🌌 Analysis of Spaces in Hugging Face




Dataset: Weyaxi/huggingface-spaces-codes
🤗 Huggingface Spaces is a very good, easy-to-use platform to publish various types of applications in seconds and host them freely. With so many positive aspects of Huggingface Spaces, there are now more than 180k spaces in the hub.
❓ How was this made?
Three months ago, I decided to clone all spaces and create a dataset out of them while showcasing meaningful statistics.
After a while, when I tried to scrape approximately 160k spaces, I understood that this was nearly impossible and not necessary to that extent. So, I sorted the spaces based on their likes and tried to scrape 20k of them instead of ~160k.
After encountering this issue, I faced another problem: large files hosted on spaces. So, I focused only on code files within the spaces. Thus, I proceeded to only scrape code files.
Interestingly, there were also spaces with 0 likes at the end of the lists! So, if your space had 0 likes and was lucky enough to get into my list, I scraped them too :)
🚀 Resulting dataset
After a long period of time, dealing with rate limiting issues, etc., the final result was approximately 130k files and 2 GB of data. Then another problem arose:
The disk usage wasn't much, but there were a significant number of files.
- I tried traditional techniques, but they failed.
- I also attempted to upload it using the multi-commit feature in the Huggingface Hub library, but that also failed because it was uploading too few files in one commit.
I then solved the problem by modifying the library code itself!
It turns out that multi-commit uploads a certain amount of files per commit (I don't remember the exact amount), so I changed that amount to 18000.
I then published the dataset here:
https://huggingface.co./datasets/Weyaxi/huggingface-spaces-codes
📊 Dataset Statistics
After all of this processing, let's dive deep into the statistics. Here is the overview of the statistics of the spaces that I scrabed.
| Language | File Extension | File Counts | File Size (MB) | Line Counts |
|---|---|---|---|---|
| Python | .py | 141,560 | 1079.0 | 28,653,744 |
| SQL | .sql | 21 | 523.6 | 645 |
| JavaScript | .js | 6,790 | 369.8 | 2,137,054 |
| Markdown | .md | 63,237 | 273.4 | 3,110,443 |
| HTML | .html | 1,953 | 265.8 | 516,020 |
| C | .c | 1,320 | 132.2 | 3,558,826 |
| Go | .go | 429 | 46.3 | 6,331 |
| CSS | .css | 3,097 | 25.6 | 386,334 |
| C Header | .h | 2,824 | 20.4 | 570,948 |
| C++ | .cpp | 1,117 | 15.3 | 494,939 |
| TypeScript | .ts | 4,158 | 14.8 | 439,551 |
| TSX | .tsx | 4,273 | 9.4 | 306,416 |
| Shell | .sh | 3,294 | 5.5 | 171,943 |
| Perl | .pm | 92 | 4.2 | 128,594 |
| C# | .cs | 22 | 3.9 | 41,265 |
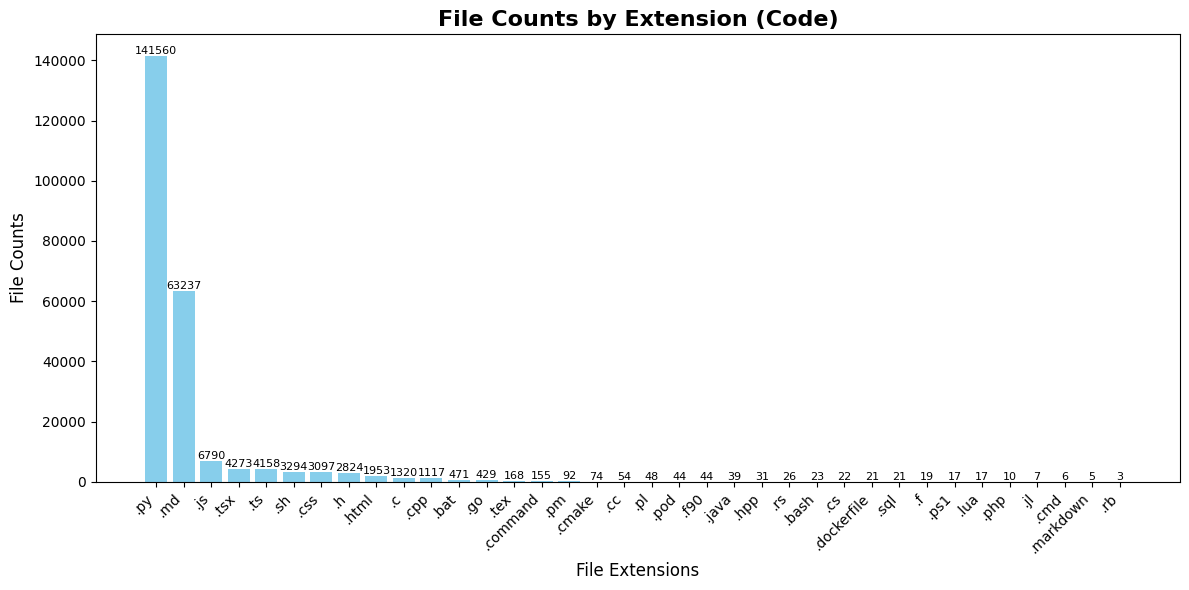
🖥️ Language
As we probably expected, Python is the most used language by a significant margin, while Markdown and JavaScript come after that. (Love Python ❤️)
📁 Size
If we look at the file size chart, we can see that Python takes up more space among the other languages. SQL comes after that, and I think that's because of the database files hosted in Hugging Face Spaces. After SQL, we come across JavaScript again :)

📝 Line Count
Python's line count is the highest among other languages, but we encounter another language that comes in second place. Our good old friend: C. C has the most line count in Hugging Face Spaces after Python.

Spaces Staticts
🛠️ Software Development Kit (SDK)
Huggingface offers many Software Development Kits (SDKs) to create our spaces. We can see from the chart that the awesome Gradio, which I personally love and use, is the most used SDK in Hugging Face Spaces, while Streamlit comes after that.

🏛️ License
As we can see from the chart I provided, the majority of spaces have no license, while the MIT and Apache licenses come in first place after that.
