Multilabel Classification using Mistral-7B on a single GPU with quantization and LoRA








LLMs have impressed with there abilities to solve a wide variety of tasks, not only for natural language but also in a multimodal setting. Due to their size ("smaller" LLMs still have > 1 billion parameters) and hardware requirements it is not easy to finetune them out of the box for people without a large compute budget. However, there are techniques that can reduce the number of parameters and improve the efficiency of these models, such as LoRA and quantization. In this article, I will demonstrate how to use these techniques with the Huggingface (HF) libraries transformers, bitsandbytes and peft, which provide Python implementations of these methods. I will also show you how to apply Mistal 7b, a state-of-the-art LLM, to a multiclass classification task. This guide is by no means the first of its kind and there are other great resource that go over this topic such as this one. Nevertheless I did not find any specific resources on multiclass classification which is why I hope this article is of interest to some. The python script from which the code samples below are taken can be found here: link to repository
Imports
All required imports for the code snippets below
import os
import random
import functools
import csv
import numpy as np
import torch
import torch.nn.functional as F
from sklearn.metrics import f1_score
from skmultilearn.model_selection import iterative_train_test_split
from datasets import Dataset, DatasetDict
from peft import (
LoraConfig,
prepare_model_for_kbit_training,
get_peft_model
)
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
Trainer
)
Dataset
We will be using this Kaggle dataset on Topic Modeling for Research Articles based on title and abstract.
Data Example
ID: 5
TITLE: Comparative study of Discrete Wavelet Transforms and Wavelet Tensor Train decomposition to feature extraction of FTIR data of medicinal plants
ABSTRACT: Fourier-transform infra-red (FTIR) spectra of samples from 7 plant species were used to explore the influence of preprocessing and feature extraction on efficiency of machine learning algorithms. …
Computer Science: 1
Physics: 0
Mathematics: 0
Statistics: 1
Quantitative Biology: 0
Quantitative Finance: 0
We create a HF dataset from train.csv as this is required later on when using other functions/classes from HF libraries.
# set random seed
random.seed(0)
# load data
with open('train.csv', newline='') as csvfile:
data = list(csv.reader(csvfile, delimiter=','))
header_row = data.pop(0)
# shuffle data
random.shuffle(data)
# reshape
idx, text, labels = list(zip(*[(int(row[0]), f'Title: {row[1].strip()}\n\nAbstract: {row[2].strip()}', row[3:]) for row in data]))
labels = np.array(labels, dtype=int)
# create label weights
label_weights = 1 - labels.sum(axis=0) / labels.sum()
# stratified train test split for multilabel ds
row_ids = np.arange(len(labels))
train_idx, y_train, val_idx, y_val = iterative_train_test_split(row_ids[:,np.newaxis], labels, test_size = 0.1)
x_train = [text[i] for i in train_idx.flatten()]
x_val = [text[i] for i in val_idx.flatten()]
# create hf dataset
ds = DatasetDict({
'train': Dataset.from_dict({'text': x_train, 'labels': y_train}),
'val': Dataset.from_dict({'text': x_val, 'labels': y_val})
})
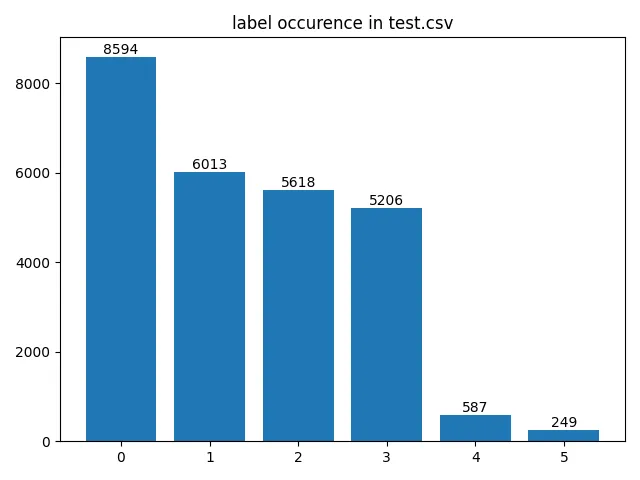
One slightly exotic package used in this snippet is probably skmultilearn which I exclusively use for the function iterative_train_test_split. This creates an even split for unbalanced multilabel datasets which is the case for this example as you can see in the visualization below. Therefore we also generate weights for our labels which we later use for calculating the loss because we would like to assign higher weights to underrepresented classes. The use of a weighted loss function is of course very dependent on your use case and the cost of trading off global accuracy vs individual class accuracy.
Initialize the model
Next we initialize our model and tokenizer. As already mentioned in the introduction we will use Mistral 7b which showed great results on a wide variety of nlp benchmarks. The code below should however work for any decoder-only LLM from the HF hub.
For finetuning we use LoRA to learn two lower dimensional diff matrices instead of having to finetune the full parameter matrix. You can find more details about lora in the paper. Since we do not need to change the pre-trained parameters during finetuning with LoRA we can quantize them using the bitsandbytes library from HF. In addition to our model we of course also need to intialize a tokenizer to preprocess our dataset.
# model name
model_name = 'mistralai/Mistral-7B-v0.1'
# preprocess dataset with tokenizer
def tokenize_examples(examples, tokenizer):
tokenized_inputs = tokenizer(examples['text'])
tokenized_inputs['labels'] = examples['labels']
return tokenized_inputs
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenized_ds = ds.map(functools.partial(tokenize_examples, tokenizer=tokenizer), batched=True)
tokenized_ds = tokenized_ds.with_format('torch')
# qunatization config
quantization_config = BitsAndBytesConfig(
load_in_4bit = True, # enable 4-bit quantization
bnb_4bit_quant_type = 'nf4', # information theoretically optimal dtype for normally distributed weights
bnb_4bit_use_double_quant = True, # quantize quantized weights //insert xzibit meme
bnb_4bit_compute_dtype = torch.bfloat16 # optimized fp format for ML
)
# lora config
lora_config = LoraConfig(
r = 16, # the dimension of the low-rank matrices
lora_alpha = 8, # scaling factor for LoRA activations vs pre-trained weight activations
target_modules = ['q_proj', 'k_proj', 'v_proj', 'o_proj'],
lora_dropout = 0.05, # dropout probability of the LoRA layers
bias = 'none', # wether to train bias weights, set to 'none' for attention layers
task_type = 'SEQ_CLS'
)
# load model
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
quantization_config=quantization_config,
num_labels=labels.shape[1]
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
model.config.pad_token_id = tokenizer.pad_token_id
As you can see from target_modules in LoraConfig we only apply finetuning to the attention weights. This works quite well and is more parameter efficient as the biggest share of parameters in a Transformer layer comes from the FeedForward Network which we freeze and quantize. r is the dimensionality of the LoRA matrices which in our case are 4096x16 and 16x4096, quite a bit smaller than the full 4096x4096 weight matrices in the Mistral attention layers.
The HF class AutoModelForSequenceClassification initializes the base model with an additional (untrained) linear classification layer on top of the last token embedding. This layer is automatically excluded from quantization and we finetune it with the rest of the LoRA weights.
Training
We are almost ready to finetune our model with the HF Trainer class, after preparing our dataset and setting up our model configuration. But before we do that, we have to define some custom functions that our trainer will use.
- Data Collator
We need to tell the trainer how it should preprocess batches coming from the dataset before they can be passed to the model. - Metrics
We furthermore need pass a function to the trainer which defines the evaluation metrics we want to compute in addition to the loss.
# define custom batch preprocessor
def collate_fn(batch, tokenizer):
dict_keys = ['input_ids', 'attention_mask', 'labels']
d = {k: [dic[k] for dic in batch] for k in dict_keys}
d['input_ids'] = torch.nn.utils.rnn.pad_sequence(
d['input_ids'], batch_first=True, padding_value=tokenizer.pad_token_id
)
d['attention_mask'] = torch.nn.utils.rnn.pad_sequence(
d['attention_mask'], batch_first=True, padding_value=0
)
d['labels'] = torch.stack(d['labels'])
return d
# define which metrics to compute for evaluation
def compute_metrics(p):
predictions, labels = p
f1_micro = f1_score(labels, predictions > 0, average = 'micro')
f1_macro = f1_score(labels, predictions > 0, average = 'macro')
f1_weighted = f1_score(labels, predictions > 0, average = 'weighted')
return {
'f1_micro': f1_micro,
'f1_macro': f1_macro,
'f1_weighted': f1_weighted
}
Furthermore we also need to define a custom trainer class to be able to calculate our multilabel loss which treats each output neuron as a binary classification instance. To be able to use our label weights for the loss we also need to define it as a class attribute in the __init__ method so the compute_loss method has access to it.
# create custom trainer class to be able to pass label weights and calculate mutilabel loss
class CustomTrainer(Trainer):
def __init__(self, label_weights, **kwargs):
super().__init__(**kwargs)
self.label_weights = label_weights
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss
loss = F.binary_cross_entropy_with_logits(logits, labels.to(torch.float32), pos_weight=self.label_weights)
return (loss, outputs) if return_outputs else loss
Now everything is ready and we can let HF do its magic. (depending on your GPU memory you might need/want to adjust the batch size, this was tested on a GPU with 16gb RAM)
# define training args
training_args = TrainingArguments(
output_dir = 'multilabel_classification',
learning_rate = 1e-4,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
num_train_epochs = 10,
weight_decay = 0.01,
evaluation_strategy = 'epoch',
save_strategy = 'epoch',
load_best_model_at_end = True
)
# train
trainer = CustomTrainer(
model = model,
args = training_args,
train_dataset = tokenized_ds['train'],
eval_dataset = tokenized_ds['val'],
tokenizer = tokenizer,
data_collator = functools.partial(collate_fn, tokenizer=tokenizer),
compute_metrics = compute_metrics,
label_weights = torch.tensor(label_weights, device=model.device)
)
trainer.train()
# save model
peft_model_id = 'multilabel_mistral'
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
Thats it! You just finetuned a state-of-the-art LLM for multilabel classification. You can load your saved model with this snippet take from the HF docs.
# load model
peft_model_id = 'multilabel_mistral'
model = AutoModelForSequenceClassification.from_pretrained(peft_model_id)
I hope with this article I was able to shed some light on how to leverage HF implentations of compute and memory efficient techniques such as LoRA and quantization for a finetuning task. From my experience there is alot of documentation about this for the most straightforward use cases but as soon as you requirements deviate a bit some adaptions are required such as defining a custom Trainer class.





