
Abdullah Al Asif
commited on
Commit
·
78cb487
1
Parent(s):
b8fac3d
--base
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .env.template +41 -0
- .gitignore +166 -0
- LICENSE +21 -0
- README.md +101 -3
- assets/system_architecture.svg +0 -0
- assets/timing_chart.png +0 -0
- assets/video_demo.mov +3 -0
- data/models/kokoro.pth +3 -0
- data/voices/af.pt +3 -0
- data/voices/af_alloy.pt +3 -0
- data/voices/af_aoede.pt +3 -0
- data/voices/af_bella.pt +3 -0
- data/voices/af_bella_nicole.pt +3 -0
- data/voices/af_heart.pt +3 -0
- data/voices/af_jessica.pt +3 -0
- data/voices/af_kore.pt +3 -0
- data/voices/af_nicole.pt +3 -0
- data/voices/af_nicole_sky.pt +3 -0
- data/voices/af_nova.pt +3 -0
- data/voices/af_river.pt +3 -0
- data/voices/af_sarah.pt +3 -0
- data/voices/af_sarah_nicole.pt +3 -0
- data/voices/af_sky.pt +3 -0
- data/voices/af_sky_adam.pt +3 -0
- data/voices/af_sky_emma.pt +3 -0
- data/voices/af_sky_emma_isabella.pt +3 -0
- data/voices/am_adam.pt +3 -0
- data/voices/am_michael.pt +3 -0
- data/voices/bf_alice.pt +3 -0
- data/voices/bf_emma.pt +3 -0
- data/voices/bf_isabella.pt +3 -0
- data/voices/bm_george.pt +3 -0
- data/voices/bm_lewis.pt +3 -0
- data/voices/ef_dora.pt +3 -0
- data/voices/if_sara.pt +3 -0
- data/voices/jf_alpha.pt +3 -0
- data/voices/jf_gongitsune.pt +3 -0
- data/voices/pf_dora.pt +3 -0
- data/voices/zf_xiaoxiao.pt +3 -0
- data/voices/zf_xiaoyi.pt +3 -0
- requirements.txt +16 -0
- speech_to_speech.py +334 -0
- src/config/config.json +26 -0
- src/core/kokoro.py +156 -0
- src/models/istftnet.py +523 -0
- src/models/models.py +372 -0
- src/models/plbert.py +15 -0
- src/utils/__init__.py +35 -0
- src/utils/audio.py +42 -0
- src/utils/audio_io.py +48 -0
.env.template
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
HUGGINGFACE_TOKEN= TOKEN_GOES_HERE
|
| 2 |
+
OICE_NAME=af_nicole
|
| 3 |
+
SPEED=1.2
|
| 4 |
+
|
| 5 |
+
# LLM settings
|
| 6 |
+
LM_STUDIO_URL=http://localhost:1234/v1
|
| 7 |
+
OLLAMA_URL = http://localhost:11434/api/chat
|
| 8 |
+
DEFAULT_SYSTEM_PROMPT=You are a friendly, helpful, and intelligent assistant. Begin your responses with phrases like 'Umm,' 'So,' or similar. Focus on the user query and reply directly to the user in the first person ('I'), responding promptly and naturally. Do not include any additional information or context in your responses.
|
| 9 |
+
MAX_TOKENS=512
|
| 10 |
+
NUM_THREADS=2
|
| 11 |
+
LLM_TEMPERATURE=0.9
|
| 12 |
+
LLM_STREAM=true
|
| 13 |
+
LLM_RETRY_DELAY=0.5
|
| 14 |
+
MAX_RETRIES=3
|
| 15 |
+
|
| 16 |
+
# Model names
|
| 17 |
+
VAD_MODEL=pyannote/segmentation-3.0
|
| 18 |
+
WHISPER_MODEL=openai/whisper-tiny.en
|
| 19 |
+
LLM_MODEL=qwen2.5:0.5b-instruct-q8_0
|
| 20 |
+
TTS_MODEL=kokoro.pth
|
| 21 |
+
|
| 22 |
+
# VAD settings
|
| 23 |
+
VAD_MIN_DURATION_ON=0.1
|
| 24 |
+
VAD_MIN_DURATION_OFF=0.1
|
| 25 |
+
|
| 26 |
+
# Audio settings
|
| 27 |
+
CHUNK=256
|
| 28 |
+
FORMAT=pyaudio.paFloat32
|
| 29 |
+
CHANNELS=1
|
| 30 |
+
RATE=16000
|
| 31 |
+
OUTPUT_SAMPLE_RATE=24000
|
| 32 |
+
RECORD_DURATION=5
|
| 33 |
+
SILENCE_THRESHOLD=0.01
|
| 34 |
+
INTERRUPTION_THRESHOLD=0.01
|
| 35 |
+
MAX_SILENCE_DURATION=1
|
| 36 |
+
SPEECH_CHECK_TIMEOUT=0.1
|
| 37 |
+
SPEECH_CHECK_THRESHOLD=0.02
|
| 38 |
+
ROLLING_BUFFER_TIME=0.5
|
| 39 |
+
TARGET_SIZE = 25
|
| 40 |
+
PLAYBACK_DELAY = 0.001
|
| 41 |
+
FIRST_SENTENCE_SIZE = 2
|
.gitignore
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
output/
|
| 6 |
+
test/
|
| 7 |
+
test.py
|
| 8 |
+
data/logs/
|
| 9 |
+
examples/
|
| 10 |
+
generated_audio/
|
| 11 |
+
# C extensions
|
| 12 |
+
*.so
|
| 13 |
+
.vscode/
|
| 14 |
+
|
| 15 |
+
# Distribution / packaging
|
| 16 |
+
.Python
|
| 17 |
+
build/
|
| 18 |
+
develop-eggs/
|
| 19 |
+
dist/
|
| 20 |
+
downloads/
|
| 21 |
+
eggs/
|
| 22 |
+
.eggs/
|
| 23 |
+
lib/
|
| 24 |
+
lib64/
|
| 25 |
+
parts/
|
| 26 |
+
sdist/
|
| 27 |
+
var/
|
| 28 |
+
wheels/
|
| 29 |
+
share/python-wheels/
|
| 30 |
+
*.egg-info/
|
| 31 |
+
.installed.cfg
|
| 32 |
+
*.egg
|
| 33 |
+
MANIFEST
|
| 34 |
+
|
| 35 |
+
# PyInstaller
|
| 36 |
+
# Usually these files are written by a python script from a template
|
| 37 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 38 |
+
*.manifest
|
| 39 |
+
*.spec
|
| 40 |
+
|
| 41 |
+
# Installer logs
|
| 42 |
+
pip-log.txt
|
| 43 |
+
pip-delete-this-directory.txt
|
| 44 |
+
|
| 45 |
+
# Unit test / coverage reports
|
| 46 |
+
htmlcov/
|
| 47 |
+
.tox/
|
| 48 |
+
.nox/
|
| 49 |
+
.coverage
|
| 50 |
+
.coverage.*
|
| 51 |
+
.cache
|
| 52 |
+
nosetests.xml
|
| 53 |
+
coverage.xml
|
| 54 |
+
*.cover
|
| 55 |
+
*.py,cover
|
| 56 |
+
.hypothesis/
|
| 57 |
+
.pytest_cache/
|
| 58 |
+
cover/
|
| 59 |
+
|
| 60 |
+
# Translations
|
| 61 |
+
*.mo
|
| 62 |
+
*.pot
|
| 63 |
+
|
| 64 |
+
# Django stuff:
|
| 65 |
+
*.log
|
| 66 |
+
local_settings.py
|
| 67 |
+
db.sqlite3
|
| 68 |
+
db.sqlite3-journal
|
| 69 |
+
|
| 70 |
+
# Flask stuff:
|
| 71 |
+
instance/
|
| 72 |
+
.webassets-cache
|
| 73 |
+
|
| 74 |
+
# Scrapy stuff:
|
| 75 |
+
.scrapy
|
| 76 |
+
|
| 77 |
+
# Sphinx documentation
|
| 78 |
+
docs/_build/
|
| 79 |
+
|
| 80 |
+
# PyBuilder
|
| 81 |
+
.pybuilder/
|
| 82 |
+
target/
|
| 83 |
+
|
| 84 |
+
# Jupyter Notebook
|
| 85 |
+
.ipynb_checkpoints
|
| 86 |
+
|
| 87 |
+
# IPython
|
| 88 |
+
profile_default/
|
| 89 |
+
ipython_config.py
|
| 90 |
+
|
| 91 |
+
# pyenv
|
| 92 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 93 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 94 |
+
# .python-version
|
| 95 |
+
|
| 96 |
+
# pipenv
|
| 97 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 98 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 99 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 100 |
+
# install all needed dependencies.
|
| 101 |
+
#Pipfile.lock
|
| 102 |
+
|
| 103 |
+
# poetry
|
| 104 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 105 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 106 |
+
# commonly ignored for libraries.
|
| 107 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 108 |
+
#poetry.lock
|
| 109 |
+
|
| 110 |
+
# pdm
|
| 111 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 112 |
+
#pdm.lock
|
| 113 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 114 |
+
# in version control.
|
| 115 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 116 |
+
.pdm.toml
|
| 117 |
+
|
| 118 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 119 |
+
__pypackages__/
|
| 120 |
+
|
| 121 |
+
# Celery stuff
|
| 122 |
+
celerybeat-schedule
|
| 123 |
+
celerybeat.pid
|
| 124 |
+
|
| 125 |
+
# SageMath parsed files
|
| 126 |
+
*.sage.py
|
| 127 |
+
|
| 128 |
+
# Environments
|
| 129 |
+
.env
|
| 130 |
+
.venv
|
| 131 |
+
env/
|
| 132 |
+
venv/
|
| 133 |
+
ENV/
|
| 134 |
+
env.bak/
|
| 135 |
+
venv.bak/
|
| 136 |
+
|
| 137 |
+
# Spyder project settings
|
| 138 |
+
.spyderproject
|
| 139 |
+
.spyproject
|
| 140 |
+
|
| 141 |
+
# Rope project settings
|
| 142 |
+
.ropeproject
|
| 143 |
+
|
| 144 |
+
# mkdocs documentation
|
| 145 |
+
/site
|
| 146 |
+
|
| 147 |
+
# mypy
|
| 148 |
+
.mypy_cache/
|
| 149 |
+
.dmypy.json
|
| 150 |
+
dmypy.json
|
| 151 |
+
|
| 152 |
+
# Pyre type checker
|
| 153 |
+
.pyre/
|
| 154 |
+
|
| 155 |
+
# pytype static type analyzer
|
| 156 |
+
.pytype/
|
| 157 |
+
|
| 158 |
+
# Cython debug symbols
|
| 159 |
+
cython_debug/
|
| 160 |
+
|
| 161 |
+
# PyCharm
|
| 162 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 163 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 164 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 165 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 166 |
+
#.idea/
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2025 Abdullah Al Asif
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,3 +1,101 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# On Device Speech to Speech Conversational AI
|
| 2 |
+

|
| 3 |
+
|
| 4 |
+
This is realtime on-device speech-to-speech AI model. It used a series to tools to achieve that. It uses a combination of voice activity detection, speech recognition, language models, and text-to-speech synthesis to create a seamless and responsive conversational AI experience. The system is designed to run on-device, ensuring low latency and minimal data usage.
|
| 5 |
+
|
| 6 |
+
<h2 style="color: yellow;">HOW TO RUN IT</h2>
|
| 7 |
+
|
| 8 |
+
1. **Prerequisites:**
|
| 9 |
+
- Install Python 3.8+ (tested with 3.12)
|
| 10 |
+
- Install [eSpeak NG](https://github.com/espeak-ng/espeak-ng/releases/tag/1.52.0) (required for voice synthesis)
|
| 11 |
+
- Install Ollama from https://ollama.ai/
|
| 12 |
+
|
| 13 |
+
2. **Setup:**
|
| 14 |
+
- Clone the repository `git clone https://github.com/asiff00/On-Device-Speech-to-Speech-Conversational-AI.git`
|
| 15 |
+
- Run `git lfs pull` to download the models and voices
|
| 16 |
+
- Copy `.env.template` to `.env`
|
| 17 |
+
- Add your HuggingFace token to `.env`
|
| 18 |
+
- Twin other parameters there, if needed [Optional]
|
| 19 |
+
- Install requirements: `pip install -r requirements.txt`
|
| 20 |
+
- Add any missing packages if not already installed `pip install <package_name>`
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
4. **Run Ollama:**
|
| 24 |
+
- Start Ollama service
|
| 25 |
+
- Run: `ollama run qwen2.5:0.5b-instruct-q8_0` or any other model of your choice
|
| 26 |
+
|
| 27 |
+
5. **Start Application:**
|
| 28 |
+
- Run: `python speech_to_speech.py`
|
| 29 |
+
- Wait for initialization (models loading)
|
| 30 |
+
- Start talking when you see "Voice Chat Bot Ready"
|
| 31 |
+
- Long press `Ctrl+C` to stop the application
|
| 32 |
+
</details>
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
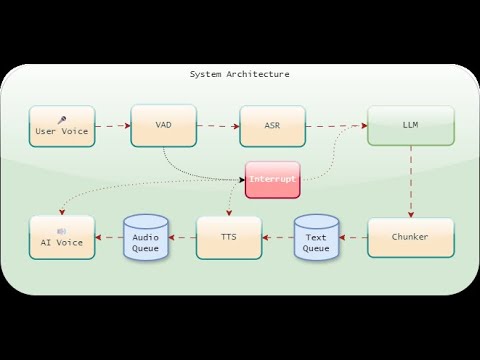
We basically put a few models together to work in a multi-threaded architecture, where each component operates independently but is integrated through a queue management system to ensure performance and responsiveness.
|
| 36 |
+
|
| 37 |
+
## The flow works as follows: Loop (VAD -> Whisper -> LM -> TextChunker -> TTS)
|
| 38 |
+
To achieve that we use:
|
| 39 |
+
- **Voice Activity Detection**: Pyannote:pyannote/segmentation-3.0
|
| 40 |
+
- **Speech Recognition**: Whisper:whisper-tiny.en (OpenAI)
|
| 41 |
+
- **Language Model**: LM Studio/Ollama with qwen2.5:0.5b-instruct-q8_0
|
| 42 |
+
- **Voice Synthesis**: Kokoro:hexgrad/Kokoro-82M (Version 0.19, 16bit)
|
| 43 |
+
|
| 44 |
+
We use custom text processing and queues to manage data, with separate queues for text and audio. This setup allows the system to handle heavy tasks without slowing down. We also use an interrupt mechanism allowing the user to interrupt the AI at any time. This makes the conversation feel more natural and responsive rather than just a generic TTS engine.
|
| 45 |
+
|
| 46 |
+
## Demo Video:
|
| 47 |
+
A demo video is uploaded here. Either click on the thumbnail or click on the YouTube link: [https://youtu.be/x92FLnwf-nA](https://youtu.be/x92FLnwf-nA).
|
| 48 |
+
|
| 49 |
+
[](https://youtu.be/x92FLnwf-nA)
|
| 50 |
+
|
| 51 |
+
## Performance:
|
| 52 |
+

|
| 53 |
+
|
| 54 |
+
I ran this test on an AMD Ryzen 5600G, 16 GB, SSD, and No-GPU setup, achieving consistent ~2s latency. On average, it takes around 1.5s for the system to respond to a user query from the point the user says the last word. Although I haven't tested this on a GPU, I believe testing on a GPU would significantly improve performance and responsiveness.
|
| 55 |
+
|
| 56 |
+
## How do we reduce latency?
|
| 57 |
+
### Priority based text chunking
|
| 58 |
+
We capitalize on the streaming output of the language model to reduce latency. Instead of waiting for the entire response to be generated, we process and deliver each chunk of text as soon as they become available, form phrases, and send it to the TTS engine queue. We play the audio as soon as it becomes available. This way, the user gets a very fast response, while the rest of the response is being generated.
|
| 59 |
+
|
| 60 |
+
Our custom `TextChunker` analyzes incoming text streams from the language model and splits them into chunks suitable for the voice synthesizer. It uses a combination of sentence breaks (like periods, question marks, and exclamation points) and semantic breaks (like "and", "but", and "however") to determine the best places to split the text, ensuring natural-sounding speech output.
|
| 61 |
+
|
| 62 |
+
The `TextChunker` maintains a set of break points:
|
| 63 |
+
- **Sentence breaks**: `.`, `!`, `?` (highest priority)
|
| 64 |
+
- **Semantic breaks** with priority levels:
|
| 65 |
+
- Level 4: `however`, `therefore`, `furthermore`, `moreover`, `nevertheless`
|
| 66 |
+
- Level 3: `while`, `although`, `unless`, `since`
|
| 67 |
+
- Level 2: `and`, `but`, `because`, `then`
|
| 68 |
+
- **Punctuation breaks**: `;` (4), `:` (4), `,` (3), `-` (2)
|
| 69 |
+
|
| 70 |
+
When processing text, the `TextChunker` uses a priority-based system:
|
| 71 |
+
1. Looks for sentence-ending punctuation first (highest priority 5)
|
| 72 |
+
2. Checks for semantic break words with their associated priority levels
|
| 73 |
+
3. Falls back to punctuation marks with lower priorities
|
| 74 |
+
4. Splits at target word count if no natural breaks are found
|
| 75 |
+
|
| 76 |
+
The text chunking method significantly reduces perceived latency by processing and delivering the first chunk of text as soon as it becomes available. Let's consider a hypothetical system where the language model generates responses at a certain rate. If we imagine a scenario where the model produces a response of N words at a rate of R words per second, waiting for the complete response would introduce a delay of N/R seconds before any audio is produced. With text chunking, the system can start processing the first M words as soon as they are ready (after M/R seconds), while the remaining words continue to be generated. This means the user hears the initial part of the response in just M/R seconds, while the rest streams in naturally.
|
| 77 |
+
|
| 78 |
+
### Leading filler word LLM Prompting
|
| 79 |
+
We use a another little trick in the LLM prompt to speed up the system’s first response. We ask the LLM to start its reply with filler words like “umm,” “so,” or “well.” These words have a special role in language: they create natural pauses and breaks. Since these are single-word responses, they take only milliseconds to convert to audio. When we apply our chunking rules, the system splits the response at the filler word (e.g., “umm,”) and sends that tiny chunk to the TTS engine. This lets the bot play the audio for “umm” almost instantly, reducing perceived latency. The filler words act as natural “bridges” to mask processing delays. Even a short “umm” gives the illusion of a fluid conversation, while the system works on generating the rest of the response in the background. Longer chunks after the filler word might take more time to process, but the initial pause feels intentional and human-like.
|
| 80 |
+
|
| 81 |
+
We have fallback plans for cases when the LLM fails to start its response with fillers. In those cases, we put hand breaks at 2 to 5 words, which comes with a cost of a bit of choppiness at the beginning but that feels less painful than the system taking a long time to give the first response.
|
| 82 |
+
|
| 83 |
+
**In practice,** this approach can reduce perceived latency by up to 50-70%, depending on the length of the response and the speed of the language model. For example, in a typical conversation where responses average 15-20 words, our techniques can bring the initial response time down from 1.5-2 seconds to just `0.5-0.7` seconds, making the interaction feel much more natural and immediate.
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
## Resources
|
| 88 |
+
This project utilizes the following resources:
|
| 89 |
+
* **Text-to-Speech Model:** [Kokoro](https://huggingface.co/hexgrad/Kokoro-82M)
|
| 90 |
+
* **Speech-to-Text Model:** [Whisper](https://huggingface.co/openai/whisper-tiny.en)
|
| 91 |
+
* **Voice Activity Detection Model:** [Pyannote](https://huggingface.co/pyannote/segmentation-3.0)
|
| 92 |
+
* **Large Language Model Server:** [Ollama](https://ollama.ai/)
|
| 93 |
+
* **Fallback Text-to-Speech Engine:** [eSpeak NG](https://github.com/espeak-ng/espeak-ng/releases/tag/1.52.0)
|
| 94 |
+
|
| 95 |
+
## Acknowledgements
|
| 96 |
+
This project draws inspiration and guidance from the following articles and repositories, among others:
|
| 97 |
+
* [Realtime speech to speech conversation with MiniCPM-o](https://github.com/OpenBMB/MiniCPM-o)
|
| 98 |
+
* [A Comparative Guide to OpenAI and Ollama APIs](https://medium.com/@zakkyang/a-comparative-guide-to-openai-and-ollama-apis-with-cheathsheet-5aae6e515953)
|
| 99 |
+
* [Building Production-Ready TTS with Kokoro-82M](https://medium.com/@simeon.emanuilov/kokoro-82m-building-production-ready-tts-with-82m-parameters-unfoldai-98e36ff286b9)
|
| 100 |
+
* [Kokoro-82M: The Best TTS Model in Just 82 Million Parameters](https://medium.com/data-science-in-your-pocket/kokoro-82m-the-best-tts-model-in-just-82-million-parameters-512b4ba4f94c)
|
| 101 |
+
* [StyleTTS2 Model Implementation](https://github.com/yl4579/StyleTTS2/blob/main/models.py)
|
assets/system_architecture.svg
ADDED

|
assets/timing_chart.png
ADDED

|
assets/video_demo.mov
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4aa16650f035a094e65d759ac07e9050ccf22204f77816776b957cea203caf9c
|
| 3 |
+
size 11758861
|
data/models/kokoro.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:70cbf37f84610967f2ca72dadb95456fdd8b6c72cdd6dc7372c50f525889ff0c
|
| 3 |
+
size 163731194
|
data/voices/af.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fad4192fd8a840f925b0e3fc2be54e20531f91a9ac816a485b7992ca0bd83ebf
|
| 3 |
+
size 524355
|
data/voices/af_alloy.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6d877149dd8b348fbad12e5845b7e43d975390e9f3b68a811d1d86168bef5aa3
|
| 3 |
+
size 523425
|
data/voices/af_aoede.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c03bd1a4c3716c2d8eaa3d50022f62d5c31cfbd6e15933a00b17fefe13841cc4
|
| 3 |
+
size 523425
|
data/voices/af_bella.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2828c6c2f94275ef3441a2edfcf48293298ee0f9b56ce70fb2e344345487b922
|
| 3 |
+
size 524449
|
data/voices/af_bella_nicole.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d41525cea0e607c8c775adad8a81faa015d5ddafcbc66d9454c5c6aaef12137a
|
| 3 |
+
size 524623
|
data/voices/af_heart.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0ab5709b8ffab19bfd849cd11d98f75b60af7733253ad0d67b12382a102cb4ff
|
| 3 |
+
size 523425
|
data/voices/af_jessica.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cdfdccb8cc975aa34ee6b89642963b0064237675de0e41a30ae64cc958dd4e87
|
| 3 |
+
size 523435
|
data/voices/af_kore.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8bfbc512321c3db49dff984ac675fa5ac7eaed5a96cc31104d3a9080e179d69d
|
| 3 |
+
size 523420
|
data/voices/af_nicole.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9401802fb0b7080c324dec1a75d60f31d977ced600a99160e095dbc5a1172692
|
| 3 |
+
size 524454
|
data/voices/af_nicole_sky.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:587f36a3a2d9f295cd5538a923747be2fe398bbd81598896bac07bbdb7ff25b0
|
| 3 |
+
size 524623
|
data/voices/af_nova.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0233676ddc21908c37a1f102f6b88a59e4e5c1bd764983616eb9eda629dbcd2
|
| 3 |
+
size 523420
|
data/voices/af_river.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e149459bd9c084416b74756b9bd3418256a8b839088abb07d463730c369dab8f
|
| 3 |
+
size 523425
|
data/voices/af_sarah.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ba7918c4ace6ace4221e7e01eb3a6d16596cba9729850551c758cd2ad3a4cd08
|
| 3 |
+
size 524449
|
data/voices/af_sarah_nicole.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fa529793c4853a4107bb9857023a0ceb542466c664340ba0aeeb7c8570b2c51c
|
| 3 |
+
size 524623
|
data/voices/af_sky.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9f16f1bb778de36a177ae4b0b6f1e59783d5f4d3bcecf752c3e1ee98299b335e
|
| 3 |
+
size 524375
|
data/voices/af_sky_adam.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2fa5978fab741ccd0d2a4992e34c85a7498f61062a665257a9d9b315dca327c3
|
| 3 |
+
size 524464
|
data/voices/af_sky_emma.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfb3af5b8a0cbdd07d76fd201b572437ba2b048c03b65f2535a1f2810d01a99f
|
| 3 |
+
size 524464
|
data/voices/af_sky_emma_isabella.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12852daf302220b828a49a1d9089def6ff2b81fdab0a9ee500c66b0f37a2052f
|
| 3 |
+
size 524509
|
data/voices/am_adam.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1921528b400a553f66528c27899d95780918fe33b1ac7e2a871f6a0de475f176
|
| 3 |
+
size 524444
|
data/voices/am_michael.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a255c9562c363103adc56c09b7daf837139d3bdaa8bd4dd74847ab1e3e8c28be
|
| 3 |
+
size 524459
|
data/voices/bf_alice.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d292651b6af6c0d81705c2580dcb4463fccc0ff7b8d618a471dbb4e45655b3f3
|
| 3 |
+
size 523425
|
data/voices/bf_emma.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:992e6d8491b8926ef4a16205250e51a21d9924405a5d37e2db6e94adfd965c3b
|
| 3 |
+
size 524365
|
data/voices/bf_isabella.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0865a03931230100167f7a81d394b143c072efe2d7e4c4a87b5c54d6283f580
|
| 3 |
+
size 524365
|
data/voices/bm_george.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7d763dfe13e934357f4d8322b718787d79e32f2181e29ca0cf6aa637d8092b96
|
| 3 |
+
size 524464
|
data/voices/bm_lewis.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f70d9ea4d65f522f224628f06d86ea74279faae23bd7e765848a374aba916b76
|
| 3 |
+
size 524449
|
data/voices/ef_dora.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d9d69b0f8a2b87a345f269d89639f89dfbd1a6c9da0c498ae36dd34afcf35530
|
| 3 |
+
size 523420
|
data/voices/if_sara.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c0b253b955fe32f1a1a86006aebe83d050ea95afd0e7be15182f087deedbf55
|
| 3 |
+
size 523425
|
data/voices/jf_alpha.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1bf4c9dc69e45ee46183b071f4db766349aac5592acbcfeaf051018048a5d787
|
| 3 |
+
size 523425
|
data/voices/jf_gongitsune.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b171917f18f351e65f2bf9657700cd6bfec4e65589c297525b9cf3c20105770
|
| 3 |
+
size 523351
|
data/voices/pf_dora.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:07e4ff987c5d5a8c3995efd15cc4f0db7c4c15e881b198d8ab7f67ecf51f5eb7
|
| 3 |
+
size 523425
|
data/voices/zf_xiaoxiao.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfaf6f2ded1ee56f1ff94fcd2b0e6cdf32e5b794bdc05b44e7439d44aef5887c
|
| 3 |
+
size 523440
|
data/voices/zf_xiaoyi.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b5235dbaeef85a4c613bf78af9a88ff63c25bac5f26ba77e36186d8b7ebf05e2
|
| 3 |
+
size 523430
|
requirements.txt
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
phonemizer
|
| 2 |
+
torch
|
| 3 |
+
transformers
|
| 4 |
+
scipy
|
| 5 |
+
munch
|
| 6 |
+
sounddevice
|
| 7 |
+
python-multipart
|
| 8 |
+
soundfile
|
| 9 |
+
pydantic
|
| 10 |
+
requests
|
| 11 |
+
python-dotenv
|
| 12 |
+
numpy
|
| 13 |
+
pyaudio
|
| 14 |
+
pyannote.audio
|
| 15 |
+
torch_audiomentations
|
| 16 |
+
pydantic_settings
|
speech_to_speech.py
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import msvcrt
|
| 2 |
+
import traceback
|
| 3 |
+
import time
|
| 4 |
+
import requests
|
| 5 |
+
import time
|
| 6 |
+
from transformers import WhisperProcessor, WhisperForConditionalGeneration
|
| 7 |
+
from src.utils.config import settings
|
| 8 |
+
from src.utils import (
|
| 9 |
+
VoiceGenerator,
|
| 10 |
+
get_ai_response,
|
| 11 |
+
play_audio_with_interrupt,
|
| 12 |
+
init_vad_pipeline,
|
| 13 |
+
detect_speech_segments,
|
| 14 |
+
record_continuous_audio,
|
| 15 |
+
check_for_speech,
|
| 16 |
+
transcribe_audio,
|
| 17 |
+
)
|
| 18 |
+
from src.utils.audio_queue import AudioGenerationQueue
|
| 19 |
+
from src.utils.llm import parse_stream_chunk
|
| 20 |
+
import threading
|
| 21 |
+
from src.utils.text_chunker import TextChunker
|
| 22 |
+
|
| 23 |
+
settings.setup_directories()
|
| 24 |
+
timing_info = {
|
| 25 |
+
"vad_start": None,
|
| 26 |
+
"transcription_start": None,
|
| 27 |
+
"llm_first_token": None,
|
| 28 |
+
"audio_queued": None,
|
| 29 |
+
"first_audio_play": None,
|
| 30 |
+
"playback_start": None,
|
| 31 |
+
"end": None,
|
| 32 |
+
"transcription_duration": None,
|
| 33 |
+
}
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def process_input(
|
| 37 |
+
session: requests.Session,
|
| 38 |
+
user_input: str,
|
| 39 |
+
messages: list,
|
| 40 |
+
generator: VoiceGenerator,
|
| 41 |
+
speed: float,
|
| 42 |
+
) -> tuple[bool, None]:
|
| 43 |
+
"""Processes user input, generates a response, and handles audio output.
|
| 44 |
+
|
| 45 |
+
Args:
|
| 46 |
+
session (requests.Session): The requests session to use.
|
| 47 |
+
user_input (str): The user's input text.
|
| 48 |
+
messages (list): The list of messages to send to the LLM.
|
| 49 |
+
generator (VoiceGenerator): The voice generator object.
|
| 50 |
+
speed (float): The playback speed.
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
tuple[bool, None]: A tuple containing a boolean indicating if the process was interrupted and None.
|
| 54 |
+
"""
|
| 55 |
+
global timing_info
|
| 56 |
+
timing_info = {k: None for k in timing_info}
|
| 57 |
+
timing_info["vad_start"] = time.perf_counter()
|
| 58 |
+
|
| 59 |
+
messages.append({"role": "user", "content": user_input})
|
| 60 |
+
print("\nThinking...")
|
| 61 |
+
start_time = time.time()
|
| 62 |
+
try:
|
| 63 |
+
response_stream = get_ai_response(
|
| 64 |
+
session=session,
|
| 65 |
+
messages=messages,
|
| 66 |
+
llm_model=settings.LLM_MODEL,
|
| 67 |
+
llm_url=settings.OLLAMA_URL,
|
| 68 |
+
max_tokens=settings.MAX_TOKENS,
|
| 69 |
+
stream=True,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
if not response_stream:
|
| 73 |
+
print("Failed to get AI response stream.")
|
| 74 |
+
return False, None
|
| 75 |
+
|
| 76 |
+
audio_queue = AudioGenerationQueue(generator, speed)
|
| 77 |
+
audio_queue.start()
|
| 78 |
+
chunker = TextChunker()
|
| 79 |
+
complete_response = []
|
| 80 |
+
|
| 81 |
+
playback_thread = threading.Thread(
|
| 82 |
+
target=lambda: audio_playback_worker(audio_queue)
|
| 83 |
+
)
|
| 84 |
+
playback_thread.daemon = True
|
| 85 |
+
playback_thread.start()
|
| 86 |
+
|
| 87 |
+
for chunk in response_stream:
|
| 88 |
+
data = parse_stream_chunk(chunk)
|
| 89 |
+
if not data or "choices" not in data:
|
| 90 |
+
continue
|
| 91 |
+
|
| 92 |
+
choice = data["choices"][0]
|
| 93 |
+
if "delta" in choice and "content" in choice["delta"]:
|
| 94 |
+
content = choice["delta"]["content"]
|
| 95 |
+
if content:
|
| 96 |
+
if not timing_info["llm_first_token"]:
|
| 97 |
+
timing_info["llm_first_token"] = time.perf_counter()
|
| 98 |
+
print(content, end="", flush=True)
|
| 99 |
+
chunker.current_text.append(content)
|
| 100 |
+
|
| 101 |
+
text = "".join(chunker.current_text)
|
| 102 |
+
if chunker.should_process(text):
|
| 103 |
+
if not timing_info["audio_queued"]:
|
| 104 |
+
timing_info["audio_queued"] = time.perf_counter()
|
| 105 |
+
remaining = chunker.process(text, audio_queue)
|
| 106 |
+
chunker.current_text = [remaining]
|
| 107 |
+
complete_response.append(text[: len(text) - len(remaining)])
|
| 108 |
+
|
| 109 |
+
if choice.get("finish_reason") == "stop":
|
| 110 |
+
final_text = "".join(chunker.current_text).strip()
|
| 111 |
+
if final_text:
|
| 112 |
+
chunker.process(final_text, audio_queue)
|
| 113 |
+
complete_response.append(final_text)
|
| 114 |
+
break
|
| 115 |
+
|
| 116 |
+
messages.append({"role": "assistant", "content": " ".join(complete_response)})
|
| 117 |
+
print()
|
| 118 |
+
|
| 119 |
+
time.sleep(0.1)
|
| 120 |
+
audio_queue.stop()
|
| 121 |
+
playback_thread.join()
|
| 122 |
+
|
| 123 |
+
def playback_wrapper():
|
| 124 |
+
timing_info["playback_start"] = time.perf_counter()
|
| 125 |
+
result = audio_playback_worker(audio_queue)
|
| 126 |
+
return result
|
| 127 |
+
|
| 128 |
+
playback_thread = threading.Thread(target=playback_wrapper)
|
| 129 |
+
|
| 130 |
+
timing_info["end"] = time.perf_counter()
|
| 131 |
+
print_timing_chart(timing_info)
|
| 132 |
+
return False, None
|
| 133 |
+
|
| 134 |
+
except Exception as e:
|
| 135 |
+
print(f"\nError during streaming: {str(e)}")
|
| 136 |
+
if "audio_queue" in locals():
|
| 137 |
+
audio_queue.stop()
|
| 138 |
+
return False, None
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def audio_playback_worker(audio_queue) -> tuple[bool, None]:
|
| 142 |
+
"""Manages audio playback in a separate thread, handling interruptions.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
audio_queue (AudioGenerationQueue): The audio queue object.
|
| 146 |
+
|
| 147 |
+
Returns:
|
| 148 |
+
tuple[bool, None]: A tuple containing a boolean indicating if the playback was interrupted and the interrupt audio data.
|
| 149 |
+
"""
|
| 150 |
+
global timing_info
|
| 151 |
+
was_interrupted = False
|
| 152 |
+
interrupt_audio = None
|
| 153 |
+
|
| 154 |
+
try:
|
| 155 |
+
while True:
|
| 156 |
+
speech_detected, audio_data = check_for_speech()
|
| 157 |
+
if speech_detected:
|
| 158 |
+
was_interrupted = True
|
| 159 |
+
interrupt_audio = audio_data
|
| 160 |
+
break
|
| 161 |
+
|
| 162 |
+
audio_data, _ = audio_queue.get_next_audio()
|
| 163 |
+
if audio_data is not None:
|
| 164 |
+
if not timing_info["first_audio_play"]:
|
| 165 |
+
timing_info["first_audio_play"] = time.perf_counter()
|
| 166 |
+
|
| 167 |
+
was_interrupted, interrupt_data = play_audio_with_interrupt(audio_data)
|
| 168 |
+
if was_interrupted:
|
| 169 |
+
interrupt_audio = interrupt_data
|
| 170 |
+
break
|
| 171 |
+
else:
|
| 172 |
+
time.sleep(settings.PLAYBACK_DELAY)
|
| 173 |
+
|
| 174 |
+
if (
|
| 175 |
+
not audio_queue.is_running
|
| 176 |
+
and audio_queue.sentence_queue.empty()
|
| 177 |
+
and audio_queue.audio_queue.empty()
|
| 178 |
+
):
|
| 179 |
+
break
|
| 180 |
+
|
| 181 |
+
except Exception as e:
|
| 182 |
+
print(f"Error in audio playback: {str(e)}")
|
| 183 |
+
|
| 184 |
+
return was_interrupted, interrupt_audio
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def main():
|
| 188 |
+
"""Main function to run the voice chat bot."""
|
| 189 |
+
with requests.Session() as session:
|
| 190 |
+
try:
|
| 191 |
+
session = requests.Session()
|
| 192 |
+
generator = VoiceGenerator(settings.MODELS_DIR, settings.VOICES_DIR)
|
| 193 |
+
messages = [{"role": "system", "content": settings.DEFAULT_SYSTEM_PROMPT}]
|
| 194 |
+
print("\nInitializing Whisper model...")
|
| 195 |
+
whisper_processor = WhisperProcessor.from_pretrained(settings.WHISPER_MODEL)
|
| 196 |
+
whisper_model = WhisperForConditionalGeneration.from_pretrained(
|
| 197 |
+
settings.WHISPER_MODEL
|
| 198 |
+
)
|
| 199 |
+
print("\nInitializing Voice Activity Detection...")
|
| 200 |
+
vad_pipeline = init_vad_pipeline(settings.HUGGINGFACE_TOKEN)
|
| 201 |
+
print("\n=== Voice Chat Bot Initializing ===")
|
| 202 |
+
print("Device being used:", generator.device)
|
| 203 |
+
print("\nInitializing voice generator...")
|
| 204 |
+
result = generator.initialize(settings.TTS_MODEL, settings.VOICE_NAME)
|
| 205 |
+
print(result)
|
| 206 |
+
speed = settings.SPEED
|
| 207 |
+
try:
|
| 208 |
+
print("\nWarming up the LLM model...")
|
| 209 |
+
health = session.get("http://localhost:11434", timeout=3)
|
| 210 |
+
if health.status_code != 200:
|
| 211 |
+
print("Ollama not running! Start it first.")
|
| 212 |
+
return
|
| 213 |
+
response_stream = get_ai_response(
|
| 214 |
+
session=session,
|
| 215 |
+
messages=[
|
| 216 |
+
{"role": "system", "content": settings.DEFAULT_SYSTEM_PROMPT},
|
| 217 |
+
{"role": "user", "content": "Hi!"},
|
| 218 |
+
],
|
| 219 |
+
llm_model=settings.LLM_MODEL,
|
| 220 |
+
llm_url=settings.OLLAMA_URL,
|
| 221 |
+
max_tokens=settings.MAX_TOKENS,
|
| 222 |
+
stream=False,
|
| 223 |
+
)
|
| 224 |
+
if not response_stream:
|
| 225 |
+
print("Failed to initialized the AI model!")
|
| 226 |
+
return
|
| 227 |
+
except requests.RequestException as e:
|
| 228 |
+
print(f"Warmup failed: {str(e)}")
|
| 229 |
+
|
| 230 |
+
print("\n\n=== Voice Chat Bot Ready ===")
|
| 231 |
+
print("The bot is now listening for speech.")
|
| 232 |
+
print("Just start speaking, and I'll respond automatically!")
|
| 233 |
+
print("You can interrupt me anytime by starting to speak.")
|
| 234 |
+
while True:
|
| 235 |
+
try:
|
| 236 |
+
if msvcrt.kbhit():
|
| 237 |
+
user_input = input("\nYou (text): ").strip()
|
| 238 |
+
|
| 239 |
+
if user_input.lower() == "quit":
|
| 240 |
+
print("Goodbye!")
|
| 241 |
+
break
|
| 242 |
+
|
| 243 |
+
audio_data = record_continuous_audio()
|
| 244 |
+
if audio_data is not None:
|
| 245 |
+
speech_segments = detect_speech_segments(
|
| 246 |
+
vad_pipeline, audio_data
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
if speech_segments is not None:
|
| 250 |
+
print("\nTranscribing detected speech...")
|
| 251 |
+
timing_info["transcription_start"] = time.perf_counter()
|
| 252 |
+
|
| 253 |
+
user_input = transcribe_audio(
|
| 254 |
+
whisper_processor, whisper_model, speech_segments
|
| 255 |
+
)
|
| 256 |
+
|
| 257 |
+
timing_info["transcription_duration"] = (
|
| 258 |
+
time.perf_counter() - timing_info["transcription_start"]
|
| 259 |
+
)
|
| 260 |
+
if user_input.strip():
|
| 261 |
+
print(f"You (voice): {user_input}")
|
| 262 |
+
was_interrupted, speech_data = process_input(
|
| 263 |
+
session, user_input, messages, generator, speed
|
| 264 |
+
)
|
| 265 |
+
if was_interrupted and speech_data is not None:
|
| 266 |
+
speech_segments = detect_speech_segments(
|
| 267 |
+
vad_pipeline, speech_data
|
| 268 |
+
)
|
| 269 |
+
if speech_segments is not None:
|
| 270 |
+
print("\nTranscribing interrupted speech...")
|
| 271 |
+
user_input = transcribe_audio(
|
| 272 |
+
whisper_processor,
|
| 273 |
+
whisper_model,
|
| 274 |
+
speech_segments,
|
| 275 |
+
)
|
| 276 |
+
if user_input.strip():
|
| 277 |
+
print(f"You (voice): {user_input}")
|
| 278 |
+
process_input(
|
| 279 |
+
session,
|
| 280 |
+
user_input,
|
| 281 |
+
messages,
|
| 282 |
+
generator,
|
| 283 |
+
speed,
|
| 284 |
+
)
|
| 285 |
+
else:
|
| 286 |
+
print("No clear speech detected, please try again.")
|
| 287 |
+
if session is not None:
|
| 288 |
+
session.headers.update({"Connection": "keep-alive"})
|
| 289 |
+
if hasattr(session, "connection_pool"):
|
| 290 |
+
session.connection_pool.clear()
|
| 291 |
+
|
| 292 |
+
except KeyboardInterrupt:
|
| 293 |
+
print("\nStopping...")
|
| 294 |
+
break
|
| 295 |
+
except Exception as e:
|
| 296 |
+
print(f"Error: {str(e)}")
|
| 297 |
+
continue
|
| 298 |
+
|
| 299 |
+
except Exception as e:
|
| 300 |
+
print(f"Error: {str(e)}")
|
| 301 |
+
print("\nFull traceback:")
|
| 302 |
+
traceback.print_exc()
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
def print_timing_chart(metrics):
|
| 306 |
+
"""Prints timing chart from global metrics"""
|
| 307 |
+
base_time = metrics["vad_start"]
|
| 308 |
+
events = [
|
| 309 |
+
("User stopped speaking", metrics["vad_start"]),
|
| 310 |
+
("VAD started", metrics["vad_start"]),
|
| 311 |
+
("Transcription started", metrics["transcription_start"]),
|
| 312 |
+
("LLM first token", metrics["llm_first_token"]),
|
| 313 |
+
("Audio queued", metrics["audio_queued"]),
|
| 314 |
+
("First audio played", metrics["first_audio_play"]),
|
| 315 |
+
("Playback started", metrics["playback_start"]),
|
| 316 |
+
("End-to-end response", metrics["end"]),
|
| 317 |
+
]
|
| 318 |
+
|
| 319 |
+
print("\nTiming Chart:")
|
| 320 |
+
print(f"{'Event':<25} | {'Time (s)':>9} | {'Δ+':>6}")
|
| 321 |
+
print("-" * 45)
|
| 322 |
+
|
| 323 |
+
prev_time = base_time
|
| 324 |
+
for name, t in events:
|
| 325 |
+
if t is None:
|
| 326 |
+
continue
|
| 327 |
+
elapsed = t - base_time
|
| 328 |
+
delta = t - prev_time
|
| 329 |
+
print(f"{name:<25} | {elapsed:9.2f} | {delta:6.2f}")
|
| 330 |
+
prev_time = t
|
| 331 |
+
|
| 332 |
+
|
| 333 |
+
if __name__ == "__main__":
|
| 334 |
+
main()
|
src/config/config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"decoder": {
|
| 3 |
+
"type": "istftnet",
|
| 4 |
+
"upsample_kernel_sizes": [20, 12],
|
| 5 |
+
"upsample_rates": [10, 6],
|
| 6 |
+
"gen_istft_hop_size": 5,
|
| 7 |
+
"gen_istft_n_fft": 20,
|
| 8 |
+
"resblock_dilation_sizes": [
|
| 9 |
+
[1, 3, 5],
|
| 10 |
+
[1, 3, 5],
|
| 11 |
+
[1, 3, 5]
|
| 12 |
+
],
|
| 13 |
+
"resblock_kernel_sizes": [3, 7, 11],
|
| 14 |
+
"upsample_initial_channel": 512
|
| 15 |
+
},
|
| 16 |
+
"dim_in": 64,
|
| 17 |
+
"dropout": 0.2,
|
| 18 |
+
"hidden_dim": 512,
|
| 19 |
+
"max_conv_dim": 512,
|
| 20 |
+
"max_dur": 50,
|
| 21 |
+
"multispeaker": true,
|
| 22 |
+
"n_layer": 3,
|
| 23 |
+
"n_mels": 80,
|
| 24 |
+
"n_token": 178,
|
| 25 |
+
"style_dim": 128
|
| 26 |
+
}
|
src/core/kokoro.py
ADDED
|
@@ -0,0 +1,156 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import phonemizer
|
| 2 |
+
import os
|
| 3 |
+
import re
|
| 4 |
+
import torch
|
| 5 |
+
from dotenv import load_dotenv
|
| 6 |
+
load_dotenv()
|
| 7 |
+
|
| 8 |
+
"""Initialize eSpeak environment variables. Must be called before any other imports."""
|
| 9 |
+
os.environ["PHONEMIZER_ESPEAK_LIBRARY"] = r"C:\Program Files\eSpeak NG\libespeak-ng.dll"
|
| 10 |
+
os.environ["PHONEMIZER_ESPEAK_PATH"] = r"C:\Program Files\eSpeak NG\espeak-ng.exe"
|
| 11 |
+
|
| 12 |
+
def split_num(num):
|
| 13 |
+
num = num.group()
|
| 14 |
+
if '.' in num:
|
| 15 |
+
return num
|
| 16 |
+
elif ':' in num:
|
| 17 |
+
h, m = [int(n) for n in num.split(':')]
|
| 18 |
+
if m == 0:
|
| 19 |
+
return f"{h} o'clock"
|
| 20 |
+
elif m < 10:
|
| 21 |
+
return f'{h} oh {m}'
|
| 22 |
+
return f'{h} {m}'
|
| 23 |
+
year = int(num[:4])
|
| 24 |
+
if year < 1100 or year % 1000 < 10:
|
| 25 |
+
return num
|
| 26 |
+
left, right = num[:2], int(num[2:4])
|
| 27 |
+
s = 's' if num.endswith('s') else ''
|
| 28 |
+
if 100 <= year % 1000 <= 999:
|
| 29 |
+
if right == 0:
|
| 30 |
+
return f'{left} hundred{s}'
|
| 31 |
+
elif right < 10:
|
| 32 |
+
return f'{left} oh {right}{s}'
|
| 33 |
+
return f'{left} {right}{s}'
|
| 34 |
+
|
| 35 |
+
def flip_money(m):
|
| 36 |
+
m = m.group()
|
| 37 |
+
bill = 'dollar' if m[0] == '$' else 'pound'
|
| 38 |
+
if m[-1].isalpha():
|
| 39 |
+
return f'{m[1:]} {bill}s'
|
| 40 |
+
elif '.' not in m:
|
| 41 |
+
s = '' if m[1:] == '1' else 's'
|
| 42 |
+
return f'{m[1:]} {bill}{s}'
|
| 43 |
+
b, c = m[1:].split('.')
|
| 44 |
+
s = '' if b == '1' else 's'
|
| 45 |
+
c = int(c.ljust(2, '0'))
|
| 46 |
+
coins = f"cent{'' if c == 1 else 's'}" if m[0] == '$' else ('penny' if c == 1 else 'pence')
|
| 47 |
+
return f'{b} {bill}{s} and {c} {coins}'
|
| 48 |
+
|
| 49 |
+
def point_num(num):
|
| 50 |
+
a, b = num.group().split('.')
|
| 51 |
+
return ' point '.join([a, ' '.join(b)])
|
| 52 |
+
|
| 53 |
+
def normalize_text(text):
|
| 54 |
+
text = text.replace(chr(8216), "'").replace(chr(8217), "'")
|
| 55 |
+
text = text.replace('«', chr(8220)).replace('»', chr(8221))
|
| 56 |
+
text = text.replace(chr(8220), '"').replace(chr(8221), '"')
|
| 57 |
+
text = text.replace('(', '«').replace(')', '»')
|
| 58 |
+
for a, b in zip('、。!,:;?', ',.!,:;?'):
|
| 59 |
+
text = text.replace(a, b+' ')
|
| 60 |
+
text = re.sub(r'[^\S \n]', ' ', text)
|
| 61 |
+
text = re.sub(r' +', ' ', text)
|
| 62 |
+
text = re.sub(r'(?<=\n) +(?=\n)', '', text)
|
| 63 |
+
text = re.sub(r'\bD[Rr]\.(?= [A-Z])', 'Doctor', text)
|
| 64 |
+
text = re.sub(r'\b(?:Mr\.|MR\.(?= [A-Z]))', 'Mister', text)
|
| 65 |
+
text = re.sub(r'\b(?:Ms\.|MS\.(?= [A-Z]))', 'Miss', text)
|
| 66 |
+
text = re.sub(r'\b(?:Mrs\.|MRS\.(?= [A-Z]))', 'Mrs', text)
|
| 67 |
+
text = re.sub(r'\betc\.(?! [A-Z])', 'etc', text)
|
| 68 |
+
text = re.sub(r'(?i)\b(y)eah?\b', r"\1e'a", text)
|
| 69 |
+
text = re.sub(r'\d*\.\d+|\b\d{4}s?\b|(?<!:)\b(?:[1-9]|1[0-2]):[0-5]\d\b(?!:)', split_num, text)
|
| 70 |
+
text = re.sub(r'(?<=\d),(?=\d)', '', text)
|
| 71 |
+
text = re.sub(r'(?i)[$£]\d+(?:\.\d+)?(?: hundred| thousand| (?:[bm]|tr)illion)*\b|[$£]\d+\.\d\d?\b', flip_money, text)
|
| 72 |
+
text = re.sub(r'\d*\.\d+', point_num, text)
|
| 73 |
+
text = re.sub(r'(?<=\d)-(?=\d)', ' to ', text)
|
| 74 |
+
text = re.sub(r'(?<=\d)S', ' S', text)
|
| 75 |
+
text = re.sub(r"(?<=[BCDFGHJ-NP-TV-Z])'?s\b", "'S", text)
|
| 76 |
+
text = re.sub(r"(?<=X')S\b", 's', text)
|
| 77 |
+
text = re.sub(r'(?:[A-Za-z]\.){2,} [a-z]', lambda m: m.group().replace('.', '-'), text)
|
| 78 |
+
text = re.sub(r'(?i)(?<=[A-Z])\.(?=[A-Z])', '-', text)
|
| 79 |
+
return text.strip()
|
| 80 |
+
|
| 81 |
+
def get_vocab():
|
| 82 |
+
_pad = "$"
|
| 83 |
+
_punctuation = ';:,.!?¡¿—…"«»“” '
|
| 84 |
+
_letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
|
| 85 |
+
_letters_ipa = "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ"
|
| 86 |
+
symbols = [_pad] + list(_punctuation) + list(_letters) + list(_letters_ipa)
|
| 87 |
+
dicts = {}
|
| 88 |
+
for i in range(len((symbols))):
|
| 89 |
+
dicts[symbols[i]] = i
|
| 90 |
+
return dicts
|
| 91 |
+
|
| 92 |
+
VOCAB = get_vocab()
|
| 93 |
+
def tokenize(ps):
|
| 94 |
+
return [i for i in map(VOCAB.get, ps) if i is not None]
|
| 95 |
+
|
| 96 |
+
phonemizers = dict(
|
| 97 |
+
a=phonemizer.backend.EspeakBackend(language='en-us', preserve_punctuation=True, with_stress=True),
|
| 98 |
+
b=phonemizer.backend.EspeakBackend(language='en-gb', preserve_punctuation=True, with_stress=True),
|
| 99 |
+
)
|
| 100 |
+
def phonemize(text, lang, norm=True):
|
| 101 |
+
if norm:
|
| 102 |
+
text = normalize_text(text)
|
| 103 |
+
ps = phonemizers[lang].phonemize([text])
|
| 104 |
+
ps = ps[0] if ps else ''
|
| 105 |
+
# https://en.wiktionary.org/wiki/kokoro#English
|
| 106 |
+
ps = ps.replace('kəkˈoːɹoʊ', 'kˈoʊkəɹoʊ').replace('kəkˈɔːɹəʊ', 'kˈəʊkəɹəʊ')
|
| 107 |
+
ps = ps.replace('ʲ', 'j').replace('r', 'ɹ').replace('x', 'k').replace('ɬ', 'l')
|
| 108 |
+
ps = re.sub(r'(?<=[a-zɹː])(?=hˈʌndɹɪd)', ' ', ps)
|
| 109 |
+
ps = re.sub(r' z(?=[;:,.!?¡¿—…"«»“” ]|$)', 'z', ps)
|
| 110 |
+
if lang == 'a':
|
| 111 |
+
ps = re.sub(r'(?<=nˈaɪn)ti(?!ː)', 'di', ps)
|
| 112 |
+
ps = ''.join(filter(lambda p: p in VOCAB, ps))
|
| 113 |
+
return ps.strip()
|
| 114 |
+
|
| 115 |
+
def length_to_mask(lengths):
|
| 116 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 117 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 118 |
+
return mask
|
| 119 |
+
|
| 120 |
+
@torch.no_grad()
|
| 121 |
+
def forward(model, tokens, ref_s, speed):
|
| 122 |
+
device = ref_s.device
|
| 123 |
+
tokens = torch.LongTensor([[0, *tokens, 0]]).to(device)
|
| 124 |
+
input_lengths = torch.LongTensor([tokens.shape[-1]]).to(device)
|
| 125 |
+
text_mask = length_to_mask(input_lengths).to(device)
|
| 126 |
+
bert_dur = model.bert(tokens, attention_mask=(~text_mask).int())
|
| 127 |
+
d_en = model.bert_encoder(bert_dur).transpose(-1, -2)
|
| 128 |
+
s = ref_s[:, 128:]
|
| 129 |
+
d = model.predictor.text_encoder(d_en, s, input_lengths, text_mask)
|
| 130 |
+
x, _ = model.predictor.lstm(d)
|
| 131 |
+
duration = model.predictor.duration_proj(x)
|
| 132 |
+
duration = torch.sigmoid(duration).sum(axis=-1) / speed
|
| 133 |
+
pred_dur = torch.round(duration).clamp(min=1).long()
|
| 134 |
+
pred_aln_trg = torch.zeros(input_lengths, pred_dur.sum().item())
|
| 135 |
+
c_frame = 0
|
| 136 |
+
for i in range(pred_aln_trg.size(0)):
|
| 137 |
+
pred_aln_trg[i, c_frame:c_frame + pred_dur[0,i].item()] = 1
|
| 138 |
+
c_frame += pred_dur[0,i].item()
|
| 139 |
+
en = d.transpose(-1, -2) @ pred_aln_trg.unsqueeze(0).to(device)
|
| 140 |
+
F0_pred, N_pred = model.predictor.F0Ntrain(en, s)
|
| 141 |
+
t_en = model.text_encoder(tokens, input_lengths, text_mask)
|
| 142 |
+
asr = t_en @ pred_aln_trg.unsqueeze(0).to(device)
|
| 143 |
+
return model.decoder(asr, F0_pred, N_pred, ref_s[:, :128]).squeeze().cpu().numpy()
|
| 144 |
+
|
| 145 |
+
def generate(model, text, voicepack, lang='a', speed=1, ps=None):
|
| 146 |
+
ps = ps or phonemize(text, lang)
|
| 147 |
+
tokens = tokenize(ps)
|
| 148 |
+
if not tokens:
|
| 149 |
+
return None
|
| 150 |
+
elif len(tokens) > 510:
|
| 151 |
+
tokens = tokens[:510]
|
| 152 |
+
print('Truncated to 510 tokens')
|
| 153 |
+
ref_s = voicepack[len(tokens)]
|
| 154 |
+
out = forward(model, tokens, ref_s, speed)
|
| 155 |
+
ps = ''.join(next(k for k, v in VOCAB.items() if i == v) for i in tokens)
|
| 156 |
+
return out, ps
|
src/models/istftnet.py
ADDED
|
@@ -0,0 +1,523 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Modules/istftnet.py
|
| 2 |
+
from scipy.signal import get_window
|
| 3 |
+
from torch.nn import Conv1d, ConvTranspose1d
|
| 4 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
import torch.nn.functional as F
|
| 9 |
+
|
| 10 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Modules/utils.py
|
| 11 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 12 |
+
classname = m.__class__.__name__
|
| 13 |
+
if classname.find("Conv") != -1:
|
| 14 |
+
m.weight.data.normal_(mean, std)
|
| 15 |
+
|
| 16 |
+
def get_padding(kernel_size, dilation=1):
|
| 17 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 18 |
+
|
| 19 |
+
LRELU_SLOPE = 0.1
|
| 20 |
+
|
| 21 |
+
class AdaIN1d(nn.Module):
|
| 22 |
+
def __init__(self, style_dim, num_features):
|
| 23 |
+
super().__init__()
|
| 24 |
+
self.norm = nn.InstanceNorm1d(num_features, affine=False)
|
| 25 |
+
self.fc = nn.Linear(style_dim, num_features*2)
|
| 26 |
+
|
| 27 |
+
def forward(self, x, s):
|
| 28 |
+
h = self.fc(s)
|
| 29 |
+
h = h.view(h.size(0), h.size(1), 1)
|
| 30 |
+
gamma, beta = torch.chunk(h, chunks=2, dim=1)
|
| 31 |
+
return (1 + gamma) * self.norm(x) + beta
|
| 32 |
+
|
| 33 |
+
class AdaINResBlock1(torch.nn.Module):
|
| 34 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5), style_dim=64):
|
| 35 |
+
super(AdaINResBlock1, self).__init__()
|
| 36 |
+
self.convs1 = nn.ModuleList([
|
| 37 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 38 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 39 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 40 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 41 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 42 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 43 |
+
])
|
| 44 |
+
self.convs1.apply(init_weights)
|
| 45 |
+
|
| 46 |
+
self.convs2 = nn.ModuleList([
|
| 47 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 48 |
+
padding=get_padding(kernel_size, 1))),
|
| 49 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 50 |
+
padding=get_padding(kernel_size, 1))),
|
| 51 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 52 |
+
padding=get_padding(kernel_size, 1)))
|
| 53 |
+
])
|
| 54 |
+
self.convs2.apply(init_weights)
|
| 55 |
+
|
| 56 |
+
self.adain1 = nn.ModuleList([
|
| 57 |
+
AdaIN1d(style_dim, channels),
|
| 58 |
+
AdaIN1d(style_dim, channels),
|
| 59 |
+
AdaIN1d(style_dim, channels),
|
| 60 |
+
])
|
| 61 |
+
|
| 62 |
+
self.adain2 = nn.ModuleList([
|
| 63 |
+
AdaIN1d(style_dim, channels),
|
| 64 |
+
AdaIN1d(style_dim, channels),
|
| 65 |
+
AdaIN1d(style_dim, channels),
|
| 66 |
+
])
|
| 67 |
+
|
| 68 |
+
self.alpha1 = nn.ParameterList([nn.Parameter(torch.ones(1, channels, 1)) for i in range(len(self.convs1))])
|
| 69 |
+
self.alpha2 = nn.ParameterList([nn.Parameter(torch.ones(1, channels, 1)) for i in range(len(self.convs2))])
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def forward(self, x, s):
|
| 73 |
+
for c1, c2, n1, n2, a1, a2 in zip(self.convs1, self.convs2, self.adain1, self.adain2, self.alpha1, self.alpha2):
|
| 74 |
+
xt = n1(x, s)
|
| 75 |
+
xt = xt + (1 / a1) * (torch.sin(a1 * xt) ** 2) # Snake1D
|
| 76 |
+
xt = c1(xt)
|
| 77 |
+
xt = n2(xt, s)
|
| 78 |
+
xt = xt + (1 / a2) * (torch.sin(a2 * xt) ** 2) # Snake1D
|
| 79 |
+
xt = c2(xt)
|
| 80 |
+
x = xt + x
|
| 81 |
+
return x
|
| 82 |
+
|
| 83 |
+
def remove_weight_norm(self):
|
| 84 |
+
for l in self.convs1:
|
| 85 |
+
remove_weight_norm(l)
|
| 86 |
+
for l in self.convs2:
|
| 87 |
+
remove_weight_norm(l)
|
| 88 |
+
|
| 89 |
+
class TorchSTFT(torch.nn.Module):
|
| 90 |
+
def __init__(self, filter_length=800, hop_length=200, win_length=800, window='hann'):
|
| 91 |
+
super().__init__()
|
| 92 |
+
self.filter_length = filter_length
|
| 93 |
+
self.hop_length = hop_length
|
| 94 |
+
self.win_length = win_length
|
| 95 |
+
self.window = torch.from_numpy(get_window(window, win_length, fftbins=True).astype(np.float32))
|
| 96 |
+
|
| 97 |
+
def transform(self, input_data):
|
| 98 |
+
forward_transform = torch.stft(
|
| 99 |
+
input_data,
|
| 100 |
+
self.filter_length, self.hop_length, self.win_length, window=self.window.to(input_data.device),
|
| 101 |
+
return_complex=True)
|
| 102 |
+
|
| 103 |
+
return torch.abs(forward_transform), torch.angle(forward_transform)
|
| 104 |
+
|
| 105 |
+
def inverse(self, magnitude, phase):
|
| 106 |
+
inverse_transform = torch.istft(
|
| 107 |
+
magnitude * torch.exp(phase * 1j),
|
| 108 |
+
self.filter_length, self.hop_length, self.win_length, window=self.window.to(magnitude.device))
|
| 109 |
+
|
| 110 |
+
return inverse_transform.unsqueeze(-2) # unsqueeze to stay consistent with conv_transpose1d implementation
|
| 111 |
+
|
| 112 |
+
def forward(self, input_data):
|
| 113 |
+
self.magnitude, self.phase = self.transform(input_data)
|
| 114 |
+
reconstruction = self.inverse(self.magnitude, self.phase)
|
| 115 |
+
return reconstruction
|
| 116 |
+
|
| 117 |
+
class SineGen(torch.nn.Module):
|
| 118 |
+
""" Definition of sine generator
|
| 119 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 120 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 121 |
+
voiced_threshold = 0,
|
| 122 |
+
flag_for_pulse=False)
|
| 123 |
+
samp_rate: sampling rate in Hz
|
| 124 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 125 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 126 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 127 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 128 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 129 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 130 |
+
segment is always sin(np.pi) or cos(0)
|
| 131 |
+
"""
|
| 132 |
+
|
| 133 |
+
def __init__(self, samp_rate, upsample_scale, harmonic_num=0,
|
| 134 |
+
sine_amp=0.1, noise_std=0.003,
|
| 135 |
+
voiced_threshold=0,
|
| 136 |
+
flag_for_pulse=False):
|
| 137 |
+
super(SineGen, self).__init__()
|
| 138 |
+
self.sine_amp = sine_amp
|
| 139 |
+
self.noise_std = noise_std
|
| 140 |
+
self.harmonic_num = harmonic_num
|
| 141 |
+
self.dim = self.harmonic_num + 1
|
| 142 |
+
self.sampling_rate = samp_rate
|
| 143 |
+
self.voiced_threshold = voiced_threshold
|
| 144 |
+
self.flag_for_pulse = flag_for_pulse
|
| 145 |
+
self.upsample_scale = upsample_scale
|
| 146 |
+
|
| 147 |
+
def _f02uv(self, f0):
|
| 148 |
+
# generate uv signal
|
| 149 |
+
uv = (f0 > self.voiced_threshold).type(torch.float32)
|
| 150 |
+
return uv
|
| 151 |
+
|
| 152 |
+
def _f02sine(self, f0_values):
|
| 153 |
+
""" f0_values: (batchsize, length, dim)
|
| 154 |
+
where dim indicates fundamental tone and overtones
|
| 155 |
+
"""
|
| 156 |
+
# convert to F0 in rad. The interger part n can be ignored
|
| 157 |
+
# because 2 * np.pi * n doesn't affect phase
|
| 158 |
+
rad_values = (f0_values / self.sampling_rate) % 1
|
| 159 |
+
|
| 160 |
+
# initial phase noise (no noise for fundamental component)
|
| 161 |
+
rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], \
|
| 162 |
+
device=f0_values.device)
|
| 163 |
+
rand_ini[:, 0] = 0
|
| 164 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 165 |
+
|
| 166 |
+
# instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
|
| 167 |
+
if not self.flag_for_pulse:
|
| 168 |
+
# # for normal case
|
| 169 |
+
|
| 170 |
+
# # To prevent torch.cumsum numerical overflow,
|
| 171 |
+
# # it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
|
| 172 |
+
# # Buffer tmp_over_one_idx indicates the time step to add -1.
|
| 173 |
+
# # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
|
| 174 |
+
# tmp_over_one = torch.cumsum(rad_values, 1) % 1
|
| 175 |
+
# tmp_over_one_idx = (padDiff(tmp_over_one)) < 0
|
| 176 |
+
# cumsum_shift = torch.zeros_like(rad_values)
|
| 177 |
+
# cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 178 |
+
|
| 179 |
+
# phase = torch.cumsum(rad_values, dim=1) * 2 * np.pi
|
| 180 |
+
rad_values = torch.nn.functional.interpolate(rad_values.transpose(1, 2),
|
| 181 |
+
scale_factor=1/self.upsample_scale,
|
| 182 |
+
mode="linear").transpose(1, 2)
|
| 183 |
+
|
| 184 |
+
# tmp_over_one = torch.cumsum(rad_values, 1) % 1
|
| 185 |
+
# tmp_over_one_idx = (padDiff(tmp_over_one)) < 0
|
| 186 |
+
# cumsum_shift = torch.zeros_like(rad_values)
|
| 187 |
+
# cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 188 |
+
|
| 189 |
+
phase = torch.cumsum(rad_values, dim=1) * 2 * np.pi
|
| 190 |
+
phase = torch.nn.functional.interpolate(phase.transpose(1, 2) * self.upsample_scale,
|
| 191 |
+
scale_factor=self.upsample_scale, mode="linear").transpose(1, 2)
|
| 192 |
+
sines = torch.sin(phase)
|
| 193 |
+
|
| 194 |
+
else:
|
| 195 |
+
# If necessary, make sure that the first time step of every
|
| 196 |
+
# voiced segments is sin(pi) or cos(0)
|
| 197 |
+
# This is used for pulse-train generation
|
| 198 |
+
|
| 199 |
+
# identify the last time step in unvoiced segments
|
| 200 |
+
uv = self._f02uv(f0_values)
|
| 201 |
+
uv_1 = torch.roll(uv, shifts=-1, dims=1)
|
| 202 |
+
uv_1[:, -1, :] = 1
|
| 203 |
+
u_loc = (uv < 1) * (uv_1 > 0)
|
| 204 |
+
|
| 205 |
+
# get the instantanouse phase
|
| 206 |
+
tmp_cumsum = torch.cumsum(rad_values, dim=1)
|
| 207 |
+
# different batch needs to be processed differently
|
| 208 |
+
for idx in range(f0_values.shape[0]):
|
| 209 |
+
temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
|
| 210 |
+
temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
|
| 211 |
+
# stores the accumulation of i.phase within
|
| 212 |
+
# each voiced segments
|
| 213 |
+
tmp_cumsum[idx, :, :] = 0
|
| 214 |
+
tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
|
| 215 |
+
|
| 216 |
+
# rad_values - tmp_cumsum: remove the accumulation of i.phase
|
| 217 |
+
# within the previous voiced segment.
|
| 218 |
+
i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
|
| 219 |
+
|
| 220 |
+
# get the sines
|
| 221 |
+
sines = torch.cos(i_phase * 2 * np.pi)
|
| 222 |
+
return sines
|
| 223 |
+
|
| 224 |
+
def forward(self, f0):
|
| 225 |
+
""" sine_tensor, uv = forward(f0)
|
| 226 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 227 |
+
f0 for unvoiced steps should be 0
|
| 228 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 229 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 230 |
+
"""
|
| 231 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim,
|
| 232 |
+
device=f0.device)
|
| 233 |
+
# fundamental component
|
| 234 |
+
fn = torch.multiply(f0, torch.FloatTensor([[range(1, self.harmonic_num + 2)]]).to(f0.device))
|
| 235 |
+
|
| 236 |
+
# generate sine waveforms
|
| 237 |
+
sine_waves = self._f02sine(fn) * self.sine_amp
|
| 238 |
+
|
| 239 |
+
# generate uv signal
|
| 240 |
+
# uv = torch.ones(f0.shape)
|
| 241 |
+
# uv = uv * (f0 > self.voiced_threshold)
|
| 242 |
+
uv = self._f02uv(f0)
|
| 243 |
+
|
| 244 |
+
# noise: for unvoiced should be similar to sine_amp
|
| 245 |
+
# std = self.sine_amp/3 -> max value ~ self.sine_amp
|
| 246 |
+
# . for voiced regions is self.noise_std
|
| 247 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 248 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 249 |
+
|
| 250 |
+
# first: set the unvoiced part to 0 by uv
|
| 251 |
+
# then: additive noise
|
| 252 |
+
sine_waves = sine_waves * uv + noise
|
| 253 |
+
return sine_waves, uv, noise
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 257 |
+
""" SourceModule for hn-nsf
|
| 258 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 259 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 260 |
+
sampling_rate: sampling_rate in Hz
|
| 261 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 262 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 263 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 264 |
+
note that amplitude of noise in unvoiced is decided
|
| 265 |
+
by sine_amp
|
| 266 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 267 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 268 |
+
F0_sampled (batchsize, length, 1)
|
| 269 |
+
Sine_source (batchsize, length, 1)
|
| 270 |
+
noise_source (batchsize, length 1)
|
| 271 |
+
uv (batchsize, length, 1)
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
def __init__(self, sampling_rate, upsample_scale, harmonic_num=0, sine_amp=0.1,
|
| 275 |
+
add_noise_std=0.003, voiced_threshod=0):
|
| 276 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 277 |
+
|
| 278 |
+
self.sine_amp = sine_amp
|
| 279 |
+
self.noise_std = add_noise_std
|
| 280 |
+
|
| 281 |
+
# to produce sine waveforms
|
| 282 |
+
self.l_sin_gen = SineGen(sampling_rate, upsample_scale, harmonic_num,
|
| 283 |
+
sine_amp, add_noise_std, voiced_threshod)
|
| 284 |
+
|
| 285 |
+
# to merge source harmonics into a single excitation
|
| 286 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 287 |
+
self.l_tanh = torch.nn.Tanh()
|
| 288 |
+
|
| 289 |
+
def forward(self, x):
|
| 290 |
+
"""
|
| 291 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 292 |
+
F0_sampled (batchsize, length, 1)
|
| 293 |
+
Sine_source (batchsize, length, 1)
|
| 294 |
+
noise_source (batchsize, length 1)
|
| 295 |
+
"""
|
| 296 |
+
# source for harmonic branch
|
| 297 |
+
with torch.no_grad():
|
| 298 |
+
sine_wavs, uv, _ = self.l_sin_gen(x)
|
| 299 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 300 |
+
|
| 301 |
+
# source for noise branch, in the same shape as uv
|
| 302 |
+
noise = torch.randn_like(uv) * self.sine_amp / 3
|
| 303 |
+
return sine_merge, noise, uv
|
| 304 |
+
def padDiff(x):
|
| 305 |
+
return F.pad(F.pad(x, (0,0,-1,1), 'constant', 0) - x, (0,0,0,-1), 'constant', 0)
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
class Generator(torch.nn.Module):
|
| 309 |
+
def __init__(self, style_dim, resblock_kernel_sizes, upsample_rates, upsample_initial_channel, resblock_dilation_sizes, upsample_kernel_sizes, gen_istft_n_fft, gen_istft_hop_size):
|
| 310 |
+
super(Generator, self).__init__()
|
| 311 |
+
|
| 312 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 313 |
+
self.num_upsamples = len(upsample_rates)
|
| 314 |
+
resblock = AdaINResBlock1
|
| 315 |
+
|
| 316 |
+
self.m_source = SourceModuleHnNSF(
|
| 317 |
+
sampling_rate=24000,
|
| 318 |
+
upsample_scale=np.prod(upsample_rates) * gen_istft_hop_size,
|
| 319 |
+
harmonic_num=8, voiced_threshod=10)
|
| 320 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates) * gen_istft_hop_size)
|
| 321 |
+
self.noise_convs = nn.ModuleList()
|
| 322 |
+
self.noise_res = nn.ModuleList()
|
| 323 |
+
|
| 324 |
+
self.ups = nn.ModuleList()
|
| 325 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 326 |
+
self.ups.append(weight_norm(
|
| 327 |
+
ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)),
|
| 328 |
+
k, u, padding=(k-u)//2)))
|
| 329 |
+
|
| 330 |
+
self.resblocks = nn.ModuleList()
|
| 331 |
+
for i in range(len(self.ups)):
|
| 332 |
+
ch = upsample_initial_channel//(2**(i+1))
|
| 333 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes,resblock_dilation_sizes)):
|
| 334 |
+
self.resblocks.append(resblock(ch, k, d, style_dim))
|
| 335 |
+
|
| 336 |
+
c_cur = upsample_initial_channel // (2 ** (i + 1))
|
| 337 |
+
|
| 338 |
+
if i + 1 < len(upsample_rates): #
|
| 339 |
+
stride_f0 = np.prod(upsample_rates[i + 1:])
|
| 340 |
+
self.noise_convs.append(Conv1d(
|
| 341 |
+
gen_istft_n_fft + 2, c_cur, kernel_size=stride_f0 * 2, stride=stride_f0, padding=(stride_f0+1) // 2))
|
| 342 |
+
self.noise_res.append(resblock(c_cur, 7, [1,3,5], style_dim))
|
| 343 |
+
else:
|
| 344 |
+
self.noise_convs.append(Conv1d(gen_istft_n_fft + 2, c_cur, kernel_size=1))
|
| 345 |
+
self.noise_res.append(resblock(c_cur, 11, [1,3,5], style_dim))
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
self.post_n_fft = gen_istft_n_fft
|
| 349 |
+
self.conv_post = weight_norm(Conv1d(ch, self.post_n_fft + 2, 7, 1, padding=3))
|
| 350 |
+
self.ups.apply(init_weights)
|
| 351 |
+
self.conv_post.apply(init_weights)
|
| 352 |
+
self.reflection_pad = torch.nn.ReflectionPad1d((1, 0))
|
| 353 |
+
self.stft = TorchSTFT(filter_length=gen_istft_n_fft, hop_length=gen_istft_hop_size, win_length=gen_istft_n_fft)
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
def forward(self, x, s, f0):
|
| 357 |
+
with torch.no_grad():
|
| 358 |
+
f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t
|
| 359 |
+
|
| 360 |
+
har_source, noi_source, uv = self.m_source(f0)
|
| 361 |
+
har_source = har_source.transpose(1, 2).squeeze(1)
|
| 362 |
+
har_spec, har_phase = self.stft.transform(har_source)
|
| 363 |
+
har = torch.cat([har_spec, har_phase], dim=1)
|
| 364 |
+
|
| 365 |
+
for i in range(self.num_upsamples):
|
| 366 |
+
x = F.leaky_relu(x, LRELU_SLOPE)
|
| 367 |
+
x_source = self.noise_convs[i](har)
|
| 368 |
+
x_source = self.noise_res[i](x_source, s)
|
| 369 |
+
|
| 370 |
+
x = self.ups[i](x)
|
| 371 |
+
if i == self.num_upsamples - 1:
|
| 372 |
+
x = self.reflection_pad(x)
|
| 373 |
+
|
| 374 |
+
x = x + x_source
|
| 375 |
+
xs = None
|
| 376 |
+
for j in range(self.num_kernels):
|
| 377 |
+
if xs is None:
|
| 378 |
+
xs = self.resblocks[i*self.num_kernels+j](x, s)
|
| 379 |
+
else:
|
| 380 |
+
xs += self.resblocks[i*self.num_kernels+j](x, s)
|
| 381 |
+
x = xs / self.num_kernels
|
| 382 |
+
x = F.leaky_relu(x)
|
| 383 |
+
x = self.conv_post(x)
|
| 384 |
+
spec = torch.exp(x[:,:self.post_n_fft // 2 + 1, :])
|
| 385 |
+
phase = torch.sin(x[:, self.post_n_fft // 2 + 1:, :])
|
| 386 |
+
return self.stft.inverse(spec, phase)
|
| 387 |
+
|
| 388 |
+
def fw_phase(self, x, s):
|
| 389 |
+
for i in range(self.num_upsamples):
|
| 390 |
+
x = F.leaky_relu(x, LRELU_SLOPE)
|
| 391 |
+
x = self.ups[i](x)
|
| 392 |
+
xs = None
|
| 393 |
+
for j in range(self.num_kernels):
|
| 394 |
+
if xs is None:
|
| 395 |
+
xs = self.resblocks[i*self.num_kernels+j](x, s)
|
| 396 |
+
else:
|
| 397 |
+
xs += self.resblocks[i*self.num_kernels+j](x, s)
|
| 398 |
+
x = xs / self.num_kernels
|
| 399 |
+
x = F.leaky_relu(x)
|
| 400 |
+
x = self.reflection_pad(x)
|
| 401 |
+
x = self.conv_post(x)
|
| 402 |
+
spec = torch.exp(x[:,:self.post_n_fft // 2 + 1, :])
|
| 403 |
+
phase = torch.sin(x[:, self.post_n_fft // 2 + 1:, :])
|
| 404 |
+
return spec, phase
|
| 405 |
+
|
| 406 |
+
def remove_weight_norm(self):
|
| 407 |
+
print('Removing weight norm...')
|
| 408 |
+
for l in self.ups:
|
| 409 |
+
remove_weight_norm(l)
|
| 410 |
+
for l in self.resblocks:
|
| 411 |
+
l.remove_weight_norm()
|
| 412 |
+
remove_weight_norm(self.conv_pre)
|
| 413 |
+
remove_weight_norm(self.conv_post)
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
class AdainResBlk1d(nn.Module):
|
| 417 |
+
def __init__(self, dim_in, dim_out, style_dim=64, actv=nn.LeakyReLU(0.2),
|
| 418 |
+
upsample='none', dropout_p=0.0):
|
| 419 |
+
super().__init__()
|
| 420 |
+
self.actv = actv
|
| 421 |
+
self.upsample_type = upsample
|
| 422 |
+
self.upsample = UpSample1d(upsample)
|
| 423 |
+
self.learned_sc = dim_in != dim_out
|
| 424 |
+
self._build_weights(dim_in, dim_out, style_dim)
|
| 425 |
+
self.dropout = nn.Dropout(dropout_p)
|
| 426 |
+
|
| 427 |
+
if upsample == 'none':
|
| 428 |
+
self.pool = nn.Identity()
|
| 429 |
+
else:
|
| 430 |
+
self.pool = weight_norm(nn.ConvTranspose1d(dim_in, dim_in, kernel_size=3, stride=2, groups=dim_in, padding=1, output_padding=1))
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
def _build_weights(self, dim_in, dim_out, style_dim):
|
| 434 |
+
self.conv1 = weight_norm(nn.Conv1d(dim_in, dim_out, 3, 1, 1))
|
| 435 |
+
self.conv2 = weight_norm(nn.Conv1d(dim_out, dim_out, 3, 1, 1))
|
| 436 |
+
self.norm1 = AdaIN1d(style_dim, dim_in)
|
| 437 |
+
self.norm2 = AdaIN1d(style_dim, dim_out)
|
| 438 |
+
if self.learned_sc:
|
| 439 |
+
self.conv1x1 = weight_norm(nn.Conv1d(dim_in, dim_out, 1, 1, 0, bias=False))
|
| 440 |
+
|
| 441 |
+
def _shortcut(self, x):
|
| 442 |
+
x = self.upsample(x)
|
| 443 |
+
if self.learned_sc:
|
| 444 |
+
x = self.conv1x1(x)
|
| 445 |
+
return x
|
| 446 |
+
|
| 447 |
+
def _residual(self, x, s):
|
| 448 |
+
x = self.norm1(x, s)
|
| 449 |
+
x = self.actv(x)
|
| 450 |
+
x = self.pool(x)
|
| 451 |
+
x = self.conv1(self.dropout(x))
|
| 452 |
+
x = self.norm2(x, s)
|
| 453 |
+
x = self.actv(x)
|
| 454 |
+
x = self.conv2(self.dropout(x))
|
| 455 |
+
return x
|
| 456 |
+
|
| 457 |
+
def forward(self, x, s):
|
| 458 |
+
out = self._residual(x, s)
|
| 459 |
+
out = (out + self._shortcut(x)) / np.sqrt(2)
|
| 460 |
+
return out
|
| 461 |
+
|
| 462 |
+
class UpSample1d(nn.Module):
|
| 463 |
+
def __init__(self, layer_type):
|
| 464 |
+
super().__init__()
|
| 465 |
+
self.layer_type = layer_type
|
| 466 |
+
|
| 467 |
+
def forward(self, x):
|
| 468 |
+
if self.layer_type == 'none':
|
| 469 |
+
return x
|
| 470 |
+
else:
|
| 471 |
+
return F.interpolate(x, scale_factor=2, mode='nearest')
|
| 472 |
+
|
| 473 |
+
class Decoder(nn.Module):
|
| 474 |
+
def __init__(self, dim_in=512, F0_channel=512, style_dim=64, dim_out=80,
|
| 475 |
+
resblock_kernel_sizes = [3,7,11],
|
| 476 |
+
upsample_rates = [10, 6],
|
| 477 |
+
upsample_initial_channel=512,
|
| 478 |
+
resblock_dilation_sizes=[[1,3,5], [1,3,5], [1,3,5]],
|
| 479 |
+
upsample_kernel_sizes=[20, 12],
|
| 480 |
+
gen_istft_n_fft=20, gen_istft_hop_size=5):
|
| 481 |
+
super().__init__()
|
| 482 |
+
|
| 483 |
+
self.decode = nn.ModuleList()
|
| 484 |
+
|
| 485 |
+
self.encode = AdainResBlk1d(dim_in + 2, 1024, style_dim)
|
| 486 |
+
|
| 487 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 488 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 489 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 1024, style_dim))
|
| 490 |
+
self.decode.append(AdainResBlk1d(1024 + 2 + 64, 512, style_dim, upsample=True))
|
| 491 |
+
|
| 492 |
+
self.F0_conv = weight_norm(nn.Conv1d(1, 1, kernel_size=3, stride=2, groups=1, padding=1))
|
| 493 |
+
|
| 494 |
+
self.N_conv = weight_norm(nn.Conv1d(1, 1, kernel_size=3, stride=2, groups=1, padding=1))
|
| 495 |
+
|
| 496 |
+
self.asr_res = nn.Sequential(
|
| 497 |
+
weight_norm(nn.Conv1d(512, 64, kernel_size=1)),
|
| 498 |
+
)
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
self.generator = Generator(style_dim, resblock_kernel_sizes, upsample_rates,
|
| 502 |
+
upsample_initial_channel, resblock_dilation_sizes,
|
| 503 |
+
upsample_kernel_sizes, gen_istft_n_fft, gen_istft_hop_size)
|
| 504 |
+
|
| 505 |
+
def forward(self, asr, F0_curve, N, s):
|
| 506 |
+
F0 = self.F0_conv(F0_curve.unsqueeze(1))
|
| 507 |
+
N = self.N_conv(N.unsqueeze(1))
|
| 508 |
+
|
| 509 |
+
x = torch.cat([asr, F0, N], axis=1)
|
| 510 |
+
x = self.encode(x, s)
|
| 511 |
+
|
| 512 |
+
asr_res = self.asr_res(asr)
|
| 513 |
+
|
| 514 |
+
res = True
|
| 515 |
+
for block in self.decode:
|
| 516 |
+
if res:
|
| 517 |
+
x = torch.cat([x, asr_res, F0, N], axis=1)
|
| 518 |
+
x = block(x, s)
|
| 519 |
+
if block.upsample_type != "none":
|
| 520 |
+
res = False
|
| 521 |
+
|
| 522 |
+
x = self.generator(x, s, F0_curve)
|
| 523 |
+
return x
|
src/models/models.py
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/models.py
|
| 2 |
+
from .istftnet import AdaIN1d, Decoder
|
| 3 |
+
from munch import Munch
|
| 4 |
+
from pathlib import Path
|
| 5 |
+
from .plbert import load_plbert
|
| 6 |
+
from torch.nn.utils import weight_norm, spectral_norm
|
| 7 |
+
import json
|
| 8 |
+
import numpy as np
|
| 9 |
+
import os
|
| 10 |
+
import os.path as osp
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
class LinearNorm(torch.nn.Module):
|
| 16 |
+
def __init__(self, in_dim, out_dim, bias=True, w_init_gain='linear'):
|
| 17 |
+
super(LinearNorm, self).__init__()
|
| 18 |
+
self.linear_layer = torch.nn.Linear(in_dim, out_dim, bias=bias)
|
| 19 |
+
|
| 20 |
+
torch.nn.init.xavier_uniform_(
|
| 21 |
+
self.linear_layer.weight,
|
| 22 |
+
gain=torch.nn.init.calculate_gain(w_init_gain))
|
| 23 |
+
|
| 24 |
+
def forward(self, x):
|
| 25 |
+
return self.linear_layer(x)
|
| 26 |
+
|
| 27 |
+
class LayerNorm(nn.Module):
|
| 28 |
+
def __init__(self, channels, eps=1e-5):
|
| 29 |
+
super().__init__()
|
| 30 |
+
self.channels = channels
|
| 31 |
+
self.eps = eps
|
| 32 |
+
|
| 33 |
+
self.gamma = nn.Parameter(torch.ones(channels))
|
| 34 |
+
self.beta = nn.Parameter(torch.zeros(channels))
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
x = x.transpose(1, -1)
|
| 38 |
+
x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
|
| 39 |
+
return x.transpose(1, -1)
|
| 40 |
+
|
| 41 |
+
class TextEncoder(nn.Module):
|
| 42 |
+
def __init__(self, channels, kernel_size, depth, n_symbols, actv=nn.LeakyReLU(0.2)):
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.embedding = nn.Embedding(n_symbols, channels)
|
| 45 |
+
|
| 46 |
+
padding = (kernel_size - 1) // 2
|
| 47 |
+
self.cnn = nn.ModuleList()
|
| 48 |
+
for _ in range(depth):
|
| 49 |
+
self.cnn.append(nn.Sequential(
|
| 50 |
+
weight_norm(nn.Conv1d(channels, channels, kernel_size=kernel_size, padding=padding)),
|
| 51 |
+
LayerNorm(channels),
|
| 52 |
+
actv,
|
| 53 |
+
nn.Dropout(0.2),
|
| 54 |
+
))
|
| 55 |
+
# self.cnn = nn.Sequential(*self.cnn)
|
| 56 |
+
|
| 57 |
+
self.lstm = nn.LSTM(channels, channels//2, 1, batch_first=True, bidirectional=True)
|
| 58 |
+
|
| 59 |
+
def forward(self, x, input_lengths, m):
|
| 60 |
+
x = self.embedding(x) # [B, T, emb]
|
| 61 |
+
x = x.transpose(1, 2) # [B, emb, T]
|
| 62 |
+
m = m.to(input_lengths.device).unsqueeze(1)
|
| 63 |
+
x.masked_fill_(m, 0.0)
|
| 64 |
+
|
| 65 |
+
for c in self.cnn:
|
| 66 |
+
x = c(x)
|
| 67 |
+
x.masked_fill_(m, 0.0)
|
| 68 |
+
|
| 69 |
+
x = x.transpose(1, 2) # [B, T, chn]
|
| 70 |
+
|
| 71 |
+
input_lengths = input_lengths.cpu().numpy()
|
| 72 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 73 |
+
x, input_lengths, batch_first=True, enforce_sorted=False)
|
| 74 |
+
|
| 75 |
+
self.lstm.flatten_parameters()
|
| 76 |
+
x, _ = self.lstm(x)
|
| 77 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 78 |
+
x, batch_first=True)
|
| 79 |
+
|
| 80 |
+
x = x.transpose(-1, -2)
|
| 81 |
+
x_pad = torch.zeros([x.shape[0], x.shape[1], m.shape[-1]])
|
| 82 |
+
|
| 83 |
+
x_pad[:, :, :x.shape[-1]] = x
|
| 84 |
+
x = x_pad.to(x.device)
|
| 85 |
+
|
| 86 |
+
x.masked_fill_(m, 0.0)
|
| 87 |
+
|
| 88 |
+
return x
|
| 89 |
+
|
| 90 |
+
def inference(self, x):
|
| 91 |
+
x = self.embedding(x)
|
| 92 |
+
x = x.transpose(1, 2)
|
| 93 |
+
x = self.cnn(x)
|
| 94 |
+
x = x.transpose(1, 2)
|
| 95 |
+
self.lstm.flatten_parameters()
|
| 96 |
+
x, _ = self.lstm(x)
|
| 97 |
+
return x
|
| 98 |
+
|
| 99 |
+
def length_to_mask(self, lengths):
|
| 100 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 101 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 102 |
+
return mask
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class UpSample1d(nn.Module):
|
| 106 |
+
def __init__(self, layer_type):
|
| 107 |
+
super().__init__()
|
| 108 |
+
self.layer_type = layer_type
|
| 109 |
+
|
| 110 |
+
def forward(self, x):
|
| 111 |
+
if self.layer_type == 'none':
|
| 112 |
+
return x
|
| 113 |
+
else:
|
| 114 |
+
return F.interpolate(x, scale_factor=2, mode='nearest')
|
| 115 |
+
|
| 116 |
+
class AdainResBlk1d(nn.Module):
|
| 117 |
+
def __init__(self, dim_in, dim_out, style_dim=64, actv=nn.LeakyReLU(0.2),
|
| 118 |
+
upsample='none', dropout_p=0.0):
|
| 119 |
+
super().__init__()
|
| 120 |
+
self.actv = actv
|
| 121 |
+
self.upsample_type = upsample
|
| 122 |
+
self.upsample = UpSample1d(upsample)
|
| 123 |
+
self.learned_sc = dim_in != dim_out
|
| 124 |
+
self._build_weights(dim_in, dim_out, style_dim)
|
| 125 |
+
self.dropout = nn.Dropout(dropout_p)
|
| 126 |
+
|
| 127 |
+
if upsample == 'none':
|
| 128 |
+
self.pool = nn.Identity()
|
| 129 |
+
else:
|
| 130 |
+
self.pool = weight_norm(nn.ConvTranspose1d(dim_in, dim_in, kernel_size=3, stride=2, groups=dim_in, padding=1, output_padding=1))
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def _build_weights(self, dim_in, dim_out, style_dim):
|
| 134 |
+
self.conv1 = weight_norm(nn.Conv1d(dim_in, dim_out, 3, 1, 1))
|
| 135 |
+
self.conv2 = weight_norm(nn.Conv1d(dim_out, dim_out, 3, 1, 1))
|
| 136 |
+
self.norm1 = AdaIN1d(style_dim, dim_in)
|
| 137 |
+
self.norm2 = AdaIN1d(style_dim, dim_out)
|
| 138 |
+
if self.learned_sc:
|
| 139 |
+
self.conv1x1 = weight_norm(nn.Conv1d(dim_in, dim_out, 1, 1, 0, bias=False))
|
| 140 |
+
|
| 141 |
+
def _shortcut(self, x):
|
| 142 |
+
x = self.upsample(x)
|
| 143 |
+
if self.learned_sc:
|
| 144 |
+
x = self.conv1x1(x)
|
| 145 |
+
return x
|
| 146 |
+
|
| 147 |
+
def _residual(self, x, s):
|
| 148 |
+
x = self.norm1(x, s)
|
| 149 |
+
x = self.actv(x)
|
| 150 |
+
x = self.pool(x)
|
| 151 |
+
x = self.conv1(self.dropout(x))
|
| 152 |
+
x = self.norm2(x, s)
|
| 153 |
+
x = self.actv(x)
|
| 154 |
+
x = self.conv2(self.dropout(x))
|
| 155 |
+
return x
|
| 156 |
+
|
| 157 |
+
def forward(self, x, s):
|
| 158 |
+
out = self._residual(x, s)
|
| 159 |
+
out = (out + self._shortcut(x)) / np.sqrt(2)
|
| 160 |
+
return out
|
| 161 |
+
|
| 162 |
+
class AdaLayerNorm(nn.Module):
|
| 163 |
+
def __init__(self, style_dim, channels, eps=1e-5):
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.channels = channels
|
| 166 |
+
self.eps = eps
|
| 167 |
+
|
| 168 |
+
self.fc = nn.Linear(style_dim, channels*2)
|
| 169 |
+
|
| 170 |
+
def forward(self, x, s):
|
| 171 |
+
x = x.transpose(-1, -2)
|
| 172 |
+
x = x.transpose(1, -1)
|
| 173 |
+
|
| 174 |
+
h = self.fc(s)
|
| 175 |
+
h = h.view(h.size(0), h.size(1), 1)
|
| 176 |
+
gamma, beta = torch.chunk(h, chunks=2, dim=1)
|
| 177 |
+
gamma, beta = gamma.transpose(1, -1), beta.transpose(1, -1)
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
x = F.layer_norm(x, (self.channels,), eps=self.eps)
|
| 181 |
+
x = (1 + gamma) * x + beta
|
| 182 |
+
return x.transpose(1, -1).transpose(-1, -2)
|
| 183 |
+
|
| 184 |
+
class ProsodyPredictor(nn.Module):
|
| 185 |
+
|
| 186 |
+
def __init__(self, style_dim, d_hid, nlayers, max_dur=50, dropout=0.1):
|
| 187 |
+
super().__init__()
|
| 188 |
+
|
| 189 |
+
self.text_encoder = DurationEncoder(sty_dim=style_dim,
|
| 190 |
+
d_model=d_hid,
|
| 191 |
+
nlayers=nlayers,
|
| 192 |
+
dropout=dropout)
|
| 193 |
+
|
| 194 |
+
self.lstm = nn.LSTM(d_hid + style_dim, d_hid // 2, 1, batch_first=True, bidirectional=True)
|
| 195 |
+
self.duration_proj = LinearNorm(d_hid, max_dur)
|
| 196 |
+
|
| 197 |
+
self.shared = nn.LSTM(d_hid + style_dim, d_hid // 2, 1, batch_first=True, bidirectional=True)
|
| 198 |
+
self.F0 = nn.ModuleList()
|
| 199 |
+
self.F0.append(AdainResBlk1d(d_hid, d_hid, style_dim, dropout_p=dropout))
|
| 200 |
+
self.F0.append(AdainResBlk1d(d_hid, d_hid // 2, style_dim, upsample=True, dropout_p=dropout))
|
| 201 |
+
self.F0.append(AdainResBlk1d(d_hid // 2, d_hid // 2, style_dim, dropout_p=dropout))
|
| 202 |
+
|
| 203 |
+
self.N = nn.ModuleList()
|
| 204 |
+
self.N.append(AdainResBlk1d(d_hid, d_hid, style_dim, dropout_p=dropout))
|
| 205 |
+
self.N.append(AdainResBlk1d(d_hid, d_hid // 2, style_dim, upsample=True, dropout_p=dropout))
|
| 206 |
+
self.N.append(AdainResBlk1d(d_hid // 2, d_hid // 2, style_dim, dropout_p=dropout))
|
| 207 |
+
|
| 208 |
+
self.F0_proj = nn.Conv1d(d_hid // 2, 1, 1, 1, 0)
|
| 209 |
+
self.N_proj = nn.Conv1d(d_hid // 2, 1, 1, 1, 0)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def forward(self, texts, style, text_lengths, alignment, m):
|
| 213 |
+
d = self.text_encoder(texts, style, text_lengths, m)
|
| 214 |
+
|
| 215 |
+
batch_size = d.shape[0]
|
| 216 |
+
text_size = d.shape[1]
|
| 217 |
+
|
| 218 |
+
# predict duration
|
| 219 |
+
input_lengths = text_lengths.cpu().numpy()
|
| 220 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 221 |
+
d, input_lengths, batch_first=True, enforce_sorted=False)
|
| 222 |
+
|
| 223 |
+
m = m.to(text_lengths.device).unsqueeze(1)
|
| 224 |
+
|
| 225 |
+
self.lstm.flatten_parameters()
|
| 226 |
+
x, _ = self.lstm(x)
|
| 227 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 228 |
+
x, batch_first=True)
|
| 229 |
+
|
| 230 |
+
x_pad = torch.zeros([x.shape[0], m.shape[-1], x.shape[-1]])
|
| 231 |
+
|
| 232 |
+
x_pad[:, :x.shape[1], :] = x
|
| 233 |
+
x = x_pad.to(x.device)
|
| 234 |
+
|
| 235 |
+
duration = self.duration_proj(nn.functional.dropout(x, 0.5, training=self.training))
|
| 236 |
+
|
| 237 |
+
en = (d.transpose(-1, -2) @ alignment)
|
| 238 |
+
|
| 239 |
+
return duration.squeeze(-1), en
|
| 240 |
+
|
| 241 |
+
def F0Ntrain(self, x, s):
|
| 242 |
+
x, _ = self.shared(x.transpose(-1, -2))
|
| 243 |
+
|
| 244 |
+
F0 = x.transpose(-1, -2)
|
| 245 |
+
for block in self.F0:
|
| 246 |
+
F0 = block(F0, s)
|
| 247 |
+
F0 = self.F0_proj(F0)
|
| 248 |
+
|
| 249 |
+
N = x.transpose(-1, -2)
|
| 250 |
+
for block in self.N:
|
| 251 |
+
N = block(N, s)
|
| 252 |
+
N = self.N_proj(N)
|
| 253 |
+
|
| 254 |
+
return F0.squeeze(1), N.squeeze(1)
|
| 255 |
+
|
| 256 |
+
def length_to_mask(self, lengths):
|
| 257 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 258 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 259 |
+
return mask
|
| 260 |
+
|
| 261 |
+
class DurationEncoder(nn.Module):
|
| 262 |
+
|
| 263 |
+
def __init__(self, sty_dim, d_model, nlayers, dropout=0.1):
|
| 264 |
+
super().__init__()
|
| 265 |
+
self.lstms = nn.ModuleList()
|
| 266 |
+
for _ in range(nlayers):
|
| 267 |
+
self.lstms.append(nn.LSTM(d_model + sty_dim,
|
| 268 |
+
d_model // 2,
|
| 269 |
+
num_layers=1,
|
| 270 |
+
batch_first=True,
|
| 271 |
+
bidirectional=True,
|
| 272 |
+
dropout=dropout))
|
| 273 |
+
self.lstms.append(AdaLayerNorm(sty_dim, d_model))
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
self.dropout = dropout
|
| 277 |
+
self.d_model = d_model
|
| 278 |
+
self.sty_dim = sty_dim
|
| 279 |
+
|
| 280 |
+
def forward(self, x, style, text_lengths, m):
|
| 281 |
+
masks = m.to(text_lengths.device)
|
| 282 |
+
|
| 283 |
+
x = x.permute(2, 0, 1)
|
| 284 |
+
s = style.expand(x.shape[0], x.shape[1], -1)
|
| 285 |
+
x = torch.cat([x, s], axis=-1)
|
| 286 |
+
x.masked_fill_(masks.unsqueeze(-1).transpose(0, 1), 0.0)
|
| 287 |
+
|
| 288 |
+
x = x.transpose(0, 1)
|
| 289 |
+
input_lengths = text_lengths.cpu().numpy()
|
| 290 |
+
x = x.transpose(-1, -2)
|
| 291 |
+
|
| 292 |
+
for block in self.lstms:
|
| 293 |
+
if isinstance(block, AdaLayerNorm):
|
| 294 |
+
x = block(x.transpose(-1, -2), style).transpose(-1, -2)
|
| 295 |
+
x = torch.cat([x, s.permute(1, -1, 0)], axis=1)
|
| 296 |
+
x.masked_fill_(masks.unsqueeze(-1).transpose(-1, -2), 0.0)
|
| 297 |
+
else:
|
| 298 |
+
x = x.transpose(-1, -2)
|
| 299 |
+
x = nn.utils.rnn.pack_padded_sequence(
|
| 300 |
+
x, input_lengths, batch_first=True, enforce_sorted=False)
|
| 301 |
+
block.flatten_parameters()
|
| 302 |
+
x, _ = block(x)
|
| 303 |
+
x, _ = nn.utils.rnn.pad_packed_sequence(
|
| 304 |
+
x, batch_first=True)
|
| 305 |
+
x = F.dropout(x, p=self.dropout, training=self.training)
|
| 306 |
+
x = x.transpose(-1, -2)
|
| 307 |
+
|
| 308 |
+
x_pad = torch.zeros([x.shape[0], x.shape[1], m.shape[-1]])
|
| 309 |
+
|
| 310 |
+
x_pad[:, :, :x.shape[-1]] = x
|
| 311 |
+
x = x_pad.to(x.device)
|
| 312 |
+
|
| 313 |
+
return x.transpose(-1, -2)
|
| 314 |
+
|
| 315 |
+
def inference(self, x, style):
|
| 316 |
+
x = self.embedding(x.transpose(-1, -2)) * np.sqrt(self.d_model)
|
| 317 |
+
style = style.expand(x.shape[0], x.shape[1], -1)
|
| 318 |
+
x = torch.cat([x, style], axis=-1)
|
| 319 |
+
src = self.pos_encoder(x)
|
| 320 |
+
output = self.transformer_encoder(src).transpose(0, 1)
|
| 321 |
+
return output
|
| 322 |
+
|
| 323 |
+
def length_to_mask(self, lengths):
|
| 324 |
+
mask = torch.arange(lengths.max()).unsqueeze(0).expand(lengths.shape[0], -1).type_as(lengths)
|
| 325 |
+
mask = torch.gt(mask+1, lengths.unsqueeze(1))
|
| 326 |
+
return mask
|
| 327 |
+
|
| 328 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/utils.py
|
| 329 |
+
def recursive_munch(d):
|
| 330 |
+
if isinstance(d, dict):
|
| 331 |
+
return Munch((k, recursive_munch(v)) for k, v in d.items())
|
| 332 |
+
elif isinstance(d, list):
|
| 333 |
+
return [recursive_munch(v) for v in d]
|
| 334 |
+
else:
|
| 335 |
+
return d
|
| 336 |
+
|
| 337 |
+
def build_model(path, device):
|
| 338 |
+
config = Path(__file__).parent.parent / 'config' / 'config.json'
|
| 339 |
+
assert config.exists(), f'Config path incorrect: config.json not found at {config}'
|
| 340 |
+
with open(config, 'r') as r:
|
| 341 |
+
args = recursive_munch(json.load(r))
|
| 342 |
+
assert args.decoder.type == 'istftnet', f'Unknown decoder type: {args.decoder.type}'
|
| 343 |
+
decoder = Decoder(dim_in=args.hidden_dim, style_dim=args.style_dim, dim_out=args.n_mels,
|
| 344 |
+
resblock_kernel_sizes = args.decoder.resblock_kernel_sizes,
|
| 345 |
+
upsample_rates = args.decoder.upsample_rates,
|
| 346 |
+
upsample_initial_channel=args.decoder.upsample_initial_channel,
|
| 347 |
+
resblock_dilation_sizes=args.decoder.resblock_dilation_sizes,
|
| 348 |
+
upsample_kernel_sizes=args.decoder.upsample_kernel_sizes,
|
| 349 |
+
gen_istft_n_fft=args.decoder.gen_istft_n_fft, gen_istft_hop_size=args.decoder.gen_istft_hop_size)
|
| 350 |
+
text_encoder = TextEncoder(channels=args.hidden_dim, kernel_size=5, depth=args.n_layer, n_symbols=args.n_token)
|
| 351 |
+
predictor = ProsodyPredictor(style_dim=args.style_dim, d_hid=args.hidden_dim, nlayers=args.n_layer, max_dur=args.max_dur, dropout=args.dropout)
|
| 352 |
+
bert = load_plbert()
|
| 353 |
+
bert_encoder = nn.Linear(bert.config.hidden_size, args.hidden_dim)
|
| 354 |
+
for parent in [bert, bert_encoder, predictor, decoder, text_encoder]:
|
| 355 |
+
for child in parent.children():
|
| 356 |
+
if isinstance(child, nn.RNNBase):
|
| 357 |
+
child.flatten_parameters()
|
| 358 |
+
model = Munch(
|
| 359 |
+
bert=bert.to(device).eval(),
|
| 360 |
+
bert_encoder=bert_encoder.to(device).eval(),
|
| 361 |
+
predictor=predictor.to(device).eval(),
|
| 362 |
+
decoder=decoder.to(device).eval(),
|
| 363 |
+
text_encoder=text_encoder.to(device).eval(),
|
| 364 |
+
)
|
| 365 |
+
for key, state_dict in torch.load(path, map_location='cpu', weights_only=True)['net'].items():
|
| 366 |
+
assert key in model, key
|
| 367 |
+
try:
|
| 368 |
+
model[key].load_state_dict(state_dict)
|
| 369 |
+
except:
|
| 370 |
+
state_dict = {k[7:]: v for k, v in state_dict.items()}
|
| 371 |
+
model[key].load_state_dict(state_dict, strict=False)
|
| 372 |
+
return model
|
src/models/plbert.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# https://github.com/yl4579/StyleTTS2/blob/main/Utils/PLBERT/util.py
|
| 2 |
+
from transformers import AlbertConfig, AlbertModel
|
| 3 |
+
|
| 4 |
+
class CustomAlbert(AlbertModel):
|
| 5 |
+
def forward(self, *args, **kwargs):
|
| 6 |
+
# Call the original forward method
|
| 7 |
+
outputs = super().forward(*args, **kwargs)
|
| 8 |
+
# Only return the last_hidden_state
|
| 9 |
+
return outputs.last_hidden_state
|
| 10 |
+
|
| 11 |
+
def load_plbert():
|
| 12 |
+
plbert_config = {'vocab_size': 178, 'hidden_size': 768, 'num_attention_heads': 12, 'intermediate_size': 2048, 'max_position_embeddings': 512, 'num_hidden_layers': 12, 'dropout': 0.1}
|
| 13 |
+
albert_base_configuration = AlbertConfig(**plbert_config)
|
| 14 |
+
bert = CustomAlbert(albert_base_configuration)
|
| 15 |
+
return bert
|
src/utils/__init__.py
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .audio import play_audio
|
| 2 |
+
from .voice import load_voice, quick_mix_voice, split_into_sentences
|
| 3 |
+
from .generator import VoiceGenerator
|
| 4 |
+
from .llm import filter_response, get_ai_response
|
| 5 |
+
from .audio_utils import save_audio_file, generate_and_play_sentences
|
| 6 |
+
from .commands import handle_commands
|
| 7 |
+
from .speech import (
|
| 8 |
+
init_vad_pipeline, detect_speech_segments, record_audio,
|
| 9 |
+
record_continuous_audio, check_for_speech, play_audio_with_interrupt,
|
| 10 |
+
transcribe_audio
|
| 11 |
+
)
|
| 12 |
+
from .config import settings
|
| 13 |
+
from .text_chunker import TextChunker
|
| 14 |
+
|
| 15 |
+
__all__ = [
|
| 16 |
+
'play_audio',
|
| 17 |
+
'load_voice',
|
| 18 |
+
'quick_mix_voice',
|
| 19 |
+
'split_into_sentences',
|
| 20 |
+
'VoiceGenerator',
|
| 21 |
+
'filter_response',
|
| 22 |
+
'get_ai_response',
|
| 23 |
+
'save_audio_file',
|
| 24 |
+
'generate_and_play_sentences',
|
| 25 |
+
'handle_commands',
|
| 26 |
+
'init_vad_pipeline',
|
| 27 |
+
'detect_speech_segments',
|
| 28 |
+
'record_audio',
|
| 29 |
+
'record_continuous_audio',
|
| 30 |
+
'check_for_speech',
|
| 31 |
+
'play_audio_with_interrupt',
|
| 32 |
+
'transcribe_audio',
|
| 33 |
+
'settings',
|
| 34 |
+
'TextChunker',
|
| 35 |
+
]
|
src/utils/audio.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import sounddevice as sd
|
| 3 |
+
import time
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def play_audio(audio_data: np.ndarray, sample_rate: int = 24000):
|
| 7 |
+
"""
|
| 8 |
+
Play audio directly using sounddevice.
|
| 9 |
+
|
| 10 |
+
Args:
|
| 11 |
+
audio_data (np.ndarray): The audio data to play.
|
| 12 |
+
sample_rate (int, optional): The sample rate of the audio data. Defaults to 24000.
|
| 13 |
+
"""
|
| 14 |
+
try:
|
| 15 |
+
sd.play(audio_data, sample_rate)
|
| 16 |
+
sd.wait()
|
| 17 |
+
except Exception as e:
|
| 18 |
+
print(f"Error playing audio: {str(e)}")
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def stream_audio_chunks(
|
| 22 |
+
audio_chunks: list, sample_rate: int = 24000, pause_duration: float = 0.2
|
| 23 |
+
):
|
| 24 |
+
"""
|
| 25 |
+
Stream audio chunks one after another with a small pause between them.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
audio_chunks (list): A list of audio chunks to play.
|
| 29 |
+
sample_rate (int, optional): The sample rate of the audio data. Defaults to 24000.
|
| 30 |
+
pause_duration (float, optional): The duration of the pause between chunks in seconds. Defaults to 0.2.
|
| 31 |
+
"""
|
| 32 |
+
try:
|
| 33 |
+
for chunk in audio_chunks:
|
| 34 |
+
if len(chunk) == 0:
|
| 35 |
+
continue
|
| 36 |
+
sd.play(chunk, sample_rate)
|
| 37 |
+
sd.wait()
|
| 38 |
+
time.sleep(pause_duration)
|
| 39 |
+
except Exception as e:
|
| 40 |
+
print(f"Error streaming audio chunks: {str(e)}")
|
| 41 |
+
finally:
|
| 42 |
+
sd.stop()
|
src/utils/audio_io.py
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import soundfile as sf
|
| 3 |
+
import sounddevice as sd
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from typing import Tuple, Optional
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def save_audio_file(
|
| 10 |
+
audio_data: np.ndarray, output_dir: Path, sample_rate: int = 24000
|
| 11 |
+
) -> Path:
|
| 12 |
+
"""
|
| 13 |
+
Save audio data to a WAV file with a timestamp in the filename.
|
| 14 |
+
|
| 15 |
+
Args:
|
| 16 |
+
audio_data (np.ndarray): The audio data to save. Can be a single array or a list of arrays.
|
| 17 |
+
output_dir (Path): The directory to save the audio file in.
|
| 18 |
+
sample_rate (int, optional): The sample rate of the audio data. Defaults to 24000.
|
| 19 |
+
|
| 20 |
+
Returns:
|
| 21 |
+
Path: The path to the saved audio file.
|
| 22 |
+
"""
|
| 23 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
|
| 24 |
+
output_path = output_dir / f"output_{timestamp}.wav"
|
| 25 |
+
|
| 26 |
+
if isinstance(audio_data, list):
|
| 27 |
+
audio_data = np.concatenate(audio_data)
|
| 28 |
+
|
| 29 |
+
sf.write(str(output_path), audio_data, sample_rate)
|
| 30 |
+
return output_path
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def play_audio(
|
| 34 |
+
audio_data: np.ndarray, sample_rate: int = 24000
|
| 35 |
+
) -> Tuple[bool, Optional[np.ndarray]]:
|
| 36 |
+
"""
|
| 37 |
+
Play audio data using sounddevice.
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
audio_data (np.ndarray): The audio data to play.
|
| 41 |
+
sample_rate (int, optional): The sample rate of the audio data. Defaults to 24000.
|
| 42 |
+
|
| 43 |
+
Returns:
|
| 44 |
+
Tuple[bool, Optional[np.ndarray]]: A tuple containing a boolean indicating if the playback was interrupted (always False here) and an optional numpy array representing the interrupted audio (always None here).
|
| 45 |
+
"""
|
| 46 |
+
sd.play(audio_data, sample_rate)
|
| 47 |
+
sd.wait()
|
| 48 |
+
return False, None
|