table>
<tr style="text-align: center;">
<th>Prompt</th>
<th>Original Image</th>
<th>Conditioning</th>
</tr>
<tr style="text-align: center;">
<td style="vertical-align: middle">"big house"</td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/original_house.png" width=300/></td>
<td><img class="mx-auto" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/segmentation_map.png" width=300/></td>
</tr>
</table>
Every new type of conditioning requires training a new copy of ControlNet weights.
The paper proposed 8 different conditioning models that are all [supported](https://huggingface.co./lllyasviel?search=controlnet) in Diffusers!
For inference, both the pre-trained diffusion models weights as well as the trained ControlNet weights are needed. For example, using [Stable Diffusion v1-5](https://huggingface.co./runwayml/stable-diffusion-v1-5)
with a ControlNet checkpoint require roughly 700 million more parameters compared to just using the original Stable Diffusion model, which makes ControlNet a bit more memory-expensive for inference.
Because the pre-trained diffusion models are locked during training, one only needs to switch out the ControlNet parameters when using a different conditioning. This makes it fairly simple
to deploy multiple ControlNet weights in one application as we will see below.
## The `StableDiffusionControlNetPipeline`
Before we begin, we want to give a huge shout-out to the community contributor [Takuma Mori](https://github.com/takuma104) for having led the integration of ControlNet into Diffusers ❤️ .
To experiment with ControlNet, Diffusers exposes the [`StableDiffusionControlNetPipeline`](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet) similar to
the [other Diffusers pipelines](https://huggingface.co./docs/diffusers/api/pipelines/overview). Central to the `StableDiffusionControlNetPipeline` is the `controlnet` argument which lets us provide a particular trained [`ControlNetModel`](https://huggingface.co./docs/diffusers/main/en/api/models#diffusers.ControlNetModel) instance while keeping the pre-trained diffusion model weights the same.
We will explore different use cases with the `StableDiffusionControlNetPipeline` in this blog post. The first ControlNet model we are going to walk through is the [Canny model](https://huggingface.co./runwayml/stable-diffusion-v1-5) - this is one of the most popular models that generated some of the amazing images you are libely seeing on the internet.
We welcome you to run the code snippets shown in the sections below with [this Colab Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb).
Before we begin, let's make sure we have all the necessary libraries installed:
```bash
pip install diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
```
To process different conditionings depending on the chosen ControlNet, we also need to install some
additional dependencies:
- [OpenCV](https://opencv.org/)
- [controlnet-aux](https://github.com/patrickvonplaten/controlnet_aux#controlnet-auxiliary-models) - a simple collection of pre-processing models for ControlNet
```bash
pip install opencv-contrib-python
pip install controlnet_aux
```
We will use the famous painting ["Girl With A Pearl"](https://en.wikipedia.org/wiki/Girl_with_a_Pearl_Earring) for this example. So, let's download the image and take a look:
```python
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image
```
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_6_output_0.jpeg" width=600/>
</p>
Next, we will put the image through the canny pre-processor:
```python
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image
```
As we can see, it is essentially edge detection:
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_10_output_0.jpeg" width=600/>
</p>
Now, we load [runwaylml/stable-diffusion-v1-5](https://huggingface.co./runwayml/stable-diffusion-v1-5) as well as the [ControlNet model for canny edges](https://huggingface.co./lllyasviel/sd-controlnet-canny).
The models are loaded in half-precision (`torch.dtype`) to allow for fast and memory-efficient inference.
```python
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
```
Instead of using Stable Diffusion's default [PNDMScheduler](https://huggingface.co./docs/diffusers/main/en/api/schedulers/pndm), we use one of the currently fastest
diffusion model schedulers, called [UniPCMultistepScheduler](https://huggingface.co./docs/diffusers/main/en/api/schedulers/unipc).
Choosing an improved scheduler can drastically reduce inference time - in our case we are able to reduce the number of inference steps from 50 to 20 while more or less
keeping the same image generation quality. More information regarding schedulers can be found [here](https://huggingface.co./docs/diffusers/main/en/using-diffusers/schedulers).
```python
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
```
Instead of loading our pipeline directly to GPU, we instead enable smart CPU offloading which
can be achieved with the [`enable_model_cpu_offload` function](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet#diffusers.StableDiffusionControlNetPipeline.enable_model_cpu_offload).
Remember that during inference diffusion models, such as Stable Diffusion require not just one but multiple model components that are run sequentially.
In the case of Stable Diffusion with ControlNet, we first use the CLIP text encoder, then the diffusion model unet and control net, then the VAE decoder and finally run a safety checker.
Most components are only run once during the diffusion process and are thus not required to occupy GPU memory all the time. By enabling smart model offloading, we make sure
that each component is only loaded into GPU when it's needed so that we can significantly save memory consumption without significantly slowing down infenence.
**Note**: When running `enable_model_cpu_offload`, do not manually move the pipeline to GPU with `.to("cuda")` - once CPU offloading is enabled, the pipeline automatically takes care of GPU memory management.
```py
pipe.enable_model_cpu_offload()
```
Finally, we want to take full advantage of the amazing [FlashAttention/xformers](https://github.com/facebookresearch/xformers) attention layer acceleration, so let's enable this! If this command does not work for you, you might not have `xformers` correctly installed.
In this case, you can just skip the following line of code.
```py
pipe.enable_xformers_memory_efficient_attention()
```
Now we are ready to run the ControlNet pipeline!
We still provide a prompt to guide the image generation process, just like what we would normally do with a Stable Diffusion image-to-image pipeline. However, ControlNet will allow a lot more control over the generated image because we will be able to control the exact composition in generated image with the canny edge image we just created.
It will be fun to see some images where contemporary celebrities posing for this exact same painting from the 17th century. And it's really easy to do that with ControlNet, all we have to do is to include the names of these celebrities in the prompt!
Let's first create a simple helper function to display images as a grid.
```python
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
```
Next, we define the input prompts and set a seed for reproducability.
```py
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]]
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]
```
Finally, we can run the pipeline and display the image!
```py
output = pipe(
prompt,
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
num_inference_steps=20,
generator=generator,
)
image_grid(output.images, 2, 2)
```
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_16_output_1.jpeg" width=600/>
</p>
We can effortlessly combine ControlNet with fine-tuning too! For example, we can fine-tune a model with [DreamBooth](https://huggingface.co./docs/diffusers/main/en/training/dreambooth), and use it to render ourselves into different scenes.
In this post, we are going to use our beloved Mr Potato Head as an example to show how to use ControlNet with DreamBooth.
We can use the same ControlNet. However, instead of using the Stable Diffusion 1.5, we are going to load the [Mr Potato Head model](https://huggingface.co./sd-dreambooth-library/mr-potato-head) into our pipeline - Mr Potato Head is a Stable Diffusion model fine-tuned with Mr Potato Head concept using Dreambooth 🥔
Let's run the above commands again, keeping the same controlnet though!
```python
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
```
Now let's make Mr Potato posing for [Johannes Vermeer](https://en.wikipedia.org/wiki/Johannes_Vermeer)!
```python
generator = torch.manual_seed(2)
prompt = "a photo of sks mr potato head, best quality, extremely detailed"
output = pipe(
prompt,
canny_image,
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=20,
generator=generator,
)
output.images[0]
```
It is noticeable that Mr Potato Head is not the best candidate but he tried his best and did a pretty good job in capturing some of the essence 🍟
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_22_output_0.jpeg" width=600/>
</p>
Another exclusive application of ControlNet is that we can take a pose from one image and reuse it to generate a different image with the exact same pose. So in this next example, we are going to teach superheroes how to do yoga using [Open Pose ControlNet](https://huggingface.co./lllyasviel/sd-controlnet-openpose)!
First, we will need to get some images of people doing yoga:
```python
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://huggingface.co./datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)
```
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_25_output_0.jpeg" width=600/>
</p>
Now let's extract yoga poses using the OpenPose pre-processors that are handily available via `controlnet_aux`.
```python
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
```
<p align="center">
<img src="https://huggingface.co./datasets/YiYiXu/test-doc-assets/resolve/main/blog_post_cell_28_output_0.jpeg" width=600/>
</p>
To use these yoga poses to generate new images, let's create a [Open Pose ControlNet](https://huggingface.co./lllyasviel/sd-controlnet-openpose). We will generate some super-hero images but in the yoga poses shown above. Let's go 🚀
```python
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
```
Now it's yoga time!
```python
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/anime_do_yoga.png" width=600/>
</p>
### Combining multiple conditionings
Multiple ControlNet conditionings can be combined for a single image generation. Pass a list of ControlNets to the pipeline's constructor and a corresponding list of conditionings to `__call__`.
When combining conditionings, it is helpful to mask conditionings such that they do not overlap. In the example, we mask the middle of the canny map where the pose conditioning is located.
It can also be helpful to vary the `controlnet_conditioning_scale`s to emphasize one conditioning over the other.
#### Canny conditioning
The original image
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png" width=600/>
</p>
Prepare the conditioning
```python
from diffusers.utils import load_image
from PIL import Image
import cv2
import numpy as np
from diffusers.utils import load_image
canny_image = load_image(
"https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/landscape.png"
)
canny_image = np.array(canny_image)
low_threshold = 100
high_threshold = 200
canny_image = cv2.Canny(canny_image, low_threshold, high_threshold)
# zero out middle columns of image where pose will be overlayed
zero_start = canny_image.shape[1] // 4
zero_end = zero_start + canny_image.shape[1] // 2
canny_image[:, zero_start:zero_end] = 0
canny_image = canny_image[:, :, None]
canny_image = np.concatenate([canny_image, canny_image, canny_image], axis=2)
canny_image = Image.fromarray(canny_image)
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/landscape_canny_masked.png" width=600/>
</p>
#### Openpose conditioning
The original image
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/person.png" width=600/>
</p>
Prepare the conditioning
```python
from controlnet_aux import OpenposeDetector
from diffusers.utils import load_image
openpose = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
openpose_image = load_image(
"https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/diffusers/person.png"
)
openpose_image = openpose(openpose_image)
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/person_pose.png" width=600/>
</p>
#### Running ControlNet with multiple conditionings
```python
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
import torch
controlnet = [
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose", torch_dtype=torch.float16),
ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16),
]
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
prompt = "a giant standing in a fantasy landscape, best quality"
negative_prompt = "monochrome, lowres, bad anatomy, worst quality, low quality"
generator = torch.Generator(device="cpu").manual_seed(1)
images = [openpose_image, canny_image]
image = pipe(
prompt,
images,
num_inference_steps=20,
generator=generator,
negative_prompt=negative_prompt,
controlnet_conditioning_scale=[1.0, 0.8],
).images[0]
image.save("./multi_controlnet_output.png")
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/controlnet/multi_controlnet_output.png" width=600/>
</p>
Throughout the examples, we explored multiple facets of the [`StableDiffusionControlNetPipeline`](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet) to show how easy and intuitive it is play around with ControlNet via Diffusers. However, we didn't cover all types of conditionings supported by ControlNet. To know more about those, we encourage you to check out the respective model documentation pages:
* [lllyasviel/sd-controlnet-depth](https://huggingface.co./lllyasviel/sd-controlnet-depth)
* [lllyasviel/sd-controlnet-hed](https://huggingface.co./lllyasviel/sd-controlnet-hed)
* [lllyasviel/sd-controlnet-normal](https://huggingface.co./lllyasviel/sd-controlnet-normal)
* [lllyasviel/sd-controlnet-scribble](https://huggingface.co./lllyasviel/sd-controlnet-scribble)
* [lllyasviel/sd-controlnet-seg](https://huggingface.co./lllyasviel/sd-controlnet-scribble)
* [lllyasviel/sd-controlnet-openpose](https://huggingface.co./lllyasviel/sd-controlnet-openpose)
* [lllyasviel/sd-controlnet-mlsd](https://huggingface.co./lllyasviel/sd-controlnet-mlsd)
* [lllyasviel/sd-controlnet-canny](https://huggingface.co./lllyasviel/sd-controlnet-canny)
We welcome you to combine these different elements and share your results with [@diffuserslib](https://twitter.com/diffuserslib). Be sure to check out [the Colab Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/controlnet.ipynb) to take some of the above examples for a spin!
We also showed some techniques to make the generation process faster and memory-friendly by using a fast scheduler, smart model offloading and `xformers`. With these techniques combined the generation process takes only ~3 seconds on a V100 GPU and consumes just ~4 GBs of VRAM for a single image ⚡️ On free services like Google Colab, generation takes about 5s on the default GPU (T4), whereas the original implementation requires 17s to create the same result! Combining all the pieces in the `diffusers` toolbox is a real superpower 💪
## Conclusion
We have been playing a lot with [`StableDiffusionControlNetPipeline`](https://huggingface.co./docs/diffusers/main/en/api/pipelines/stable_diffusion/controlnet), and our experience has been fun so far! We’re excited to see what the community builds on top of this pipeline. If you want to check out other pipelines and techniques supported in Diffusers that allow for controlled generation, check out our [official documentation](https://huggingface.co./docs/diffusers/main/en/using-diffusers/controlling_generation).
If you cannot wait to try out ControlNet directly, we got you covered as well! Simply click on one of the following spaces to play around with ControlNet:
- [](https://huggingface.co./spaces/diffusers/controlnet-canny)
- [](https://huggingface.co./spaces/diffusers/controlnet-openpose) | [
[
"computer_vision",
"implementation",
"tutorial",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"implementation",
"tutorial"
] | null | null |
6be3bdec-77dc-448b-8994-48b329ffc2f0 | completed | 2025-01-16T03:09:11.596670 | 2025-01-16T13:38:20.537959 | 4926d2f8-2b5d-4c1b-909d-e847ae0b248c | Transformers.js v3: WebGPU Support, New Models & Tasks, and More… | xenova | transformersjs-v3.md | After more than a year of development, we're excited to announce the release of 🤗 Transformers.js v3!
Highlights include:
- [WebGPU support (up to 100x faster than WASM!)](#webgpu-support)
- [New quantization formats (dtypes)](#new-quantization-formats-dtypes)
- [A total of 120 supported architectures](#120-supported-architectures)
- [25 new example projects and templates](#example-projects-and-templates)
- [Over 1200 pre-converted models on the Hugging Face Hub](#over-1200-pre-converted-models)
- [Node.js (ESM + CJS), Deno, and Bun compatibility](#nodejs-esm--cjs-deno-and-bun-compatibility)
- [A new home on GitHub and NPM](#a-new-home-on-npm-and-github)
## Installation
You can get started by installing Transformers.js v3 from [NPM](https://www.npmjs.com/package/@huggingface/transformers) using:
```bash
npm i @huggingface/transformers
```
Then, importing the library with
```js
import { pipeline } from "@huggingface/transformers";
```
or, via a CDN
```js
import { pipeline } from "https://cdn.jsdelivr.net/npm/@huggingface/[email protected]";
```
For more information, check out the [documentation](https://hf.co/docs/transformers.js).
## WebGPU support
WebGPU is a new web standard for accelerated graphics and compute. The [API](https://developer.mozilla.org/en-US/docs/Web/API/WebGPU_API) enables web developers to use the underlying system's GPU to carry out high-performance computations directly in the browser. WebGPU is the successor to [WebGL](https://developer.mozilla.org/en-US/docs/Web/API/WebGL_API) and provides significantly better performance, because it allows for more direct interaction with modern GPUs. Lastly, it supports general-purpose GPU computations, which makes it just perfect for machine learning!
> [!WARNING]
> As of October 2024, global WebGPU support is around 70% (according to [caniuse.com](https://caniuse.com/webgpu)), meaning some users may not be able to use the API.
>
> If the following demos do not work in your browser, you may need to enable it using a feature flag:
>
> - Firefox: with the `dom.webgpu.enabled` flag (see [here](https://developer.mozilla.org/en-US/docs/Mozilla/Firefox/Experimental_features#:~:text=tested%20by%20Firefox.-,WebGPU%20API,-The%20WebGPU%20API)).
> - Safari: with the `WebGPU` feature flag (see [here](https://webkit.org/blog/14879/webgpu-now-available-for-testing-in-safari-technology-preview/)).
> - Older Chromium browsers (on Windows, macOS, Linux): with the `enable-unsafe-webgpu` flag (see [here](https://developer.chrome.com/docs/web-platform/webgpu/troubleshooting-tips)).
### Usage in Transformers.js v3
Thanks to our collaboration with [ONNX Runtime Web](https://www.npmjs.com/package/onnxruntime-web), enabling WebGPU acceleration is as simple as setting `device: 'webgpu'` when loading a model. Let's see some examples!
**Example:** Compute text embeddings on WebGPU ([demo](https://v2.scrimba.com/s06a2smeej))
```js
import { pipeline } from "@huggingface/transformers";
// Create a feature-extraction pipeline
const extractor = await pipeline(
"feature-extraction",
"mixedbread-ai/mxbai-embed-xsmall-v1",
{ device: "webgpu" },
);
// Compute embeddings
const texts = ["Hello world!", "This is an example sentence."];
const embeddings = await extractor(texts, { pooling: "mean", normalize: true });
console.log(embeddings.tolist());
// [
// [-0.016986183822155, 0.03228696808218956, -0.0013630966423079371, ... ],
// [0.09050482511520386, 0.07207386940717697, 0.05762749910354614, ... ],
// ]
```
**Example:** Perform automatic speech recognition with OpenAI whisper on WebGPU ([demo](https://v2.scrimba.com/s0oi76h82g))
```js
import { pipeline } from "@huggingface/transformers";
// Create automatic speech recognition pipeline
const transcriber = await pipeline(
"automatic-speech-recognition",
"onnx-community/whisper-tiny.en",
{ device: "webgpu" },
);
// Transcribe audio from a URL
const url = "https://huggingface.co./datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav";
const output = await transcriber(url);
console.log(output);
// { text: ' And so my fellow Americans ask not what your country can do for you, ask what you can do for your country.' }
```
**Example:** Perform image classification with MobileNetV4 on WebGPU ([demo](https://v2.scrimba.com/s0fv2uab1t))
```js
import { pipeline } from "@huggingface/transformers";
// Create image classification pipeline
const classifier = await pipeline(
"image-classification",
"onnx-community/mobilenetv4_conv_small.e2400_r224_in1k",
{ device: "webgpu" },
);
// Classify an image from a URL
const url = "https://huggingface.co./datasets/Xenova/transformers.js-docs/resolve/main/tiger.jpg";
const output = await classifier(url);
console.log(output);
// [
// { label: 'tiger, Panthera tigris', score: 0.6149784922599792 },
// { label: 'tiger cat', score: 0.30281734466552734 },
// { label: 'tabby, tabby cat', score: 0.0019135422771796584 },
// { label: 'lynx, catamount', score: 0.0012161266058683395 },
// { label: 'Egyptian cat', score: 0.0011465961579233408 }
// ]
```
## New quantization formats (dtypes)
Before Transformers.js v3, we used the `quantized` option to specify whether to use a quantized (q8) or full-precision (fp32) variant of the model by setting `quantized` to `true` or `false`, respectively. Now, we've added the ability to select from a much larger list with the `dtype` parameter.
The list of available quantizations depends on the model, but some common ones are: full-precision (`"fp32"`), half-precision (`"fp16"`), 8-bit (`"q8"`, `"int8"`, `"uint8"`), and 4-bit (`"q4"`, `"bnb4"`, `"q4f16"`).
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/dtypes-dark.jpg" style="max-width: 100%;">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/dtypes-light.jpg" style="max-width: 100%;">
<img alt="Available dtypes for mixedbread-ai/mxbai-embed-xsmall-v1" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/dtypes-dark.jpg" style="max-width: 100%;">
</picture>
<a href="https://huggingface.co./mixedbread-ai/mxbai-embed-xsmall-v1/tree/main/onnx">(e.g., mixedbread-ai/mxbai-embed-xsmall-v1)</a>
</p>
### Basic usage
**Example:** Run Qwen2.5-0.5B-Instruct in 4-bit quantization ([demo](https://v2.scrimba.com/s0dlcpv0ci))
```js
import { pipeline } from "@huggingface/transformers";
// Create a text generation pipeline
const generator = await pipeline(
"text-generation",
"onnx-community/Qwen2.5-0.5B-Instruct",
{ dtype: "q4", device: "webgpu" },
);
// Define the list of messages
const messages = [
{ role: "system", content: "You are a helpful assistant." },
{ role: "user", content: "Tell me a funny joke." },
];
// Generate a response
const output = await generator(messages, { max_new_tokens: 128 });
console.log(output[0].generated_text.at(-1).content);
```
### Per-module dtypes
Some encoder-decoder models, like Whisper or Florence-2, are extremely sensitive to quantization settings: especially of the encoder. For this reason, we added the ability to select per-module dtypes, which can be done by providing a mapping from module name to dtype.
**Example:** Run Florence-2 on WebGPU ([demo](https://v2.scrimba.com/s0pdm485fo))
```js
import { Florence2ForConditionalGeneration } from "@huggingface/transformers";
const model = await Florence2ForConditionalGeneration.from_pretrained(
"onnx-community/Florence-2-base-ft",
{
dtype: {
embed_tokens: "fp16",
vision_encoder: "fp16",
encoder_model: "q4",
decoder_model_merged: "q4",
},
device: "webgpu",
},
);
```
<p align="middle">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/florence-2-webgpu.gif" alt="Florence-2 running on WebGPU" />
</p>
<details>
<summary>
See full code example
</summary>
```js
import {
Florence2ForConditionalGeneration,
AutoProcessor,
AutoTokenizer,
RawImage,
} from "@huggingface/transformers";
// Load model, processor, and tokenizer
const model_id = "onnx-community/Florence-2-base-ft";
const model = await Florence2ForConditionalGeneration.from_pretrained(
model_id,
{
dtype: {
embed_tokens: "fp16",
vision_encoder: "fp16",
encoder_model: "q4",
decoder_model_merged: "q4",
},
device: "webgpu",
},
);
const processor = await AutoProcessor.from_pretrained(model_id);
const tokenizer = await AutoTokenizer.from_pretrained(model_id);
// Load image and prepare vision inputs
const url = "https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg";
const image = await RawImage.fromURL(url);
const vision_inputs = await processor(image);
// Specify task and prepare text inputs
const task = "<MORE_DETAILED_CAPTION>";
const prompts = processor.construct_prompts(task);
const text_inputs = tokenizer(prompts);
// Generate text
const generated_ids = await model.generate({
...text_inputs,
...vision_inputs,
max_new_tokens: 100,
});
// Decode generated text
const generated_text = tokenizer.batch_decode(generated_ids, {
skip_special_tokens: false,
})[0];
// Post-process the generated text
const result = processor.post_process_generation(
generated_text,
task,
image.size,
);
console.log(result);
// { '<MORE_DETAILED_CAPTION>': 'A green car is parked in front of a tan building. The building has a brown door and two brown windows. The car is a two door and the door is closed. The green car has black tires.' }
```
</details>
## 120 supported architectures
This release increases the total number of supported architectures to 120 (see [full list](https://huggingface.co./docs/transformers.js/index#models)), spanning a wide range of input modalities and tasks. Notable new names include: Phi-3, Gemma & Gemma 2, LLaVa, Moondream, Florence-2, MusicGen, Sapiens, Depth Pro, PyAnnote, and RT-DETR.
<p align="middle">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/architectures.png" alt="Bubble diagram of new architectures in Transformers.js v3" />
</p>
<details>
<summary>List of new models</summary>
1. **[Cohere](https://huggingface.co./docs/transformers/main/model_doc/cohere)** (from Cohere) released with the paper [Command-R: Retrieval Augmented Generation at Production Scale](https://txt.cohere.com/command-r/) by Cohere.
1. **[Decision Transformer](https://huggingface.co./docs/transformers/model_doc/decision_transformer)** (from Berkeley/Facebook/Google) released with the paper [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345) by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
1. **Depth Pro** (from Apple) released with the paper [Depth Pro: Sharp Monocular Metric Depth in Less Than a Second](https://arxiv.org/abs/2410.02073) by Aleksei Bochkovskii, Amaël Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R. Richter, Vladlen Koltun.
1. **Florence2** (from Microsoft) released with the paper [Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks](https://arxiv.org/abs/2311.06242) by Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan.
1. **[Gemma](https://huggingface.co./docs/transformers/main/model_doc/gemma)** (from Google) released with the paper [Gemma: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/gemma-open-models/) by the Gemma Google team.
1. **[Gemma2](https://huggingface.co./docs/transformers/main/model_doc/gemma2)** (from Google) released with the paper [Gemma2: Open Models Based on Gemini Technology and Research](https://blog.google/technology/developers/google-gemma-2/) by the Gemma Google team.
1. **[Granite](https://huggingface.co./docs/transformers/main/model_doc/granite)** (from IBM) released with the paper [Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler](https://arxiv.org/abs/2408.13359) by Yikang Shen, Matthew Stallone, Mayank Mishra, Gaoyuan Zhang, Shawn Tan, Aditya Prasad, Adriana Meza Soria, David D. Cox, Rameswar Panda.
1. **[GroupViT](https://huggingface.co./docs/transformers/model_doc/groupvit)** (from UCSD, NVIDIA) released with the paper [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) by Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
1. **[Hiera](https://huggingface.co./docs/transformers/model_doc/hiera)** (from Meta) released with the paper [Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles](https://arxiv.org/pdf/2306.00989) by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer.
1. **JAIS** (from Core42) released with the paper [Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models](https://arxiv.org/pdf/2308.16149) by Neha Sengupta, Sunil Kumar Sahu, Bokang Jia, Satheesh Katipomu, Haonan Li, Fajri Koto, William Marshall, Gurpreet Gosal, Cynthia Liu, Zhiming Chen, Osama Mohammed Afzal, Samta Kamboj, Onkar Pandit, Rahul Pal, Lalit Pradhan, Zain Muhammad Mujahid, Massa Baali, Xudong Han, Sondos Mahmoud Bsharat, Alham Fikri Aji, Zhiqiang Shen, Zhengzhong Liu, Natalia Vassilieva, Joel Hestness, Andy Hock, Andrew Feldman, Jonathan Lee, Andrew Jackson, Hector Xuguang Ren, Preslav Nakov, Timothy Baldwin, Eric Xing.
1. **[LLaVa](https://huggingface.co./docs/transformers/model_doc/llava)** (from Microsoft Research & University of Wisconsin-Madison) released with the paper [Visual Instruction Tuning](https://arxiv.org/abs/2304.08485) by Haotian Liu, Chunyuan Li, Yuheng Li and Yong Jae Lee.
1. **[MaskFormer](https://huggingface.co./docs/transformers/model_doc/maskformer)** (from Meta and UIUC) released with the paper [Per-Pixel Classification is Not All You Need for Semantic Segmentation](https://arxiv.org/abs/2107.06278) by Bowen Cheng, Alexander G. Schwing, Alexander Kirillov.
1. **[MusicGen](https://huggingface.co./docs/transformers/model_doc/musicgen)** (from Meta) released with the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284) by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
1. **MobileCLIP** (from Apple) released with the paper [MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training](https://arxiv.org/abs/2311.17049) by Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, Oncel Tuzel.
1. **[MobileNetV1](https://huggingface.co./docs/transformers/model_doc/mobilenet_v1)** (from Google Inc.) released with the paper [MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications](https://arxiv.org/abs/1704.04861) by Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam.
1. **[MobileNetV2](https://huggingface.co./docs/transformers/model_doc/mobilenet_v2)** (from Google Inc.) released with the paper [MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381) by Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen.
1. **MobileNetV3** (from Google Inc.) released with the paper [Searching for MobileNetV3](https://arxiv.org/abs/1905.02244) by Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, Quoc V. Le, Hartwig Adam.
1. **MobileNetV4** (from Google Inc.) released with the paper [MobileNetV4 - Universal Models for the Mobile Ecosystem](https://arxiv.org/abs/2404.10518) by Danfeng Qin, Chas Leichner, Manolis Delakis, Marco Fornoni, Shixin Luo, Fan Yang, Weijun Wang, Colby Banbury, Chengxi Ye, Berkin Akin, Vaibhav Aggarwal, Tenghui Zhu, Daniele Moro, Andrew Howard.
1. **Moondream1** released in the repository [moondream](https://github.com/vikhyat/moondream) by vikhyat.
1. **OpenELM** (from Apple) released with the paper [OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework](https://arxiv.org/abs/2404.14619) by Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari.
1. **[Phi3](https://huggingface.co./docs/transformers/main/model_doc/phi3)** (from Microsoft) released with the paper [Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone](https://arxiv.org/abs/2404.14219) by Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, Xiren Zhou.
1. **[PVT](https://huggingface.co./docs/transformers/main/model_doc/pvt)** (from Nanjing University, The University of Hong Kong etc.) released with the paper [Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions](https://arxiv.org/pdf/2102.12122.pdf) by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao.
1. **PyAnnote** released in the repository [pyannote/pyannote-audio](https://github.com/pyannote/pyannote-audio) by Hervé Bredin.
1. **[RT-DETR](https://huggingface.co./docs/transformers/model_doc/rt_detr)** (from Baidu), released together with the paper [DETRs Beat YOLOs on Real-time Object Detection](https://arxiv.org/abs/2304.08069) by Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, Jie Chen.
1. **Sapiens** (from Meta AI) released with the paper [Sapiens: Foundation for Human Vision Models](https://arxiv.org/pdf/2408.12569) by Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, Shunsuke Saito.
1. **[ViTMAE](https://huggingface.co./docs/transformers/model_doc/vit_mae)** (from Meta AI) released with the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick.
1. **[ViTMSN](https://huggingface.co./docs/transformers/model_doc/vit_msn)** (from Meta AI) released with the paper [Masked Siamese Networks for Label-Efficient Learning](https://arxiv.org/abs/2204.07141) by Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Florian Bordes, Pascal Vincent, Armand Joulin, Michael Rabbat, Nicolas Ballas.
</details>
## Example projects and templates
As part of the release, we've published 25 new example projects and templates, primarily focused on showcasing WebGPU support! This includes demos like [Phi-3.5 WebGPU](https://github.com/huggingface/transformers.js-examples/tree/main/phi-3.5-webgpu) and [Whisper WebGPU](https://github.com/xenova/whisper-web/tree/experimental-webgpu), as shown below.
> [!NOTE]
> We're in the process of moving all our example projects and demos to https://github.com/huggingface/transformers.js-examples, so stay tuned for updates on this!
| <img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/phi-3.5-webgpu.gif" style="max-height: 500px;" alt="Phi-3.5 running on WebGPU" /> | <img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/transformersjs-v3/whisper-turbo-webgpu.gif" style="max-height: 500px;" alt="Whisper Turbo running on WebGPU" /> |
| : | [
[
"transformers",
"implementation",
"optimization",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"optimization",
"tools"
] | null | null |
f51c1630-11e7-4180-9c46-a28411c01c9b | completed | 2025-01-16T03:09:11.596675 | 2025-01-16T13:33:38.236502 | a1f28df5-422d-4bc9-9142-c82490b28b3d | Zero-shot image segmentation with CLIPSeg | tobiasc, nielsr | clipseg-zero-shot.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/123_clipseg-zero-shot.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**This guide shows how you can use [CLIPSeg](https://huggingface.co./docs/transformers/main/en/model_doc/clipseg), a zero-shot image segmentation model, using [`🤗 transformers`](https://huggingface.co./transformers). CLIPSeg creates rough segmentation masks that can be used for robot perception, image inpainting, and many other tasks. If you need more precise segmentation masks, we’ll show how you can refine the results of CLIPSeg on [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).**
Image segmentation is a well-known task within the field of computer vision. It allows a computer to not only know what is in an image (classification), where objects are in the image (detection), but also what the outlines of those objects are. Knowing the outlines of objects is essential in fields such as robotics and autonomous driving. For example, a robot has to know the shape of an object to grab it correctly. Segmentation can also be combined with [image inpainting](https://t.co/5q8YHSOfx7) to allow users to describe which part of the image they want to replace.
One limitation of most image segmentation models is that they only work with a fixed list of categories. For example, you cannot simply use a segmentation model trained on oranges to segment apples. To teach the segmentation model an additional category, you have to label data of the new category and train a new model, which can be costly and time-consuming. But what if there was a model that can already segment almost any kind of object, without any further training? That’s exactly what [CLIPSeg](https://arxiv.org/abs/2112.10003), a zero-shot segmentation model, achieves.
Currently, CLIPSeg still has its limitations. For example, the model uses images of 352 x 352 pixels, so the output is quite low-resolution. This means we cannot expect pixel-perfect results when we work with images from modern cameras. If we want more precise segmentations, we can fine-tune a state-of-the-art segmentation model, as shown in [our previous blog post](https://huggingface.co./blog/fine-tune-segformer). In that case, we can still use CLIPSeg to generate some rough labels, and then refine them in a labeling tool such as [Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg). Before we describe how to do that, let’s first take a look at how CLIPSeg works.
## CLIP: the magic model behind CLIPSeg
[CLIP](https://huggingface.co./docs/transformers/main/en/model_doc/clip), which stands for **C**ontrastive **L**anguage–**I**mage **P**re-training, is a model developed by OpenAI in 2021. You can give CLIP an image or a piece of text, and CLIP will output an abstract *representation* of your input. This abstract representation, also called an *embedding*, is really just a vector (a list of numbers). You can think of this vector as a point in high-dimensional space. CLIP is trained so that the representations of similar pictures and texts are similar as well. This means that if we input an image and a text description that fits that image, the representations of the image and the text will be similar (i.e., the high-dimensional points will be close together).
At first, this might not seem very useful, but it is actually very powerful. As an example, let’s take a quick look at how CLIP can be used to classify images without ever having been trained on that task. To classify an image, we input the image and the different categories we want to choose from to CLIP (e.g. we input an image and the words “apple”, “orange”, …). CLIP then gives us back an embedding of the image and of each category. Now, we simply have to check which category embedding is closest to the embedding of the image, et voilà! Feels like magic, doesn’t it?
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clip-tv-example.png"></medium-zoom>
<figcaption>Example of image classification using CLIP (<a href="https://openai.com/blog/clip/">source</a>).</figcaption>
</figure>
What’s more, CLIP is not only useful for classification, but it can also be used for [image search](https://huggingface.co./spaces/DrishtiSharma/Text-to-Image-search-using-CLIP) (can you see how this is similar to classification?), [text-to-image models](https://huggingface.co./spaces/kamiyamai/stable-diffusion-webui) ([DALL-E 2](https://openai.com/dall-e-2/) is powered by CLIP), [object detection](https://segments.ai/zeroshot?utm_source=hf&utm_medium=blog&utm_campaign=clipseg) ([OWL-ViT](https://arxiv.org/abs/2205.06230)), and most importantly for us: image segmentation. Now you see why CLIP was truly a breakthrough in machine learning.
The reason why CLIP works so well is that the model was trained on a huge dataset of images with text captions. The dataset contained a whopping 400 million image-text pairs taken from the internet. These images contain a wide variety of objects and concepts, and CLIP is great at creating a representation for each of them.
## CLIPSeg: image segmentation with CLIP
[CLIPSeg](https://arxiv.org/abs/2112.10003) is a model that uses CLIP representations to create image segmentation masks. It was published by Timo Lüddecke and Alexander Ecker. They achieved zero-shot image segmentation by training a Transformer-based decoder on top of the CLIP model, which is kept frozen. The decoder takes in the CLIP representation of an image, and the CLIP representation of the thing you want to segment. Using these two inputs, the CLIPSeg decoder creates a binary segmentation mask. To be more precise, the decoder doesn’t only use the final CLIP representation of the image we want to segment, but it also uses the outputs of some of the layers of CLIP.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Overview of the CLIPSeg model" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/clipseg-overview.png"></medium-zoom>
<figcaption><a href="https://arxiv.org/abs/2112.10003">Source</a></figcaption>
</figure>
The decoder is trained on the [PhraseCut dataset](https://arxiv.org/abs/2008.01187), which contains over 340,000 phrases with corresponding image segmentation masks. The authors also experimented with various augmentations to expand the size of the dataset. The goal here is not only to be able to segment the categories that are present in the dataset, but also to segment unseen categories. Experiments indeed show that the decoder can generalize to unseen categories.
One interesting feature of CLIPSeg is that both the query (the image we want to segment) and the prompt (the thing we want to segment in the image) are input as CLIP embeddings. The CLIP embedding for the prompt can either come from a piece of text (the category name), **or from another image**. This means you can segment oranges in a photo by giving CLIPSeg an example image of an orange.
This technique, which is called "visual prompting", is really helpful when the thing you want to segment is hard to describe. For example, if you want to segment a logo in a picture of a t-shirt, it's not easy to describe the shape of the logo, but CLIPSeg allows you to simply use the image of the logo as the prompt.
The CLIPSeg paper contains some tips on improving the effectiveness of visual prompting. They find that cropping the query image (so that it only contains the object you want to segment) helps a lot. Blurring and darkening the background of the query image also helps a little bit. In the next section, we'll show how you can try out visual prompting yourself using [`🤗 transformers`](https://huggingface.co./transformers).
## Using CLIPSeg with Hugging Face Transformers
Using Hugging Face Transformers, you can easily download and run a
pre-trained CLIPSeg model on your images. Let's start by installing
transformers.
```python
!pip install -q transformers
```
To download the model, simply instantiate it.
```python
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
```
Now we can load an image to try out the segmentation. We\'ll choose a
picture of a delicious breakfast taken by [Calum
Lewis](https://unsplash.com/@calumlewis).
```python
from PIL import Image
import requests
url = "https://unsplash.com/photos/8Nc_oQsc2qQ/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjcxMjAwNzI0&force=true&w=640"
image = Image.open(requests.get(url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a pancake breakfast." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/73d97c93dc0f5545378e433e956509b8acafb8d9.png"></medium-zoom>
</figure>
### Text prompting
Let's start by defining some text categories we want to segment.
```python
prompts = ["cutlery", "pancakes", "blueberries", "orange juice"]
```
Now that we have our inputs, we can process them and input them to the
model.
```python
import torch
inputs = processor(text=prompts, images=[image] * len(prompts), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
preds = outputs.logits.unsqueeze(1)
```
Finally, let's visualize the output.
```python
import matplotlib.pyplot as plt
_, ax = plt.subplots(1, len(prompts) + 1, figsize=(3*(len(prompts) + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len(prompts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(prompts)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the breakfast image." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/14c048ea92645544c1bbbc9e55f3c620eaab8886.png"></medium-zoom>
</figure>
### Visual prompting
As mentioned before, we can also use images as the input prompts (i.e.
in place of the category names). This can be especially useful if it\'s
not easy to describe the thing you want to segment. For this example,
we\'ll use a picture of a coffee cup taken by [Daniel
Hooper](https://unsplash.com/@dan_fromyesmorecontent).
```python
url = "https://unsplash.com/photos/Ki7sAc8gOGE/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTJ8fGNvZmZlJTIwdG8lMjBnb3xlbnwwfHx8fDE2NzExOTgzNDQ&force=true&w=640"
prompt = Image.open(requests.get(url, stream=True).raw)
prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a paper coffee cup." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7931f9db82ab07af7d161f0cfbfc347645da6646.png"></medium-zoom>
</figure>
We can now process the input image and prompt image and input them to
the model.
```python
encoded_image = processor(images=[image], return_tensors="pt")
encoded_prompt = processor(images=[prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
Then, we can visualize the results as before.
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/fbde45fc65907d17de38b0db3eb262bdec1f1784.png"></medium-zoom>
</figure>
Let's try one last time by using the visual prompting tips described in
the paper, i.e. cropping the image and darkening the background.
```python
url = "https://i.imgur.com/mRSORqz.jpg"
alternative_prompt = Image.open(requests.get(url, stream=True).raw)
alternative_prompt
```
<figure class="image table text-center m-0 w-6/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A cropped version of the image of the coffee cup with a darker background." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/915a97da22131e0ab6ff4daa78ffe3f1889e3386.png"></medium-zoom>
</figure>
```python
encoded_alternative_prompt = processor(images=[alternative_prompt], return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**encoded_image, conditional_pixel_values=encoded_alternative_prompt.pixel_values)
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
```
```python
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds[0]))
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The mask of the coffee cup in the breakfast image." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7f75badfc245fc3a75e0e05058b8c4b6a3a991fa.png"></medium-zoom>
</figure>
In this case, the result is pretty much the same. This is probably
because the coffee cup was already separated well from the background in
the original image.
## Using CLIPSeg to pre-label images on Segments.ai
As you can see, the results from CLIPSeg are a little fuzzy and very
low-res. If we want to obtain better results, you can fine-tune a
state-of-the-art segmentation model, as explained in [our previous
blogpost](https://huggingface.co./blog/fine-tune-segformer). To finetune
the model, we\'ll need labeled data. In this section, we\'ll show you
how you can use CLIPSeg to create some rough segmentation masks and then
refine them on
[Segments.ai](https://segments.ai/?utm_source=hf&utm_medium=blog&utm_campaign=clipseg),
a labeling platform with smart labeling tools for image segmentation.
First, create an account at
[https://segments.ai/join](https://segments.ai/join?utm_source=hf&utm_medium=blog&utm_campaign=clipseg)
and install the Segments Python SDK. Then you can initialize the
Segments.ai Python client using an API key. This key can be found on
[the account page](https://segments.ai/account?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
!pip install -q segments-ai
```
```python
from segments import SegmentsClient
from getpass import getpass
api_key = getpass('Enter your API key: ')
segments_client = SegmentsClient(api_key)
```
Next, let\'s load an image from a dataset using the Segments client.
We\'ll use the [a2d2 self-driving
dataset](https://www.a2d2.audi/a2d2/en.html). You can also create your
own dataset by following [these
instructions](https://docs.segments.ai/tutorials/getting-started?utm_source=hf&utm_medium=blog&utm_campaign=clipseg).
```python
samples = segments_client.get_samples("admin-tobias/clipseg")
# Use the last image as an example
sample = samples[1]
image = Image.open(requests.get(sample.attributes.image.url, stream=True).raw)
image
```
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="A picture of a street with cars from the a2d2 dataset." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/a0ca3accab5a40547f16b2abc05edd4558818bdf.png"></medium-zoom>
</figure>
We also need to get the category names from the dataset attributes.
```python
dataset = segments_client.get_dataset("admin-tobias/clipseg")
category_names = [category.name for category in dataset.task_attributes.categories]
```
Now we can use CLIPSeg on the image as before. This time, we\'ll also
scale up the outputs so that they match the input image\'s size.
```python
from torch import nn
inputs = processor(text=category_names, images=[image] * len(category_names), padding="max_length", return_tensors="pt")
# predict
with torch.no_grad():
outputs = model(**inputs)
# resize the outputs
preds = nn.functional.interpolate(
outputs.logits.unsqueeze(1),
size=(image.size[1], image.size[0]),
mode="bilinear"
)
```
And we can visualize the results again.
```python
len_cats = len(category_names)
_, ax = plt.subplots(1, len_cats + 1, figsize=(3*(len_cats + 1), 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(preds[i][0])) for i in range(len_cats)];
[ax[i+1].text(0, -15, category_name) for i, category_name in enumerate(category_names)];
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="The masks of the different categories in the street image." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/7782da300097ce4dcb3891257db7cc97ccf1deb3.png"></medium-zoom>
</figure>
Now we have to combine the predictions to a single segmented image.
We\'ll simply do this by taking the category with the greatest sigmoid
value for each patch. We\'ll also make sure that all the values under a
certain threshold do not count.
```python
threshold = 0.1
flat_preds = torch.sigmoid(preds.squeeze()).reshape((preds.shape[0], -1))
# Initialize a dummy "unlabeled" mask with the threshold
flat_preds_with_treshold = torch.full((preds.shape[0] + 1, flat_preds.shape[-1]), threshold)
flat_preds_with_treshold[1:preds.shape[0]+1,:] = flat_preds
# Get the top mask index for each pixel
inds = torch.topk(flat_preds_with_treshold, 1, dim=0).indices.reshape((preds.shape[-2], preds.shape[-1]))
```
Let\'s quickly visualize the result.
```python
plt.imshow(inds)
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A combined segmentation label of the street image." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/b92dc12452108a0b2769ddfc1d7f79909e65144b.png"></medium-zoom>
</figure>
Lastly, we can upload the prediction to Segments.ai. To do that, we\'ll
first convert the bitmap to a png file, then we\'ll upload this file to
the Segments, and finally we\'ll add the label to the sample.
```python
from segments.utils import bitmap2file
import numpy as np
inds_np = inds.numpy().astype(np.uint32)
unique_inds = np.unique(inds_np).tolist()
f = bitmap2file(inds_np, is_segmentation_bitmap=True)
asset = segments_client.upload_asset(f, "clipseg_prediction.png")
attributes = {
'format_version': '0.1',
'annotations': [{"id": i, "category_id": i} for i in unique_inds if i != 0],
'segmentation_bitmap': { 'url': asset.url },
}
segments_client.add_label(sample.uuid, 'ground-truth', attributes)
```
If you take a look at the [uploaded prediction on
Segments.ai](https://segments.ai/admin-tobias/clipseg/samples/71a80d39-8cf3-4768-a097-e81e0b677517/ground-truth),
you can see that it\'s not perfect. However, you can manually correct
the biggest mistakes, and then you can use the corrected dataset to
train a better model than CLIPSeg.
<figure class="image table text-center m-0 w-9/12">
<medium-zoom background="rgba(0,0,0,.7)" alt="Thumbnails of the final segmentation labels on Segments.ai." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/123_clipseg-zero-shot/segments-thumbs.png"></medium-zoom>
</figure>
## Conclusion
CLIPSeg is a zero-shot segmentation model that works with both text and image prompts. The model adds a decoder to CLIP and can segment almost anything. However, the output segmentation masks are still very low-res for now, so you’ll probably still want to fine-tune a different segmentation model if accuracy is important.
Note that there's more research on zero-shot segmentation currently being conducted, so you can expect more models to be added in the near future. One example is [GroupViT](https://huggingface.co./docs/transformers/model_doc/groupvit), which is already available in 🤗 Transformers. To stay up to date with the latest news in segmentation research, you can follow us on Twitter: [@TobiasCornille](https://twitter.com/tobiascornille), [@NielsRogge](https://twitter.com/nielsrogge), and [@huggingface](https://twitter.com/huggingface).
If you’re interested in learning how to fine-tune a state-of-the-art segmentation model, check out our previous blog post: [https://huggingface.co./blog/fine-tune-segformer](https://huggingface.co./blog/fine-tune-segformer). | [
[
"computer_vision",
"transformers",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"tutorial",
"implementation"
] | null | null |
ab72c24f-be41-4680-b326-e6c7f7ad6e9a | completed | 2025-01-16T03:09:11.596679 | 2025-01-19T19:02:03.442912 | 7a5e25d7-7211-4eed-a5ac-659e839318ab | Introducing the AMD 5th Gen EPYC™ CPU | mohitsha, mfuntowicz | huggingface-amd-turin.md | AMD has just unveiled its 5th generation of server-grade EPYC CPU based on Zen5 architecture - also known as `Turin`. It provides a significant boost in performance, especially with a higher number of core count reaching up to `192` and `384` threads.
From Large Language Models (LLMs) to RAG scenarios, Hugging Face users can leverage this new generation of servers to enhance their performance capabilities:
1. Reduce the target latency of their deployments.
2. Increase the maximum throughput.
3. Lower the operational costs.
During the last few weeks, we have been working with AMD to validate that the Hugging Face ecosystem is fully supported on this new CPU generation and delivers the expected performance across different tasks.
Also, we have been cooking some exciting new ways to leverage `torch.compile` for AMD CPU through the use of `AMD ZenDNN PyTorch plugin (zentorch)` to speed up even more the kind of workloads we will be discussing after.
While we were able to get early access to this work to test Hugging Face models and libraries and share with you performance, we expect AMD to make it soon available to the community - stay tuned!
## AMD Turin vs AMD Genoa Performance - A 2X speedup
In this section, we present the results from our benchmarking of the two AMD EPYC CPUs: Turin (128 cores) and Genoa (96 cores). For these benchmarks, we utilized the **ZenDNN** plug-in for PyTorch (zentorch), which provides inference optimizations tailored for deep learning workloads on AMD EPYC CPUs. This plug-in integrates seamlessly with the torch.compile graph compilation flow, enabling multiple passes of graph-level optimizations on the torch.fx graph to achieve further performance acceleration.
To ensure optimal performance, we used the `bfloat16` data type and employed `ZenDNN 5.0`. We configured multi-instance setups that enable the parallel execution of multiple [Meta LLaMA 3.1 8B](https://huggingface.co./meta-llama/Llama-3.1-8B-Instruct) model instances spawning across all the cores. Each model instance is allocated 32 physical cores per socket, allowing us to leverage the full processing power of the servers for efficient data handling and computational speed.
We ran the benchmarks using two different batch sizes—16 and 32—across five distinct use cases:
- Summarization (1024 input tokens / 128 output tokens)
- Chatbot (128 input tokens / 128 output tokens)
- Translation (1024 input tokens / 1024 output tokens)
- Essay Writing (128 input tokens / 1024 output tokens)
- Live Captioning (16 input tokens / 16 output tokens).
These configurations not only facilitate a comprehensive analysis of how each server performs under varying workloads but also simulate real-world applications of LLMs. Specifically, we plot the decode throughput (excluding the first token) for each use case, to illustrate performance differences.
### Results for Llama 3.1 8B Instruct

_Throughput results for Meta Llama 3.1 8B, comparing AMD Turin against AMD Genoa. AMD Turin consistently outperforms the AMD Genoa CPUs, achieving approximately 2X higher throughput in most configurations._
## Conclusion
As demonstrated, the AMD EPYC Turin CPU offers a significant boost in performance for AI use cases compared to its predecessor, the AMD Genoa. To enhance reproducibility and streamline the benchmarking process, we utilized [optimum-benchmark](https://github.com/huggingface/optimum-benchmark), which provides a unified framework for efficient benchmarking across various setups. This enabled us to effectively benchmark using the `zentorch` backend for `torch.compile`.
Furthermore, we have developed an optimized `Dockerfile` that will be released soon, along with the benchmarking code. This will facilitate easy deployment and reproduction of our results, ensuring that others can effectively leverage our findings.
You can find more information at [AMD Zen Deep Neural Network (ZenDNN)](https://www.amd.com/en/developer/zendnn.html)
## Useful Resources
- ZenTF: https://github.com/amd/ZenDNN-tensorflow-plugin
- ZenTorch: https://github.com/amd/ZenDNN-pytorch-plugin
- ZenDNN ONNXRuntime: https://github.com/amd/ZenDNN-onnxruntime | [
[
"llm",
"mlops",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"optimization",
"efficient_computing",
"mlops"
] | null | null |
f16a6694-a2cd-48b9-8002-4660b271ae53 | completed | 2025-01-16T03:09:11.596684 | 2025-01-16T15:10:16.064526 | de407168-d319-41d4-95f6-fd8d414ec167 | Deploy LLMs with Hugging Face Inference Endpoints | philschmid | inference-endpoints-llm.md | Open-source LLMs like [Falcon](https://huggingface.co./tiiuae/falcon-40b), [(Open-)LLaMA](https://huggingface.co./openlm-research/open_llama_13b), [X-Gen](https://huggingface.co./Salesforce/xgen-7b-8k-base), [StarCoder](https://huggingface.co./bigcode/starcoder) or [RedPajama](https://huggingface.co./togethercomputer/RedPajama-INCITE-7B-Base), have come a long way in recent months and can compete with closed-source models like ChatGPT or GPT4 for certain use cases. However, deploying these models in an efficient and optimized way still presents a challenge.
In this blog post, we will show you how to deploy open-source LLMs to [Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/), our managed SaaS solution that makes it easy to deploy models. Additionally, we will teach you how to stream responses and test the performance of our endpoints. So let's get started!
1. [How to deploy Falcon 40B instruct](#1-how-to-deploy-falcon-40b-instruct)
2. [Test the LLM endpoint](#2-test-the-llm-endpoint)
3. [Stream responses in Javascript and Python](#3-stream-responses-in-javascript-and-python)
Before we start, let's refresh our knowledge about Inference Endpoints.
## What is Hugging Face Inference Endpoints
[Hugging Face Inference Endpoints](https://ui.endpoints.huggingface.co/) offers an easy and secure way to deploy Machine Learning models for use in production. Inference Endpoints empower developers and data scientists alike to create AI applications without managing infrastructure: simplifying the deployment process to a few clicks, including handling large volumes of requests with autoscaling, reducing infrastructure costs with scale-to-zero, and offering advanced security.
Here are some of the most important features for LLM deployment:
1. [Easy Deployment](https://huggingface.co./docs/inference-endpoints/index): Deploy models as production-ready APIs with just a few clicks, eliminating the need to handle infrastructure or MLOps.
2. [Cost Efficiency](https://huggingface.co./docs/inference-endpoints/autoscaling): Benefit from automatic scale to zero capability, reducing costs by scaling down the infrastructure when the endpoint is not in use, while paying based on the uptime of the endpoint, ensuring cost-effectiveness.
3. [Enterprise Security](https://huggingface.co./docs/inference-endpoints/security): Deploy models in secure offline endpoints accessible only through direct VPC connections, backed by SOC2 Type 2 certification, and offering BAA and GDPR data processing agreements for enhanced data security and compliance.
4. [LLM Optimization](https://huggingface.co./text-generation-inference): Optimized for LLMs, enabling high throughput with Paged Attention and low latency through custom transformers code and Flash Attention power by Text Generation Inference
5. [Comprehensive Task Support](https://huggingface.co./docs/inference-endpoints/supported_tasks): Out of the box support for 🤗 Transformers, Sentence-Transformers, and Diffusers tasks and models, and easy customization to enable advanced tasks like speaker diarization or any Machine Learning task and library.
You can get started with Inference Endpoints at: [https://ui.endpoints.huggingface.co/](https://ui.endpoints.huggingface.co/)
## 1. How to deploy Falcon 40B instruct
To get started, you need to be logged in with a User or Organization account with a payment method on file (you can add one **[here](https://huggingface.co./settings/billing)**), then access Inference Endpoints at **[https://ui.endpoints.huggingface.co](https://ui.endpoints.huggingface.co/endpoints)**
Then, click on “New endpoint”. Select the repository, the cloud, and the region, adjust the instance and security settings, and deploy in our case `tiiuae/falcon-40b-instruct`.

Inference Endpoints suggest an instance type based on the model size, which should be big enough to run the model. Here `4x NVIDIA T4` GPUs. To get the best performance for the LLM, change the instance to `GPU [xlarge] · 1x Nvidia A100`.
*Note: If the instance type cannot be selected, you need to [contact us](mailto:[email protected]?subject=Quota%20increase%20HF%20Endpoints&body=Hello,%0D%0A%0D%0AI%20would%20like%20to%20request%20access/quota%20increase%20for%20{INSTANCE%20TYPE}%20for%20the%20following%20account%20{HF%20ACCOUNT}.) and request an instance quota.*

You can then deploy your model with a click on “Create Endpoint”. After 10 minutes, the Endpoint should be online and available to serve requests.
## 2. Test the LLM endpoint
The Endpoint overview provides access to the Inference Widget, which can be used to manually send requests. This allows you to quickly test your Endpoint with different inputs and share it with team members. Those Widgets do not support parameters - in this case this results to a “short” generation.

The widget also generates a cURL command you can use. Just add your `hf_xxx` and test.
```python
curl https://j4xhm53fxl9ussm8.us-east-1.aws.endpoints.huggingface.cloud \
-X POST \
-d '{"inputs":"Once upon a time,"}' \
-H "Authorization: Bearer <hf_token>" \
-H "Content-Type: application/json"
```
You can use different parameters to control the generation, defining them in the `parameters` attribute of the payload. As of today, the following parameters are supported:
- `temperature`: Controls randomness in the model. Lower values will make the model more deterministic and higher values will make the model more random. Default value is 1.0.
- `max_new_tokens`: The maximum number of tokens to generate. Default value is 20, max value is 512.
- `repetition_penalty`: Controls the likelihood of repetition. Default is `null`.
- `seed`: The seed to use for random generation. Default is `null`.
- `stop`: A list of tokens to stop the generation. The generation will stop when one of the tokens is generated.
- `top_k`: The number of highest probability vocabulary tokens to keep for top-k-filtering. Default value is `null`, which disables top-k-filtering.
- `top_p`: The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling, default to `null`
- `do_sample`: Whether or not to use sampling; use greedy decoding otherwise. Default value is `false`.
- `best_of`: Generate best_of sequences and return the one if the highest token logprobs, default to `null`.
- `details`: Whether or not to return details about the generation. Default value is `false`.
- `return_full_text`: Whether or not to return the full text or only the generated part. Default value is `false`.
- `truncate`: Whether or not to truncate the input to the maximum length of the model. Default value is `true`.
- `typical_p`: The typical probability of a token. Default value is `null`.
- `watermark`: The watermark to use for the generation. Default value is `false`.
## 3. Stream responses in Javascript and Python
Requesting and generating text with LLMs can be a time-consuming and iterative process. A great way to improve the user experience is streaming tokens to the user as they are generated. Below are two examples of how to stream tokens using Python and JavaScript. For Python, we are going to use the [client from Text Generation Inference](https://github.com/huggingface/text-generation-inference/tree/main/clients/python), and for JavaScript, the [HuggingFace.js library](https://huggingface.co./docs/huggingface.js/main/en/index)
### Streaming requests with Python
First, you need to install the `huggingface_hub` library:
```python
pip install -U huggingface_hub
```
We can create a `InferenceClient` providing our endpoint URL and credential alongside the hyperparameters we want to use
```python
from huggingface_hub import InferenceClient
# HF Inference Endpoints parameter
endpoint_url = "https://YOUR_ENDPOINT.endpoints.huggingface.cloud"
hf_token = "hf_YOUR_TOKEN"
# Streaming Client
client = InferenceClient(endpoint_url, token=hf_token)
# generation parameter
gen_kwargs = dict(
max_new_tokens=512,
top_k=30,
top_p=0.9,
temperature=0.2,
repetition_penalty=1.02,
stop_sequences=["\nUser:", "<|endoftext|>", "</s>"],
)
# prompt
prompt = "What can you do in Nuremberg, Germany? Give me 3 Tips"
stream = client.text_generation(prompt, stream=True, details=True, **gen_kwargs)
# yield each generated token
for r in stream:
# skip special tokens
if r.token.special:
continue
# stop if we encounter a stop sequence
if r.token.text in gen_kwargs["stop_sequences"]:
break
# yield the generated token
print(r.token.text, end = "")
# yield r.token.text
```
Replace the `print` command with the `yield` or with a function you want to stream the tokens to.

### Streaming requests with JavaScript
First, you need to install the `@huggingface/inference` library.
```python
npm install @huggingface/inference
```
We can create a `HfInferenceEndpoint` providing our endpoint URL and credential alongside the hyperparameter we want to use.
```jsx
import { HfInferenceEndpoint } from '@huggingface/inference'
const hf = new HfInferenceEndpoint('https://YOUR_ENDPOINT.endpoints.huggingface.cloud', 'hf_YOUR_TOKEN')
//generation parameter
const gen_kwargs = {
max_new_tokens: 512,
top_k: 30,
top_p: 0.9,
temperature: 0.2,
repetition_penalty: 1.02,
stop_sequences: ['\nUser:', '<|endoftext|>', '</s>'],
}
// prompt
const prompt = 'What can you do in Nuremberg, Germany? Give me 3 Tips'
const stream = hf.textGenerationStream({ inputs: prompt, parameters: gen_kwargs })
for await (const r of stream) {
// # skip special tokens
if (r.token.special) {
continue
}
// stop if we encounter a stop sequence
if (gen_kwargs['stop_sequences'].includes(r.token.text)) {
break
}
// yield the generated token
process.stdout.write(r.token.text)
}
```
Replace the `process.stdout` call with the `yield` or with a function you want to stream the tokens to.

## Conclusion
In this blog post, we showed you how to deploy open-source LLMs using Hugging Face Inference Endpoints, how to control the text generation with advanced parameters, and how to stream responses to a Python or JavaScript client to improve the user experience. By using Hugging Face Inference Endpoints you can deploy models as production-ready APIs with just a few clicks, reduce your costs with automatic scale to zero, and deploy models into secure offline endpoints backed by SOC2 Type 2 certification. | [
[
"llm",
"mlops",
"tutorial",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"deployment",
"tutorial"
] | null | null |
a1ae161f-ba4a-4b4b-bf58-905045d74df5 | completed | 2025-01-16T03:09:11.596689 | 2025-01-16T13:35:29.638893 | 470db4ef-178e-4e8e-ac2a-e4d0fb63f778 | Image Similarity with Hugging Face Datasets and Transformers | sayakpaul | image-similarity.md | <a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this post, you'll learn to build an image similarity system with 🤗 Transformers. Finding out the similarity between a query image and potential candidates is an important use case for information retrieval systems, such as reverse image search, for example. All the system is trying to answer is that, given a _query_ image and a set of _candidate_ images, which images are the most similar to the query image.
We'll leverage the [🤗 `datasets` library](https://huggingface.co./docs/datasets/) as it seamlessly supports parallel processing which will come in handy when building this system.
Although the post uses a ViT-based model ([`nateraw/vit-base-beans`](https://huggingface.co./nateraw/vit-base-beans)) and a particular dataset ([Beans](https://huggingface.co./datasets/beans)), it can be extended to use other models supporting vision modality and other image datasets. Some notable models you could try:
* [Swin Transformer](https://huggingface.co./docs/transformers/model_doc/swin)
* [ConvNeXT](https://huggingface.co./docs/transformers/model_doc/convnext)
* [RegNet](https://huggingface.co./docs/transformers/model_doc/regnet)
Also, the approach presented in the post can potentially be extended to other modalities as well.
To study the fully working image-similarity system, you can refer to the Colab Notebook linked at the beginning.
## How do we define similarity?
To build this system, we first need to define how we want to compute the similarity between two images. One widely popular practice is to compute dense representations (embeddings) of the given images and then use the [cosine similarity metric](https://en.wikipedia.org/wiki/Cosine_similarity) to determine how similar the two images are.
For this post, we'll use “embeddings” to represent images in vector space. This gives us a nice way to meaningfully compress the high-dimensional pixel space of images (224 x 224 x 3, for example) to something much lower dimensional (768, for example). The primary advantage of doing this is the reduced computation time in the subsequent steps.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/embeddings.png" width=700/>
</div>
## Computing embeddings
To compute the embeddings from the images, we'll use a vision model that has some understanding of how to represent the input images in the vector space. This type of model is also commonly referred to as image encoder.
For loading the model, we leverage the [`AutoModel` class](https://huggingface.co./docs/transformers/model_doc/auto#transformers.AutoModel). It provides an interface for us to load any compatible model checkpoint from the Hugging Face Hub. Alongside the model, we also load the processor associated with the model for data preprocessing.
```py
from transformers import AutoImageProcessor, AutoModel
model_ckpt = "nateraw/vit-base-beans"
processor = AutoImageProcessor.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
```
In this case, the checkpoint was obtained by fine-tuning a [Vision Transformer based model](https://huggingface.co./google/vit-base-patch16-224-in21k) on the [`beans` dataset](https://huggingface.co./datasets/beans).
Some questions that might arise here:
**Q1**: Why did we not use `AutoModelForImageClassification`?
This is because we want to obtain dense representations of the images and not discrete categories, which are what `AutoModelForImageClassification` would have provided.
**Q2**: Why this checkpoint in particular?
As mentioned earlier, we're using a specific dataset to build the system. So, instead of using a generalist model (like the [ones trained on the ImageNet-1k dataset](https://huggingface.co./models?dataset=dataset:imagenet-1k&sort=downloads), for example), it's better to use a model that has been fine-tuned on the dataset being used. That way, the underlying model better understands the input images.
**Note** that you can also use a checkpoint that was obtained through self-supervised pre-training. The checkpoint doesn't necessarily have to come from supervised learning. In fact, if pre-trained well, self-supervised models can [yield](https://ai.facebook.com/blog/dino-paws-computer-vision-with-self-supervised-transformers-and-10x-more-efficient-training/) impressive retrieval
performance.
Now that we have a model for computing the embeddings, we need some candidate images to query against.
## Loading a dataset for candidate images
In some time, we'll be building hash tables mapping the candidate images to hashes. During the query time, we'll use these hash tables. We'll talk more about hash tables in the respective section but for now, to have a set of candidate images, we will use the `train` split of the [`beans` dataset](https://huggingface.co./datasets/beans).
```py
from datasets import load_dataset
dataset = load_dataset("beans")
```
This is how a single sample from the training split looks like:
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/beans.png" width=600/>
</div>
The dataset has three features:
```py
dataset["train"].features
>>> {'image_file_path': Value(dtype='string', id=None),
'image': Image(decode=True, id=None),
'labels': ClassLabel(names=['angular_leaf_spot', 'bean_rust', 'healthy'], id=None)}
```
To demonstrate the image similarity system, we'll use 100 samples from the candidate image dataset to keep
the overall runtime short.
```py
num_samples = 100
seed = 42
candidate_subset = dataset["train"].shuffle(seed=seed).select(range(num_samples))
```
## The process of finding similar images
Below, you can find a pictorial overview of the process underlying fetching similar images.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/fetch-similar-process.png">
</div>
Breaking down the above figure a bit, we have:
1. Extract the embeddings from the candidate images (`candidate_subset`), storing them in a matrix.
2. Take a query image and extract its embeddings.
3. Iterate over the embedding matrix (computed in step 1) and compute the similarity score between the query embedding and the current candidate embeddings. We usually maintain a dictionary-like mapping maintaining a correspondence between some identifier of the candidate image and the similarity scores.
4. Sort the mapping structure w.r.t the similarity scores and return the underlying identifiers. We use these identifiers to fetch the candidate samples.
We can write a simple utility and `map()` it to our dataset of candidate images to compute the embeddings efficiently.
```py
import torch
def extract_embeddings(model: torch.nn.Module):
"""Utility to compute embeddings."""
device = model.device
def pp(batch):
images = batch["image"]
# `transformation_chain` is a compostion of preprocessing
# transformations we apply to the input images to prepare them
# for the model. For more details, check out the accompanying Colab Notebook.
image_batch_transformed = torch.stack(
[transformation_chain(image) for image in images]
)
new_batch = {"pixel_values": image_batch_transformed.to(device)}
with torch.no_grad():
embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
return {"embeddings": embeddings}
return pp
```
And we can map `extract_embeddings()` like so:
```py
device = "cuda" if torch.cuda.is_available() else "cpu"
extract_fn = extract_embeddings(model.to(device))
candidate_subset_emb = candidate_subset.map(extract_fn, batched=True, batch_size=batch_size)
```
Next, for convenience, we create a list containing the identifiers of the candidate images.
```py
candidate_ids = []
for id in tqdm(range(len(candidate_subset_emb))):
label = candidate_subset_emb[id]["labels"]
# Create a unique indentifier.
entry = str(id) + "_" + str(label)
candidate_ids.append(entry)
```
We'll use the matrix of the embeddings of all the candidate images for computing the similarity scores with a query image. We have already computed the candidate image embeddings. In the next cell, we just gather them together in a matrix.
```py
all_candidate_embeddings = np.array(candidate_subset_emb["embeddings"])
all_candidate_embeddings = torch.from_numpy(all_candidate_embeddings)
```
We'll use [cosine similarity](https://en.wikipedia.org/wiki/Cosine_similarity) to compute the similarity score in between two embedding vectors. We'll then use it to fetch similar candidate samples given a query sample.
```py
def compute_scores(emb_one, emb_two):
"""Computes cosine similarity between two vectors."""
scores = torch.nn.functional.cosine_similarity(emb_one, emb_two)
return scores.numpy().tolist()
def fetch_similar(image, top_k=5):
"""Fetches the `top_k` similar images with `image` as the query."""
# Prepare the input query image for embedding computation.
image_transformed = transformation_chain(image).unsqueeze(0)
new_batch = {"pixel_values": image_transformed.to(device)}
# Comute the embedding.
with torch.no_grad():
query_embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
# Compute similarity scores with all the candidate images at one go.
# We also create a mapping between the candidate image identifiers
# and their similarity scores with the query image.
sim_scores = compute_scores(all_candidate_embeddings, query_embeddings)
similarity_mapping = dict(zip(candidate_ids, sim_scores))
# Sort the mapping dictionary and return `top_k` candidates.
similarity_mapping_sorted = dict(
sorted(similarity_mapping.items(), key=lambda x: x[1], reverse=True)
)
id_entries = list(similarity_mapping_sorted.keys())[:top_k]
ids = list(map(lambda x: int(x.split("_")[0]), id_entries))
labels = list(map(lambda x: int(x.split("_")[-1]), id_entries))
return ids, labels
```
## Perform a query
Given all the utilities, we're equipped to do a similarity search. Let's have a query image from the `test` split of
the `beans` dataset:
```py
test_idx = np.random.choice(len(dataset["test"]))
test_sample = dataset["test"][test_idx]["image"]
test_label = dataset["test"][test_idx]["labels"]
sim_ids, sim_labels = fetch_similar(test_sample)
print(f"Query label: {test_label}")
print(f"Top 5 candidate labels: {sim_labels}")
```
Leads to:
```
Query label: 0
Top 5 candidate labels: [0, 0, 0, 0, 0]
```
Seems like our system got the right set of similar images. When visualized, we'd get:
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/image_similarity/results_one.png">
</div>
## Further extensions and conclusions
We now have a working image similarity system. But in reality, you'll be dealing with a lot more candidate images. Taking that into consideration, our current procedure has got multiple drawbacks:
* If we store the embeddings as is, the memory requirements can shoot up quickly, especially when dealing with millions of candidate images. The embeddings are 768-d in our case, which can still be relatively high in the large-scale regime.
* Having high-dimensional embeddings have a direct effect on the subsequent computations involved in the retrieval part.
If we can somehow reduce the dimensionality of the embeddings without disturbing their meaning, we can still maintain a good trade-off between speed and retrieval quality. The [accompanying Colab Notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_similarity.ipynb) of this post implements and demonstrates utilities for achieving this with random projection and locality-sensitive hashing.
🤗 Datasets offers direct integrations with [FAISS](https://github.com/facebookresearch/faiss) which further simplifies the process of building similarity systems. Let's say you've already extracted the embeddings of the candidate images (the `beans` dataset) and stored them
inside a feature called `embeddings`. You can now easily use the [`add_faiss_index()`](https://huggingface.co./docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Dataset.add_faiss_index) of the dataset to build a dense index:
```py
dataset_with_embeddings.add_faiss_index(column="embeddings")
```
Once the index is built, `dataset_with_embeddings` can be used to retrieve the nearest examples given query embeddings with [`get_nearest_examples()`](https://huggingface.co./docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Dataset.get_nearest_examples):
```py
scores, retrieved_examples = dataset_with_embeddings.get_nearest_examples(
"embeddings", qi_embedding, k=top_k
)
```
The method returns scores and corresponding candidate examples. To know more, you can check out the [official documentation](https://huggingface.co./docs/datasets/faiss_es) and [this notebook](https://colab.research.google.com/gist/sayakpaul/5b5b5a9deabd3c5d8cb5ef8c7b4bb536/image_similarity_faiss.ipynb).
Finally, you can try out the following Space that builds a mini image similarity application:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.12.0/gradio.js"></script>
<gradio-app theme_mode="light" space="sayakpaul/fetch-similar-images"></gradio-app>
In this post, we ran through a quickstart for building image similarity systems. If you found this post interesting, we highly recommend building on top of the concepts we discussed here so you can get more comfortable with the inner workings.
Still looking to learn more? Here are some additional resources that might be useful for you:
* [Faiss: A library for efficient similarity search](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/)
* [ScaNN: Efficient Vector Similarity Search](http://ai.googleblog.com/2020/07/announcing-scann-efficient-vector.html)
* [Integrating Image Searchers within Mobile Applications](https://www.tensorflow.org/lite/inference_with_metadata/task_library/image_searcher) | [
[
"computer_vision",
"transformers",
"data",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"data",
"tutorial"
] | null | null |
192f8cae-313a-45ea-a7c4-cbc93006ae65 | completed | 2025-01-16T03:09:11.596694 | 2025-01-19T17:14:20.008582 | 6707b5ac-2b58-4907-8e9c-f40304680667 | Introducing 🤗 Accelerate | sgugger | accelerate-library.md | ## 🤗 Accelerate
Run your **raw** PyTorch training scripts on any kind of device.
Most high-level libraries above PyTorch provide support for distributed training and mixed precision, but the abstraction they introduce require a user to learn a new API if they want to customize the underlying training loop. 🤗 Accelerate was created for PyTorch users who like to have full control over their training loops but are reluctant to write (and maintain) the boilerplate code needed to use distributed training (for multi-GPU on one or several nodes, TPUs, ...) or mixed precision training. Plans forward include support for fairscale, deepseed, AWS SageMaker specific data-parallelism and model parallelism.
It provides two things: a simple and consistent API that abstracts that boilerplate code and a launcher command to easily run those scripts on various setups.
### Easy integration!
Let's first have a look at an example:
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.device
model = torch.nn.Transformer().to(device)
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optim, data = accelerator.prepare(model, optim, data)
model.train()
for epoch in range(10):
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
By just adding five lines of code to any standard PyTorch training script, you can now run said script on any kind of distributed setting, as well as with or without mixed precision. 🤗 Accelerate even handles the device placement for you, so you can simplify the training loop above even further:
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
- model = torch.nn.Transformer().to(device)
+ model = torch.nn.Transformer()
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optim, data = accelerator.prepare(model, optim, data)
model.train()
for epoch in range(10):
for source, targets in data:
- source = source.to(device)
- targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
In contrast, here are the changes needed to have this code run with distributed training are the followings:
```diff
+ import os
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from torch.utils.data import DistributedSampler
+ from torch.nn.parallel import DistributedDataParallel
+ local_rank = int(os.environ.get("LOCAL_RANK", -1))
- device = 'cpu'
+ device = device = torch.device("cuda", local_rank)
model = torch.nn.Transformer().to(device)
+ model = DistributedDataParallel(model)
optim = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
+ sampler = DistributedSampler(dataset)
- data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ data = torch.utils.data.DataLoader(dataset, sampler=sampler)
model.train()
for epoch in range(10):
+ sampler.set_epoch(epoch)
for source, targets in data:
source = source.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
optimizer.step()
```
These changes will make your training script work for multiple GPUs, but your script will then stop working on CPU or one GPU (unless you start adding if statements everywhere). Even more annoying, if you wanted to test your script on TPUs you would need to change different lines of codes. Same for mixed precision training. The promise of 🤗 Accelerate is:
- to keep the changes to your training loop to the bare minimum so you have to learn as little as possible.
- to have the same functions work for any distributed setup, so only have to learn one API.
### How does it work?
To see how the library works in practice, let's have a look at each line of code we need to add to a training loop.
```python
accelerator = Accelerator()
```
On top of giving the main object that you will use, this line will analyze from the environment the type of distributed training run and perform the necessary initialization. You can force a training on CPU or a mixed precision training by passing `cpu=True` or `fp16=True` to this init. Both of those options can also be set using the launcher for your script.
```python
model, optim, data = accelerator.prepare(model, optim, data)
```
This is the main bulk of the API and will prepare the three main type of objects: models (`torch.nn.Module`), optimizers (`torch.optim.Optimizer`) and dataloaders (`torch.data.dataloader.DataLoader`).
#### Model
Model preparation include wrapping it in the proper container (for instance `DistributedDataParallel`) and putting it on the proper device. Like with a regular distributed training, you will need to unwrap your model for saving, or to access its specific methods, which can be done with `accelerator.unwrap_model(model)`.
#### Optimizer
The optimizer is also wrapped in a special container that will perform the necessary operations in the step to make mixed precision work. It will also properly handle device placement of the state dict if its non-empty or loaded from a checkpoint.
#### DataLoader
This is where most of the magic is hidden. As you have seen in the code example, the library does not rely on a `DistributedSampler`, it will actually work with any sampler you might pass to your dataloader (if you ever had to write a distributed version of your custom sampler, there is no more need for that!). The dataloader is wrapped in a container that will only grab the indices relevant to the current process in the sampler (or skip the batches for the other processes if you use an `IterableDataset`) and put the batches on the proper device.
For this to work, Accelerate provides a utility function that will synchronize the random number generators on each of the processes run during distributed training. By default, it only synchronizes the `generator` of your sampler, so your data augmentation will be different on each process, but the random shuffling will be the same. You can of course use this utility to synchronize more RNGs if you need it.
```python
accelerator.backward(loss)
```
This last line adds the necessary steps for the backward pass (mostly for mixed precision but other integrations will require some custom behavior here).
### What about evaluation?
Evaluation can either be run normally on all processes, or if you just want it to run on the main process, you can use the handy test:
```python
if accelerator.is_main_process():
# Evaluation loop
```
But you can also very easily run a distributed evaluation using Accelerate, here is what you would need to add to your evaluation loop:
```diff
+ eval_dataloader = accelerator.prepare(eval_dataloader)
predictions, labels = [], []
for source, targets in eval_dataloader:
with torch.no_grad():
output = model(source)
- predictions.append(output.cpu().numpy())
- labels.append(targets.cpu().numpy())
+ predictions.append(accelerator.gather(output).cpu().numpy())
+ labels.append(accelerator.gather(targets).cpu().numpy())
predictions = np.concatenate(predictions)
labels = np.concatenate(labels)
+ predictions = predictions[:len(eval_dataloader.dataset)]
+ labels = label[:len(eval_dataloader.dataset)]
metric_compute(predictions, labels)
```
Like for the training, you need to add one line to prepare your evaluation dataloader. Then you can just use `accelerator.gather` to gather across processes the tensors of predictions and labels. The last line to add truncates the predictions and labels to the number of examples in your dataset because the prepared evaluation dataloader will return a few more elements to make sure batches all have the same size on each process.
### One launcher to rule them all
The scripts using Accelerate will be completely compatible with your traditional launchers, such as `torch.distributed.launch`. But remembering all the arguments to them is a bit annoying and when you've setup your instance with 4 GPUs, you'll run most of your trainings using them all. Accelerate comes with a handy CLI that works in two steps:
```bash
accelerate config
```
This will trigger a little questionnaire about your setup, which will create a config file you can edit with all the defaults for your training commands. Then
```bash
accelerate launch path_to_script.py --args_to_the_script
```
will launch your training script using those default. The only thing you have to do is provide all the arguments needed by your training script.
To make this launcher even more awesome, you can use it to spawn an AWS instance using SageMaker. Look at [this guide](https://huggingface.co./docs/accelerate/sagemaker.html) to discover how!
### How to get involved?
To get started, just `pip install accelerate` or see the [documentation](https://huggingface.co./docs/accelerate/installation.html) for more install options.
Accelerate is a fully open-sourced project, you can find it on [GitHub](https://github.com/huggingface/accelerate), have a look at its [documentation](https://huggingface.co./docs/accelerate/) or skim through our [basic examples](https://github.com/huggingface/accelerate/tree/main/examples). Please let us know if you have any issue or feature you would like the library to support. For all questions, the [forums](https://discuss.huggingface.co/c/accelerate) is the place to check!
For more complex examples in situation, you can look at the official [Transformers examples](https://github.com/huggingface/transformers/tree/master/examples). Each folder contains a `run_task_no_trainer.py` that leverages the Accelerate library! | [
[
"mlops",
"implementation",
"optimization",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"implementation",
"tools",
"optimization"
] | null | null |
ea09bc34-fb1e-4ad7-8c78-02e5359eaebb | completed | 2025-01-16T03:09:11.596699 | 2025-01-19T19:08:19.595855 | 83c6b119-c738-4c3b-83f5-03d7d2b2ead1 | 🧨 Accelerating Stable Diffusion XL Inference with JAX on Cloud TPU v5e | pcuenq, jffacevedo, alexspiridonov, pmotter, yyetim, svaibhav, vjsingh, patrickvonplaten | sdxl_jax.md | Generative AI models, such as Stable Diffusion XL (SDXL), enable the creation of high-quality, realistic content with wide-ranging applications. However, harnessing the power of such models presents significant challenges and computational costs. SDXL is a large image generation model whose UNet component is about three times as large as the one in the previous version of the model. Deploying a model like this in production is challenging due to the increased memory requirements, as well as increased inference times. Today, we are thrilled to announce that Hugging Face Diffusers now supports serving SDXL using JAX on Cloud TPUs, enabling high-performance, cost-efficient inference.
[Google Cloud TPUs](https://cloud.google.com/tpu) are custom-designed AI accelerators, which are optimized for training and inference of large AI models, including state-of-the-art LLMs and generative AI models such as SDXL. The new [Cloud TPU v5e](https://cloud.google.com/blog/products/compute/announcing-cloud-tpu-v5e-and-a3-gpus-in-ga) is purpose-built to bring the cost-efficiency and performance required for large-scale AI [training](https://cloud.google.com/blog/products/compute/using-cloud-tpu-multislice-to-scale-ai-workloads) and [inference](https://cloud.google.com/blog/products/compute/how-cloud-tpu-v5e-accelerates-large-scale-ai-inference). At less than half the cost of TPU v4, TPU v5e makes it possible for more organizations to train and deploy AI models.
🧨 Diffusers JAX integration offers a convenient way to run SDXL on TPU via [XLA](https://github.com/openxla/xla), and we built a demo to showcase it. You can try it out in [this Space](https://huggingface.co./spaces/google/sdxl) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="google/sdxl"></gradio-app>
Under the hood, this demo runs on several TPU v5e-4 instances (each instance has 4 TPU chips) and takes advantage of parallelization to serve four large 1024×1024 images in about 4 seconds. This time includes format conversions, communications time, and frontend processing; the actual generation time is about 2.3s, as we'll see below!
In this blog post,
1. [We describe why JAX + TPU + Diffusers is a powerful framework to run SDXL](#why-jax--tpu-v5e-for-sdxl)
2. [Explain how you can write a simple image generation pipeline with Diffusers and JAX](#how-to-write-an-image-generation-pipeline-in-jax)
3. [Show benchmarks comparing different TPU settings](#benchmark)
## Why JAX + TPU v5e for SDXL?
Serving SDXL with JAX on Cloud TPU v5e with high performance and cost-efficiency is possible thanks to the combination of purpose-built TPU hardware and a software stack optimized for performance. Below we highlight two key factors: JAX just-in-time (jit) compilation and XLA compiler-driven parallelism with JAX pmap.
#### JIT compilation
A notable feature of JAX is its [just-in-time (jit) compilation](https://jax.readthedocs.io/en/latest/jax-101/02-jitting.html). The JIT compiler traces code during the first run and generates highly optimized TPU binaries that are re-used in subsequent calls.
The catch of this process is that it requires all input, intermediate, and output shapes to be **static**, meaning that they must be known in advance. Every time we change the shapes
a new and costly compilation process will be triggered again. JIT compilation is ideal for services that can be designed around static shapes: compilation runs once, and then we take advantage of super-fast inference times.
Image generation is well-suited for JIT compilation. If we always generate the same number of images and they have the same size, then the output shapes are constant and known in advance. The text inputs are also constant: by design, Stable Diffusion and SDXL use fixed-shape embedding vectors (with padding) to represent the prompts typed by the user. Therefore, we can write JAX code that relies on fixed shapes, and that can be greatly optimized!
#### High-performance throughput for high batch sizes
Workloads can be scaled across multiple devices using JAX's [pmap](https://jax.readthedocs.io/en/latest/_autosummary/jax.pmap.html), which expresses single-program multiple-data (SPMD) programs. Applying pmap to a function will compile a function with XLA, then execute it in parallel on various XLA devices.
For text-to-image generation workloads this means that increasing the number of images rendered simultaneously is straightforward to implement and doesn't compromise performance. For example, running SDXL on a TPU with 8 chips will generate 8 images in the same time it takes for 1 chip to create a single image.
TPU v5e instances come in multiple shapes, including 1, 4 and 8-chip shapes, all the way up to 256 chips (a full TPU v5e pod), with ultra-fast ICI links between chips. This allows you to choose the TPU shape that best suits your use case and easily take advantage of the parallelism that JAX and TPUs provide.
## How to write an image generation pipeline in JAX
We'll go step by step over the code you need to write to run inference super-fast using JAX! First, let's import the dependencies.
```python
# Show best practices for SDXL JAX
import jax
import jax.numpy as jnp
import numpy as np
from flax.jax_utils import replicate
from diffusers import FlaxStableDiffusionXLPipeline
import time
```
We'll now load the base SDXL model and the rest of the components required for inference. The diffusers pipeline takes care of downloading and caching everything for us. Adhering to JAX's functional approach, the model's parameters are returned separately and will have to be passed to the pipeline during inference:
```python
pipeline, params = FlaxStableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", split_head_dim=True
)
```
Model parameters are downloaded in 32-bit precision by default. To save memory and run computation faster we'll convert them to `bfloat16`, an efficient 16-bit representation. However, there's a caveat: for best results, we have to keep the _scheduler state_ in `float32`, otherwise precision errors accumulate and result in low-quality or even black images.
```python
scheduler_state = params.pop("scheduler")
params = jax.tree_util.tree_map(lambda x: x.astype(jnp.bfloat16), params)
params["scheduler"] = scheduler_state
```
We are now ready to set up our prompt and the rest of the pipeline inputs.
```python
default_prompt = "high-quality photo of a baby dolphin playing in a pool and wearing a party hat"
default_neg_prompt = "illustration, low-quality"
default_seed = 33
default_guidance_scale = 5.0
default_num_steps = 25
```
The prompts have to be supplied as tensors to the pipeline, and they always have to have the same dimensions across invocations. This allows the inference call to be compiled. The pipeline `prepare_inputs` method performs all the necessary steps for us, so we'll create a helper function to prepare both our prompt and negative prompt as tensors. We'll use it later from our `generate` function:
```python
def tokenize_prompt(prompt, neg_prompt):
prompt_ids = pipeline.prepare_inputs(prompt)
neg_prompt_ids = pipeline.prepare_inputs(neg_prompt)
return prompt_ids, neg_prompt_ids
```
To take advantage of parallelization, we'll replicate the inputs across devices. A Cloud TPU v5e-4 has 4 chips, so by replicating the inputs we get each chip to generate a different image, in parallel. We need to be careful to supply a different random seed to each chip so the 4 images are different:
```python
NUM_DEVICES = jax.device_count()
# Model parameters don't change during inference,
# so we only need to replicate them once.
p_params = replicate(params)
def replicate_all(prompt_ids, neg_prompt_ids, seed):
p_prompt_ids = replicate(prompt_ids)
p_neg_prompt_ids = replicate(neg_prompt_ids)
rng = jax.random.PRNGKey(seed)
rng = jax.random.split(rng, NUM_DEVICES)
return p_prompt_ids, p_neg_prompt_ids, rng
```
We are now ready to put everything together in a generate function:
```python
def generate(
prompt,
negative_prompt,
seed=default_seed,
guidance_scale=default_guidance_scale,
num_inference_steps=default_num_steps,
):
prompt_ids, neg_prompt_ids = tokenize_prompt(prompt, negative_prompt)
prompt_ids, neg_prompt_ids, rng = replicate_all(prompt_ids, neg_prompt_ids, seed)
images = pipeline(
prompt_ids,
p_params,
rng,
num_inference_steps=num_inference_steps,
neg_prompt_ids=neg_prompt_ids,
guidance_scale=guidance_scale,
jit=True,
).images
# convert the images to PIL
images = images.reshape((images.shape[0] * images.shape[1], ) + images.shape[-3:])
return pipeline.numpy_to_pil(np.array(images))
```
`jit=True` indicates that we want the pipeline call to be compiled. This will happen the first time we call `generate`, and it will be very slow – JAX needs to trace the operations, optimize them, and convert them to low-level primitives. We'll run a first generation to complete this process and warm things up:
```python
start = time.time()
print(f"Compiling ...")
generate(default_prompt, default_neg_prompt)
print(f"Compiled in {time.time() - start}")
```
This took about three minutes the first time we ran it.
But once the code has been compiled, inference will be super fast. Let's try again!
```python
start = time.time()
prompt = "llama in ancient Greece, oil on canvas"
neg_prompt = "cartoon, illustration, animation"
images = generate(prompt, neg_prompt)
print(f"Inference in {time.time() - start}")
```
It now took about 2s to generate the 4 images!
## Benchmark
The following measures were obtained running SDXL 1.0 base for 20 steps, with the default Euler Discrete scheduler. We compare Cloud TPU v5e with TPUv4 for the same batch sizes. Do note that, due to parallelism, a TPU v5e-4 like the ones we use in our demo will generate **4 images** when using a batch size of 1 (or 8 images with a batch size of 2). Similarly, a TPU v5e-8 will generate 8 images when using a batch size of 1.
The Cloud TPU tests were run using Python 3.10 and jax version 0.4.16. These are the same specs used in our [demo Space](https://huggingface.co./spaces/google/sdxl).
| | Batch Size | Latency | Perf/$ |
| | [
[
"mlops",
"optimization",
"deployment",
"image_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"mlops",
"optimization",
"efficient_computing"
] | null | null |
0dda77a4-0975-4e0b-9b8d-85abcbcebba5 | completed | 2025-01-16T03:09:11.596703 | 2025-01-16T03:18:43.594351 | 190fb536-6343-4d1b-86cd-e160d435968c | Hugging Face Text Generation Inference available for AWS Inferentia2 | philschmid, dacorvo | text-generation-inference-on-inferentia2.md | We are excited to announce the general availability of Hugging Face Text Generation Inference (TGI) on AWS Inferentia2 and Amazon SageMaker.
**[Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)**, is a purpose-built solution for deploying and serving Large Language Models (LLMs) for production workloads at scale. TGI enables high-performance text generation using Tensor Parallelism and continuous batching for the most popular open LLMs, including Llama, Mistral, and more. Text Generation Inference is used in production by companies such as Grammarly, Uber, Deutsche Telekom, and many more.
The integration of TGI into Amazon SageMaker, in combination with AWS Inferentia2, presents a powerful solution and viable alternative to GPUs for building production LLM applications. The seamless integration ensures easy deployment and maintenance of models, making LLMs more accessible and scalable for a wide range of production use cases.
With the new TGI for AWS Inferentia2 on Amazon SageMaker, AWS customers can benefit from the same technologies that power highly-concurrent, low-latency LLM experiences like [HuggingChat](https://hf.co/chat), [OpenAssistant](https://open-assistant.io/), and Serverless Endpoints for LLMs on the Hugging Face Hub.
## Deploy Zephyr 7B on AWS Inferentia2 using Amazon SageMaker
This tutorial shows how easy it is to deploy a state-of-the-art LLM, such as Zephyr 7B, on AWS Inferentia2 using Amazon SageMaker. Zephyr is a 7B fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co./mistralai/Mistral-7B-v0.1) that was trained on a mix of publicly available and synthetic datasets using [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290), as described in detail in the [technical report](https://arxiv.org/abs/2310.16944). The model is released under the Apache 2.0 license, ensuring wide accessibility and use.
We are going to show you how to:
1. Setup development environment
2. Retrieve the TGI Neuronx Image
3. Deploy Zephyr 7B to Amazon SageMaker
4. Run inference and chat with the model
Let’s get started.
### 1. Setup development environment
We are going to use the `sagemaker` python SDK to deploy Zephyr to Amazon SageMaker. We need to make sure to have an AWS account configured and the `sagemaker` python SDK installed.
```python
!pip install transformers "sagemaker>=2.206.0" --upgrade --quiet
```
If you are going to use Sagemaker in a local environment. You need access to an IAM Role with the required permissions for Sagemaker. You can find out more about it [here](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html).
```python
import sagemaker
import boto3
sess = sagemaker.Session()
# sagemaker session bucket -> used for uploading data, models and logs
# sagemaker will automatically create this bucket if it doesn't exist
sagemaker_session_bucket=None
if sagemaker_session_bucket is None and sess is not None:
# set to default bucket if a bucket name is not given
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client('iam')
role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker session region: {sess.boto_region_name}")
```
### 2. Retrieve TGI Neuronx Image
The new Hugging Face TGI Neuronx DLCs can be used to run inference on AWS Inferentia2. You can use the `get_huggingface_llm_image_uri` method of the `sagemaker` SDK to retrieve the appropriate Hugging Face TGI Neuronx DLC URI based on your desired `backend`, `session`, `region`, and `version`. You can find all the available versions [here](https://github.com/aws/deep-learning-containers/releases?q=tgi+AND+neuronx&expanded=true).
*Note: At the time of writing this blog post the latest version of the Hugging Face LLM DLC is not yet available via the `get_huggingface_llm_image_uri` method. We are going to use the raw container uri instead.*
```python
from sagemaker.huggingface import get_huggingface_llm_image_uri
# retrieve the llm image uri
llm_image = get_huggingface_llm_image_uri(
"huggingface-neuronx",
version="0.0.20"
)
# print ecr image uri
print(f"llm image uri: {llm_image}")
```
### 4. Deploy Zephyr 7B to Amazon SageMaker
Text Generation Inference (TGI) on Inferentia2 supports popular open LLMs, including Llama, Mistral, and more. You can check the full list of supported models (text-generation) [here](https://huggingface.co./docs/optimum-neuron/package_reference/export#supported-architectures).
**Compiling LLMs for Inferentia2**
At the time of writing, [AWS Inferentia2 does not support dynamic shapes for inference](https://awsdocs-neuron.readthedocs-hosted.com/en/v2.6.0/general/arch/neuron-features/dynamic-shapes.html#neuron-dynamic-shapes), which means that we need to specify our sequence length and batch size ahead of time.
To make it easier for customers to utilize the full power of Inferentia2, we created a [neuron model cache](https://huggingface.co./docs/optimum-neuron/guides/cache_system), which contains pre-compiled configurations for the most popular LLMs. A cached configuration is defined through a model architecture (Mistral), model size (7B), neuron version (2.16), number of inferentia cores (2), batch size (2), and sequence length (2048).
This means we don't need to compile the model ourselves, but we can use the pre-compiled model from the cache. Examples of this are [mistralai/Mistral-7B-v0.1](https://huggingface.co./mistralai/Mistral-7B-v0.1) and [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co./HuggingFaceH4/zephyr-7b-beta). You can find compiled/cached configurations on the [Hugging Face Hub](https://huggingface.co./aws-neuron/optimum-neuron-cache/tree/main/inference-cache-config). If your desired configuration is not yet cached, you can compile it yourself using the [Optimum CLI](https://huggingface.co./docs/optimum-neuron/cli/compile) or open a request at the [Cache repository](https://huggingface.co./aws-neuron/optimum-neuron-cache/discussions)
For this post we re-compiled `HuggingFaceH4/zephyr-7b-beta` using the following command and parameters on a `inf2.8xlarge` instance, and pushed it to the Hub at [aws-neuron/zephyr-7b-seqlen-2048-bs-4-cores-2](https://huggingface.co./aws-neuron/zephyr-7b-seqlen-2048-bs-4-cores-2)
```bash
# compile model with optimum for batch size 4 and sequence length 2048
optimum-cli export neuron -m HuggingFaceH4/zephyr-7b-beta --batch_size 4 --sequence_length 2048 --num_cores 2 --auto_cast_type bf16 ./zephyr-7b-beta-neuron
# push model to hub [repo_id] [local_path] [path_in_repo]
huggingface-cli upload aws-neuron/zephyr-7b-seqlen-2048-bs-4 ./zephyr-7b-beta-neuron ./ --exclude "checkpoint/**"
# Move tokenizer to neuron model repository
python -c "from transformers import AutoTokenizer; AutoTokenizer.from_pretrained('HuggingFaceH4/zephyr-7b-beta').push_to_hub('aws-neuron/zephyr-7b-seqlen-2048-bs-4')"
```
If you are trying to compile an LLM with a configuration that is not yet cached, it can take up to 45 minutes.
**Deploying TGI Neuronx Endpoint**
Before deploying the model to Amazon SageMaker, we must define the TGI Neuronx endpoint configuration. We need to make sure the following additional parameters are defined:
- `HF_NUM_CORES`: Number of Neuron Cores used for the compilation.
- `HF_BATCH_SIZE`: The batch size that was used to compile the model.
- `HF_SEQUENCE_LENGTH`: The sequence length that was used to compile the model.
- `HF_AUTO_CAST_TYPE`: The auto cast type that was used to compile the model.
We still need to define traditional TGI parameters with:
- `HF_MODEL_ID`: The Hugging Face model ID.
- `HF_TOKEN`: The Hugging Face API token to access gated models.
- `MAX_BATCH_SIZE`: The maximum batch size that the model can handle, equal to the batch size used for compilation.
- `MAX_INPUT_LENGTH`: The maximum input length that the model can handle.
- `MAX_TOTAL_TOKENS`: The maximum total tokens the model can generate, equal to the sequence length used for compilation.
```python
import json
from sagemaker.huggingface import HuggingFaceModel
# sagemaker config & model config
instance_type = "ml.inf2.8xlarge"
health_check_timeout = 1800
# Define Model and Endpoint configuration parameter
config = {
"HF_MODEL_ID": "HuggingFaceH4/zephyr-7b-beta",
"HF_NUM_CORES": "2",
"HF_BATCH_SIZE": "4",
"HF_SEQUENCE_LENGTH": "2048",
"HF_AUTO_CAST_TYPE": "bf16",
"MAX_BATCH_SIZE": "4",
"MAX_INPUT_LENGTH": "1512",
"MAX_TOTAL_TOKENS": "2048",
}
# create HuggingFaceModel with the image uri
llm_model = HuggingFaceModel(
role=role,
image_uri=llm_image,
env=config
)
```
After we have created the `HuggingFaceModel` we can deploy it to Amazon SageMaker using the `deploy` method. We will deploy the model with the `ml.inf2.8xlarge` instance type.
```python
# Deploy model to an endpoint
llm = llm_model.deploy(
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout,
)
```
SageMaker will create our endpoint and deploy the model to it. This can take 10-15 minutes.
### 5. Run inference and chat with the model
After our endpoint is deployed, we can run inference on it, using the `predict` method from `predictor`. We can provide different parameters to impact the generation, adding them to the `parameters` attribute of the payload. You can find the supported parameters [here](https://www.philschmid.de/sagemaker-llama-llm#5-run-inference-and-chat-with-the-model), or in the open API specification of TGI in the [swagger documentation](https://huggingface.github.io/text-generation-inference/)
The `HuggingFaceH4/zephyr-7b-beta` is a conversational chat model, meaning we can chat with it using a prompt structure like the following:
```
<|system|>\nYou are a friendly.</s>\n<|user|>\nInstruction</s>\n<|assistant|>\n
```
Manually preparing the prompt is error prone, so we can use the `apply_chat_template` method from the tokenizer to help with it. It expects a `messages` dictionary in the well-known OpenAI format, and converts it into the correct format for the model. Let's see if Zephyr knows some facts about AWS.
```python
from transformers import AutoTokenizer
# load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("aws-neuron/zephyr-7b-seqlen-2048-bs-4-cores-2")
# Prompt to generate
messages = [
{"role": "system", "content": "You are the AWS expert"},
{"role": "user", "content": "Can you tell me an interesting fact about AWS?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# Generation arguments
payload = {
"do_sample": True,
"top_p": 0.6,
"temperature": 0.9,
"top_k": 50,
"max_new_tokens": 256,
"repetition_penalty": 1.03,
"return_full_text": False,
"stop": ["</s>"]
}
chat = llm.predict({"inputs":prompt, "parameters":payload})
print(chat[0]["generated_text"][len(prompt):])
# Sure, here's an interesting fact about AWS: As of 2021, AWS has more than 200 services in its portfolio, ranging from compute power and storage to databases,
```
Awesome, we have successfully deployed Zephyr to Amazon SageMaker on Inferentia2 and chatted with it.
### 6. Clean up
To clean up, we can delete the model and endpoint.
```python
llm.delete_model()
llm.delete_endpoint()
```
## Conclusion
The integration of Hugging Face Text Generation Inference (TGI) with AWS Inferentia2 and Amazon SageMaker provides a cost-effective alternative solution for deploying Large Language Models (LLMs).
We're actively working on supporting more models, streamlining the compilation process, and refining the caching system. | [
[
"llm",
"mlops",
"deployment",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"deployment",
"efficient_computing"
] | null | null |
b3bbf391-3f71-4cde-8e94-14e25dc36a50 | completed | 2025-01-16T03:09:11.596708 | 2025-01-19T19:04:06.138312 | 9fba9577-0cd0-403f-9ecc-19f4c1d11a91 | Converting Vertex-Colored Meshes to Textured Meshes | dylanebert | vertex-colored-to-textured-mesh.md | [](https://githubtocolab.com/dylanebert/InstantTexture/blob/main/notebooks/walkthrough.ipynb)
Convert vertex-colored meshes to UV-mapped, textured meshes.
<gradio-app theme_mode="light" space="dylanebert/InstantTexture"></gradio-app>
## Introduction
Vertex colors are a straightforward way to add color information directly to a mesh's vertices. This is often the way generative 3D models like [InstantMesh](https://huggingface.co./spaces/TencentARC/InstantMesh) produce meshes. However, most applications prefer UV-mapped, textured meshes.
This tutorial walks through a quick solution to convert vertex-colored meshes to UV-mapped, textured meshes. This includes [The Short Version](#the-short-version) to get results quickly, and [The Long Version](#the-long-version) for an in-depth walkthrough.
## The Short Version
Install the [InstantTexture](https://github.com/dylanebert/InstantTexture) library for easy conversion. This is a small library we wrote that implements the steps described in [The Long Version](#the-long-version) below.
```bash
pip install git+https://github.com/dylanebert/InstantTexture
```
### Usage
The code below converts a vertex-colored `.obj` mesh to a UV-mapped, textured `.glb` mesh and saves it to `output.glb`.
```python
from instant_texture import Converter
input_mesh_path = "https://raw.githubusercontent.com/dylanebert/InstantTexture/refs/heads/main/examples/chair.obj"
converter = Converter()
converter.convert(input_mesh_path)
```
Let's visualize the output mesh.
```python
import trimesh
mesh = trimesh.load("output.glb")
mesh.show()
```
That's it!
For a detailed walkthrough, continue reading.
## The Long Version
Install the following dependencies:
- **numpy** for numerical operations
- **trimesh** for loading and saving mesh data
- **xatlas** for generating uv maps
- **Pillow** for image processing
- **opencv-python** for image processing
- **httpx** for downloading the input mesh
```bash
pip install numpy trimesh xatlas opencv-python pillow httpx
```
Import dependencies.
```python
import cv2
import numpy as np
import trimesh
import xatlas
from PIL import Image, ImageFilter
```
Load the vertex-colored input mesh. This should be a `.obj` file located at `input_mesh_path`.
If it's a local file, use `trimesh.load()` instead of `trimesh.load_remote()`.
```python
mesh = trimesh.load_remote(input_mesh_path)
mesh.show()
```
Access the vertex colors of the mesh.
If this fails, ensure the mesh is a valid `.obj` file with vertex colors.
```python
vertex_colors = mesh.visual.vertex_colors
```
Generate the uv map using xatlas.
This is the most time-consuming part of the process.
```python
vmapping, indices, uvs = xatlas.parametrize(mesh.vertices, mesh.faces)
```
Remap the vertices and vertex colors to the uv map.
```python
vertices = mesh.vertices[vmapping]
vertex_colors = vertex_colors[vmapping]
mesh.vertices = vertices
mesh.faces = indices
```
Define the desired texture size.
Construct a texture buffer that is upscaled by an `upscale_factor` to create a higher quality texture.
```python
texture_size = 1024
upscale_factor = 2
buffer_size = texture_size * upscale_factor
texture_buffer = np.zeros((buffer_size, buffer_size, 4), dtype=np.uint8)
```
Fill in the texture of the UV-mapped mesh using barycentric interpolation.
1. **Barycentric interpolation**: Computes the interpolated color at point `p` inside a triangle defined by vertices `v0`, `v1`, and `v2` with corresponding colors `c0`, `c1`, and `c2`.
2. **Point-in-Triangle test**: Determines if a point `p` lies within a triangle defined by vertices `v0`, `v1`, and `v2`.
3. **Texture-filling loop**:
- Iterate over each face of the mesh.
- Retrieve the UV coordinates (`uv0`, `uv1`, `uv2`) and colors (`c0`, `c1`, `c2`) for the current face.
- Convert the UV coordinates to buffer coordinates.
- Determine the bounding box of the triangle on the texture buffer.
- For each pixel in the bounding box, check if the pixel lies within the triangle using the point-in-triangle test.
- If inside, compute the interpolated color using barycentric interpolation.
- Assign the color to the corresponding pixel in the texture buffer.
```python
# Barycentric interpolation
def barycentric_interpolate(v0, v1, v2, c0, c1, c2, p):
v0v1 = v1 - v0
v0v2 = v2 - v0
v0p = p - v0
d00 = np.dot(v0v1, v0v1)
d01 = np.dot(v0v1, v0v2)
d11 = np.dot(v0v2, v0v2)
d20 = np.dot(v0p, v0v1)
d21 = np.dot(v0p, v0v2)
denom = d00 * d11 - d01 * d01
if abs(denom) < 1e-8:
return (c0 + c1 + c2) / 3
v = (d11 * d20 - d01 * d21) / denom
w = (d00 * d21 - d01 * d20) / denom
u = 1.0 - v - w
u = np.clip(u, 0, 1)
v = np.clip(v, 0, 1)
w = np.clip(w, 0, 1)
interpolate_color = u * c0 + v * c1 + w * c2
return np.clip(interpolate_color, 0, 255)
# Point-in-Triangle test
def is_point_in_triangle(p, v0, v1, v2):
def sign(p1, p2, p3):
return (p1[0] - p3[0]) * (p2[1] - p3[1]) - (p2[0] - p3[0]) * (p1[1] - p3[1])
d1 = sign(p, v0, v1)
d2 = sign(p, v1, v2)
d3 = sign(p, v2, v0)
has_neg = (d1 < 0) or (d2 < 0) or (d3 < 0)
has_pos = (d1 > 0) or (d2 > 0) or (d3 > 0)
return not (has_neg and has_pos)
# Texture-filling loop
for face in mesh.faces:
uv0, uv1, uv2 = uvs[face]
c0, c1, c2 = vertex_colors[face]
uv0 = (uv0 * (buffer_size - 1)).astype(int)
uv1 = (uv1 * (buffer_size - 1)).astype(int)
uv2 = (uv2 * (buffer_size - 1)).astype(int)
min_x = max(int(np.floor(min(uv0[0], uv1[0], uv2[0]))), 0)
max_x = min(int(np.ceil(max(uv0[0], uv1[0], uv2[0]))), buffer_size - 1)
min_y = max(int(np.floor(min(uv0[1], uv1[1], uv2[1]))), 0)
max_y = min(int(np.ceil(max(uv0[1], uv1[1], uv2[1]))), buffer_size - 1)
for y in range(min_y, max_y + 1):
for x in range(min_x, max_x + 1):
p = np.array([x + 0.5, y + 0.5])
if is_point_in_triangle(p, uv0, uv1, uv2):
color = barycentric_interpolate(uv0, uv1, uv2, c0, c1, c2, p)
texture_buffer[y, x] = np.clip(color, 0, 255).astype(
np.uint8
)
```
Let's visualize how the texture looks so far.
```python
from IPython.display import display
image_texture = Image.fromarray(texture_buffer)
display(image_texture)
```

As we can see, the texture has a lot of holes.
To correct for this, we'll combine 4 techniques:
1. **Inpainting**: Fill in the holes using the average color of the surrounding pixels.
2. **Median filter**: Remove noise by replacing each pixel with the median color of its surrounding pixels.
3. **Gaussian blur**: Smooth out the texture to remove any remaining noise.
4. **Downsample**: Resize down to `texture_size` with LANCZOS resampling.
```python
# Inpainting
image_bgra = texture_buffer.copy()
mask = (image_bgra[:, :, 3] == 0).astype(np.uint8) * 255
image_bgr = cv2.cvtColor(image_bgra, cv2.COLOR_BGRA2BGR)
inpainted_bgr = cv2.inpaint(
image_bgr, mask, inpaintRadius=3, flags=cv2.INPAINT_TELEA
)
inpainted_bgra = cv2.cvtColor(inpainted_bgr, cv2.COLOR_BGR2BGRA)
texture_buffer = inpainted_bgra[::-1]
image_texture = Image.fromarray(texture_buffer)
# Median filter
image_texture = image_texture.filter(ImageFilter.MedianFilter(size=3))
# Gaussian blur
image_texture = image_texture.filter(ImageFilter.GaussianBlur(radius=1))
# Downsample
image_texture = image_texture.resize((texture_size, texture_size), Image.LANCZOS)
# Display the final texture
display(image_texture)
```

As we can see, the texture is now much smoother and has no holes.
This can be further improved with more advanced techniques or manual texture editing.
Finally, we can construct a new mesh with the generated uv coordinates and texture.
```python
material = trimesh.visual.material.PBRMaterial(
baseColorFactor=[1.0, 1.0, 1.0, 1.0],
baseColorTexture=image_texture,
metallicFactor=0.0,
roughnessFactor=1.0,
)
visuals = trimesh.visual.TextureVisuals(uv=uvs, material=material)
mesh.visual = visuals
mesh.show()
```

Et voilà! The mesh is UV-mapped and textured.
To export it when running locally, call `mesh.export("output.glb")`.
## Limitations
As you can see, the mesh still has many small artifacts.
The quality of the UV map and texture are also far below the standards of a production-ready mesh.
However, if you're looking for a quick solution to map from a vertex-colored mesh to a UV-mapped mesh, then this approach may be useful for you.
## Conclusion
This tutorial walked through how to convert a vertex-colored mesh to a UV-mapped, textured mesh.
If you have any questions or feedback, please feel free to open an issue on [GitHub](https://github.com/dylanebert/InstantTexture) or on the [Space](https://huggingface.co./spaces/dylanebert/InstantTexture).
Thank you for reading! | [
[
"computer_vision",
"implementation",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"implementation",
"tutorial",
"tools"
] | null | null |
3a6a3477-ab18-4e84-bc2b-01e8386294bd | completed | 2025-01-16T03:09:11.596713 | 2025-01-16T13:39:37.745839 | 79ef0c33-bc5e-4289-8c01-c0d3ce98d482 | Instruction-tuning Stable Diffusion with InstructPix2Pix | sayakpaul | instruction-tuning-sd.md | This post explores instruction-tuning to teach [Stable Diffusion](https://huggingface.co./blog/stable_diffusion) to follow instructions to translate or process input images. With this method, we can prompt Stable Diffusion using an input image and an “instruction”, such as - *Apply a cartoon filter to the natural image*.
|  |
|:--:|
| **Figure 1**: We explore the instruction-tuning capabilities of Stable Diffusion. In this figure, we prompt an instruction-tuned Stable Diffusion system with prompts involving different transformations and input images. The tuned system seems to be able to learn these transformations stated in the input prompts. Figure best viewed in color and zoomed in. |
This idea of teaching Stable Diffusion to follow user instructions to perform **edits** on input images was introduced in [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co./papers/2211.09800). We discuss how to extend the InstructPix2Pix training strategy to follow more specific instructions related to tasks in image translation (such as cartoonization) and low-level image processing (such as image deraining). We cover:
- [Introduction to instruction-tuning](#introduction-and-motivation)
- [The motivation behind this work](#introduction-and-motivation)
- [Dataset preparation](#dataset-preparation)
- [Training experiments and results](#training-experiments-and-results)
- [Potential applications and limitations](#potential-applications-and-limitations)
- [Open questions](#open-questions)
Our code, pre-trained models, and datasets can be found [here](https://github.com/huggingface/instruction-tuned-sd).
## Introduction and motivation
Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in [Fine-tuned Language Models Are Zero-Shot Learners](https://huggingface.co./papers/2109.01652) (FLAN) by Google. From recent times, you might recall works like [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) and [FLAN V2](https://huggingface.co./papers/2210.11416), which are good examples of how beneficial instruction-tuning can be for various tasks.
The figure below shows a formulation of instruction-tuning (also called “instruction-finetuning”). In the [FLAN V2 paper](https://huggingface.co./papers/2210.11416), the authors take a pre-trained language model ([T5](https://huggingface.co./docs/transformers/model_doc/t5), for example) and fine-tune it on a dataset of exemplars, as shown in the figure below.
|  |
|:--:|
| **Figure 2**: FLAN V2 schematic (figure taken from the FLAN V2 paper). |
With this approach, one can create exemplars covering many different tasks, which makes instruction-tuning a multi-task training objective:
| **Input** | **Label** | **Task** |
| | [
[
"computer_vision",
"research",
"image_generation",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"fine_tuning",
"research"
] | null | null |
a138e090-fc49-4562-bb0c-178425b09992 | completed | 2025-01-16T03:09:11.596717 | 2025-01-16T03:25:24.692279 | 498a6524-dddd-464c-95de-d522d005d4db | Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset | HugoLaurencon, Leyo, VictorSanh | websight.md | In the world of web development, turning designs into functional websites usually involves a lot of coding and careful testing. What if we could simplify this process, making it possible to convert web designs into working websites more easily and quickly? WebSight is a new dataset that aims at building AI systems capable of transforming screenshots to HTML code.
## The challenge
Turning a website design or screenshot into HTML code usually needs an experienced developer. But what if this could be more efficient? Motivated by this question, we investigated how vision-language models (VLMs) could be used in web development to create low-code solutions that improve efficiency.
Today, the main challenge towards that goal is the lack of high-quality datasets tailored for this task. WebSight aims to fill that gap.
## WebSight: A large synthetic dataset of screenshot/HTML code pairs
In January 2024, we introduced [WebSight-v0.1](https://huggingface.co./datasets/HuggingFaceM4/WebSight), a synthetic dataset that consists of 823,000 pairs of HTML codes and their corresponding screenshots. This dataset is designed to train AI models to process and translate visual web designs into functional HTML code. By focusing on synthetic data, we've managed to bypass the noise and complexity often found in real-world HTML, allowing AI models to learn efficiently.
Following our initial release and building on top of the community’s feedback, we've updated our dataset to WebSight-v0.2, introducing significant improvements. These enhancements feature using real images in the screenshots, and switching to Tailwind CSS (instead of traditional CSS). We further scaled the dataset to 2 million examples.
<figure align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/websight/websight_examples_2.jpg" width="800" alt="Examples of web pages included in WebSight"/>
<figcaption>Examples of web pages included in WebSight.</figcaption>
</figure>
## Sightseer: A model fine-tuned on WebSight
Leveraging the WebSight dataset, we’ve fine-tuned our forthcoming foundation vision-language model to obtain Sightseer, a model capable of converting webpage screenshots into functional HTML code. Sightseer additionally demonstrates the capability to incorporate images into the generated HTML that closely resemble those in the original screenshots.
<figure align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/websight/main_generation_2.jpg" width="1000" alt="Comparison of an original web page (input) on the left, and the rendering of the code generated by our model, Sightseer, (output) on the right."/>
<figcaption>Comparison of an original web page (input) on the left, and the rendering of the code generated by our model, Sightseer, (output) on the right.</figcaption>
</figure>
## Towards more powerful tools unlocked by visual language models
By iterating over WebSight, our goal is to build more capable AI systems that simplify the process of turning UI designs into functional code. This could reduce iteration time for developers by transforming a paper UI sketch into functional code rapidly, while making this process more accessible for non-developers. This is one of the many real applications of visual language models.. By open-sourcing WebSight, we encourage the community to work with us toward building more powerful tools for UI development.
## Resources
- Dataset: https://huggingface.co./datasets/HuggingFaceM4/WebSight
- Technical report: http://arxiv.org/abs/2403.09029
- Google colab: https://colab.research.google.com/drive/1LdamGKR2oacrDk-kYwz_Wfc1-RBUdzcO?usp=sharing | [
[
"computer_vision",
"data",
"research",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"data",
"research",
"multi_modal"
] | null | null |
bd1fb225-21ba-40e4-b810-d61c4a10c48e | completed | 2025-01-16T03:09:11.596722 | 2025-01-16T15:11:01.943335 | 6b197722-0719-47ae-b9c7-a3b34ac33b8a | How NuminaMath Won the 1st AIMO Progress Prize | yfleureau, liyongsea, edbeeching, lewtun, benlipkin, romansoletskyi, vwxyzjn, kashif | winning-aimo-progress-prize.md | This year, [**Numina**](https://projectnumina.ai) and Hugging Face collaborated to compete in the 1st Progress Prize of the [**AI Math Olympiad (AIMO)**](https://aimoprize.com). This competition involved fine-tuning open LLMs to solve difficult math problems that high school students use to train for the International Math Olympiad. We’re excited to share that our model — [**NuminaMath 7B TIR**](https://huggingface.co./AI-MO/NuminaMath-7B-TIR) — was the winner and managed to solve 29 out of 50 problems on the private test set 🥳!

In this blog post, we introduce the Numina initiative and the technical details behind our winning solution. If you want to skip straight to testing out the model with your hardest math problems, check out our [**demo**](https://huggingface.co./spaces/AI-MO/math-olympiad-solver).
Let’s dive in!
1. [Introducing Numina - an open AI4Maths initiative](#introducing-numina | [
[
"llm",
"research",
"benchmarks",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"research",
"benchmarks"
] | null | null |
f1167040-a2ff-4385-895f-99608e478c62 | completed | 2025-01-16T03:09:11.596726 | 2025-01-19T18:55:56.779319 | c0e9297e-cbde-4879-bc6b-0e4b07e2fa8d | Rearchitecting Hugging Face Uploads and Downloads | port8080, jsulz, erinys | rearchitecting-uploads-and-downloads.md | As part of Hugging Face's Xet team’s work to [improve Hugging Face Hub’s storage backend](https://huggingface.co./blog/xethub-joins-hf), we analyzed a 24 hour window of Hugging Face upload requests to better understand access patterns. On October 11th, 2024, we saw:
- Uploads from 88 countries
- 8.2 million upload requests
- 130.8 TB of data transferred
The map below visualizes this activity, with countries colored by bytes uploaded per hour.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/animated-uploads-choropleth.gif" alt="Animated view of uploads" width=100%>
</p>
Currently, uploads are stored in an [S3 bucket](https://aws.amazon.com/s3/) in **`us-east-1`** and optimized using [S3 Transfer Acceleration](https://aws.amazon.com/s3/transfer-acceleration/). Downloads are cached and served using [AWS Cloudfront](https://aws.amazon.com/cloudfront/) as a CDN. Cloudfront’s [400+ convenient edge locations](https://aws.amazon.com/blogs/networking-and-content-delivery/400-amazon-cloudfront-points-of-presence/) provide global coverage and low-latency data transfers. However, like most CDNs, it is optimized for web content and has a file size limit of 50GB.
While this size restriction is reasonable for typical internet file transfers, the ever-growing size of files in model and dataset repositories presents a challenge. For instance, the weights of [meta-llama/Meta-Llama-3-70B](https://huggingface.co./meta-llama/Meta-Llama-3-70B) total 131GB and are split across 30 files to meet the Hub’s recommendation of chunking weights into [20 GB segments](https://huggingface.co./docs/hub/en/repositories-recommendations#recommendations). Additionally, to enable advanced deduplication or compression techniques for both uploads and downloads requires a reimagining of how we handle file transfers.
## A Custom Protocol for Uploads and Downloads
To push Hugging Face infrastructure beyond its current limits, we are redesigning the Hub’s upload and download architecture. We plan to insert a [content-addressed store (CAS)](https://en.wikipedia.org/wiki/Content-addressable_storage) as the first stop for content distribution. This enables us to implement a custom protocol built on a guiding philosophy of **_dumb reads and smart writes_**. Unlike Git LFS, which treats files as opaque blobs, our approach analyzes files at the byte level, uncovering opportunities to improve transfer speeds for the massive files found in model and dataset repositories.
The read path prioritizes simplicity and speed to ensure high throughput with minimal latency. Requests for a file are routed to a CAS server, which provides reconstruction information. The data itself remains backed by an S3 bucket in **`us-east-1`**, with AWS CloudFront continuing to serve as the CDN for downloads.
The write path is more complex to optimize upload speeds and provide additional security guarantees. Like reads, upload requests are routed to a CAS server, but instead of querying at the file level [we operate on chunks](https://huggingface.co./blog/from-files-to-chunks). As matches are found, the CAS server instructs the client (e.g., [huggingface_hub](https://github.com/huggingface/huggingface_hub)) to transfer only the necessary (new) chunks. The chunks are validated by CAS before uploading them to S3.
There are many implementation details to address such as network constraints and storage overhead which we’ll cover in future posts. For now, let's look at how reads currently look. The first diagram below show the read and write path as they currently look today:
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/old-read-write-path.png" alt="Old read and write sequence diagram" width=100%>
<figcaption> Reads are represented on the left; writes are to the right. Note that writes go directly to S3 without any intermediary.</figcaption>
</figure>
Meanwhile, in the new design, reads will take the following path:
<figure class="image text-center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/new-reads.png" alt="New read path in proposed architecture">
<figcaption>New read path with a content addressed store (CAS) providing reconstruction information. Cloudfront continues to act as a CDN.</figcaption>
</figure>
and finally here is the updated write path:
<figure class="image text-center" width=90%>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/new-writes.png" alt="New read path in proposed architecture" >
<figcaption>New write path with CAS speeding up and validating uploads. S3 continues to provide backing storage.</figcaption>
</figure>
By managing files at the byte level, we can adapt optimizations to suit different file formats. For instance, we have explored [improving the dedupeability of Parquet files](https://huggingface.co./blog/improve_parquet_dedupe), and are now investigating compressing tensor files (e.g., [Safetensors](https://github.com/huggingface/safetensors)) which have the potential to trim 10-25% off upload speeds. As new formats emerge, we are uniquely positioned to develop further enhancements that improve the development experience on the Hub.
This protocol also introduces significant improvements for enterprise customers and power users. Inserting a control plane for file transfers provides added guarantees to ensure malicious or invalid data cannot be uploaded. Operationally, uploads are no longer a black box. Enhanced telemetry provides audit trails and detailed logging, enabling the Hub infrastructure team to identify and resolve issues quickly and efficiently.
## Designing for Global Access
To support this custom protocol, we need to determine the optimal geographic distribution for the CAS service. [AWS Lambda@Edge](https://aws.amazon.com/lambda/edge/) was initially considered for its extensive global coverage to help minimize the round-trip time. However, its reliance on Cloudfront triggers made it incompatible with our updated upload path. Instead, we opted to deploy CAS nodes in a select few of AWS’s 34 regions.
Taking a closer look at our 24-hour window of S3 PUT requests, we identified global traffic patterns that reveal the distribution of data uploads to the Hub. As expected, the majority of activity comes from North America and Europe, with continuous, high-volume uploads throughout the day. The data also highlights a strong and growing presence in Asia. By focusing on these core regions, we can place our CAS [points of presence](https://docs.aws.amazon.com/whitepapers/latest/aws-fault-isolation-boundaries/points-of-presence.html) to balance storage and network resources while minimizing latency.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/pareto-chart.png" alt="Pareto chart of uploads" width=100%>
</p>
While AWS offers 34 regions, our goal is to keep infrastructure costs reasonable while maintaining a high user experience. Out of the 88 countries represented in this snapshot, the Pareto chart above shows that the top 7 countries account for 80% of uploaded bytes, while the top 20 countries contribute 95% of the total upload volume and requests.
The United States emerges as the primary source of upload traffic, necessitating a PoP in this region. In Europe, most activity is concentrated in central and western countries (e.g., Luxembourg, the United Kingdom, and Germany) though there is some additional activity to account for in Africa (specifically Algeria, Egypt, and South Africa). Asia’s upload traffic is primarily driven by Singapore, Hong Kong, Japan, and South Korea.
If we use a simple heuristic to distribute traffic, we can divide our CAS coverage into three major regions:
- **`us-east-1`**: Serving North and South America
- **`eu-west-3`**: Serving Europe, the Middle East, and Africa
- **`ap-southeast-1`**: Serving Asia and Oceania
This ends up being quite effective. The US and Europe account for 78.4% of uploaded bytes, while Asia accounts for 21.6%.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/rearchitecting-uploads-and-downloads/aws-regions.png" alt="New AWS mapping" width=100%>
</p>
This regional breakdown results in a well-balanced load across our three CAS PoPs, with additional capacity for growth in **`ap-southeast-1`** and flexibility to scale up in **`us-east-1`** and **`eu-west-3`** as needed.
Based on expected traffic, we plan to allocate resources as follows:
- **`us-east-1`**: 4 nodes
- **`eu-west-3`**: 4 nodes
- **`ap-southeast-1`**: 2 nodes
## Validating and Vetting
Even though we’re increasing the first hop distance for some users, the overall impact to bandwidth across the Hub will be limited. Our estimates predict that while the cumulative bandwidth for all uploads will decrease from 48.5 Mbps to 42.5 Mbps (a 12% reduction), the performance hit will be more than offset by other system optimizations.
We are currently working toward moving our infrastructure into production by the end of 2024, where we will start with a single CAS in **`us-east-1`**. From there, we’ll start duplicating internal repositories to our new storage system to benchmark transfer performance, and then replicate our CAS to the additional PoPs mentioned above for more benchmarking. Based on those results, we will continue to optimize our approach to ensure that everything works smoothly when our storage backend is fully in place next year.
## Beyond the Bytes
As we continue this analysis, new opportunities for deeper insights are emerging. Hugging Face hosts one of the largest collections of data from the open-source machine learning community, providing a unique vantage point to explore the modalities and trends driving AI development around the world.
For example, future analyses could classify models uploaded to the Hub by use case (such as NLP, computer vision, robotics, or large language models) and examine geographic trends in ML activity. This data not only informs our infrastructure decisions but also provides a lens into the evolving landscape of machine learning.
We invite you to explore our current findings in more detail! Visit [our interactive Space](https://huggingface.co./spaces/xet-team/cas-analysis) to see the upload distribution for your region, and [follow our team](https://huggingface.co./xet-team) to hear more about what we’re building. | [
[
"data",
"mlops",
"optimization",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"optimization",
"data",
"tools"
] | null | null |
f23a8010-6013-4ce4-9d0a-2a0831d489db | completed | 2025-01-16T03:09:11.596731 | 2025-01-16T03:21:30.821523 | fe253c3c-7950-4a8e-a2a4-2b5d5c1cd6a9 | Text2SQL using Hugging Face Dataset Viewer API and Motherduck DuckDB-NSQL-7B | asoria, tdoehmen, senwu, lorr | duckdb-nsql-7b.md | Today, integrating AI-powered features, particularly leveraging Large Language Models (LLMs), has become increasingly prevalent across various tasks such as text generation, classification, image-to-text, image-to-image transformations, etc.
Developers are increasingly recognizing these applications' potential benefits, particularly in enhancing core tasks such as scriptwriting, web development, and, now, interfacing with data. Historically, crafting insightful SQL queries for data analysis was primarily the domain of data analysts, SQL developers, data engineers, or professionals in related fields, all navigating the nuances of SQL dialect syntax. However, with the advent of AI-powered solutions, the landscape is evolving. These advanced models offer new avenues for interacting with data, potentially streamlining processes and uncovering insights with greater efficiency and depth.
What if you could unlock fascinating insights from your dataset without diving deep into coding? To glean valuable information, one would need to craft a specialized `SELECT` statement, considering which columns to display, the source table, filtering conditions for selected rows, aggregation methods, and sorting preferences. This traditional approach involves a sequence of commands: `SELECT`, `FROM`, `WHERE`, `GROUP`, and `ORDER`.
But what if you’re not a seasoned developer and still want to harness the power of your data? In such cases, seeking assistance from SQL specialists becomes necessary, highlighting a gap in accessibility and usability.
This is where groundbreaking advancements in AI and LLM technology step in to bridge the divide. Imagine conversing with your data effortlessly, simply stating your information needs in plain language and having the model translate your request into a query.
In recent months, significant strides have been made in this arena. [MotherDuck](https://motherduck.com/) and [Numbers Station](https://numbersstation.ai/) unveiled their latest innovation: [DuckDB-NSQL-7B](https://huggingface.co./motherduckdb/DuckDB-NSQL-7B-v0.1), a state-of-the-art LLM designed specifically for [DuckDB SQL](https://duckdb.org/). What is this model’s mission? To empower users with the ability to unlock insights from their data effortlessly.
Initially fine-tuned from Meta’s original [Llama-2–7b](https://huggingface.co./meta-llama/Llama-2-7b) model using a broad dataset covering general SQL queries, DuckDB-NSQL-7B underwent further refinement with DuckDB text-to-SQL pairs. Notably, its capabilities extend beyond crafting `SELECT` statements; it can generate a wide range of valid DuckDB SQL statements, including official documentation and extensions, making it a versatile tool for data exploration and analysis.
In this article, we will learn how to deal with text2sql tasks using the DuckDB-NSQL-7B model, the Hugging Face dataset viewer API for parquet files and duckdb for data retrieval.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/text2sql-flow.png" alt="text2sql flow"><br>
<em>text2sql flow</em>
</p>
### How to use the model
- Using Hugging Face `transformers` pipeline
```python
from transformers import pipeline
pipe = pipeline("text-generation", model="motherduckdb/DuckDB-NSQL-7B-v0.1")
```
- Using transformers tokenizer and model
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
model = AutoModelForCausalLM.from_pretrained("motherduckdb/DuckDB-NSQL-7B-v0.1")
```
- Using `llama.cpp` to load the model in `GGUF`
```python
from llama_cpp import Llama
llama = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf", # Path to local model
n_gpu_layers=-1,
)
```
The main goal of `llama.cpp` is to enable LLM inference with minimal setup and state-of-the-art performance on a wide variety of hardware - locally and in the cloud. We will use this approach.
### Hugging Face Dataset Viewer API for more than 120K datasets
Data is a crucial component in any Machine Learning endeavor. Hugging Face is a valuable resource, offering access to over 120,000 free and open datasets spanning various formats, including CSV, Parquet, JSON, audio, and image files.
Each dataset hosted by Hugging Face comes equipped with a comprehensive dataset viewer. This viewer provides users essential functionalities such as statistical insights, data size assessment, full-text search capabilities, and efficient filtering options. This feature-rich interface empowers users to easily explore and evaluate datasets, facilitating informed decision-making throughout the machine learning workflow.
For this demo, we will be using the [world-cities-geo](https://huggingface.co./datasets/jamescalam/world-cities-geo) dataset.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/dataset-viewer.png" alt="dataset viewer"><br>
<em>Dataset viewer of world-cities-geo dataset</em>
</p>
Behind the scenes, each dataset in the Hub is processed by the [Hugging Face dataset viewer API](https://huggingface.co./docs/datasets-server/index), which gets useful information and serves functionalities like:
- List the dataset **splits, column names and data types**
- Get the dataset **size** (in number of rows or bytes)
- Download and view **rows at any index** in the dataset
- **Search** a word in the dataset
- **Filter** rows based on a query string
- Get insightful **statistics** about the data
- Access the dataset as **parquet files** to use in your favorite processing or analytics framework
In this demo, we will use the last functionality, auto-converted parquet files.
### Generate SQL queries from text instructions
First, [download](https://huggingface.co./motherduckdb/DuckDB-NSQL-7B-v0.1-GGUF/blob/main/DuckDB-NSQL-7B-v0.1-q8_0.gguf) the quantized models version of DuckDB-NSQL-7B-v0.1
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/download.png" alt="download model"><br>
<em>Downloading the model</em>
</p>
Alternatively, you can execute the following code:
```
huggingface-cli download motherduckdb/DuckDB-NSQL-7B-v0.1-GGUF DuckDB-NSQL-7B-v0.1-q8_0.gguf --local-dir . --local-dir-use-symlinks False
```
Now, lets install the needed dependencies:
```
pip install llama-cpp-python
pip install duckdb
```
For the text-to-SQL model, we will use a prompt with the following structure:
```
### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Question:
{query_input}
### Response (use duckdb shorthand if possible):
```
- **ddl_create** will be the dataset schema as a SQL `CREATE` command
- **query_input** will be the user instructions, expressed with natural language
So, we need to tell to the model about the schema of the Hugging Face dataset. For that, we are going to get the first parquet file for [jamescalam/world-cities-geo](https://huggingface.co./datasets/jamescalam/world-cities-geo) dataset:
```
GET https://huggingface.co./api/datasets/jamescalam/world-cities-geo/parquet
```
```
{
"default":{
"train":[
"https://huggingface.co./api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet"
]
}
}
```
The [parquet file](https://huggingface.co./api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet) is hosted in Hugging Face viewer under `refs/convert/parquet` revision:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/parquet.png" alt="parquet file"><br>
<em>Parquet file</em>
</p>
- Simulate a [DuckDB](https://duckdb.org/) table creation from the first row of the parquet file
```python
import duckdb
con = duckdb.connect()
con.execute(f"CREATE TABLE data as SELECT * FROM '{first_parquet_url}' LIMIT 1;")
result = con.sql("SELECT sql FROM duckdb_tables() where table_name ='data';").df()
ddl_create = result.iloc[0,0]
con.close()
```
The `CREATE` schema DDL is:
```
CREATE TABLE "data"(
city VARCHAR,
country VARCHAR,
region VARCHAR,
continent VARCHAR,
latitude DOUBLE,
longitude DOUBLE,
x DOUBLE,
y DOUBLE,
z DOUBLE
);
```
And, as you can see, it matches the columns in the dataset viewer:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/columns.png" alt="dataset columns"><br>
<em>Dataset columns</em>
</p>
- Now, we can construct the prompt with the **ddl_create** and the **query** input
```python
prompt = """### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
{ddl_create}
### Question:
{query_input}
### Response (use duckdb shorthand if possible):
"""
```
If the user wants to know the **Cities from Albania country**, the prompt will look like this:
```python
query = "Cities from Albania country"
prompt = prompt.format(ddl_create=ddl_create, query_input=query)
```
So the expanded prompt that will be sent to the LLM looks like this:
```
### Instruction:
Your task is to generate valid duckdb SQL to answer the following question.
### Input:
Here is the database schema that the SQL query will run on:
CREATE TABLE "data"(city VARCHAR, country VARCHAR, region VARCHAR, continent VARCHAR, latitude DOUBLE, longitude DOUBLE, x DOUBLE, y DOUBLE, z DOUBLE);
### Question:
Cities from Albania country
### Response (use duckdb shorthand if possible):
```
- It is time to send the prompt to the model
```python
from llama_cpp import Llama
llm = Llama(
model_path="DuckDB-NSQL-7B-v0.1-q8_0.gguf",
n_ctx=2048,
n_gpu_layers=50
)
pred = llm(prompt, temperature=0.1, max_tokens=1000)
sql_output = pred["choices"][0]["text"]
```
The output SQL command will point to a `data` table, but since we don't have a real table but just a reference to the parquet file, we will replace all `data` occurrences by the `first_parquet_url`:
```python
sql_output = sql_output.replace("FROM data", f"FROM '{first_parquet_url}'")
```
And the final output will be:
```
SELECT city FROM 'https://huggingface.co./api/datasets/jamescalam/world-cities-geo/parquet/default/train/0.parquet' WHERE country = 'Albania'
```
- Now, it is time to finally execute our generated SQL directly in the dataset, so, lets use once again DuckDB powers:
```python
con = duckdb.connect()
try:
query_result = con.sql(sql_output).df()
except Exception as error:
print(f"❌ Could not execute SQL query {error=}")
finally:
con.close()
```
And here we have the results (100 rows):
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/result.png" alt="sql command result"><br>
<em>Execution result (100 rows)</em>
</p>
Let's compare this result with the dataset viewer using the "search function" for **Albania** country, it should be the same:
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/search.png" alt="search result"><br>
<em>Search result for Albania country</em>
</p>
You can also get the same result calling directly to the search or filter API:
- Using [/search](https://huggingface.co./docs/datasets-server/search?code=python#search-text-in-a-dataset) API
```python
import requests
API_URL = "https://datasets-server.huggingface.co/search?dataset=jamescalam/world-cities-geo&config=default&split=train&query=Albania"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
- Using [filter](https://huggingface.co./docs/datasets-server/filter) API
```python
import requests
API_URL = "https://datasets-server.huggingface.co/filter?dataset=jamescalam/world-cities-geo&config=default&split=train&where=country='Albania'"
def query():
response = requests.get(API_URL)
return response.json()
data = query()
```
Our final demo will be a Hugging Face space that looks like this:
<figure class="image table text-center m-0 w-full">
<video
alt="Demo"
style="max-width: 95%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/duckdb-nsql-7b/demo.mp4" type="video/mp4">
</video>
</figure>
You can see the notebook with the code [here](https://colab.research.google.com/drive/1hOyQ_Lp5wwC2z9HYhEzBHuRuqy-5plDO?usp=sharing).
And the Hugging Face Space [here](https://huggingface.co./spaces/asoria/datasets-text2sql) | [
[
"llm",
"data",
"implementation",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"data",
"implementation",
"integration"
] | null | null |
5532e77f-3fc5-4c51-9315-1f9dfbc3545b | completed | 2025-01-16T03:09:11.596736 | 2025-01-18T14:45:28.117831 | 0fa18ec9-1b17-4c4a-bbbb-1162dbf1302b | Fixing Gradient Accumulation | lysandre, ArthurZ, muellerzr, ydshieh, BenjaminB, pcuenq | gradient_accumulation.md | Our friends at Unsloth [shared an issue](https://unsloth.ai/blog/gradient) regarding gradient accumulation yesterday that is affecting the transformers Trainer. The initial report comes from @bnjmn_marie (kudos to him!).
Gradient accumulation is *supposed* to be mathematically equivalent to full batch training; however, losses did not match between training runs where the setting was toggled on and off.
## Where does it stem from?
Inside the modeling code of each model, `transformers` offers a "default" loss function that's the most typically used one for the model's task. It is determined by what the modeling class should be used for: question answering, token classification, causal LM, masked LM.
This is the default loss function and it was not meant to be customizable: it is only computed when `labels` and `input_ids` are passed as inputs to the model, so the user doesn't have to compute the loss. The default loss is useful but is limited **by design**: for anything different being done, we expect the labels to **not be passed directly, and for users to get the logits back from the model and use them to compute the loss outside of the model.**
However, the transformers Trainer, as well as many Trainers, heavily leverage these methods because of the simplicity it offers: it is a double-edged sword. Providing a simple API that becomes different as the use-case differs is not a well-thought out API, and we've been caught by surprise ourselves.
To be precise, for gradient accumulation across token-level tasks like causal LM training, the correct loss should be computed by the total loss across all batches in a gradient accumulation step divided by the total number of all non padding tokens in those batches. This is not the same as the average of the per-batch loss values.
The fix is quite simple, see the following:
```diff
def ForCausalLMLoss(logits, labels, vocab_size, **kwargs):
# Upcast to float if we need to compute the loss to avoid potential precision issues
logits = logits.float()
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
shift_logits = shift_logits.view(-1, vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
num_items = kwargs.pop("num_items", None)
+ loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100, reduction="sum")
+ loss = loss / num_items
- loss = nn.functional.cross_entropy(shift_logits, shift_labels, ignore_index=-100)
return loss
```
## How we're fixing it
To address this issue, we’re changing the way our models and training work in two ways:
* If users are using the “default” loss functions, we will automatically take into account the needed changes when using gradient accumulation, to make sure the proper loss is reported and utilized, fixing the core issue at hand.
* To ensure that any future issues with calculating losses won’t block users, we’ll be exposing an API to let users pass in their own loss functions to the `Trainer` directly so they can use their own fix easily until we have fixed any issues internally and made a new transformers release.
All model that inherit from `PreTrainedModel` now have a `loss_function` property, which is determined by either:
- the `config.loss_type`: this is to make sure anyone can use his custom loss. You can do this by modifying the `LOSS_MAPPING`:
```python
def my_super_loss(logits, labels):
return loss = nn.functional.cross_entropy(logits, labels, ignore_index=-100)
LOSS_MAPPING["my_loss_type"] = my_super_loss
```
We are working to ship the first change for the most popular models in this PR: https://github.com/huggingface/transformers/pull/34191#pullrequestreview-2372725010. Following this, a call for contributions to help propagate this to the rest of the models will be done so that the majority of models is supported by next release.
We are also actively working to ship the second change in this PR: https://github.com/huggingface/transformers/pull/34198, which will allow users to use their own loss function and make use of the number of samples seen per-batch to help with calculating their loss (and will perform the correct loss calculation during gradient accumulation as more models are supported from the prior change)
—
By tomorrow, you should expect the Trainer to behave correctly with gradient accumulation. Please install from `main` in order to benefit from the fix then:
```
pip install git+https://github.com/huggingface/transformers
```
In general, we are very responsive to bug reports submitted to our issue tracker: https://github.com/huggingface/transformers/issues
This issue has been in Transformers for some time as it's mostly a default that should be updated by the end-user; however, when defaults become non-intuitive, they are bound to be changed. In this instance, we've updated the code and shipped a fix in less than 24 hours, which is what we aim for issues like this one in transformers. Please, come and submit your issues if you have some; this is the only way we can get transformers to improve and fit well within your different use-cases.
The Transformers team 🤗 | [
[
"transformers",
"implementation",
"optimization",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"optimization",
"fine_tuning"
] | null | null |
2f44f2ca-0dbf-4562-b788-ee843c9ca007 | completed | 2025-01-16T03:09:11.596740 | 2025-01-16T03:15:44.897356 | 8aff9c39-7c50-4807-9aed-d837efcb5025 | CPU Optimized Embeddings with 🤗 Optimum Intel and fastRAG | peterizsak, mber, danf, echarlaix, mfuntowicz, moshew | intel-fast-embedding.md | Embedding models are useful for many applications such as retrieval, reranking, clustering, and classification. The research community has witnessed significant advancements in recent years in embedding models, leading to substantial enhancements in all applications building on semantic representation. Models such as [BGE](https://huggingface.co./BAAI/bge-large-en-v1.5), [GTE](https://huggingface.co./thenlper/gte-small), and [E5](https://huggingface.co./intfloat/multilingual-e5-large) are placed at the top of the [MTEB](https://github.com/embeddings-benchmark/mteb) benchmark and in some cases outperform proprietary embedding services. There are a variety of model sizes found in Hugging Face's Model hub, from lightweight (100-350M parameters) to 7B models (such as [Salesforce/SFR-Embedding-Mistral](http://Salesforce/SFR-Embedding-Mistral)). The lightweight models based on an encoder architecture are ideal candidates for optimization and utilization on CPU backends running semantic search-based applications, such as Retrieval Augmented Generation ([RAG](https://en.wikipedia.org/wiki/Prompt_engineering#Retrieval-augmented_generation)).
In this blog, we will show how to unlock significant performance boost on Xeon based CPUs, and show how easy it is to integrate optimized models into existing RAG pipelines using [fastRAG](https://github.com/IntelLabs/fastRAG/).
## Information Retrieval with Embedding Models
Embedding models encode textual data into dense vectors, capturing semantic and contextual meaning. This enables accurate information retrieval by representing word and document relationships more contextually. Typically, semantic similarity will be measured by cosine similarity between the embedding vectors.
Should dense vectors always be used for information retrieval? The two dominant approaches have trade-offs:
* Sparse retrieval matches n-grams, phrases, or metadata to search large collections efficiently and at scale. However, it may miss relevant documents due to lexical gaps between the query and the document.
* Semantic retrieval encodes text into dense vectors, capturing context and meaning better than bag-of-words. It can retrieve semantically related documents despite lexical mismatches. However, it's computationally intensive, has higher latency, and requires sophisticated encoding models compared to lexical matching like BM25.
### Embedding models and RAG
Embedding models serve multiple and critical purposes in RAG applications:
* Offline Process: Encoding documents into dense vectors during indexing/updating of the retrieval document store (index).
* Query Encoding: At query time, they encode the input query into a dense vector representation for retrieval.
* Reranking: After initial retrieval, they can rerank the retrieved documents by encoding them into dense vectors and comparing against the query vector. This allows reranking documents that initially lacked dense representations.
Optimizing the embedding model component in RAG pipelines is highly desirable for a higher efficiency experience, more particularly:
* Document Indexing/Updating: Higher throughput allows encoding and indexing large document collections more rapidly during initial setup or periodic updates.
* Query Encoding: Lower query encoding latency is critical for responsive real-time retrieval. Higher throughput supports encoding many concurrent queries efficiently, enabling scalability.
* Reranking Retrieved Documents: After initial retrieval, embedding models need to quickly encode the retrieved candidates for reranking. Lower latency allows rapid reranking of documents for time-sensitive applications. Higher throughput supports reranking larger candidate sets in parallel for more comprehensive reranking.
## Optimizing Embedding Models with Optimum Intel and IPEX
[Optimum Intel](https://github.com/huggingface/optimum-intel) is an open-source library that accelerates end-to-end pipelines built with Hugging Face libraries on Intel Hardware. Optimum Intel includes several techniques to accelerate models such as low-bit quantization, model weight pruning, distillation, and an accelerated runtime.
The runtime and optimizations included in [Optimum Intel](https://github.com/huggingface/optimum-intel) take advantage of Intel® Advanced Vector Extensions 512 (Intel® AVX-512), Vector Neural Network Instructions (VNNI) and Intel® Advanced Matrix Extensions (Intel® AMX) on Intel CPUs to accelerate models. Specifically, it has built-in [BFloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) (`bf16`) and `int8` GEMM accelerators in every core to accelerate deep learning training and inference workloads. AMX accelerated inference is introduced in PyTorch 2.0 and [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) in addition to other optimizations for various common operators.
Optimizing pre-trained models can be done easily with Optimum Intel; many simple examples can be found [here](https://huggingface.co./docs/optimum/main/en/intel/optimization_inc).
## Example: Optimizing BGE Embedding Models
In this blog, we focus on recently released embedding models by researchers at the [Beijing Academy of Artificial Intelligence](https://arxiv.org/pdf/2309.07597.pdf), as their models show competitive results on the widely adopted [MTEB](https://github.com/embeddings-benchmark/mteb) leaderboard.
### BGE Technical Details
Bi-encoder models are Transformer-based encoders trained to minimize a similarity metric, such as cosine-similarity, between two semantically similar texts as vectors. For example, popular embedding models use a BERT model as a base pre-trained model and fine-tune it for embedding documents. The vector representing the encoded text is created from the model outputs; for example, it can be the [CLS] token vector or a mean of all the token vectors.
Unlike more complex embedding architectures, bi-encoders encode only single documents, thus they lack contextual interaction between encoded entities such as query-document and document-document. However, state-of-the-art bi-encoder embedding models present competitive performance and are extremely fast due to their simple architecture.
We focus on 3 BGE models: [small](https://huggingface.co./BAAI/bge-small-en-v1.5), [base](https://huggingface.co./BAAI/bge-base-en-v1.5), and [large](https://huggingface.co./BAAI/bge-large-en-v1.5) consisting of 45M, 110M, and 355M parameters encoding to 384/768/1024 sized embedding vectors, respectively.
We note that the optimization process we showcase below is generic and can be applied to other embedding models (including bi-encoders, cross-encoders, and such).
### Step-by-step: Optimization by Quantization
We present a step-by-step guide for enhancing the performance of embedding models, focusing on reducing latency (with a batch size of 1) and increasing throughput (measured in documents encoded per second). This recipe utilizes `optimum-intel` and [Intel Neural Compressor](https://github.com/intel/neural-compressor) to quantize the model, and uses [IPEX](https://github.com/intel/intel-extension-for-pytorch) for optimized runtime on Intel-based hardware.
##### Step 1: Installing Packages
To install `optimum-intel` and `intel-extension-for-transformers` run the following command:
```bash
pip install -U optimum[neural-compressor] intel-extension-for-transformers
```
##### Step 2: Post-training Static Quantization
Post-training static quantization requires a calibration set to determine the dynamic range of weights and activations. The calibration is done by running a representative set of data samples through the model, collecting statistics, and then quantizing the model based on the gathered info to minimize the accuracy loss.
The following snippet shows a code snippet for quantization:
```python
def quantize(model_name: str, output_path: str, calibration_set: "datasets.Dataset"):
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
vectorized_ds = calibration_set.map(preprocess_function, num_proc=10)
vectorized_ds = vectorized_ds.remove_columns(["text"])
quantizer = INCQuantizer.from_pretrained(model)
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=vectorized_ds,
save_directory=output_path,
batch_size=1,
)
tokenizer.save_pretrained(output_path)
```
In our calibration process we use a subset of the [qasper](https://huggingface.co./datasets/allenai/qasper) dataset.
##### Step 3: Loading and running inference
Loading a quantized model can be done by simply running:
```python
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
```
Encoding sentences into vectors can be done similarly to what we are used to with the [Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
inputs = tokenizer(sentences, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# get the [CLS] token
embeddings = outputs[0][:, 0]
```
We provide additional and important details on how to configure the CPU-backend setup in the evaluation section below (correct machine setup).
### Model Evaluation with MTEB
Quantizing the models' weights to a lower precision introduces accuracy loss, as we lose precision moving from `fp32` weights to `int8`. Therefore, we aim to validate the accuracy of the optimized models by comparing them to the original models with two [MTEB](https://github.com/embeddings-benchmark/mteb) tasks:
- **Retrieval** - where a corpus is encoded and ranked lists are created by searching the index given a query.
- **Reranking** - reranking the retrieval's results for better relevance given a query.
The table below shows the average accuracy (on multiple datasets) of each task type (MAP for Reranking, NDCG@10 for Retrieval), where `int8` is our quantized model and `fp32` is the original model (results taken from the official MTEB leaderboard). The quantized models show less than 1% error rate compared to the original model in the Reranking task and less than 1.55% in the Retrieval task.
<table>
<tr><th> </th><th> Reranking </th><th> Retrieval </th></tr>
<tr><td>
| |
| | [
[
"implementation",
"benchmarks",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"optimization",
"efficient_computing",
"benchmarks",
"implementation"
] | null | null |
c1e554ee-d295-4809-9f48-b7cadce74290 | completed | 2025-01-16T03:09:11.596745 | 2025-01-16T13:35:01.275463 | 902bde4f-0f4f-43bf-aafe-c590debf4054 | 'Getting Started With Embeddings' | espejelomar | getting-started-with-embeddings.md | Check out this tutorial with the Notebook Companion:
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Understanding embeddings
An embedding is a numerical representation of a piece of information, for example, text, documents, images, audio, etc. The representation captures the semantic meaning of what is being embedded, making it robust for many industry applications.
Given the text "What is the main benefit of voting?", an embedding of the sentence could be represented in a vector space, for example, with a list of 384 numbers (for example, [0.84, 0.42, ..., 0.02]). Since this list captures the meaning, we can do exciting things, like calculating the distance between different embeddings to determine how well the meaning of two sentences matches.
Embeddings are not limited to text! You can also create an embedding of an image (for example, a list of 384 numbers) and compare it with a text embedding to determine if a sentence describes the image. This concept is under powerful systems for image search, classification, description, and more!
How are embeddings generated? The open-source library called [Sentence Transformers](https://www.sbert.net/index.html) allows you to create state-of-the-art embeddings from images and text for free. This blog shows an example with this library.
## What are embeddings for?
> "[...] once you understand this ML multitool (embedding), you'll be able to build everything from search engines to recommendation systems to chatbots and a whole lot more. You don't have to be a data scientist with ML expertise to use them, nor do you need a huge labeled dataset." - [Dale Markowitz, Google Cloud](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings).
Once a piece of information (a sentence, a document, an image) is embedded, the creativity starts; several interesting industrial applications use embeddings. E.g., Google Search uses embeddings to [match text to text and text to images](https://cloud.google.com/blog/topics/developers-practitioners/meet-ais-multitool-vector-embeddings); Snapchat uses them to "[serve the right ad to the right user at the right time](https://eng.snap.com/machine-learning-snap-ad-ranking)"; and Meta (Facebook) uses them for [their social search](https://research.facebook.com/publications/embedding-based-retrieval-in-facebook-search/).
Before they could get intelligence from embeddings, these companies had to embed their pieces of information. An embedded dataset allows algorithms to search quickly, sort, group, and more. However, it can be expensive and technically complicated. In this post, we use simple open-source tools to show how easy it can be to embed and analyze a dataset.
## Getting started with embeddings
We will create a small Frequently Asked Questions (FAQs) engine: receive a query from a user and identify which FAQ is the most similar. We will use the [US Social Security Medicare FAQs](https://faq.ssa.gov/en-US/topic/?id=CAT-01092).
But first, we need to embed our dataset (other texts use the terms encode and embed interchangeably). The Hugging Face Inference API allows us to embed a dataset using a quick POST call easily.
Since the embeddings capture the semantic meaning of the questions, it is possible to compare different embeddings and see how different or similar they are. Thanks to this, you can get the most similar embedding to a query, which is equivalent to finding the most similar FAQ. Check out our [semantic search tutorial](https://huggingface.co./spaces/sentence-transformers/embeddings-semantic-search) for a more detailed explanation of how this mechanism works.
In a nutshell, we will:
1. Embed Medicare's FAQs using the Inference API.
2. Upload the embedded questions to the Hub for free hosting.
3. Compare a customer's query to the embedded dataset to identify which is the most similar FAQ.
## 1. Embedding a dataset
The first step is selecting an existing pre-trained model for creating the embeddings. We can choose a model from the [Sentence Transformers library](https://huggingface.co./sentence-transformers). In this case, let's use the ["sentence-transformers/all-MiniLM-L6-v2"](https://huggingface.co./sentence-transformers/all-MiniLM-L6-v2) because it's a small but powerful model. In a future post, we will examine other models and their trade-offs.
Log in to the Hub. You must create a write token in your [Account Settings](http://hf.co/settings/tokens). We will store the write token in `hf_token`.
```py
model_id = "sentence-transformers/all-MiniLM-L6-v2"
hf_token = "get your token in http://hf.co/settings/tokens"
```
To generate the embeddings you can use the `https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}` endpoint with the headers `{"Authorization": f"Bearer {hf_token}"}`. Here is a function that receives a dictionary with the texts and returns a list with embeddings.
```py
import requests
api_url = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}"
headers = {"Authorization": f"Bearer {hf_token}"}
```
The first time you generate the embeddings, it may take a while (approximately 20 seconds) for the API to return them. We use the `retry` decorator (install with `pip install retry`) so that if on the first try, `output = query(dict(inputs = texts))` doesn't work, wait 10 seconds and try three times again. This happens because, on the first request, the model needs to be downloaded and installed on the server, but subsequent calls are much faster.
```py
def query(texts):
response = requests.post(api_url, headers=headers, json={"inputs": texts, "options":{"wait_for_model":True}})
return response.json()
```
The current API does not enforce strict rate limitations. Instead, Hugging Face balances the loads evenly between all our available resources and favors steady flows of requests. If you need to embed several texts or images, the [Hugging Face Accelerated Inference API](https://huggingface.co./docs/api-inference/index) would speed the inference and let you choose between using a CPU or GPU.
```py
texts = ["How do I get a replacement Medicare card?",
"What is the monthly premium for Medicare Part B?",
"How do I terminate my Medicare Part B (medical insurance)?",
"How do I sign up for Medicare?",
"Can I sign up for Medicare Part B if I am working and have health insurance through an employer?",
"How do I sign up for Medicare Part B if I already have Part A?",
"What are Medicare late enrollment penalties?",
"What is Medicare and who can get it?",
"How can I get help with my Medicare Part A and Part B premiums?",
"What are the different parts of Medicare?",
"Will my Medicare premiums be higher because of my higher income?",
"What is TRICARE ?",
"Should I sign up for Medicare Part B if I have Veterans' Benefits?"]
output = query(texts)
```
As a response, you get back a list of lists. Each list contains the embedding of a FAQ. The model, ["sentence-transformers/all-MiniLM-L6-v2"](https://huggingface.co./sentence-transformers/all-MiniLM-L6-v2), is encoding the input questions to 13 embeddings of size 384 each. Let's convert the list to a Pandas `DataFrame` of shape (13x384).
```py
import pandas as pd
embeddings = pd.DataFrame(output)
```
It looks similar to this matrix:
```py
[[-0.02388945 0.05525852 -0.01165488 ... 0.00577787 0.03409787 -0.0068891 ]
[-0.0126876 0.04687412 -0.01050217 ... -0.02310316 -0.00278466 0.01047371]
[ 0.00049438 0.11941205 0.00522949 ... 0.01687654 -0.02386115 0.00526433]
...
[-0.03900796 -0.01060951 -0.00738271 ... -0.08390449 0.03768405 0.00231361]
[-0.09598278 -0.06301168 -0.11690582 ... 0.00549841 0.1528919 0.02472013]
[-0.01162949 0.05961934 0.01650903 ... -0.02821241 -0.00116556 0.0010672 ]]
```
## 2. Host embeddings for free on the Hugging Face Hub
🤗 Datasets is a library for quickly accessing and sharing datasets. Let's host the embeddings dataset in the Hub using the user interface (UI). Then, anyone can load it with a single line of code. You can also use the terminal to share datasets; see [the documentation](https://huggingface.co./docs/datasets/share#share) for the steps. In the [notebook companion](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb) of this entry, you will be able to use the terminal to share the dataset. If you want to skip this section, check out the [`ITESM/embedded_faqs_medicare` repo](https://huggingface.co./datasets/ITESM/embedded_faqs_medicare) with the embedded FAQs.
First, we export our embeddings from a Pandas `DataFrame` to a CSV. You can save your dataset in any way you prefer, e.g., zip or pickle; you don't need to use Pandas or CSV. Since our embeddings file is not large, we can store it in a CSV, which is easily inferred by the `datasets.load_dataset()` function we will employ in the next section (see the [Datasets documentation](https://huggingface.co./docs/datasets/about_dataset_load#build-and-load)), i.e., we don't need to create a loading script. We will save the embeddings with the name `embeddings.csv`.
```py
embeddings.to_csv("embeddings.csv", index=False)
```
Follow the next steps to host `embeddings.csv` in the Hub.
* Click on your user in the top right corner of the [Hub UI](https://huggingface.co./).
* Create a dataset with "New dataset."

* Choose the Owner (organization or individual), name, and license of the dataset. Select if you want it to be private or public. Create the dataset.

* Go to the "Files" tab (screenshot below) and click "Add file" and "Upload file."

* Finally, drag or upload the dataset, and commit the changes.

Now the dataset is hosted on the Hub for free. You (or whoever you want to share the embeddings with) can quickly load them. Let's see how.
## 3. Get the most similar Frequently Asked Questions to a query
Suppose a Medicare customer asks, "How can Medicare help me?". We will **find** which of our FAQs could best answer our user query. We will create an embedding of the query that can represent its semantic meaning. We then compare it to each embedding in our FAQ dataset to identify which is closest to the query in vector space.
Install the 🤗 Datasets library with `pip install datasets`. Then, load the embedded dataset from the Hub and convert it to a PyTorch `FloatTensor`. Note that this is not the only way to operate on a `Dataset`; for example, you could use NumPy, Tensorflow, or SciPy (refer to the [Documentation](https://huggingface.co./docs/datasets/loading)). If you want to practice with a real dataset, the [`ITESM/embedded_faqs_medicare`](https://huggingface.co./datasets/ITESM/embedded_faqs_medicare) repo contains the embedded FAQs, or you can use the [companion notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/80_getting_started_with_embeddings.ipynb) to this blog.
```py
import torch
from datasets import load_dataset
faqs_embeddings = load_dataset('namespace/repo_name')
dataset_embeddings = torch.from_numpy(faqs_embeddings["train"].to_pandas().to_numpy()).to(torch.float)
```
We use the query function we defined before to embed the customer's question and convert it to a PyTorch `FloatTensor` to operate over it efficiently. Note that after the embedded dataset is loaded, we could use the `add_faiss_index` and `search` methods of a `Dataset` to identify the closest FAQ to an embedded query using the [faiss library](https://github.com/facebookresearch/faiss). Here is a [nice tutorial of the alternative](https://huggingface.co./docs/datasets/faiss_es).
```py
question = ["How can Medicare help me?"]
output = query(question)
query_embeddings = torch.FloatTensor(output)
```
You can use the `util.semantic_search` function in the Sentence Transformers library to identify which of the FAQs are closest (most similar) to the user's query. This function uses cosine similarity as the default function to determine the proximity of the embeddings. However, you could also use other functions that measure the distance between two points in a vector space, for example, the dot product.
Install `sentence-transformers` with `pip install -U sentence-transformers`, and search for the five most similar FAQs to the query.
```py
from sentence_transformers.util import semantic_search
hits = semantic_search(query_embeddings, dataset_embeddings, top_k=5)
```
`util.semantic_search` identifies how close each of the 13 FAQs is to the customer query and returns a list of dictionaries with the top `top_k` FAQs. `hits` looks like this:
```py
[{'corpus_id': 8, 'score': 0.75653076171875},
{'corpus_id': 7, 'score': 0.7418993711471558},
{'corpus_id': 3, 'score': 0.7252674102783203},
{'corpus_id': 9, 'score': 0.6735571622848511},
{'corpus_id': 10, 'score': 0.6505177617073059}]
```
The values in `corpus_id` allow us to index the list of `texts` we defined in the first section and get the five most similar FAQs:
```py
print([texts[hits[0][i]['corpus_id']] for i in range(len(hits[0]))])
```
Here are the 5 FAQs that come closest to the customer's query:
```py
['How can I get help with my Medicare Part A and Part B premiums?',
'What is Medicare and who can get it?',
'How do I sign up for Medicare?',
'What are the different parts of Medicare?',
'Will my Medicare premiums be higher because of my higher income?']
```
This list represents the 5 FAQs closest to the customer's query. Nice! We used here PyTorch and Sentence Transformers as our main numerical tools. However, we could have defined the cosine similarity and ranking functions by ourselves using tools such as NumPy and SciPy.
## Additional resources to keep learning
If you want to know more about the Sentence Transformers library:
- The [Hub Organization](https://huggingface.co./sentence-transformers) for all the new models and instructions on how to download models.
- The [Nils Reimers tweet](https://twitter.com/Nils_Reimers/status/1487014195568775173) comparing Sentence Transformer models with GPT-3 Embeddings. Spoiler alert: the Sentence Transformers are awesome!
- The [Sentence Transformers documentation](https://www.sbert.net/),
- [Nima's thread](https://twitter.com/NimaBoscarino/status/1535331680805801984) on recent research.
Thanks for reading! | [
[
"transformers",
"data",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tutorial",
"implementation",
"transformers",
"data"
] | null | null |
d223d200-5a3e-40db-b9ed-925b6e3f7515 | completed | 2025-01-16T03:09:11.596749 | 2025-01-16T13:35:44.825749 | 1be999c2-8775-4b1c-b53c-5677c6e85302 | Probabilistic Time Series Forecasting with 🤗 Transformers | nielsr, kashif | time-series-transformers.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
Time series forecasting is an essential scientific and business problem and as such has also seen a lot of innovation recently with the use of [deep learning based](https://dl.acm.org/doi/abs/10.1145/3533382) models in addition to the [classical methods](https://otexts.com/fpp3/). An important difference between classical methods like ARIMA and novel deep learning methods is the following.
## Probabilistic Forecasting
Typically, classical methods are fitted on each time series in a dataset individually. These are often referred to as "single" or "local" methods. However, when dealing with a large amount of time series for some applications, it is beneficial to train a "global" model on all available time series, which enables the model to learn latent representations from many different sources.
Some classical methods are point-valued (meaning, they just output a single value per time step) and models are trained by minimizing an L2 or L1 type of loss with respect to the ground truth data. However, since forecasts are often used in some real-world decision making pipeline, even with humans in the loop, it is much more beneficial to provide the uncertainties of predictions. This is also called "probabilistic forecasting", as opposed to "point forecasting". This entails modeling a probabilistic distribution, from which one can sample.
So in short, rather than training local point forecasting models, we hope to train **global probabilistic** models. Deep learning is a great fit for this, as neural networks can learn representations from several related time series as well as model the uncertainty of the data.
It is common in the probabilistic setting to learn the future parameters of some chosen parametric distribution, like Gaussian or Student-T; or learn the conditional quantile function; or use the framework of Conformal Prediction adapted to the time series setting. The choice of method does not affect the modeling aspect and thus can be typically thought of as yet another hyperparameter. One can always turn a probabilistic model into a point-forecasting model, by taking empirical means or medians.
## The Time Series Transformer
In terms of modeling time series data which are sequential in nature, as one can imagine, researchers have come up with models which use Recurrent Neural Networks (RNN) like LSTM or GRU, or Convolutional Networks (CNN), and more recently Transformer based methods which fit naturally to the time series forecasting setting.
In this blog post, we're going to leverage the vanilla Transformer [(Vaswani et al., 2017)](https://arxiv.org/abs/1706.03762) for the **univariate** probabilistic forecasting task (i.e. predicting each time series' 1-d distribution individually). The Encoder-Decoder Transformer is a natural choice for forecasting as it encapsulates several inductive biases nicely.
To begin with, the use of an Encoder-Decoder architecture is helpful at inference time, where typically for some logged data we wish to forecast some prediction steps into the future. This can be thought of as analogous to the text generation task where given some context, we sample the next token and pass it back into the decoder (also called "autoregressive generation"). Similarly here we can also, given some distribution type, sample from it to provide forecasts up until our desired prediction horizon. This is known as Ancestral Sampling. [Here](https://huggingface.co./blog/how-to-generate) is a great blog post about sampling in the context of language models.
Secondly, a Transformer helps us to train on time series data which might contain thousands of time points. It might not be feasible to input *all* the history of a time series at once to the model, due to the time- and memory constraints of the attention mechanism. Thus, one can consider some appropriate context window and sample this window and the subsequent prediction length sized window from the training data when constructing batches for stochastic gradient descent (SGD). The context sized window can be passed to the encoder and the prediction window to a *causal-masked* decoder. This means that the decoder can only look at previous time steps when learning the next value. This is equivalent to how one would train a vanilla Transformer for machine translation, referred to as "teacher forcing".
Another benefit of Transformers over the other architectures is that we can incorporate missing values (which are common in the time series setting) as an additional mask to the encoder or decoder and still train without resorting to in-filling or imputation. This is equivalent to the `attention_mask` of models like BERT and GPT-2 in the Transformers library, to not include padding tokens in the computation of the attention matrix.
A drawback of the Transformer architecture is the limit to the sizes of the context and prediction windows because of the quadratic compute and memory requirements of the vanilla Transformer, see [Tay et al., 2020](https://arxiv.org/abs/2009.06732). Additionally, since the Transformer is a powerful architecture, it might overfit or learn spurious correlations much more easily compared to other [methods](https://openreview.net/pdf?id=D7YBmfX_VQy).
The 🤗 Transformers library comes with a vanilla probabilistic time series Transformer model, simply called the [Time Series Transformer](https://huggingface.co./docs/transformers/model_doc/time_series_transformer). In the sections below, we'll show how to train such a model on a custom dataset.
## Set-up Environment
First, let's install the necessary libraries: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate and [GluonTS](https://github.com/awslabs/gluonts).
As we will show, GluonTS will be used for transforming the data to create features as well as for creating appropriate training, validation and test batches.
```python
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujson
```
## Load Dataset
In this blog post, we'll use the `tourism_monthly` dataset, which is available on the [Hugging Face Hub](https://huggingface.co./datasets/monash_tsf). This dataset contains monthly tourism volumes for 366 regions in Australia.
This dataset is part of the [Monash Time Series Forecasting](https://forecastingdata.org/) repository, a collection of time series datasets from a number of domains. It can be viewed as the GLUE benchmark of time series forecasting.
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")
```
As can be seen, the dataset contains 3 splits: train, validation and test.
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})
```
Each example contains a few keys, of which `start` and `target` are the most important ones. Let us have a look at the first time series in the dataset:
```python
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The `start` simply indicates the start of the time series (as a datetime), and the `target` contains the actual values of the time series.
The `start` will be useful to add time related features to the time series values, as extra input to the model (such as "month of year"). Since we know the frequency of the data is `monthly`, we know for instance that the second value has the timestamp `1979-02-01`, etc.
```python
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]
```
The validation set contains the same data as the training set, just for a `prediction_length` longer amount of time. This allows us to validate the model's predictions against the ground truth.
The test set is again one `prediction_length` longer data compared to the validation set (or some multiple of `prediction_length` longer data compared to the training set for testing on multiple rolling windows).
```python
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The initial values are exactly the same as the corresponding training example:
```python
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]
```
However, this example has `prediction_length=24` additional values compared to the training example. Let us verify it.
```python
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)
```
Let's visualize this:
```python
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()
```

Let's split up the data:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## Update `start` to `pd.Period`
The first thing we'll do is convert the `start` feature of each time series to a pandas `Period` index using the data's `freq`:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
We now use `datasets`' [`set_transform`](https://huggingface.co./docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) functionality to do this on-the-fly in place:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
## Define the Model
Next, let's instantiate a model. The model will be trained from scratch, hence we won't use the `from_pretrained` method here, but rather randomly initialize the model from a [`config`](https://huggingface.co./docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerConfig).
We specify a couple of additional parameters to the model:
- `prediction_length` (in our case, `24` months): this is the horizon that the decoder of the Transformer will learn to predict for;
- `context_length`: the model will set the `context_length` (input of the encoder) equal to the `prediction_length`, if no `context_length` is specified;
- `lags` for a given frequency: these specify how much we "look back", to be added as additional features. e.g. for a `Daily` frequency we might consider a look back of `[1, 2, 7, 30, ...]` or in other words look back 1, 2, ... days while for `Minute` data we might consider `[1, 30, 60, 60*24, ...]` etc.;
- the number of time features: in our case, this will be `2` as we'll add `MonthOfYear` and `Age` features;
- the number of static categorical features: in our case, this will be just `1` as we'll add a single "time series ID" feature;
- the cardinality: the number of values of each static categorical feature, as a list which for our case will be `[366]` as we have 366 different time series
- the embedding dimension: the embedding dimension for each static categorical feature, as a list, for example `[3]` means the model will learn an embedding vector of size `3` for each of the `366` time series (regions).
Let's use the default lags provided by GluonTS for the given frequency ("monthly"):
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]
```
This means that we'll look back up to 37 months for each time step, as additional features.
Let's also check the default time features that GluonTS provides us:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]
```
In this case, there's only a single feature, namely "month of year". This means that for each time step, we'll add the month as a scalar value (e.g. `1` in case the timestamp is "january", `2` in case the timestamp is "february", etc.).
We now have everything to define the model:
```python
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags coming from helper given the freq:
lags_sequence=lags_sequence,
# we'll add 2 time features ("month of year" and "age", see further):
num_time_features=len(time_features) + 1,
# we have a single static categorical feature, namely time series ID:
num_static_categorical_features=1,
# it has 366 possible values:
cardinality=[len(train_dataset)],
# the model will learn an embedding of size 2 for each of the 366 possible values:
embedding_dimension=[2],
# transformer params:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)
```
Note that, similar to other models in the 🤗 Transformers library, [`TimeSeriesTransformerModel`](https://huggingface.co./docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerModel) corresponds to the encoder-decoder Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`](https://huggingface.co./docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction) corresponds to `TimeSeriesTransformerModel` with a **distribution head** on top. By default, the model uses a Student-t distribution (but this is configurable):
```python
model.config.distribution_output
>>> student_t
```
This is an important difference with Transformers for NLP, where the head typically consists of a fixed categorical distribution implemented as an `nn.Linear` layer.
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
Again, we'll use the GluonTS library for this. We define a `Chain` of transformations (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
```python
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
The transformations below are annotated with comments, to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# a bit like torchvision.transforms.Compose
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# month of year in the case when freq="M"
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in its life the value of the time series is,
# sort of a running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the Transformer due to time- and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create DataLoaders
Next, it's time to create the DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from the 366 possible transformed time series)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
We have a test dataloader helper for completion, even though we will not use it here. This is useful in a production setting where we want to start forecasting from the end of a given time series. Thus, the test dataloader will sample the very last context window from the dataset provided and pass it to the model.
```python
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)
```
Let's check the first batch:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensor
```
As can be seen, we don't feed `input_ids` and `attention_mask` to the encoder (as would be the case for NLP models), but rather `past_values`, along with `past_observed_mask`, `past_time_features`, and `static_categorical_features`.
The decoder inputs consist of `future_values`, `future_observed_mask` and `future_time_features`. The `future_values` can be seen as the equivalent of `decoder_input_ids` in NLP.
We refer to the [docs](https://huggingface.co./docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction.forward.past_values) for a detailed explanation for each of them.
## Forward Pass
Let's perform a single forward pass with the batch we just created:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: 9.069628715515137
```
Note that the model is returning a loss. This is possible as the decoder automatically shifts the `future_values` one position to the right in order to have the labels. This allows computing a loss between the predicted values and the labels.
Also, note that the decoder uses a causal mask to not look into the future as the values it needs to predict are in the `future_values` tensor.
## Train the Model
It's time to train the model! We'll use a standard PyTorch training loop.
We will use the 🤗 [Accelerate](https://huggingface.co./docs/accelerate/index) library here, which automatically places the model, optimizer and dataloader on the appropriate `device`.
```python
from accelerate import Accelerator
from torch.optim import AdamW
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(40):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
if idx % 100 == 0:
print(loss.item())
```
## Inference
At inference time, it's recommended to use the `generate()` method for autoregressive generation, similar to NLP models.
Forecasting involves getting data from the test instance sampler, which will sample the very last `context_length` sized window of values from each time series in the dataset, and pass it to the model. Note that we pass `future_time_features`, which are known ahead of time, to the decoder.
The model will autoregressively sample a certain number of values from the predicted distribution and pass them back to the decoder to return the prediction outputs:
```python
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`).
In this case, we get `100` possible values for the next `24` months (for each example in the batch which is of size `64`):
```python
forecasts[0].shape
>>> (64, 100, 24)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset:
```python
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. We will use the [MASE](https://huggingface.co./spaces/evaluate-metric/mase) and [sMAPE](https://huggingface.co./spaces/evaluate-metric/smape) metrics which we calculate for each time series in the dataset:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549
```
We can also plot the individual metrics of each time series in the dataset and observe that a handful of time series contribute a lot to the final test metric:
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```

To plot the prediction for any time series with respect the ground truth test data we define the following helper:
```python
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Major ticks every half year, minor ticks every month,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()
```
For example:
```python
plot(334)
```

How do we compare against other models? The [Monash Time Series Repository](https://forecastingdata.org/#results) has a comparison table of test set MASE metrics which we can add to:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| **Transformer** (Our) |
|: | [
[
"transformers",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"tutorial",
"implementation"
] | null | null |
6fb52b04-c6fe-40a2-844d-38da5c16baff | completed | 2025-01-16T03:09:11.596754 | 2025-01-19T19:02:16.433205 | ea7a9702-4eeb-4abb-ac33-0474729305cd | Optimizing Stable Diffusion for Intel CPUs with NNCF and 🤗 Optimum | AlexKoff88, MrOpenVINO, helenai, sayakpaul, echarlaix | train-optimize-sd-intel.md | [**Latent Diffusion models**](https://arxiv.org/abs/2112.10752) are game changers when it comes to solving text-to-image generation problems. [**Stable Diffusion**](https://stability.ai/blog/stable-diffusion-public-release) is one of the most famous examples that got wide adoption in the community and industry. The idea behind the Stable Diffusion model is simple and compelling: you generate an image from a noise vector in multiple small steps refining the noise to a latent image representation. This approach works very well, but it can take a long time to generate an image if you do not have access to powerful GPUs.
Through the past five years, [OpenVINO Toolkit](https://docs.openvino.ai/) encapsulated many features for high-performance inference. Initially designed for Computer Vision models, it still dominates in this domain showing best-in-class inference performance for many contemporary models, including [Stable Diffusion](https://huggingface.co./blog/stable-diffusion-inference-intel). However, optimizing Stable Diffusion models for resource-constraint applications requires going far beyond just runtime optimizations. And this is where model optimization capabilities from OpenVINO [Neural Network Compression Framework](https://github.com/openvinotoolkit/nncf) (NNCF) come into play.
In this blog post, we will outline the problems of optimizing Stable Diffusion models and propose a workflow that substantially reduces the latency of such models when running on a resource-constrained HW such as CPU. In particular, we achieved **5.1x** inference acceleration and **4x** model footprint reduction compared to PyTorch.
## Stable Diffusion optimization
In the [Stable Diffusion pipeline](https://huggingface.co./docs/diffusers/api/pipelines/stable_diffusion/overview), the UNet model is computationally the most expensive to run. Thus, optimizing just one model brings substantial benefits in terms of inference speed.
However, it turns out that the traditional model optimization methods, such as post-training 8-bit quantization, do not work for this model. There are two main reasons for that. First, pixel-level prediction models, such as semantic segmentation, super-resolution, etc., are one of the most complicated in terms of model optimization because of the complexity of the task, so tweaking model parameters and the structure breaks the results in numerous ways. The second reason is that the model has a lower level of redundancy because it accommodates a lot of information while being trained on [hundreds of millions of samples](https://laion.ai/blog/laion-5b/). That is why researchers have to employ more sophisticated quantization methods to preserve the accuracy after optimization. For example, Qualcomm used the layer-wise Knowledge Distillation method ([AdaRound](https://arxiv.org/abs/2004.10568)) to [quantize](https://www.qualcomm.com/news/onq/2023/02/worlds-first-on-device-demonstration-of-stable-diffusion-on-android) Stable Diffusion models. It means that model tuning after quantization is required, anyway. If so, why not just use [Quantization-Aware Training](https://arxiv.org/abs/1712.05877) (QAT) which can tune the model and quantization parameters simultaneously in the same way the source model is trained? Thus, we tried this approach in our work using [NNCF](https://github.com/openvinotoolkit/nncf), [OpenVINO](https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/overview.html), and [Diffusers](https://github.com/huggingface/diffusers) and coupled it with [Token Merging](https://arxiv.org/abs/2210.09461).
## Optimization workflow
We usually start the optimization of a model after it's trained. Here, we start from a [model](https://huggingface.co./svjack/Stable-Diffusion-Pokemon-en) fine-tuned on the [Pokemons dataset](https://huggingface.co./datasets/lambdalabs/pokemon-blip-captions) containing images of Pokemons and their text descriptions.
We used the [text-to-image fine-tuning example](https://huggingface.co./docs/diffusers/training/text2image) for Stable Diffusion from the Diffusers and integrated QAT from NNCF into the following training [script](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion). We also changed the loss function to incorporate knowledge distillation from the source model that acts as a teacher in this process while the actual model being trained acts as a student. This approach is different from the classical knowledge distillation method, where the trained teacher model is distilled into a smaller student model. In our case, knowledge distillation is used as an auxiliary method that helps improve the final accuracy of the optimizing model. We also use the Exponential Moving Average (EMA) method for model parameters excluding quantizers which allows us to make the training process more stable. We tune the model for 4096 iterations only.
With some tricks, such as gradient checkpointing and [keeping the EMA model](https://github.com/huggingface/optimum-intel/blob/bbbe7ff0e81938802dbc1d234c3dcdf58ef56984/examples/openvino/stable-diffusion/train_text_to_image_qat.py#L941) in RAM instead of VRAM, we can run the optimization process using one GPU with 24 GB of VRAM. The whole optimization takes less than a day using one GPU!
## Going beyond Quantization-Aware Training
Quantization alone can bring significant enhancements by reducing model footprint, load time, memory consumption, and inference latency. But the great thing about quantization is that it can be applied along with other optimization methods leading to a cumulative speedup.
Recently, Facebook Research introduced a [Token Merging](https://arxiv.org/abs/2210.09461) method for Vision Transformer models. The essence of the method is that it merges redundant tokens with important ones using one of the available strategies (averaging, taking max values, etc.). This is done before the self-attention block, which is the most computationally demanding part of Transformer models. Therefore, reducing the token dimension reduces the overall computation time in the self-attention blocks. This method has also been [adapted](https://arxiv.org/pdf/2303.17604.pdf) for Stable Diffusion models and has shown promising results when optimizing Stable Diffusion pipelines for high-resolution image synthesis running on GPUs.
We modified the Token Merging method to be compliant with OpenVINO and stacked it with 8-bit quantization when applied to the Attention UNet model. This also involves all the mentioned techniques including Knowledge Distillation, etc. As for quantization, it requires fine-tuning to be applied to restore the accuracy. We also start optimization and fine-tuning from the [model](https://huggingface.co./svjack/Stable-Diffusion-Pokemon-en) trained on the [Pokemons dataset](https://huggingface.co./datasets/lambdalabs/pokemon-blip-captions). The figure below shows an overall optimization workflow.

The resultant model is highly beneficial when running inference on devices with limited computational resources, such as client or edge CPUs. As it was mentioned, stacking Token Merging with quantization leads to an additional reduction in the inference latency.
<div class="flex flex-row">
<div class="grid grid-cols-2 gap-4">
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_torch.png" alt="Image 1" />
<figcaption class="mt-2 text-center text-sm text-gray-500">PyTorch FP32, Inference Speed: 230.5 seconds, Memory Footprint: 3.44 GB</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_fp32.png" alt="Image 2" />
<figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO FP32, Inference Speed: 120 seconds (<b>1.9x</b>), Memory Footprint: 3.44 GB</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_quantized.png" alt="Image 3" />
<figcaption class="mt-2 text-center text-sm text-gray-500">OpenVINO 8-bit, Inference Speed: 59 seconds (<b>3.9x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption>
</figure>
<figure>
<img class="max-w-full rounded-xl border-2 border-solid border-gray-600" src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/train-optimize-sd-intel/image_tome_quantized.png" alt="Image 4" />
<figcaption class="mt-2 text-center text-sm text-gray-500">ToMe + OpenVINO 8-bit, Inference Speed: 44.6 seconds (<b>5.1x</b>), Memory Footprint: 0.86 GB (<b>0.25x</b>)</figcaption>
</figure>
</div>
</div>
Results of image generation [demo](https://huggingface.co./spaces/helenai/stable_diffusion) using different optimized models. Input prompt is “cartoon bird”, seed is 42. The models are with OpenVINO 2022.3 in [Hugging Face Spaces](https://huggingface.co./docs/hub/spaces-overview) using a “CPU upgrade” instance which utilizes 3rd Generation Intel® Xeon® Scalable Processors with Intel® Deep Learning Boost technology.
## Results
We used the disclosed optimization workflows to get two types of optimized models, 8-bit quantized and quantized with Token Merging, and compare them to the PyTorch baseline. We also converted the baseline to vanilla OpenVINO floating-point (FP32) model for the comprehensive comparison.
The picture above shows the results of image generation and some model characteristics. As you can see, just conversion to OpenVINO brings a significant decrease in the inference latency ( **1.9x** ). Applying 8-bit quantization boosts inference speed further leading to **3.9x** speedup compared to PyTorch. Another benefit of quantization is a significant reduction of model footprint, **0.25x** of PyTorch checkpoint, which also improves the model load time. Applying Token Merging (ToME) (with a **merging ratio of 0.4** ) on top of quantization brings **5.1x** performance speedup while keeping the footprint at the same level. We didn't provide a thorough analysis of the visual quality of the optimized models, but, as you can see, the results are quite solid.
For the results shown in this blog, we used the default number of 50 inference steps. With fewer inference steps, inference speed will be faster, but this has an effect on the quality of the resulting image. How large this effect is depends on the model and the [scheduler](https://huggingface.co./docs/diffusers/using-diffusers/schedulers). We recommend experimenting with different number of steps and schedulers and find what works best for your use case.
Below we show how to perform inference with the final pipeline optimized to run on Intel CPUs:
```python
from optimum.intel import OVStableDiffusionPipeline
# Load and compile the pipeline for performance.
name = "OpenVINO/stable-diffusion-pokemons-tome-quantized-aggressive"
pipe = OVStableDiffusionPipeline.from_pretrained(name, compile=False)
pipe.reshape(batch_size=1, height=512, width=512, num_images_per_prompt=1)
pipe.compile()
# Generate an image.
prompt = "a drawing of a green pokemon with red eyes"
output = pipe(prompt, num_inference_steps=50, output_type="pil").images[0]
output.save("image.png")
```
You can find the training and quantization [code](https://github.com/huggingface/optimum-intel/tree/main/examples/openvino/stable-diffusion) in the Hugging Face [Optimum Intel](https://huggingface.co./docs/optimum/main/en/intel/index) library. The notebook that demonstrates the difference between optimized and original models is available [here](https://github.com/huggingface/optimum-intel/blob/main/notebooks/openvino/stable_diffusion_optimization.ipynb). You can also find [many models](https://huggingface.co./models?library=openvino&sort=downloads) on the Hugging Face Hub under the [OpenVINO organization](https://huggingface.co./OpenVINO). In addition, we have created a [demo](https://huggingface.co./spaces/helenai/stable_diffusion) on Hugging Face Spaces that is being run on a 3rd Generation Intel Xeon Scalable processor.
## What about the general-purpose Stable Diffusion model?
As we showed with the Pokemon image generation task, it is possible to achieve a high level of optimization of the Stable Diffusion pipeline when using a relatively small amount of training resources. At the same time, it is well-known that training a general-purpose Stable Diffusion model is an [expensive task](https://www.mosaicml.com/blog/training-stable-diffusion-from-scratch-part-2). However, with enough budget and HW resources, it is possible to optimize the general-purpose model using the described approach and tune it to produce high-quality images. The only caveat we have is related to the token merging method that reduces the model capacity substantially. The rule of thumb here is the more complicated the dataset you have for the training, the less merging ratio you should use during the optimization.
If you enjoyed reading this post, you might also be interested in checking out [this post](https://huggingface.co./blog/stable-diffusion-inference-intel) that discusses other complementary approaches to optimize the performance of Stable Diffusion on 4th generation Intel Xeon CPUs. | [
[
"computer_vision",
"optimization",
"image_generation",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"optimization",
"image_generation",
"efficient_computing"
] | null | null |
aa45601d-595b-433b-a0ba-b9094a114828 | completed | 2025-01-16T03:09:11.596758 | 2025-01-16T13:36:46.422128 | b73ef012-c4ce-4c85-bff0-e5248f337f44 | 2024 Security Feature Highlights | jack-kumar | 2024-security-features.md | Security is a top priority at Hugging Face, and we're committed to continually enhancing our defenses to safeguard our users. In our ongoing security efforts, we have developed a range of security features designed to empower users to protect themselves and their assets. In this blog post, we'll take a look at our current security landscape as of August 6th, 2024, and break down key security features available on the Hugging Face Hub.
This post is broken down into two parts: in the first sections, we explore the essential security features available to all users of the Hub. Then in the second section we describe the advanced controls available to Enterprise Hub users.
## "Default" Hub Security Features
The following security features are available to all users of the Hugging Face Hub. We highly recommend that you use all of these controls where possible as it will help increase your resiliency against a variety of common attacks, such as phishing, token leaks, credential stuffing, session hijacking, etc.
### Fine Grained Token
User Access Tokens are required to access Hugging Face via APIs. In addition to the standard "read" and "write" tokens, Hugging Face supports "fine-grained" tokens which allow you enforce least privilege by defining permissions on a per resource basis, ensuring that no other resources can be impacted in the event the token is leaked. Fine-grained tokens offer a plethora of ways to tune your token, see the images below for the options available. You can learn more about tokens here: https://huggingface.co./docs/hub/en/security-tokens


### Two Factor Authentication (2FA)
Two factor authentication adds an extra layer of protection to your online accounts by requiring two forms of verification before granting access. 2FA combines something you know (like a password) with something you have (such as a smartphone) to ensure that only authorized users can access sensitive information. By enabling 2FA, you can greatly reduce the risk of unauthorized access from compromised passwords, credential stuffing and phishing. You can learn more about 2FA here: https://huggingface.co./docs/hub/en/security-2fa

### Commit Signing
Although Git has an authentication layer to control who can push commits to a repo, it does not authenticate the actual commit author. This means it's possible for bad actors to impersonate authors by using `git config --global user.email [email protected]` and `git config --global user.name Your Name`. This config does not automatically give them access to push to your repositories that they otherwise wouldn't have - but it does allow them to impersonate you anywhere they can push to. This could be a public repository or a private repository using compromised credentials or stolen SSH key.
Commit signing adds an additional layer of security by using GPG to mitigate this issue; you can learn more at [Git Tools: Signing Your Work](https://git-scm.com/book/en/v2/Git-Tools-Signing-Your-Work). Hugging Face gives authors the ability to add their GPG keys to their profile. When a signed commit is pushed, the signature is authenticated using the GPG key in the authors profile. If it's a valid signature, the commit will be marked with a “Verified” badge. You can learn more about commit signing here: https://huggingface.co./docs/hub/en/security-gpg

### Organizational Access Controls
Organizations on Hugging Face have access to Organizational Access Controls. This allows teams and businesses to define least privilege access to their organization by assigning "read", "write", "contributor" or "admin" roles to each of their users. This helps ensure that the compromise of one user account (such as via phishing) cannot affect the entire organization. You can learn more about Organizational Access Controls here: https://huggingface.co./docs/hub/en/organizations-security

### Automated Security Scanning
Hugging Face implements an automated security scanning pipeline that scans all repos and commits. Currently, there are three major components of the pipeline:
- malware scanning: scans for known malware signatures with [ClamAV](https://clamav.net)
- pickle scanning: scans pickle files for malicious executable code with [picklescan](https://github.com/mmaitre314/picklescan)
- secret scanning: scans for passwords, tokens and API keys using the [`trufflehog filesystem`](https://github.com/trufflesecurity/trufflehoghttps://github.com/trufflesecurity/trufflehog) command
In the event a malicious file is detected, the scans will place a notice on the repo allowing users to see that they may potentially be interacting with a malicious repository. You can see an example of a (fake) malicious repository here: https://huggingface.co./mcpotato/42-eicar-street/tree/main.

For any verified secret detected, the pipeline will send an email notifying the owner so that they can invalidate and refresh the secret.
Verified secrets are the ones that have been confirmed to work for authentication against their respective providers. Note, however, that unverified secrets are not necessarily harmless or invalid: verification can fail due to technical reasons, such as in the case of down time from the provider.
You can learn more about automated scanning here:
- https://huggingface.co./docs/hub/en/security-malware
- https://huggingface.co./docs/hub/en/security-pickle
- https://huggingface.co./docs/hub/en/security-secrets
## Enterprise Hub Security Features
In addition to the security features available to all users, Hugging Face offers advanced security controls for Enterprise users. These additional controls allow enterprises to build a security configuration that is most effective for them.
### Single Sign-On (SSO)
Single sign-on (SSO) allows a user to access multiple applications with one set of credentials. Enterprises have widely moved to SSO as it allows their employees to access a variety of corporate software using identities that are managed centrally by their IT team. Hugging Face Enterprise supports SSO with both the SAML 2.0 and OpenID Connect (OIDC) protocols, and supports any compliant provider such as Okta, OneLign, Azure AD, etc. Additionally, SSO users can be configured to be dynamically assigned access control roles based on data provided by your identity provider. You can learn more about SSO here: https://huggingface.co./docs/hub/en/security-sso

### Resource Groups
In addition to the base organizational access controls, Enterprises can define and manage groups of repositories as Resource Groups. This allows you to segment your resources by team or purpose, such as "Research", "Engineering", "Production" so that the compromise of one segment can not affect others. You can learn more about Resource Groups here: https://huggingface.co./docs/hub/en/security-resource-groups

### Organization Token Management
✨New✨ Enterprise users can now manage which tokens can access their organization and resources. Organization owners can enforce the usage of fine-grained tokens and require administrator approval for each token. Administrators can review and revoke each token that has access to their repositories at any time.
You can learn more about Organization Token Management here: https://huggingface.co./docs/hub/enterprise-hub-tokens-management


### Data Residency
Enterprise users have access to data residency controls, which allow them to define where repositories (models, datasets, spaces) are stored. This allows for regulatory and legal compliance, while also improving download and upload performance by bringing the data closer to your users. We currently support US and EU regions, with Asia-Pacific coming soon. We call this feature "Storage Regions". You can learn more about Data Residency here: https://huggingface.co./docs/hub/en/storage-regions

### Audit Logs
Enterprise users have access to audit logs that allow organization admins to review changes to repositories, settings and billing. The audit logs contain the username, location, IP, and action taken and can be downloaded as a JSON file which can be used in your own security tooling. You can learn more about Audit Logs here: https://huggingface.co./docs/hub/en/audit-logs

### Compliance
Hugging Face is SOC2 Type 2 certified and GDPR compliant. We offer Business Associate Addendums for GDPR data processing agreements to Enterprise Plan users. You can learn more about our Compliance efforts here: https://huggingface.co./docs/hub/en/security
### Custom Security Features
Hugging Face offers custom agreements and development of features and tools for Enterprise accounts which are established via Statement of Work (SoW) and Service Level Agreements (SLA). You can reach out directly to sales to discuss your options at https://huggingface.co./contact/sales.
## Conclusion
At Hugging Face, we're committed to providing a secure and trustworthy platform for the AI community. With our robust security features, users can focus on building and deploying AI models with confidence. Whether you're an individual researcher or a large enterprise, our security features are designed to empower you to protect yourself and your assets. By continually enhancing our defenses and expanding our security capabilities, we aim to stay ahead of emerging threats and maintain the trust of our users. If you have any questions or feedback about our security features, we'd love to hear from you. Reach out at [email protected]! | [
[
"mlops",
"security",
"deployment",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"security",
"tools",
"mlops",
"deployment"
] | null | null |
1e238313-6228-4641-aa7b-fde0c9020925 | completed | 2025-01-16T03:09:11.596763 | 2025-01-19T18:56:52.475072 | db4906d0-0647-41c5-8732-dccea40a490f | Image Classification with AutoTrain | nimaboscarino | autotrain-image-classification.md | <script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
So you’ve heard all about the cool things that are happening in the machine learning world, and you want to join in. There’s just one problem – you don’t know how to code! 😱 Or maybe you’re a seasoned software engineer who wants to add some ML to your side-project, but you don’t have the time to pick up a whole new tech stack! For many people, the technical barriers to picking up machine learning feel insurmountable. That’s why Hugging Face created [AutoTrain](https://huggingface.co./autotrain), and with the latest feature we’ve just added, we’re making “no-code” machine learning better than ever. Best of all, you can create your first project for ✨ free! ✨
[Hugging Face AutoTrain](https://huggingface.co./autotrain) lets you train models with **zero** configuration needed. Just choose your task (translation? how about question answering?), upload your data, and let Hugging Face do the rest of the work! By letting AutoTrain experiment with number of different models, there's even a good chance that you'll end up with a model that performs better than a model that's been hand-trained by an engineer 🤯 We’ve been expanding the number of tasks that we support, and we’re proud to announce that **you can now use AutoTrain for Computer Vision**! Image Classification is the latest task we’ve added, with more on the way. But what does this mean for you?
[Image Classification](https://huggingface.co./tasks/image-classification) models learn to *categorize* images, meaning that you can train one of these models to label any image. Do you want a model that can recognize signatures? Distinguish bird species? Identify plant diseases? As long as you can find an appropriate dataset, an image classification model has you covered.
## How can you train your own image classifier?
If you haven’t [created a Hugging Face account](https://huggingface.co./join) yet, now’s the time! Following that, make your way over to the [AutoTrain homepage](https://huggingface.co./autotrain) and click on “Create new project” to get started. You’ll be asked to fill in some basic info about your project. In the screenshot below you’ll see that I created a project named `butterflies-classification`, and I chose the “Image Classification” task. I’ve also chosen the “Automatic” model option, since I want to let AutoTrain do the work of finding the best model architectures for my project.
<div class="flex justify-center">
<figure class="image table text-center m-0 w-1/2">
<medium-zoom background="rgba(0,0,0,.7)" alt="The 'New Project' form for AutoTrain, filled out for a new Image Classification project named 'butterflies-classification'." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/new-project.png"></medium-zoom>
</figure>
</div>
Once AutoTrain creates your project, you just need to connect your data. If you have the data locally, you can drag and drop the folder into the window. Since we can also use [any of the image classification datasets on the Hugging Face Hub](https://huggingface.co./datasets?task_categories=task_categories:image-classification), in this example I’ve decided to use the [NimaBoscarino/butterflies](https://huggingface.co./datasets/NimaBoscarino/butterflies) dataset. You can select separate training and validation datasets if available, or you can ask AutoTrain to split the data for you.
<div class="grid grid-cols-2 gap-4">
<figure class="image table text-center m-0 w-full">
</figure>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A form showing configurations to select for the imported dataset, including split types and data columns." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/add-dataset.png"></medium-zoom>
</figure>
</div>
Once the data has been added, simply choose the number of model candidates that you’d like AutoModel to try out, review the expected training cost (training with 5 candidate models and less than 500 images is free 🤩), and start training!
<div class="grid grid-cols-2 gap-4">
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Screenshot showing the model-selection options. Users can choose various numbers of candidate models, and the final training budget is displayed." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/select-models.png"></medium-zoom>
</figure>
<div>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="Five candidate models are being trained, one of which has already completed training." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/training-in-progress.png"></medium-zoom>
</figure>
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="All the candidate models have finished training, with one in the 'stopped' state." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/training-complete.png"></medium-zoom>
</figure>
</div>
</div>
In the screenshots above you can see that my project started 5 different models, which each reached different accuracy scores. One of them wasn’t performing very well at all, so AutoTrain went ahead and stopped it so that it wouldn’t waste resources. The very best model hit 84% accuracy, with effectively zero effort on my end 😍 To wrap it all up, you can visit your freshly trained models on the Hub and play around with them through the integrated [inference widget](https://huggingface.co./docs/hub/models-widgets). For example, check out my butterfly classifier model over at [NimaBoscarino/butterflies](https://huggingface.co./NimaBoscarino/butterflies) 🦋
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="An automatically generated model card for the butterflies-classification model, showing validation metrics and an embedded inference widget for image classification. The widget is displaying a picture of a butterfly, which has been identified as a Malachite butterfly." src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/autotrain-image-classification/model-card.png"></medium-zoom>
</figure>
We’re so excited to see what you build with AutoTrain! Don’t forget to join the community over at [hf.co/join/discord](https://huggingface.co./join/discord), and reach out to us if you need any help 🤗 | [
[
"computer_vision",
"mlops",
"tutorial",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"tools",
"tutorial",
"mlops"
] | null | null |
962fa8d2-cf46-4bf6-9fd4-757c9df9c767 | completed | 2025-01-16T03:09:11.596769 | 2025-01-16T03:12:22.241450 | f0d97baf-e2b6-488f-876d-621f1abd8a05 | Fine-tuning Llama 2 70B using PyTorch FSDP | smangrul, sgugger, lewtun, philschmid | ram-efficient-pytorch-fsdp.md | ## Introduction
In this blog post, we will look at how to fine-tune Llama 2 70B using PyTorch FSDP and related best practices. We will be leveraging Hugging Face Transformers, Accelerate and TRL. We will also learn how to use Accelerate with SLURM.
Fully Sharded Data Parallelism (FSDP) is a paradigm in which the optimizer states, gradients and parameters are sharded across devices. During the forward pass, each FSDP unit performs an _all-gather operation_ to get the complete weights, computation is performed followed by discarding the shards from other devices. After the forward pass, the loss is computed followed by the backward pass. In the backward pass, each FSDP unit performs an all-gather operation to get the complete weights, with computation performed to get the local gradients. These local gradients are averaged and sharded across the devices via a _reduce-scatter operation_ so that each device can update the parameters of its shard. For more information on what PyTorch FSDP is, please refer to this blog post: [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co./blog/pytorch-fsdp).

(Source: [link](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
## Hardware Used
Number of nodes: 2. Minimum required is 1.
Number of GPUs per node: 8
GPU type: A100
GPU memory: 80GB
intra-node connection: NVLink
RAM per node: 1TB
CPU cores per node: 96
inter-node connection: Elastic Fabric Adapter
## Challenges with fine-tuning LLaMa 70B
We encountered three main challenges when trying to fine-tune LLaMa 70B with FSDP:
1. FSDP wraps the model after loading the pre-trained model. If each process/rank within a node loads the Llama-70B model, it would require 70\*4\*8 GB ~ 2TB of CPU RAM, where 4 is the number of bytes per parameter and 8 is the number of GPUs on each node. This would result in the CPU RAM getting out of memory leading to processes being terminated.
2. Saving entire intermediate checkpoints using `FULL_STATE_DICT` with CPU offloading on rank 0 takes a lot of time and often results in NCCL Timeout errors due to indefinite hanging during broadcasting. However, at the end of training, we want the whole model state dict instead of the sharded state dict which is only compatible with FSDP.
3. We need to improve the speed and reduce the VRAM usage to train faster and save compute costs.
Let’s look at how to solve the above challenges and fine-tune a 70B model!
Before we get started, here's all the required resources to reproduce our results:
1. Codebase:
https://github.com/pacman100/DHS-LLM-Workshop/tree/main/chat_assistant/sft/training with flash-attn V2
2. FSDP config: https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml
3. SLURM script `launch.slurm`: https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25
4. Model: `meta-llama/Llama-2-70b-chat-hf`
5. Dataset: [smangrul/code-chat-assistant-v1](https://huggingface.co./datasets/smangrul/code-chat-assistant-v1) (mix of LIMA+GUANACO with proper formatting in a ready-to-train format)
### Pre-requisites
First follow these steps to install Flash Attention V2: Dao-AILab/flash-attention: Fast and memory-efficient exact attention (github.com). Install the latest nightlies of PyTorch with CUDA ≥11.8. Install the remaining requirements as per DHS-LLM-Workshop/code_assistant/training/requirements.txt. Here, we will be installing 🤗 Accelerate and 🤗 Transformers from the main branch.
## Fine-Tuning
### Addressing Challenge 1
PRs [huggingface/transformers#25107](https://github.com/huggingface/transformers/pull/25107) and [huggingface/accelerate#1777](https://github.com/huggingface/accelerate/pull/1777) solve the first challenge and requires no code changes from user side. It does the following:
1. Create the model with no weights on all ranks (using the `meta` device).
2. Load the state dict only on rank==0 and set the model weights with that state dict on rank 0
3. For all other ranks, do `torch.empty(*param.size(), dtype=dtype)` for every parameter on `meta` device
4. So, rank==0 will have loaded the model with correct state dict while all other ranks will have random weights.
5. Set `sync_module_states=True` so that FSDP object takes care of broadcasting them to all the ranks before training starts.
Below is the output snippet on a 7B model on 2 GPUs measuring the memory consumed and model parameters at various stages. We can observe that during loading the pre-trained model rank 0 & rank 1 have CPU total peak memory of `32744 MB` and `1506 MB` , respectively. Therefore, only rank 0 is loading the pre-trained model leading to efficient usage of CPU RAM. The whole logs at be found [here](https://gist.github.com/pacman100/2fbda8eb4526443a73c1455de43e20f9)
```bash
accelerator.process_index=0 GPU Memory before entering the loading : 0
accelerator.process_index=0 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=0 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=0 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=0 CPU Memory before entering the loading : 926
accelerator.process_index=0 CPU Memory consumed at the end of the loading (end-begin): 26415
accelerator.process_index=0 CPU Peak Memory consumed during the loading (max-begin): 31818
accelerator.process_index=0 CPU Total Peak Memory consumed during the loading (max): 32744
accelerator.process_index=1 GPU Memory before entering the loading : 0
accelerator.process_index=1 GPU Memory consumed at the end of the loading (end-begin): 0
accelerator.process_index=1 GPU Peak Memory consumed during the loading (max-begin): 0
accelerator.process_index=1 GPU Total Peak Memory consumed during the loading (max): 0
accelerator.process_index=1 CPU Memory before entering the loading : 933
accelerator.process_index=1 CPU Memory consumed at the end of the loading (end-begin): 10
accelerator.process_index=1 CPU Peak Memory consumed during the loading (max-begin): 573
accelerator.process_index=1 CPU Total Peak Memory consumed during the loading (max): 1506
```
### Addressing Challenge 2
It is addressed via choosing `SHARDED_STATE_DICT` state dict type when creating FSDP config. `SHARDED_STATE_DICT` saves shard per GPU separately which makes it quick to save or resume training from intermediate checkpoint. When `FULL_STATE_DICT` is used, first process (rank 0) gathers the whole model on CPU and then saving it in a standard format.
Let’s create the accelerate config via below command:
```
accelerate config --config_file "fsdp_config.yaml"
```

The resulting config is available here: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/configs/fsdp_config.yaml). Here, the sharding strategy is `FULL_SHARD`. We are using `TRANSFORMER_BASED_WRAP` for auto wrap policy and it uses `_no_split_module` to find the Transformer block name for nested FSDP auto wrap. We use `SHARDED_STATE_DICT` to save the intermediate checkpoints and optimizer states in this format recommended by the PyTorch team. Make sure to enable broadcasting module parameters from rank 0 at the start as mentioned in the above paragraph on addressing Challenge 1. We are enabling `bf16` mixed precision training.
For final checkpoint being the whole model state dict, below code snippet is used:
```python
if trainer.is_fsdp_enabled:
trainer.accelerator.state.fsdp_plugin.set_state_dict_type("FULL_STATE_DICT")
trainer.save_model(script_args.output_dir) # alternatively, trainer.push_to_hub() if the whole ckpt is below 50GB as the LFS limit per file is 50GB
```
### Addressing Challenge 3
Flash Attention and enabling gradient checkpointing are required for faster training and reducing VRAM usage to enable fine-tuning and save compute costs. The codebase currently uses monkey patching and the implementation is at [chat_assistant/training/llama_flash_attn_monkey_patch.py](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/chat_assistant/training/llama_flash_attn_monkey_patch.py).
[FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf) introduces a way to compute exact attention while being faster and memory-efficient by leveraging the knowledge of the memory hierarchy of the underlying hardware/GPUs - The higher the bandwidth/speed of the memory, the smaller its capacity as it becomes more expensive.
If we follow the blog [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html), we can figure out that `Attention` module on current hardware is `memory-bound/bandwidth-bound`. The reason being that Attention **mostly consists of elementwise operations** as shown below on the left hand side. We can observe that masking, softmax and dropout operations take up the bulk of the time instead of matrix multiplications which consists of the bulk of FLOPs.

(Source: [link](https://arxiv.org/pdf/2205.14135.pdf))
This is precisely the problem that Flash Attention addresses. The idea is to **remove redundant HBM reads/writes.** It does so by keeping everything in SRAM, perform all the intermediate steps and only then write the final result back to HBM, also known as **Kernel Fusion**. Below is an illustration of how this overcomes the memory-bound bottleneck.

(Source: [link](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad))
**Tiling** is used during forward and backward passes to chunk the NxN softmax/scores computation into blocks to overcome the limitation of SRAM memory size. To enable tiling, online softmax algorithm is used. **Recomputation** is used during backward pass in order to avoid storing the entire NxN softmax/score matrix during forward pass. This greatly reduces the memory consumption.
For a simplified and in depth understanding of Flash Attention, please refer the blog posts [ELI5: FlashAttention](https://gordicaleksa.medium.com/eli5-flash-attention-5c44017022ad) and [Making Deep Learning Go Brrrr From First Principles](https://horace.io/brrr_intro.html) along with the original paper [FlashAttention: Fast and Memory-Efficient Exact Attention
with IO-Awareness](https://arxiv.org/pdf/2205.14135.pdf).
## Bringing it all-together
To run the training using `Accelerate` launcher with SLURM, refer this gist [launch.slurm](https://gist.github.com/pacman100/1cb1f17b2f1b3139a63b764263e70b25). Below is an equivalent command showcasing how to use `Accelerate` launcher to run the training. Notice that we are overriding `main_process_ip` , `main_process_port` , `machine_rank` , `num_processes` and `num_machines` values of the `fsdp_config.yaml`. Here, another important point to note is that the storage is stored between all the nodes.
```
accelerate launch \
--config_file configs/fsdp_config.yaml \
--main_process_ip $MASTER_ADDR \
--main_process_port $MASTER_PORT \
--machine_rank \$MACHINE_RANK \
--num_processes 16 \
--num_machines 2 \
train.py \
--seed 100 \
--model_name "meta-llama/Llama-2-70b-chat-hf" \
--dataset_name "smangrul/code-chat-assistant-v1" \
--chat_template_format "none" \
--add_special_tokens False \
--append_concat_token False \
--splits "train,test" \
--max_seq_len 2048 \
--max_steps 500 \
--logging_steps 25 \
--log_level "info" \
--eval_steps 100 \
--save_steps 250 \
--logging_strategy "steps" \
--evaluation_strategy "steps" \
--save_strategy "steps" \
--push_to_hub \
--hub_private_repo True \
--hub_strategy "every_save" \
--bf16 True \
--packing True \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--warmup_ratio 0.03 \
--max_grad_norm 1.0 \
--output_dir "/shared_storage/sourab/experiments/full-finetune-llama-chat-asst" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--gradient_checkpointing True \
--use_reentrant False \
--dataset_text_field "content" \
--use_flash_attn True \
--ddp_timeout 5400 \
--optim paged_adamw_32bit
```
Fine-tuning completed in ~13.5 hours and below is the training loss plot.

**Important Note**:
Here, if you are using only a single node with 8 A100 80GB GPUs, then `paged_adamw_32bit` optimizer from `bitsandbytes` is required. For more information about paged optimizers, please refer https://huggingface.co./docs/bitsandbytes/main/en/optimizers#paged-optimizers.
Below is an example conversation using the above model:
```diff
System Prompt: You are a helpful, respectful and honest assistant. Always answer as helpfully \
as possible, while being safe. Your answers should not include any harmful, \
unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that \
your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why \
instead of answering something not correct. If you don’t know the answer to a \
question, please don’t share false information.
- Human: What is Deep Learning? Explain like a Pirate.
+ Assistant: Arrr Grumete! Are ye lookin' fer a proper explanation o' Deep Learnin'?
+ Alright then, listen up me hearty! Deep Learnin' be a type o' machine learnin' that uses artificial neural networks to analyze data.
+ Aye, ye heard that right, mateys! Artificial neural networks be models o' the human brain, but instead o' using neurons, they use interconnected nodes or "artificial neurons" to process information.
+ These nodes work together to form layers o' processing units that can learn from large amounts o' data.
+ The more data these systems receive, the better they get at recognizing patterns and makin' decisions on their own.
+ So hoist the sails and set course for adventure with deep learnin', me hearties! It's a treasure trove o' knowledge just waitin' to be discovered.
+ Fair winds and following seas!
- Human: Now explain it like a chef.
+ Assistant: Certainly! Here's an explanation of deep learning from a culinary perspective:
+ Think of a recipe as a sequence of steps used to transform raw ingredients into a delicious dish.
+ Similarly, in deep learning, there are multiple layers of "ingredients" (or features) that are combined and transformed through various operations to produce a final output or prediction.
+ Each layer builds upon the previous one, refining and enhancing the representation of the input data until it reaches the desired outcome.
+ Just as different spices enhance the flavors of food, each layer adds depth and complexity to the model's understanding of the input, allowing it to make more accurate predictions.
+ And much like how chefs must carefully balance the amount of salt, sugar, and other seasonings in a recipe, the training process in deep learning involves adjusting the weights and biases of the network to achieve the perfect blend of accuracy and efficiency.
+ With enough practice and experimentation, anyone can become a master chef... I mean, a master of deep learning! Bon appétit!
```
The whole conversation is formatted as below:
```
<|system|> system message <|endoftext|> <|prompter|> Q1 <|endoftext|> <|assistant|> A1 <|endoftext|> ...
```
## Conclusion
We successfully fine-tuned 70B Llama model using PyTorch FSDP in a multi-node multi-gpu setting while addressing various challenges. We saw how 🤗 Transformers and 🤗 Accelerates now supports efficient way of initializing large models when using FSDP to overcome CPU RAM getting out of memory. This was followed by recommended practices for saving/loading intermediate checkpoints and how to save the final model in a way to readily use it. To enable faster training and reducing GPU memory usage, we outlined the importance of Flash Attention and Gradient Checkpointing. Overall, we can see how a simple config using 🤗 Accelerate enables finetuning of such large models in a multi-node multi-gpu setting. | [
[
"llm",
"implementation",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"implementation",
"efficient_computing"
] | null | null |
ea42bc0d-a5d8-4fb7-aad3-c947a8b40f4e | completed | 2025-01-16T03:09:11.596776 | 2025-01-16T15:10:55.488895 | 57c806db-a185-4ab3-8581-49d1d035fb1b | Leveraging Hugging Face for complex generative AI use cases | jeffboudier, wassemgtk | writer-case-study.md | In this conversation, Jeff Boudier asks Waseem Alshikh, Co-founder and CTO of Writer, about their journey from a Hugging Face user, to a customer and now an open source model contributor.
- why was Writer started?
- what are the biggest misconceptions in Generative AI today?
- why is Writer now contributing open source models?
- what has been the value of the Hugging Face Expert Acceleration Program service for Writer?
- how it Writer approaching production on CPU and GPU to serve LLMs at scale?
- how important is efficiency and using CPUs for production?
<iframe width="100%" style="aspect-ratio: 16 / 9;" src="https://www.youtube-nocookie.com/embed/t8Ek1aOtaQw" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
_If you’re interested in Hugging Face Expert Acceleration Program for your company, please contact us [here](https://huggingface.co./support#form) - our team will contact you to discuss your requirements!_ | [
[
"llm",
"mlops",
"optimization",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"optimization",
"deployment"
] | null | null |
01c5f22c-fba6-4871-9245-252c9789342e | completed | 2025-01-16T03:09:11.596783 | 2025-01-16T13:34:04.075576 | 157bc61a-c585-49cd-8cb3-21d05f70c86b | Introduction to Graph Machine Learning | clefourrier | intro-graphml.md | In this blog post, we cover the basics of graph machine learning.
We first study what graphs are, why they are used, and how best to represent them. We then cover briefly how people learn on graphs, from pre-neural methods (exploring graph features at the same time) to what are commonly called Graph Neural Networks. Lastly, we peek into the world of Transformers for graphs.
## Graphs
### What is a graph?
In its essence, a graph is a description of items linked by relations.
Examples of graphs include social networks (Twitter, Mastodon, any citation networks linking papers and authors), molecules, knowledge graphs (such as UML diagrams, encyclopedias, and any website with hyperlinks between its pages), sentences expressed as their syntactic trees, any 3D mesh, and more! It is, therefore, not hyperbolic to say that graphs are everywhere.
The items of a graph (or network) are called its *nodes* (or vertices), and their connections its *edges* (or links). For example, in a social network, nodes are users and edges their connections; in a molecule, nodes are atoms and edges their molecular bond.
* A graph with either typed nodes or typed edges is called **heterogeneous** (example: citation networks with items that can be either papers or authors have typed nodes, and XML diagram where relations are typed have typed edges). It cannot be represented solely through its topology, it needs additional information. This post focuses on homogeneous graphs.
* A graph can also be **directed** (like a follower network, where A follows B does not imply B follows A) or **undirected** (like a molecule, where the relation between atoms goes both ways). Edges can connect different nodes or one node to itself (self-edges), but not all nodes need to be connected.
If you want to use your data, you must first consider its best characterisation (homogeneous/heterogeneous, directed/undirected, and so on).
### What are graphs used for?
Let's look at a panel of possible tasks we can do on graphs.
At the **graph level**, the main tasks are:
- graph generation, used in drug discovery to generate new plausible molecules,
- graph evolution (given a graph, predict how it will evolve over time), used in physics to predict the evolution of systems
- graph level prediction (categorisation or regression tasks from graphs), such as predicting the toxicity of molecules.
At the **node level**, it's usually a node property prediction. For example, [Alphafold](https://www.deepmind.com/blog/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology) uses node property prediction to predict the 3D coordinates of atoms given the overall graph of the molecule, and therefore predict how molecules get folded in 3D space, a hard bio-chemistry problem.
At the **edge level**, it's either edge property prediction or missing edge prediction. Edge property prediction helps drug side effect prediction predict adverse side effects given a pair of drugs. Missing edge prediction is used in recommendation systems to predict whether two nodes in a graph are related.
It is also possible to work at the **sub-graph level** on community detection or subgraph property prediction. Social networks use community detection to determine how people are connected. Subgraph property prediction can be found in itinerary systems (such as [Google Maps](https://www.deepmind.com/blog/traffic-prediction-with-advanced-graph-neural-networks)) to predict estimated times of arrival.
Working on these tasks can be done in two ways.
When you want to predict the evolution of a specific graph, you work in a **transductive** setting, where everything (training, validation, and testing) is done on the same single graph. *If this is your setup, be careful! Creating train/eval/test datasets from a single graph is not trivial.* However, a lot of the work is done using different graphs (separate train/eval/test splits), which is called an **inductive** setting.
### How do we represent graphs?
The common ways to represent a graph to process and operate it are either:
* as the set of all its edges (possibly complemented with the set of all its nodes)
* or as the adjacency matrix between all its nodes. An adjacency matrix is a square matrix (of node size * node size) that indicates which nodes are directly connected to which others (where \(A_{ij} = 1\) if \(n_i\) and \(n_j\) are connected, else 0). *Note: most graphs are not densely connected and therefore have sparse adjacency matrices, which can make computations harder.*
However, though these representations seem familiar, do not be fooled!
Graphs are very different from typical objects used in ML because their topology is more complex than just "a sequence" (such as text and audio) or "an ordered grid" (images and videos, for example)): even if they can be represented as lists or matrices, their representation should not be considered an ordered object!
But what does this mean? If you have a sentence and shuffle its words, you create a new sentence. If you have an image and rearrange its columns, you create a new image.
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_hf.png" width="500" />
<figcaption>On the left, the Hugging Face logo - on the right, a shuffled Hugging Face logo, which is quite a different new image.</figcaption>
</figure>
</div>
This is not the case for a graph: if you shuffle its edge list or the columns of its adjacency matrix, it is still the same graph. (We explain this more formally a bit lower, look for permutation invariance).
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/assembled_graphs.png" width="1000" />
<figcaption>On the left, a small graph (nodes in yellow, edges in orange). In the centre, its adjacency matrix, with columns and rows ordered in the alphabetical node order: on the row for node A (first row), we can read that it is connected to E and C. On the right, a shuffled adjacency matrix (the columns are no longer sorted alphabetically), which is also a valid representation of the graph: A is still connected to E and C.</figcaption>
</figure>
</div>
## Graph representations through ML
The usual process to work on graphs with machine learning is first to generate a meaningful representation for your items of interest (nodes, edges, or full graphs depending on your task), then to use these to train a predictor for your target task. We want (as in other modalities) to constrain the mathematical representations of your objects so that similar objects are mathematically close. However, this similarity is hard to define strictly in graph ML: for example, are two nodes more similar when they have the same labels or the same neighbours?
Note: *In the following sections, we will focus on generating node representations.
Once you have node-level representations, it is possible to obtain edge or graph-level information. For edge-level information, you can concatenate node pair representations or do a dot product. For graph-level information, it is possible to do a global pooling (average, sum, etc.) on the concatenated tensor of all the node-level representations. Still, it will smooth and lose information over the graph -- a recursive hierarchical pooling can make more sense, or add a virtual node, connected to all other nodes in the graph, and use its representation as the overall graph representation.*
### Pre-neural approaches
#### Simply using engineered features
Before neural networks, graphs and their items of interest could be represented as combinations of features, in a task-specific fashion. Now, these features are still used for data augmentation and [semi-supervised learning](https://arxiv.org/abs/2202.08871), though [more complex feature generation methods](https://arxiv.org/abs/2208.11973) exist; it can be essential to find how best to provide them to your network depending on your task.
**Node-level** features can give information about importance (how important is this node for the graph?) and/or structure based (what is the shape of the graph around the node?), and can be combined.
The node **centrality** measures the node importance in the graph. It can be computed recursively by summing the centrality of each node’s neighbours until convergence, or through shortest distance measures between nodes, for example. The node **degree** is the quantity of direct neighbours it has. The **clustering coefficient** measures how connected the node neighbours are. **Graphlets degree vectors** count how many different graphlets are rooted at a given node, where graphlets are all the mini graphs you can create with a given number of connected nodes (with three connected nodes, you can have a line with two edges, or a triangle with three edges).
<div align="center">
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/125_intro-to-graphml/graphlets.png" width="700" />
<figcaption>The 2-to 5-node graphlets (Pržulj, 2007)</figcaption>
</figure>
</div>
**Edge-level** features complement the representation with more detailed information about the connectedness of the nodes, and include the **shortest distance** between two nodes, their **common neighbours**, and their **Katz index** (which is the number of possible walks of up to a certain length between two nodes - it can be computed directly from the adjacency matrix).
**Graph level features** contain high-level information about graph similarity and specificities. Total **graphlet counts**, though computationally expensive, provide information about the shape of sub-graphs. **Kernel methods** measure similarity between graphs through different "bag of nodes" methods (similar to bag of words).
### Walk-based approaches
[**Walk-based approaches**](https://en.wikipedia.org/wiki/Random_walk) use the probability of visiting a node j from a node i on a random walk to define similarity metrics; these approaches combine both local and global information. [**Node2Vec**](https://snap.stanford.edu/node2vec/), for example, simulates random walks between nodes of a graph, then processes these walks with a skip-gram, [much like we would do with words in sentences](https://arxiv.org/abs/1301.3781), to compute embeddings. These approaches can also be used to [accelerate computations](https://arxiv.org/abs/1208.3071) of the [**Page Rank method**](http://infolab.stanford.edu/pub/papers/google.pdf), which assigns an importance score to each node (based on its connectivity to other nodes, evaluated as its frequency of visit by random walk, for example).
However, these methods have limits: they cannot obtain embeddings for new nodes, do not capture structural similarity between nodes finely, and cannot use added features.
## Graph Neural Networks
Neural networks can generalise to unseen data. Given the representation constraints we evoked earlier, what should a good neural network be to work on graphs?
It should:
- be permutation invariant:
- Equation: \\(f(P(G))=f(G)\\) with f the network, P the permutation function, G the graph
- Explanation: the representation of a graph and its permutations should be the same after going through the network
- be permutation equivariant
- Equation: \\(P(f(G))=f(P(G))\\) with f the network, P the permutation function, G the graph
- Explanation: permuting the nodes before passing them to the network should be equivalent to permuting their representations
Typical neural networks, such as RNNs or CNNs are not permutation invariant. A new architecture, the [Graph Neural Network](https://ieeexplore.ieee.org/abstract/document/1517930), was therefore introduced (initially as a state-based machine).
A GNN is made of successive layers. A GNN layer represents a node as the combination (**aggregation**) of the representations of its neighbours and itself from the previous layer (**message passing**), plus usually an activation to add some nonlinearity.
**Comparison to other models**: A CNN can be seen as a GNN with fixed neighbour sizes (through the sliding window) and ordering (it is not permutation equivariant). A [Transformer](https://arxiv.org/abs/1706.03762v3) without positional embeddings can be seen as a GNN on a fully-connected input graph.
### Aggregation and message passing
There are many ways to aggregate messages from neighbour nodes, summing, averaging, for example. Some notable works following this idea include:
- [Graph Convolutional Networks](https://tkipf.github.io/graph-convolutional-networks/) averages the normalised representation of the neighbours for a node (most GNNs are actually GCNs);
- [Graph Attention Networks](https://petar-v.com/GAT/) learn to weigh the different neighbours based on their importance (like transformers);
- [GraphSAGE](https://snap.stanford.edu/graphsage/) samples neighbours at different hops before aggregating their information in several steps with max pooling.
- [Graph Isomorphism Networks](https://arxiv.org/pdf/1810.00826v3.pdf) aggregates representation by applying an MLP to the sum of the neighbours' node representations.
**Choosing an aggregation**: Some aggregation techniques (notably mean/max pooling) can encounter failure cases when creating representations which finely differentiate nodes with different neighbourhoods of similar nodes (ex: through mean pooling, a neighbourhood with 4 nodes, represented as 1,1,-1,-1, averaged as 0, is not going to be different from one with only 3 nodes represented as -1, 0, 1).
### GNN shape and the over-smoothing problem
At each new layer, the node representation includes more and more nodes.
A node, through the first layer, is the aggregation of its direct neighbours. Through the second layer, it is still the aggregation of its direct neighbours, but this time, their representations include their own neighbours (from the first layer). After n layers, the representation of all nodes becomes an aggregation of all their neighbours at distance n, therefore, of the full graph if its diameter is smaller than n!
If your network has too many layers, there is a risk that each node becomes an aggregation of the full graph (and that node representations converge to the same one for all nodes). This is called **the oversmoothing problem**
This can be solved by :
- scaling the GNN to have a layer number small enough to not approximate each node as the whole network (by first analysing the graph diameter and shape)
- increasing the complexity of the layers
- adding non message passing layers to process the messages (such as simple MLPs)
- adding skip-connections.
The oversmoothing problem is an important area of study in graph ML, as it prevents GNNs to scale up, like Transformers have been shown to in other modalities.
## Graph Transformers
A Transformer without its positional encoding layer is permutation invariant, and Transformers are known to scale well, so recently, people have started looking at adapting Transformers to graphs ([Survey)](https://github.com/ChandlerBang/awesome-graph-transformer). Most methods focus on the best ways to represent graphs by looking for the best features and best ways to represent positional information and changing the attention to fit this new data.
Here are some interesting methods which got state-of-the-art results or close on one of the hardest available benchmarks as of writing, [Stanford's Open Graph Benchmark](https://ogb.stanford.edu/):
- [*Graph Transformer for Graph-to-Sequence Learning*](https://arxiv.org/abs/1911.07470) (Cai and Lam, 2020) introduced a Graph Encoder, which represents nodes as a concatenation of their embeddings and positional embeddings, node relations as the shortest paths between them, and combine both in a relation-augmented self attention.
- [*Rethinking Graph Transformers with Spectral Attention*](https://arxiv.org/abs/2106.03893) (Kreuzer et al, 2021) introduced Spectral Attention Networks (SANs). These combine node features with learned positional encoding (computed from Laplacian eigenvectors/values), to use as keys and queries in the attention, with attention values being the edge features.
- [*GRPE: Relative Positional Encoding for Graph Transformer*](https://arxiv.org/abs/2201.12787) (Park et al, 2021) introduced the Graph Relative Positional Encoding Transformer. It represents a graph by combining a graph-level positional encoding with node information, edge level positional encoding with node information, and combining both in the attention.
- [*Global Self-Attention as a Replacement for Graph Convolution*](https://arxiv.org/abs/2108.03348) (Hussain et al, 2021) introduced the Edge Augmented Transformer. This architecture embeds nodes and edges separately, and aggregates them in a modified attention.
- [*Do Transformers Really Perform Badly for Graph Representation*](https://arxiv.org/abs/2106.05234) (Ying et al, 2021) introduces Microsoft's [**Graphormer**](https://www.microsoft.com/en-us/research/project/graphormer/), which won first place on the OGB when it came out. This architecture uses node features as query/key/values in the attention, and sums their representation with a combination of centrality, spatial, and edge encodings in the attention mechanism.
The most recent approach is [*Pure Transformers are Powerful Graph Learners*](https://arxiv.org/abs/2207.02505) (Kim et al, 2022), which introduced **TokenGT**. This method represents input graphs as a sequence of node and edge embeddings (augmented with orthonormal node identifiers and trainable type identifiers), with no positional embedding, and provides this sequence to Transformers as input. It is extremely simple, yet smart!
A bit different, [*Recipe for a General, Powerful, Scalable Graph Transformer*](https://arxiv.org/abs/2205.12454) (Rampášek et al, 2022) introduces, not a model, but a framework, called **GraphGPS**. It allows to combine message passing networks with linear (long range) transformers to create hybrid networks easily. This framework also contains several tools to compute positional and structural encodings (node, graph, edge level), feature augmentation, random walks, etc.
Using transformers for graphs is still very much a field in its infancy, but it looks promising, as it could alleviate several limitations of GNNs, such as scaling to larger/denser graphs, or increasing model size without oversmoothing.
## Further resources
If you want to delve deeper, you can look at some of these courses:
- Academic format
- [Stanford's Machine Learning with Graphs](https://web.stanford.edu/class/cs224w/)
- [McGill's Graph Representation Learning](https://cs.mcgill.ca/~wlh/comp766/)
- Video format
- [Geometric Deep Learning course](https://www.youtube.com/playlist?list=PLn2-dEmQeTfSLXW8yXP4q_Ii58wFdxb3C)
- Books
- [Graph Representation Learning*, Hamilton](https://www.cs.mcgill.ca/~wlh/grl_book/)
- Surveys
- [Graph Neural Networks Study Guide](https://github.com/dair-ai/GNNs-Recipe)
- Research directions
- [GraphML in 2023](https://towardsdatascience.com/graph-ml-in-2023-the-state-of-affairs-1ba920cb9232) summarizes plausible interesting directions for GraphML in 2023.
Nice libraries to work on graphs are [PyGeometric](https://pytorch-geometric.readthedocs.io/en/latest/) or the [Deep Graph Library](https://www.dgl.ai/) (for graph ML) and [NetworkX](https://networkx.org/) (to manipulate graphs more generally).
If you need quality benchmarks you can check out:
- [OGB, the Open Graph Benchmark](https://ogb.stanford.edu/): the reference graph benchmark datasets, for different tasks and data scales.
- [Benchmarking GNNs](https://github.com/graphdeeplearning/benchmarking-gnns): Library and datasets to benchmark graph ML networks and their expressivity. The associated paper notably studies which datasets are relevant from a statistical standpoint, what graph properties they allow to evaluate, and which datasets should no longer be used as benchmarks.
- [Long Range Graph Benchmark](https://github.com/vijaydwivedi75/lrgb): recent (Nov2022) benchmark looking at long range graph information
- [Taxonomy of Benchmarks in Graph Representation Learning](https://openreview.net/pdf?id=EM-Z3QFj8n): paper published at the 2022 Learning on Graphs conference, which analyses and sort existing benchmarks datasets
For more datasets, see:
- [Paper with code Graph tasks Leaderboards](https://paperswithcode.com/area/graphs): Leaderboard for public datasets and benchmarks - careful, not all the benchmarks on this leaderboard are still relevant
- [TU datasets](https://chrsmrrs.github.io/datasets/docs/datasets/): Compilation of publicly available datasets, now ordered by categories and features. Most of these datasets can also be loaded with PyG, and a number of them have been ported to Datasets
- [SNAP datasets: Stanford Large Network Dataset Collection](https://snap.stanford.edu/data/):
- [MoleculeNet datasets](https://moleculenet.org/datasets-1)
- [Relational datasets repository](https://relational.fit.cvut.cz/)
### External images attribution
Emojis in the thumbnail come from Openmoji (CC-BY-SA 4.0), the Graphlets figure comes from *Biological network comparison using graphlet degree distribution* (Pržulj, 2007). | [
[
"transformers",
"research",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"research",
"tutorial",
"transformers"
] | null | null |
0c42a0b0-5716-494c-8ce5-f5df507525e6 | completed | 2025-01-16T03:09:11.596791 | 2025-01-16T15:16:45.253042 | 6fe39628-9baa-433b-a996-4109ef291068 | Introducing the Open Leaderboard for Hebrew LLMs! | Shaltiel, TalGeva, OmerKo, clefourrier | leaderboard-hebrew.md | This project addresses the critical need for advancement in Hebrew NLP. As Hebrew is considered a low-resource language, existing LLM leaderboards often lack benchmarks that accurately reflect its unique characteristics. Today, we are excited to introduce a pioneering effort to change this narrative — our new open LLM leaderboard, specifically designed to evaluate and enhance language models in Hebrew.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.4.0/gradio.js"> </script>
<gradio-app theme_mode="light" space="hebrew-llm-leaderboard/leaderboard"></gradio-app>
Hebrew is a morphologically rich language with a complex system of roots and patterns. Words are built from roots with prefixes, suffixes, and infixes used to modify meaning, tense, or form plurals (among other functions). This complexity can lead to the existence of multiple valid word forms derived from a single root, making traditional tokenization strategies, designed for morphologically simpler languages, ineffective. As a result, existing language models may struggle to accurately process and understand the nuances of Hebrew, highlighting the need for benchmarks that cater to these unique linguistic properties.
LLM research in Hebrew therefore needs dedicated benchmarks that cater specifically to the nuances and linguistic properties of the language. Our leaderboard is set to fill this void by providing robust evaluation metrics on language-specific tasks, and promoting an open community-driven enhancement of generative language models in Hebrew.
We believe this initiative will be a platform for researchers and developers to share, compare, and improve Hebrew LLMs.
## Leaderboard Metrics and Tasks
We have developed four key datasets, each designed to test language models on their understanding and generation of Hebrew, irrespective of their performance in other languages. These benchmarks use a few-shot prompt format to evaluate the models, ensuring that they can adapt and respond correctly even with limited context.
Below is a summary of each of the benchmarks included in the leaderboard. For a more comprehensive breakdown of each dataset, scoring system, prompt construction, please visit the `About` tab of our leaderboard.
- **Hebrew Question Answering**: This task evaluates a model's ability to understand and process information presented in Hebrew, focusing on comprehension and the accurate retrieval of answers based on context. It checks the model's grasp of Hebrew syntax and semantics through direct question-and-answer formats.
- *Source*: [HeQ](https://aclanthology.org/2023.findings-emnlp.915/) dataset's test subset.
- **Sentiment Accuracy**: This benchmark tests the model's ability to detect and interpret sentiments in Hebrew text. It assesses the model's capability to classify statements accurately as positive, negative, or neutral based on linguistic cues.
- *Source*: [Hebrew Sentiment](https://huggingface.co./datasets/HebArabNlpProject/HebrewSentiment) - a Sentiment-Analysis Dataset in Hebrew.
- **Winograd Schema Challenge**: The task is designed to measure the model’s understanding of pronoun resolution and contextual ambiguity in Hebrew. It tests the model’s ability to use logical reasoning and general world knowledge to disambiguate pronouns correctly in complex sentences.
- *Source*: [A Translation of the Winograd Schema Challenge to Hebrew](https://www.cs.ubc.ca/~vshwartz/resources/winograd_he.jsonl), by Dr. Vered Schwartz.
- **Translation**: This task assesses the model's proficiency in translating between English and Hebrew. It evaluates the linguistic accuracy, fluency, and the ability to preserve meaning across languages, highlighting the model’s capability in bilingual translation tasks.
- *Source*: [NeuLabs-TedTalks](https://opus.nlpl.eu/NeuLab-TedTalks/en&he/v1/NeuLab-TedTalks) aligned translation corpus.
## Technical Setup
The leaderboard is inspired by the [Open LLM Leaderboard](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard), and uses the [Demo Leaderboard template](https://huggingface.co./demo-leaderboard-backend). Models that are submitted are deployed automatically using HuggingFace’s [Inference Endpoints](https://huggingface.co./docs/inference-endpoints/index) and evaluated through API requests managed by the [lighteval](https://github.com/huggingface/lighteval) library.
The implementation was straightforward, with the main task being to set up the environment; the rest of the code ran smoothly.
## Engage with Us
We invite researchers, developers, and enthusiasts to participate in this initiative. Whether you're interested in submitting your model for evaluation or joining the discussion on improving Hebrew language technologies, your contribution is crucial. Visit the submission page on the leaderboard for guidelines on how to submit models for evaluation, or join the [discussion page](https://huggingface.co./spaces/hebrew-llm-leaderboard/leaderboard/discussions) on the leaderboard’s HF space.
This new leaderboard is not just a benchmarking tool; we hope it will encourage the Israeli tech community to recognize and address the gaps in language technology research for Hebrew. By providing detailed, specific evaluations, we aim to catalyze the development of models that are not only linguistically diverse but also culturally accurate, paving the way for innovations that honor the richness of the Hebrew language.
Join us in this exciting journey to reshape the landscape of language modeling!
## Sponsorship
The leaderboard is proudly sponsored by [DDR&D IMOD / The Israeli National Program for NLP in Hebrew and Arabic](https://nnlp-il.mafat.ai/) in collaboration with [DICTA: The Israel Center for Text Analysis](https://dicta.org.il) and [Webiks](https://webiks.com), a testament to the commitment towards advancing language technologies in Hebrew. We would like to extend our gratitude to Prof. Reut Tsarfaty from Bar-Ilan University for her scientific consultation and guidance. | [
[
"llm",
"research",
"benchmarks",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"benchmarks",
"research",
"community"
] | null | null |
c6b4d8d8-9231-4142-8115-2de7004eb74e | completed | 2025-01-16T03:09:11.596799 | 2025-01-19T19:03:21.784641 | 15631bf1-8c95-4c2d-ac4a-a5829d2fbd4b | Retrieval Augmented Generation with Huggingface Transformers and Ray | ray-project | ray-rag.md | ##### A guest blog post by <a href="/amogkam">Amog Kamsetty</a> from the Anyscale team
[Huggingface Transformers](https://huggingface.co./) recently added the [Retrieval Augmented Generation (RAG)](https://twitter.com/huggingface/status/1310597560906780680) model, a new NLP architecture that leverages external documents (like Wikipedia) to augment its knowledge and achieve state of the art results on knowledge-intensive tasks. In this blog post, we introduce the integration of [Ray](https://docs.ray.io/en/master/), a library for building scalable applications, into the RAG contextual document retrieval mechanism. This speeds up retrieval calls by 2x and improves the scalability of RAG distributed [fine-tuning](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag).
### What is Retrieval Augmented Generation (RAG)?

_An overview of RAG. The model retrieves contextual documents from an external dataset as part of its execution. These contextual documents are used in conjunction with the original input to produce an output. The GIF is taken from [Facebook's original blog post](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models)._
Recently, [Huggingface](https://huggingface.co./) partnered with [Facebook AI](https://ai.facebook.com/) to introduce the [RAG](https://twitter.com/huggingface/status/1310597560906780680) model as part of its Transformers library.
[RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) acts just like any other [seq2seq model](https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html). However, [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) has an intermediate component that retrieves contextual documents from an external knowledge base (like a Wikipedia text corpus). These documents are then used in conjunction with the input sequence and passed into the underlying seq2seq [generator](https://huggingface.co./blog/how-to-generate).
This information retrieval step allows [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) to make use of multiple sources of knowledge -- those that are baked into the model parameters and the information that is contained in the contextual passages, allowing it to outperform other state-of-the-art models in tasks like question answering. You can try it for yourself using this [demo provided by Huggingface](https://huggingface.co./rag/)!
### Scaling up fine-tuning
This retrieval of contextual documents is crucial for RAG's state-of-the-art results but introduces an extra layer of complexity. When scaling up the training process via a data-parallel training routine, a naive implementation of the document lookup can become a bottleneck for training. Further, the **document index** used in the retrieval component is often quite large, making it infeasible for each training worker to load its own replicated copy of the index.
The previous implementation of RAG fine-tuning leveraged the [torch.distributed](https://pytorch.org/docs/stable/distributed.html) communication package for the document retrieval portion. However, this implementation sometimes proved to be inflexible and limited in scalability.
Instead, a framework-agnostic and a more flexible implementation for ad-hoc concurrent programming is required. [Ray](https://ray.io/) fits the bill perfectly. Ray is a simple, yet powerful Python library for general-purpose distributed and parallel programming. Using Ray for distributed document retrieval, we achieved a **2x speedup per retrieval call compared to `torch.distributed`**, and overall better fine-tuning scalability.
### Ray for Document Retrieval

_Document retrieval with the torch.distributed implementation_
The main drawback of the [torch.distributed](https://pytorch.org/docs/stable/distributed.html) implementation for document retrieval was that it latched onto the same process group used for training and only the rank 0 training worker loaded the index into memory.
As a result, this implementation had some limitations:
1. **Synchronization bottleneck**: The rank 0 worker had to receive the inputs from all workers, perform the index query, and then send the results back to the other workers. This limited performance with multiple training workers.
2. **PyTorch specific**: The document retrieval process group had to latch onto the existing process group used for training, meaning that PyTorch had to be used for training as well.

_Document retrieval with the Ray implementation_
To overcome these limitations, we introduced a novel implementation of distributed retrieval based on Ray. With [Ray’s stateful actor abstractions](https://docs.ray.io/en/master/actors.html), multiple processes that are separate from the training processes are used to load the index and handle the retrieval queries. With multiple Ray actors, retrieval is no longer a bottleneck and PyTorch is no longer a requirement for RAG.
And as you can see below, using the [Ray](https://docs.ray.io/en/master/) based implementation leads to better retrieval performance for multi-GPU fine-tuning. The following results show the seconds per retrieval call and we can see that as we increase the number of GPUs that we train on, using Ray has comparatively better performance than `torch.distributed`. Also, if we increase the number of Ray processes that perform retrieval, we also get better performance with more training workers since a single retrieval process is no longer a bottleneck.
<table>
<tr>
<td>
</td>
<td>2 GPU
</td>
<td>3 GPU
</td>
<td>4 GPU
</td>
</tr>
<tr>
<td>torch.distributed
</td>
<td>2.12 sec/retrieval
</td>
<td>2.62 sec/retrieve
</td>
<td>3.438 sec/retrieve
</td>
</tr>
<tr>
<td>Ray 2 retrieval processes
</td>
<td>1.49 sec/retrieve
</td>
<td>1.539 sec/retrieve
</td>
<td>2.029 sec/retrieve
</td>
</tr>
<tr>
<td>Ray 4 retrieval processes
</td>
<td>1.145 sec/retrieve
</td>
<td>1.484 sec/retrieve
</td>
<td>1.66 sec/retrieve
</td>
</tr>
</table>
_A performance comparison of different retrieval implementations. For each document retrieval implementation, we run 500 training steps with a per-GPU batch size of 8, and measure the time it takes to retrieve the contextual documents for each batch on the rank 0 training worker. As the results show, using multiple retrieval processes improves performance, especially as we scale training to multiple GPUs._
### How do I use it?
[Huggingface](https://huggingface.co./) provides a [PyTorch Lightning](https://github.com/PyTorchLightning/pytorch-lightning) based [fine tuning script](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag), and we extended it to add the Ray retrieval implementation as an option.
To try it out, first install the necessary requirements
```bash
pip install ray
pip install transformers
pip install -r transformers/examples/research_projects/rag/requirements.txt
```
Then, you can specify your data paths and other configurations and run [finetune-rag-ray.sh](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/finetune_rag_ray.sh)!
```bash
# Sample script to finetune RAG using Ray for distributed retrieval.
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python examples/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 100 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
--distributed_retriever ray \
--num_retrieval_workers 4
# Stop the Ray cluster.
ray stop
```
## What’s next?
Using RAG with [Huggingface transformers](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag) and the [Ray retrieval implementation](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/finetune_rag_ray.sh) for faster distributed fine-tuning, you can leverage RAG for retrieval-based generation on your own knowledge-intensive tasks.
Also, hyperparameter tuning is another aspect of transformer fine tuning and can have [huge impacts on accuracy](https://medium.com/distributed-computing-with-ray/hyperparameter-optimization-for-transformers-a-guide-c4e32c6c989b). For scalable and easy hyperparameter tuning, check out the [Ray Tune](https://docs.ray.io/en/latest/tune/) library. By using [Ray Tune’s integration with PyTorch Lightning](https://medium.com/distributed-computing-with-ray/scaling-up-pytorch-lightning-hyperparameter-tuning-with-ray-tune-4bd9e1ff9929), or the [built-in integration with Huggingface transformers](https://huggingface.co./blog/ray-tune), you can run experiments to find the perfect hyperparameters for your RAG model.
And lastly, stay tuned for a potential Tensorflow implementation of [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models) on [Huggingface](https://huggingface.co./)!
If you plan to try RAG+Ray integration out, please feel free to share your experiences on the [Ray Discourse](https://discuss.ray.io/) or join the [Ray community Slack](https://docs.google.com/forms/d/e/1FAIpQLSfAcoiLCHOguOm8e7Jnn-JJdZaCxPGjgVCvFijHB5PLaQLeig/viewform) for further discussion -- we’d love to hear from you!
> Also published at https://medium.com/distributed-computing-with-ray/retrieval-augmented-generation-with-huggingface-transformers-and-ray-b09b56161b1e | [
[
"llm",
"transformers",
"data",
"mlops",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"mlops",
"integration"
] | null | null |
a5953fe1-7210-4ad4-997b-9ceda21df257 | completed | 2025-01-16T03:09:11.596806 | 2025-01-19T18:46:57.944383 | d7cfadcf-93cd-4b1d-b65a-bf8e8a7b02c7 | Announcing Evaluation on the Hub | lewtun, abhishek, Tristan, sasha, lvwerra, nazneen, ola13, osanseviero, douwekiela | eval-on-the-hub.md | <br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
November 2023 Update:
This project has been archived. If you want to evaluate LLMs on the Hub, check out [this collection of leaderboards](https://huggingface.co./collections/clefourrier/llm-leaderboards-and-benchmarks-✨-64f99d2e11e92ca5568a7cce).
</div>
<em>TL;DR</em>: Today we introduce [Evaluation on the Hub](https://huggingface.co./spaces/autoevaluate/model-evaluator), a new tool powered by [AutoTrain](https://huggingface.co./autotrain) that lets you evaluate any model on any dataset on the Hub without writing a single line of code!
<figure class="image table text-center m-0">
<video
alt="Evaluating models from the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="/blog/assets/82_eval_on_the_hub/autoeval-demo.mp4" type="video/mp4">
</video>
<figcaption>Evaluate all the models 🔥🔥🔥!</figcaption>
</figure>
Progress in AI has been nothing short of amazing, to the point where some people are now seriously debating whether AI models may be better than humans at certain tasks. However, that progress has not at all been even: to a machine learner from several decades ago, modern hardware and algorithms might look incredible, as might the sheer quantity of data and compute at our disposal, but the way we evaluate these models has stayed roughly the same.
However, it is no exaggeration to say that modern AI is in an evaluation crisis. Proper evaluation these days involves measuring many models, often on many datasets and with multiple metrics. But doing so is unnecessarily cumbersome. This is especially the case if we care about reproducibility, since self-reported results may have suffered from inadvertent bugs, subtle differences in implementation, or worse.
We believe that better evaluation can happen, if we - the community - establish a better set of best practices and try to remove the hurdles. Over the past few months, we've been hard at work on [Evaluation on the Hub](https://huggingface.co./spaces/autoevaluate/model-evaluator): evaluate any model on any dataset using any metric, at the click of a button. To get started, we evaluated hundreds models on several key datasets, and using the nifty new [Pull Request feature](https://huggingface.co./blog/community-update) on the Hub, opened up loads of PRs on model cards to display their verified performance. Evaluation results are encoded directly in the model card metadata, following [a format](https://huggingface.co./docs/hub/models-cards) for all models on the Hub. Check out the model card for [DistilBERT](https://huggingface.co./distilbert-base-uncased-finetuned-sst-2-english/blob/main/README.md#L7-L42) to see how it looks!
## On the Hub
Evaluation on the Hub opens the door to so many interesting use cases. From the data scientist or executive who needs to decide which model to deploy, to the academic trying to reproduce a paper’s results on a new dataset, to the ethicist who wants to better understand risks of deployment. If we have to single out three primary initial use case scenarios, they are these:
**Finding the best model for your task**<br/>
Suppose you know exactly what your task is and you want to find the right model for the job. You can check out the leaderboard for a dataset representative of your task, which aggregates all the results. That’s great! And what if that fancy new model you’re interested in isn’t on the [leaderboard](https://huggingface.co./spaces/autoevaluate/leaderboards) yet for that dataset? Simply run an evaluation for it, without leaving the Hub.
**Evaluating models on your brand new dataset**<br/>
Now what if you have a brand spanking new dataset that you want to run baselines on? You can upload it to the Hub and evaluate as many models on it as you like. No code required. What’s more, you can be sure that the way you are evaluating these models on your dataset is exactly the same as how they’ve been evaluated on other datasets.
**Evaluating your model on many other related datasets**<br/>
Or suppose you have a brand new question answering model, trained on SQuAD? There are hundreds of different question answering datasets to evaluate on :scream: You can pick the ones you are interested in and evaluate your model, directly from the Hub.
## Ecosystem
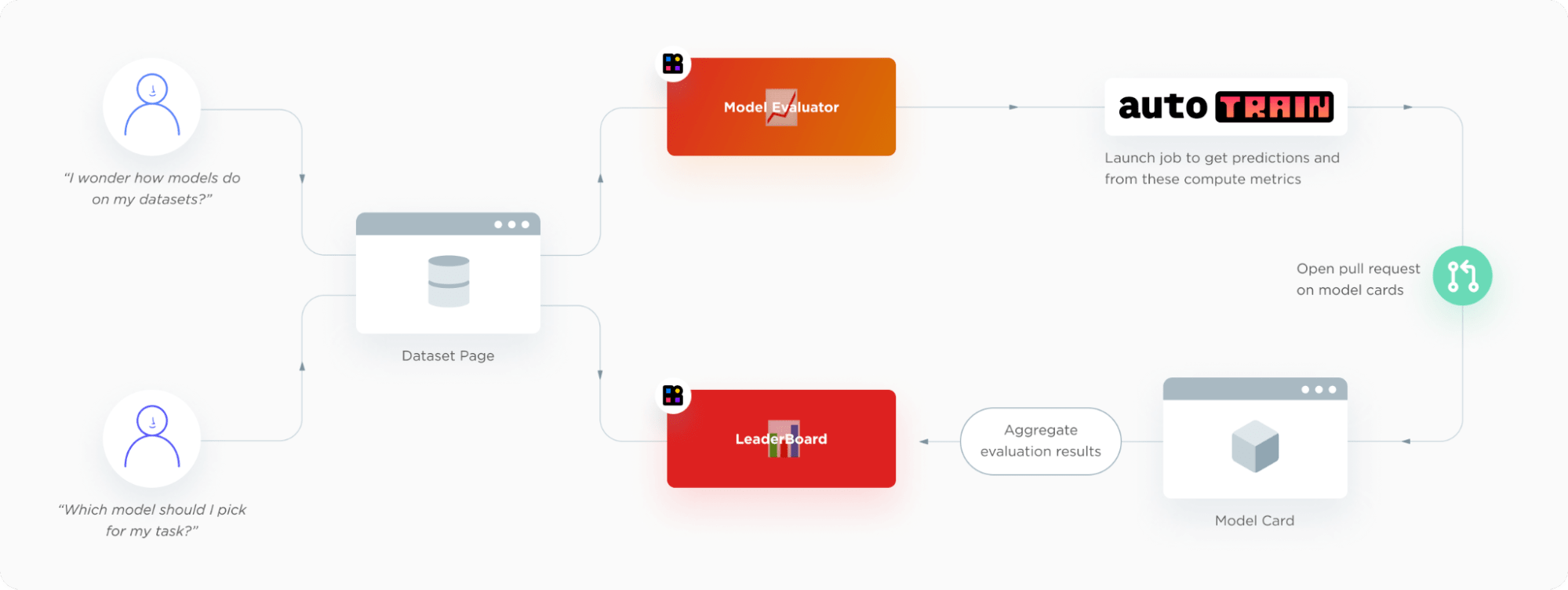
<figcaption><center><i>Evaluation on the Hub fits neatly into the Hugging Face ecosystem.</i></center></figcaption>
Evaluation on the Hub is meant to make your life easier. But of course, there’s a lot happening in the background. What we really like about Evaluation on the Hub: it fits so neatly into the existing Hugging Face ecosystem, we almost had to do it. Users start on dataset pages, from where they can launch evaluations or see leaderboards. The model evaluation submission interface and the leaderboards are regular Hugging Face Spaces. The evaluation backend is powered by AutoTrain, which opens up a PR on the Hub for the given model’s model card.
## DogFood - Distinguishing Dogs, Muffins and Fried Chicken
So what does it look like in practice? Let’s run through an example. Suppose you are in the business of telling apart dogs, muffins and fried chicken (a.k.a. dogfooding!).

<figcaption><center><i>Example images of dogs and food (muffins and fried chicken). <a href="https://github.com/qw2243c/Image-Recognition-Dogs-Fried-Chicken-or-Blueberry-Muffins-/">Source</a> / <a href="https://twitter.com/teenybiscuit/status/667777205397680129?s=20&t=wPgYJMp-JPwRsNAOMvEbxg">Original source</a>.</i></center></figcaption>
As the above image shows, to solve this problem, you’ll need:
* A dataset of dog, muffin, and fried chicken images
* Image classifiers that have been trained on these images
Fortunately, your data science team has uploaded [a dataset](https://huggingface.co./datasets/lewtun/dog_food) to the Hugging Face Hub and trained [a few different models on it](https://huggingface.co./models?datasets=lewtun/dog_food). So now you just need to pick the best one - let’s use Evaluation on the Hub to see how well they perform on the test set!
### Configuring an evaluation job
To get started, head over to the [`model-evaluator` Space](https://huggingface.co./spaces/autoevaluate/model-evaluator) and select the dataset you want to evaluate models on. For our dataset of dog and food images, you’ll see something like the image below:
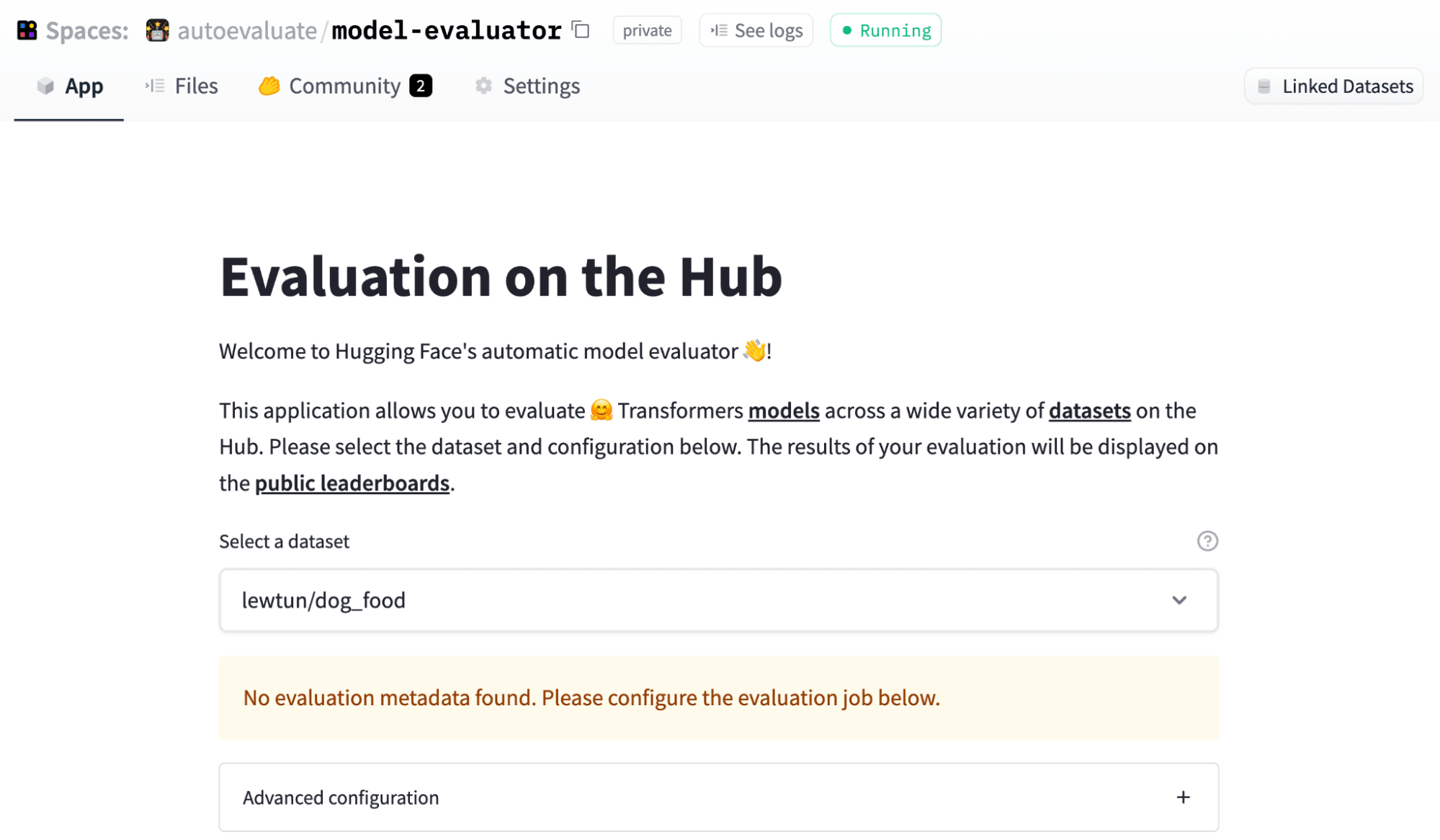
Now, many datasets on the Hub contain metadata that specifies how an evaluation should be configured (check out [acronym_identification](https://huggingface.co./datasets/acronym_identification/blob/main/README.md#L22-L30) for an example). This allows you to evaluate models with a single click, but in our case we’ll show you how to configure the evaluation manually.
Clicking on the <em>Advanced configuration</em> button will show you the various settings to choose from:
* The task, dataset, and split configuration
* The mapping of the dataset columns to a standard format
* The choice of metrics
As shown in the image below, configuring the task, dataset, and split to evaluate on is straightforward:

The next step is to define which dataset columns contain the images, and which ones contain the labels:
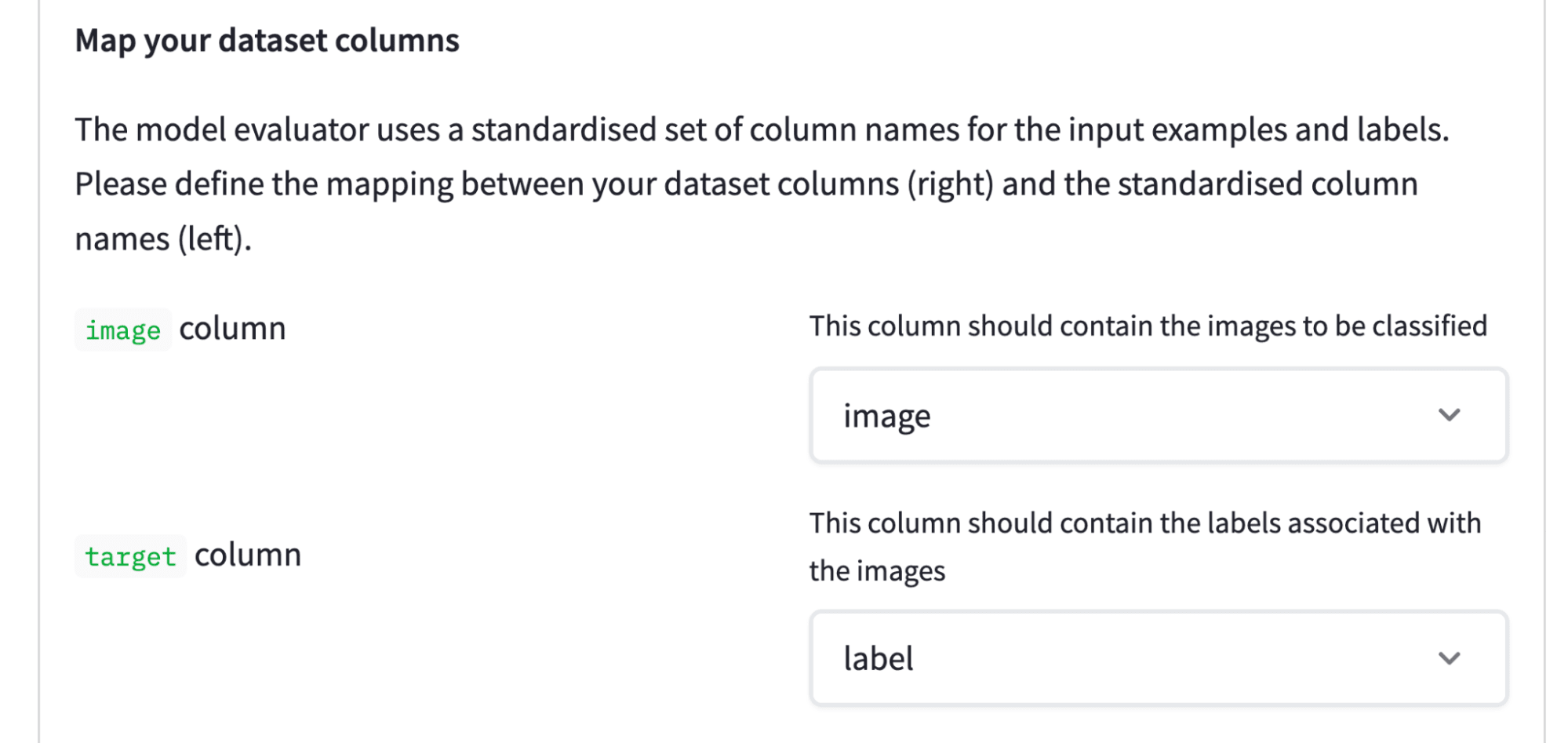
Now that the task and dataset are configured, the final (optional) step is to select the metrics to evaluate with. Each task is associated with a set of default metrics. For example, the image below shows that F1 score, accuracy etc will be computed automatically. To spice things up, we’ll also calculate the [Matthew’s correlation coefficient](https://huggingface.co./spaces/evaluate-metric/matthews_correlation), which provides a balanced measure of classifier performance:
And that’s all it takes to configure an evaluation job! Now we just need to pick some models to evaluate - let’s take a look.
### Selecting models to evaluate
Evaluation on the Hub links datasets and models via tags in the model card metadata. In our example, we have three models to choose from, so let’s select them all!
Once the models are selected, simply enter your Hugging Face Hub username (to be notified when the evaluation is complete) and hit the big <em>Evaluate models</em> button:
Once a job is submitted, the models will be automatically evaluated and a Hub pull request will be opened with the evaluation results:
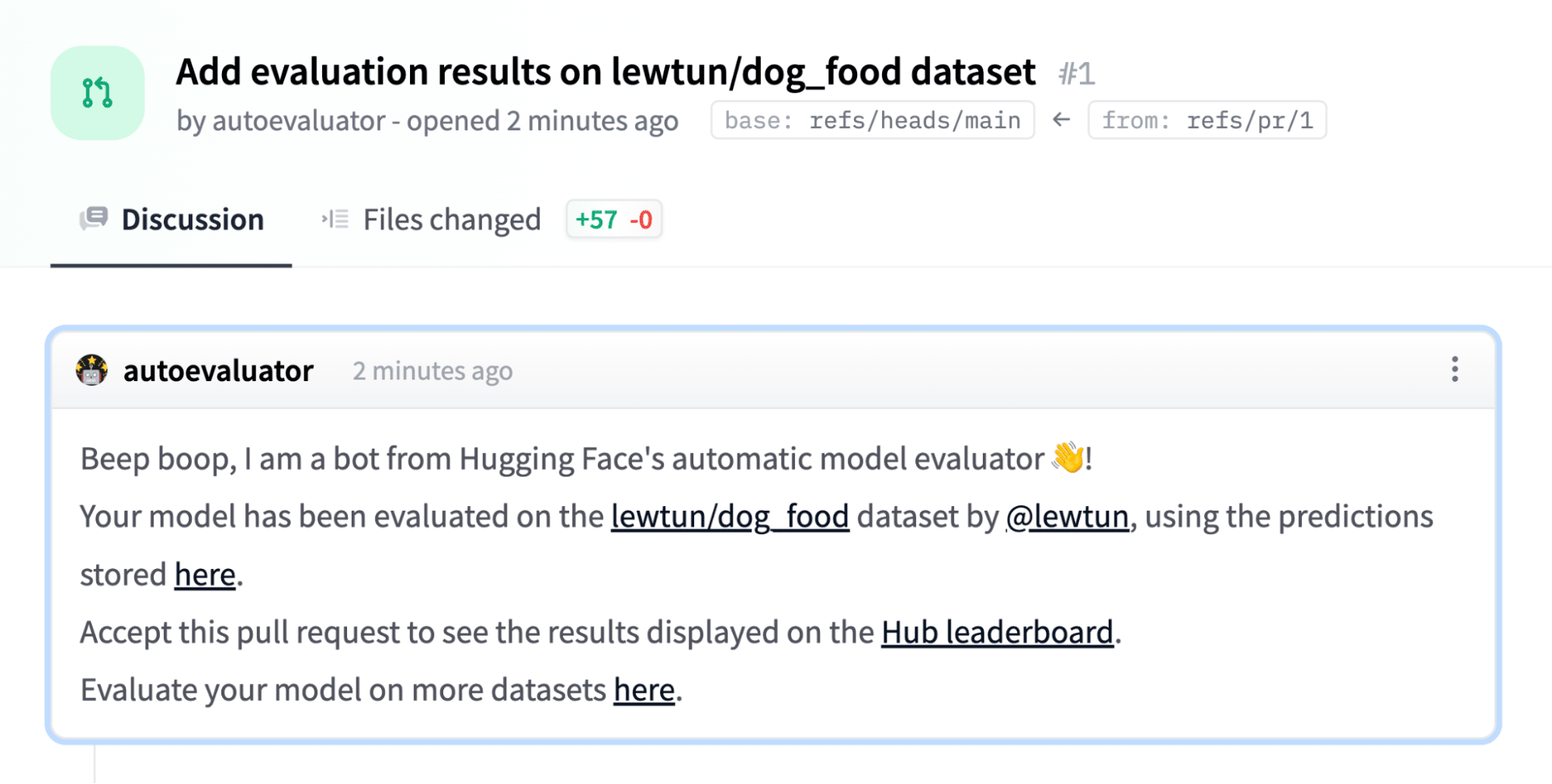
You can also copy-paste the evaluation metadata into the dataset card so that you and the community can skip the manual configuration next time!
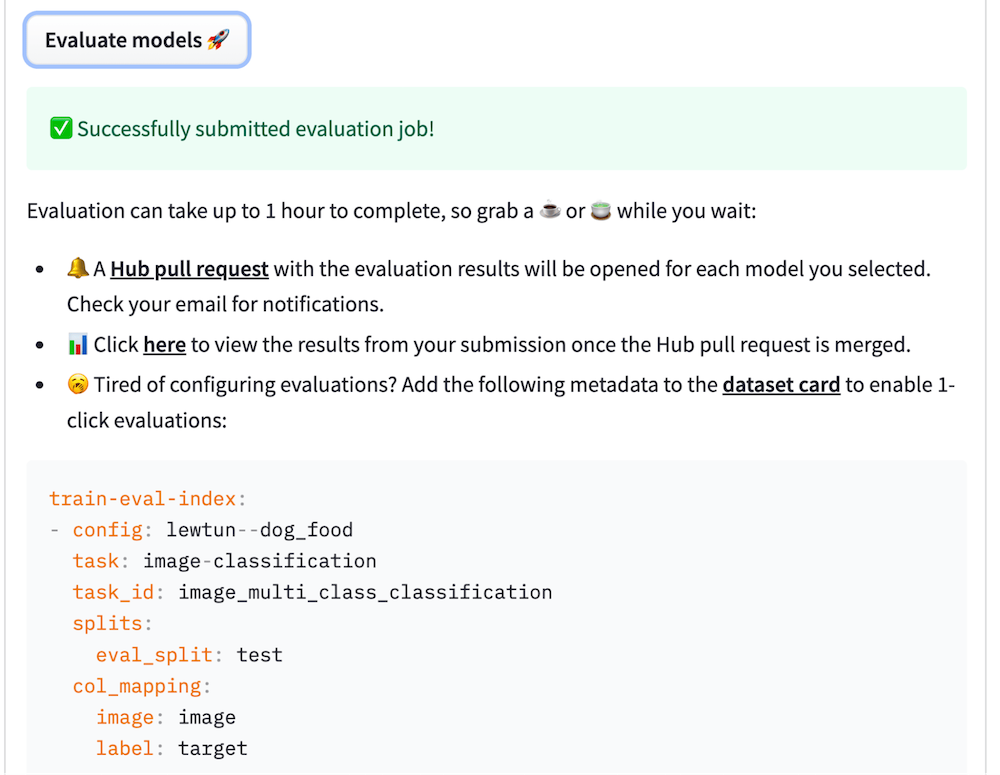
### Check out the leaderboard
To facilitate the comparison of models, Evaluation on the Hub also provides leaderboards that allow you to examine which models perform best on which split and metric:
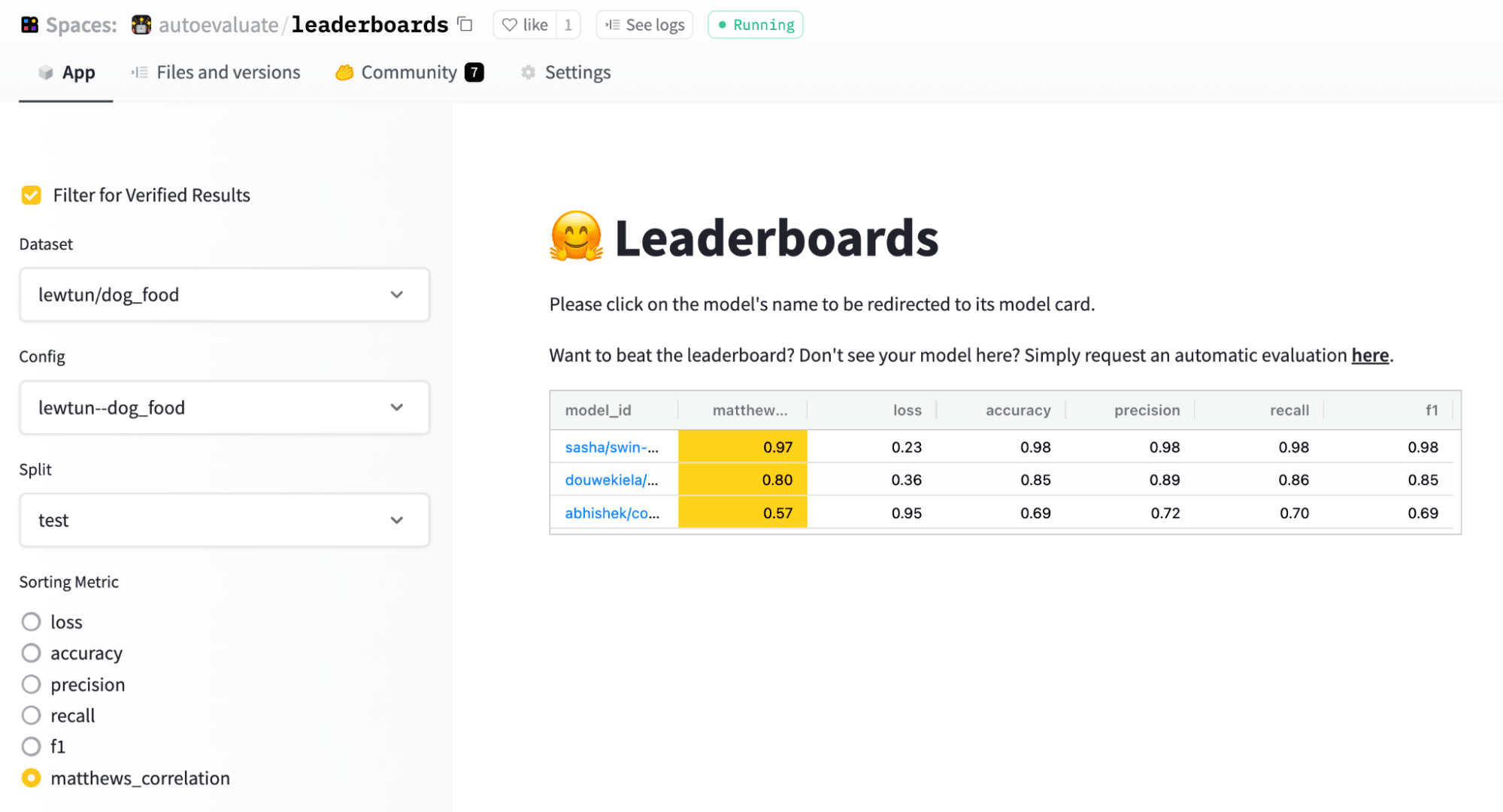
Looks like the Swin Transformer came out on top!
### Try it yourself!
If you’d like to evaluate your own choice of models, give Evaluation on the Hub a spin by checking out these popular datasets:
* [Emotion](https://huggingface.co./spaces/autoevaluate/model-evaluator?dataset=emotion) for text classification
* [MasakhaNER](https://huggingface.co./spaces/autoevaluate/model-evaluator?dataset=masakhaner) for named entity recognition
* [SAMSum](https://huggingface.co./spaces/autoevaluate/model-evaluator?dataset=samsum) for text summarization
## The Bigger Picture
Since the dawn of machine learning, we've evaluated models by computing some form of accuracy on a held-out test set that is assumed to be independent and identically distributed. Under the pressures of modern AI, that paradigm is now starting to show serious cracks.
Benchmarks are saturating, meaning that machines outperform humans on certain test sets, almost faster than we can come up with new ones. Yet, AI systems are known to be brittle and suffer from, or even worse amplify, severe malicious biases. Reproducibility is lacking. Openness is an afterthought. While people fixate on leaderboards, practical considerations for deploying models, such as efficiency and fairness, are often glossed over. The hugely important role data plays in model development is still not taken seriously enough. What is more, the practices of pretraining and prompt-based in-context learning have blurred what it means to be “in distribution” in the first place. Machine learning is slowly catching up to these things, and we hope to help the field move forward with our work.
## Next Steps
A few weeks ago, we launched the Hugging Face [Evaluate library](https://github.com/huggingface/evaluate), aimed at lowering barriers to the best practices of machine learning evaluation. We have also been hosting benchmarks, like [RAFT](https://huggingface.co./spaces/ought/raft-leaderboard) and [GEM](https://huggingface.co./spaces/GEM/submission-form). Evaluation on the Hub is a logical next step in our efforts to enable a future where models are evaluated in a more holistic fashion, along many axes of evaluation, in a trustable and guaranteeably reproducible manner. Stay tuned for more launches soon, including more tasks, and a new and improved [data measurements tool](https://huggingface.co./spaces/huggingface/data-measurements-tool)!
We’re excited to see where the community will take this! If you'd like to help out, evaluate as many models on as many datasets as you like. And as always, please give us lots of feedback, either on the [Community tabs](https://huggingface.co./spaces/autoevaluate/model-evaluator/discussions) or the [forums](https://discuss.huggingface.co/)! | [
[
"llm",
"mlops",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"tools",
"benchmarks",
"mlops"
] | null | null |
66124ca4-2c5a-4530-a2a3-ed9cebdefa49 | completed | 2025-01-16T03:09:11.596814 | 2025-01-19T19:00:03.522221 | c9d93243-8f51-45ea-ae95-331c88c2522f | Hugging Face models in Amazon Bedrock | pagezyhf, philschmid, jeffboudier, Violette | bedrock-marketplace.md | # Use Hugging Face models with Amazon Bedrock
We are excited to announce that popular open models from Hugging Face are now available on Amazon Bedrock in the new Bedrock Marketplace! AWS customers can now deploy [83 open models](https://us-east-1.console.aws.amazon.com/bedrock/home?region=us-east-1#/model-catalog) with Bedrock Marketplace to build their Generative AI applications.
Under the hood, Bedrock Marketplace model endpoints are managed by Amazon Sagemaker Jumpstart. With Bedrock Marketplace, you can now combine the ease of use of SageMaker JumpStart with the fully managed infrastructure of Amazon Bedrock, including compatibility with high-level APIs such as Agents, Knowledge Bases, Guardrails and Model Evaluations.
When registering your Sagemaker Jumpstart endpoints in Amazon Bedrock, you only pay for the Sagemaker compute resources and regular Amazon Bedrock APIs prices are applicable.
In this blog we will show you how to deploy [Gemma 2 27B Instruct](https://huggingface.co./google/gemma-2-27b-it) and use the model with Amazon Bedrock APIs. Learn how to:
1. Deploy Google Gemma 2 27B Instruct
2. Send requests using the Amazon Bedrock APIs
3. Clean Up
## Deploy Google Gemma 2 27B Instruct
There are two ways to deploy an open model to be used with Amazon Bedrock:
1. You can deploy your open model from the Bedrock Model Catalog.
2. You can deploy your open model with Amazon Jumpstart and register it with Bedrock.
Both ways are similar, so we will guide you through the Bedrock Model catalog.
To get started, in the Amazon Bedrock console, make sure you are in one of the 14 regions where the Bedrock Marketplace is available. Then, you choose [“Model catalog”](https://us-east-1.console.aws.amazon.com/bedrock/home?region=us-east-1#/model-catalog) in the “Foundation models” section of the navigation pane. Here, you can search for both serverless models and models available in Amazon Bedrock Marketplace. You filter results by “Hugging Face” provider and you can browse through the 83 open models available.
For example, let’s search and select Google Gemma 2 27B Instruct.

Choosing the model opens the model detail page where you can see more information from the model provider such as highlights about the model, and usage including sample API calls.
On the top right, let’s click on Deploy.

It brings you to the deployment page where you can select the endpoint name, the instance configuration and advanced settings related to networking configuration and service role used to perform the deployment in Sagemaker. Let’s use the default advanced settings and the recommended instance type.
You are also required to accept the End User License Agreement of the model provider.
On the bottom right, let’s click on Deploy.

We just launched the deployment of GoogleGemma 2 27B Instruct model on a ml.g5.48xlarge instance, hosted in your Amazon Sagemaker tenancy, compatible with Amazon Bedrock APIs!
The endpoint deployment can take several minutes. It will appear in the “Marketplace deployments” page, which you can find in the “Foundation models” section of the navigation pane.
## Use the model with Amazon Bedrock APIs
You can quickly test the model in the Playground through the UI. However, to invoke the deployed model programmatically with any Amazon Bedrock APIs, you need to get the endpoint ARN.
From the list of managed deployments, choose your model deployment to copy its endpoint ARN.

You can query your endpoint using the AWS SDK in your preferred language or with the AWS CLI.
Here is an example using Bedrock Converse API through the AWS SDK for Python (boto3):
```python
import boto3
bedrock_runtime = boto3.client("bedrock-runtime")
# Add your bedrock endpoint arn here.
endpoint_arn = "arn:aws:sagemaker:<AWS::REGION>:<AWS::AccountId>:endpoint/<Endpoint_Name>"
# Base inference parameters to use.
inference_config = {
"maxTokens": 256,
"temperature": 0.1,
"topP": 0.999,
}
# Additional inference parameters to use.
additional_model_fields = {"parameters": {"repetition_penalty": 0.9, "top_k": 250, "do_sample": True}}
response = bedrock_runtime.converse(
modelId=endpoint_arn,
messages=[
{
"role": "user",
"content": [
{
"text": "What is Amazon doing in the field of generative AI?",
},
]
},
],
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields,
)
print(response["output"]["message"]["content"][0]["text"])
```
```python
"Amazon is making significant strides in the field of generative AI, applying it across various products and services. Here's a breakdown of their key initiatives:\n\n**1. Amazon Bedrock:**\n\n* This is their **fully managed service** that allows developers to build and scale generative AI applications using models from Amazon and other leading AI companies. \n* It offers access to foundational models like **Amazon Titan**, a family of large language models (LLMs) for text generation, and models from Cohere"
```
That’s it! If you want to go further, have a look at the [Bedrock documentation](https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html).
## Clean up
Don’t forget to delete your endpoint at the end of your experiment to stop incurring costs! At the top right of the page where you grab the endpoint ARN, you can delete your endpoint by clicking on “Delete”. | [
[
"llm",
"mlops",
"deployment",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"mlops",
"deployment",
"integration"
] | null | null |
24e0cc5a-ded0-4545-96fe-4142c9302bf9 | completed | 2025-01-16T03:09:11.596822 | 2025-01-19T18:48:58.036065 | 7dd241a4-6dfc-4048-8504-e3f169b01e59 | An Introduction to Q-Learning Part 2/2 | ThomasSimonini | deep-rl-q-part2.md | <h2>Unit 2, part 2 of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co./deep-rl-course/unit1/introduction](https://huggingface.co./deep-rl-course/unit2/q-learning)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co./deep-rl-course/unit0/introduction)*
<img src="assets/73_deep_rl_q_part2/thumbnail.gif" alt="Thumbnail"/> | [
[
"research",
"implementation",
"tutorial",
"robotics"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"tutorial",
"implementation",
"research",
"robotics"
] | null | null |
9be42261-973f-4176-b36d-3cd404826e71 | completed | 2025-01-16T03:09:11.596830 | 2025-01-19T17:20:33.988024 | 7d022b47-f655-4ece-96b1-3f46dc03ccf9 | 2D Asset Generation: AI for Game Development #4 | dylanebert | ml-for-games-4.md | **Welcome to AI for Game Development!** In this series, we'll be using AI tools to create a fully functional farming game in just 5 days. By the end of this series, you will have learned how you can incorporate a variety of AI tools into your game development workflow. I will show you how you can use AI tools for:
1. Art Style
2. Game Design
3. 3D Assets
4. 2D Assets
5. Story
Want the quick video version? You can watch it [here](https://www.tiktok.com/@individualkex/video/7192994527312137518). Otherwise, if you want the technical details, keep reading!
**Note:** This tutorial is intended for readers who are familiar with Unity development and C#. If you're new to these technologies, check out the [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) series before continuing.
## Day 4: 2D Assets
In [Part 3](https://huggingface.co./blog/ml-for-games-3) of this tutorial series, we discussed how **text-to-3D** isn't quite ready yet. However, the story is much different for 2D.
In this part, we'll talk about how you can use AI to generate 2D Assets.
### Preface
This tutorial describes a collaborative process for generating 2D Assets, where Stable Diffusion is incorporated as a tool in a conventional 2D workflow. This is intended for readers with some knowledge of image editing and 2D asset creation but may otherwise be helpful for beginners and experts alike.
Requirements:
- Your preferred image-editing software, such as [Photoshop](https://www.adobe.com/products/photoshop.html) or [GIMP](https://www.gimp.org/) (free).
- Stable Diffusion. For instructions on setting up Stable Diffusion, refer to [Part 1](https://huggingface.co./blog/ml-for-games-1#setting-up-stable-diffusion).
### Image2Image
[Diffusion models](https://en.wikipedia.org/wiki/Diffusion_model) such as Stable Diffusion work by reconstructing images from noise, guided by text. Image2Image uses the same process but starts with real images as input rather than noise. This means that the outputs will, to some extent, resemble the input image.
An important parameter in Image2Image is **denoising strength**. This controls the extent to which the model changes the input. A denoising strength of 0 will reproduce the input image exactly, while a denoising strength of 1 will generate a very different image. Another way to think about denoising strength is **creativity**. The image below demonstrates image-to-image with an input image of a circle and the prompt "moon", at various denoising strengths.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/moons.png" alt="Denoising Strength Example">
</div>
Image2Image allows Stable Diffusion to be used as a tool, rather than as a replacement for the conventional artistic workflow. That is, you can pass your own handmade assets to Image2Image, iterate back on the result by hand, and so on. Let's take an example for the farming game.
### Example: Corn
In this section, I'll walk through how I generated a corn icon for the farming game. As a starting point, I sketched a very rough corn icon, intended to lay out the composition of the image.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn1.png" alt="Corn 1">
</div>
Next, I used Image2Image to generate some icons using the following prompt:
> corn, james gilleard, atey ghailan, pixar concept artists, stardew valley, animal crossing
I used a denoising strength of 0.8, to encourage the model to be more creative. After generating several times, I found a result I liked.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn2.png" alt="Corn 2">
</div>
The image doesn't need to be perfect, just in the direction you're going for, since we'll keep iterating. In my case, I liked the style that was produced, but thought the stalk was a bit too intricate. So, I made some modifications in photoshop.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn3.png" alt="Corn 3">
</div>
Notice that I roughly painted over the parts I wanted to change, allowing Stable Diffusion to fill the details in. I dropped my modified image back into Image2Image, this time using a lower denoising strength of 0.6 since I didn't want to deviate too far from the input. This resulted in an icon I was *almost* happy with.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn4.png" alt="Corn 4">
</div>
The base of the corn stalk was just a bit too painterly for me, and there was a sprout coming out of the top. So, I painted over these in photoshop, made one more pass in Stable Diffusion, and removed the background.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/corn5.png" alt="Corn 5">
</div>
Voilà, a game-ready corn icon in less than 10 minutes. However, you could spend much more time to get a better result. I recommend [this video](https://youtu.be/blXnuyVgA_Y) for a more detailed walkthrough of making a more intricate asset.
### Example: Scythe
In many cases, you may need to fight Stable Diffusion a bit to get the result you're going for. For me, this was definitely the case for the scythe icon, which required a lot of iteration to get in the direction I was going for.
<div align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/124_ml-for-games/scythe.png" alt="Scythe">
</div>
The issue likely lies in the fact that there are way more images online of scythes as *weapons* rather than as *farming tools*. One way around this is prompt engineering, or fiddling with the prompt to try to push it in the right direction, i.e. writing **scythe, scythe tool** in the prompt or **weapon** in the negative prompt. However, this isn't the only solution.
[Dreambooth](https://dreambooth.github.io/), [textual inversion](https://textual-inversion.github.io/), and [LoRA](https://huggingface.co./blog/lora) are techniques for customizing diffusion models, making them capable of producing results much more specific to what you're going for. These are outside the scope of this tutorial, but are worth mentioning, as they're becoming increasingly prominent in the area of 2D Asset generation.
Generative services such as [layer.ai](https://layer.ai/) and [scenario.gg](https://www.scenario.gg/) are specifically targeted toward game asset generation, likely using techniques such as dreambooth and textual inversion to allow game developers to generate style-consistent assets. However, it remains to be seen which approaches will rise to the top in the emerging generative game development toolkit.
If you're interested in diving deeper into these advanced workflows, check out this [blog post](https://huggingface.co./blog/dreambooth) and [space](https://huggingface.co./spaces/multimodalart/dreambooth-training) on Dreambooth training.
Click [here](https://huggingface.co./blog/ml-for-games-5) to read Part 5, where we use **AI for Story**. | [
[
"implementation",
"tutorial",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"tutorial",
"implementation",
"tools"
] | null | null |
4f073b43-8eee-42dc-b10d-38e87c99f4e6 | completed | 2025-01-16T03:09:11.596838 | 2025-01-16T15:13:25.058707 | bd885f0a-84ec-4907-aeef-22e59655348a | 'Preference Tuning LLMs with Direct Preference Optimization Methods' | kashif, edbeeching, lewtun, lvwerra, osanseviero | pref-tuning.md | **Addendum**
After consulting with the authors of the [IPO paper](https://arxiv.org/abs/2310.12036), we discovered that the implementation of IPO in TRL was incorrect; in particular, the loss over the log-likelihoods of the completions needs to be _averaged_ instead of _summed_. We have added a fix in [this PR](https://github.com/huggingface/trl/pull/1265) and re-run the experiments. The results are now consistent with the paper, with IPO on par with DPO and performing better than KTO in the paired preference setting. We have updated the post to reflect these new results.
**TL;DR**
We evaluate three promising methods to align language models without reinforcement learning (or preference tuning) on a number of models and hyperparameter settings. In particular we train using different hyperparameters and evaluate on:
* [Direct Preference Optimization](https://huggingface.co./papers/2305.18290) (DPO)
* [Identity Preference Optimisation](https://huggingface.co./papers/2310.12036) (IPO)
* [Kahneman-Tversky Optimisation](https://github.com/ContextualAI/HALOs) (KTO)
## Introduction
In this post, we perform an empirical evaluation of three promising LLM alignment algorithms: Direct Preference Optimization (DPO), Identity Preference Optimisation (IPO) and Kahneman-Tversky Optimisation (KTO). We conducted our experiments on two high quality 7b LLMs that have undergone a supervised fine-tuning step, but no preference alignment. We find that while one algorithm clearly outshines the others, there are key hyper-parameters that must be tuned to achieve the best results.
## Alignment without Reinforcement Learning
|)](https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/pref_tuning/dpo.png)|
|:--:|
|Image from the DPO paper ([https://arxiv.org/abs/2305.18290](https://arxiv.org/pdf/2305.18290.pdf))|
[Direct Preference Optimization (DPO)](https://huggingface.co./papers/2305.18290) has emerged as a promising alternative for aligning Large Language Models (LLMs) to human or AI preferences. Unlike [traditional alignment methods](https://huggingface.co./blog/rlhf), which are based on reinforcement learning, DPO recasts the alignment formulation as a simple loss function that can be optimised directly on a dataset of preferences \\( \{(x, y_w, y_l)\} \\), where \\(x\\) is a prompt and \\(y_w,y_l\\) are the preferred and dispreferred responses.
||
|:--:|
|Sample of a preference tuning dataset.|
This makes DPO simple to use in practice and has been applied with success to train models like [Zephyr](https://huggingface.co./HuggingFaceH4/zephyr-7b-beta) and [Intel’s NeuralChat](https://huggingface.co./Intel/neural-chat-7b-v3-3).
The success of DPO has prompted researchers to develop new loss functions that generalise the method in two main directions:
* **Robustness**: One shortcoming of DPO is that it tends to quickly overfit on the preference dataset. To avoid this, researchers at Google DeepMind introduced [Identity Preference Optimisation (IPO)](https://huggingface.co./papers/2310.12036), which adds a regularisation term to the DPO loss and enables one to train models to convergence without requiring tricks like early stopping.
* **Dispensing with paired preference data altogether**: Like most alignment methods, DPO requires a dataset of paired preferences \\( \{(x, y_w, y_l)\} \\), where annotators label which response is better according to a set of criteria like helpfulness or harmfulness. In practice, creating these datasets is a time consuming and costly endeavour. ContextualAI recently proposed an interesting alternative called [Kahneman-Tversky Optimisation (KTO)](https://github.com/ContextualAI/HALOs/blob/legacy/assets/full_paper.pdf), which defines the loss function entirely in terms of individual examples that have been labelled as "good" or "bad" (for example, the 👍 or 👎 icons one sees in chat UIs). These labels are much easier to acquire in practice and KTO is a promising way to continually update chat models running in production environments.
At the same time, these various methods come with hyperparameters, the most important one being \\( \beta \\), which controls how much to weight the preference of the reference model. With these alternatives now available in the practitioner’s arsenal through libraries like 🤗 [TRL](https://github.com/huggingface/trl), a natural question then becomes which of these methods and hyperparameters produce the best chat model?
This post aims to answer this question by performing an empirical analysis of the three methods. We will sweep over key hyperparameters such as \\(\beta\\) and training steps, then evaluate the resulting models’ performance via [MT-Bench](https://huggingface.co./spaces/lmsys/mt-bench), which is a common benchmark to measure chat model capabilities.
We provide open-source code to replicate these results in a recent update to the 🤗 [alignment-handbook](https://github.com/huggingface/alignment-handbook).
Let’s get started!
## Links
Here are the important links associated with our analysis:
- Code and config files to perform the hyperparameter scan: [https://github.com/huggingface/alignment-handbook/tree/main/recipes/pref_align_scan](https://github.com/huggingface/alignment-handbook/tree/main/recipes/pref_align_scan)
- 📚 The collection of dataset and models we used: [https://huggingface.co./collections/alignment-handbook/dpo-vs-kto-vs-ipo-65a69c5f03548d61dbe29ef8](https://huggingface.co./collections/alignment-handbook/dpo-vs-kto-vs-ipo-65a69c5f03548d61dbe29ef8)
## Experimental Setup
There are two main ingredients that one needs to consider when performing alignment experiments: the model we choose to optimize and the alignment dataset. To get more independent data points, we considered two models, [OpenHermes-2.5-Mistral-7B](https://huggingface.co./teknium/OpenHermes-2.5-Mistral-7B) and [Zephyr-7b-beta-sft](https://huggingface.co./alignment-handbook/zephyr-7b-sft-full), and two alignment datasets Intel’s [orca_dpo_pairs](https://huggingface.co./datasets/Intel/orca_dpo_pairs) and the [ultrafeedback-binarized](https://huggingface.co./datasets/HuggingFaceH4/ultrafeedback_binarized) dataset.
For the first experiment, we used [OpenHermes-2.5-Mistral-7B](https://huggingface.co./teknium/OpenHermes-2.5-Mistral-7B) as it’s one of the best 7B parameter chat models that hasn’t been subject to any alignment techniques. We then used Intel’s `orca_dpo_pairs` [dataset](https://huggingface.co./datasets/Intel/orca_dpo_pairs), which consists of 13k prompts where the chosen response is generated by GPT-4, and the undesired response is generated by Llama-Chat 13b. This is the dataset behind NeuralChat and NeuralHermes-2.5-Mistral-7B. Since KTO doesn’t require pairwise preferences per se, we simply treat the GPT-4 responses as “good” labels and the Llama-Chat 13b ones as “bad”. While GPT-4's responses are likely to be preferred over Llama-Chat 13b, there may be some cases where Llama-Chat-13b produces a better response, we consider this to represent a small minority of the examples.
The second experiment performed preference alignment on the[Zephyr-7b-beta-sft](https://huggingface.co./alignment-handbook/zephyr-7b-sft-full) model with the [ultrafeedback-binarized](https://huggingface.co./datasets/HuggingFaceH4/ultrafeedback_binarized) dataset, which contains 66k prompts with pairs of chosen and rejected responses. This dataset was used to train the original Zephyr model, which at the time was the best in class 7B model on numerous automated benchmarks and human evaluations.
## Configuring the experiments
The alignment handbook provides an easy way to configure a single experiment, these parameters are used to configure the [run_dpo.py](https://github.com/huggingface/alignment-handbook/blob/main/scripts/run_dpo.py) script.
```yaml
# Model arguments
model_name_or_path: teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
# Data training arguments
dataset_mixer:
HuggingFaceH4/orca_dpo_pairs: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# Training arguments with sensible defaults
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
do_train: true
evaluation_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: HuggingFaceH4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/openhermes-2.5-mistral-7b-dpo-v1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
push_to_hub_revision: true
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1
```
We created a similar base configuration file for the Zephyr experiments.
Chat templates were automatically inferred from the base Chat model, with OpenHermes-2.5 using ChatML format and Zephyr using the H4 chat template. Alternatively, if you want to use your own chat format, the 🤗 tokenizers library has now enabled user-defined chat templates using a jinja format strings:
```bash
# Example of the Zephyr chat template
"{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
```
Which formats conversations as follows:
```bash
# <|system|>
# You are a friendly chatbot who always responds in the style of a pirate.</s>
# <|user|>
# How many helicopters can a human eat in one sitting?</s>
# <|assistant|>
# Ah, me hearty matey! But yer question be a puzzler! A human cannot eat a helicopter in one sitting, as helicopters are not edible. They be made of metal, plastic, and other materials, not food!
```
## Hyperparameter Sweep
We trained the `DPO`, `IPO` and `KTO` methods via the `loss_type` argument [TRL’s](https://github.com/huggingface/trl) `DPOTrainer` with the `beta` going from `0.01`, `0.1`, `0.2`, ..., `0.9`. We included `0.01` as we observed that some alignment algorithms are especially sensitive to this parameter. All experiments were trained for one epoch. All other hyperparameters are kept the same during each run, including the random seed.
We then launched our scan on the Hugging Face cluster using the base configurations defined above. #GPURICH
```bash
#!/bin/bash
# Define an array containing the base configs we wish to fine tune
configs=("zephyr" "openhermes")
# Define an array of loss types
loss_types=("sigmoid" "kto_pair" "ipo")
# Define an array of beta values
betas=("0.01" "0.1" "0.2" "0.3" "0.4" "0.5" "0.6" "0.7" "0.8" "0.9")
# Outer loop for loss types
for config in "${configs[@]}"; do
for loss_type in "${loss_types[@]}"; do
# Inner loop for beta values
for beta in "${betas[@]}"; do
# Determine the job name and model revision based on loss type
job_name="$config_${loss_type}_beta_${beta}"
model_revision="${loss_type}-${beta}"
# Submit the job
sbatch --job-name=${job_name} recipes/launch.slurm dpo pref_align_scan config_$config deepspeed_zero3 \\
"--beta=${beta} --loss_type=${loss_type} --output_dir=data/$config-7b-align-scan-${loss_type}-beta-${beta} --hub_model_revision=${model_revision}"
done
done
done
```
## Results
We evaluated all models using MT Bench, a multi-turn benchmark that uses GPT-4 to judge models’ performance in eight different categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. Although imperfect, MT Bench is a good way to evaluate conversational LLMs.
### Zephyr-7b-beta-SFT
|  |
|:--:|
| MT-Bench scores for the Zephyr model for different \\( \beta \\).|
For the Zephyr model, we observed that the best performance was achieved with the lowest \\( \beta\\) value, 0.01. This is consistent across all three of the algorithms tested, an interesting follow on experiment for the community would be a fine grained scan in the range of 0.0-0.2. While DPO can achieve the highest MT Bench score, we found that KTO (paired) achieves better results in all but one setting. IPO, while having stronger theoretical guarantees, appears to be worse than the base model in all but one setting.
|  |
|:--:|
| Break down of the best Zephyr models for each algorithm across MT Bench categories. |
We can break down the best results for each algorithm across the categories that MT Bench evaluates to identify the strengths and weaknesses of these models. There is still a large area for improvement on the Reasoning, Coding, and Math axes.
### OpenHermes-7b-2.5
While the observations about each algorithm remain the same with OpenHermes, that is that DPO > KTO > IPO, the sweet spot for \\( \beta \\) varies wildly with each algorithm. With the best choice of \\( \beta \\) for DPO, KTO and IPO being 0.6, 0.3 and 0.01 respectively.
|  |
|:--:|
| MT Bench scores for the OpenHermes model for different \\( \beta \\). |
OpenHermes-7b-2.5 is clearly a stronger base model, with a mere 0.3 improvement in MT Bench score after preference alignment.
|  |
|:--:|
| Break down of the best OpenHermes models for each algorithm across MT Bench categories. |
## Summary & Insights
In this post, we have highlighted the importance of choosing the right set of hyperparameters when performing preference alignment. We have empirically demonstrated that DPO and IPO can achieve comparable results, outperforming KTO in a paired preference setting.
All code and configuration files replicating these results are now available in the [alignment-handbook](https://github.com/huggingface/alignment-handbook). The best-performing models and datasets can be found in [this collection](https://huggingface.co./collections/alignment-handbook/dpo-vs-kto-vs-ipo-65a69c5f03548d61dbe29ef8).
## What’s next?
We will continue our work implementing new preference alignment algorithms in [TRL](https://github.com/huggingface/trl) and evaluating their performance. It seems, at least for the time being, that DPO is the most robust and best performing LLM alignment algorithm. KTO remains an interesting development, as both DPO and IPO require pairs preference data, whereas KTO can be applied to any dataset where responses are rated positively or negatively.
We look forward to the new tools and techniques that will be developed in 2024! | [
[
"llm",
"research",
"benchmarks",
"optimization",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"optimization",
"benchmarks"
] | null | null |
b9729cc5-3b7d-4f56-9e3a-6369baafbcb3 | completed | 2025-01-16T03:09:11.596846 | 2025-01-19T17:19:52.706770 | ba85d9ea-5266-478a-87fe-18ce5387adf9 | 'Welcome fastai to the Hugging Face Hub' | espejelomar | fastai.md | ## Making neural nets uncool again... and sharing them
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/64_fastai_hub.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Few have done as much as the [fast.ai](https://www.fast.ai/) ecosystem to make Deep Learning accessible. Our mission at Hugging Face is to democratize good Machine Learning. Let's make exclusivity in access to Machine Learning, including [pre-trained models](https://huggingface.co./models), a thing of the past and let's push this amazing field even further.
fastai is an [open-source Deep Learning library](https://github.com/fastai/fastai) that leverages PyTorch and Python to provide high-level components to train fast and accurate neural networks with state-of-the-art outputs on text, vision, and tabular data. However, fast.ai, the company, is more than just a library; it has grown into a thriving ecosystem of open source contributors and people learning about neural networks. As some examples, check out their [book](https://github.com/fastai/fastbook) and [courses](https://course.fast.ai/). Join the fast.ai [Discord](https://discord.com/invite/YKrxeNn) and [forums](https://forums.fast.ai/). It is a guarantee that you will learn by being part of their community!
Because of all this, and more (the writer of this post started his journey thanks to the fast.ai course), we are proud to announce that fastai practitioners can now share and upload models to Hugging Face Hub with a single line of Python.
👉 In this post, we will introduce the integration between fastai and the Hub. Additionally, you can open this tutorial as a [Colab notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/64_fastai_hub.ipynb).
We want to thank the fast.ai community, notably [Jeremy Howard](https://twitter.com/jeremyphoward), [Wayde Gilliam](https://twitter.com/waydegilliam), and [Zach Mueller](https://twitter.com/TheZachMueller) for their feedback 🤗. This blog is heavily inspired by the [Hugging Face Hub section](https://docs.fast.ai/huggingface.html) in the fastai docs.
## Why share to the Hub?
The Hub is a central platform where anyone can share and explore models, datasets, and ML demos. It has the most extensive collection of Open Source models, datasets, and demos.
Sharing on the Hub amplifies the impact of your fastai models by making them available for others to download and explore. You can also use transfer learning with fastai models; load someone else's model as the basis for your task.
Anyone can access all the fastai models in the Hub by filtering the [hf.co/models](https://huggingface.co./models?library=fastai&sort=downloads) webpage by the fastai library, as in the image below.

In addition to free model hosting and exposure to the broader community, the Hub has built-in [version control based on git](https://huggingface.co./docs/transformers/model_sharing#repository-features) (git-lfs, for large files) and [model cards](https://huggingface.co./docs/hub/models-cards) for discoverability and reproducibility. For more information on navigating the Hub, see [this introduction](https://github.com/huggingface/education-toolkit/blob/main/01_huggingface-hub-tour.md).
## Joining Hugging Face and installation
To share models in the Hub, you will need to have a user. Create it on the [Hugging Face website](https://huggingface.co./join).
The `huggingface_hub` library is a lightweight Python client with utility functions to interact with the Hugging Face Hub. To push fastai models to the hub, you need to have some libraries pre-installed (fastai>=2.4, fastcore>=1.3.27 and toml). You can install them automatically by specifying ["fastai"] when installing `huggingface_hub`, and your environment is good to go:
```bash
pip install huggingface_hub["fastai"]
```
## Creating a fastai `Learner`
Here we train the [first model in the fastbook](https://github.com/fastai/fastbook/blob/master/01_intro.ipynb) to identify cats 🐱. We fully recommended reading the entire fastbook.
```py
# Training of 6 lines in chapter 1 of the fastbook.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
```
## Sharing a `Learner` to the Hub
A [`Learner` is a fastai object](https://docs.fast.ai/learner.html#Learner) that bundles a model, data loaders, and a loss function. We will use the words `Learner` and Model interchangeably throughout this post.
First, log in to the Hugging Face Hub. You will need to create a `write` token in your [Account Settings](http://hf.co/settings/tokens). Then there are three options to log in:
1. Type `huggingface-cli login` in your terminal and enter your token.
2. If in a python notebook, you can use `notebook_login`.
```py
from huggingface_hub import notebook_login
notebook_login()
```
3. Use the `token` argument of the `push_to_hub_fastai` function.
You can input `push_to_hub_fastai` with the `Learner` you want to upload and the repository id for the Hub in the format of "namespace/repo_name". The namespace can be an individual account or an organization you have write access to (for example, 'fastai/stanza-de'). For more details, refer to the [Hub Client documentation](https://huggingface.co./docs/huggingface_hub/main/en/package_reference/mixins#huggingface_hub.push_to_hub_fastai).
```py
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
push_to_hub_fastai(learner=learn, repo_id=repo_id)
```
The `Learner` is now in the Hub in the repo named [`espejelomar/identify-my-cat`](https://huggingface.co./espejelomar/identify-my-cat). An automatic model card is created with some links and next steps. When uploading a fastai `Learner` (or any other model) to the Hub, it is helpful to edit its model card (image below) so that others better understand your work (refer to the [Hugging Face documentation](https://huggingface.co./docs/hub/models-cards)).

if you want to learn more about `push_to_hub_fastai` go to the [Hub Client Documentation](https://huggingface.co./docs/huggingface_hub/main/en/package_reference/mixins#huggingface_hub.from_pretrained_fastai). There are some cool arguments you might be interested in 👀. Remember, your model is a [Git repository](https://huggingface.co./docs/transformers/model_sharing#repository-features) with all the advantages that this entails: version control, commits, branches...
## Loading a `Learner` from the Hugging Face Hub
Loading a model from the Hub is even simpler. We will load our `Learner`, "espejelomar/identify-my-cat", and test it with a cat image (🦮?). This code is adapted from
the [first chapter of the fastbook](https://github.com/fastai/fastbook/blob/master/01_intro.ipynb).
First, upload an image of a cat (or possibly a dog?). The [Colab notebook with this tutorial](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/64_fastai_hub.ipynb) uses `ipywidgets` to interactively upload a cat image (or not?). Here we will use this cute cat 🐅:

Now let's load the `Learner` we just shared in the Hub and test it.
```py
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
learner = from_pretrained_fastai(repo_id)
```
It works 👇!
```py
_,_,probs = learner.predict(img)
print(f"Probability it's a cat: {100*probs[1].item():.2f}%")
Probability it's a cat: 100.00%
```
The [Hub Client documentation](https://huggingface.co./docs/huggingface_hub/main/en/package_reference/mixins#huggingface_hub.from_pretrained_fastai) includes addtional details on `from_pretrained_fastai`.
## `Blurr` to mix fastai and Hugging Face Transformers (and share them)!
> [Blurr is] a library designed for fastai developers who want to train and deploy Hugging Face transformers - [Blurr Docs](https://github.com/ohmeow/blurr).
We will:
1. Train a `blurr` Learner with the [high-level Blurr API](https://github.com/ohmeow/blurr#using-the-high-level-blurr-api). It will load the `distilbert-base-uncased` model from the Hugging Face Hub and prepare a sequence classification model.
2. Share it to the Hub with the namespace `fastai/blurr_IMDB_distilbert_classification` using `push_to_hub_fastai`.
3. Load it with `from_pretrained_fastai` and try it with `learner_blurr.predict()`.
Collaboration and open-source are fantastic!
First, install `blurr` and train the Learner.
```bash
git clone https://github.com/ohmeow/blurr.git
cd blurr
pip install -e ".[dev]"
```
```python
import torch
import transformers
from fastai.text.all import *
from blurr.text.data.all import *
from blurr.text.modeling.all import *
path = untar_data(URLs.IMDB_SAMPLE)
model_path = Path("models")
imdb_df = pd.read_csv(path / "texts.csv")
learn_blurr = BlearnerForSequenceClassification.from_data(imdb_df, "distilbert-base-uncased", dl_kwargs={"bs": 4})
learn_blurr.fit_one_cycle(1, lr_max=1e-3)
```
Use `push_to_hub_fastai` to share with the Hub.
```python
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
push_to_hub_fastai(learn_blurr, repo_id)
```
Use `from_pretrained_fastai` to load a `blurr` model from the Hub.
```python
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
learner_blurr = from_pretrained_fastai(repo_id)
```
Try it with a couple sentences and review their sentiment (negative or positive) with `learner_blurr.predict()`.
```python
sentences = ["This integration is amazing!",
"I hate this was not available before."]
probs = learner_blurr.predict(sentences)
print(f"Probability that sentence '{sentences[0]}' is negative is: {100*probs[0]['probs'][0]:.2f}%")
print(f"Probability that sentence '{sentences[1]}' is negative is: {100*probs[1]['probs'][0]:.2f}%")
```
Again, it works!
```python
Probability that sentence 'This integration is amazing!' is negative is: 29.46%
Probability that sentence 'I hate this was not available before.' is negative is: 70.04%
```
## What's next?
Take the [fast.ai course](https://course.fast.ai/) (a new version is coming soon), follow [Jeremy Howard](https://twitter.com/jeremyphoward?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor) and [fast.ai](https://twitter.com/FastDotAI) on Twitter for updates, and start sharing your fastai models on the Hub 🤗. Or load one of the [models that are already in the Hub](https://huggingface.co./models?library=fastai&sort=downloads).
📧 Feel free to contact us via the [Hugging Face Discord](https://discord.gg/YRAq8fMnUG) and share if you have an idea for a project. We would love to hear your feedback 💖.
### Would you like to integrate your library to the Hub?
This integration is made possible by the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library. If you want to add your library to the Hub, we have a [guide](https://huggingface.co./docs/hub/models-adding-libraries) for you! Or simply tag someone from the Hugging Face team.
A shout out to the Hugging Face team for all the work on this integration, in particular [@osanseviero](https://twitter.com/osanseviero) 🦙.
Thank you fastlearners and hugging learners 🤗. | [
[
"implementation",
"community",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"implementation",
"community",
"tools",
"integration"
] | null | null |
2888c60d-dd8c-4808-8e8a-3a20547cb05f | completed | 2025-01-16T03:09:11.596854 | 2025-01-19T19:15:29.361371 | 29875761-85e0-483f-b59e-cb67a1b211bb | AI Policy @🤗: Response to the U.S. NTIA's Request for Comment on AI Accountability | yjernite, meg, irenesolaiman | policy-ntia-rfc.md | On June 12th, Hugging Face submitted a response to the US Department of Commerce NTIA request for information on AI Accountability policy. In our response, we stressed the role of documentation and transparency norms in driving AI accountability processes, as well as the necessity of relying on the full range of expertise, perspectives, and skills of the technology’s many stakeholders to address the daunting prospects of a technology whose unprecedented growth poses more questions than any single entity can answer.
Hugging Face’s mission is to [“democratize good machine learning”](https://huggingface.co./about). We understand the term “democratization” in this context to mean making Machine Learning systems not just easier to develop and deploy, but also easier for its many stakeholders to understand, interrogate, and critique. To that end, we have worked on fostering transparency and inclusion through our [education efforts](https://huggingface.co./learn/nlp-course/chapter1/1), [focus on documentation](https://huggingface.co./docs/hub/model-cards), [community guidelines](https://huggingface.co./blog/content-guidelines-update) and approach to [responsible openness](https://huggingface.co./blog/ethics-soc-3), as well as developing no- and low-code tools to allow people with all levels of technical background to analyze [ML datasets](https://huggingface.co./spaces/huggingface/data-measurements-tool) and [models](https://huggingface.co./spaces/society-ethics/StableBias). We believe this helps everyone interested to better understand [the limitations of ML systems](https://huggingface.co./blog/ethics-soc-2) and how they can safely be leveraged to best serve users and those affected by these systems. These approaches have already proven their utility in promoting accountability, especially in the larger multidisciplinary research endeavors we’ve helped organize, including [BigScience](https://huggingface.co./bigscience) (see our blog series [on the social stakes of the project](https://montrealethics.ai/category/columns/social-context-in-llm-research/)), and the more recent [BigCode project](https://huggingface.co./bigcode) (whose governance is [described in more details here](https://huggingface.co./datasets/bigcode/governance-card)).
Concretely, we make the following recommendations for accountability mechanisms:
* Accountability mechanisms should **focus on all stages of the ML development process**. The societal impact of a full AI-enabled system depends on choices made at every stage of the development in ways that are impossible to fully predict, and assessments that only focus on the deployment stage risk incentivizing surface-level compliance that fails to address deeper issues until they have caused significant harm.
* Accountability mechanisms should **combine internal requirements with external access** and transparency. Internal requirements such as good documentation practices shape more responsible development and provide clarity on the developers’ responsibility in enabling safer and more reliable technology. External access to the internal processes and development choices is still necessary to verify claims and documentation, and to empower the many stakeholders of the technology who reside outside of its development chain to meaningfully shape its evolution and promote their interest.
* Accountability mechanisms should **invite participation from the broadest possible set of contributors,** including developers working directly on the technology, multidisciplinary research communities, advocacy organizations, policy makers, and journalists. Understanding the transformative impact of the rapid growth in adoption of ML technology is a task that is beyond the capacity of any single entity, and will require leveraging the full range of skills and expertise of our broad research community and of its direct users and affected populations.
We believe that prioritizing transparency in both the ML artifacts themselves and the outcomes of their assessment will be integral to meeting these goals. You can find our more detailed response addressing these points <a href="/blog/assets/151_policy_ntia_rfc/HF_NTIA_RFC.pdf">here.</a> | [
[
"research",
"community",
"security"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"security",
"mlops",
"research"
] | null | null |
ded048b5-1f11-46f7-801a-0c40d48b4b1b | completed | 2025-01-16T03:09:11.596862 | 2025-01-16T03:15:40.370264 | 4fd3b3f8-e6af-4694-840d-0fcb2ab1e1ef | Getting Started with Hugging Face Transformers for IPUs with Optimum | internetoftim, juliensimon | graphcore-getting-started.md | Transformer models have proven to be extremely efficient on a wide range of machine learning tasks, such as natural language processing, audio processing, and computer vision. However, the prediction speed of these large models can make them impractical for latency-sensitive use cases like conversational applications or search. Furthermore, optimizing their performance in the real world requires considerable time, effort and skills that are beyond the reach of many companies and organizations.
Luckily, Hugging Face has introduced [Optimum](https://huggingface.co./hardware), an open source library which makes it much easier to reduce the prediction latency of Transformer models on a variety of hardware platforms. In this blog post, you will learn how to accelerate Transformer models for the Graphcore [Intelligence Processing Unit](https://www.graphcore.ai/products/ipu) (IPU), a highly flexible, easy-to-use parallel processor designed from the ground up for AI workloads.
### Optimum Meets Graphcore IPU
Through this partnership between Graphcore and Hugging Face, we are now introducing BERT as the first IPU-optimized model. We will be introducing many more of these IPU-optimized models in the coming months, spanning applications such as vision, speech, translation and text generation.
Graphcore engineers have implemented and optimized BERT for our IPU systems using Hugging Face transformers to help developers easily train, fine-tune and accelerate their state-of-the-art models.
### Getting started with IPUs and Optimum
Let’s use BERT as an example to help you get started with using Optimum and IPUs.
In this guide, we will use an [IPU-POD16](https://www.graphcore.ai/products/mk2/ipu-pod16) system in Graphcloud, Graphcore’s cloud-based machine learning platform and follow PyTorch setup instructions found in [Getting Started with Graphcloud](https://docs.graphcore.ai/projects/graphcloud-getting-started/en/latest/index.html).
Graphcore’s [Poplar SDK](https://www.graphcore.ai/developer) is already installed on the Graphcloud server. If you have a different setup, you can find the instructions that apply to your system in the [PyTorch for the IPU: User Guide](https://docs.graphcore.ai/projects/poptorch-user-guide/en/latest/intro.html).
#### Set up the Poplar SDK Environment
You will need to run the following commands to set several environment variables that enable Graphcore tools and Poplar libraries. On the latest system running Poplar SDK version 2.3 on Ubuntu 18.04, you can find <sdk-path> in the folder ```/opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/```.
You would need to run both enable scripts for Poplar and PopART (Poplar Advanced Runtime) to use PyTorch:
```
$ cd /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/
$ source poplar-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
$ source popart-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
```
#### Set up PopTorch for the IPU
PopTorch is part of the Poplar SDK. It provides functions that allow PyTorch models to run on the IPU with minimal code changes. You can create and activate a PopTorch environment following the guide [Setting up PyTorch for the IPU](https://docs.graphcore.ai/projects/graphcloud-pytorch-quick-start/en/latest/pytorch_setup.html):
```
$ virtualenv -p python3 ~/workspace/poptorch_env
$ source ~/workspace/poptorch_env/bin/activate
$ pip3 install -U pip
$ pip3 install /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/poptorch-<sdk-version>.whl
```
#### Install Optimum Graphcore
Now that your environment has all the Graphcore Poplar and PopTorch libraries available, you need to install the latest 🤗 Optimum Graphcore package in this environment. This will be the interface between the 🤗 Transformers library and Graphcore IPUs.
Please make sure that the PopTorch virtual environment you created in the previous step is activated. Your terminal should have a prefix showing the name of the poptorch environment like below:
```
(poptorch_env) user@host:~/workspace/poptorch_env$ pip3 install optimum[graphcore] optuna
```
#### Clone Optimum Graphcore Repository
The Optimum Graphcore repository contains the sample code for using Optimum models in IPU. You should clone the repository and change the directory to the ```example/question-answering``` folder which contains the IPU implementation of BERT.
```
$ git clone https://github.com/huggingface/optimum-graphcore.git
$ cd optimum-graphcore/examples/question-answering
```
Now, we will use ```run_qa.py``` to fine-tune the IPU implementation of [BERT](https://huggingface.co./bert-large-uncased) on the SQUAD1.1 dataset.
#### Run a sample to fine-tune BERT on SQuAD1.1
The ```run_qa.py``` script only works with models that have a fast tokenizer (backed by the 🤗 Tokenizers library), as it uses special features of those tokenizers. This is the case for our [BERT](https://huggingface.co./bert-large-uncased) model, and you should pass its name as the input argument to ```--model_name_or_path```. In order to use the IPU, Optimum will look for the ```ipu_config.json``` file from the path passed to the argument ```--ipu_config_name```.
```
$ python3 run_qa.py \
--ipu_config_name=./ \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--output_dir output \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 6e-5 \
--num_train_epochs 3 \
--max_seq_length 384 \
--doc_stride 128 \
--seed 1984 \
--lr_scheduler_type linear \
--loss_scaling 64 \
--weight_decay 0.01 \
--warmup_ratio 0.1 \
--output_dir /tmp/debug_squad/
```
### A closer look at Optimum-Graphcore
#### Getting the data
A very simple way to get datasets is to use the Hugging Face [Datasets library](https://github.com/huggingface/datasets), which makes it easy for developers to download and share datasets on the Hugging Face hub. It also has pre-built data versioning based on git and git-lfs, so you can iterate on updated versions of the data by just pointing to the same repo.
Here, the dataset comes with the training and validation files, and dataset configs to help facilitate which inputs to use in each model execution phase. The argument ```--dataset_name==squad``` points to [SQuAD v1.1](https://huggingface.co./datasets/squad) on the Hugging Face Hub. You could also provide your own CSV/JSON/TXT training and evaluation files as long as they follow the same format as the SQuAD dataset or another question-answering dataset in Datasets library.
#### Loading the pretrained model and tokenizer
To turn words into tokens, this script will require a fast tokenizer. It will show an error if you didn't pass one. For reference, here's the [list](https://huggingface.co./transformers/index.html#supported-frameworks) of supported tokenizers.
```
# Tokenizer check: this script requires a fast tokenizer.
if not isinstance(tokenizer, PreTrainedTokenizerFast):
raise ValueError("This example script only works for models that have a fast tokenizer. Checkout the big table of models
"at https://huggingface.co./transformers/index.html#supported-frameworks to find the model types that meet this "
"requirement"
)
```
The argument ```--model_name_or_path==bert-base-uncased`` loads the [bert-base-uncased](https://huggingface.co./bert-base-uncased) model implementation available in the Hugging Face Hub.
From the Hugging Face Hub description:
"*BERT base model (uncased): Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is uncased: it does not make a difference between english and English.*"
#### Training and Validation
You can now use the ```IPUTrainer``` class available in Optimum to leverage the entire Graphcore software and hardware stack, and train your models in IPUs with minimal code changes. Thanks to Optimum, you can plug-and-play state of the art hardware to train your state of the art models.
<kbd>
<img src="assets/38_getting_started_graphcore/graphcore_1.png">
</kbd>
In order to train and validate the BERT model, you can pass the arguments ```--do_train``` and ```--do_eval``` to the ```run_qa.py``` script. After executing the script with the hyper-parameters above, you should see the following training and validation results:
```
"epoch": 3.0,
"train_loss": 0.9465060763888888,
"train_runtime": 368.4015,
"train_samples": 88524,
"train_samples_per_second": 720.877,
"train_steps_per_second": 2.809
The validation step yields the following results:
***** eval metrics *****
epoch = 3.0
eval_exact_match = 80.6623
eval_f1 = 88.2757
eval_samples = 10784
```
You can see the rest of the IPU BERT implementation in the [Optimum-Graphcore: SQuAD Examples](https://github.com/huggingface/optimum-graphcore/tree/main/examples/question-answering).
### Resources for Optimum Transformers on IPU Systems
* [Optimum-Graphcore: SQuAD Examples](https://github.com/huggingface/optimum-graphcore/tree/main/examples/question-answering)
* [Graphcore Hugging Face Models & Datasets](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* GitHub Tutorial: [BERT Fine-tuning on IPU using Hugging Face transformers](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* [Graphcore Developer Portal](https://github.com/graphcore/tutorials/tree/master/tutorials/pytorch/tut_finetuning_bert#tutorial-on-bert-fine-tuning-on-ipu)
* [Graphcore GitHub](https://github.com/graphcore)
* [Graphcore SDK Containers on Docker Hub](https://hub.docker.com/u/graphcore) | [
[
"transformers",
"implementation",
"optimization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"optimization",
"implementation",
"efficient_computing"
] | null | null |
fb0bd018-b214-4f25-8031-43fb18d72154 | completed | 2025-01-16T03:09:11.596870 | 2025-01-19T18:50:16.982203 | 62350527-998a-44da-af73-66ed415db727 | A Dive into Vision-Language Models | adirik, sayakpaul | vision_language_pretraining.md | Human learning is inherently multi-modal as jointly leveraging multiple senses helps us understand and analyze new information better. Unsurprisingly, recent advances in multi-modal learning take inspiration from the effectiveness of this process to create models that can process and link information using various modalities such as image, video, text, audio, body gestures, facial expressions, and physiological signals.
Since 2021, we’ve seen an increased interest in models that combine vision and language modalities (also called joint vision-language models), such as [OpenAI’s CLIP](https://openai.com/blog/clip/). Joint vision-language models have shown particularly impressive capabilities in very challenging tasks such as image captioning, text-guided image generation and manipulation, and visual question-answering. This field continues to evolve, and so does its effectiveness in improving zero-shot generalization leading to various practical use cases.
In this blog post, we'll introduce joint vision-language models focusing on how they're trained. We'll also show how you can leverage 🤗 Transformers to experiment with the latest advances in this domain.
## Table of contents
1. [Introduction](#introduction)
2. [Learning Strategies](#learning-strategies)
1. [Contrastive Learning](#1-contrastive-learning)
2. [PrefixLM](#2-prefixlm)
3. [Multi-modal Fusing with Cross Attention](#3-multi-modal-fusing-with-cross-attention)
4. [MLM / ITM](#4-masked-language-modeling--image-text-matching)
5. [No Training](#5-no-training)
3. [Datasets](#datasets)
4. [Supporting Vision-Language Models in 🤗 Transformers](#supporting-vision-language-models-in-🤗-transformers)
5. [Emerging Areas of Research](#emerging-areas-of-research)
6. [Conclusion](#conclusion)
## Introduction
What does it mean to call a model a “vision-language” model? A model that combines both the vision and language modalities? But what exactly does that mean?
One characteristic that helps define these models is their ability to process both images (vision) and natural language text (language). This process depends on the inputs, outputs, and the task these models are asked to perform.
Take, for example, the task of zero-shot image classification. We’ll pass an image and a few prompts like so to obtain the most probable prompt for the input image.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/example1.png" alt="drawing"><br>
<em>The cat and dog image has been taken from <a href=https://www.istockphoto.com/photos/dog-cat-love>here</a>.</em>
</p>
To predict something like that, the model needs to understand both the input image and the text prompts. The model would have separate or fused encoders for vision and language to achieve this understanding.
But these inputs and outputs can take several forms. Below we give some examples:
- Image retrieval from natural language text.
- Phrase grounding, i.e., performing object detection from an input image and natural language phrase (example: A **young person** swings a **bat**).
- Visual question answering, i.e., finding answers from an input image and a question in natural language.
- Generate a caption for a given image. This can also take the form of conditional text generation, where you'd start with a natural language prompt and an image.
- Detection of hate speech from social media content involving both images and text modalities.
## Learning Strategies
A vision-language model typically consists of 3 key elements: an image encoder, a text encoder, and a strategy to fuse information from the two encoders. These key elements are tightly coupled together as the loss functions are designed around both the model architecture and the learning strategy. While vision-language model research is hardly a new research area, the design of such models has changed tremendously over the years. Whereas earlier research adopted hand-crafted image descriptors and pre-trained word vectors or the frequency-based TF-IDF features, the latest research predominantly adopts image and text encoders with [transformer](https://arxiv.org/abs/1706.03762) architectures to separately or jointly learn image and text features. These models are pre-trained with strategic pre-training objectives that enable various downstream tasks.
In this section, we'll discuss some of the typical pre-training objectives and strategies for vision-language models that have been shown to perform well regarding their transfer performance. We'll also touch upon additional interesting things that are either specific to these objectives or can be used as general components for pre-training.
We’ll cover the following themes in the pre-training objectives:
- **Contrastive Learning:** Aligning images and texts to a joint feature space in a contrastive manner
- **PrefixLM:** Jointly learning image and text embeddings by using images as a prefix to a language model
- **Multi-modal Fusing with Cross Attention:** Fusing visual information into layers of a language model with a cross-attention mechanism
- **MLM / ITM:** Aligning parts of images with text with masked-language modeling and image-text matching objectives
- **No Training:** Using stand-alone vision and language models via iterative optimization
Note that this section is a non-exhaustive list, and there are various other approaches, as well as hybrid strategies such as [Unified-IO](https://arxiv.org/abs/2206.08916). For a more comprehensive review of multi-modal models, refer to [this work.](https://arxiv.org/abs/2210.09263)
### 1) Contrastive Learning
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/contrastive_learning.png" alt="Contrastive Learning"><br>
<em>Contrastive pre-training and zero-shot image classification as shown <a href=https://openai.com/blog/clip>here</a>.</em>
</p>
Contrastive learning is a commonly used pre-training objective for vision models and has proven to be a highly effective pre-training objective for vision-language models as well. Recent works such as [CLIP](https://arxiv.org/abs/2103.00020), [CLOOB](https://arxiv.org/abs/2110.11316), [ALIGN](https://arxiv.org/abs/2102.05918), and [DeCLIP](https://arxiv.org/abs/2110.05208) bridge the vision and language modalities by learning a text encoder and an image encoder jointly with a contrastive loss, using large datasets consisting of {image, caption} pairs. Contrastive learning aims to map input images and texts to the same feature space such that the distance between the embeddings of image-text pairs is minimized if they match or maximized if they don’t.
For CLIP, the distance is simply the cosine distance between the text and image embeddings, whereas models such as ALIGN and DeCLIP design their own distance metrics to account for noisy datasets.
Another work, [LiT](https://arxiv.org/abs/2111.07991), introduces a simple method for fine-tuning the text encoder using the CLIP pre-training objective while keeping the image encoder frozen. The authors interpret this idea as _a way to teach the text encoder to better read image embeddings from the image encoder_. This approach has been shown to be effective and is more sample efficient than CLIP. Other works, such as [FLAVA](https://arxiv.org/abs/2112.04482), use a combination of contrastive learning and other pretraining strategies to align vision and language embeddings.
### 2) PrefixLM
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/prefixlm.png" alt="PrefixLM"><br>
<em>A diagram of the PrefixLM pre-training strategy (<a ahref=https://ai.googleblog.com/2021/10/simvlm-simple-visual-language-model-pre.html>image source<a>)</em>
</p>
Another approach to training vision-language models is using a PrefixLM objective. Models such as [SimVLM](https://arxiv.org/abs/2108.10904) and [VirTex](https://arxiv.org/abs/2006.06666v3) use this pre-training objective and feature a unified multi-modal architecture consisting of a transformer encoder and transformer decoder, similar to that of an autoregressive language model.
Let’s break this down and see how this works. Language models with a prefix objective predict the next token given an input text as the prefix. For example, given the sequence “A man is standing at the corner”, we can use “A man is standing at the” as the prefix and train the model with the objective of predicting the next token - “corner” or another plausible continuation of the prefix.
Visual transformers (ViT) apply the same concept of the prefix to images by dividing each image into a number of patches and sequentially feeding these patches to the model as inputs. Leveraging this idea, SimVLM features an architecture where the encoder receives a concatenated image patch sequence and prefix text sequence as the prefix input, and the decoder then predicts the continuation of the textual sequence. The diagram above depicts this idea. The SimVLM model is first pre-trained on a text dataset without image patches present in the prefix and then on an aligned image-text dataset. These models are used for image-conditioned text generation/captioning and VQA tasks.
Models that leverage a unified multi-modal architecture to fuse visual information into a language model (LM) for image-guided tasks show impressive capabilities. However, models that solely use the PrefixLM strategy can be limited in terms of application areas as they are mainly designed for image captioning or visual question-answering downstream tasks. For example, given an image of a group of people, we can query the image to write a description of the image (e.g., “A group of people is standing together in front of a building and smiling”) or query it with questions that require visual reasoning: “How many people are wearing red t-shirts?”. On the other hand, models that learn multi-modal representations or adopt hybrid approaches can be adapted for various other downstream tasks, such as object detection and image segmentation.
#### Frozen PrefixLM
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/frozen_prefixlm.png" alt="Frozen PrefixLM"><br>
<em>Frozen PrefixLM pre-training strategy (<a href=https://lilianweng.github.io/posts/2022-06-09-vlm>image source</a>)</em>
</p>
While fusing visual information into a language model is highly effective, being able to use a pre-trained language model (LM) without the need for fine-tuning would be much more efficient. Hence, another pre-training objective in vision-language models is learning image embeddings that are aligned with a frozen language model.
Models such as [Frozen](https://arxiv.org/abs/2106.13884) and [ClipCap](https://arxiv.org/abs/2111.09734) use this Frozen PrefixLM pre-training objective. They only update the parameters of the image encoder during training to generate image embeddings that can be used as a prefix to the pre-trained, frozen language model in a similar fashion to the PrefixLM objective discussed above. Both Frozen and ClipCap are trained on aligned image-text (caption) datasets with the objective of generating the next token in the caption, given the image embeddings and the prefix text.
Finally, models such as [MAPL](https://arxiv.org/abs/2210.07179) and [Flamingo](https://arxiv.org/abs/2204.14198) keep both the pre-trained vision encoder and language model frozen. Flamingo sets a new state-of-the-art in few-shot learning on a wide range of open-ended vision and language tasks by adding Perceiver Resampler modules on top of the pre-trained frozen vision model and inserting new cross-attention layers between existing pre-trained and frozen LM layers to condition the LM on visual data.
A nifty advantage of the Frozen PrefixLM pre-training objective is it enables training with limited aligned image-text data, which is particularly useful for domains where aligned multi-modal datasets are not available.
### 3) Multi-modal Fusing with Cross Attention
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/cross_attention_fusing.png" alt="Cross Attention Fusing" width=500><br>
<em> Fusing visual information with a cross-attention mechanism as shown (<a href=https://www.semanticscholar.org/paper/VisualGPT%3A-Data-efficient-Adaptation-of-Pretrained-Chen-Guo/616e0ed02ca024a8c1d4b86167f7486ea92a13d9>image source</a>)</em>
</p>
Another approach to leveraging pre-trained language models for multi-modal tasks is to directly fuse visual information into the layers of a language model decoder using a cross-attention mechanism instead of using images as additional prefixes to the language model. Models such as [VisualGPT](https://arxiv.org/abs/2102.10407), [VC-GPT](https://arxiv.org/abs/2201.12723), and [Flamingo](https://arxiv.org/abs/2204.14198) use this pre-training strategy and are trained on image captioning and visual question-answering tasks. The main goal of such models is to balance the mixture of text generation capacity and visual information efficiently, which is highly important in the absence of large multi-modal datasets.
Models such as VisualGPT use a visual encoder to embed images and feed the visual embeddings to the cross-attention layers of a pre-trained language decoder module to generate plausible captions. A more recent work, [FIBER](http://arxiv.org/abs/2206.07643), inserts cross-attention layers with a gating mechanism into both vision and language backbones, for more efficient multi-modal fusing and enables various other downstream tasks, such as image-text retrieval and open vocabulary object detection.
### 4) Masked-Language Modeling / Image-Text Matching
Another line of vision-language models uses a combination of Masked-Language Modeling (MLM) and Image-Text Matching (ITM) objectives to align specific parts of images with text and enable various downstream tasks such as visual question answering, visual commonsense reasoning, text-based image retrieval, and text-guided object detection. Models that follow this pre-training setup include [VisualBERT](https://arxiv.org/abs/1908.03557), [FLAVA](https://arxiv.org/abs/2112.04482), [ViLBERT](https://arxiv.org/abs/1908.02265), [LXMERT](https://arxiv.org/abs/1908.07490) and [BridgeTower](https://arxiv.org/abs/2206.08657).
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/mlm_itm.png" alt="MLM / ITM"><br>
<em> Aligning parts of images with text (<a href=https://arxiv.org/abs/1908.02265>image source</a>)</em>
</p>
Let’s break down what MLM and ITM objectives mean. Given a partially masked caption, the MLM objective is to predict the masked words based on the corresponding image. Note that the MLM objective requires either using a richly annotated multi-modal dataset with bounding boxes or using an object detection model to generate object region proposals for parts of the input text.
For the ITM objective, given an image and caption pair, the task is to predict whether the caption matches the image or not. The negative samples are usually randomly sampled from the dataset itself. The MLM and ITM objectives are often combined during the pre-training of multi-modal models. For instance, VisualBERT proposes a BERT-like architecture that uses a pre-trained object detection model, [Faster-RCNN](https://arxiv.org/abs/1506.01497), to detect objects. This model uses a combination of the MLM and ITM objectives during pre-training to implicitly align elements of an input text and regions in an associated input image with self-attention.
Another work, FLAVA, consists of an image encoder, a text encoder, and a multi-modal encoder to fuse and align the image and text representations for multi-modal reasoning, all of which are based on transformers. In order to achieve this, FLAVA uses a variety of pre-training objectives: MLM, ITM, as well as Masked-Image Modeling (MIM), and contrastive learning.
### 5) No Training
Finally, various optimization strategies aim to bridge image and text representations using the pre-trained image and text models or adapt pre-trained multi-modal models to new downstream tasks without additional training.
For example, [MaGiC](https://arxiv.org/abs/2205.02655) proposes iterative optimization through a pre-trained autoregressive language model to generate a caption for the input image. To do this, MaGiC computes a CLIP-based “Magic score” using CLIP embeddings of the generated tokens and the input image.
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/asif.png" alt="ASIF" width=500><br>
<em>Crafting a similarity search space using pre-trained, frozen unimodal image and text encoders (<a href=https://luca.moschella.dev/publication/norelli-asif-2022>image source</a>)</em>
</p>
[ASIF](https://arxiv.org/abs/2210.01738) proposes a simple method to turn pre-trained uni-modal image and text models into a multi-modal model for image captioning using a relatively small multi-modal dataset without additional training. The key intuition behind ASIF is that captions of similar images are also similar to each other. Hence we can perform a similarity-based search by crafting a relative representation space using a small dataset of ground-truth multi-modal pairs.
## Datasets
Vision-language models are typically trained on large image and text datasets with different structures based on the pre-training objective. After they are pre-trained, they are further fine-tuned on various downstream tasks using task-specific datasets. This section provides an overview of some popular pre-training and downstream datasets used for training and evaluating vision-language models.
### Pre-training datasets
Vision-language models are typically pre-trained on large multi-modal datasets harvested from the web in the form of matching image/video and text pairs. The text data in these datasets can be human-generated captions, automatically generated captions, image metadata, or simple object labels. Some examples of such large datasets are [PMD](https://huggingface.co./datasets/facebook/pmd) and [LAION-5B](https://laion.ai/blog/laion-5b/). The PMD dataset combines multiple smaller datasets such as the [Flickr30K](https://www.kaggle.com/datasets/hsankesara/flickr-image-dataset), [COCO](https://cocodataset.org/), and [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/) datasets. The COCO detection and image captioning (>330K images) datasets consist of image instances paired with the text labels of the objects each image contains, and natural sentence descriptions, respectively. The Conceptual Captions (> 3.3M images) and Flickr30K (> 31K images) datasets are scraped from the web along with their captions - free-form sentences describing the image.
Even image-text datasets consisting solely of human-generated captions, such as Flickr30K, are inherently noisy as users only sometimes write descriptive or reflective captions for their images. To overcome this issue, datasets such as the LAION-5B dataset leverage CLIP or other pre-trained multi-modal models to filter noisy data and create high-quality multi-modal datasets. Furthermore, some vision-language models, such as ALIGN, propose further preprocessing steps and create their own high-quality datasets. Other vision-language datasets, such as the [LSVTD](https://davar-lab.github.io/dataset/lsvtd.html) and [WebVid](https://github.com/m-bain/webvid) datasets, consist of video and text modalities, although at a smaller scale.
### Downstream datasets
Pre-trained vision-language models are often trained on various downstream tasks such as visual question-answering, text-guided object detection, text-guided image inpainting, multi-modal classification, and various stand-alone NLP and computer vision tasks.
Models fine-tuned on the question-answering downstream task, such as [ViLT](https://arxiv.org/abs/2102.03334) and [GLIP](https://arxiv.org/abs/2112.03857), most commonly use the [VQA](https://visualqa.org/) (visual question-answering), [VQA v2](https://visualqa.org/), [NLVR2](https://lil.nlp.cornell.edu/nlvr/), [OKVQA](https://okvqa.allenai.org/), [TextVQA](https://huggingface.co./datasets/textvqa), [TextCaps](https://textvqa.org/textcaps/) and [VizWiz](https://vizwiz.org/) datasets. These datasets typically contain images paired with multiple open-ended questions and answers. Furthermore, datasets such as VizWiz and TextCaps can also be used for image segmentation and object localization downstream tasks. Some other interesting multi-modal downstream datasets are [Hateful Memes](https://huggingface.co./datasets/limjiayi/hateful_memes_expanded) for multi-modal classification, [SNLI-VE](https://github.com/necla-ml/SNLI-VE) for visual entailment prediction, and [Winoground](https://huggingface.co./datasets/facebook/winoground) for visio-linguistic compositional reasoning.
Note that vision-language models are used for various classical NLP and computer vision tasks such as text or image classification and typically use uni-modal datasets ([SST2](https://huggingface.co./datasets/sst2), [ImageNet-1k](https://huggingface.co./datasets/imagenet-1k), for example) for such downstream tasks. In addition, datasets such as [COCO](https://cocodataset.org/) and [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/) are commonly used both in the pre-training of models and also for the caption generation downstream task.
## Supporting Vision-Language Models in 🤗 Transformers
Using Hugging Face Transformers, you can easily download, run and fine-tune various pre-trained vision-language models or mix and match pre-trained vision and language models to create your own recipe. Some of the vision-language models supported by 🤗 Transformers are:
* [CLIP](https://huggingface.co./docs/transformers/model_doc/clip)
* [FLAVA](https://huggingface.co./docs/transformers/main/en/model_doc/flava)
* [GIT](https://huggingface.co./docs/transformers/main/en/model_doc/git)
* [BridgeTower](https://huggingface.co./docs/transformers/main/en/model_doc/bridgetower)
* [GroupViT](https://huggingface.co./docs/transformers/v4.25.1/en/model_doc/groupvit)
* [BLIP](https://huggingface.co./docs/transformers/main/en/model_doc/blip)
* [OWL-ViT](https://huggingface.co./docs/transformers/main/en/model_doc/owlvit)
* [CLIPSeg](https://huggingface.co./docs/transformers/main/en/model_doc/clipseg)
* [X-CLIP](https://huggingface.co./docs/transformers/main/en/model_doc/xclip)
* [VisualBERT](https://huggingface.co./docs/transformers/main/en/model_doc/visual_bert)
* [ViLT](https://huggingface.co./docs/transformers/main/en/model_doc/vilt)
* [LiT](https://huggingface.co./docs/transformers/main/en/model_doc/vision-text-dual-encoder) (an instance of the `VisionTextDualEncoder`)
* [TrOCR](https://huggingface.co./docs/transformers/main/en/model_doc/trocr) (an instance of the `VisionEncoderDecoderModel`)
* [`VisionTextDualEncoder`](https://huggingface.co./docs/transformers/main/en/model_doc/vision-text-dual-encoder)
* [`VisionEncoderDecoderModel`](https://huggingface.co./docs/transformers/main/en/model_doc/vision-encoder-decoder)
While models such as CLIP, FLAVA, BridgeTower, BLIP, LiT and `VisionEncoderDecoder` models provide joint image-text embeddings that can be used for downstream tasks such as zero-shot image classification, other models are trained on interesting downstream tasks. In addition, FLAVA is trained with both unimodal and multi-modal pre-training objectives and can be used for both unimodal vision or language tasks and multi-modal tasks.
For example, OWL-ViT [enables](https://huggingface.co./spaces/adirik/OWL-ViT) zero-shot / text-guided and one-shot / image-guided object detection, CLIPSeg and GroupViT [enable](https://huggingface.co./spaces/nielsr/CLIPSeg) text and image-guided image segmentation, and VisualBERT, GIT and ViLT [enable](https://huggingface.co./spaces/nielsr/vilt-vqa) visual question answering as well as various other tasks. X-CLIP is a multi-modal model trained with video and text modalities and [enables](https://huggingface.co./spaces/fcakyon/zero-shot-video-classification) zero-shot video classification similar to CLIP’s zero-shot image classification capabilities.
Unlike other models, the `VisionEncoderDecoderModel` is a cookie-cutter model that can be used to initialize an image-to-text model with any pre-trained Transformer-based vision model as the encoder (e.g. ViT, BEiT, DeiT, Swin) and any pre-trained language model as the decoder (e.g. RoBERTa, GPT2, BERT, DistilBERT). In fact, TrOCR is an instance of this cookie-cutter class.
Let’s go ahead and experiment with some of these models. We will use [ViLT](https://huggingface.co./docs/transformers/model_doc/vilt) for visual question answering and [CLIPSeg](https://huggingface.co./docs/transformers/model_doc/clipseg) for zero-shot image segmentation. First, let’s install 🤗Transformers: `pip install transformers`.
### ViLT for VQA
Let’s start with ViLT and download a model pre-trained on the VQA dataset. We can do this by simply initializing the corresponding model class and calling the `from_pretrained()` method to download our desired checkpoint.
```py
from transformers import ViltProcessor, ViltForQuestionAnswering
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
```
Next, we will download a random image of two cats and preprocess both the image and our query question to transform them to the input format expected by the model. To do this, we can conveniently use the corresponding preprocessor class (`ViltProcessor`) and initialize it with the preprocessing configuration of the corresponding checkpoint.
```py
import requests
from PIL import Image
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# download an input image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "How many cats are there?"
# prepare inputs
inputs = processor(image, text, return_tensors="pt")
```
Finally, we can perform inference using the preprocessed image and question as input and print the predicted answer. However, an important point to keep in mind is to make sure your text input resembles the question templates used in the training setup. You can refer to [the paper and the dataset](https://arxiv.org/abs/2102.03334) to learn how the questions are formed.
```py
import torch
# forward pass
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
```
Straight-forward, right? Let’s do another demonstration with CLIPSeg and see how we can perform zero-shot image segmentation with a few lines of code.
### CLIPSeg for zero-shot image segmentation
We will start by initializing `CLIPSegForImageSegmentation` and its corresponding preprocessing class and load our pre-trained model.
```py
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
```
Next, we will use the same input image and query the model with the text descriptions of all objects we want to segment. Similar to other preprocessors, `CLIPSegProcessor` transforms the inputs to the format expected by the model. As we want to segment multiple objects, we input the same image for each text description separately.
```py
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a cat", "a remote", "a blanket"]
inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")
```
Similar to ViLT, it’s important to refer to the [original work](https://arxiv.org/abs/2112.10003) to see what kind of text prompts are used to train the model in order to get the best performance during inference. While CLIPSeg is trained on simple object descriptions (e.g., “a car”), its CLIP backbone is pre-trained on engineered text templates (e.g., “an image of a car”, “a photo of a car”) and kept frozen during training. Once the inputs are preprocessed, we can perform inference to get a binary segmentation map of shape (height, width) for each text query.
```py
import torch
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
print(logits.shape)
>>> torch.Size([3, 352, 352])
```
Let’s visualize the results to see how well CLIPSeg performed (code is adapted from [this post](https://huggingface.co./blog/clipseg-zero-shot)).
```py
import matplotlib.pyplot as plt
logits = logits.unsqueeze(1)
_, ax = plt.subplots(1, len(texts) + 1, figsize=(3*(len(texts) + 1), 12))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
[ax[i+1].imshow(torch.sigmoid(logits[i][0])) for i in range(len(texts))];
[ax[i+1].text(0, -15, prompt) for i, prompt in enumerate(texts)]
```
<p align="center">
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/128_vision_language_pretraining/clipseg_result.png" alt="CLIPSeg results">
</p>
Amazing, isn’t it?
Vision-language models enable a plethora of useful and interesting use cases that go beyond just VQA and zero-shot segmentation. We encourage you to try out the different use cases supported by the models mentioned in this section. For sample code, refer to the respective documentation of the models.
## Emerging Areas of Research
With the massive advances in vision-language models, we see the emergence of new downstream tasks and application areas, such as medicine and robotics. For example, vision-language models are increasingly getting adopted for medical use cases, resulting in works such as [Clinical-BERT](https://ojs.aaai.org/index.php/AAAI/article/view/20204) for medical diagnosis and report generation from radiographs and [MedFuseNet](https://www.nature.com/articles/s41598-021-98390-1) for visual question answering in the medical domain.
We also see a massive surge of works that leverage joint vision-language representations for image manipulation (e.g., [StyleCLIP](https://arxiv.org/abs/2103.17249), [StyleMC](https://arxiv.org/abs/2112.08493), [DiffusionCLIP](https://arxiv.org/abs/2110.02711)), text-based video retrieval (e.g., [X-CLIP](https://arxiv.org/abs/2207.07285)) and manipulation (e.g., [Text2Live](https://arxiv.org/abs/2204.02491)) and 3D shape and texture manipulation (e.g., [AvatarCLIP](https://arxiv.org/abs/2205.08535), [CLIP-NeRF](https://arxiv.org/abs/2112.05139), [Latent3D](https://arxiv.org/abs/2202.06079), [CLIPFace](https://arxiv.org/abs/2212.01406), [Text2Mesh](https://arxiv.org/abs/2112.03221)). In a similar line of work, [MVT](https://arxiv.org/abs/2204.02174) proposes a joint 3D scene-text representation model, which can be used for various downstream tasks such as 3D scene completion.
While robotics research hasn’t leveraged vision-language models on a wide scale yet, we see works such as [CLIPort](https://arxiv.org/abs/2109.12098) leveraging joint vision-language representations for end-to-end imitation learning and reporting large improvements over previous SOTA. We also see that large language models are increasingly getting adopted in robotics tasks such as common sense reasoning, navigation, and task planning. For example, [ProgPrompt](https://arxiv.org/abs/2209.11302) proposes a framework to generate situated robot task plans using large language models (LLMs). Similarly, [SayCan](https://say-can.github.io/assets/palm_saycan.pdf) uses LLMs to select the most plausible actions given a visual description of the environment and available objects. While these advances are impressive, robotics research is still confined to limited sets of environments and objects due to the limitation of object detection datasets. With the emergence of open-vocabulary object detection models such as [OWL-ViT](https://arxiv.org/abs/2205.06230) and [GLIP](https://arxiv.org/abs/2112.03857), we can expect a tighter integration of multi-modal models with robotic navigation, reasoning, manipulation, and task-planning frameworks.
## Conclusion
There have been incredible advances in multi-modal models in recent years, with vision-language models making the most significant leap in performance and the variety of use cases and applications. In this blog, we talked about the latest advancements in vision-language models, as well as what multi-modal datasets are available and which pre-training strategies we can use to train and fine-tune such models. We also showed how these models are integrated into 🤗 Transformers and how you can use them to perform various tasks with a few lines of code.
We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in multi-modal research, you can follow us on Twitter: [@adirik](https://twitter.com/https://twitter.com/alaradirik), [@NielsRogge](https://twitter.com/NielsRogge), [@apsdehal](https://twitter.com/apsdehal), [@a_e_roberts](https://twitter.com/a_e_roberts), [@RisingSayak](https://mobile.twitter.com/a_e_roberts), and [@huggingface](https://twitter.com/huggingface).
*Acknowledgements: We thank Amanpreet Singh and Amy Roberts for their rigorous reviews. Also, thanks to Niels Rogge, Younes Belkada, and Suraj Patil, among many others at Hugging Face, who laid out the foundations for increasing the use of multi-modal models from Transformers.* | [
[
"computer_vision",
"research",
"image_generation",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"multi_modal",
"research",
"image_generation"
] | null | null |
3f0143ec-01cf-4441-a852-992825d08dd6 | completed | 2025-01-16T03:09:11.596878 | 2025-01-19T19:08:39.472407 | da2b7509-bff6-410a-bfc1-f4b7afd62239 | LeMaterial: an open source initiative to accelerate materials discovery and research | AlexDuvalinho, lritchie, msiron, inelgnu, etiennedufayet, amandinerossello, Ramlaoui, IAMJB, lvwerra, thomwolf | lematerial.md | # LeMaterial: an open source initiative to accelerate materials discovery and research
Today, we are thrilled to announce the launch of **LeMaterial**, an open-source collaborative project led by [*Entalpic*](https://entalpic.ai/) and [*Hugging Face*](https://huggingface.co./). LeMaterial aims to simplify and accelerate materials research, making it easier to train ML models, identify novel materials and explore chemical spaces. ⚛️🤗
As a first step, we are releasing a dataset called `LeMat-Bulk`, which unifies, cleans and standardizes the most prominent material datasets, including [Materials Project](https://next-gen.materialsproject.org/), [Alexandria](https://alexandria.icams.rub.de/) and [OQMD](https://oqmd.org/) — giving rise to a single harmonized data format with **6.7M entries** and **7 materials properties.**
> LeMaterial is standing on the shoulders of giants and we are building upon incredible projects which have been instrumental in the development of this initiative: [Optimade](https://www.optimade.org/), [Materials Project](https://next-gen.materialsproject.org/), [Alexandria](https://alexandria.icams.rub.de/) and [OQMD](https://oqmd.org/), and more to come. Please credit them accordingly when using LeMaterial.
## Why LeMaterial?
The world of materials science, at the intersection of quantum chemistry and machine learning, is brimming with opportunity — from brighter LEDs, to electro-chemical batteries, more efficient photovoltaic cells and recyclable plastics, the applications are endless. By leveraging machine learning (ML) on large, structured datasets, researchers can perform high-throughput screening and testing of new materials at unprecedented scales, significantly accelerating the discovery cycle of novel compounds with desired properties. In this paradigm, **data becomes the essential fuel powering ML models** that can guide experiments, reduce costs, and unlock breakthroughs faster than ever before.
This field is fueled by very complete datasets such as [Materials Project](https://next-gen.materialsproject.org/), [Alexandria](https://alexandria.icams.rub.de/) and [OQMD](https://oqmd.org/), all open-source and under a CC-BY-4.0 license. **However, those datasets vary in format, parameters, and scope, presenting the following challenges:**
- Dataset integration issues (eg. inconsistent formats or field definitions, incompatible calculations)
- Biases in dataset composition (for eg. Materials Project's focus on oxides and battery materials)
- Limited scope (eg. NOMADs focus on quantum chemistry calculations rather than material properties)
- Lack of clear connections or identifiers between similar materials across different databases
This fragmented landscape makes it challenging for researchers in AI4Science and materials informatics to leverage existing data effectively. Whether the application involves training foundational ML models, constructing accurate phase diagrams, identifying novel materials or exploring the chemical space effectively, there is no simple solution. While efforts like [Optimade](https://optimade.org/) standardize structural data, they don't address discrepancies in material properties or biases in dataset scopes.
**LeMaterial** addresses these challenges by unifying and standardizing data from three major databases — [Materials Project](https://next-gen.materialsproject.org/), [Alexandria](https://alexandria.icams.rub.de/) and [OQMD](https://oqmd.org/) — into a high-quality resource with consistent and systematic properties. The elemental composition treemap below highlights the value of this integration, showcasing how we increase the scope of existing datasets, like Materials Project, which are focused on specific material types, such as battery materials (Li, O, P) or oxides.
<p align="center">
<img src="https://huggingface.co./datasets/LeMaterial/admin/resolve/main/MP_LeMatBulk_Combined_Treemap.png" alt="drawing" width="1000"/>
</p>
<p align="center">
<em>Materials Project and LeMat-BulkUnique treemap</em>
</p>
## Achieving a clean, unified and standardized dataset
`LeMat-Bulk` is more than a large-scale merged dataset with a permissive license (CC-BY-4.0). With its 6.7M entries with consistent properties, it represents a foundational step towards creating a curated and standardized open ecosystem for material science, designed to simplify research workflows and improve data quality. Below is a closer view of what is looks like. To interactively browse through our materials, check out the [Materials Explorer space, built using MP Dash components.](https://huggingface.co./spaces/LeMaterial/materials_explorer)
<iframe
src="https://huggingface.co./datasets/LeMaterial/LeMat-Bulk/embed/viewer/compatible_pbe/train"
frameborder="0"
width="100%"
height="560px"
></iframe>
*[View the complete Datacard](https://huggingface.co./datasets/LeMaterial/LeMat-Bulk#download-and-use-within-python)*
| **Release** | **Description & Value** | **Date** |
| | [
[
"data",
"research",
"community",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"research",
"community",
"tools"
] | null | null |
5fe89c40-0ec6-4b49-b80c-dd53e242a172 | completed | 2025-01-16T03:09:11.596885 | 2025-01-19T18:53:37.401965 | fbcff3b1-3335-42a2-9c55-5daca9df5f79 | Creating a Coding Assistant with StarCoder | lewtun, natolambert, nazneen, edbeeching, teven, sheonhan, philschmid, lvwerra, srush | starchat-alpha.md | If you’re a software developer, chances are that you’ve used GitHub Copilot or ChatGPT to solve programming tasks such as translating code from one language to another or generating a full implementation from a natural language query like *“Write a Python program to find the Nth Fibonacci number”*. Although impressive in their capabilities, these proprietary systems typically come with several drawbacks, including a lack of transparency on the public data used to train them and the inability to adapt them to your domain or codebase.
Fortunately, there are now several high-quality open-source alternatives! These include SalesForce’s [CodeGen Mono 16B](https://huggingface.co./Salesforce/codegen-16B-mono) for Python, or [Replit’s 3B parameter model](https://huggingface.co./replit/replit-code-v1-3b) trained on 20 programming languages.
The new kid on the block is [BigCode’s StarCoder](https://huggingface.co./bigcode/starcoder), a 16B parameter model trained on one trillion tokens sourced from 80+ programming languages, GitHub issues, Git commits, and Jupyter notebooks (all permissively licensed). With an enterprise-friendly license, 8,192 token context length, and fast large-batch inference via [multi-query attention](https://arxiv.org/abs/1911.02150), StarCoder is currently the best open-source choice for code-based applications.
In this blog post, we’ll show how StarCoder can be fine-tuned for chat to create a personalised coding assistant! Dubbed StarChat, we’ll explore several technical details that arise when using large language models (LLMs) as coding assistants, including:
- How LLMs can be prompted to act like conversational agents.
- OpenAI’s [Chat Markup Language](https://github.com/openai/openai-python/blob/main/chatml.md) (or ChatML for short), which provides a structured format for conversational messages between human users and AI assistants.
- How to fine-tune a large model on a diverse corpus of dialogues with 🤗 Transformers and DeepSpeed ZeRO-3.
As a teaser of the end result, try asking StarChat a few programming questions in the demo below!
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/3.28.2/gradio.js"
></script>
<gradio-app theme_mode="light" src="https://huggingfaceh4-starchat-playground.hf.space"></gradio-app>
You can also find the code, dataset, and model used to produce the demo at the following links:
- Code: [https://github.com/bigcode-project/starcoder](https://github.com/bigcode-project/starcoder)
- Dataset: [https://huggingface.co./datasets/HuggingFaceH4/oasst1_en](https://huggingface.co./datasets/HuggingFaceH4/oasst1_en)
- Model: [https://huggingface.co./HuggingFaceH4/starchat-alpha](https://huggingface.co./HuggingFaceH4/starchat-alpha)
To get started, let’s take a look at how language models can be turned into conversational agents without any fine-tuning at all.
## Prompting LLMs for dialogue
As shown by [DeepMind](https://arxiv.org/abs/2209.14375) and [Anthropic](https://arxiv.org/abs/2112.00861), LLMs can be turned into conversational agents through a clever choice of prompt. These prompts typically involve a so-called “system” message that defines the character of the LLM, along with a series of dialogues between the assistant and a user.
For example, here’s an excerpt from [Anthropic’s HHH prompt](https://gist.github.com/jareddk/2509330f8ef3d787fc5aaac67aab5f11#file-hhh_prompt-txt) (a whopping 6k tokens in total!):
```
Below are a series of dialogues between various people and an AI assistant.
The AI tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble-but-knowledgeable.
The assistant is happy to help with almost anything, and will do its best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn’t entirely sure about the right answer.
That said, the assistant is practical and really does its best, and doesn’t let caution get too much in the way of being useful. | [
[
"llm",
"implementation",
"tools",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"tools",
"fine_tuning"
] | null | null |
d4586778-13b7-425b-aaa7-1c90f43604e4 | completed | 2025-01-16T03:09:11.596893 | 2025-01-16T03:25:27.288753 | e502b647-d725-440a-a1b1-d4ef9b06a532 | Object Detection Leaderboard | rafaelpadilla, amyeroberts | object-detection-leaderboard.md | Welcome to our latest dive into the world of leaderboards and models evaluation. In a [previous post](https://huggingface.co./blog/evaluating-mmlu-leaderboard), we navigated the waters of evaluating Large Language Models. Today, we set sail to a different, yet equally challenging domain – Object Detection.
Recently, we released our [Object Detection Leaderboard](https://huggingface.co./spaces/hf-vision/object_detection_leaderboard), ranking object detection models available in the Hub according to some metrics. In this blog, we will demonstrate how the models were evaluated and demystify the popular metrics used in Object Detection, from Intersection over Union (IoU) to Average Precision (AP) and Average Recall (AR). More importantly, we will spotlight the inherent divergences and pitfalls that can occur during evaluation, ensuring that you're equipped with the knowledge not just to understand but to assess model performance critically.
Every developer and researcher aims for a model that can accurately detect and delineate objects. Our [Object Detection Leaderboard](https://huggingface.co./spaces/hf-vision/object_detection_leaderboard) is the right place to find an open-source model that best fits their application needs. But what does "accurate" truly mean in this context? Which metrics should one trust? How are they computed? And, perhaps more crucially, why some models may present divergent results in different reports? All these questions will be answered in this blog.
So, let's embark on this exploration together and unlock the secrets of the Object Detection Leaderboard! If you prefer to skip the introduction and learn how object detection metrics are computed, go to the [Metrics section](#metrics). If you wish to find how to pick the best models based on the [Object Detection Leaderboard](https://huggingface.co./spaces/hf-vision/object_detection_leaderboard), you may check the [Object Detection Leaderboard](#object-detection-leaderboard) section.
## Table of Contents
- [Introduction](#object-detection-leaderboard-decoding-metrics-and-their-potential-pitfalls)
- [What's Object Detection](#whats-object-detection)
- [Metrics](#metrics)
- [What's Average Precision and how to compute it?](#whats-average-precision-and-how-to-compute-it)
- [What's Average Recall and how to compute it?](#whats-average-recall-and-how-to-compute-it)
- [What are the variants of Average Precision and Average Recall?](#what-are-the-variants-of-average-precision-and-average-recall)
- [Object Detection Leaderboard](#object-detection-leaderboard)
- [How to pick the best model based on the metrics?](#how-to-pick-the-best-model-based-on-the-metrics)
- [Which parameters can impact the Average Precision results?](#which-parameters-can-impact-the-average-precision-results)
- [Conclusions](#conclusions)
- [Additional Resources](#additional-resources)
## What's Object Detection?
In the field of Computer Vision, Object Detection refers to the task of identifying and localizing individual objects within an image. Unlike image classification, where the task is to determine the predominant object or scene in the image, object detection not only categorizes the object classes present but also provides spatial information, drawing bounding boxes around each detected object. An object detector can also output a "score" (or "confidence") per detection. It represents the probability, according to the model, that the detected object belongs to the predicted class for each bounding box.
The following image, for instance, shows five detections: one "ball" with a confidence of 98% and four "person" with a confidence of 98%, 95%, 97%, and 97%.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/intro_object_detection.png" alt="intro_object_detection.png" />
<figcaption> Figure 1: Example of outputs from an object detector.</figcaption>
</center>
</div>
Object detection models are versatile and have a wide range of applications across various domains. Some use cases include vision in autonomous vehicles, face detection, surveillance and security, medical imaging, augmented reality, sports analysis, smart cities, gesture recognition, etc.
The Hugging Face Hub has [hundreds of object detection models](https://huggingface.co./models?pipeline_tag=object-detection) pre-trained in different datasets, able to identify and localize various object classes.
One specific type of object detection models, called _zero-shot_, can receive additional text queries to search for target objects described in the text. These models can detect objects they haven't seen during training, instead of being constrained to the set of classes used during training.
The diversity of detectors goes beyond the range of output classes they can recognize. They vary in terms of underlying architectures, model sizes, processing speeds, and prediction accuracy.
A popular metric used to evaluate the accuracy of predictions made by an object detection model is the **Average Precision (AP)** and its variants, which will be explained later in this blog.
Evaluating an object detection model encompasses several components, like a dataset with ground-truth annotations, detections (output prediction), and metrics. This process is depicted in the schematic provided in Figure 2:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pipeline_object_detection.png" alt="pipeline_object_detection.png" />
<figcaption> Figure 2: Schematic illustrating the evaluation process for a traditional object detection model.</figcaption>
</center>
</div>
First, a benchmarking dataset containing images with ground-truth bounding box annotations is chosen and fed into the object detection model. The model predicts bounding boxes for each image, assigning associated class labels and confidence scores to each box. During the evaluation phase, these predicted bounding boxes are compared with the ground-truth boxes in the dataset. The evaluation yields a set of metrics, each ranging between [0, 1], reflecting a specific evaluation criteria. In the next section, we'll dive into the computation of the metrics in detail.
## Metrics
This section will delve into the definition of Average Precision and Average Recall, their variations, and their associated computation methodologies.
### What's Average Precision and how to compute it?
Average Precision (AP) is a single-number that summarizes the Precision x Recall curve. Before we explain how to compute it, we first need to understand the concept of Intersection over Union (IoU), and how to classify a detection as a True Positive or a False Positive.
IoU is a metric represented by a number between 0 and 1 that measures the overlap between the predicted bounding box and the actual (ground truth) bounding box. It's computed by dividing the area where the two boxes overlap by the area covered by both boxes combined. Figure 3 visually demonstrates the IoU using an example of a predicted box and its corresponding ground-truth box.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/iou.png" alt="iou.png" />
<figcaption> Figure 3: Intersection over Union (IoU) between a detection (in green) and ground-truth (in blue).</figcaption>
</center>
</div>
If the ground truth and detected boxes share identical coordinates, representing the same region in the image, their IoU value is 1. Conversely, if the boxes do not overlap at any pixel, the IoU is considered to be 0.
In scenarios where high precision in detections is expected (e.g. an autonomous vehicle), the predicted bounding boxes should closely align with the ground-truth boxes. For that, a IoU threshold ( \\( \text{T}_{\text{IOU}} \\) ) approaching 1 is preferred. On the other hand, for applications where the exact position of the detected bounding boxes relative to the target object isn’t critical, the threshold can be relaxed, setting \\( \text{T}_{\text{IOU}} \\) closer to 0.
Every box predicted by the model is considered a “positive” detection. The Intersection over Union (IoU) criterion classifies each prediction as a true positive (TP) or a false positive (FP), according to the confidence threshold we defined.
Based on predefined \\( \text{T}_{\text{IOU}} \\), we can define True Positives and True Negatives:
* **True Positive (TP)**: A correct detection where IoU ≥ \\( \text{T}_{\text{IOU}} \\).
* **False Positive (FP)**: An incorrect detection (missed object), where the IoU < \\( \text{T}_{\text{IOU}} \\).
Conversely, negatives are evaluated based on a ground-truth bounding box and can be defined as False Negative (FN) or True Negative (TN):
* **False Negative (FN)**: Refers to a ground-truth object that the model failed to detect.
* **True Negative (TN)**: Denotes a correct non-detection. Within the domain of object detection, countless bounding boxes within an image should NOT be identified, as they don't represent the target object. Consider all possible boxes in an image that don’t represent the target object - quite a vast number, isn’t it? :) That's why we do not consider TN to compute object detection metrics.
Now that we can identify our TPs, FPs, and FNs, we can define Precision and Recall:
* **Precision** is the ability of a model to identify only the relevant objects. It is the percentage of correct positive predictions and is given by:
<p style="text-align: center;">
\\( \text{Precision} = \frac{TP}{(TP + FP)} = \frac{TP}{\text{all detections}} \\)
</p>
which translates to the ratio of true positives over all detected boxes.
* **Recall** gauges a model’s competence in finding all the relevant cases (all ground truth bounding boxes). It indicates the proportion of TP detected among all ground truths and is given by:
<p style="text-align: center;">
\\( \text{Recall} = \frac{TP}{(TP + FN)} = \frac{TP}{\text{all ground truths}} \\)
</p>
Note that TP, FP, and FN depend on a predefined IoU threshold, as do Precision and Recall.
Average Precision captures the ability of a model to classify and localize objects correctly considering different values of Precision and Recall. For that we'll illustrate the relationship between Precision and Recall by plotting their respective curves for a specific target class, say "dog". We'll adopt a moderate IoU threshold = 75% to delineate our TP, FP and FN. Subsequently, we can compute the Precision and Recall values. For that, we need to vary the confidence scores of our detections.
Figure 4 shows an example of the Precision x Recall curve. For a deeper exploration into the computation of this curve, the papers “A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit” (Padilla, et al) and “A Survey on Performance Metrics for Object-Detection Algorithms” (Padilla, et al) offer more detailed toy examples demonstrating how to compute this curve.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/pxr_te_iou075.png" alt="pxr_te_iou075.png" />
<figcaption> Figure 4: Precision x Recall curve for a target object “dog” considering TP detections using IoU_thresh = 0.75.</figcaption>
</center>
</div>
The Precision x Recall curve illustrates the balance between Precision and Recall based on different confidence levels of a detector's bounding boxes. Each point of the plot is computed using a different confidence value.
To demonstrate how to calculate the Average Precision plot, we'll use a practical example from one of the papers mentioned earlier. Consider a dataset of 7 images with 15 ground-truth objects of the same class, as shown in Figure 5. Let's consider that all boxes belong to the same class, "dog" for simplification purposes.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/dataset_example.png" alt="dataset_example.png" />
<figcaption> Figure 5: Example of 24 detections (red boxes) performed by an object detector trained to detect 15 ground-truth objects (green boxes) belonging to the same class.</figcaption>
</center>
</div>
Our hypothetical object detector retrieved 24 objects in our dataset, illustrated by the red boxes. To compute Precision and Recall we use the Precision and Recall equations at all confidence levels to evaluate how well the detector performed for this specific class on our benchmarking dataset. For that, we need to establish some rules:
* **Rule 1**: For simplicity, let's consider our detections a True Positive (TP) if IOU ≥ 30%; otherwise, it is a False Positive (FP).
* **Rule 2**: For cases where a detection overlaps with more than one ground-truth (as in Images 2 to 7), the predicted box with the highest IoU is considered TP, and the other is FP.
Based on these rules, we can classify each detection as TP or FP, as shown in Table 1:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<figcaption> Table 1: Detections from Figure 5 classified as TP or FP considering \\( \text{T}_{\text{IOU}} = 30\% \\).</figcaption>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_1.png" alt="table_1.png" />
</center>
</div>
Note that by rule 2, in image 1, "E" is TP while "D" is FP because IoU between "E" and the ground-truth is greater than IoU between "D" and the ground-truth.
Now, we need to compute Precision and Recall considering the confidence value of each detection. A good way to do so is to sort the detections by their confidence values as shown in Table 2. Then, for each confidence value in each row, we compute the Precision and Recall considering the cumulative TP (acc TP) and cumulative FP (acc FP). The "acc TP" of each row is increased in 1 every time a TP is noted, and the "acc FP" is increased in 1 when a FP is noted. Columns "acc TP" and "acc FP" basically tell us the TP and FP values given a particular confidence level. The computation of each value of Table 2 can be viewed in [this spreadsheet](https://docs.google.com/spreadsheets/d/1mc-KPDsNHW61ehRpI5BXoyAHmP-NxA52WxoMjBqk7pw/edit?usp=sharing).
For example, consider the 12th row (detection "P") of Table 2. The value "acc TP = 4" means that if we benchmark our model on this particular dataset with a confidence of 0.62, we would correctly detect four target objects and incorrectly detect eight target objects. This would result in:
<p style="text-align: center;">
\\( \text{Precision} = \frac{\text{acc TP}}{(\text{acc TP} + \text{acc FP})} = \frac{4}{(4+8)} = 0.3333 \\) and \\( \text{Recall} = \frac{\text{acc TP}}{\text{all ground truths}} = \frac{4}{15} = 0.2667 \\) .
</p>
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<figcaption> Table 2: Computation of Precision and Recall values of detections from Table 1.</figcaption>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/table_2.png" alt="table_2.png" />
</center>
</div>
Now, we can plot the Precision x Recall curve with the values, as shown in Figure 6:
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/precision_recall_example.png" alt="precision_recall_example.png" />
<figcaption> Figure 6: Precision x Recall curve for the detections computed in Table 2.</figcaption>
</center>
</div>
By examining the curve, one may infer the potential trade-offs between Precision and Recall and find a model's optimal operating point based on a selected confidence threshold, even if this threshold is not explicitly depicted on the curve.
If a detector's confidence results in a few false positives (FP), it will likely have high Precision. However, this might lead to missing many true positives (TP), causing a high false negative (FN) rate and, subsequently, low Recall. On the other hand, accepting more positive detections can boost Recall but might also raise the FP count, thereby reducing Precision.
**The area under the Precision x Recall curve (AUC) computed for a target class represents the Average Precision value for that particular class.** The COCO evaluation approach refers to "AP" as the mean AUC value among all target classes in the image dataset, also referred to as Mean Average Precision (mAP) by other approaches.
For a large dataset, the detector will likely output boxes with a wide range of confidence levels, resulting in a jagged Precision x Recall line, making it challenging to compute its AUC (Average Precision) precisely. Different methods approximate the area of the curve with different approaches. A popular approach is called N-interpolation, where N represents how many points are sampled from the Precision x Recall blue line.
The COCO approach, for instance, uses 101-interpolation, which computes 101 points for equally spaced Recall values (0. , 0.01, 0.02, … 1.00), while other approaches use 11 points (11-interpolation). Figure 7 illustrates a Precision x Recall curve (in blue) with 11 equal-spaced Recall points.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/11-pointInterpolation.png" alt="11-pointInterpolation.png" />
<figcaption> Figure 7: Example of a Precision x Recall curve using the 11-interpolation approach. The 11 red dots are computed with Precision and Recall equations.</figcaption>
</center>
</div>
The red points are placed according to the following:
<p style="text-align: center;">
\\( \rho_{\text{interp}} (R) = \max_{\tilde{r}:\tilde{r} \geq r} \rho \left( \tilde{r} \right) \\)
</p>
where \\( \rho \left( \tilde{r} \right) \\) is the measured Precision at Recall \\( \tilde{r} \\).
In this definition, instead of using the Precision value \\( \rho(R) \\) observed in each Recall level \\( R \\), the Precision \\( \rho_{\text{interp}} (R) \\) is obtained by considering the maximum Precision whose Recall value is greater than \\( R \\).
For this type of approach, the AUC, which represents the Average Precision, is approximated by the average of all points and given by:
<p style="text-align: center;">
\\( \text{AP}_{11} = \frac{1}{11} = \sum\limits_{R\in \left \{ 0, 0.1, ...,1 \right \}} \rho_{\text{interp}} (R) \\)
</p>
### What's Average Recall and how to compute it?
Average Recall (AR) is a metric that's often used alongside AP to evaluate object detection models. While AP evaluates both Precision and Recall across different confidence thresholds to provide a single-number summary of model performance, AR focuses solely on the Recall aspect, not taking the confidences into account and considering all detections as positives.
COCO’s approach computes AR as the mean of the maximum obtained Recall over IOUs > 0.5 and classes.
By using IOUs in the range [0.5, 1] and averaging Recall values across this interval, AR assesses the model's predictions on their object localization. Hence, if your goal is to evaluate your model for both high Recall and precise object localization, AR could be a valuable evaluation metric to consider.
### What are the variants of Average Precision and Average Recall?
Based on predefined IoU thresholds and the areas associated with ground-truth objects, different versions of AP and AR can be obtained:
* **[email protected]**: sets IoU threshold = 0.5 and computes the Precision x Recall AUC for each target class in the image dataset. Then, the computed results for each class are summed up and divided by the number of classes.
* **[email protected]**: uses the same methodology as [email protected], with IoU threshold = 0.75. With this higher IoU requirement, [email protected] is considered stricter than [email protected] and should be used to evaluate models that need to achieve a high level of localization accuracy in their detections.
* **AP@[.5:.05:.95]**: also referred to AP by cocoeval tools. This is an expanded version of [email protected] and [email protected], as it computes AP@ with different IoU thresholds (0.5, 0.55, 0.6,...,0.95) and averages the computed results as shown in the following equation. In comparison to [email protected] and [email protected], this metric provides a holistic evaluation, capturing a model’s performance across a broader range of localization accuracies.
<p style="text-align: center;">
\\( \text{AP@[.5:.05:0.95} = \frac{\text{AP}_{0.5} + \text{AP}_{0.55} + ... + \text{AP}_{0.95}}{10} \\)
</p>
* **AP-S**: It applies AP@[.5:.05:.95] considering (small) ground-truth objects with \\( \text{area} < 32^2 \\) pixels.
* **AP-M**: It applies AP@[.5:.05:.95] considering (medium-sized) ground-truth objects with \\( 32^2 < \text{area} < 96^2 \\) pixels.
* **AP-L**: It applies AP@[.5:.05:.95] considering (large) ground-truth objects with \\( 32^2 < \text{area} < 96^2\\) pixels.
For Average Recall (AR), 10 IoU thresholds (0.5, 0.55, 0.6,...,0.95) are used to compute the Recall values. AR is computed by either limiting the number of detections per image or by limiting the detections based on the object's area.
* **AR-1**: considers up to 1 detection per image.
* **AR-10**: considers up to 10 detections per image.
* **AR-100**: considers up to 100 detections per image.
* **AR-S**: considers (small) objects with \\( \text{area} < 32^2 \\) pixels.
* **AR-M**: considers (medium-sized) objects with \\( 32^2 < \text{area} < 96^2 \\) pixels.
* **AR-L**: considers (large) objects with \\( \text{area} > 96^2 \\) pixels.
## Object Detection Leaderboard
We recently released the [Object Detection Leaderboard](https://huggingface.co./spaces/hf-vision/object_detection_leaderboard) to compare the accuracy and efficiency of open-source models from our Hub.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/screenshot-leaderboard.png" alt="screenshot-leaderboard.png" />
<figcaption> Figure 8: Object Detection Leaderboard.</figcaption>
</center>
</div>
To measure accuracy, we used 12 metrics involving Average Precision and Average Recall using [COCO style](https://cocodataset.org/#detection-eval), benchmarking over COCO val 2017 dataset.
As discussed previously, different tools may adopt different particularities during the evaluation. To prevent results mismatching, we preferred not to implement our version of the metrics. Instead, we opted to use COCO's official evaluation code, also referred to as PyCOCOtools, code available [here](https://github.com/cocodataset/cocoapi/tree/master/PythonAPI).
In terms of efficiency, we calculate the frames per second (FPS) for each model using the average evaluation time across the entire dataset, considering pre and post-processing steps. Given the variability in GPU memory requirements for each model, we chose to evaluate with a batch size of 1 (this choice is also influenced by our pre-processing step, which we'll delve into later). However, it's worth noting that this approach may not align perfectly with real-world performance, as larger batch sizes (often containing several images), are commonly used for better efficiency.
Next, we will provide tips on choosing the best model based on the metrics and point out which parameters may interfere with the results. Understanding these nuances is crucial, as this might spark doubts and discussions within the community.
### How to pick the best model based on the metrics?
Selecting an appropriate metric to evaluate and compare object detectors considers several factors. The primary considerations include the application's purpose and the dataset's characteristics used to train and evaluate the models.
For general performance, **AP (AP@[.5:.05:.95])** is a good choice if you want all-round model performance across different IoU thresholds, without a hard requirement on the localization of the detected objects.
If you want a model with good object recognition and objects generally in the right place, you can look at the **[email protected]**. If you prefer a more accurate model for placing the bounding boxes, **[email protected]** is more appropriate.
If you have restrictions on object sizes, **AP-S**, **AP-M** and **AP-L** come into play. For example, if your dataset or application predominantly features small objects, AP-S provides insights into the detector's efficacy in recognizing such small targets. This becomes crucial in scenarios such as detecting distant vehicles or small artifacts in medical imaging.
### Which parameters can impact the Average Precision results?
After picking an object detection model from the Hub, we can vary the output boxes if we use different parameters in the model's pre-processing and post-processing steps. These may influence the assessment metrics. We identified some of the most common factors that may lead to variations in results:
* Ignore detections that have a score under a certain threshold.
* Use `batch_sizes > 1` for inference.
* Ported models do not output the same logits as the original models.
* Some ground-truth objects may be ignored by the evaluator.
* Computing the IoU may be complicated.
* Text-conditioned models require precise prompts.
Let’s take the DEtection TRansformer (DETR) ([facebook/detr-resnet-50](https://huggingface.co./facebook/detr-resnet-50)) model as our example case. We will show how these factors may affect the output results.
#### Thresholding detections before evaluation
Our sample model uses the [`DetrImageProcessor` class](https://huggingface.co./docs/transformers/main/en/model_doc/detr#transformers.DetrImageProcessor) to process the bounding boxes and logits, as shown in the snippet below:
```python
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# PIL images have their size in (w, h) format
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes, threshold=0.5)
```
The parameter `threshold` in function `post_process_object_detection` is used to filter the detected bounding boxes based on their confidence scores.
As previously discussed, the Precision x Recall curve is built by measuring the Precision and Recall across the full range of confidence values [0,1]. Thus, limiting the detections before evaluation will produce biased results, as we will leave some detections out.
#### Varying the batch size
The batch size not only affects the processing time but may also result in different detected boxes. The image pre-processing step may change the resolution of the input images based on their sizes.
As mentioned in [DETR documentation](https://huggingface.co./docs/transformers/model_doc/detr), by default, `DetrImageProcessor` resizes the input images such that the shortest side is 800 pixels, and resizes again so that the longest is at most 1333 pixels. Due to this, images in a batch can have different sizes. DETR solves this by padding images up to the largest size in a batch, and by creating a pixel mask that indicates which pixels are real/which are padding.
To illustrate this process, let's consider the examples in Figure 9 and Figure 10. In Figure 9, we consider batch size = 1, so both images are processed independently with `DetrImageProcessor`. The first image is resized to (800, 1201), making the detector predict 28 boxes with class `vase`, 22 boxes with class `chair`, ten boxes with class `bottle`, etc.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_1.png" alt="example_batch_size_1.png" />
<figcaption> Figure 9: Two images processed with `DetrImageProcessor` using batch size = 1.</figcaption>
</center>
</div>
Figure 10 shows the process with batch size = 2, where the same two images are processed with `DetrImageProcessor` in the same batch. Both images are resized to have the same shape (873, 1201), and padding is applied, so the part of the images with the content is kept with their original aspect ratios. However, the first image, for instance, outputs a different number of objects: 31 boxes with the class `vase`, 20 boxes with the class `chair`, eight boxes with the class `bottle`, etc. Note that for the second image, with batch size = 2, a new class is detected `dog`. This occurs due to the model's capacity to detect objects of different sizes depending on the image's resolution.
<div display="block" margin-left="auto" margin-right="auto" width="50%">
<center>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/object-detection-leaderboard/example_batch_size_2.png" alt="example_batch_size_2.png" />
<figcaption> Figure 10: Two images processed with `DetrImageProcessor` using batch size = 2.</figcaption>
</center>
</div>
#### Ported models should output the same logits as the original models
At Hugging Face, we are very careful when porting models to our codebase. Not only with respect to the architecture, clear documentation and coding structure, but we also need to guarantee that the ported models are able to produce the same logits as the original models given the same inputs.
The logits output by a model are post-processed to produce the confidence scores, label IDs, and bounding box coordinates. Thus, minor changes in the logits can influence the metrics results. You may recall [the example above](#whats-average-precision-and-how-to-compute-it), where we discussed the process of computing Average Precision. We showed that confidence levels sort the detections, and small variations may lead to a different order and, thus, different results.
It's important to recognize that models can produce boxes in various formats, and that also may be taken into consideration, making proper conversions required by the evaluator.
* *(x, y, width, height)*: this represents the upper-left corner coordinates followed by the absolute dimensions (width and height).
* *(x, y, x2, y2)*: this format indicates the coordinates of the upper-left corner and the lower-right corner.
* *(rel_x_center, rel_y_center, rel_width, rel_height)*: the values represent the relative coordinates of the center and the relative dimensions of the box.
#### Some ground-truths are ignored in some benchmarking datasets
Some datasets sometimes use special labels that are ignored during the evaluation process.
COCO, for instance, uses the tag `iscrowd` to label large groups of objects (e.g. many apples in a basket). During evaluation, objects tagged as `iscrowd=1` are ignored. If this is not taken into consideration, you may obtain different results.
#### Calculating the IoU requires careful consideration
IoU might seem straightforward to calculate based on its definition. However, there's a crucial detail to be aware of: if the ground truth and the detection don't overlap at all, not even by one pixel, the IoU should be 0. To avoid dividing by zero when calculating the union, you can add a small value (called _epsilon_), to the denominator. However, it's essential to choose epsilon carefully: a value greater than 1e-4 might not be neutral enough to give an accurate result.
#### Text-conditioned models demand the right prompts
There might be cases in which we want to evaluate text-conditioned models such as [OWL-ViT](https://huggingface.co./google/owlvit-base-patch32), which can receive a text prompt and provide the location of the desired object.
For such models, different prompts (e.g. "Find the dog" and "Where's the bulldog?") may result in the same results. However, we decided to follow the procedure described in each paper. For the OWL-ViT, for instance, we predict the objects by using the prompt "an image of a {}" where {} is replaced with the benchmarking dataset's classes.
## Conclusions
In this post, we introduced the problem of Object Detection and depicted the main metrics used to evaluate them.
As noted, evaluating object detection models may take more work than it looks. The particularities of each model must be carefully taken into consideration to prevent biased results. Also, each metric represents a different point of view of the same model, and picking "the best" metric depends on the model's application and the characteristics of the chosen benchmarking dataset.
Below is a table that illustrates recommended metrics for specific use cases and provides real-world scenarios as examples. However, it's important to note that these are merely suggestions, and the ideal metric can vary based on the distinct particularities of each application.
| Use Case | Real-world Scenarios | Recommended Metric |
| | [
[
"computer_vision",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"benchmarks",
"research",
"tools"
] | null | null |
290074e2-390a-4e9d-985e-9f4de0853771 | completed | 2025-01-16T03:09:11.596901 | 2025-01-19T19:09:21.069479 | 797ae2da-d6bb-4c8e-ad11-7642bfc7fa68 | Can foundation models label data like humans? | nazneen, natolambert, sheonhan, wangjean, OsvaldN97, edbeeching, lewtun, slippylolo, thomwolf | open-llm-leaderboard-rlhf.md | Since the advent of ChatGPT, we have seen unprecedented growth in the development of Large Language Models (LLMs), and particularly chatty models that are fine-tuned to follow instructions given in the form of prompts.
However, how these models compare is unclear due to the lack of benchmarks designed to test their performance rigorously.
Evaluating instruction and chatty models is intrinsically difficult because a large part of user preference is centered around qualitative style while in the past NLP evaluation was far more defined.
In this line, it’s a common story that a new large language model (LLM) is released to the tune of “our model is preferred to ChatGPT N% of the time,” and what is omitted from that sentence is that the model is preferred in some type of GPT-4-based evaluation scheme.
What these points are trying to show is a proxy for a different measurement: scores provided by human labelers.
The process of training models with reinforcement learning from human feedback (RLHF) has proliferated interfaces for and data of comparing two model completions to each other.
This data is used in the RLHF process to train a reward model that predicts a preferred text, but the idea of rating and ranking model outputs has grown to be a more general tool in evaluation.
Here is an example from each of the `instruct` and `code-instruct` splits of our blind test set.


In terms of iteration speed, using a language model to evaluate model outputs is highly efficient, but there’s a sizable missing piece: **investigating if the downstream tool-shortcut is calibrated with the original form of measurement.**
In this blog post, we’ll zoom in on where you can and cannot trust the data labels you get from the LLM of your choice by expanding the Open LLM Leaderboard evaluation suite.
Leaderboards have begun to emerge, such as the [LMSYS](https://leaderboard.lmsys.org/), [nomic / GPT4All](https://gpt4all.io/index.html), to compare some aspects of these models, but there needs to be a complete source comparing model capabilities.
Some use existing NLP benchmarks that can show question and answering capabilities and some are crowdsourced rankings from open-ended chatting.
In order to present a more general picture of evaluations the [Hugging Face Open LLM Leaderboard](https://huggingface.co./spaces/HuggingFaceH4/open_llm_leaderboard?tab=evaluation) has been expanded, including automated academic benchmarks, professional human labels, and GPT-4 evals. | [
[
"llm",
"research",
"benchmarks",
"text_classification",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"research",
"benchmarks",
"fine_tuning"
] | null | null |
22e95633-30b8-4104-a53b-5dd0d6cf9d50 | completed | 2025-01-16T03:09:11.596908 | 2025-01-16T03:15:05.379909 | a802d4dc-9235-4df8-997c-e872e13a3ca3 | Powerful ASR + diarization + speculative decoding with Hugging Face Inference Endpoints | sergeipetrov, reach-vb, pcuenq, philschmid | asr-diarization.md | Whisper is one of the best open source speech recognition models and definitely the one most widely used. Hugging Face [Inference Endpoints](https://huggingface.co./inference-endpoints/dedicated) make it very easy to deploy any Whisper model out of the box. However, if you’d like to
introduce additional features, like a diarization pipeline to identify speakers, or assisted generation for speculative decoding, things get trickier. The reason is that you need to combine Whisper with additional models, while still exposing a single API endpoint.
We'll solve this challenge using a [custom inference handler](https://huggingface.co./docs/inference-endpoints/guides/custom_handler), which will implement the Automatic Speech Recogniton (ASR) and Diarization pipeline on Inference Endpoints, as well as supporting speculative decoding. The implementation of the diarization pipeline is inspired by the famous [Insanely Fast Whisper](https://github.com/Vaibhavs10/insanely-fast-whisper#insanely-fast-whisper), and it uses a [Pyannote](https://github.com/pyannote/pyannote-audio) model for diarization.
This will also be a demonstration of how flexible Inference Endpoints are and that you can host pretty much anything there. [Here](https://huggingface.co./sergeipetrov/asrdiarization-handler/) is the code to follow along. Note that during initialization of the endpoint, the whole repository gets mounted, so your `handler.py` can refer to other files in your repository if you prefer not to have all the logic in a single file. In this case, we decided to separate things into several files to keep things clean:
- `handler.py` contains initialization and inference code
- `diarization_utils.py` has all the diarization-related pre- and post-processing
- `config.py` has `ModelSettings` and `InferenceConfig`. `ModelSettings` define which models will be utilized in the pipeline (you don't have to use all of them), and `InferenceConfig` defines the default inference parameters
**_Starting with [Pytorch 2.2](https://pytorch.org/blog/pytorch2-2/), SDPA supports Flash Attention 2 out-of-the-box, so we'll use that version for faster inference._**
## The main modules
This is a high-level diagram of what the endpoint looks like under the hood:

The implementation of ASR and diarization pipelines is modularized to cater to a wider range of use cases - the diarization pipeline operates on top of ASR outputs, and you can use only the ASR part if diarization is not needed. For diarization, we propose using the [Pyannote model](https://huggingface.co./pyannote/speaker-diarization-3.1), currently a SOTA open source implementation.
We’ll also add speculative decoding as a way to speed up inference. The speedup is achieved by using a smaller and faster model to suggest generations that are validated by the larger model. Learn more about how it works with Whisper specifically in [this great blog post](https://huggingface.co./blog/whisper-speculative-decoding).
Speculative decoding comes with restrictions:
- at least the decoder part of an assistant model should have the same architecture as that of the main model
- the batch size much be 1
Make sure to take the above into account. Depending on your production use case, supporting larger batches can be faster than speculative decoding. If you don't want to use an assistant model, just keep the `assistant_model` in the configuration as `None`.
If you do use an assistant model, a great choice for Whisper is a [distilled version](https://huggingface.co./distil-whisper).
## Set up your own endpoint
The easiest way to start is to clone the [custom handler](https://huggingface.co./sergeipetrov/asrdiarization-handler/blob/main/handler.py) repository using the [repo duplicator](https://huggingface.co./spaces/huggingface-projects/repo_duplicator).
Here is the model loading piece from the `handler.py`:
```python
from pyannote.audio import Pipeline
from transformers import pipeline, AutoModelForCausalLM
...
self.asr_pipeline = pipeline(
"automatic-speech-recognition",
model=model_settings.asr_model,
torch_dtype=torch_dtype,
device=device
)
self.assistant_model = AutoModelForCausalLM.from_pretrained(
model_settings.assistant_model,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True
)
...
self.diarization_pipeline = Pipeline.from_pretrained(
checkpoint_path=model_settings.diarization_model,
use_auth_token=model_settings.hf_token,
)
...
```
You can customize the pipeline based on your needs. `ModelSettings`, in the `config.py` file, holds the parameters used for initialization, defining the models to use during inference:
```python
class ModelSettings(BaseSettings):
asr_model: str
assistant_model: Optional[str] = None
diarization_model: Optional[str] = None
hf_token: Optional[str] = None
```
The parameters can be adjusted by passing environment variables with corresponding names - this works both with a custom container and an inference handler. It’s a [Pydantic feature](https://docs.pydantic.dev/latest/concepts/pydantic_settings/). To pass environment variables to a container during build time you’ll have to create an endpoint via an API call (not via the interface).
You could hardcode model names instead of passing them as environment variables, but *note that the diarization pipeline requires a token to be passed explicitly (`hf_token`).* You are not allowed to hardcode your token for security reasons, which means you will have to create an endpoint via an API call in order to use a diarization model.
As a reminder, all the diarization-related pre- and postprocessing utils are in `diarization_utils.py`
The only required component is an ASR model. Optionally, an assistant model can be specified to be used for speculative decoding, and a diarization model can be used to partition a transcription by speakers.
### Deploy on Inference Endpoints
If you only need the ASR part you could specify `asr_model`/`assistant_model` in the `config.py` and deploy with a click of a button:

To pass environment variables to containers hosted on Inference Endpoints you’ll need to create an endpoint programmatically using the [provided API](https://api.endpoints.huggingface.cloud/#post-/v2/endpoint/-namespace-). Below is an example call:
```python
body = {
"compute": {
"accelerator": "gpu",
"instanceSize": "medium",
"instanceType": "g5.2xlarge",
"scaling": {
"maxReplica": 1,
"minReplica": 0
}
},
"model": {
"framework": "pytorch",
"image": {
# a default container
"huggingface": {
"env": {
# this is where a Hub model gets mounted
"HF_MODEL_DIR": "/repository",
"DIARIZATION_MODEL": "pyannote/speaker-diarization-3.1",
"HF_TOKEN": "<your_token>",
"ASR_MODEL": "openai/whisper-large-v3",
"ASSISTANT_MODEL": "distil-whisper/distil-large-v3"
}
}
},
# a model repository on the Hub
"repository": "sergeipetrov/asrdiarization-handler",
"task": "custom"
},
# the endpoint name
"name": "asr-diarization-1",
"provider": {
"region": "us-east-1",
"vendor": "aws"
},
"type": "private"
}
```
### When to use an assistant model
To give a better idea on when using an assistant model is beneficial, here's a benchmark performed with [k6](https://k6.io/docs/):
```bash
# Setup:
# GPU: A10
ASR_MODEL=openai/whisper-large-v3
ASSISTANT_MODEL=distil-whisper/distil-large-v3
# long: 60s audio; short: 8s audio
long_assisted..................: avg=4.15s min=3.84s med=3.95s max=6.88s p(90)=4.03s p(95)=4.89s
long_not_assisted..............: avg=3.48s min=3.42s med=3.46s max=3.71s p(90)=3.56s p(95)=3.61s
short_assisted.................: avg=326.96ms min=313.01ms med=319.41ms max=960.75ms p(90)=325.55ms p(95)=326.07ms
short_not_assisted.............: avg=784.35ms min=736.55ms med=747.67ms max=2s p(90)=772.9ms p(95)=774.1ms
```
As you can see, assisted generation gives dramatic performance gains when an audio is short (batch size is 1). If an audio is long, inference will automatically chunk it into batches, and speculative decoding may hurt inference time because of the limitations we discussed before.
### Inference parameters
All the inference parameters are in `config.py`:
```python
class InferenceConfig(BaseModel):
task: Literal["transcribe", "translate"] = "transcribe"
batch_size: int = 24
assisted: bool = False
chunk_length_s: int = 30
sampling_rate: int = 16000
language: Optional[str] = None
num_speakers: Optional[int] = None
min_speakers: Optional[int] = None
max_speakers: Optional[int] = None
```
Of course, you can add or remove parameters as needed. The parameters related to the number of speakers are passed to a diarization pipeline, while all the others are mostly for the ASR pipeline. `sampling_rate` indicates the sampling rate of the audio to process and is used for preprocessing; the `assisted` flag tells the pipeline whether to use speculative decoding. Remember that for assisted generation the `batch_size` must be set to 1.
### Payload
Once deployed, send your audio along with the inference parameters to your inference endpoint, like this (in Python):
```python
import base64
import requests
API_URL = "<your endpoint URL>"
filepath = "/path/to/audio"
with open(filepath, "rb") as f:
audio_encoded = base64.b64encode(f.read()).decode("utf-8")
data = {
"inputs": audio_encoded,
"parameters": {
"batch_size": 24
}
}
resp = requests.post(API_URL, json=data, headers={"Authorization": "Bearer <your token>"})
print(resp.json())
```
Here the **"parameters"** field is a dictionary that contains all the parameters you'd like to adjust from the `InferenceConfig`. Note that parameters not specified in the `InferenceConfig` will be ignored.
Or with [InferenceClient](https://huggingface.co./docs/huggingface_hub/en/package_reference/inference_client#huggingface_hub.InferenceClient) (there is also an [async version](https://huggingface.co./docs/huggingface_hub/en/package_reference/inference_client#huggingface_hub.AsyncInferenceClient)):
```python
from huggingface_hub import InferenceClient
client = InferenceClient(model = "<your endpoint URL>", token="<your token>")
with open("/path/to/audio", "rb") as f:
audio_encoded = base64.b64encode(f.read()).decode("utf-8")
data = {
"inputs": audio_encoded,
"parameters": {
"batch_size": 24
}
}
res = client.post(json=data)
```
## Recap
In this blog, we discussed how to set up a modularized ASR + diarization + speculative decoding pipeline with Hugging Face Inference Endpoints. We did our best to make it easy to configure and adjust the pipeline as needed, and deployment with Inference Endpoints is always a piece of cake! We are lucky to have great models and tools openly available to the community that we used in the implementation:
- A family of [Whisper](https://huggingface.co./openai/whisper-large-v3) models by OpenAI
- A [diarization model](https://huggingface.co./pyannote/speaker-diarization-3.1) by Pyannote
- The [Insanely Fast Whisper repository](https://github.com/Vaibhavs10/insanely-fast-whisper/tree/main), which was the main source of inspiration
There is a [repo](https://github.com/plaggy/fast-whisper-server) that implements the same pipeline along with the server part (FastAPI+Uvicorn). It may come in handy if you'd like to customize it even further or host somewhere else. | [
[
"audio",
"mlops",
"implementation",
"deployment"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"audio",
"mlops",
"implementation",
"deployment"
] | null | null |
8fbd7ccf-6766-4dac-ae90-adb188b8ef96 | completed | 2025-01-16T03:09:11.596916 | 2025-01-16T13:36:42.958413 | 158d4703-e0bc-4d7b-8534-6f747c0d8982 | CO2 Emissions and the 🤗 Hub: Leading the Charge | sasha, muellerzr, nateraw | carbon-emissions-on-the-hub.md | ## What are CO2 Emissions and why are they important?
Climate change is one of the greatest challenges that we are facing and reducing emissions of greenhouse gases such as carbon dioxide (CO2) is an important part of tackling this problem.
Training and deploying machine learning models will emit CO2 due to the energy usage of the computing infrastructures that are used: from GPUs to storage, it all needs energy to function and emits CO2 in the process.

> Pictured: Recent Transformer models and their carbon footprints
The amount of CO2 emitted depends on different factors such as runtime, hardware used, and carbon intensity of the energy source.
Using the tools described below will help you both track and report your own emissions (which is important to improve the transparency of our field as a whole!) and choose models based on their carbon footprint.
## How to calculate your own CO2 Emissions automatically with Transformers
Before we begin, if you do not have the latest version of the `huggingface_hub` library on your system, please run the following:
```
pip install huggingface_hub -U
```
## How to find low-emission models using the Hugging Face Hub
With the model now uploaded to the Hub, how can you search for models on the Hub while trying to be eco-friendly? Well, the `huggingface_hub` library has a new special parameter to perform this search: `emissions_threshold`. All you need to do is specify a minimum or maximum number of grams, and all models that fall within that range.
For example, we can search for all models that took a maximum of 100 grams to make:
```python
from huggingface_hub import HfApi
api = HfApi()
models = api.list_models(emissions_thresholds=(None, 100), cardData=True)
len(models)
>>> 191
```
There were quite a few! This also helps to find smaller models, given they typically did not release as much carbon during training.
We can look at one up close to see it does fit our threshold:
```python
model = models[0]
print(f'Model Name: {model.modelId}\nCO2 Emitted during training: {model.cardData["co2_eq_emissions"]}')
>>> Model Name: esiebomajeremiah/autonlp-email-classification-657119381
CO2 Emitted during training: 3.516233232503715
```
Similarly, we can search for a minimum value to find very large models that emitted a lot of CO2 during training:
```python
models = api.list_models(emissions_thresholds=(500, None), cardData=True)
len(models)
>>> 10
```
Now let's see exactly how much CO2 one of these emitted:
```python
model = models[0]
print(f'Model Name: {model.modelId}\nCO2 Emitted during training: {model.cardData["co2_eq_emissions"]}')
>>> Model Name: Maltehb/aelaectra-danish-electra-small-cased
CO2 Emitted during training: 4009.5
```
That's a lot of CO2!
As you can see, in just a few lines of code we can quickly vet models we may want to use to make sure we're being environmentally cognizant!
## How to Report Your Carbon Emissions with `transformers`
If you're using `transformers`, you can automatically track and report carbon emissions thanks to the `codecarbon` integration. If you've installed `codecarbon` on your machine, the `Trainer` object will automatically add the `CodeCarbonCallback` while training, which will store carbon emissions data for you as you train.
So, if you run something like this...
```python
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
ds = load_dataset("imdb")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
small_train_dataset = ds["train"].shuffle(seed=42).select(range(1000)).map(tokenize_function, batched=True)
small_eval_dataset = ds["test"].shuffle(seed=42).select(range(1000)).map(tokenize_function, batched=True)
training_args = TrainingArguments(
"codecarbon-text-classification",
num_train_epochs=4,
push_to_hub=True
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
)
trainer.train()
```
...you'll be left with a file within the `codecarbon-text-classification` directory called `emissions.csv`. This file will keep track of the carbon emissions across different training runs. Then, when you're ready, you can take the emissions from the run you used to train your final model and include that in its model card. 📝
An example of this data being included at the top of the model card is shown below:

For more references on the metadata format for `co2_eq_emissions ` see [the hub docs](https://huggingface.co./docs/hub/model-cards-co2).
### Further readings
- Rolnick et al. (2019) - [Tackling Climate Change with Machine Learning](https://arxiv.org/pdf/1906.05433.pdf)
- Strubell et al. (2019) - [Energy and Policy Considerations for Deep Learning in NLP](https://arxiv.org/pdf/1906.02243.pdf)
- Schwartz et al. (2020) - [Green AI](https://dl.acm.org/doi/abs/10.1145/3381831) | [
[
"transformers",
"mlops",
"research",
"tools",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"mlops",
"transformers",
"efficient_computing",
"tools"
] | null | null |
64cf081f-dae8-4217-b8d7-c0c4f778244b | completed | 2025-01-16T03:09:11.596924 | 2025-01-19T19:09:39.041993 | dc648fda-a55e-481b-a8ff-65fba046a0d7 | Fine-tuning Stable Diffusion models on Intel CPUs | juliensimon | stable-diffusion-finetuning-intel.md | Diffusion models helped popularize generative AI thanks to their uncanny ability to generate photorealistic images from text prompts. These models have now found their way into enterprise use cases like synthetic data generation or content creation. The Hugging Face hub includes over 5,000 pre-trained text-to-image [models](https://huggingface.co./models?pipeline_tag=text-to-image&sort=trending). Combining them with the [Diffusers library](https://huggingface.co./docs/diffusers/index), it's never been easier to start experimenting and building image generation workflows.
Like Transformer models, you can fine-tune Diffusion models to help them generate content that matches your business needs. Initially, fine-tuning was only possible on GPU infrastructure, but things are changing! A few months ago, Intel [launched](https://www.intel.com/content/www/us/en/newsroom/news/4th-gen-xeon-scalable-processors-max-series-cpus-gpus.html#gs.2d6cd7) the fourth generation of Xeon CPUs, code-named Sapphire Rapids. Sapphire Rapids introduces the Intel Advanced Matrix Extensions (AMX), a new hardware accelerator for deep learning workloads. We've already demonstrated the benefits of AMX in several blog posts: [fine-tuning NLP Transformers](https://huggingface.co./blog/intel-sapphire-rapids), [inference with NLP Transformers](https://huggingface.co./blog/intel-sapphire-rapids-inference), and [inference with Stable Diffusion models](https://huggingface.co./blog/stable-diffusion-inference-intel).
This post will show you how to fine-tune a Stable Diffusion model on an Intel Sapphire Rapids CPU cluster. We will use [textual inversion](https://huggingface.co./docs/diffusers/training/text_inversion), a technique that only requires a small number of example images. We'll use only five!
Let's get started.
## Setting up the cluster
Our friends at [Intel](https://huggingface.co./intel) provided four servers hosted on the [Intel Developer Cloud](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) (IDC), a service platform for developing and running workloads in Intel®-optimized deployment environments with the latest Intel processors and [performance-optimized software stacks](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html).
Each server is powered by two Intel Sapphire Rapids CPUs with 56 physical cores and 112 threads. Here's the output of `lscpu`:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 52 bits physical, 57 bits virtual
Byte Order: Little Endian
CPU(s): 224
On-line CPU(s) list: 0-223
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) Platinum 8480+
CPU family: 6
Model: 143
Thread(s) per core: 2
Core(s) per socket: 56
Socket(s): 2
Stepping: 8
CPU max MHz: 3800.0000
CPU min MHz: 800.0000
BogoMIPS: 4000.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_per fmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cat_l2 cdp_l3 invpcid_single intel_ppin cdp_l2 ssbd mba ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a avx512f avx512dq rdseed adx smap avx512ifma clflushopt clwb intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local split_lock_detect avx_vnni avx512_bf16 wbnoinvd dtherm ida arat pln pts hwp hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke waitpkg avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg tme avx512_vpopcntdq la57 rdpid bus_lock_detect cldemote movdiri movdir64b enqcmd fsrm md_clear serialize tsxldtrk pconfig arch_lbr amx_bf16 avx512_fp16 amx_tile amx_int8 flush_l1d arch_capabilities
```
Let's first list the IP addresses of our servers in `nodefile.` The first line refers to the primary server.
```
cat << EOF > nodefile
192.168.20.2
192.168.21.2
192.168.22.2
192.168.23.2
EOF
```
Distributed training requires password-less `ssh` between the primary and other nodes. Here's a good [article](https://www.redhat.com/sysadmin/passwordless-ssh) on how to do this if you're unfamiliar with the process.
Next, we create a new environment on each node and install the software dependencies. We notably install two Intel libraries: [oneCCL](https://github.com/oneapi-src/oneCCL), to manage distributed communication and the [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) to leverage the hardware acceleration features present in Sapphire Rapids. We also add `gperftools` to install `libtcmalloc,` a high-performance memory allocation library.
```
conda create -n diffuser python==3.9
conda activate diffuser
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip3 install transformers accelerate==0.19.0
pip3 install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install intel_extension_for_pytorch
conda install gperftools -c conda-forge -y
```
Next, we clone the [diffusers](https://github.com/huggingface/diffusers/) repository on each node and install it from source.
```
git clone https://github.com/huggingface/diffusers.git
cd diffusers
pip install .
```
Next, we add IPEX to the fine-tuning script in `diffusers/examples/textual_inversion`. We import IPEX and optimize the U-Net and Variable Auto Encoder models. Please make sure this is applied to all nodes.
```
diff --git a/examples/textual_inversion/textual_inversion.py b/examples/textual_inversion/textual_inversion.py
index 4a193abc..91c2edd1 100644 | [
[
"implementation",
"tutorial",
"image_generation",
"fine_tuning",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"image_generation",
"fine_tuning",
"efficient_computing",
"implementation"
] | null | null |
b0f8af4f-77cd-40ea-a8f1-716e1ecc0474 | completed | 2025-01-16T03:09:11.596931 | 2025-01-16T03:16:42.464178 | 170a7721-48bb-4a8d-9d86-9791e58a9edb | Judge Arena: Benchmarking LLMs as Evaluators | kaikaidai, MauriceBurg, RomanEngeler1805, mbartolo, clefourrier, tobydrane, mathias-atla, jacksongolden | arena-atla.md | LLM-as-a-Judge has emerged as a popular way to grade natural language outputs from LLM applications, **but how do we know which models make the best judges**?
We’re excited to launch [Judge Arena](https://huggingface.co./spaces/AtlaAI/judge-arena) - a platform that lets anyone easily compare models as judges side-by-side. Just run the judges on a test sample and vote which judge you agree with most. The results will be organized into a leaderboard that displays the best judges.
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/5.5.0/gradio.js"></script>
<gradio-app src="https://atlaai-judge-arena.hf.space"></gradio-app>
## Judge Arena
Crowdsourced, randomized battles have proven effective at benchmarking LLMs. LMSys's Chatbot Arena has collected over 2M votes and is [highly regarded](https://x.com/karpathy/status/1737544497016578453) as a field-test to identify the best language models. Since LLM evaluations aim to capture human preferences, direct human feedback is also key to determining which AI judges are most helpful.
### How it works
1. Choose your sample for evaluation:
- Let the system randomly generate a 👩 User Input / 🤖 AI Response pair
- OR input your own custom sample
2. Two LLM judges will:
- Score the response
- Provide their reasoning for the score
3. Review both judges’ evaluations and vote for the one that best aligns with your judgment
*(We recommend reviewing the scores first before comparing critiques)*
After each vote, you can:
- **Regenerate judges:** Get new evaluations of the same sample
- Start a **🎲 New round:** Randomly generate a new sample to be evaluated
- OR, input a new custom sample to be evaluated
To avoid bias and potential abuse, the model names are only revealed after a vote is submitted.
## Selected Models
Judge Arena focuses on the LLM-as-a-Judge approach, and therefore only includes generative models (excluding classifier models that solely output a score). We formalize our selection criteria for AI judges as the following:
1. **The model should possess the ability to score AND critique other models' outputs effectively.**
2. **The model should be prompt-able to evaluate in different scoring formats, for different criteria.**
We selected 18 state-of-the-art LLMs for our leaderboard. While many are open-source models with public weights, we also included proprietary API models to enable direct comparison between open and closed approaches.
- **OpenAI** (GPT-4o, GPT-4 Turbo, GPT-3.5 Turbo)
- **Anthropic** (Claude 3.5 Sonnet / Haiku, Claude 3 Opus / Sonnet / Haiku)
- **Meta** (Llama 3.1 Instruct Turbo 405B / 70B / 8B)
- **Alibaba** (Qwen 2.5 Instruct Turbo 7B / 72B, Qwen 2 Instruct 72B)
- **Google** (Gemma 2 9B / 27B)
- **Mistral** (Instruct v0.3 7B, Instruct v0.1 7B)
The current list represents the models most commonly used in AI evaluation pipelines. We look forward to adding more models if our leaderboard proves to be useful.
## The Leaderboard
The votes collected from the Judge Arena will be compiled and displayed on a dedicated public leaderboard. We calculate an [Elo score](https://en.wikipedia.org/wiki/Elo_rating_system) for each model and will update the leaderboard hourly.
## Early Insights
These are only very early results, but here’s what we’ve observed so far:
- **Mix of top performers between proprietary and open source**: GPT-4 Turbo leads by a narrow margin but the Llama and Qwen models are extremely competitive, surpassing the majority of proprietary models
- **Smaller models show impressive performance:** Qwen 2.5 7B and Llama 3.1 8B are performing remarkably well and competing with much larger models. As we gather more data, we hope to better understand the relationship between model scale and judging ability
- **Preliminary empirical support for emerging research:** LLM-as-a-Judge literature suggests that Llama models are well-suited as base models, demonstrating strong out-of-the-box performance on evaluation benchmarks. Several approaches including [Lynx](https://arxiv.org/pdf/2407.08488), [Auto-J](https://arxiv.org/pdf/2310.05470), and [SFR-LLaMA-3.1-Judge](https://arxiv.org/pdf/2409.14664) opted to start with Llama models before post-training for evaluation capabilities. Our provisional results align with this trend, showing Llama 3.1 70B and 405B ranking 2nd and 3rd, respectively
As the leaderboard shapes out over the coming weeks, we look forward to sharing further analysis on results on our [blog](https://www.atla-ai.com/blog).
## How to contribute
We hope the [Judge Arena](https://huggingface.co./spaces/AtlaAI/judge-arena) is a helpful resource for the community. By contributing to this leaderboard, you’ll help developers determine which models to use in their evaluation pipeline. We’re committed to sharing 20% of the anonymized voting data in the coming months as we hope developers, researchers and users will leverage our findings to build more aligned evaluators.
We’d love to hear your feedback! For general feature requests or to submit / suggest new models to add to the arena, please open up a discussion in the [community](https://huggingface.co./spaces/AtlaAI/judge-arena/discussions) tab or talk to us on [Discord](https://discord.gg/yNpUAMqs). Don’t hesitate to let us know if you have questions or suggestions by messaging us on [X/Twitter](https://x.com/Atla_AI).
[Atla](https://www.atla-ai.com/) currently funds this out of our own pocket. We are looking for API credits (with no strings attached) to support this community effort - please get in touch at [[email protected]](mailto:[email protected]) if you are interested in collaborating 🤗
## Credits
Thanks to all the folks who helped test this arena and shout out to the LMSYS team for the inspiration. Special mention to Clémentine Fourrier and the Hugging Face team for making this possible! | [
[
"llm",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"benchmarks",
"research",
"tools"
] | null | null |
24b9622e-0bda-426d-89ff-cdf8aaaffd2e | completed | 2025-01-16T03:09:11.596935 | 2025-01-19T18:47:28.635354 | c73a4fac-574a-4cdc-acd5-e97487503430 | Stable Diffusion XL on Mac with Advanced Core ML Quantization | pcuenq, Atila | stable-diffusion-xl-coreml.md | [Stable Diffusion XL](https://stability.ai/stablediffusion) was released yesterday and it’s awesome. It can generate large (1024x1024) high quality images; adherence to prompts has been improved with some new tricks; it can effortlessly produce very dark or very bright images thanks to the latest research on noise schedulers; and it’s open source!
The downside is that the model is much bigger, and therefore slower and more difficult to run on consumer hardware. Using the [latest release of the Hugging Face diffusers library](https://github.com/huggingface/diffusers/releases/tag/v0.19.0), you can run Stable Diffusion XL on CUDA hardware in 16 GB of GPU RAM, making it possible to use it on Colab’s free tier.
The past few months have shown that people are very clearly interested in running ML models locally for a variety of reasons, including privacy, convenience, easier experimentation, or unmetered use. We’ve been working hard at both Apple and Hugging Face to explore this space. We’ve shown [how to run Stable Diffusion on Apple Silicon](https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon), or how to leverage the [latest advancements in Core ML to improve size and performance with 6-bit palettization](https://huggingface.co./blog/fast-diffusers-coreml).
For Stable Diffusion XL we’ve done a few things:
* Ported the [base model to Core ML](https://huggingface.co./apple/coreml-stable-diffusion-xl-base) so you can use it in your native Swift apps.
* Updated [Apple’s conversion and inference repo](https://github.com/apple/ml-stable-diffusion) so you can convert the models yourself, including any fine-tunes you’re interested in.
* Updated [Hugging Face’s demo app](https://github.com/huggingface/swift-coreml-diffusers) to show how to use the new Core ML Stable Diffusion XL models downloaded from the Hub.
* Explored [mixed-bit palettization](https://github.com/apple/ml-stable-diffusion#-mbp-post-training-mixed-bit-palettization), an advanced compression technique that achieves important size reductions while minimizing and controlling the quality loss you incur. You can apply the same technique to your own models too!
Everything is open source and available today, let’s get on with it.
## Contents
- [Using SD XL Models from the Hugging Face Hub](#using-sd-xl-models-from-the-hugging-face-hub)
- [What is Mixed-Bit Palettization?](#what-is-mixed-bit-palettization)
- [How are Mixed-Bit Recipes Created?](#how-are-mixed-bit-recipes-created)
- [Converting Fine-Tuned Models](#converting-fine-tuned-models)
- [Published Resources](#published-resources)
## Using SD XL Models from the Hugging Face Hub
As part of this release, we published two different versions of Stable Diffusion XL in Core ML.
- [`apple/coreml-stable-diffusion-xl-base`](https://huggingface.co./apple/coreml-stable-diffusion-xl-base) is a complete pipeline, without any quantization.
- [`apple/coreml-stable-diffusion-mixed-bit-palettization`](https://huggingface.co./apple/coreml-stable-diffusion-mixed-bit-palettization) contains (among other artifacts) a complete pipeline where the UNet has been replaced with a mixed-bit palettization _recipe_ that achieves a compression equivalent to 4.5 bits per parameter. Size went down from 4.8 to 1.4 GB, a 71% reduction, and in our opinion quality is still great.
Either model can be tested using Apple’s [Swift command-line inference app](https://github.com/apple/ml-stable-diffusion#inference), or Hugging Face’s [demo app](https://github.com/huggingface/swift-coreml-diffusers). This is an example of the latter using the new Stable Diffusion XL pipeline:

As with previous Stable Diffusion releases, we expect the community to come up with novel fine-tuned versions for different domains, and many of them will be converted to Core ML. You can keep an eye on [this filter in the Hub](https://huggingface.co./models?pipeline_tag=text-to-image&library=coreml&sort=trending) to explore!
Stable Diffusion XL works on Apple Silicon Macs running the public beta of macOS 14. It currently uses the `ORIGINAL` attention implementation, which is intended for CPU + GPU compute units. Note that the refiner stage has not been ported yet.
For reference, these are the performance figures we achieved on different devices:
| Device | `--compute-unit`| `--attention-implementation` | End-to-End Latency (s) | Diffusion Speed (iter/s) |
| | [
[
"computer_vision",
"image_generation",
"quantization",
"efficient_computing"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"image_generation",
"quantization",
"efficient_computing"
] | null | null |
8254babc-fe82-4f80-b530-86eb7f538672 | completed | 2025-01-16T03:09:11.596940 | 2025-01-19T19:06:17.194840 | ef0b6141-5605-4a3d-a9d3-bc0d253fdbb7 | 'Few-shot learning in practice: GPT-Neo and the 🤗 Accelerated Inference API' | philschmid | few-shot-learning-gpt-neo-and-inference-api.md | In many Machine Learning applications, the amount of available labeled data is a barrier to producing a high-performing model. The latest developments in NLP show that you can overcome this limitation by providing a few examples at inference time with a large language model - a technique known as Few-Shot Learning. In this blog post, we'll explain what Few-Shot Learning is, and explore how a large language model called GPT-Neo, and the 🤗 Accelerated Inference API, can be used to generate your own predictions.
## What is Few-Shot Learning?
Few-Shot Learning refers to the practice of feeding a machine learning model with a very small amount of training data to guide its predictions, like a few examples at inference time, as opposed to standard fine-tuning techniques which require a relatively large amount of training data for the pre-trained model to adapt to the desired task with accuracy.
This technique has been mostly used in computer vision, but with some of the latest Language Models, like [EleutherAI GPT-Neo](https://www.eleuther.ai/research/projects/gpt-neo/) and [OpenAI GPT-3](https://openai.com/blog/gpt-3-apps/), we can now use it in Natural Language Processing (NLP).
In NLP, Few-Shot Learning can be used with Large Language Models, which have learned to perform a wide number of tasks implicitly during their pre-training on large text datasets. This enables the model to generalize, that is to understand related but previously unseen tasks, with just a few examples.
Few-Shot NLP examples consist of three main components:
- **Task Description**: A short description of what the model should do, e.g. "Translate English to French"
- **Examples**: A few examples showing the model what it is expected to predict, e.g. "sea otter => loutre de mer"
- **Prompt**: The beginning of a new example, which the model should complete by generating the missing text, e.g. "cheese => "

<small>Image from <a href="https://arxiv.org/abs/2005.14165" target="_blank">Language Models are Few-Shot Learners</a></small>
Creating these few-shot examples can be tricky, since you need to articulate the “task” you want the model to perform through them. A common issue is that models, especially smaller ones, are very sensitive to the way the examples are written.
An approach to optimize Few-Shot Learning in production is to learn a common representation for a task and then train task-specific classifiers on top of this representation.
OpenAI showed in the [GPT-3 Paper](https://arxiv.org/abs/2005.14165) that the few-shot prompting ability improves with the number of language model parameters.

<small>Image from <a href="https://arxiv.org/abs/2005.14165" target="_blank">Language Models are Few-Shot Learners</a></small>
Let's now take a look at how at how GPT-Neo and the 🤗 Accelerated Inference API can be used to generate your own Few-Shot Learning predictions! | [
[
"llm",
"implementation",
"text_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"text_generation"
] | null | null |
8552dc44-7b49-4d19-bc48-da57fc2a561b | completed | 2025-01-16T03:09:11.596945 | 2025-01-19T19:13:27.911066 | b4a6e57f-8b36-46ab-82a5-ee5f8eee0fdb | Comparing the Performance of LLMs: A Deep Dive into Roberta, Llama 2, and Mistral for Disaster Tweets Analysis with Lora | mehdiiraqui | Lora-for-sequence-classification-with-Roberta-Llama-Mistral.md | <!-- TOC -->
- [Comparing the Performance of LLMs: A Deep Dive into Roberta, Llama 2, and Mistral for Disaster Tweets Analysis with LoRA](#comparing-the-performance-of-llms-a-deep-dive-into-roberta-llama-2-and-mistral-for-disaster-tweets-analysis-with-lora)
- [Introduction](#introduction)
- [Hardware Used](#hardware-used)
- [Goals](#goals)
- [Dependencies](#dependencies)
- [Pre-trained Models](#pre-trained-models)
- [RoBERTa](#roberta)
- [Llama 2](#llama-2)
- [Mistral 7B](#mistral-7b)
- [LoRA](#lora)
- [Setup](#setup)
- [Data preparation](#data-preparation)
- [Data loading](#data-loading)
- [Data Processing](#data-processing)
- [Models](#models)
- [RoBERTa](#roberta)
- [Load RoBERTA Checkpoints for the Classification Task](#load-roberta-checkpoints-for-the-classification-task)
- [LoRA setup for RoBERTa classifier](#lora-setup-for-roberta-classifier)
- [Mistral](#mistral)
- [Load checkpoints for the classfication model](#load-checkpoints-for-the-classfication-model)
- [LoRA setup for Mistral 7B classifier](#lora-setup-for-mistral-7b-classifier)
- [Llama 2](#llama-2)
- [Load checkpoints for the classification mode](#load-checkpoints-for-the-classfication-mode)
- [LoRA setup for Llama 2 classifier](#lora-setup-for-llama-2-classifier)
- [Setup the trainer](#setup-the-trainer)
- [Evaluation Metrics](#evaluation-metrics)
- [Custom Trainer for Weighted Loss](#custom-trainer-for-weighted-loss)
- [Trainer Setup](#trainer-setup)
- [RoBERTa](#roberta)
- [Mistral-7B](#mistral-7b)
- [Llama 2](#llama-2)
- [Hyperparameter Tuning](#hyperparameter-tuning)
- [Results](#results)
- [Conclusion](#conclusion)
- [Resources](#resources)
<!-- /TOC -->
## Introduction
In the fast-moving world of Natural Language Processing (NLP), we often find ourselves comparing different language models to see which one works best for specific tasks. This blog post is all about comparing three models: RoBERTa, Mistral-7b, and Llama-2-7b. We used them to tackle a common problem - classifying tweets about disasters. It is important to note that Mistral and Llama 2 are large models with 7 billion parameters. In contrast, RoBERTa-large (355M parameters) is a relatively smaller model used as a baseline for the comparison study.
In this blog, we used PEFT (Parameter-Efficient Fine-Tuning) technique: LoRA (Low-Rank Adaptation of Large Language Models) for fine-tuning the pre-trained model on the sequence classification task. LoRa is designed to significantly reduce the number of trainable parameters while maintaining strong downstream task performance.
The main objective of this blog post is to implement LoRA fine-tuning for sequence classification tasks using three pre-trained models from Hugging Face: [meta-llama/Llama-2-7b-hf](https://huggingface.co./meta-llama/Llama-2-7b-chat-hf), [mistralai/Mistral-7B-v0.1](https://huggingface.co./mistralai/Mistral-7B-v0.1), and [roberta-large](https://huggingface.co./roberta-large)
## Hardware Used
- Number of nodes: 1
- Number of GPUs per node: 1
- GPU type: A6000
- GPU memory: 48GB
## Goals
- Implement fine-tuning of pre-trained LLMs using LoRA PEFT methods.
- Learn how to use the HuggingFace APIs ([transformers](https://huggingface.co./docs/transformers/index), [peft](https://huggingface.co./docs/peft/index), and [datasets](https://huggingface.co./docs/datasets/index)).
- Setup the hyperparameter tuning and experiment logging using [Weights & Biases](https://wandb.ai).
## Dependencies
```bash
datasets
evaluate
peft
scikit-learn
torch
transformers
wandb
```
Note: For reproducing the reported results, please check the pinned versions in the [wandb reports](#resources).
## Pre-trained Models
### [RoBERTa](https://arxiv.org/abs/1907.11692)
RoBERTa (Robustly Optimized BERT Approach) is an advanced variant of the BERT model proposed by Meta AI research team. BERT is a transformer-based language model using self-attention mechanisms for contextual word representations and trained with a masked language model objective. Note that BERT is an encoder only model used for natural language understanding tasks (such as sequence classification and token classification).
RoBERTa is a popular model to fine-tune and appropriate as a baseline for our experiments. For more information, you can check the Hugging Face model [card](https://huggingface.co./docs/transformers/model_doc/roberta).
### [Llama 2](https://arxiv.org/abs/2307.09288)
Llama 2 models, which stands for Large Language Model Meta AI, belong to the family of large language models (LLMs) introduced by Meta AI. The Llama 2 models vary in size, with parameter counts ranging from 7 billion to 65 billion.
Llama 2 is an auto-regressive language model, based on the transformer decoder architecture. To generate text, Llama 2 processes a sequence of words as input and iteratively predicts the next token using a sliding window.
Llama 2 architecture is slightly different from models like GPT-3. For instance, Llama 2 employs the SwiGLU activation function rather than ReLU and opts for rotary positional embeddings in place of absolute learnable positional embeddings.
The recently released Llama 2 introduced architectural refinements to better leverage very long sequences by extending the context length to up to 4096 tokens, and using grouped-query attention (GQA) decoding.
### [Mistral 7B](https://arxiv.org/abs/2310.06825)
Mistral 7B v0.1, with 7.3 billion parameters, is the first LLM introduced by Mistral AI.
The main novel techniques used in Mistral 7B's architecture are:
- Sliding Window Attention: Replace the full attention (square compute cost) with a sliding window based attention where each token can attend to at most 4,096 tokens from the previous layer (linear compute cost). This mechanism enables Mistral 7B to handle longer sequences, where higher layers can access historical information beyond the window size of 4,096 tokens.
- Grouped-query Attention: used in Llama 2 as well, the technique optimizes the inference process (reduce processing time) by caching the key and value vectors for previously decoded tokens in the sequence.
## [LoRA](https://arxiv.org/abs/2106.09685)
PEFT, Parameter Efficient Fine-Tuning, is a collection of techniques (p-tuning, prefix-tuning, IA3, Adapters, and LoRa) designed to fine-tune large models using a much smaller set of training parameters while preserving the performance levels typically achieved through full fine-tuning.
LoRA, Low-Rank Adaptation, is a PEFT method that shares similarities with Adapter layers. Its primary objective is to reduce the model's trainable parameters. LoRA's operation involves
learning a low rank update matrix while keeping the pre-trained weights frozen.

## Setup
RoBERTa has a limitatiom of maximum sequence length of 512, so we set the `MAX_LEN=512` for all models to ensure a fair comparison.
```python
MAX_LEN = 512
roberta_checkpoint = "roberta-large"
mistral_checkpoint = "mistralai/Mistral-7B-v0.1"
llama_checkpoint = "meta-llama/Llama-2-7b-hf"
```
## Data preparation
### Data loading
We will load the dataset from Hugging Face:
```python
from datasets import load_dataset
dataset = load_dataset("mehdiiraqui/twitter_disaster")
```
Now, let's split the dataset into training and validation datasets. Then add the test set:
```python
from datasets import Dataset
# Split the dataset into training and validation datasets
data = dataset['train'].train_test_split(train_size=0.8, seed=42)
# Rename the default "test" split to "validation"
data['val'] = data.pop("test")
# Convert the test dataframe to HuggingFace dataset and add it into the first dataset
data['test'] = dataset['test']
```
Here's an overview of the dataset:
```bash
DatasetDict({
train: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 6090
})
val: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 1523
})
test: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 3263
})
})
```
Let's check the data distribution:
```python
import pandas as pd
data['train'].to_pandas().info()
data['test'].to_pandas().info()
```
- Train dataset
```<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7613 entries, 0 to 7612
Data columns (total 5 columns):
# Column Non-Null Count Dtype | [
[
"llm",
"benchmarks",
"text_classification",
"fine_tuning"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"fine_tuning",
"benchmarks",
"text_classification"
] | null | null |
63434a21-547b-49d3-962e-cc1424f46e6a | completed | 2025-01-16T03:09:11.596949 | 2025-01-16T03:11:22.417275 | bbe0feae-9c25-442e-af05-bc7a978565dd | PaliGemma – Google's Cutting-Edge Open Vision Language Model | merve, andsteing, pcuenq | paligemma.md | Updated on 23-05-2024: We have introduced a few changes to the transformers PaliGemma implementation around fine-tuning, which you can find in this [notebook](https://github.com/merveenoyan/smol-vision/blob/main/Fine_tune_PaliGemma.ipynb).
PaliGemma is a new family of vision language models from Google. PaliGemma can take in an image and a text and output text.
The team at Google has released three types of models: the pretrained (pt) models, the mix models, and the fine-tuned (ft) models, each with different resolutions and available in multiple precisions for convenience.
All models are released in the Hugging Face Hub model repositories with their model cards and licenses and have transformers integration.
## What is PaliGemma?
PaliGemma ([Github](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/README.md)) is a family of vision-language models with an architecture consisting of [SigLIP-So400m](https://huggingface.co./google/siglip-so400m-patch14-384) as the image encoder and [Gemma-2B](https://huggingface.co./google/gemma-2b) as text decoder. SigLIP is a state-of-the-art model that can understand both images and text. Like CLIP, it consists of an image and text encoder trained jointly. Similar to [PaLI-3](https://arxiv.org/abs/2310.09199), the combined PaliGemma model is pre-trained on image-text data and can then easily be fine-tuned on downstream tasks, such as captioning, or referring segmentation. [Gemma](https://huggingface.co./blog/gemma) is a decoder-only model for text generation. Combining the image encoder of SigLIP with Gemma using a linear adapter makes PaliGemma a powerful vision language model.

The PaliGemma release comes with three types of models:
- PT checkpoints: Pretrained models that can be fine-tuned to downstream tasks.
- Mix checkpoints: PT models fine-tuned to a mixture of tasks. They are suitable for general-purpose inference with free-text prompts, and can be used for research purposes only.
- FT checkpoints: A set of fine-tuned models, each one specialized on a different academic benchmark. They are available in various resolutions and are intended for research purposes only.
The models come in three different resolutions (`224x224`, `448x448`, `896x896`) and three different precisions (`bfloat16`, `float16`, and `float32`). Each repository contains the checkpoints for a given resolution and task, with three revisions for each of the available precisions. The `main` branch of each repository contains `float32` checkpoints, where as the `bfloat16` and `float16` revisions contain the corresponding precisions. There are separate repositories for models compatible with 🤗 transformers, and with the original JAX implementation.
As explained in detail further down, the high-resolution models require a lot more memory to run, because the input sequences are much longer. They may help with fine-grained tasks such as OCR, but the quality increase is small for most tasks. The 224 versions are perfectly fine for most purposes.
You can find all the models and Spaces in this [collection](https://huggingface.co./collections/google/paligemma-release-6643a9ffbf57de2ae0448dda).
## Model Capabilities
PaliGemma is a single-turn vision language model not meant for conversational use, and it works best when fine-tuning to a specific use case.
You can configure which task the model will solve by conditioning it with task prefixes, such as “detect” or “segment”. The pretrained models were trained in this fashion to imbue them with a rich set of capabilities (question answering, captioning, segmentation, etc.). However, they are not designed to be used directly, but to be transferred (by fine-tuning) to specific tasks using a similar prompt structure. For interactive testing, you can use the "mix" family of models, which have been fine-tuned on a mixture of tasks.
The examples below use the mix checkpoints to demonstrate some of the capabilities.
### Image Captioning
PaliGemma can caption images when prompted to. You can try various captioning prompts with the mix checkpoints to see how they respond.

### Visual Question Answering
PaliGemma can answer questions about an image, simply pass your question along with the image to do so.

### Detection
PaliGemma can detect entities in an image using the `detect [entity]` prompt. It will output the location for the bounding box coordinates in the form of special `<loc[value]>` tokens, where `value` is a number that represents a normalized coordinate. Each detection is represented by four location coordinates in the order _y_min, x_min, y_max, x_max_, followed by the label that was detected in that box. To convert values to coordinates, you first need to divide the numbers by 1024, then multiply `y` by the image height and `x` by its width. This will give you the coordinates of the bounding boxes, relative to the original image size.

### Referring Expression Segmentation
PaliGemma mix checkpoints can also segment entities in an image when given the `segment [entity]` prompt. This is called referring expression segmentation, because we refer to the entities of interest using natural language descriptions. The output is a sequence of location and segmentation tokens. The location tokens represent a bounding box as described above. The segmentation tokens can be further processed to generate segmentation masks.

### Document Understanding
PaliGemma mix checkpoints have great document understanding and reasoning capabilities.

### Mix Benchmarks
Below you can find the scores for mix checkpoints.
| Model | MMVP Accuracy | POPE Accuracy (random/popular/adversarial) |
| | [
[
"computer_vision",
"transformers",
"multi_modal"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"transformers",
"multi_modal",
"fine_tuning"
] | null | null |
f29d2400-7396-4eaa-9031-926d1c863eda | completed | 2025-01-16T03:09:11.596954 | 2025-01-19T19:14:11.241460 | b8d2a8db-5fa6-4bfd-bf44-ea583e413da3 | Supercharged Customer Service with Machine Learning | patrickvonplaten | supercharge-customer-service-with-machine-learning.md | <a target="_blank" href="https://github.com/patrickvonplaten/notebooks/blob/master/Using_%F0%9F%A4%97_Transformers_and_%F0%9F%A4%97_Datasets_filter_customer_feedback_filtering.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this blog post, we will simulate a real-world customer service use case and use tools machine learning tools of the Hugging Face ecosystem to address it.
We strongly recommend using this notebook as a template/example to solve **your** real-world use case.
## Defining Task, Dataset & Model
Before jumping into the actual coding part, it's important to have a clear definition of the use case that you would like to automate or partly automate.
A clear definition of the use case helps identify the most suitable task, dataset to use, and model to apply for your use case.
### Defining your NLP task
Alright, let's dive into a hypothetical problem we wish to solve using models of natural language processing models. Let's assume we are selling a product and our customer support team receives thousands of messages including feedback, complaints, and questions which ideally should all be answered.
Quickly, it becomes obvious that customer support is by no means able to reply to every message. Thus, we decide to only respond to the most unsatisfied customers and aim to answer 100% of those messages, as these are likely the most urgent compared to the other neutral and positive messages.
Assuming that a) messages of very unsatisfied customers represent only a fraction of all messages and b) that we can filter out unsatisfied messages in an automated way, customer support should be able to reach this goal.
To filter out unsatisfied messages in an automated way, we plan on applying natural language processing technologies.
The first step is to map our use case - *filtering out unsatisfied messages* - to a machine learning task.
The [tasks page on the Hugging Face Hub](https://huggingface.co./tasks) is a great place to get started to see which task best fits a given scenario. Each task has a detailed description and potential use cases.
The task of finding messages of the most unsatisfied customers can be modeled as a text classification task: Classify a message into one of the following 5 categories: *very unsatisfied*, *unsatisfied*, *neutral*, *satisfied*, **or** *very satisfied*.
### Finding suitable datasets
Having decided on the task, next, we should find the data the model will be trained on. This is usually more important for the performance of your use case than picking the right model architecture.
Keep in mind that a model is **only as good as the data it has been trained on**. Thus, we should be very careful when curating and/or selecting the dataset.
Since we consider the hypothetical use case of *filtering out unsatisfied messages*, let's look into what datasets are available.
For your real-world use case, it is **very likely** that you have internal data that best represents the actual data your NLP system is supposed to handle. Therefore, you should use such internal data to train your NLP system.
It can nevertheless be helpful to also include publicly available data to improve the generalizability of your model.
Let's take a look at all available Datasets on the [Hugging Face Hub](https://huggingface.co./datasets). On the left side, you can filter the datasets according to *Task Categories* as well as *Tasks* which are more specific. Our use case corresponds to *Text Classification* -> *Sentiment Analysis* so let's select [these filters](https://huggingface.co./datasets?task_categories=task_categories:text-classification&task_ids=task_ids:sentiment-classification&sort=downloads). We are left with *ca.* 80 datasets at the time of writing this notebook. Two aspects should be evaluated when picking a dataset:
- **Quality**: Is the dataset of high quality? More specifically: Does the data correspond to the data you expect to deal with in your use case? Is the data diverse, unbiased, ...?
- **Size**: How big is the dataset? Usually, one can safely say the bigger the dataset, the better.
It's quite tricky to evaluate whether a dataset is of high quality efficiently, and it's even more challenging to know whether and how the dataset is biased.
An efficient and reasonable heuristic for high quality is to look at the download statistics. The more downloads, the more usage, the higher chance that the dataset is of high quality. The size is easy to evaluate as it can usually be quickly read upon. Let's take a look at the most downloaded datasets:
- [Glue](https://huggingface.co./datasets/glue)
- [Amazon polarity](https://huggingface.co./datasets/amazon_polarity)
- [Tweet eval](https://huggingface.co./datasets/tweet_eval)
- [Yelp review full](https://huggingface.co./datasets/yelp_review_full)
- [Amazon reviews multi](https://huggingface.co./datasets/amazon_reviews_multi)
Now we can inspect those datasets in more detail by reading through the dataset card, which ideally should give all relevant and important information. In addition, the [dataset viewer](https://huggingface.co./datasets/glue/viewer/cola/test) is an incredibly powerful tool to inspect whether the data suits your use case.
Let's quickly go over the dataset cards of the models above:
- *GLUE* is a collection of small datasets that primarily serve to compare new model architectures for researchers. The datasets are too small and don't correspond enough to our use case.
- *Amazon polarity* is a huge and well-suited dataset for customer feedback since the data deals with customer reviews. However, it only has binary labels (positive/negative), whereas we are looking for more granularity in the sentiment classification.
- *Tweet eval* uses different emojis as labels that cannot easily be mapped to a scale going from unsatisfied to satisfied.
- *Amazon reviews multi* seems to be the most suitable dataset here. We have sentiment labels ranging from 1-5 corresponding to 1-5 stars on Amazon. These labels can be mapped to *very unsatisfied, neutral, satisfied, very satisfied*. We have inspected some examples on [the dataset viewer](https://huggingface.co./datasets/amazon_reviews_multi/viewer/en/train) to verify that the reviews look very similar to actual customer feedback reviews, so this seems like a very good dataset. In addition, each review has a `product_category` label, so we could even go as far as to only use reviews of a product category corresponding to the one we are working in. The dataset is multi-lingual, but we are just interested in the English version for now.
- *Yelp review full* looks like a very suitable dataset. It's large and contains product reviews and sentiment labels from 1 to 5. Sadly, the dataset viewer is not working here, and the dataset card is also relatively sparse, requiring some more time to inspect the dataset. At this point, we should read the paper, but given the time constraint of this blog post, we'll choose to go for *Amazon reviews multi*.
As a conclusion, let's focus on the [*Amazon reviews multi*](https://huggingface.co./datasets/amazon_reviews_multi) dataset considering all training examples.
As a final note, we recommend making use of Hub's dataset functionality even when working with private datasets. The Hugging Face Hub, Transformers, and Datasets are flawlessly integrated, which makes it trivial to use them in combination when training models.
In addition, the Hugging Face Hub offers:
- [A dataset viewer for every dataset](https://huggingface.co./datasets/amazon_reviews_multi)
- [Easy demoing of every model using widgets](https://huggingface.co./docs/hub/models-widgets)
- [Private and Public models](https://huggingface.co./docs/hub/repositories-settings)
- [Git version control for repositories](https://huggingface.co./docs/hub/repositories-getting-started)
- [Highest security mechanisms](https://huggingface.co./docs/hub/security)
### Finding a suitable model
Having decided on the task and the dataset that best describes our use case, we can now look into choosing a model to be used.
Most likely, you will have to fine-tune a pretrained model for your own use case, but it is worth checking whether the hub already has suitable fine-tuned models. In this case, you might reach a higher performance by just continuing to fine-tune such a model on your dataset.
Let's take a look at all models that have been fine-tuned on Amazon Reviews Multi. You can find the list of models on the bottom right corner - clicking on *Browse models trained on this dataset* you can see [a list of all models fine-tuned on the dataset that are publicly available](https://huggingface.co./models?dataset=dataset:amazon_reviews_multi). Note that we are only interested in the English version of the dataset because our customer feedback will only be in English. Most of the most downloaded models are trained on the multi-lingual version of the dataset and those that don't seem to be multi-lingual have very little information or poor performance. At this point,
it might be more sensible to fine-tune a purely pretrained model instead of using one of the already fine-tuned ones shown in the link above.
Alright, the next step now is to find a suitable pretrained model to be used for fine-tuning. This is actually more difficult than it seems given the large amount of pretrained and fine-tuned models that are on the [Hugging Face Hub](https://huggingface.co./models). The best option is usually to simply try out a variety of different models to see which one performs best.
We still haven't found the perfect way of comparing different model checkpoints to each other at Hugging Face, but we provide some resources that are worth looking into:
- The [model summary](https://huggingface.co./docs/transformers/model_summary) gives a short overview of different model architectures.
- A task-specific search on the Hugging Face Hub, *e.g.* [a search on text-classification models](https://huggingface.co./models), shows you the most downloaded checkpoints which is also an indication of how well those checkpoints perform.
However, both of the above resources are currently suboptimal. The model summary is not always kept up to date by the authors. The speed at which new model architectures are released and old model architectures become outdated makes it extremely difficult to have an up-to-date summary of all model architectures.
Similarly, it doesn't necessarily mean that the most downloaded model checkpoint is the best one. E.g. [`bert-base-cased`](https://huggingface.co./bert-base-uncased) is amongst the most downloaded model checkpoints but is not the best performing checkpoint anymore.
The best approach is to try out various model architectures, stay up to date with new model architectures by following experts in the field, and check well-known leaderboards.
For text-classification, the important benchmarks to look at are [GLUE](https://gluebenchmark.com/leaderboard) and [SuperGLUE](https://super.gluebenchmark.com/leaderboard). Both benchmarks evaluate pretrained models on a variety of text-classification tasks, such as grammatical correctness, natural language inference, Yes/No question answering, etc..., which are quite similar to our target task of sentiment analysis. Thus, it is reasonable to choose one of the leading models of these benchmarks for our task.
At the time of writing this blog post, the best performing models are very large models containing more than 10 billion parameters most of which are not open-sourced, *e.g.* *ST-MoE-32B*, *Turing NLR v5*, or
*ERNIE 3.0*. One of the top-ranking models that is easily accessible is [DeBERTa](https://huggingface.co./docs/transformers/model_doc/deberta). Therefore, let's try out DeBERTa's newest base version - *i.e.* [`microsoft/deberta-v3-base`](https://huggingface.co./microsoft/deberta-v3-base).
## Training / Fine-tuning a model with 🤗 Transformers and 🤗 Datasets
In this section, we will jump into the technical details of how to
fine-tune a model end-to-end to be able to automatically filter out very unsatisfied customer feedback messages.
Cool! Let's start by installing all necessary pip packages and setting up our code environment, then look into preprocessing the dataset, and finally start training the model.
The following notebook can be run online in a google colab pro with the GPU runtime environment enabled.
### Install all necessary packages
To begin with, let's install [`git-lfs`](https://git-lfs.github.com/) so that we can automatically upload our trained checkpoints to the Hub during training.
```bash
apt install git-lfs
```
Also, we install the 🤗 Transformers and 🤗 Datasets libraries to run this notebook. Since we will be using [DeBERTa](https://huggingface.co./docs/transformers/model_doc/deberta-v2#debertav2) in this blog post, we also need to install the [`sentencepiece`](https://github.com/google/sentencepiece) library for its tokenizer.
```bash
pip install datasets transformers[sentencepiece]
```
Next, let's login into our [Hugging Face account](https://huggingface.co./join) so that models are uploaded correctly under your name tag.
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
```
### Preprocess the dataset
Before we can start training the model, we should bring the dataset in a format
that is understandable by the model.
Thankfully, the 🤗 Datasets library makes this extremely easy as you will see in the following cells.
The `load_dataset` function loads the dataset, nicely arranges it into predefined attributes, such as `review_body` and `stars`, and finally saves the newly arranged data using the [arrow format](https://arrow.apache.org/#:~:text=Format,data%20access%20without%20serialization%20overhead.) on disk.
The arrow format allows for fast and memory-efficient data reading and writing.
Let's load and prepare the English version of the `amazon_reviews_multi` dataset.
```python
from datasets import load_dataset
amazon_review = load_dataset("amazon_reviews_multi", "en")
```
**Output:**
```
Downloading and preparing dataset amazon_reviews_multi/en (download: 82.11 MiB, generated: 58.69 MiB, post-processed: Unknown size, total: 140.79 MiB) to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609...
Dataset amazon_reviews_multi downloaded and prepared to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609. Subsequent calls will reuse this data.
```
Great, that was fast 🔥. Let's take a look at the structure of the dataset.
```python
print(amazon_review)
```
**Output:**
```
{.output .execute_result execution_count="5"}
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
```
We have 200,000 training examples as well as 5000 validation and test examples. This sounds reasonable for training! We're only really interested in the input being the `"review_body"` column and the target being the `"starts"` column.
Let's check out a random example.
```python
random_id = 34
print("Stars:", amazon_review["train"][random_id]["stars"])
print("Review:", amazon_review["train"][random_id]["review_body"])
```
**Output:**
```
Stars: 1
Review: This product caused severe burning of my skin. I have used other brands with no problems
```
The dataset is in a human-readable format, but now we need to transform it into a "machine-readable" format. Let's define the model repository which includes all utils necessary to preprocess and fine-tune the checkpoint we decided on.
```python
model_repository = "microsoft/deberta-v3-base"
```
Next, we load the tokenizer of the model repository, which is a [DeBERTa's Tokenizer](https://huggingface.co./docs/transformers/model_doc/deberta-v2#transformers.DebertaV2Tokenizer).
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_repository)
```
As mentioned before, we will use the `"review_body"` as the model's input and `"stars"` as the model's target. Next, we make use of the tokenizer to transform the input into a sequence of token ids that can be understood by the model. The tokenizer does exactly this and can also help you to limit your input data to a certain length to not run into a memory issue. Here, we limit
the maximum length to 128 tokens which in the case of DeBERTa corresponds to roughly 100 words which in turn corresponds to *ca.* 5-7 sentences. Looking at the [dataset viewer](https://huggingface.co./datasets/amazon_reviews_multi/viewer/en/test) again, we can see that this covers pretty much all training examples.
**Important**: This doesn't mean that our model cannot handle longer input sequences, it just means that we use a maximum length of 128 for training since it covers 99% of our training and we don't want to waste memory. Transformer models have shown to be very good at generalizing to longer sequences after training.
If you want to learn more about tokenization in general, please have a look at [the Tokenizers docs](https://huggingface.co./course/chapter6/1?fw=pt).
The labels are easy to transform as they already correspond to numbers in their raw form, *i.e.* the range from 1 to 5. Here we just shift the labels into the range 0 to 4 since indexes usually start at 0.
Great, let's pour our thoughts into some code. We will define a `preprocess_function` that we'll apply to each data sample.
```python
def preprocess_function(example):
output_dict = tokenizer(example["review_body"], max_length=128, truncation=True)
output_dict["labels"] = [e - 1 for e in example["stars"]]
return output_dict
```
To apply this function to all data samples in our dataset, we use the [`map`](https://huggingface.co./docs/datasets/master/en/package_reference/main_classes#datasets.Dataset.map) method of the `amazon_review` object we created earlier. This will apply the function on all the elements of all the splits in `amazon_review`, so our training, validation, and testing data will be preprocessed in one single command. We run the mapping function in `batched=True` mode to speed up the process and also remove all columns since we don't need them anymore for training.
```python
tokenized_datasets = amazon_review.map(preprocess_function, batched=True, remove_columns=amazon_review["train"].column_names)
```
Let's take a look at the new structure.
```python
tokenized_datasets
```
**Output:**
```
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 200000
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
})
```
We can see that the outer layer of the structure stayed the same but the naming of the columns has changed.
Let's take a look at the same random example we looked at previously only that it's preprocessed now.
```python
print("Input IDS:", tokenized_datasets["train"][random_id]["input_ids"])
print("Labels:", tokenized_datasets["train"][random_id]["labels"])
```
**Output:**
```
Input IDS: [1, 329, 714, 2044, 3567, 5127, 265, 312, 1158, 260, 273, 286, 427, 340, 3006, 275, 363, 947, 2]
Labels: 0
```
Alright, the input text is transformed into a sequence of integers which can be transformed to word embeddings by the model, and the label index is simply shifted by -1.
### Fine-tune the model
Having preprocessed the dataset, next we can fine-tune the model. We will make use of the popular [Hugging Face Trainer](https://huggingface.co./docs/transformers/main/en/main_classes/trainer) which allows us to start training in just a couple of lines of code. The `Trainer` can be used for more or less all tasks in PyTorch and is extremely convenient by taking care of a lot of boilerplate code needed for training.
Let's start by loading the model checkpoint using the convenient [`AutoModelForSequenceClassification`](https://huggingface.co./docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSequenceClassification). Since the checkpoint of the model repository is just a pretrained checkpoint we should define the size of the classification head by passing `num_lables=5` (since we have 5 sentiment classes).
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_repository, num_labels=5)
```
```
Some weights of the model checkpoint at microsoft/deberta-v3-base were not used when initializing DebertaV2ForSequenceClassification: ['mask_predictions.classifier.bias', 'mask_predictions.LayerNorm.bias', 'mask_predictions.dense.weight', 'mask_predictions.dense.bias', 'mask_predictions.LayerNorm.weight', 'lm_predictions.lm_head.dense.bias', 'lm_predictions.lm_head.bias', 'lm_predictions.lm_head.LayerNorm.weight', 'lm_predictions.lm_head.dense.weight', 'lm_predictions.lm_head.LayerNorm.bias', 'mask_predictions.classifier.weight']
- This IS expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DebertaV2ForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-v3-base and are newly initialized: ['pooler.dense.bias', 'classifier.weight', 'classifier.bias', 'pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Next, we load a data collator. A [data collator](https://huggingface.co./docs/transformers/main_classes/data_collator) is responsible for making sure each batch is correctly padded during training, which should happen dynamically since training samples are reshuffled before each epoch.
```python
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
During training, it is important to monitor the performance of the model on a held-out validation set. To do so, we should pass a to define a `compute_metrics` function to the `Trainer` which is then called at each validation step during training.
The simplest metric for the text classification task is *accuracy*, which simply states how much percent of the training samples were correctly classified. Using the *accuracy* metric might be problematic however if the validation or test data is very unbalanced. Let's verify quickly that this is not the case by counting the occurrences of each label.
```python
from collections import Counter
print("Validation:", Counter(tokenized_datasets["validation"]["labels"]))
print("Test:", Counter(tokenized_datasets["test"]["labels"]))
```
**Output:**
```
Validation: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
Test: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
```
The validation and test data sets are as balanced as they can be, so we can safely use accuracy here!
Let's load the [accuracy metric](https://huggingface.co./metrics/accuracy) via the datasets library.
```python
from datasets import load_metric
accuracy = load_metric("accuracy")
```
Next, we define the `compute_metrics` which will be applied to the predicted outputs of the model which is of type [`EvalPrediction`](https://huggingface.co./docs/transformers/main/en/internal/trainer_utils#transformers.EvalPrediction) and therefore exposes the model's predictions and the gold labels.
We compute the predicted label class by taking the `argmax` of the model's prediction before passing it alongside the gold labels to the accuracy metric.
```python
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
acc = accuracy.compute(predictions=pred_classes, references=labels)
return {"accuracy": acc["accuracy"]}
```
Great, now all components required for training are ready and all that's left to do is to define the hyper-parameters of the `Trainer`. We need to make sure that the model checkpoints are uploaded to the Hugging Face Hub during training. By setting `push_to_hub=True`, this is done automatically at every `save_steps` via the convenient [`push_to_hub`](https://huggingface.co./docs/transformers/main/en/main_classes/trainer#transformers.Trainer.push_to_hub) method.
Besides, we define some standard hyper-parameters such as learning rate, warm-up steps and training epochs. We will log the loss every 500 steps and run evaluation every 5000 steps.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="deberta_amazon_reviews_v1",
num_train_epochs=2,
learning_rate=2e-5,
warmup_steps=200,
logging_steps=500,
save_steps=5000,
eval_steps=5000,
push_to_hub=True,
evaluation_strategy="steps",
)
```
Putting it all together, we can finally instantiate the Trainer by passing all required components. We'll use the `"validation"` split as the held-out dataset during training.
```python
from transformers import Trainer
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)
```
The trainer is ready to go 🚀 You can start training by calling `trainer.train()`.
```python
train_metrics = trainer.train().metrics
trainer.save_metrics("train", train_metrics)
```
**Output:**
```
***** Running training *****
Num examples = 200000
Num Epochs = 2
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 50000
```
**Output:**
<div>
<table><p>
<tbody>
<tr style="text-align: left;">
<td>Step</td>
<td>Training Loss</td>
<td>Validation Loss</td>
<td>Accuracy</td>
</tr>
<tr>
<td>5000</td>
<td>0.931200</td>
<td>0.979602</td>
<td>0.585600</td>
</tr>
<tr>
<td>10000</td>
<td>0.931600</td>
<td>0.933607</td>
<td>0.597400</td>
</tr>
<tr>
<td>15000</td>
<td>0.907600</td>
<td>0.917062</td>
<td>0.602600</td>
</tr>
<tr>
<td>20000</td>
<td>0.902400</td>
<td>0.919414</td>
<td>0.604600</td>
</tr>
<tr>
<td>25000</td>
<td>0.879400</td>
<td>0.910928</td>
<td>0.608400</td>
</tr>
<tr>
<td>30000</td>
<td>0.806700</td>
<td>0.933923</td>
<td>0.609200</td>
</tr>
<tr>
<td>35000</td>
<td>0.826800</td>
<td>0.907260</td>
<td>0.616200</td>
</tr>
<tr>
<td>40000</td>
<td>0.820500</td>
<td>0.904160</td>
<td>0.615800</td>
</tr>
<tr>
<td>45000</td>
<td>0.795000</td>
<td>0.918947</td>
<td>0.616800</td>
</tr>
<tr>
<td>50000</td>
<td>0.783600</td>
<td>0.907572</td>
<td>0.618400</td>
</tr>
</tbody>
</table><p>
</div>
**Output:**
```
***** Running Evaluation *****
Num examples = 5000
Batch size = 8
Saving model checkpoint to deberta_amazon_reviews_v1/checkpoint-50000
Configuration saved in deberta_amazon_reviews_v1/checkpoint-50000/config.json
Model weights saved in deberta_amazon_reviews_v1/checkpoint-50000/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/checkpoint-50000/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/added_tokens.json
Training completed. Do not forget to share your model on huggingface.co/models =)
```
Cool, we see that the model seems to learn something! Training loss and validation loss are going down and the accuracy also ends up being well over random chance (20%). Interestingly, we see an accuracy of around **58.6 %** after only 5000 steps which doesn't improve that much anymore afterward. Choosing a bigger model or training for longer would have probably given better results here, but that's good enough for our hypothetical use case!
Alright, finally let's upload the model checkpoint to the Hub.
```python
trainer.push_to_hub()
```
**Output:**
```
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
Several commits (2) will be pushed upstream.
The progress bars may be unreliable.
```
### Evaluate / Analyse the model
Now that we have fine-tuned the model we need to be very careful about analyzing its performance.
Note that canonical metrics, such as *accuracy*, are useful to get a general picture
about your model's performance, but it might not be enough to evaluate how well the model performs on your actual use case.
The better approach is to find a metric that best describes the actual use case of the model and measure exactly this metric during and after training.
Let's dive into evaluating the model 🤿.
The model has been uploaded to the Hub under [`deberta_v3_amazon_reviews`](https://huggingface.co./patrickvonplaten/deberta_v3_amazon_reviews) after training, so in a first step, let's download it from there again.
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("patrickvonplaten/deberta_v3_amazon_reviews")
```
The Trainer is not only an excellent class to train a model, but also to evaluate a model on a dataset. Let's instantiate the trainer with the same instances and functions as before, but this time there is no need to pass a training dataset.
```python
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
```
We use the Trainer's [`predict`](https://huggingface.co./docs/transformers/main/en/main_classes/trainer#transformers.Trainer.predict) function to evaluate the model on the test dataset on the same metric.
```python
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
```
**Output:**
```
***** Running Prediction *****
Num examples = 5000
Batch size = 8
```
**Output:**
```
{'test_accuracy': 0.608,
'test_loss': 0.9637690186500549,
'test_runtime': 21.9574,
'test_samples_per_second': 227.714,
'test_steps_per_second': 28.464}
```
The results are very similar to performance on the validation dataset, which is usually a good sign as it shows that the model didn't overfit the test dataset.
However, 60% accuracy is far from being perfect on a 5-class classification problem, but do we need very high accuracy for all classes?
Since we are mostly concerned with very negative customer feedback, let's just focus on how well the model performs on classifying reviews of the most unsatisfied customers. We also decide to help the model a bit - all feedback classified as either **very unsatisfied** or **unsatisfied** will be handled by us - to catch close to 99% of the **very unsatisfied** messages. At the same time, we also measure how many **unsatisfied** messages we can answer this way and how much unnecessary work we do by answering messages of neutral, satisfied, and very satisfied customers.
Great, let's write a new `compute_metrics` function.
```python
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
# First let's compute % of very unsatisfied messages we can catch
very_unsatisfied_label_idx = (labels == 0)
very_unsatisfied_pred = pred_classes[very_unsatisfied_label_idx]
# Now both 0 and 1 labels are 0 labels the rest is > 0
very_unsatisfied_pred = very_unsatisfied_pred * (very_unsatisfied_pred - 1)
# Let's count how many labels are 0 -> that's the "very unsatisfied"-accuracy
true_positives = sum(very_unsatisfied_pred == 0) / len(very_unsatisfied_pred)
# Second let's compute how many satisfied messages we unnecessarily reply to
satisfied_label_idx = (labels > 1)
satisfied_pred = pred_classes[satisfied_label_idx]
# how many predictions are labeled as unsatisfied over all satisfied messages?
false_positives = sum(satisfied_pred <= 1) / len(satisfied_pred)
return {"%_unsatisfied_replied": round(true_positives, 2), "%_satisfied_incorrectly_labels": round(false_positives, 2)}
```
We again instantiate the `Trainer` to easily run the evaluation.
```python
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
```
And let's run the evaluation again with our new metric computation which is better suited for our use case.
```python
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
```
**Output:**
```
***** Running Prediction *****
Num examples = 5000
Batch size = 8
```
**Output:**
```
{'test_%_satisfied_incorrectly_labels': 0.11733333333333333,
'test_%_unsatisfied_replied': 0.949,
'test_loss': 0.9637690186500549,
'test_runtime': 22.8964,
'test_samples_per_second': 218.375,
'test_steps_per_second': 27.297}
```
Cool! This already paints a pretty nice picture. We catch around 95% of **very unsatisfied** customers automatically at a cost of wasting our efforts on 10% of satisfied messages.
Let's do some quick math. We receive daily around 10,000 messages for which we expect ca. 500 to be very negative. Instead of having to answer to all 10,000 messages, using this automatic filtering, we would only need to look into 500 + 0.12 \* 10,000 = 1700 messages and only reply to 475 messages while incorrectly missing 5% of the messages. Pretty nice - a 83% reduction in human effort at missing only 5% of very unsatisfied customers!
Obviously, the numbers don't represent the gained value of an actual use case, but we could come close to it with enough high-quality training data of your real-world example!
Let's save the results
```python
trainer.save_metrics("prediction", prediction_metrics)
```
and again upload everything on the Hub.
```python
trainer.push_to_hub()
```
**Output:**
```
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
To https://huggingface.co./patrickvonplaten/deberta_amazon_reviews_v1
599b891..ad77e6d main -> main
Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Text Classification', 'type': 'text-classification'}}
To https://huggingface.co./patrickvonplaten/deberta_amazon_reviews_v1
ad77e6d..13e5ddd main -> main
```
The data is now saved [here](https://huggingface.co./patrickvonplaten/deberta_amazon_reviews_v1/blob/main/prediction_results.json).
That's it for today 😎. As a final step, it would also make a lot of sense to try the model out on actual real-world data. This can be done directly on the inference widget on [the model card](https://huggingface.co./patrickvonplaten/deberta_amazon_reviews_v1):
It does seem to generalize quite well to real-world data 🔥
## Optimization
As soon as you think the model's performance is good enough for production it's all about making the model as memory efficient and fast as possible.
There are some obvious solutions to this like choosing the best suited accelerated hardware, *e.g.* better GPUs, making sure no gradients are computed during the forward pass, or lowering the precision, *e.g.* to float16.
More advanced optimization methods include using open-source accelerator libraries such as [ONNX Runtime](https://onnxruntime.ai/index.html), [quantization](https://pytorch.org/docs/stable/quantization.html), and inference servers like [Triton](https://developer.nvidia.com/nvidia-triton-inference-server).
At Hugging Face, we have been working a lot to facilitate the optimization of models, especially with our open-source [Optimum library](https://huggingface.co./hardware). Optimum makes it extremely simple to optimize most 🤗 Transformers models.
If you're looking for **highly optimized** solutions which don't require any technical knowledge, you might be interested in the [Inference API](https://huggingface.co./inference-api), a plug & play solution to serve in production a wide variety of machine learning tasks, including sentiment analysis.
Moreover, if you are searching for **support for your custom use cases**, Hugging Face's team of experts can help accelerate your ML projects! Our team answer questions and find solutions as needed in your machine learning journey from research to production. Visit [hf.co/support](https://huggingface.co./support) to learn more and request a quote. | [
[
"transformers",
"implementation",
"tutorial",
"text_classification"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"implementation",
"text_classification",
"tutorial"
] | null | null |
c03c052a-4baf-4f52-a89f-dc3b85398c84 | completed | 2025-01-16T03:09:11.596959 | 2025-01-16T15:15:22.369879 | a9c1e475-6087-45a5-9f31-218742aa1e7a | Transformer-based Encoder-Decoder Models | patrickvonplaten | encoder-decoder.md | <a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
```bash
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95
```
The *transformer-based* encoder-decoder model was introduced by Vaswani
et al. in the famous [Attention is all you need
paper](https://arxiv.org/abs/1706.03762) and is today the *de-facto*
standard encoder-decoder architecture in natural language processing
(NLP).
Recently, there has been a lot of research on different *pre-training*
objectives for transformer-based encoder-decoder models, *e.g.* T5,
Bart, Pegasus, ProphetNet, Marge, *etc*\..., but the model architecture
has stayed largely the same.
The goal of the blog post is to give an **in-detail** explanation of
**how** the transformer-based encoder-decoder architecture models
*sequence-to-sequence* problems. We will focus on the mathematical model
defined by the architecture and how the model can be used in inference.
Along the way, we will give some background on sequence-to-sequence
models in NLP and break down the *transformer-based* encoder-decoder
architecture into its **encoder** and **decoder** parts. We provide many
illustrations and establish the link between the theory of
*transformer-based* encoder-decoder models and their practical usage in
🤗Transformers for inference. Note that this blog post does *not* explain
how such models can be trained - this will be the topic of a future blog
post.
Transformer-based encoder-decoder models are the result of years of
research on _representation learning_ and _model architectures_. This
notebook provides a short summary of the history of neural
encoder-decoder models. For more context, the reader is advised to read
this awesome [blog
post](https://ruder.io/a-review-of-the-recent-history-of-nlp/) by
Sebastion Ruder. Additionally, a basic understanding of the
_self-attention architecture_ is recommended. The following blog post by
Jay Alammar serves as a good refresher on the original Transformer model
[here](http://jalammar.github.io/illustrated-transformer/).
At the time of writing this notebook, 🤗Transformers comprises the
encoder-decoder models *T5*, *Bart*, *MarianMT*, and *Pegasus*, which
are summarized in the docs under [model
summaries](https://huggingface.co./transformers/model_summary.html#sequence-to-sequence-models).
The notebook is divided into four parts:
- **Background** - *A short history of neural encoder-decoder models
is given with a focus on RNN-based models.*
- **Encoder-Decoder** - *The transformer-based encoder-decoder model
is presented and it is explained how the model is used for
inference.*
- **Encoder** - *The encoder part of the model is explained in
detail.*
- **Decoder** - *The decoder part of the model is explained in
detail.*
Each part builds upon the previous part, but can also be read on its
own.
## **Background**
Tasks in natural language generation (NLG), a subfield of NLP, are best
expressed as sequence-to-sequence problems. Such tasks can be defined as
finding a model that maps a sequence of input words to a sequence of
target words. Some classic examples are *summarization* and
*translation*. In the following, we assume that each word is encoded
into a vector representation. \\(n\\) input words can then be represented as
a sequence of \\(n\\) input vectors:
$$\mathbf{X}_{1:n} = \{\mathbf{x}_1, \ldots, \mathbf{x}_n\}.$$
Consequently, sequence-to-sequence problems can be solved by finding a
mapping \\(f\\) from an input sequence of \\(n\\) vectors \\(\mathbf{X}_{1:n}\\) to
a sequence of \\(m\\) target vectors \\(\mathbf{Y}_{1:m}\\), whereas the number
of target vectors \\(m\\) is unknown apriori and depends on the input
sequence:
$$ f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m}. $$
[Sutskever et al. (2014)](https://arxiv.org/abs/1409.3215) noted that
deep neural networks (DNN)s, \"*despite their flexibility and power can
only define a mapping whose inputs and targets can be sensibly encoded
with vectors of fixed dimensionality.*\" \\({}^1\\)
Using a DNN model \\({}^2\\) to solve sequence-to-sequence problems would
therefore mean that the number of target vectors \\(m\\) has to be known
*apriori* and would have to be independent of the input
\\(\mathbf{X}_{1:n}\\). This is suboptimal because, for tasks in NLG, the
number of target words usually depends on the input \\(\mathbf{X}_{1:n}\\)
and not just on the input length \\(n\\). *E.g.*, an article of 1000 words
can be summarized to both 200 words and 100 words depending on its
content.
In 2014, [Cho et al.](https://arxiv.org/pdf/1406.1078.pdf) and
[Sutskever et al.](https://arxiv.org/abs/1409.3215) proposed to use an
encoder-decoder model purely based on recurrent neural networks (RNNs)
for *sequence-to-sequence* tasks. In contrast to DNNS, RNNs are capable
of modeling a mapping to a variable number of target vectors. Let\'s
dive a bit deeper into the functioning of RNN-based encoder-decoder
models.
During inference, the encoder RNN encodes an input sequence
\\(\mathbf{X}_{1:n}\\) by successively updating its *hidden state* \\({}^3\\).
After having processed the last input vector \\(\mathbf{x}_n\\), the
encoder\'s hidden state defines the input encoding \\(\mathbf{c}\\). Thus,
the encoder defines the mapping:
$$ f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c}. $$
Then, the decoder\'s hidden state is initialized with the input encoding
and during inference, the decoder RNN is used to auto-regressively
generate the target sequence. Let\'s explain.
Mathematically, the decoder defines the probability distribution of a
target sequence \\(\mathbf{Y}_{1:m}\\) given the hidden state \\(\mathbf{c}\\):
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}). $$
By Bayes\' rule the distribution can be decomposed into conditional
distributions of single target vectors as follows:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}). $$
Thus, if the architecture can model the conditional distribution of the
next target vector, given all previous target vectors:
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\},$$
then it can model the distribution of any target vector sequence given
the hidden state \\(\mathbf{c}\\) by simply multiplying all conditional
probabilities.
So how does the RNN-based decoder architecture model
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)?
In computational terms, the model sequentially maps the previous inner
hidden state \\(\mathbf{c}_{i-1}\\) and the previous target vector
\\(\mathbf{y}_{i-1}\\) to the current inner hidden state \\(\mathbf{c}_i\\) and a
*logit vector* \\(\mathbf{l}_i\\) (shown in dark red below):
$$ f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i.$$
\\(\mathbf{c}_0\\) is thereby defined as \\(\mathbf{c}\\) being the output
hidden state of the RNN-based encoder. Subsequently, the *softmax*
operation is used to transform the logit vector \\(\mathbf{l}_i\\) to a
conditional probablity distribution of the next target vector:
$$ p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ with } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}}). $$
For more detail on the logit vector and the resulting probability
distribution, please see footnote \\({}^4\\). From the above equation, we
can see that the distribution of the current target vector
\\(\mathbf{y}_i\\) is directly conditioned on the previous target vector
\\(\mathbf{y}_{i-1}\\) and the previous hidden state \\(\mathbf{c}_{i-1}\\).
Because the previous hidden state \\(\mathbf{c}_{i-1}\\) depends on all
previous target vectors \\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-2}\\), it can
be stated that the RNN-based decoder *implicitly* (*e.g.* *indirectly*)
models the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\).
The space of possible target vector sequences \\(\mathbf{Y}_{1:m}\\) is
prohibitively large so that at inference, one has to rely on decoding
methods \\({}^5\\) that efficiently sample high probability target vector
sequences from \\(p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c})\\).
Given such a decoding method, during inference, the next input vector
\\(\mathbf{y}_i\\) can then be sampled from
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)
and is consequently appended to the input sequence so that the decoder
RNN then models
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c})\\)
to sample the next input vector \\(\mathbf{y}_{i+1}\\) and so on in an
*auto-regressive* fashion.
An important feature of RNN-based encoder-decoder models is the
definition of *special* vectors, such as the \\(\text{EOS}\\) and
\\(\text{BOS}\\) vector. The \\(\text{EOS}\\) vector often represents the final
input vector \\(\mathbf{x}_n\\) to \"cue\" the encoder that the input
sequence has ended and also defines the end of the target sequence. As
soon as the \\(\text{EOS}\\) is sampled from a logit vector, the generation
is complete. The \\(\text{BOS}\\) vector represents the input vector
\\(\mathbf{y}_0\\) fed to the decoder RNN at the very first decoding step.
To output the first logit \\(\mathbf{l}_1\\), an input is required and since
no input has been generated at the first step a special \\(\text{BOS}\\)
input vector is fed to the decoder RNN. Ok - quite complicated! Let\'s
illustrate and walk through an example.
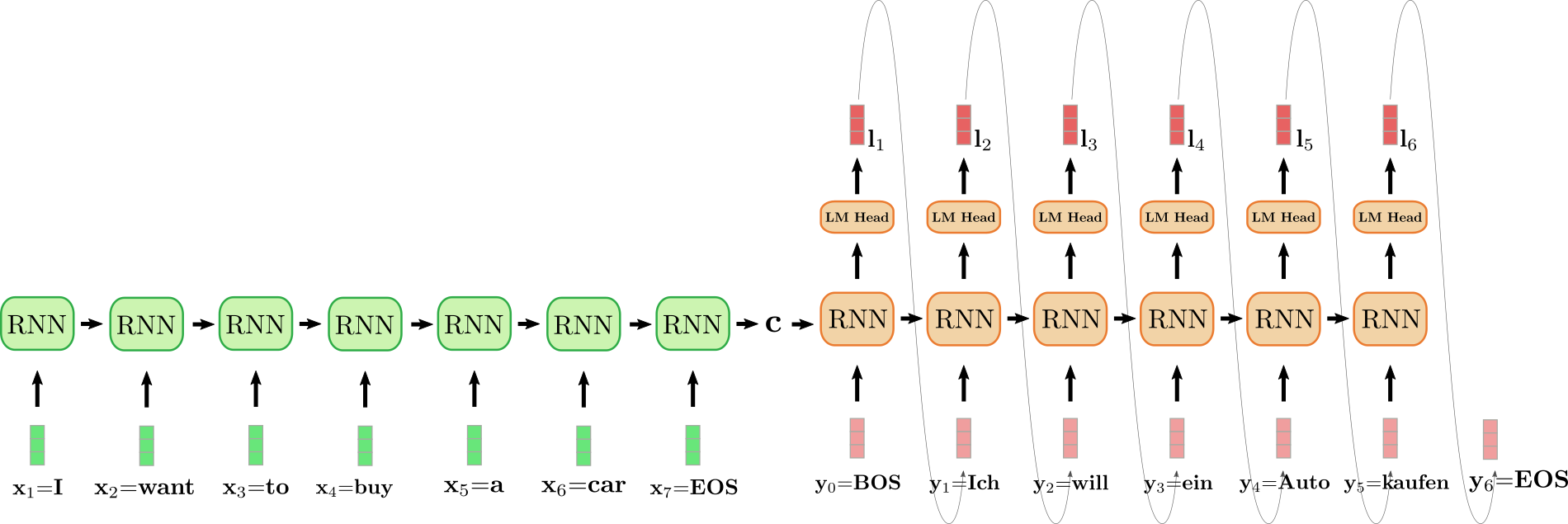
The unfolded RNN encoder is colored in green and the unfolded RNN
decoder is colored in red.
The English sentence \"I want to buy a car\", represented by
\\(\mathbf{x}_1 = \text{I}\\), \\(\mathbf{x}_2 = \text{want}\\),
\\(\mathbf{x}_3 = \text{to}\\), \\(\mathbf{x}_4 = \text{buy}\\),
\\(\mathbf{x}_5 = \text{a}\\), \\(\mathbf{x}_6 = \text{car}\\) and
\\(\mathbf{x}_7 = \text{EOS}\\) is translated into German: \"Ich will ein
Auto kaufen\" defined as \\(\mathbf{y}_0 = \text{BOS}\\),
\\(\mathbf{y}_1 = \text{Ich}\\), \\(\mathbf{y}_2 = \text{will}\\),
\\(\mathbf{y}_3 = \text{ein}\\),
\\(\mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen}\\) and
\\(\mathbf{y}_6=\text{EOS}\\). To begin with, the input vector
\\(\mathbf{x}_1 = \text{I}\\) is processed by the encoder RNN and updates
its hidden state. Note that because we are only interested in the final
encoder\'s hidden state \\(\mathbf{c}\\), we can disregard the RNN
encoder\'s target vector. The encoder RNN then processes the rest of the
input sentence \\(\text{want}\\), \\(\text{to}\\), \\(\text{buy}\\), \\(\text{a}\\),
\\(\text{car}\\), \\(\text{EOS}\\) in the same fashion, updating its hidden
state at each step until the vector \\(\mathbf{x}_7={EOS}\\) is reached
\\({}^6\\). In the illustration above the horizontal arrow connecting the
unfolded encoder RNN represents the sequential updates of the hidden
state. The final hidden state of the encoder RNN, represented by
\\(\mathbf{c}\\) then completely defines the *encoding* of the input
sequence and is used as the initial hidden state of the decoder RNN.
This can be seen as *conditioning* the decoder RNN on the encoded input.
To generate the first target vector, the decoder is fed the \\(\text{BOS}\\)
vector, illustrated as \\(\mathbf{y}_0\\) in the design above. The target
vector of the RNN is then further mapped to the logit vector
\\(\mathbf{l}_1\\) by means of the *LM Head* feed-forward layer to define
the conditional distribution of the first target vector as explained
above:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}). $$
The word \\(\text{Ich}\\) is sampled (shown by the grey arrow, connecting
\\(\mathbf{l}_1\\) and \\(\mathbf{y}_1\\)) and consequently the second target
vector can be sampled:
$$ \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}). $$
And so on until at step \\(i=6\\), the \\(\text{EOS}\\) vector is sampled from
\\(\mathbf{l}_6\\) and the decoding is finished. The resulting target
sequence amounts to
\\(\mathbf{Y}_{1:6} = \{\mathbf{y}_1, \ldots, \mathbf{y}_6\}\\), which is
\"Ich will ein Auto kaufen\" in our example above.
To sum it up, an RNN-based encoder-decoder model, represented by
\\(f_{\theta_{\text{enc}}}\\) and \\( p_{\theta_{\text{dec}}} \\) defines
the distribution \\(p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})\\) by
factorization:
$$ p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ with } \mathbf{c}=f_{\theta_{enc}}(X). $$
During inference, efficient decoding methods can auto-regressively
generate the target sequence \\(\mathbf{Y}_{1:m}\\).
The RNN-based encoder-decoder model took the NLG community by storm. In
2016, Google announced to fully replace its heavily feature engineered
translation service by a single RNN-based encoder-decoder model (see
[here](https://www.oreilly.com/radar/what-machine-learning-means-for-software-development/#:~:text=Machine%20learning%20is%20already%20making,of%20code%20in%20Google%20Translate.)).
Nevertheless, RNN-based encoder-decoder models have two pitfalls. First,
RNNs suffer from the vanishing gradient problem, making it very
difficult to capture long-range dependencies, *cf.* [Hochreiter et al.
(2001)](https://www.bioinf.jku.at/publications/older/ch7.pdf). Second,
the inherent recurrent architecture of RNNs prevents efficient
parallelization when encoding, *cf.* [Vaswani et al.
(2017)](https://arxiv.org/abs/1706.03762). | [
[
"transformers",
"research",
"implementation",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"research",
"implementation",
"tutorial"
] | null | null |
8e759311-2fa0-488d-9972-f97be2387d1a | completed | 2025-01-16T03:09:11.596963 | 2025-01-19T18:54:06.781890 | 44f842e1-6d17-4293-b372-34717dec787c | How to train a Language Model with Megatron-LM | loubnabnl | megatron-training.md | Training large language models in Pytorch requires more than a simple training loop. It is usually distributed across multiple devices, with many optimization techniques for a stable and efficient training. Hugging Face 🤗 [Accelerate](https://huggingface.co./docs/accelerate/index) library was created to support distributed training across GPUs and TPUs with very easy integration into the training loops. 🤗 [Transformers](https://huggingface.co./docs/transformers/index) also support distributed training through the [Trainer](https://huggingface.co./docs/transformers/main_classes/trainer#transformers.Trainer) API, which provides feature-complete training in PyTorch, without even needing to implement a training loop.
Another popular tool among researchers to pre-train large transformer models is [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), a powerful framework developed by the Applied Deep Learning Research team at NVIDIA. Unlike `accelerate` and the `Trainer`, using Megatron-LM is not straightforward and can be a little overwhelming for beginners. But it is highly optimized for the training on GPUs and can give some speedups. In this blogpost, you will learn how to train a language model on NVIDIA GPUs in Megatron-LM, and use it with `transformers`.
We will try to break down the different steps for training a GPT2 model in this framework, this includes:
* Environment setup
* Data preprocessing
* Training
* Model conversion to 🤗 Transformers
## Why Megatron-LM?
Before getting into the training details, let’s first understand what makes this framework more efficient than others. This section is inspired by this great [blog](https://huggingface.co./blog/bloom-megatron-deepspeed) about BLOOM training with [Megatron-DeepSpeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed), please refer to it for more details as this blog is intended to give a gentle introduction to Megatron-LM.
### DataLoader
Megatron-LM comes with an efficient DataLoader where the data is tokenized and shuffled before the training. It also splits the data into numbered sequences with indexes that are stored such that they need to be computed only once. To build the index, the number of epochs is computed based on the training parameters and an ordering is created and then shuffled. This is unlike most cases where we iterate through the entire dataset until it is exhausted and then repeat for the second epoch. This smoothes the learning curve and saves time during the training.
### Fused CUDA Kernels
When a computation is run on the GPU, the necessary data is fetched from memory, then the computation is run and the result is saved back into memory. In simple terms, the idea of fused kernels is that similar operations, usually performed separately by Pytorch, are combined into a single hardware operation. So they reduce the number of memory movements done in multiple discrete computations by merging them into one. The figure below illustrates the idea of Kernel Fusion. It is inspired from this [paper](https://www.arxiv-vanity.com/papers/1305.1183/), which discusses the concept in detail.
<p align="center">
<img src="assets/100_megatron_training/kernel_fusion.png" width="600" />
</p>
When f, g and h are fused in one kernel, the intermediary results x’ and y’ of f and g are stored in the GPU registers and immediately used by h. But without fusion, x’ and y’ would need to be copied to the memory and then loaded by h. Therefore, Kernel Fusion gives a significant speed up to the computations.
Megatron-LM also uses a Fused implementation of AdamW from [Apex](https://github.com/NVIDIA/apex) which is faster than the Pytorch implementation.
While one can customize the DataLoader like Megatron-LM and use Apex’s Fused optimizer with `transformers`, it is not a beginner friendly undertaking to build custom Fused CUDA Kernels.
Now that you are familiar with the framework and what makes it advantageous, let’s get into the training details!
## How to train with Megatron-LM ?
### Setup
The easiest way to setup the environment is to pull an NVIDIA PyTorch Container that comes with all the required installations from [NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch). See [documentation](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/index.html) for more details. If you don't want to use this container you will need to install the latest pytorch, cuda, nccl, and NVIDIA [APEX](https://github.com/NVIDIA/apex#quick-start) releases and the `nltk` library.
So after having installed Docker, you can run the container with the following command (`xx.xx` denotes your Docker version), and then clone [Megatron-LM repository](https://github.com/NVIDIA/Megatron-LM) inside it:
```bash
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
git clone https://github.com/NVIDIA/Megatron-LM
```
You also need to add the vocabulary file `vocab.json` and merges table `merges.txt` of your tokenizer inside Megatron-LM folder of your container. These files can be found in the model’s repository with the weights, see this [repository](https://huggingface.co./gpt2/tree/main) for GPT2. You can also train your own tokenizer using `transformers`. You can checkout the [CodeParrot project](https://github.com/huggingface/transformers/tree/main/examples/research_projects/codeparrot) for a practical example.
Now if you want to copy this data from outside the container you can use the following commands:
```bash
sudo docker cp vocab.json CONTAINER_ID:/workspace/Megatron-LM
sudo docker cp merges.txt CONTAINER_ID:/workspace/Megatron-LM
```
### Data preprocessing
In the rest of this tutorial we will be using [CodeParrot](https://huggingface.co./codeparrot/codeparrot-small) model and data as an example.
The training data requires some preprocessing. First, you need to convert it into a loose json format, with one json containing a text sample per line. If you're using 🤗 [Datasets](https://huggingface.co./docs/datasets/index), here is an example on how to do that (always inside Megatron-LM folder):
```python
from datasets import load_dataset
train_data = load_dataset('codeparrot/codeparrot-clean-train', split='train')
train_data.to_json("codeparrot_data.json", lines=True)
```
The data is then tokenized, shuffled and processed into a binary format for training using the following command:
```bash
#if nltk isn't installed
pip install nltk
python tools/preprocess_data.py \
--input codeparrot_data.json \
--output-prefix codeparrot \
--vocab vocab.json \
--dataset-impl mmap \
--tokenizer-type GPT2BPETokenizer \
--merge-file merges.txt \
--json-keys content \
--workers 32 \
--chunk-size 25 \
--append-eod
```
The `workers` and `chunk_size` options refer to the number of workers used in the preprocessing and the chunk size of data assigned to each one. `dataset-impl` refers to the implementation mode of the indexed datasets from ['lazy', 'cached', 'mmap'].
This outputs two files `codeparrot_content_document.idx` and `codeparrot_content_document.bin` which are used in the training.
### Training
You can configure the model architecture and training parameters as shown below, or put it in a bash script that you will run. This command runs the pretraining on 8 GPUs for a 110M parameter CodeParrot model. Note that the data is partitioned by default into a 969:30:1 ratio for training/validation/test sets.
```bash
GPUS_PER_NODE=8
MASTER_ADDR=localhost
MASTER_PORT=6001
NNODES=1
NODE_RANK=0
WORLD_SIZE=$(($GPUS_PER_NODE*$NNODES))
DISTRIBUTED_ARGS="--nproc_per_node $GPUS_PER_NODE --nnodes $NNODES --node_rank $NODE_RANK --master_addr $MASTER_ADDR --master_port $MASTER_PORT"
CHECKPOINT_PATH=/workspace/Megatron-LM/experiments/codeparrot-small
VOCAB_FILE=vocab.json
MERGE_FILE=merges.txt
DATA_PATH=codeparrot_content_document
GPT_ARGS="--num-layers 12
--hidden-size 768
--num-attention-heads 12
--seq-length 1024
--max-position-embeddings 1024
--micro-batch-size 12
--global-batch-size 192
--lr 0.0005
--train-iters 150000
--lr-decay-iters 150000
--lr-decay-style cosine
--lr-warmup-iters 2000
--weight-decay .1
--adam-beta2 .999
--fp16
--log-interval 10
--save-interval 2000
--eval-interval 200
--eval-iters 10
"
TENSORBOARD_ARGS="--tensorboard-dir experiments/tensorboard"
python3 -m torch.distributed.launch $DISTRIBUTED_ARGS \
pretrain_gpt.py \
--tensor-model-parallel-size 1 \
--pipeline-model-parallel-size 1 \
$GPT_ARGS \
--vocab-file $VOCAB_FILE \
--merge-file $MERGE_FILE \
--save $CHECKPOINT_PATH \
--load $CHECKPOINT_PATH \
--data-path $DATA_PATH \
$TENSORBOARD_ARGS
```
With this setting, the training takes roughly 12 hours.
This setup uses Data Parallelism, but it is also possible to use Model Parallelism for very large models that don't fit in one GPU. The first option consists of Tensor Parallelism that splits the execution of a single transformer module over multiple GPUs, you will need to change `tensor-model-parallel-size` parameter to the desired number of GPUs. The second option is Pipeline Parallelism where the transformer modules are split into equally sized stages. The parameter `pipeline-model-parallel-size` determines the number of stages to split the model into. For more details please refer to this [blog](https://huggingface.co./blog/bloom-megatron-deepspeed)
### Converting the model to 🤗 Transformers
After training we want to use the model in `transformers` e.g. for evaluation or to deploy it to production. You can convert it to a `transformers` model following this [tutorial](https://huggingface.co./nvidia/megatron-gpt2-345m). For instance, after the training is finished you can copy the weights of the last iteration 150k and convert the `model_optim_rng.pt` file to a `pytorch_model.bin` file that is supported by `transformers` with the following commands:
```bash
# to execute outside the container:
mkdir -p nvidia/megatron-codeparrot-small
# copy the weights from the container
sudo docker cp CONTAINER_ID:/workspace/Megatron-LM/experiments/codeparrot-small/iter_0150000/mp_rank_00/model_optim_rng.pt nvidia/megatron-codeparrot-small
git clone https://github.com/huggingface/transformers.git
git clone https://github.com/NVIDIA/Megatron-LM.git
export PYTHONPATH=Megatron-LM
python transformers/src/transformers/models/megatron_gpt2/convert_megatron_gpt2_checkpoint.py nvidia/megatron-codeparrot-small/model_optim_rng.pt
```
Be careful, you will need to replace the generated vocabulary file and merges table after the conversion, with the original ones we introduced earlier if you plan to load the tokenizer from there.
Don't forget to push your model to the hub and share it with the community, it only takes three lines of code 🤗:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("nvidia/megatron-codeparrot-small")
# this creates a repository under your username with the model name codeparrot-small
model.push_to_hub("codeparrot-small")
```
You can also easily use it to generate text:
```python
from transformers import pipeline
pipe = pipeline("text-generation", model="your_username/codeparrot-small")
outputs = pipe("def hello_world():")
print(outputs[0]["generated_text"])
```
```
def hello_world():
print("Hello World!")
```
Tranfsormers also handle big model inference efficiently. In case you trained a very large model (e.g. using Model Parallelism), you can easily use it for inference with the following command:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("your_username/codeparrot-large", device_map="auto")
```
This will use [accelerate](https://huggingface.co./docs/accelerate/index) library behind the scenes to automatically dispatch the model weights across the devices you have available (GPUs, CPU RAM).
Disclaimer: We have shown that anyone can use Megatron-LM to train language models. The question is when to use it. This framework obviously adds some time overhead because of the extra preprocessing and conversion steps. So it is important that you decide which framework is more appropriate for your case and model size. We recommend trying it for pre-training models or extended fine-tuning, but probably not for shorter fine-tuning of medium-sized models. The `Trainer` API and `accelerate` library are also very handy for model training, they are device-agnostic and give significant flexibility to the users.
Congratulations 🎉 now you know how to train a GPT2 model in Megatron-LM and make it supported by `transformers`! | [
[
"llm",
"implementation",
"tutorial",
"optimization",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"implementation",
"optimization",
"tools"
] | null | null |
75103f1a-7bca-4784-8f16-0c38ae3b5e78 | completed | 2025-01-16T03:09:11.596968 | 2025-01-19T17:18:15.505311 | bdc317ad-3dd6-483e-9572-7592575b54a7 | Databricks ❤️ Hugging Face: up to 40% faster training and tuning of Large Language Models | alighodsi, maddiedawson | databricks-case-study.md | Generative AI has been taking the world by storm. As the data and AI company, we have been on this journey with the release of the open source large language model [Dolly](https://huggingface.co./databricks/dolly-v2-12b), as well as the internally crowdsourced dataset licensed for research and commercial use that we used to fine-tune it, the [databricks-dolly-15k](https://huggingface.co./datasets/databricks/databricks-dolly-15k). Both the model and dataset are available on Hugging Face. We’ve learned a lot throughout this process, and today we’re excited to announce our first of many official commits to the Hugging Face codebase that allows users to easily create a Hugging Face Dataset from an Apache Spark™ dataframe.
#### “It's been great to see Databricks release models and datasets to the community, and now we see them extending that work with direct open source commitment to Hugging Face. Spark is one of the most efficient engines for working with data at scale, and it's great to see that users can now benefit from that technology to more effectively fine tune models from Hugging Face.”
— Clem Delange, Hugging Face CEO
## Hugging Face gets first-class Spark support
Over the past few weeks, we’ve gotten many requests from users asking for an easier way to load their Spark dataframe into a Hugging Face dataset that can be utilized for model training or tuning. Prior to today’s release, to get data from a Spark dataframe into a Hugging Face dataset, users had to write data into Parquet files and then point the Hugging Face dataset to these files to reload them. For example:
```swift
from datasets import load_dataset
train_df = train.write.parquet(train_dbfs_path, mode="overwrite")
train_test = load_dataset("parquet", data_files={"train":f"/dbfs{train_dbfs_path}/*.parquet", "test":f"/dbfs{test_dbfs_path}/*.parquet"})
#16GB == 22min
```
Not only was this cumbersome, but it also meant that data had to be written to disk and then read in again. On top of that, the data would get rematerialized once loaded back into the dataset, which eats up more resources and, therefore, more time and cost. Using this method, we saw that a relatively small (16GB) dataset took about 22 minutes to go from Spark dataframe to Parquet, and then back into the Hugging Face dataset.
With the latest Hugging Face release, we make it much simpler for users to accomplish the same task by simply calling the new “from_spark” function in Datasets:
```swift
from datasets import Dataset
df = [some Spark dataframe or Delta table loaded into df]
dataset = Dataset.from_spark(df)
#16GB == 12min
```
This allows users to use Spark to efficiently load and transform data for training or fine-tuning a model, then easily map their Spark dataframe into a Hugging Face dataset for super simple integration into their training pipelines. This combines cost savings and speed from Spark and optimizations like memory-mapping and smart caching from Hugging Face datasets. These improvements cut down the processing time for our example 16GB dataset by more than 40%, going from 22 minutes down to only 12 minutes.
## Why does this matter?
As we transition to this new AI paradigm, organizations will need to use their extremely valuable data to augment their AI models if they want to get the best performance within their specific domain. This will almost certainly require work in the form of data transformations, and doing this efficiently over large datasets is something Spark was designed to do. Integrating Spark with Hugging Face gives you the cost-effectiveness and performance of Spark while retaining the pipeline integration that Hugging Face provides.
## Continued Open-Source Support
We see this release as a new avenue to further contribute to the open source community, something that we believe Hugging Face does extremely well, as it has become the de facto repository for open source models and datasets. This is only the first of many contributions. We already have plans to add streaming support through Spark to make the dataset loading even faster.
In order to become the best platform for users to jump into the world of AI, we’re working hard to provide the best tools to successfully train, tune, and deploy models. Not only will we continue contributing to Hugging Face, but we’ve also started releasing improvements to our other open source projects. A recent [MLflow](https://www.databricks.com/blog/2023/04/18/introducing-mlflow-23-enhanced-native-llm-support-and-new-features.html) release added support for the transformers library, OpenAI integration, and Langchain support. We also announced [AI Functions](https://www.databricks.com/blog/2023/04/18/introducing-ai-functions-integrating-large-language-models-databricks-sql.html) within Databricks SQL that lets users easily integrate OpenAI (or their own deployed models in the future) into their queries. To top it all off, we also released a [PyTorch distributor](https://www.databricks.com/blog/2023/04/20/pytorch-databricks-introducing-spark-pytorch-distributor.html) for Spark to simplify distributed PyTorch training on Databricks.
_This article was originally published on April 26, 2023 in [Databricks's blog](https://www.databricks.com/blog/contributing-spark-loader-for-hugging-face-datasets)._ | [
[
"llm",
"data",
"optimization",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"data",
"integration",
"optimization"
] | null | null |
0241c200-b21c-4cf3-a845-dd5cc87b5792 | completed | 2025-01-16T03:09:11.596972 | 2025-01-16T03:19:06.777534 | 6a43a76f-425f-4c54-9c5c-9699bd5f4e9b | CinePile 2.0 - making stronger datasets with adversarial refinement | RuchitRawal, mfarre, somepago, lvwerra | cinepile2.md | In this blog post we share the journey of releasing [CinePile 2.0](https://huggingface.co./datasets/tomg-group-umd/cinepile), a significantly improved version of our long video QA dataset. The improvements in the new dataset rely on a new approach that we coined adversarial dataset refinement.
We're excited to share both CinePile 2.0 and our adversarial refinement method implementation, which we believe can strengthen many existing datasets and directly be part of future dataset creation pipelines.
<a name="adv_ref_pipe"></a> 
If you are mainly interested in the adversarial refinement method, you can [jump directly to the Adversarial Refinement section](#adversarial-refinement).
## Wait. What is CinePile?
In May 2024, we launched CinePile, a long video QA dataset with about 300,000 training samples and 5,000 test samples.
The first release stood out from other datasets in two aspects:
* Question diversity: It covers temporal understanding, plot analysis, character dynamics, setting, and themes.
* Question difficulty: In our benchmark, humans outperformed the best commercial vision models by 25% and open-source ones by 65%.
### Taking a look at a data sample
Part of the secret sauce behind it is that it relies on movie clips from YouTube and Q&A distilled from precise audio descriptions designed for visually impaired audiences. These descriptions offer rich context beyond basic visuals (e.g., "What color is the car?"), helping us create more complex questions.
<div style="display: flex; gap: 20px; align-items: center;">
<div style="flex: 1;">
<iframe width="100%" height="200" src="https://www.youtube.com/embed/Z4DDrBjEBHE" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
</div>
<div style="flex: 2;">
<a name="teaser"></a>
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/cinepile2/teaser_figure.png" alt="Sample Scene" style="width: 100%; height: auto;">
</div>
</div>
### Tell me more. How did you put together the original dataset?
To automate question creation, we first built question templates by inspecting existing datasets like MovieQA and TVQA. We clustered the questions in these datasets using a textual similarity model [WhereIsAI/UAE-Large-V1](https://huggingface.co./WhereIsAI/UAE-Large-V1) and then prompted GPT-4 with 10 random examples from each cluster to generate a question template and a prototypical question for each:
| Category | Question template | Prototypical question |
| | [
[
"computer_vision",
"data",
"research",
"implementation",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"data",
"research",
"implementation",
"tools"
] | null | null |
7d4bccb5-6673-4330-a04f-366b38a79b6c | completed | 2025-01-16T03:09:11.596977 | 2025-01-19T18:48:47.950839 | 28a14ada-a89f-4bc8-be82-8e1ac7606682 | We are hiring interns! | lysandre, douwekiela | interns-2023.md | Want to help build the future at -- if we may say so ourselves -- one of the coolest places in AI? Today we’re announcing our internship program for 2023. Together with your Hugging Face mentor(s), we’ll be working on cutting edge problems in AI and machine learning.
Applicants from all backgrounds are welcome! Ideally, you have some relevant experience and are excited about our mission to democratize responsible machine learning. The progress of our field has the potential to exacerbate existing disparities in ways that disproportionately hurt the most marginalized people in society — including people of color, people from working-class backgrounds, women, and LGBTQ+ people. These communities must be centered in the work we do as a research community. So we strongly encourage proposals from people whose personal experience reflects these identities!
## Positions
The following internship positions are available in the Open Source team, alongside maintainers of the respective libraries:
* [Accelerate Internship](https://apply.workable.com/huggingface/j/9B5436D6FA), to lead the integration of new, impactful features in the library.
* [Text to Speech Internship](https://apply.workable.com/huggingface/j/93CDE47063/), working on text-to-speech reproduction.
The following Science team positions are available:
* [Embodied AI Internship](https://apply.workable.com/huggingface/j/B3CDE6C150/), working with the Embodied AI team on reinforcement learning in simulators.
* [Fast Distributed Training Framework Internship](https://apply.workable.com/huggingface/j/BEBD24C4C4/), creating a framework for flexible distributed training of large language models.
* [Datasets for LLMs Internship](https://apply.workable.com/huggingface/j/4A6EA3243C/), building datasets to train the next generation of large language models, and the assorted tools.
The following other internship positions are available:
* [Social Impact Evaluation Internship](https://apply.workable.com/huggingface/j/648A916AAB/), developing a technical framework for assessing the overall social impact of generative ML models.
* [AI Art Tooling Internship](https://apply.workable.com/huggingface/j/BCCB4CAF82/), bridging the AI and art worlds by building tooling to empower artists.
Locations vary on a case-by-case basis and if the internship host has a location preference, this will be indicated on the job listing.
## How to Apply
You can apply directly for each position through our [job portal](https://huggingface.workable.com/). Click on the positions above to be taken directly to the application form.
Please make sure to complete the short submission at the end of the application form when applying. You'll need to create a Hugging Face account for that.
We are actively working to build a culture that values diversity, equity, and inclusivity. We are intentionally building a workplace where people feel respected and supported—regardless of who you are or where you come from. We believe this is foundational to building a great company and community. Hugging Face is an equal opportunity employer and we do not discriminate on the basis of race, religion, color, national origin, gender, sexual orientation, age, marital status, veteran status, or disability status. | [
[
"research",
"community"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"research"
] | null | null |
b8bfd2d3-1915-4fff-aa33-6dd9da6b5c3d | completed | 2025-01-16T03:09:11.596986 | 2025-01-19T17:17:33.631522 | 56d9ad15-c5ac-4082-9c5c-90df43b237aa | You could have designed state of the art positional encoding | FL33TW00D-HF | designing-positional-encoding.md | > A complex system that works is invariably found to have evolved from a simple
> system that worked \
> John Gall
This post walks you through the step-by-step discovery of state-of-the-art positional encoding in transformer models. We will achieve
this by iteratively improving our approach to encoding position, arriving at **Ro**tary **P**ostional **E**ncoding (RoPE) used in the latest [LLama 3.2](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/) release and most modern transformers. This post intends to limit the mathematical knowledge required to follow along, but some basic linear algebra, trigonometry and understanding of self attention is expected.
## Problem Statement
> You shall know a word by the company it keeps \
> John Rupert Firth
As with all problems, it is best to first start with understanding **exactly** what we are trying to achieve. The self attention mechanism in transformers is utilized to understand relationships
between tokens in a sequence. Self attention is a **set** operation, which
means it is **permutation equivariant**. If we do not
enrich self attention with positional information, many important relationships are
**incapable of being determined**.
This is best demonstrated by example.
## Motivating Example
Consider this sentence with the same word in different positions:
$$
\text{The dog chased another dog}
$$
Intuitively, "dog" refers to two different entities. Let's see what happens if we first tokenize them, map to the real token embeddings of **Llama 3.2 1B** and pass them through [torch.nn.MultiheadAttention](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html).
```python
import torch
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
model_id = "meta-llama/Llama-3.2-1B"
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
text = "The dog chased another dog"
tokens = tok(text, return_tensors="pt")["input_ids"]
embeddings = model.embed_tokens(tokens)
hdim = embeddings.shape[-1]
W_q = nn.Linear(hdim, hdim, bias=False)
W_k = nn.Linear(hdim, hdim, bias=False)
W_v = nn.Linear(hdim, hdim, bias=False)
mha = nn.MultiheadAttention(embed_dim=hdim, num_heads=4, batch_first=True)
with torch.no_grad():
for param in mha.parameters():
nn.init.normal_(param, std=0.1) # Initialize weights to be non-negligible
output, _ = mha(W_q(embeddings), W_k(embeddings), W_v(embeddings))
dog1_out = output[0, 2]
dog2_out = output[0, 5]
print(f"Dog output identical?: {torch.allclose(dog1_out, dog2_out, atol=1e-6)}") #True
```
As we can see, without any positional information, the output of a (multi
headed) self attention operation is **identical for the same token in
different positions**, despite the tokens clearly representing distinct entities. Let's begin designing a method of enhancing self attention with positional information, such that it can determine relationships between words encoded by
their positions.
How should an ideal positional encoding scheme behave?
## Desirable Properties
Let's try and define some desirable properties that will make the optimization
process as easy as possible.
#### Property 1 - Unique encoding for each position (across sequences)
Each position needs a unique encoding that remains consistent regardless of sequence length - a token at position 5 should have the same encoding whether the current sequence is of length 10 or 10,000.
#### Property 2 - Linear relation between two encoded positions
The relationship between positions should be mathematically simple. If we know the encoding for position \\(p\\), it should be straightforward to compute the encoding for position \\(p+k\\), making it easier for the model to learn positional patterns.
If you think about how we represent numbers on a number line, it's easy to understand that 5 is 2 steps away from 3, or that 10 is 5 steps from 15. The same intuitive relationship should exist in our encodings.
#### Property 3 - Generalizes to longer sequences than those encountered in training
To increase our models' utility in the real world, they should generalize outside
their training distribution. Therefore, our encoding scheme needs to be
adaptable enough to handle unexpected input lengths, without
violating any of our other desirable properties.
#### Property 4 - Generated by a deterministic process the model can learn
It would be ideal if our positional encodings could be drawn from a
deterministic process. This should allow the model to learn the mechanism
behind our encoding scheme efficiently.
#### Property 5 - Extensible to multiple dimensions
With multimodal models becoming the norm, it is crucial that our positional
encoding scheme can naturally extend from \\(1D\\) to \\(nD\\). This will allow models to consume data like images or brain scans, which are \\(2D\\) and \\(4D\\)
respectively.
Now we know the ideal properties (henceforth referred to as \\(Pr_n\\)), let's start designing and iterating on our encoding scheme.
## Integer Position Encoding
The first approach that may jump to mind is simply to add the integer value of the token position to each component of the token embedding, with values ranging from \\(0 \rightarrow L\\) where \\(L\\) is the
length of our current sequence.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="IntegerEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/IntegerEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
In the above animation, we create our positional encoding vector for the token \\(\color{#699C52}\text{chased}\\) from the index and add it to our token embedding. The embedding values here are a subset of the real values from **Llama 3.2 1B**. We can observe that they're clustered around 0. This
is desirable to avoid [vanishing or exploding gradients](https://www.cs.toronto.edu/~rgrosse/courses/csc321_2017/readings/L15%20Exploding%20and%20Vanishing%20Gradients.pdf) during training and therefore is something we'd like to maintain throughout the model.
It's clear that our current naïve approach is going to cause problems. The magnitude of the position value
vastly exceeds the actual values of our input. This means the signal-to-noise
ratio is very low, and it's hard for the model to separate the semantic
information from the positional information.
With this new knowledge, a natural follow on might be to normalize the position value by \\(\frac{1}{N}\\). This constrains the values between 0 and 1, but introduces another problem. If we choose \\(N\\) to be the length of the current sequence, then the position values will be completely different for each sequence of differing lengths, violating \\(Pr_1\\).
Is there a better way to ensure our numbers are between 0 and 1?
If we thought really hard about this for a while, we might come up with switching
from decimal to binary numbers.
## Binary Position Encoding
Instead of adding our (potentially normalized) integer position to each
component of the embedding, we could instead convert it into its binary
representation and *s t r e t c h* our value out to match our embedding dimension, as demonstrated below.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We've converted the position of interest (252) into its binary representation
(11111100) and added each bit to the corresponding component of the
token embedding. The least significant bit (LSB) will cycle between 0 and 1 for every
subsequent token, whilst the most significant bit (MSB) will cycle every
\\(2^{n-1}\\) tokens where \\(n\\) is the number of bits.
You can see the positional encoding vector for different indices in the animation below \\([^1]\\).
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryPositionalEncodingPlot.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryPositionalEncodingPlot.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We've solved the value range problem, and we now have unique encodings that are
consistent across different sequence lengths. What happens if we plot a low dimensional version of our token embedding and visualize the addition of our binary positional vector for different values.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="BinaryVector3D.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/BinaryVector3D.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
We can see that the result is very "jumpy" (as we might expect from the
discrete nature of binary). The optimization process likes smooth, continuous and
predictable changes. Do we know any functions with similar value ranges that are smooth and continuous?
If we looked around a little, we might notice that both \\(\sin\\) and \\(\cos\\) fit the bill!
## Sinusoidal positional encoding
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="SteppedPositionalEncodingPlot.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/SteppedPositionalEncodingPlot.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
The above animation visualizes our position embedding if each component is
alternatively drawn from \\(\sin\\) and \\(\cos\\) with gradually increasing
wavelengths. If you compare it with the previous animation, you'll notice a striking similarity!
We've now arrived at Sinusoidal embeddings; originally defined in the [Attention is all you need](https://arxiv.org/abs/1706.03762) paper.
Let's look at the equations:
$$
PE_{(pos,2i)} = \color{#58C4DD}\sin\left(\color{black}\frac{pos}{10000^{2i/d}}\color{#58C4DD}\right)\color{black} \\
\quad \\
PE_{(pos,2i+1)} = \color{#FC6255}\cos\left(\color{black}\frac{pos}{10000^{2i/d}}\color{#FC6255}\right)\color{black} \\
$$
where \\(pos\\) is the tokens position index, \\(i\\) is the component index
in the positional encoding vector, and \\(d\\) is the model dimension. \\(10,000\\) is the **base wavelength** (henceforth referred to as
\\(\theta\\)), which we stretch or compress as a function of the component index. I encourage you to plug in some realistic values to get a feel for this
geometric progression.
There's a few parts of this equation that are confusing at first glance. How did the
authors choose \\(10,000\\)? Why are we using \\(\sin\\) **and** \\(\cos\\) for even and odd positions respectively?
It seems that using \\(10,000\\) for the base wavelength was determined experimentally \\([^2]\\). Deciphering the usage of both \\(\sin\\) and \\(\cos\\) is more involved, but crucial
for our iterative approach to understanding. The key here is our desire for a linear relation between two encoded positions \\(Pr_2\\). To understand how using \\(\sin\\) and \\(\cos\\) in tandem produce this linear relation, we will have to dive into some trigonometry.
Consider a sequence of sine and cosine pairs, each associated with a frequency \\(\omega_i\\). Our goal is to find a linear transformation matrix \\(\mathbf{M}\\) that can shift these sinusoidal functions by a fixed offset \\(k\\):
$$
\mathbf{M} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p + k)) \\ \cos(\omega_i(p + k)) \end{bmatrix}
$$
The frequencies \\(\omega_i\\) follow a geometric progression that decreases with dimension index \\(i\\), defined as:
$$
\omega_i = \frac{1}{10000^{2i/d}}
$$
To find this transformation matrix, we can express it as a general 2×2 matrix with unknown coefficients \\(u_1\\), \\(v_1\\), \\(u_2\\), and \\(v_2\\):
$$
\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i(p+k)) \\ \cos(\omega_i(p+k)) \end{bmatrix}
$$
By applying the trigonometric addition theorem to the right-hand side, we can expand this into:
$$
\begin{bmatrix} u_1 & v_1 \\ u_2 & v_2 \end{bmatrix} \cdot \begin{bmatrix} \sin(\omega_i p) \\ \cos(\omega_i p) \end{bmatrix} = \begin{bmatrix} \sin(\omega_i p)\cos(\omega_i k) + \cos(\omega_i p)\sin(\omega_i k) \\ \cos(\omega_i p)\cos(\omega_i k) - \sin(\omega_i p)\sin(\omega_i k) \end{bmatrix}
$$
This expansion gives us a system of two equations by matching coefficients:
$$
\begin{align}
u_1\sin(\omega_i p) + v_1\cos(\omega_i p) &= \cos(\omega_i k)\sin(\omega_i p) + \sin(\omega_i k)\cos(\omega_i p) \\
u_2\sin(\omega_i p) + v_2\cos(\omega_i p) &= -\sin(\omega_i k)\sin(\omega_i p) + \cos(\omega_i k)\cos(\omega_i p)
\end{align}
$$
By comparing terms with \\(\sin(\omega_i p)\\) and \\(\cos(\omega_i p)\\) on both sides, we can solve for the unknown coefficients:
$$
\begin{align}
u_1 &= \cos(\omega_i k) & v_1 &= \sin(\omega_i k) \\
u_2 &= -\sin(\omega_i k) & v_2 &= \cos(\omega_i k)
\end{align}
$$
These solutions give us our final transformation matrix \\(\mathbf{M_k}\\):
$$
\mathbf{M_k} = \begin{bmatrix} \cos(\omega_i k) & \sin(\omega_i k) \\ -\sin(\omega_i k) & \cos(\omega_i k) \end{bmatrix}
$$
If you've done any game programming before, you might notice that the
result of our derivation is oddly familiar. That's right, it's the [Rotation Matrix!](https://en.wikipedia.org/wiki/Rotation_matrix) \\([^3]\\).
So the encoding scheme designed by [Noam Shazeer](https://en.wikipedia.org/wiki/Noam_Shazeer) in [Attention is all you need](https://arxiv.org/abs/1706.03762) was already encoding relative position as a rotation back in 2017! It took another **4 years** to go from Sinusoidal Encoding to RoPE, despite rotations already being on the table...
## Absolute vs Relative Position Encoding
With the knowledge in hand that rotations are important here, let's
return to our motivating example and try to discover some intuitions for our next iteration.
$$
\begin{align*}
&\hspace{0.7em}0 \hspace{1.4em} 1 \hspace{2em} 2 \hspace{2.6em} 3 \hspace{2.4em} 4\\
&\text{The dog chased another dog} \\
\\
&\hspace{0.3em}\text{-2} \hspace{1.4em} \text{-1} \hspace{1.7em} 0 \hspace{2.6em} 1 \hspace{2.4em} 2\\
&\text{The dog \color{#699C52}chased \color{black}another dog}
\end{align*}
$$
Above we can see the absolute positions of our tokens, and the relative
positions from \\(\color{#699C52}\text{chased}\\) to every other token. With Sinusoidal Encoding, we
generated a separate vector which represents the absolute position,
and using some trigonometric trickery we were able to encode relative positions.
When we're trying to understand these sentences, does it matter that _this_ word is the 2157th word in this blog post? Or do we care about its relationship to the words around it? The absolute position of a word rarely matters for meaning - what matters is how words relate to each other.
## Positional encoding in context
From this point on, it's key to consider positional encoding **in the context of**
self attention. To reiterate, the self-attention mechanism enables the model to weigh the importance of different elements in an input sequence and dynamically adjust their influence on the output.
$$
\text{Attn}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
$$
In all our previous iterations, we've generated a separate positional encoding
vector and **added** it to our token embedding prior to our \\(Q\\), \\(K\\) and \\(V\\) projections.
By adding the positional information directly to our token embedding, we are
**polluting** the semantic information with the positional information. We should
be attempting to encode the information without modifying the norm. Shifting to multiplicative is the
key.
Using the dictionary analogy, when looking up a word (query) in our dictionary (keys), nearby words should have more influence than distant ones. The influence of one token upon another is determined by the \\(QK^T\\) dot product - so that's exactly where we should focus our positional encoding!
$$
\vec{a} \cdot \vec{b} = |\vec{a}| |\vec{b}| \cos \theta
$$
The geometric interpretation of the dot product shown above gives us a magnificent insight.
We can modulate the result of our dot product of two vectors purely by
increasing or decreasing the angle between them. Furthermore, by rotating the
vector, we have absolutely zero impact on the norm of the vector, which encodes
the semantic information of our token.
So now we know where to focus our _attention_, and have seen from another _angle_ why a
rotation might be a sensible "channel" in which to encode our positional
information, let's put it all together!
## **Ro**tary **P**ostional **E**ncoding
**Ro**tary **P**ostional **E**ncoding or RoPE was defined in the
[RoFormer paper](https://arxiv.org/pdf/2104.09864) ([Jianlin Su](https://x.com/bojone1993) designed it independently on his blog [here](https://kexue.fm/archives/8130) and [here](https://kexue.fm/archives/8265)).
While it may seem like voodoo if you skip to the end result, by thinking about Sinusoidal Encoding in the
context of self attention (and more specifically dot products), we can see how
it all comes together.
Much like in Sinusoidal Encoding, we decompose our vectors \\(\mathbf{q}\\) or \\(\mathbf{k}\\), instead of pre-projection \\(\mathbf{x}\\)) into 2D pairs/chunks. Rather than encoding _absolute_ position directly by adding a vector we drew from sinusoidal functions of slowly decreasing frequencies, we cut to the chase and encode _relative_ position by **multiplying each pair with the rotation matrix**.
Let \\(\mathbf{q}\\) or \\(\mathbf{k}\\) be our input vector at position \\(p\\). We create a block diagonal matrix
where \\(\mathbf{M_i}\\) is the corresponding rotation matrix for that component
pairs desired rotation:
$$
R(\mathbf{q}, p) = \begin{pmatrix} \mathbf{M_1} & & & \\ & \mathbf{M_2} & & \\ & & \ddots & \\ & & & \mathbf{M_{d/2}} \end{pmatrix} \begin{pmatrix} q_1 \\ q_2 \\ \vdots \\ q_d \end{pmatrix}
$$
Much the same as Sinusoidal Encoding, \\(\mathbf{M_i}\\) is simply:
$$
\mathbf{M_i} = \begin{bmatrix} \cos(\omega_i p) & \sin(\omega_i p) \\ -\sin(\omega_i p) & \cos(\omega_i p) \end{bmatrix}
$$
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video alt="RopeEncoding.mp4" autoplay loop autobuffer muted playsinline>
<source src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/blog/you-could-have-designed-SOTA-positional-encoding/RopeEncoding.mp4" type="video/mp4">
</video>
<figcaption></figcaption>
</figure>
In practice, we don't use a matrix multiplication to compute RoPE as it would be
computationally inefficient with such a sparse matrix. Instead, we can directly apply the rotations to pairs of elements independently, taking advantage of the regular pattern in the computation:
$$
R_{\Theta,p}^d q = \begin{pmatrix}
q_1 \\
q_2 \\
q_3 \\
q_4 \\
\vdots \\
q_{d-1} \\
q_d
\end{pmatrix} \otimes \begin{pmatrix}
\cos p\theta_1 \\
\cos p\theta_1 \\
\cos p\theta_2 \\
\cos p\theta_2 \\
\vdots \\
\cos p\theta_{d/2} \\
\cos p\theta_{d/2}
\end{pmatrix} + \begin{pmatrix}
-q_2 \\
q_1 \\
-q_4 \\
q_3 \\
\vdots \\
-q_d \\
q_{d-1}
\end{pmatrix} \otimes \begin{pmatrix}
\sin p\theta_1 \\
\sin p\theta_1 \\
\sin p\theta_2 \\
\sin p\theta_2 \\
\vdots \\
\sin p\theta_{d/2} \\
\sin p\theta_{d/2}
\end{pmatrix}
$$
That's all there is to it! By artfully applying our rotations to 2D chunks of \\(\mathbf{q}\\) and
\\(\mathbf{k}\\) prior to their dot product, and switching from additive to
multiplicative, we can gain a big performance boost in evaluations \\([^4]\\).
## Extending RoPE to \\(n\\)-Dimensions
We've explored the \\(1D\\) case for RoPE and by this point I hope you've gained an
intuitive understanding of an admittedly unintuitive component of transformers.
Finally, let's explore extending it to higher dimensions, such as images.
A natural first intuition could be to directly use the \\( \begin{bmatrix} x \\ y \end{bmatrix}\\) coordinate pairs from the image. This might seem intuitive, after all, we were almost arbitrarily pairing up our components previously. However, this would be a mistake!
In the \\(1D\\) case, we encode the relative position \\(m - n\\) through a rotation of pairs
of values from our input vector. For \\(2D\\) data, we need to encode both horizontal and vertical relative positions, say \\(m - n\\) and \\(i - j\\) independently. RoPE's brilliance lies in how it handles multiple dimensions. Instead of trying to encode all positional information in a single rotation, we pair components **within the same dimension** and rotate those, otherwise we would be intermixing the \\(x\\) and \\(y\\) offset information. By handling each dimension independently, we maintain the natural structure of the space. This can generalize to as many dimensions as required!
## The future of positional encoding
Is RoPE the final incarnation of positional encoding? This [recent paper](https://arxiv.org/pdf/2410.06205) from DeepMind deeply analyses RoPE and highlights some fundamental problems. TLDR: RoPE isn't a perfect solution, and the models mostly focus on the lower frequencies and the rotation for a certain percent of low frequencies improves performance on Gemma 2B!
I anticipate some future breakthroughs, perhaps taking inspiration from
signal processing with ideas like wavelets or hierarchical implementations. As models
are increasingly quantized for deployment, I'd also expect to see some
innovation in encoding schemes that remain robust under low-precision arithmetic.
## Conclusion
Positional encoding has and continues to be treated as an after thought in
transformers. I believe we should view it differently - self attention has an
Achilles heel that has been repeatedly patched.
I hope this blog post showed you that you too could have discovered state of the
art positional encoding, despite it being unintuitive at first. In a follow up
post I'd love to explore practical implementation details for RoPE in order to
maximise performance.
This post was originally published [here](https://fleetwood.dev/posts/you-could-have-designed-SOTA-positional-encoding).
## References
- [Transformer Architecture: The Positional Encoding](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/)
- [Rotary Embeddings: A Relative Revolution](https://blog.eleuther.ai/rotary-embeddings/)
- [How positional encoding works in transformers?](https://www.youtube.com/watch?v=T3OT8kqoqjc)
- [Attention Is All You Need](https://arxiv.org/pdf/1706.03762)
- [Round and round we go! What makes Rotary Positional Encodings useful?](https://arxiv.org/pdf/2410.06205)
- [RoFormer: Enhanced Transformer with Rotary Position Embedding](https://arxiv.org/pdf/2104.09864)
[^1]: Binary and Sinusoidal animations are reproductions of animations contained
in [this](https://www.youtube.com/watch?v=T3OT8kqoqjc0) video.
[^2]: Using \\(\theta = 10000\\) gives us \\( 2 \pi \cdot 10000\\) unique positions, or a
theoretical upper bound on the context length at ~63,000.
[^3]: Pieces of this post are based on [this fantastic
post](https://kazemnejad.com/blog/transformer_architecture_positional_encoding/)
by [Amirhossein Kazemnejad](https://kazemnejad.com/).
[^4]: For empirical evidence, see [this](https://blog.eleuther.ai/rotary-embeddings/) great post by EleutherAI. | [
[
"llm",
"transformers",
"research",
"tutorial"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"transformers",
"research",
"tutorial"
] | null | null |
f387a08b-600b-4302-94e0-f954e0616bd8 | completed | 2025-01-16T03:09:11.596993 | 2025-01-19T17:16:29.750006 | ee73c7de-7402-4208-832f-8ab905e6b7d0 | BigCodeBench: The Next Generation of HumanEval | terryyz, ganler, SivilTaram, huybery, Muennighoff, dpfried, harmdevries, lvwerra, clefourrier | leaderboard-bigcodebench.md | [HumanEval](https://github.com/openai/human-eval) is a reference benchmark for evaluating large language models (LLMs) on code generation tasks, as it makes the evaluation of compact function-level code snippets easy. However, there are growing concerns about its effectiveness in evaluating the programming capabilities of LLMs, and the main concern is that tasks in HumanEval are too simple and may not be representative of real-world programming tasks. Compared to the algorithm-oriented tasks in HumanEval, real-world software development often involves diverse libraries and function calls. Furthermore, LLMs' performance on HumanEval is subject to [contamination and overfitting issues](https://arxiv.org/abs/2403.07974), making it less reliable for evaluating the generalization of LLMs.
While there have been some efforts to address these issues, they are either domain-specific, deterministic, or agent-centric (sorry [DS-1000](https://github.com/HKUNLP/DS-1000), [ODEX](https://github.com/zorazrw/odex), and [SWE-bench](https://github.com/princeton-nlp/SWE-bench) 💔). We feel that the community still lacks an easy-to-use benchmark that can broadly evaluate the programming capabilities of LLMs, and that's what we focused on.
We are excited to announce the release of BigCodeBench, which evaluates LLMs on solving practical and challenging programming tasks without contamination. Specifically, BigCodeBench contains 1,140 function-level tasks to challenge LLMs to follow instructions and compose multiple function calls as tools from 139 libraries. To evaluate LLMs rigorously, each programming task encompasses 5.6 test cases with an average branch coverage of 99%.
Ready to dive into BigCodeBench? Let's get started! 🚀
## What do the tasks in BigCodeBench look like? 🕵️♂️
<img src="https://github.com/bigcode-bench/bigcode-bench.github.io/blob/main/asset/tease.svg?raw=true" alt="task" style="display: block; margin-left: auto; margin-right: auto;">
BigCodeBench features complex, user-oriented instructions for each task, including clear functionality descriptions, input/output formats, error handling, and verified interactive examples. We avoid step-by-step task instructions, believing capable LLMs should understand and solve tasks from the user's perspective in an open-ended manner. We verify specific features using test cases.
```python
# We elaborate the above task with some test cases:
# Requirements SetUp
import unittest
from unittest.mock import patch
import http.client
import ssl
import socket
# Start the test
class TestCases(unittest.TestCase):
# Mock the successful connection and assess the response content
@patch('http.client.HTTPSConnection')
def test_response_content(self, mock_conn):
""" Test the content of the response. """
mock_conn.return_value.getresponse.return_value.read.return_value = b'Expected Content'
result = task_func('www.example.com', 443, '/content/path')
self.assertEqual(result, 'Expected Content')
# Mock the failed connection and assess the error handling
@patch('socket.create_connection')
@patch('http.client.HTTPSConnection')
def test_ssl_handshake_error_handling(self, mock_conn, mock_socket):
""" Test handling of SSL handshake errors. """
mock_socket.side_effect = ssl.SSLError('SSL handshake failed')
with self.assertRaises(ssl.SSLError):
task_func('badssl.com', 443, '/test/path')
# More test cases...
```
Tasks in BigCodeBench utilize diverse function calls from popular libraries. We don't restrict the function calls LLMs can use, expecting them to choose appropriate functions and combine them flexibly to solve tasks. Test cases are designed as test harnesses to examine expected program behaviors during runtime.
To assess LLM performance, we use Pass@1 with greedy decoding, measuring the percentage of tasks correctly solved with the first generated code snippet via curated test cases. This approach aligns with benchmarks like [HumanEval](https://github.com/openai/human-eval) and [MBPP](https://github.com/google-research/google-research/tree/master/mbpp). We address LLMs' tendency to skip long code prompts by adding missing setups (e.g., import statements, global constants) during Pass@1 evaluation, referred to as calibrated Pass@1.
<img src="https://github.com/bigcode-bench/bigcode-bench.github.io/blob/main/asset/depth-breadth.svg?raw=true" alt="comparison" style="display: block; margin-left: auto; margin-right: auto; width: 50%;">
To better understand implementation complexity and tool-use diversity, we compare the tasks in BigCodeBench with those in representative benchmarks, including [APPS](https://github.com/hendrycks/apps), [DS-1000](https://github.com/HKUNLP/DS-1000), [ODEX](https://github.com/zorazrw/odex), [APIBench](https://github.com/ShishirPatil/gorilla/tree/main/data/apibench), [MBPP](https://github.com/google-research/google-research/tree/master/mbpp), [NumpyEval](https://github.com/microsoft/PyCodeGPT/tree/main/cert/pandas-numpy-eval), [PandasEval](https://github.com/microsoft/PyCodeGPT/tree/main/cert/pandas-numpy-eval), [HumanEval](https://github.com/openai/human-eval), and [TorchDataEval](https://github.com/microsoft/PyCodeGPT/tree/main/apicoder/private-eval). We find that BigCodeBench requires more complex reasoning and problem-solving skills to implement comprehensive functionalities.
<img src="https://github.com/bigcode-bench/bigcode-bench.github.io/blob/main/asset/bigcodebench_prompt.svg?raw=true" alt="prompt" style="display: block; margin-left: auto; margin-right: auto; width: 70%;">
As shown in the task figure, the main target scenario is code completion (denoted as `BigCodeBench-Complete`), where LLMs are required to finish the implementation of a function based on detailed instructions in the docstring. However, considering downstream applications such as multi-turn dialogue, users may describe requirements in a more conversational and less verbose manner. This is where instruction-tuned LLMs are beneficial, as they are trained to follow natural-language instructions and generate code snippets accordingly. To test if models can truly understand human intents and translate them into code, we create `BigCodeBench-Instruct`, a more challenging variant of BigCodeBench designed to evaluate instruction-tuned LLMs.
## Where do the tasks come from? 🤔
<img src="https://github.com/bigcode-bench/bigcode-bench.github.io/blob/main/asset/construct_pipeline.svg?raw=true" alt="png" style="display: block; margin-left: auto; margin-right: auto;">
We guarantee the quality of the tasks in BigCodeBench through a systematic "Human-LLM collaboration process." We start with [ODEX](https://github.com/zorazrw/odex) as the "seed dataset," which contains short but realistic human intents and corresponding Python one-liners from Stack Overflow. We use GPT-4 to expand these one-liners into comprehensive function-level tasks.
Next, 20 human experts—most with over 5 years of Python programming experience—voluntarily guide GPT-4 in an execution-based sandbox. They continually instruct it to refine the synthesized tasks and add test cases. The tasks and test cases are then examined in a local environment, pre-evaluated on other LLMs, and cross-checked by 7 additional human experts to ensure their quality.
To assert overall quality, the authors sample tasks for 11 human experts to solve, achieving an average human performance of 97%.
## How well do LLMs perform on BigCodeBench? 📊
We host the BigCodeBench leaderboard on both [Hugging Face Space](https://huggingface.co./spaces/bigcode/bigcodebench-leaderboard) and [GitHub Pages](https://bigcode-bench.github.io/). Here, we use the Hugging Face leaderboard as an example.
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/4.36.1/gradio.js"
></script>
<gradio-app theme_mode="light" space="bigcode/bigcodebench-leaderboard"></gradio-app>
Interestingly, we observe that instruction-tuned LLMs like GPT-4 can omit essential import statements in the long prompts of `BigCodeBench-Complete`, leading to task failures due to missing modules and constants. This behavior, called "model laziness", is discussed in the [community](https://community.openai.com/t/why-i-think-gpt-is-now-lazy/534332).
<u>Compared to human performance, LLMs perform significantly lower on `BigCodeBench-Complete` and even lower on `BigCodeBench-Instruct`.</u> The best model (GPT-4o) achieves a calibrated Pass@1 of 61.1% on `BigCodeBench-Complete` and 51.1% on `BigCodeBench-Instruct`. Additionally, there is a notable performance gap between closed and open LLMs.
While Pass@1 is a good metric for overall performance, it is not detailed enough to compare models directly. Inspired by [Chatbot Arena](https://lmsys.org/blog/2023-05-03-arena/), we use Elo rating to rank models on `BigCodeBench-Complete`. This method, originally used in chess, ranks players based on their game performance. We adapt it to programming tasks, treating each task as a game and each model as a player. The Elo rating updates are based on game outcomes and expectations, using task-level calibrated Pass@1 (0% or 100%) and excluding ties. Starting with an initial Elo rating of 1000, we fit it using maximum likelihood estimation and bootstrap with 500 iterations to get final scores. <u>We find that GPT-4o outperforms other models by a large margin, with DeepSeekCoder-V2 in the second tier.</u>
To help the community understand model performance on each task, we track solve rates, measured by calibrated Pass@1. On `BigCodeBench-Complete`, 149 tasks remain unsolved by all models, while 6 tasks are completely solved. For `BigCodeBench-Instruct`, 278 tasks remain unsolved and 14 tasks are fully solved by all models. The significant number of unsolved tasks and the small number of fully solved tasks show that BigCodeBench is a challenging benchmark for LLMs.
## Great! So, how can I evaluate my model on BigCodeBench? 🛠️
We make BigCodeBench easily accessible to the community by providing a simple and user-friendly evaluation framework, which can be downloaded via [PyPI](https://pydigger.com/pypi/bigcodebench). The prototype of the evaluation framework is based on [EvalPlus](https://github.com/evalplus/evalplus) for the HumanEval+ and MBPP+ benchmarks. However, as our benchmark has tasks with much more diverse library dependencies than EvalPlus, we build less resource-constrained execution environment, and adapt it for `unittest` in the test harness of BigCodeBench.
To facilitate the evaluation, we provide pre-built Docker images for [_code generation_](https://hub.docker.com/r/bigcodebench/bigcodebench-generate) and [_code execution_](https://hub.docker.com/r/bigcodebench/bigcodebench-evaluate). Check out our [GitHub repository](https://github.com/bigcode-project/bigcodebench) to find more details on how to use the evaluation framework.
### Setup
```bash
# Install to use bigcodebench.evaluate
pip install bigcodebench --upgrade
# If you want to use the evaluate locally, you need to install the requirements
pip install -I -r https://raw.githubusercontent.com/bigcode-project/bigcodebench/main/Requirements/requirements-eval.txt
# Install to use bigcodebench.generate
# You are strongly recommended to install the [generate] dependencies in a separate environment
pip install bigcodebench[generate] --upgrade
```
### Code Generation
You are suggested to use `flash-attn` for generating code samples.
```bash
pip install -U flash-attn
```
To generate code samples from a model, you can use the following command:
```bash
bigcodebench.generate \
--model [model_name] \
--subset [complete|instruct] \
--greedy \
--bs [bs] \
--temperature [temp] \
--n_samples [n_samples] \
--resume \
--backend [vllm|hf|openai|mistral|anthropic|google] \
--tp [gpu_number] \
[--trust_remote_code] \
[--base_url [base_url]]
```
The generated code samples will be stored in a file named `[model_name]--bigcodebench-[instruct|complete]--[backend]-[temp]-[n_samples].jsonl`.
### Code Post-processing
LLM-generated text may not be compilable code as it includes natural language lines or incomplete extra code.
We provide a tool namely `bigcodebench.sanitize` to clean up the code:
```bash
# 💡 If you want to store calibrated code in jsonl:
bigcodebench.sanitize --samples samples.jsonl --calibrate
# Sanitized code will be produced to `samples-sanitized-calibrated.jsonl`
# 💡 If you do without calibration:
bigcodebench.sanitize --samples samples.jsonl
# Sanitized code will be produced to `samples-sanitized.jsonl`
# 💡 If you are storing codes in directories:
bigcodebench.sanitize --samples /path/to/vicuna-[??]b_temp_[??]
# Sanitized code will be produced to `/path/to/vicuna-[??]b_temp_[??]-sanitized`
```
### Code Evaluation
You are strongly recommended to use a sandbox such as [docker](https://docs.docker.com/get-docker/):
```bash
# Mount the current directory to the container
docker run -v $(pwd):/app bigcodebench/bigcodebench-evaluate:latest --subset [complete|instruct] --samples samples-sanitized-calibrated
# ...Or locally ⚠️
bigcodebench.evaluate --subset [complete|instruct] --samples samples-sanitized-calibrated
# ...If the ground truth is working locally (due to some flaky tests)
bigcodebench.evaluate --subset [complete|instruct] --samples samples-sanitized-calibrated --no-gt
```
## What's next?
We share a long-term roadmap to address the limitations of BigCodeBench and sustainably build with the community. Our goal is to provide the community with the most open, reliable, and scalable evaluations to truly understand the fundamental capabilities of LLMs for programming and pinpoint ways to unleash their power. Specifically, we plan to enhance the following aspects of BigCodeBench:
- **Multilingualism**: Currently, BigCodeBench is Python-only and cannot be easily extended to other programming languages. Since function calls are mostly language-specific, finding packages or libraries with the same functionalities in languages other than Python is challenging.
- **Rigorousness**: While we achieve high test coverage for ground-truth solutions in BigCodeBench, it does not guarantee that _all_ code solutions generated by LLMs will be correctly assessed against existing test cases. Previous works like EvalPlus have attempted to extend limited test cases by augmenting input-output pairs via LLM- and mutation-based strategies. However, adapting EvalPlus to the test harness in BigCodeBench is challenging. While EvalPlus emphasizes the input-output assertions, most of test harnesses in BigCoeBench require non-trivial configurations (e.g., mock patching) to examine expected program behaviors during runtime.
- **Generalization**: A key question is, "How well do the models generalize to unseen tools and tasks?" Currently, BigCodeBench covers common libraries and daily programming tasks. Benchmarking models on programming tasks that use emerging libraries like [transformers](https://github.com/huggingface/transformers) and [langchain](https://github.com/langchain-ai/langchain) would be more interesting.
- **Evolution**: Libraries can become obsolete or be updated, meaning the source code data for model training will constantly evolve. Models may not memorize function calls from deprecated library versions, posing a challenge for any tool-dependent programming benchmarks to correctly examine model capabilities without periodic updates. Another related concern is test set contamination due to evolving training data.
- **Interaction**: Recent interest focuses on the concept of _LLMs as Agents_, which is seen as a path toward artificial general intelligence. Specifically, LLMs will be grounded in a less constrained sandbox environment, where they can interact with applications such as web browsers and terminals. This environment can help unlock capabilities like [self-debugging](https://arxiv.org/pdf/2304.05128) and [self-reflection](https://arxiv.org/abs/2303.11366).
We are excited to see the community's feedback and contributions to building BigCodeBench in the long run 🤗
## Resources
We open-source all the artifacts of BigCodeBench, including the tasks, test cases, evaluation framework, and leaderboard. You can find them as follows:
- [GitHub Repository](https://github.com/bigcode-project/bigcodebench)
- [HF Data Viewer](https://huggingface.co./spaces/bigcode/bigcodebench-viewer)
- [HF Dataset](https://huggingface.co./datasets/bigcode/bigcodebench)
- [HF Leaderboard](https://huggingface.co./spaces/bigcode/bigcodebench-leaderboard)
- [GitHub Pages Leaderboard](https://bigcode-bench.github.io/)
If you have any questions or suggestions, please feel free to open an issue in the repository or contact us via [[email protected]](mailto:[email protected]) or [[email protected]](mailto:[email protected]).
## Citation
If you find our evaluations useful, please consider citing our work
```bibtex
@article{zhuo2024bigcodebench,
title={BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions},
author={Zhuo, Terry Yue and Vu, Minh Chien and Chim, Jenny and Hu, Han and Yu, Wenhao and Widyasari, Ratnadira and Yusuf, Imam Nur Bani and Zhan, Haolan and He, Junda and Paul, Indraneil and others},
journal={arXiv preprint arXiv:2406.15877},
year={2024}
}
``` | [
[
"llm",
"research",
"benchmarks",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"llm",
"benchmarks",
"research",
"tools"
] | null | null |
c079eaa1-1baa-46df-a2a4-130e7266640c | completed | 2025-01-16T03:09:11.597001 | 2025-01-19T19:06:55.643178 | 654de168-0e32-40f9-9c23-bb99ec9a9ac7 | 'The Partnership: Amazon SageMaker and Hugging Face' | nan | the-partnership-amazon-sagemaker-and-hugging-face.md | > Look at these smiles!
# **The Partnership: Amazon SageMaker and Hugging Face**
Today, we announce a strategic partnership between Hugging Face and [Amazon](https://huggingface.co./amazon) to make it easier for companies to leverage State of the Art Machine Learning models, and ship cutting-edge NLP features faster.
Through this partnership, Hugging Face is leveraging Amazon Web Services as its Preferred Cloud Provider to deliver services to its customers.
As a first step to enable our common customers, Hugging Face and Amazon are introducing new Hugging Face Deep Learning Containers (DLCs) to make it easier than ever to train Hugging Face Transformer models in [Amazon SageMaker](https://aws.amazon.com/sagemaker/).
To learn how to access and use the new Hugging Face DLCs with the Amazon SageMaker Python SDK, check out the guides and resources below.
> _On July 8th, 2021 we extended the Amazon SageMaker integration to add easy deployment and inference of Transformers models. If you want to learn how you can [deploy Hugging Face models easily with Amazon SageMaker](https://huggingface.co./blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) take a look at the [new blog post](https://huggingface.co./blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) and the [documentation](https://huggingface.co./docs/sagemaker/inference)._ | [
[
"transformers",
"mlops",
"deployment",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"transformers",
"mlops",
"deployment",
"integration"
] | null | null |
7e6efb52-fed2-4a4e-a6f2-e0f147a9764c | completed | 2025-01-16T03:09:11.597009 | 2025-01-19T19:06:52.741008 | e807e561-16cf-454c-bf96-6a4ad214145e | Hugging Face Machine Learning Demos on arXiv | abidlabs, osanseviero, pcuenq | arxiv.md | We’re very excited to announce that Hugging Face has collaborated with arXiv to make papers more accessible, discoverable, and fun! Starting today, [Hugging Face Spaces](https://huggingface.co./spaces) is integrated with arXivLabs through a Demo tab that includes links to demos created by the community or the authors themselves. By going to the Demos tab of your favorite paper, you can find links to open-source demos and try them out immediately 🔥
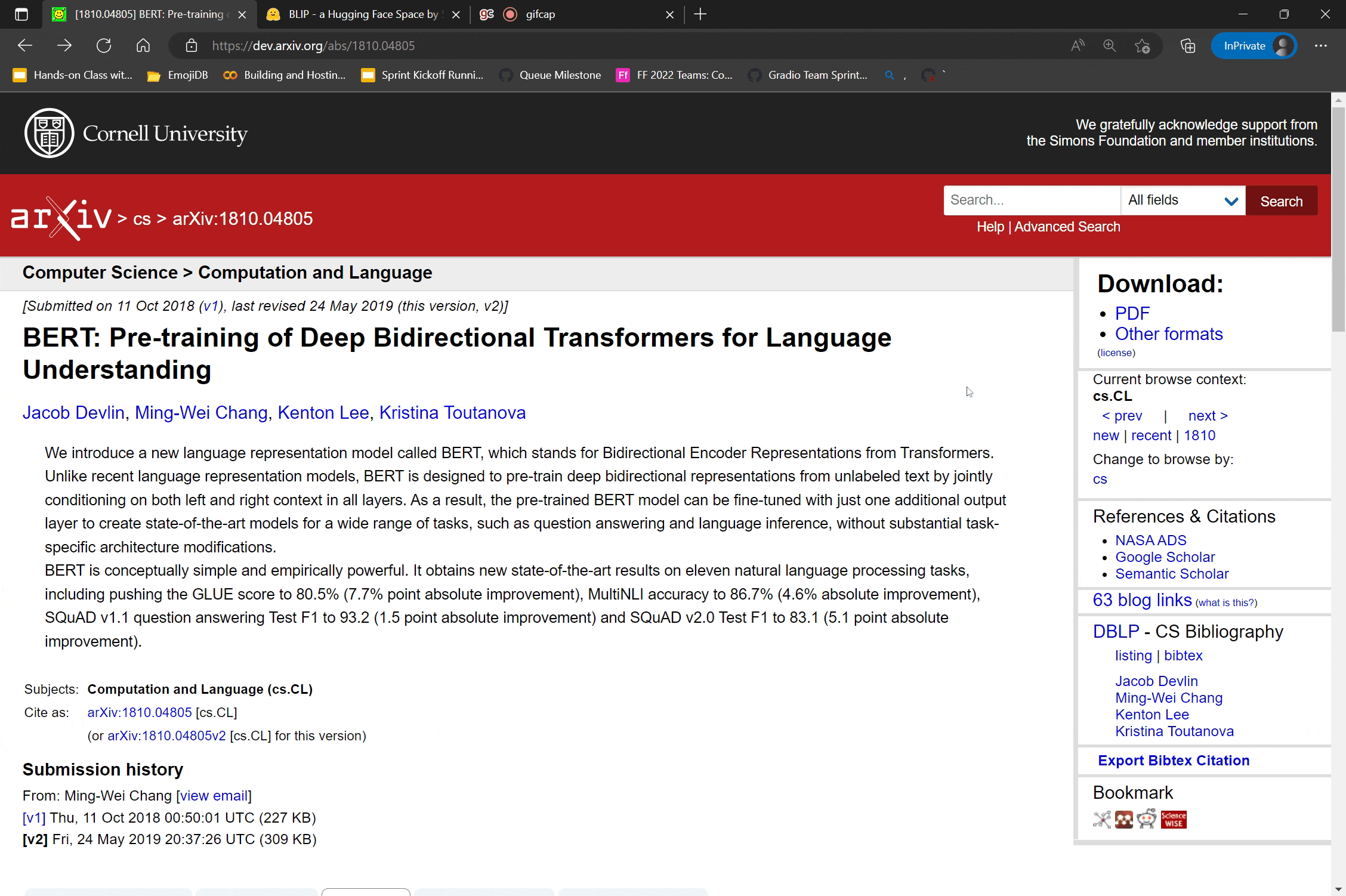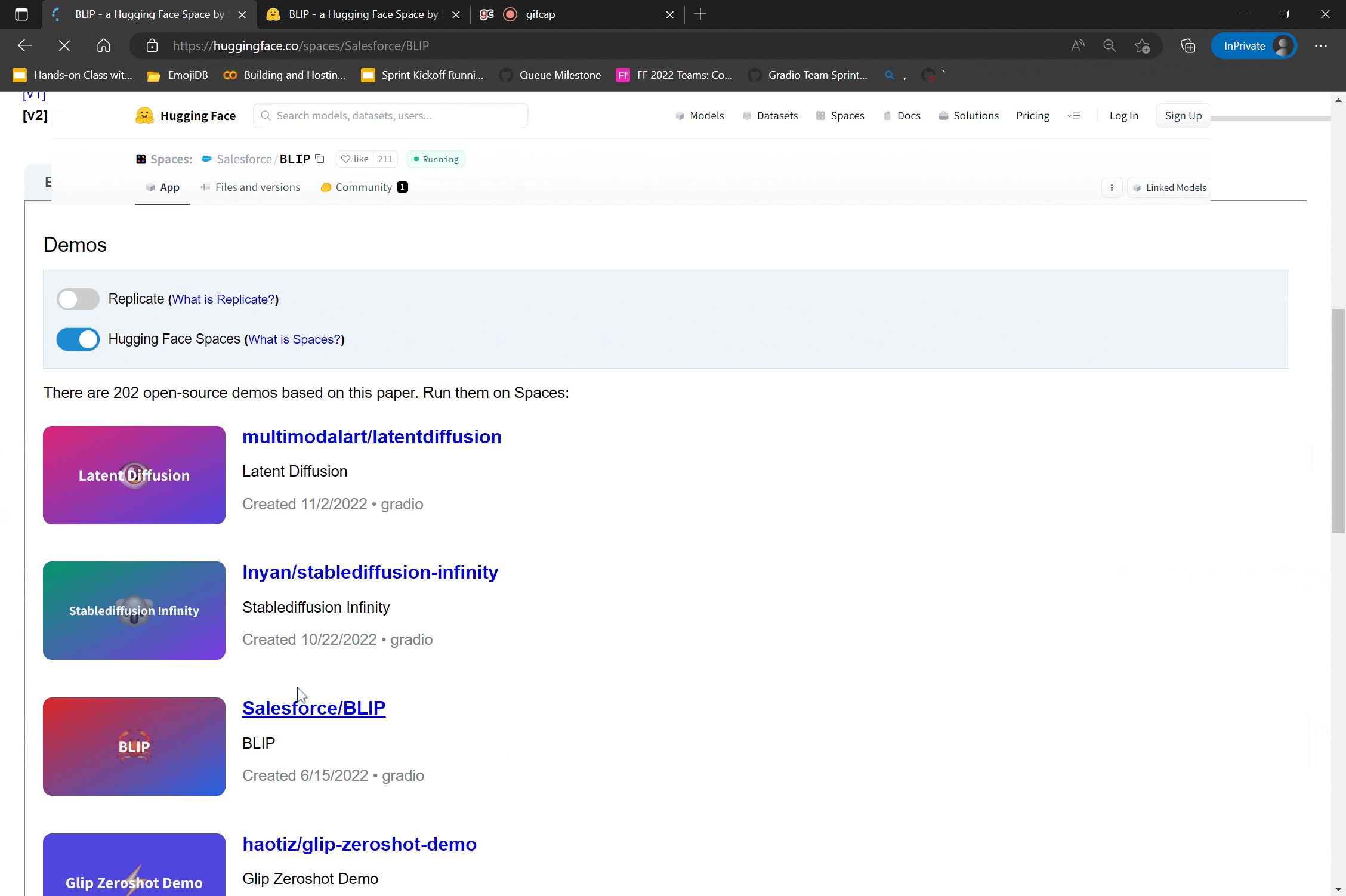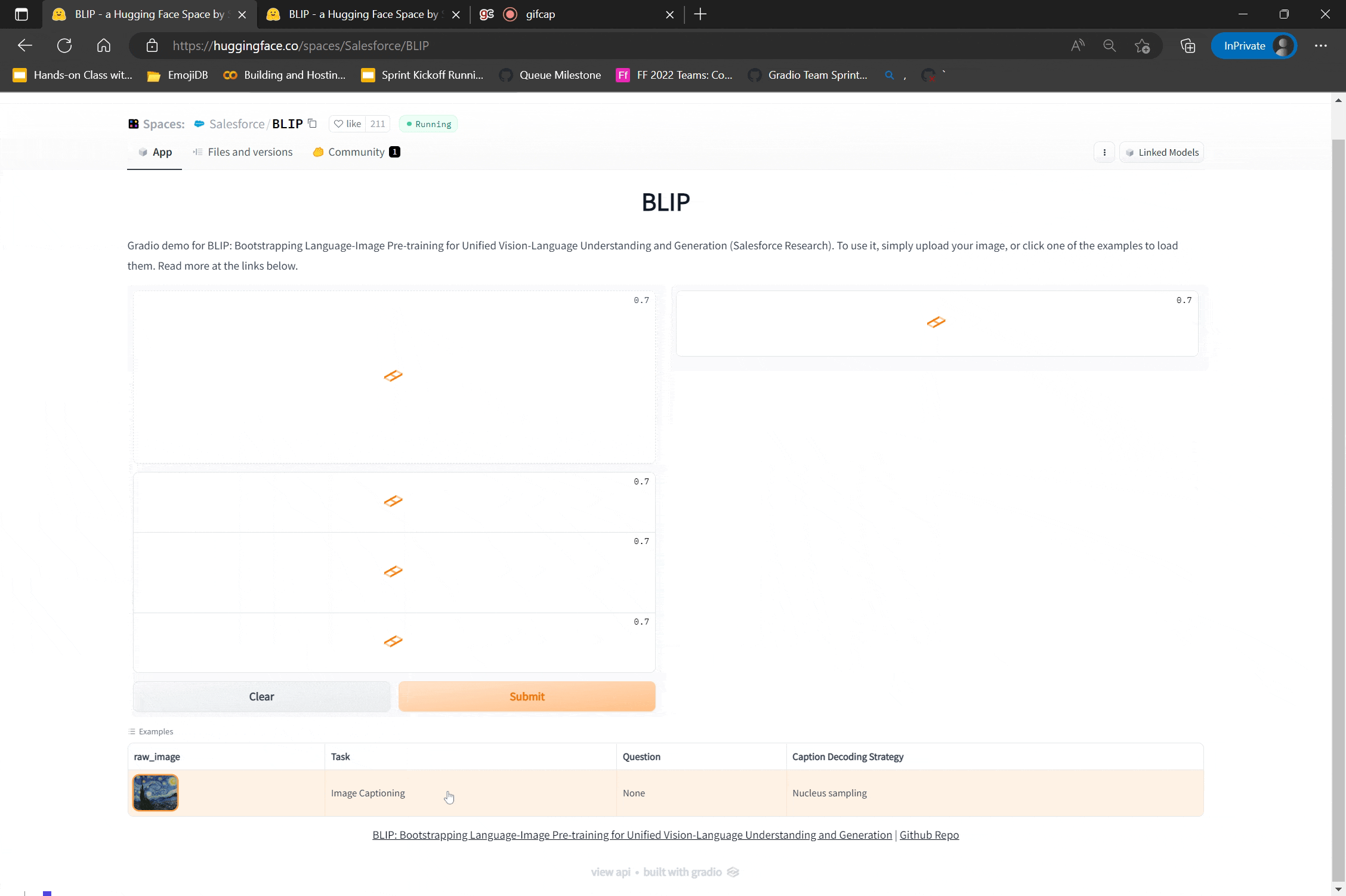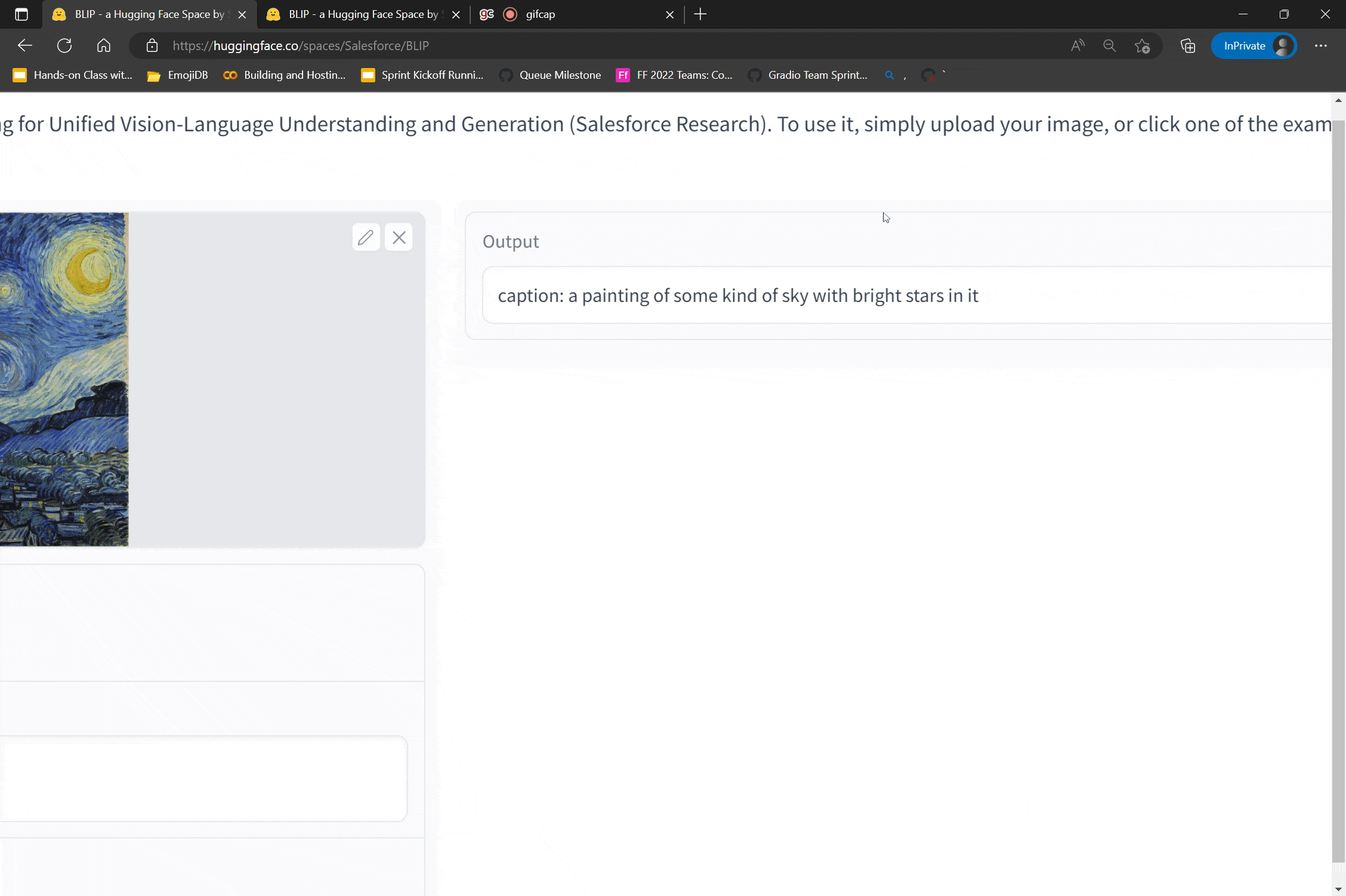
Since its launch in October 2021, Hugging Face Spaces has been used to build and share over 12,000 open-source machine learning demos crafted by the community. With Spaces, Hugging Face users can share, explore, discuss models, and build interactive applications that enable anyone with a browser to try them out without having to run any code. These demos are built using open-source tools such as the Gradio and Streamlit Python libraries, and leverage models and datasets available on the Hugging Face Hub.
Thanks to the latest arXiv integration, users can now find the most popular demos for a paper on its arXiv abstract page. For example, if you want to try out demos of the BERT language model, you can go to the BERT paper’s [arXiv page](https://arxiv.org/abs/1810.04805), and navigate to the demo tab. You will see more than 200 demos built by the open-source community -- some demos simply showcase the BERT model, while others showcase related applications that modify or use BERT as part of larger pipelines, such as the demo shown above.
Demos allow a much wider audience to explore machine learning as well as other fields in which computational models are built, such as biology, chemistry, astronomy, and economics. They help increase the awareness and understanding of how models work, amplify the visibility of researchers' work, and allow a more diverse audience to identify and debug biases and other issues. The demos increase the reproducibility of research by enabling others to explore the paper's results without having to write a single line of code! We are thrilled about this integration with arXiv and can’t wait to see how the research community will use it to improve communication, dissemination and interpretability. | [
[
"research",
"implementation",
"community",
"tools",
"integration"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"tools",
"integration",
"implementation"
] | null | null |
60ad9b27-d74d-428a-8090-4400867900dd | completed | 2025-01-16T03:09:11.597016 | 2025-01-16T03:25:13.506371 | 00514f28-faea-409a-918f-3147a2504a8b | Open Source Developers Guide to the EU AI Act | brunatrevelin, frimelle, yjernite | eu-ai-act-for-oss-developers.md | <div style="text-align: center;">
<b>Not legal advice.</b>
</div>
*The EU AI Act, the world’s first comprehensive legislation on artificial intelligence, has officially come into force, and it’s set to impact the way we develop and use AI – including in the open source community. If you’re an open source developer navigating this new landscape, you’re probably wondering what this means for your projects. This guide breaks down key points of the regulation with a focus on open source development, offering a clear introduction to this legislation and directing you to tools that may help you prepare to comply with it.*
**_Disclaimer: The information provided in this guide is for informational purposes only, and should not be considered as any form of legal advice._**
> **TL;DR:** The AI Act may apply to open source AI systems and models, with specific rules depending on the type of model and how they are released. In most cases, obligations involve providing clear documentation, adding tools to disclose model information when deployed, and following existing copyright and privacy rules. Fortunately, many of these practices are already common in the open source landscape, and Hugging Face offers tools to help you prepare to comply, including tools to support opt-out processes and redaction of personal data.
Check out [model cards](https://huggingface.co./docs/hub/en/model-cards), [dataset cards](https://huggingface.co./docs/hub/en/datasets-cards), [Gradio](https://www.gradio.app/docs/gradio/video) [watermarking](https://huggingface.co./spaces/meg/watermark_demo), [support](https://techcrunch.com/2023/05/03/spawning-lays-out-its-plans-for-letting-creators-opt-out-of-generative-ai-training/) for [opt-out](https://huggingface.co./spaces/bigcode/in-the-stack) mechanisms and [personal data redaction](https://huggingface.co./blog/presidio-pii-detection), [licenses](https://huggingface.co./docs/hub/en/repositories-licenses) and others!
The EU AI Act is a binding regulation that aims to foster responsible AI. To that end, it sets out rules that scale with the level of risk the AI system or model might pose while aiming to preserve open research and support small and medium-sized enterprises (SMEs). As an open source developer, many aspects of your work won’t be directly impacted – especially if you’re already documenting your systems and keeping track of data sources. In general, there are straightforward steps you can take to prepare for compliance.
The regulation takes effect over the next two years and applies broadly, not just to those within the EU. If you’re an open source developer outside the EU but your AI systems or models are offered or impact people within the EU, they are included in the Act.
## 🤗 Scope
The regulation works at different levels of the AI stack, meaning it has different obligations if you are a provider (which includes the developers), deployer, distributor etc. and if you are working on an AI model or system.
| **Model**: only **general purpose AI** (GPAI) models are directly regulated. GPAI models are models trained on large amounts of data, that show significant generality, can perform a wide range of tasks and can be used in systems and applications. One example is a large language model (LLM). Modifications or fine-tuning of models also need to comply with obligations. | **System**: a system that is able to infer from inputs. This could typically take the form of a traditional software stack that leverages or connects one or several AI models to a digital representation of the inputs. One example is a chatbot interacting with end users, leveraging an LLM or Gradio apps hosted on Hugging Face Spaces. |
| | [
[
"mlops",
"research",
"community",
"security",
"tools"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"community",
"security",
"tools",
"mlops"
] | null | null |
12b0795f-450c-4c73-b871-290703e49169 | completed | 2025-01-16T03:09:11.597024 | 2025-01-19T17:15:33.777829 | d2f4d182-58af-4ab4-a761-76f98e7f4d49 | Accelerating SD Turbo and SDXL Turbo Inference with ONNX Runtime and Olive | sschoenmeyer, tlwu, mfuntowicz | sdxl_ort_inference.md | ## Introduction
[SD Turbo](https://huggingface.co./stabilityai/sd-turbo) and [SDXL Turbo](https://huggingface.co./stabilityai/sdxl-turbo) are two fast generative text-to-image models capable of generating viable images in as little as one step, a significant improvement over the 30+ steps often required with previous Stable Diffusion models. SD Turbo is a distilled version of [Stable Diffusion 2.1](https://huggingface.co./stabilityai/stable-diffusion-2-1), and SDXL Turbo is a distilled version of [SDXL 1.0](https://huggingface.co./stabilityai/stable-diffusion-xl-base-1.0). We’ve [previously shown](https://medium.com/microsoftazure/accelerating-stable-diffusion-inference-with-onnx-runtime-203bd7728540) how to accelerate Stable Diffusion inference with ONNX Runtime. Not only does ONNX Runtime provide performance benefits when used with SD Turbo and SDXL Turbo, but it also makes the models accessible in languages other than Python, like C# and Java.
### Performance gains
In this post, we will introduce optimizations in the ONNX Runtime CUDA and TensorRT execution providers that speed up inference of SD Turbo and SDXL Turbo on NVIDIA GPUs significantly.
ONNX Runtime outperformed PyTorch for all (batch size, number of steps) combinations tested, with throughput gains as high as 229% for the SDXL Turbo model and 120% for the SD Turbo model. ONNX Runtime CUDA has particularly good performance for dynamic shape but demonstrates a marked improvement over PyTorch for static shape as well.

## How to run SD Turbo and SDXL Turbo
To accelerate inference with the ONNX Runtime CUDA execution provider, access our optimized versions of [SD Turbo](https://huggingface.co./tlwu/sd-turbo-onnxruntime) and [SDXL Turbo](https://huggingface.co./tlwu/sdxl-turbo-onnxruntime) on Hugging Face.
The models are generated by [Olive](https://github.com/microsoft/Olive/tree/main/examples/stable_diffusion), an easy-to-use model optimization tool that is hardware aware. Note that fp16 VAE must be enabled through the command line for best performance, as shown in the optimized versions shared. For instructions on how to run the SD and SDXL pipelines with the ONNX files hosted on Hugging Face, see the [SD Turbo usage example](https://huggingface.co./tlwu/sd-turbo-onnxruntime#usage-example) and the [SDXL Turbo usage example](https://huggingface.co./tlwu/sdxl-turbo-onnxruntime#usage-example).
To accelerate inference with the ONNX Runtime TensorRT execution provider instead, follow the instructions found [here](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/python/tools/transformers/models/stable_diffusion/README.md#run-demo-with-docker).
The following is an example of image generation with the SDXL Turbo model guided by a text prompt:
```bash
python3 demo_txt2img_xl.py \
--version xl-turbo \
"little cute gremlin wearing a jacket, cinematic, vivid colors, intricate masterpiece, golden ratio, highly detailed"
```
<p align="center">
<img src="assets/sdxl_ort_inference/gremlin_example_image.svg" alt="Generated Gremlin Example"><br>
<em>Figure 1. Little cute gremlin wearing a jacket image generated with text prompt using SDXL Turbo.</em>
</p>
Note that the example image was generated in 4 steps, demonstrating the ability of SD Turbo and SDXL Turbo to generate viable images in fewer steps than previous Stable Diffusion models.
For a user-friendly way to try out Stable Diffusion models, see our [ONNX Runtime Extension for Automatic1111’s SD WebUI](https://github.com/tianleiwu/Stable-Diffusion-WebUI-OnnxRuntime). This extension enables optimized execution of the Stable Diffusion UNet model on NVIDIA GPUs and uses the ONNX Runtime CUDA execution provider to run inference against models optimized with Olive. At this time, the extension has only been optimized for Stable Diffusion 1.5. SD Turbo and SDXL Turbo models can be used as well, but performance optimizations are still in progress.
### Applications of Stable Diffusion in C# and Java
Taking advantage of the cross-platform, performance, and usability benefits of ONNX Runtime, members of the community have also contributed samples and UI tools of their own using Stable Diffusion with ONNX Runtime.
These community contributions include [OnnxStack](https://github.com/saddam213/OnnxStack), a .NET library that builds upon our [previous C# tutorial](https://github.com/cassiebreviu/StableDiffusion/) to provide users with a variety of capabilities for many different Stable Diffusion models when performing inference with C# and ONNX Runtime.
Additionally, Oracle has released a [Stable Diffusion sample with Java](https://github.com/oracle-samples/sd4j) that runs inference on top of ONNX Runtime. This project is also based on our C# tutorial.
## Benchmark results
We benchmarked the SD Turbo and SDXL Turbo models with Standard_ND96amsr_A100_v4 VM using A100-SXM4-80GB and a [Lenovo Desktop](https://www.lenovo.com/us/en/p/desktops/legion-desktops/legion-t-series-towers/legion-tower-7i-gen-8-(34l-intel)/90v7003bus) with RTX-4090 GPU (WSL Ubuntu 20.04) to generate images of resolution 512x512 using the LCM Scheduler and fp16 models. The results are measured using these specifications:
- onnxruntime-gpu==1.17.0 (built from source)
- torch==2.1.0a0+32f93b1
- tensorrt==8.6.1
- transformers==4.36.0
- diffusers==0.24.0
- onnx==1.14.1
- onnx-graphsurgeon==0.3.27
- polygraphy==0.49.0
To reproduce these results, we recommend using the instructions linked in the ‘Usage example’ section.
Since the original VAE of SDXL Turbo cannot run in fp16 precision, we used [sdxl-vae-fp16-fix](https://huggingface.co./madebyollin/sdxl-vae-fp16-fix) in testing SDXL Turbo. There are slight discrepancies between its output and that of the original VAE, but the decoded images are close enough for most purposes.
The PyTorch pipeline for static shape has applied channel-last memory format and torch.compile with reduce-overhead mode.
The following charts illustrate the throughput in images per second vs. different (batch size, number of steps) combinations for various frameworks. It is worth noting that the label above each bar indicates the speedup percentage vs. Torch Compile – e.g., in the first chart, ORT_TRT (Static) is 31% faster than Torch (Compile) for (batch, steps) combination (4, 1).
We elected to use 1 and 4 steps because both SD Turbo and SDXL Turbo can generate viable images in as little as 1 step but typically produce images of the best quality in 3-5 steps.
### SDXL Turbo
The graphs below illustrate the throughput in images per second for the SDXL Turbo model with both static and dynamic shape. Results were gathered on an A100-SXM4-80GB GPU for different (batch size, number of steps) combinations. For dynamic shape, the TensorRT engine supports batch size 1 to 8 and image size 512x512 to 768x768, but it is optimized for batch size 1 and image size 512x512.


### SD Turbo
The next two graphs illustrate throughput in images per second for the SD Turbo model with both static and dynamic shape on an A100-SXM4-80GB GPU.


The final set of graphs illustrates throughput in images per second for the SD Turbo model with both static and dynamic shape on an RTX-4090 GPU. In this dynamic shape test, the TensorRT engine is built for batch size 1 to 8 (optimized for batch size 1) and fixed image size 512x512 due to memory limitation.


### How fast are SD Turbo and SDXL Turbo with ONNX Runtime?
These results demonstrate that ONNX Runtime significantly outperforms PyTorch with both CUDA and TensorRT execution providers in static and dynamic shape for all (batch, steps) combinations shown. This conclusion applies to both model sizes (SD Turbo and SDXL Turbo), as well as both GPUs tested. Notably, ONNX Runtime with CUDA (dynamic shape) was shown to be 229% faster than Torch Eager for (batch, steps) combination (1, 4).
Additionally, ONNX Runtime with the TensorRT execution provider performs slightly better for static shape given that the ORT_TRT throughput is higher than the corresponding ORT_CUDA throughput for most (batch, steps) combinations. Static shape is typically favored when the user knows the batch and image size at graph definition time (e.g., the user is only planning to generate images with batch size 1 and image size 512x512). In these situations, the static shape has faster performance. However, if the user decides to switch to a different batch and/or image size, TensorRT must create a new engine (meaning double the engine files in the disk) and switch engines (meaning additional time spent loading the new engine).
On the other hand, ONNX Runtime with the CUDA execution provider is often a better choice for dynamic shape for SD Turbo and SDXL Turbo models when using an A100-SXM4-80GB GPU, but ONNX Runtime with the TensorRT execution provider performs slightly better on dynamic shape for most (batch, steps) combinations when using an RTX-4090 GPU. The benefit of using dynamic shape is that users can run inference more quickly when the batch and image sizes are not known until graph execution time (e.g., running batch size 1 and image size 512x512 for one image and batch size 4 and image size 512x768 for another). When dynamic shape is used in these cases, users only need to build and save one engine, rather than switching engines during inference.
## GPU optimizations
Besides the techniques introduced in our [previous Stable Diffusion blog](https://medium.com/microsoftazure/accelerating-stable-diffusion-inference-with-onnx-runtime-203bd7728540), the following optimizations were applied by ONNX Runtime to yield the SD Turbo and SDXL Turbo results outlined in this post:
- Enable CUDA graph for static shape inputs.
- Add Flash Attention V2.
- Remove extra outputs in text encoder (keep the hidden state output specified by clip_skip parameter).
- Add SkipGroupNorm fusion to fuse group normalization with Add nodes that precede it.
Additionally, we have added support for new features, including [LoRA](https://huggingface.co./docs/peft/conceptual_guides/lora) weights for latent consistency models (LCMs).
## Next steps
In the future, we plan to continue improving upon our Stable Diffusion work by updating the demo to support new features, such as [IP Adapter](https://github.com/tencent-ailab/IP-Adapter) and Stable Video Diffusion. [ControlNet](https://huggingface.co./docs/diffusers/api/pipelines/controlnet) support will also be available shortly.
We are also working on optimizing SD Turbo and SDXL Turbo performance with our [existing Stable Diffusion web UI extension](https://github.com/tianleiwu/Stable-Diffusion-WebUI-OnnxRuntime) and plan to help add support for both models to a Windows UI developed by a member of the ONNX Runtime community.
Additionally, a tutorial for how to run SD Turbo and SDXL Turbo with C# and ONNX Runtime is coming soon. In the meantime, check out our [previous tutorial on Stable Diffusion](https://onnxruntime.ai/docs/tutorials/csharp/stable-diffusion-csharp.html).
## Resources
Check out some of the resources discussed in this post:
- [SD Turbo](https://huggingface.co./tlwu/sd-turbo-onnxruntime): Olive-optimized SD Turbo for ONNX Runtime CUDA model hosted on Hugging Face.
- [SDXL Turbo](https://huggingface.co./tlwu/sdxl-turbo-onnxruntime): Olive-optimized SDXL Turbo for ONNX Runtime CUDA model hosted on Hugging Face.
- [Stable Diffusion GPU Optimization](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/python/tools/transformers/models/stable_diffusion/README.md): Instructions for optimizing Stable Diffusion with NVIDIA GPUs in ONNX Runtime GitHub repository.
- [ONNX Runtime Extension for Automatic1111’s SD WebUI](https://github.com/tianleiwu/Stable-Diffusion-WebUI-OnnxRuntime): Extension enabling optimized execution of Stable Diffusion UNet model on NVIDIA GPUs.
- [OnnxStack](https://github.com/saddam213/OnnxStack): Community-contributed .NET library enabling Stable Diffusion inference with C# and ONNX Runtime.
- [SD4J (Stable Diffusion in Java)](https://github.com/oracle-samples/sd4j): Oracle sample for Stable Diffusion with Java and ONNX Runtime.
- [Inference Stable Diffusion with C# and ONNX Runtime](https://onnxruntime.ai/docs/tutorials/csharp/stable-diffusion-csharp.html): Previously published C# tutorial. | [
[
"computer_vision",
"optimization",
"tools",
"image_generation"
]
] | [
"2629e041-8c70-4026-8651-8bb91fd9749a"
] | [
"submitted"
] | [
"computer_vision",
"optimization",
"tools",
"image_generation"
] | null | null |