
repo_id
stringlengths 4
110
| author
stringlengths 2
27
⌀ | model_type
stringlengths 2
29
⌀ | files_per_repo
int64 2
15.4k
| downloads_30d
int64 0
19.9M
| library
stringlengths 2
37
⌀ | likes
int64 0
4.34k
| pipeline
stringlengths 5
30
⌀ | pytorch
bool 2
classes | tensorflow
bool 2
classes | jax
bool 2
classes | license
stringlengths 2
30
| languages
stringlengths 4
1.63k
⌀ | datasets
stringlengths 2
2.58k
⌀ | co2
stringclasses 29
values | prs_count
int64 0
125
| prs_open
int64 0
120
| prs_merged
int64 0
15
| prs_closed
int64 0
28
| discussions_count
int64 0
218
| discussions_open
int64 0
148
| discussions_closed
int64 0
70
| tags
stringlengths 2
513
| has_model_index
bool 2
classes | has_metadata
bool 1
class | has_text
bool 1
class | text_length
int64 401
598k
| is_nc
bool 1
class | readme
stringlengths 0
598k
| hash
stringlengths 32
32
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
nejox/distilbert-base-uncased-distilled-squad-coffee20230108 | nejox | distilbert | 12 | 3 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,969 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-squad-coffee20230108
This model is a fine-tuned version of [distilbert-base-uncased-distilled-squad](https://huggingface.co./distilbert-base-uncased-distilled-squad) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.3444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 89 | 1.9198 |
| 2.3879 | 2.0 | 178 | 1.8526 |
| 1.5528 | 3.0 | 267 | 1.8428 |
| 1.1473 | 4.0 | 356 | 2.4035 |
| 0.7375 | 5.0 | 445 | 2.3232 |
| 0.5986 | 6.0 | 534 | 2.4550 |
| 0.4252 | 7.0 | 623 | 3.2831 |
| 0.2612 | 8.0 | 712 | 3.2129 |
| 0.143 | 9.0 | 801 | 3.7849 |
| 0.143 | 10.0 | 890 | 3.8476 |
| 0.0984 | 11.0 | 979 | 4.1742 |
| 0.0581 | 12.0 | 1068 | 4.3476 |
| 0.0157 | 13.0 | 1157 | 4.3818 |
| 0.0131 | 14.0 | 1246 | 4.3357 |
| 0.0059 | 15.0 | 1335 | 4.3444 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.11.0+cu113
- Datasets 2.8.0
- Tokenizers 0.13.2
| ac50711e4c51d792b26d642b1aa8a847 |
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_stsb_128 | gokuls | mobilebert | 17 | 2 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,040 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_stsb_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co./google/mobilebert-uncased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1533
- Pearson: 0.0554
- Spearmanr: 0.0563
- Combined Score: 0.0558
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 2.5973 | 1.0 | 45 | 1.2342 | -0.0353 | -0.0325 | -0.0339 |
| 1.0952 | 2.0 | 90 | 1.1740 | 0.0434 | 0.0419 | 0.0426 |
| 1.0581 | 3.0 | 135 | 1.1533 | 0.0554 | 0.0563 | 0.0558 |
| 1.0455 | 4.0 | 180 | 1.2131 | 0.0656 | 0.0690 | 0.0673 |
| 0.9795 | 5.0 | 225 | 1.3883 | 0.0868 | 0.0858 | 0.0863 |
| 0.9197 | 6.0 | 270 | 1.4141 | 0.1181 | 0.1148 | 0.1165 |
| 0.8182 | 7.0 | 315 | 1.3460 | 0.1771 | 0.1853 | 0.1812 |
| 0.6796 | 8.0 | 360 | 1.1577 | 0.2286 | 0.2340 | 0.2313 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| d67261525a22e75eab30846a0dbc5531 |
microsoft/xclip-base-patch16-hmdb-2-shot | microsoft | xclip | 10 | 2 | transformers | 0 | feature-extraction | true | false | false | mit | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision', 'video-classification'] | true | true | true | 2,425 | false |
# X-CLIP (base-sized model)
X-CLIP model (base-sized, patch resolution of 16) trained in a few-shot fashion (K=2) on [HMDB-51](https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/). It was introduced in the paper [Expanding Language-Image Pretrained Models for General Video Recognition](https://arxiv.org/abs/2208.02816) by Ni et al. and first released in [this repository](https://github.com/microsoft/VideoX/tree/master/X-CLIP).
This model was trained using 32 frames per video, at a resolution of 224x224.
Disclaimer: The team releasing X-CLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
X-CLIP is a minimal extension of [CLIP](https://huggingface.co./docs/transformers/model_doc/clip) for general video-language understanding. The model is trained in a contrastive way on (video, text) pairs.

This allows the model to be used for tasks like zero-shot, few-shot or fully supervised video classification and video-text retrieval.
## Intended uses & limitations
You can use the raw model for determining how well text goes with a given video. See the [model hub](https://huggingface.co./models?search=microsoft/xclip) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co./transformers/main/model_doc/xclip.html#).
## Training data
This model was trained on [HMDB-51](https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/).
### Preprocessing
The exact details of preprocessing during training can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L247).
The exact details of preprocessing during validation can be found [here](https://github.com/microsoft/VideoX/blob/40f6d177e0a057a50ac69ac1de6b5938fd268601/X-CLIP/datasets/build.py#L285).
During validation, one resizes the shorter edge of each frame, after which center cropping is performed to a fixed-size resolution (like 224x224). Next, frames are normalized across the RGB channels with the ImageNet mean and standard deviation.
## Evaluation results
This model achieves a top-1 accuracy of 53.0%.
| c78f56c7cbd357af76c7855b4177f332 |
facebook/wmt19-en-ru | facebook | fsmt | 9 | 3,395 | transformers | 4 | translation | true | false | false | apache-2.0 | ['en', 'ru'] | ['wmt19'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation', 'wmt19', 'facebook'] | false | true | true | 3,248 | false |
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for en-ru.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co./facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co./facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co./facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co./facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-ru"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Машинное обучение - это здорово, не так ли?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
en-ru | [36.4](http://matrix.statmt.org/matrix/output/1914?run_id=6724) | 33.47
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
| 09fd5ca751e6c96921792d1b942ec023 |
PeterBanning71/t5-small-finetuned-xsum-finetuned-bioMedv3 | PeterBanning71 | t5 | 12 | 8 | transformers | 0 | summarization | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization', 'generated_from_trainer'] | true | true | true | 2,181 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-finetuned-bioMedv3
This model is a fine-tuned version of [PeterBanning71/t5-small-finetuned-xsum](https://huggingface.co./PeterBanning71/t5-small-finetuned-xsum) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 6.1056
- Rouge1: 4.8565
- Rouge2: 0.4435
- Rougel: 3.9735
- Rougelsum: 4.415
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 1 | 8.4025 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 2.0 | 2 | 8.4025 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 3.0 | 3 | 7.7250 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 4.0 | 4 | 7.1617 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 5.0 | 5 | 6.7113 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 6.0 | 6 | 6.3646 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 7.0 | 7 | 6.1056 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
| No log | 8.0 | 8 | 6.1056 | 4.8565 | 0.4435 | 3.9735 | 4.415 | 19.0 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| fd41830000499dbb6d5db2af04fc04e4 |
yip-i/xls-r-53-copy | yip-i | wav2vec2 | 6 | 1 | transformers | 0 | null | true | false | true | apache-2.0 | ['multilingual'] | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['speech'] | false | true | true | 2,197 | false |
# Wav2Vec2-XLSR-53
[Facebook's XLSR-Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co./blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.13979)
Authors: Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, Michael Auli
**Abstract**
This paper presents XLSR which learns cross-lingual speech representations by pretraining a single model from the raw waveform of speech in multiple languages. We build on wav2vec 2.0 which is trained by solving a contrastive task over masked latent speech representations and jointly learns a quantization of the latents shared across languages. The resulting model is fine-tuned on labeled data and experiments show that cross-lingual pretraining significantly outperforms monolingual pretraining. On the CommonVoice benchmark, XLSR shows a relative phoneme error rate reduction of 72% compared to the best known results. On BABEL, our approach improves word error rate by 16% relative compared to a comparable system. Our approach enables a single multilingual speech recognition model which is competitive to strong individual models. Analysis shows that the latent discrete speech representations are shared across languages with increased sharing for related languages. We hope to catalyze research in low-resource speech understanding by releasing XLSR-53, a large model pretrained in 53 languages.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_%F0%9F%A4%97_Transformers.ipynb) for more information on how to fine-tune the model.

| fb0df48764b64890ae5c043865e65d6e |
google/t5-11b-ssm-wq | google | t5 | 9 | 8 | transformers | 1 | text2text-generation | true | true | false | apache-2.0 | ['en'] | ['c4', 'wikipedia', 'web_questions'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 2,413 | false |
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co./datasets/c4), subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co./datasets/wikipedia), and finally fine-tuned on [Web Questions (WQ)](https://huggingface.co./datasets/web_questions).
**Note**: The model was fine-tuned on 100% of the train splits of [Web Questions (WQ)](https://huggingface.co./datasets/web_questions) for 10k steps.
Other community Checkpoints: [here](https://huggingface.co./models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Results on Web Questions - Test Set
|Id | link | Exact Match |
|---|---|---|
|**T5-11b**|**https://huggingface.co./google/t5-11b-ssm-wq**|**44.7**|
|T5-xxl|https://huggingface.co./google/t5-xxl-ssm-wq|43.5|
## Usage
The model can be used as follows for **closed book question answering**:
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
t5_qa_model = AutoModelForSeq2SeqLM.from_pretrained("google/t5-11b-ssm-wq")
t5_tok = AutoTokenizer.from_pretrained("google/t5-11b-ssm-wq")
input_ids = t5_tok("When was Franklin D. Roosevelt born?", return_tensors="pt").input_ids
gen_output = t5_qa_model.generate(input_ids)[0]
print(t5_tok.decode(gen_output, skip_special_tokens=True))
```
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.
 | 421f2b02195337d45d10a6dd9600d571 |
josetapia/hygpt2-clm | josetapia | gpt2 | 17 | 4 | transformers | 0 | text-generation | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 980 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hygpt2-clm
This model is a fine-tuned version of [gpt2](https://huggingface.co./gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 4000
### Training results
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2
- Datasets 1.18.4
- Tokenizers 0.11.6
| 4e288d13e1a2a45f6aa2104c6a908f1d |
terzimert/bert-finetuned-ner-v2.2 | terzimert | bert | 12 | 7 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['caner'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,545 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-v2.2
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co./bert-base-multilingual-cased) on the caner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3595
- Precision: 0.8823
- Recall: 0.8497
- F1: 0.8657
- Accuracy: 0.9427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2726 | 1.0 | 3228 | 0.4504 | 0.7390 | 0.7287 | 0.7338 | 0.9107 |
| 0.2057 | 2.0 | 6456 | 0.3679 | 0.8633 | 0.8446 | 0.8538 | 0.9385 |
| 0.1481 | 3.0 | 9684 | 0.3595 | 0.8823 | 0.8497 | 0.8657 | 0.9427 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| c1a5f866053a6d759a96278f6c27ab14 |
openclimatefix/nowcasting_cnn_v4 | openclimatefix | null | 4 | 0 | transformers | 1 | null | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['nowcasting', 'forecasting', 'timeseries', 'remote-sensing'] | false | true | true | 962 | false |
# Nowcasting CNN
## Model description
3d conv model, that takes in different data streams
architecture is roughly
1. satellite image time series goes into many 3d convolution layers.
2. nwp time series goes into many 3d convolution layers.
3. Final convolutional layer goes to full connected layer. This is joined by
other data inputs like
- pv yield
- time variables
Then there ~4 fully connected layers which end up forecasting the
pv yield / gsp into the future
## Intended uses & limitations
Forecasting short term PV power for different regions and nationally in the UK
## How to use
[More information needed]
## Limitations and bias
[More information needed]
## Training data
Training data is EUMETSAT RSS imagery over the UK, on-the-ground PV data, and NWP predictions.
## Training procedure
[More information needed]
## Evaluation results
[More information needed]
| 409a984bb15368014d80cc8164fc5303 |
Thant123/distilbert-base-uncased-finetuned-emotion | Thant123 | distilbert | 12 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,343 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2270
- Accuracy: 0.924
- F1: 0.9241
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8204 | 1.0 | 250 | 0.3160 | 0.9035 | 0.9008 |
| 0.253 | 2.0 | 500 | 0.2270 | 0.924 | 0.9241 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
| ffacf1d2dcc9b780be66d5ad7b68e5e2 |
philschmid/roberta-base-squad2-optimized | philschmid | null | 15 | 3 | generic | 0 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['endpoints-template', 'optimum'] | false | true | true | 9,622 | false |
# Optimized and Quantized [deepset/roberta-base-squad2](https://huggingface.co./deepset/roberta-base-squad2) with a custom handler.py
This repository implements a `custom` handler for `question-answering` for 🤗 Inference Endpoints for accelerated inference using [🤗 Optiumum](https://huggingface.co./docs/optimum/index). The code for the customized handler is in the [handler.py](https://huggingface.co./philschmid/roberta-base-squad2-optimized/blob/main/handler.py).
Below is also describe how we converted & optimized the model, based on the [Accelerate Transformers with Hugging Face Optimum](https://huggingface.co./blog/optimum-inference) blog post. You can also check out the [notebook](https://huggingface.co./philschmid/roberta-base-squad2-optimized/blob/main/optimize_model.ipynb).
### expected Request payload
```json
{
"inputs": {
"question": "As what is Philipp working?",
"context": "Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science. In the past I designed and implemented cloud-native machine learning architectures for fin-tech and insurance companies. I found my passion for cloud concepts and machine learning 5 years ago. Since then I never stopped learning. Currently, I am focusing myself in the area NLP and how to leverage models like BERT, Roberta, T5, ViT, and GPT2 to generate business value."
}
}
```
below is an example on how to run a request using Python and `requests`.
## Run Request
```python
import json
from typing import List
import requests as r
import base64
ENDPOINT_URL = ""
HF_TOKEN = ""
def predict(question:str=None,context:str=None):
payload = {"inputs": {"question": question, "context": context}}
response = r.post(
ENDPOINT_URL, headers={"Authorization": f"Bearer {HF_TOKEN}"}, json=payload
)
return response.json()
prediction = predict(
question="As what is Philipp working?",
context="Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science."
)
```
expected output
```python
{
'score': 0.4749588668346405,
'start': 88,
'end': 102,
'answer': 'Technical Lead'
}
```
# Convert & Optimize model with Optimum
Steps:
1. [Convert model to ONNX](#1-convert-model-to-onnx)
2. [Optimize & quantize model with Optimum](#2-optimize--quantize-model-with-optimum)
3. [Create Custom Handler for Inference Endpoints](#3-create-custom-handler-for-inference-endpoints)
4. [Test Custom Handler Locally](#4-test-custom-handler-locally)
5. [Push to repository and create Inference Endpoint](#5-push-to-repository-and-create-inference-endpoint)
Helpful links:
* [Accelerate Transformers with Hugging Face Optimum](https://huggingface.co./blog/optimum-inference)
* [Optimizing Transformers for GPUs with Optimum](https://www.philschmid.de/optimizing-transformers-with-optimum-gpu)
* [Optimum Documentation](https://huggingface.co./docs/optimum/onnxruntime/modeling_ort)
* [Create Custom Handler Endpoints](https://link-to-docs)
## Setup & Installation
```python
%%writefile requirements.txt
optimum[onnxruntime]==1.4.0
mkl-include
mkl
```
```python
!pip install -r requirements.txt
```
## 0. Base line Performance
```python
from transformers import pipeline
qa = pipeline("question-answering",model="deepset/roberta-base-squad2")
```
Okay, let's test the performance (latency) with sequence length of 128.
```python
context="Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science. In the past I designed and implemented cloud-native machine learning architectures for fin-tech and insurance companies. I found my passion for cloud concepts and machine learning 5 years ago. Since then I never stopped learning. Currently, I am focusing myself in the area NLP and how to leverage models like BERT, Roberta, T5, ViT, and GPT2 to generate business value."
question="As what is Philipp working?"
payload = {"inputs": {"question": question, "context": context}}
```
```python
from time import perf_counter
import numpy as np
def measure_latency(pipe,payload):
latencies = []
# warm up
for _ in range(10):
_ = pipe(question=payload["inputs"]["question"], context=payload["inputs"]["context"])
# Timed run
for _ in range(50):
start_time = perf_counter()
_ = pipe(question=payload["inputs"]["question"], context=payload["inputs"]["context"])
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
return f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}"
print(f"Vanilla model {measure_latency(qa,payload)}")
# Vanilla model Average latency (ms) - 64.15 +\- 2.44
```
## 1. Convert model to ONNX
```python
from optimum.onnxruntime import ORTModelForQuestionAnswering
from transformers import AutoTokenizer
from pathlib import Path
model_id="deepset/roberta-base-squad2"
onnx_path = Path(".")
# load vanilla transformers and convert to onnx
model = ORTModelForQuestionAnswering.from_pretrained(model_id, from_transformers=True)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# save onnx checkpoint and tokenizer
model.save_pretrained(onnx_path)
tokenizer.save_pretrained(onnx_path)
```
## 2. Optimize & quantize model with Optimum
```python
from optimum.onnxruntime import ORTOptimizer, ORTQuantizer
from optimum.onnxruntime.configuration import OptimizationConfig, AutoQuantizationConfig
# Create the optimizer
optimizer = ORTOptimizer.from_pretrained(model)
# Define the optimization strategy by creating the appropriate configuration
optimization_config = OptimizationConfig(optimization_level=99) # enable all optimizations
# Optimize the model
optimizer.optimize(save_dir=onnx_path, optimization_config=optimization_config)
```
```python
# create ORTQuantizer and define quantization configuration
dynamic_quantizer = ORTQuantizer.from_pretrained(onnx_path, file_name="model_optimized.onnx")
dqconfig = AutoQuantizationConfig.avx512_vnni(is_static=False, per_channel=False)
# apply the quantization configuration to the model
model_quantized_path = dynamic_quantizer.quantize(
save_dir=onnx_path,
quantization_config=dqconfig,
)
```
## 3. Create Custom Handler for Inference Endpoints
```python
%%writefile handler.py
from typing import Dict, List, Any
from optimum.onnxruntime import ORTModelForQuestionAnswering
from transformers import AutoTokenizer, pipeline
class EndpointHandler():
def __init__(self, path=""):
# load the optimized model
self.model = ORTModelForQuestionAnswering.from_pretrained(path, file_name="model_optimized_quantized.onnx")
self.tokenizer = AutoTokenizer.from_pretrained(path)
# create pipeline
self.pipeline = pipeline("question-answering", model=self.model, tokenizer=self.tokenizer)
def __call__(self, data: Any) -> List[List[Dict[str, float]]]:
"""
Args:
data (:obj:):
includes the input data and the parameters for the inference.
Return:
A :obj:`list`:. The list contains the answer and scores of the inference inputs
"""
inputs = data.get("inputs", data)
# run the model
prediction = self.pipeline(**inputs)
# return prediction
return prediction
```
## 4. Test Custom Handler Locally
```python
from handler import EndpointHandler
# init handler
my_handler = EndpointHandler(path=".")
# prepare sample payload
context="Hello, my name is Philipp and I live in Nuremberg, Germany. Currently I am working as a Technical Lead at Hugging Face to democratize artificial intelligence through open source and open science. In the past I designed and implemented cloud-native machine learning architectures for fin-tech and insurance companies. I found my passion for cloud concepts and machine learning 5 years ago. Since then I never stopped learning. Currently, I am focusing myself in the area NLP and how to leverage models like BERT, Roberta, T5, ViT, and GPT2 to generate business value."
question="As what is Philipp working?"
payload = {"inputs": {"question": question, "context": context}}
# test the handler
my_handler(payload)
```
```python
from time import perf_counter
import numpy as np
def measure_latency(handler,payload):
latencies = []
# warm up
for _ in range(10):
_ = handler(payload)
# Timed run
for _ in range(50):
start_time = perf_counter()
_ = handler(payload)
latency = perf_counter() - start_time
latencies.append(latency)
# Compute run statistics
time_avg_ms = 1000 * np.mean(latencies)
time_std_ms = 1000 * np.std(latencies)
return f"Average latency (ms) - {time_avg_ms:.2f} +\- {time_std_ms:.2f}"
print(f"Optimized & Quantized model {measure_latency(my_handler,payload)}")
#
```
`Optimized & Quantized model Average latency (ms) - 29.90 +\- 0.53`
`Vanilla model Average latency (ms) - 64.15 +\- 2.44`
## 5. Push to repository and create Inference Endpoint
```python
# add all our new files
!git add *
# commit our files
!git commit -m "add custom handler"
# push the files to the hub
!git push
```
| 8561f0d74d18810e336a6fc8caf0ae6d |
MaggieXM/distilbert-base-uncased-finetuned-squad | MaggieXM | distilbert | 20 | 5 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | ['squad'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,109 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.01
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 0.01 | 56 | 4.8054 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| b71ec1cf30fd6b9f371d478067525884 |
jonatasgrosman/exp_w2v2t_pt_vp-nl_s6 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['pt'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'pt'] | false | true | true | 467 | false | # exp_w2v2t_pt_vp-nl_s6
Fine-tuned [facebook/wav2vec2-large-nl-voxpopuli](https://huggingface.co./facebook/wav2vec2-large-nl-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (pt)](https://huggingface.co./datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 7a000bd97bc0b74b5287e62948946ec7 |
hsohn3/cchs-bert-visit-uncased-wordlevel-block512-batch8-ep10 | hsohn3 | bert | 8 | 4 | transformers | 0 | fill-mask | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,340 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# hsohn3/cchs-bert-visit-uncased-wordlevel-block512-batch8-ep10
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co./bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.9857
- Epoch: 9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 4.4277 | 0 |
| 3.1148 | 1 |
| 3.0454 | 2 |
| 3.0227 | 3 |
| 3.0048 | 4 |
| 3.0080 | 5 |
| 2.9920 | 6 |
| 2.9963 | 7 |
| 2.9892 | 8 |
| 2.9857 | 9 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.8.2
- Datasets 2.3.2
- Tokenizers 0.12.1
| d1d10ad0216333d9b17d1427aae2e8d4 |
shumail/wav2vec2-base-timit-demo-colab | shumail | wav2vec2 | 24 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,341 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co./facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8686
- Wer: 0.6263
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.0505 | 13.89 | 500 | 3.0760 | 1.0 |
| 1.2748 | 27.78 | 1000 | 0.8686 | 0.6263 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.11.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| 21419281cc9c65d8413aab2df9d3ffbe |
fveredas/xlm-roberta-base-finetuned-panx-de | fveredas | xlm-roberta | 16 | 5 | transformers | 0 | token-classification | true | false | false | mit | null | ['xtreme'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,320 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co./xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1365
- F1: 0.8649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2553 | 1.0 | 525 | 0.1575 | 0.8279 |
| 0.1284 | 2.0 | 1050 | 0.1386 | 0.8463 |
| 0.0813 | 3.0 | 1575 | 0.1365 | 0.8649 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.1+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
| 91b7a03e208a0ae34eca0e47fccabdb1 |
kurianbenoy/music_genre_classification_baseline | kurianbenoy | null | 4 | 0 | fastai | 1 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['fastai'] | false | true | true | 736 | false |
# Amazing!
🥳 Congratulations on hosting your fastai model on the Hugging Face Hub!
# Some next steps
1. Fill out this model card with more information (see the template below and the [documentation here](https://huggingface.co./docs/hub/model-repos))!
2. Create a demo in Gradio or Streamlit using 🤗 Spaces ([documentation here](https://huggingface.co./docs/hub/spaces)).
3. Join the fastai community on the [Fastai Discord](https://discord.com/invite/YKrxeNn)!
Greetings fellow fastlearner 🤝! Don't forget to delete this content from your model card.
---
# Model card
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
| f36361bbf3a4111abdeda44875b284bc |
mkhairil/distillbert-finetuned-indonlusmsa | mkhairil | distilbert | 12 | 8 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['indonlu'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 948 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distillbert-finetuned-indonlusmsa
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the indonlu dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
| 42b35bdf153d04de3bdfd39be5fd4cfc |
Alred/bart-base-finetuned-summarization-cnn-ver2 | Alred | bart | 15 | 5 | transformers | 0 | summarization | true | false | false | apache-2.0 | null | ['cnn_dailymail'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization', 'generated_from_trainer'] | true | true | true | 1,176 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-finetuned-summarization-cnn-ver2
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co./facebook/bart-base) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 2.1715
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3329 | 1.0 | 5742 | 2.1715 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| 25269342aaf4d9a62e88d8b1b5ab5e8a |
manandey/wav2vec2-large-xlsr-_irish | manandey | wav2vec2 | 9 | 7 | transformers | 0 | automatic-speech-recognition | true | false | true | apache-2.0 | ['ga'] | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['audio', 'automatic-speech-recognition', 'speech', 'xlsr-fine-tuning-week', 'hf-asr-leaderboard'] | true | true | true | 3,265 | false | # Wav2Vec2-Large-XLSR-53-Irish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co./facebook/wav2vec2-large-xlsr-53) in Irish using the [Common Voice](https://huggingface.co./datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ga-IE", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("manandey/wav2vec2-large-xlsr-_irish")
model = Wav2Vec2ForCTC.from_pretrained("manandey/wav2vec2-large-xlsr-_irish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ga-IE", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("manandey/wav2vec2-large-xlsr-_irish")
model = Wav2Vec2ForCTC.from_pretrained("manandey/wav2vec2-large-xlsr-_irish")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\’\–\(\)]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 42.34%
## Training
The Common Voice `train`, `validation` datasets were used for training. | 5019d14cdddfee6804b9e3be5a44eb38 |
Helsinki-NLP/opus-mt-it-vi | Helsinki-NLP | marian | 11 | 38 | transformers | 0 | translation | true | true | false | apache-2.0 | ['it', 'vi'] | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 2,001 | false |
### ita-vie
* source group: Italian
* target group: Vietnamese
* OPUS readme: [ita-vie](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-vie/README.md)
* model: transformer-align
* source language(s): ita
* target language(s): vie
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-vie/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-vie/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-vie/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ita.vie | 36.2 | 0.535 |
### System Info:
- hf_name: ita-vie
- source_languages: ita
- target_languages: vie
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-vie/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['it', 'vi']
- src_constituents: {'ita'}
- tgt_constituents: {'vie', 'vie_Hani'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-vie/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ita-vie/opus-2020-06-17.test.txt
- src_alpha3: ita
- tgt_alpha3: vie
- short_pair: it-vi
- chrF2_score: 0.535
- bleu: 36.2
- brevity_penalty: 1.0
- ref_len: 2144.0
- src_name: Italian
- tgt_name: Vietnamese
- train_date: 2020-06-17
- src_alpha2: it
- tgt_alpha2: vi
- prefer_old: False
- long_pair: ita-vie
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 | 449a6592d1e9c61ddf102c80ed93f5c6 |
coreml/coreml-stable-diffusion-v1-5 | coreml | null | 6 | 0 | null | 5 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['coreml', 'stable-diffusion', 'text-to-image'] | false | true | true | 13,867 | false |
# Core ML Converted Model
This model was converted to Core ML for use on Apple Silicon devices by following Apple's instructions [here](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml).<br>
Provide the model to an app such as [Mochi Diffusion](https://github.com/godly-devotion/MochiDiffusion) to generate images.<br>
`split_einsum` version is compatible with all compute unit options including Neural Engine.<br>
`original` version is only compatible with CPU & GPU option.
# Stable Diffusion v1-5 Model Card
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co./blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and the [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion).
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Original GitHub Repository
1. Download the weights
- [v1-5-pruned-emaonly.ckpt](https://huggingface.co./runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt) - 4.27GB, ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.ckpt](https://huggingface.co./runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned.ckpt) - 7.7GB, ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion).
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co./spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co./dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co./CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co./datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co./datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co./CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co./CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co./CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co./runwayml/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co./runwayml/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:
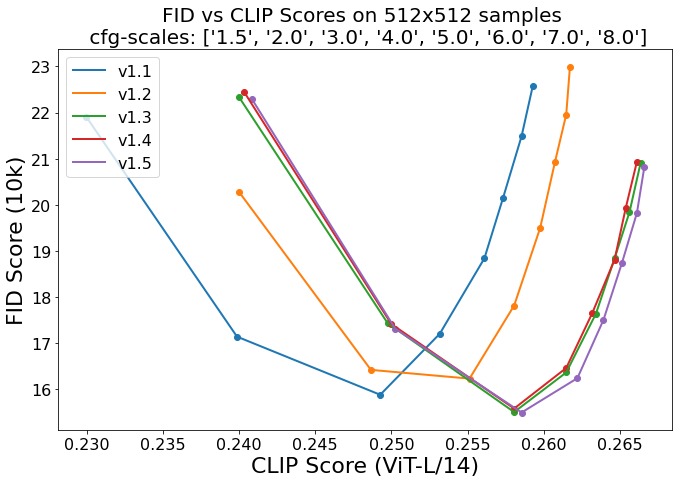
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co./dalle-mini/dalle-mini).* | ff6dc79182f70d5525127385a73ba0ee |
jonatasgrosman/exp_w2v2t_pl_wavlm_s250 | jonatasgrosman | wavlm | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['pl'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'pl'] | false | true | true | 439 | false | # exp_w2v2t_pl_wavlm_s250
Fine-tuned [microsoft/wavlm-large](https://huggingface.co./microsoft/wavlm-large) for speech recognition using the train split of [Common Voice 7.0 (pl)](https://huggingface.co./datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 2ae287b7aad1344a15917389c6575372 |
Manishkalra/finetuning-movie-sentiment-model-9000-samples | Manishkalra | distilbert | 13 | 7 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,061 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-movie-sentiment-model-9000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4040
- Accuracy: 0.9178
- F1: 0.9155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
| 7ef4c70555b92d4568f030df0ffc5331 |
gokuls/mobilebert_add_GLUE_Experiment_logit_kd_pretrain_rte | gokuls | mobilebert | 17 | 2 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,629 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_logit_kd_pretrain_rte
This model is a fine-tuned version of [gokuls/mobilebert_add_pre-training-complete](https://huggingface.co./gokuls/mobilebert_add_pre-training-complete) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Accuracy: 0.5271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.0 | 1.0 | 20 | nan | 0.5271 |
| 0.0 | 2.0 | 40 | nan | 0.5271 |
| 0.0 | 3.0 | 60 | nan | 0.5271 |
| 0.0 | 4.0 | 80 | nan | 0.5271 |
| 0.0 | 5.0 | 100 | nan | 0.5271 |
| 0.0 | 6.0 | 120 | nan | 0.5271 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| d0cde83f8c26abb80591ae721ba50e2a |
Sahara/finetuning-sentiment-model-3000-samples | Sahara | distilbert | 13 | 12 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['imdb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,055 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-3000-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3322
- Accuracy: 0.8533
- F1: 0.8562
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| 900f912994c36c1ea4886ea41a8f8ee4 |
Nadav/camembert-base-squad-fr | Nadav | camembert | 10 | 7 | transformers | 0 | question-answering | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,226 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# camembert-base-squad-fr
This model is a fine-tuned version of [camembert-base](https://huggingface.co./camembert-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5182
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.2
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.7504 | 1.0 | 3581 | 1.6470 |
| 1.4776 | 2.0 | 7162 | 1.5182 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
| 27076f2df421437249dcc32fb253bc30 |
jonatasgrosman/exp_w2v2r_fr_vp-100k_gender_male-10_female-0_s626 | jonatasgrosman | wav2vec2 | 10 | 3 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['fr'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'fr'] | false | true | true | 499 | false | # exp_w2v2r_fr_vp-100k_gender_male-10_female-0_s626
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co./facebook/wav2vec2-large-100k-voxpopuli) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co./datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| 64dffcb720500b36cba63de43180e27a |
karolill/nb-bert-finetuned-on-norec | karolill | bert | 8 | 4 | transformers | 0 | text-classification | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 630 | false | # NB-BERT fine-tuned on NoReC
## Description
This model is based on the pre-trained [NB-BERT-large model](https://huggingface.co./NbAiLab/nb-bert-large?text=P%C3%A5+biblioteket+kan+du+l%C3%A5ne+en+%5BMASK%5D.). It is a model for sentiment analysis.
## Data for fine-tuning
This model was fine-tuned on 1000 exemples from the [NoReC train dataset](https://github.com/ltgoslo/norec) that belonged to the screen category. The training lasted 3 epochs with a learning rate of 5e-5. The code used to create this model (and some additional models) can be found on [Github](https://github.com/Karolill/NB-BERT-fine-tuned-on-english). | db8876a697ac2ee74b1e4f99bfbae95c |
lmvasque/readability-es-benchmark-mbert-es-sentences-3class | lmvasque | bert | 9 | 5 | transformers | 0 | text-classification | true | false | false | cc-by-4.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 6,041 | false |
## Readability benchmark (ES): mbert-es-sentences-3class
This project is part of a series of models from the paper "A Benchmark for Neural Readability Assessment of Texts in Spanish".
You can find more details about the project in our [GitHub](https://github.com/lmvasque/readability-es-benchmark).
## Models
Our models were fine-tuned in multiple settings, including readability assessment in 2-class (simple/complex) and 3-class (basic/intermediate/advanced) for sentences and paragraph datasets.
You can find more details in our [paper](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link).
These are the available models you can use (current model page in bold):
| Model | Granularity | # classes |
|-----------------------------------------------------------------------------------------------------------|----------------|:---------:|
| [BERTIN (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-bertin-es-paragraphs-2class) | paragraphs | 2 |
| [BERTIN (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-bertin-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-es-paragraphs-2class) | paragraphs | 2 |
| [mBERT (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-es-paragraphs-3class) | paragraphs | 3 |
| [mBERT (EN+ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-en-es-paragraphs-3class) | paragraphs | 3 |
| [BERTIN (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-bertin-es-sentences-2class) | sentences | 2 |
| **[mBERT (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-es-sentences-3class)** | **sentences** | **3** |
| [mBERT (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-es-sentences-2class) | sentences | 2 |
| [mBERT (ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-es-sentences-3class) | sentences | 3 |
| [mBERT (EN+ES)](https://huggingface.co./lmvasque/readability-es-benchmark-mbert-en-es-sentences-3class) | sentences | 3 |
For the zero-shot setting, we used the original models [BERTIN](bertin-project/bertin-roberta-base-spanish) and [mBERT](https://huggingface.co./bert-base-multilingual-uncased) with no further training.
## Results
These are our results for all the readability models in different settings. Please select your model based on the desired performance:
| Granularity | Model | F1 Score (2-class) | Precision (2-class) | Recall (2-class) | F1 Score (3-class) | Precision (3-class) | Recall (3-class) |
|-------------|---------------|:-------------------:|:---------------------:|:------------------:|:--------------------:|:---------------------:|:------------------:|
| Paragraph | Baseline (TF-IDF+LR) | 0.829 | 0.832 | 0.827 | 0.556 | 0.563 | 0.550 |
| Paragraph | BERTIN (Zero) | 0.308 | 0.222 | 0.500 | 0.227 | 0.284 | 0.338 |
| Paragraph | BERTIN (ES) | 0.924 | 0.923 | 0.925 | 0.772 | 0.776 | 0.768 |
| Paragraph | mBERT (Zero) | 0.308 | 0.222 | 0.500 | 0.253 | 0.312 | 0.368 |
| Paragraph | mBERT (EN) | - | - | - | 0.505 | 0.560 | 0.552 |
| Paragraph | mBERT (ES) | **0.933** | **0.932** | **0.936** | 0.776 | 0.777 | 0.778 |
| Paragraph | mBERT (EN+ES) | - | - | - | **0.779** | **0.783** | **0.779** |
| Sentence | Baseline (TF-IDF+LR) | 0.811 | 0.814 | 0.808 | 0.525 | 0.531 | 0.521 |
| Sentence | BERTIN (Zero) | 0.367 | 0.290 | 0.500 | 0.188 | 0.232 | 0.335 |
| Sentence | BERTIN (ES) | **0.900** | **0.900** | **0.900** | **0.699** | **0.701** | **0.698** |
| Sentence | mBERT (Zero) | 0.367 | 0.290 | 0.500 | 0.278 | 0.329 | 0.351 |
| Sentence | mBERT (EN) | - | - | - | 0.521 | 0.565 | 0.539 |
| Sentence | mBERT (ES) | 0.893 | 0.891 | 0.896 | 0.688 | 0.686 | 0.691 |
| Sentence | mBERT (EN+ES) | - | - | - | 0.679 | 0.676 | 0.682 |
## Citation
If you use our results and scripts in your research, please cite our work: "[A Benchmark for Neural Readability Assessment of Texts in Spanish](https://drive.google.com/file/d/1KdwvqrjX8MWYRDGBKeHmiR1NCzDcVizo/view?usp=share_link)" (to be published)
```
@inproceedings{vasquez-rodriguez-etal-2022-benchmarking,
title = "A Benchmark for Neural Readability Assessment of Texts in Spanish",
author = "V{\'a}squez-Rodr{\'\i}guez, Laura and
Cuenca-Jim{\'\e}nez, Pedro-Manuel and
Morales-Esquivel, Sergio Esteban and
Alva-Manchego, Fernando",
booktitle = "Workshop on Text Simplification, Accessibility, and Readability (TSAR-2022), EMNLP 2022",
month = dec,
year = "2022",
}
``` | febbe796a5f094ef6ad3bf1db2d17a6a |
AshishBalhara/distilbert-base-uncased-distilled-clinc | AshishBalhara | distilbert | 10 | 2 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['clinc_oos'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,730 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2699
- Accuracy: 0.9458
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 9
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.2203 | 1.0 | 318 | 3.1656 | 0.7532 |
| 2.4201 | 2.0 | 636 | 1.5891 | 0.8558 |
| 1.1961 | 3.0 | 954 | 0.8037 | 0.9152 |
| 0.5996 | 4.0 | 1272 | 0.4888 | 0.9326 |
| 0.3306 | 5.0 | 1590 | 0.3589 | 0.9439 |
| 0.2079 | 6.0 | 1908 | 0.3070 | 0.9439 |
| 0.1458 | 7.0 | 2226 | 0.2809 | 0.9458 |
| 0.1155 | 8.0 | 2544 | 0.2740 | 0.9461 |
| 0.1021 | 9.0 | 2862 | 0.2699 | 0.9458 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.13.0+cu116
- Datasets 1.16.1
- Tokenizers 0.10.3
| 9073c9738e9938c44e81a35e81987bb6 |
kaejo98/bart-base-question-generation | kaejo98 | bart | 11 | 20 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,038 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-base-question-generation
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co./facebook/bart-base) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.15
- num_epochs: 5
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.1
- Pytorch 1.13.0
- Datasets 2.6.1
- Tokenizers 0.13.1
| 57de9dffeaa30d6dea822e0166a216b0 |
Gausstein26/wav2vec2-base-50k | Gausstein26 | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,845 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-50k
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5640
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 10.7005 | 0.48 | 300 | 5.3021 | 1.0 |
| 3.9938 | 0.96 | 600 | 3.4997 | 1.0 |
| 3.591 | 1.44 | 900 | 3.5641 | 1.0 |
| 3.6168 | 1.92 | 1200 | 3.5641 | 1.0 |
| 3.6252 | 2.4 | 1500 | 3.5641 | 1.0 |
| 3.6137 | 2.88 | 1800 | 3.5641 | 1.0 |
| 3.6124 | 3.36 | 2100 | 3.5641 | 1.0 |
| 3.6171 | 3.84 | 2400 | 3.5641 | 1.0 |
| 3.6436 | 4.32 | 2700 | 3.5641 | 1.0 |
| 3.6189 | 4.8 | 3000 | 3.5640 | 1.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| 39af85ca3a18ca97b7a4395f05670bd2 |
microsoft/resnet-34 | microsoft | resnet | 6 | 689 | transformers | 2 | image-classification | true | true | false | apache-2.0 | null | ['imagenet-1k'] | null | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ['vision', 'image-classification'] | false | true | true | 2,572 | false |
# ResNet-34 v1.5
ResNet model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by He et al.
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ResNet (Residual Network) is a convolutional neural network that democratized the concepts of residual learning and skip connections. This enables to train much deeper models.
This is ResNet v1.5, which differs from the original model: in the bottleneck blocks which require downsampling, v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution. This difference makes ResNet50 v1.5 slightly more accurate (\~0.5% top1) than v1, but comes with a small performance drawback (~5% imgs/sec) according to [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch).

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co./models?search=resnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ResNetForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/resnet-34")
model = ResNetForImageClassification.from_pretrained("microsoft/resnet-34")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
```
For more code examples, we refer to the [documentation](https://huggingface.co./docs/transformers/main/en/model_doc/resnet).
### BibTeX entry and citation info
```bibtex
@inproceedings{he2016deep,
title={Deep residual learning for image recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={770--778},
year={2016}
}
```
| 3a6fe139d3e20966c9c19b9645d70dca |
torchxrayvision/densenet121-res224-rsna | torchxrayvision | null | 4 | 2 | null | 0 | image-classification | false | false | false | apache-2.0 | null | ['nih-pc-chex-mimic_ch-google-openi-rsna'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision', 'image-classification'] | false | true | true | 3,755 | false |
# densenet121-res224-rsna
A DenseNet is a type of convolutional neural network that utilises dense connections between layers, through Dense Blocks, where we connect all layers (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers.
### How to use
Here is how to use this model to classify an image of xray:
Note: Each pretrained model has 18 outputs. The `all` model has every output trained. However, for the other weights some targets are not trained and will predict randomly becuase they do not exist in the training dataset. The only valid outputs are listed in the field `{dataset}.pathologies` on the dataset that corresponds to the weights.
Benchmarks of the modes are here: [BENCHMARKS.md](https://github.com/mlmed/torchxrayvision/blob/master/BENCHMARKS.md)
```python
import urllib.request
import skimage
import torch
import torch.nn.functional as F
import torchvision
import torchvision.transforms
import torchxrayvision as xrv
model_name = "densenet121-res224-rsna"
img_url = "https://huggingface.co./spaces/torchxrayvision/torchxrayvision-classifier/resolve/main/16747_3_1.jpg"
img_path = "xray.jpg"
urllib.request.urlretrieve(img_url, img_path)
model = xrv.models.get_model(model_name, from_hf_hub=True)
img = skimage.io.imread(img_path)
img = xrv.datasets.normalize(img, 255)
# Check that images are 2D arrays
if len(img.shape) > 2:
img = img[:, :, 0]
if len(img.shape) < 2:
print("error, dimension lower than 2 for image")
# Add color channel
img = img[None, :, :]
transform = torchvision.transforms.Compose([xrv.datasets.XRayCenterCrop()])
img = transform(img)
with torch.no_grad():
img = torch.from_numpy(img).unsqueeze(0)
preds = model(img).cpu()
output = {
k: float(v)
for k, v in zip(xrv.datasets.default_pathologies, preds[0].detach().numpy())
}
print(output)
```
For more code examples, we refer to the [example scripts](https://github.com/kamalkraj/torchxrayvision/blob/master/scripts).
### Citation
Primary TorchXRayVision paper: [https://arxiv.org/abs/2111.00595](https://arxiv.org/abs/2111.00595)
```
Joseph Paul Cohen, Joseph D. Viviano, Paul Bertin, Paul Morrison, Parsa Torabian, Matteo Guarrera, Matthew P Lungren, Akshay Chaudhari, Rupert Brooks, Mohammad Hashir, Hadrien Bertrand
TorchXRayVision: A library of chest X-ray datasets and models.
https://github.com/mlmed/torchxrayvision, 2020
@article{Cohen2020xrv,
author = {Cohen, Joseph Paul and Viviano, Joseph D. and Bertin, Paul and Morrison, Paul and Torabian, Parsa and Guarrera, Matteo and Lungren, Matthew P and Chaudhari, Akshay and Brooks, Rupert and Hashir, Mohammad and Bertrand, Hadrien},
journal = {https://github.com/mlmed/torchxrayvision},
title = {{TorchXRayVision: A library of chest X-ray datasets and models}},
url = {https://github.com/mlmed/torchxrayvision},
year = {2020}
arxivId = {2111.00595},
}
```
and this paper which initiated development of the library: [https://arxiv.org/abs/2002.02497](https://arxiv.org/abs/2002.02497)
```
Joseph Paul Cohen and Mohammad Hashir and Rupert Brooks and Hadrien Bertrand
On the limits of cross-domain generalization in automated X-ray prediction.
Medical Imaging with Deep Learning 2020 (Online: https://arxiv.org/abs/2002.02497)
@inproceedings{cohen2020limits,
title={On the limits of cross-domain generalization in automated X-ray prediction},
author={Cohen, Joseph Paul and Hashir, Mohammad and Brooks, Rupert and Bertrand, Hadrien},
booktitle={Medical Imaging with Deep Learning},
year={2020},
url={https://arxiv.org/abs/2002.02497}
}
```
| 505e2b3064723731502eeedb68525169 |
luhua/chinese_pretrain_mrc_macbert_large | luhua | bert | 7 | 960 | transformers | 7 | question-answering | true | false | false | apache-2.0 | ['zh'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 848 | false |
## Chinese MRC macbert-large
* 使用大量中文MRC数据训练的macbert-large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
| 92981deba62ebeb06ea120c1d0cea854 |
sudheer997/distilbert-base-uncased-finetuned-emotion | sudheer997 | distilbert | 12 | 4 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,344 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2264
- Accuracy: 0.9275
- F1: 0.9275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8546 | 1.0 | 250 | 0.3415 | 0.902 | 0.8975 |
| 0.2647 | 2.0 | 500 | 0.2264 | 0.9275 | 0.9275 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 09e96c41e3c29e83426fd262ed70d129 |
Yehor/wav2vec2-xls-r-300m-uk-with-lm | Yehor | wav2vec2 | 19 | 9 | transformers | 3 | automatic-speech-recognition | true | false | false | apache-2.0 | ['uk'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_7_0', 'generated_from_trainer', 'uk'] | true | true | true | 2,482 | false |
# Ukrainian STT model (with Language Model)
🇺🇦 Join Ukrainian Speech Recognition Community - https://t.me/speech_recognition_uk
⭐ See other Ukrainian models - https://github.com/egorsmkv/speech-recognition-uk
- Have a look on an updated 300m model: https://huggingface.co./Yehor/wav2vec2-xls-r-300m-uk-with-small-lm
- Have a look on a better model with more parameters: https://huggingface.co./Yehor/wav2vec2-xls-r-1b-uk-with-lm
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_7_0 - UK dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3015
- Wer: 0.3377
- Cer: 0.0708
The above results present evaluation without the language model.
## Model description
On 100 test example the model shows the following results:
Without LM:
- WER: 0.2647
- CER: 0.0469
With LM:
- WER: 0.1568
- CER: 0.0289
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 20
- total_train_batch_size: 160
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 3.0255 | 7.93 | 500 | 2.5514 | 0.9921 | 0.9047 |
| 1.3809 | 15.86 | 1000 | 0.4065 | 0.5361 | 0.1201 |
| 1.2355 | 23.8 | 1500 | 0.3474 | 0.4618 | 0.1033 |
| 1.1956 | 31.74 | 2000 | 0.3617 | 0.4580 | 0.1005 |
| 1.1416 | 39.67 | 2500 | 0.3182 | 0.4074 | 0.0891 |
| 1.0996 | 47.61 | 3000 | 0.3166 | 0.3985 | 0.0875 |
| 1.0427 | 55.55 | 3500 | 0.3116 | 0.3835 | 0.0828 |
| 0.9961 | 63.49 | 4000 | 0.3137 | 0.3757 | 0.0807 |
| 0.9575 | 71.42 | 4500 | 0.2992 | 0.3632 | 0.0771 |
| 0.9154 | 79.36 | 5000 | 0.3015 | 0.3502 | 0.0740 |
| 0.8994 | 87.3 | 5500 | 0.3004 | 0.3425 | 0.0723 |
| 0.871 | 95.24 | 6000 | 0.3016 | 0.3394 | 0.0713 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.18.1.dev0
- Tokenizers 0.11.0
| ddc10d9e0cf5c2d5baf616b10f77be7e |
it5/it5-efficient-small-el32-repubblica-to-ilgiornale | it5 | t5 | 18 | 3 | transformers | 0 | text2text-generation | true | true | true | apache-2.0 | ['it'] | ['gsarti/change_it'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['italian', 'sequence-to-sequence', 'efficient', 'newspaper', 'ilgiornale', 'repubblica', 'style-transfer'] | true | true | true | 4,264 | false | # IT5 Cased Small Efficient EL32 for News Headline Style Transfer (Repubblica to Il Giornale) 🗞️➡️🗞️ 🇮🇹
*Shout-out to [Stefan Schweter](https://github.com/stefan-it) for contributing the pre-trained efficient model!*
This repository contains the checkpoint for the [IT5 Cased Small Efficient EL32](https://huggingface.co./it5/it5-efficient-small-el32) model fine-tuned on news headline style transfer in the Repubblica to Il Giornale direction on the Italian CHANGE-IT dataset as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
Efficient IT5 models differ from the standard ones by adopting a different vocabulary that enables cased text generation and an [optimized model architecture](https://arxiv.org/abs/2109.10686) to improve performances while reducing parameter count. The Small-EL32 replaces the original encoder from the T5 Small architecture with a 32-layer deep encoder, showing improved performances over the base model.
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
The model is trained to generate a headline in the style of Il Giornale from the full body of an article written in the style of Repubblica. Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
r2g = pipeline("text2text-generation", model='it5/it5-efficient-small-el32-repubblica-to-ilgiornale')
r2g("Arriva dal Partito nazionalista basco (Pnv) la conferma che i cinque deputati che siedono in parlamento voteranno la sfiducia al governo guidato da Mariano Rajoy. Pochi voti, ma significativi quelli della formazione politica di Aitor Esteban, che interverrà nel pomeriggio. Pur con dimensioni molto ridotte, il partito basco si è trovato a fare da ago della bilancia in aula. E il sostegno alla mozione presentata dai Socialisti potrebbe significare per il primo ministro non trovare quei 176 voti che gli servono per continuare a governare. \" Perché dovrei dimettermi io che per il momento ho la fiducia della Camera e quella che mi è stato data alle urne \", ha detto oggi Rajoy nel suo intervento in aula, mentre procedeva la discussione sulla mozione di sfiducia. Il voto dei baschi ora cambia le carte in tavola e fa crescere ulteriormente la pressione sul premier perché rassegni le sue dimissioni. La sfiducia al premier, o un'eventuale scelta di dimettersi, porterebbe alle estreme conseguenze lo scandalo per corruzione che ha investito il Partito popolare. Ma per ora sembra pensare a tutt'altro. \"Non ha intenzione di dimettersi - ha detto il segretario generale del Partito popolare , María Dolores de Cospedal - Non gioverebbe all'interesse generale o agli interessi del Pp\".")
>>> [{"generated_text": "il nazionalista rajoy: 'voteremo la sfiducia'"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/it5-efficient-small-el32-repubblica-to-ilgiornale")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/it5-efficient-small-el32-repubblica-to-ilgiornale")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
| 70db3b7ae2d781068dff302cf9b67401 |
LysandreJik/testing | LysandreJik | distilbert | 24 | 4 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,061 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testing
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6644
- Accuracy: 0.6814
- F1: 0.8105
- Combined Score: 0.7459
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 10
### Training results
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.11.0
- Tokenizers 0.10.3
| e5aa2fe722ebd3f2e3beefe57cd8446a |
SfinOe/stable-diffusion-v2-1 | SfinOe | null | 18 | 15 | diffusers | 0 | text-to-image | false | false | false | openrail++ | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'text-to-image'] | false | true | true | 12,114 | false |
# Stable Diffusion v2-1 Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1 model, codebase available [here](https://github.com/Stability-AI/stablediffusion).
This `stable-diffusion-2-1` model is fine-tuned from [stable-diffusion-2](https://huggingface.co./stabilityai/stable-diffusion-2) (`768-v-ema.ckpt`) with an additional 55k steps on the same dataset (with `punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_768-ema-pruned.ckpt` [here](https://huggingface.co./stabilityai/stable-diffusion-2-1/blob/main/v2-1_768-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co./stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default DDIM, in this example we are swapping it to DPMSolverMultistepScheduler):
```python
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
model_id = "stabilityai/stable-diffusion-2-1"
# Use the DPMSolverMultistepScheduler (DPM-Solver++) scheduler here instead
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co./dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints:
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://huggingface.co./runwayml/stable-diffusion-inpainting).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:

Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co./dalle-mini/dalle-mini).*
| fe9e1cdc45333400917d375824dbe07a |
hamidov02/wav2vec2-large-xls-hun-53h-colab | hamidov02 | wav2vec2 | 9 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,350 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-hun-53h-colab
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co./facebook/wav2vec2-large-xlsr-53) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6027
- Wer: 0.4618
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 23
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 13.4225 | 0.67 | 100 | 3.7750 | 1.0 |
| 3.4121 | 1.34 | 200 | 3.3166 | 1.0 |
| 3.2263 | 2.01 | 300 | 3.1403 | 1.0 |
| 3.0038 | 2.68 | 400 | 2.2474 | 0.9990 |
| 1.2243 | 3.35 | 500 | 0.8174 | 0.7666 |
| 0.6368 | 4.03 | 600 | 0.6306 | 0.6633 |
| 0.4426 | 4.7 | 700 | 0.6151 | 0.6648 |
| 0.3821 | 5.37 | 800 | 0.5765 | 0.6138 |
| 0.3337 | 6.04 | 900 | 0.5522 | 0.5785 |
| 0.2832 | 6.71 | 1000 | 0.5822 | 0.5691 |
| 0.2485 | 7.38 | 1100 | 0.5626 | 0.5449 |
| 0.2335 | 8.05 | 1200 | 0.5866 | 0.5662 |
| 0.2031 | 8.72 | 1300 | 0.5574 | 0.5420 |
| 0.1925 | 9.39 | 1400 | 0.5572 | 0.5297 |
| 0.1793 | 10.07 | 1500 | 0.5878 | 0.5185 |
| 0.1652 | 10.74 | 1600 | 0.6173 | 0.5243 |
| 0.1663 | 11.41 | 1700 | 0.5807 | 0.5133 |
| 0.1544 | 12.08 | 1800 | 0.5979 | 0.5154 |
| 0.148 | 12.75 | 1900 | 0.5545 | 0.4986 |
| 0.138 | 13.42 | 2000 | 0.5798 | 0.4947 |
| 0.1353 | 14.09 | 2100 | 0.5670 | 0.5028 |
| 0.1283 | 14.76 | 2200 | 0.5862 | 0.4957 |
| 0.1271 | 15.43 | 2300 | 0.6009 | 0.4961 |
| 0.1108 | 16.11 | 2400 | 0.5873 | 0.4975 |
| 0.1182 | 16.78 | 2500 | 0.6013 | 0.4893 |
| 0.103 | 17.45 | 2600 | 0.6165 | 0.4898 |
| 0.1084 | 18.12 | 2700 | 0.6186 | 0.4838 |
| 0.1014 | 18.79 | 2800 | 0.6122 | 0.4767 |
| 0.1009 | 19.46 | 2900 | 0.5981 | 0.4793 |
| 0.1004 | 20.13 | 3000 | 0.6034 | 0.4770 |
| 0.0922 | 20.8 | 3100 | 0.6127 | 0.4663 |
| 0.09 | 21.47 | 3200 | 0.5967 | 0.4672 |
| 0.0893 | 22.15 | 3300 | 0.6051 | 0.4611 |
| 0.0817 | 22.82 | 3400 | 0.6027 | 0.4618 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.18.3
- Tokenizers 0.10.3
| af63d676d2f0b56d1f5c8d55d2bef6d9 |
Charalampos/whisper-new | Charalampos | whisper | 14 | 2 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['el'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,317 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Greek
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co./openai/whisper-base) on the mozilla-foundation/common_voice_11_0 el dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3444
- Wer: 231.8841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.5 | 2 | 1.3444 | 231.8841 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.8.1.dev0
- Tokenizers 0.13.2
| 81ff0cb7249db2f1c03fa77c00aba031 |
PaddyP/distilbert-base-uncased-finetuned-emotion | PaddyP | distilbert | 12 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,335 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2302
- Accuracy: 0.922
- F1: 0.9218
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 250 | 0.3344 | 0.903 | 0.9004 |
| No log | 2.0 | 500 | 0.2302 | 0.922 | 0.9218 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.1
- Datasets 2.0.0
- Tokenizers 0.10.3
| 273a7d6292504c7de9d52f0f6e59d80c |
sd-concepts-library/manga-style | sd-concepts-library | null | 13 | 0 | null | 6 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,424 | false | ### Manga style on Stable Diffusion
This is the `<manga>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:








| b9cfe7378f4a2aebab4af1e914f23ef6 |
google/multiberts-seed_2-step_1000k | google | bert | 8 | 33 | transformers | 0 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['multiberts', 'multiberts-seed_2', 'multiberts-seed_2-step_1000k'] | false | true | true | 3,527 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 2, Step 1000k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #2, captured at step 1000k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co./bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_1000k')
model = TFBertModel.from_pretrained("google/multiberts-seed_2-step_1000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2-step_1000k')
model = BertModel.from_pretrained("google/multiberts-seed_2-step_1000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
| eda5f85611a7e6697f8395dc9df69d3f |
milyiyo/multi-minilm-finetuned-amazon-review | milyiyo | bert | 35 | 3 | transformers | 0 | text-classification | true | false | false | mit | null | ['amazon_reviews_multi'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,826 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# multi-minilm-finetuned-amazon-review
This model is a fine-tuned version of [microsoft/Multilingual-MiniLM-L12-H384](https://huggingface.co./microsoft/Multilingual-MiniLM-L12-H384) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2436
- Accuracy: 0.5422
- F1: 0.5435
- Precision: 0.5452
- Recall: 0.5422
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:---------:|:------:|
| 1.0049 | 1.0 | 2500 | 1.0616 | 0.5352 | 0.5268 | 0.5347 | 0.5352 |
| 0.9172 | 2.0 | 5000 | 1.0763 | 0.5432 | 0.5412 | 0.5444 | 0.5432 |
| 0.8285 | 3.0 | 7500 | 1.1077 | 0.5408 | 0.5428 | 0.5494 | 0.5408 |
| 0.7361 | 4.0 | 10000 | 1.1743 | 0.5342 | 0.5399 | 0.5531 | 0.5342 |
| 0.6538 | 5.0 | 12500 | 1.2436 | 0.5422 | 0.5435 | 0.5452 | 0.5422 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
| bbea158b23d3bd1f242a66420d2e24b5 |
thomas0104/whisper_large_v2_zh_tw | thomas0104 | whisper | 31 | 10 | transformers | 1 | automatic-speech-recognition | true | false | false | apache-2.0 | ['zh'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,769 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper large-v2 zh-tw
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co./openai/whisper-large-v2) on the mozilla-foundation/common_voice_11_0 zh-TW dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1603
- Wer: 40.3946
- Cer: 41.1041
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
Training: "mozilla-foundation/common_voice_11_0","zh-TW","train"
evaluation: "mozilla-foundation/common_voice_11_0","zh-TW","test"
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:--------:|
| 2.87 | 0.2 | 1000 | 3.0804 | 192.9556 | 192.6466 |
| 2.6143 | 0.4 | 2000 | 2.4951 | 96.5525 | 96.6443 |
| 1.863 | 0.6 | 3000 | 2.0882 | 69.3188 | 69.6395 |
| 1.1665 | 1.14 | 4000 | 1.4647 | 50.5666 | 51.5850 |
| 0.6674 | 1.34 | 5000 | 1.1603 | 40.3946 | 41.1041 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
| 98f37609420e3ef0611174e3c40e0038 |
Helsinki-NLP/opus-mt-tc-big-itc-eu | Helsinki-NLP | marian | 13 | 4 | transformers | 0 | translation | true | true | false | cc-by-4.0 | ['es', 'eu'] | null | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['translation', 'opus-mt-tc'] | true | true | true | 7,012 | false | # opus-mt-tc-big-itc-eu
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
- [Training](#training)
- [Evaluation](#evaluation)
- [Citation Information](#citation-information)
- [Acknowledgements](#acknowledgements)
## Model Details
Neural machine translation model for translating from Italic languages (itc) to Basque (eu).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
**Model Description:**
- **Developed by:** Language Technology Research Group at the University of Helsinki
- **Model Type:** Translation (transformer-big)
- **Release**: 2022-07-23
- **License:** CC-BY-4.0
- **Language(s):**
- Source Language(s): fra ita spa
- Target Language(s): eus
- Language Pair(s): spa-eus
- Valid Target Language Labels:
- **Original Model**: [opusTCv20210807_transformer-big_2022-07-23.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-eus/opusTCv20210807_transformer-big_2022-07-23.zip)
- **Resources for more information:**
- [OPUS-MT-train GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
- More information about released models for this language pair: [OPUS-MT itc-eus README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/itc-eus/README.md)
- [More information about MarianNMT models in the transformers library](https://huggingface.co./docs/transformers/model_doc/marian)
- [Tatoeba Translation Challenge](https://github.com/Helsinki-NLP/Tatoeba-Challenge/
## Uses
This model can be used for translation and text-to-text generation.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware that the model is trained on various public data sets that may contain content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## How to Get Started With the Model
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Il est riche.",
"¿Correcto?"
]
model_name = "pytorch-models/opus-mt-tc-big-itc-eu"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Aberatsa da.
# Zuzena?
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-itc-eu")
print(pipe("Il est riche."))
# expected output: Aberatsa da.
```
## Training
- **Data**: opusTCv20210807 ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
- **Pre-processing**: SentencePiece (spm32k,spm32k)
- **Model Type:** transformer-big
- **Original MarianNMT Model**: [opusTCv20210807_transformer-big_2022-07-23.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-eus/opusTCv20210807_transformer-big_2022-07-23.zip)
- **Training Scripts**: [GitHub Repo](https://github.com/Helsinki-NLP/OPUS-MT-train)
## Evaluation
* test set translations: [opusTCv20210807_transformer-big_2022-07-23.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-eus/opusTCv20210807_transformer-big_2022-07-23.test.txt)
* test set scores: [opusTCv20210807_transformer-big_2022-07-23.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/itc-eus/opusTCv20210807_transformer-big_2022-07-23.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| spa-eus | tatoeba-test-v2021-08-07 | 0.60699 | 32.4 | 1850 | 10945 |
## Citation Information
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 8b9f0b0
* port time: Sat Aug 13 00:08:07 EEST 2022
* port machine: LM0-400-22516.local
| 1ed70a370ef245ed1976a60c852add9a |
scasutt/wav2vec2-large-xlsr-53_toy_train_data_fast_10pct | scasutt | wav2vec2 | 7 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,418 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53_toy_train_data_fast_10pct
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co./facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6983
- Wer: 0.5026
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.3619 | 1.05 | 250 | 3.4334 | 1.0 |
| 3.0818 | 2.1 | 500 | 3.4914 | 1.0 |
| 2.3245 | 3.15 | 750 | 1.6483 | 0.9486 |
| 1.0233 | 4.2 | 1000 | 0.8817 | 0.7400 |
| 0.7522 | 5.25 | 1250 | 0.7374 | 0.6529 |
| 0.5343 | 6.3 | 1500 | 0.6972 | 0.6068 |
| 0.4452 | 7.35 | 1750 | 0.6757 | 0.5740 |
| 0.4275 | 8.4 | 2000 | 0.6789 | 0.5551 |
| 0.3688 | 9.45 | 2250 | 0.6468 | 0.5394 |
| 0.3363 | 10.5 | 2500 | 0.6798 | 0.5358 |
| 0.3036 | 11.55 | 2750 | 0.6439 | 0.5265 |
| 0.3173 | 12.6 | 3000 | 0.6898 | 0.5196 |
| 0.2985 | 13.65 | 3250 | 0.6791 | 0.5169 |
| 0.288 | 14.7 | 3500 | 0.6442 | 0.5090 |
| 0.2673 | 15.75 | 3750 | 0.6984 | 0.5119 |
| 0.2575 | 16.81 | 4000 | 0.7146 | 0.5084 |
| 0.239 | 17.86 | 4250 | 0.6847 | 0.5040 |
| 0.2266 | 18.91 | 4500 | 0.6900 | 0.5028 |
| 0.22 | 19.96 | 4750 | 0.6983 | 0.5026 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0+cu102
- Datasets 2.0.0
- Tokenizers 0.11.6
| ad6cf658f624b957a20d1f76b1637d68 |
kyonimouto/hoyu-ai | kyonimouto | null | 9 | 0 | null | 0 | null | false | false | false | other | ['ja'] | ['hoyu256'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['PyTorch'] | false | true | true | 801 | false |
Diffusion GANというコードを使ってつくりました
https://github.com/Zhendong-Wang/Diffusion-GAN
つかいかた
試してないので動かなかったらごめんなさい
- 環境をととのえる
- 最近のNVIDIA製GPUがついたパソコンにLinuxを入れることをおすすめします
- PytorchをCUDAありでインストールしてください
- https://pytorch.org/get-started/locally/
- conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
- Gitもインストールしてください
- sudo apt install git
- Diffusion-GANをgithubからローカルにcloneしてください
- git clone https://github.com/Zhendong-Wang/Diffusion-GAN
- diffusion-projected-ganというフォルダを開いてください
- ここの"Files and versions"から"best_model.pkl"をクリックしてダウンロードし、diffusion-projected-ganの中に保存してください
- 以下のコマンドで画像を生成します
- python gen_images.py --outdir=out --seeds=0-10 --network=./best_model.pkl
- パッケージがインストールされていないというエラーが出たら適宜インストールしてください
- outフォルダに生成された画像が入っています
商用利用などはご遠慮ください | 5820d86ecd93456d7e8e645e11ad9c1b |
fathyshalab/all-roberta-large-v1-meta-1-16-5 | fathyshalab | roberta | 11 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,507 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# all-roberta-large-v1-meta-1-16-5
This model is a fine-tuned version of [sentence-transformers/all-roberta-large-v1](https://huggingface.co./sentence-transformers/all-roberta-large-v1) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4797
- Accuracy: 0.28
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.7721 | 1.0 | 1 | 2.6529 | 0.1889 |
| 2.2569 | 2.0 | 2 | 2.5866 | 0.2333 |
| 1.9837 | 3.0 | 3 | 2.5340 | 0.2644 |
| 1.6425 | 4.0 | 4 | 2.4980 | 0.2756 |
| 1.4612 | 5.0 | 5 | 2.4797 | 0.28 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
| 00bb1723ac003e09ff759f2718cdffd8 |
sd-dreambooth-library/quino | sd-dreambooth-library | null | 65 | 62 | diffusers | 7 | text-to-image | false | false | false | creativeml-openrail-m | null | null | null | 1 | 1 | 0 | 0 | 2 | 2 | 0 | ['text-to-image'] | false | true | true | 6,144 | false | ### quino Dreambooth model trained by machinelearnear with [Hugging Face Dreambooth Training Space](https://huggingface.co./spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
artequino (use that on your prompt)

| f7376fefdb0e0fbc960890f4996a147f |
T-Systems-onsite/cross-en-de-roberta-sentence-transformer | T-Systems-onsite | xlm-roberta | 10 | 106,465 | transformers | 14 | feature-extraction | true | true | false | mit | ['de', 'en', 'multilingual'] | ['stsb_multi_mt'] | null | 2 | 0 | 2 | 0 | 1 | 1 | 0 | ['sentence_embedding', 'search', 'pytorch', 'xlm-roberta', 'roberta', 'xlm-r-distilroberta-base-paraphrase-v1', 'paraphrase'] | false | true | true | 7,627 | false |
# Cross English & German RoBERTa for Sentence Embeddings
This model is intended to [compute sentence (text) embeddings](https://www.sbert.net/examples/applications/computing-embeddings/README.html) for English and German text. These embeddings can then be compared with [cosine-similarity](https://en.wikipedia.org/wiki/Cosine_similarity) to find sentences with a similar semantic meaning. For example this can be useful for [semantic textual similarity](https://www.sbert.net/docs/usage/semantic_textual_similarity.html), [semantic search](https://www.sbert.net/docs/usage/semantic_search.html), or [paraphrase mining](https://www.sbert.net/docs/usage/paraphrase_mining.html). To do this you have to use the [Sentence Transformers Python framework](https://github.com/UKPLab/sentence-transformers).
The speciality of this model is that it also works cross-lingually. Regardless of the language, the sentences are translated into very similar vectors according to their semantics. This means that you can, for example, enter a search in German and find results according to the semantics in German and also in English. Using a xlm model and _multilingual finetuning with language-crossing_ we reach performance that even exceeds the best current dedicated English large model (see Evaluation section below).
> Sentence-BERT (SBERT) is a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair from 65hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
Source: [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
This model is fine-tuned from [Philip May](https://may.la/) and open-sourced by [T-Systems-onsite](https://www.t-systems-onsite.de/). Special thanks to [Nils Reimers](https://www.nils-reimers.de/) for your awesome open-source work, the Sentence Transformers, the models and your help on GitHub.
## How to use
To use this model install the `sentence-transformers` package (see here: <https://github.com/UKPLab/sentence-transformers>).
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('T-Systems-onsite/cross-en-de-roberta-sentence-transformer')
```
For details of usage and examples see here:
- [Computing Sentence Embeddings](https://www.sbert.net/docs/usage/computing_sentence_embeddings.html)
- [Semantic Textual Similarity](https://www.sbert.net/docs/usage/semantic_textual_similarity.html)
- [Paraphrase Mining](https://www.sbert.net/docs/usage/paraphrase_mining.html)
- [Semantic Search](https://www.sbert.net/docs/usage/semantic_search.html)
- [Cross-Encoders](https://www.sbert.net/docs/usage/cross-encoder.html)
- [Examples on GitHub](https://github.com/UKPLab/sentence-transformers/tree/master/examples)
## Training
The base model is [xlm-roberta-base](https://huggingface.co./xlm-roberta-base). This model has been further trained by [Nils Reimers](https://www.nils-reimers.de/) on a large scale paraphrase dataset for 50+ languages. [Nils Reimers](https://www.nils-reimers.de/) about this [on GitHub](https://github.com/UKPLab/sentence-transformers/issues/509#issuecomment-712243280):
>A paper is upcoming for the paraphrase models.
>
>These models were trained on various datasets with Millions of examples for paraphrases, mainly derived from Wikipedia edit logs, paraphrases mined from Wikipedia and SimpleWiki, paraphrases from news reports, AllNLI-entailment pairs with in-batch-negative loss etc.
>
>In internal tests, they perform much better than the NLI+STSb models as they have see more and broader type of training data. NLI+STSb has the issue that they are rather narrow in their domain and do not contain any domain specific words / sentences (like from chemistry, computer science, math etc.). The paraphrase models has seen plenty of sentences from various domains.
>
>More details with the setup, all the datasets, and a wider evaluation will follow soon.
The resulting model called `xlm-r-distilroberta-base-paraphrase-v1` has been released here: <https://github.com/UKPLab/sentence-transformers/releases/tag/v0.3.8>
Building on this cross language model we fine-tuned it for English and German language on the [STSbenchmark](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) dataset. For German language we used the dataset of our [German STSbenchmark dataset](https://github.com/t-systems-on-site-services-gmbh/german-STSbenchmark) which has been translated with [deepl.com](https://www.deepl.com/translator). Additionally to the German and English training samples we generated samples of English and German crossed. We call this _multilingual finetuning with language-crossing_. It doubled the traing-datasize and tests show that it further improves performance.
We did an automatic hyperparameter search for 33 trials with [Optuna](https://github.com/optuna/optuna). Using 10-fold crossvalidation on the deepl.com test and dev dataset we found the following best hyperparameters:
- batch_size = 8
- num_epochs = 2
- lr = 1.026343323298136e-05,
- eps = 4.462251033010287e-06
- weight_decay = 0.04794438776350409
- warmup_steps_proportion = 0.1609010732760181
The final model was trained with these hyperparameters on the combination of the train and dev datasets from English, German and the crossings of them. The testset was left for testing.
# Evaluation
The evaluation has been done on English, German and both languages crossed with the STSbenchmark test data. The evaluation-code is available on [Colab](https://colab.research.google.com/drive/1gtGnKq_dYU_sDYqMohTYVMVpxMJjyH0M?usp=sharing). As the metric for evaluation we use the Spearman’s rank correlation between the cosine-similarity of the sentence embeddings and STSbenchmark labels.
| Model Name | Spearman<br/>German | Spearman<br/>English | Spearman<br/>EN-DE & DE-EN<br/>(cross) |
|---------------------------------------------------------------|-------------------|--------------------|------------------|
| xlm-r-distilroberta-base-paraphrase-v1 | 0.8079 | 0.8350 | 0.7983 |
| [xlm-r-100langs-bert-base-nli-stsb-mean-tokens](https://huggingface.co./sentence-transformers/xlm-r-100langs-bert-base-nli-stsb-mean-tokens) | 0.7877 | 0.8465 | 0.7908 |
| xlm-r-bert-base-nli-stsb-mean-tokens | 0.7877 | 0.8465 | 0.7908 |
| [roberta-large-nli-stsb-mean-tokens](https://huggingface.co./sentence-transformers/roberta-large-nli-stsb-mean-tokens) | 0.6371 | 0.8639 | 0.4109 |
| [T-Systems-onsite/<br/>german-roberta-sentence-transformer-v2](https://huggingface.co./T-Systems-onsite/german-roberta-sentence-transformer-v2) | 0.8529 | 0.8634 | 0.8415 |
| **T-Systems-onsite/<br/>cross-en-de-roberta-sentence-transformer** | **0.8550** | **0.8660** | **0.8525** |
## License
Copyright (c) 2020 Philip May, T-Systems on site services GmbH
Licensed under the MIT License (the "License"); you may not use this work except in compliance with the License. You may obtain a copy of the License by reviewing the file [LICENSE](https://huggingface.co./T-Systems-onsite/cross-en-de-roberta-sentence-transformer/blob/main/LICENSE) in the repository.
| 39507c8ae82169a34201c6131c064719 |
gokuls/distilbert_add_GLUE_Experiment_mrpc | gokuls | distilbert | 17 | 4 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,301 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert_add_GLUE_Experiment_mrpc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6028
- Accuracy: 0.6961
- F1: 0.8171
- Combined Score: 0.7566
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6617 | 1.0 | 15 | 0.6507 | 0.6838 | 0.8122 | 0.7480 |
| 0.6412 | 2.0 | 30 | 0.6290 | 0.6838 | 0.8122 | 0.7480 |
| 0.6315 | 3.0 | 45 | 0.6252 | 0.6838 | 0.8122 | 0.7480 |
| 0.6319 | 4.0 | 60 | 0.6236 | 0.6838 | 0.8122 | 0.7480 |
| 0.6321 | 5.0 | 75 | 0.6225 | 0.6838 | 0.8122 | 0.7480 |
| 0.616 | 6.0 | 90 | 0.6028 | 0.6961 | 0.8171 | 0.7566 |
| 0.5469 | 7.0 | 105 | 0.6485 | 0.6446 | 0.7349 | 0.6898 |
| 0.4436 | 8.0 | 120 | 0.7536 | 0.6838 | 0.7909 | 0.7374 |
| 0.3794 | 9.0 | 135 | 0.7805 | 0.6961 | 0.7898 | 0.7430 |
| 0.3158 | 10.0 | 150 | 0.8811 | 0.6838 | 0.7825 | 0.7331 |
| 0.281 | 11.0 | 165 | 0.9246 | 0.6863 | 0.7881 | 0.7372 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
| 9a7f7f884ae4664ffba19c3a471bd26f |
jonatasgrosman/exp_w2v2t_fr_xls-r_s250 | jonatasgrosman | wav2vec2 | 10 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['fr'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'fr'] | false | true | true | 453 | false | # exp_w2v2t_fr_xls-r_s250
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (fr)](https://huggingface.co./datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| fd90a5b962e7ad7a21c5907fb71b16bd |
tbosse/bert-base-german-cased-noisy-pretrain-fine-tuned_v1.2 | tbosse | bert | 13 | 5 | transformers | 0 | token-classification | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,040 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-german-cased-noisy-pretrain-fine-tuned_v1.2
This model is a fine-tuned version of [tbosse/bert-base-german-cased-finetuned-subj_preTrained_with_noisyData_v1.2](https://huggingface.co./tbosse/bert-base-german-cased-finetuned-subj_preTrained_with_noisyData_v1.2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2810
- Precision: 0.7874
- Recall: 0.7514
- F1: 0.7690
- Accuracy: 0.9147
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 33 | 0.3078 | 0.7675 | 0.5943 | 0.6699 | 0.8842 |
| No log | 2.0 | 66 | 0.2535 | 0.7729 | 0.7486 | 0.7605 | 0.9073 |
| No log | 3.0 | 99 | 0.2417 | 0.7714 | 0.7714 | 0.7714 | 0.9119 |
| No log | 4.0 | 132 | 0.2532 | 0.8031 | 0.7343 | 0.7672 | 0.9142 |
| No log | 5.0 | 165 | 0.2675 | 0.7834 | 0.7543 | 0.7686 | 0.9142 |
| No log | 6.0 | 198 | 0.2750 | 0.7870 | 0.76 | 0.7733 | 0.9159 |
| No log | 7.0 | 231 | 0.2810 | 0.7874 | 0.7514 | 0.7690 | 0.9147 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
| 12a2266c62d438271e4b1db92134a6a7 |
slplab/wav2vec2-large-xlsr-53-korean-nia13-asia-9634_001 | slplab | wav2vec2 | 11 | 7 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,215 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xlsr-53-korean-samsung-60k
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co./facebook/wav2vec2-large-xlsr-53) on the NIA13 ASIA dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
Training Data
- Data Name: NIA13 ASIA
- Num. of Samples: 9,634
- Audio Length: 9H 42M
Evaluation Data
- Data Name: NIA13 ASIA
- Num. of Samples: 3,707
- Audio Length: 3H 37M
Test Data
- Data Name: NIA13 ASIA (Same as the Evaluation Data)
- Num. of Samples: 3,707
- Audio Length: 3H 37M
## Training procedure

### Training hyperparameters
The following hyperparameters were used during training:

### Training results
- Validation Phone Error Rate: 19.90%
- Test Phone Error Rate: 19.90%
### Framework versions
- Transformers 4.21.3
- Pytorch 1.12.1
- Datasets 2.4.0
- Tokenizers 0.12.1 | aa6ec52905440e0969c9a8fafc6cf76e |
ZinebSN/whisper-small-swedish-Test-3000 | ZinebSN | whisper | 41 | 6 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['sv'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['hf-asr-leaderboard', 'generated_from_trainer'] | true | true | true | 1,422 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Swedish -3000
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co./openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2974
- Wer: 19.6042
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1448 | 1.29 | 1000 | 0.2953 | 21.4245 |
| 0.0188 | 2.59 | 2000 | 0.2879 | 20.0882 |
| 0.0233 | 3.88 | 3000 | 0.2974 | 19.6042 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
| fa8176c8386386acd76dd2a3c9c6097c |
gokuls/mobilebert_add_GLUE_Experiment_logit_kd_qqp_256 | gokuls | mobilebert | 17 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,201 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_logit_kd_qqp_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co./google/mobilebert-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8027
- Accuracy: 0.7596
- F1: 0.6364
- Combined Score: 0.6980
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 1.2838 | 1.0 | 2843 | 1.2200 | 0.6318 | 0.0 | 0.3159 |
| 1.0184 | 2.0 | 5686 | 0.8422 | 0.7473 | 0.5924 | 0.6698 |
| 0.8633 | 3.0 | 8529 | 0.8232 | 0.7520 | 0.5963 | 0.6742 |
| 0.834 | 4.0 | 11372 | 0.8193 | 0.7563 | 0.6271 | 0.6917 |
| 0.812 | 5.0 | 14215 | 0.8027 | 0.7596 | 0.6364 | 0.6980 |
| 0.7871 | 6.0 | 17058 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 7.0 | 19901 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 8.0 | 22744 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 9.0 | 25587 | nan | 0.6318 | 0.0 | 0.3159 |
| 0.0 | 10.0 | 28430 | nan | 0.6318 | 0.0 | 0.3159 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| 8466e0635a43675a0b34bc6de87930da |
tkubotake/xlm-roberta-base-finetuned-panx-fr | tkubotake | xlm-roberta | 9 | 8 | transformers | 0 | token-classification | true | false | false | mit | null | ['xtreme'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,375 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [tkubotake/xlm-roberta-base-finetuned-panx-de](https://huggingface.co./tkubotake/xlm-roberta-base-finetuned-panx-de) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4157
- F1: 0.8636
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0847 | 1.0 | 191 | 0.4066 | 0.8524 |
| 0.0574 | 2.0 | 382 | 0.4025 | 0.8570 |
| 0.0333 | 3.0 | 573 | 0.4157 | 0.8636 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| 0ceb5eeffb629c282138058fc91c160c |
andreduarte/distilbert-base-uncased-finetuned-cola | andreduarte | distilbert | 13 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7818
- Matthews Correlation: 0.5492
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5257 | 1.0 | 535 | 0.5238 | 0.4004 |
| 0.3516 | 2.0 | 1070 | 0.5173 | 0.5206 |
| 0.2402 | 3.0 | 1605 | 0.5623 | 0.5301 |
| 0.1871 | 4.0 | 2140 | 0.7421 | 0.5387 |
| 0.1386 | 5.0 | 2675 | 0.7818 | 0.5492 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.12.1+cu113
- Datasets 2.7.1
- Tokenizers 0.13.2
| 816c3a137dbc59a8a3c0d2e72b4ccb58 |
google/multiberts-seed_3-step_20k | google | bert | 8 | 14 | transformers | 0 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['multiberts', 'multiberts-seed_3', 'multiberts-seed_3-step_20k'] | false | true | true | 3,515 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 3, Step 20k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #3, captured at step 20k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co./bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3-step_20k')
model = TFBertModel.from_pretrained("google/multiberts-seed_3-step_20k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3-step_20k')
model = BertModel.from_pretrained("google/multiberts-seed_3-step_20k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
| 5054951bf7630834ee3b7576a7d32102 |
Zekunli/flan-t5-large-extraction-cnndm_fs0.1-all | Zekunli | t5 | 10 | 10 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,397 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-extraction-cnndm_fs0.1-all
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co./google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6225
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 48
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.0798 | 0.11 | 200 | 1.7813 |
| 1.8704 | 0.23 | 400 | 1.7363 |
| 1.8398 | 0.34 | 600 | 1.7100 |
| 1.8068 | 0.45 | 800 | 1.6951 |
| 1.8013 | 0.56 | 1000 | 1.6851 |
| 1.8008 | 0.68 | 1200 | 1.6769 |
| 1.783 | 0.79 | 1400 | 1.6609 |
| 1.7459 | 0.9 | 1600 | 1.6578 |
| 1.7394 | 1.02 | 1800 | 1.6605 |
| 1.7036 | 1.13 | 2000 | 1.6464 |
| 1.705 | 1.24 | 2200 | 1.6442 |
| 1.6903 | 1.36 | 2400 | 1.6505 |
| 1.6864 | 1.47 | 2600 | 1.6394 |
| 1.7005 | 1.58 | 2800 | 1.6349 |
| 1.6858 | 1.69 | 3000 | 1.6380 |
| 1.6722 | 1.81 | 3200 | 1.6343 |
| 1.6512 | 1.92 | 3400 | 1.6319 |
| 1.6717 | 2.03 | 3600 | 1.6336 |
| 1.636 | 2.15 | 3800 | 1.6352 |
| 1.643 | 2.26 | 4000 | 1.6225 |
| 1.6308 | 2.37 | 4200 | 1.6227 |
| 1.6115 | 2.48 | 4400 | 1.6278 |
| 1.6342 | 2.6 | 4600 | 1.6249 |
| 1.6301 | 2.71 | 4800 | 1.6320 |
| 1.6164 | 2.82 | 5000 | 1.6302 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
| bbfcc5bbc997d13f85a7be0129ab2efa |
praf-choub/bart-CaPE-xsum | praf-choub | bart | 9 | 5 | transformers | 0 | summarization | true | false | false | bsd-3-clause | ['en'] | ['xsum'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['summarization'] | false | true | true | 630 | false |
Citation
```
@misc{https://doi.org/10.48550/arxiv.2110.07166,
doi = {10.48550/ARXIV.2110.07166},
url = {https://arxiv.org/abs/2110.07166},
author = {Choubey, Prafulla Kumar and Fabbri, Alexander R. and Vig, Jesse and Wu, Chien-Sheng and Liu, Wenhao and Rajani, Nazneen Fatema},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {CaPE: Contrastive Parameter Ensembling for Reducing Hallucination in Abstractive Summarization},
publisher = {arXiv},
year = {2021},
copyright = {Creative Commons Attribution 4.0 International}
}
``` | 2468d26b38f2b16cbf690b197616995b |
DrishtiSharma/wav2vec2-large-xls-r-300m-as-g1 | DrishtiSharma | wav2vec2 | 12 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['as'] | ['mozilla-foundation/common_voice_8_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'mozilla-foundation/common_voice_8_0', 'generated_from_trainer', 'as', 'robust-speech-event', 'model_for_talk', 'hf-asr-leaderboard'] | true | true | true | 3,861 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-as-g1
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - AS dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3327
- Wer: 0.5744
### Evaluation Commands
1. To evaluate on mozilla-foundation/common_voice_8_0 with test split
python eval.py --model_id DrishtiSharma/wav2vec2-large-xls-r-300m-as-g1 --dataset mozilla-foundation/common_voice_8_0 --config as --split test --log_outputs
2. To evaluate on speech-recognition-community-v2/dev_data
Assamese language isn't available in speech-recognition-community-v2/dev_data
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 200
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 14.1958 | 5.26 | 100 | 7.1919 | 1.0 |
| 5.0035 | 10.51 | 200 | 3.9362 | 1.0 |
| 3.6193 | 15.77 | 300 | 3.4451 | 1.0 |
| 3.4852 | 21.05 | 400 | 3.3536 | 1.0 |
| 2.8489 | 26.31 | 500 | 1.6451 | 0.9100 |
| 0.9568 | 31.56 | 600 | 1.0514 | 0.7561 |
| 0.4865 | 36.82 | 700 | 1.0434 | 0.7184 |
| 0.322 | 42.1 | 800 | 1.0825 | 0.7210 |
| 0.2383 | 47.36 | 900 | 1.1304 | 0.6897 |
| 0.2136 | 52.62 | 1000 | 1.1150 | 0.6854 |
| 0.179 | 57.87 | 1100 | 1.2453 | 0.6875 |
| 0.1539 | 63.15 | 1200 | 1.2211 | 0.6704 |
| 0.1303 | 68.41 | 1300 | 1.2859 | 0.6747 |
| 0.1183 | 73.67 | 1400 | 1.2775 | 0.6721 |
| 0.0994 | 78.92 | 1500 | 1.2321 | 0.6404 |
| 0.0991 | 84.21 | 1600 | 1.2766 | 0.6524 |
| 0.0887 | 89.46 | 1700 | 1.3026 | 0.6344 |
| 0.0754 | 94.72 | 1800 | 1.3199 | 0.6704 |
| 0.0693 | 99.97 | 1900 | 1.3044 | 0.6361 |
| 0.0568 | 105.26 | 2000 | 1.3541 | 0.6254 |
| 0.0536 | 110.51 | 2100 | 1.3320 | 0.6249 |
| 0.0529 | 115.77 | 2200 | 1.3370 | 0.6271 |
| 0.048 | 121.05 | 2300 | 1.2757 | 0.6031 |
| 0.0419 | 126.31 | 2400 | 1.2661 | 0.6172 |
| 0.0349 | 131.56 | 2500 | 1.2897 | 0.6048 |
| 0.0309 | 136.82 | 2600 | 1.2688 | 0.5962 |
| 0.0278 | 142.1 | 2700 | 1.2885 | 0.5954 |
| 0.0254 | 147.36 | 2800 | 1.2988 | 0.5915 |
| 0.0223 | 152.62 | 2900 | 1.3153 | 0.5941 |
| 0.0216 | 157.87 | 3000 | 1.2936 | 0.5937 |
| 0.0186 | 163.15 | 3100 | 1.2906 | 0.5877 |
| 0.0156 | 168.41 | 3200 | 1.3476 | 0.5962 |
| 0.0158 | 173.67 | 3300 | 1.3363 | 0.5847 |
| 0.0142 | 178.92 | 3400 | 1.3367 | 0.5847 |
| 0.0153 | 184.21 | 3500 | 1.3105 | 0.5757 |
| 0.0119 | 189.46 | 3600 | 1.3255 | 0.5705 |
| 0.0115 | 194.72 | 3700 | 1.3340 | 0.5787 |
| 0.0103 | 199.97 | 3800 | 1.3327 | 0.5744 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
| 06836b810af39f2736d85422bdc5412c |
adiharush/tu-nlpweb-w22-g18-e6 | adiharush | distilbert | 8 | 16 | transformers | 0 | question-answering | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 920 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# result
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2.0
### Training results
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
| c4d6bc071fd5b40401576730a87dbdee |
PaddlePaddle/uie-medium | PaddlePaddle | ernie | 7 | 0 | paddlenlp | 0 | null | false | false | false | apache-2.0 | ['zh'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 4,353 | false |
[](https://github.com/PaddlePaddle/PaddleNLP)
# PaddlePaddle/uie-medium
Information extraction suffers from its varying targets, heterogeneous structures, and demand-specific schemas. The unified text-to-structure generation framework, namely UIE, can universally model different IE tasks, adaptively generate targeted structures, and collaboratively learn general IE abilities from different knowledge sources. Specifically, UIE uniformly encodes different extraction structures via a structured extraction language, adaptively generates target extractions via a schema-based prompt mechanism - structural schema instructor, and captures the common IE abilities via a large-scale pre-trained text-to-structure model. Experiments show that UIE achieved the state-of-the-art performance on 4 IE tasks, 13 datasets, and on all supervised, low-resource, and few-shot settings for a wide range of entity, relation, event and sentiment extraction tasks and their unification. These results verified the effectiveness, universality, and transferability of UIE.
UIE Paper: https://arxiv.org/abs/2203.12277
PaddleNLP released UIE model series for Information Extraction of texts and multi-modal documents which use the ERNIE 3.0 models as the pre-trained language models and were finetuned on a large amount of information extraction data.

## Available Models
| Model Name | Usage Scenarios | Supporting Tasks |
| :----------------------------------------------------------: | :--------------------------------------------------------- | :--------------------------------------------------- |
| `uie-base`<br />`uie-medium`<br />`uie-mini`<br />`uie-micro`<br />`uie-nano` | For **plain text** The **extractive** model of the scene supports **Chinese** | Supports entity, relation, event, opinion extraction |
| `uie-base-en` | An **extractive** model for **plain text** scenarios, supports **English** | Supports entity, relation, event, opinion extraction |
| `uie-m-base`<br />`uie-m-large` | An **extractive** model for **plain text** scenarios, supporting **Chinese and English** | Supports entity, relation, event, opinion extraction |
| <b>`uie-x-base`</b> | An **extractive** model for **plain text** and **document** scenarios, supports **Chinese and English** | Supports entity, relation, event, opinion extraction on both plain text and documents/pictures/tables |
## Performance on Text Dataset
We conducted experiments on the in-house test sets of the three different domains of Internet, medical care, and finance:
<table>
<tr><th row_span='2'><th colspan='2'>finance<th colspan='2'>healthcare<th colspan='2'>internet
<tr><td><th>0-shot<th>5-shot<th>0-shot<th>5-shot<th>0-shot<th>5-shot
<tr><td>uie-base (12L768H)<td>46.43<td>70.92<td><b>71.83</b><td>85.72<td>78.33<td>81.86
<tr><td>uie-medium (6L768H)<td>41.11<td>64.53<td>65.40<td>75.72<td>78.32<td>79.68
<tr><td>uie-mini (6L384H)<td>37.04<td>64.65<td>60.50<td>78.36<td>72.09<td>76.38
<tr><td>uie-micro (4L384H)<td>37.53<td>62.11<td>57.04<td>75.92<td>66.00<td>70.22
<tr><td>uie-nano (4L312H)<td>38.94<td>66.83<td>48.29<td>76.74<td>62.86<td>72.35
<tr><td>uie-m-large (24L1024H)<td><b>49.35</b><td><b>74.55</b><td>70.50<td><b>92.66</b ><td>78.49<td><b>83.02</b>
<tr><td>uie-m-base (12L768H)<td>38.46<td>74.31<td>63.37<td>87.32<td>76.27<td>80.13
<tr><td>🧾🎓<b>uie-x-base (12L768H)</b><td>48.84<td>73.87<td>65.60<td>88.81<td><b>79.36</b> <td>81.65
</table>
0-shot means that no training data is directly used for prediction through paddlenlp.Taskflow, and 5-shot means that each category contains 5 pieces of labeled data for model fine-tuning. Experiments show that UIE can further improve the performance with a small amount of data (few-shot).
> Detailed Info: https://github.com/PaddlePaddle/PaddleNLP/blob/develop/applications/information_extraction/README_en.md | 23016a311de271c35d1cf8e0e7c41f1a |
Salesforce/blip2-flan-t5-xl-coco | Salesforce | blip-2 | 11 | 7 | transformers | 1 | image-to-text | true | false | false | mit | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['vision', 'image-to-text', 'image-captioning', 'visual-question-answering'] | false | true | true | 2,029 | false |
# BLIP-2, Flan T5-xl, fine-tuned on COCO
BLIP-2 model, leveraging [Flan T5-xl](https://huggingface.co./google/flan-t5-xl) (a large language model).
It was introduced in the paper [BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models](https://arxiv.org/abs/2301.12597) by Li et al. and first released in [this repository](https://github.com/salesforce/LAVIS/tree/main/projects/blip2).
Disclaimer: The team releasing BLIP-2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BLIP-2 consists of 3 models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a large language model.
The authors initialize the weights of the image encoder and large language model from pre-trained checkpoints and keep them frozen
while training the Querying Transformer, which is a BERT-like Transformer encoder that maps a set of "query tokens" to query embeddings,
which bridge the gap between the embedding space of the image encoder and the large language model.
The goal for the model is simply to predict the next text token, giving the query embeddings and the previous text.
<img src="https://huggingface.co./datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/blip2_architecture.jpg"
alt="drawing" width="600"/>
This allows the model to be used for tasks like:
- image captioning
- visual question answering (VQA)
- chat-like conversations by feeding the image and the previous conversation as prompt to the model
## Intended uses & limitations
You can use the raw model for conditional text generation given an image and optional text. See the [model hub](https://huggingface.co./models?search=Salesforce/blip) to look for
fine-tuned versions on a task that interests you.
### How to use
For code examples, we refer to the [documentation](https://huggingface.co./docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example). | 16fd192d2c19228210efc52bbf85be93 |
TestZee/t5-small-finetuned-xum-test | TestZee | t5 | 7 | 3 | transformers | 0 | text2text-generation | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,169 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# TestZee/t5-small-finetuned-xum-test
This model is a fine-tuned version of [t5-small](https://huggingface.co./t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 2.9733
- Validation Loss: 2.6463
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 2.9733 | 2.6463 | 0 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.8.2
- Datasets 2.3.2
- Tokenizers 0.12.1
| bc3616ed76b830d500dcfc4b1075ec34 |
sd-concepts-library/sherhook-painting-v2 | sd-concepts-library | null | 14 | 0 | null | 3 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,648 | false | ### Sherhook Painting v2 on Stable Diffusion
This is the `<sherhook>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:









| cf40b9acce2f8d693d45b053c3e2bc82 |
EIStakovskii/french_toxicity_classifier_plus | EIStakovskii | camembert | 8 | 6 | transformers | 0 | text-classification | true | false | false | other | ['fr'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 940 | false | This model was trained for toxicity labeling. Label_1 means TOXIC, Label_0 means NOT TOXIC
The model was fine-tuned based off [the CamemBERT language model](https://huggingface.co./camembert-base).
The accuracy is 93% on the test split during training and 79% on a manually picked (and thus harder) sample of 200 sentences (100 label 1, 100 label 0) at the end of the training.
The model was finetuned on 32k sentences. The train data was the translations of the English data (around 30k sentences) from [the multilingual_detox dataset](https://github.com/s-nlp/multilingual_detox) by [Skolkovo Institute](https://huggingface.co./SkolkovoInstitute) using [the opus-mt-en-fr translation model](https://huggingface.co./Helsinki-NLP/opus-mt-en-fr) by [Helsinki-NLP](https://huggingface.co./Helsinki-NLP) and the data from [the jigsaw dataset](https://www.kaggle.com/competitions/jigsaw-multilingual-toxic-comment-classification/data) on kaggle. | b6b0ef02d30aa35570f0dceb32f4b53d |
Najeen/bert-finetuned-ner | Najeen | bert | 16 | 13 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['conll2003'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,518 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co./bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0621
- Precision: 0.9357
- Recall: 0.9507
- F1: 0.9432
- Accuracy: 0.9865
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0861 | 1.0 | 1756 | 0.0695 | 0.9142 | 0.9293 | 0.9217 | 0.9811 |
| 0.0341 | 2.0 | 3512 | 0.0632 | 0.9256 | 0.9478 | 0.9366 | 0.9856 |
| 0.0178 | 3.0 | 5268 | 0.0621 | 0.9357 | 0.9507 | 0.9432 | 0.9865 |
### Framework versions
- Transformers 4.22.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 8621ab6ec6418bf39fed49c8333196f3 |
yingqin/wav2vec2-base-timit-eng | yingqin | wav2vec2 | 11 | 0 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,984 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-eng
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co./facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5047
- Wer: 0.2233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 3.5485 | 1.0 | 500 | 1.9954 | 1.0042 |
| 0.9068 | 2.01 | 1000 | 0.6418 | 0.4572 |
| 0.4398 | 3.01 | 1500 | 0.4586 | 0.3629 |
| 0.3023 | 4.02 | 2000 | 0.4464 | 0.3248 |
| 0.2328 | 5.02 | 2500 | 0.4019 | 0.2969 |
| 0.1899 | 6.02 | 3000 | 0.4363 | 0.2961 |
| 0.163 | 7.03 | 3500 | 0.4832 | 0.2872 |
| 0.1442 | 8.03 | 4000 | 0.4421 | 0.2801 |
| 0.1246 | 9.04 | 4500 | 0.4757 | 0.2659 |
| 0.1122 | 10.04 | 5000 | 0.4693 | 0.2648 |
| 0.102 | 11.04 | 5500 | 0.4834 | 0.2549 |
| 0.0919 | 12.05 | 6000 | 0.4558 | 0.2633 |
| 0.0866 | 13.05 | 6500 | 0.4527 | 0.2641 |
| 0.0762 | 14.06 | 7000 | 0.4394 | 0.2565 |
| 0.0705 | 15.06 | 7500 | 0.5240 | 0.2609 |
| 0.0647 | 16.06 | 8000 | 0.4980 | 0.2522 |
| 0.0608 | 17.07 | 8500 | 0.5163 | 0.2589 |
| 0.0576 | 18.07 | 9000 | 0.4991 | 0.2565 |
| 0.0499 | 19.08 | 9500 | 0.4750 | 0.2457 |
| 0.047 | 20.08 | 10000 | 0.5162 | 0.2447 |
| 0.0418 | 21.08 | 10500 | 0.4801 | 0.2413 |
| 0.0383 | 22.09 | 11000 | 0.4961 | 0.2394 |
| 0.0342 | 23.09 | 11500 | 0.5209 | 0.2386 |
| 0.032 | 24.1 | 12000 | 0.4970 | 0.2364 |
| 0.0293 | 25.1 | 12500 | 0.4789 | 0.2309 |
| 0.0265 | 26.1 | 13000 | 0.4948 | 0.2302 |
| 0.0269 | 27.11 | 13500 | 0.4917 | 0.2249 |
| 0.0237 | 28.11 | 14000 | 0.4991 | 0.2238 |
| 0.022 | 29.12 | 14500 | 0.5047 | 0.2233 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.13.0+cu116
- Datasets 1.18.3
- Tokenizers 0.13.2
| eab774a0e012c13bad9929acc0880242 |
itzo/bert-base-uncased-fine-tuned-on-clinc_oos-dataset | itzo | bert | 14 | 0 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['clinc_oos'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,623 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-fine-tuned-on-clinc_oos-dataset
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co./bert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2811
- Accuracy Score: 0.9239
- F1 Score: 0.9213
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy Score | F1 Score |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:--------:|
| 4.4271 | 1.0 | 239 | 3.5773 | 0.6116 | 0.5732 |
| 3.0415 | 2.0 | 478 | 2.4076 | 0.8390 | 0.8241 |
| 2.1182 | 3.0 | 717 | 1.7324 | 0.8994 | 0.8934 |
| 1.5897 | 4.0 | 956 | 1.3863 | 0.9210 | 0.9171 |
| 1.3458 | 5.0 | 1195 | 1.2811 | 0.9239 | 0.9213 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
| ac01da7b3425e866fb056ed1a1333feb |
jonatasgrosman/exp_w2v2r_de_xls-r_accent_germany-10_austria-0_s728 | jonatasgrosman | wav2vec2 | 10 | 3 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['de'] | ['mozilla-foundation/common_voice_7_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['automatic-speech-recognition', 'de'] | false | true | true | 481 | false | # exp_w2v2r_de_xls-r_accent_germany-10_austria-0_s728
Fine-tuned [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) for speech recognition using the train split of [Common Voice 7.0 (de)](https://huggingface.co./datasets/mozilla-foundation/common_voice_7_0).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool.
| aeaedfa8904f849d3fd51e5afd8c2ca9 |
Froddan/frost | Froddan | null | 12 | 0 | null | 3 | text-to-image | false | false | false | cc0-1.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['stable-diffusion', 'text-to-image'] | false | true | true | 1,425 | false |
# Stable Diffusion fine tuned on photographs of frozen nature
### Usage
Use by adding the keyword "frostography" to the prompt. The model was trained with the "nature" classname, which can also be added to the prompt.
## Samples
I hope it gives you an idea of what kind of styles can be created with this model.
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_nature_1.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_nature_2.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_car_1.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_fish_1.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_fish_2.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/frostography_moon.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/tmp3vde80fz.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/tmpffxdfi38.png" width="256px"/>
<img src="https://huggingface.co./Froddan/frost/resolve/main/tmpmiz28zo5.png" width="256px"/>
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co./docs/diffusers/api/pipelines/stable_diffusion).
| b20d8a7549f6f3dcb45240890a11804d |
surfingdoggo/ddpm-butterflies-128 | surfingdoggo | null | 13 | 0 | diffusers | 0 | null | false | false | false | apache-2.0 | ['en'] | ['huggan/smithsonian_butterflies_subset'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 1,234 | false |
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co./surfingdoggo/ddpm-butterflies-128/tensorboard?#scalars)
| 2fc542ff3b4b4e735376953a7950d023 |
MultiBertGunjanPatrick/multiberts-seed-4-400k | MultiBertGunjanPatrick | bert | 7 | 4 | transformers | 0 | null | true | false | false | apache-2.0 | ['en'] | ['bookcorpus', 'wikipedia'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['exbert', 'multiberts', 'multiberts-seed-4'] | false | true | true | 6,483 | false | # MultiBERTs Seed 4 Checkpoint 400k (uncased)
Seed 4 intermediate checkpoint 400k MultiBERTs (pretrained BERT) model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/pdf/2106.16163.pdf) and first released in
[this repository](https://github.com/google-research/language/tree/master/language/multiberts). This is an intermediate checkpoint.
The final checkpoint can be found at [multiberts-seed-4](https://hf.co/multberts-seed-4). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing MultiBERTs did not write a model card for this model so this model card has been written by [gchhablani](https://hf.co/gchhablani).
## Model description
MultiBERTs models are transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the MultiBERTs model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co./models?filter=multiberts) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('multiberts-seed-4-400k')
model = BertModel.from_pretrained("multiberts-seed-4-400k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. This bias will also affect all fine-tuned versions of this model. For an understanding of bias of this particular
checkpoint, please try out this checkpoint with the snippet present in the [Limitation and bias section](https://huggingface.co./bert-base-uncased#limitations-and-bias) of the [bert-base-uncased](https://huggingface.co./bert-base-uncased) checkpoint.
## Training data
The MultiBERTs models were pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The full model was trained on 16 Cloud TPU v2 chips for two million steps with a batch size
of 256. The sequence length was set to 512 throughout. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-16163,
author = {Thibault Sellam and
Steve Yadlowsky and
Jason Wei and
Naomi Saphra and
Alexander D'Amour and
Tal Linzen and
Jasmijn Bastings and
Iulia Turc and
Jacob Eisenstein and
Dipanjan Das and
Ian Tenney and
Ellie Pavlick},
title = {The MultiBERTs: {BERT} Reproductions for Robustness Analysis},
journal = {CoRR},
volume = {abs/2106.16163},
year = {2021},
url = {https://arxiv.org/abs/2106.16163},
eprinttype = {arXiv},
eprint = {2106.16163},
timestamp = {Mon, 05 Jul 2021 15:15:50 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-16163.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co./exbert/?model=multiberts">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
| f4fc4d69fb7b99c4f447db75fa1586f2 |
sd-concepts-library/isabell-schulte-pviii-12tiles-3000steps-style | sd-concepts-library | null | 17 | 0 | null | 0 | null | false | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 2,723 | false | ### Isabell Schulte - PVIII - 12tiles - 3000steps - Style on Stable Diffusion
This is the `<isabell-schulte-p8-style-12tiles-3000s>` concept taught to Stable Diffusion via Textual Inversion. You can load this concept into the [Stable Conceptualizer](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_conceptualizer_inference.ipynb) notebook. You can also train your own concepts and load them into the concept libraries using [this notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb).
Here is the new concept you will be able to use as a `style`:












| e67a4e0608960c550db5dfa918350859 |
Celal11/resnet-50-finetuned-FER2013-0.003-CKPlus | Celal11 | resnet | 9 | 9 | transformers | 0 | image-classification | true | false | false | apache-2.0 | null | ['image_folder'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,424 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet-50-finetuned-FER2013-0.003-CKPlus
This model is a fine-tuned version of [Celal11/resnet-50-finetuned-FER2013-0.003](https://huggingface.co./Celal11/resnet-50-finetuned-FER2013-0.003) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0614
- Accuracy: 0.9848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6689 | 0.97 | 27 | 0.1123 | 0.9797 |
| 0.2929 | 1.97 | 54 | 0.0614 | 0.9848 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
| 258f8c517ed1cc09d06c87b9abe4f706 |
nvia/distilbert-base-uncased-finetuned-cola | nvia | distilbert | 13 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,571 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8024
- Matthews Correlation: 0.5275
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5261 | 1.0 | 535 | 0.5320 | 0.4152 |
| 0.3482 | 2.0 | 1070 | 0.4960 | 0.5049 |
| 0.2364 | 3.0 | 1605 | 0.6204 | 0.5123 |
| 0.186 | 4.0 | 2140 | 0.7605 | 0.5232 |
| 0.139 | 5.0 | 2675 | 0.8024 | 0.5275 |
### Framework versions
- Transformers 4.21.2
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| bc8ac23fd5c6facf328aed17a638f8e1 |
cahya/gpt2-small-indonesian-522M | cahya | gpt2 | 10 | 195 | transformers | 3 | text-generation | true | true | true | mit | ['id'] | ['Indonesian Wikipedia'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 3,000 | false |
# Indonesian GPT2 small model
## Model description
It is GPT2-small model pre-trained with indonesian Wikipedia using a causal language modeling (CLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness,
we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='cahya/gpt2-small-indonesian-522M')
>>> set_seed(42)
>>> generator("Kerajaan Majapahit adalah", max_length=30, num_return_sequences=5, num_beams=10)
[{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini berdiri pada abad ke-14'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-16. Kerajaan ini berdiri pada abad ke-14'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini berdiri pada abad ke-15'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-16. Kerajaan ini berdiri pada abad ke-15'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini merupakan kelanjutan dari Kerajaan Majapahit yang'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
model_name='cahya/gpt2-small-indonesian-522M'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2Model.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
model_name='cahya/gpt2-small-indonesian-522M'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = TFGPT2Model.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and
a vocabulary size of 52,000. The inputs are sequences of 128 consecutive tokens.
| be8f290cf1935e1ff95a2058d3a46791 |
rmihaylov/gpt2-small-theseus-bg | rmihaylov | gpt2 | 10 | 6 | transformers | 0 | text-generation | true | false | false | mit | ['bg'] | ['oscar', 'chitanka', 'wikipedia'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['torch'] | false | true | true | 2,748 | false |
# GPT-2
Pretrained model on Bulgarian language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
## Model description
This is the **SMALL** version compressed via [progressive module replacing](https://arxiv.org/abs/2002.02925).
The compression was executed on Bulgarian text from [OSCAR](https://oscar-corpus.com/post/oscar-2019/), [Chitanka](https://chitanka.info/) and [Wikipedia](https://bg.wikipedia.org/).
## Intended uses & limitations
You can use the raw model for:
- text generation
- auto-complete
- spelling correction
Or fine-tune it to a downstream task.
### How to use
Here is how to use this model in PyTorch:
```python
>>> from transformers import AutoModel, AutoTokenizer
>>>
>>> model_id = "rmihaylov/gpt2-small-theseus-bg"
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> model = AutoModel.from_pretrained(model_id, trust_remote_code=True)
>>>
>>> input_ids = tokenizer.encode(
>>> "Здравей,",
>>> add_special_tokens=False,
>>> return_tensors='pt')
>>>
>>> output_ids = model.generate(
>>> input_ids,
>>> do_sample=True,
>>> max_length=50,
>>> top_p=0.92,
>>> pad_token_id=2,
>>> top_k=0)
>>>
>>> output = tokenizer.decode(output_ids[0])
>>>
>>> output = output.replace('<|endoftext|>', '\n\n\n')
>>> output = output.replace('<|unknown|>', '')
>>> output = output.replace('▁', ' ')
>>> output = output.replace('<|n|>', '\n')
>>>
>>> print(output)
Здравей, извинявай, но не мога да заспя.
Джини се обърна и забеляза колко са прегърнати.
— Почакай, Джини. Не мога да повярвам, че е възможно! Толкова искам да те видя.
— Обеща
```
### Limitations and bias
As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes. | d5d2d5d2d97953e6a68ef4d84c6f1ced |
askainet/bart_lfqa | askainet | bart | 8 | 259 | transformers | 1 | text2text-generation | true | false | false | mit | ['en'] | ['vblagoje/lfqa', 'vblagoje/lfqa_support_docs'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 3,175 | false |
## Introduction
See [blog post](https://towardsdatascience.com/long-form-qa-beyond-eli5-an-updated-dataset-and-approach-319cb841aabb) for more details.
## Usage
```python
import torch
from transformers import AutoTokenizer, AutoModel, AutoModelForSeq2SeqLM
model_name = "vblagoje/bart_lfqa"
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
model = model.to(device)
# it all starts with a question/query
query = "Why does water heated to room temperature feel colder than the air around it?"
# given the question above suppose these documents below were found in some document store
documents = ["when the skin is completely wet. The body continuously loses water by...",
"at greater pressures. There is an ambiguity, however, as to the meaning of the terms 'heating' and 'cooling'...",
"are not in a relation of thermal equilibrium, heat will flow from the hotter to the colder, by whatever pathway...",
"air condition and moving along a line of constant enthalpy toward a state of higher humidity. A simple example ...",
"Thermal contact conductance In physics, thermal contact conductance is the study of heat conduction between solid ..."]
# concatenate question and support documents into BART input
conditioned_doc = "<P> " + " <P> ".join([d for d in documents])
query_and_docs = "question: {} context: {}".format(query, conditioned_doc)
model_input = tokenizer(query_and_docs, truncation=True, padding=True, return_tensors="pt")
generated_answers_encoded = model.generate(input_ids=model_input["input_ids"].to(device),
attention_mask=model_input["attention_mask"].to(device),
min_length=64,
max_length=256,
do_sample=False,
early_stopping=True,
num_beams=8,
temperature=1.0,
top_k=None,
top_p=None,
eos_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
num_return_sequences=1)
tokenizer.batch_decode(generated_answers_encoded, skip_special_tokens=True,clean_up_tokenization_spaces=True)
# below is the abstractive answer generated by the model
["When you heat water to room temperature, it loses heat to the air around it. When you cool it down, it gains heat back from the air, which is why it feels colder than the air surrounding it. It's the same reason why you feel cold when you turn on a fan. The air around you is losing heat, and the water is gaining heat."]
```
## Author
- Vladimir Blagojevic: `dovlex [at] gmail.com` [Twitter](https://twitter.com/vladblagoje) | [LinkedIn](https://www.linkedin.com/in/blagojevicvladimir/) | 5300d763d13a5da45266d46acf0e6fad |
Helsinki-NLP/opus-mt-tiv-fr | Helsinki-NLP | marian | 10 | 7 | transformers | 0 | translation | true | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['translation'] | false | true | true | 776 | false |
### opus-mt-tiv-fr
* source languages: tiv
* target languages: fr
* OPUS readme: [tiv-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/tiv-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/tiv-fr/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/tiv-fr/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/tiv-fr/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.tiv.fr | 22.3 | 0.389 |
| 7b67510791791498937cfc16d663c61f |
chintagunta85/test_ner3 | chintagunta85 | distilbert | 12 | 5 | transformers | 0 | token-classification | true | false | false | apache-2.0 | null | ['pv_dataset'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 3,115 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test_ner3
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the pv_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2983
- Precision: 0.6698
- Recall: 0.6499
- F1: 0.6597
- Accuracy: 0.9607
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1106 | 1.0 | 1813 | 0.1128 | 0.6050 | 0.5949 | 0.5999 | 0.9565 |
| 0.0705 | 2.0 | 3626 | 0.1190 | 0.6279 | 0.6122 | 0.6200 | 0.9585 |
| 0.0433 | 3.0 | 5439 | 0.1458 | 0.6342 | 0.5983 | 0.6157 | 0.9574 |
| 0.0301 | 4.0 | 7252 | 0.1453 | 0.6305 | 0.6818 | 0.6552 | 0.9594 |
| 0.0196 | 5.0 | 9065 | 0.1672 | 0.6358 | 0.6871 | 0.6605 | 0.9594 |
| 0.0133 | 6.0 | 10878 | 0.1931 | 0.6427 | 0.6138 | 0.6279 | 0.9587 |
| 0.0104 | 7.0 | 12691 | 0.1948 | 0.6657 | 0.6511 | 0.6583 | 0.9607 |
| 0.0081 | 8.0 | 14504 | 0.2243 | 0.6341 | 0.6574 | 0.6455 | 0.9586 |
| 0.0054 | 9.0 | 16317 | 0.2432 | 0.6547 | 0.6318 | 0.6431 | 0.9588 |
| 0.0041 | 10.0 | 18130 | 0.2422 | 0.6717 | 0.6397 | 0.6553 | 0.9605 |
| 0.0041 | 11.0 | 19943 | 0.2415 | 0.6571 | 0.6420 | 0.6495 | 0.9601 |
| 0.0027 | 12.0 | 21756 | 0.2567 | 0.6560 | 0.6590 | 0.6575 | 0.9601 |
| 0.0023 | 13.0 | 23569 | 0.2609 | 0.6640 | 0.6495 | 0.6566 | 0.9606 |
| 0.002 | 14.0 | 25382 | 0.2710 | 0.6542 | 0.6670 | 0.6606 | 0.9598 |
| 0.0012 | 15.0 | 27195 | 0.2766 | 0.6692 | 0.6539 | 0.6615 | 0.9610 |
| 0.001 | 16.0 | 29008 | 0.2938 | 0.6692 | 0.6415 | 0.6551 | 0.9603 |
| 0.0007 | 17.0 | 30821 | 0.2969 | 0.6654 | 0.6490 | 0.6571 | 0.9604 |
| 0.0007 | 18.0 | 32634 | 0.3035 | 0.6628 | 0.6456 | 0.6541 | 0.9601 |
| 0.0007 | 19.0 | 34447 | 0.2947 | 0.6730 | 0.6489 | 0.6607 | 0.9609 |
| 0.0004 | 20.0 | 36260 | 0.2983 | 0.6698 | 0.6499 | 0.6597 | 0.9607 |
### Framework versions
- Transformers 4.21.0
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
| 8a0cc7b56d4a0f40c904b187353855c0 |
MeshalAlamr/wav2vec2-xls-r-300m-ar-9 | MeshalAlamr | wav2vec2 | 11 | 5 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | null | ['common_voice'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,848 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-ar-9
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co./facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 86.4276
- Wer: 0.1947
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 64
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 120
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 6312.2087 | 4.71 | 400 | 616.6482 | 1.0 |
| 1928.3641 | 9.41 | 800 | 135.8992 | 0.6373 |
| 502.0017 | 14.12 | 1200 | 84.4729 | 0.3781 |
| 299.4288 | 18.82 | 1600 | 76.2488 | 0.3132 |
| 224.0057 | 23.53 | 2000 | 77.6899 | 0.2868 |
| 183.0379 | 28.24 | 2400 | 77.7943 | 0.2725 |
| 160.6119 | 32.94 | 2800 | 79.4487 | 0.2643 |
| 142.7342 | 37.65 | 3200 | 81.3426 | 0.2523 |
| 127.1061 | 42.35 | 3600 | 83.4995 | 0.2489 |
| 114.0666 | 47.06 | 4000 | 82.9293 | 0.2416 |
| 108.4024 | 51.76 | 4400 | 78.6118 | 0.2330 |
| 99.6215 | 56.47 | 4800 | 87.1001 | 0.2328 |
| 95.5135 | 61.18 | 5200 | 84.0371 | 0.2260 |
| 88.2917 | 65.88 | 5600 | 85.9637 | 0.2278 |
| 82.5884 | 70.59 | 6000 | 81.7456 | 0.2237 |
| 77.6827 | 75.29 | 6400 | 88.2686 | 0.2184 |
| 73.313 | 80.0 | 6800 | 85.1965 | 0.2183 |
| 69.61 | 84.71 | 7200 | 86.1655 | 0.2100 |
| 65.6991 | 89.41 | 7600 | 84.0606 | 0.2106 |
| 62.6059 | 94.12 | 8000 | 83.8724 | 0.2036 |
| 57.8635 | 98.82 | 8400 | 85.2078 | 0.2012 |
| 55.2126 | 103.53 | 8800 | 86.6009 | 0.2021 |
| 53.1746 | 108.24 | 9200 | 88.4284 | 0.1975 |
| 52.3969 | 112.94 | 9600 | 85.2846 | 0.1972 |
| 49.8386 | 117.65 | 10000 | 86.4276 | 0.1947 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 1.18.4
- Tokenizers 0.11.6
| a6f363e939775d062d96c1642c6d9774 |
kevinbror/bertbaseuncasedny | kevinbror | bert | 4 | 5 | transformers | 0 | question-answering | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 2,332 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bertbaseuncasedny
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co./bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3901
- Train End Logits Accuracy: 0.8823
- Train Start Logits Accuracy: 0.8513
- Validation Loss: 1.2123
- Validation End Logits Accuracy: 0.7291
- Validation Start Logits Accuracy: 0.6977
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 29508, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.2597 | 0.6683 | 0.6277 | 1.0151 | 0.7214 | 0.6860 | 0 |
| 0.7699 | 0.7820 | 0.7427 | 1.0062 | 0.7342 | 0.6996 | 1 |
| 0.5343 | 0.8425 | 0.8064 | 1.1162 | 0.7321 | 0.7010 | 2 |
| 0.3901 | 0.8823 | 0.8513 | 1.2123 | 0.7291 | 0.6977 | 3 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.6.4
- Datasets 2.1.0
- Tokenizers 0.12.1
| c15bb7d6eec15ca4812bb1e404ab0af5 |
YSKartal/bert-base-turkish-cased-turkish_offensive_trained_model | YSKartal | bert | 10 | 3 | transformers | 1 | text-classification | false | true | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,633 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# YSKartal/bert-base-turkish-cased-turkish_offensive_trained_model
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co./dbmdz/bert-base-turkish-cased) on [offenseval2020_tr](https://huggingface.co./datasets/offenseval2020_tr) dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0365
- Validation Loss: 0.4846
- Train F1: 0.6993
- Epoch: 3
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 7936, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train F1 | Epoch |
|:----------:|:---------------:|:--------:|:-----:|
| 0.3003 | 0.2664 | 0.6971 | 0 |
| 0.1866 | 0.3018 | 0.6990 | 1 |
| 0.0860 | 0.3803 | 0.7032 | 2 |
| 0.0365 | 0.4846 | 0.6993 | 3 |
### Framework versions
- Transformers 4.23.1
- TensorFlow 2.9.2
- Datasets 2.6.1
- Tokenizers 0.13.1
| 91d9eacdbd242cca4314a93c35532887 |
vijayv500/DialoGPT-small-Big-Bang-Theory-Series-Transcripts | vijayv500 | gpt2 | 8 | 5 | transformers | 0 | conversational | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['conversational'] | false | true | true | 1,376 | false | ## I fine-tuned DialoGPT-small model on "The Big Bang Theory" TV Series dataset from Kaggle (https://www.kaggle.com/mitramir5/the-big-bang-theory-series-transcript)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("vijayv500/DialoGPT-small-Big-Bang-Theory-Series-Transcripts")
model = AutoModelForCausalLM.from_pretrained("vijayv500/DialoGPT-small-Big-Bang-Theory-Series-Transcripts")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature = 0.8
)
# pretty print last ouput tokens from bot
print("TBBT Bot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` | d240c7a766b3932490dcabd61a635eb1 |
gokuls/mobilebert_sa_GLUE_Experiment_logit_kd_mrpc | gokuls | mobilebert | 17 | 3 | transformers | 0 | text-classification | true | false | false | apache-2.0 | ['en'] | ['glue'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 2,362 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_sa_GLUE_Experiment_logit_kd_mrpc
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co./google/mobilebert-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5133
- Accuracy: 0.6740
- F1: 0.7772
- Combined Score: 0.7256
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6228 | 1.0 | 29 | 0.5556 | 0.6838 | 0.8122 | 0.7480 |
| 0.611 | 2.0 | 58 | 0.5551 | 0.6838 | 0.8122 | 0.7480 |
| 0.6095 | 3.0 | 87 | 0.5538 | 0.6838 | 0.8122 | 0.7480 |
| 0.6062 | 4.0 | 116 | 0.5503 | 0.6838 | 0.8122 | 0.7480 |
| 0.5825 | 5.0 | 145 | 0.5262 | 0.6985 | 0.8167 | 0.7576 |
| 0.4981 | 6.0 | 174 | 0.5197 | 0.6936 | 0.8038 | 0.7487 |
| 0.468 | 7.0 | 203 | 0.5133 | 0.6740 | 0.7772 | 0.7256 |
| 0.3901 | 8.0 | 232 | 0.5382 | 0.6838 | 0.7757 | 0.7297 |
| 0.323 | 9.0 | 261 | 0.6140 | 0.6789 | 0.7657 | 0.7223 |
| 0.2674 | 10.0 | 290 | 0.5512 | 0.6740 | 0.7687 | 0.7214 |
| 0.2396 | 11.0 | 319 | 0.6467 | 0.6667 | 0.7631 | 0.7149 |
| 0.2127 | 12.0 | 348 | 0.7811 | 0.6716 | 0.7690 | 0.7203 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
| 57cffc13464954ffb0d98f2e3dca23b1 |
NhatPham/wav2vec2-base-finetuned-ks | NhatPham | wav2vec2 | 10 | 7 | transformers | 0 | audio-classification | true | false | false | apache-2.0 | null | ['superb'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,559 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ks
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co./facebook/wav2vec2-base) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1258
- Accuracy: 0.9793
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1561 | 1.0 | 399 | 1.1127 | 0.6643 |
| 0.4803 | 2.0 | 798 | 0.3547 | 0.9687 |
| 0.2855 | 3.0 | 1197 | 0.1663 | 0.9763 |
| 0.1987 | 4.0 | 1596 | 0.1258 | 0.9793 |
| 0.2097 | 5.0 | 1995 | 0.1171 | 0.9791 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
| 6e1f259c065268bc3b6931280804e637 |
igorcadelima/distilbert-base-uncased-finetuned-emotion | igorcadelima | distilbert | 12 | 1 | transformers | 0 | text-classification | true | false | false | apache-2.0 | null | ['emotion'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,338 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co./distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2147
- Accuracy: 0.927
- F1: 0.9270
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8181 | 1.0 | 250 | 0.3036 | 0.9085 | 0.9064 |
| 0.2443 | 2.0 | 500 | 0.2147 | 0.927 | 0.9270 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.12.0
- Datasets 1.16.1
- Tokenizers 0.10.3
| 852a2b2c1ba227bf1245d6203986ed9c |
hsohn3/ehr-bert-base-uncased-cchs-wordlevel | hsohn3 | bert | 8 | 2 | transformers | 1 | fill-mask | false | true | false | apache-2.0 | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['generated_from_keras_callback'] | true | true | true | 1,544 | false |
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# hsohn3/ehr-bert-base-uncased-cchs-wordlevel
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co./bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.7374
- Epoch: 9
## Model description
- model: bert-base-uncased (train from scratch)
- tokenizer: BertTokenizer + WordLevel splitter
## Intended uses & limitations
More information needed
## Training and evaluation data
- data_source: cchs (10,000 visits)
- data_format: visit-level texts concatenated by `[SEP]` token
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 1e-04, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
- block_size: 512
- batch_size: 4
- num_epochs: 10
- mlm_probability: 0.15
### Training results
| Train Loss | Epoch |
|:----------:|:-----:|
| 3.8857 | 0 |
| 3.7525 | 1 |
| 3.7505 | 2 |
| 3.7493 | 3 |
| 3.7412 | 4 |
| 3.7432 | 5 |
| 3.7428 | 6 |
| 3.7409 | 7 |
| 3.7394 | 8 |
| 3.7374 | 9 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.8.2
- Datasets 2.3.2
- Tokenizers 0.12.1
| 8a9301a30bbdf63cfb3e69f4b2fa51e9 |
emilios/whisper-medium-el-n3 | emilios | whisper | 101 | 25 | transformers | 0 | automatic-speech-recognition | true | false | false | apache-2.0 | ['el'] | ['mozilla-foundation/common_voice_11_0'] | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['whisper-event', 'generated_from_trainer'] | true | true | true | 1,983 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper medium Greek El Greco
This model is a fine-tuned version of [emilios/whisper-medium-el-n2](https://huggingface.co./emilios/whisper-medium-el-n2) on the mozilla-foundation/common_voice_11_0 el dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5669
- Wer: 9.8997
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 11000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:-------:|
| 0.0014 | 58.82 | 1000 | 0.4951 | 10.3640 |
| 0.0006 | 117.65 | 2000 | 0.5181 | 10.2805 |
| 0.0007 | 175.82 | 3000 | 0.5317 | 10.1133 |
| 0.0004 | 234.65 | 4000 | 0.5396 | 10.1226 |
| 0.0004 | 293.47 | 5000 | 0.5532 | 10.1040 |
| 0.0013 | 352.29 | 6000 | 0.5645 | 10.0854 |
| 0.0002 | 411.12 | 7000 | 0.5669 | 10.1133 |
| 0.0001 | 469.94 | 8000 | 0.5669 | 9.8997 |
| 0.0001 | 528.76 | 9000 | 0.5645 | 9.9276 |
| 0.0001 | 587.82 | 10000 | 0.5674 | 9.9647 |
| 0.0003 | 646.82 | 11000 | 0.5669 | 9.9461 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 2.0.0.dev20221216+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
| fdba85ecbbebd93a2ae4b94d1eeaa4f2 |
nlpie/bio-miniALBERT-128 | nlpie | bert | 8 | 3 | transformers | 0 | fill-mask | true | false | false | mit | null | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | [] | false | true | true | 2,117 | false |
# Model
miniALBERT is a recursive transformer model which uses cross-layer parameter sharing, embedding factorisation, and bottleneck adapters to achieve high parameter efficiency.
Since miniALBERT is a compact model, it is trained using a layer-to-layer distillation technique, using the BioBERT-v1.1 model as the teacher. Currently, this model is trained for 100K steps on the PubMed Abstracts dataset.
In terms of architecture, this model uses an embedding dimension of 128, a hidden size of 768, an MLP expansion rate of 4, and a reduction factor of 16 for bottleneck adapters. In general, this model uses 6 recursions and has a unique parameter count of 11 million parameters.
# Usage
Since miniALBERT uses a unique architecture it can not be loaded using ts.AutoModel for now. To load the model, first, clone the miniALBERT GitHub project, using the below code:
```bash
git clone https://github.com/nlpie-research/MiniALBERT.git
```
Then use the ```sys.path.append``` to add the miniALBERT files to your project and then import the miniALBERT modeling file using the below code:
```bash
import sys
sys.path.append("PATH_TO_CLONED_PROJECT/MiniALBERT/")
from minialbert_modeling import MiniAlbertForSequenceClassification, MiniAlbertForTokenClassification
```
Finally, load the model like a regular model in the transformers library using the below code:
```Python
# For NER use the below code
model = MiniAlbertForTokenClassification.from_pretrained("nlpie/bio-miniALBERT-128")
# For Sequence Classification use the below code
model = MiniAlbertForTokenClassification.from_pretrained("nlpie/bio-miniALBERT-128")
```
In addition, For efficient fine-tuning using the pre-trained bottleneck adapters use the below code:
```Python
model.trainAdaptersOnly()
```
# Citation
If you use the model, please cite our paper:
```
@article{nouriborji2022minialbert,
title={MiniALBERT: Model Distillation via Parameter-Efficient Recursive Transformers},
author={Nouriborji, Mohammadmahdi and Rohanian, Omid and Kouchaki, Samaneh and Clifton, David A},
journal={arXiv preprint arXiv:2210.06425},
year={2022}
}
```
| 196599766a4fa28ee1ed67e75b376edc |
Lucapro/test-model | Lucapro | t5 | 13 | 8 | transformers | 0 | text2text-generation | true | false | false | apache-2.0 | ['en', 'ro'] | ['wmt16'] | null | 1 | 1 | 0 | 0 | 0 | 0 | 0 | ['generated_from_trainer'] | true | true | true | 1,017 | false |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tst-translation
This model is a fine-tuned version of [t5-small](https://huggingface.co./t5-small) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5889
- Bleu: 13.3161
- Gen Len: 42.493
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.25.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.6.1
- Tokenizers 0.13.1
| dd23cd43c9fcd35b06757c9be3491225 |
google/multiberts-seed_0-step_1700k | google | bert | 8 | 22 | transformers | 0 | null | true | true | false | apache-2.0 | ['en'] | null | null | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ['multiberts', 'multiberts-seed_0', 'multiberts-seed_0-step_1700k'] | false | true | true | 3,527 | false |
# MultiBERTs, Intermediate Checkpoint - Seed 0, Step 1700k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #0, captured at step 1700k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co./bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_0-step_1700k')
model = TFBertModel.from_pretrained("google/multiberts-seed_0-step_1700k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_0-step_1700k')
model = BertModel.from_pretrained("google/multiberts-seed_0-step_1700k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
| 0f1f2445c07c2f221b49efc529d7efd5 |