Spaces:
Runtime error

Runtime error

Commit
·
5e681ff
1
Parent(s):
10a4e3e
init
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- 11887_pesto-pasta_Rita-1x1-1-501c953b29074ab193e2b5ad36e64648.jpg +0 -0
- 4645808729_2dfc59b6a5_z.jpg +0 -0
- 5944609705_4664531909_z.jpg +0 -0
- 900.jpeg +0 -0
- COCO_train2014_000000194806.jpg +0 -0
- COCO_train2014_000000318365.jpg +0 -0
- COCO_train2014_000000572279.jpg +0 -0
- bad_words.txt +403 -0
- bcee7a-20190225-a-london-underground-sign.jpg +0 -0
- chinchilla_web-1024x683.jpg +0 -0
- dogs.jpeg +0 -0
- hummus.jpg +0 -0
- icl_demo.py +325 -0
- istockphoto-622434332-1024x1024.jpg +0 -0
- open_flamingo/.DS_Store +0 -0
- open_flamingo/.github/workflows/black.yml +10 -0
- open_flamingo/.gitignore +141 -0
- open_flamingo/HISTORY.md +15 -0
- open_flamingo/LICENSE +21 -0
- open_flamingo/Makefile +19 -0
- open_flamingo/README.md +247 -0
- open_flamingo/TERMS_AND_CONDITIONS.md +15 -0
- open_flamingo/_optim_utils.py +1741 -0
- open_flamingo/docs/flamingo.png +0 -0
- open_flamingo/environment.yml +10 -0
- open_flamingo/open_flamingo/__init__.py +2 -0
- open_flamingo/open_flamingo/eval/README.md +47 -0
- open_flamingo/open_flamingo/eval/__init__.py +1 -0
- open_flamingo/open_flamingo/eval/classification.py +147 -0
- open_flamingo/open_flamingo/eval/classification_utils.py +1014 -0
- open_flamingo/open_flamingo/eval/coco_metric.py +22 -0
- open_flamingo/open_flamingo/eval/eval_datasets.py +154 -0
- open_flamingo/open_flamingo/eval/eval_model.py +73 -0
- open_flamingo/open_flamingo/eval/evaluate.py +1247 -0
- open_flamingo/open_flamingo/eval/models/blip.py +113 -0
- open_flamingo/open_flamingo/eval/models/open_flamingo.py +176 -0
- open_flamingo/open_flamingo/eval/models/utils.py +10 -0
- open_flamingo/open_flamingo/eval/ok_vqa_utils.py +214 -0
- open_flamingo/open_flamingo/eval/vqa_metric.py +583 -0
- open_flamingo/open_flamingo/scripts/convert_mmc4_to_wds.py +76 -0
- open_flamingo/open_flamingo/scripts/run_eval.sh +74 -0
- open_flamingo/open_flamingo/scripts/run_train.sh +32 -0
- open_flamingo/open_flamingo/src/__init__.py +0 -0
- open_flamingo/open_flamingo/src/factory.py +132 -0
- open_flamingo/open_flamingo/src/flamingo.py +356 -0
- open_flamingo/open_flamingo/src/flamingo_lm.py +169 -0
- open_flamingo/open_flamingo/src/helpers.py +279 -0
- open_flamingo/open_flamingo/src/utils.py +48 -0
- open_flamingo/open_flamingo/train/README.md +63 -0
- open_flamingo/open_flamingo/train/__init__.py +1 -0
11887_pesto-pasta_Rita-1x1-1-501c953b29074ab193e2b5ad36e64648.jpg
ADDED
|
|
4645808729_2dfc59b6a5_z.jpg
ADDED

|
5944609705_4664531909_z.jpg
ADDED

|
900.jpeg
ADDED

|
COCO_train2014_000000194806.jpg
ADDED

|
COCO_train2014_000000318365.jpg
ADDED

|
COCO_train2014_000000572279.jpg
ADDED

|
bad_words.txt
ADDED
|
@@ -0,0 +1,403 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
2g1c
|
| 2 |
+
2 girls 1 cup
|
| 3 |
+
acrotomophilia
|
| 4 |
+
alabama hot pocket
|
| 5 |
+
alaskan pipeline
|
| 6 |
+
anal
|
| 7 |
+
anilingus
|
| 8 |
+
anus
|
| 9 |
+
apeshit
|
| 10 |
+
arsehole
|
| 11 |
+
ass
|
| 12 |
+
asshole
|
| 13 |
+
assmunch
|
| 14 |
+
auto erotic
|
| 15 |
+
autoerotic
|
| 16 |
+
babeland
|
| 17 |
+
baby batter
|
| 18 |
+
baby juice
|
| 19 |
+
ball gag
|
| 20 |
+
ball gravy
|
| 21 |
+
ball kicking
|
| 22 |
+
ball licking
|
| 23 |
+
ball sack
|
| 24 |
+
ball sucking
|
| 25 |
+
bangbros
|
| 26 |
+
bangbus
|
| 27 |
+
bareback
|
| 28 |
+
barely legal
|
| 29 |
+
barenaked
|
| 30 |
+
bastard
|
| 31 |
+
bastardo
|
| 32 |
+
bastinado
|
| 33 |
+
bbw
|
| 34 |
+
bdsm
|
| 35 |
+
beaner
|
| 36 |
+
beaners
|
| 37 |
+
beaver cleaver
|
| 38 |
+
beaver lips
|
| 39 |
+
beastiality
|
| 40 |
+
bestiality
|
| 41 |
+
big black
|
| 42 |
+
big breasts
|
| 43 |
+
big knockers
|
| 44 |
+
big tits
|
| 45 |
+
bimbos
|
| 46 |
+
birdlock
|
| 47 |
+
bitch
|
| 48 |
+
bitches
|
| 49 |
+
black cock
|
| 50 |
+
blonde action
|
| 51 |
+
blonde on blonde action
|
| 52 |
+
blowjob
|
| 53 |
+
blow job
|
| 54 |
+
blow your load
|
| 55 |
+
blue waffle
|
| 56 |
+
blumpkin
|
| 57 |
+
bollocks
|
| 58 |
+
bondage
|
| 59 |
+
boner
|
| 60 |
+
boob
|
| 61 |
+
boobs
|
| 62 |
+
booty call
|
| 63 |
+
brown showers
|
| 64 |
+
brunette action
|
| 65 |
+
bukkake
|
| 66 |
+
bulldyke
|
| 67 |
+
bullet vibe
|
| 68 |
+
bullshit
|
| 69 |
+
bung hole
|
| 70 |
+
bunghole
|
| 71 |
+
busty
|
| 72 |
+
butt
|
| 73 |
+
buttcheeks
|
| 74 |
+
butthole
|
| 75 |
+
camel toe
|
| 76 |
+
camgirl
|
| 77 |
+
camslut
|
| 78 |
+
camwhore
|
| 79 |
+
carpet muncher
|
| 80 |
+
carpetmuncher
|
| 81 |
+
chocolate rosebuds
|
| 82 |
+
cialis
|
| 83 |
+
circlejerk
|
| 84 |
+
cleveland steamer
|
| 85 |
+
clit
|
| 86 |
+
clitoris
|
| 87 |
+
clover clamps
|
| 88 |
+
clusterfuck
|
| 89 |
+
cock
|
| 90 |
+
cocks
|
| 91 |
+
coprolagnia
|
| 92 |
+
coprophilia
|
| 93 |
+
cornhole
|
| 94 |
+
coon
|
| 95 |
+
coons
|
| 96 |
+
creampie
|
| 97 |
+
cum
|
| 98 |
+
cumming
|
| 99 |
+
cumshot
|
| 100 |
+
cumshots
|
| 101 |
+
cunnilingus
|
| 102 |
+
cunt
|
| 103 |
+
darkie
|
| 104 |
+
date rape
|
| 105 |
+
daterape
|
| 106 |
+
deep throat
|
| 107 |
+
deepthroat
|
| 108 |
+
dendrophilia
|
| 109 |
+
dick
|
| 110 |
+
dildo
|
| 111 |
+
dingleberry
|
| 112 |
+
dingleberries
|
| 113 |
+
dirty pillows
|
| 114 |
+
dirty sanchez
|
| 115 |
+
doggie style
|
| 116 |
+
doggiestyle
|
| 117 |
+
doggy style
|
| 118 |
+
doggystyle
|
| 119 |
+
dog style
|
| 120 |
+
dolcett
|
| 121 |
+
domination
|
| 122 |
+
dominatrix
|
| 123 |
+
dommes
|
| 124 |
+
donkey punch
|
| 125 |
+
double dong
|
| 126 |
+
double penetration
|
| 127 |
+
dp action
|
| 128 |
+
dry hump
|
| 129 |
+
dvda
|
| 130 |
+
eat my ass
|
| 131 |
+
ecchi
|
| 132 |
+
ejaculation
|
| 133 |
+
erotic
|
| 134 |
+
erotism
|
| 135 |
+
escort
|
| 136 |
+
eunuch
|
| 137 |
+
fag
|
| 138 |
+
faggot
|
| 139 |
+
fecal
|
| 140 |
+
felch
|
| 141 |
+
fellatio
|
| 142 |
+
feltch
|
| 143 |
+
female squirting
|
| 144 |
+
femdom
|
| 145 |
+
figging
|
| 146 |
+
fingerbang
|
| 147 |
+
fingering
|
| 148 |
+
fisting
|
| 149 |
+
foot fetish
|
| 150 |
+
footjob
|
| 151 |
+
frotting
|
| 152 |
+
fuck
|
| 153 |
+
fuck buttons
|
| 154 |
+
fuckin
|
| 155 |
+
fucking
|
| 156 |
+
fucktards
|
| 157 |
+
fudge packer
|
| 158 |
+
fudgepacker
|
| 159 |
+
futanari
|
| 160 |
+
gangbang
|
| 161 |
+
gang bang
|
| 162 |
+
gay sex
|
| 163 |
+
genitals
|
| 164 |
+
giant cock
|
| 165 |
+
girl on
|
| 166 |
+
girl on top
|
| 167 |
+
girls gone wild
|
| 168 |
+
goatcx
|
| 169 |
+
goatse
|
| 170 |
+
god damn
|
| 171 |
+
gokkun
|
| 172 |
+
golden shower
|
| 173 |
+
goodpoop
|
| 174 |
+
goo girl
|
| 175 |
+
goregasm
|
| 176 |
+
grope
|
| 177 |
+
group sex
|
| 178 |
+
g-spot
|
| 179 |
+
guro
|
| 180 |
+
hand job
|
| 181 |
+
handjob
|
| 182 |
+
hard core
|
| 183 |
+
hardcore
|
| 184 |
+
hentai
|
| 185 |
+
homoerotic
|
| 186 |
+
honkey
|
| 187 |
+
hooker
|
| 188 |
+
horny
|
| 189 |
+
hot carl
|
| 190 |
+
hot chick
|
| 191 |
+
how to kill
|
| 192 |
+
how to murder
|
| 193 |
+
huge fat
|
| 194 |
+
humping
|
| 195 |
+
incest
|
| 196 |
+
intercourse
|
| 197 |
+
jack off
|
| 198 |
+
jail bait
|
| 199 |
+
jailbait
|
| 200 |
+
jelly donut
|
| 201 |
+
jerk off
|
| 202 |
+
jigaboo
|
| 203 |
+
jiggaboo
|
| 204 |
+
jiggerboo
|
| 205 |
+
jizz
|
| 206 |
+
juggs
|
| 207 |
+
kike
|
| 208 |
+
kinbaku
|
| 209 |
+
kinkster
|
| 210 |
+
kinky
|
| 211 |
+
knobbing
|
| 212 |
+
leather restraint
|
| 213 |
+
leather straight jacket
|
| 214 |
+
lemon party
|
| 215 |
+
livesex
|
| 216 |
+
lolita
|
| 217 |
+
lovemaking
|
| 218 |
+
make me come
|
| 219 |
+
male squirting
|
| 220 |
+
masturbate
|
| 221 |
+
masturbating
|
| 222 |
+
masturbation
|
| 223 |
+
menage a trois
|
| 224 |
+
milf
|
| 225 |
+
missionary position
|
| 226 |
+
mong
|
| 227 |
+
motherfucker
|
| 228 |
+
mound of venus
|
| 229 |
+
mr hands
|
| 230 |
+
muff diver
|
| 231 |
+
muffdiving
|
| 232 |
+
nambla
|
| 233 |
+
nawashi
|
| 234 |
+
negro
|
| 235 |
+
neonazi
|
| 236 |
+
nigga
|
| 237 |
+
nigger
|
| 238 |
+
nig nog
|
| 239 |
+
nimphomania
|
| 240 |
+
nipple
|
| 241 |
+
nipples
|
| 242 |
+
nsfw
|
| 243 |
+
nsfw images
|
| 244 |
+
nude
|
| 245 |
+
nudity
|
| 246 |
+
nutten
|
| 247 |
+
nympho
|
| 248 |
+
nymphomania
|
| 249 |
+
octopussy
|
| 250 |
+
omorashi
|
| 251 |
+
one cup two girls
|
| 252 |
+
one guy one jar
|
| 253 |
+
orgasm
|
| 254 |
+
orgy
|
| 255 |
+
paedophile
|
| 256 |
+
paki
|
| 257 |
+
panties
|
| 258 |
+
panty
|
| 259 |
+
pedobear
|
| 260 |
+
pedophile
|
| 261 |
+
pegging
|
| 262 |
+
penis
|
| 263 |
+
phone sex
|
| 264 |
+
piece of shit
|
| 265 |
+
pikey
|
| 266 |
+
pissing
|
| 267 |
+
piss pig
|
| 268 |
+
pisspig
|
| 269 |
+
playboy
|
| 270 |
+
pleasure chest
|
| 271 |
+
pole smoker
|
| 272 |
+
ponyplay
|
| 273 |
+
poof
|
| 274 |
+
poon
|
| 275 |
+
poontang
|
| 276 |
+
punany
|
| 277 |
+
poop chute
|
| 278 |
+
poopchute
|
| 279 |
+
porn
|
| 280 |
+
porno
|
| 281 |
+
pornography
|
| 282 |
+
prince albert piercing
|
| 283 |
+
pthc
|
| 284 |
+
pubes
|
| 285 |
+
pussy
|
| 286 |
+
queaf
|
| 287 |
+
queef
|
| 288 |
+
quim
|
| 289 |
+
raghead
|
| 290 |
+
raging boner
|
| 291 |
+
rape
|
| 292 |
+
raping
|
| 293 |
+
rapist
|
| 294 |
+
rectum
|
| 295 |
+
reverse cowgirl
|
| 296 |
+
rimjob
|
| 297 |
+
rimming
|
| 298 |
+
rosy palm
|
| 299 |
+
rosy palm and her 5 sisters
|
| 300 |
+
rusty trombone
|
| 301 |
+
sadism
|
| 302 |
+
santorum
|
| 303 |
+
scat
|
| 304 |
+
schlong
|
| 305 |
+
scissoring
|
| 306 |
+
semen
|
| 307 |
+
sex
|
| 308 |
+
sexcam
|
| 309 |
+
sexo
|
| 310 |
+
sexy
|
| 311 |
+
sexual
|
| 312 |
+
sexually
|
| 313 |
+
sexuality
|
| 314 |
+
shaved beaver
|
| 315 |
+
shaved pussy
|
| 316 |
+
shemale
|
| 317 |
+
shibari
|
| 318 |
+
shit
|
| 319 |
+
shitblimp
|
| 320 |
+
shitty
|
| 321 |
+
shota
|
| 322 |
+
shrimping
|
| 323 |
+
skeet
|
| 324 |
+
slanteye
|
| 325 |
+
slut
|
| 326 |
+
s&m
|
| 327 |
+
smut
|
| 328 |
+
snatch
|
| 329 |
+
snowballing
|
| 330 |
+
sodomize
|
| 331 |
+
sodomy
|
| 332 |
+
spastic
|
| 333 |
+
spic
|
| 334 |
+
splooge
|
| 335 |
+
splooge moose
|
| 336 |
+
spooge
|
| 337 |
+
spread legs
|
| 338 |
+
spunk
|
| 339 |
+
strap on
|
| 340 |
+
strapon
|
| 341 |
+
strappado
|
| 342 |
+
strip club
|
| 343 |
+
style doggy
|
| 344 |
+
suck
|
| 345 |
+
sucks
|
| 346 |
+
suicide girls
|
| 347 |
+
sultry women
|
| 348 |
+
swastika
|
| 349 |
+
swinger
|
| 350 |
+
tainted love
|
| 351 |
+
taste my
|
| 352 |
+
tea bagging
|
| 353 |
+
threesome
|
| 354 |
+
throating
|
| 355 |
+
thumbzilla
|
| 356 |
+
tied up
|
| 357 |
+
tight white
|
| 358 |
+
tit
|
| 359 |
+
tits
|
| 360 |
+
titties
|
| 361 |
+
titty
|
| 362 |
+
tongue in a
|
| 363 |
+
topless
|
| 364 |
+
tosser
|
| 365 |
+
towelhead
|
| 366 |
+
tranny
|
| 367 |
+
tribadism
|
| 368 |
+
tub girl
|
| 369 |
+
tubgirl
|
| 370 |
+
tushy
|
| 371 |
+
twat
|
| 372 |
+
twink
|
| 373 |
+
twinkie
|
| 374 |
+
two girls one cup
|
| 375 |
+
undressing
|
| 376 |
+
upskirt
|
| 377 |
+
urethra play
|
| 378 |
+
urophilia
|
| 379 |
+
vagina
|
| 380 |
+
venus mound
|
| 381 |
+
viagra
|
| 382 |
+
vibrator
|
| 383 |
+
violet wand
|
| 384 |
+
vorarephilia
|
| 385 |
+
voyeur
|
| 386 |
+
voyeurweb
|
| 387 |
+
voyuer
|
| 388 |
+
vulva
|
| 389 |
+
wank
|
| 390 |
+
wetback
|
| 391 |
+
wet dream
|
| 392 |
+
white power
|
| 393 |
+
whore
|
| 394 |
+
worldsex
|
| 395 |
+
wrapping men
|
| 396 |
+
wrinkled starfish
|
| 397 |
+
xx
|
| 398 |
+
xxx
|
| 399 |
+
yaoi
|
| 400 |
+
yellow showers
|
| 401 |
+
yiffy
|
| 402 |
+
zoophilia
|
| 403 |
+
🖕
|
bcee7a-20190225-a-london-underground-sign.jpg
ADDED

|
chinchilla_web-1024x683.jpg
ADDED

|
dogs.jpeg
ADDED

|
hummus.jpg
ADDED

|
icl_demo.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from PIL import Image
|
| 4 |
+
|
| 5 |
+
demo_imgs = [
|
| 6 |
+
["chinchilla_web-1024x683.jpg", "shiba-inu-dog-in-the-snow.jpg"],
|
| 7 |
+
["4645808729_2dfc59b6a5_z.jpg", "5944609705_4664531909_z.jpg"],
|
| 8 |
+
["COCO_train2014_000000310472.jpg", "COCO_train2014_000000194806.jpg"],
|
| 9 |
+
[
|
| 10 |
+
"bcee7a-20190225-a-london-underground-sign.jpg",
|
| 11 |
+
"istockphoto-622434332-1024x1024.jpg",
|
| 12 |
+
],
|
| 13 |
+
["dogs.jpeg", "pandas.jpg"],
|
| 14 |
+
["11887_pesto-pasta_Rita-1x1-1-501c953b29074ab193e2b5ad36e64648.jpg", "hummus.jpg"],
|
| 15 |
+
]
|
| 16 |
+
demo_texts = [
|
| 17 |
+
[
|
| 18 |
+
"Output: This is a chinchilla. They are mainly found in Chile.",
|
| 19 |
+
"Output: This is a shiba. They are very popular in Japan.",
|
| 20 |
+
],
|
| 21 |
+
[
|
| 22 |
+
"Output: a man and a woman on a train looking at their cell phones.",
|
| 23 |
+
"Output: a lavish reception room with black and white tiled floor.",
|
| 24 |
+
],
|
| 25 |
+
[
|
| 26 |
+
"Question: Describe the scene. Answer: A black and yellow fire hydrant sitting on a sidewalk. The sidewalk is made from red bricks.",
|
| 27 |
+
"Question: What is the man trying to catch? Answer: The man is catching a white kite that his friend is flying. The two men are on a beach.",
|
| 28 |
+
],
|
| 29 |
+
['Output: "Underground"', 'Output: "Congress Ave"'],
|
| 30 |
+
["Output: 2 dogs", "Output: 3 pandas"],
|
| 31 |
+
[
|
| 32 |
+
"Output: Step 1: Cook 8 oz. of pasta until al dente, then drain and set aside. Step 2: In a food processor, blend 2 cups fresh basil leaves, 1/2 cup grated Parmesan cheese, 1/2 cup pine nuts, 2 cloves garlic, and 1/4 cup olive oil until smooth. Step 3: Toss the pesto sauce with the cooked pasta until evenly coated. Step 4: Serve hot and enjoy!",
|
| 33 |
+
"Output: Step 1: Drain and rinse a can of chickpeas. Step 2: Add chickpeas to a food processor along with 2-3 cloves of garlic, 2 tbsp of tahini, 2 tbsp of lemon juice, and 1/4 cup of olive oil. Step 3: Process until smooth, scraping down the sides as needed. Step 4: Add salt and pepper to taste. Step 5: If the hummus is too thick, add water 1 tbsp at a time until desired consistency is reached. Step 6: Serve with a drizzle of olive oil and some paprika for garnish. Enjoy!",
|
| 34 |
+
],
|
| 35 |
+
]
|
| 36 |
+
|
| 37 |
+
# cd to open_flamingo dir and pip install .
|
| 38 |
+
import os
|
| 39 |
+
os.system("cd open_flamingo && pip install .")
|
| 40 |
+
|
| 41 |
+
from open_flamingo import create_model_and_transforms
|
| 42 |
+
|
| 43 |
+
# read bad_words.txt
|
| 44 |
+
with open("bad_words.txt", "r") as f:
|
| 45 |
+
bad_words = f.read().splitlines()
|
| 46 |
+
bad_words = set([word.strip().lower() for word in bad_words])
|
| 47 |
+
|
| 48 |
+
model, image_processor, tokenizer = create_model_and_transforms(
|
| 49 |
+
clip_vision_encoder_pretrained="openai",
|
| 50 |
+
clip_vision_encoder_path="ViT-L-14",
|
| 51 |
+
lang_encoder_path="togethercomputer/RedPajama-INCITE-Base-3B-v1",
|
| 52 |
+
tokenizer_path="togethercomputer/RedPajama-INCITE-Base-3B-v1",
|
| 53 |
+
cross_attn_every_n_layers=2,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
model.eval()
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def generate(
|
| 60 |
+
idx,
|
| 61 |
+
image,
|
| 62 |
+
text,
|
| 63 |
+
example_one_image=None,
|
| 64 |
+
example_one_text=None,
|
| 65 |
+
example_two_image=None,
|
| 66 |
+
example_two_text=None,
|
| 67 |
+
tc=True
|
| 68 |
+
):
|
| 69 |
+
if not tc:
|
| 70 |
+
raise gr.Error("Please read the terms and conditions.")
|
| 71 |
+
|
| 72 |
+
if image is None:
|
| 73 |
+
raise gr.Error("Please upload an image.")
|
| 74 |
+
|
| 75 |
+
example_one_image = (
|
| 76 |
+
Image.open(demo_imgs[idx][0])
|
| 77 |
+
if example_one_image is None
|
| 78 |
+
else example_one_image
|
| 79 |
+
)
|
| 80 |
+
example_one_text = (
|
| 81 |
+
demo_texts[idx][0]
|
| 82 |
+
if example_one_text is None
|
| 83 |
+
else f"Output: {example_one_text}"
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
example_two_image = (
|
| 87 |
+
Image.open(demo_imgs[idx][1])
|
| 88 |
+
if example_two_image is None
|
| 89 |
+
else example_two_image
|
| 90 |
+
)
|
| 91 |
+
example_two_text = (
|
| 92 |
+
demo_texts[idx][1]
|
| 93 |
+
if example_two_text is None
|
| 94 |
+
else f"Output: {example_two_text}"
|
| 95 |
+
)
|
| 96 |
+
|
| 97 |
+
if (
|
| 98 |
+
example_one_image is None
|
| 99 |
+
or example_one_text is None
|
| 100 |
+
or example_two_image is None
|
| 101 |
+
or example_two_text is None
|
| 102 |
+
):
|
| 103 |
+
raise gr.Error("Please fill in all the fields (image and text).")
|
| 104 |
+
|
| 105 |
+
demo_plus_text = f"<image>{example_one_text}<|endofchunk|><image>{example_two_text}<|endofchunk|>"
|
| 106 |
+
demo_plus_text += (
|
| 107 |
+
"<image>Output:" if idx != 2 else f"<image>Question: {text.strip()} Answer:"
|
| 108 |
+
)
|
| 109 |
+
# demo_plus_image = [example_one_image, example_two_image, image]
|
| 110 |
+
|
| 111 |
+
# print(demo_plus_image)
|
| 112 |
+
print(demo_plus_text)
|
| 113 |
+
|
| 114 |
+
lang_x = tokenizer(demo_plus_text, return_tensors="pt")
|
| 115 |
+
input_ids = lang_x["input_ids"]
|
| 116 |
+
attention_mask = lang_x["attention_mask"]
|
| 117 |
+
|
| 118 |
+
vision_x = [image_processor(example_one_image).unsqueeze(0), image_processor(example_two_image).unsqueeze(0), image_processor(image).unsqueeze(0)]
|
| 119 |
+
vision_x = torch.cat(vision_x, dim=0)
|
| 120 |
+
vision_x = vision_x.unsqueeze(1).unsqueeze(0)
|
| 121 |
+
print(vision_x.shape)
|
| 122 |
+
|
| 123 |
+
# with torch.cuda.amp.autocast(dtype=torch.bfloat16):
|
| 124 |
+
output = model.generate(
|
| 125 |
+
vision_x=vision_x,
|
| 126 |
+
lang_x=input_ids,
|
| 127 |
+
attention_mask=attention_mask,
|
| 128 |
+
max_new_tokens=100,
|
| 129 |
+
num_beams=1,
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
gen_text = tokenizer.decode(
|
| 133 |
+
output[0][len(input_ids[0]):], skip_special_tokens=True
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
print(gen_text)
|
| 137 |
+
gen_text = gen_text.split("Output")[0]
|
| 138 |
+
gen_text = gen_text.split("Question")[0]
|
| 139 |
+
|
| 140 |
+
for word in gen_text.split(" "):
|
| 141 |
+
word = (
|
| 142 |
+
word.strip()
|
| 143 |
+
.lower()
|
| 144 |
+
.replace(".", "")
|
| 145 |
+
.replace(",", "")
|
| 146 |
+
.replace("?", "")
|
| 147 |
+
.replace("!", "")
|
| 148 |
+
)
|
| 149 |
+
if word in bad_words:
|
| 150 |
+
print("Found bad word: ", word)
|
| 151 |
+
raise gr.Error(
|
| 152 |
+
"We found harmful language in the generated text. Please try again."
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
return (
|
| 156 |
+
f"Output:{gen_text}"
|
| 157 |
+
if idx != 2
|
| 158 |
+
else f"Question: {text.strip()} Answer: {gen_text}"
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
with gr.Blocks() as demo:
|
| 163 |
+
# As a consequence, you should treat this model as a research prototype and not as a production-ready model. Before using this demo please familiarize yourself with our [model card](https://github.com/mlfoundations/open_flamingo/blob/main/MODEL_CARD.md) and [terms and conditions](https://github.com/mlfoundations/open_flamingo/blob/main/TERMS_AND_CONDITIONS.md)
|
| 164 |
+
gr.Markdown(
|
| 165 |
+
"""
|
| 166 |
+
# 🦩 OpenFlamingo-9B Demo
|
| 167 |
+
|
| 168 |
+
Blog post: [An open-source framework for training vision-language models with in-context learning (like GPT-4!)]()
|
| 169 |
+
GitHub: [open_flamingo](https://github.com/mlfoundations/open_flamingo)
|
| 170 |
+
|
| 171 |
+
In this demo we implement an interactive interface that showcases the in-context learning capabilities of the OpenFlamingo-9B model, a large multimodal model trained on top of LLaMA-7B.
|
| 172 |
+
The model is trained on an interleaved mixture of text and images and is able to generate text conditioned on sequences of images/text. To safeguard against harmful generations, we detect toxic text in the model output and reject it. However, we understand that this is not a perfect solution and we encourage you to use this demo responsibly. If you find that the model is generating harmful text, please report it using this [form](https://forms.gle/StbcPvyyW2p3Pc7z6).
|
| 173 |
+
|
| 174 |
+
Note: This model is still a work in progress and is not fully trained. We are releasing it to showcase the capabilities of the framework and to get feedback from the community.
|
| 175 |
+
"""
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
with gr.Accordion("See terms and conditions"):
|
| 179 |
+
gr.Markdown("""**Please read the following information carefully before proceeding.**
|
| 180 |
+
OpenFlamingo is a **research prototype** that aims to enable users to interact with AI through both language and images. AI agents equipped with both language and visual understanding can be useful on a larger variety of tasks compared to models that communicate solely via language. By releasing an open-source research prototype, we hope to help the research community better understand the risks and limitations of modern visual-language AI models and accelerate the development of safer and more reliable methods.
|
| 181 |
+
**Limitations.** OpenFlamingo is built on top of the LLaMA large language model developed by Meta AI. Large language models, including LLaMA, are trained on mostly unfiltered internet data, and have been shown to be able to produce toxic, unethical, inaccurate, and harmful content. On top of this, OpenFlamingo’s ability to support visual inputs creates additional risks, since it can be used in a wider variety of applications; image+text models may carry additional risks specific to multimodality. Please use discretion when assessing the accuracy or appropriateness of the model’s outputs, and be mindful before sharing its results.
|
| 182 |
+
**Privacy and data collection.** This demo does NOT store any personal information on its users, and it does NOT store user queries.
|
| 183 |
+
**Licensing.** As OpenFlamingo is built on top of the LLaMA large language model from Meta AI, the LLaMA license agreement (as documented in the Meta request form) also applies.""")
|
| 184 |
+
read_tc = gr.Checkbox(
|
| 185 |
+
label="I have read and agree to the terms and conditions")
|
| 186 |
+
|
| 187 |
+
with gr.Tab("📷 Image Captioning"):
|
| 188 |
+
with gr.Row():
|
| 189 |
+
with gr.Column(scale=1):
|
| 190 |
+
demo_image_one = gr.Image(value=Image.open(demo_imgs[1][0])
|
| 191 |
+
)
|
| 192 |
+
demo_text_one = gr.Textbox(
|
| 193 |
+
value=demo_texts[1][0], label="Demonstration sample 1", lines=2
|
| 194 |
+
)
|
| 195 |
+
with gr.Column(scale=1):
|
| 196 |
+
demo_image_two = gr.Image(value=Image.open(demo_imgs[1][1])
|
| 197 |
+
)
|
| 198 |
+
demo_text_two = gr.Textbox(
|
| 199 |
+
value=demo_texts[1][1], label="Demonstration sample 2", lines=2
|
| 200 |
+
)
|
| 201 |
+
with gr.Column(scale=1):
|
| 202 |
+
query_image = gr.Image(type="pil")
|
| 203 |
+
text_output = gr.Textbox(value="Output:", label="Model output")
|
| 204 |
+
|
| 205 |
+
run_btn = gr.Button("Run model")
|
| 206 |
+
|
| 207 |
+
def on_click_fn(img): return generate(1, img, "", tc=read_tc)
|
| 208 |
+
run_btn.click(on_click_fn, inputs=[query_image], outputs=[text_output])
|
| 209 |
+
|
| 210 |
+
with gr.Tab("🦓 Animal recognition"):
|
| 211 |
+
with gr.Row():
|
| 212 |
+
with gr.Column(scale=1):
|
| 213 |
+
demo_image_one = gr.Image(
|
| 214 |
+
value=Image.open(demo_imgs[0][0])
|
| 215 |
+
)
|
| 216 |
+
demo_text_one = gr.Textbox(
|
| 217 |
+
value=demo_texts[0][0], label="Demonstration sample 1", lines=2
|
| 218 |
+
)
|
| 219 |
+
with gr.Column(scale=1):
|
| 220 |
+
demo_image_two = gr.Image(
|
| 221 |
+
value=Image.open(demo_imgs[0][1])
|
| 222 |
+
)
|
| 223 |
+
demo_text_two = gr.Textbox(
|
| 224 |
+
value=demo_texts[0][1], label="Demonstration sample 2", lines=2
|
| 225 |
+
)
|
| 226 |
+
with gr.Column(scale=1):
|
| 227 |
+
query_image = gr.Image(type="pil")
|
| 228 |
+
text_output = gr.Textbox(value="Output:", label="Model output")
|
| 229 |
+
|
| 230 |
+
run_btn = gr.Button("Run model")
|
| 231 |
+
|
| 232 |
+
def on_click_fn(img): return generate(0, img, "", tc=read_tc)
|
| 233 |
+
run_btn.click(on_click_fn, inputs=[query_image], outputs=[text_output])
|
| 234 |
+
|
| 235 |
+
with gr.Tab("🔢 Counting objects"):
|
| 236 |
+
with gr.Row():
|
| 237 |
+
with gr.Column(scale=1):
|
| 238 |
+
demo_image_one = gr.Image(
|
| 239 |
+
value=Image.open(demo_imgs[4][0])
|
| 240 |
+
)
|
| 241 |
+
demo_text_one = gr.Textbox(
|
| 242 |
+
value=demo_texts[4][0], label="Demonstration sample 1", lines=2
|
| 243 |
+
)
|
| 244 |
+
with gr.Column(scale=1):
|
| 245 |
+
demo_image_two = gr.Image(
|
| 246 |
+
value=Image.open(demo_imgs[4][1])
|
| 247 |
+
)
|
| 248 |
+
demo_text_two = gr.Textbox(
|
| 249 |
+
value=demo_texts[4][1], label="Demonstration sample 2", lines=2
|
| 250 |
+
)
|
| 251 |
+
with gr.Column(scale=1):
|
| 252 |
+
query_image = gr.Image(type="pil")
|
| 253 |
+
text_output = gr.Textbox(value="Output:", label="Model output")
|
| 254 |
+
|
| 255 |
+
run_btn = gr.Button("Run model")
|
| 256 |
+
|
| 257 |
+
def on_click_fn(img): return generate(4, img, "", tc=read_tc)
|
| 258 |
+
run_btn.click(on_click_fn, inputs=[query_image], outputs=[text_output])
|
| 259 |
+
|
| 260 |
+
with gr.Tab("🕵️ Visual Question Answering"):
|
| 261 |
+
with gr.Row():
|
| 262 |
+
with gr.Column(scale=1):
|
| 263 |
+
demo_image_one = gr.Image(
|
| 264 |
+
value=Image.open(demo_imgs[2][0])
|
| 265 |
+
)
|
| 266 |
+
demo_text_one = gr.Textbox(
|
| 267 |
+
value=demo_texts[2][0], label="Demonstration sample 1", lines=2
|
| 268 |
+
)
|
| 269 |
+
with gr.Column(scale=1):
|
| 270 |
+
demo_image_two = gr.Image(
|
| 271 |
+
value=Image.open(demo_imgs[2][1])
|
| 272 |
+
)
|
| 273 |
+
demo_text_two = gr.Textbox(
|
| 274 |
+
value=demo_texts[2][1], label="Demonstration sample 2", lines=2
|
| 275 |
+
)
|
| 276 |
+
with gr.Column(scale=1):
|
| 277 |
+
query_image = gr.Image(type="pil")
|
| 278 |
+
question = gr.Textbox(
|
| 279 |
+
label="Question: (e.g. 'What is the color of the object?' without \"Question:\" prefix)"
|
| 280 |
+
)
|
| 281 |
+
text_output = gr.Textbox(value="", label="Model output")
|
| 282 |
+
|
| 283 |
+
run_btn = gr.Button("Run model")
|
| 284 |
+
def on_click_fn(img, txt): return generate(2, img, txt, tc=read_tc)
|
| 285 |
+
run_btn.click(
|
| 286 |
+
on_click_fn, inputs=[query_image, question], outputs=[text_output]
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
with gr.Tab("🌎 Custom"):
|
| 290 |
+
gr.Markdown(
|
| 291 |
+
"""### Customize the demonstration by uploading your own images and text samples.
|
| 292 |
+
### **Note: Any text prompt you use will be prepended with an 'Output:', so you don't need to include it in your prompt.**"""
|
| 293 |
+
)
|
| 294 |
+
with gr.Row():
|
| 295 |
+
with gr.Column(scale=1):
|
| 296 |
+
demo_image_one = gr.Image(type="pil")
|
| 297 |
+
demo_text_one = gr.Textbox(
|
| 298 |
+
label="Demonstration sample 1", lines=2)
|
| 299 |
+
with gr.Column(scale=1):
|
| 300 |
+
demo_image_two = gr.Image(type="pil")
|
| 301 |
+
demo_text_two = gr.Textbox(
|
| 302 |
+
label="Demonstration sample 2", lines=2)
|
| 303 |
+
with gr.Column(scale=1):
|
| 304 |
+
query_image = gr.Image(type="pil")
|
| 305 |
+
text_output = gr.Textbox(value="Output:", label="Model output")
|
| 306 |
+
|
| 307 |
+
run_btn = gr.Button("Run model")
|
| 308 |
+
|
| 309 |
+
def on_click_fn(img, example_img_1, example_txt_1, example_img_2, example_txt_2): return generate(
|
| 310 |
+
-1, img, "", example_img_1, example_txt_1, example_img_2, example_txt_2, tc=read_tc
|
| 311 |
+
)
|
| 312 |
+
run_btn.click(
|
| 313 |
+
on_click_fn,
|
| 314 |
+
inputs=[
|
| 315 |
+
query_image,
|
| 316 |
+
demo_image_one,
|
| 317 |
+
demo_text_one,
|
| 318 |
+
demo_image_two,
|
| 319 |
+
demo_text_two,
|
| 320 |
+
],
|
| 321 |
+
outputs=[text_output],
|
| 322 |
+
)
|
| 323 |
+
|
| 324 |
+
demo.queue(concurrency_count=1)
|
| 325 |
+
demo.launch()
|
istockphoto-622434332-1024x1024.jpg
ADDED

|
open_flamingo/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
open_flamingo/.github/workflows/black.yml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Lint
|
| 2 |
+
|
| 3 |
+
on: [push, pull_request]
|
| 4 |
+
|
| 5 |
+
jobs:
|
| 6 |
+
lint:
|
| 7 |
+
runs-on: ubuntu-latest
|
| 8 |
+
steps:
|
| 9 |
+
- uses: actions/checkout@v2
|
| 10 |
+
- uses: psf/black@stable
|
open_flamingo/.gitignore
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.pt
|
| 2 |
+
*.json
|
| 3 |
+
|
| 4 |
+
wandb/
|
| 5 |
+
|
| 6 |
+
# Byte-compiled / optimized / DLL files
|
| 7 |
+
__pycache__/
|
| 8 |
+
*.py[cod]
|
| 9 |
+
*$py.class
|
| 10 |
+
|
| 11 |
+
# C extensions
|
| 12 |
+
*.so
|
| 13 |
+
|
| 14 |
+
# Distribution / packaging
|
| 15 |
+
.Python
|
| 16 |
+
build/
|
| 17 |
+
develop-eggs/
|
| 18 |
+
dist/
|
| 19 |
+
downloads/
|
| 20 |
+
eggs/
|
| 21 |
+
.eggs/
|
| 22 |
+
lib/
|
| 23 |
+
lib64/
|
| 24 |
+
parts/
|
| 25 |
+
sdist/
|
| 26 |
+
var/
|
| 27 |
+
wheels/
|
| 28 |
+
pip-wheel-metadata/
|
| 29 |
+
share/python-wheels/
|
| 30 |
+
*.egg-info/
|
| 31 |
+
.installed.cfg
|
| 32 |
+
*.egg
|
| 33 |
+
MANIFEST
|
| 34 |
+
|
| 35 |
+
# PyInstaller
|
| 36 |
+
# Usually these files are written by a python script from a template
|
| 37 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 38 |
+
*.manifest
|
| 39 |
+
*.spec
|
| 40 |
+
|
| 41 |
+
# Installer logs
|
| 42 |
+
pip-log.txt
|
| 43 |
+
pip-delete-this-directory.txt
|
| 44 |
+
|
| 45 |
+
# Unit test / coverage reports
|
| 46 |
+
htmlcov/
|
| 47 |
+
.tox/
|
| 48 |
+
.nox/
|
| 49 |
+
.coverage
|
| 50 |
+
.coverage.*
|
| 51 |
+
.cache
|
| 52 |
+
nosetests.xml
|
| 53 |
+
coverage.xml
|
| 54 |
+
*.cover
|
| 55 |
+
*.py,cover
|
| 56 |
+
.hypothesis/
|
| 57 |
+
.pytest_cache/
|
| 58 |
+
|
| 59 |
+
# Translations
|
| 60 |
+
*.mo
|
| 61 |
+
*.pot
|
| 62 |
+
|
| 63 |
+
# Django stuff:
|
| 64 |
+
*.log
|
| 65 |
+
local_settings.py
|
| 66 |
+
db.sqlite3
|
| 67 |
+
db.sqlite3-journal
|
| 68 |
+
|
| 69 |
+
# Flask stuff:
|
| 70 |
+
instance/
|
| 71 |
+
.webassets-cache
|
| 72 |
+
|
| 73 |
+
# Scrapy stuff:
|
| 74 |
+
.scrapy
|
| 75 |
+
|
| 76 |
+
# Sphinx documentation
|
| 77 |
+
docs/_build/
|
| 78 |
+
|
| 79 |
+
# PyBuilder
|
| 80 |
+
target/
|
| 81 |
+
|
| 82 |
+
# Jupyter Notebook
|
| 83 |
+
.ipynb_checkpoints
|
| 84 |
+
|
| 85 |
+
# IPython
|
| 86 |
+
profile_default/
|
| 87 |
+
ipython_config.py
|
| 88 |
+
|
| 89 |
+
# pyenv
|
| 90 |
+
.python-version
|
| 91 |
+
|
| 92 |
+
# pipenv
|
| 93 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 94 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 95 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 96 |
+
# install all needed dependencies.
|
| 97 |
+
#Pipfile.lock
|
| 98 |
+
|
| 99 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 100 |
+
__pypackages__/
|
| 101 |
+
|
| 102 |
+
# Celery stuff
|
| 103 |
+
celerybeat-schedule
|
| 104 |
+
celerybeat.pid
|
| 105 |
+
|
| 106 |
+
# SageMath parsed files
|
| 107 |
+
*.sage.py
|
| 108 |
+
|
| 109 |
+
# Environments
|
| 110 |
+
.env
|
| 111 |
+
.venv
|
| 112 |
+
env/
|
| 113 |
+
venv/
|
| 114 |
+
ENV/
|
| 115 |
+
env.bak/
|
| 116 |
+
venv.bak/
|
| 117 |
+
|
| 118 |
+
# Pycharm project settings
|
| 119 |
+
.idea
|
| 120 |
+
|
| 121 |
+
# Spyder project settings
|
| 122 |
+
.spyderproject
|
| 123 |
+
.spyproject
|
| 124 |
+
|
| 125 |
+
# Rope project settings
|
| 126 |
+
.ropeproject
|
| 127 |
+
|
| 128 |
+
# mkdocs documentation
|
| 129 |
+
/site
|
| 130 |
+
|
| 131 |
+
# mypy
|
| 132 |
+
.mypy_cache/
|
| 133 |
+
.dmypy.json
|
| 134 |
+
dmypy.json
|
| 135 |
+
|
| 136 |
+
*.out
|
| 137 |
+
src/wandb
|
| 138 |
+
wandb
|
| 139 |
+
|
| 140 |
+
# Pyre type checker
|
| 141 |
+
.pyre/
|
open_flamingo/HISTORY.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 2.0.0
|
| 2 |
+
* Add gradient checkpointing, FullyShardedDataParallel
|
| 3 |
+
* Model releases
|
| 4 |
+
* (CLIP ViT-L-14 / MPT-1B)
|
| 5 |
+
* (CLIP ViT-L-14 / MPT-1B Dolly)
|
| 6 |
+
* (CLIP ViT-L-14 / RedPajama-3B)
|
| 7 |
+
* (CLIP ViT-L-14 / RedPajama-3B Instruct)
|
| 8 |
+
* (CLIP ViT-L-14 / MPT-7B)
|
| 9 |
+
* Remove color jitter when training
|
| 10 |
+
* Fix cross-attention bug when calling generate()
|
| 11 |
+
|
| 12 |
+
## 1.0.0
|
| 13 |
+
|
| 14 |
+
* Initial code release
|
| 15 |
+
* Early model release (CLIP ViT-L-14 / LLaMA-7B)
|
open_flamingo/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 Anas Awadalla, Irena Gao, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, Ludwig Schmidt.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
open_flamingo/Makefile
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
install: ## [Local development] Upgrade pip, install requirements, install package.
|
| 2 |
+
python -m pip install -U pip
|
| 3 |
+
python -m pip install -e .
|
| 4 |
+
|
| 5 |
+
install-dev: ## [Local development] Install test requirements
|
| 6 |
+
python -m pip install -r requirements-test.txt
|
| 7 |
+
|
| 8 |
+
lint: ## [Local development] Run mypy, pylint and black
|
| 9 |
+
python -m mypy open_flamingo
|
| 10 |
+
python -m pylint open_flamingo
|
| 11 |
+
python -m black --check -l 120 open_flamingo
|
| 12 |
+
|
| 13 |
+
black: ## [Local development] Auto-format python code using black
|
| 14 |
+
python -m black -l 120 .
|
| 15 |
+
|
| 16 |
+
.PHONY: help
|
| 17 |
+
|
| 18 |
+
help: # Run `make help` to get help on the make commands
|
| 19 |
+
@grep -E '^[0-9a-zA-Z_-]+:.*?## .*$$' $(MAKEFILE_LIST) | sort | awk 'BEGIN {FS = ":.*?## "}; {printf "\033[36m%-30s\033[0m %s\n", $$1, $$2}'
|
open_flamingo/README.md
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 🦩 OpenFlamingo
|
| 2 |
+
|
| 3 |
+
[](https://badge.fury.io/py/open_flamingo)
|
| 4 |
+
|
| 5 |
+
Blog posts: [1](https://laion.ai/blog/open-flamingo/), [2]() | Paper (coming soon)
|
| 6 |
+
|
| 7 |
+
Welcome to our open source implementation of DeepMind's [Flamingo](https://www.deepmind.com/blog/tackling-multiple-tasks-with-a-single-visual-language-model)!
|
| 8 |
+
|
| 9 |
+
In this repository, we provide a PyTorch implementation for training and evaluating OpenFlamingo models.
|
| 10 |
+
If you have any questions, please feel free to open an issue. We also welcome contributions!
|
| 11 |
+
|
| 12 |
+
# Table of Contents
|
| 13 |
+
- [Installation](#installation)
|
| 14 |
+
- [Approach](#approach)
|
| 15 |
+
* [Model architecture](#model-architecture)
|
| 16 |
+
- [Usage](#usage)
|
| 17 |
+
* [Initializing an OpenFlamingo model](#initializing-an-openflamingo-model)
|
| 18 |
+
* [Generating text](#generating-text)
|
| 19 |
+
- [Training](#training)
|
| 20 |
+
* [Dataset](#dataset)
|
| 21 |
+
- [Evaluation](#evaluation)
|
| 22 |
+
- [Future plans](#future-plans)
|
| 23 |
+
- [Team](#team)
|
| 24 |
+
- [Acknowledgments](#acknowledgments)
|
| 25 |
+
- [Citing](#citing)
|
| 26 |
+
|
| 27 |
+
# Installation
|
| 28 |
+
|
| 29 |
+
To install the package in an existing environment, run
|
| 30 |
+
```
|
| 31 |
+
pip install open-flamingo
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
or to create a conda environment for running OpenFlamingo, run
|
| 35 |
+
```
|
| 36 |
+
conda env create -f environment.yml
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
# Approach
|
| 40 |
+
OpenFlamingo is a multimodal language model that can be used for a variety of tasks. It is trained on a large multimodal dataset (e.g. Multimodal C4) and can be used to generate text conditioned on interleaved images/text. For example, OpenFlamingo can be used to generate a caption for an image, or to generate a question given an image and a text passage. The benefit of this approach is that we are able to rapidly adapt to new tasks using in-context learning.
|
| 41 |
+
|
| 42 |
+
## Model architecture
|
| 43 |
+
OpenFlamingo combines a pretrained vision encoder and a language model using cross attention layers. The model architecture is shown below.
|
| 44 |
+
|
| 45 |
+

|
| 46 |
+
Credit: [Flamingo](https://www.deepmind.com/blog/tackling-multiple-tasks-with-a-single-visual-language-model)
|
| 47 |
+
|
| 48 |
+
# Usage
|
| 49 |
+
## Initializing an OpenFlamingo model
|
| 50 |
+
We support pretrained vision encoders from the [OpenCLIP](https://github.com/mlfoundations/open_clip) package, which includes OpenAI's pretrained models.
|
| 51 |
+
We also support pretrained language models from the `transformers` package, such as [MPT](https://huggingface.co/models?search=mosaicml%20mpt), [RedPajama](https://huggingface.co/models?search=redpajama), [LLaMA](https://huggingface.co/models?search=llama), [OPT](https://huggingface.co/models?search=opt), [GPT-Neo](https://huggingface.co/models?search=gpt-neo), [GPT-J](https://huggingface.co/models?search=gptj), and [Pythia](https://huggingface.co/models?search=pythia) models.
|
| 52 |
+
|
| 53 |
+
``` python
|
| 54 |
+
from open_flamingo import create_model_and_transforms
|
| 55 |
+
|
| 56 |
+
model, image_processor, tokenizer = create_model_and_transforms(
|
| 57 |
+
clip_vision_encoder_path="ViT-L-14",
|
| 58 |
+
clip_vision_encoder_pretrained="openai",
|
| 59 |
+
lang_encoder_path="anas-awadalla/mpt-1b-redpajama-200b",
|
| 60 |
+
tokenizer_path="anas-awadalla/mpt-1b-redpajama-200b",
|
| 61 |
+
cross_attn_every_n_layers=1
|
| 62 |
+
)
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## Released OpenFlamingo models
|
| 66 |
+
We have trained the following OpenFlamingo models so far.
|
| 67 |
+
|
| 68 |
+
|# params|Language model|Vision encoder|Xattn frequency*|COCO 4-shot CIDEr**|VQAv2 4-shot Accuracy**|Weights|
|
| 69 |
+
|------------|--------------|--------------|----------|-----------|-------|----|
|
| 70 |
+
|3B| mosaicml/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | - | - |[Link](https://huggingface.co/openflamingo/OpenFlamingo-3B-vitl-mpt1b)|
|
| 71 |
+
|3B| mosaicml/mpt-1b-redpajama-200b-dolly | openai CLIP ViT-L/14 | 1 | 82.7 | - |[Link](https://huggingface.co/openflamingo/OpenFlamingo-3B-vitl-mpt1b-langinstruct)|
|
| 72 |
+
|4B| togethercomputer/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81.8 | -| [Link](https://huggingface.co/openflamingo/OpenFlamingo-4B-vitl-rpj3b)|
|
| 73 |
+
|4B| togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85.8 | - | [Link](https://huggingface.co/openflamingo/OpenFlamingo-4B-vitl-rpj3b-langinstruct)|
|
| 74 |
+
|9B| mosaicml/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | - | [Link](https://huggingface.co/openflamingo/OpenFlamingo-9B-vitl-mpt7b)|
|
| 75 |
+
|
| 76 |
+
*\* Xattn frequency refers to the `--cross_attn_every_n_layers` argument.*
|
| 77 |
+
|
| 78 |
+
*\*\* 4-shot COCO and VQAv2 performances were calculated over a sample of 5000 test split examples, following the [Flamingo paper](https://arxiv.org/abs/2204.14198).*
|
| 79 |
+
|
| 80 |
+
Note: as part of our v2 release, we have deprecated a previous LLaMA-based checkpoint. However, you can continue to use our older checkpoint using the new codebase.
|
| 81 |
+
|
| 82 |
+
## Downloading pretrained weights
|
| 83 |
+
|
| 84 |
+
To instantiate an OpenFlamingo model with one of our released weights, initialize the model as above and use the following code.
|
| 85 |
+
|
| 86 |
+
```python
|
| 87 |
+
# grab model checkpoint from huggingface hub
|
| 88 |
+
from huggingface_hub import hf_hub_download
|
| 89 |
+
import torch
|
| 90 |
+
|
| 91 |
+
checkpoint_path = hf_hub_download("openflamingo/OpenFlamingo-3B-vitl-mpt1b", "checkpoint.pt")
|
| 92 |
+
model.load_state_dict(torch.load(checkpoint_path), strict=False)
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
## Generating text
|
| 96 |
+
Below is an example of generating text conditioned on interleaved images/text. In particular, let's try few-shot image captioning.
|
| 97 |
+
|
| 98 |
+
``` python
|
| 99 |
+
from PIL import Image
|
| 100 |
+
import requests
|
| 101 |
+
|
| 102 |
+
"""
|
| 103 |
+
Step 1: Load images
|
| 104 |
+
"""
|
| 105 |
+
demo_image_one = Image.open(
|
| 106 |
+
requests.get(
|
| 107 |
+
"http://images.cocodataset.org/val2017/000000039769.jpg", stream=True
|
| 108 |
+
).raw
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
demo_image_two = Image.open(
|
| 112 |
+
requests.get(
|
| 113 |
+
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg",
|
| 114 |
+
stream=True
|
| 115 |
+
).raw
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
query_image = Image.open(
|
| 119 |
+
requests.get(
|
| 120 |
+
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg",
|
| 121 |
+
stream=True
|
| 122 |
+
).raw
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
"""
|
| 127 |
+
Step 2: Preprocessing images
|
| 128 |
+
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
|
| 129 |
+
batch_size x num_media x num_frames x channels x height x width.
|
| 130 |
+
In this case batch_size = 1, num_media = 3, num_frames = 1,
|
| 131 |
+
channels = 3, height = 224, width = 224.
|
| 132 |
+
"""
|
| 133 |
+
vision_x = [image_processor(demo_image_one).unsqueeze(0), image_processor(demo_image_two).unsqueeze(0), image_processor(query_image).unsqueeze(0)]
|
| 134 |
+
vision_x = torch.cat(vision_x, dim=0)
|
| 135 |
+
vision_x = vision_x.unsqueeze(1).unsqueeze(0)
|
| 136 |
+
|
| 137 |
+
"""
|
| 138 |
+
Step 3: Preprocessing text
|
| 139 |
+
Details: In the text we expect an <image> special token to indicate where an image is.
|
| 140 |
+
We also expect an <|endofchunk|> special token to indicate the end of the text
|
| 141 |
+
portion associated with an image.
|
| 142 |
+
"""
|
| 143 |
+
tokenizer.padding_side = "left" # For generation padding tokens should be on the left
|
| 144 |
+
lang_x = tokenizer(
|
| 145 |
+
["<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of"],
|
| 146 |
+
return_tensors="pt",
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
"""
|
| 151 |
+
Step 4: Generate text
|
| 152 |
+
"""
|
| 153 |
+
generated_text = model.generate(
|
| 154 |
+
vision_x=vision_x,
|
| 155 |
+
lang_x=lang_x["input_ids"],
|
| 156 |
+
attention_mask=lang_x["attention_mask"],
|
| 157 |
+
max_new_tokens=20,
|
| 158 |
+
num_beams=3,
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
print("Generated text: ", tokenizer.decode(generated_text[0]))
|
| 162 |
+
```
|
| 163 |
+
|
| 164 |
+
# Training
|
| 165 |
+
We provide training scripts in `open_flamingo/train`. We provide an example Slurm script in `open_flamingo/scripts/run_train.py`, as well as the following example command:
|
| 166 |
+
```
|
| 167 |
+
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py \
|
| 168 |
+
--lm_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 169 |
+
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 170 |
+
--cross_attn_every_n_layers 1 \
|
| 171 |
+
--dataset_resampled \
|
| 172 |
+
--batch_size_mmc4 32 \
|
| 173 |
+
--batch_size_laion 64 \
|
| 174 |
+
--train_num_samples_mmc4 125000\
|
| 175 |
+
--train_num_samples_laion 250000 \
|
| 176 |
+
--loss_multiplier_laion 0.2 \
|
| 177 |
+
--workers=4 \
|
| 178 |
+
--run_name OpenFlamingo-3B-vitl-mpt1b \
|
| 179 |
+
--num_epochs 480 \
|
| 180 |
+
--warmup_steps 1875 \
|
| 181 |
+
--mmc4_textsim_threshold 0.24 \
|
| 182 |
+
--laion_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 183 |
+
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 184 |
+
--report_to_wandb
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
*Note: The MPT-1B [base](https://huggingface.co/mosaicml/mpt-1b-redpajama-200b) and [instruct](https://huggingface.co/mosaicml/mpt-1b-redpajama-200b-dolly) modeling code does not accept the `labels` kwarg or compute cross-entropy loss directly within `forward()`, as expected by our codebase. We suggest using a modified version of the MPT-1B models found [here](https://huggingface.co/anas-awadalla/mpt-1b-redpajama-200b) and [here](https://huggingface.co/anas-awadalla/mpt-1b-redpajama-200b-dolly).*
|
| 188 |
+
|
| 189 |
+
For more details, see our [training README](https://github.com/mlfoundations/open_flamingo/tree/main/open_flamingo/train).
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
# Evaluation
|
| 193 |
+
An example evaluation script is at `open_flamingo/scripts/run_eval.sh`. Please see our [evaluation README](https://github.com/mlfoundations/open_flamingo/tree/main/open_flamingo/eval) for more details.
|
| 194 |
+
|
| 195 |
+
Before evaluating the model, you will need to install the coco evaluation package by running the following command:
|
| 196 |
+
```
|
| 197 |
+
pip install pycocoevalcap
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
To run evaluations on OKVQA you will need to run the following command:
|
| 201 |
+
```
|
| 202 |
+
import nltk
|
| 203 |
+
nltk.download('wordnet')
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
# Future plans
|
| 208 |
+
- [ ] Add support for video input
|
| 209 |
+
|
| 210 |
+
# Team
|
| 211 |
+
|
| 212 |
+
OpenFlamingo is developed by:
|
| 213 |
+
|
| 214 |
+
[Anas Awadalla*](https://anas-awadalla.streamlit.app/), [Irena Gao*](https://i-gao.github.io/), [Joshua Gardner](https://homes.cs.washington.edu/~jpgard/), [Jack Hessel](https://jmhessel.com/), [Yusuf Hanafy](https://www.linkedin.com/in/yusufhanafy/), [Wanrong Zhu](https://wanrong-zhu.com/), [Kalyani Marathe](https://sites.google.com/uw.edu/kalyanimarathe/home?authuser=0), [Yonatan Bitton](https://yonatanbitton.github.io/), [Samir Gadre](https://sagadre.github.io/), [Shiori Sagawa](https://cs.stanford.edu/~ssagawa/), [Jenia Jitsev](https://scholar.google.de/citations?user=p1FuAMkAAAAJ&hl=en), [Simon Kornblith](https://simonster.com/), [Pang Wei Koh](https://koh.pw/), [Gabriel Ilharco](https://gabrielilharco.com/), [Mitchell Wortsman](https://mitchellnw.github.io/), [Ludwig Schmidt](https://people.csail.mit.edu/ludwigs/).
|
| 215 |
+
|
| 216 |
+
The team is primarily from the University of Washington, Stanford, AI2, UCSB, and Google.
|
| 217 |
+
|
| 218 |
+
# Acknowledgments
|
| 219 |
+
This code is based on Lucidrains' [flamingo implementation](https://github.com/lucidrains/flamingo-pytorch) and David Hansmair's [flamingo-mini repo](https://github.com/dhansmair/flamingo-mini). Thank you for making your code public! We also thank the [OpenCLIP](https://github.com/mlfoundations/open_clip) team as we use their data loading code and take inspiration from their library design.
|
| 220 |
+
|
| 221 |
+
We would also like to thank [Jean-Baptiste Alayrac](https://www.jbalayrac.com) and [Antoine Miech](https://antoine77340.github.io) for their advice, [Rohan Taori](https://www.rohantaori.com/), [Nicholas Schiefer](https://nicholasschiefer.com/), [Deep Ganguli](https://hai.stanford.edu/people/deep-ganguli), [Thomas Liao](https://thomasliao.com/), [Tatsunori Hashimoto](https://thashim.github.io/), and [Nicholas Carlini](https://nicholas.carlini.com/) for their help with assessing the safety risks of our release, and to [Stability AI](https://stability.ai) for providing us with compute resources to train these models.
|
| 222 |
+
|
| 223 |
+
# Citing
|
| 224 |
+
If you found this repository useful, please consider citing:
|
| 225 |
+
|
| 226 |
+
```
|
| 227 |
+
@software{anas_awadalla_2023_7733589,
|
| 228 |
+
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
|
| 229 |
+
title = {OpenFlamingo},
|
| 230 |
+
month = mar,
|
| 231 |
+
year = 2023,
|
| 232 |
+
publisher = {Zenodo},
|
| 233 |
+
version = {v0.1.1},
|
| 234 |
+
doi = {10.5281/zenodo.7733589},
|
| 235 |
+
url = {https://doi.org/10.5281/zenodo.7733589}
|
| 236 |
+
}
|
| 237 |
+
```
|
| 238 |
+
|
| 239 |
+
```
|
| 240 |
+
@article{Alayrac2022FlamingoAV,
|
| 241 |
+
title={Flamingo: a Visual Language Model for Few-Shot Learning},
|
| 242 |
+
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
|
| 243 |
+
journal={ArXiv},
|
| 244 |
+
year={2022},
|
| 245 |
+
volume={abs/2204.14198}
|
| 246 |
+
}
|
| 247 |
+
```
|
open_flamingo/TERMS_AND_CONDITIONS.md
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
**Please read the following information carefully before proceeding.**
|
| 2 |
+
|
| 3 |
+
OpenFlamingo is a **research prototype** that aims to enable users to interact with AI through both language and images. AI agents equipped with both language and visual understanding can be useful on a larger variety of tasks compared to models that communicate solely via language. By releasing an open-source research prototype, we hope to help the research community better understand the risks and limitations of modern visual-language AI models and accelerate the development of safer and more reliable methods.
|
| 4 |
+
|
| 5 |
+
- [ ] I understand that OpenFlamingo is a research prototype and I will only use it for non-commercial research purposes.
|
| 6 |
+
|
| 7 |
+
**Limitations.** OpenFlamingo is built on top of the LLaMA large language model developed by Meta AI. Large language models, including LLaMA, are trained on mostly unfiltered internet data, and have been shown to be able to produce toxic, unethical, inaccurate, and harmful content. On top of this, OpenFlamingo’s ability to support visual inputs creates additional risks, since it can be used in a wider variety of applications; image+text models may carry additional risks specific to multimodality. Please use discretion when assessing the accuracy or appropriateness of the model’s outputs, and be mindful before sharing its results.
|
| 8 |
+
|
| 9 |
+
- [ ] I understand that OpenFlamingo may produce unintended, inappropriate, offensive, and/or inaccurate results. I agree to take full responsibility for any use of the OpenFlamingo outputs that I generate.
|
| 10 |
+
|
| 11 |
+
**Privacy and data collection.** This demo does NOT store any personal information on its users, and it does NOT store user queries.
|
| 12 |
+
|
| 13 |
+
**Licensing.** As OpenFlamingo is built on top of the LLaMA large language model from Meta AI, the LLaMA license agreement (as documented in the Meta request form) also applies.
|
| 14 |
+
|
| 15 |
+
- [ ] I have read and agree to the terms of the LLaMA license agreement.
|
open_flamingo/_optim_utils.py
ADDED
|
@@ -0,0 +1,1741 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import functools
|
| 3 |
+
import warnings
|
| 4 |
+
from dataclasses import dataclass
|
| 5 |
+
from typing import (
|
| 6 |
+
Any,
|
| 7 |
+
cast,
|
| 8 |
+
Dict,
|
| 9 |
+
Iterable,
|
| 10 |
+
Iterator,
|
| 11 |
+
List,
|
| 12 |
+
NamedTuple,
|
| 13 |
+
Optional,
|
| 14 |
+
Sequence,
|
| 15 |
+
Set,
|
| 16 |
+
Tuple,
|
| 17 |
+
Union,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
import torch.distributed as dist
|
| 22 |
+
import torch.distributed.fsdp._traversal_utils as traversal_utils
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
from torch.distributed._shard.sharded_tensor import ShardedTensor
|
| 25 |
+
from torch.distributed.fsdp._common_utils import (
|
| 26 |
+
_apply_to_modules,
|
| 27 |
+
_FSDPState,
|
| 28 |
+
_get_module_fsdp_state_if_fully_sharded_module,
|
| 29 |
+
_get_param_to_fqns,
|
| 30 |
+
_module_handles,
|
| 31 |
+
clean_tensor_name,
|
| 32 |
+
)
|
| 33 |
+
from torch.distributed.fsdp._fsdp_extensions import _ext_chunk_tensor
|
| 34 |
+
from torch.distributed.fsdp._runtime_utils import _clear_grads_if_needed, _lazy_init
|
| 35 |
+
from torch.distributed.fsdp._shard_utils import _gather_state_dict
|
| 36 |
+
from torch.distributed.fsdp.api import ShardingStrategy
|
| 37 |
+
from torch.distributed.fsdp.flat_param import FlatParameter, FlatParamHandle
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
@dataclass
|
| 41 |
+
class FSDPParamInfo:
|
| 42 |
+
state: _FSDPState
|
| 43 |
+
flat_param: FlatParameter
|
| 44 |
+
param_indices: Dict[str, int]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def sorted_items(dictionary: Dict[str, Any]) -> Iterator[Tuple[str, Any]]:
|
| 48 |
+
keys = sorted(dictionary.keys())
|
| 49 |
+
for k in keys:
|
| 50 |
+
yield k, dictionary[k]
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class _ConsolidatedOptimState:
|
| 54 |
+
"""
|
| 55 |
+
This holds the consolidated optimizer state on the target rank. Positive-
|
| 56 |
+
dimension tensor state is communicated across ranks, while zero-dimension
|
| 57 |
+
tensor state and non-tensor state is taken directly from the target rank.
|
| 58 |
+
|
| 59 |
+
PyTorch version 1.12 moved to using zero-dimension tensors for scalar
|
| 60 |
+
values, but user implemented optimizers may still use float (i.e. a
|
| 61 |
+
non-tensor). Thus, we support both and handle them identically.
|
| 62 |
+
|
| 63 |
+
Attributes:
|
| 64 |
+
tensor_state (Dict[str, torch.Tensor]): Mapping from positive-dimension
|
| 65 |
+
tensor state name to the unsharded flattened tensor representing
|
| 66 |
+
the state.
|
| 67 |
+
zero_dim_tensor_state (Dict[str, torch.Tensor]): Mapping from zero-
|
| 68 |
+
dimension tensor state name to its value.
|
| 69 |
+
non_tensor_state (Dict[str, Any]): Mapping from non-tensor state
|
| 70 |
+
name to its value.
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
tensor_state: Dict[str, torch.Tensor] = {}
|
| 74 |
+
zero_dim_tensor_state: Dict[str, torch.Tensor] = {}
|
| 75 |
+
non_tensor_state: Dict[str, Any] = {}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class _PosDimTensorInfo(NamedTuple):
|
| 79 |
+
"""
|
| 80 |
+
Meatadata for positive-dimension tensors used internally for
|
| 81 |
+
:meth:`scatter_full_optim_state_dict`.
|
| 82 |
+
|
| 83 |
+
Attributes:
|
| 84 |
+
shape (torch.Size): Sharded tensor shape (which is equal to the
|
| 85 |
+
unsharded tensor shape if the tensor is optimizer state for a
|
| 86 |
+
non-FSDP parameter and is hence not sharded).
|
| 87 |
+
dtype (torch.dtype): Data type of the tensor.
|
| 88 |
+
"""
|
| 89 |
+
|
| 90 |
+
shape: torch.Size
|
| 91 |
+
dtype: torch.dtype
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
class _OptimStateKey(NamedTuple):
|
| 95 |
+
"""
|
| 96 |
+
This represents an optimizer state key that may be used commonly across
|
| 97 |
+
ranks. It is based on the unflattened parameter names rather than parameter
|
| 98 |
+
IDs to make it indepenendent of each rank's own optimizer construction.
|
| 99 |
+
"""
|
| 100 |
+
|
| 101 |
+
unflat_param_names: Tuple[str, ...]
|
| 102 |
+
is_fsdp_managed: bool
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def _unflatten_optim_state(
|
| 106 |
+
fsdp_param_info: FSDPParamInfo,
|
| 107 |
+
flat_param_state: Dict[str, Any],
|
| 108 |
+
to_save: bool,
|
| 109 |
+
shard_state: bool,
|
| 110 |
+
) -> List[Dict[str, Any]]:
|
| 111 |
+
"""
|
| 112 |
+
Unflattens the optimizer state, consisting of the "state" part and the
|
| 113 |
+
"param_groups" part. Unflattening the "state" part involves consolidating
|
| 114 |
+
the state on the target rank and remapping from flattened to unflattened
|
| 115 |
+
parameter IDs, and the "param_groups" part only involves remapping from
|
| 116 |
+
flattened to unflattened parameter IDs.
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
fsdp_param_info (FSDPParamInfo): The fsdp state and the target flatten
|
| 120 |
+
parameter.
|
| 121 |
+
flat_param_state (Dict[str, Any]): Entry for the flattened parameter
|
| 122 |
+
in the "state" part of the optimizer state dict.
|
| 123 |
+
to_save (bool): Whether to save the state on this rank.
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
List[Dict[str, Any]]: A :class:`list` holding the entries in the
|
| 127 |
+
"state" part of the optimizer state dict corresponding to the
|
| 128 |
+
unflattened parameters comprising the flattened parameter if on the
|
| 129 |
+
target rank or an empty :class:`list` otherwise. The final optimizer
|
| 130 |
+
state dict will need to map these entries using the proper unflattened
|
| 131 |
+
parameter IDs.
|
| 132 |
+
"""
|
| 133 |
+
assert (
|
| 134 |
+
not shard_state or to_save
|
| 135 |
+
), "If ``shard_state`` is True, ``to_save`` has to be True."
|
| 136 |
+
consolidated_state = _communicate_optim_state(
|
| 137 |
+
fsdp_param_info,
|
| 138 |
+
flat_param_state,
|
| 139 |
+
)
|
| 140 |
+
if to_save:
|
| 141 |
+
unflat_param_state = _unflatten_communicated_optim_state(
|
| 142 |
+
fsdp_param_info,
|
| 143 |
+
consolidated_state,
|
| 144 |
+
shard_state,
|
| 145 |
+
)
|
| 146 |
+
for optim_state in unflat_param_state:
|
| 147 |
+
for key in list(optim_state.keys()):
|
| 148 |
+
state = optim_state[key]
|
| 149 |
+
if isinstance(state, torch.Tensor):
|
| 150 |
+
optim_state[key] = state.cpu()
|
| 151 |
+
return unflat_param_state
|
| 152 |
+
else:
|
| 153 |
+
return []
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def _is_zero_dim_tensor(x: Any) -> bool:
|
| 157 |
+
return torch.is_tensor(x) and x.dim() == 0
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def _communicate_optim_state(
|
| 161 |
+
fsdp_param_info: FSDPParamInfo,
|
| 162 |
+
flat_param_state: Dict[str, Any],
|
| 163 |
+
) -> _ConsolidatedOptimState:
|
| 164 |
+
"""
|
| 165 |
+
Communicates the optimizer state for a flattened parameter across ranks.
|
| 166 |
+
All ranks will hold the entire non-sharded optimizer state on GPU.
|
| 167 |
+
|
| 168 |
+
If ``N`` is the number of tensor optimizer states in the optimizer state
|
| 169 |
+
dict, then the communication complexity is 0 if ``N = 0`` and ``N + 1``
|
| 170 |
+
otherwise (where the plus 1 comes from all-gathering the padding per rank).
|
| 171 |
+
|
| 172 |
+
Args:
|
| 173 |
+
fsdp_param_info (FSDPParamInfo): The fsdp state and the target flatten
|
| 174 |
+
parameter.
|
| 175 |
+
flat_param_state (Dict[str, Any]): The entry in the "state" part of the
|
| 176 |
+
optimizer state dict corresponding to the flattened parameter.
|
| 177 |
+
|
| 178 |
+
Returns:
|
| 179 |
+
ConsolidatedOptimState: Consolidated optimizer state for the target
|
| 180 |
+
flattened parameter.
|
| 181 |
+
"""
|
| 182 |
+
fsdp_state = fsdp_param_info.state
|
| 183 |
+
flat_param = fsdp_param_info.flat_param
|
| 184 |
+
state = _ConsolidatedOptimState()
|
| 185 |
+
tensor_state, zero_dim_tensor_state, non_tensor_state = (
|
| 186 |
+
state.tensor_state,
|
| 187 |
+
state.zero_dim_tensor_state,
|
| 188 |
+
state.non_tensor_state,
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
for state_name, value in sorted_items(flat_param_state):
|
| 192 |
+
# Positive-dimension tensor state: communicate across ranks
|
| 193 |
+
if torch.is_tensor(value) and value.dim() > 0:
|
| 194 |
+
# If the parameter is not sharded, then neither is the
|
| 195 |
+
# positive-dimension tensor state, so no need to communicate it --
|
| 196 |
+
# we take the target rank's value
|
| 197 |
+
if (
|
| 198 |
+
fsdp_state.world_size == 1
|
| 199 |
+
or fsdp_state.sharding_strategy == ShardingStrategy.NO_SHARD
|
| 200 |
+
):
|
| 201 |
+
tensor_state[state_name] = value
|
| 202 |
+
continue
|
| 203 |
+
if not value.is_cuda:
|
| 204 |
+
value = value.to(fsdp_state.compute_device)
|
| 205 |
+
# Assume that positive-dimension tensor optimizer state
|
| 206 |
+
# has the same shape as the sharded flattened parameter
|
| 207 |
+
buffer_size = flat_param._full_param_padded.size() # type: ignore[attr-defined]
|
| 208 |
+
tensor_buffer = value.new_zeros(*buffer_size)
|
| 209 |
+
dist.all_gather_into_tensor(
|
| 210 |
+
tensor_buffer, value, group=fsdp_state.process_group
|
| 211 |
+
)
|
| 212 |
+
torch.cuda.synchronize()
|
| 213 |
+
unpadded_numel = cast(
|
| 214 |
+
nn.Parameter, flat_param._unpadded_unsharded_size
|
| 215 |
+
).numel()
|
| 216 |
+
tensor_state[state_name] = tensor_buffer[:unpadded_numel]
|
| 217 |
+
# Zero-dimension tensor state and non-tensor state: take this rank's
|
| 218 |
+
# value directly
|
| 219 |
+
else:
|
| 220 |
+
if _is_zero_dim_tensor(value):
|
| 221 |
+
zero_dim_tensor_state[state_name] = value
|
| 222 |
+
else:
|
| 223 |
+
non_tensor_state[state_name] = value
|
| 224 |
+
return state
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def _unflatten_communicated_optim_state(
|
| 228 |
+
fsdp_param_info: FSDPParamInfo,
|
| 229 |
+
state: _ConsolidatedOptimState,
|
| 230 |
+
shard_state: bool,
|
| 231 |
+
) -> List[Dict[str, Any]]:
|
| 232 |
+
"""
|
| 233 |
+
Unflattens the communicated optimizer state (given by ``tensor_state``,
|
| 234 |
+
``non_tensor_state``, and ``zero_dim_tensor_state``) for a single flattened
|
| 235 |
+
parameter. This should only be called on the target rank.
|
| 236 |
+
|
| 237 |
+
Args:
|
| 238 |
+
fsdp_param_info (FSDPParamInfo): The fsdp state and the target flatten
|
| 239 |
+
parameter.
|
| 240 |
+
state (_ConsolidatedOptimState): Consolidated optimizer state.
|
| 241 |
+
|
| 242 |
+
Returns:
|
| 243 |
+
List[Dict[str, Any]]: A :class:`list` holding the entries in the
|
| 244 |
+
"state" part of the optimizer state dict corresponding to the
|
| 245 |
+
unflattened parameters comprising the flattened parameter. The final
|
| 246 |
+
optimizer state dict will need to map these entries using the proper
|
| 247 |
+
unflattened parameter IDs.
|
| 248 |
+
"""
|
| 249 |
+
fsdp_state = fsdp_param_info.state
|
| 250 |
+
flat_param = fsdp_param_info.flat_param
|
| 251 |
+
unflat_param_state: List[Dict[str, Any]] = []
|
| 252 |
+
flat_param_views: Dict[str, Iterator] = {}
|
| 253 |
+
num_unflat_params = flat_param._num_params
|
| 254 |
+
tensor_state, zero_dim_tensor_state, non_tensor_state = (
|
| 255 |
+
state.tensor_state,
|
| 256 |
+
state.zero_dim_tensor_state,
|
| 257 |
+
state.non_tensor_state,
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
for _ in range(num_unflat_params):
|
| 261 |
+
unflat_state_param = {}
|
| 262 |
+
# Add positive-dimension tensor state: unflatten with views
|
| 263 |
+
for state_name, flat_tensor in sorted_items(tensor_state):
|
| 264 |
+
views_generated = state_name in flat_param_views
|
| 265 |
+
if not views_generated:
|
| 266 |
+
views = FlatParamHandle._get_unflat_views(flat_param, flat_tensor)
|
| 267 |
+
flat_param_views[state_name] = views
|
| 268 |
+
else:
|
| 269 |
+
views = flat_param_views[state_name]
|
| 270 |
+
optim_state: Union[torch.Tensor, ShardedTensor] = next(views)
|
| 271 |
+
if shard_state:
|
| 272 |
+
assert fsdp_state.process_group is not None
|
| 273 |
+
optim_state = _ext_chunk_tensor(
|
| 274 |
+
optim_state,
|
| 275 |
+
fsdp_state.rank,
|
| 276 |
+
fsdp_state.world_size,
|
| 277 |
+
torch.cuda.device_count(),
|
| 278 |
+
fsdp_state.process_group,
|
| 279 |
+
)
|
| 280 |
+
unflat_state_param[state_name] = optim_state
|
| 281 |
+
|
| 282 |
+
# Add zero-dimension tensor state: take the target rank's value
|
| 283 |
+
for state_name, zero_dim_tensor in sorted_items(zero_dim_tensor_state):
|
| 284 |
+
unflat_state_param[state_name] = zero_dim_tensor
|
| 285 |
+
# Add non-tensor state: take the target rank's value
|
| 286 |
+
for state_name, non_tensor in sorted_items(non_tensor_state):
|
| 287 |
+
unflat_state_param[state_name] = non_tensor
|
| 288 |
+
unflat_param_state.append(unflat_state_param)
|
| 289 |
+
return unflat_param_state
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
def _flatten_optim_state_dict(
|
| 293 |
+
optim_state_dict: Dict[str, Any],
|
| 294 |
+
model: nn.Module,
|
| 295 |
+
shard_state: bool,
|
| 296 |
+
use_orig_params: bool = False,
|
| 297 |
+
optim: Optional[torch.optim.Optimizer] = None,
|
| 298 |
+
) -> Dict[str, Any]:
|
| 299 |
+
"""
|
| 300 |
+
Flattens the full optimizer state dict, still keying by unflattened
|
| 301 |
+
parameter names. If ``shard_state=True``, then FSDP-managed
|
| 302 |
+
``FlatParameter`` 's optimizer states are sharded, and otherwise, they are
|
| 303 |
+
kept unsharded.
|
| 304 |
+
|
| 305 |
+
If ``use_orig_params`` is True, each rank will have all FSDP-managed
|
| 306 |
+
parameters but some of these parameters may be empty due to the sharding.
|
| 307 |
+
For a regular optim.Optimizer, states for those empty parameters will
|
| 308 |
+
not be initialized. So, when aggregating the FQNs across ranks, no assert
|
| 309 |
+
will be raised on a rank even if it does not have all the states -- it is
|
| 310 |
+
valid and FSDP know how to aggregate them. However, FSDP has to ignore
|
| 311 |
+
handling those parameters that are not managed by FSDP and do not exist on
|
| 312 |
+
the local rank -- it is managed by other parallelism and FSDP does not
|
| 313 |
+
know ho to handle/aggregate them.
|
| 314 |
+
|
| 315 |
+
Note that ``_flatten_tensor_optim_state`` does not need ``optim`` to
|
| 316 |
+
flatten/shard the state. However, NamedOptimizer and KeyedOptimizer require
|
| 317 |
+
all the states even if the corresponding parameters are empty. To this end,
|
| 318 |
+
``optim`` will be used to to get the initial state of the empty parameters.
|
| 319 |
+
``optim`` should only be non-None if the ``optim` is KeyedOptimizer or
|
| 320 |
+
NamedOptimizer.
|
| 321 |
+
|
| 322 |
+
Returns:
|
| 323 |
+
Dict[str, Any]: The flattened optimizer state dict.
|
| 324 |
+
"""
|
| 325 |
+
unflat_osd = optim_state_dict
|
| 326 |
+
if "state" not in unflat_osd or "param_groups" not in unflat_osd:
|
| 327 |
+
raise ValueError(
|
| 328 |
+
'`optim_state_dict` must have the keys "state" and '
|
| 329 |
+
'"param_groups" to be a valid optimizer state dict'
|
| 330 |
+
)
|
| 331 |
+
param_to_fqns = _get_param_to_fqns(model)
|
| 332 |
+
fqn_to_fsdp_param_info = _get_fqn_to_fsdp_param_info(model)
|
| 333 |
+
|
| 334 |
+
# Construct the "state" part
|
| 335 |
+
flat_osd_state: Dict[Union[_OptimStateKey, str], Any] = {}
|
| 336 |
+
unflat_osd_state = unflat_osd["state"]
|
| 337 |
+
all_state_keys = set(unflat_osd_state.keys())
|
| 338 |
+
|
| 339 |
+
# local_state_dict is used to construct states of empty parameters.
|
| 340 |
+
# This should only be used if is_named_optimizer=True.
|
| 341 |
+
local_state_dict: Dict[str, Any] = {}
|
| 342 |
+
local_state_clean_fqns: Dict[str, str] = {}
|
| 343 |
+
if optim is not None:
|
| 344 |
+
local_state_dict = optim.state_dict()["state"]
|
| 345 |
+
for fqn in local_state_dict.keys():
|
| 346 |
+
clean_fqn = clean_tensor_name(fqn)
|
| 347 |
+
local_state_clean_fqns[clean_fqn] = fqn
|
| 348 |
+
|
| 349 |
+
for param, unflat_param_names in param_to_fqns.items():
|
| 350 |
+
fqn = unflat_param_names[0]
|
| 351 |
+
if fqn not in unflat_osd_state:
|
| 352 |
+
continue
|
| 353 |
+
all_state_keys.difference_update(unflat_param_names)
|
| 354 |
+
if fqn in fqn_to_fsdp_param_info:
|
| 355 |
+
fsdp_param_info = fqn_to_fsdp_param_info[fqn]
|
| 356 |
+
if use_orig_params:
|
| 357 |
+
assert (
|
| 358 |
+
shard_state
|
| 359 |
+
), "If use_orig_params is True, shard_state must be True."
|
| 360 |
+
flat_state = _shard_orig_param_state(
|
| 361 |
+
fsdp_param_info,
|
| 362 |
+
fqn,
|
| 363 |
+
unflat_osd_state[fqn],
|
| 364 |
+
)
|
| 365 |
+
else:
|
| 366 |
+
flat_state = _flatten_optim_state(
|
| 367 |
+
fsdp_param_info,
|
| 368 |
+
unflat_osd_state,
|
| 369 |
+
unflat_param_names,
|
| 370 |
+
shard_state,
|
| 371 |
+
)
|
| 372 |
+
key = _OptimStateKey(tuple(unflat_param_names), True)
|
| 373 |
+
# Only include non-empty states since as expected by
|
| 374 |
+
# `torch.optim.Optimizer` s unless the optimizer is KeyedOptimizer
|
| 375 |
+
# or NamedOptimizer.
|
| 376 |
+
if flat_state:
|
| 377 |
+
flat_osd_state[key] = flat_state
|
| 378 |
+
elif optim is not None: # NamedOptimizer or KeyedOptimizer case.
|
| 379 |
+
assert len(unflat_param_names) == 1
|
| 380 |
+
local_wrapped_fqn = local_state_clean_fqns.get(fqn, "")
|
| 381 |
+
if local_wrapped_fqn:
|
| 382 |
+
flat_osd_state[key] = copy.deepcopy(
|
| 383 |
+
local_state_dict[local_wrapped_fqn]
|
| 384 |
+
)
|
| 385 |
+
else: # do not flatten non-FSDP parameters' states
|
| 386 |
+
assert len(unflat_param_names) == 1
|
| 387 |
+
key = _OptimStateKey(tuple(unflat_param_names), False)
|
| 388 |
+
flat_osd_state[key] = copy.copy(unflat_osd_state[fqn])
|
| 389 |
+
|
| 390 |
+
# Handle user-defined state, states that are not accosiated with parameters.
|
| 391 |
+
for key in all_state_keys:
|
| 392 |
+
flat_osd_state[key] = copy.copy(unflat_osd_state[key])
|
| 393 |
+
|
| 394 |
+
# Construct the "param_groups" part -- copy as is since it will be
|
| 395 |
+
# rekeyed later according to the target rank's optimizer
|
| 396 |
+
flat_osd_param_groups = copy.deepcopy(unflat_osd["param_groups"])
|
| 397 |
+
return {"state": flat_osd_state, "param_groups": flat_osd_param_groups}
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def _flatten_optim_state(
|
| 401 |
+
fsdp_param_info: FSDPParamInfo,
|
| 402 |
+
unflat_osd_state: Dict[str, Dict[str, Any]],
|
| 403 |
+
unflat_param_names: List[str],
|
| 404 |
+
shard_state: bool,
|
| 405 |
+
) -> Dict[str, Any]:
|
| 406 |
+
"""
|
| 407 |
+
Flattens the optimizer state in ``full_optim_state_dict`` for a single
|
| 408 |
+
flattened parameter in ``fsdp_param_info`` corresponding to the unflattened
|
| 409 |
+
parameter names in ``unflat_param_names``.
|
| 410 |
+
|
| 411 |
+
Args:
|
| 412 |
+
unflat_osd_state (Dict[str, Dict[str, Any]]): The "state" part of the
|
| 413 |
+
optimizer state dict corresponding to the unflattened parameters.
|
| 414 |
+
unflat_param_names (List[str]): A :class:`list` of unflattened
|
| 415 |
+
parameter names corresponding to the flattened parameter
|
| 416 |
+
``flat_param``.
|
| 417 |
+
fsdp_param_info (FSDPParamInfo): The fsdp state and the target flatten
|
| 418 |
+
parameter.
|
| 419 |
+
shard_state (bool): Whether to shard flattened positive-dimension
|
| 420 |
+
tensor state; if ``False``, then the full flattened tensor is
|
| 421 |
+
kept in the returned :class:`dict.
|
| 422 |
+
|
| 423 |
+
Returns:
|
| 424 |
+
Dict[str, Any]: A :class:`dict` mapping state names to their values for
|
| 425 |
+
a particular flattened parameter. The sharded optimizer state dict's
|
| 426 |
+
"state" part will map a key to this returned value.
|
| 427 |
+
"""
|
| 428 |
+
fsdp_state = fsdp_param_info.state
|
| 429 |
+
flat_param = fsdp_param_info.flat_param
|
| 430 |
+
num_unflat_params = len(unflat_param_names)
|
| 431 |
+
assert num_unflat_params > 0, (
|
| 432 |
+
"Expects at least one unflattened parameter corresponding to the "
|
| 433 |
+
"flattened parameter"
|
| 434 |
+
)
|
| 435 |
+
unflat_param_shapes = flat_param._shapes
|
| 436 |
+
num_unflat_param_shapes = len(unflat_param_shapes)
|
| 437 |
+
assert (
|
| 438 |
+
num_unflat_params == num_unflat_param_shapes
|
| 439 |
+
), f"Expects {num_unflat_params} shapes but got {num_unflat_param_shapes}"
|
| 440 |
+
|
| 441 |
+
# Check if these unflattened parameters have any optimizer state
|
| 442 |
+
has_state = [
|
| 443 |
+
bool(unflat_param_name in unflat_osd_state)
|
| 444 |
+
for unflat_param_name in unflat_param_names
|
| 445 |
+
]
|
| 446 |
+
# If none of the unflattened parameters comprising this flattened parameter
|
| 447 |
+
# have any state, then we do not want an entry in the optimizer state dict
|
| 448 |
+
if not any(has_state):
|
| 449 |
+
return {} # no need to flatten any state
|
| 450 |
+
# There may still be some unflattened parameters with state and some
|
| 451 |
+
# without
|
| 452 |
+
unflat_param_states = [
|
| 453 |
+
_gather_state_dict(
|
| 454 |
+
unflat_osd_state[unflat_param_name], pg=fsdp_state.process_group
|
| 455 |
+
)
|
| 456 |
+
if unflat_param_name in unflat_osd_state
|
| 457 |
+
else None
|
| 458 |
+
for unflat_param_name in unflat_param_names
|
| 459 |
+
]
|
| 460 |
+
# Check that the unflattened parameters have the same state names
|
| 461 |
+
state_names = None
|
| 462 |
+
for unflat_param_state in unflat_param_states:
|
| 463 |
+
if unflat_param_state is None:
|
| 464 |
+
continue
|
| 465 |
+
if state_names is None:
|
| 466 |
+
state_names = set(unflat_param_state.keys())
|
| 467 |
+
else:
|
| 468 |
+
if state_names != set(unflat_param_state.keys()):
|
| 469 |
+
raise ValueError(
|
| 470 |
+
"Differing optimizer state names for the unflattened "
|
| 471 |
+
f"parameters: {unflat_param_names}"
|
| 472 |
+
)
|
| 473 |
+
assert state_names is not None
|
| 474 |
+
|
| 475 |
+
# Flatten the state
|
| 476 |
+
flat_state: Dict[str, Any] = {}
|
| 477 |
+
for state_name in state_names:
|
| 478 |
+
state_values = [
|
| 479 |
+
unflat_param_state[state_name] if unflat_param_state is not None else None
|
| 480 |
+
for unflat_param_state in unflat_param_states
|
| 481 |
+
]
|
| 482 |
+
non_none_state_values = [v for v in state_values if v is not None]
|
| 483 |
+
are_pos_dim_tensors = are_zero_dim_tensors = are_non_tensors = True
|
| 484 |
+
for v in non_none_state_values:
|
| 485 |
+
are_pos_dim_tensors &= torch.is_tensor(v) and v.dim() > 0
|
| 486 |
+
are_zero_dim_tensors &= _is_zero_dim_tensor(v)
|
| 487 |
+
are_non_tensors &= not torch.is_tensor(v)
|
| 488 |
+
types = {type(v) for v in non_none_state_values}
|
| 489 |
+
if len(types) != 1 or not (
|
| 490 |
+
are_pos_dim_tensors or are_zero_dim_tensors or are_non_tensors
|
| 491 |
+
):
|
| 492 |
+
raise ValueError(
|
| 493 |
+
f"Differing optimizer state types for state {state_name}, "
|
| 494 |
+
f"values {non_none_state_values}, and unflattened parameter "
|
| 495 |
+
f"names {unflat_param_names}"
|
| 496 |
+
)
|
| 497 |
+
if are_pos_dim_tensors:
|
| 498 |
+
flat_tensor = _flatten_tensor_optim_state(
|
| 499 |
+
state_name,
|
| 500 |
+
state_values,
|
| 501 |
+
unflat_param_names,
|
| 502 |
+
unflat_param_shapes,
|
| 503 |
+
flat_param,
|
| 504 |
+
)
|
| 505 |
+
if shard_state:
|
| 506 |
+
# Shard the flattened tensor immediately to minimize max memory
|
| 507 |
+
# usage
|
| 508 |
+
sharded_flat_tensor, _ = FlatParamHandle._get_shard(
|
| 509 |
+
flat_tensor,
|
| 510 |
+
fsdp_state.rank,
|
| 511 |
+
fsdp_state.world_size,
|
| 512 |
+
)
|
| 513 |
+
flat_state[state_name] = sharded_flat_tensor
|
| 514 |
+
else:
|
| 515 |
+
flat_state[state_name] = flat_tensor
|
| 516 |
+
elif are_zero_dim_tensors:
|
| 517 |
+
flat_state[state_name] = _flatten_zero_dim_tensor_optim_state(
|
| 518 |
+
state_name,
|
| 519 |
+
state_values,
|
| 520 |
+
unflat_param_names,
|
| 521 |
+
)
|
| 522 |
+
else:
|
| 523 |
+
assert are_non_tensors
|
| 524 |
+
flat_state[state_name] = _flatten_non_tensor_optim_state(
|
| 525 |
+
state_name,
|
| 526 |
+
state_values,
|
| 527 |
+
unflat_param_names,
|
| 528 |
+
)
|
| 529 |
+
|
| 530 |
+
return flat_state
|
| 531 |
+
|
| 532 |
+
|
| 533 |
+
def _flatten_tensor_optim_state(
|
| 534 |
+
state_name: str,
|
| 535 |
+
pos_dim_tensors: List[torch.Tensor],
|
| 536 |
+
unflat_param_names: List[str],
|
| 537 |
+
unflat_param_shapes: Sequence[torch.Size],
|
| 538 |
+
flat_param: FlatParameter,
|
| 539 |
+
) -> torch.Tensor:
|
| 540 |
+
"""
|
| 541 |
+
Flattens the positive-dimension tensor optimizer state given by the values
|
| 542 |
+
``tensors`` for the state ``state_name`` for a single flattened parameter
|
| 543 |
+
``flat_param`` corresponding to the unflattened parameter names
|
| 544 |
+
``unflat_param_names`` and unflatted parameter shapes
|
| 545 |
+
``unflat_param_shapes``. This flattens each unflattened parameter's tensor
|
| 546 |
+
state into one tensor.
|
| 547 |
+
|
| 548 |
+
NOTE: We use zero tensors for any unflattened parameters without state
|
| 549 |
+
since some value is required to fill those entries. This assumes that the
|
| 550 |
+
zero tensor is mathematically equivalent to having no state, which is true
|
| 551 |
+
for Adam's "exp_avg" and "exp_avg_sq" but may not be true for all
|
| 552 |
+
optimizers.
|
| 553 |
+
|
| 554 |
+
Args:
|
| 555 |
+
state_name (str): Optimizer state name.
|
| 556 |
+
pos_dim_tensors (List[torch.Tensor]): Positive-dimension tensor
|
| 557 |
+
optimizer state values for the unflattened parameters corresponding
|
| 558 |
+
to the single flattened parameter.
|
| 559 |
+
unflat_param_names (List[str]): A :class:`list` of unflattened
|
| 560 |
+
parameter names corresponding to the single flattened parameter.
|
| 561 |
+
unflat_param_shapes (List[torch.Size]): Unflattened parameter shapes
|
| 562 |
+
corresponding to the single flattened parameter.
|
| 563 |
+
flat_param (FlatParameter): The flattened parameter.
|
| 564 |
+
|
| 565 |
+
Returns:
|
| 566 |
+
torch.Tensor: A flattened tensor containing the optimizer state
|
| 567 |
+
corresponding to ``state_name`` constructed by concatenating the
|
| 568 |
+
unflattened parameter tensor states in ``pos_dim_tensors`` (using zero
|
| 569 |
+
tensors for any unflattened parameters without the state).
|
| 570 |
+
"""
|
| 571 |
+
non_none_tensors = [t for t in pos_dim_tensors if t is not None]
|
| 572 |
+
# Check that all are tensors with the same dtype
|
| 573 |
+
dtypes = {t.dtype for t in non_none_tensors}
|
| 574 |
+
if len(dtypes) != 1:
|
| 575 |
+
raise ValueError(
|
| 576 |
+
"All unflattened parameters comprising a single flattened "
|
| 577 |
+
"parameter must have positive-dimension tensor state with the "
|
| 578 |
+
f"same dtype but got dtypes {dtypes} for state {state_name} and "
|
| 579 |
+
f"unflattened parameter names {unflat_param_names}"
|
| 580 |
+
)
|
| 581 |
+
dtype = next(iter(dtypes))
|
| 582 |
+
# Check that each tensor state matches its parameter's shape
|
| 583 |
+
for tensor, shape in zip(pos_dim_tensors, unflat_param_shapes):
|
| 584 |
+
if tensor is None and len(shape) == 0:
|
| 585 |
+
raise ValueError("Flattening a zero-dimension parameter is not supported")
|
| 586 |
+
elif tensor is not None and tensor.shape != shape:
|
| 587 |
+
raise ValueError(
|
| 588 |
+
"Tensor optimizer state does not have same shape as its "
|
| 589 |
+
f"parameter: {tensor.shape} {shape}"
|
| 590 |
+
)
|
| 591 |
+
# Flatten the tensor states: we do not need to add any padding since the
|
| 592 |
+
# flattened optimizer state tensor sharded via `_get_shard()`, which pads
|
| 593 |
+
# the shard as needed (just like for the flattened parameter)
|
| 594 |
+
cpu_device = torch.device("cpu")
|
| 595 |
+
tensors = [
|
| 596 |
+
torch.flatten(state_value.to(cpu_device))
|
| 597 |
+
if state_value is not None
|
| 598 |
+
else torch.flatten(
|
| 599 |
+
torch.zeros(
|
| 600 |
+
size=shape,
|
| 601 |
+
dtype=dtype,
|
| 602 |
+
device=cpu_device,
|
| 603 |
+
)
|
| 604 |
+
)
|
| 605 |
+
for state_value, shape in zip(pos_dim_tensors, unflat_param_shapes)
|
| 606 |
+
]
|
| 607 |
+
flat_tensor = torch.cat(tensors)
|
| 608 |
+
flat_param_shape = flat_param._unpadded_unsharded_size # type: ignore[attr-defined]
|
| 609 |
+
assert flat_tensor.shape == flat_param_shape, (
|
| 610 |
+
f"tensor optim state: {flat_tensor.shape} "
|
| 611 |
+
f"flattened parameter: {flat_param_shape}"
|
| 612 |
+
)
|
| 613 |
+
return flat_tensor
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
def _flatten_zero_dim_tensor_optim_state(
|
| 617 |
+
state_name: str,
|
| 618 |
+
zero_dim_tensors: List[torch.Tensor],
|
| 619 |
+
unflat_param_names: List[str],
|
| 620 |
+
) -> torch.Tensor:
|
| 621 |
+
"""
|
| 622 |
+
Flattens the zero-dimension tensor optimizer state given by the values
|
| 623 |
+
``zero_dim_tensors`` for the state ``state_name`` for a single flattened
|
| 624 |
+
parameter corresponding to the unflattened parameter names
|
| 625 |
+
``unflat_param_names`` by enforcing that all tensors are the same and using
|
| 626 |
+
that common value.
|
| 627 |
+
|
| 628 |
+
NOTE: The requirement that the tensors are the same across all unflattened
|
| 629 |
+
parameters comprising the flattened parameter is needed to maintain the
|
| 630 |
+
invariant that FSDP performs the same computation as its non-sharded
|
| 631 |
+
equivalent. This means that none of the unflattened parameters can be
|
| 632 |
+
missing this state since imposing a value may differ from having no value.
|
| 633 |
+
For example, for Adam's "step", no value means maximum bias correction,
|
| 634 |
+
while having some positive value means less bias correction.
|
| 635 |
+
|
| 636 |
+
Args:
|
| 637 |
+
state_name (str): Optimizer state name.
|
| 638 |
+
zero_dim_tensors (List[torch.Tensor]): Zero-dimension optimizer state
|
| 639 |
+
for the unflattened parameters corresponding to the single
|
| 640 |
+
flattened parameter.
|
| 641 |
+
unflat_param_names (List[str]): A :class:`list` of unflattened
|
| 642 |
+
parameter names corresponding to the single flattened parameter.
|
| 643 |
+
|
| 644 |
+
Returns:
|
| 645 |
+
torch.Tensor: A zero-dimensional tensor giving the value of the state
|
| 646 |
+
``state_name`` for all unflattened parameters corresponding to the
|
| 647 |
+
names ``unflat_param_names``.
|
| 648 |
+
"""
|
| 649 |
+
non_none_tensors = [t for t in zero_dim_tensors if t is not None]
|
| 650 |
+
# Enforce that all have the same value and dtype
|
| 651 |
+
values_set = {t.item() if t is not None else None for t in zero_dim_tensors}
|
| 652 |
+
dtypes = {t.dtype if t is not None else None for t in zero_dim_tensors}
|
| 653 |
+
if (
|
| 654 |
+
len(non_none_tensors) != len(zero_dim_tensors)
|
| 655 |
+
or len(values_set) != 1
|
| 656 |
+
or len(dtypes) != 1
|
| 657 |
+
):
|
| 658 |
+
raise ValueError(
|
| 659 |
+
"All unflattened parameters comprising a single flattened "
|
| 660 |
+
"parameter must have scalar state with the same value and dtype "
|
| 661 |
+
f"but got values {values_set} and dtypes {dtypes} for state "
|
| 662 |
+
f"{state_name} and unflattened parameter names "
|
| 663 |
+
f"{unflat_param_names}"
|
| 664 |
+
)
|
| 665 |
+
value = next(iter(values_set))
|
| 666 |
+
dtype = next(iter(dtypes))
|
| 667 |
+
return torch.tensor(value, dtype=dtype, device=torch.device("cpu"))
|
| 668 |
+
|
| 669 |
+
|
| 670 |
+
def _flatten_non_tensor_optim_state(
|
| 671 |
+
state_name: str,
|
| 672 |
+
non_tensors: List[Any],
|
| 673 |
+
unflat_param_names: List[str],
|
| 674 |
+
) -> Any:
|
| 675 |
+
"""
|
| 676 |
+
Flattens the non-tensor optimizer state given by the values ``non_tensors``
|
| 677 |
+
for the state ``state_name`` for a single flattened parameter corresponding
|
| 678 |
+
to the unflattened parameter names ``unflat_param_names`` by enforcing that
|
| 679 |
+
all values are the same and using that common value.
|
| 680 |
+
|
| 681 |
+
See the note in :func:`_flatten_zero_dim_tensor_optim_state`.
|
| 682 |
+
|
| 683 |
+
Args:
|
| 684 |
+
state_name (str): Optimizer state name.
|
| 685 |
+
non_tensors (List[Any]): Non-tensor optimizer state for the unflattened
|
| 686 |
+
parameters corresponding to the single flattened parameter.
|
| 687 |
+
unflat_param_names (List[str]): A :class:`list` of unflattened
|
| 688 |
+
parameter names corresponding to the single flattened parameter.
|
| 689 |
+
|
| 690 |
+
Returns:
|
| 691 |
+
Any: A non-tensor giving the value of the state ``state_name`` for all
|
| 692 |
+
unflattened parameters corresponding to the names
|
| 693 |
+
``unflat_param_names``.
|
| 694 |
+
"""
|
| 695 |
+
non_none_non_tensors = [nt for nt in non_tensors if nt is not None]
|
| 696 |
+
# Enforce that all have the same value (same type already checked)
|
| 697 |
+
non_tensor_set = set(non_tensors)
|
| 698 |
+
if len(non_none_non_tensors) != len(non_tensors) or len(non_tensor_set) != 1:
|
| 699 |
+
raise ValueError(
|
| 700 |
+
"All unflattened parameters comprising a single flattened "
|
| 701 |
+
"parameter must have scalar state with the same value and dtype "
|
| 702 |
+
f"but got values {non_tensor_set} for state {state_name} and "
|
| 703 |
+
f"unflattened parameter names {unflat_param_names}"
|
| 704 |
+
)
|
| 705 |
+
non_tensor = next(iter(non_tensor_set))
|
| 706 |
+
return non_tensor
|
| 707 |
+
|
| 708 |
+
|
| 709 |
+
def _process_pos_dim_tensor_state(
|
| 710 |
+
flat_optim_state_dict: Dict[str, Any],
|
| 711 |
+
world_size: int,
|
| 712 |
+
) -> Dict[str, Any]:
|
| 713 |
+
"""
|
| 714 |
+
Processes positive-dimension tensor states in ``flat_optim_state_dict`` by
|
| 715 |
+
replacing them with metadata. This is done so the processed optimizer state
|
| 716 |
+
dict can be broadcast from rank 0 to all ranks without copying those tensor
|
| 717 |
+
states, and thus, this is meant to only be called on rank 0.
|
| 718 |
+
|
| 719 |
+
Args:
|
| 720 |
+
flat_optim_state_dict (Dict[str, Any]): Flattened optimizer state dict
|
| 721 |
+
with the positive-dimension tensor states unsharded.
|
| 722 |
+
|
| 723 |
+
Returns:
|
| 724 |
+
Dict[str, Any]: The flattened optimizer state dict with positive-
|
| 725 |
+
dimension tensor states replaced by metadata.
|
| 726 |
+
"""
|
| 727 |
+
flat_osd = flat_optim_state_dict # alias
|
| 728 |
+
no_tensor_osd: Dict[str, Any] = {"state": {}}
|
| 729 |
+
for key, param_state in flat_osd["state"].items():
|
| 730 |
+
no_tensor_osd["state"][key] = {}
|
| 731 |
+
for state_name, value in sorted_items(param_state):
|
| 732 |
+
is_pos_dim_tensor_state = torch.is_tensor(value) and value.dim() > 0
|
| 733 |
+
if not is_pos_dim_tensor_state:
|
| 734 |
+
no_tensor_osd["state"][key][state_name] = value
|
| 735 |
+
continue
|
| 736 |
+
if key.is_fsdp_managed: # FSDP parameter
|
| 737 |
+
sharded_size = FlatParamHandle._get_sharded_size(
|
| 738 |
+
value, rank=0, world_size=world_size
|
| 739 |
+
)
|
| 740 |
+
assert len(sharded_size) == 1, f"{sharded_size}"
|
| 741 |
+
info = _PosDimTensorInfo(sharded_size, value.dtype)
|
| 742 |
+
else: # non-FSDP parameter
|
| 743 |
+
info = _PosDimTensorInfo(value.shape, value.dtype)
|
| 744 |
+
no_tensor_osd["state"][key][state_name] = info
|
| 745 |
+
no_tensor_osd["param_groups"] = flat_osd["param_groups"]
|
| 746 |
+
return no_tensor_osd
|
| 747 |
+
|
| 748 |
+
|
| 749 |
+
def _broadcast_processed_optim_state_dict(
|
| 750 |
+
processed_optim_state_dict: Optional[Dict[str, Any]],
|
| 751 |
+
rank: int,
|
| 752 |
+
group,
|
| 753 |
+
) -> Dict[str, Any]:
|
| 754 |
+
"""
|
| 755 |
+
Broadcasts the processed optimizer state dict from rank 0 to all ranks.
|
| 756 |
+
|
| 757 |
+
Args:
|
| 758 |
+
processed_optim_state_dict (Optional[Dict[str, Any]]): The flattened
|
| 759 |
+
optimizer state dict with positive-dimension tensor states replaced
|
| 760 |
+
with metadata if on rank 0; ignored otherwise.
|
| 761 |
+
|
| 762 |
+
Returns:
|
| 763 |
+
Dict[str, Any]: The processed optimizer state dict.
|
| 764 |
+
"""
|
| 765 |
+
# Broadcast the two data structures rank 0 to all ranks
|
| 766 |
+
obj_list = [processed_optim_state_dict] if rank == 0 else [None]
|
| 767 |
+
dist.broadcast_object_list(obj_list, src=0, group=group)
|
| 768 |
+
processed_optim_state_dict = obj_list[0] # type: ignore[assignment]
|
| 769 |
+
assert processed_optim_state_dict is not None
|
| 770 |
+
# Keep zero-dimension tensors on CPU
|
| 771 |
+
return processed_optim_state_dict
|
| 772 |
+
|
| 773 |
+
|
| 774 |
+
def _broadcast_pos_dim_tensor_states(
|
| 775 |
+
processed_optim_state_dict: Dict[str, Any],
|
| 776 |
+
flat_optim_state_dict: Optional[Dict[str, Any]],
|
| 777 |
+
rank: int,
|
| 778 |
+
world_size: int,
|
| 779 |
+
group,
|
| 780 |
+
broadcast_device: torch.device,
|
| 781 |
+
) -> Dict[str, Any]:
|
| 782 |
+
"""
|
| 783 |
+
Takes ``processed_optim_state_dict``, which has metadata in place of
|
| 784 |
+
positive-dimension tensor states, and broadcasts those tensor states from
|
| 785 |
+
rank 0 to all ranks. For tensor states corresponding to FSDP parameters,
|
| 786 |
+
rank 0 shards the tensor and broadcasts shard-by-shard, and for tensor
|
| 787 |
+
states corresponding to non-FSDP parameters, rank 0 broadcasts the full
|
| 788 |
+
tensor.
|
| 789 |
+
|
| 790 |
+
Args:
|
| 791 |
+
processed_optim_state_dict (Dict[str, Any]): The flattened optimizer
|
| 792 |
+
state dict with positive-dimension tensor states replaced with
|
| 793 |
+
metadata; this should be returned by
|
| 794 |
+
:meth:`_process_pos_dim_tensor_state` and non-empty on all ranks.
|
| 795 |
+
flat_optim_state_dict (Optional[Dict[str, Any]]): The flattened
|
| 796 |
+
unsharded optimizer state dict with the actual positive-dimension
|
| 797 |
+
tensor states if on rank 0; ignored on nonzero ranks.
|
| 798 |
+
|
| 799 |
+
Returns:
|
| 800 |
+
Dict[str, Any]: The optimizer state dict with the positive-dimension
|
| 801 |
+
tensor state correctly populated via ``broadcast()`` s from rank 0.
|
| 802 |
+
"""
|
| 803 |
+
assert (
|
| 804 |
+
rank != 0 or flat_optim_state_dict is not None
|
| 805 |
+
), "Expects rank 0 to pass in the flattened optimizer state dict"
|
| 806 |
+
no_tensor_osd = processed_optim_state_dict # alias
|
| 807 |
+
flat_osd = flat_optim_state_dict # alias
|
| 808 |
+
for key, param_state in no_tensor_osd["state"].items():
|
| 809 |
+
for state_name, value in sorted_items(param_state):
|
| 810 |
+
is_pos_dim_tensor_state = isinstance(value, _PosDimTensorInfo)
|
| 811 |
+
if not is_pos_dim_tensor_state:
|
| 812 |
+
continue
|
| 813 |
+
if rank == 0:
|
| 814 |
+
assert flat_osd is not None
|
| 815 |
+
unsharded_tensor = flat_osd["state"][key][state_name]
|
| 816 |
+
else:
|
| 817 |
+
unsharded_tensor = None
|
| 818 |
+
shape, dtype = value.shape, value.dtype
|
| 819 |
+
if key.is_fsdp_managed: # FSDP parameter
|
| 820 |
+
_broadcast_sharded_pos_dim_tensor_state(
|
| 821 |
+
unsharded_tensor,
|
| 822 |
+
param_state,
|
| 823 |
+
state_name,
|
| 824 |
+
shape,
|
| 825 |
+
dtype,
|
| 826 |
+
broadcast_device,
|
| 827 |
+
rank,
|
| 828 |
+
world_size,
|
| 829 |
+
group,
|
| 830 |
+
) # modify `param_state` destructively
|
| 831 |
+
else: # non-FSDP parameter
|
| 832 |
+
_broadcast_unsharded_pos_dim_tensor_state(
|
| 833 |
+
unsharded_tensor,
|
| 834 |
+
param_state,
|
| 835 |
+
state_name,
|
| 836 |
+
shape,
|
| 837 |
+
dtype,
|
| 838 |
+
broadcast_device,
|
| 839 |
+
rank,
|
| 840 |
+
group,
|
| 841 |
+
) # modify `param_state` destructively
|
| 842 |
+
return no_tensor_osd
|
| 843 |
+
|
| 844 |
+
|
| 845 |
+
def _broadcast_sharded_pos_dim_tensor_state(
|
| 846 |
+
unsharded_tensor: Optional[torch.Tensor],
|
| 847 |
+
param_state: Dict[str, Any],
|
| 848 |
+
state_name: str,
|
| 849 |
+
shape: torch.Size,
|
| 850 |
+
dtype: torch.dtype,
|
| 851 |
+
broadcast_device: torch.device,
|
| 852 |
+
rank: int,
|
| 853 |
+
world_size: int,
|
| 854 |
+
group,
|
| 855 |
+
) -> None:
|
| 856 |
+
"""
|
| 857 |
+
Broadcasts positive-dimension tensor state for the state ``state_name``
|
| 858 |
+
corresponding to an FSDP parameter shard-by-shard, only to be saved on the
|
| 859 |
+
relevant rank. This modifies ``param_state`` destructively.
|
| 860 |
+
|
| 861 |
+
Args:
|
| 862 |
+
unsharded_tensor (Optional[torch.Tensor]): Unsharded tensor from which
|
| 863 |
+
to broadcast shards if on rank 0; ignored otherwise.
|
| 864 |
+
shape (torch.Size): Shape of the sharded tensor; same on all ranks.
|
| 865 |
+
"""
|
| 866 |
+
get_shard: Optional[functools.partial[Tuple[torch.Tensor, int]]] = None
|
| 867 |
+
if rank == 0:
|
| 868 |
+
assert (
|
| 869 |
+
unsharded_tensor is not None
|
| 870 |
+
), "Expects rank 0 to pass in the unsharded tensor"
|
| 871 |
+
get_shard = functools.partial(
|
| 872 |
+
FlatParamHandle._get_shard,
|
| 873 |
+
unsharded_tensor,
|
| 874 |
+
)
|
| 875 |
+
for target_rank in range(1, world_size):
|
| 876 |
+
if rank == 0:
|
| 877 |
+
assert get_shard is not None
|
| 878 |
+
sharded_tensor = get_shard(target_rank, world_size)[0].to(broadcast_device)
|
| 879 |
+
else:
|
| 880 |
+
sharded_tensor = torch.zeros(
|
| 881 |
+
shape,
|
| 882 |
+
requires_grad=False,
|
| 883 |
+
dtype=dtype,
|
| 884 |
+
device=broadcast_device,
|
| 885 |
+
)
|
| 886 |
+
dist.broadcast(sharded_tensor, src=0, group=group)
|
| 887 |
+
# Only keep the shard on the target rank and keep it on the broadcast
|
| 888 |
+
# device, which is typically GPU
|
| 889 |
+
if rank == target_rank:
|
| 890 |
+
param_state[state_name] = sharded_tensor
|
| 891 |
+
else:
|
| 892 |
+
del sharded_tensor
|
| 893 |
+
# Lastly, shard on rank 0
|
| 894 |
+
if rank != 0:
|
| 895 |
+
return
|
| 896 |
+
param_state[state_name] = get_shard(0, world_size)[0].to(broadcast_device) # type: ignore[misc]
|
| 897 |
+
|
| 898 |
+
|
| 899 |
+
def _broadcast_unsharded_pos_dim_tensor_state(
|
| 900 |
+
unsharded_tensor: Optional[torch.Tensor],
|
| 901 |
+
param_state: Dict[str, Any],
|
| 902 |
+
state_name: str,
|
| 903 |
+
shape: torch.Size,
|
| 904 |
+
dtype: torch.dtype,
|
| 905 |
+
broadcast_device: torch.device,
|
| 906 |
+
rank: int,
|
| 907 |
+
group,
|
| 908 |
+
) -> None:
|
| 909 |
+
"""
|
| 910 |
+
Broadcasts positive-dimension tensor state for the state ``state_name``
|
| 911 |
+
corresponding to an unsharded non-FSDP parameter from rank 0 to all ranks.
|
| 912 |
+
This modifies ``param_state`` destructively.
|
| 913 |
+
|
| 914 |
+
Args:
|
| 915 |
+
unsharded_tensor (Optional[torch.Tensor]): Unsharded tensor to
|
| 916 |
+
broadcast if on rank 0; ignored otherwise.
|
| 917 |
+
"""
|
| 918 |
+
if rank == 0:
|
| 919 |
+
assert (
|
| 920 |
+
unsharded_tensor is not None
|
| 921 |
+
), "Expects rank 0 to pass in the unsharded tensor"
|
| 922 |
+
assert (
|
| 923 |
+
shape == unsharded_tensor.shape
|
| 924 |
+
), f"Shape mismatch: {shape} {unsharded_tensor.shape}"
|
| 925 |
+
assert (
|
| 926 |
+
dtype == unsharded_tensor.dtype
|
| 927 |
+
), f"dtype mismatch: {dtype} {unsharded_tensor.dtype}"
|
| 928 |
+
unsharded_tensor = unsharded_tensor.to(broadcast_device)
|
| 929 |
+
else:
|
| 930 |
+
unsharded_tensor = torch.zeros(
|
| 931 |
+
shape,
|
| 932 |
+
requires_grad=False,
|
| 933 |
+
dtype=dtype,
|
| 934 |
+
device=broadcast_device,
|
| 935 |
+
)
|
| 936 |
+
dist.broadcast(unsharded_tensor, src=0, group=group)
|
| 937 |
+
# Keep the tensor on the broadcast device, which is typically GPU
|
| 938 |
+
param_state[state_name] = unsharded_tensor
|
| 939 |
+
|
| 940 |
+
|
| 941 |
+
def _rekey_sharded_optim_state_dict(
|
| 942 |
+
sharded_osd: Dict[str, Any],
|
| 943 |
+
model: nn.Module,
|
| 944 |
+
optim: torch.optim.Optimizer,
|
| 945 |
+
optim_input: Optional[
|
| 946 |
+
Union[
|
| 947 |
+
List[Dict[str, Any]],
|
| 948 |
+
Iterable[nn.Parameter],
|
| 949 |
+
]
|
| 950 |
+
],
|
| 951 |
+
using_optim_input: bool,
|
| 952 |
+
is_named_optimizer: bool = False,
|
| 953 |
+
) -> Dict[str, Any]:
|
| 954 |
+
"""
|
| 955 |
+
Rekeys the optimizer state dict from unflattened parameter names to
|
| 956 |
+
flattened parameter IDs according to the calling rank's ``optim``, which
|
| 957 |
+
may be different across ranks. In particular, the unflattened parameter
|
| 958 |
+
names are represented as :class:`_OptimStateKey` s.
|
| 959 |
+
"""
|
| 960 |
+
param_to_fqns = _get_param_to_fqns(model)
|
| 961 |
+
flat_param_to_fqn = _get_flat_param_to_fqn(model)
|
| 962 |
+
param_to_param_key: Dict[nn.Parameter, Union[int, str]] = cast(
|
| 963 |
+
Dict[nn.Parameter, Union[int, str]],
|
| 964 |
+
(
|
| 965 |
+
_get_param_to_param_id_from_optim_input(model, optim_input)
|
| 966 |
+
if using_optim_input
|
| 967 |
+
else _get_param_to_param_key(
|
| 968 |
+
optim, model, is_named_optimizer, param_to_fqns, flat_param_to_fqn
|
| 969 |
+
)
|
| 970 |
+
),
|
| 971 |
+
)
|
| 972 |
+
# All parameter keys in `param_to_param_key` should be in
|
| 973 |
+
# `param_to_fqns` -- strict inequality follows when not all parameters are
|
| 974 |
+
# passed to the optimizer
|
| 975 |
+
assert len(param_to_param_key) <= len(param_to_fqns)
|
| 976 |
+
|
| 977 |
+
unflat_param_names_to_flat_param_key: Dict[
|
| 978 |
+
Tuple[str, ...], Union[int, str]
|
| 979 |
+
] = {} # for "state"
|
| 980 |
+
unflat_param_name_to_flat_param_key: Dict[
|
| 981 |
+
str, Union[int, str]
|
| 982 |
+
] = {} # for "param_groups"
|
| 983 |
+
for param, unflat_param_names in param_to_fqns.items():
|
| 984 |
+
if param not in param_to_param_key:
|
| 985 |
+
# This parameter was not passed to the optimizer
|
| 986 |
+
continue
|
| 987 |
+
flat_param_key = param_to_param_key[param]
|
| 988 |
+
unflat_param_names_to_flat_param_key[tuple(unflat_param_names)] = flat_param_key
|
| 989 |
+
for unflat_param_name in unflat_param_names:
|
| 990 |
+
unflat_param_name_to_flat_param_key[unflat_param_name] = flat_param_key
|
| 991 |
+
|
| 992 |
+
sharded_osd_state = sharded_osd["state"]
|
| 993 |
+
rekeyed_osd_state: Dict[Union[str, int], Any] = {}
|
| 994 |
+
for key, param_state in sharded_osd_state.items():
|
| 995 |
+
if isinstance(key, str):
|
| 996 |
+
rekeyed_osd_state[key] = param_state
|
| 997 |
+
continue
|
| 998 |
+
flat_param_key = unflat_param_names_to_flat_param_key.get(
|
| 999 |
+
key.unflat_param_names, key.unflat_param_names
|
| 1000 |
+
)
|
| 1001 |
+
rekeyed_osd_state[flat_param_key] = param_state
|
| 1002 |
+
|
| 1003 |
+
rekeyed_osd_param_groups: List[Dict[str, Any]] = []
|
| 1004 |
+
for unflat_param_group in sharded_osd["param_groups"]:
|
| 1005 |
+
flat_param_group = copy.deepcopy(unflat_param_group)
|
| 1006 |
+
flat_param_keys = sorted(
|
| 1007 |
+
{
|
| 1008 |
+
unflat_param_name_to_flat_param_key[unflat_param_name]
|
| 1009 |
+
for unflat_param_name in unflat_param_group["params"]
|
| 1010 |
+
}
|
| 1011 |
+
)
|
| 1012 |
+
flat_param_group["params"] = flat_param_keys
|
| 1013 |
+
rekeyed_osd_param_groups.append(flat_param_group)
|
| 1014 |
+
|
| 1015 |
+
return {"state": rekeyed_osd_state, "param_groups": rekeyed_osd_param_groups}
|
| 1016 |
+
|
| 1017 |
+
|
| 1018 |
+
def _get_param_id_to_param_from_optim_input(
|
| 1019 |
+
model: nn.Module,
|
| 1020 |
+
optim_input: Optional[
|
| 1021 |
+
Union[
|
| 1022 |
+
List[Dict[str, Any]],
|
| 1023 |
+
Iterable[nn.Parameter],
|
| 1024 |
+
]
|
| 1025 |
+
] = None,
|
| 1026 |
+
) -> Dict[int, nn.Parameter]:
|
| 1027 |
+
"""
|
| 1028 |
+
Constructs a mapping from parameter IDs to parameters. This may be used
|
| 1029 |
+
both for models with ``FlatParameter`` s and without.
|
| 1030 |
+
|
| 1031 |
+
NOTE: This method is only preserved for backward compatibility. The method
|
| 1032 |
+
:meth:`_get_param_key_to_param` is the preferred code path that does not
|
| 1033 |
+
rely on ``optim_input``.
|
| 1034 |
+
|
| 1035 |
+
NOTE: We critically assume that, whether the optimizer input is a list of
|
| 1036 |
+
parameters or a list of parameter groups, :class:`torch.optim.Optimizer`
|
| 1037 |
+
enumerates the parameter IDs in order. In other words, for a parameter list
|
| 1038 |
+
input, the parameter IDs should be in that list order, and for a parameter
|
| 1039 |
+
groups input, the parameter IDs should be in order within each parameter
|
| 1040 |
+
group and in order across parameter groups.
|
| 1041 |
+
|
| 1042 |
+
Args:
|
| 1043 |
+
model (nn.Module): Model whose parameters are passed into the
|
| 1044 |
+
optimizer.
|
| 1045 |
+
optim_input (Optional[Union[List[Dict[str, Any]],
|
| 1046 |
+
Iterable[nn.Parameter]]]): Input passed into the optimizer
|
| 1047 |
+
representing either a :class:`list` of parameter groups or an
|
| 1048 |
+
iterable of parameters; if ``None``, then this method assumes the
|
| 1049 |
+
input was ``model.parameters()``. (Default: ``None``)
|
| 1050 |
+
|
| 1051 |
+
Returns:
|
| 1052 |
+
List[nn.Parameter]: Mapping from parameter IDs to parameters,
|
| 1053 |
+
where the parameter ID is implicitly the index in the :class:`list`.
|
| 1054 |
+
"""
|
| 1055 |
+
# Assume the standard case of passing `model.parameters()` to the optimizer
|
| 1056 |
+
# if `optim_input` is not specified
|
| 1057 |
+
if optim_input is None:
|
| 1058 |
+
return {pid: param for pid, param in enumerate(model.parameters())}
|
| 1059 |
+
try:
|
| 1060 |
+
params = cast(List[nn.Parameter], list(optim_input))
|
| 1061 |
+
except TypeError as e:
|
| 1062 |
+
raise TypeError(
|
| 1063 |
+
"Optimizer input should be an iterable of Tensors or dicts, "
|
| 1064 |
+
f"but got {optim_input}"
|
| 1065 |
+
) from e
|
| 1066 |
+
if len(params) == 0:
|
| 1067 |
+
raise ValueError("Optimizer input should not be empty")
|
| 1068 |
+
|
| 1069 |
+
# Check if the optimizer input represents tensors or parameter groups
|
| 1070 |
+
all_tensors = True
|
| 1071 |
+
all_dicts = True
|
| 1072 |
+
for param in params:
|
| 1073 |
+
all_tensors &= isinstance(param, torch.Tensor)
|
| 1074 |
+
all_dicts &= isinstance(param, dict)
|
| 1075 |
+
if not all_tensors and not all_dicts:
|
| 1076 |
+
raise TypeError("Optimizer input should be an iterable of Tensors or dicts")
|
| 1077 |
+
if all_tensors:
|
| 1078 |
+
return {pid: param for pid, param in enumerate(params)}
|
| 1079 |
+
assert all_dicts
|
| 1080 |
+
param_id_to_param: List[nn.Parameter] = []
|
| 1081 |
+
for param_group in params:
|
| 1082 |
+
has_params_key = "params" in param_group # type: ignore[operator]
|
| 1083 |
+
assert has_params_key, (
|
| 1084 |
+
'A parameter group should map "params" to a list of the '
|
| 1085 |
+
"parameters in the group"
|
| 1086 |
+
)
|
| 1087 |
+
for param in param_group["params"]: # type: ignore[index]
|
| 1088 |
+
# Implicitly map `flat_param_id` (current length of the list) to
|
| 1089 |
+
# `param`
|
| 1090 |
+
param_id_to_param.append(param)
|
| 1091 |
+
return {pid: param for pid, param in enumerate(param_id_to_param)}
|
| 1092 |
+
|
| 1093 |
+
|
| 1094 |
+
def _get_flat_param_to_fqn(model: torch.nn.Module) -> Dict[nn.Parameter, str]:
|
| 1095 |
+
def module_fn(module, prefix, flat_param_to_fqn):
|
| 1096 |
+
for param_name, param in module.named_parameters(recurse=False):
|
| 1097 |
+
if type(param) is not FlatParameter:
|
| 1098 |
+
continue
|
| 1099 |
+
fqn = clean_tensor_name(prefix + param_name)
|
| 1100 |
+
flat_param_to_fqn[param] = fqn
|
| 1101 |
+
|
| 1102 |
+
def return_fn(flat_param_to_fqn):
|
| 1103 |
+
return flat_param_to_fqn
|
| 1104 |
+
|
| 1105 |
+
flat_param_to_fqn_ret: Dict[torch.nn.Parameter, str] = {}
|
| 1106 |
+
return _apply_to_modules(
|
| 1107 |
+
model,
|
| 1108 |
+
module_fn,
|
| 1109 |
+
return_fn,
|
| 1110 |
+
[fqn for fqn, _ in model.named_parameters()],
|
| 1111 |
+
flat_param_to_fqn_ret,
|
| 1112 |
+
)
|
| 1113 |
+
|
| 1114 |
+
|
| 1115 |
+
def _get_param_key_to_param(
|
| 1116 |
+
optim: torch.optim.Optimizer,
|
| 1117 |
+
model: Optional[nn.Module] = None,
|
| 1118 |
+
is_named_optimizer: bool = False,
|
| 1119 |
+
param_to_fqns: Optional[Dict[nn.Parameter, List[str]]] = None,
|
| 1120 |
+
flat_param_to_fqn: Optional[Dict[nn.Parameter, str]] = None,
|
| 1121 |
+
) -> Dict[Union[int, str], nn.Parameter]:
|
| 1122 |
+
"""
|
| 1123 |
+
Constructs a mapping from parameter keys to parameters. For the regular
|
| 1124 |
+
optimizers, the keys are parameter IDs. For NamedOptimizer, the keys
|
| 1125 |
+
are FQNs. This API may be used both for models with ``FlatParameter`` s and
|
| 1126 |
+
without.
|
| 1127 |
+
"""
|
| 1128 |
+
clean_fqn_to_curr_fqn: Dict[str, str] = {}
|
| 1129 |
+
if is_named_optimizer:
|
| 1130 |
+
assert (
|
| 1131 |
+
param_to_fqns is not None and flat_param_to_fqn is not None
|
| 1132 |
+
), "The optimizer is a NamedOptimizer, `param_to_fqns` must not be None."
|
| 1133 |
+
assert model is not None
|
| 1134 |
+
for key, _ in model.named_parameters():
|
| 1135 |
+
clean_fqn_to_curr_fqn[clean_tensor_name(key)] = key
|
| 1136 |
+
|
| 1137 |
+
param_key_to_param: Dict[Union[str, int], nn.Parameter] = {}
|
| 1138 |
+
pid = 0
|
| 1139 |
+
for param_group in optim.param_groups:
|
| 1140 |
+
if is_named_optimizer:
|
| 1141 |
+
for param in param_group["params"]:
|
| 1142 |
+
assert flat_param_to_fqn is not None
|
| 1143 |
+
if param in flat_param_to_fqn:
|
| 1144 |
+
# FlatParameter case
|
| 1145 |
+
key = flat_param_to_fqn[param]
|
| 1146 |
+
else:
|
| 1147 |
+
assert param_to_fqns is not None
|
| 1148 |
+
# use_orig_params case
|
| 1149 |
+
assert len(param_to_fqns[param]) == 1
|
| 1150 |
+
key = param_to_fqns[param][0]
|
| 1151 |
+
key = clean_fqn_to_curr_fqn[key]
|
| 1152 |
+
param_key_to_param[key] = param
|
| 1153 |
+
else:
|
| 1154 |
+
for param in param_group["params"]:
|
| 1155 |
+
param_key_to_param[pid] = param
|
| 1156 |
+
pid += 1
|
| 1157 |
+
|
| 1158 |
+
return param_key_to_param
|
| 1159 |
+
|
| 1160 |
+
|
| 1161 |
+
def _get_param_to_param_key(
|
| 1162 |
+
optim: torch.optim.Optimizer,
|
| 1163 |
+
model: Optional[nn.Module] = None,
|
| 1164 |
+
is_named_optimizer: bool = False,
|
| 1165 |
+
param_to_fqns: Optional[Dict[nn.Parameter, List[str]]] = None,
|
| 1166 |
+
flat_param_to_fqn: Optional[Dict[nn.Parameter, str]] = None,
|
| 1167 |
+
) -> Dict[nn.Parameter, Union[int, str]]:
|
| 1168 |
+
"""
|
| 1169 |
+
Constructs the inverse mapping of :func:`_get_param_key_to_param`. This API
|
| 1170 |
+
only supports the case where `optim` is a regular optimizer, not NamedOptimizer.
|
| 1171 |
+
So the parameter keys will be parameter id.
|
| 1172 |
+
"""
|
| 1173 |
+
param_id_to_param = _get_param_key_to_param(
|
| 1174 |
+
optim, model, is_named_optimizer, param_to_fqns, flat_param_to_fqn
|
| 1175 |
+
)
|
| 1176 |
+
return {param: param_id for param_id, param in param_id_to_param.items()}
|
| 1177 |
+
|
| 1178 |
+
|
| 1179 |
+
def _get_param_to_param_id_from_optim_input(
|
| 1180 |
+
model: nn.Module,
|
| 1181 |
+
optim_input: Optional[
|
| 1182 |
+
Union[
|
| 1183 |
+
List[Dict[str, Any]],
|
| 1184 |
+
Iterable[nn.Parameter],
|
| 1185 |
+
]
|
| 1186 |
+
] = None,
|
| 1187 |
+
) -> Dict[nn.Parameter, int]:
|
| 1188 |
+
"""Constructs the inverse mapping of :func:`_get_param_id_to_param_from_optim_input`."""
|
| 1189 |
+
param_id_to_param = _get_param_id_to_param_from_optim_input(model, optim_input)
|
| 1190 |
+
return {param: param_id for param_id, param in param_id_to_param.items()}
|
| 1191 |
+
|
| 1192 |
+
|
| 1193 |
+
def _check_missing_keys_on_rank(
|
| 1194 |
+
r0_optim_state_keys: List[_OptimStateKey],
|
| 1195 |
+
optim_state_key_to_param_key: Dict[_OptimStateKey, Union[str, int]],
|
| 1196 |
+
param_key_to_param: Dict[Union[str, int], nn.Parameter],
|
| 1197 |
+
group: Optional[dist.ProcessGroup],
|
| 1198 |
+
) -> None:
|
| 1199 |
+
# Ensure that all ranks have at least the optimizer states needed by
|
| 1200 |
+
# rank 0's optimizer
|
| 1201 |
+
missing_keys: List[_OptimStateKey] = []
|
| 1202 |
+
for r0_optim_state_key in r0_optim_state_keys:
|
| 1203 |
+
if r0_optim_state_key not in optim_state_key_to_param_key:
|
| 1204 |
+
# A parameter from rank 0's optimizer does not exist for this
|
| 1205 |
+
# rank's optimizer
|
| 1206 |
+
missing_keys.append(r0_optim_state_key)
|
| 1207 |
+
continue
|
| 1208 |
+
param_key = optim_state_key_to_param_key[r0_optim_state_key]
|
| 1209 |
+
if isinstance(param_key, int):
|
| 1210 |
+
assert param_key >= 0 and param_key < len(
|
| 1211 |
+
param_key_to_param
|
| 1212 |
+
), "Check the `param_key_to_param` construction"
|
| 1213 |
+
device = torch.device("cuda", torch.cuda.current_device())
|
| 1214 |
+
num_missing = torch.tensor([len(missing_keys)], dtype=torch.int32, device=device)
|
| 1215 |
+
dist.all_reduce(num_missing, group=group)
|
| 1216 |
+
if num_missing.item() > 0:
|
| 1217 |
+
obj_list = [None for _ in range(dist.get_world_size(group))]
|
| 1218 |
+
dist.all_gather_object(obj_list, missing_keys, group=group)
|
| 1219 |
+
error_msg = (
|
| 1220 |
+
"FSDP currently requires each rank to have at least the "
|
| 1221 |
+
"optimizer states needed by rank 0's optimizer but some ranks "
|
| 1222 |
+
"are missing some of those states"
|
| 1223 |
+
)
|
| 1224 |
+
for rank, keys in enumerate(obj_list):
|
| 1225 |
+
keys = cast(List[_OptimStateKey], keys)
|
| 1226 |
+
if len(keys) > 0:
|
| 1227 |
+
error_msg += (
|
| 1228 |
+
f"\nRank {rank} is missing states for the parameters: "
|
| 1229 |
+
f"{[key.unflat_param_names for key in keys]}"
|
| 1230 |
+
)
|
| 1231 |
+
raise RuntimeError(error_msg)
|
| 1232 |
+
|
| 1233 |
+
|
| 1234 |
+
def _map_param_key_to_optim_keys(
|
| 1235 |
+
optim_state_dict: Dict[str, Any],
|
| 1236 |
+
group: Optional[dist.ProcessGroup],
|
| 1237 |
+
param_key_to_param: Dict[Union[int, str], nn.Parameter],
|
| 1238 |
+
param_to_fqns: Dict[nn.Parameter, List[str]],
|
| 1239 |
+
fqn_to_fsdp_param_info: Dict[str, FSDPParamInfo],
|
| 1240 |
+
merge_keys: bool = False,
|
| 1241 |
+
) -> Tuple[List[_OptimStateKey], Dict[_OptimStateKey, Union[int, str]]]:
|
| 1242 |
+
"""
|
| 1243 |
+
Construct the local mapping between the ``_OptimStateKey`` and parameter keys
|
| 1244 |
+
and all the ``_OptimStateKey`` across ranks. If ``merge_keys`` is False, rank0
|
| 1245 |
+
must contain all the ``_OptimStateKey``, an exception will be raised otherwise.
|
| 1246 |
+
Note that ``merge_keys`` should equal to ``use_orig_params``.
|
| 1247 |
+
"""
|
| 1248 |
+
rank = dist.get_rank(group)
|
| 1249 |
+
optim_state_key_to_param_key: Dict[_OptimStateKey, Union[int, str]] = {} # local
|
| 1250 |
+
all_optim_state_keys: List[_OptimStateKey] = []
|
| 1251 |
+
|
| 1252 |
+
for param_key, param in param_key_to_param.items():
|
| 1253 |
+
# Do not include parameters without state to avoid empty mappings
|
| 1254 |
+
# just like in normal `torch.optim.Optimizer.state_dict()`
|
| 1255 |
+
if param_key not in optim_state_dict["state"]:
|
| 1256 |
+
continue
|
| 1257 |
+
fqns = param_to_fqns[param]
|
| 1258 |
+
is_fsdp_managed = isinstance(param, FlatParameter)
|
| 1259 |
+
if is_fsdp_managed:
|
| 1260 |
+
assert fqns[0] in fqn_to_fsdp_param_info, (
|
| 1261 |
+
fqns[0],
|
| 1262 |
+
list(fqn_to_fsdp_param_info.keys()),
|
| 1263 |
+
)
|
| 1264 |
+
is_fsdp_managed = fqns[0] in fqn_to_fsdp_param_info
|
| 1265 |
+
optim_state_key = _OptimStateKey(
|
| 1266 |
+
unflat_param_names=tuple(fqns),
|
| 1267 |
+
is_fsdp_managed=is_fsdp_managed,
|
| 1268 |
+
)
|
| 1269 |
+
if rank == 0 or merge_keys:
|
| 1270 |
+
all_optim_state_keys.append(optim_state_key)
|
| 1271 |
+
optim_state_key_to_param_key[optim_state_key] = param_key
|
| 1272 |
+
|
| 1273 |
+
if merge_keys:
|
| 1274 |
+
all_keys: List[List[_OptimStateKey]] = [
|
| 1275 |
+
[] for _ in range(dist.get_world_size(group))
|
| 1276 |
+
]
|
| 1277 |
+
dist.all_gather_object(all_keys, all_optim_state_keys, group=group)
|
| 1278 |
+
merge_all_optim_state_keys = [
|
| 1279 |
+
key for local_keys in all_keys for key in local_keys
|
| 1280 |
+
]
|
| 1281 |
+
all_optim_state_keys = sorted(set(merge_all_optim_state_keys))
|
| 1282 |
+
else:
|
| 1283 |
+
key_obj_list: List[Optional[List[_OptimStateKey]]] = (
|
| 1284 |
+
[all_optim_state_keys] if rank == 0 else [None]
|
| 1285 |
+
)
|
| 1286 |
+
dist.broadcast_object_list(key_obj_list, src=0, group=group)
|
| 1287 |
+
assert key_obj_list[0] is not None
|
| 1288 |
+
all_optim_state_keys = key_obj_list[0]
|
| 1289 |
+
_check_missing_keys_on_rank(
|
| 1290 |
+
all_optim_state_keys,
|
| 1291 |
+
optim_state_key_to_param_key,
|
| 1292 |
+
param_key_to_param,
|
| 1293 |
+
group,
|
| 1294 |
+
)
|
| 1295 |
+
|
| 1296 |
+
return all_optim_state_keys, optim_state_key_to_param_key
|
| 1297 |
+
|
| 1298 |
+
|
| 1299 |
+
def _unflatten_param_groups(
|
| 1300 |
+
state_dict: Dict[str, Any],
|
| 1301 |
+
param_key_to_param: Dict[Union[int, str], nn.Parameter],
|
| 1302 |
+
param_to_fqns: Dict[nn.Parameter, List[str]],
|
| 1303 |
+
) -> List[Dict[str, Any]]:
|
| 1304 |
+
param_groups: List[Dict[str, Any]] = []
|
| 1305 |
+
for flat_param_group in state_dict["param_groups"]:
|
| 1306 |
+
unflat_param_group = copy.deepcopy(flat_param_group)
|
| 1307 |
+
param_group_params = [
|
| 1308 |
+
param_key_to_param[flat_param_key]
|
| 1309 |
+
for flat_param_key in flat_param_group["params"]
|
| 1310 |
+
]
|
| 1311 |
+
nested_unflat_param_names = [
|
| 1312 |
+
param_to_fqns[param] for param in param_group_params
|
| 1313 |
+
]
|
| 1314 |
+
unflat_param_group["params"] = [
|
| 1315 |
+
unflat_param_name
|
| 1316 |
+
for unflat_param_names in nested_unflat_param_names
|
| 1317 |
+
for unflat_param_name in unflat_param_names
|
| 1318 |
+
] # flatten the list of lists
|
| 1319 |
+
param_groups.append(unflat_param_group)
|
| 1320 |
+
return param_groups
|
| 1321 |
+
|
| 1322 |
+
|
| 1323 |
+
def _is_named_optimizer(optim_state_dict: Dict[str, Any]) -> bool:
|
| 1324 |
+
state = optim_state_dict.get("state", None)
|
| 1325 |
+
if not state:
|
| 1326 |
+
# If we cannot find a state, assume it is not NamedOptimizer as
|
| 1327 |
+
# NamedOptimizer has eagerly initialization.
|
| 1328 |
+
return False
|
| 1329 |
+
try:
|
| 1330 |
+
key = next(iter(state.keys()))
|
| 1331 |
+
except Exception as e:
|
| 1332 |
+
raise Exception(optim_state_dict) from e
|
| 1333 |
+
return isinstance(key, str)
|
| 1334 |
+
|
| 1335 |
+
|
| 1336 |
+
def _optim_state_dict(
|
| 1337 |
+
model: nn.Module,
|
| 1338 |
+
optim: torch.optim.Optimizer,
|
| 1339 |
+
optim_state_dict: Dict[str, Any],
|
| 1340 |
+
optim_input: Optional[
|
| 1341 |
+
Union[
|
| 1342 |
+
List[Dict[str, Any]],
|
| 1343 |
+
Iterable[nn.Parameter],
|
| 1344 |
+
]
|
| 1345 |
+
],
|
| 1346 |
+
rank0_only: bool,
|
| 1347 |
+
shard_state: bool,
|
| 1348 |
+
group: Optional[dist.ProcessGroup],
|
| 1349 |
+
using_optim_input: bool,
|
| 1350 |
+
use_orig_params: bool = False,
|
| 1351 |
+
) -> Dict[str, Any]:
|
| 1352 |
+
"""
|
| 1353 |
+
Consolidates the optimizer state and returns it as a :class:`dict`
|
| 1354 |
+
following the convention of :meth:`torch.optim.Optimizer.state_dict`,
|
| 1355 |
+
i.e. with keys ``"state"`` and ``"param_groups"``.
|
| 1356 |
+
The flattened parameters in ``FSDP`` modules contained in ``model``
|
| 1357 |
+
are mapped back to their unflattened parameters.
|
| 1358 |
+
|
| 1359 |
+
Parameter keys are not well-defined. For a regular optimizer, the optimizer
|
| 1360 |
+
state_dict contains a mapping from parameter IDs to parameter states.
|
| 1361 |
+
Parameter IDs are the order of parameters in ``optim.param_groups()`` across
|
| 1362 |
+
all the groups. This API also allows user to pass ``optim_input`` for the
|
| 1363 |
+
mapping between parameters and parameter IDs. Using ``optim_input`` is being
|
| 1364 |
+
deprecated.
|
| 1365 |
+
|
| 1366 |
+
If the optimizer is a ``NamedOptimizer``, the optimizer state_dict does not
|
| 1367 |
+
contain parameter IDs mapping but a mapping from parameter FQNs to parameter
|
| 1368 |
+
states. This API finds the mapping from FQNs to parameters if the optimizer
|
| 1369 |
+
is a ``NamedOptimizer``.
|
| 1370 |
+
|
| 1371 |
+
If ``use_orig_params`` is True, each rank will have all FSDP-managed
|
| 1372 |
+
parameters but some of these parameters may be empty due to the sharding.
|
| 1373 |
+
For a regular optim.Optimizer, states for those empty parameters will
|
| 1374 |
+
not be initialized. So, when aggregating the FQNs across ranks, no assert
|
| 1375 |
+
will be raised on a rank even if it does not have all the states -- it is
|
| 1376 |
+
valid and FSDP know how to aggregate them. However, FSDP has to ignore
|
| 1377 |
+
handling those parameters that are not managed by FSDP and do not exist on
|
| 1378 |
+
the local rank -- it is managed by other parallelism and FSDP does not
|
| 1379 |
+
know ho to handle/aggregate them.
|
| 1380 |
+
|
| 1381 |
+
Args:
|
| 1382 |
+
model (nn.Module): Root module (which may or may not be a
|
| 1383 |
+
:class:`FullyShardedDataParallel` instance) whose parameters
|
| 1384 |
+
were passed into the optimizer ``optim``.
|
| 1385 |
+
optim (torch.optim.Optimizer): Optimizer for ``model`` 's
|
| 1386 |
+
parameters.
|
| 1387 |
+
rank0_only (bool): If ``True``, saves the populated :class:`dict`
|
| 1388 |
+
only on rank 0; if ``False``, saves it on all ranks. (Default:
|
| 1389 |
+
``True``)
|
| 1390 |
+
shard_state (bool): If ``True``, shard and distribute all
|
| 1391 |
+
non-zero-dimension states.
|
| 1392 |
+
|
| 1393 |
+
Returns:
|
| 1394 |
+
Dict[str, Any]: A :class:`dict` containing the optimizer state for
|
| 1395 |
+
``model`` 's original unflattened parameters and including keys
|
| 1396 |
+
"state" and "param_groups" following the convention of
|
| 1397 |
+
:meth:`torch.optim.Optimizer.state_dict`. If ``rank0_only=False``,
|
| 1398 |
+
then nonzero ranks return an empty :class:`dict`.
|
| 1399 |
+
"""
|
| 1400 |
+
_clear_grads_if_needed(traversal_utils._get_fsdp_handles(model))
|
| 1401 |
+
to_save = not rank0_only or (dist.get_rank(group) == 0 or shard_state)
|
| 1402 |
+
fsdp_osd: Dict[str, Any] = {"state": {}, "param_groups": []} if to_save else {}
|
| 1403 |
+
fsdp_osd_state: Dict[str, Any] = fsdp_osd["state"] if to_save else {}
|
| 1404 |
+
param_to_fqns = _get_param_to_fqns(model)
|
| 1405 |
+
flat_param_to_fqn = _get_flat_param_to_fqn(model)
|
| 1406 |
+
is_named_optimizer = _is_named_optimizer(optim_state_dict)
|
| 1407 |
+
|
| 1408 |
+
param_key_to_param = cast(
|
| 1409 |
+
Dict[Union[int, str], nn.Parameter],
|
| 1410 |
+
(
|
| 1411 |
+
_get_param_id_to_param_from_optim_input(model, optim_input)
|
| 1412 |
+
if using_optim_input
|
| 1413 |
+
else _get_param_key_to_param(
|
| 1414 |
+
optim, model, is_named_optimizer, param_to_fqns, flat_param_to_fqn
|
| 1415 |
+
)
|
| 1416 |
+
),
|
| 1417 |
+
)
|
| 1418 |
+
fqn_to_fsdp_param_info = _get_fqn_to_fsdp_param_info(model)
|
| 1419 |
+
|
| 1420 |
+
all_optim_state_keys, optim_state_key_to_param_key = _map_param_key_to_optim_keys(
|
| 1421 |
+
optim_state_dict,
|
| 1422 |
+
group,
|
| 1423 |
+
param_key_to_param,
|
| 1424 |
+
param_to_fqns,
|
| 1425 |
+
fqn_to_fsdp_param_info,
|
| 1426 |
+
merge_keys=use_orig_params,
|
| 1427 |
+
)
|
| 1428 |
+
|
| 1429 |
+
# Iterate in rank 0's flattened parameter ID order to ensure aligned
|
| 1430 |
+
# all-gathers across ranks
|
| 1431 |
+
for optim_state_key in all_optim_state_keys:
|
| 1432 |
+
param_key: Union[str, int, None] = optim_state_key_to_param_key.get(
|
| 1433 |
+
optim_state_key, None
|
| 1434 |
+
)
|
| 1435 |
+
|
| 1436 |
+
if param_key is None:
|
| 1437 |
+
assert use_orig_params, (
|
| 1438 |
+
"If use_orig_params is False, we must be able to find the "
|
| 1439 |
+
f"corresponding param id. {optim_state_key} {param_key}"
|
| 1440 |
+
)
|
| 1441 |
+
if not optim_state_key.is_fsdp_managed:
|
| 1442 |
+
continue
|
| 1443 |
+
|
| 1444 |
+
if optim_state_key.is_fsdp_managed:
|
| 1445 |
+
# If there are multiple unflat_param_names (not use_orig_params),
|
| 1446 |
+
# they share the same FSDPParamInfo. So the first unflat_param_name
|
| 1447 |
+
# is sufficient to fetch the FSDPParamInfo.
|
| 1448 |
+
fqn = optim_state_key.unflat_param_names[0]
|
| 1449 |
+
fsdp_param_info = fqn_to_fsdp_param_info[fqn]
|
| 1450 |
+
if use_orig_params:
|
| 1451 |
+
state = (
|
| 1452 |
+
{} if param_key is None else optim_state_dict["state"][param_key]
|
| 1453 |
+
)
|
| 1454 |
+
unflat_state = [
|
| 1455 |
+
_gather_orig_param_state(
|
| 1456 |
+
fsdp_param_info, fqn, state, shard_state, group
|
| 1457 |
+
)
|
| 1458 |
+
]
|
| 1459 |
+
else:
|
| 1460 |
+
unflat_state = _unflatten_optim_state(
|
| 1461 |
+
fsdp_param_info,
|
| 1462 |
+
optim_state_dict["state"][param_key],
|
| 1463 |
+
to_save,
|
| 1464 |
+
shard_state,
|
| 1465 |
+
)
|
| 1466 |
+
if to_save:
|
| 1467 |
+
assert len(unflat_state) == len(optim_state_key.unflat_param_names)
|
| 1468 |
+
for unflat_param_name, unflat_param_state in zip(
|
| 1469 |
+
optim_state_key.unflat_param_names,
|
| 1470 |
+
unflat_state,
|
| 1471 |
+
):
|
| 1472 |
+
fsdp_osd_state[unflat_param_name] = unflat_param_state
|
| 1473 |
+
elif to_save:
|
| 1474 |
+
assert len(optim_state_key.unflat_param_names) == 1
|
| 1475 |
+
unflat_param_name = optim_state_key.unflat_param_names[0]
|
| 1476 |
+
fsdp_osd_state[unflat_param_name] = copy.copy(
|
| 1477 |
+
optim_state_dict["state"][param_key]
|
| 1478 |
+
)
|
| 1479 |
+
for state_name, value in sorted_items(fsdp_osd_state[unflat_param_name]):
|
| 1480 |
+
if torch.is_tensor(value):
|
| 1481 |
+
fsdp_osd_state[unflat_param_name][state_name] = value.cpu()
|
| 1482 |
+
|
| 1483 |
+
if to_save:
|
| 1484 |
+
flat_param_fqns = set(flat_param_to_fqn.values())
|
| 1485 |
+
for key, value in optim_state_dict["state"].items():
|
| 1486 |
+
if key in fsdp_osd_state:
|
| 1487 |
+
continue
|
| 1488 |
+
if key in flat_param_fqns:
|
| 1489 |
+
continue
|
| 1490 |
+
if key in param_key_to_param:
|
| 1491 |
+
continue
|
| 1492 |
+
# This key is not recognized by FSDP. It may be a user-defined state
|
| 1493 |
+
# or some parameters state that FSDP is unable to map from
|
| 1494 |
+
# ``optim.param_groups``.
|
| 1495 |
+
warnings.warn(
|
| 1496 |
+
f"Found a optim state, {key}, that FSDP cannot process. FSDP "
|
| 1497 |
+
"will directly copy everything to the returned state_dict. In "
|
| 1498 |
+
"most cases, this is a user-defined state that is not "
|
| 1499 |
+
"associated with any particular parameter. Another possible "
|
| 1500 |
+
"case is this state is managed by DMP. Otherwise, there may "
|
| 1501 |
+
" be a mismatched assumption of optim_state_dict of this mode."
|
| 1502 |
+
)
|
| 1503 |
+
fsdp_osd_state[key] = value
|
| 1504 |
+
|
| 1505 |
+
fsdp_osd["param_groups"] = _unflatten_param_groups(
|
| 1506 |
+
optim_state_dict, param_key_to_param, param_to_fqns
|
| 1507 |
+
)
|
| 1508 |
+
|
| 1509 |
+
return fsdp_osd
|
| 1510 |
+
|
| 1511 |
+
|
| 1512 |
+
def _get_fqn_to_fsdp_param_info(model: nn.Module) -> Dict[str, FSDPParamInfo]:
|
| 1513 |
+
"""
|
| 1514 |
+
Construct the mapping from a param's fqn to its corresponding ``FSDPParamInfo``
|
| 1515 |
+
if the param is managed by FSDP. ``FlatParameter._fqns`` only stores the first
|
| 1516 |
+
FQN of a shared parameter. So the keys in the mapping are guaranteed to map
|
| 1517 |
+
to unique parameters.
|
| 1518 |
+
"""
|
| 1519 |
+
|
| 1520 |
+
def module_fn(module, prefix, fqn_to_param_info):
|
| 1521 |
+
fsdp_state = _get_module_fsdp_state_if_fully_sharded_module(module)
|
| 1522 |
+
if fsdp_state is None:
|
| 1523 |
+
return
|
| 1524 |
+
_lazy_init(fsdp_state, module)
|
| 1525 |
+
handles = _module_handles(fsdp_state, module)
|
| 1526 |
+
if not handles:
|
| 1527 |
+
return
|
| 1528 |
+
flat_param = handles[0].flat_param
|
| 1529 |
+
fsdp_param_info = FSDPParamInfo(fsdp_state, flat_param, {})
|
| 1530 |
+
for idx, local_fqn in enumerate(flat_param._fqns):
|
| 1531 |
+
fqn = clean_tensor_name(prefix + local_fqn)
|
| 1532 |
+
if fqn in fqn_to_param_info:
|
| 1533 |
+
assert fqn_to_param_info[fqn].flat_param == flat_param
|
| 1534 |
+
fqn_to_param_info[fqn] = fsdp_param_info
|
| 1535 |
+
fsdp_param_info.param_indices[fqn] = idx
|
| 1536 |
+
|
| 1537 |
+
def return_fn(fqn_to_param_info):
|
| 1538 |
+
return fqn_to_param_info
|
| 1539 |
+
|
| 1540 |
+
fqn_to_param_info: Dict[str, FSDPParamInfo] = {}
|
| 1541 |
+
# FlatParameter._fqns stores the local fqn, starting from the root of the
|
| 1542 |
+
# FSDP. Using _apply_to_modules() with model (may not be the FSDP root
|
| 1543 |
+
# module) allows us to construct the global fqn.
|
| 1544 |
+
return _apply_to_modules(
|
| 1545 |
+
model,
|
| 1546 |
+
module_fn,
|
| 1547 |
+
return_fn,
|
| 1548 |
+
[fqn for fqn, _ in model.named_parameters()],
|
| 1549 |
+
fqn_to_param_info,
|
| 1550 |
+
)
|
| 1551 |
+
|
| 1552 |
+
|
| 1553 |
+
@dataclass
|
| 1554 |
+
class StateInfo:
|
| 1555 |
+
tensors: Dict[str, _PosDimTensorInfo]
|
| 1556 |
+
scalar_tensors: Dict[str, torch.Tensor]
|
| 1557 |
+
non_tensors: Dict[str, Any]
|
| 1558 |
+
|
| 1559 |
+
|
| 1560 |
+
@dataclass
|
| 1561 |
+
class AllGatherInfo:
|
| 1562 |
+
tensors: List[torch.Tensor]
|
| 1563 |
+
numels: List[int]
|
| 1564 |
+
work: Optional[dist.Work]
|
| 1565 |
+
|
| 1566 |
+
|
| 1567 |
+
def _all_gather_optim_state(
|
| 1568 |
+
fsdp_state: _FSDPState,
|
| 1569 |
+
optim_state: Dict[str, Any],
|
| 1570 |
+
group=None,
|
| 1571 |
+
) -> Dict[str, Any]:
|
| 1572 |
+
"""
|
| 1573 |
+
All-gathering state from all the ranks. This API is slow as it uses
|
| 1574 |
+
``all_gather_object``. However, optim state_dict is not in the critical path.
|
| 1575 |
+
We can fuse the communication across differnt state if the performance
|
| 1576 |
+
becomes a problem.
|
| 1577 |
+
"""
|
| 1578 |
+
# Allgather the scalar tensor state, non-tensor states and tensors metadata.
|
| 1579 |
+
processed_state = StateInfo({}, {}, {})
|
| 1580 |
+
for state_name, value in sorted_items(optim_state):
|
| 1581 |
+
if torch.is_tensor(value):
|
| 1582 |
+
if value.dim() == 0:
|
| 1583 |
+
# Ensure that `step` is on CPU.
|
| 1584 |
+
processed_state.scalar_tensors[state_name] = value.cpu()
|
| 1585 |
+
else:
|
| 1586 |
+
processed_state.tensors[state_name] = _PosDimTensorInfo(
|
| 1587 |
+
value.shape, value.dtype
|
| 1588 |
+
)
|
| 1589 |
+
else:
|
| 1590 |
+
processed_state.non_tensors = value
|
| 1591 |
+
object_list: List[StateInfo] = [
|
| 1592 |
+
processed_state for _ in range(fsdp_state.world_size)
|
| 1593 |
+
]
|
| 1594 |
+
dist.all_gather_object(object_list, processed_state, group=group)
|
| 1595 |
+
|
| 1596 |
+
# Convert the gathered, pre-proccessed state of each rank to the original one.
|
| 1597 |
+
gathered_state: Dict[str, Any] = {}
|
| 1598 |
+
|
| 1599 |
+
all_tensor_states = sorted(
|
| 1600 |
+
{n for state in object_list for n in state.tensors.keys()}
|
| 1601 |
+
)
|
| 1602 |
+
empty_ranks: Set[int] = set()
|
| 1603 |
+
for name in all_tensor_states:
|
| 1604 |
+
numels = []
|
| 1605 |
+
dtype = torch.float
|
| 1606 |
+
_empty_ranks: Set[int] = set()
|
| 1607 |
+
for rank, object_state in enumerate(object_list):
|
| 1608 |
+
numels.append(0)
|
| 1609 |
+
info = object_state.tensors.get(name, None)
|
| 1610 |
+
if info is not None:
|
| 1611 |
+
numels[-1] = info.shape.numel()
|
| 1612 |
+
dtype = info.dtype
|
| 1613 |
+
if numels[-1] == 0:
|
| 1614 |
+
_empty_ranks.add(rank)
|
| 1615 |
+
|
| 1616 |
+
empty_func = functools.partial(
|
| 1617 |
+
torch.empty, dtype=dtype, device=fsdp_state.compute_device
|
| 1618 |
+
)
|
| 1619 |
+
if empty_ranks:
|
| 1620 |
+
assert empty_ranks == _empty_ranks
|
| 1621 |
+
empty_ranks = _empty_ranks
|
| 1622 |
+
local_state = optim_state.get(name, empty_func(0))
|
| 1623 |
+
local_state = local_state.to(fsdp_state.compute_device)
|
| 1624 |
+
tensors = [
|
| 1625 |
+
empty_func(numel) if rank != fsdp_state.rank else local_state
|
| 1626 |
+
for rank, numel in enumerate(numels)
|
| 1627 |
+
]
|
| 1628 |
+
work = dist.all_gather(
|
| 1629 |
+
tensors, local_state, group=fsdp_state.process_group, async_op=True
|
| 1630 |
+
)
|
| 1631 |
+
gathered_state[name] = AllGatherInfo(tensors, numels, work)
|
| 1632 |
+
|
| 1633 |
+
for rank, object_state in enumerate(object_list):
|
| 1634 |
+
if rank in empty_ranks:
|
| 1635 |
+
continue
|
| 1636 |
+
for name, non_tensor_value in object_state.non_tensors.items():
|
| 1637 |
+
curr_non_tensor_value = gathered_state.get(name, None)
|
| 1638 |
+
assert (
|
| 1639 |
+
curr_non_tensor_value is None
|
| 1640 |
+
or curr_non_tensor_value == non_tensor_value
|
| 1641 |
+
), f"Different ranks have different values for {name}."
|
| 1642 |
+
gathered_state[name] = non_tensor_value
|
| 1643 |
+
|
| 1644 |
+
for name, scalar_tensor_value in object_state.scalar_tensors.items():
|
| 1645 |
+
curr_scalar_tensor_value = gathered_state.get(name, None)
|
| 1646 |
+
assert curr_scalar_tensor_value is None or torch.equal(
|
| 1647 |
+
scalar_tensor_value, curr_scalar_tensor_value
|
| 1648 |
+
), f"Different ranks have different values for {name}."
|
| 1649 |
+
gathered_state[name] = scalar_tensor_value
|
| 1650 |
+
|
| 1651 |
+
for name, value in list(gathered_state.items()):
|
| 1652 |
+
if not isinstance(value, AllGatherInfo):
|
| 1653 |
+
continue
|
| 1654 |
+
assert value.work is not None
|
| 1655 |
+
value.work.wait()
|
| 1656 |
+
gathered_state[name] = torch.cat(
|
| 1657 |
+
[
|
| 1658 |
+
rank_tensor[:rank_numel]
|
| 1659 |
+
for rank_tensor, rank_numel in zip(value.tensors, value.numels)
|
| 1660 |
+
if rank_numel > 0
|
| 1661 |
+
]
|
| 1662 |
+
)
|
| 1663 |
+
|
| 1664 |
+
return gathered_state
|
| 1665 |
+
|
| 1666 |
+
|
| 1667 |
+
def _gather_orig_param_state(
|
| 1668 |
+
fsdp_param_info: FSDPParamInfo,
|
| 1669 |
+
fqn: str,
|
| 1670 |
+
optim_state: Dict[str, Any],
|
| 1671 |
+
shard_state: bool,
|
| 1672 |
+
group=None,
|
| 1673 |
+
) -> Dict[str, Any]:
|
| 1674 |
+
"""
|
| 1675 |
+
Gather the optimizer state for the original parameter with the name ``fqn``.
|
| 1676 |
+
This API should only be used when ``use_orig_params`` is True.
|
| 1677 |
+
"""
|
| 1678 |
+
fsdp_state = fsdp_param_info.state
|
| 1679 |
+
assert (
|
| 1680 |
+
fsdp_state._use_orig_params
|
| 1681 |
+
), "_gather_orig_param_state only support use_orig_params=True case"
|
| 1682 |
+
flat_param = fsdp_param_info.flat_param
|
| 1683 |
+
param_idx = fsdp_param_info.param_indices[fqn]
|
| 1684 |
+
if (
|
| 1685 |
+
fsdp_state.world_size == 1
|
| 1686 |
+
or fsdp_state.sharding_strategy == ShardingStrategy.NO_SHARD
|
| 1687 |
+
):
|
| 1688 |
+
return optim_state
|
| 1689 |
+
|
| 1690 |
+
gathered_state = _all_gather_optim_state(fsdp_state, optim_state, group=group)
|
| 1691 |
+
|
| 1692 |
+
# Unflatten state values.
|
| 1693 |
+
for state_name, value in list(gathered_state.items()):
|
| 1694 |
+
if not torch.is_tensor(value) or value.dim() == 0:
|
| 1695 |
+
continue
|
| 1696 |
+
|
| 1697 |
+
value = value[: flat_param._numels[param_idx]].reshape(
|
| 1698 |
+
flat_param._shapes[param_idx]
|
| 1699 |
+
)
|
| 1700 |
+
if shard_state:
|
| 1701 |
+
assert fsdp_state.process_group is not None
|
| 1702 |
+
value = _ext_chunk_tensor(
|
| 1703 |
+
value,
|
| 1704 |
+
fsdp_state.rank,
|
| 1705 |
+
fsdp_state.world_size,
|
| 1706 |
+
torch.cuda.device_count(),
|
| 1707 |
+
fsdp_state.process_group,
|
| 1708 |
+
)
|
| 1709 |
+
value = value.cpu()
|
| 1710 |
+
gathered_state[state_name] = value
|
| 1711 |
+
return gathered_state
|
| 1712 |
+
|
| 1713 |
+
|
| 1714 |
+
def _shard_orig_param_state(
|
| 1715 |
+
fsdp_param_info: FSDPParamInfo,
|
| 1716 |
+
fqn: str,
|
| 1717 |
+
optim_state: Dict[str, Any],
|
| 1718 |
+
) -> Dict[str, Any]:
|
| 1719 |
+
"""
|
| 1720 |
+
Shard the optimizer state for the original parameter with the name ``fqn``.
|
| 1721 |
+
This API should only be used when ``use_orig_params`` is True.
|
| 1722 |
+
"""
|
| 1723 |
+
if not optim_state:
|
| 1724 |
+
return {}
|
| 1725 |
+
fsdp_state = fsdp_param_info.state
|
| 1726 |
+
flat_param = fsdp_param_info.flat_param
|
| 1727 |
+
param_idx = fsdp_param_info.param_indices[fqn]
|
| 1728 |
+
|
| 1729 |
+
optim_state = _gather_state_dict(optim_state, fsdp_state.process_group)
|
| 1730 |
+
start, end = flat_param._shard_indices # type: ignore[attr-defined]
|
| 1731 |
+
if not (start <= param_idx <= end and flat_param._shard_param_offsets): # type: ignore[attr-defined]
|
| 1732 |
+
return {}
|
| 1733 |
+
param_start, param_end = flat_param._shard_param_offsets[param_idx - start] # type: ignore[attr-defined]
|
| 1734 |
+
|
| 1735 |
+
# Flatten and shard the state.
|
| 1736 |
+
new_optim_state: Dict[str, Any] = {}
|
| 1737 |
+
for state_name, value in optim_state.items():
|
| 1738 |
+
if torch.is_tensor(value) and value.dim() > 0:
|
| 1739 |
+
value = value.flatten()[param_start : param_end + 1]
|
| 1740 |
+
new_optim_state[state_name] = value
|
| 1741 |
+
return new_optim_state
|
open_flamingo/docs/flamingo.png
ADDED
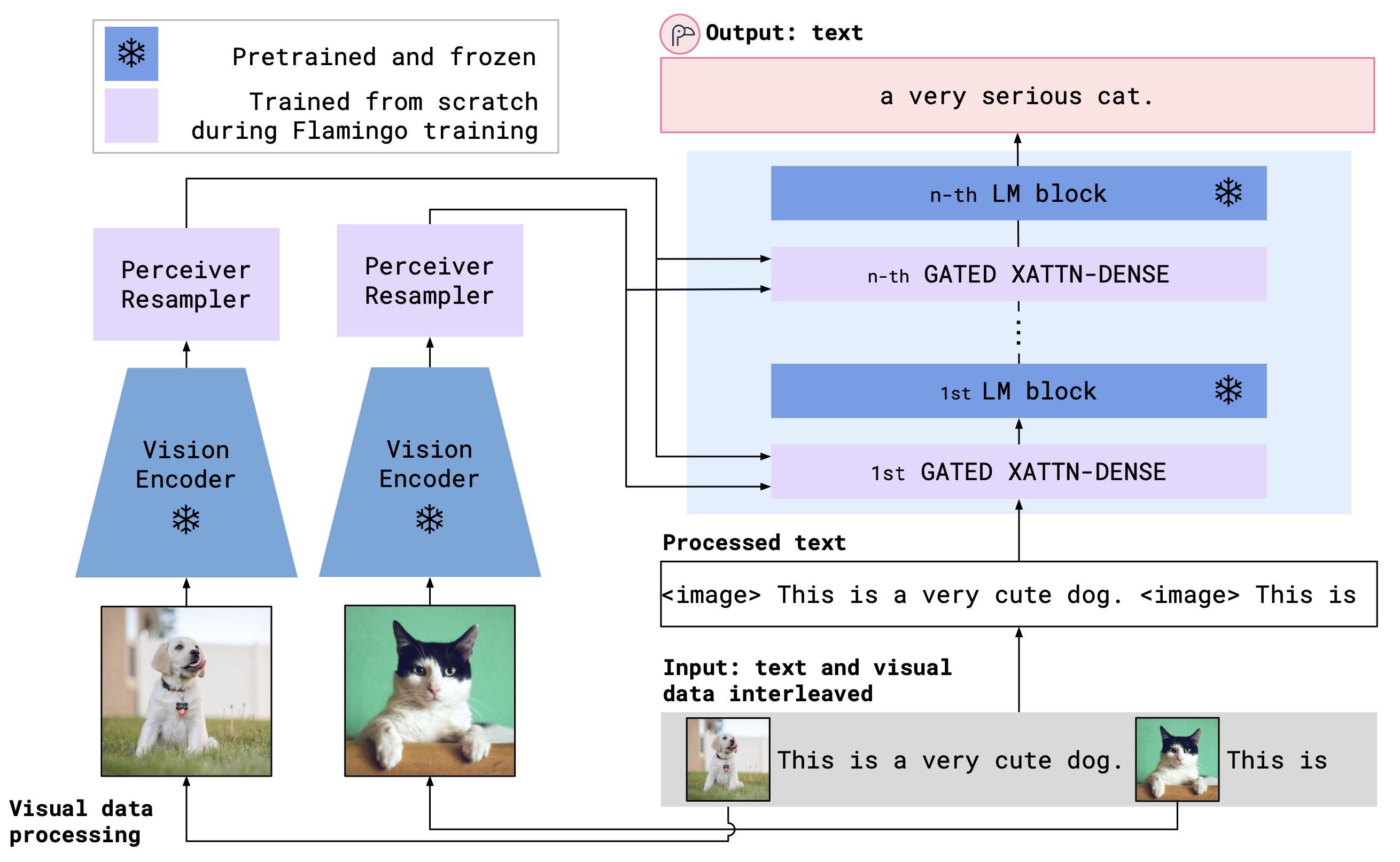
|
open_flamingo/environment.yml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: openflamingo
|
| 2 |
+
channels:
|
| 3 |
+
- defaults
|
| 4 |
+
dependencies:
|
| 5 |
+
- python=3.9
|
| 6 |
+
- conda-forge::openjdk
|
| 7 |
+
- pip
|
| 8 |
+
- pip:
|
| 9 |
+
- -r requirements.txt
|
| 10 |
+
- -e .
|
open_flamingo/open_flamingo/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .src.flamingo import Flamingo
|
| 2 |
+
from .src.factory import create_model_and_transforms
|
open_flamingo/open_flamingo/eval/README.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenFlamingo Evaluation Suite
|
| 2 |
+
|
| 3 |
+
This is the evaluation module of OpenFlamingo. It contains a set of utilities for evaluating multimodal models on various benchmarking datasets.
|
| 4 |
+
|
| 5 |
+
*This module is a work in progress! We will be updating this README as it develops. In the meantime, if you notice an issue, please file a Bug Report or Feature Request [here](https://github.com/mlfoundations/open_flamingo/issues/new/choose).*
|
| 6 |
+
|
| 7 |
+
## Supported datasets
|
| 8 |
+
|
| 9 |
+
|Dataset|Task|Metric|Evaluation method|
|
| 10 |
+
|-------|----|------|-----------------|
|
| 11 |
+
|[COCO](https://arxiv.org/abs/1405.0312)|Captioning|CIDEr|Generation|
|
| 12 |
+
|[Flickr-30K](https://aclanthology.org/Q14-1006/)|Captioning|CIDEr|Generation|
|
| 13 |
+
|[VQAv2](https://arxiv.org/abs/1612.00837v3)|VQA|VQA accuracy|Generation|
|
| 14 |
+
|[OK-VQA](https://arxiv.org/abs/1906.00067)|VQA|VQA accuracy|Generation|
|
| 15 |
+
|[TextVQA](https://arxiv.org/abs/1904.08920)|VQA|VQA accuracy|Generation|
|
| 16 |
+
|[VizWiz](https://arxiv.org/abs/1802.08218)|VQA|VQA accuracy|Generation|
|
| 17 |
+
|[Hateful Memes](https://arxiv.org/abs/2005.04790)|Classification|ROC AUC|Logprobs|
|
| 18 |
+
|[ImageNet](https://arxiv.org/abs/1409.0575)|Classification|Top-1 accuracy|Logprobs|
|
| 19 |
+
|
| 20 |
+
When evaluating a model using `num_shots` shots, we sample the exemplars from the training split. Performance is evaluated on a disjoint test split, subsampled to `--num_samples` examples (or using the full test split if `--num_samples=-1`).
|
| 21 |
+
|
| 22 |
+
## Sample scripts
|
| 23 |
+
Our codebase uses DistributedDataParallel to parallelize evaluation by default, so please make sure to set the `MASTER_ADDR` and `MASTER_PORT` environment variables or use `torchrun`. We provide a sample Slurm evaluation script in `open_flamingo/open_flamingo/scripts/run_eval.sh`.
|
| 24 |
+
|
| 25 |
+
We also support evaluating at a lower precision using the `--precision` flag. We find minimal difference between evaluating at full precision vs. amp_bf16.
|
| 26 |
+
|
| 27 |
+
To evaluate one of our pretrained checkpoints, we suggest first downloading a local copy of the weights, as follows:
|
| 28 |
+
|
| 29 |
+
```
|
| 30 |
+
# grab model checkpoint from huggingface hub
|
| 31 |
+
from huggingface_hub import hf_hub_download
|
| 32 |
+
HF_TOKEN="<your-hf-token-here>"
|
| 33 |
+
|
| 34 |
+
checkpoint_path = hf_hub_download("openflamingo/OpenFlamingo-3B-vitl-mpt1b", "checkpoint.pt")
|
| 35 |
+
checkpoint_path= hf_hub_download("openflamingo/OpenFlamingo-3B-vitl-mpt1b",
|
| 36 |
+
"checkpoint.pt",
|
| 37 |
+
local_dir="openflamingo/OpenFlamingo-3B-vitl-mpt1b",
|
| 38 |
+
cache_dir="openflamingo/OpenFlamingo-3B-vitl-mpt1b",
|
| 39 |
+
local_dir_use_symlinks=False,
|
| 40 |
+
token=HF_TOKEN)
|
| 41 |
+
print(checkpoint_path)
|
| 42 |
+
## openflamingo/OpenFlamingo-3B-vitl-mpt1b/checkpoint.pt
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
This should place the OpenFlamingo model at the expected location in the evaluation script.
|
| 46 |
+
|
| 47 |
+
For TextVQA and VizWiz we expect annotations to be formatted differently than the original datasets. We provide the custom annotations in `open_flamingo/open_flamingo/eval/data/`.
|
open_flamingo/open_flamingo/eval/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
open_flamingo/open_flamingo/eval/classification.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Sequence, Tuple
|
| 2 |
+
import re
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def postprocess_classification_generation(predictions) -> str:
|
| 8 |
+
return re.split("Prompt|Completion", predictions, 1)[0]
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def compute_classification_accuracy(predictions: Sequence[Dict[str, str]]) -> float:
|
| 12 |
+
"""Compute the accuracy of a sequence of predictions."""
|
| 13 |
+
|
| 14 |
+
def _preprocess_fn(s):
|
| 15 |
+
"""Function to preprocess both targets and predictions."""
|
| 16 |
+
return s.lower()
|
| 17 |
+
|
| 18 |
+
is_correct = [
|
| 19 |
+
_preprocess_fn(x["prediction"]) == _preprocess_fn(x["class_label"])
|
| 20 |
+
for x in predictions
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
return np.mean(is_correct).item()
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def compute_shifted_logits_and_labels(
|
| 27 |
+
logits: torch.Tensor, encodings, tokenizer, eoc_token_id
|
| 28 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 29 |
+
"""Helper function to compute shifted logits and labels.
|
| 30 |
+
|
| 31 |
+
This allows for straightforward computation of the loss on shift_logits
|
| 32 |
+
and shift_labels such that the nth element of logits computes the n-1th
|
| 33 |
+
element of the original labels (in the outputs, the nth element of logits
|
| 34 |
+
corresponds to the nth element of the labels).
|
| 35 |
+
|
| 36 |
+
Elements in shift_labels that correspond to inputs are masked with values
|
| 37 |
+
of -100 (by default in hf, loss is only computed on token IDs >= 0).
|
| 38 |
+
|
| 39 |
+
Returns: tuple containing two elements:
|
| 40 |
+
shift_logits: a float Tensor of shape [batch_size, seq_len - 1].
|
| 41 |
+
shift_labels: an integer Tensor of shape [batch_size, seq_len - 1]
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
labels = encodings["input_ids"].clone()
|
| 45 |
+
|
| 46 |
+
# convert padding and EOC tokens to -100 so they are ignored in loss
|
| 47 |
+
labels[labels == tokenizer.pad_token_id] = -100
|
| 48 |
+
labels[labels == eoc_token_id] = -100
|
| 49 |
+
|
| 50 |
+
# Convert all tokens in prefix until separator to -100 so they are
|
| 51 |
+
# ignored in loss
|
| 52 |
+
for idx in range(len(labels)):
|
| 53 |
+
# Find the location of the last token of prefix *from right*,
|
| 54 |
+
# since the first non-padding token of the sequence will also be
|
| 55 |
+
# eos_token (because bos_token and eos_token are the same for
|
| 56 |
+
# the tokenizer).
|
| 57 |
+
end_of_prefix = -labels[idx].tolist()[::-1].index(tokenizer.eos_token_id) - 1
|
| 58 |
+
labels[idx, : end_of_prefix + 1] = -100
|
| 59 |
+
|
| 60 |
+
# Shift so that tokens < n predict n. The shifted tensors both have
|
| 61 |
+
# shape [batch_size, seq_len - 1].
|
| 62 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 63 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 64 |
+
|
| 65 |
+
return shift_logits, shift_labels
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def compute_per_sample_probs(
|
| 69 |
+
encodings, tokenizer, logits: torch.Tensor, eoc_token_id
|
| 70 |
+
) -> torch.Tensor:
|
| 71 |
+
"""Helper function to compute per-sample probability of the input sequence.
|
| 72 |
+
|
| 73 |
+
Assumes <eos token> is used to separate inputs from targets in the
|
| 74 |
+
prompt text
|
| 75 |
+
"""
|
| 76 |
+
shift_logits, shift_labels = compute_shifted_logits_and_labels(
|
| 77 |
+
logits, encodings, tokenizer, eoc_token_id
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
# Tuple of tensors for unmasked label tokens. The first element of the
|
| 81 |
+
# tuple contains the batch indices; the second element contains the
|
| 82 |
+
# sequence indices.
|
| 83 |
+
unmasked_indices = torch.nonzero(shift_labels != -100, as_tuple=True)
|
| 84 |
+
# Tensor where the i^th element is the token_id corresponding to the i^th
|
| 85 |
+
# element of unmasked_indices
|
| 86 |
+
unmasked_token_ids = shift_labels[unmasked_indices]
|
| 87 |
+
|
| 88 |
+
# 3d tensor of [batch_idx, sequence_position, token_id] for unmasked tokens.
|
| 89 |
+
target_idxs = torch.column_stack([*unmasked_indices, unmasked_token_ids])
|
| 90 |
+
target_idxs = target_idxs.to(shift_logits.device)
|
| 91 |
+
|
| 92 |
+
# Sanity check that every element in batch has at least one unmasked
|
| 93 |
+
# target token
|
| 94 |
+
assert torch.all(
|
| 95 |
+
torch.bincount(target_idxs[:, 0]) != 0
|
| 96 |
+
), "At least one element in batch has no unmasked target tokens."
|
| 97 |
+
|
| 98 |
+
# Renormalize over tokens to make sure they are proper probabilities via
|
| 99 |
+
# softmax over the token dimension.
|
| 100 |
+
shift_probs = torch.nn.functional.softmax(shift_logits, 2)
|
| 101 |
+
|
| 102 |
+
# Compute the probability of the target sequence (as the product of the
|
| 103 |
+
# probability of the individual tokens in the sequence).
|
| 104 |
+
target_probs = torch.ones(len(shift_labels), device=shift_logits.device)
|
| 105 |
+
for i, j, k in target_idxs:
|
| 106 |
+
target_probs[i] *= shift_probs[i, j, k]
|
| 107 |
+
|
| 108 |
+
return target_probs
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def compute_per_sample_loss(encodings, tokenizer, logits, eoc_token_id) -> torch.Tensor:
|
| 112 |
+
"""Helper function to compute per-sample classification loss.
|
| 113 |
+
|
| 114 |
+
Assumes <eos token> is used to separate inputs from targets in the
|
| 115 |
+
prompt text
|
| 116 |
+
"""
|
| 117 |
+
shift_logits, shift_labels = compute_shifted_logits_and_labels(
|
| 118 |
+
logits, encodings, tokenizer, eoc_token_id
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
device = shift_logits.device
|
| 122 |
+
|
| 123 |
+
# Loss is computed token-wise, on Tensors of shape
|
| 124 |
+
# [batch_size * (seq_len - 1), vocab_size]
|
| 125 |
+
# and returns a loss tensor of shape
|
| 126 |
+
# [batch_size * (seq_len - 1)]. Most of the tokens will be masked
|
| 127 |
+
# in this computation.
|
| 128 |
+
loss = torch.nn.functional.cross_entropy(
|
| 129 |
+
shift_logits.view(-1, shift_logits.size(-1)),
|
| 130 |
+
shift_labels.view(-1).to(device),
|
| 131 |
+
reduction="none",
|
| 132 |
+
)
|
| 133 |
+
|
| 134 |
+
# Reshape to [batch_size, seq_len - 1]
|
| 135 |
+
loss = loss.view(shift_logits.size(0), shift_logits.size(1)).cpu()
|
| 136 |
+
|
| 137 |
+
# loss_mask is 1 for tokens we want included in the loss, and 0 for tokens
|
| 138 |
+
# that should be ignored in the loss.
|
| 139 |
+
loss_mask = (shift_labels != -100).int().cpu()
|
| 140 |
+
|
| 141 |
+
loss *= loss_mask
|
| 142 |
+
|
| 143 |
+
# Compute per-element loss : sum loss over all (unmasked) tokens and
|
| 144 |
+
# divide by number of variable tokens to obtain tensor of
|
| 145 |
+
# shape [batch_size,]
|
| 146 |
+
loss = loss.sum(dim=1) / (shift_labels != -100).sum(dim=1).float()
|
| 147 |
+
return loss
|
open_flamingo/open_flamingo/eval/classification_utils.py
ADDED
|
@@ -0,0 +1,1014 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# classnames via https://github.com/mlfoundations/wise-ft/blob/master/src/datasets/imagenet_classnames.py#L1
|
| 2 |
+
IMAGENET_CLASSNAMES = [
|
| 3 |
+
"tench",
|
| 4 |
+
"goldfish",
|
| 5 |
+
"great white shark",
|
| 6 |
+
"tiger shark",
|
| 7 |
+
"hammerhead shark",
|
| 8 |
+
"electric ray",
|
| 9 |
+
"stingray",
|
| 10 |
+
"rooster",
|
| 11 |
+
"hen",
|
| 12 |
+
"ostrich",
|
| 13 |
+
"brambling",
|
| 14 |
+
"goldfinch",
|
| 15 |
+
"house finch",
|
| 16 |
+
"junco",
|
| 17 |
+
"indigo bunting",
|
| 18 |
+
"American robin",
|
| 19 |
+
"bulbul",
|
| 20 |
+
"jay",
|
| 21 |
+
"magpie",
|
| 22 |
+
"chickadee",
|
| 23 |
+
"American dipper",
|
| 24 |
+
"kite (bird of prey)",
|
| 25 |
+
"bald eagle",
|
| 26 |
+
"vulture",
|
| 27 |
+
"great grey owl",
|
| 28 |
+
"fire salamander",
|
| 29 |
+
"smooth newt",
|
| 30 |
+
"newt",
|
| 31 |
+
"spotted salamander",
|
| 32 |
+
"axolotl",
|
| 33 |
+
"American bullfrog",
|
| 34 |
+
"tree frog",
|
| 35 |
+
"tailed frog",
|
| 36 |
+
"loggerhead sea turtle",
|
| 37 |
+
"leatherback sea turtle",
|
| 38 |
+
"mud turtle",
|
| 39 |
+
"terrapin",
|
| 40 |
+
"box turtle",
|
| 41 |
+
"banded gecko",
|
| 42 |
+
"green iguana",
|
| 43 |
+
"Carolina anole",
|
| 44 |
+
"desert grassland whiptail lizard",
|
| 45 |
+
"agama",
|
| 46 |
+
"frilled-necked lizard",
|
| 47 |
+
"alligator lizard",
|
| 48 |
+
"Gila monster",
|
| 49 |
+
"European green lizard",
|
| 50 |
+
"chameleon",
|
| 51 |
+
"Komodo dragon",
|
| 52 |
+
"Nile crocodile",
|
| 53 |
+
"American alligator",
|
| 54 |
+
"triceratops",
|
| 55 |
+
"worm snake",
|
| 56 |
+
"ring-necked snake",
|
| 57 |
+
"eastern hog-nosed snake",
|
| 58 |
+
"smooth green snake",
|
| 59 |
+
"kingsnake",
|
| 60 |
+
"garter snake",
|
| 61 |
+
"water snake",
|
| 62 |
+
"vine snake",
|
| 63 |
+
"night snake",
|
| 64 |
+
"boa constrictor",
|
| 65 |
+
"African rock python",
|
| 66 |
+
"Indian cobra",
|
| 67 |
+
"green mamba",
|
| 68 |
+
"sea snake",
|
| 69 |
+
"Saharan horned viper",
|
| 70 |
+
"eastern diamondback rattlesnake",
|
| 71 |
+
"sidewinder rattlesnake",
|
| 72 |
+
"trilobite",
|
| 73 |
+
"harvestman",
|
| 74 |
+
"scorpion",
|
| 75 |
+
"yellow garden spider",
|
| 76 |
+
"barn spider",
|
| 77 |
+
"European garden spider",
|
| 78 |
+
"southern black widow",
|
| 79 |
+
"tarantula",
|
| 80 |
+
"wolf spider",
|
| 81 |
+
"tick",
|
| 82 |
+
"centipede",
|
| 83 |
+
"black grouse",
|
| 84 |
+
"ptarmigan",
|
| 85 |
+
"ruffed grouse",
|
| 86 |
+
"prairie grouse",
|
| 87 |
+
"peafowl",
|
| 88 |
+
"quail",
|
| 89 |
+
"partridge",
|
| 90 |
+
"african grey parrot",
|
| 91 |
+
"macaw",
|
| 92 |
+
"sulphur-crested cockatoo",
|
| 93 |
+
"lorikeet",
|
| 94 |
+
"coucal",
|
| 95 |
+
"bee eater",
|
| 96 |
+
"hornbill",
|
| 97 |
+
"hummingbird",
|
| 98 |
+
"jacamar",
|
| 99 |
+
"toucan",
|
| 100 |
+
"duck",
|
| 101 |
+
"red-breasted merganser",
|
| 102 |
+
"goose",
|
| 103 |
+
"black swan",
|
| 104 |
+
"tusker",
|
| 105 |
+
"echidna",
|
| 106 |
+
"platypus",
|
| 107 |
+
"wallaby",
|
| 108 |
+
"koala",
|
| 109 |
+
"wombat",
|
| 110 |
+
"jellyfish",
|
| 111 |
+
"sea anemone",
|
| 112 |
+
"brain coral",
|
| 113 |
+
"flatworm",
|
| 114 |
+
"nematode",
|
| 115 |
+
"conch",
|
| 116 |
+
"snail",
|
| 117 |
+
"slug",
|
| 118 |
+
"sea slug",
|
| 119 |
+
"chiton",
|
| 120 |
+
"chambered nautilus",
|
| 121 |
+
"Dungeness crab",
|
| 122 |
+
"rock crab",
|
| 123 |
+
"fiddler crab",
|
| 124 |
+
"red king crab",
|
| 125 |
+
"American lobster",
|
| 126 |
+
"spiny lobster",
|
| 127 |
+
"crayfish",
|
| 128 |
+
"hermit crab",
|
| 129 |
+
"isopod",
|
| 130 |
+
"white stork",
|
| 131 |
+
"black stork",
|
| 132 |
+
"spoonbill",
|
| 133 |
+
"flamingo",
|
| 134 |
+
"little blue heron",
|
| 135 |
+
"great egret",
|
| 136 |
+
"bittern bird",
|
| 137 |
+
"crane bird",
|
| 138 |
+
"limpkin",
|
| 139 |
+
"common gallinule",
|
| 140 |
+
"American coot",
|
| 141 |
+
"bustard",
|
| 142 |
+
"ruddy turnstone",
|
| 143 |
+
"dunlin",
|
| 144 |
+
"common redshank",
|
| 145 |
+
"dowitcher",
|
| 146 |
+
"oystercatcher",
|
| 147 |
+
"pelican",
|
| 148 |
+
"king penguin",
|
| 149 |
+
"albatross",
|
| 150 |
+
"grey whale",
|
| 151 |
+
"killer whale",
|
| 152 |
+
"dugong",
|
| 153 |
+
"sea lion",
|
| 154 |
+
"Chihuahua",
|
| 155 |
+
"Japanese Chin",
|
| 156 |
+
"Maltese",
|
| 157 |
+
"Pekingese",
|
| 158 |
+
"Shih Tzu",
|
| 159 |
+
"King Charles Spaniel",
|
| 160 |
+
"Papillon",
|
| 161 |
+
"toy terrier",
|
| 162 |
+
"Rhodesian Ridgeback",
|
| 163 |
+
"Afghan Hound",
|
| 164 |
+
"Basset Hound",
|
| 165 |
+
"Beagle",
|
| 166 |
+
"Bloodhound",
|
| 167 |
+
"Bluetick Coonhound",
|
| 168 |
+
"Black and Tan Coonhound",
|
| 169 |
+
"Treeing Walker Coonhound",
|
| 170 |
+
"English foxhound",
|
| 171 |
+
"Redbone Coonhound",
|
| 172 |
+
"borzoi",
|
| 173 |
+
"Irish Wolfhound",
|
| 174 |
+
"Italian Greyhound",
|
| 175 |
+
"Whippet",
|
| 176 |
+
"Ibizan Hound",
|
| 177 |
+
"Norwegian Elkhound",
|
| 178 |
+
"Otterhound",
|
| 179 |
+
"Saluki",
|
| 180 |
+
"Scottish Deerhound",
|
| 181 |
+
"Weimaraner",
|
| 182 |
+
"Staffordshire Bull Terrier",
|
| 183 |
+
"American Staffordshire Terrier",
|
| 184 |
+
"Bedlington Terrier",
|
| 185 |
+
"Border Terrier",
|
| 186 |
+
"Kerry Blue Terrier",
|
| 187 |
+
"Irish Terrier",
|
| 188 |
+
"Norfolk Terrier",
|
| 189 |
+
"Norwich Terrier",
|
| 190 |
+
"Yorkshire Terrier",
|
| 191 |
+
"Wire Fox Terrier",
|
| 192 |
+
"Lakeland Terrier",
|
| 193 |
+
"Sealyham Terrier",
|
| 194 |
+
"Airedale Terrier",
|
| 195 |
+
"Cairn Terrier",
|
| 196 |
+
"Australian Terrier",
|
| 197 |
+
"Dandie Dinmont Terrier",
|
| 198 |
+
"Boston Terrier",
|
| 199 |
+
"Miniature Schnauzer",
|
| 200 |
+
"Giant Schnauzer",
|
| 201 |
+
"Standard Schnauzer",
|
| 202 |
+
"Scottish Terrier",
|
| 203 |
+
"Tibetan Terrier",
|
| 204 |
+
"Australian Silky Terrier",
|
| 205 |
+
"Soft-coated Wheaten Terrier",
|
| 206 |
+
"West Highland White Terrier",
|
| 207 |
+
"Lhasa Apso",
|
| 208 |
+
"Flat-Coated Retriever",
|
| 209 |
+
"Curly-coated Retriever",
|
| 210 |
+
"Golden Retriever",
|
| 211 |
+
"Labrador Retriever",
|
| 212 |
+
"Chesapeake Bay Retriever",
|
| 213 |
+
"German Shorthaired Pointer",
|
| 214 |
+
"Vizsla",
|
| 215 |
+
"English Setter",
|
| 216 |
+
"Irish Setter",
|
| 217 |
+
"Gordon Setter",
|
| 218 |
+
"Brittany dog",
|
| 219 |
+
"Clumber Spaniel",
|
| 220 |
+
"English Springer Spaniel",
|
| 221 |
+
"Welsh Springer Spaniel",
|
| 222 |
+
"Cocker Spaniel",
|
| 223 |
+
"Sussex Spaniel",
|
| 224 |
+
"Irish Water Spaniel",
|
| 225 |
+
"Kuvasz",
|
| 226 |
+
"Schipperke",
|
| 227 |
+
"Groenendael dog",
|
| 228 |
+
"Malinois",
|
| 229 |
+
"Briard",
|
| 230 |
+
"Australian Kelpie",
|
| 231 |
+
"Komondor",
|
| 232 |
+
"Old English Sheepdog",
|
| 233 |
+
"Shetland Sheepdog",
|
| 234 |
+
"collie",
|
| 235 |
+
"Border Collie",
|
| 236 |
+
"Bouvier des Flandres dog",
|
| 237 |
+
"Rottweiler",
|
| 238 |
+
"German Shepherd Dog",
|
| 239 |
+
"Dobermann",
|
| 240 |
+
"Miniature Pinscher",
|
| 241 |
+
"Greater Swiss Mountain Dog",
|
| 242 |
+
"Bernese Mountain Dog",
|
| 243 |
+
"Appenzeller Sennenhund",
|
| 244 |
+
"Entlebucher Sennenhund",
|
| 245 |
+
"Boxer",
|
| 246 |
+
"Bullmastiff",
|
| 247 |
+
"Tibetan Mastiff",
|
| 248 |
+
"French Bulldog",
|
| 249 |
+
"Great Dane",
|
| 250 |
+
"St. Bernard",
|
| 251 |
+
"husky",
|
| 252 |
+
"Alaskan Malamute",
|
| 253 |
+
"Siberian Husky",
|
| 254 |
+
"Dalmatian",
|
| 255 |
+
"Affenpinscher",
|
| 256 |
+
"Basenji",
|
| 257 |
+
"pug",
|
| 258 |
+
"Leonberger",
|
| 259 |
+
"Newfoundland dog",
|
| 260 |
+
"Great Pyrenees dog",
|
| 261 |
+
"Samoyed",
|
| 262 |
+
"Pomeranian",
|
| 263 |
+
"Chow Chow",
|
| 264 |
+
"Keeshond",
|
| 265 |
+
"brussels griffon",
|
| 266 |
+
"Pembroke Welsh Corgi",
|
| 267 |
+
"Cardigan Welsh Corgi",
|
| 268 |
+
"Toy Poodle",
|
| 269 |
+
"Miniature Poodle",
|
| 270 |
+
"Standard Poodle",
|
| 271 |
+
"Mexican hairless dog (xoloitzcuintli)",
|
| 272 |
+
"grey wolf",
|
| 273 |
+
"Alaskan tundra wolf",
|
| 274 |
+
"red wolf or maned wolf",
|
| 275 |
+
"coyote",
|
| 276 |
+
"dingo",
|
| 277 |
+
"dhole",
|
| 278 |
+
"African wild dog",
|
| 279 |
+
"hyena",
|
| 280 |
+
"red fox",
|
| 281 |
+
"kit fox",
|
| 282 |
+
"Arctic fox",
|
| 283 |
+
"grey fox",
|
| 284 |
+
"tabby cat",
|
| 285 |
+
"tiger cat",
|
| 286 |
+
"Persian cat",
|
| 287 |
+
"Siamese cat",
|
| 288 |
+
"Egyptian Mau",
|
| 289 |
+
"cougar",
|
| 290 |
+
"lynx",
|
| 291 |
+
"leopard",
|
| 292 |
+
"snow leopard",
|
| 293 |
+
"jaguar",
|
| 294 |
+
"lion",
|
| 295 |
+
"tiger",
|
| 296 |
+
"cheetah",
|
| 297 |
+
"brown bear",
|
| 298 |
+
"American black bear",
|
| 299 |
+
"polar bear",
|
| 300 |
+
"sloth bear",
|
| 301 |
+
"mongoose",
|
| 302 |
+
"meerkat",
|
| 303 |
+
"tiger beetle",
|
| 304 |
+
"ladybug",
|
| 305 |
+
"ground beetle",
|
| 306 |
+
"longhorn beetle",
|
| 307 |
+
"leaf beetle",
|
| 308 |
+
"dung beetle",
|
| 309 |
+
"rhinoceros beetle",
|
| 310 |
+
"weevil",
|
| 311 |
+
"fly",
|
| 312 |
+
"bee",
|
| 313 |
+
"ant",
|
| 314 |
+
"grasshopper",
|
| 315 |
+
"cricket insect",
|
| 316 |
+
"stick insect",
|
| 317 |
+
"cockroach",
|
| 318 |
+
"praying mantis",
|
| 319 |
+
"cicada",
|
| 320 |
+
"leafhopper",
|
| 321 |
+
"lacewing",
|
| 322 |
+
"dragonfly",
|
| 323 |
+
"damselfly",
|
| 324 |
+
"red admiral butterfly",
|
| 325 |
+
"ringlet butterfly",
|
| 326 |
+
"monarch butterfly",
|
| 327 |
+
"small white butterfly",
|
| 328 |
+
"sulphur butterfly",
|
| 329 |
+
"gossamer-winged butterfly",
|
| 330 |
+
"starfish",
|
| 331 |
+
"sea urchin",
|
| 332 |
+
"sea cucumber",
|
| 333 |
+
"cottontail rabbit",
|
| 334 |
+
"hare",
|
| 335 |
+
"Angora rabbit",
|
| 336 |
+
"hamster",
|
| 337 |
+
"porcupine",
|
| 338 |
+
"fox squirrel",
|
| 339 |
+
"marmot",
|
| 340 |
+
"beaver",
|
| 341 |
+
"guinea pig",
|
| 342 |
+
"common sorrel horse",
|
| 343 |
+
"zebra",
|
| 344 |
+
"pig",
|
| 345 |
+
"wild boar",
|
| 346 |
+
"warthog",
|
| 347 |
+
"hippopotamus",
|
| 348 |
+
"ox",
|
| 349 |
+
"water buffalo",
|
| 350 |
+
"bison",
|
| 351 |
+
"ram (adult male sheep)",
|
| 352 |
+
"bighorn sheep",
|
| 353 |
+
"Alpine ibex",
|
| 354 |
+
"hartebeest",
|
| 355 |
+
"impala (antelope)",
|
| 356 |
+
"gazelle",
|
| 357 |
+
"arabian camel",
|
| 358 |
+
"llama",
|
| 359 |
+
"weasel",
|
| 360 |
+
"mink",
|
| 361 |
+
"European polecat",
|
| 362 |
+
"black-footed ferret",
|
| 363 |
+
"otter",
|
| 364 |
+
"skunk",
|
| 365 |
+
"badger",
|
| 366 |
+
"armadillo",
|
| 367 |
+
"three-toed sloth",
|
| 368 |
+
"orangutan",
|
| 369 |
+
"gorilla",
|
| 370 |
+
"chimpanzee",
|
| 371 |
+
"gibbon",
|
| 372 |
+
"siamang",
|
| 373 |
+
"guenon",
|
| 374 |
+
"patas monkey",
|
| 375 |
+
"baboon",
|
| 376 |
+
"macaque",
|
| 377 |
+
"langur",
|
| 378 |
+
"black-and-white colobus",
|
| 379 |
+
"proboscis monkey",
|
| 380 |
+
"marmoset",
|
| 381 |
+
"white-headed capuchin",
|
| 382 |
+
"howler monkey",
|
| 383 |
+
"titi monkey",
|
| 384 |
+
"Geoffroy's spider monkey",
|
| 385 |
+
"common squirrel monkey",
|
| 386 |
+
"ring-tailed lemur",
|
| 387 |
+
"indri",
|
| 388 |
+
"Asian elephant",
|
| 389 |
+
"African bush elephant",
|
| 390 |
+
"red panda",
|
| 391 |
+
"giant panda",
|
| 392 |
+
"snoek fish",
|
| 393 |
+
"eel",
|
| 394 |
+
"silver salmon",
|
| 395 |
+
"rock beauty fish",
|
| 396 |
+
"clownfish",
|
| 397 |
+
"sturgeon",
|
| 398 |
+
"gar fish",
|
| 399 |
+
"lionfish",
|
| 400 |
+
"pufferfish",
|
| 401 |
+
"abacus",
|
| 402 |
+
"abaya",
|
| 403 |
+
"academic gown",
|
| 404 |
+
"accordion",
|
| 405 |
+
"acoustic guitar",
|
| 406 |
+
"aircraft carrier",
|
| 407 |
+
"airliner",
|
| 408 |
+
"airship",
|
| 409 |
+
"altar",
|
| 410 |
+
"ambulance",
|
| 411 |
+
"amphibious vehicle",
|
| 412 |
+
"analog clock",
|
| 413 |
+
"apiary",
|
| 414 |
+
"apron",
|
| 415 |
+
"trash can",
|
| 416 |
+
"assault rifle",
|
| 417 |
+
"backpack",
|
| 418 |
+
"bakery",
|
| 419 |
+
"balance beam",
|
| 420 |
+
"balloon",
|
| 421 |
+
"ballpoint pen",
|
| 422 |
+
"Band-Aid",
|
| 423 |
+
"banjo",
|
| 424 |
+
"baluster / handrail",
|
| 425 |
+
"barbell",
|
| 426 |
+
"barber chair",
|
| 427 |
+
"barbershop",
|
| 428 |
+
"barn",
|
| 429 |
+
"barometer",
|
| 430 |
+
"barrel",
|
| 431 |
+
"wheelbarrow",
|
| 432 |
+
"baseball",
|
| 433 |
+
"basketball",
|
| 434 |
+
"bassinet",
|
| 435 |
+
"bassoon",
|
| 436 |
+
"swimming cap",
|
| 437 |
+
"bath towel",
|
| 438 |
+
"bathtub",
|
| 439 |
+
"station wagon",
|
| 440 |
+
"lighthouse",
|
| 441 |
+
"beaker",
|
| 442 |
+
"military hat (bearskin or shako)",
|
| 443 |
+
"beer bottle",
|
| 444 |
+
"beer glass",
|
| 445 |
+
"bell tower",
|
| 446 |
+
"baby bib",
|
| 447 |
+
"tandem bicycle",
|
| 448 |
+
"bikini",
|
| 449 |
+
"ring binder",
|
| 450 |
+
"binoculars",
|
| 451 |
+
"birdhouse",
|
| 452 |
+
"boathouse",
|
| 453 |
+
"bobsleigh",
|
| 454 |
+
"bolo tie",
|
| 455 |
+
"poke bonnet",
|
| 456 |
+
"bookcase",
|
| 457 |
+
"bookstore",
|
| 458 |
+
"bottle cap",
|
| 459 |
+
"hunting bow",
|
| 460 |
+
"bow tie",
|
| 461 |
+
"brass memorial plaque",
|
| 462 |
+
"bra",
|
| 463 |
+
"breakwater",
|
| 464 |
+
"breastplate",
|
| 465 |
+
"broom",
|
| 466 |
+
"bucket",
|
| 467 |
+
"buckle",
|
| 468 |
+
"bulletproof vest",
|
| 469 |
+
"high-speed train",
|
| 470 |
+
"butcher shop",
|
| 471 |
+
"taxicab",
|
| 472 |
+
"cauldron",
|
| 473 |
+
"candle",
|
| 474 |
+
"cannon",
|
| 475 |
+
"canoe",
|
| 476 |
+
"can opener",
|
| 477 |
+
"cardigan",
|
| 478 |
+
"car mirror",
|
| 479 |
+
"carousel",
|
| 480 |
+
"tool kit",
|
| 481 |
+
"cardboard box / carton",
|
| 482 |
+
"car wheel",
|
| 483 |
+
"automated teller machine",
|
| 484 |
+
"cassette",
|
| 485 |
+
"cassette player",
|
| 486 |
+
"castle",
|
| 487 |
+
"catamaran",
|
| 488 |
+
"CD player",
|
| 489 |
+
"cello",
|
| 490 |
+
"mobile phone",
|
| 491 |
+
"chain",
|
| 492 |
+
"chain-link fence",
|
| 493 |
+
"chain mail",
|
| 494 |
+
"chainsaw",
|
| 495 |
+
"storage chest",
|
| 496 |
+
"chiffonier",
|
| 497 |
+
"bell or wind chime",
|
| 498 |
+
"china cabinet",
|
| 499 |
+
"Christmas stocking",
|
| 500 |
+
"church",
|
| 501 |
+
"movie theater",
|
| 502 |
+
"cleaver",
|
| 503 |
+
"cliff dwelling",
|
| 504 |
+
"cloak",
|
| 505 |
+
"clogs",
|
| 506 |
+
"cocktail shaker",
|
| 507 |
+
"coffee mug",
|
| 508 |
+
"coffeemaker",
|
| 509 |
+
"spiral or coil",
|
| 510 |
+
"combination lock",
|
| 511 |
+
"computer keyboard",
|
| 512 |
+
"candy store",
|
| 513 |
+
"container ship",
|
| 514 |
+
"convertible",
|
| 515 |
+
"corkscrew",
|
| 516 |
+
"cornet",
|
| 517 |
+
"cowboy boot",
|
| 518 |
+
"cowboy hat",
|
| 519 |
+
"cradle",
|
| 520 |
+
"construction crane",
|
| 521 |
+
"crash helmet",
|
| 522 |
+
"crate",
|
| 523 |
+
"infant bed",
|
| 524 |
+
"Crock Pot",
|
| 525 |
+
"croquet ball",
|
| 526 |
+
"crutch",
|
| 527 |
+
"cuirass",
|
| 528 |
+
"dam",
|
| 529 |
+
"desk",
|
| 530 |
+
"desktop computer",
|
| 531 |
+
"rotary dial telephone",
|
| 532 |
+
"diaper",
|
| 533 |
+
"digital clock",
|
| 534 |
+
"digital watch",
|
| 535 |
+
"dining table",
|
| 536 |
+
"dishcloth",
|
| 537 |
+
"dishwasher",
|
| 538 |
+
"disc brake",
|
| 539 |
+
"dock",
|
| 540 |
+
"dog sled",
|
| 541 |
+
"dome",
|
| 542 |
+
"doormat",
|
| 543 |
+
"drilling rig",
|
| 544 |
+
"drum",
|
| 545 |
+
"drumstick",
|
| 546 |
+
"dumbbell",
|
| 547 |
+
"Dutch oven",
|
| 548 |
+
"electric fan",
|
| 549 |
+
"electric guitar",
|
| 550 |
+
"electric locomotive",
|
| 551 |
+
"entertainment center",
|
| 552 |
+
"envelope",
|
| 553 |
+
"espresso machine",
|
| 554 |
+
"face powder",
|
| 555 |
+
"feather boa",
|
| 556 |
+
"filing cabinet",
|
| 557 |
+
"fireboat",
|
| 558 |
+
"fire truck",
|
| 559 |
+
"fire screen",
|
| 560 |
+
"flagpole",
|
| 561 |
+
"flute",
|
| 562 |
+
"folding chair",
|
| 563 |
+
"football helmet",
|
| 564 |
+
"forklift",
|
| 565 |
+
"fountain",
|
| 566 |
+
"fountain pen",
|
| 567 |
+
"four-poster bed",
|
| 568 |
+
"freight car",
|
| 569 |
+
"French horn",
|
| 570 |
+
"frying pan",
|
| 571 |
+
"fur coat",
|
| 572 |
+
"garbage truck",
|
| 573 |
+
"gas mask or respirator",
|
| 574 |
+
"gas pump",
|
| 575 |
+
"goblet",
|
| 576 |
+
"go-kart",
|
| 577 |
+
"golf ball",
|
| 578 |
+
"golf cart",
|
| 579 |
+
"gondola",
|
| 580 |
+
"gong",
|
| 581 |
+
"gown",
|
| 582 |
+
"grand piano",
|
| 583 |
+
"greenhouse",
|
| 584 |
+
"radiator grille",
|
| 585 |
+
"grocery store",
|
| 586 |
+
"guillotine",
|
| 587 |
+
"hair clip",
|
| 588 |
+
"hair spray",
|
| 589 |
+
"half-track",
|
| 590 |
+
"hammer",
|
| 591 |
+
"hamper",
|
| 592 |
+
"hair dryer",
|
| 593 |
+
"hand-held computer",
|
| 594 |
+
"handkerchief",
|
| 595 |
+
"hard disk drive",
|
| 596 |
+
"harmonica",
|
| 597 |
+
"harp",
|
| 598 |
+
"combine harvester",
|
| 599 |
+
"hatchet",
|
| 600 |
+
"holster",
|
| 601 |
+
"home theater",
|
| 602 |
+
"honeycomb",
|
| 603 |
+
"hook",
|
| 604 |
+
"hoop skirt",
|
| 605 |
+
"gymnastic horizontal bar",
|
| 606 |
+
"horse-drawn vehicle",
|
| 607 |
+
"hourglass",
|
| 608 |
+
"iPod",
|
| 609 |
+
"clothes iron",
|
| 610 |
+
"carved pumpkin",
|
| 611 |
+
"jeans",
|
| 612 |
+
"jeep",
|
| 613 |
+
"T-shirt",
|
| 614 |
+
"jigsaw puzzle",
|
| 615 |
+
"rickshaw",
|
| 616 |
+
"joystick",
|
| 617 |
+
"kimono",
|
| 618 |
+
"knee pad",
|
| 619 |
+
"knot",
|
| 620 |
+
"lab coat",
|
| 621 |
+
"ladle",
|
| 622 |
+
"lampshade",
|
| 623 |
+
"laptop computer",
|
| 624 |
+
"lawn mower",
|
| 625 |
+
"lens cap",
|
| 626 |
+
"letter opener",
|
| 627 |
+
"library",
|
| 628 |
+
"lifeboat",
|
| 629 |
+
"lighter",
|
| 630 |
+
"limousine",
|
| 631 |
+
"ocean liner",
|
| 632 |
+
"lipstick",
|
| 633 |
+
"slip-on shoe",
|
| 634 |
+
"lotion",
|
| 635 |
+
"music speaker",
|
| 636 |
+
"loupe magnifying glass",
|
| 637 |
+
"sawmill",
|
| 638 |
+
"magnetic compass",
|
| 639 |
+
"messenger bag",
|
| 640 |
+
"mailbox",
|
| 641 |
+
"tights",
|
| 642 |
+
"one-piece bathing suit",
|
| 643 |
+
"manhole cover",
|
| 644 |
+
"maraca",
|
| 645 |
+
"marimba",
|
| 646 |
+
"mask",
|
| 647 |
+
"matchstick",
|
| 648 |
+
"maypole",
|
| 649 |
+
"maze",
|
| 650 |
+
"measuring cup",
|
| 651 |
+
"medicine cabinet",
|
| 652 |
+
"megalith",
|
| 653 |
+
"microphone",
|
| 654 |
+
"microwave oven",
|
| 655 |
+
"military uniform",
|
| 656 |
+
"milk can",
|
| 657 |
+
"minibus",
|
| 658 |
+
"miniskirt",
|
| 659 |
+
"minivan",
|
| 660 |
+
"missile",
|
| 661 |
+
"mitten",
|
| 662 |
+
"mixing bowl",
|
| 663 |
+
"mobile home",
|
| 664 |
+
"ford model t",
|
| 665 |
+
"modem",
|
| 666 |
+
"monastery",
|
| 667 |
+
"monitor",
|
| 668 |
+
"moped",
|
| 669 |
+
"mortar and pestle",
|
| 670 |
+
"graduation cap",
|
| 671 |
+
"mosque",
|
| 672 |
+
"mosquito net",
|
| 673 |
+
"vespa",
|
| 674 |
+
"mountain bike",
|
| 675 |
+
"tent",
|
| 676 |
+
"computer mouse",
|
| 677 |
+
"mousetrap",
|
| 678 |
+
"moving van",
|
| 679 |
+
"muzzle",
|
| 680 |
+
"metal nail",
|
| 681 |
+
"neck brace",
|
| 682 |
+
"necklace",
|
| 683 |
+
"baby pacifier",
|
| 684 |
+
"notebook computer",
|
| 685 |
+
"obelisk",
|
| 686 |
+
"oboe",
|
| 687 |
+
"ocarina",
|
| 688 |
+
"odometer",
|
| 689 |
+
"oil filter",
|
| 690 |
+
"pipe organ",
|
| 691 |
+
"oscilloscope",
|
| 692 |
+
"overskirt",
|
| 693 |
+
"bullock cart",
|
| 694 |
+
"oxygen mask",
|
| 695 |
+
"product packet / packaging",
|
| 696 |
+
"paddle",
|
| 697 |
+
"paddle wheel",
|
| 698 |
+
"padlock",
|
| 699 |
+
"paintbrush",
|
| 700 |
+
"pajamas",
|
| 701 |
+
"palace",
|
| 702 |
+
"pan flute",
|
| 703 |
+
"paper towel",
|
| 704 |
+
"parachute",
|
| 705 |
+
"parallel bars",
|
| 706 |
+
"park bench",
|
| 707 |
+
"parking meter",
|
| 708 |
+
"railroad car",
|
| 709 |
+
"patio",
|
| 710 |
+
"payphone",
|
| 711 |
+
"pedestal",
|
| 712 |
+
"pencil case",
|
| 713 |
+
"pencil sharpener",
|
| 714 |
+
"perfume",
|
| 715 |
+
"Petri dish",
|
| 716 |
+
"photocopier",
|
| 717 |
+
"plectrum",
|
| 718 |
+
"Pickelhaube",
|
| 719 |
+
"picket fence",
|
| 720 |
+
"pickup truck",
|
| 721 |
+
"pier",
|
| 722 |
+
"piggy bank",
|
| 723 |
+
"pill bottle",
|
| 724 |
+
"pillow",
|
| 725 |
+
"ping-pong ball",
|
| 726 |
+
"pinwheel",
|
| 727 |
+
"pirate ship",
|
| 728 |
+
"drink pitcher",
|
| 729 |
+
"block plane",
|
| 730 |
+
"planetarium",
|
| 731 |
+
"plastic bag",
|
| 732 |
+
"plate rack",
|
| 733 |
+
"farm plow",
|
| 734 |
+
"plunger",
|
| 735 |
+
"Polaroid camera",
|
| 736 |
+
"pole",
|
| 737 |
+
"police van",
|
| 738 |
+
"poncho",
|
| 739 |
+
"pool table",
|
| 740 |
+
"soda bottle",
|
| 741 |
+
"plant pot",
|
| 742 |
+
"potter's wheel",
|
| 743 |
+
"power drill",
|
| 744 |
+
"prayer rug",
|
| 745 |
+
"printer",
|
| 746 |
+
"prison",
|
| 747 |
+
"missile",
|
| 748 |
+
"projector",
|
| 749 |
+
"hockey puck",
|
| 750 |
+
"punching bag",
|
| 751 |
+
"purse",
|
| 752 |
+
"quill",
|
| 753 |
+
"quilt",
|
| 754 |
+
"race car",
|
| 755 |
+
"racket",
|
| 756 |
+
"radiator",
|
| 757 |
+
"radio",
|
| 758 |
+
"radio telescope",
|
| 759 |
+
"rain barrel",
|
| 760 |
+
"recreational vehicle",
|
| 761 |
+
"fishing casting reel",
|
| 762 |
+
"reflex camera",
|
| 763 |
+
"refrigerator",
|
| 764 |
+
"remote control",
|
| 765 |
+
"restaurant",
|
| 766 |
+
"revolver",
|
| 767 |
+
"rifle",
|
| 768 |
+
"rocking chair",
|
| 769 |
+
"rotisserie",
|
| 770 |
+
"eraser",
|
| 771 |
+
"rugby ball",
|
| 772 |
+
"ruler measuring stick",
|
| 773 |
+
"sneaker",
|
| 774 |
+
"safe",
|
| 775 |
+
"safety pin",
|
| 776 |
+
"salt shaker",
|
| 777 |
+
"sandal",
|
| 778 |
+
"sarong",
|
| 779 |
+
"saxophone",
|
| 780 |
+
"scabbard",
|
| 781 |
+
"weighing scale",
|
| 782 |
+
"school bus",
|
| 783 |
+
"schooner",
|
| 784 |
+
"scoreboard",
|
| 785 |
+
"CRT monitor",
|
| 786 |
+
"screw",
|
| 787 |
+
"screwdriver",
|
| 788 |
+
"seat belt",
|
| 789 |
+
"sewing machine",
|
| 790 |
+
"shield",
|
| 791 |
+
"shoe store",
|
| 792 |
+
"shoji screen / room divider",
|
| 793 |
+
"shopping basket",
|
| 794 |
+
"shopping cart",
|
| 795 |
+
"shovel",
|
| 796 |
+
"shower cap",
|
| 797 |
+
"shower curtain",
|
| 798 |
+
"ski",
|
| 799 |
+
"balaclava ski mask",
|
| 800 |
+
"sleeping bag",
|
| 801 |
+
"slide rule",
|
| 802 |
+
"sliding door",
|
| 803 |
+
"slot machine",
|
| 804 |
+
"snorkel",
|
| 805 |
+
"snowmobile",
|
| 806 |
+
"snowplow",
|
| 807 |
+
"soap dispenser",
|
| 808 |
+
"soccer ball",
|
| 809 |
+
"sock",
|
| 810 |
+
"solar thermal collector",
|
| 811 |
+
"sombrero",
|
| 812 |
+
"soup bowl",
|
| 813 |
+
"keyboard space bar",
|
| 814 |
+
"space heater",
|
| 815 |
+
"space shuttle",
|
| 816 |
+
"spatula",
|
| 817 |
+
"motorboat",
|
| 818 |
+
"spider web",
|
| 819 |
+
"spindle",
|
| 820 |
+
"sports car",
|
| 821 |
+
"spotlight",
|
| 822 |
+
"stage",
|
| 823 |
+
"steam locomotive",
|
| 824 |
+
"through arch bridge",
|
| 825 |
+
"steel drum",
|
| 826 |
+
"stethoscope",
|
| 827 |
+
"scarf",
|
| 828 |
+
"stone wall",
|
| 829 |
+
"stopwatch",
|
| 830 |
+
"stove",
|
| 831 |
+
"strainer",
|
| 832 |
+
"tram",
|
| 833 |
+
"stretcher",
|
| 834 |
+
"couch",
|
| 835 |
+
"stupa",
|
| 836 |
+
"submarine",
|
| 837 |
+
"suit",
|
| 838 |
+
"sundial",
|
| 839 |
+
"sunglasses",
|
| 840 |
+
"sunglasses",
|
| 841 |
+
"sunscreen",
|
| 842 |
+
"suspension bridge",
|
| 843 |
+
"mop",
|
| 844 |
+
"sweatshirt",
|
| 845 |
+
"swim trunks / shorts",
|
| 846 |
+
"swing",
|
| 847 |
+
"electrical switch",
|
| 848 |
+
"syringe",
|
| 849 |
+
"table lamp",
|
| 850 |
+
"tank",
|
| 851 |
+
"tape player",
|
| 852 |
+
"teapot",
|
| 853 |
+
"teddy bear",
|
| 854 |
+
"television",
|
| 855 |
+
"tennis ball",
|
| 856 |
+
"thatched roof",
|
| 857 |
+
"front curtain",
|
| 858 |
+
"thimble",
|
| 859 |
+
"threshing machine",
|
| 860 |
+
"throne",
|
| 861 |
+
"tile roof",
|
| 862 |
+
"toaster",
|
| 863 |
+
"tobacco shop",
|
| 864 |
+
"toilet seat",
|
| 865 |
+
"torch",
|
| 866 |
+
"totem pole",
|
| 867 |
+
"tow truck",
|
| 868 |
+
"toy store",
|
| 869 |
+
"tractor",
|
| 870 |
+
"semi-trailer truck",
|
| 871 |
+
"tray",
|
| 872 |
+
"trench coat",
|
| 873 |
+
"tricycle",
|
| 874 |
+
"trimaran",
|
| 875 |
+
"tripod",
|
| 876 |
+
"triumphal arch",
|
| 877 |
+
"trolleybus",
|
| 878 |
+
"trombone",
|
| 879 |
+
"hot tub",
|
| 880 |
+
"turnstile",
|
| 881 |
+
"typewriter keyboard",
|
| 882 |
+
"umbrella",
|
| 883 |
+
"unicycle",
|
| 884 |
+
"upright piano",
|
| 885 |
+
"vacuum cleaner",
|
| 886 |
+
"vase",
|
| 887 |
+
"vaulted or arched ceiling",
|
| 888 |
+
"velvet fabric",
|
| 889 |
+
"vending machine",
|
| 890 |
+
"vestment",
|
| 891 |
+
"viaduct",
|
| 892 |
+
"violin",
|
| 893 |
+
"volleyball",
|
| 894 |
+
"waffle iron",
|
| 895 |
+
"wall clock",
|
| 896 |
+
"wallet",
|
| 897 |
+
"wardrobe",
|
| 898 |
+
"military aircraft",
|
| 899 |
+
"sink",
|
| 900 |
+
"washing machine",
|
| 901 |
+
"water bottle",
|
| 902 |
+
"water jug",
|
| 903 |
+
"water tower",
|
| 904 |
+
"whiskey jug",
|
| 905 |
+
"whistle",
|
| 906 |
+
"hair wig",
|
| 907 |
+
"window screen",
|
| 908 |
+
"window shade",
|
| 909 |
+
"Windsor tie",
|
| 910 |
+
"wine bottle",
|
| 911 |
+
"airplane wing",
|
| 912 |
+
"wok",
|
| 913 |
+
"wooden spoon",
|
| 914 |
+
"wool",
|
| 915 |
+
"split-rail fence",
|
| 916 |
+
"shipwreck",
|
| 917 |
+
"sailboat",
|
| 918 |
+
"yurt",
|
| 919 |
+
"website",
|
| 920 |
+
"comic book",
|
| 921 |
+
"crossword",
|
| 922 |
+
"traffic or street sign",
|
| 923 |
+
"traffic light",
|
| 924 |
+
"dust jacket",
|
| 925 |
+
"menu",
|
| 926 |
+
"plate",
|
| 927 |
+
"guacamole",
|
| 928 |
+
"consomme",
|
| 929 |
+
"hot pot",
|
| 930 |
+
"trifle",
|
| 931 |
+
"ice cream",
|
| 932 |
+
"popsicle",
|
| 933 |
+
"baguette",
|
| 934 |
+
"bagel",
|
| 935 |
+
"pretzel",
|
| 936 |
+
"cheeseburger",
|
| 937 |
+
"hot dog",
|
| 938 |
+
"mashed potatoes",
|
| 939 |
+
"cabbage",
|
| 940 |
+
"broccoli",
|
| 941 |
+
"cauliflower",
|
| 942 |
+
"zucchini",
|
| 943 |
+
"spaghetti squash",
|
| 944 |
+
"acorn squash",
|
| 945 |
+
"butternut squash",
|
| 946 |
+
"cucumber",
|
| 947 |
+
"artichoke",
|
| 948 |
+
"bell pepper",
|
| 949 |
+
"cardoon",
|
| 950 |
+
"mushroom",
|
| 951 |
+
"Granny Smith apple",
|
| 952 |
+
"strawberry",
|
| 953 |
+
"orange",
|
| 954 |
+
"lemon",
|
| 955 |
+
"fig",
|
| 956 |
+
"pineapple",
|
| 957 |
+
"banana",
|
| 958 |
+
"jackfruit",
|
| 959 |
+
"cherimoya (custard apple)",
|
| 960 |
+
"pomegranate",
|
| 961 |
+
"hay",
|
| 962 |
+
"carbonara",
|
| 963 |
+
"chocolate syrup",
|
| 964 |
+
"dough",
|
| 965 |
+
"meatloaf",
|
| 966 |
+
"pizza",
|
| 967 |
+
"pot pie",
|
| 968 |
+
"burrito",
|
| 969 |
+
"red wine",
|
| 970 |
+
"espresso",
|
| 971 |
+
"tea cup",
|
| 972 |
+
"eggnog",
|
| 973 |
+
"mountain",
|
| 974 |
+
"bubble",
|
| 975 |
+
"cliff",
|
| 976 |
+
"coral reef",
|
| 977 |
+
"geyser",
|
| 978 |
+
"lakeshore",
|
| 979 |
+
"promontory",
|
| 980 |
+
"sandbar",
|
| 981 |
+
"beach",
|
| 982 |
+
"valley",
|
| 983 |
+
"volcano",
|
| 984 |
+
"baseball player",
|
| 985 |
+
"bridegroom",
|
| 986 |
+
"scuba diver",
|
| 987 |
+
"rapeseed",
|
| 988 |
+
"daisy",
|
| 989 |
+
"yellow lady's slipper",
|
| 990 |
+
"corn",
|
| 991 |
+
"acorn",
|
| 992 |
+
"rose hip",
|
| 993 |
+
"horse chestnut seed",
|
| 994 |
+
"coral fungus",
|
| 995 |
+
"agaric",
|
| 996 |
+
"gyromitra",
|
| 997 |
+
"stinkhorn mushroom",
|
| 998 |
+
"earth star fungus",
|
| 999 |
+
"hen of the woods mushroom",
|
| 1000 |
+
"bolete",
|
| 1001 |
+
"corn cob",
|
| 1002 |
+
"toilet paper",
|
| 1003 |
+
]
|
| 1004 |
+
IMAGENET_1K_CLASS_ID_TO_LABEL = dict(
|
| 1005 |
+
zip(range(len(IMAGENET_CLASSNAMES)), IMAGENET_CLASSNAMES)
|
| 1006 |
+
)
|
| 1007 |
+
|
| 1008 |
+
HM_CLASSNAMES = [
|
| 1009 |
+
"no",
|
| 1010 |
+
"yes",
|
| 1011 |
+
"true",
|
| 1012 |
+
"false",
|
| 1013 |
+
]
|
| 1014 |
+
HM_CLASS_ID_TO_LABEL = {0: "no", 1: "yes", 2: "yes", 3: "no"}
|
open_flamingo/open_flamingo/eval/coco_metric.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pycocoevalcap.eval import COCOEvalCap
|
| 2 |
+
from pycocotools.coco import COCO
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def compute_cider(
|
| 6 |
+
result_path,
|
| 7 |
+
annotations_path,
|
| 8 |
+
):
|
| 9 |
+
# create coco object and coco_result object
|
| 10 |
+
coco = COCO(annotations_path)
|
| 11 |
+
coco_result = coco.loadRes(result_path)
|
| 12 |
+
|
| 13 |
+
# create coco_eval object by taking coco and coco_result
|
| 14 |
+
coco_eval = COCOEvalCap(coco, coco_result)
|
| 15 |
+
coco_eval.params["image_id"] = coco_result.getImgIds()
|
| 16 |
+
coco_eval.evaluate()
|
| 17 |
+
|
| 18 |
+
return coco_eval.eval
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def postprocess_captioning_generation(predictions):
|
| 22 |
+
return predictions.split("Output", 1)[0]
|
open_flamingo/open_flamingo/eval/eval_datasets.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
|
| 4 |
+
from PIL import Image
|
| 5 |
+
from torch.utils.data import Dataset
|
| 6 |
+
from torchvision.datasets import ImageFolder
|
| 7 |
+
|
| 8 |
+
from open_flamingo.eval.classification_utils import IMAGENET_1K_CLASS_ID_TO_LABEL
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class CaptionDataset(Dataset):
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
image_train_dir_path,
|
| 15 |
+
annotations_path,
|
| 16 |
+
is_train,
|
| 17 |
+
dataset_name,
|
| 18 |
+
image_val_dir_path=None,
|
| 19 |
+
):
|
| 20 |
+
self.image_train_dir_path = image_train_dir_path
|
| 21 |
+
self.image_val_dir_path = image_val_dir_path
|
| 22 |
+
self.annotations = []
|
| 23 |
+
self.is_train = is_train
|
| 24 |
+
self.dataset_name = dataset_name
|
| 25 |
+
|
| 26 |
+
full_annotations = json.load(open(annotations_path))["images"]
|
| 27 |
+
|
| 28 |
+
for i in range(len(full_annotations)):
|
| 29 |
+
if self.is_train and full_annotations[i]["split"] != "train":
|
| 30 |
+
continue
|
| 31 |
+
elif not self.is_train and full_annotations[i]["split"] != "test":
|
| 32 |
+
continue
|
| 33 |
+
|
| 34 |
+
self.annotations.append(full_annotations[i])
|
| 35 |
+
|
| 36 |
+
def __len__(self):
|
| 37 |
+
return len(self.annotations)
|
| 38 |
+
|
| 39 |
+
def __getitem__(self, idx):
|
| 40 |
+
if self.dataset_name == "coco":
|
| 41 |
+
image = Image.open(
|
| 42 |
+
os.path.join(
|
| 43 |
+
self.image_train_dir_path, self.annotations[idx]["filename"]
|
| 44 |
+
)
|
| 45 |
+
if self.annotations[idx]["filepath"] == "train2014"
|
| 46 |
+
else os.path.join(
|
| 47 |
+
self.image_val_dir_path, self.annotations[idx]["filename"]
|
| 48 |
+
)
|
| 49 |
+
)
|
| 50 |
+
elif self.dataset_name == "flickr":
|
| 51 |
+
image = Image.open(
|
| 52 |
+
os.path.join(
|
| 53 |
+
self.image_train_dir_path, self.annotations[idx]["filename"]
|
| 54 |
+
)
|
| 55 |
+
)
|
| 56 |
+
image.load()
|
| 57 |
+
caption = self.annotations[idx]["sentences"][0]["raw"]
|
| 58 |
+
return {
|
| 59 |
+
"image": image,
|
| 60 |
+
"caption": caption,
|
| 61 |
+
"image_id": self.annotations[idx]["cocoid"]
|
| 62 |
+
if self.dataset_name == "coco"
|
| 63 |
+
else self.annotations[idx]["filename"].split(".")[0],
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class VQADataset(Dataset):
|
| 68 |
+
def __init__(
|
| 69 |
+
self, image_dir_path, question_path, annotations_path, is_train, dataset_name
|
| 70 |
+
):
|
| 71 |
+
self.questions = json.load(open(question_path, "r"))["questions"]
|
| 72 |
+
if annotations_path is not None:
|
| 73 |
+
self.answers = json.load(open(annotations_path, "r"))["annotations"]
|
| 74 |
+
else:
|
| 75 |
+
self.answers = None
|
| 76 |
+
self.image_dir_path = image_dir_path
|
| 77 |
+
self.is_train = is_train
|
| 78 |
+
self.dataset_name = dataset_name
|
| 79 |
+
if self.dataset_name in {"vqav2", "ok_vqa"}:
|
| 80 |
+
self.img_coco_split = self.image_dir_path.strip("/").split("/")[-1]
|
| 81 |
+
assert self.img_coco_split in {"train2014", "val2014", "test2015"}
|
| 82 |
+
|
| 83 |
+
def __len__(self):
|
| 84 |
+
return len(self.questions)
|
| 85 |
+
|
| 86 |
+
def get_img_path(self, question):
|
| 87 |
+
if self.dataset_name in {"vqav2", "ok_vqa"}:
|
| 88 |
+
return os.path.join(
|
| 89 |
+
self.image_dir_path,
|
| 90 |
+
f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg"
|
| 91 |
+
if self.is_train
|
| 92 |
+
else f"COCO_{self.img_coco_split}_{question['image_id']:012d}.jpg",
|
| 93 |
+
)
|
| 94 |
+
elif self.dataset_name == "vizwiz":
|
| 95 |
+
return os.path.join(self.image_dir_path, question["image_id"])
|
| 96 |
+
elif self.dataset_name == "textvqa":
|
| 97 |
+
return os.path.join(self.image_dir_path, f"{question['image_id']}.jpg")
|
| 98 |
+
else:
|
| 99 |
+
raise Exception(f"Unknown VQA dataset {self.dataset_name}")
|
| 100 |
+
|
| 101 |
+
def __getitem__(self, idx):
|
| 102 |
+
question = self.questions[idx]
|
| 103 |
+
img_path = self.get_img_path(question)
|
| 104 |
+
image = Image.open(img_path)
|
| 105 |
+
image.load()
|
| 106 |
+
results = {
|
| 107 |
+
"image": image,
|
| 108 |
+
"question": question["question"],
|
| 109 |
+
"question_id": question["question_id"],
|
| 110 |
+
}
|
| 111 |
+
if self.answers is not None:
|
| 112 |
+
answers = self.answers[idx]
|
| 113 |
+
results["answers"] = [a["answer"] for a in answers["answers"]]
|
| 114 |
+
return results
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class ImageNetDataset(ImageFolder):
|
| 118 |
+
"""Class to represent the ImageNet1k dataset."""
|
| 119 |
+
|
| 120 |
+
def __init__(self, root, **kwargs):
|
| 121 |
+
super().__init__(root=root, **kwargs)
|
| 122 |
+
|
| 123 |
+
def __getitem__(self, idx):
|
| 124 |
+
sample, target = super().__getitem__(idx)
|
| 125 |
+
target_label = IMAGENET_1K_CLASS_ID_TO_LABEL[target]
|
| 126 |
+
return {
|
| 127 |
+
"id": idx,
|
| 128 |
+
"image": sample,
|
| 129 |
+
"class_id": target, # numeric ID of the ImageNet class
|
| 130 |
+
"class_name": target_label, # human-readable name of ImageNet class
|
| 131 |
+
}
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
class HatefulMemesDataset(Dataset):
|
| 135 |
+
def __init__(self, image_dir_path, annotations_path):
|
| 136 |
+
self.image_dir_path = image_dir_path
|
| 137 |
+
with open(annotations_path, "r") as f:
|
| 138 |
+
self.annotations = [json.loads(line) for line in f]
|
| 139 |
+
|
| 140 |
+
def __len__(self):
|
| 141 |
+
return len(self.annotations)
|
| 142 |
+
|
| 143 |
+
def __getitem__(self, idx):
|
| 144 |
+
annotation = self.annotations[idx]
|
| 145 |
+
img_path = os.path.join(self.image_dir_path, annotation["img"].split("/")[-1])
|
| 146 |
+
image = Image.open(img_path)
|
| 147 |
+
image.load()
|
| 148 |
+
return {
|
| 149 |
+
"id": idx,
|
| 150 |
+
"image": image,
|
| 151 |
+
"ocr": annotation["text"],
|
| 152 |
+
"class_name": "yes" if annotation["label"] == 1 else "no",
|
| 153 |
+
"class_id": annotation["label"],
|
| 154 |
+
}
|
open_flamingo/open_flamingo/eval/eval_model.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import abc
|
| 2 |
+
import argparse
|
| 3 |
+
from typing import List
|
| 4 |
+
from torch.nn.parallel import DistributedDataParallel as DDP
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class BaseEvalModel(abc.ABC):
|
| 9 |
+
"""Base class encapsulating functionality needed to evaluate a model."""
|
| 10 |
+
|
| 11 |
+
def __init__(self, args: List[str]):
|
| 12 |
+
"""Initialize model.
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
args: arguments to model. These should be parsed, or if the model
|
| 16 |
+
has no applicable arguments, an error should be thrown if `args`
|
| 17 |
+
is non-empty.
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def init_distributed(self):
|
| 21 |
+
"""Wrap model as DDP."""
|
| 22 |
+
self.model = DDP(self.model, device_ids=[self.device])
|
| 23 |
+
|
| 24 |
+
def set_device(self, device):
|
| 25 |
+
"""Set device for model."""
|
| 26 |
+
self.device = device
|
| 27 |
+
self.model = self.model.to(device)
|
| 28 |
+
|
| 29 |
+
def get_outputs(
|
| 30 |
+
self,
|
| 31 |
+
batch_text: List[str],
|
| 32 |
+
batch_images: List[List[Image.Image]],
|
| 33 |
+
min_generation_length: int,
|
| 34 |
+
max_generation_length: int,
|
| 35 |
+
num_beams: int,
|
| 36 |
+
length_penalty: float,
|
| 37 |
+
) -> List[str]:
|
| 38 |
+
"""Get outputs for a batch of images and text.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
batch_text: list of text strings, with the text "<image>" in place
|
| 42 |
+
of any images to be included.
|
| 43 |
+
batch_images: images to provide to model. Should be a list of lists,
|
| 44 |
+
where each list contains the images for a single example.
|
| 45 |
+
max_generation_length: maximum length of the generated caption.
|
| 46 |
+
Defaults to 10.
|
| 47 |
+
num_beams: number of beams to use for beam search. Defaults to 3.
|
| 48 |
+
length_penalty: length penalty for beam search. Defaults to -2.0.
|
| 49 |
+
|
| 50 |
+
Returns:
|
| 51 |
+
List of decoded output strings.
|
| 52 |
+
"""
|
| 53 |
+
|
| 54 |
+
def vqa_prompt(self, question, answer=None) -> str:
|
| 55 |
+
"""Get the prompt to use for VQA evaluation. If the answer is not provided, it should be left blank to be generated by the model.
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
The prompt to use for VQA.
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
def caption_prompt(self, caption=None) -> str:
|
| 62 |
+
"""Get the prompt to use for caption evaluation. If the caption is not provided, it should be left blank to be generated by the model.
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
The prompt to use for captioning.
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def classification_prompt(self, class_str=None) -> str:
|
| 69 |
+
"""Get the prompt to use for classification evaluation. If the class_str is not provided, it should be left blank to be generated by the model.
|
| 70 |
+
|
| 71 |
+
Returns:
|
| 72 |
+
The prompt to use for classification.
|
| 73 |
+
"""
|
open_flamingo/open_flamingo/eval/evaluate.py
ADDED
|
@@ -0,0 +1,1247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import importlib
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import uuid
|
| 7 |
+
from collections import defaultdict
|
| 8 |
+
|
| 9 |
+
from einops import repeat
|
| 10 |
+
import more_itertools
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
from sklearn.metrics import roc_auc_score
|
| 14 |
+
|
| 15 |
+
from coco_metric import compute_cider, postprocess_captioning_generation
|
| 16 |
+
from eval_datasets import (
|
| 17 |
+
CaptionDataset,
|
| 18 |
+
VQADataset,
|
| 19 |
+
ImageNetDataset,
|
| 20 |
+
HatefulMemesDataset,
|
| 21 |
+
)
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
from eval_datasets import VQADataset, ImageNetDataset
|
| 26 |
+
from classification_utils import (
|
| 27 |
+
IMAGENET_CLASSNAMES,
|
| 28 |
+
IMAGENET_1K_CLASS_ID_TO_LABEL,
|
| 29 |
+
HM_CLASSNAMES,
|
| 30 |
+
HM_CLASS_ID_TO_LABEL,
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
from eval_model import BaseEvalModel
|
| 34 |
+
|
| 35 |
+
from ok_vqa_utils import postprocess_ok_vqa_generation
|
| 36 |
+
from open_flamingo.src.flamingo import Flamingo
|
| 37 |
+
from vqa_metric import compute_vqa_accuracy, postprocess_vqa_generation
|
| 38 |
+
|
| 39 |
+
from open_flamingo.train.distributed import init_distributed_device, world_info_from_env
|
| 40 |
+
|
| 41 |
+
parser = argparse.ArgumentParser()
|
| 42 |
+
|
| 43 |
+
parser.add_argument(
|
| 44 |
+
"--model",
|
| 45 |
+
type=str,
|
| 46 |
+
help="Model name. Currently only `OpenFlamingo` is supported.",
|
| 47 |
+
default="open_flamingo",
|
| 48 |
+
)
|
| 49 |
+
parser.add_argument(
|
| 50 |
+
"--results_file", type=str, default=None, help="JSON file to save results"
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
# Trial arguments
|
| 54 |
+
parser.add_argument("--shots", nargs="+", default=[0, 4, 8, 16, 32], type=int)
|
| 55 |
+
parser.add_argument(
|
| 56 |
+
"--num_trials",
|
| 57 |
+
type=int,
|
| 58 |
+
default=1,
|
| 59 |
+
help="Number of trials to run for each shot using different demonstrations",
|
| 60 |
+
)
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--trial_seeds",
|
| 63 |
+
nargs="+",
|
| 64 |
+
type=int,
|
| 65 |
+
default=[42],
|
| 66 |
+
help="Seeds to use for each trial for picking demonstrations and eval sets",
|
| 67 |
+
)
|
| 68 |
+
parser.add_argument(
|
| 69 |
+
"--num_samples", type=int, default=-1, help="Number of samples to evaluate on. -1 for all samples."
|
| 70 |
+
)
|
| 71 |
+
parser.add_argument(
|
| 72 |
+
"--query_set_size", type=int, default=2048, help="Size of demonstration query set"
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
parser.add_argument("--batch_size", type=int, default=8)
|
| 76 |
+
|
| 77 |
+
parser.add_argument("--use_kv_caching_for_classification",
|
| 78 |
+
action="store_true",
|
| 79 |
+
help="Use key-value caching for classification evals to speed it up. Currently this doesn't underperforms for MPT models."
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
# Per-dataset evaluation flags
|
| 83 |
+
parser.add_argument(
|
| 84 |
+
"--eval_coco",
|
| 85 |
+
action="store_true",
|
| 86 |
+
default=False,
|
| 87 |
+
help="Whether to evaluate on COCO.",
|
| 88 |
+
)
|
| 89 |
+
parser.add_argument(
|
| 90 |
+
"--eval_vqav2",
|
| 91 |
+
action="store_true",
|
| 92 |
+
default=False,
|
| 93 |
+
help="Whether to evaluate on VQAV2.",
|
| 94 |
+
)
|
| 95 |
+
parser.add_argument(
|
| 96 |
+
"--eval_ok_vqa",
|
| 97 |
+
action="store_true",
|
| 98 |
+
default=False,
|
| 99 |
+
help="Whether to evaluate on OK-VQA.",
|
| 100 |
+
)
|
| 101 |
+
parser.add_argument(
|
| 102 |
+
"--eval_vizwiz",
|
| 103 |
+
action="store_true",
|
| 104 |
+
default=False,
|
| 105 |
+
help="Whether to evaluate on VizWiz.",
|
| 106 |
+
)
|
| 107 |
+
parser.add_argument(
|
| 108 |
+
"--eval_textvqa",
|
| 109 |
+
action="store_true",
|
| 110 |
+
default=False,
|
| 111 |
+
help="Whether to evaluate on TextVQA.",
|
| 112 |
+
)
|
| 113 |
+
parser.add_argument(
|
| 114 |
+
"--eval_imagenet",
|
| 115 |
+
action="store_true",
|
| 116 |
+
default=False,
|
| 117 |
+
help="Whether to evaluate on ImageNet.",
|
| 118 |
+
)
|
| 119 |
+
parser.add_argument(
|
| 120 |
+
"--eval_flickr30",
|
| 121 |
+
action="store_true",
|
| 122 |
+
default=False,
|
| 123 |
+
help="Whether to evaluate on Flickr30.",
|
| 124 |
+
)
|
| 125 |
+
parser.add_argument(
|
| 126 |
+
"--eval_hateful_memes",
|
| 127 |
+
action="store_true",
|
| 128 |
+
default=False,
|
| 129 |
+
help="Whether to evaluate on Hateful Memes.",
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
# Dataset arguments
|
| 133 |
+
|
| 134 |
+
## Flickr30 Dataset
|
| 135 |
+
parser.add_argument(
|
| 136 |
+
"--flickr_image_dir_path",
|
| 137 |
+
type=str,
|
| 138 |
+
help="Path to the flickr30/flickr30k_images directory.",
|
| 139 |
+
default=None,
|
| 140 |
+
)
|
| 141 |
+
parser.add_argument(
|
| 142 |
+
"--flickr_karpathy_json_path",
|
| 143 |
+
type=str,
|
| 144 |
+
help="Path to the dataset_flickr30k.json file.",
|
| 145 |
+
default=None,
|
| 146 |
+
)
|
| 147 |
+
parser.add_argument(
|
| 148 |
+
"--flickr_annotations_json_path",
|
| 149 |
+
type=str,
|
| 150 |
+
help="Path to the dataset_flickr30k_coco_style.json file.",
|
| 151 |
+
)
|
| 152 |
+
## COCO Dataset
|
| 153 |
+
parser.add_argument(
|
| 154 |
+
"--coco_train_image_dir_path",
|
| 155 |
+
type=str,
|
| 156 |
+
default=None,
|
| 157 |
+
)
|
| 158 |
+
parser.add_argument(
|
| 159 |
+
"--coco_val_image_dir_path",
|
| 160 |
+
type=str,
|
| 161 |
+
default=None,
|
| 162 |
+
)
|
| 163 |
+
parser.add_argument(
|
| 164 |
+
"--coco_karpathy_json_path",
|
| 165 |
+
type=str,
|
| 166 |
+
default=None,
|
| 167 |
+
)
|
| 168 |
+
parser.add_argument(
|
| 169 |
+
"--coco_annotations_json_path",
|
| 170 |
+
type=str,
|
| 171 |
+
default=None,
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
## VQAV2 Dataset
|
| 175 |
+
parser.add_argument(
|
| 176 |
+
"--vqav2_train_image_dir_path",
|
| 177 |
+
type=str,
|
| 178 |
+
default=None,
|
| 179 |
+
)
|
| 180 |
+
parser.add_argument(
|
| 181 |
+
"--vqav2_train_questions_json_path",
|
| 182 |
+
type=str,
|
| 183 |
+
default=None,
|
| 184 |
+
)
|
| 185 |
+
parser.add_argument(
|
| 186 |
+
"--vqav2_train_annotations_json_path",
|
| 187 |
+
type=str,
|
| 188 |
+
default=None,
|
| 189 |
+
)
|
| 190 |
+
parser.add_argument(
|
| 191 |
+
"--vqav2_test_image_dir_path",
|
| 192 |
+
type=str,
|
| 193 |
+
default=None,
|
| 194 |
+
)
|
| 195 |
+
parser.add_argument(
|
| 196 |
+
"--vqav2_test_questions_json_path",
|
| 197 |
+
type=str,
|
| 198 |
+
default=None,
|
| 199 |
+
)
|
| 200 |
+
parser.add_argument(
|
| 201 |
+
"--vqav2_test_annotations_json_path",
|
| 202 |
+
type=str,
|
| 203 |
+
default=None,
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
## OK-VQA Dataset
|
| 207 |
+
parser.add_argument(
|
| 208 |
+
"--ok_vqa_train_image_dir_path",
|
| 209 |
+
type=str,
|
| 210 |
+
help="Path to the vqav2/train2014 directory.",
|
| 211 |
+
default=None,
|
| 212 |
+
)
|
| 213 |
+
parser.add_argument(
|
| 214 |
+
"--ok_vqa_train_questions_json_path",
|
| 215 |
+
type=str,
|
| 216 |
+
help="Path to the v2_OpenEnded_mscoco_train2014_questions.json file.",
|
| 217 |
+
default=None,
|
| 218 |
+
)
|
| 219 |
+
parser.add_argument(
|
| 220 |
+
"--ok_vqa_train_annotations_json_path",
|
| 221 |
+
type=str,
|
| 222 |
+
help="Path to the v2_mscoco_train2014_annotations.json file.",
|
| 223 |
+
default=None,
|
| 224 |
+
)
|
| 225 |
+
parser.add_argument(
|
| 226 |
+
"--ok_vqa_test_image_dir_path",
|
| 227 |
+
type=str,
|
| 228 |
+
help="Path to the vqav2/val2014 directory.",
|
| 229 |
+
default=None,
|
| 230 |
+
)
|
| 231 |
+
parser.add_argument(
|
| 232 |
+
"--ok_vqa_test_questions_json_path",
|
| 233 |
+
type=str,
|
| 234 |
+
help="Path to the v2_OpenEnded_mscoco_val2014_questions.json file.",
|
| 235 |
+
default=None,
|
| 236 |
+
)
|
| 237 |
+
parser.add_argument(
|
| 238 |
+
"--ok_vqa_test_annotations_json_path",
|
| 239 |
+
type=str,
|
| 240 |
+
help="Path to the v2_mscoco_val2014_annotations.json file.",
|
| 241 |
+
default=None,
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
## VizWiz Dataset
|
| 245 |
+
parser.add_argument(
|
| 246 |
+
"--vizwiz_train_image_dir_path",
|
| 247 |
+
type=str,
|
| 248 |
+
help="Path to the vizwiz train images directory.",
|
| 249 |
+
default=None,
|
| 250 |
+
)
|
| 251 |
+
parser.add_argument(
|
| 252 |
+
"--vizwiz_test_image_dir_path",
|
| 253 |
+
type=str,
|
| 254 |
+
help="Path to the vizwiz test images directory.",
|
| 255 |
+
default=None,
|
| 256 |
+
)
|
| 257 |
+
parser.add_argument(
|
| 258 |
+
"--vizwiz_train_questions_json_path",
|
| 259 |
+
type=str,
|
| 260 |
+
help="Path to the vizwiz questions json file.",
|
| 261 |
+
default=None,
|
| 262 |
+
)
|
| 263 |
+
parser.add_argument(
|
| 264 |
+
"--vizwiz_train_annotations_json_path",
|
| 265 |
+
type=str,
|
| 266 |
+
help="Path to the vizwiz annotations json file.",
|
| 267 |
+
default=None,
|
| 268 |
+
)
|
| 269 |
+
parser.add_argument(
|
| 270 |
+
"--vizwiz_test_questions_json_path",
|
| 271 |
+
type=str,
|
| 272 |
+
help="Path to the vizwiz questions json file.",
|
| 273 |
+
default=None,
|
| 274 |
+
)
|
| 275 |
+
parser.add_argument(
|
| 276 |
+
"--vizwiz_test_annotations_json_path",
|
| 277 |
+
type=str,
|
| 278 |
+
help="Path to the vizwiz annotations json file.",
|
| 279 |
+
default=None,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
# TextVQA Dataset
|
| 283 |
+
parser.add_argument(
|
| 284 |
+
"--textvqa_image_dir_path",
|
| 285 |
+
type=str,
|
| 286 |
+
help="Path to the textvqa images directory.",
|
| 287 |
+
default=None,
|
| 288 |
+
)
|
| 289 |
+
parser.add_argument(
|
| 290 |
+
"--textvqa_train_questions_json_path",
|
| 291 |
+
type=str,
|
| 292 |
+
help="Path to the textvqa questions json file.",
|
| 293 |
+
default=None,
|
| 294 |
+
)
|
| 295 |
+
parser.add_argument(
|
| 296 |
+
"--textvqa_train_annotations_json_path",
|
| 297 |
+
type=str,
|
| 298 |
+
help="Path to the textvqa annotations json file.",
|
| 299 |
+
default=None,
|
| 300 |
+
)
|
| 301 |
+
parser.add_argument(
|
| 302 |
+
"--textvqa_test_questions_json_path",
|
| 303 |
+
type=str,
|
| 304 |
+
help="Path to the textvqa questions json file.",
|
| 305 |
+
default=None,
|
| 306 |
+
)
|
| 307 |
+
parser.add_argument(
|
| 308 |
+
"--textvqa_test_annotations_json_path",
|
| 309 |
+
type=str,
|
| 310 |
+
help="Path to the textvqa annotations json file.",
|
| 311 |
+
default=None,
|
| 312 |
+
)
|
| 313 |
+
|
| 314 |
+
## Imagenet dataset
|
| 315 |
+
parser.add_argument("--imagenet_root", type=str, default="/tmp")
|
| 316 |
+
|
| 317 |
+
## Hateful Memes dataset
|
| 318 |
+
parser.add_argument(
|
| 319 |
+
"--hateful_memes_image_dir_path",
|
| 320 |
+
type=str,
|
| 321 |
+
default=None,
|
| 322 |
+
)
|
| 323 |
+
parser.add_argument(
|
| 324 |
+
"--hateful_memes_train_annotations_json_path",
|
| 325 |
+
type=str,
|
| 326 |
+
default=None,
|
| 327 |
+
)
|
| 328 |
+
parser.add_argument(
|
| 329 |
+
"--hateful_memes_test_annotations_json_path",
|
| 330 |
+
type=str,
|
| 331 |
+
default=None,
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
# Distributed evaluation
|
| 335 |
+
parser.add_argument(
|
| 336 |
+
"--dist-url",
|
| 337 |
+
default="env://",
|
| 338 |
+
type=str,
|
| 339 |
+
help="url used to set up distributed training",
|
| 340 |
+
)
|
| 341 |
+
parser.add_argument(
|
| 342 |
+
"--dist-backend", default="nccl", type=str, help="distributed backend"
|
| 343 |
+
)
|
| 344 |
+
parser.add_argument(
|
| 345 |
+
"--horovod",
|
| 346 |
+
default=False,
|
| 347 |
+
action="store_true",
|
| 348 |
+
help="Use horovod for distributed training.",
|
| 349 |
+
)
|
| 350 |
+
parser.add_argument(
|
| 351 |
+
"--no-set-device-rank",
|
| 352 |
+
default=False,
|
| 353 |
+
action="store_true",
|
| 354 |
+
help="Don't set device index from local rank (when CUDA_VISIBLE_DEVICES restricted to one per proc).",
|
| 355 |
+
)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
def main():
|
| 359 |
+
args, leftovers = parser.parse_known_args()
|
| 360 |
+
module = importlib.import_module(f"open_flamingo.eval.models.{args.model}")
|
| 361 |
+
|
| 362 |
+
model_args = {
|
| 363 |
+
leftovers[i].lstrip("-"): leftovers[i + 1] for i in range(0, len(leftovers), 2)
|
| 364 |
+
}
|
| 365 |
+
eval_model = module.EvalModel(model_args)
|
| 366 |
+
|
| 367 |
+
# set up distributed evaluation
|
| 368 |
+
args.local_rank, args.rank, args.world_size = world_info_from_env()
|
| 369 |
+
device_id = init_distributed_device(args)
|
| 370 |
+
eval_model.set_device(device_id)
|
| 371 |
+
eval_model.init_distributed()
|
| 372 |
+
|
| 373 |
+
if args.model != "open_flamingo" and args.shots != [0]:
|
| 374 |
+
raise ValueError("Only 0 shot eval is supported for non-open_flamingo models")
|
| 375 |
+
|
| 376 |
+
if len(args.trial_seeds) != args.num_trials:
|
| 377 |
+
raise ValueError("Number of trial seeds must be == number of trials.")
|
| 378 |
+
|
| 379 |
+
results = defaultdict(list)
|
| 380 |
+
|
| 381 |
+
if args.eval_flickr30:
|
| 382 |
+
print("Evaluating on Flickr30k...")
|
| 383 |
+
for shot in args.shots:
|
| 384 |
+
scores = []
|
| 385 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 386 |
+
cider_score = evaluate_captioning(
|
| 387 |
+
args,
|
| 388 |
+
eval_model=eval_model,
|
| 389 |
+
num_shots=shot,
|
| 390 |
+
seed=seed,
|
| 391 |
+
dataset_name="flickr",
|
| 392 |
+
min_generation_length=12,
|
| 393 |
+
max_generation_length=30,
|
| 394 |
+
num_beams=5,
|
| 395 |
+
)
|
| 396 |
+
if args.rank == 0:
|
| 397 |
+
print(f"Shots {shot} Trial {trial} CIDEr score: {cider_score}")
|
| 398 |
+
scores.append(cider_score)
|
| 399 |
+
|
| 400 |
+
if args.rank == 0:
|
| 401 |
+
print(f"Shots {shot} Mean CIDEr score: {np.nanmean(scores)}")
|
| 402 |
+
results["flickr30"].append(
|
| 403 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 404 |
+
)
|
| 405 |
+
|
| 406 |
+
if args.eval_coco:
|
| 407 |
+
print("Evaluating on COCO...")
|
| 408 |
+
for shot in args.shots:
|
| 409 |
+
scores = []
|
| 410 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 411 |
+
cider_score = evaluate_captioning(
|
| 412 |
+
args,
|
| 413 |
+
eval_model=eval_model,
|
| 414 |
+
num_shots=shot,
|
| 415 |
+
seed=seed,
|
| 416 |
+
dataset_name="coco",
|
| 417 |
+
)
|
| 418 |
+
if args.rank == 0:
|
| 419 |
+
print(f"Shots {shot} Trial {trial} CIDEr score: {cider_score}")
|
| 420 |
+
scores.append(cider_score)
|
| 421 |
+
|
| 422 |
+
if args.rank == 0:
|
| 423 |
+
print(f"Shots {shot} Mean CIDEr score: {np.nanmean(scores)}")
|
| 424 |
+
results["coco"].append(
|
| 425 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 426 |
+
)
|
| 427 |
+
|
| 428 |
+
if args.eval_ok_vqa:
|
| 429 |
+
print("Evaluating on OK-VQA...")
|
| 430 |
+
for shot in args.shots:
|
| 431 |
+
scores = []
|
| 432 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 433 |
+
ok_vqa_score = evaluate_vqa(
|
| 434 |
+
args=args,
|
| 435 |
+
eval_model=eval_model,
|
| 436 |
+
num_shots=shot,
|
| 437 |
+
seed=seed,
|
| 438 |
+
dataset_name="ok_vqa",
|
| 439 |
+
)
|
| 440 |
+
if args.rank == 0:
|
| 441 |
+
print(f"Shots {shot} Trial {trial} OK-VQA score: {ok_vqa_score}")
|
| 442 |
+
scores.append(ok_vqa_score)
|
| 443 |
+
|
| 444 |
+
if args.rank == 0:
|
| 445 |
+
print(f"Shots {shot} Mean OK-VQA score: {np.nanmean(scores)}")
|
| 446 |
+
results["ok_vqa"].append(
|
| 447 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 448 |
+
)
|
| 449 |
+
|
| 450 |
+
if args.eval_vqav2:
|
| 451 |
+
print("Evaluating on VQAv2...")
|
| 452 |
+
for shot in args.shots:
|
| 453 |
+
scores = []
|
| 454 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 455 |
+
vqa_score = evaluate_vqa(
|
| 456 |
+
args=args,
|
| 457 |
+
eval_model=eval_model,
|
| 458 |
+
num_shots=shot,
|
| 459 |
+
seed=seed,
|
| 460 |
+
dataset_name="vqav2",
|
| 461 |
+
)
|
| 462 |
+
if args.rank == 0:
|
| 463 |
+
print(f"Shots {shot} Trial {trial} VQA score: {vqa_score}")
|
| 464 |
+
scores.append(vqa_score)
|
| 465 |
+
|
| 466 |
+
if args.rank == 0:
|
| 467 |
+
print(f"Shots {shot} Mean VQA score: {np.nanmean(scores)}")
|
| 468 |
+
results["vqav2"].append(
|
| 469 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 470 |
+
)
|
| 471 |
+
|
| 472 |
+
if args.eval_vizwiz:
|
| 473 |
+
print("Evaluating on VizWiz...")
|
| 474 |
+
for shot in args.shots:
|
| 475 |
+
scores = []
|
| 476 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 477 |
+
vizwiz_score = evaluate_vqa(
|
| 478 |
+
args=args,
|
| 479 |
+
eval_model=eval_model,
|
| 480 |
+
num_shots=shot,
|
| 481 |
+
seed=seed,
|
| 482 |
+
dataset_name="vizwiz",
|
| 483 |
+
)
|
| 484 |
+
if args.rank == 0:
|
| 485 |
+
print(f"Shots {shot} Trial {trial} VizWiz score: {vizwiz_score}")
|
| 486 |
+
scores.append(vizwiz_score)
|
| 487 |
+
|
| 488 |
+
if args.rank == 0:
|
| 489 |
+
print(f"Shots {shot} Mean VizWiz score: {np.nanmean(scores)}")
|
| 490 |
+
results["vizwiz"].append(
|
| 491 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
if args.eval_textvqa:
|
| 495 |
+
print("Evaluating on TextVQA...")
|
| 496 |
+
for shot in args.shots:
|
| 497 |
+
scores = []
|
| 498 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 499 |
+
textvqa_score = evaluate_vqa(
|
| 500 |
+
args=args,
|
| 501 |
+
eval_model=eval_model,
|
| 502 |
+
num_shots=shot,
|
| 503 |
+
seed=seed,
|
| 504 |
+
dataset_name="textvqa",
|
| 505 |
+
max_generation_length=10,
|
| 506 |
+
)
|
| 507 |
+
if args.rank == 0:
|
| 508 |
+
print(f"Shots {shot} Trial {trial} TextVQA score: {textvqa_score}")
|
| 509 |
+
scores.append(textvqa_score)
|
| 510 |
+
|
| 511 |
+
if args.rank == 0:
|
| 512 |
+
print(f"Shots {shot} Mean TextVQA score: {np.nanmean(scores)}")
|
| 513 |
+
results["textvqa"].append(
|
| 514 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 515 |
+
)
|
| 516 |
+
|
| 517 |
+
if args.eval_imagenet:
|
| 518 |
+
print("Evaluating on ImageNet...")
|
| 519 |
+
for shot in args.shots:
|
| 520 |
+
scores = []
|
| 521 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 522 |
+
imagenet_score = evaluate_classification(
|
| 523 |
+
args,
|
| 524 |
+
eval_model=eval_model,
|
| 525 |
+
num_shots=shot,
|
| 526 |
+
seed=seed,
|
| 527 |
+
use_kv_caching=args.use_kv_caching_for_classification,
|
| 528 |
+
dataset_name="imagenet",
|
| 529 |
+
)
|
| 530 |
+
if args.rank == 0:
|
| 531 |
+
print(
|
| 532 |
+
f"Shots {shot} Trial {trial} " f"ImageNet score: {imagenet_score}"
|
| 533 |
+
)
|
| 534 |
+
scores.append(imagenet_score)
|
| 535 |
+
|
| 536 |
+
if args.rank == 0:
|
| 537 |
+
print(f"Shots {shot} Mean ImageNet score: {np.nanmean(scores)}")
|
| 538 |
+
results["imagenet"].append(
|
| 539 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 540 |
+
)
|
| 541 |
+
|
| 542 |
+
if args.eval_hateful_memes:
|
| 543 |
+
print("Evaluating on Hateful Memes...")
|
| 544 |
+
for shot in args.shots:
|
| 545 |
+
scores = []
|
| 546 |
+
for seed, trial in zip(args.trial_seeds, range(args.num_trials)):
|
| 547 |
+
hateful_memes_score = evaluate_classification(
|
| 548 |
+
args,
|
| 549 |
+
eval_model=eval_model,
|
| 550 |
+
num_shots=shot,
|
| 551 |
+
seed=seed,
|
| 552 |
+
use_kv_caching=args.use_kv_caching_for_classification,
|
| 553 |
+
dataset_name="hateful_memes",
|
| 554 |
+
)
|
| 555 |
+
if args.rank == 0:
|
| 556 |
+
print(
|
| 557 |
+
f"Shots {shot} Trial {trial} "
|
| 558 |
+
f"Hateful Memes score: {hateful_memes_score}"
|
| 559 |
+
)
|
| 560 |
+
scores.append(hateful_memes_score)
|
| 561 |
+
|
| 562 |
+
if args.rank == 0:
|
| 563 |
+
print(f"Shots {shot} Mean Hateful Memes score: {np.nanmean(scores)}")
|
| 564 |
+
results["hateful_memes"].append(
|
| 565 |
+
{"shots": shot, "trials": scores, "mean": np.nanmean(scores)}
|
| 566 |
+
)
|
| 567 |
+
|
| 568 |
+
if args.rank == 0 and args.results_file is not None:
|
| 569 |
+
with open(args.results_file, "w") as f:
|
| 570 |
+
json.dump(results, f)
|
| 571 |
+
|
| 572 |
+
|
| 573 |
+
def get_random_indices(num_samples, query_set_size, full_dataset, seed):
|
| 574 |
+
if num_samples + query_set_size > len(full_dataset):
|
| 575 |
+
raise ValueError(
|
| 576 |
+
f"num_samples + query_set_size must be less than {len(full_dataset)}"
|
| 577 |
+
)
|
| 578 |
+
|
| 579 |
+
# get a random subset of the dataset
|
| 580 |
+
np.random.seed(seed)
|
| 581 |
+
random_indices = np.random.choice(
|
| 582 |
+
len(full_dataset), num_samples + query_set_size, replace=False
|
| 583 |
+
)
|
| 584 |
+
return random_indices
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
def get_query_set(train_dataset, query_set_size, seed):
|
| 588 |
+
np.random.seed(seed)
|
| 589 |
+
query_set = np.random.choice(len(train_dataset), query_set_size, replace=False)
|
| 590 |
+
return [train_dataset[i] for i in query_set]
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
def prepare_eval_samples(test_dataset, num_samples, batch_size, seed):
|
| 594 |
+
np.random.seed(seed)
|
| 595 |
+
random_indices = np.random.choice(len(test_dataset), num_samples, replace=False)
|
| 596 |
+
dataset = torch.utils.data.Subset(test_dataset, random_indices)
|
| 597 |
+
sampler = torch.utils.data.distributed.DistributedSampler(dataset)
|
| 598 |
+
loader = torch.utils.data.DataLoader(
|
| 599 |
+
dataset,
|
| 600 |
+
batch_size=batch_size,
|
| 601 |
+
sampler=sampler,
|
| 602 |
+
collate_fn=custom_collate_fn,
|
| 603 |
+
)
|
| 604 |
+
return loader
|
| 605 |
+
|
| 606 |
+
|
| 607 |
+
def sample_batch_demos_from_query_set(query_set, num_samples, batch_size):
|
| 608 |
+
return [random.sample(query_set, num_samples) for _ in range(batch_size)]
|
| 609 |
+
|
| 610 |
+
|
| 611 |
+
def compute_effective_num_shots(num_shots, model_type):
|
| 612 |
+
if model_type == "open_flamingo":
|
| 613 |
+
return num_shots if num_shots > 0 else 2
|
| 614 |
+
return num_shots
|
| 615 |
+
|
| 616 |
+
|
| 617 |
+
def custom_collate_fn(batch):
|
| 618 |
+
collated_batch = {}
|
| 619 |
+
for key in batch[0].keys():
|
| 620 |
+
collated_batch[key] = [item[key] for item in batch]
|
| 621 |
+
return collated_batch
|
| 622 |
+
|
| 623 |
+
|
| 624 |
+
def evaluate_captioning(
|
| 625 |
+
args: argparse.Namespace,
|
| 626 |
+
eval_model: BaseEvalModel,
|
| 627 |
+
seed: int = 42,
|
| 628 |
+
min_generation_length: int = 0,
|
| 629 |
+
max_generation_length: int = 20,
|
| 630 |
+
num_beams: int = 3,
|
| 631 |
+
length_penalty: float = 0.0,
|
| 632 |
+
num_shots: int = 8,
|
| 633 |
+
dataset_name: str = "coco",
|
| 634 |
+
):
|
| 635 |
+
"""Evaluate a model on COCO dataset.
|
| 636 |
+
|
| 637 |
+
Args:
|
| 638 |
+
args (argparse.Namespace): arguments
|
| 639 |
+
eval_model (BaseEvalModel): model to evaluate
|
| 640 |
+
seed (int, optional): seed for random number generator. Defaults to 42.
|
| 641 |
+
max_generation_length (int, optional): maximum length of the generated caption. Defaults to 20.
|
| 642 |
+
num_beams (int, optional): number of beams to use for beam search. Defaults to 3.
|
| 643 |
+
length_penalty (float, optional): length penalty for beam search. Defaults to -2.0.
|
| 644 |
+
num_shots (int, optional): number of in-context samples to use. Defaults to 8.
|
| 645 |
+
dataset_name (str, optional): dataset to evaluate on. Can be "coco" or "flickr". Defaults to "coco".
|
| 646 |
+
Returns:
|
| 647 |
+
float: CIDEr score
|
| 648 |
+
|
| 649 |
+
"""
|
| 650 |
+
|
| 651 |
+
if dataset_name == "coco":
|
| 652 |
+
image_train_dir_path = args.coco_train_image_dir_path
|
| 653 |
+
image_val_dir_path = args.coco_val_image_dir_path
|
| 654 |
+
annotations_path = args.coco_karpathy_json_path
|
| 655 |
+
elif dataset_name == "flickr":
|
| 656 |
+
image_train_dir_path = (
|
| 657 |
+
args.flickr_image_dir_path
|
| 658 |
+
) # Note: calling this "train" for consistency with COCO but Flickr only has one split for images
|
| 659 |
+
image_val_dir_path = None
|
| 660 |
+
annotations_path = args.flickr_karpathy_json_path
|
| 661 |
+
else:
|
| 662 |
+
raise ValueError(f"Unsupported dataset: {dataset_name}")
|
| 663 |
+
|
| 664 |
+
train_dataset = CaptionDataset(
|
| 665 |
+
image_train_dir_path=image_train_dir_path,
|
| 666 |
+
image_val_dir_path=image_val_dir_path,
|
| 667 |
+
annotations_path=annotations_path,
|
| 668 |
+
is_train=True,
|
| 669 |
+
dataset_name=dataset_name if dataset_name != "nocaps" else "coco",
|
| 670 |
+
)
|
| 671 |
+
|
| 672 |
+
test_dataset = CaptionDataset(
|
| 673 |
+
image_train_dir_path=image_train_dir_path,
|
| 674 |
+
image_val_dir_path=image_val_dir_path,
|
| 675 |
+
annotations_path=annotations_path,
|
| 676 |
+
is_train=False,
|
| 677 |
+
dataset_name=dataset_name,
|
| 678 |
+
)
|
| 679 |
+
|
| 680 |
+
effective_num_shots = compute_effective_num_shots(num_shots, args.model)
|
| 681 |
+
|
| 682 |
+
test_dataset = prepare_eval_samples(
|
| 683 |
+
test_dataset,
|
| 684 |
+
args.num_samples if args.num_samples > 0 else len(test_dataset),
|
| 685 |
+
args.batch_size,
|
| 686 |
+
seed,
|
| 687 |
+
)
|
| 688 |
+
|
| 689 |
+
in_context_samples = get_query_set(train_dataset, args.query_set_size, seed)
|
| 690 |
+
|
| 691 |
+
predictions = defaultdict()
|
| 692 |
+
|
| 693 |
+
for batch in tqdm(test_dataset, desc=f"Running inference {dataset_name.upper()}"):
|
| 694 |
+
batch_demo_samples = sample_batch_demos_from_query_set(
|
| 695 |
+
in_context_samples, effective_num_shots, len(batch["image"])
|
| 696 |
+
)
|
| 697 |
+
|
| 698 |
+
batch_images = []
|
| 699 |
+
batch_text = []
|
| 700 |
+
for i in range(len(batch["image"])):
|
| 701 |
+
if num_shots > 0:
|
| 702 |
+
context_images = [x["image"] for x in batch_demo_samples[i]]
|
| 703 |
+
else:
|
| 704 |
+
context_images = []
|
| 705 |
+
batch_images.append(context_images + [batch["image"][i]])
|
| 706 |
+
|
| 707 |
+
context_text = "".join(
|
| 708 |
+
[
|
| 709 |
+
eval_model.get_caption_prompt(caption=x["caption"].strip())
|
| 710 |
+
for x in batch_demo_samples[i]
|
| 711 |
+
]
|
| 712 |
+
)
|
| 713 |
+
|
| 714 |
+
# Keep the text but remove the image tags for the zero-shot case
|
| 715 |
+
if num_shots == 0:
|
| 716 |
+
context_text = context_text.replace("<image>", "")
|
| 717 |
+
|
| 718 |
+
batch_text.append(context_text + eval_model.get_caption_prompt())
|
| 719 |
+
|
| 720 |
+
outputs = eval_model.get_outputs(
|
| 721 |
+
batch_images=batch_images,
|
| 722 |
+
batch_text=batch_text,
|
| 723 |
+
min_generation_length=min_generation_length,
|
| 724 |
+
max_generation_length=max_generation_length,
|
| 725 |
+
num_beams=num_beams,
|
| 726 |
+
length_penalty=length_penalty,
|
| 727 |
+
)
|
| 728 |
+
|
| 729 |
+
new_predictions = [
|
| 730 |
+
postprocess_captioning_generation(out).replace('"', "") for out in outputs
|
| 731 |
+
]
|
| 732 |
+
|
| 733 |
+
for i, sample_id in enumerate(batch["image_id"]):
|
| 734 |
+
predictions[sample_id] = {
|
| 735 |
+
"caption": new_predictions[i],
|
| 736 |
+
}
|
| 737 |
+
|
| 738 |
+
# all gather
|
| 739 |
+
all_predictions = [None] * args.world_size
|
| 740 |
+
torch.distributed.all_gather_object(all_predictions, predictions) # list of dicts
|
| 741 |
+
|
| 742 |
+
if args.rank != 0:
|
| 743 |
+
return
|
| 744 |
+
|
| 745 |
+
all_predictions = {
|
| 746 |
+
k: v for d in all_predictions for k, v in d.items()
|
| 747 |
+
} # merge dicts
|
| 748 |
+
|
| 749 |
+
# save the predictions to a temporary file
|
| 750 |
+
results_path = f"{dataset_name}results_{uuid.uuid4()}.json"
|
| 751 |
+
|
| 752 |
+
with open(results_path, "w") as f:
|
| 753 |
+
f.write(
|
| 754 |
+
json.dumps(
|
| 755 |
+
[
|
| 756 |
+
{"image_id": k, "caption": all_predictions[k]["caption"]}
|
| 757 |
+
for k in all_predictions
|
| 758 |
+
],
|
| 759 |
+
indent=4,
|
| 760 |
+
)
|
| 761 |
+
)
|
| 762 |
+
|
| 763 |
+
metrics = compute_cider(
|
| 764 |
+
result_path=results_path,
|
| 765 |
+
annotations_path=args.coco_annotations_json_path
|
| 766 |
+
if dataset_name == "coco"
|
| 767 |
+
else args.flickr_annotations_json_path,
|
| 768 |
+
)
|
| 769 |
+
|
| 770 |
+
# delete the temporary file
|
| 771 |
+
os.remove(results_path)
|
| 772 |
+
|
| 773 |
+
return metrics["CIDEr"] * 100.0
|
| 774 |
+
|
| 775 |
+
|
| 776 |
+
def evaluate_vqa(
|
| 777 |
+
args: argparse.Namespace,
|
| 778 |
+
eval_model: BaseEvalModel,
|
| 779 |
+
seed: int = 42,
|
| 780 |
+
min_generation_length: int = 0,
|
| 781 |
+
max_generation_length: int = 5,
|
| 782 |
+
num_beams: int = 3,
|
| 783 |
+
length_penalty: float = -2.0,
|
| 784 |
+
num_shots: int = 8,
|
| 785 |
+
dataset_name: str = "vqav2",
|
| 786 |
+
):
|
| 787 |
+
"""
|
| 788 |
+
Evaluate a model on VQA datasets. Currently supports VQA v2.0, OK-VQA, VizWiz and TextVQA.
|
| 789 |
+
|
| 790 |
+
Args:
|
| 791 |
+
args (argparse.Namespace): arguments
|
| 792 |
+
eval_model (BaseEvalModel): model to evaluate
|
| 793 |
+
seed (int, optional): random seed. Defaults to 42.
|
| 794 |
+
max_generation_length (int, optional): max generation length. Defaults to 5.
|
| 795 |
+
num_beams (int, optional): number of beams to use for beam search. Defaults to 3.
|
| 796 |
+
length_penalty (float, optional): length penalty for beam search. Defaults to -2.0.
|
| 797 |
+
num_shots (int, optional): number of shots to use. Defaults to 8.
|
| 798 |
+
dataset_name (string): type of vqa dataset: currently supports vqav2, ok_vqa. Defaults to vqav2.
|
| 799 |
+
Returns:
|
| 800 |
+
float: accuracy score
|
| 801 |
+
"""
|
| 802 |
+
|
| 803 |
+
if dataset_name == "ok_vqa":
|
| 804 |
+
train_image_dir_path = args.ok_vqa_train_image_dir_path
|
| 805 |
+
train_questions_json_path = args.ok_vqa_train_questions_json_path
|
| 806 |
+
train_annotations_json_path = args.ok_vqa_train_annotations_json_path
|
| 807 |
+
test_image_dir_path = args.ok_vqa_test_image_dir_path
|
| 808 |
+
test_questions_json_path = args.ok_vqa_test_questions_json_path
|
| 809 |
+
test_annotations_json_path = args.ok_vqa_test_annotations_json_path
|
| 810 |
+
elif dataset_name == "vqav2":
|
| 811 |
+
train_image_dir_path = args.vqav2_train_image_dir_path
|
| 812 |
+
train_questions_json_path = args.vqav2_train_questions_json_path
|
| 813 |
+
train_annotations_json_path = args.vqav2_train_annotations_json_path
|
| 814 |
+
test_image_dir_path = args.vqav2_test_image_dir_path
|
| 815 |
+
test_questions_json_path = args.vqav2_test_questions_json_path
|
| 816 |
+
test_annotations_json_path = args.vqav2_test_annotations_json_path
|
| 817 |
+
elif dataset_name == "vizwiz":
|
| 818 |
+
train_image_dir_path = args.vizwiz_train_image_dir_path
|
| 819 |
+
train_questions_json_path = args.vizwiz_train_questions_json_path
|
| 820 |
+
train_annotations_json_path = args.vizwiz_train_annotations_json_path
|
| 821 |
+
test_image_dir_path = args.vizwiz_test_image_dir_path
|
| 822 |
+
test_questions_json_path = args.vizwiz_test_questions_json_path
|
| 823 |
+
test_annotations_json_path = args.vizwiz_test_annotations_json_path
|
| 824 |
+
elif dataset_name == "textvqa":
|
| 825 |
+
train_image_dir_path = args.textvqa_image_dir_path
|
| 826 |
+
train_questions_json_path = args.textvqa_train_questions_json_path
|
| 827 |
+
train_annotations_json_path = args.textvqa_train_annotations_json_path
|
| 828 |
+
test_image_dir_path = args.textvqa_image_dir_path
|
| 829 |
+
test_questions_json_path = args.textvqa_test_questions_json_path
|
| 830 |
+
test_annotations_json_path = args.textvqa_test_annotations_json_path
|
| 831 |
+
else:
|
| 832 |
+
raise ValueError(f"Unsupported dataset: {dataset_name}")
|
| 833 |
+
|
| 834 |
+
train_dataset = VQADataset(
|
| 835 |
+
image_dir_path=train_image_dir_path,
|
| 836 |
+
question_path=train_questions_json_path,
|
| 837 |
+
annotations_path=train_annotations_json_path,
|
| 838 |
+
is_train=True,
|
| 839 |
+
dataset_name=dataset_name,
|
| 840 |
+
)
|
| 841 |
+
|
| 842 |
+
test_dataset = VQADataset(
|
| 843 |
+
image_dir_path=test_image_dir_path,
|
| 844 |
+
question_path=test_questions_json_path,
|
| 845 |
+
annotations_path=test_annotations_json_path,
|
| 846 |
+
is_train=False,
|
| 847 |
+
dataset_name=dataset_name,
|
| 848 |
+
)
|
| 849 |
+
|
| 850 |
+
effective_num_shots = compute_effective_num_shots(num_shots, args.model)
|
| 851 |
+
|
| 852 |
+
test_dataset = prepare_eval_samples(
|
| 853 |
+
test_dataset,
|
| 854 |
+
args.num_samples if args.num_samples > 0 else len(test_dataset),
|
| 855 |
+
args.batch_size,
|
| 856 |
+
seed,
|
| 857 |
+
)
|
| 858 |
+
|
| 859 |
+
in_context_samples = get_query_set(train_dataset, args.query_set_size, seed)
|
| 860 |
+
predictions = []
|
| 861 |
+
|
| 862 |
+
for batch in tqdm(test_dataset, desc=f"Running inference {dataset_name.upper()}"):
|
| 863 |
+
batch_demo_samples = sample_batch_demos_from_query_set(
|
| 864 |
+
in_context_samples, effective_num_shots, len(batch["image"])
|
| 865 |
+
)
|
| 866 |
+
|
| 867 |
+
batch_images = []
|
| 868 |
+
batch_text = []
|
| 869 |
+
for i in range(len(batch["image"])):
|
| 870 |
+
if num_shots > 0:
|
| 871 |
+
context_images = [x["image"] for x in batch_demo_samples[i]]
|
| 872 |
+
else:
|
| 873 |
+
context_images = []
|
| 874 |
+
batch_images.append(context_images + [batch["image"][i]])
|
| 875 |
+
|
| 876 |
+
context_text = "".join(
|
| 877 |
+
[
|
| 878 |
+
eval_model.get_vqa_prompt(
|
| 879 |
+
question=x["question"], answer=x["answers"][0]
|
| 880 |
+
)
|
| 881 |
+
for x in batch_demo_samples[i]
|
| 882 |
+
]
|
| 883 |
+
)
|
| 884 |
+
|
| 885 |
+
# Keep the text but remove the image tags for the zero-shot case
|
| 886 |
+
if num_shots == 0:
|
| 887 |
+
context_text = context_text.replace("<image>", "")
|
| 888 |
+
|
| 889 |
+
batch_text.append(
|
| 890 |
+
context_text + eval_model.get_vqa_prompt(question=batch["question"][i])
|
| 891 |
+
)
|
| 892 |
+
|
| 893 |
+
outputs = eval_model.get_outputs(
|
| 894 |
+
batch_images=batch_images,
|
| 895 |
+
batch_text=batch_text,
|
| 896 |
+
min_generation_length=min_generation_length,
|
| 897 |
+
max_generation_length=max_generation_length,
|
| 898 |
+
num_beams=num_beams,
|
| 899 |
+
length_penalty=length_penalty,
|
| 900 |
+
)
|
| 901 |
+
|
| 902 |
+
process_function = (
|
| 903 |
+
postprocess_ok_vqa_generation
|
| 904 |
+
if dataset_name == "ok_vqa"
|
| 905 |
+
else postprocess_vqa_generation
|
| 906 |
+
)
|
| 907 |
+
|
| 908 |
+
new_predictions = map(process_function, outputs)
|
| 909 |
+
|
| 910 |
+
for new_prediction, sample_id in zip(new_predictions, batch["question_id"]):
|
| 911 |
+
predictions.append({"answer": new_prediction, "question_id": sample_id})
|
| 912 |
+
|
| 913 |
+
# all gather
|
| 914 |
+
all_predictions = [None] * args.world_size
|
| 915 |
+
torch.distributed.all_gather_object(all_predictions, predictions) # list of lists
|
| 916 |
+
if args.rank != 0:
|
| 917 |
+
return
|
| 918 |
+
|
| 919 |
+
all_predictions = [
|
| 920 |
+
item for sublist in all_predictions for item in sublist
|
| 921 |
+
] # flatten
|
| 922 |
+
|
| 923 |
+
# save the predictions to a temporary file
|
| 924 |
+
random_uuid = str(uuid.uuid4())
|
| 925 |
+
with open(f"{dataset_name}results_{random_uuid}.json", "w") as f:
|
| 926 |
+
f.write(json.dumps(all_predictions, indent=4))
|
| 927 |
+
|
| 928 |
+
if test_annotations_json_path is not None:
|
| 929 |
+
acc = compute_vqa_accuracy(
|
| 930 |
+
f"{dataset_name}results_{random_uuid}.json",
|
| 931 |
+
test_questions_json_path,
|
| 932 |
+
test_annotations_json_path,
|
| 933 |
+
)
|
| 934 |
+
# delete the temporary file
|
| 935 |
+
os.remove(f"{dataset_name}results_{random_uuid}.json")
|
| 936 |
+
|
| 937 |
+
else:
|
| 938 |
+
print("No annotations provided, skipping accuracy computation.")
|
| 939 |
+
print("Temporary file saved to:", f"{dataset_name}results_{random_uuid}.json")
|
| 940 |
+
acc = None
|
| 941 |
+
|
| 942 |
+
return acc
|
| 943 |
+
|
| 944 |
+
|
| 945 |
+
def evaluate_classification(
|
| 946 |
+
args: argparse.Namespace,
|
| 947 |
+
eval_model,
|
| 948 |
+
seed: int = 42,
|
| 949 |
+
num_shots: int = 8,
|
| 950 |
+
use_kv_caching=False,
|
| 951 |
+
dataset_name: str = "imagenet",
|
| 952 |
+
):
|
| 953 |
+
"""
|
| 954 |
+
Evaluate a model on classification dataset.
|
| 955 |
+
|
| 956 |
+
Args:
|
| 957 |
+
eval_model (BaseEvalModel): model to evaluate
|
| 958 |
+
imagenet_root (str): path to imagenet root for the specified split.
|
| 959 |
+
seed (int, optional): random seed. Defaults to 42.
|
| 960 |
+
num_shots (int, optional): number of shots to use. Defaults to 8.
|
| 961 |
+
dataset_name (str, optional): dataset name. Defaults to "imagenet".
|
| 962 |
+
|
| 963 |
+
Returns:
|
| 964 |
+
float: accuracy score
|
| 965 |
+
"""
|
| 966 |
+
if args.model != "open_flamingo":
|
| 967 |
+
raise NotImplementedError(
|
| 968 |
+
"evaluate_classification is currently only supported for OpenFlamingo "
|
| 969 |
+
"models"
|
| 970 |
+
)
|
| 971 |
+
batch_size = args.batch_size
|
| 972 |
+
num_samples = args.num_samples
|
| 973 |
+
np.random.seed(seed)
|
| 974 |
+
model, tokenizer = eval_model.model, eval_model.tokenizer
|
| 975 |
+
|
| 976 |
+
if dataset_name == "imagenet":
|
| 977 |
+
train_dataset = ImageNetDataset(os.path.join(args.imagenet_root, "train"))
|
| 978 |
+
test_dataset = ImageNetDataset(os.path.join(args.imagenet_root, "val"))
|
| 979 |
+
elif dataset_name == "hateful_memes":
|
| 980 |
+
train_dataset = HatefulMemesDataset(
|
| 981 |
+
args.hateful_memes_image_dir_path,
|
| 982 |
+
args.hateful_memes_train_annotations_json_path,
|
| 983 |
+
)
|
| 984 |
+
test_dataset = HatefulMemesDataset(
|
| 985 |
+
args.hateful_memes_image_dir_path,
|
| 986 |
+
args.hateful_memes_test_annotations_json_path,
|
| 987 |
+
)
|
| 988 |
+
else:
|
| 989 |
+
raise ValueError(f"Unsupported dataset {dataset_name}")
|
| 990 |
+
|
| 991 |
+
effective_num_shots = compute_effective_num_shots(num_shots, args.model)
|
| 992 |
+
|
| 993 |
+
test_dataloader = prepare_eval_samples(
|
| 994 |
+
test_dataset,
|
| 995 |
+
args.num_samples if args.num_samples > 0 else len(test_dataset),
|
| 996 |
+
batch_size,
|
| 997 |
+
seed,
|
| 998 |
+
)
|
| 999 |
+
|
| 1000 |
+
acc1 = 0
|
| 1001 |
+
acc5 = 0
|
| 1002 |
+
|
| 1003 |
+
if dataset_name == "imagenet":
|
| 1004 |
+
prompt_text = "<image>Output:"
|
| 1005 |
+
elif dataset_name == "hateful_memes":
|
| 1006 |
+
prompt_text = "<image>is an image with: '{meme_text}' written on it. Is it hateful? Answer: "
|
| 1007 |
+
|
| 1008 |
+
predictions = []
|
| 1009 |
+
|
| 1010 |
+
for batch_idx, batch in tqdm(
|
| 1011 |
+
enumerate(test_dataloader), desc=f"Running inference {dataset_name}", disable=args.rank != 0
|
| 1012 |
+
):
|
| 1013 |
+
batch_images = []
|
| 1014 |
+
batch_text = []
|
| 1015 |
+
|
| 1016 |
+
for idx in range(len(batch["image"])):
|
| 1017 |
+
# Choose a different set of random context samples for each sample
|
| 1018 |
+
# from the training set
|
| 1019 |
+
context_indices = np.random.choice(
|
| 1020 |
+
len(train_dataset), effective_num_shots, replace=False
|
| 1021 |
+
)
|
| 1022 |
+
|
| 1023 |
+
in_context_samples = [train_dataset[i] for i in context_indices]
|
| 1024 |
+
|
| 1025 |
+
if num_shots > 0:
|
| 1026 |
+
vision_x = [
|
| 1027 |
+
eval_model.image_processor(data["image"]).unsqueeze(0)
|
| 1028 |
+
for data in in_context_samples
|
| 1029 |
+
]
|
| 1030 |
+
else:
|
| 1031 |
+
vision_x = []
|
| 1032 |
+
|
| 1033 |
+
vision_x = vision_x + [eval_model.image_processor(batch["image"][idx]).unsqueeze(0)]
|
| 1034 |
+
batch_images.append(torch.cat(vision_x, dim=0))
|
| 1035 |
+
|
| 1036 |
+
def sample_to_prompt(sample):
|
| 1037 |
+
if dataset_name == "hateful_memes":
|
| 1038 |
+
return prompt_text.replace("{meme_text}", sample["ocr"])
|
| 1039 |
+
else:
|
| 1040 |
+
return prompt_text
|
| 1041 |
+
|
| 1042 |
+
context_text = "".join(
|
| 1043 |
+
f"{sample_to_prompt(in_context_samples[i])}{in_context_samples[i]['class_name']}<|endofchunk|>"
|
| 1044 |
+
for i in range(effective_num_shots)
|
| 1045 |
+
)
|
| 1046 |
+
|
| 1047 |
+
# Keep the text but remove the image tags for the zero-shot case
|
| 1048 |
+
if num_shots == 0:
|
| 1049 |
+
context_text = context_text.replace("<image>", "")
|
| 1050 |
+
|
| 1051 |
+
batch_text.append(context_text)
|
| 1052 |
+
|
| 1053 |
+
# shape [B, T_img, C, h, w]
|
| 1054 |
+
vision_x = torch.stack(batch_images, dim=0)
|
| 1055 |
+
# shape [B, T_img, 1, C, h, w] where 1 is the frame dimension
|
| 1056 |
+
vision_x = vision_x.unsqueeze(2)
|
| 1057 |
+
|
| 1058 |
+
# Cache the context text: tokenize context and prompt,
|
| 1059 |
+
# e.g. '<context> a picture of a '
|
| 1060 |
+
text_x = [
|
| 1061 |
+
context_text
|
| 1062 |
+
+ sample_to_prompt({k: batch[k][idx] for k in batch.keys()})
|
| 1063 |
+
for idx, context_text in enumerate(batch_text)
|
| 1064 |
+
]
|
| 1065 |
+
|
| 1066 |
+
ctx_and_prompt_tokenized = tokenizer(
|
| 1067 |
+
text_x,
|
| 1068 |
+
return_tensors="pt",
|
| 1069 |
+
padding="longest",
|
| 1070 |
+
max_length=2000,
|
| 1071 |
+
)
|
| 1072 |
+
|
| 1073 |
+
ctx_and_prompt_input_ids = ctx_and_prompt_tokenized["input_ids"].to(eval_model.device)
|
| 1074 |
+
ctx_and_prompt_attention_mask = ctx_and_prompt_tokenized["attention_mask"].to(eval_model.device).bool()
|
| 1075 |
+
|
| 1076 |
+
def _detach_pkvs(pkvs):
|
| 1077 |
+
"""Detach a set of past key values."""
|
| 1078 |
+
return list([tuple([x.detach() for x in inner]) for inner in pkvs])
|
| 1079 |
+
|
| 1080 |
+
if use_kv_caching:
|
| 1081 |
+
eval_model.cache_media(input_ids=ctx_and_prompt_input_ids, vision_x=vision_x.to(eval_model.device))
|
| 1082 |
+
|
| 1083 |
+
with torch.no_grad():
|
| 1084 |
+
precomputed = eval_model.model(
|
| 1085 |
+
vision_x=None,
|
| 1086 |
+
lang_x=ctx_and_prompt_input_ids,
|
| 1087 |
+
attention_mask=ctx_and_prompt_attention_mask,
|
| 1088 |
+
clear_conditioned_layers=False,
|
| 1089 |
+
use_cache=True,
|
| 1090 |
+
)
|
| 1091 |
+
|
| 1092 |
+
precomputed_pkvs = _detach_pkvs(precomputed.past_key_values)
|
| 1093 |
+
precomputed_logits = precomputed.logits.detach()
|
| 1094 |
+
else:
|
| 1095 |
+
precomputed_pkvs = None
|
| 1096 |
+
precomputed_logits = None
|
| 1097 |
+
|
| 1098 |
+
if dataset_name == "imagenet":
|
| 1099 |
+
all_class_names = IMAGENET_CLASSNAMES
|
| 1100 |
+
else:
|
| 1101 |
+
all_class_names = HM_CLASSNAMES
|
| 1102 |
+
|
| 1103 |
+
if dataset_name == "imagenet":
|
| 1104 |
+
class_id_to_name = IMAGENET_1K_CLASS_ID_TO_LABEL
|
| 1105 |
+
else:
|
| 1106 |
+
class_id_to_name = HM_CLASS_ID_TO_LABEL
|
| 1107 |
+
|
| 1108 |
+
overall_probs = []
|
| 1109 |
+
for class_name in all_class_names:
|
| 1110 |
+
past_key_values = None
|
| 1111 |
+
# Tokenize only the class name and iteratively decode the model's
|
| 1112 |
+
# predictions for this class.
|
| 1113 |
+
classname_tokens = tokenizer(
|
| 1114 |
+
class_name, add_special_tokens=False, return_tensors="pt"
|
| 1115 |
+
)["input_ids"].to(eval_model.device)
|
| 1116 |
+
|
| 1117 |
+
if classname_tokens.ndim == 1: # Case: classname is only 1 token
|
| 1118 |
+
classname_tokens = torch.unsqueeze(classname_tokens, 1)
|
| 1119 |
+
|
| 1120 |
+
classname_tokens = repeat(
|
| 1121 |
+
classname_tokens, "b s -> (repeat b) s", repeat=len(batch_text)
|
| 1122 |
+
)
|
| 1123 |
+
|
| 1124 |
+
if use_kv_caching:
|
| 1125 |
+
# Compute the outputs one token at a time, using cached
|
| 1126 |
+
# activations.
|
| 1127 |
+
|
| 1128 |
+
# Initialize the elementwise predictions with the last set of
|
| 1129 |
+
# logits from precomputed; this will correspond to the predicted
|
| 1130 |
+
# probability of the first position/token in the imagenet
|
| 1131 |
+
# classname. We will append the logits for each token to this
|
| 1132 |
+
# list (each element has shape [B, 1, vocab_size]).
|
| 1133 |
+
elementwise_logits = [precomputed_logits[:, -2:-1, :]]
|
| 1134 |
+
|
| 1135 |
+
for token_idx in range(classname_tokens.shape[1]):
|
| 1136 |
+
_lang_x = classname_tokens[:, token_idx].reshape((-1, 1))
|
| 1137 |
+
outputs = eval_model.get_logits(
|
| 1138 |
+
lang_x=_lang_x,
|
| 1139 |
+
past_key_values=(
|
| 1140 |
+
past_key_values if token_idx > 0 else precomputed_pkvs
|
| 1141 |
+
),
|
| 1142 |
+
clear_conditioned_layers=False,
|
| 1143 |
+
)
|
| 1144 |
+
past_key_values = _detach_pkvs(outputs.past_key_values)
|
| 1145 |
+
elementwise_logits.append(outputs.logits.detach())
|
| 1146 |
+
|
| 1147 |
+
# logits/probs has shape [B, classname_tokens + 1, vocab_size]
|
| 1148 |
+
logits = torch.concat(elementwise_logits, 1)
|
| 1149 |
+
probs = torch.softmax(logits, dim=-1)
|
| 1150 |
+
|
| 1151 |
+
# collect the probability of the generated token -- probability
|
| 1152 |
+
# at index 0 corresponds to the token at index 1.
|
| 1153 |
+
probs = probs[:, :-1, :] # shape [B, classname_tokens, vocab_size]
|
| 1154 |
+
|
| 1155 |
+
gen_probs = torch.gather(probs, 2, classname_tokens[:, :, None]).squeeze(-1).cpu()
|
| 1156 |
+
|
| 1157 |
+
class_prob = torch.prod(gen_probs, 1).numpy()
|
| 1158 |
+
else:
|
| 1159 |
+
# Compute the outputs without using cached
|
| 1160 |
+
# activations.
|
| 1161 |
+
|
| 1162 |
+
# contatenate the class name tokens to the end of the context
|
| 1163 |
+
# tokens
|
| 1164 |
+
_lang_x = torch.cat([ctx_and_prompt_input_ids, classname_tokens], dim=1)
|
| 1165 |
+
_attention_mask = torch.cat(
|
| 1166 |
+
[
|
| 1167 |
+
ctx_and_prompt_attention_mask,
|
| 1168 |
+
torch.ones_like(classname_tokens).bool(),
|
| 1169 |
+
],
|
| 1170 |
+
dim=1,
|
| 1171 |
+
)
|
| 1172 |
+
|
| 1173 |
+
outputs = eval_model.get_logits(
|
| 1174 |
+
vision_x=vision_x.to(eval_model.device),
|
| 1175 |
+
lang_x=_lang_x.to(eval_model.device),
|
| 1176 |
+
attention_mask=_attention_mask.to(eval_model.device),
|
| 1177 |
+
clear_conditioned_layers=True,
|
| 1178 |
+
)
|
| 1179 |
+
|
| 1180 |
+
logits = outputs.logits.detach().float()
|
| 1181 |
+
probs = torch.softmax(logits, dim=-1)
|
| 1182 |
+
|
| 1183 |
+
# get probability of the generated class name tokens
|
| 1184 |
+
gen_probs = probs[:, ctx_and_prompt_input_ids.shape[1]-1:_lang_x.shape[1], :]
|
| 1185 |
+
gen_probs = torch.gather(gen_probs, 2, classname_tokens[:, :, None]).squeeze(-1).cpu()
|
| 1186 |
+
class_prob = torch.prod(gen_probs, 1).numpy()
|
| 1187 |
+
|
| 1188 |
+
overall_probs.append(class_prob)
|
| 1189 |
+
|
| 1190 |
+
overall_probs = np.row_stack(overall_probs).T # shape [B, num_classes]
|
| 1191 |
+
|
| 1192 |
+
eval_model.uncache_media()
|
| 1193 |
+
|
| 1194 |
+
def topk(probs_ary: np.ndarray, k: int) -> np.ndarray:
|
| 1195 |
+
"""Return the indices of the top k elements in probs_ary."""
|
| 1196 |
+
return np.argsort(probs_ary)[::-1][:k]
|
| 1197 |
+
|
| 1198 |
+
for i in range(len(batch_text)):
|
| 1199 |
+
highest_prob_idxs = topk(overall_probs[i], 5)
|
| 1200 |
+
|
| 1201 |
+
top5 = [class_id_to_name[pred] for pred in highest_prob_idxs]
|
| 1202 |
+
|
| 1203 |
+
y_i = batch["class_name"][i]
|
| 1204 |
+
acc5 += int(y_i in set(top5))
|
| 1205 |
+
acc1 += int(y_i == top5[0])
|
| 1206 |
+
|
| 1207 |
+
if dataset_name == "hateful_memes":
|
| 1208 |
+
# sum over the probabilities of the different classes
|
| 1209 |
+
binary_probs = [overall_probs[i][0] + overall_probs[i][3], overall_probs[i][1] + overall_probs[i][2]]
|
| 1210 |
+
|
| 1211 |
+
predictions.append({
|
| 1212 |
+
"id": batch["id"][i],
|
| 1213 |
+
"gt_label": y_i,
|
| 1214 |
+
"pred_label": top5[0],
|
| 1215 |
+
"pred_score": binary_probs[highest_prob_idxs[0]] if dataset_name == "hateful_memes" else None, # only for hateful memes
|
| 1216 |
+
})
|
| 1217 |
+
|
| 1218 |
+
# all gather
|
| 1219 |
+
all_predictions = [None] * args.world_size
|
| 1220 |
+
torch.distributed.all_gather_object(all_predictions, predictions) # list of lists
|
| 1221 |
+
if args.rank != 0:
|
| 1222 |
+
return
|
| 1223 |
+
|
| 1224 |
+
all_predictions = [
|
| 1225 |
+
item for sublist in all_predictions for item in sublist
|
| 1226 |
+
] # flatten
|
| 1227 |
+
|
| 1228 |
+
# Hack to remove samples with duplicate ids (only necessary for multi-GPU evaluation)
|
| 1229 |
+
all_predictions = {pred["id"]: pred for pred in all_predictions}.values()
|
| 1230 |
+
|
| 1231 |
+
assert len(all_predictions) == len(test_dataset) # sanity check
|
| 1232 |
+
|
| 1233 |
+
if dataset_name == "hateful_memes":
|
| 1234 |
+
# return ROC-AUC score
|
| 1235 |
+
gts = [pred["gt_label"] for pred in all_predictions]
|
| 1236 |
+
pred_scores = [pred["pred_score"] for pred in all_predictions]
|
| 1237 |
+
return roc_auc_score(gts, pred_scores)
|
| 1238 |
+
else:
|
| 1239 |
+
# return top-1 accuracy
|
| 1240 |
+
acc1 = sum(
|
| 1241 |
+
int(pred["gt_label"] == pred["pred_label"])
|
| 1242 |
+
for pred in all_predictions
|
| 1243 |
+
)
|
| 1244 |
+
return float(acc1) / len(all_predictions)
|
| 1245 |
+
|
| 1246 |
+
if __name__ == "__main__":
|
| 1247 |
+
main()
|
open_flamingo/open_flamingo/eval/models/blip.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from transformers import Blip2Processor, Blip2ForConditionalGeneration
|
| 7 |
+
from open_flamingo.eval.eval_model import BaseEvalModel
|
| 8 |
+
from open_flamingo.eval.models.utils import unwrap_model
|
| 9 |
+
|
| 10 |
+
class EvalModel(BaseEvalModel):
|
| 11 |
+
"""BLIP-2 model evaluation.
|
| 12 |
+
|
| 13 |
+
Attributes:
|
| 14 |
+
model (nn.Module): Underlying Torch model.
|
| 15 |
+
tokenizer (transformers.PreTrainedTokenizer): Tokenizer for model.
|
| 16 |
+
device: Index of GPU to use, or the string "cpu"
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
def __init__(self, model_args):
|
| 20 |
+
assert (
|
| 21 |
+
"processor_path" in model_args
|
| 22 |
+
and "lm_path" in model_args
|
| 23 |
+
and "device" in model_args
|
| 24 |
+
), "BLIP-2 requires processor_path, lm_path, and device arguments to be specified"
|
| 25 |
+
|
| 26 |
+
self.device = (
|
| 27 |
+
int(model_args["device"])
|
| 28 |
+
if ("device" in model_args and model_args["device"] >= 0)
|
| 29 |
+
else "cpu"
|
| 30 |
+
)
|
| 31 |
+
self.processor = Blip2Processor.from_pretrained(model_args["processor_path"])
|
| 32 |
+
self.model = Blip2ForConditionalGeneration.from_pretrained(
|
| 33 |
+
model_args["lm_path"]
|
| 34 |
+
)
|
| 35 |
+
self.model.to(self.device)
|
| 36 |
+
self.model.eval()
|
| 37 |
+
self.processor.tokenizer.padding_side = "left"
|
| 38 |
+
|
| 39 |
+
def _prepare_images(self, batch: List[List[torch.Tensor]]) -> torch.Tensor:
|
| 40 |
+
"""Preprocess images and stack them.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
batch: A list of lists of images.
|
| 44 |
+
|
| 45 |
+
Returns:
|
| 46 |
+
A Tensor of shape
|
| 47 |
+
(batch_size, channels, height, width).
|
| 48 |
+
"""
|
| 49 |
+
batch_images = None
|
| 50 |
+
assert all(
|
| 51 |
+
len(example) == 1 for example in batch
|
| 52 |
+
), "BLIP-2 only supports one image per example"
|
| 53 |
+
|
| 54 |
+
for example in batch:
|
| 55 |
+
assert len(example) == 1, "BLIP-2 only supports one image per example"
|
| 56 |
+
batch_images = torch.cat(
|
| 57 |
+
[
|
| 58 |
+
batch_images,
|
| 59 |
+
self.processor.image_processor(example, return_tensors="pt")[
|
| 60 |
+
"pixel_values"
|
| 61 |
+
],
|
| 62 |
+
]
|
| 63 |
+
if batch_images is not None
|
| 64 |
+
else [
|
| 65 |
+
self.processor.image_processor(example, return_tensors="pt")[
|
| 66 |
+
"pixel_values"
|
| 67 |
+
]
|
| 68 |
+
],
|
| 69 |
+
dim=0,
|
| 70 |
+
)
|
| 71 |
+
return batch_images
|
| 72 |
+
|
| 73 |
+
def get_outputs(
|
| 74 |
+
self,
|
| 75 |
+
batch_text: List[str],
|
| 76 |
+
batch_images: List[List[Image.Image]],
|
| 77 |
+
max_generation_length: int,
|
| 78 |
+
num_beams: int,
|
| 79 |
+
length_penalty: float,
|
| 80 |
+
) -> List[str]:
|
| 81 |
+
encodings = self.processor.tokenizer(
|
| 82 |
+
batch_text,
|
| 83 |
+
padding="longest",
|
| 84 |
+
truncation=True,
|
| 85 |
+
return_tensors="pt",
|
| 86 |
+
max_length=2000,
|
| 87 |
+
)
|
| 88 |
+
input_ids = encodings["input_ids"]
|
| 89 |
+
attention_mask = encodings["attention_mask"]
|
| 90 |
+
|
| 91 |
+
with torch.inference_mode():
|
| 92 |
+
outputs = unwrap_model(self.model).generate(
|
| 93 |
+
self._prepare_images(batch_images).to(self.device),
|
| 94 |
+
input_ids.to(self.device),
|
| 95 |
+
attention_mask=attention_mask.to(self.device),
|
| 96 |
+
max_new_tokens=max_generation_length,
|
| 97 |
+
min_new_tokens=8,
|
| 98 |
+
num_beams=num_beams,
|
| 99 |
+
length_penalty=length_penalty,
|
| 100 |
+
)
|
| 101 |
+
|
| 102 |
+
return self.processor.tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
| 103 |
+
|
| 104 |
+
def get_vqa_prompt(self, question, answer=None) -> str:
|
| 105 |
+
return (
|
| 106 |
+
f"Question:{question} Short answer:{answer if answer is not None else ''}"
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
def get_caption_prompt(self, caption=None) -> str:
|
| 110 |
+
return f"A photo of {caption if caption is not None else ''}"
|
| 111 |
+
|
| 112 |
+
def get_classification_prompt(self, class_str=None) -> str:
|
| 113 |
+
raise NotImplementedError
|
open_flamingo/open_flamingo/eval/models/open_flamingo.py
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from open_flamingo.eval.eval_model import BaseEvalModel
|
| 7 |
+
from open_flamingo.src.factory import create_model_and_transforms
|
| 8 |
+
from contextlib import suppress
|
| 9 |
+
from open_flamingo.eval.models.utils import unwrap_model
|
| 10 |
+
|
| 11 |
+
class EvalModel(BaseEvalModel):
|
| 12 |
+
"""OpenFlamingo model evaluation.
|
| 13 |
+
|
| 14 |
+
Attributes:
|
| 15 |
+
model (nn.Module): Underlying Torch model.
|
| 16 |
+
tokenizer (transformers.PreTrainedTokenizer): Tokenizer for model.
|
| 17 |
+
device: Index of GPU to use, or the string "CPU"
|
| 18 |
+
"""
|
| 19 |
+
|
| 20 |
+
def __init__(self, model_args):
|
| 21 |
+
assert (
|
| 22 |
+
"vision_encoder_path" in model_args
|
| 23 |
+
and "lm_path" in model_args
|
| 24 |
+
and "checkpoint_path" in model_args
|
| 25 |
+
and "lm_tokenizer_path" in model_args
|
| 26 |
+
and "cross_attn_every_n_layers" in model_args
|
| 27 |
+
and "vision_encoder_pretrained" in model_args
|
| 28 |
+
and "precision" in model_args
|
| 29 |
+
), "OpenFlamingo requires vision_encoder_path, lm_path, device, checkpoint_path, lm_tokenizer_path, cross_attn_every_n_layers, vision_encoder_pretrained, and precision arguments to be specified"
|
| 30 |
+
|
| 31 |
+
self.device = (
|
| 32 |
+
model_args["device"]
|
| 33 |
+
if ("device" in model_args and model_args["device"] >= 0)
|
| 34 |
+
else "cpu"
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
(
|
| 38 |
+
self.model,
|
| 39 |
+
self.image_processor,
|
| 40 |
+
self.tokenizer,
|
| 41 |
+
) = create_model_and_transforms(
|
| 42 |
+
model_args["vision_encoder_path"],
|
| 43 |
+
model_args["vision_encoder_pretrained"],
|
| 44 |
+
model_args["lm_path"],
|
| 45 |
+
model_args["lm_tokenizer_path"],
|
| 46 |
+
cross_attn_every_n_layers=int(model_args["cross_attn_every_n_layers"]),
|
| 47 |
+
)
|
| 48 |
+
checkpoint = torch.load(model_args["checkpoint_path"], map_location="cpu")
|
| 49 |
+
if "model_state_dict" in checkpoint:
|
| 50 |
+
checkpoint = checkpoint["model_state_dict"]
|
| 51 |
+
checkpoint = {k.replace("module.", ""): v for k, v in checkpoint.items()}
|
| 52 |
+
self.model.load_state_dict(checkpoint, strict=False)
|
| 53 |
+
self.model.to(self.device)
|
| 54 |
+
self.model.eval()
|
| 55 |
+
self.tokenizer.padding_side = "left"
|
| 56 |
+
|
| 57 |
+
# autocast
|
| 58 |
+
self.autocast = get_autocast(model_args["precision"])
|
| 59 |
+
self.cast_dtype = get_cast_dtype(model_args["precision"])
|
| 60 |
+
|
| 61 |
+
def _prepare_images(self, batch: List[List[torch.Tensor]]) -> torch.Tensor:
|
| 62 |
+
"""Preprocess images and stack them.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
batch: A list of lists of images.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
A Tensor of shape
|
| 69 |
+
(batch_size, images_per_example, frames, channels, height, width).
|
| 70 |
+
"""
|
| 71 |
+
images_per_example = max(len(x) for x in batch)
|
| 72 |
+
batch_images = None
|
| 73 |
+
for iexample, example in enumerate(batch):
|
| 74 |
+
for iimage, image in enumerate(example):
|
| 75 |
+
preprocessed = self.image_processor(image)
|
| 76 |
+
|
| 77 |
+
if batch_images is None:
|
| 78 |
+
batch_images = torch.zeros(
|
| 79 |
+
(len(batch), images_per_example, 1) + preprocessed.shape,
|
| 80 |
+
dtype=preprocessed.dtype,
|
| 81 |
+
)
|
| 82 |
+
batch_images[iexample, iimage, 0] = preprocessed
|
| 83 |
+
return batch_images
|
| 84 |
+
|
| 85 |
+
def get_outputs(
|
| 86 |
+
self,
|
| 87 |
+
batch_text: List[str],
|
| 88 |
+
batch_images: List[List[Image.Image]],
|
| 89 |
+
min_generation_length: int,
|
| 90 |
+
max_generation_length: int,
|
| 91 |
+
num_beams: int,
|
| 92 |
+
length_penalty: float,
|
| 93 |
+
) -> List[str]:
|
| 94 |
+
encodings = self.tokenizer(
|
| 95 |
+
batch_text,
|
| 96 |
+
padding="longest",
|
| 97 |
+
truncation=True,
|
| 98 |
+
return_tensors="pt",
|
| 99 |
+
max_length=2000,
|
| 100 |
+
)
|
| 101 |
+
input_ids = encodings["input_ids"]
|
| 102 |
+
attention_mask = encodings["attention_mask"]
|
| 103 |
+
|
| 104 |
+
with torch.inference_mode():
|
| 105 |
+
with self.autocast():
|
| 106 |
+
outputs = unwrap_model(self.model).generate(
|
| 107 |
+
self._prepare_images(batch_images).to(
|
| 108 |
+
self.device, dtype=self.cast_dtype, non_blocking=True
|
| 109 |
+
),
|
| 110 |
+
input_ids.to(self.device, dtype=self.cast_dtype, non_blocking=True),
|
| 111 |
+
attention_mask=attention_mask.to(
|
| 112 |
+
self.device, dtype=self.cast_dtype, non_blocking=True
|
| 113 |
+
),
|
| 114 |
+
min_new_tokens=min_generation_length,
|
| 115 |
+
max_new_tokens=max_generation_length,
|
| 116 |
+
num_beams=num_beams,
|
| 117 |
+
length_penalty=length_penalty,
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
outputs = outputs[:, len(input_ids[0]) :]
|
| 121 |
+
|
| 122 |
+
return self.tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
| 123 |
+
|
| 124 |
+
def get_logits(
|
| 125 |
+
self,
|
| 126 |
+
lang_x: torch.Tensor,
|
| 127 |
+
vision_x: torch.Tensor = None,
|
| 128 |
+
attention_mask: torch.Tensor = None,
|
| 129 |
+
past_key_values: torch.Tensor = None,
|
| 130 |
+
clear_conditioned_layers: bool = False,
|
| 131 |
+
):
|
| 132 |
+
with torch.inference_mode():
|
| 133 |
+
with self.autocast():
|
| 134 |
+
outputs = self.model(
|
| 135 |
+
vision_x=vision_x,
|
| 136 |
+
lang_x=lang_x,
|
| 137 |
+
attention_mask=attention_mask,
|
| 138 |
+
clear_conditioned_layers=clear_conditioned_layers,
|
| 139 |
+
past_key_values=past_key_values,
|
| 140 |
+
use_cache=(past_key_values is not None),
|
| 141 |
+
)
|
| 142 |
+
return outputs
|
| 143 |
+
|
| 144 |
+
def encode_vision_x(self, image_tensor: torch.Tensor):
|
| 145 |
+
unwrap_model(self.model)._encode_vision_x(image_tensor.to(self.device))
|
| 146 |
+
|
| 147 |
+
def uncache_media(self):
|
| 148 |
+
unwrap_model(self.model).uncache_media()
|
| 149 |
+
|
| 150 |
+
def cache_media(self, input_ids, vision_x):
|
| 151 |
+
unwrap_model(self.model).cache_media(input_ids=input_ids, vision_x=vision_x)
|
| 152 |
+
|
| 153 |
+
def get_vqa_prompt(self, question, answer=None) -> str:
|
| 154 |
+
return f"<image>Question:{question} Short answer:{answer if answer is not None else ''}{'<|endofchunk|>' if answer is not None else ''}"
|
| 155 |
+
|
| 156 |
+
def get_caption_prompt(self, caption=None) -> str:
|
| 157 |
+
return f"<image>Output:{caption if caption is not None else ''}{'<|endofchunk|>' if caption is not None else ''}"
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def get_cast_dtype(precision: str):
|
| 161 |
+
cast_dtype = None
|
| 162 |
+
if precision == "bf16":
|
| 163 |
+
cast_dtype = torch.bfloat16
|
| 164 |
+
elif precision == "fp16":
|
| 165 |
+
cast_dtype = torch.float16
|
| 166 |
+
return cast_dtype
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def get_autocast(precision):
|
| 170 |
+
if precision == "amp":
|
| 171 |
+
return torch.cuda.amp.autocast
|
| 172 |
+
elif precision == "amp_bfloat16" or precision == "amp_bf16":
|
| 173 |
+
# amp_bfloat16 is more stable than amp float16 for clip training
|
| 174 |
+
return lambda: torch.cuda.amp.autocast(dtype=torch.bfloat16)
|
| 175 |
+
else:
|
| 176 |
+
return suppress
|
open_flamingo/open_flamingo/eval/models/utils.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
|
| 3 |
+
def unwrap_model(model):
|
| 4 |
+
"""
|
| 5 |
+
Unwrap a model from a DataParallel or DistributedDataParallel wrapper.
|
| 6 |
+
"""
|
| 7 |
+
if isinstance(model, (nn.DataParallel, nn.parallel.DistributedDataParallel)):
|
| 8 |
+
return model.module
|
| 9 |
+
else:
|
| 10 |
+
return model
|
open_flamingo/open_flamingo/eval/ok_vqa_utils.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Those are manual mapping that are not caught by our stemming rules or would
|
| 2 |
+
# would be done incorrectly by our automatic stemming rule. In details,
|
| 3 |
+
# the keys of the _MANUAL_MATCHES dict contains the original word and the value
|
| 4 |
+
# contains the transformation of the word expected by the OKVQA stemming rule.
|
| 5 |
+
# These manual rules were found by checking the `raw_answers` and the `answers`
|
| 6 |
+
# fields of the released OKVQA dataset and checking all things that were not
|
| 7 |
+
# properly mapped by our automatic rules. In particular some of the mapping
|
| 8 |
+
# are sometimes constant, e.g. christmas -> christmas which was incorrectly
|
| 9 |
+
# singularized by our inflection.singularize.
|
| 10 |
+
import re
|
| 11 |
+
import nltk
|
| 12 |
+
from nltk.corpus.reader import VERB
|
| 13 |
+
import inflection
|
| 14 |
+
|
| 15 |
+
_MANUAL_MATCHES = {
|
| 16 |
+
"police": "police",
|
| 17 |
+
"las": "las",
|
| 18 |
+
"vegas": "vegas",
|
| 19 |
+
"yes": "yes",
|
| 20 |
+
"jeans": "jean",
|
| 21 |
+
"hell's": "hell",
|
| 22 |
+
"domino's": "domino",
|
| 23 |
+
"morning": "morn",
|
| 24 |
+
"clothes": "cloth",
|
| 25 |
+
"are": "are",
|
| 26 |
+
"riding": "ride",
|
| 27 |
+
"leaves": "leaf",
|
| 28 |
+
"dangerous": "danger",
|
| 29 |
+
"clothing": "cloth",
|
| 30 |
+
"texting": "text",
|
| 31 |
+
"kiting": "kite",
|
| 32 |
+
"firefighters": "firefight",
|
| 33 |
+
"ties": "tie",
|
| 34 |
+
"married": "married",
|
| 35 |
+
"teething": "teeth",
|
| 36 |
+
"gloves": "glove",
|
| 37 |
+
"tennis": "tennis",
|
| 38 |
+
"dining": "dine",
|
| 39 |
+
"directions": "direct",
|
| 40 |
+
"waves": "wave",
|
| 41 |
+
"christmas": "christmas",
|
| 42 |
+
"drives": "drive",
|
| 43 |
+
"pudding": "pud",
|
| 44 |
+
"coding": "code",
|
| 45 |
+
"plating": "plate",
|
| 46 |
+
"quantas": "quanta",
|
| 47 |
+
"hornes": "horn",
|
| 48 |
+
"graves": "grave",
|
| 49 |
+
"mating": "mate",
|
| 50 |
+
"paned": "pane",
|
| 51 |
+
"alertness": "alert",
|
| 52 |
+
"sunbathing": "sunbath",
|
| 53 |
+
"tenning": "ten",
|
| 54 |
+
"wetness": "wet",
|
| 55 |
+
"urinating": "urine",
|
| 56 |
+
"sickness": "sick",
|
| 57 |
+
"braves": "brave",
|
| 58 |
+
"firefighting": "firefight",
|
| 59 |
+
"lenses": "lens",
|
| 60 |
+
"reflections": "reflect",
|
| 61 |
+
"backpackers": "backpack",
|
| 62 |
+
"eatting": "eat",
|
| 63 |
+
"designers": "design",
|
| 64 |
+
"curiousity": "curious",
|
| 65 |
+
"playfulness": "play",
|
| 66 |
+
"blindness": "blind",
|
| 67 |
+
"hawke": "hawk",
|
| 68 |
+
"tomatoe": "tomato",
|
| 69 |
+
"rodeoing": "rodeo",
|
| 70 |
+
"brightness": "bright",
|
| 71 |
+
"circuses": "circus",
|
| 72 |
+
"skateboarders": "skateboard",
|
| 73 |
+
"staring": "stare",
|
| 74 |
+
"electronics": "electron",
|
| 75 |
+
"electicity": "elect",
|
| 76 |
+
"mountainous": "mountain",
|
| 77 |
+
"socializing": "social",
|
| 78 |
+
"hamburgers": "hamburg",
|
| 79 |
+
"caves": "cave",
|
| 80 |
+
"transitions": "transit",
|
| 81 |
+
"wading": "wade",
|
| 82 |
+
"creame": "cream",
|
| 83 |
+
"toileting": "toilet",
|
| 84 |
+
"sautee": "saute",
|
| 85 |
+
"buildings": "build",
|
| 86 |
+
"belongings": "belong",
|
| 87 |
+
"stockings": "stock",
|
| 88 |
+
"walle": "wall",
|
| 89 |
+
"cumulis": "cumuli",
|
| 90 |
+
"travelers": "travel",
|
| 91 |
+
"conducter": "conduct",
|
| 92 |
+
"browsing": "brows",
|
| 93 |
+
"pooping": "poop",
|
| 94 |
+
"haircutting": "haircut",
|
| 95 |
+
"toppings": "top",
|
| 96 |
+
"hearding": "heard",
|
| 97 |
+
"sunblocker": "sunblock",
|
| 98 |
+
"bases": "base",
|
| 99 |
+
"markings": "mark",
|
| 100 |
+
"mopeds": "mope",
|
| 101 |
+
"kindergartener": "kindergarten",
|
| 102 |
+
"pies": "pie",
|
| 103 |
+
"scrapbooking": "scrapbook",
|
| 104 |
+
"couponing": "coupon",
|
| 105 |
+
"meetings": "meet",
|
| 106 |
+
"elevators": "elev",
|
| 107 |
+
"lowes": "low",
|
| 108 |
+
"men's": "men",
|
| 109 |
+
"childrens": "children",
|
| 110 |
+
"shelves": "shelve",
|
| 111 |
+
"paintings": "paint",
|
| 112 |
+
"raines": "rain",
|
| 113 |
+
"paring": "pare",
|
| 114 |
+
"expressions": "express",
|
| 115 |
+
"routes": "rout",
|
| 116 |
+
"pease": "peas",
|
| 117 |
+
"vastness": "vast",
|
| 118 |
+
"awning": "awn",
|
| 119 |
+
"boy's": "boy",
|
| 120 |
+
"drunkenness": "drunken",
|
| 121 |
+
"teasing": "teas",
|
| 122 |
+
"conferences": "confer",
|
| 123 |
+
"ripeness": "ripe",
|
| 124 |
+
"suspenders": "suspend",
|
| 125 |
+
"earnings": "earn",
|
| 126 |
+
"reporters": "report",
|
| 127 |
+
"kid's": "kid",
|
| 128 |
+
"containers": "contain",
|
| 129 |
+
"corgie": "corgi",
|
| 130 |
+
"porche": "porch",
|
| 131 |
+
"microwaves": "microwave",
|
| 132 |
+
"batter's": "batter",
|
| 133 |
+
"sadness": "sad",
|
| 134 |
+
"apartments": "apart",
|
| 135 |
+
"oxygenize": "oxygen",
|
| 136 |
+
"striping": "stripe",
|
| 137 |
+
"purring": "pure",
|
| 138 |
+
"professionals": "profession",
|
| 139 |
+
"piping": "pipe",
|
| 140 |
+
"farmer's": "farmer",
|
| 141 |
+
"potatoe": "potato",
|
| 142 |
+
"emirates": "emir",
|
| 143 |
+
"womens": "women",
|
| 144 |
+
"veteran's": "veteran",
|
| 145 |
+
"wilderness": "wilder",
|
| 146 |
+
"propellers": "propel",
|
| 147 |
+
"alpes": "alp",
|
| 148 |
+
"charioteering": "chariot",
|
| 149 |
+
"swining": "swine",
|
| 150 |
+
"illness": "ill",
|
| 151 |
+
"crepte": "crept",
|
| 152 |
+
"adhesives": "adhesive",
|
| 153 |
+
"regent's": "regent",
|
| 154 |
+
"decorations": "decor",
|
| 155 |
+
"rabbies": "rabbi",
|
| 156 |
+
"overseas": "oversea",
|
| 157 |
+
"travellers": "travel",
|
| 158 |
+
"casings": "case",
|
| 159 |
+
"smugness": "smug",
|
| 160 |
+
"doves": "dove",
|
| 161 |
+
"nationals": "nation",
|
| 162 |
+
"mustange": "mustang",
|
| 163 |
+
"ringe": "ring",
|
| 164 |
+
"gondoliere": "gondolier",
|
| 165 |
+
"vacationing": "vacate",
|
| 166 |
+
"reminders": "remind",
|
| 167 |
+
"baldness": "bald",
|
| 168 |
+
"settings": "set",
|
| 169 |
+
"glaced": "glace",
|
| 170 |
+
"coniferous": "conifer",
|
| 171 |
+
"revelations": "revel",
|
| 172 |
+
"personals": "person",
|
| 173 |
+
"daughter's": "daughter",
|
| 174 |
+
"badness": "bad",
|
| 175 |
+
"projections": "project",
|
| 176 |
+
"polarizing": "polar",
|
| 177 |
+
"vandalizers": "vandal",
|
| 178 |
+
"minerals": "miner",
|
| 179 |
+
"protesters": "protest",
|
| 180 |
+
"controllers": "control",
|
| 181 |
+
"weddings": "wed",
|
| 182 |
+
"sometimes": "sometime",
|
| 183 |
+
"earing": "ear",
|
| 184 |
+
}
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
class OKVQAStemmer:
|
| 188 |
+
"""Stemmer to match OKVQA v1.1 procedure."""
|
| 189 |
+
|
| 190 |
+
def __init__(self):
|
| 191 |
+
self._wordnet_lemmatizer = nltk.stem.WordNetLemmatizer()
|
| 192 |
+
|
| 193 |
+
def stem(self, input_string):
|
| 194 |
+
"""Apply stemming."""
|
| 195 |
+
word_and_pos = nltk.pos_tag(nltk.tokenize.word_tokenize(input_string))
|
| 196 |
+
stemmed_words = []
|
| 197 |
+
for w, p in word_and_pos:
|
| 198 |
+
if w in _MANUAL_MATCHES:
|
| 199 |
+
w = _MANUAL_MATCHES[w]
|
| 200 |
+
elif w.endswith("ing"):
|
| 201 |
+
w = self._wordnet_lemmatizer.lemmatize(w, VERB)
|
| 202 |
+
elif p.startswith("NNS") or p.startswith("NNPS"):
|
| 203 |
+
w = inflection.singularize(w)
|
| 204 |
+
stemmed_words.append(w)
|
| 205 |
+
return " ".join(stemmed_words)
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
stemmer = OKVQAStemmer()
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
def postprocess_ok_vqa_generation(predictions) -> str:
|
| 212 |
+
prediction = re.split("Question|Answer|Short", predictions, 1)[0]
|
| 213 |
+
prediction_stem = stemmer.stem(prediction)
|
| 214 |
+
return prediction_stem
|
open_flamingo/open_flamingo/eval/vqa_metric.py
ADDED
|
@@ -0,0 +1,583 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import datetime
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import re
|
| 7 |
+
import sys
|
| 8 |
+
|
| 9 |
+
# Interface for accessing the VQA dataset.
|
| 10 |
+
|
| 11 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 12 |
+
# (https://github.com/pdollar/coco/blob/master/PythonAPI/pycocotools/coco.py).
|
| 13 |
+
|
| 14 |
+
# The following functions are defined:
|
| 15 |
+
# VQA - VQA class that loads VQA annotation file and prepares data structures.
|
| 16 |
+
# getQuesIds - Get question ids that satisfy given filter conditions.
|
| 17 |
+
# getImgIds - Get image ids that satisfy given filter conditions.
|
| 18 |
+
# loadQA - Load questions and answers with the specified question ids.
|
| 19 |
+
# showQA - Display the specified questions and answers.
|
| 20 |
+
# loadRes - Load result file and create result object.
|
| 21 |
+
|
| 22 |
+
# Help on each function can be accessed by: "help(COCO.function)"
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class VQA:
|
| 26 |
+
def __init__(self, annotation_file=None, question_file=None):
|
| 27 |
+
"""
|
| 28 |
+
Constructor of VQA helper class for reading and visualizing questions and answers.
|
| 29 |
+
:param annotation_file (str): location of VQA annotation file
|
| 30 |
+
:return:
|
| 31 |
+
"""
|
| 32 |
+
# load dataset
|
| 33 |
+
self.dataset = {}
|
| 34 |
+
self.questions = {}
|
| 35 |
+
self.qa = {}
|
| 36 |
+
self.qqa = {}
|
| 37 |
+
self.imgToQA = {}
|
| 38 |
+
if not annotation_file == None and not question_file == None:
|
| 39 |
+
print("loading VQA annotations and questions into memory...")
|
| 40 |
+
time_t = datetime.datetime.utcnow()
|
| 41 |
+
dataset = json.load(open(annotation_file, "r"))
|
| 42 |
+
questions = json.load(open(question_file, "r"))
|
| 43 |
+
print(datetime.datetime.utcnow() - time_t)
|
| 44 |
+
self.dataset = dataset
|
| 45 |
+
self.questions = questions
|
| 46 |
+
self.createIndex()
|
| 47 |
+
|
| 48 |
+
def createIndex(self):
|
| 49 |
+
# create index
|
| 50 |
+
print("creating index...")
|
| 51 |
+
imgToQA = {ann["image_id"]: [] for ann in self.dataset["annotations"]}
|
| 52 |
+
qa = {ann["question_id"]: [] for ann in self.dataset["annotations"]}
|
| 53 |
+
qqa = {ann["question_id"]: [] for ann in self.dataset["annotations"]}
|
| 54 |
+
for ann in self.dataset["annotations"]:
|
| 55 |
+
imgToQA[ann["image_id"]] += [ann]
|
| 56 |
+
qa[ann["question_id"]] = ann
|
| 57 |
+
for ques in self.questions["questions"]:
|
| 58 |
+
qqa[ques["question_id"]] = ques
|
| 59 |
+
print("index created!")
|
| 60 |
+
|
| 61 |
+
# create class members
|
| 62 |
+
self.qa = qa
|
| 63 |
+
self.qqa = qqa
|
| 64 |
+
self.imgToQA = imgToQA
|
| 65 |
+
|
| 66 |
+
def info(self):
|
| 67 |
+
"""
|
| 68 |
+
Print information about the VQA annotation file.
|
| 69 |
+
:return:
|
| 70 |
+
"""
|
| 71 |
+
for key, value in self.dataset["info"].items():
|
| 72 |
+
print("%s: %s" % (key, value))
|
| 73 |
+
|
| 74 |
+
def getQuesIds(self, imgIds=[], quesTypes=[], ansTypes=[]):
|
| 75 |
+
"""
|
| 76 |
+
Get question ids that satisfy given filter conditions. default skips that filter
|
| 77 |
+
:param imgIds (int array) : get question ids for given imgs
|
| 78 |
+
quesTypes (str array) : get question ids for given question types
|
| 79 |
+
ansTypes (str array) : get question ids for given answer types
|
| 80 |
+
:return: ids (int array) : integer array of question ids
|
| 81 |
+
"""
|
| 82 |
+
imgIds = imgIds if type(imgIds) == list else [imgIds]
|
| 83 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 84 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 85 |
+
|
| 86 |
+
if len(imgIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 87 |
+
anns = self.dataset["annotations"]
|
| 88 |
+
else:
|
| 89 |
+
if not len(imgIds) == 0:
|
| 90 |
+
anns = sum(
|
| 91 |
+
[self.imgToQA[imgId] for imgId in imgIds if imgId in self.imgToQA],
|
| 92 |
+
[],
|
| 93 |
+
)
|
| 94 |
+
else:
|
| 95 |
+
anns = self.dataset["annotations"]
|
| 96 |
+
anns = (
|
| 97 |
+
anns
|
| 98 |
+
if len(quesTypes) == 0
|
| 99 |
+
else [ann for ann in anns if ann["question_type"] in quesTypes]
|
| 100 |
+
)
|
| 101 |
+
anns = (
|
| 102 |
+
anns
|
| 103 |
+
if len(ansTypes) == 0
|
| 104 |
+
else [ann for ann in anns if ann["answer_type"] in ansTypes]
|
| 105 |
+
)
|
| 106 |
+
ids = [ann["question_id"] for ann in anns]
|
| 107 |
+
return ids
|
| 108 |
+
|
| 109 |
+
def getImgIds(self, quesIds=[], quesTypes=[], ansTypes=[]):
|
| 110 |
+
"""
|
| 111 |
+
Get image ids that satisfy given filter conditions. default skips that filter
|
| 112 |
+
:param quesIds (int array) : get image ids for given question ids
|
| 113 |
+
quesTypes (str array) : get image ids for given question types
|
| 114 |
+
ansTypes (str array) : get image ids for given answer types
|
| 115 |
+
:return: ids (int array) : integer array of image ids
|
| 116 |
+
"""
|
| 117 |
+
quesIds = quesIds if type(quesIds) == list else [quesIds]
|
| 118 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 119 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 120 |
+
|
| 121 |
+
if len(quesIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 122 |
+
anns = self.dataset["annotations"]
|
| 123 |
+
else:
|
| 124 |
+
if not len(quesIds) == 0:
|
| 125 |
+
anns = sum(
|
| 126 |
+
[self.qa[quesId] for quesId in quesIds if quesId in self.qa], []
|
| 127 |
+
)
|
| 128 |
+
else:
|
| 129 |
+
anns = self.dataset["annotations"]
|
| 130 |
+
anns = (
|
| 131 |
+
anns
|
| 132 |
+
if len(quesTypes) == 0
|
| 133 |
+
else [ann for ann in anns if ann["question_type"] in quesTypes]
|
| 134 |
+
)
|
| 135 |
+
anns = (
|
| 136 |
+
anns
|
| 137 |
+
if len(ansTypes) == 0
|
| 138 |
+
else [ann for ann in anns if ann["answer_type"] in ansTypes]
|
| 139 |
+
)
|
| 140 |
+
ids = [ann["image_id"] for ann in anns]
|
| 141 |
+
return ids
|
| 142 |
+
|
| 143 |
+
def loadQA(self, ids=[]):
|
| 144 |
+
"""
|
| 145 |
+
Load questions and answers with the specified question ids.
|
| 146 |
+
:param ids (int array) : integer ids specifying question ids
|
| 147 |
+
:return: qa (object array) : loaded qa objects
|
| 148 |
+
"""
|
| 149 |
+
if type(ids) == list:
|
| 150 |
+
return [self.qa[id] for id in ids]
|
| 151 |
+
elif type(ids) == int:
|
| 152 |
+
return [self.qa[ids]]
|
| 153 |
+
|
| 154 |
+
def showQA(self, anns):
|
| 155 |
+
"""
|
| 156 |
+
Display the specified annotations.
|
| 157 |
+
:param anns (array of object): annotations to display
|
| 158 |
+
:return: None
|
| 159 |
+
"""
|
| 160 |
+
if len(anns) == 0:
|
| 161 |
+
return 0
|
| 162 |
+
for ann in anns:
|
| 163 |
+
quesId = ann["question_id"]
|
| 164 |
+
print("Question: %s" % (self.qqa[quesId]["question"]))
|
| 165 |
+
for ans in ann["answers"]:
|
| 166 |
+
print("Answer %d: %s" % (ans["answer_id"], ans["answer"]))
|
| 167 |
+
|
| 168 |
+
def loadRes(self, resFile, quesFile):
|
| 169 |
+
"""
|
| 170 |
+
Load result file and return a result object.
|
| 171 |
+
:param resFile (str) : file name of result file
|
| 172 |
+
:return: res (obj) : result api object
|
| 173 |
+
"""
|
| 174 |
+
res = VQA()
|
| 175 |
+
res.questions = json.load(open(quesFile))
|
| 176 |
+
res.dataset["info"] = copy.deepcopy(self.questions["info"])
|
| 177 |
+
res.dataset["task_type"] = copy.deepcopy(self.questions["task_type"])
|
| 178 |
+
res.dataset["data_type"] = copy.deepcopy(self.questions["data_type"])
|
| 179 |
+
res.dataset["data_subtype"] = copy.deepcopy(self.questions["data_subtype"])
|
| 180 |
+
res.dataset["license"] = copy.deepcopy(self.questions["license"])
|
| 181 |
+
|
| 182 |
+
print("Loading and preparing results... ")
|
| 183 |
+
time_t = datetime.datetime.utcnow()
|
| 184 |
+
anns = json.load(open(resFile))
|
| 185 |
+
assert type(anns) == list, "results is not an array of objects"
|
| 186 |
+
annsQuesIds = [ann["question_id"] for ann in anns]
|
| 187 |
+
# print set of question ids that do not have corresponding annotations
|
| 188 |
+
|
| 189 |
+
# assert set(annsQuesIds) == set(self.getQuesIds()), \
|
| 190 |
+
# 'Results do not correspond to current VQA set. Either the results do not have predictions for all question ids in annotation file or there is atleast one question id that does not belong to the question ids in the annotation file.'
|
| 191 |
+
for ann in anns:
|
| 192 |
+
quesId = ann["question_id"]
|
| 193 |
+
if res.dataset["task_type"] == "Multiple Choice":
|
| 194 |
+
assert (
|
| 195 |
+
ann["answer"] in self.qqa[quesId]["multiple_choices"]
|
| 196 |
+
), "predicted answer is not one of the multiple choices"
|
| 197 |
+
qaAnn = self.qa[quesId]
|
| 198 |
+
ann["image_id"] = qaAnn["image_id"]
|
| 199 |
+
ann["question_type"] = qaAnn["question_type"]
|
| 200 |
+
if "answer_type" in ann:
|
| 201 |
+
ann["answer_type"] = qaAnn["answer_type"]
|
| 202 |
+
print(
|
| 203 |
+
"DONE (t=%0.2fs)" % ((datetime.datetime.utcnow() - time_t).total_seconds())
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
res.dataset["annotations"] = anns
|
| 207 |
+
res.createIndex()
|
| 208 |
+
return res
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class VQAEval:
|
| 212 |
+
def __init__(self, vqa, vqaRes, n=2):
|
| 213 |
+
self.n = n
|
| 214 |
+
self.accuracy = {}
|
| 215 |
+
self.evalQA = {}
|
| 216 |
+
self.evalQuesType = {}
|
| 217 |
+
self.evalAnsType = {}
|
| 218 |
+
self.vqa = vqa
|
| 219 |
+
self.vqaRes = vqaRes
|
| 220 |
+
if not vqa is None and not vqaRes is None:
|
| 221 |
+
self.params = {"question_id": vqaRes.getQuesIds()}
|
| 222 |
+
self.contractions = {
|
| 223 |
+
"aint": "ain't",
|
| 224 |
+
"arent": "aren't",
|
| 225 |
+
"cant": "can't",
|
| 226 |
+
"couldve": "could've",
|
| 227 |
+
"couldnt": "couldn't",
|
| 228 |
+
"couldn'tve": "couldn't've",
|
| 229 |
+
"couldnt've": "couldn't've",
|
| 230 |
+
"didnt": "didn't",
|
| 231 |
+
"doesnt": "doesn't",
|
| 232 |
+
"dont": "don't",
|
| 233 |
+
"hadnt": "hadn't",
|
| 234 |
+
"hadnt've": "hadn't've",
|
| 235 |
+
"hadn'tve": "hadn't've",
|
| 236 |
+
"hasnt": "hasn't",
|
| 237 |
+
"havent": "haven't",
|
| 238 |
+
"hed": "he'd",
|
| 239 |
+
"hed've": "he'd've",
|
| 240 |
+
"he'dve": "he'd've",
|
| 241 |
+
"hes": "he's",
|
| 242 |
+
"howd": "how'd",
|
| 243 |
+
"howll": "how'll",
|
| 244 |
+
"hows": "how's",
|
| 245 |
+
"Id've": "I'd've",
|
| 246 |
+
"I'dve": "I'd've",
|
| 247 |
+
"Im": "I'm",
|
| 248 |
+
"Ive": "I've",
|
| 249 |
+
"isnt": "isn't",
|
| 250 |
+
"itd": "it'd",
|
| 251 |
+
"itd've": "it'd've",
|
| 252 |
+
"it'dve": "it'd've",
|
| 253 |
+
"itll": "it'll",
|
| 254 |
+
"let's": "let's",
|
| 255 |
+
"maam": "ma'am",
|
| 256 |
+
"mightnt": "mightn't",
|
| 257 |
+
"mightnt've": "mightn't've",
|
| 258 |
+
"mightn'tve": "mightn't've",
|
| 259 |
+
"mightve": "might've",
|
| 260 |
+
"mustnt": "mustn't",
|
| 261 |
+
"mustve": "must've",
|
| 262 |
+
"neednt": "needn't",
|
| 263 |
+
"notve": "not've",
|
| 264 |
+
"oclock": "o'clock",
|
| 265 |
+
"oughtnt": "oughtn't",
|
| 266 |
+
"ow's'at": "'ow's'at",
|
| 267 |
+
"'ows'at": "'ow's'at",
|
| 268 |
+
"'ow'sat": "'ow's'at",
|
| 269 |
+
"shant": "shan't",
|
| 270 |
+
"shed've": "she'd've",
|
| 271 |
+
"she'dve": "she'd've",
|
| 272 |
+
"she's": "she's",
|
| 273 |
+
"shouldve": "should've",
|
| 274 |
+
"shouldnt": "shouldn't",
|
| 275 |
+
"shouldnt've": "shouldn't've",
|
| 276 |
+
"shouldn'tve": "shouldn't've",
|
| 277 |
+
"somebody'd": "somebodyd",
|
| 278 |
+
"somebodyd've": "somebody'd've",
|
| 279 |
+
"somebody'dve": "somebody'd've",
|
| 280 |
+
"somebodyll": "somebody'll",
|
| 281 |
+
"somebodys": "somebody's",
|
| 282 |
+
"someoned": "someone'd",
|
| 283 |
+
"someoned've": "someone'd've",
|
| 284 |
+
"someone'dve": "someone'd've",
|
| 285 |
+
"someonell": "someone'll",
|
| 286 |
+
"someones": "someone's",
|
| 287 |
+
"somethingd": "something'd",
|
| 288 |
+
"somethingd've": "something'd've",
|
| 289 |
+
"something'dve": "something'd've",
|
| 290 |
+
"somethingll": "something'll",
|
| 291 |
+
"thats": "that's",
|
| 292 |
+
"thered": "there'd",
|
| 293 |
+
"thered've": "there'd've",
|
| 294 |
+
"there'dve": "there'd've",
|
| 295 |
+
"therere": "there're",
|
| 296 |
+
"theres": "there's",
|
| 297 |
+
"theyd": "they'd",
|
| 298 |
+
"theyd've": "they'd've",
|
| 299 |
+
"they'dve": "they'd've",
|
| 300 |
+
"theyll": "they'll",
|
| 301 |
+
"theyre": "they're",
|
| 302 |
+
"theyve": "they've",
|
| 303 |
+
"twas": "'twas",
|
| 304 |
+
"wasnt": "wasn't",
|
| 305 |
+
"wed've": "we'd've",
|
| 306 |
+
"we'dve": "we'd've",
|
| 307 |
+
"weve": "we've",
|
| 308 |
+
"werent": "weren't",
|
| 309 |
+
"whatll": "what'll",
|
| 310 |
+
"whatre": "what're",
|
| 311 |
+
"whats": "what's",
|
| 312 |
+
"whatve": "what've",
|
| 313 |
+
"whens": "when's",
|
| 314 |
+
"whered": "where'd",
|
| 315 |
+
"wheres": "where's",
|
| 316 |
+
"whereve": "where've",
|
| 317 |
+
"whod": "who'd",
|
| 318 |
+
"whod've": "who'd've",
|
| 319 |
+
"who'dve": "who'd've",
|
| 320 |
+
"wholl": "who'll",
|
| 321 |
+
"whos": "who's",
|
| 322 |
+
"whove": "who've",
|
| 323 |
+
"whyll": "why'll",
|
| 324 |
+
"whyre": "why're",
|
| 325 |
+
"whys": "why's",
|
| 326 |
+
"wont": "won't",
|
| 327 |
+
"wouldve": "would've",
|
| 328 |
+
"wouldnt": "wouldn't",
|
| 329 |
+
"wouldnt've": "wouldn't've",
|
| 330 |
+
"wouldn'tve": "wouldn't've",
|
| 331 |
+
"yall": "y'all",
|
| 332 |
+
"yall'll": "y'all'll",
|
| 333 |
+
"y'allll": "y'all'll",
|
| 334 |
+
"yall'd've": "y'all'd've",
|
| 335 |
+
"y'alld've": "y'all'd've",
|
| 336 |
+
"y'all'dve": "y'all'd've",
|
| 337 |
+
"youd": "you'd",
|
| 338 |
+
"youd've": "you'd've",
|
| 339 |
+
"you'dve": "you'd've",
|
| 340 |
+
"youll": "you'll",
|
| 341 |
+
"youre": "you're",
|
| 342 |
+
"youve": "you've",
|
| 343 |
+
}
|
| 344 |
+
self.manualMap = {
|
| 345 |
+
"none": "0",
|
| 346 |
+
"zero": "0",
|
| 347 |
+
"one": "1",
|
| 348 |
+
"two": "2",
|
| 349 |
+
"three": "3",
|
| 350 |
+
"four": "4",
|
| 351 |
+
"five": "5",
|
| 352 |
+
"six": "6",
|
| 353 |
+
"seven": "7",
|
| 354 |
+
"eight": "8",
|
| 355 |
+
"nine": "9",
|
| 356 |
+
"ten": "10",
|
| 357 |
+
}
|
| 358 |
+
self.articles = ["a", "an", "the"]
|
| 359 |
+
|
| 360 |
+
self.periodStrip = re.compile("(?!<=\d)(\.)(?!\d)")
|
| 361 |
+
self.commaStrip = re.compile("(\d)(\,)(\d)")
|
| 362 |
+
self.punct = [
|
| 363 |
+
";",
|
| 364 |
+
r"/",
|
| 365 |
+
"[",
|
| 366 |
+
"]",
|
| 367 |
+
'"',
|
| 368 |
+
"{",
|
| 369 |
+
"}",
|
| 370 |
+
"(",
|
| 371 |
+
")",
|
| 372 |
+
"=",
|
| 373 |
+
"+",
|
| 374 |
+
"\\",
|
| 375 |
+
"_",
|
| 376 |
+
"-",
|
| 377 |
+
">",
|
| 378 |
+
"<",
|
| 379 |
+
"@",
|
| 380 |
+
"`",
|
| 381 |
+
",",
|
| 382 |
+
"?",
|
| 383 |
+
"!",
|
| 384 |
+
]
|
| 385 |
+
|
| 386 |
+
def evaluate(self, quesIds=None):
|
| 387 |
+
if quesIds == None:
|
| 388 |
+
quesIds = [quesId for quesId in self.params["question_id"]]
|
| 389 |
+
gts = {}
|
| 390 |
+
res = {}
|
| 391 |
+
for quesId in quesIds:
|
| 392 |
+
gts[quesId] = self.vqa.qa[quesId]
|
| 393 |
+
res[quesId] = self.vqaRes.qa[quesId]
|
| 394 |
+
|
| 395 |
+
# =================================================
|
| 396 |
+
# Compute accuracy
|
| 397 |
+
# =================================================
|
| 398 |
+
accQA = []
|
| 399 |
+
accQuesType = {}
|
| 400 |
+
accAnsType = {}
|
| 401 |
+
print("computing accuracy")
|
| 402 |
+
step = 0
|
| 403 |
+
for quesId in quesIds:
|
| 404 |
+
for ansDic in gts[quesId]["answers"]:
|
| 405 |
+
ansDic["answer"] = ansDic["answer"].replace("\n", " ")
|
| 406 |
+
ansDic["answer"] = ansDic["answer"].replace("\t", " ")
|
| 407 |
+
ansDic["answer"] = ansDic["answer"].strip()
|
| 408 |
+
resAns = res[quesId]["answer"]
|
| 409 |
+
resAns = resAns.replace("\n", " ")
|
| 410 |
+
resAns = resAns.replace("\t", " ")
|
| 411 |
+
resAns = resAns.strip()
|
| 412 |
+
resAns = self.processPunctuation(resAns)
|
| 413 |
+
resAns = self.processDigitArticle(resAns)
|
| 414 |
+
gtAcc = []
|
| 415 |
+
|
| 416 |
+
for ansDic in gts[quesId]["answers"]:
|
| 417 |
+
ansDic["answer"] = self.processPunctuation(ansDic["answer"])
|
| 418 |
+
ansDic["answer"] = self.processDigitArticle(ansDic["answer"])
|
| 419 |
+
|
| 420 |
+
for gtAnsDatum in gts[quesId]["answers"]:
|
| 421 |
+
otherGTAns = [
|
| 422 |
+
item for item in gts[quesId]["answers"] if item != gtAnsDatum
|
| 423 |
+
]
|
| 424 |
+
matchingAns = [item for item in otherGTAns if item["answer"] == resAns]
|
| 425 |
+
acc = min(1, float(len(matchingAns)) / 3)
|
| 426 |
+
gtAcc.append(acc)
|
| 427 |
+
quesType = gts[quesId]["question_type"]
|
| 428 |
+
ansType = (
|
| 429 |
+
gts[quesId]["answer_type"] if "answer_type" in gts[quesId] else "other"
|
| 430 |
+
)
|
| 431 |
+
avgGTAcc = float(sum(gtAcc)) / len(gtAcc)
|
| 432 |
+
accQA.append(avgGTAcc)
|
| 433 |
+
if quesType not in accQuesType:
|
| 434 |
+
accQuesType[quesType] = []
|
| 435 |
+
accQuesType[quesType].append(avgGTAcc)
|
| 436 |
+
if ansType not in accAnsType:
|
| 437 |
+
accAnsType[ansType] = []
|
| 438 |
+
accAnsType[ansType].append(avgGTAcc)
|
| 439 |
+
self.setEvalQA(quesId, avgGTAcc)
|
| 440 |
+
self.setEvalQuesType(quesId, quesType, avgGTAcc)
|
| 441 |
+
self.setEvalAnsType(quesId, ansType, avgGTAcc)
|
| 442 |
+
if step % 100 == 0:
|
| 443 |
+
self.updateProgress(step / float(len(quesIds)))
|
| 444 |
+
step = step + 1
|
| 445 |
+
|
| 446 |
+
self.setAccuracy(accQA, accQuesType, accAnsType)
|
| 447 |
+
print("Done computing accuracy")
|
| 448 |
+
|
| 449 |
+
def processPunctuation(self, inText):
|
| 450 |
+
outText = inText
|
| 451 |
+
for p in self.punct:
|
| 452 |
+
if (p + " " in inText or " " + p in inText) or (
|
| 453 |
+
re.search(self.commaStrip, inText) != None
|
| 454 |
+
):
|
| 455 |
+
outText = outText.replace(p, "")
|
| 456 |
+
else:
|
| 457 |
+
outText = outText.replace(p, " ")
|
| 458 |
+
outText = self.periodStrip.sub("", outText, re.UNICODE)
|
| 459 |
+
return outText
|
| 460 |
+
|
| 461 |
+
def processDigitArticle(self, inText):
|
| 462 |
+
outText = []
|
| 463 |
+
tempText = inText.lower().split()
|
| 464 |
+
for word in tempText:
|
| 465 |
+
word = self.manualMap.setdefault(word, word)
|
| 466 |
+
if word not in self.articles:
|
| 467 |
+
outText.append(word)
|
| 468 |
+
else:
|
| 469 |
+
pass
|
| 470 |
+
for wordId, word in enumerate(outText):
|
| 471 |
+
if word in self.contractions:
|
| 472 |
+
outText[wordId] = self.contractions[word]
|
| 473 |
+
outText = " ".join(outText)
|
| 474 |
+
return outText
|
| 475 |
+
|
| 476 |
+
def setAccuracy(self, accQA, accQuesType, accAnsType):
|
| 477 |
+
self.accuracy["overall"] = round(100 * float(sum(accQA)) / len(accQA), self.n)
|
| 478 |
+
self.accuracy["perQuestionType"] = {
|
| 479 |
+
quesType: round(
|
| 480 |
+
100 * float(sum(accQuesType[quesType])) / len(accQuesType[quesType]),
|
| 481 |
+
self.n,
|
| 482 |
+
)
|
| 483 |
+
for quesType in accQuesType
|
| 484 |
+
}
|
| 485 |
+
self.accuracy["perAnswerType"] = {
|
| 486 |
+
ansType: round(
|
| 487 |
+
100 * float(sum(accAnsType[ansType])) / len(accAnsType[ansType]), self.n
|
| 488 |
+
)
|
| 489 |
+
for ansType in accAnsType
|
| 490 |
+
}
|
| 491 |
+
|
| 492 |
+
def setEvalQA(self, quesId, acc):
|
| 493 |
+
self.evalQA[quesId] = round(100 * acc, self.n)
|
| 494 |
+
|
| 495 |
+
def setEvalQuesType(self, quesId, quesType, acc):
|
| 496 |
+
if quesType not in self.evalQuesType:
|
| 497 |
+
self.evalQuesType[quesType] = {}
|
| 498 |
+
self.evalQuesType[quesType][quesId] = round(100 * acc, self.n)
|
| 499 |
+
|
| 500 |
+
def setEvalAnsType(self, quesId, ansType, acc):
|
| 501 |
+
if ansType not in self.evalAnsType:
|
| 502 |
+
self.evalAnsType[ansType] = {}
|
| 503 |
+
self.evalAnsType[ansType][quesId] = round(100 * acc, self.n)
|
| 504 |
+
|
| 505 |
+
def updateProgress(self, progress):
|
| 506 |
+
barLength = 20
|
| 507 |
+
status = ""
|
| 508 |
+
if isinstance(progress, int):
|
| 509 |
+
progress = float(progress)
|
| 510 |
+
if not isinstance(progress, float):
|
| 511 |
+
progress = 0
|
| 512 |
+
status = "error: progress var must be float\r\n"
|
| 513 |
+
if progress < 0:
|
| 514 |
+
progress = 0
|
| 515 |
+
status = "Halt...\r\n"
|
| 516 |
+
if progress >= 1:
|
| 517 |
+
progress = 1
|
| 518 |
+
status = "Done...\r\n"
|
| 519 |
+
block = int(round(barLength * progress))
|
| 520 |
+
text = "\rFinshed Percent: [{0}] {1}% {2}".format(
|
| 521 |
+
"#" * block + "-" * (barLength - block), int(progress * 100), status
|
| 522 |
+
)
|
| 523 |
+
sys.stdout.write(text)
|
| 524 |
+
sys.stdout.flush()
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
def compute_vqa_accuracy(result_json_path, question_json_path, annotation_json_path):
|
| 528 |
+
"""Compute the VQA accuracy metric.
|
| 529 |
+
|
| 530 |
+
Args:
|
| 531 |
+
result_json_path (str): Path to the json file with model outputs
|
| 532 |
+
question_json_path (str): Path to the json file with questions
|
| 533 |
+
annotation_json_path (str): Path to the json file with annotations
|
| 534 |
+
|
| 535 |
+
Returns:
|
| 536 |
+
float: VQA accuracy
|
| 537 |
+
"""
|
| 538 |
+
# coding: utf-8
|
| 539 |
+
# dataDir = data_dir
|
| 540 |
+
|
| 541 |
+
# set up file names and paths
|
| 542 |
+
# versionType = 'v2_' # this should be '' when using VQA v2.0 dataset
|
| 543 |
+
# 'OpenEnded' only for v2.0. 'OpenEnded' or 'MultipleChoice' for v1.0
|
| 544 |
+
# taskType = 'OpenEnded'
|
| 545 |
+
# 'mscoco' only for v1.0. 'mscoco' for real and 'abstract_v002' for abstract for v1.0.
|
| 546 |
+
# dataType = 'mscoco'
|
| 547 |
+
# dataSubType = 'train2014'
|
| 548 |
+
# annFile = '%s/%s%s_%s_annotations.json' % (
|
| 549 |
+
# dataDir, versionType, dataType, dataSubType)
|
| 550 |
+
# quesFile = '%s/%s%s_%s_%s_questions.json' % (
|
| 551 |
+
# dataDir, versionType, taskType, dataType, dataSubType)
|
| 552 |
+
# imgDir = '%s/%s/%s/' % (dataDir, dataType, dataSubType)
|
| 553 |
+
# resultType = res_file_name
|
| 554 |
+
# fileTypes = ['results', 'accuracy',
|
| 555 |
+
# 'evalQA', 'evalQuesType', 'evalAnsType']
|
| 556 |
+
|
| 557 |
+
# An example result json file has been provided in './Results' folder.
|
| 558 |
+
|
| 559 |
+
# [resFile, accuracyFile, evalQAFile, evalQuesTypeFile, evalAnsTypeFile] = ['%s/%s%s_%s_%s_%s_%s.json' % (dataDir, versionType, taskType, dataType, dataSubType,
|
| 560 |
+
# resultType, fileType) for fileType in fileTypes]
|
| 561 |
+
|
| 562 |
+
# create vqa object and vqaRes object
|
| 563 |
+
vqa = VQA(annotation_json_path, question_json_path)
|
| 564 |
+
vqaRes = vqa.loadRes(result_json_path, question_json_path)
|
| 565 |
+
|
| 566 |
+
# create vqaEval object by taking vqa and vqaRes
|
| 567 |
+
# n is precision of accuracy (number of places after decimal), default is 2
|
| 568 |
+
vqaEval = VQAEval(vqa, vqaRes, n=2)
|
| 569 |
+
|
| 570 |
+
# evaluate results
|
| 571 |
+
"""
|
| 572 |
+
If you have a list of question ids on which you would like to evaluate your results, pass it as a list to below function
|
| 573 |
+
By default it uses all the question ids in annotation file
|
| 574 |
+
"""
|
| 575 |
+
vqaEval.evaluate()
|
| 576 |
+
|
| 577 |
+
return vqaEval.accuracy["overall"]
|
| 578 |
+
|
| 579 |
+
|
| 580 |
+
def postprocess_vqa_generation(predictions):
|
| 581 |
+
answer = re.split("Question|Answer|Short", predictions, 1)[0]
|
| 582 |
+
answer = re.split(", ", answer, 1)[0]
|
| 583 |
+
return answer
|
open_flamingo/open_flamingo/scripts/convert_mmc4_to_wds.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import uuid
|
| 5 |
+
import zipfile
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import base64
|
| 8 |
+
from io import BytesIO
|
| 9 |
+
|
| 10 |
+
import braceexpand
|
| 11 |
+
import webdataset as wds
|
| 12 |
+
|
| 13 |
+
arg_parser = argparse.ArgumentParser()
|
| 14 |
+
arg_parser.add_argument(
|
| 15 |
+
"--output_dir",
|
| 16 |
+
type=str,
|
| 17 |
+
help="Pass in the directory where the output shards (as tar files) will be written to.",
|
| 18 |
+
)
|
| 19 |
+
arg_parser.add_argument(
|
| 20 |
+
"--zip_files",
|
| 21 |
+
type=str,
|
| 22 |
+
help="Pass in a list of MMC4 shards in the format path_to_shard/shard_{0..23098}.zip",
|
| 23 |
+
)
|
| 24 |
+
arg_parser.add_argument(
|
| 25 |
+
"--image_dir",
|
| 26 |
+
type=str,
|
| 27 |
+
help="Pass in the directory where the images have been downloaded to.",
|
| 28 |
+
)
|
| 29 |
+
args = arg_parser.parse_args()
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def main():
|
| 33 |
+
os.makedirs(args.output_dir, exist_ok=True)
|
| 34 |
+
|
| 35 |
+
doc_shards = list(braceexpand.braceexpand(args.zip_files))
|
| 36 |
+
|
| 37 |
+
with wds.ShardWriter(args.output_dir + "/%09d.tar") as sink:
|
| 38 |
+
for idx in range(len(doc_shards)):
|
| 39 |
+
# Open the ZIP archive and extract the JSON file
|
| 40 |
+
with zipfile.ZipFile(doc_shards[idx], "r") as zip_file:
|
| 41 |
+
# Assumes the JSON file is the first file in the archive
|
| 42 |
+
json_filename = zip_file.namelist()[0]
|
| 43 |
+
with zip_file.open(json_filename, "r") as json_file:
|
| 44 |
+
for sample_data in json_file:
|
| 45 |
+
# get image names from json
|
| 46 |
+
sample_data = json.loads(sample_data)
|
| 47 |
+
image_info = sample_data["image_info"]
|
| 48 |
+
image_names = [image["image_name"] for image in image_info]
|
| 49 |
+
|
| 50 |
+
# Add each image to the tar file
|
| 51 |
+
for img_idx, image_name in enumerate(image_names):
|
| 52 |
+
try:
|
| 53 |
+
# load image
|
| 54 |
+
img = Image.open(
|
| 55 |
+
os.path.join(args.image_dir, str(idx), image_name)
|
| 56 |
+
).convert("RGB")
|
| 57 |
+
buffered = BytesIO()
|
| 58 |
+
img.save(buffered, format="JPEG")
|
| 59 |
+
img_str = base64.b64encode(buffered.getvalue())
|
| 60 |
+
# convert to base64
|
| 61 |
+
sample_data["image_info"][img_idx][
|
| 62 |
+
"image_base64"
|
| 63 |
+
] = str(img_str)
|
| 64 |
+
except FileNotFoundError:
|
| 65 |
+
print(
|
| 66 |
+
f"Did not find {image_name} downloaded. This can happen if the url is now 404."
|
| 67 |
+
)
|
| 68 |
+
except Exception as e:
|
| 69 |
+
print(f"Error processing {image_name}: {e}")
|
| 70 |
+
|
| 71 |
+
key_str = uuid.uuid4().hex
|
| 72 |
+
sink.write({"__key__": key_str, "json": sample_data})
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
main()
|
open_flamingo/open_flamingo/scripts/run_eval.sh
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
#SBATCH --nodes=1
|
| 3 |
+
#SBATCH --ntasks-per-node=2
|
| 4 |
+
#SBATCH --gpus-per-task=1
|
| 5 |
+
|
| 6 |
+
<<com
|
| 7 |
+
Example Slurm evaluation script.
|
| 8 |
+
Notes:
|
| 9 |
+
- VQAv2 test-dev and test-std annotations are not publicly available.
|
| 10 |
+
To evaluate on these splits, please follow the VQAv2 instructions and submit to EvalAI.
|
| 11 |
+
This script will evaluate on the val split.
|
| 12 |
+
com
|
| 13 |
+
|
| 14 |
+
export PYTHONFAULTHANDLER=1
|
| 15 |
+
export CUDA_LAUNCH_BLOCKING=0
|
| 16 |
+
export HOSTNAMES=`scontrol show hostnames "$SLURM_JOB_NODELIST"`
|
| 17 |
+
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
|
| 18 |
+
export MASTER_PORT=$(shuf -i 0-65535 -n 1)
|
| 19 |
+
export COUNT_NODE=`scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l`
|
| 20 |
+
|
| 21 |
+
echo go $COUNT_NODE
|
| 22 |
+
echo $HOSTNAMES
|
| 23 |
+
|
| 24 |
+
export PYTHONPATH="$PYTHONPATH:open_flamingo"
|
| 25 |
+
srun --cpu_bind=v --accel-bind=gn python open_flamingo/open_flamingo/eval/evaluate.py \
|
| 26 |
+
--vision_encoder_path ViT-L-14 \
|
| 27 |
+
--vision_encoder_pretrained openai\
|
| 28 |
+
--lm_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 29 |
+
--lm_tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 30 |
+
--cross_attn_every_n_layers 1 \
|
| 31 |
+
--checkpoint_path "openflamingo/OpenFlamingo-3B-vitl-mpt1b/checkpoint.pt" \
|
| 32 |
+
--results_file "results.json" \
|
| 33 |
+
--precision amp_bf16 \
|
| 34 |
+
--batch_size 8 \
|
| 35 |
+
--eval_coco \
|
| 36 |
+
--eval_vqav2 \
|
| 37 |
+
--eval_flickr30 \
|
| 38 |
+
--eval_ok_vqa \
|
| 39 |
+
--eval_textvqa \
|
| 40 |
+
--eval_vizwiz \
|
| 41 |
+
--eval_hateful_memes \
|
| 42 |
+
--coco_train_image_dir_path "/path/to/mscoco_karpathy/train2014" \
|
| 43 |
+
--coco_val_image_dir_path "/path/to/mscoco_karpathy/val2014" \
|
| 44 |
+
--coco_karpathy_json_path "/path/to/mscoco_karpathy/dataset_coco.json" \
|
| 45 |
+
--coco_annotations_json_path "/path/to/mscoco_karpathy/annotations/captions_val2014.json" \
|
| 46 |
+
--vqav2_train_image_dir_path "/path/to/vqav2/train2014" \
|
| 47 |
+
--vqav2_train_annotations_json_path "/path/to/vqav2/v2_mscoco_train2014_annotations.json" \
|
| 48 |
+
--vqav2_train_questions_json_path "/path/to/vqav2/v2_OpenEnded_mscoco_train2014_questions.json" \
|
| 49 |
+
--vqav2_test_image_dir_path "/path/to/vqav2/val2014" \
|
| 50 |
+
--vqav2_test_annotations_json_path "/path/to/vqav2/v2_mscoco_val2014_annotations.json" \
|
| 51 |
+
--vqav2_test_questions_json_path "/path/to/vqav2/v2_OpenEnded_mscoco_val2014_questions.json" \
|
| 52 |
+
--flickr_image_dir_path "/path/to/flickr30k/flickr30k-images" \
|
| 53 |
+
--flickr_karpathy_json_path "/path/to/flickr30k/dataset_flickr30k.json" \
|
| 54 |
+
--flickr_annotations_json_path "/path/to/flickr30k/dataset_flickr30k_coco_style.json" \
|
| 55 |
+
--ok_vqa_train_image_dir_path "/path/to/okvqa/train2014" \
|
| 56 |
+
--ok_vqa_train_annotations_json_path "/path/to/okvqa/mscoco_train2014_annotations.json" \
|
| 57 |
+
--ok_vqa_train_questions_json_path "/path/to/okvqa/OpenEnded_mscoco_train2014_questions.json" \
|
| 58 |
+
--ok_vqa_test_image_dir_path "/path/to/okvqa/val2014" \
|
| 59 |
+
--ok_vqa_test_annotations_json_path "/path/to/okvqa/mscoco_val2014_annotations.json" \
|
| 60 |
+
--ok_vqa_test_questions_json_path "/path/to/okvqa/OpenEnded_mscoco_val2014_questions.json" \
|
| 61 |
+
--textvqa_image_dir_path "/path/to/textvqa/train_images/" \
|
| 62 |
+
--textvqa_train_questions_json_path "/path/to/textvqa/train_questions_vqa_format.json" \
|
| 63 |
+
--textvqa_train_annotations_json_path "/path/to/textvqa/train_annotations_vqa_format.json" \
|
| 64 |
+
--textvqa_test_questions_json_path "/path/to/textvqa/val_questions_vqa_format.json" \
|
| 65 |
+
--textvqa_test_annotations_json_path "/path/to/textvqa/val_annotations_vqa_format.json" \
|
| 66 |
+
--vizwiz_train_image_dir_path "/path/to/v7w/train" \
|
| 67 |
+
--vizwiz_test_image_dir_path "/path/to/v7w/val" \
|
| 68 |
+
--vizwiz_train_questions_json_path "/path/to/v7w/train_questions_vqa_format.json" \
|
| 69 |
+
--vizwiz_train_annotations_json_path "/path/to/v7w/train_annotations_vqa_format.json" \
|
| 70 |
+
--vizwiz_test_questions_json_path "/path/to/v7w/val_questions_vqa_format.json" \
|
| 71 |
+
--vizwiz_test_annotations_json_path "/path/to/v7w/val_annotations_vqa_format.json" \
|
| 72 |
+
--hateful_memes_image_dir_path "/path/to/hateful_memes/img" \
|
| 73 |
+
--hateful_memes_train_annotations_json_path "/path/to/hateful_memes/train.json" \
|
| 74 |
+
--hateful_memes_test_annotations_json_path "/path/to/hateful_memes/dev.json" \
|
open_flamingo/open_flamingo/scripts/run_train.sh
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
#SBATCH --nodes 1
|
| 3 |
+
#SBATCH --ntasks-per-node=8
|
| 4 |
+
#SBATCH --gpus-per-task=1
|
| 5 |
+
|
| 6 |
+
export PYTHONFAULTHANDLER=1
|
| 7 |
+
export CUDA_LAUNCH_BLOCKING=0
|
| 8 |
+
export HOSTNAMES=`scontrol show hostnames "$SLURM_JOB_NODELIST"`
|
| 9 |
+
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
|
| 10 |
+
export MASTER_PORT=15000
|
| 11 |
+
export COUNT_NODE=`scontrol show hostnames "$SLURM_JOB_NODELIST" | wc -l`
|
| 12 |
+
|
| 13 |
+
export PYTHONPATH="$PYTHONPATH:open_flamingo"
|
| 14 |
+
srun --cpu_bind=v --accel-bind=gn python open_flamingo/open_flamingo/train/train.py \
|
| 15 |
+
--lm_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 16 |
+
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 17 |
+
--cross_attn_every_n_layers 1 \
|
| 18 |
+
--dataset_resampled \
|
| 19 |
+
--batch_size_mmc4 32 \
|
| 20 |
+
--batch_size_laion 64 \
|
| 21 |
+
--train_num_samples_mmc4 125000\
|
| 22 |
+
--train_num_samples_laion 250000 \
|
| 23 |
+
--loss_multiplier_laion 0.2 \
|
| 24 |
+
--workers=4 \
|
| 25 |
+
--run_name OpenFlamingo-3B-vitl-mpt1b \
|
| 26 |
+
--num_epochs 480 \
|
| 27 |
+
--warmup_steps 1875 \
|
| 28 |
+
--mmc4_textsim_threshold 0.24 \
|
| 29 |
+
--laion_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 30 |
+
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 31 |
+
--gradient_checkpointing \
|
| 32 |
+
--report_to_wandb \
|
open_flamingo/open_flamingo/src/__init__.py
ADDED
|
File without changes
|
open_flamingo/open_flamingo/src/factory.py
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 2 |
+
import open_clip
|
| 3 |
+
|
| 4 |
+
from .flamingo import Flamingo
|
| 5 |
+
from .flamingo_lm import FlamingoLMMixin
|
| 6 |
+
from .utils import extend_instance
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def create_model_and_transforms(
|
| 10 |
+
clip_vision_encoder_path: str,
|
| 11 |
+
clip_vision_encoder_pretrained: str,
|
| 12 |
+
lang_encoder_path: str,
|
| 13 |
+
tokenizer_path: str,
|
| 14 |
+
cross_attn_every_n_layers: int = 1,
|
| 15 |
+
use_local_files: bool = False,
|
| 16 |
+
decoder_layers_attr_name: str = None,
|
| 17 |
+
freeze_lm_embeddings: bool = False,
|
| 18 |
+
**flamingo_kwargs,
|
| 19 |
+
):
|
| 20 |
+
"""
|
| 21 |
+
Initialize a Flamingo model from a pretrained vision encoder and language encoder.
|
| 22 |
+
Appends special tokens to the tokenizer and freezes backbones.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
clip_vision_encoder_path (str): path to pretrained clip model (e.g. "ViT-B-32")
|
| 26 |
+
clip_vision_encoder_pretrained (str): name of pretraining dataset for clip model (e.g. "laion2b_s32b_b79k")
|
| 27 |
+
lang_encoder_path (str): path to pretrained language encoder
|
| 28 |
+
tokenizer_path (str): path to pretrained tokenizer
|
| 29 |
+
cross_attn_every_n_layers (int, optional): determines how often to add a cross-attention layer. Defaults to 1.
|
| 30 |
+
use_local_files (bool, optional): whether to use local files. Defaults to False.
|
| 31 |
+
decoder_layers_attr_name (str, optional): name of the decoder layers attribute. Defaults to None.
|
| 32 |
+
Returns:
|
| 33 |
+
Flamingo: Flamingo model from pretrained vision and language encoders
|
| 34 |
+
Image processor: Pipeline to preprocess input images
|
| 35 |
+
Tokenizer: A tokenizer for the language model
|
| 36 |
+
"""
|
| 37 |
+
vision_encoder, _, image_processor = open_clip.create_model_and_transforms(
|
| 38 |
+
clip_vision_encoder_path, pretrained=clip_vision_encoder_pretrained
|
| 39 |
+
)
|
| 40 |
+
# set the vision encoder to output the visual features
|
| 41 |
+
vision_encoder.visual.output_tokens = True
|
| 42 |
+
|
| 43 |
+
text_tokenizer = AutoTokenizer.from_pretrained(
|
| 44 |
+
tokenizer_path,
|
| 45 |
+
local_files_only=use_local_files,
|
| 46 |
+
trust_remote_code=True,
|
| 47 |
+
)
|
| 48 |
+
# add Flamingo special tokens to the tokenizer
|
| 49 |
+
text_tokenizer.add_special_tokens(
|
| 50 |
+
{"additional_special_tokens": ["<|endofchunk|>", "<image>"]}
|
| 51 |
+
)
|
| 52 |
+
if text_tokenizer.pad_token is None:
|
| 53 |
+
# Issue: GPT models don't have a pad token, which we use to
|
| 54 |
+
# modify labels for the loss.
|
| 55 |
+
text_tokenizer.add_special_tokens({"pad_token": "<PAD>"})
|
| 56 |
+
|
| 57 |
+
lang_encoder = AutoModelForCausalLM.from_pretrained(
|
| 58 |
+
lang_encoder_path,
|
| 59 |
+
local_files_only=use_local_files,
|
| 60 |
+
trust_remote_code=True,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# hacks for MPT-1B, which doesn't have a get_input_embeddings method
|
| 64 |
+
if "mpt-1b-redpajama-200b" in lang_encoder_path:
|
| 65 |
+
|
| 66 |
+
class EmbeddingFnMixin:
|
| 67 |
+
def get_input_embeddings(self):
|
| 68 |
+
return self.transformer.wte
|
| 69 |
+
|
| 70 |
+
def set_input_embeddings(self, new_embeddings):
|
| 71 |
+
self.transformer.wte = new_embeddings
|
| 72 |
+
|
| 73 |
+
extend_instance(lang_encoder, EmbeddingFnMixin)
|
| 74 |
+
|
| 75 |
+
# convert LM to FlamingoLM
|
| 76 |
+
extend_instance(lang_encoder, FlamingoLMMixin)
|
| 77 |
+
|
| 78 |
+
if decoder_layers_attr_name is None:
|
| 79 |
+
decoder_layers_attr_name = _infer_decoder_layers_attr_name(lang_encoder)
|
| 80 |
+
lang_encoder.set_decoder_layers_attr_name(decoder_layers_attr_name)
|
| 81 |
+
lang_encoder.resize_token_embeddings(len(text_tokenizer))
|
| 82 |
+
|
| 83 |
+
model = Flamingo(
|
| 84 |
+
vision_encoder,
|
| 85 |
+
lang_encoder,
|
| 86 |
+
text_tokenizer.encode("<|endofchunk|>")[-1],
|
| 87 |
+
text_tokenizer.encode("<image>")[-1],
|
| 88 |
+
vis_dim=open_clip.get_model_config(clip_vision_encoder_path)["vision_cfg"][
|
| 89 |
+
"width"
|
| 90 |
+
],
|
| 91 |
+
cross_attn_every_n_layers=cross_attn_every_n_layers,
|
| 92 |
+
**flamingo_kwargs,
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
# Freeze all parameters
|
| 96 |
+
model.requires_grad_(False)
|
| 97 |
+
assert sum(p.numel() for p in model.parameters() if p.requires_grad) == 0
|
| 98 |
+
|
| 99 |
+
# Unfreeze perceiver, gated_cross_attn_layers, and LM input embeddings
|
| 100 |
+
model.perceiver.requires_grad_(True)
|
| 101 |
+
model.lang_encoder.gated_cross_attn_layers.requires_grad_(True)
|
| 102 |
+
if not freeze_lm_embeddings:
|
| 103 |
+
model.lang_encoder.get_input_embeddings().requires_grad_(True)
|
| 104 |
+
# TODO: investigate also training the output embeddings when untied
|
| 105 |
+
|
| 106 |
+
print(
|
| 107 |
+
f"Flamingo model initialized with {sum(p.numel() for p in model.parameters() if p.requires_grad)} trainable parameters"
|
| 108 |
+
)
|
| 109 |
+
|
| 110 |
+
return model, image_processor, text_tokenizer
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def _infer_decoder_layers_attr_name(model):
|
| 114 |
+
for k in __KNOWN_DECODER_LAYERS_ATTR_NAMES:
|
| 115 |
+
if k.lower() in model.__class__.__name__.lower():
|
| 116 |
+
return __KNOWN_DECODER_LAYERS_ATTR_NAMES[k]
|
| 117 |
+
|
| 118 |
+
raise ValueError(
|
| 119 |
+
f"We require the attribute name for the nn.ModuleList in the decoder storing the transformer block layers. Please supply this string manually."
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
__KNOWN_DECODER_LAYERS_ATTR_NAMES = {
|
| 124 |
+
"opt": "model.decoder.layers",
|
| 125 |
+
"gptj": "transformer.h",
|
| 126 |
+
"gpt-j": "transformer.h",
|
| 127 |
+
"pythia": "gpt_neox.layers",
|
| 128 |
+
"llama": "model.layers",
|
| 129 |
+
"gptneoxforcausallm": "gpt_neox.layers",
|
| 130 |
+
"mpt": "transformer.blocks",
|
| 131 |
+
"mosaicgpt": "transformer.blocks",
|
| 132 |
+
}
|
open_flamingo/open_flamingo/src/flamingo.py
ADDED
|
@@ -0,0 +1,356 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from einops import rearrange
|
| 3 |
+
from torch import nn
|
| 4 |
+
from .helpers import PerceiverResampler
|
| 5 |
+
from torch.distributed.fsdp.wrap import (
|
| 6 |
+
enable_wrap,
|
| 7 |
+
wrap,
|
| 8 |
+
)
|
| 9 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast
|
| 10 |
+
from torch.distributed.fsdp import (
|
| 11 |
+
FullyShardedDataParallel as FSDP,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
from .utils import apply_with_stopping_condition
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class Flamingo(nn.Module):
|
| 18 |
+
def __init__(
|
| 19 |
+
self,
|
| 20 |
+
vision_encoder: nn.Module,
|
| 21 |
+
lang_encoder: nn.Module,
|
| 22 |
+
eoc_token_id: int,
|
| 23 |
+
media_token_id: int,
|
| 24 |
+
vis_dim: int,
|
| 25 |
+
cross_attn_every_n_layers: int = 1,
|
| 26 |
+
gradient_checkpointing: bool = False,
|
| 27 |
+
):
|
| 28 |
+
"""
|
| 29 |
+
Args:
|
| 30 |
+
vision_encoder (nn.Module): HF CLIPModel
|
| 31 |
+
lang_encoder (nn.Module): HF causal language model
|
| 32 |
+
eoc_token_id (int): Token id for <|endofchunk|>
|
| 33 |
+
media_token_id (int): Token id for <image>
|
| 34 |
+
vis_dim (int): Dimension of the visual features.
|
| 35 |
+
Visual features are projected to match this shape along the last dimension.
|
| 36 |
+
cross_attn_every_n_layers (int, optional): How often to apply cross attention after transformer layer. Defaults to 1.
|
| 37 |
+
"""
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.eoc_token_id = eoc_token_id
|
| 40 |
+
self.media_token_id = media_token_id
|
| 41 |
+
self.vis_dim = vis_dim
|
| 42 |
+
if hasattr(lang_encoder.config, "d_model"):
|
| 43 |
+
self.lang_dim = lang_encoder.config.d_model # mpt uses d_model
|
| 44 |
+
else:
|
| 45 |
+
self.lang_dim = lang_encoder.config.hidden_size
|
| 46 |
+
|
| 47 |
+
self.vision_encoder = vision_encoder.visual
|
| 48 |
+
self.perceiver = PerceiverResampler(dim=self.vis_dim)
|
| 49 |
+
self.lang_encoder = lang_encoder
|
| 50 |
+
self.lang_encoder.init_flamingo(
|
| 51 |
+
media_token_id=media_token_id,
|
| 52 |
+
lang_hidden_size=self.lang_dim,
|
| 53 |
+
vis_hidden_size=self.vis_dim,
|
| 54 |
+
cross_attn_every_n_layers=cross_attn_every_n_layers,
|
| 55 |
+
gradient_checkpointing=gradient_checkpointing,
|
| 56 |
+
)
|
| 57 |
+
self._use_gradient_checkpointing = gradient_checkpointing
|
| 58 |
+
self.perceiver._use_gradient_checkpointing = gradient_checkpointing
|
| 59 |
+
|
| 60 |
+
def forward(
|
| 61 |
+
self,
|
| 62 |
+
vision_x: torch.Tensor,
|
| 63 |
+
lang_x: torch.Tensor,
|
| 64 |
+
attention_mask: torch.Tensor = None,
|
| 65 |
+
labels: torch.Tensor = None,
|
| 66 |
+
clear_conditioned_layers: bool = True,
|
| 67 |
+
past_key_values=None,
|
| 68 |
+
use_cache: bool = False,
|
| 69 |
+
):
|
| 70 |
+
"""
|
| 71 |
+
Forward pass of Flamingo.
|
| 72 |
+
|
| 73 |
+
Args:
|
| 74 |
+
vision_x (torch.Tensor): Vision input
|
| 75 |
+
shape (B, T_img, F, C, H, W) with F=1
|
| 76 |
+
lang_x (torch.Tensor): Language input ids
|
| 77 |
+
shape (B, T_txt)
|
| 78 |
+
attention_mask (torch.Tensor, optional): Attention mask. Defaults to None.
|
| 79 |
+
labels (torch.Tensor, optional): Labels. Defaults to None.
|
| 80 |
+
clear_conditioned_layers: if True, clear the conditioned layers
|
| 81 |
+
once the foward pass is completed. Set this to false if the
|
| 82 |
+
same set of images will be reused in another subsequent
|
| 83 |
+
forward pass.
|
| 84 |
+
past_key_values: pre-computed values to pass to language model.
|
| 85 |
+
See past_key_values documentation in Hugging Face
|
| 86 |
+
CausalLM models.
|
| 87 |
+
use_cache: whether to use cached key values. See use_cache
|
| 88 |
+
documentation in Hugging Face CausalLM models.
|
| 89 |
+
"""
|
| 90 |
+
assert (
|
| 91 |
+
self.lang_encoder.initialized_flamingo
|
| 92 |
+
), "Flamingo layers are not initialized. Please call `init_flamingo` first."
|
| 93 |
+
|
| 94 |
+
assert (
|
| 95 |
+
self.lang_encoder._use_cached_vision_x or vision_x is not None
|
| 96 |
+
), "Must provide either vision_x or have precached media using cache_media()."
|
| 97 |
+
|
| 98 |
+
if self.lang_encoder._use_cached_vision_x:
|
| 99 |
+
# Case: use cached; vision_x should be cached and other
|
| 100 |
+
# vision-related inputs should not be provided.
|
| 101 |
+
assert (
|
| 102 |
+
vision_x is None
|
| 103 |
+
), "Expect vision_x to be None when media has been cached using cache_media(). Try uncache_media() first."
|
| 104 |
+
assert self.lang_encoder.is_conditioned()
|
| 105 |
+
|
| 106 |
+
else:
|
| 107 |
+
# Case: do not use caching (i.e. this is a standard forward pass);
|
| 108 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 109 |
+
self._condition_media_locations(input_ids=lang_x)
|
| 110 |
+
|
| 111 |
+
output = self.lang_encoder(
|
| 112 |
+
input_ids=lang_x,
|
| 113 |
+
attention_mask=attention_mask,
|
| 114 |
+
labels=labels,
|
| 115 |
+
past_key_values=past_key_values,
|
| 116 |
+
use_cache=use_cache,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
if clear_conditioned_layers:
|
| 120 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 121 |
+
|
| 122 |
+
return output
|
| 123 |
+
|
| 124 |
+
def generate(
|
| 125 |
+
self,
|
| 126 |
+
vision_x: torch.Tensor,
|
| 127 |
+
lang_x: torch.Tensor,
|
| 128 |
+
attention_mask: torch.Tensor = None,
|
| 129 |
+
num_beams=1,
|
| 130 |
+
min_new_tokens=None,
|
| 131 |
+
max_new_tokens=None,
|
| 132 |
+
temperature=1.0,
|
| 133 |
+
top_k=0,
|
| 134 |
+
top_p=1.0,
|
| 135 |
+
no_repeat_ngram_size=0,
|
| 136 |
+
prefix_allowed_tokens_fn=None,
|
| 137 |
+
length_penalty=1.0,
|
| 138 |
+
num_return_sequences=1,
|
| 139 |
+
do_sample=False,
|
| 140 |
+
early_stopping=False,
|
| 141 |
+
):
|
| 142 |
+
"""
|
| 143 |
+
Generate text conditioned on vision and language inputs.
|
| 144 |
+
|
| 145 |
+
Args:
|
| 146 |
+
vision_x (torch.Tensor): Vision input
|
| 147 |
+
shape (B, T_img, F, C, H, W)
|
| 148 |
+
images in the same chunk are collated along T_img, and frames are collated along F
|
| 149 |
+
currently only F=1 is supported (single-frame videos)
|
| 150 |
+
lang_x (torch.Tensor): Language input
|
| 151 |
+
shape (B, T_txt)
|
| 152 |
+
max_length (int, optional): Maximum length of the output. Defaults to None.
|
| 153 |
+
attention_mask (torch.Tensor, optional): Attention mask. Defaults to None.
|
| 154 |
+
num_beams (int, optional): Number of beams. Defaults to 1.
|
| 155 |
+
max_new_tokens (int, optional): Maximum new tokens. Defaults to None.
|
| 156 |
+
temperature (float, optional): Temperature. Defaults to 1.0.
|
| 157 |
+
top_k (int, optional): Top k. Defaults to 0.
|
| 158 |
+
top_p (float, optional): Top p. Defaults to 1.0.
|
| 159 |
+
no_repeat_ngram_size (int, optional): No repeat ngram size. Defaults to 0.
|
| 160 |
+
length_penalty (float, optional): Length penalty. Defaults to 1.0.
|
| 161 |
+
num_return_sequences (int, optional): Number of return sequences. Defaults to 1.
|
| 162 |
+
do_sample (bool, optional): Do sample. Defaults to False.
|
| 163 |
+
early_stopping (bool, optional): Early stopping. Defaults to False.
|
| 164 |
+
Returns:
|
| 165 |
+
torch.Tensor: lang_x with generated tokens appended to it
|
| 166 |
+
"""
|
| 167 |
+
if num_beams > 1:
|
| 168 |
+
vision_x = vision_x.repeat_interleave(num_beams, dim=0)
|
| 169 |
+
|
| 170 |
+
self.lang_encoder._use_cached_vision_x = True
|
| 171 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 172 |
+
|
| 173 |
+
output = self.lang_encoder.generate(
|
| 174 |
+
input_ids=lang_x,
|
| 175 |
+
attention_mask=attention_mask,
|
| 176 |
+
eos_token_id=self.eoc_token_id,
|
| 177 |
+
num_beams=num_beams,
|
| 178 |
+
min_new_tokens=min_new_tokens,
|
| 179 |
+
max_new_tokens=max_new_tokens,
|
| 180 |
+
temperature=temperature,
|
| 181 |
+
top_k=top_k,
|
| 182 |
+
top_p=top_p,
|
| 183 |
+
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
|
| 184 |
+
no_repeat_ngram_size=no_repeat_ngram_size,
|
| 185 |
+
length_penalty=length_penalty,
|
| 186 |
+
num_return_sequences=num_return_sequences,
|
| 187 |
+
do_sample=do_sample,
|
| 188 |
+
early_stopping=early_stopping,
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 192 |
+
self.lang_encoder._use_cached_vision_x = False
|
| 193 |
+
return output
|
| 194 |
+
|
| 195 |
+
def _encode_vision_x(self, vision_x: torch.Tensor):
|
| 196 |
+
"""
|
| 197 |
+
Compute media tokens from vision input by passing it through vision encoder and conditioning language model.
|
| 198 |
+
Args:
|
| 199 |
+
vision_x (torch.Tensor): Vision input
|
| 200 |
+
shape (B, T_img, F, C, H, W)
|
| 201 |
+
Images in the same chunk are collated along T_img, and frames are collated along F
|
| 202 |
+
Currently only F=1 is supported (single-frame videos)
|
| 203 |
+
|
| 204 |
+
rearrange code based on https://github.com/dhansmair/flamingo-mini
|
| 205 |
+
"""
|
| 206 |
+
|
| 207 |
+
assert vision_x.ndim == 6, "vision_x should be of shape (b, T_img, F, C, H, W)"
|
| 208 |
+
b, T, F = vision_x.shape[:3]
|
| 209 |
+
assert F == 1, "Only single frame supported"
|
| 210 |
+
|
| 211 |
+
vision_x = rearrange(vision_x, "b T F c h w -> (b T F) c h w")
|
| 212 |
+
with torch.no_grad():
|
| 213 |
+
vision_x = self.vision_encoder(vision_x)[1]
|
| 214 |
+
vision_x = rearrange(vision_x, "(b T F) v d -> b T F v d", b=b, T=T, F=F)
|
| 215 |
+
vision_x = self.perceiver(vision_x)
|
| 216 |
+
|
| 217 |
+
for layer in self.lang_encoder._get_decoder_layers():
|
| 218 |
+
layer.condition_vis_x(vision_x)
|
| 219 |
+
|
| 220 |
+
def wrap_fsdp(self, wrapper_kwargs, device_id):
|
| 221 |
+
"""
|
| 222 |
+
Manually wraps submodules for FSDP and move other parameters to device_id.
|
| 223 |
+
|
| 224 |
+
Why manually wrap?
|
| 225 |
+
- all parameters within the FSDP wrapper must have the same requires_grad.
|
| 226 |
+
We have a mix of frozen and unfrozen parameters.
|
| 227 |
+
- model.vision_encoder.visual needs to be individually wrapped or encode_vision_x errors
|
| 228 |
+
See: https://github.com/pytorch/pytorch/issues/82461#issuecomment-1269136344
|
| 229 |
+
|
| 230 |
+
The rough wrapping structure is:
|
| 231 |
+
- FlamingoModel
|
| 232 |
+
- FSDP(FSDP(vision_encoder))
|
| 233 |
+
- FSDP(FSDP(perceiver))
|
| 234 |
+
- lang_encoder
|
| 235 |
+
- FSDP(FSDP(input_embeddings))
|
| 236 |
+
- FlamingoLayers
|
| 237 |
+
- FSDP(FSDP(gated_cross_attn_layer))
|
| 238 |
+
- FSDP(FSDP(decoder_layer))
|
| 239 |
+
- FSDP(FSDP(output_embeddings))
|
| 240 |
+
- other parameters
|
| 241 |
+
|
| 242 |
+
Known issues:
|
| 243 |
+
- Our FSDP strategy is not compatible with tied embeddings. If the LM embeddings are tied,
|
| 244 |
+
train with DDP or set the --freeze_lm_embeddings flag to true.
|
| 245 |
+
- With FSDP + gradient ckpting, one can increase the batch size with seemingly no upper bound.
|
| 246 |
+
Although the training curves look okay, we found that downstream performance dramatically
|
| 247 |
+
degrades if the batch size is unreasonably large (e.g., 100 MMC4 batch size for OPT-125M).
|
| 248 |
+
|
| 249 |
+
FAQs about our FSDP wrapping strategy:
|
| 250 |
+
Why double wrap?
|
| 251 |
+
As of torch==2.0.1, FSDP's _post_forward_hook and _post_backward_hook
|
| 252 |
+
only free gathered parameters if the module is NOT FSDP root.
|
| 253 |
+
|
| 254 |
+
Why unfreeze the decoder_layers?
|
| 255 |
+
See https://github.com/pytorch/pytorch/issues/95805
|
| 256 |
+
As of torch==2.0.1, FSDP's _post_backward_hook is only registed if the flat param
|
| 257 |
+
requires_grad=True. We need the postback to fire to avoid OOM.
|
| 258 |
+
To effectively freeze the decoder layers, we exclude them from the optimizer.
|
| 259 |
+
|
| 260 |
+
What is assumed to be frozen v. unfrozen?
|
| 261 |
+
We assume that the model is being trained under normal Flamingo settings
|
| 262 |
+
with these lines being called in factory.py:
|
| 263 |
+
```
|
| 264 |
+
# Freeze all parameters
|
| 265 |
+
model.requires_grad_(False)
|
| 266 |
+
assert sum(p.numel() for p in model.parameters() if p.requires_grad) == 0
|
| 267 |
+
|
| 268 |
+
# Unfreeze perceiver, gated_cross_attn_layers, and LM input embeddings
|
| 269 |
+
model.perceiver.requires_grad_(True)
|
| 270 |
+
model.lang_encoder.gated_cross_attn_layers.requires_grad_(True)
|
| 271 |
+
[optional] model.lang_encoder.get_input_embeddings().requires_grad_(True)
|
| 272 |
+
```
|
| 273 |
+
"""
|
| 274 |
+
# unfreeze the decoder layers
|
| 275 |
+
for block in self.lang_encoder.old_decoder_blocks:
|
| 276 |
+
block.requires_grad_(True)
|
| 277 |
+
|
| 278 |
+
# wrap in FSDP
|
| 279 |
+
with enable_wrap(wrapper_cls=FSDP, **wrapper_kwargs):
|
| 280 |
+
self.perceiver = wrap(wrap(self.perceiver))
|
| 281 |
+
self.lang_encoder.old_decoder_blocks = nn.ModuleList(
|
| 282 |
+
wrap(wrap(block)) for block in self.lang_encoder.old_decoder_blocks
|
| 283 |
+
)
|
| 284 |
+
self.lang_encoder.gated_cross_attn_layers = nn.ModuleList(
|
| 285 |
+
wrap(wrap(layer)) if layer is not None else None
|
| 286 |
+
for layer in self.lang_encoder.gated_cross_attn_layers
|
| 287 |
+
)
|
| 288 |
+
self.lang_encoder.init_flamingo_layers(self._use_gradient_checkpointing)
|
| 289 |
+
self.lang_encoder.set_input_embeddings(
|
| 290 |
+
wrap(wrap(self.lang_encoder.get_input_embeddings()))
|
| 291 |
+
)
|
| 292 |
+
self.lang_encoder.set_output_embeddings(
|
| 293 |
+
wrap(wrap(self.lang_encoder.get_output_embeddings()))
|
| 294 |
+
)
|
| 295 |
+
self.vision_encoder = wrap(wrap(self.vision_encoder)) # frozen
|
| 296 |
+
|
| 297 |
+
# manually move non-FSDP managed parameters to device_id
|
| 298 |
+
# these are all in lang_encoder
|
| 299 |
+
apply_with_stopping_condition(
|
| 300 |
+
module=self.lang_encoder,
|
| 301 |
+
apply_fn=lambda m: m.to(device_id),
|
| 302 |
+
apply_condition=lambda m: len(list(m.children())) == 0,
|
| 303 |
+
stopping_condition=lambda m: isinstance(m, FSDP),
|
| 304 |
+
)
|
| 305 |
+
|
| 306 |
+
# exclude the original decoder layers from the optimizer
|
| 307 |
+
for block in self.lang_encoder.old_decoder_blocks:
|
| 308 |
+
for p in block.parameters():
|
| 309 |
+
p.exclude_from_optimizer = True
|
| 310 |
+
|
| 311 |
+
# set up clip_grad_norm_ function
|
| 312 |
+
def clip_grad_norm_(max_norm):
|
| 313 |
+
self.perceiver.clip_grad_norm_(max_norm)
|
| 314 |
+
for layer in self.lang_encoder.gated_cross_attn_layers:
|
| 315 |
+
if layer is not None:
|
| 316 |
+
layer.clip_grad_norm_(max_norm)
|
| 317 |
+
self.lang_encoder.get_input_embeddings().clip_grad_norm_(max_norm)
|
| 318 |
+
|
| 319 |
+
self.clip_grad_norm_ = clip_grad_norm_
|
| 320 |
+
|
| 321 |
+
def _condition_media_locations(self, input_ids: torch.Tensor):
|
| 322 |
+
"""
|
| 323 |
+
Compute the media token locations from lang_x and condition the language model on these.
|
| 324 |
+
Args:
|
| 325 |
+
input_ids (torch.Tensor): Language input
|
| 326 |
+
shape (B, T_txt)
|
| 327 |
+
"""
|
| 328 |
+
media_locations = input_ids == self.media_token_id
|
| 329 |
+
|
| 330 |
+
for layer in self.lang_encoder._get_decoder_layers():
|
| 331 |
+
layer.condition_media_locations(media_locations)
|
| 332 |
+
|
| 333 |
+
def cache_media(self, input_ids: torch.Tensor, vision_x: torch.Tensor):
|
| 334 |
+
"""
|
| 335 |
+
Pre-cache a prompt/sequence of images / text for log-likelihood evaluations.
|
| 336 |
+
All subsequent calls to forward() will generate attending to the LAST
|
| 337 |
+
image in vision_x.
|
| 338 |
+
This is not meant to be used to cache things for generate().
|
| 339 |
+
Args:
|
| 340 |
+
input_ids (torch.Tensor): Language input
|
| 341 |
+
shape (B, T_txt)
|
| 342 |
+
vision_x (torch.Tensor): Vision input
|
| 343 |
+
shape (B, T_img, F, C, H, W)
|
| 344 |
+
Images in the same chunk are collated along T_img, and frames are collated along F
|
| 345 |
+
Currently only F=1 is supported (single-frame videos)
|
| 346 |
+
"""
|
| 347 |
+
self._encode_vision_x(vision_x=vision_x)
|
| 348 |
+
self._condition_media_locations(input_ids=input_ids)
|
| 349 |
+
self.lang_encoder._use_cached_vision_x = True
|
| 350 |
+
|
| 351 |
+
def uncache_media(self):
|
| 352 |
+
"""
|
| 353 |
+
Clear all conditioning.
|
| 354 |
+
"""
|
| 355 |
+
self.lang_encoder.clear_conditioned_layers()
|
| 356 |
+
self.lang_encoder._use_cached_vision_x = False
|
open_flamingo/open_flamingo/src/flamingo_lm.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
from .helpers import GatedCrossAttentionBlock
|
| 3 |
+
from .utils import getattr_recursive, setattr_recursive
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class FlamingoLayer(nn.Module):
|
| 7 |
+
"""
|
| 8 |
+
FlamingoLayer is a wrapper around the GatedCrossAttentionBlock and DecoderLayer.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
def __init__(
|
| 12 |
+
self, gated_cross_attn_layer, decoder_layer, gradient_checkpointing=False
|
| 13 |
+
):
|
| 14 |
+
super().__init__()
|
| 15 |
+
self.gated_cross_attn_layer = gated_cross_attn_layer
|
| 16 |
+
self.decoder_layer = decoder_layer
|
| 17 |
+
self.vis_x = None
|
| 18 |
+
self.media_locations = None
|
| 19 |
+
if self.gated_cross_attn_layer is not None:
|
| 20 |
+
self.gated_cross_attn_layer._use_gradient_checkpointing = (
|
| 21 |
+
gradient_checkpointing
|
| 22 |
+
)
|
| 23 |
+
self.decoder_layer._use_gradient_checkpointing = gradient_checkpointing
|
| 24 |
+
|
| 25 |
+
def is_conditioned(self) -> bool:
|
| 26 |
+
"""Check whether the layer is conditioned."""
|
| 27 |
+
return self.vis_x is not None and self.media_locations is not None
|
| 28 |
+
|
| 29 |
+
# Used this great idea from this implementation of Flamingo (https://github.com/dhansmair/flamingo-mini/)
|
| 30 |
+
def condition_vis_x(self, vis_x):
|
| 31 |
+
self.vis_x = vis_x
|
| 32 |
+
|
| 33 |
+
def condition_media_locations(self, media_locations):
|
| 34 |
+
self.media_locations = media_locations
|
| 35 |
+
|
| 36 |
+
def condition_use_cached_media(self, use_cached_media):
|
| 37 |
+
self.use_cached_media = use_cached_media
|
| 38 |
+
|
| 39 |
+
def forward(
|
| 40 |
+
self,
|
| 41 |
+
lang_x,
|
| 42 |
+
attention_mask=None,
|
| 43 |
+
**decoder_layer_kwargs,
|
| 44 |
+
):
|
| 45 |
+
# Cross attention
|
| 46 |
+
if self.gated_cross_attn_layer is not None:
|
| 47 |
+
if self.vis_x is None:
|
| 48 |
+
raise ValueError("vis_x must be conditioned before forward pass")
|
| 49 |
+
|
| 50 |
+
if self.media_locations is None:
|
| 51 |
+
raise ValueError(
|
| 52 |
+
"media_locations must be conditioned before forward pass"
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
lang_x = self.gated_cross_attn_layer(
|
| 56 |
+
lang_x,
|
| 57 |
+
self.vis_x,
|
| 58 |
+
media_locations=self.media_locations,
|
| 59 |
+
use_cached_media=self.use_cached_media,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
# Normal decoder layer
|
| 63 |
+
lang_x = self.decoder_layer(
|
| 64 |
+
lang_x, attention_mask=attention_mask, **decoder_layer_kwargs
|
| 65 |
+
)
|
| 66 |
+
return lang_x
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class FlamingoLMMixin(nn.Module):
|
| 70 |
+
"""
|
| 71 |
+
Mixin to add cross-attention layers to a language model.
|
| 72 |
+
"""
|
| 73 |
+
|
| 74 |
+
def set_decoder_layers_attr_name(self, decoder_layers_attr_name):
|
| 75 |
+
self.decoder_layers_attr_name = decoder_layers_attr_name
|
| 76 |
+
|
| 77 |
+
def _get_decoder_layers(self):
|
| 78 |
+
return getattr_recursive(self, self.decoder_layers_attr_name)
|
| 79 |
+
|
| 80 |
+
def _set_decoder_layers(self, value):
|
| 81 |
+
setattr_recursive(self, self.decoder_layers_attr_name, value)
|
| 82 |
+
|
| 83 |
+
def init_flamingo(
|
| 84 |
+
self,
|
| 85 |
+
media_token_id,
|
| 86 |
+
lang_hidden_size,
|
| 87 |
+
vis_hidden_size,
|
| 88 |
+
cross_attn_every_n_layers,
|
| 89 |
+
gradient_checkpointing,
|
| 90 |
+
):
|
| 91 |
+
"""
|
| 92 |
+
Initialize Flamingo by adding a new gated cross attn to the decoder. Store the media token id for computing the media locations.
|
| 93 |
+
"""
|
| 94 |
+
self.old_decoder_blocks = self._get_decoder_layers()
|
| 95 |
+
self.gated_cross_attn_layers = nn.ModuleList(
|
| 96 |
+
[
|
| 97 |
+
GatedCrossAttentionBlock(
|
| 98 |
+
dim=lang_hidden_size, dim_visual=vis_hidden_size
|
| 99 |
+
)
|
| 100 |
+
if (layer_idx + 1) % cross_attn_every_n_layers == 0
|
| 101 |
+
else None
|
| 102 |
+
for layer_idx, _ in enumerate(self._get_decoder_layers())
|
| 103 |
+
]
|
| 104 |
+
)
|
| 105 |
+
self.init_flamingo_layers(gradient_checkpointing)
|
| 106 |
+
self.media_token_id = media_token_id
|
| 107 |
+
self.initialized_flamingo = True
|
| 108 |
+
self._use_cached_vision_x = False
|
| 109 |
+
|
| 110 |
+
def init_flamingo_layers(self, gradient_checkpointing):
|
| 111 |
+
"""
|
| 112 |
+
Re initializes the FlamingoLayers.
|
| 113 |
+
Propagates any changes made to self.gated_corss_attn_layers or self.old_decoder_blocks
|
| 114 |
+
"""
|
| 115 |
+
self._set_decoder_layers(
|
| 116 |
+
nn.ModuleList(
|
| 117 |
+
[
|
| 118 |
+
FlamingoLayer(
|
| 119 |
+
gated_cross_attn_layer, decoder_layer, gradient_checkpointing
|
| 120 |
+
)
|
| 121 |
+
for gated_cross_attn_layer, decoder_layer in zip(
|
| 122 |
+
self.gated_cross_attn_layers, self.old_decoder_blocks
|
| 123 |
+
)
|
| 124 |
+
]
|
| 125 |
+
)
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
def forward(self, input_ids, attention_mask, **kwargs):
|
| 129 |
+
"""Condition the Flamingo layers on the media locations before forward()"""
|
| 130 |
+
if not self.initialized_flamingo:
|
| 131 |
+
raise ValueError(
|
| 132 |
+
"Flamingo layers are not initialized. Please call `init_flamingo` first."
|
| 133 |
+
)
|
| 134 |
+
|
| 135 |
+
media_locations = input_ids == self.media_token_id
|
| 136 |
+
|
| 137 |
+
# if there are media already cached and we're generating and there are no media tokens in the input,
|
| 138 |
+
# we'll assume that ALL input tokens should attend to the last previous media that is cached.
|
| 139 |
+
# this is especially important for HF generate() compatibility, since generate() calls forward()
|
| 140 |
+
# repeatedly one token at a time (with no media tokens).
|
| 141 |
+
# without this check, the model would not attend to any images when generating (after the first token)
|
| 142 |
+
use_cached_media_locations = (
|
| 143 |
+
self._use_cached_vision_x
|
| 144 |
+
and self.is_conditioned()
|
| 145 |
+
and not media_locations.any()
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
for layer in self._get_decoder_layers():
|
| 149 |
+
if not use_cached_media_locations:
|
| 150 |
+
layer.condition_media_locations(media_locations)
|
| 151 |
+
layer.condition_use_cached_media(use_cached_media_locations)
|
| 152 |
+
|
| 153 |
+
# package arguments for the other parent's forward. since we don't know the order of the arguments,
|
| 154 |
+
# make them all kwargs
|
| 155 |
+
kwargs["input_ids"] = input_ids
|
| 156 |
+
kwargs["attention_mask"] = attention_mask
|
| 157 |
+
return super().forward(
|
| 158 |
+
**kwargs
|
| 159 |
+
) # Call the other parent's forward method
|
| 160 |
+
|
| 161 |
+
def is_conditioned(self) -> bool:
|
| 162 |
+
"""Check whether all decoder layers are already conditioned."""
|
| 163 |
+
return all(l.is_conditioned() for l in self._get_decoder_layers())
|
| 164 |
+
|
| 165 |
+
def clear_conditioned_layers(self):
|
| 166 |
+
for layer in self._get_decoder_layers():
|
| 167 |
+
layer.condition_vis_x(None)
|
| 168 |
+
layer.condition_media_locations(None)
|
| 169 |
+
layer.condition_use_cached_media(None)
|
open_flamingo/open_flamingo/src/helpers.py
ADDED
|
@@ -0,0 +1,279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Based on: https://github.com/lucidrains/flamingo-pytorch
|
| 3 |
+
"""
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
from einops import rearrange, repeat
|
| 7 |
+
from einops_exts import rearrange_many
|
| 8 |
+
from torch import einsum, nn
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def exists(val):
|
| 12 |
+
return val is not None
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def FeedForward(dim, mult=4):
|
| 16 |
+
inner_dim = int(dim * mult)
|
| 17 |
+
return nn.Sequential(
|
| 18 |
+
nn.LayerNorm(dim),
|
| 19 |
+
nn.Linear(dim, inner_dim, bias=False),
|
| 20 |
+
nn.GELU(),
|
| 21 |
+
nn.Linear(inner_dim, dim, bias=False),
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class PerceiverAttention(nn.Module):
|
| 26 |
+
def __init__(self, *, dim, dim_head=64, heads=8):
|
| 27 |
+
super().__init__()
|
| 28 |
+
self.scale = dim_head**-0.5
|
| 29 |
+
self.heads = heads
|
| 30 |
+
inner_dim = dim_head * heads
|
| 31 |
+
|
| 32 |
+
self.norm_media = nn.LayerNorm(dim)
|
| 33 |
+
self.norm_latents = nn.LayerNorm(dim)
|
| 34 |
+
|
| 35 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 36 |
+
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=False)
|
| 37 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 38 |
+
|
| 39 |
+
def forward(self, x, latents):
|
| 40 |
+
"""
|
| 41 |
+
Args:
|
| 42 |
+
x (torch.Tensor): image features
|
| 43 |
+
shape (b, T, n1, D)
|
| 44 |
+
latent (torch.Tensor): latent features
|
| 45 |
+
shape (b, T, n2, D)
|
| 46 |
+
"""
|
| 47 |
+
x = self.norm_media(x)
|
| 48 |
+
latents = self.norm_latents(latents)
|
| 49 |
+
|
| 50 |
+
h = self.heads
|
| 51 |
+
|
| 52 |
+
q = self.to_q(latents)
|
| 53 |
+
kv_input = torch.cat((x, latents), dim=-2)
|
| 54 |
+
k, v = self.to_kv(kv_input).chunk(2, dim=-1)
|
| 55 |
+
q, k, v = rearrange_many((q, k, v), "b t n (h d) -> b h t n d", h=h)
|
| 56 |
+
q = q * self.scale
|
| 57 |
+
|
| 58 |
+
# attention
|
| 59 |
+
sim = einsum("... i d, ... j d -> ... i j", q, k)
|
| 60 |
+
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
|
| 61 |
+
attn = sim.softmax(dim=-1)
|
| 62 |
+
|
| 63 |
+
out = einsum("... i j, ... j d -> ... i d", attn, v)
|
| 64 |
+
out = rearrange(out, "b h t n d -> b t n (h d)", h=h)
|
| 65 |
+
return self.to_out(out)
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class PerceiverResampler(nn.Module):
|
| 69 |
+
def __init__(
|
| 70 |
+
self,
|
| 71 |
+
*,
|
| 72 |
+
dim,
|
| 73 |
+
depth=6,
|
| 74 |
+
dim_head=64,
|
| 75 |
+
heads=8,
|
| 76 |
+
num_latents=64,
|
| 77 |
+
max_num_media=None,
|
| 78 |
+
max_num_frames=None,
|
| 79 |
+
ff_mult=4,
|
| 80 |
+
):
|
| 81 |
+
super().__init__()
|
| 82 |
+
self.latents = nn.Parameter(torch.randn(num_latents, dim))
|
| 83 |
+
self.frame_embs = (
|
| 84 |
+
nn.Parameter(torch.randn(max_num_frames, dim))
|
| 85 |
+
if exists(max_num_frames)
|
| 86 |
+
else None
|
| 87 |
+
)
|
| 88 |
+
self.media_time_embs = (
|
| 89 |
+
nn.Parameter(torch.randn(max_num_media, 1, dim))
|
| 90 |
+
if exists(max_num_media)
|
| 91 |
+
else None
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
self.layers = nn.ModuleList([])
|
| 95 |
+
for _ in range(depth):
|
| 96 |
+
self.layers.append(
|
| 97 |
+
nn.ModuleList(
|
| 98 |
+
[
|
| 99 |
+
PerceiverAttention(dim=dim, dim_head=dim_head, heads=heads),
|
| 100 |
+
FeedForward(dim=dim, mult=ff_mult),
|
| 101 |
+
]
|
| 102 |
+
)
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
self.norm = nn.LayerNorm(dim)
|
| 106 |
+
|
| 107 |
+
def forward(self, x):
|
| 108 |
+
"""
|
| 109 |
+
Args:
|
| 110 |
+
x (torch.Tensor): image features
|
| 111 |
+
shape (b, T, F, v, D)
|
| 112 |
+
Returns:
|
| 113 |
+
shape (b, T, n, D) where n is self.num_latents
|
| 114 |
+
"""
|
| 115 |
+
b, T, F, v = x.shape[:4]
|
| 116 |
+
|
| 117 |
+
# frame and media time embeddings
|
| 118 |
+
if exists(self.frame_embs):
|
| 119 |
+
frame_embs = repeat(self.frame_embs[:F], "F d -> b T F v d", b=b, T=T, v=v)
|
| 120 |
+
x = x + frame_embs
|
| 121 |
+
x = rearrange(
|
| 122 |
+
x, "b T F v d -> b T (F v) d"
|
| 123 |
+
) # flatten the frame and spatial dimensions
|
| 124 |
+
if exists(self.media_time_embs):
|
| 125 |
+
x = x + self.media_time_embs[:T]
|
| 126 |
+
|
| 127 |
+
# blocks
|
| 128 |
+
latents = repeat(self.latents, "n d -> b T n d", b=b, T=T)
|
| 129 |
+
for attn, ff in self.layers:
|
| 130 |
+
latents = attn(x, latents) + latents
|
| 131 |
+
latents = ff(latents) + latents
|
| 132 |
+
return self.norm(latents)
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
# gated cross attention
|
| 136 |
+
class MaskedCrossAttention(nn.Module):
|
| 137 |
+
def __init__(
|
| 138 |
+
self,
|
| 139 |
+
*,
|
| 140 |
+
dim,
|
| 141 |
+
dim_visual,
|
| 142 |
+
dim_head=64,
|
| 143 |
+
heads=8,
|
| 144 |
+
only_attend_immediate_media=True,
|
| 145 |
+
):
|
| 146 |
+
super().__init__()
|
| 147 |
+
self.scale = dim_head**-0.5
|
| 148 |
+
self.heads = heads
|
| 149 |
+
inner_dim = dim_head * heads
|
| 150 |
+
|
| 151 |
+
self.norm = nn.LayerNorm(dim)
|
| 152 |
+
|
| 153 |
+
self.to_q = nn.Linear(dim, inner_dim, bias=False)
|
| 154 |
+
self.to_kv = nn.Linear(dim_visual, inner_dim * 2, bias=False)
|
| 155 |
+
self.to_out = nn.Linear(inner_dim, dim, bias=False)
|
| 156 |
+
|
| 157 |
+
# whether for text to only attend to immediate preceding image, or all previous images
|
| 158 |
+
self.only_attend_immediate_media = only_attend_immediate_media
|
| 159 |
+
|
| 160 |
+
def forward(self, x, media, media_locations=None, use_cached_media=False):
|
| 161 |
+
"""
|
| 162 |
+
Args:
|
| 163 |
+
x (torch.Tensor): text features
|
| 164 |
+
shape (B, T_txt, D_txt)
|
| 165 |
+
media (torch.Tensor): image features
|
| 166 |
+
shape (B, T_img, n, D_img) where n is the dim of the latents
|
| 167 |
+
media_locations: boolean mask identifying the media tokens in x
|
| 168 |
+
shape (B, T_txt)
|
| 169 |
+
use_cached_media: bool
|
| 170 |
+
If true, treat all of x as if they occur after the last media
|
| 171 |
+
registered in media_locations. T_txt does not need to exactly
|
| 172 |
+
equal media_locations.shape[1] in this case
|
| 173 |
+
"""
|
| 174 |
+
|
| 175 |
+
if not use_cached_media:
|
| 176 |
+
assert (
|
| 177 |
+
media_locations.shape[1] == x.shape[1]
|
| 178 |
+
), f"media_location.shape is {media_locations.shape} but x.shape is {x.shape}"
|
| 179 |
+
|
| 180 |
+
T_txt = x.shape[1]
|
| 181 |
+
_, T_img, n = media.shape[:3]
|
| 182 |
+
h = self.heads
|
| 183 |
+
|
| 184 |
+
x = self.norm(x)
|
| 185 |
+
|
| 186 |
+
q = self.to_q(x)
|
| 187 |
+
media = rearrange(media, "b t n d -> b (t n) d")
|
| 188 |
+
|
| 189 |
+
k, v = self.to_kv(media).chunk(2, dim=-1)
|
| 190 |
+
q, k, v = rearrange_many((q, k, v), "b n (h d) -> b h n d", h=h)
|
| 191 |
+
|
| 192 |
+
q = q * self.scale
|
| 193 |
+
|
| 194 |
+
sim = einsum("... i d, ... j d -> ... i j", q, k)
|
| 195 |
+
|
| 196 |
+
if exists(media_locations):
|
| 197 |
+
media_time = torch.arange(T_img, device=x.device) + 1
|
| 198 |
+
|
| 199 |
+
if use_cached_media:
|
| 200 |
+
# text time is set to the last cached media location
|
| 201 |
+
text_time = repeat(
|
| 202 |
+
torch.count_nonzero(media_locations, dim=1),
|
| 203 |
+
"b -> b i",
|
| 204 |
+
i=T_txt,
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
# at each boolean of True, increment the time counter (relative to media time)
|
| 208 |
+
text_time = media_locations.cumsum(dim=-1)
|
| 209 |
+
|
| 210 |
+
# text time must equal media time if only attending to most immediate image
|
| 211 |
+
# otherwise, as long as text time is greater than media time (if attending to all previous images / media)
|
| 212 |
+
mask_op = torch.eq if self.only_attend_immediate_media else torch.ge
|
| 213 |
+
|
| 214 |
+
text_to_media_mask = mask_op(
|
| 215 |
+
rearrange(text_time, "b i -> b 1 i 1"),
|
| 216 |
+
repeat(media_time, "j -> 1 1 1 (j n)", n=n),
|
| 217 |
+
)
|
| 218 |
+
sim = sim.masked_fill(~text_to_media_mask, -torch.finfo(sim.dtype).max)
|
| 219 |
+
|
| 220 |
+
sim = sim - sim.amax(dim=-1, keepdim=True).detach()
|
| 221 |
+
attn = sim.softmax(dim=-1)
|
| 222 |
+
|
| 223 |
+
if exists(media_locations) and self.only_attend_immediate_media:
|
| 224 |
+
# any text without a preceding media needs to have attention zeroed out
|
| 225 |
+
text_without_media_mask = text_time == 0
|
| 226 |
+
text_without_media_mask = rearrange(
|
| 227 |
+
text_without_media_mask, "b i -> b 1 i 1"
|
| 228 |
+
)
|
| 229 |
+
attn = attn.masked_fill(text_without_media_mask, 0.0)
|
| 230 |
+
|
| 231 |
+
out = einsum("... i j, ... j d -> ... i d", attn, v)
|
| 232 |
+
out = rearrange(out, "b h n d -> b n (h d)")
|
| 233 |
+
return self.to_out(out)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
class GatedCrossAttentionBlock(nn.Module):
|
| 237 |
+
def __init__(
|
| 238 |
+
self,
|
| 239 |
+
*,
|
| 240 |
+
dim,
|
| 241 |
+
dim_visual,
|
| 242 |
+
dim_head=64,
|
| 243 |
+
heads=8,
|
| 244 |
+
ff_mult=4,
|
| 245 |
+
only_attend_immediate_media=True,
|
| 246 |
+
):
|
| 247 |
+
super().__init__()
|
| 248 |
+
self.attn = MaskedCrossAttention(
|
| 249 |
+
dim=dim,
|
| 250 |
+
dim_visual=dim_visual,
|
| 251 |
+
dim_head=dim_head,
|
| 252 |
+
heads=heads,
|
| 253 |
+
only_attend_immediate_media=only_attend_immediate_media,
|
| 254 |
+
)
|
| 255 |
+
self.attn_gate = nn.Parameter(torch.tensor([0.0]))
|
| 256 |
+
|
| 257 |
+
self.ff = FeedForward(dim, mult=ff_mult)
|
| 258 |
+
self.ff_gate = nn.Parameter(torch.tensor([0.0]))
|
| 259 |
+
|
| 260 |
+
def forward(
|
| 261 |
+
self,
|
| 262 |
+
x,
|
| 263 |
+
media,
|
| 264 |
+
media_locations=None,
|
| 265 |
+
use_cached_media=False,
|
| 266 |
+
):
|
| 267 |
+
x = (
|
| 268 |
+
self.attn(
|
| 269 |
+
x,
|
| 270 |
+
media,
|
| 271 |
+
media_locations=media_locations,
|
| 272 |
+
use_cached_media=use_cached_media,
|
| 273 |
+
)
|
| 274 |
+
* self.attn_gate.tanh()
|
| 275 |
+
+ x
|
| 276 |
+
)
|
| 277 |
+
x = self.ff(x) * self.ff_gate.tanh() + x
|
| 278 |
+
|
| 279 |
+
return x
|
open_flamingo/open_flamingo/src/utils.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def extend_instance(obj, mixin):
|
| 2 |
+
"""Apply mixins to a class instance after creation"""
|
| 3 |
+
base_cls = obj.__class__
|
| 4 |
+
base_cls_name = obj.__class__.__name__
|
| 5 |
+
obj.__class__ = type(
|
| 6 |
+
base_cls_name, (mixin, base_cls), {}
|
| 7 |
+
) # mixin needs to go first for our forward() logic to work
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def getattr_recursive(obj, att):
|
| 11 |
+
"""
|
| 12 |
+
Return nested attribute of obj
|
| 13 |
+
Example: getattr_recursive(obj, 'a.b.c') is equivalent to obj.a.b.c
|
| 14 |
+
"""
|
| 15 |
+
if att == "":
|
| 16 |
+
return obj
|
| 17 |
+
i = att.find(".")
|
| 18 |
+
if i < 0:
|
| 19 |
+
return getattr(obj, att)
|
| 20 |
+
else:
|
| 21 |
+
return getattr_recursive(getattr(obj, att[:i]), att[i + 1 :])
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def setattr_recursive(obj, att, val):
|
| 25 |
+
"""
|
| 26 |
+
Set nested attribute of obj
|
| 27 |
+
Example: setattr_recursive(obj, 'a.b.c', val) is equivalent to obj.a.b.c = val
|
| 28 |
+
"""
|
| 29 |
+
if "." in att:
|
| 30 |
+
obj = getattr_recursive(obj, ".".join(att.split(".")[:-1]))
|
| 31 |
+
setattr(obj, att.split(".")[-1], val)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def apply_with_stopping_condition(
|
| 35 |
+
module, apply_fn, apply_condition=None, stopping_condition=None, **other_args
|
| 36 |
+
):
|
| 37 |
+
if stopping_condition(module):
|
| 38 |
+
return
|
| 39 |
+
if apply_condition(module):
|
| 40 |
+
apply_fn(module, **other_args)
|
| 41 |
+
for child in module.children():
|
| 42 |
+
apply_with_stopping_condition(
|
| 43 |
+
child,
|
| 44 |
+
apply_fn,
|
| 45 |
+
apply_condition=apply_condition,
|
| 46 |
+
stopping_condition=stopping_condition,
|
| 47 |
+
**other_args
|
| 48 |
+
)
|
open_flamingo/open_flamingo/train/README.md
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenFlamingo Training
|
| 2 |
+
To train OpenFlamingo, please ensure your environment matches that of `environment.yml`.
|
| 3 |
+
|
| 4 |
+
## Data
|
| 5 |
+
Our codebase uses [WebDataset](https://github.com/webdataset/webdataset) to efficiently load `.tar` files containing image and text sequences. We recommend resampling shards with replacement during training using the `--dataset_resampled` flag.
|
| 6 |
+
|
| 7 |
+
### LAION-2B Dataset
|
| 8 |
+
[LAION-2B](https://arxiv.org/abs/2210.08402) contains 2B web-scraped (image, text) pairs.
|
| 9 |
+
We use [img2dataset](https://github.com/rom1504/img2dataset) to download this dataset into tar files.
|
| 10 |
+
|
| 11 |
+
### Multimodal C4 Dataset
|
| 12 |
+
We train on the full version of [Multimodal C4 (MMC4)](https://github.com/allenai/mmc4), which includes 103M documents of web-scraped, interleaved image-text sequences. During training, we truncate sequences to 256 text tokens and six images per sequence.
|
| 13 |
+
|
| 14 |
+
Our codebase expects `.tar` files containing `.json` files, which include raw images encoded in base64.
|
| 15 |
+
We provide scripts to convert MMC4 to this format:
|
| 16 |
+
|
| 17 |
+
1. Download the MMC4 shards into `.zip` files using [the MMC4-provided scripts](https://github.com/allenai/mmc4/tree/main/scripts) (e.g., `fewer_facesv2.sh`).
|
| 18 |
+
2. Download the MMC4 raw images into an image directory using [the MMC4-provided scripts](https://github.com/allenai/mmc4/tree/main/scripts) (e.g., `download_images.py`).
|
| 19 |
+
2. Run `scripts/convert_mmc4_to_wds.py` to convert the downloaded items into the expected tar files.
|
| 20 |
+
|
| 21 |
+
### ChatGPT-generated sequences
|
| 22 |
+
A subset of our models (listed below) were also trained on experimental ChatGPT-generated (image, text) sequences, where images are pulled from LAION. We are working to release these sequences soon.
|
| 23 |
+
|
| 24 |
+
* OpenFlamingo-4B-vitl-rpj3b
|
| 25 |
+
* OpenFlamingo-4B-vitl-rpj3b-langinstruct
|
| 26 |
+
|
| 27 |
+
## Example training command
|
| 28 |
+
We provide a sample Slurm training script in `scripts/`. You can also modify the following command:
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
torchrun --nnodes=1 --nproc_per_node=4 train.py \
|
| 32 |
+
--lm_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 33 |
+
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \
|
| 34 |
+
--cross_attn_every_n_layers 1 \
|
| 35 |
+
--dataset_resampled \
|
| 36 |
+
--batch_size_mmc4 32 \
|
| 37 |
+
--batch_size_laion 64 \
|
| 38 |
+
--train_num_samples_mmc4 125000\
|
| 39 |
+
--train_num_samples_laion 250000 \
|
| 40 |
+
--loss_multiplier_laion 0.2 \
|
| 41 |
+
--workers=4 \
|
| 42 |
+
--run_name OpenFlamingo-3B-vitl-mpt1b \
|
| 43 |
+
--num_epochs 480 \
|
| 44 |
+
--warmup_steps 1875 \
|
| 45 |
+
--mmc4_textsim_threshold 0.24 \
|
| 46 |
+
--laion_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 47 |
+
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar" \
|
| 48 |
+
--report_to_wandb
|
| 49 |
+
```
|
| 50 |
+
*Note: The MPT-1B [base](https://huggingface.co/mosaicml/mpt-1b-redpajama-200b) and [instruct](https://huggingface.co/mosaicml/mpt-1b-redpajama-200b-dolly) modeling code does not accept the `labels` kwarg or compute cross-entropy loss directly within `forward()`, as expected by our codebase. We suggest using a modified version of the MPT-1B models found [here](https://huggingface.co/anas-awadalla/mpt-1b-redpajama-200b) and [here](https://huggingface.co/anas-awadalla/mpt-1b-redpajama-200b-dolly).*
|
| 51 |
+
|
| 52 |
+
## Distributed training
|
| 53 |
+
|
| 54 |
+
By default, `train.py` uses Pytorch's [DistributedDataParallel](https://pytorch.org/docs/stable/torch.nn.parallel.DistributedDataParallel.html) for training.
|
| 55 |
+
To use [FullyShardedDataParallel](https://pytorch.org/docs/stable/fsdp.html), use the `--fsdp` flag.
|
| 56 |
+
|
| 57 |
+
Some notes on FSDP:
|
| 58 |
+
|
| 59 |
+
* We recommend using the `--fsdp_use_orig_params` flag. If `--fsdp` is on without this flag, all language model embeddings will be unfrozen during training. (In contrast, the default behavior is to only train the newly added `<image>` and `<|endofchunk|>` tokens.)
|
| 60 |
+
* Note: we've encountered issues using OPT with this flag. Other language models should be compatible.
|
| 61 |
+
* Our current FSDP wrapping strategy does not permit training language model embeddings that use tied weights (i.e., tied input / output embeddings). To train such models with FSDP, the language model embeddings must be frozen with the `--freeze_lm_embeddings` flag.
|
| 62 |
+
|
| 63 |
+
We also implement gradient checkpointing and mixed precision training. Use the `--gradient_checkpointing` and `--precision` arguments respectively.
|
open_flamingo/open_flamingo/train/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|