
Yi-Coder
Collection
4 items
•
Updated
•
31
🐙 GitHub •
👾 Discord •
🐤 Twitter •
💬 WeChat
📝 Paper •
💪 Tech Blog •
🙌 FAQ •
📗 Learning Hub
Yi-Coder is a series of open-source code language models that delivers state-of-the-art coding performance with fewer than 10 billion parameters.
Key features:
'java', 'markdown', 'python', 'php', 'javascript', 'c++', 'c#', 'c', 'typescript', 'html', 'go', 'java_server_pages', 'dart', 'objective-c', 'kotlin', 'tex', 'swift', 'ruby', 'sql', 'rust', 'css', 'yaml', 'matlab', 'lua', 'json', 'shell', 'visual_basic', 'scala', 'rmarkdown', 'pascal', 'fortran', 'haskell', 'assembly', 'perl', 'julia', 'cmake', 'groovy', 'ocaml', 'powershell', 'elixir', 'clojure', 'makefile', 'coffeescript', 'erlang', 'lisp', 'toml', 'batchfile', 'cobol', 'dockerfile', 'r', 'prolog', 'verilog'
For model details and benchmarks, see Yi-Coder blog and Yi-Coder README.

| Name | Type | Length | Download |
|---|---|---|---|
| Yi-Coder-9B-Chat | Chat | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-1.5B-Chat | Chat | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-9B | Base | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
| Yi-Coder-1.5B | Base | 128K | 🤗 Hugging Face • 🤖 ModelScope • 🟣 wisemodel |
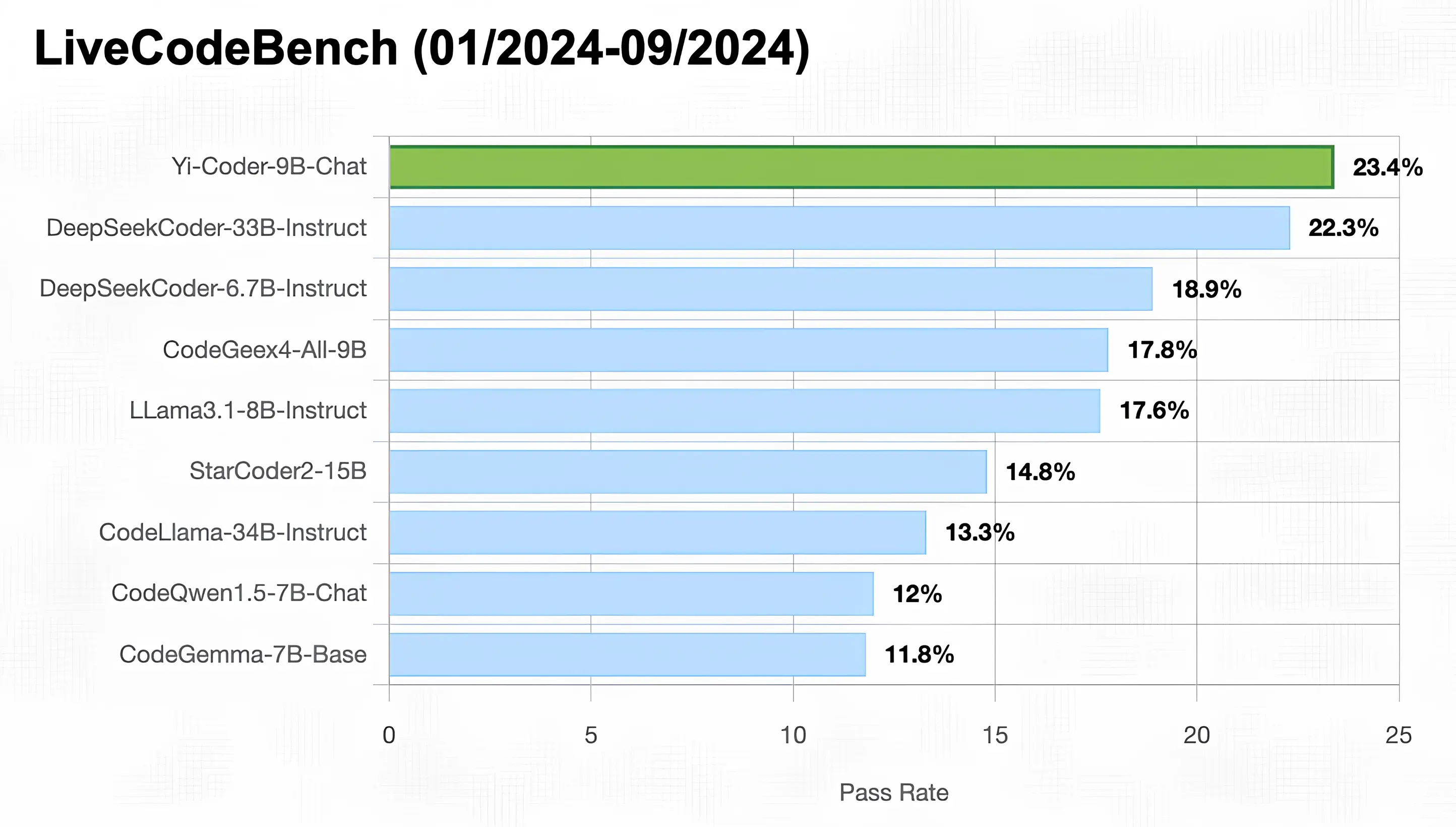
As illustrated in the figure below, Yi-Coder-9B-Chat achieved an impressive 23% pass rate in LiveCodeBench, making it the only model with under 10B parameters to surpass 20%. It also outperforms DeepSeekCoder-33B-Ins at 22.3%, CodeGeex4-9B-all at 17.8%, CodeLLama-34B-Ins at 13.3%, and CodeQwen1.5-7B-Chat at 12%.
You can use transformers to run inference with Yi-Coder models (both chat and base versions) as follows:
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" # the device to load the model onto
model_path = "01-ai/Yi-Coder-9B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto").eval()
prompt = "Write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=1024,
eos_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
For getting up and running with Yi-Coder series models quickly, see Yi-Coder README.