---
license: apache-2.0
---
# Megrez-3B-Omni: 首个端侧全模态理解开源模型

🔗 GitHub | 🏠 Demo | 📖 WeChat Official | 💬 WeChat Groups
中文 | English
## 模型简介
Megrez-3B-Omni是由无问芯穹([Infinigence AI](https://cloud.infini-ai.com/platform/ai))研发的**端侧全模态**理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,在三个方面均取得最优精度
- 在图像理解方面,基于SigLip-400M构建图像Token,在OpenCompass榜单上(综合8个主流多模态评测基准)平均得分66.2,超越LLaVA-NeXT-Yi-34B等更大参数规模的模型。Megrez-3B-Omni也是在MME、MMMU、OCRBench等测试集上目前精度最高的图像理解模型之一,在场景理解、OCR等方面具有良好表现。
- 在语言理解方面,Megrez-3B-Omni并未牺牲模型的文本处理能力,综合能力较单模态版本(Megrez-3B-Instruct)精度变化小于2%,保持在C-EVAL、MMLU/MMLU Pro、AlignBench等多个测试集上的最优精度优势,依然取得超越上一代14B模型的能力表现
- 在语音理解方面,采用Qwen2-Audio/whisper-large-v3的Encoder作为语音输入,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果
## 基础信息
|
Language Module |
Vision Module |
Audio Module |
| Architecture |
Llama-2 with GQA |
SigLip-SO400M |
Whisper-large-v3
(encoder-only) |
| # Params (Backbone) |
2.29B |
0.42B |
0.64B |
| Connector |
- |
Cross Attention |
Linear |
| # Params (Others) |
Emb: 0.31B
Softmax: 0.31B |
Connector: 0.036B |
Connector: 0.003B |
| # Params (Total) |
4B |
| # Vocab Size |
122880 |
64 tokens/slice |
- |
| Context length |
4K tokens |
| Supported languages |
Chinese & English |
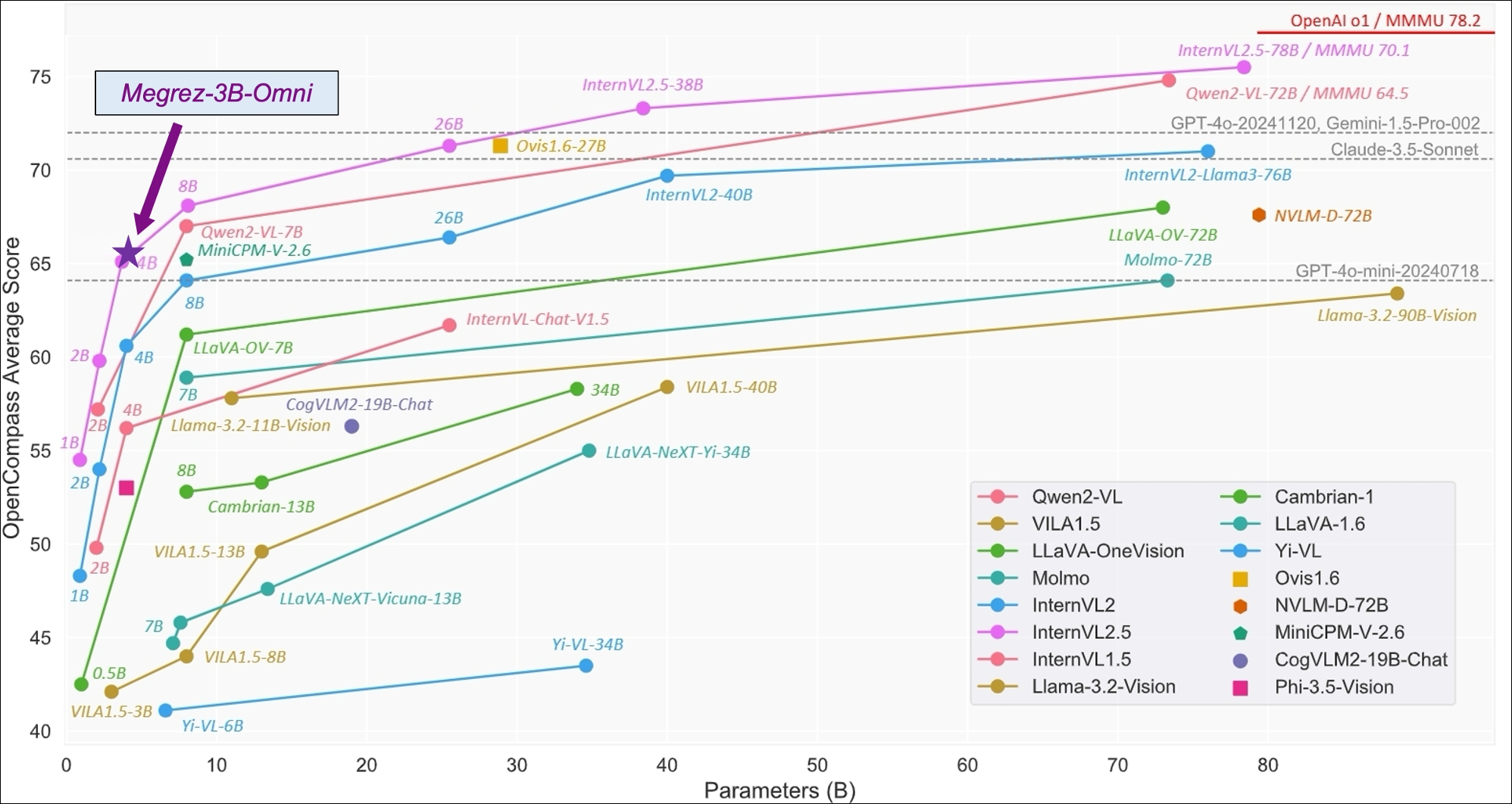
### 图片理解能力
- 上图为Megrez-3B-Omni与其他开源模型在主流图片多模态任务上的性能比较
- 下图为Megrez-3B-Omni在OpenCompass测试集上表现,图片引用自: [InternVL 2.5 Blog Post](https://internvl.github.io/blog/2024-12-05-InternVL-2.5/)
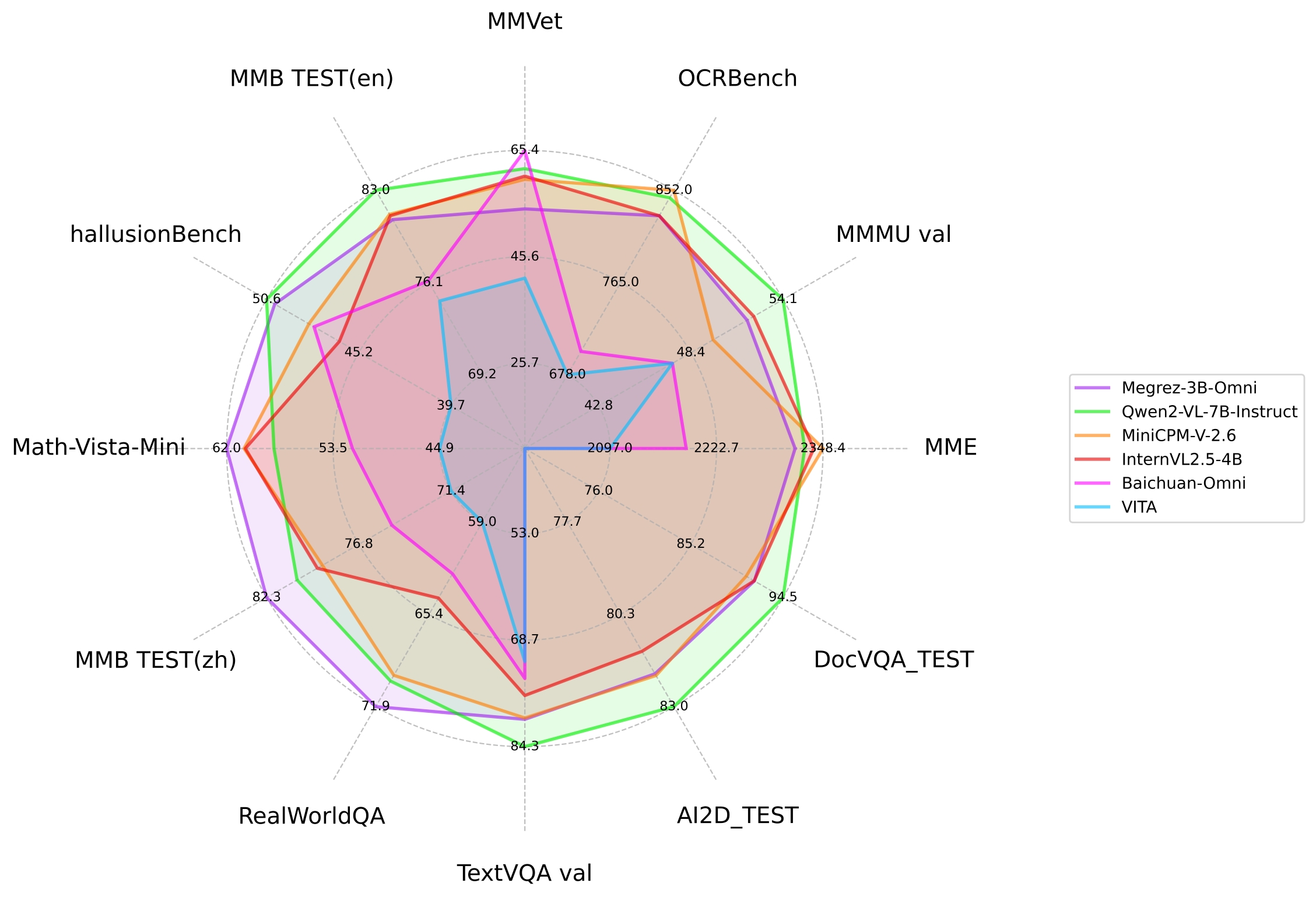
| model | basemodel | 发布时间 | OpenCompass | MME | MMMU val | OCRBench | MathVista | RealWorldQA | MMVet | hallusionBench | MMB TEST (en) | MMB TEST (zh) | TextVQA val | AI2D_TEST | MMstar | DocVQA_TEST |
|-----------------------|-----------------------|----------------|--------------------|----------|-----------|----------|-----------------|-------------|--------|----------------|--------------|--------------|-------------|-----------|-----------|-------------|
| **Megrez-3B-Omni** | **Megrez-3B** | **2024.12.16** | **66.2** | **2315** | **51.89** | **82.8** | **62** | **71.89** | **60** | **50.12** | **80.8** | **82.3** | **80.3** | **82.05** | **60.46** | **91.62** |
| Qwen2-VL-2B-Instruct | Qwen2-1.5B | 2024.08.28 | 57.2 | 1872 | 41.1 | 79.4 | 43 | 62.9 | 49.5 | 41.7 | 74.9 | 73.5 | 79.7 | 74.7 | 48 | 90.1 |
| InternVL2.5-2B | Internlm2.5-1.8B-chat | 2024.12.06 | 59.9 | 2138 | 43.6 | 80.4 | 51.3 | 60.1 | 60.8 | 42.6 | 74.7 | 71.9 | 74.3 | 74.9 | 53.7 | 88.7 |
| BlueLM-V-3B | - | 2024.11.29 | 66.1 | - | 45.1 | 82.9 | 60.8 | 66.7 | 61.8 | 48 | 83 | 80.5 | 78.4 | 85.3 | 62.3 | 87.8 |
| InternVL2.5-4B | Qwen2.5-3B-Instruct | 2024.12.06 | 65.1 | 2337 | 52.3 | 82.8 | 60.5 | 64.3 | 60.6 | 46.3 | 81.1 | 79.3 | 76.8 | 81.4 | 58.3 | 91.6 |
| Baichuan-Omni | Unknown-7B | 2024.10.11 | - | 2186 | 47.3 | 70.0 | 51.9 | 62.6 | 65.4 | 47.8 | 76.2 | 74.9 | 74.3 | - | - | - |
| MiniCPM-V-2.6 | Qwen2-7B | 2024.08.06 | 65.2 | 2348 | 49.8 | 85.2 | 60.6 | 69.7 | 60 | 48.1 | 81.2 | 79 | 80.1 | 82.1 | 57.26 | 90.8 |
| Qwen2-VL-7B-Instruct | Qwen2-7B | 2024.08.28 | 67 | 2326 | 54.1 | 84.5 | 58.2 | 70.1 | 62 | 50.6 | 83 | 80.5 | 84.3 | 83 | 60.7 | 94.5 |
| MiniCPM-Llama3-V-2.5 | Llama3-Instruct 8B | 2024.05.20 | 58.8 | 2024 | 45.8 | 72.5 | 54.3 | 63.5 | 52.8 | 42.4 | 77.2 | 74.2 | 76.6 | 78.4 | - | 84.8 |
| VITA | Mixtral 8x7B | 2024.08.12 | - | 2097 | 47.3 | 67.8 | 44.9 | 59 | 41.6 | 39.7 | 74.7 | 71.4 | 71.8 | - | - | - |
| GLM-4V-9B | GLM-4-9B | 2024.06.04 | 59.1 | 2018 | 46.9 | 77.6 | 51.1 | - | 58 | 46.6 | 81.1 | 79.4 | - | 81.1 | 58.7 | - |
| LLaVA-NeXT-Yi-34B | Yi-34B | 2024.01.18 | 55 | 2006 | 48.8 | 57.4 | 40.4 | 66 | 50.7 | 34.8 | 81.1 | 79 | 69.3 | 78.9 | 51.6 | - |
| Qwen2-VL-72B-Instruct | Qwen2-72B | 2024.08.28 | 74.8 | 2482 | 64.5 | 87.7 | 70.5 | 77.8 | 74 | 58.1 | 86.5 | 86.6 | 85.5 | 88.1 | 68.3 | 96.5 |
### 文本处理能力
| | | | | 对话&指令 | | | 中文&英文任务 | | | | 代码任务 | | 数学任务 | |
|:---------------------:|:--------:|:-----------:|:-------------------------------------:|:---------:|:---------------:|:------:|:-------------:|:----------:|:-----:|:--------:|:---------:|:-----:|:--------:|:-----:|
| models | 指令模型 | 发布时间 | # Non-Emb Params | MT-Bench | AlignBench (ZH) | IFEval | C-EVAL (ZH) | CMMLU (ZH) | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
| Megrez-3B-Omni | Y | 2024.12.16 | 2.3 | 8.4 | 6.94 | 66.5 | 84.0 | 75.3 | 73.3 | 45.2 | 72.6 | 60.6 | 63.8 | 27.3 |
| Megrez-3B-Instruct | Y | 2024.12.16 | 2.3 | 8.64 | 7.06 | 68.6 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
| Baichuan-Omni | Y | 2024.10.11 | 7.0 | - | - | - | 68.9 | 72.2 | 65.3 | - | - | - | - | - |
| VITA | Y | 2024.08.12 | 12.9 | - | - | - | 56.7 | 46.6 | 71.0 | - | - | - | 75.7 | - |
| Qwen1.5-7B | | 2024.02.04 | 6.5 | - | - | - | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
| Qwen1.5-7B-Chat | Y | 2024.02.04 | 6.5 | 7.60 | 6.20 | - | 67.3 | - | 59.5 | 29.1 | 46.3 | 48.9 | 60.3 | 23.2 |
| Qwen1.5-14B | | 2024.02.04 | 12.6 | - | - | - | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
| Qwen1.5-14B-Chat | Y | 2024.02.04 | 12.6 | 7.9 | - | - | - | - | - | - | - | - | - | - |
| Qwen2-7B | | 2024.06.07 | 6.5 | - | - | - | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
| Qwen2-7b-Instruct | Y | 2024.06.07 | 6.5 | 8.41 | 7.21 | 51.4 | 80.9 | 77.2 | 70.5 | 44.1 | 79.9 | 67.2 | 85.7 | 52.9 |
| Qwen2.5-3B-Instruct | Y | 2024.9.19 | 2.8 | - | - | - | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
| Qwen2.5-7B | | 2024.9.19 | 6.5 | - | - | - | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
| Qwen2.5-7B-Instruct | Y | 2024.09.19 | 6.5 | 8.75 | - | 74.9 | - | - | - | 56.3 | 84.8 | 79.2 | 91.6 | 75.5 |
| Llama-3.1-8B | | 2024.07.23 | 7.0 | 8.3 | 5.7 | 71.5 | 55.2 | 55.8 | 66.7 | 37.1 | - | - | 84.5 | 51.9 |
| Llama-3.2-3B | | 2024.09.25 | 2.8 | - | - | 77.4 | - | - | 63.4 | - | - | - | 77.7 | 48.0 |
| Phi-3.5-mini-instruct | Y | 2024.08.23 | 3.6 | 8.6 | 5.7 | 49.4 | 46.1 | 46.9 | 69.0 | 47.4 | 62.8 | 69.6 | 86.2 | 48.5 |
| MiniCPM3-4B | Y | 2024.09.05 | 3.9 | 8.41 | 6.74 | 68.4 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
| Yi-1.5-6B-Chat | Y | 2024.05.11 | 5.5 | 7.50 | 6.20 | - | 74.2 | 74.7 | 61.0 | - | 64.0 | 70.9 | 78.9 | 40.5 |
| GLM-4-9B-chat | Y | 2024.06.04 | 8.2 | 8.35 | 7.01 | 64.5 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
| Baichuan2-13B-Base | | 2023.09.06 | 12.6 | - | 5.25 | - | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
注:Qwen2-1.5B模型的指标在论文和Qwen2.5报告中点数不一致,当前采用原始论文中的精度
### 语音理解能力
| Model | Base model | Release Time | Fleurs test-zh | WenetSpeech test_net | WenetSpeech test_meeting |
|:----------------:|:------------------:|:-------------:|:--------------:|:--------------------:|:------------------------:|
| Megrez-3B-Omni | Megrez-3B-Instruct | 2024.12.16 | 10.8 | - | 16.4 |
| Whisper-large-v3 | - | 2023.11.06 | 12.4 | 17.5 | 30.8 |
| Qwen2-Audio-7B | Qwen2-7B | 2024.08.09 | 9 | 11 | 10.7 |
| Baichuan2-omni | Unknown-7B | 2024.10.11 | 7 | 6.9 | 8.4 |
| VITA | Mixtral 8x7B | 2024.08.12 | - | -/12.2(CER) | -/16.5(CER) |
### 速度
| | image_tokens | prefill (tokens/s) | decode (tokens/s) |
|----------------|:------------:|:------------------:|:-----------------:|
| Megrez-3B-Omni | 448 | 6312.66 | 1294.9 |
| Qwen2-VL-2B | 1378 | 7349.39 | 685.66 |
| MiniCPM-V-2_6 | 448 | 2167.09 | 452.51 |
实验设置:
- 测试环境:NVIDIA H100,vLLM下输入128个Text token和一张1480x720大小图片,输出128个token,num_seqs固定为8
- Qwen2-VL-2B虽然其具备更小尺寸的基座模型,但编码上述大小图片后的image_token相较Megrez-3B-Omni多很多,导致此实验下的decode速度小于Megrez-3B-Omni
## 快速上手
### 在线体验
[HF Chat Demo](https://huggingface.co./spaces/Infinigence/Megrez-3B-Omni)
### 本地部署
环境安装和vLLM推理代码等部署问题可以参考 [Infini-Megrez-Omni](https://github.com/infinigence/Infini-Megrez-Omni)
如下是一个使用transformers进行推理的例子,通过在content字段中分别传入text、image和audio,可以图文/图音等多种模态和模型进行交互。
```python
import torch
from transformers import AutoModelForCausalLM
path = "{{PATH_TO_PRETRAINED_MODEL}}" # Change this to the path of the model.
model = (
AutoModelForCausalLM.from_pretrained(
path,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
.eval()
.cuda()
)
# Chat with text and image
messages = [
{
"role": "user",
"content": {
"text": "Please describe the content of the image.",
"image": "./data/sample_image.jpg",
},
},
]
# Chat with audio and image
messages = [
{
"role": "user",
"content": {
"image": "./data/sample_image.jpg",
"audio": "./data/sample_audio.m4a",
},
},
]
MAX_NEW_TOKENS = 100
response = model.chat(
messages,
sampling=False,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0,
)
print(response)
```
## 注意事项
1. 请将图片尽量在首轮输入以保证推理效果,语音和文本无此限制,可以自由切换
2. 语音识别(ASR)场景下,只需要将content['text']修改为“将语音转化为文字。”
3. OCR场景下开启采样可能会引入语言模型幻觉导致的文字变化,可考虑关闭采样进行推理(sampling=False),但关闭采样可能引入模型复读
## 开源协议及使用声明
- 协议:本仓库中代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源。
- 幻觉:大模型天然存在幻觉问题,用户使用过程中请勿完全相信模型生成的内容。
- 价值观及安全性:本模型已尽全力确保训练过程中使用的数据的合规性,但由于数据的大体量及复杂性,仍有可能存在一些无法预见的问题。如果出现使用本开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
{kind=link}
{kind=link}