---
license: mit
pipeline_tag: image-feature-extraction
base_model: OpenGVLab/InternViT-300M-448px
base_model_relation: finetune
---
# InternViT-300M-448px-V2_5
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co./papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co./papers/2404.16821) [\[📜 Mini-InternVL\]](https://arxiv.org/abs/2410.16261) [\[📜 InternVL 2.5\]](https://huggingface.co./papers/2412.05271)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co./spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
## Introduction
We are excited to announce the release of `InternViT-300M-448px-V2_5`, a significant enhancement built on the foundation of `InternViT-300M-448px`. By employing **ViT incremental learning** with NTP loss (Stage 1.5), the vision encoder has improved its ability to extract visual features, enabling it to capture more comprehensive information. This improvement is particularly noticeable in domains that are underrepresented in large-scale web datasets such as LAION-5B, including multilingual OCR data and mathematical charts, among others.

## InternViT 2.5 Family
In the following table, we provide an overview of the InternViT 2.5 series.
| Model Name | HF Link |
| :-----------------------: | :-------------------------------------------------------------------: |
| InternViT-300M-448px-V2_5 | [🤗 link](https://huggingface.co./OpenGVLab/InternViT-300M-448px-V2_5) |
| InternViT-6B-448px-V2_5 | [🤗 link](https://huggingface.co./OpenGVLab/InternViT-6B-448px-V2_5) |
## Model Architecture
As shown in the following figure, InternVL 2.5 retains the same model architecture as its predecessors, InternVL 1.5 and 2.0, following the "ViT-MLP-LLM" paradigm. In this new version, we integrate a newly incrementally pre-trained InternViT with various pre-trained LLMs, including InternLM 2.5 and Qwen 2.5, using a randomly initialized MLP projector.

As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
## Training Strategy
### Dynamic High-Resolution for Multimodal Data
In InternVL 2.0 and 2.5, we extend the dynamic high-resolution training approach, enhancing its capabilities to handle multi-image and video datasets.

- For single-image datasets, the total number of tiles `n_max` are allocated to a single image for maximum resolution. Visual tokens are enclosed in `![]() ` and `` tags.
- For multi-image datasets, the total number of tiles `n_max` are distributed across all images in a sample. Each image is labeled with auxiliary tags like `Image-1` and enclosed in `
` and `` tags.
- For multi-image datasets, the total number of tiles `n_max` are distributed across all images in a sample. Each image is labeled with auxiliary tags like `Image-1` and enclosed in `![]() ` and `` tags.
- For videos, each frame is resized to 448×448. Frames are labeled with tags like `Frame-1` and enclosed in `
` and `` tags.
- For videos, each frame is resized to 448×448. Frames are labeled with tags like `Frame-1` and enclosed in `![]() ` and `` tags, similar to images.
### Single Model Training Pipeline
The training pipeline for a single model in InternVL 2.5 is structured across three stages, designed to enhance the model's visual perception and multimodal capabilities.

- **Stage 1: MLP Warmup.** In this stage, only the MLP projector is trained while the vision encoder and language model are frozen. A dynamic high-resolution training strategy is applied for better performance, despite increased cost. This phase ensures robust cross-modal alignment and prepares the model for stable multimodal training.
- **Stage 1.5: ViT Incremental Learning (Optional).** This stage allows incremental training of the vision encoder and MLP projector using the same data as Stage 1. It enhances the encoder’s ability to handle rare domains like multilingual OCR and mathematical charts. Once trained, the encoder can be reused across LLMs without retraining, making this stage optional unless new domains are introduced.
- **Stage 2: Full Model Instruction Tuning.** The entire model is trained on high-quality multimodal instruction datasets. Strict data quality controls are enforced to prevent degradation of the LLM, as noisy data can cause issues like repetitive or incorrect outputs. After this stage, the training process is complete.
## Evaluation on Vision Capability
We present a comprehensive evaluation of the vision encoder’s performance across various domains and tasks. The evaluation is divided into two key categories: (1) image classification, representing global-view semantic quality, and (2) semantic segmentation, capturing local-view semantic quality. This approach allows us to assess the representation quality of InternViT across its successive version updates. Please refer to our technical report for more details.
## Image Classification
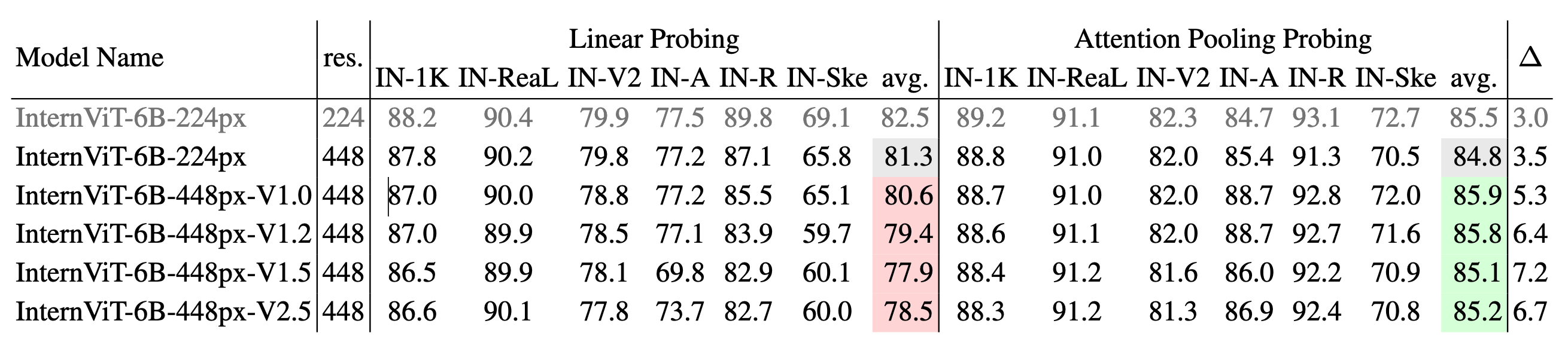
**Image classification performance across different versions of InternViT.** We use IN-1K for training and evaluate on the IN-1K validation set as well as multiple ImageNet variants, including IN-ReaL, IN-V2, IN-A, IN-R, and IN-Sketch. Results are reported for both linear probing and attention pooling probing methods, with average accuracy for each method. ∆ represents the performance gap between attention pooling probing and linear probing, where a larger ∆ suggests a shift from learning simple linear features to capturing more complex, nonlinear semantic representations.
## Semantic Segmentation Performance

**Semantic segmentation performance across different versions of InternViT.** The models are evaluated on ADE20K and COCO-Stuff-164K using three configurations: linear probing, head tuning, and full tuning. The table shows the mIoU scores for each configuration and their averages. ∆1 represents the gap between head tuning and linear probing, while ∆2 shows the gap between full tuning and linear probing. A larger ∆ value indicates a shift from simple linear features to more complex, nonlinear representations.
## Quick Start
> \[!Warning\]
> 🚨 Note: In our experience, the InternViT V2.5 series is better suited for building MLLMs than traditional computer vision tasks.
```python
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-300M-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-300M-448px-V2_5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
```
## License
This project is released under the MIT License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
` and `` tags, similar to images.
### Single Model Training Pipeline
The training pipeline for a single model in InternVL 2.5 is structured across three stages, designed to enhance the model's visual perception and multimodal capabilities.

- **Stage 1: MLP Warmup.** In this stage, only the MLP projector is trained while the vision encoder and language model are frozen. A dynamic high-resolution training strategy is applied for better performance, despite increased cost. This phase ensures robust cross-modal alignment and prepares the model for stable multimodal training.
- **Stage 1.5: ViT Incremental Learning (Optional).** This stage allows incremental training of the vision encoder and MLP projector using the same data as Stage 1. It enhances the encoder’s ability to handle rare domains like multilingual OCR and mathematical charts. Once trained, the encoder can be reused across LLMs without retraining, making this stage optional unless new domains are introduced.
- **Stage 2: Full Model Instruction Tuning.** The entire model is trained on high-quality multimodal instruction datasets. Strict data quality controls are enforced to prevent degradation of the LLM, as noisy data can cause issues like repetitive or incorrect outputs. After this stage, the training process is complete.
## Evaluation on Vision Capability
We present a comprehensive evaluation of the vision encoder’s performance across various domains and tasks. The evaluation is divided into two key categories: (1) image classification, representing global-view semantic quality, and (2) semantic segmentation, capturing local-view semantic quality. This approach allows us to assess the representation quality of InternViT across its successive version updates. Please refer to our technical report for more details.
## Image Classification

**Image classification performance across different versions of InternViT.** We use IN-1K for training and evaluate on the IN-1K validation set as well as multiple ImageNet variants, including IN-ReaL, IN-V2, IN-A, IN-R, and IN-Sketch. Results are reported for both linear probing and attention pooling probing methods, with average accuracy for each method. ∆ represents the performance gap between attention pooling probing and linear probing, where a larger ∆ suggests a shift from learning simple linear features to capturing more complex, nonlinear semantic representations.
## Semantic Segmentation Performance

**Semantic segmentation performance across different versions of InternViT.** The models are evaluated on ADE20K and COCO-Stuff-164K using three configurations: linear probing, head tuning, and full tuning. The table shows the mIoU scores for each configuration and their averages. ∆1 represents the gap between head tuning and linear probing, while ∆2 shows the gap between full tuning and linear probing. A larger ∆ value indicates a shift from simple linear features to more complex, nonlinear representations.
## Quick Start
> \[!Warning\]
> 🚨 Note: In our experience, the InternViT V2.5 series is better suited for building MLLMs than traditional computer vision tasks.
```python
import torch
from PIL import Image
from transformers import AutoModel, CLIPImageProcessor
model = AutoModel.from_pretrained(
'OpenGVLab/InternViT-300M-448px-V2_5',
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).cuda().eval()
image = Image.open('./examples/image1.jpg').convert('RGB')
image_processor = CLIPImageProcessor.from_pretrained('OpenGVLab/InternViT-300M-448px-V2_5')
pixel_values = image_processor(images=image, return_tensors='pt').pixel_values
pixel_values = pixel_values.to(torch.bfloat16).cuda()
outputs = model(pixel_values)
```
## License
This project is released under the MIT License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
