
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
Error code: JobManagerCrashedError
Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
image
image |
|---|
DF2K_BHI SISR Dataset
This is a filtered version of the DF2K dataset, specifically aimed for single image super-resolution model training.
It is a result, or is one of the testing sets, for my huggingface community blog post on my BHI-Filtering method.
Dataset Details
This is based on the DF2K dataset, which consists of 3450 images.
These images then have been tiled into 21'387 512x512px tiles for faster sisr I/O training speed.
The BHI filtering has been applied with the following default threshold values:
Blockiness < 30
HyperIQA >= 0.2
IC9600 >= 0.4
Which results in this DF2K_BHI dataset with 12'639 512x512 training tiles.
Visualization
Here is a visual example of the first few tiles that are in the dataset:

Training
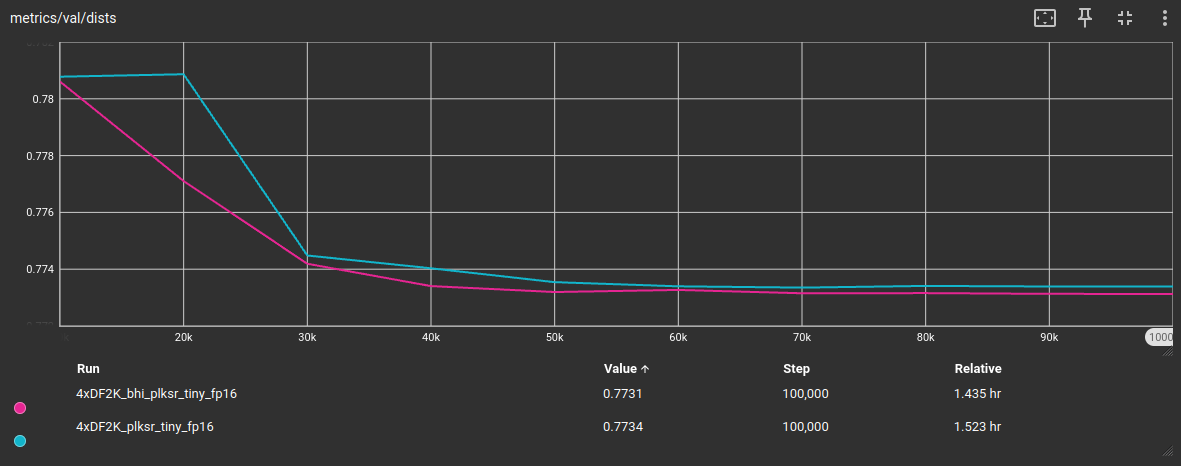
As can be seen in the following training validation tensorboard graphs (DIV2K validation dataset), this BHI-filtered version of the DF2K dataset is able to achieve higher or similiar metric scores while seeing a reduction of -40.9% in training tiles quantity.
Here is the training validation metrics on the DIV2K validation dataset, using the plksr_tiny architecture option, in comparison to the tiled full DF2K dataset:
Tiled DF2K dataset (here called X): 21'387 tiles
DF2K_BHI dataset: 12'639 tiles


- Downloads last month
- 63