Advancing European AI Sovereignty Through Racine.ai Flantier Open-Source Multimodal Models







By Racine.ai Team
The rapid advancement of AI technologies has underscored the strategic importance of sovereign capabilities in artificial intelligence, particularly in multimodal tasks such as image-and-text-to-vector retrieval. While high-performing models in this domain, such as those based on Qwen, have demonstrated remarkable accuracy, their origins outside Europe raise concerns regarding long-term technological autonomy, data governance, and industrial competitiveness.
In response, we undertook an initiative in collaboration with École Centrale d'Électronique (ECE) iLab, as part of a use case presented with MBDA, during the inauguration of the laboratory of ECE, to assess whether a European-developed open-source model by French company Hugging Face, SmolVLM, could be refined to approach the performance levels of leading Chinese models through systematic dataset curation and fine-tuning.
Our investigation began with an evaluation of SmolVLM's baseline performance, which registered around 19% accuracy on our internal Open VLM benchmark, live today with Energy—significantly below Qwen finetuned models' 90%. This discrepancy highlighted the need for targeted improvements, particularly in the model's ability to generate high-quality vector representations from multimodal inputs (aimed at document screenshot embeddings).
Racine.ai Open VLM Leaderboard – All Languages

To address this, we developed the Organized Grouped Cleaned (OGC) datasets, a collection of meticulously curated resources designed explicitly for fine-tuning SmolVLM on image-and-text-to-vector tasks, for which we open sourced the code available here. By consolidating and standardizing data from multiple sources—including ColPali, VisRAG-Ret-Train-Synthetic-data, and VDR-Multilingual-Train—we constructed a unified, positive-only dataset (OGC_2_vdr-visRAG-colpali) optimized for training efficiency. We eliminated negative samples to streamline the learning process, ensuring that each entry contained only relevant query-image pairs.
Fine-tuning SmolVLM using the OGC datasets yielded substantial improvements. The 500M parameter model achieved an average accuracy score of 0.57, while the 2B variant reached 0.767—demonstrating that even modestly sized European models can attain industrially viable performance through high-quality data augmentation.
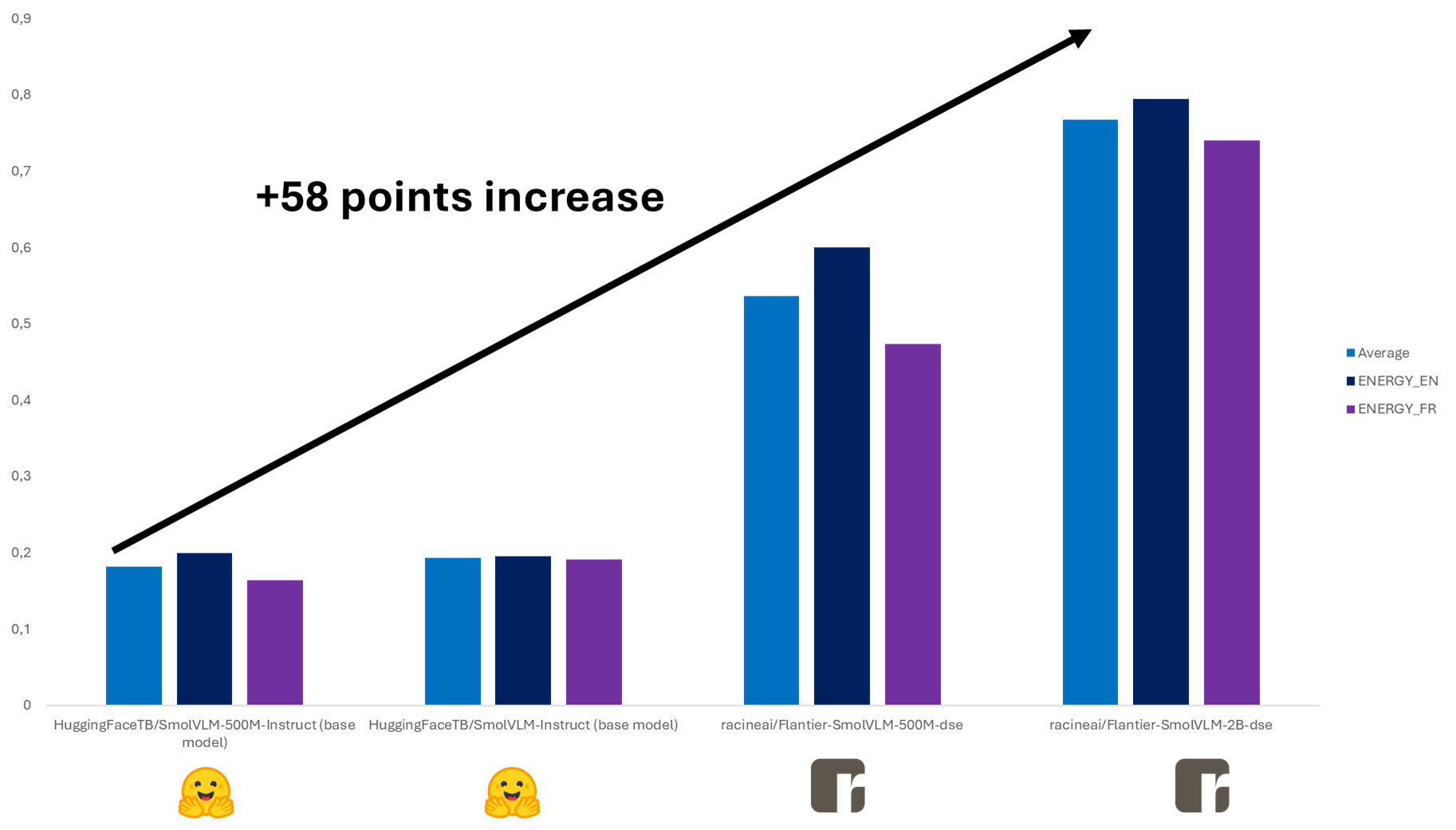
At only 0.10 below Qwen's 0.86 average (Qwen is currently used to industrialize most use cases), these results validate the potential of open-source, sovereignty-compliant alternatives.
Racine.ai Open VLM Leaderboard – English Queries Only

To contextualize these advancements, we benchmarked our fine-tuned models against existing solutions on the Open VLM Retrieval Leaderboard, which evaluates cross-lingual retrieval accuracy across sectors and languages. While Chinese models like Alibaba-NLP/gme-Qwen2-VL-2B-Instruct and vidore/colqwen2-v1.0 dominate the upper tiers, our enhanced SmolVLM (racineai/Flantier-SmolVLM-2B-dse) competes credibly, particularly in English-language tasks (0.822 average accuracy). A notable achievement is that In the English benchmark, it even achieved a mid-tier score of 0.887.
Performance in French and other European languages remains an area for further optimization, underscoring the need for broader linguistic diversification in training data.
Our approach maintains full transparency: our models, datasets, and training methodologies are publicly available to foster collaboration and iterative improvement.
The implications of this work extend beyond technical metrics. By open-sourcing every component—from base models (SmolVLM2-2.2B) to sector-specific datasets—we aim to catalyze a collaborative ecosystem where European institutions, corporations, and researchers can collectively elevate local AI capabilities. This initiative is not merely a proof of concept but a call to action: only through shared investment in data, compute, and model refinement can European AI close the gap with global leaders.
Looking ahead, we identify three critical pathways for progress:
- Expanding the linguistic and sectoral coverage of OGC datasets to address current asymmetries in multilingual performance.
- Optimizing architectural efficiencies to reduce inference costs without sacrificing accuracy.
- Establishing partnerships with industry and academia to scale data collection and validation processes.
Each of these steps aligns with the broader imperative of technological self-reliance in an era where AI sovereignty is inseparable from economic and strategic resilience.
We also expanded the dataset's applicability by creating specialized multilingual subsets for critical sectors, which were all lacking datasets on hugging face such as defense (OGC_Military) (which there were only around 20 "military" keywords datasets on Hugging Face at the time of upload), which is currently one of the largest open-source military datasets with over 160,000 rows; energy (OGC_Energy); geotechnical engineering (OGC_Geotechnie), as well as Hydrogen (OGC_Hydrogen) (which there were less than five on Hugging Face at the time of upload) all released under Apache-2.0 licenses.
We developed the OGC framework to streamline dataset merging, a critical optimization given that runtime data mapping during training can consume excessive GPU resources. By preprocessing this step on CPU, we optimized our training pipeline—achieving accuracy levels competitive with state-of-the-art models.
This work represents a total of 500,000 rows of a customized dataset and over 1 million rows in total when combined with merged datasets on the OGC format, all open source under the Apache-2.0 license.
Additionally, we open-sourced a degraded dataset—25,000 rows of OCR-degraded document images paired with their ground-truth OCR text—that addresses a critical gap in OCR model training. This dataset simulates real-world conditions encountered in production environments, particularly in defense applications where documents may be poorly scanned, photographed in suboptimal lighting, or degraded due to environmental factors.

These domain-specific datasets enable organizations to refine the model for niche use cases without compromising its generalizability. We encourage industry stakeholders to leverage these resources—either to improve their own models or to contribute to further advancements of our published models.
Our results demonstrate that European models, when paired with rigorous data curation, can achieve meaningful parity with state-of-the-art systems. The journey toward full competitiveness is iterative, but the foundation—open, adaptable, and community-driven—is now in place. We invite all stakeholders to build upon these resources, ensuring that Europe's AI future is shaped by its own institutions, values, and ambitions.
About Racine.ai:
Racine.ai is the GenAI subsidiary of TW3 Partners, specializing in delivering AI solutions tailored for enterprises operating in sovereign sectors (domaines régaliens)—including defense, energy, and critical infrastructure. By leveraging open-source, sovereignty-compliant technologies, we empower organizations to harness AI while ensuring data governance, strategic autonomy, and industrial competitiveness.
Key Resources Released:
- Models: Fine-tuned SmolVLM-500M (57% accuracy) and SmolVLM-2B (69% accuracy).
- Datasets: OGC_2_vdr-visRAG-colpali, OGC_Military, OGC_Energy, OGC_Geotechnie, OGC_Hydrogen, ocr-pdf-degraded.
- Benchmarks: Full results on the Open VLM Retrieval Leaderboard.
- OGC code
- Access: All assets and models available on Hugging Face under MIT or Apache 2.0 licenses.
Acknowledgments:
This work would not have been possible without Hugging Face’s foundational models and their open-source ecosystem, which enabled us to build, refine, and scale sovereign AI solutions.
Authors:
- Paul Lemaistre: Lead Developer at TW3 Partners & Co-Founder at Racine.ai – Adjunct Professor at École Centrale d'Électronique.
- Léo Appourchaux: AI Developer at TW3 Partners.
- André-Louis Rochet: Managing Director at TW3 Partners & Co-Founder at Racine.ai – Adjunct Professor at École Centrale d'Électronique.
