How Your Ordinary 8GB MacBook’s Untapped AI Power Can Run 70B LLM Models That Will Blow Your Mind!





Do you think your Apple MacBook is only good for making PPTs, browsing the web, and streaming shows? If so, you really don’t understand the MacBook.
Actually, the MacBook is not just about looks; its AI capability is also quite remarkable. Inside the MacBook, there is a highly capable GPU, and its architecture is especially suited for running AI models.
**We have released the new 2.8 version of AirLLM. It allows an ordinary 8GB MacBook to run top-tier 70B (billion parameter) models! **And this is without any need for quantization, pruning, or model distillation compression.
Our goal is to democratize AI, making top-tier models that previously required eight A100 GPUs run on common devices.
A 70B model, with just the model files, takes up more than 100GB. How can a regular MacBook with 8GB of RAM run it? What kind of impressive computational power is hidden inside a MacBook? We’ll clarify that today.
MacBook’s AI Capability
Apple is actually a very capable potential player in the AI field. iPhones and MacBooks have already incorporated many AI models for computational photography, facial recognition, and video processing.
Real-time AI model operation on smartphones and laptops demands high performance. Thus, Apple continuously evolves and enhances its self-developed GPU chips.
Computational photography and video processing are fundamentally similar to large language models in terms of underlying operations, primarily involving various additions, subtractions, multiplications, and divisions of large matrices. Therefore, Apple’s self-developed GPU chips can easily be competitive in the era of generative AI.
Apple’s M1, M2, M3 series GPUs are actually very suitable AI computing platforms.
Let’s look at some data:
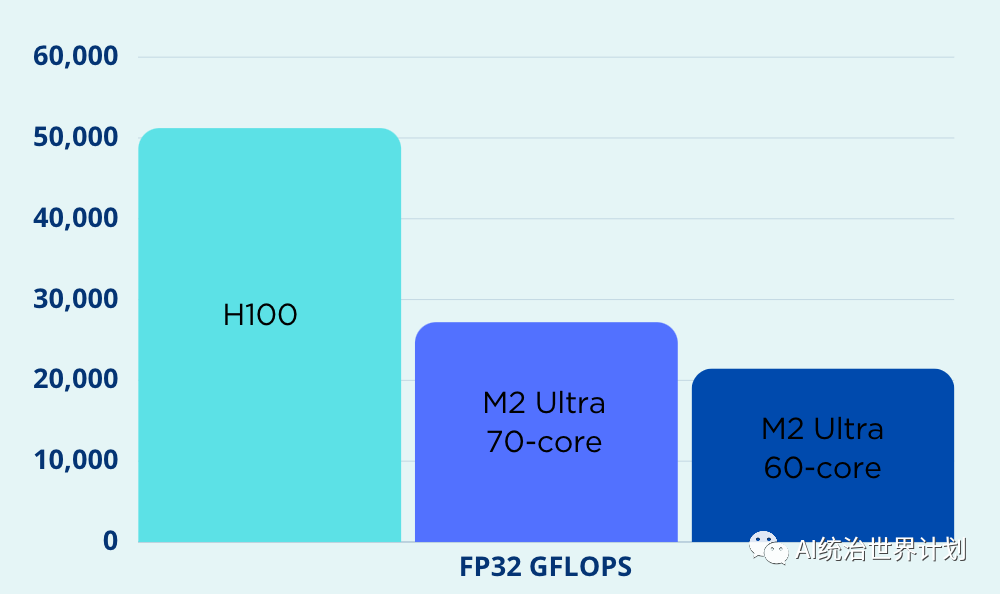
One of the main indicators of GPU capability is FLOPS (Floating-point Operations Per Second), measuring how many floating-point operations can be done per unit of time. Apple’s most powerful M2 Ultra GPU still lags behind Nvidia.
**Whereas Apple’s advantage lies in memory. **Training and inference of large language models often struggle with memory. Out-of-memory (OOM) issues are a major nightmare for large language models. Apple’s GPUs and CPUs can share memory space, allowing for more flexible expansion. The M2 Ultra GPU’s memory can reach up to 192GB, far exceeding Nvidia’s H100’s maximum of 80GB.
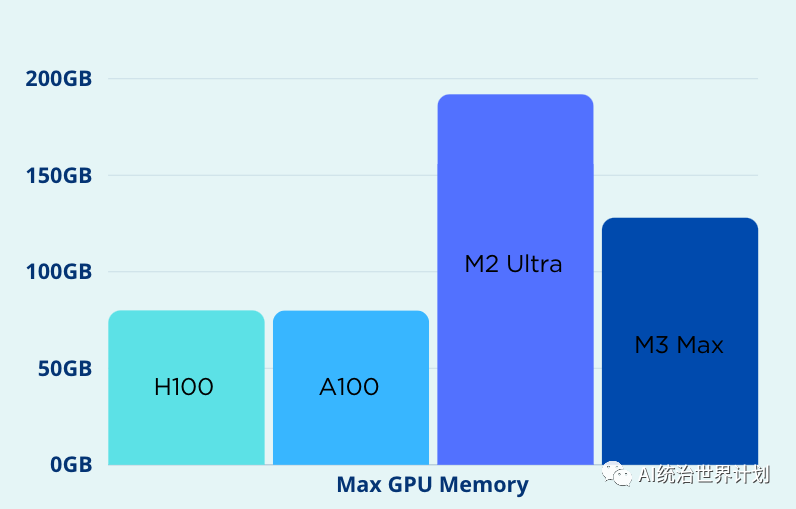
Nvidia can only optimize the GPU architecture; it has no control over the CPU. **But Apple can uniformly optimize the GPU, CPU, memory, storage, etc. For instance, Apple’s unified memory architecture allows true memory sharing between the GPU and CPU. **Data no longer needs to be transferred back and forth between CPU and GPU memory, eliminating the need for various zero-copy optimization techniques and achieving optimal performance.
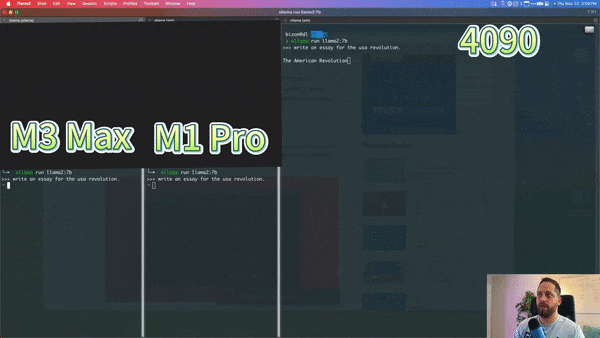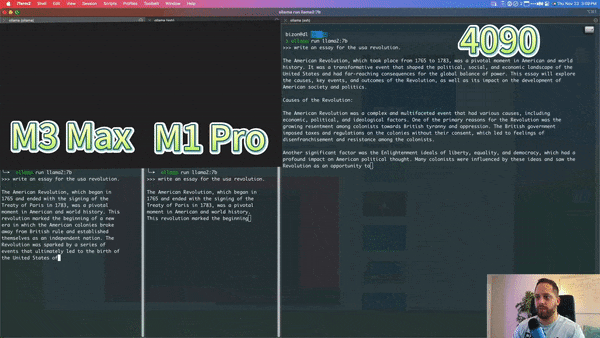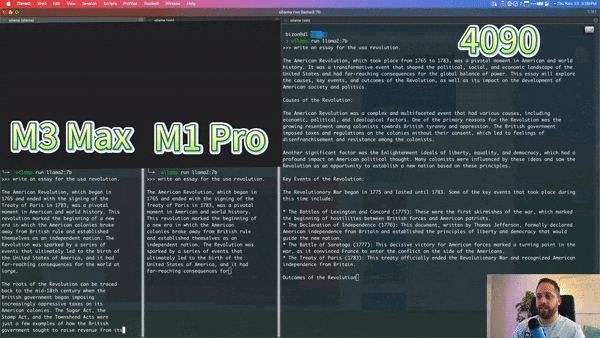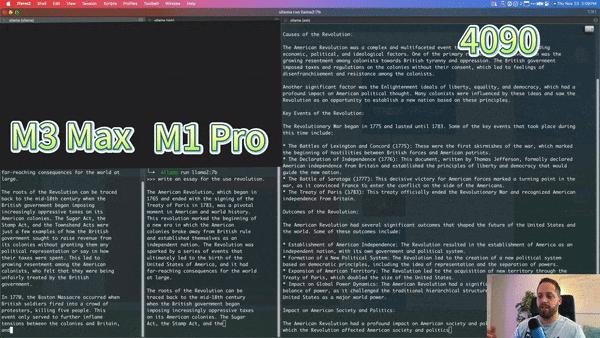
Below is a YouTube blogger’s comparison of the M3 Max, M1 Pro, and Nvidia 4090 running a 7b llama model, with the M3 Max’s speed nearing that of the 4090:
MLX Platform
Apple has released an open-source deep learning platform MLX.
MLX is very similar to PyTorch. Its programming interface and syntax are very close to Torch. Those familiar with PyTorch can easily transition to the MLX platform.
Due to the advantages of its hardware architecture design, MLX naturally supports unified memory. Tensors in memory are shared between GPU and CPU, eliminating the need for data transfer and saving a lot of extra burden.
While MLX does not have as many features as PyTorch, what I like is its simplicity, directness, and cleanliness. Perhaps due to the lack of backward compatibility burdens that PyTorch has, MLX can be more agile, making trade-offs and optimizing performance more effectively.
AirLLM Mac
The new version of AirLLM has added support based on the XLM platform. The implementation is the same as the PyTorch version.
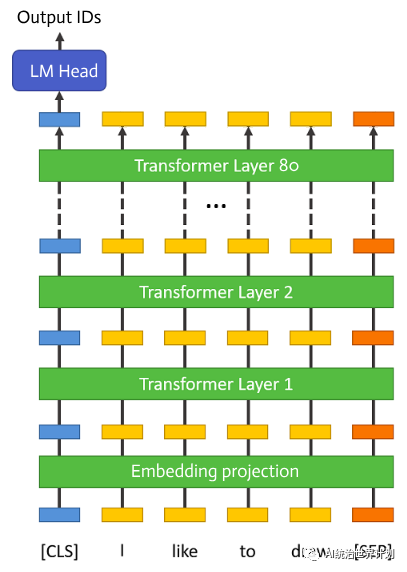
As shown in the figure above, the reason large language models are large and occupy a lot of memory is mainly due to their structure containing many “layers.” A 70B model has as many as 80 layers. But during inference, each layer is independent, relying only on the output of the previous layer.
Therefore, after running a layer, its memory can be released, keeping only the layer’s output. Based on this concept, AirLLM has implemented layered inference.
For a more detailed explanation, refer to our previous blog: here.
Using AirLLM is very simple, requiring just a few lines of code:
AirLLM is completely open source and can be found on GitHub Repo.
Welcome to visit our GitHub page and communicate with us. Suggestions and contributions are also welcome!
We will continue to openly share the latest and most effective new methods and developments in the AI field, contributing to the open-source community. Please follow us.