
lizhiyuan
commited on
Commit
•
a951ae0
1
Parent(s):
c4c3fca
update model
Browse files- .gitattributes +2 -0
- README.md +222 -3
- README_EN.md +217 -0
- assets/github-mark.png +0 -0
- assets/megrez_logo.png +0 -0
- assets/multitask.jpg +0 -0
- assets/opencompass.jpg +0 -0
- assets/wechat-group.jpg +0 -0
- assets/wechat-official.jpg +0 -0
- assets/wechat.jpg +0 -0
- audio.py +228 -0
- config.json +125 -0
- configuration_megrezo.py +87 -0
- generation_config.json +7 -0
- image_processing_megrezo.py +386 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +0 -0
- modeling_megrezo.py +328 -0
- modeling_navit_siglip.py +937 -0
- preprocessor_config.json +46 -0
- processing_megrezo.py +587 -0
- processor_config.json +7 -0
- resampler.py +783 -0
- special_tokens_map.json +10 -0
- tokenizer.json +0 -0
- tokenizer_config.json +257 -0
- tokenizer_wrapper.py +63 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
model-00001-of-00002.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model-00002-of-00002.safetensors filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,222 @@
|
|
| 1 |
-
---
|
| 2 |
-
license: apache-2.0
|
| 3 |
-
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
# Megrez-3B-Omni: 首个端侧全模态理解开源模型
|
| 5 |
+
<p align="center">
|
| 6 |
+
<img src="assets/megrez_logo.png" width="400"/>
|
| 7 |
+
<p>
|
| 8 |
+
<p align="center">
|
| 9 |
+
🔗 <a href="https://github.com/infinigence/Infini-Megrez-Omni">GitHub</a>   |   🏠 <a href="https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni">Demo</a>   |   📖 <a href="assets/png/wechat-official.jpg">WeChat Official</a>   |   💬 <a href="assets/wechat-group.jpg">WeChat Groups</a>  
|
| 10 |
+
</p>
|
| 11 |
+
<h4 align="center">
|
| 12 |
+
<p>
|
| 13 |
+
<b>中文</b> | <a href="https://huggingface.co/Infinigence/Megrez-3B-Omni/blob/main/README_EN.md">English</a>
|
| 14 |
+
<p>
|
| 15 |
+
</h4>
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
## 模型简介
|
| 19 |
+
Megrez-3B-Omni是由无问芯穹([Infinigence AI](https://cloud.infini-ai.com/platform/ai))研发的**端侧全模态**理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,在三个方面均取得最优精度
|
| 20 |
+
- 在图像理解方面,基于SigLip-400M构建图像Token,在OpenCompass榜单上(综合8个主流多模态评测基准)平均得分66.2,超越LLaVA-NeXT-Yi-34B等更大参数规模的模型。Megrez-3B-Omni也是在MME、MMMU、OCRBench等测试集上目前精度最高的图像理解模型之一,在场景理解、OCR等方面具有良好表现。
|
| 21 |
+
- 在语言理解方面,Megrez-3B-Omni并未牺牲模型的文本处理能力,综合能力较单模态版本(Megrez-3B-Instruct)精度变化小于2%,保持在C-EVAL、MMLU/MMLU Pro、AlignBench等多个测试集上的最优精度优势,依然取得超越上一代14B模型的能力表现
|
| 22 |
+
- 在语音理解方面,采用Qwen2-Audio/whisper-large-v3的Encoder作为语音输入,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## 基础信息
|
| 26 |
+
<table>
|
| 27 |
+
<thead>
|
| 28 |
+
<tr>
|
| 29 |
+
<th></th>
|
| 30 |
+
<th>Language Module</th>
|
| 31 |
+
<th>Vision Module</th>
|
| 32 |
+
<th>Audio Module</th>
|
| 33 |
+
</tr>
|
| 34 |
+
</thead>
|
| 35 |
+
<tbody>
|
| 36 |
+
<tr>
|
| 37 |
+
<td>Architecture</td>
|
| 38 |
+
<td>Llama-2 with GQA</td>
|
| 39 |
+
<td>SigLip-SO400M</td>
|
| 40 |
+
<td>Whisper-large-v3
|
| 41 |
+
(encoder-only)</td>
|
| 42 |
+
</tr>
|
| 43 |
+
<tr>
|
| 44 |
+
<td># Params (Backbone)</td>
|
| 45 |
+
<td>2.29B</td>
|
| 46 |
+
<td>0.42B</td>
|
| 47 |
+
<td>0.64B</td>
|
| 48 |
+
</tr>
|
| 49 |
+
<tr>
|
| 50 |
+
<td>Connector</td>
|
| 51 |
+
<td>-</td>
|
| 52 |
+
<td>Cross Attention</td>
|
| 53 |
+
<td>Linear</td>
|
| 54 |
+
</tr>
|
| 55 |
+
<tr>
|
| 56 |
+
<td># Params (Others)</td>
|
| 57 |
+
<td>Emb: 0.31B<br>Softmax: 0.31B</td>
|
| 58 |
+
<td>Connector: 0.036B</td>
|
| 59 |
+
<td>Connector: 0.003B</td>
|
| 60 |
+
</tr>
|
| 61 |
+
<tr>
|
| 62 |
+
<td># Params (Total)</td>
|
| 63 |
+
<td colspan="3">4B</td>
|
| 64 |
+
</tr>
|
| 65 |
+
<tr>
|
| 66 |
+
<td># Vocab Size</td>
|
| 67 |
+
<td>122880</td>
|
| 68 |
+
<td>64 tokens/slice</td>
|
| 69 |
+
<td>-</td>
|
| 70 |
+
</tr>
|
| 71 |
+
<tr>
|
| 72 |
+
<td>Context length</td>
|
| 73 |
+
<td colspan="3">4K tokens</td>
|
| 74 |
+
</tr>
|
| 75 |
+
<tr>
|
| 76 |
+
<td>Supported languages</td>
|
| 77 |
+
<td colspan="3">Chinese & English</td>
|
| 78 |
+
</tr>
|
| 79 |
+
</tbody>
|
| 80 |
+
</table>
|
| 81 |
+
|
| 82 |
+
### 图片理解能力
|
| 83 |
+
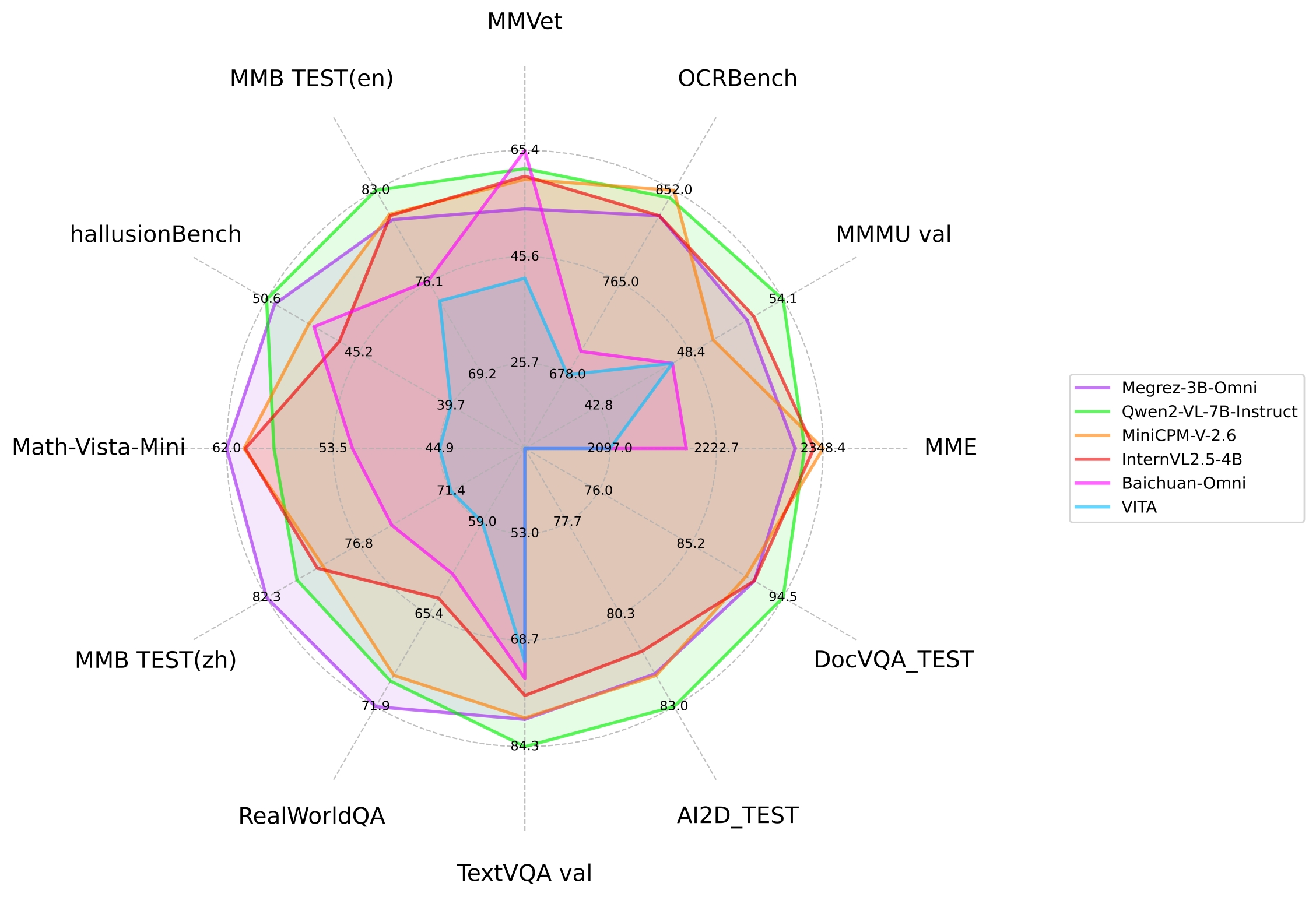
- 上图为Megrez-3B-Omni与其他开源模型在主流图片多模态任务上的性能比较
|
| 84 |
+
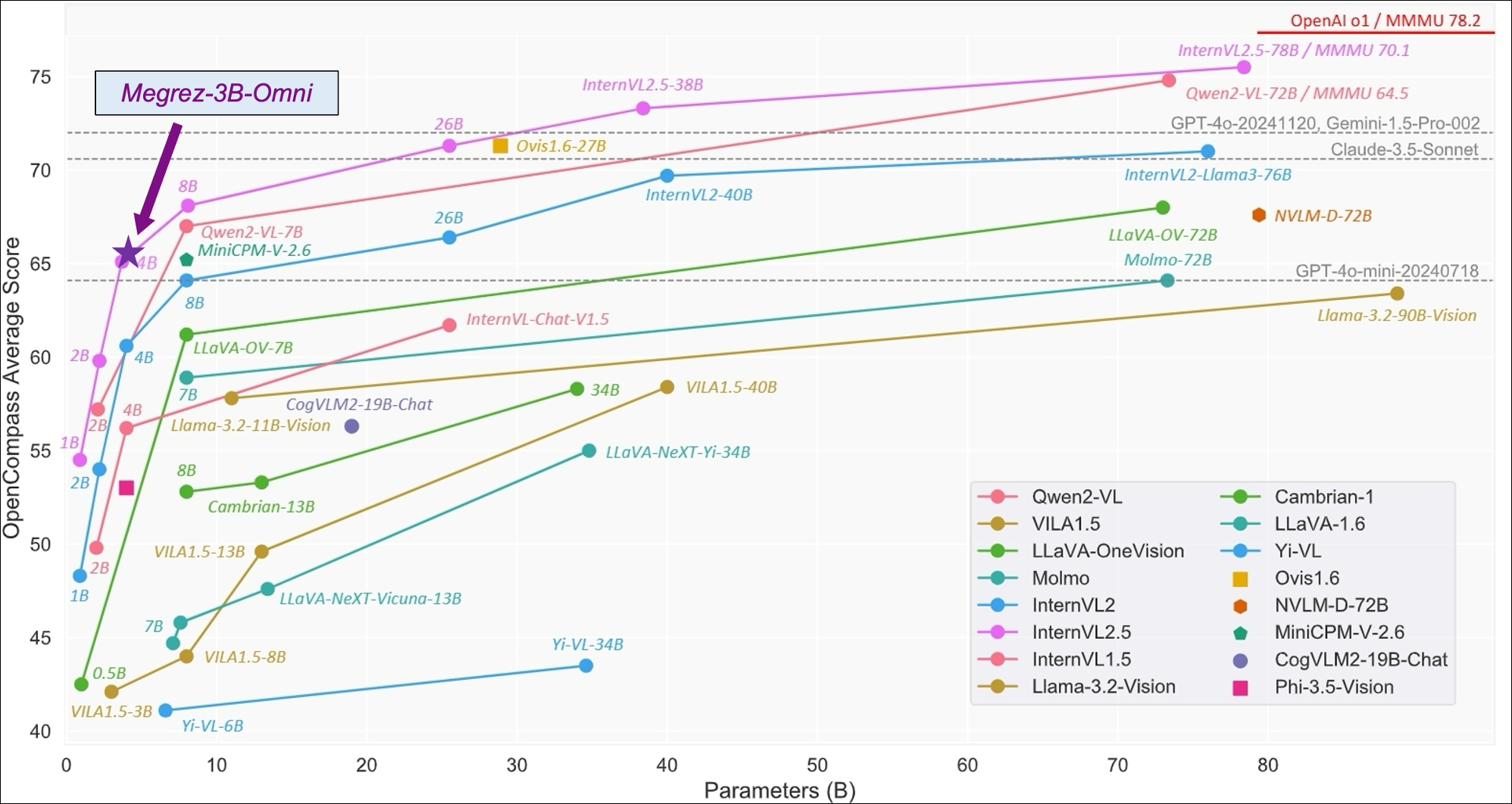
- 下图为Megrez-3B-Omni在OpenCompass测试集上表现,图片引用自: [InternVL 2.5 Blog Post](https://internvl.github.io/blog/2024-12-05-InternVL-2.5/)
|
| 85 |
+
<!-- <div style="display: flex; justify-content: space-between;">
|
| 86 |
+
<img src="assets/multitask.jpg" alt="Image 1" style="width: 45%;">
|
| 87 |
+
<img src="assets/opencompass.jpg" alt="Image 2" style="width: 45%;">
|
| 88 |
+
</div> -->
|
| 89 |
+
|
| 90 |
+

|
| 91 |
+

|
| 92 |
+
|
| 93 |
+
| model | basemodel | 发布时间 | OpenCompass | MME | MMMU val | OCRBench | MathVista | RealWorldQA | MMVet | hallusionBench | MMB TEST (en) | MMB TEST (zh) | TextVQA val | AI2D_TEST | MMstar | DocVQA_TEST |
|
| 94 |
+
|-----------------------|-----------------------|----------------|--------------------|----------|-----------|----------|-----------------|-------------|--------|----------------|--------------|--------------|-------------|-----------|-----------|-------------|
|
| 95 |
+
| **Megrez-3B-Omni** | **Megrez-3B** | **2024.12.16** | **66.2** | **2315** | **51.89** | **82.8** | **62** | **71.89** | **60** | **50.12** | **80.8** | **82.3** | **80.3** | **82.05** | **60.46** | **91.62** |
|
| 96 |
+
| Qwen2-VL-2B-Instruct | Qwen2-1.5B | 2024.08.28 | 57.2 | 1872 | 41.1 | 79.4 | 43 | 62.9 | 49.5 | 41.7 | 74.9 | 73.5 | 79.7 | 74.7 | 48 | 90.1 |
|
| 97 |
+
| InternVL2.5-2B | Internlm2.5-1.8B-chat | 2024.12.06 | 59.9 | 2138 | 43.6 | 80.4 | 51.3 | 60.1 | 60.8 | 42.6 | 74.7 | 71.9 | 74.3 | 74.9 | 53.7 | 88.7 |
|
| 98 |
+
| BlueLM-V-3B | - | 2024.11.29 | 66.1 | - | 45.1 | 82.9 | 60.8 | 66.7 | 61.8 | 48 | 83 | 80.5 | 78.4 | 85.3 | 62.3 | 87.8 |
|
| 99 |
+
| InternVL2.5-4B | Qwen2.5-3B-Instruct | 2024.12.06 | 65.1 | 2337 | 52.3 | 82.8 | 60.5 | 64.3 | 60.6 | 46.3 | 81.1 | 79.3 | 76.8 | 81.4 | 58.3 | 91.6 |
|
| 100 |
+
| Baichuan-Omni | Unknown-7B | 2024.10.11 | - | 2186 | 47.3 | 70.0 | 51.9 | 62.6 | 65.4 | 47.8 | 76.2 | 74.9 | 74.3 | - | - | - |
|
| 101 |
+
| MiniCPM-V-2.6 | Qwen2-7B | 2024.08.06 | 65.2 | 2348 | 49.8 | 85.2 | 60.6 | 69.7 | 60 | 48.1 | 81.2 | 79 | 80.1 | 82.1 | 57.26 | 90.8 |
|
| 102 |
+
| Qwen2-VL-7B-Instruct | Qwen2-7B | 2024.08.28 | 67 | 2326 | 54.1 | 84.5 | 58.2 | 70.1 | 62 | 50.6 | 83 | 80.5 | 84.3 | 83 | 60.7 | 94.5 |
|
| 103 |
+
| MiniCPM-Llama3-V-2.5 | Llama3-Instruct 8B | 2024.05.20 | 58.8 | 2024 | 45.8 | 72.5 | 54.3 | 63.5 | 52.8 | 42.4 | 77.2 | 74.2 | 76.6 | 78.4 | - | 84.8 |
|
| 104 |
+
| VITA | Mixtral 8x7B | 2024.08.12 | - | 2097 | 47.3 | 67.8 | 44.9 | 59 | 41.6 | 39.7 | 74.7 | 71.4 | 71.8 | - | - | - |
|
| 105 |
+
| GLM-4V-9B | GLM-4-9B | 2024.06.04 | 59.1 | 2018 | 46.9 | 77.6 | 51.1 | - | 58 | 46.6 | 81.1 | 79.4 | - | 81.1 | 58.7 | - |
|
| 106 |
+
| LLaVA-NeXT-Yi-34B | Yi-34B | 2024.01.18 | 55 | 2006 | 48.8 | 57.4 | 40.4 | 66 | 50.7 | 34.8 | 81.1 | 79 | 69.3 | 78.9 | 51.6 | - |
|
| 107 |
+
| Qwen2-VL-72B-Instruct | Qwen2-72B | 2024.08.28 | 74.8 | 2482 | 64.5 | 87.7 | 70.5 | 77.8 | 74 | 58.1 | 86.5 | 86.6 | 85.5 | 88.1 | 68.3 | 96.5 |
|
| 108 |
+
|
| 109 |
+
### 文本处理能力
|
| 110 |
+
| | | | | 对话&指令 | | | 中文&英文任务 | | | | 代码任务 | | 数学任务 | |
|
| 111 |
+
|:---------------------:|:--------:|:-----------:|:-------------------------------------:|:---------:|:---------------:|:------:|:-------------:|:----------:|:-----:|:--------:|:---------:|:-----:|:--------:|:-----:|
|
| 112 |
+
| models | 指令模型 | 发布时间 | # Non-Emb Params | MT-Bench | AlignBench (ZH) | IFEval | C-EVAL (ZH) | CMMLU (ZH) | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
|
| 113 |
+
| Megrez-3B-Omni | Y | 2024.12.16 | 2.3 | 8.4 | 6.94 | 66.5 | 84.0 | 75.3 | 73.3 | 45.2 | 72.6 | 60.6 | 63.8 | 27.3 |
|
| 114 |
+
| Megrez-3B-Instruct | Y | 2024.12.16 | 2.3 | 8.64 | 7.06 | 68.6 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
|
| 115 |
+
| Baichuan-Omni | Y | 2024.10.11 | 7.0 | - | - | - | 68.9 | 72.2 | 65.3 | - | - | - | - | - |
|
| 116 |
+
| VITA | Y | 2024.08.12 | 12.9 | - | - | - | 56.7 | 46.6 | 71.0 | - | - | - | 75.7 | - |
|
| 117 |
+
| Qwen1.5-7B | | 2024.02.04 | 6.5 | - | - | - | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
|
| 118 |
+
| Qwen1.5-7B-Chat | Y | 2024.02.04 | 6.5 | 7.60 | 6.20 | - | 67.3 | - | 59.5 | 29.1 | 46.3 | 48.9 | 60.3 | 23.2 |
|
| 119 |
+
| Qwen1.5-14B | | 2024.02.04 | 12.6 | - | - | - | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
|
| 120 |
+
| Qwen1.5-14B-Chat | Y | 2024.02.04 | 12.6 | 7.9 | - | - | - | - | - | - | - | - | - | - |
|
| 121 |
+
| Qwen2-7B | | 2024.06.07 | 6.5 | - | - | - | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
|
| 122 |
+
| Qwen2-7b-Instruct | Y | 2024.06.07 | 6.5 | 8.41 | 7.21 | 51.4 | 80.9 | 77.2 | 70.5 | 44.1 | 79.9 | 67.2 | 85.7 | 52.9 |
|
| 123 |
+
| Qwen2.5-3B-Instruct | Y | 2024.9.19 | 2.8 | - | - | - | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
|
| 124 |
+
| Qwen2.5-7B | | 2024.9.19 | 6.5 | - | - | - | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
|
| 125 |
+
| Qwen2.5-7B-Instruct | Y | 2024.09.19 | 6.5 | 8.75 | - | 74.9 | - | - | - | 56.3 | 84.8 | 79.2 | 91.6 | 75.5 |
|
| 126 |
+
| Llama-3.1-8B | | 2024.07.23 | 7.0 | 8.3 | 5.7 | 71.5 | 55.2 | 55.8 | 66.7 | 37.1 | - | - | 84.5 | 51.9 |
|
| 127 |
+
| Llama-3.2-3B | | 2024.09.25 | 2.8 | - | - | 77.4 | - | - | 63.4 | - | - | - | 77.7 | 48.0 |
|
| 128 |
+
| Phi-3.5-mini-instruct | Y | 2024.08.23 | 3.6 | 8.6 | 5.7 | 49.4 | 46.1 | 46.9 | 69.0 | 47.4 | 62.8 | 69.6 | 86.2 | 48.5 |
|
| 129 |
+
| MiniCPM3-4B | Y | 2024.09.05 | 3.9 | 8.41 | 6.74 | 68.4 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
|
| 130 |
+
| Yi-1.5-6B-Chat | Y | 2024.05.11 | 5.5 | 7.50 | 6.20 | - | 74.2 | 74.7 | 61.0 | - | 64.0 | 70.9 | 78.9 | 40.5 |
|
| 131 |
+
| GLM-4-9B-chat | Y | 2024.06.04 | 8.2 | 8.35 | 7.01 | 64.5 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
|
| 132 |
+
| Baichuan2-13B-Base | | 2023.09.06 | 12.6 | - | 5.25 | - | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
|
| 133 |
+
|
| 134 |
+
注:Qwen2-1.5B模型的指标在论文和Qwen2.5报告中点数不一致,当前采用原始论文中的精度
|
| 135 |
+
|
| 136 |
+
### 语音理解能力
|
| 137 |
+
| Model | Base model | Release Time | Fleurs test-zh | WenetSpeech test_net | WenetSpeech test_meeting |
|
| 138 |
+
|:----------------:|:------------------:|:-------------:|:--------------:|:--------------------:|:------------------------:|
|
| 139 |
+
| Megrez-3B-Omni | Megrez-3B-Instruct | 2024.12.16 | 10.8 | - | 16.4 |
|
| 140 |
+
| Whisper-large-v3 | - | 2023.11.06 | 12.4 | 17.5 | 30.8 |
|
| 141 |
+
| Qwen2-Audio-7B | Qwen2-7B | 2024.08.09 | 9 | 11 | 10.7 |
|
| 142 |
+
| Baichuan2-omni | Unknown-7B | 2024.10.11 | 7 | 6.9 | 8.4 |
|
| 143 |
+
| VITA | Mixtral 8x7B | 2024.08.12 | - | -/12.2(CER) | -/16.5(CER) |
|
| 144 |
+
|
| 145 |
+
### 速度
|
| 146 |
+
| | image_tokens | prefill (tokens/s) | decode (tokens/s) |
|
| 147 |
+
|----------------|:------------:|:------------------:|:-----------------:|
|
| 148 |
+
| Megrez-3B-Omni | 448 | 6312.66 | 1294.9 |
|
| 149 |
+
| Qwen2-VL-2B | 1378 | 7349.39 | 685.66 |
|
| 150 |
+
| MiniCPM-V-2_6 | 448 | 2167.09 | 452.51 |
|
| 151 |
+
|
| 152 |
+
实验设置:
|
| 153 |
+
- 测试环境:NVIDIA H100,vLLM下输入128个Text token和一张1480x720大小图片,输出128个token,num_seqs固定为8
|
| 154 |
+
- Qwen2-VL-2B虽然其具备更小尺寸的基座模型,但编码上述大小图片后的image_token相较Megrez-3B-Omni多很多,导致此实验下的decode速度小于Megrez-3B-Omni
|
| 155 |
+
|
| 156 |
+
## 快速上手
|
| 157 |
+
|
| 158 |
+
### 在线体验
|
| 159 |
+
[HF Chat Demo](https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni)
|
| 160 |
+
|
| 161 |
+
### 本地部署
|
| 162 |
+
环境安装和vLLM推理代码等部署问题可以参考 [Infini-Megrez-Omni](https://github.com/infinigence/Infini-Megrez-Omni)
|
| 163 |
+
|
| 164 |
+
如下是一个使用transformers进行推理的例子,通过在content字段中分别传入text、image和audio,可以图文/图音等多种模态和模型进行交互。
|
| 165 |
+
```python
|
| 166 |
+
import torch
|
| 167 |
+
from transformers import AutoModelForCausalLM
|
| 168 |
+
|
| 169 |
+
path = "{{PATH_TO_PRETRAINED_MODEL}}" # Change this to the path of the model.
|
| 170 |
+
|
| 171 |
+
model = (
|
| 172 |
+
AutoModelForCausalLM.from_pretrained(
|
| 173 |
+
path,
|
| 174 |
+
trust_remote_code=True,
|
| 175 |
+
torch_dtype=torch.bfloat16,
|
| 176 |
+
attn_implementation="flash_attention_2",
|
| 177 |
+
)
|
| 178 |
+
.eval()
|
| 179 |
+
.cuda()
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
# Chat with text and image
|
| 183 |
+
messages = [
|
| 184 |
+
{
|
| 185 |
+
"role": "user",
|
| 186 |
+
"content": {
|
| 187 |
+
"text": "Please describe the content of the image.",
|
| 188 |
+
"image": "./data/sample_image.jpg",
|
| 189 |
+
},
|
| 190 |
+
},
|
| 191 |
+
]
|
| 192 |
+
|
| 193 |
+
# Chat with audio and image
|
| 194 |
+
messages = [
|
| 195 |
+
{
|
| 196 |
+
"role": "user",
|
| 197 |
+
"content": {
|
| 198 |
+
"image": "./data/sample_image.jpg",
|
| 199 |
+
"audio": "./data/sample_audio.m4a",
|
| 200 |
+
},
|
| 201 |
+
},
|
| 202 |
+
]
|
| 203 |
+
|
| 204 |
+
MAX_NEW_TOKENS = 100
|
| 205 |
+
response = model.chat(
|
| 206 |
+
messages,
|
| 207 |
+
sampling=False,
|
| 208 |
+
max_new_tokens=MAX_NEW_TOKENS,
|
| 209 |
+
temperature=0,
|
| 210 |
+
)
|
| 211 |
+
print(response)
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
## 注意事项
|
| 215 |
+
1. 请将图片尽量在首轮输入以保证推理效果,语音和文本无此限制,可以自由切换
|
| 216 |
+
2. 语音识别(ASR)场景下,只需要将content['text']修改为“将语音转化为文字。”
|
| 217 |
+
3. OCR场景下开启采样可能会引入语言模型幻觉导致的文字变化,可考虑关闭采样进行推理(sampling=False),但关闭采样可能引入模型复读
|
| 218 |
+
|
| 219 |
+
## 开源协议及使用声明
|
| 220 |
+
- 协议:本仓库中代码依照 [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) 协议开源。
|
| 221 |
+
- 幻觉:大模型天然存在幻觉问题,用户使用过程中请勿完全相信模型生成的内容。
|
| 222 |
+
- 价值观及安全性:本模型已尽全力确保训练过程中使用的数据的合规性,但由于数据的大体量及复杂性,仍有可能存在一些无法预见的问题。如果出现使用本开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
README_EN.md
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
# Megrez-3B-Omni: The First Open-Source On-device LLM with Full Modality Understanding
|
| 5 |
+
<p align="center">
|
| 6 |
+
<img src="assets/megrez_logo.png" width="400"/>
|
| 7 |
+
<p>
|
| 8 |
+
<p align="center">
|
| 9 |
+
🔗 <a href="https://github.com/infinigence/Infini-Megrez-Omni">GitHub</a>   |   🏠 <a href="https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni">Demo</a>   |   📖 <a href="assets/wechat-official.jpg">WeChat Official</a>   |   💬 <a href="assets/wechat-group.jpg">WeChat Groups</a>  
|
| 10 |
+
</p>
|
| 11 |
+
<h4 align="center">
|
| 12 |
+
<p>
|
| 13 |
+
<a href="https://huggingface.co/Infinigence/Megrez-3B-Omni/blob/main/README.md">中文</a> | <b>English</b>
|
| 14 |
+
<p>
|
| 15 |
+
</h4>
|
| 16 |
+
|
| 17 |
+
## Introduction
|
| 18 |
+
**Megrez-3B-Omni** is an on-device multimodal understanding LLM model developed by **Infinigence AI** ([Infinigence AI](https://cloud.infini-ai.com/platform/ai)). It is an extension of the Megrez-3B-Instruct model and supports analysis of image, text, and audio modalities. The model achieves state-of-the-art accuracy in all three domains:
|
| 19 |
+
- Image Understanding: By utilizing SigLip-400M for constructing image tokens, Megrez-3B-Omni outperforms models with more parameters such as LLaVA-NeXT-Yi-34B. It is one of the best image understanding models among multiple mainstream benchmarks, including MME, MMMU, and OCRBench. It demonstrates excellent performance in tasks such as scene understanding and OCR.
|
| 20 |
+
- Language Understanding: Megrez-3B-Omni retains text understanding capabilities without significant trade-offs. Compared to its single-modal counterpart (Megrez-3B-Instruct), the accuracy variation is less than 2%, maintaining state-of-the-art performance on benchmarks like C-EVAL, MMLU/MMLU Pro, and AlignBench. It also outperforms previous-generation models with 14B parameters.
|
| 21 |
+
- Speech Understanding: Equipped with the encoder head of Qwen2-Audio/whisper-large-v3, the model supports both Chinese and English speech input, multi-turn conversations, and voice-based questions about input images. It can directly respond to voice commands with text and achieved leading results across multiple benchmarks.
|
| 22 |
+
|
| 23 |
+
## Model Info
|
| 24 |
+
<table>
|
| 25 |
+
<thead>
|
| 26 |
+
<tr>
|
| 27 |
+
<th></th>
|
| 28 |
+
<th>Language Module</th>
|
| 29 |
+
<th>Vision Module</th>
|
| 30 |
+
<th>Audio Module</th>
|
| 31 |
+
</tr>
|
| 32 |
+
</thead>
|
| 33 |
+
<tbody>
|
| 34 |
+
<tr>
|
| 35 |
+
<td>Architecture</td>
|
| 36 |
+
<td>Llama-2 with GQA</td>
|
| 37 |
+
<td>SigLip-SO400M</td>
|
| 38 |
+
<td>Whisper-large-v3
|
| 39 |
+
(encoder-only)</td>
|
| 40 |
+
</tr>
|
| 41 |
+
<tr>
|
| 42 |
+
<td># Params (Backbone)</td>
|
| 43 |
+
<td>2.29B</td>
|
| 44 |
+
<td>0.42B</td>
|
| 45 |
+
<td>0.64B</td>
|
| 46 |
+
</tr>
|
| 47 |
+
<tr>
|
| 48 |
+
<td>Connector</td>
|
| 49 |
+
<td>-</td>
|
| 50 |
+
<td>Cross Attention</td>
|
| 51 |
+
<td>Linear</td>
|
| 52 |
+
</tr>
|
| 53 |
+
<tr>
|
| 54 |
+
<td># Params (Others)</td>
|
| 55 |
+
<td>Emb: 0.31B<br>Softmax: 0.31B</td>
|
| 56 |
+
<td>Connector: 0.036B</td>
|
| 57 |
+
<td>Connector: 0.003B</td>
|
| 58 |
+
</tr>
|
| 59 |
+
<tr>
|
| 60 |
+
<td># Params (Total)</td>
|
| 61 |
+
<td colspan="3">4B</td>
|
| 62 |
+
</tr>
|
| 63 |
+
<tr>
|
| 64 |
+
<td># Vocab Size</td>
|
| 65 |
+
<td>122880</td>
|
| 66 |
+
<td>64 tokens/slice</td>
|
| 67 |
+
<td>-</td>
|
| 68 |
+
</tr>
|
| 69 |
+
<tr>
|
| 70 |
+
<td>Context length</td>
|
| 71 |
+
<td colspan="3">4K tokens</td>
|
| 72 |
+
</tr>
|
| 73 |
+
<tr>
|
| 74 |
+
<td>Supported languages</td>
|
| 75 |
+
<td colspan="3">Chinese & English</td>
|
| 76 |
+
</tr>
|
| 77 |
+
</tbody>
|
| 78 |
+
</table>
|
| 79 |
+
|
| 80 |
+
### Image Understanding
|
| 81 |
+
- The above image compares the performance of Megrez-3B-Omni with other open-source models on mainstream image multimodal tasks.
|
| 82 |
+
- The below image shows the performance of Megrez-3B-Omni on the OpenCompass test set. Image reference: [InternVL 2.5 Blog Post](https://internvl.github.io/blog/2024-12-05-InternVL-2.5/)
|
| 83 |
+
|
| 84 |
+

|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
| model | basemodel | release time | OpenCompass | MME | MMMU val | OCRBench | MathVista | RealWorldQA | MMVet | hallusionBench | MMB TEST (en) | MMB TEST (zh) | TextVQA val | AI2D_TEST | MMstar | DocVQA_TEST |
|
| 88 |
+
|-----------------------|-----------------------|----------------|--------------------|----------|-----------|----------|-----------------|-------------|--------|----------------|--------------|--------------|-------------|-----------|-----------|-------------|
|
| 89 |
+
| **Megrez-3B-Omni** | **Megrez-3B** | **2024.12.16** | **66.2** | **2315** | **51.89** | **82.8** | **62** | **71.89** | **60** | **50.12** | **80.8** | **82.3** | **80.3** | **82.05** | **60.46** | **91.62** |
|
| 90 |
+
| Qwen2-VL-2B-Instruct | Qwen2-1.5B | 2024.08.28 | 57.2 | 1872 | 41.1 | 79.4 | 43 | 62.9 | 49.5 | 41.7 | 74.9 | 73.5 | 79.7 | 74.7 | 48 | 90.1 |
|
| 91 |
+
| InternVL2.5-2B | Internlm2.5-1.8B-chat | 2024.12.06 | 59.9 | 2138 | 43.6 | 80.4 | 51.3 | 60.1 | 60.8 | 42.6 | 74.7 | 71.9 | 74.3 | 74.9 | 53.7 | 88.7 |
|
| 92 |
+
| BlueLM-V-3B | - | 2024.11.29 | 66.1 | - | 45.1 | 82.9 | 60.8 | 66.7 | 61.8 | 48 | 83 | 80.5 | 78.4 | 85.3 | 62.3 | 87.8 |
|
| 93 |
+
| InternVL2.5-4B | Qwen2.5-3B-Instruct | 2024.12.06 | 65.1 | 2337 | 52.3 | 82.8 | 60.5 | 64.3 | 60.6 | 46.3 | 81.1 | 79.3 | 76.8 | 81.4 | 58.3 | 91.6 |
|
| 94 |
+
| Baichuan-Omni | Unknown-7B | 2024.10.11 | - | 2186 | 47.3 | 70.0 | 51.9 | 62.6 | 65.4 | 47.8 | 76.2 | 74.9 | 74.3 | - | - | - |
|
| 95 |
+
| MiniCPM-V-2.6 | Qwen2-7B | 2024.08.06 | 65.2 | 2348 | 49.8 | 85.2 | 60.6 | 69.7 | 60 | 48.1 | 81.2 | 79 | 80.1 | 82.1 | 57.26 | 90.8 |
|
| 96 |
+
| Qwen2-VL-7B-Instruct | Qwen2-7B | 2024.08.28 | 67 | 2326 | 54.1 | 84.5 | 58.2 | 70.1 | 62 | 50.6 | 83 | 80.5 | 84.3 | 83 | 60.7 | 94.5 |
|
| 97 |
+
| MiniCPM-Llama3-V-2.5 | Llama3-Instruct 8B | 2024.05.20 | 58.8 | 2024 | 45.8 | 72.5 | 54.3 | 63.5 | 52.8 | 42.4 | 77.2 | 74.2 | 76.6 | 78.4 | - | 84.8 |
|
| 98 |
+
| VITA | Mixtral 8x7B | 2024.08.12 | - | 2097 | 47.3 | 67.8 | 44.9 | 59 | 41.6 | 39.7 | 74.7 | 71.4 | 71.8 | - | - | - |
|
| 99 |
+
| GLM-4V-9B | GLM-4-9B | 2024.06.04 | 59.1 | 2018 | 46.9 | 77.6 | 51.1 | - | 58 | 46.6 | 81.1 | 79.4 | - | 81.1 | 58.7 | - |
|
| 100 |
+
| LLaVA-NeXT-Yi-34B | Yi-34B | 2024.01.18 | 55 | 2006 | 48.8 | 57.4 | 40.4 | 66 | 50.7 | 34.8 | 81.1 | 79 | 69.3 | 78.9 | 51.6 | - |
|
| 101 |
+
| Qwen2-VL-72B-Instruct | Qwen2-72B | 2024.08.28 | 74.8 | 2482 | 64.5 | 87.7 | 70.5 | 77.8 | 74 | 58.1 | 86.5 | 86.6 | 85.5 | 88.1 | 68.3 | 96.5 |
|
| 102 |
+
|
| 103 |
+
### Text Understanding
|
| 104 |
+
| | | | | Chat&Instruction | | | Zh&En Tasks | | | | Code | | Math | |
|
| 105 |
+
|:---------------------:|:--------:|:-----------:|:-------------------------------------:|:---------:|:---------------:|:------:|:-------------:|:----------:|:-----:|:--------:|:---------:|:-----:|:--------:|:-----:|
|
| 106 |
+
| models | Instruction | Release Time | Non-Emb Params | MT-Bench | AlignBench (ZH) | IFEval | C-EVAL (ZH) | CMMLU (ZH) | MMLU | MMLU-Pro | HumanEval | MBPP | GSM8K | MATH |
|
| 107 |
+
| Megrez-3B-Omni | Y | 2024.12.16 | 2.3 | 8.4 | 6.94 | 66.5 | 84.0 | 75.3 | 73.3 | 45.2 | 72.6 | 60.6 | 63.8 | 27.3 |
|
| 108 |
+
| Megrez-3B-Instruct | Y | 2024.12.16 | 2.3 | 8.64 | 7.06 | 68.6 | 84.8 | 74.7 | 72.8 | 46.1 | 78.7 | 71.0 | 65.5 | 28.3 |
|
| 109 |
+
| Baichuan-Omni | Y | 2024.10.11 | 7.0 | - | - | - | 68.9 | 72.2 | 65.3 | - | - | - | - | - |
|
| 110 |
+
| VITA | Y | 2024.08.12 | 12.9 | - | - | - | 56.7 | 46.6 | 71.0 | - | - | - | 75.7 | - |
|
| 111 |
+
| Qwen1.5-7B | | 2024.02.04 | 6.5 | - | - | - | 74.1 | 73.1 | 61.0 | 29.9 | 36.0 | 51.6 | 62.5 | 20.3 |
|
| 112 |
+
| Qwen1.5-7B-Chat | Y | 2024.02.04 | 6.5 | 7.60 | 6.20 | - | 67.3 | - | 59.5 | 29.1 | 46.3 | 48.9 | 60.3 | 23.2 |
|
| 113 |
+
| Qwen1.5-14B | | 2024.02.04 | 12.6 | - | - | - | 78.7 | 77.6 | 67.6 | - | 37.8 | 44.0 | 70.1 | 29.2 |
|
| 114 |
+
| Qwen1.5-14B-Chat | Y | 2024.02.04 | 12.6 | 7.9 | - | - | - | - | - | - | - | - | - | - |
|
| 115 |
+
| Qwen2-7B | | 2024.06.07 | 6.5 | - | - | - | 83.2 | 83.9 | 70.3 | 40.0 | 51.2 | 65.9 | 79.9 | 44.2 |
|
| 116 |
+
| Qwen2-7b-Instruct | Y | 2024.06.07 | 6.5 | 8.41 | 7.21 | 51.4 | 80.9 | 77.2 | 70.5 | 44.1 | 79.9 | 67.2 | 85.7 | 52.9 |
|
| 117 |
+
| Qwen2.5-3B-Instruct | Y | 2024.9.19 | 2.8 | - | - | - | - | - | - | 43.7 | 74.4 | 72.7 | 86.7 | 65.9 |
|
| 118 |
+
| Qwen2.5-7B | | 2024.9.19 | 6.5 | - | - | - | - | - | 74.2 | 45.0 | 57.9 | 74.9 | 85.4 | 49.8 |
|
| 119 |
+
| Qwen2.5-7B-Instruct | Y | 2024.09.19 | 6.5 | 8.75 | - | 74.9 | - | - | - | 56.3 | 84.8 | 79.2 | 91.6 | 75.5 |
|
| 120 |
+
| Llama-3.1-8B | | 2024.07.23 | 7.0 | 8.3 | 5.7 | 71.5 | 55.2 | 55.8 | 66.7 | 37.1 | - | - | 84.5 | 51.9 |
|
| 121 |
+
| Llama-3.2-3B | | 2024.09.25 | 2.8 | - | - | 77.4 | - | - | 63.4 | - | - | - | 77.7 | 48.0 |
|
| 122 |
+
| Phi-3.5-mini-instruct | Y | 2024.08.23 | 3.6 | 8.6 | 5.7 | 49.4 | 46.1 | 46.9 | 69.0 | 47.4 | 62.8 | 69.6 | 86.2 | 48.5 |
|
| 123 |
+
| MiniCPM3-4B | Y | 2024.09.05 | 3.9 | 8.41 | 6.74 | 68.4 | 73.6 | 73.3 | 67.2 | - | 74.4 | 72.5 | 81.1 | 46.6 |
|
| 124 |
+
| Yi-1.5-6B-Chat | Y | 2024.05.11 | 5.5 | 7.50 | 6.20 | - | 74.2 | 74.7 | 61.0 | - | 64.0 | 70.9 | 78.9 | 40.5 |
|
| 125 |
+
| GLM-4-9B-chat | Y | 2024.06.04 | 8.2 | 8.35 | 7.01 | 64.5 | 75.6 | 71.5 | 72.4 | - | 71.8 | - | 79.6 | 50.6 |
|
| 126 |
+
| Baichuan2-13B-Base | | 2023.09.06 | 12.6 | - | 5.25 | - | 58.1 | 62.0 | 59.2 | - | 17.1 | 30.2 | 52.8 | 10.1 |
|
| 127 |
+
|
| 128 |
+
- The metrics for the Qwen2-1.5B model differ between the original paper and the Qwen2.5 report. Currently, the accuracy figures from the original paper are being used.
|
| 129 |
+
|
| 130 |
+
### Audio Understanding
|
| 131 |
+
| Model | Base model | Release Time | Fleurs test-zh | WenetSpeech test_net | WenetSpeech test_meeting |
|
| 132 |
+
|:----------------:|:------------------:|:-------------:|:--------------:|:--------------------:|:------------------------:|
|
| 133 |
+
| Megrez-3B-Omni | Megrez-3B-Instruct | 2024.12.16 | 10.8 | - | 16.4 |
|
| 134 |
+
| Whisper-large-v3 | - | 2023.11.06 | 12.4 | 17.5 | 30.8 |
|
| 135 |
+
| Qwen2-Audio-7B | Qwen2-7B | 2024.08.09 | 9 | 11 | 10.7 |
|
| 136 |
+
| Baichuan2-omni | Unknown-7B | 2024.10.11 | 7 | 6.9 | 8.4 |
|
| 137 |
+
| VITA | Mixtral 8x7B | 2024.08.12 | - | -/12.2(CER) | -/16.5(CER) |
|
| 138 |
+
|
| 139 |
+
### Inference Speed
|
| 140 |
+
| | image_tokens | prefill (tokens/s) | decode (tokens/s) |
|
| 141 |
+
|----------------|:------------:|:------------------:|:-----------------:|
|
| 142 |
+
| Megrez-3B-Omni | 448 | 6312.66 | 1294.9 |
|
| 143 |
+
| Qwen2-VL-2B | 1378 | 7349.39 | 685.66 |
|
| 144 |
+
| MiniCPM-V-2_6 | 448 | 2167.09 | 452.51 |
|
| 145 |
+
|
| 146 |
+
Setup:
|
| 147 |
+
- The testing environment utilizes an NVIDIA H100 GPU with vLLM. Each test includes 128 text tokens and a 720×1480 image as input, producing 128 output tokens, with `num_seqs` fixed at 8.
|
| 148 |
+
- Under this setup, the decoding speed of Qwen2-VL-2B is slower than Megrez-3B-Omni, despite having a smaller base LLM. This is due to the larger number of image tokens generated when encoding images of the specified size, which impacts actual inference speed.
|
| 149 |
+
|
| 150 |
+
## Quickstart
|
| 151 |
+
|
| 152 |
+
### Online Experience
|
| 153 |
+
[HF Chat Demo](https://huggingface.co/spaces/Infinigence/Megrez-3B-Omni)(recommend)
|
| 154 |
+
|
| 155 |
+
### Local Deployment
|
| 156 |
+
For environment installation and vLLM inference code deployment, refer to [Infini-Megrez-Omni](https://github.com/infinigence/Infini-Megrez-Omni)
|
| 157 |
+
|
| 158 |
+
Below is an example of using transformers for inference. By passing text, image, and audio in the content field, you can interact with various modalities and models.
|
| 159 |
+
```python
|
| 160 |
+
import torch
|
| 161 |
+
from transformers import AutoModelForCausalLM
|
| 162 |
+
|
| 163 |
+
path = "{{PATH_TO_PRETRAINED_MODEL}}" # Change this to the path of the model.
|
| 164 |
+
|
| 165 |
+
model = (
|
| 166 |
+
AutoModelForCausalLM.from_pretrained(
|
| 167 |
+
path,
|
| 168 |
+
trust_remote_code=True,
|
| 169 |
+
torch_dtype=torch.bfloat16,
|
| 170 |
+
attn_implementation="flash_attention_2",
|
| 171 |
+
)
|
| 172 |
+
.eval()
|
| 173 |
+
.cuda()
|
| 174 |
+
)
|
| 175 |
+
|
| 176 |
+
# Chat with text and image
|
| 177 |
+
messages = [
|
| 178 |
+
{
|
| 179 |
+
"role": "user",
|
| 180 |
+
"content": {
|
| 181 |
+
"text": "Please describe the content of the image.",
|
| 182 |
+
"image": "./data/sample_image.jpg",
|
| 183 |
+
},
|
| 184 |
+
},
|
| 185 |
+
]
|
| 186 |
+
|
| 187 |
+
# Chat with audio and image
|
| 188 |
+
messages = [
|
| 189 |
+
{
|
| 190 |
+
"role": "user",
|
| 191 |
+
"content": {
|
| 192 |
+
"image": "./data/sample_image.jpg",
|
| 193 |
+
"audio": "./data/sample_audio.m4a",
|
| 194 |
+
},
|
| 195 |
+
},
|
| 196 |
+
]
|
| 197 |
+
|
| 198 |
+
MAX_NEW_TOKENS = 100
|
| 199 |
+
response = model.chat(
|
| 200 |
+
messages,
|
| 201 |
+
sampling=False,
|
| 202 |
+
max_new_tokens=MAX_NEW_TOKENS,
|
| 203 |
+
temperature=0,
|
| 204 |
+
)
|
| 205 |
+
print(response)
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
## Notes
|
| 209 |
+
1. We recommend to put the images in the first round of chat for better inference results. There are no such restrictions for audio and text, which can be switched freely.
|
| 210 |
+
2. In the Automatic Speech Recognition (ASR) scenario, simply change content['text'] to "Convert speech to text."
|
| 211 |
+
3. In the OCR scenario, enabling sampling may introduce language model hallucinations which cause text changes. Users may consider disabling sampling in inference (sampling=False). However, disabling sampling may introduce model repetition.
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
## Open Source License and Usage Statement
|
| 215 |
+
- **License**: The code in this repository is open-sourced under the [Apache-2.0](https://www.apache.org/licenses/LICENSE-2.0) license.
|
| 216 |
+
- **Hallucination**: Large models inherently have hallucination issues. Users should not completely trust the content generated by the model.
|
| 217 |
+
- **Values and Safety**: While we have made every effort to ensure compliance of the data used during training, the large volume and complexity of the data may still lead to unforeseen issues. We disclaim any liability for problems arising from the use of this open-source model, including but not limited to data security issues, public opinion risks, or risks and problems caused by misleading, misuse, propagation, or improper utilization of the model.
|
assets/github-mark.png
ADDED

|
assets/megrez_logo.png
ADDED
|
|
assets/multitask.jpg
ADDED
|
assets/opencompass.jpg
ADDED
|
assets/wechat-group.jpg
ADDED

|
assets/wechat-official.jpg
ADDED

|
assets/wechat.jpg
ADDED

|
audio.py
ADDED
|
@@ -0,0 +1,228 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
# File: audio.py
|
| 3 |
+
# Description: None
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
from typing import Iterable, List, Optional
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from torch import Tensor
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LayerNorm(nn.LayerNorm):
|
| 16 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 17 |
+
return super().forward(x).type(x.dtype)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class Linear(nn.Linear):
|
| 21 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 22 |
+
return F.linear(
|
| 23 |
+
x,
|
| 24 |
+
self.weight.to(x.dtype),
|
| 25 |
+
None if self.bias is None else self.bias.to(x.dtype),
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class Conv1d(nn.Conv1d):
|
| 30 |
+
def _conv_forward(self, x: Tensor, weight: Tensor, bias: Optional[Tensor]) -> Tensor:
|
| 31 |
+
return super()._conv_forward(x, weight.to(x.dtype), None if bias is None else bias.to(x.dtype))
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def sinusoids(length, channels, max_timescale=10000):
|
| 35 |
+
"""Returns sinusoids for positional embedding"""
|
| 36 |
+
assert channels % 2 == 0
|
| 37 |
+
log_timescale_increment = np.log(max_timescale) / (channels // 2 - 1)
|
| 38 |
+
inv_timescales = torch.exp(-log_timescale_increment * torch.arange(channels // 2))
|
| 39 |
+
scaled_time = torch.arange(length)[:, np.newaxis] * inv_timescales[np.newaxis, :]
|
| 40 |
+
return torch.cat([torch.sin(scaled_time), torch.cos(scaled_time)], dim=1)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class MultiHeadAttention(nn.Module):
|
| 44 |
+
def __init__(self, n_state: int, n_head: int):
|
| 45 |
+
super().__init__()
|
| 46 |
+
self.n_head = n_head
|
| 47 |
+
self.query = Linear(n_state, n_state)
|
| 48 |
+
self.key = Linear(n_state, n_state, bias=False)
|
| 49 |
+
self.value = Linear(n_state, n_state)
|
| 50 |
+
self.out = Linear(n_state, n_state)
|
| 51 |
+
|
| 52 |
+
def forward(
|
| 53 |
+
self,
|
| 54 |
+
x: Tensor,
|
| 55 |
+
xa: Optional[Tensor] = None,
|
| 56 |
+
mask: Optional[Tensor] = None,
|
| 57 |
+
kv_cache: Optional[dict] = None,
|
| 58 |
+
):
|
| 59 |
+
q = self.query(x)
|
| 60 |
+
|
| 61 |
+
if kv_cache is None or xa is None or self.key not in kv_cache:
|
| 62 |
+
# hooks, if installed (i.e. kv_cache is not None), will prepend the cached kv tensors;
|
| 63 |
+
# otherwise, perform key/value projections for self- or cross-attention as usual.
|
| 64 |
+
k = self.key(x if xa is None else xa)
|
| 65 |
+
v = self.value(x if xa is None else xa)
|
| 66 |
+
else:
|
| 67 |
+
# for cross-attention, calculate keys and values once and reuse in subsequent calls.
|
| 68 |
+
k = kv_cache[self.key]
|
| 69 |
+
v = kv_cache[self.value]
|
| 70 |
+
|
| 71 |
+
wv, qk = self.qkv_attention(q, k, v, mask)
|
| 72 |
+
return self.out(wv), qk
|
| 73 |
+
|
| 74 |
+
def qkv_attention(self, q: Tensor, k: Tensor, v: Tensor, mask: Optional[Tensor] = None):
|
| 75 |
+
n_batch, n_ctx, n_state = q.shape
|
| 76 |
+
scale = (n_state // self.n_head) ** -0.25
|
| 77 |
+
q = q.view(*q.shape[:2], self.n_head, -1).permute(0, 2, 1, 3) * scale
|
| 78 |
+
k = k.view(*k.shape[:2], self.n_head, -1).permute(0, 2, 3, 1) * scale
|
| 79 |
+
v = v.view(*v.shape[:2], self.n_head, -1).permute(0, 2, 1, 3)
|
| 80 |
+
|
| 81 |
+
qk = q @ k
|
| 82 |
+
if mask is not None:
|
| 83 |
+
qk += mask
|
| 84 |
+
|
| 85 |
+
w = F.softmax(qk, dim=-1).to(q.dtype)
|
| 86 |
+
return (w @ v).permute(0, 2, 1, 3).flatten(start_dim=2), qk.detach()
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class ResidualAttentionBlock(nn.Module):
|
| 90 |
+
def __init__(self, n_state: int, n_head: int, cross_attention: bool = False):
|
| 91 |
+
super().__init__()
|
| 92 |
+
|
| 93 |
+
self.attn = MultiHeadAttention(n_state, n_head)
|
| 94 |
+
self.attn_ln = LayerNorm(n_state)
|
| 95 |
+
|
| 96 |
+
self.cross_attn = MultiHeadAttention(n_state, n_head) if cross_attention else None
|
| 97 |
+
self.cross_attn_ln = LayerNorm(n_state) if cross_attention else None
|
| 98 |
+
|
| 99 |
+
n_mlp = n_state * 4
|
| 100 |
+
self.mlp = nn.Sequential(Linear(n_state, n_mlp), nn.GELU(), Linear(n_mlp, n_state))
|
| 101 |
+
self.mlp_ln = LayerNorm(n_state)
|
| 102 |
+
|
| 103 |
+
def forward(
|
| 104 |
+
self,
|
| 105 |
+
x: Tensor,
|
| 106 |
+
xa: Optional[Tensor] = None,
|
| 107 |
+
mask: Optional[Tensor] = None,
|
| 108 |
+
kv_cache: Optional[dict] = None,
|
| 109 |
+
):
|
| 110 |
+
x = x + self.attn(self.attn_ln(x), mask=mask, kv_cache=kv_cache)[0]
|
| 111 |
+
if self.cross_attn:
|
| 112 |
+
x = x + self.cross_attn(self.cross_attn_ln(x), xa, kv_cache=kv_cache)[0]
|
| 113 |
+
x = x + self.mlp(self.mlp_ln(x))
|
| 114 |
+
return x
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class AudioEncoder(nn.Module):
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
n_mels: int,
|
| 121 |
+
n_ctx: int,
|
| 122 |
+
n_state: int,
|
| 123 |
+
n_head: int,
|
| 124 |
+
n_layer: int,
|
| 125 |
+
output_dim: int = 512,
|
| 126 |
+
avg_pool: bool = True,
|
| 127 |
+
add_audio_bos_eos_token: bool = True,
|
| 128 |
+
**kwargs,
|
| 129 |
+
):
|
| 130 |
+
super().__init__()
|
| 131 |
+
self.conv1 = Conv1d(n_mels, n_state, kernel_size=3, padding=1)
|
| 132 |
+
self.conv2 = Conv1d(n_state, n_state, kernel_size=3, stride=2, padding=1)
|
| 133 |
+
self.register_buffer("positional_embedding", sinusoids(n_ctx, n_state))
|
| 134 |
+
|
| 135 |
+
self.blocks: Iterable[ResidualAttentionBlock] = nn.ModuleList(
|
| 136 |
+
[ResidualAttentionBlock(n_state, n_head) for _ in range(n_layer)]
|
| 137 |
+
)
|
| 138 |
+
self.ln_post = LayerNorm(n_state)
|
| 139 |
+
|
| 140 |
+
if avg_pool:
|
| 141 |
+
self.avg_pooler = nn.AvgPool1d(2, stride=2)
|
| 142 |
+
else:
|
| 143 |
+
self.avg_pooler = None
|
| 144 |
+
self.proj = nn.Linear(n_state, output_dim)
|
| 145 |
+
if add_audio_bos_eos_token:
|
| 146 |
+
self.audio_bos_eos_token = nn.Embedding(2, output_dim)
|
| 147 |
+
else:
|
| 148 |
+
self.audio_bos_eos_token = None
|
| 149 |
+
self.output_dim = output_dim
|
| 150 |
+
self.n_head = n_head
|
| 151 |
+
|
| 152 |
+
def forward(self, x: Tensor, padding_mask: Tensor = None, audio_lengths: Tensor = None):
|
| 153 |
+
"""
|
| 154 |
+
x : torch.Tensor, shape = (batch_size, n_mels, n_ctx)
|
| 155 |
+
the mel spectrogram of the audio
|
| 156 |
+
"""
|
| 157 |
+
x = x.to(dtype=self.conv1.weight.dtype, device=self.conv1.weight.device)
|
| 158 |
+
if audio_lengths is not None:
|
| 159 |
+
input_mel_len = audio_lengths[:, 0] * 2
|
| 160 |
+
max_mel_len_in_batch = input_mel_len.max()
|
| 161 |
+
x = x[:, :, :max_mel_len_in_batch]
|
| 162 |
+
x = F.gelu(self.conv1(x))
|
| 163 |
+
x = F.gelu(self.conv2(x))
|
| 164 |
+
x = x.permute(0, 2, 1) # B, L, D
|
| 165 |
+
bsz = x.size(0)
|
| 166 |
+
src_len = x.size(1)
|
| 167 |
+
|
| 168 |
+
self.input_positional_embedding = self.positional_embedding[:src_len]
|
| 169 |
+
assert (
|
| 170 |
+
x.shape[1:] == self.input_positional_embedding.shape
|
| 171 |
+
), f"incorrect audio shape: {x.shape[1:], self.input_positional_embedding.shape}"
|
| 172 |
+
x = (x + self.input_positional_embedding).to(x.dtype)
|
| 173 |
+
if padding_mask is not None:
|
| 174 |
+
padding_mask = padding_mask.to(dtype=self.conv1.weight.dtype, device=self.conv1.weight.device)
|
| 175 |
+
batch_src_len = padding_mask.size(1)
|
| 176 |
+
x = x[:, :batch_src_len, :]
|
| 177 |
+
padding_mask = padding_mask.view(bsz, -1, batch_src_len)
|
| 178 |
+
padding_mask_ = padding_mask.all(1)
|
| 179 |
+
x[padding_mask_] = 0
|
| 180 |
+
key_padding_mask = (
|
| 181 |
+
padding_mask_.view(bsz, 1, 1, batch_src_len)
|
| 182 |
+
.expand(-1, self.n_head, -1, -1)
|
| 183 |
+
.reshape(bsz, self.n_head, 1, batch_src_len)
|
| 184 |
+
)
|
| 185 |
+
new_padding_mask = torch.zeros_like(key_padding_mask, dtype=x.dtype)
|
| 186 |
+
padding_mask = new_padding_mask.masked_fill(key_padding_mask, float("-inf"))
|
| 187 |
+
|
| 188 |
+
for block in self.blocks:
|
| 189 |
+
x = block(x, mask=padding_mask)
|
| 190 |
+
|
| 191 |
+
if self.avg_pooler:
|
| 192 |
+
x = x.permute(0, 2, 1)
|
| 193 |
+
x = self.avg_pooler(x)
|
| 194 |
+
x = x.permute(0, 2, 1)
|
| 195 |
+
|
| 196 |
+
x = self.ln_post(x)
|
| 197 |
+
x = self.proj(x)
|
| 198 |
+
|
| 199 |
+
if self.audio_bos_eos_token is not None:
|
| 200 |
+
bos = self.audio_bos_eos_token.weight[0][None, :]
|
| 201 |
+
eos = self.audio_bos_eos_token.weight[1][None, :]
|
| 202 |
+
else:
|
| 203 |
+
bos, eos = None, None
|
| 204 |
+
return x, bos, eos
|
| 205 |
+
|
| 206 |
+
def encode(
|
| 207 |
+
self,
|
| 208 |
+
input_audios: Tensor,
|
| 209 |
+
input_audio_lengths: Tensor,
|
| 210 |
+
audio_span_tokens: List,
|
| 211 |
+
):
|
| 212 |
+
real_input_audio_lens = input_audio_lengths[:, 0].tolist()
|
| 213 |
+
max_len_in_batch = max(real_input_audio_lens)
|
| 214 |
+
padding_mask = torch.ones([input_audios.size(0), max_len_in_batch]).to(
|
| 215 |
+
dtype=self.conv1.weight.dtype, device=self.conv1.weight.device
|
| 216 |
+
)
|
| 217 |
+
for index in range(len(input_audios)):
|
| 218 |
+
padding_mask[index, : input_audio_lengths[index][0].item()] = 0
|
| 219 |
+
x, bos, eos = self(input_audios, padding_mask, input_audio_lengths)
|
| 220 |
+
output_audios = []
|
| 221 |
+
for i in range(len(audio_span_tokens)):
|
| 222 |
+
audio_span = audio_span_tokens[i]
|
| 223 |
+
audio = x[i][: audio_span - 2]
|
| 224 |
+
if bos is not None:
|
| 225 |
+
audio = torch.concat([bos, audio, eos])
|
| 226 |
+
assert len(audio) == audio_span
|
| 227 |
+
output_audios.append(audio)
|
| 228 |
+
return output_audios
|
config.json
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/mnt/public/algm/lizhiyuan/models/megrez-o-release/pretrain_audio_stage3_vision_stage3_merge",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MegrezO"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"audio_config": {
|
| 9 |
+
"add_audio_bos_eos_token": true,
|
| 10 |
+
"avg_pool": true,
|
| 11 |
+
"n_ctx": 1500,
|
| 12 |
+
"n_head": 20,
|
| 13 |
+
"n_layer": 32,
|
| 14 |
+
"n_mels": 128,
|
| 15 |
+
"n_state": 1280,
|
| 16 |
+
"output_dim": 2560
|
| 17 |
+
},
|
| 18 |
+
"auto_map": {
|
| 19 |
+
"AutoModel": "modeling_megrezo.MegrezO",
|
| 20 |
+
"AutoModelForCausalLM": "modeling_megrezo.MegrezO",
|
| 21 |
+
"AutoConfig": "configuration_megrezo.MegrezOConfig",
|
| 22 |
+
"AutoProcessor": "processing_megrezo.MegrezOProcessor",
|
| 23 |
+
"AutoImageProcessor": "image_processing_megrezo.MegrezOImageProcessor"
|
| 24 |
+
},
|
| 25 |
+
"bos_token_id": null,
|
| 26 |
+
"drop_vision_last_layer": false,
|
| 27 |
+
"eos_token_id": 120005,
|
| 28 |
+
"hidden_act": "silu",
|
| 29 |
+
"hidden_size": 2560,
|
| 30 |
+
"initializer_range": 0.02,
|
| 31 |
+
"intermediate_size": 7168,
|
| 32 |
+
"max_position_embeddings": 4096,
|
| 33 |
+
"max_sequence_length": 4096,
|
| 34 |
+
"mlp_bias": false,
|
| 35 |
+
"model_type": "megrezo",
|
| 36 |
+
"num_attention_heads": 40,
|
| 37 |
+
"num_hidden_layers": 32,
|
| 38 |
+
"num_key_value_heads": 10,
|
| 39 |
+
"pad_token_id": 0,
|
| 40 |
+
"patch_size": 14,
|
| 41 |
+
"pretraining_tp": 1,
|
| 42 |
+
"query_num": 64,
|
| 43 |
+
"rms_norm_eps": 1e-05,
|
| 44 |
+
"rope_scaling": null,
|
| 45 |
+
"rope_theta": 5000000.0,
|
| 46 |
+
"tie_word_embeddings": false,
|
| 47 |
+
"torch_dtype": "bfloat16",
|
| 48 |
+
"transformers_version": "4.42.0",
|
| 49 |
+
"use_cache": false,
|
| 50 |
+
"vision_batch_size": 8,
|
| 51 |
+
"vision_config": {
|
| 52 |
+
"_name_or_path": "",
|
| 53 |
+
"add_cross_attention": false,
|
| 54 |
+
"architectures": null,
|
| 55 |
+
"attention_dropout": 0.0,
|
| 56 |
+
"bad_words_ids": null,
|
| 57 |
+
"begin_suppress_tokens": null,
|
| 58 |
+
"bos_token_id": null,
|
| 59 |
+
"chunk_size_feed_forward": 0,
|
| 60 |
+
"cross_attention_hidden_size": null,
|
| 61 |
+
"decoder_start_token_id": null,
|
| 62 |
+
"diversity_penalty": 0.0,
|
| 63 |
+
"do_sample": false,
|
| 64 |
+
"early_stopping": false,
|
| 65 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 66 |
+
"eos_token_id": null,
|
| 67 |
+
"exponential_decay_length_penalty": null,
|
| 68 |
+
"finetuning_task": null,
|
| 69 |
+
"forced_bos_token_id": null,
|
| 70 |
+
"forced_eos_token_id": null,
|
| 71 |
+
"hidden_act": "gelu_pytorch_tanh",
|
| 72 |
+
"hidden_size": 1152,
|
| 73 |
+
"id2label": {
|
| 74 |
+
"0": "LABEL_0",
|
| 75 |
+
"1": "LABEL_1"
|
| 76 |
+
},
|
| 77 |
+
"image_size": 980,
|
| 78 |
+
"intermediate_size": 4304,
|
| 79 |
+
"is_decoder": false,
|
| 80 |
+
"is_encoder_decoder": false,
|
| 81 |
+
"label2id": {
|
| 82 |
+
"LABEL_0": 0,
|
| 83 |
+
"LABEL_1": 1
|
| 84 |
+
},
|
| 85 |
+
"layer_norm_eps": 1e-06,
|
| 86 |
+
"length_penalty": 1.0,
|
| 87 |
+
"max_length": 20,
|
| 88 |
+
"min_length": 0,
|
| 89 |
+
"model_type": "siglip_vision_model",
|
| 90 |
+
"no_repeat_ngram_size": 0,
|
| 91 |
+
"num_attention_heads": 16,
|
| 92 |
+
"num_beam_groups": 1,
|
| 93 |
+
"num_beams": 1,
|
| 94 |
+
"num_channels": 3,
|
| 95 |
+
"num_hidden_layers": 27,
|
| 96 |
+
"num_return_sequences": 1,
|
| 97 |
+
"output_attentions": false,
|
| 98 |
+
"output_hidden_states": false,
|
| 99 |
+
"output_scores": false,
|
| 100 |
+
"pad_token_id": null,
|
| 101 |
+
"patch_size": 14,
|
| 102 |
+
"prefix": null,
|
| 103 |
+
"problem_type": null,
|
| 104 |
+
"pruned_heads": {},
|
| 105 |
+
"remove_invalid_values": false,
|
| 106 |
+
"repetition_penalty": 1.0,
|
| 107 |
+
"return_dict": true,
|
| 108 |
+
"return_dict_in_generate": false,
|
| 109 |
+
"sep_token_id": null,
|
| 110 |
+
"suppress_tokens": null,
|
| 111 |
+
"task_specific_params": null,
|
| 112 |
+
"temperature": 1.0,
|
| 113 |
+
"tf_legacy_loss": false,
|
| 114 |
+
"tie_encoder_decoder": false,
|
| 115 |
+
"tie_word_embeddings": true,
|
| 116 |
+
"tokenizer_class": null,
|
| 117 |
+
"top_k": 50,
|
| 118 |
+
"top_p": 1.0,
|
| 119 |
+
"torch_dtype": null,
|
| 120 |
+
"torchscript": false,
|
| 121 |
+
"typical_p": 1.0,
|
| 122 |
+
"use_bfloat16": false
|
| 123 |
+
},
|
| 124 |
+
"vocab_size": 122880
|
| 125 |
+
}
|
configuration_megrezo.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MegrezO model configuration"""
|
| 2 |
+
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 6 |
+
from transformers.models.llama.configuration_llama import LlamaConfig
|
| 7 |
+
from transformers.utils import logging
|
| 8 |
+
|
| 9 |
+
from .modeling_navit_siglip import SiglipVisionConfig
|
| 10 |
+
|
| 11 |
+
logger = logging.get_logger(__name__)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class AudioConfig(PretrainedConfig):
|
| 15 |
+
model_type = "megrezo"
|
| 16 |
+
|
| 17 |
+
def __init__(
|
| 18 |
+
self,
|
| 19 |
+
n_mels: int = 128,
|
| 20 |
+
n_ctx: int = 1500,
|
| 21 |
+
n_state: int = 1280,
|
| 22 |
+
n_head: int = 20,
|
| 23 |
+
n_layer: int = 32,
|
| 24 |
+
output_dim: int = 2560,
|
| 25 |
+
avg_pool: bool = True,
|
| 26 |
+
add_audio_bos_eos_token: bool = True,
|
| 27 |
+
**kwargs,
|
| 28 |
+
):
|
| 29 |
+
super().__init__(**kwargs)
|
| 30 |
+
|
| 31 |
+
self.n_mels = n_mels
|
| 32 |
+
self.n_ctx = n_ctx
|
| 33 |
+
self.n_state = n_state
|
| 34 |
+
self.n_head = n_head
|
| 35 |
+
self.n_layer = n_layer
|
| 36 |
+
self.output_dim = output_dim
|
| 37 |
+
self.avg_pool = avg_pool
|
| 38 |
+
self.add_audio_bos_eos_token = add_audio_bos_eos_token
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class MegrezOConfig(LlamaConfig):
|
| 42 |
+
model_type = "megrezo"
|
| 43 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 44 |
+
is_composition = True
|
| 45 |
+
|
| 46 |
+
_default_audio_config = {
|
| 47 |
+
"n_mels": 128,
|
| 48 |
+
"n_ctx": 1500,
|
| 49 |
+
"n_state": 1280,
|
| 50 |
+
"n_head": 20,
|
| 51 |
+
"n_layer": 32,
|
| 52 |
+
"output_dim": 2560,
|
| 53 |
+
"avg_pool": True,
|
| 54 |
+
"add_audio_bos_eos_token": True,
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
_default_vision_config = {
|
| 58 |
+
"intermediate_size": 4304,
|
| 59 |
+
"num_hidden_layers": 27,
|
| 60 |
+
"num_attention_heads": 16,
|
| 61 |
+
"image_size": 980,
|
| 62 |
+
"hidden_size": 1152,
|
| 63 |
+
"patch_size": 16,
|
| 64 |
+
"model_type": "siglip_vision_model",
|
| 65 |
+
}
|
| 66 |
+
|
| 67 |
+
def __init__(
|
| 68 |
+
self,
|
| 69 |
+
audio_config: Optional[AudioConfig] = None,
|
| 70 |
+
vision_config: Optional[SiglipVisionConfig] = None,
|
| 71 |
+
**kwargs,
|
| 72 |
+
):
|
| 73 |
+
super().__init__(**kwargs)
|
| 74 |
+
|
| 75 |
+
if audio_config is None:
|
| 76 |
+
self.audio_config = AudioConfig(**self._default_audio_config)
|
| 77 |
+
elif isinstance(audio_config, dict):
|
| 78 |
+
self.audio_config = AudioConfig(**audio_config)
|
| 79 |
+
elif isinstance(audio_config, AudioConfig):
|
| 80 |
+
self.audio_config = audio_config
|
| 81 |
+
|
| 82 |
+
if vision_config is None:
|
| 83 |
+
self.vision_config = SiglipVisionConfig(**self._default_vision_config)
|
| 84 |
+
elif isinstance(vision_config, dict):
|
| 85 |
+
self.vision_config = SiglipVisionConfig(**vision_config)
|
| 86 |
+
elif isinstance(vision_config, SiglipVisionConfig):
|
| 87 |
+
self.vision_config = vision_config
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"eos_token_id": [120000, 120005],
|
| 4 |
+
"pad_token_id": 120002,
|
| 5 |
+
"transformers_version": "4.42.0",
|
| 6 |
+
"use_cache": false
|
| 7 |
+
}
|
image_processing_megrezo.py
ADDED
|
@@ -0,0 +1,386 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Optional, Union, Dict, Any, List
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import math
|
| 5 |
+
import PIL.Image
|
| 6 |
+
import PIL.ImageSequence
|
| 7 |
+
import numpy as np
|
| 8 |
+
import PIL
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
from transformers.utils import TensorType, requires_backends, is_torch_dtype, is_torch_device
|
| 12 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 13 |
+
from transformers import AutoImageProcessor
|
| 14 |
+
from transformers.image_transforms import to_channel_dimension_format
|
| 15 |
+
from transformers.image_utils import (
|
| 16 |
+
valid_images,
|
| 17 |
+
is_torch_tensor,
|
| 18 |
+
to_numpy_array,
|
| 19 |
+
infer_channel_dimension_format,
|
| 20 |
+
ChannelDimension,
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def recursive_converter(converter, value):
|
| 25 |
+
if isinstance(value, list):
|
| 26 |
+
new_value = []
|
| 27 |
+
for v in value:
|
| 28 |
+
new_value += [recursive_converter(converter, v)]
|
| 29 |
+
return new_value
|
| 30 |
+
else:
|
| 31 |
+
return converter(value)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class MegrezOBatchFeature(BatchFeature):
|
| 35 |
+
r"""
|
| 36 |
+
Extend from BatchFeature for supporting various image size
|
| 37 |
+
"""
|
| 38 |
+
|
| 39 |
+
def __init__(self, data: Optional[Dict[str, Any]] = None, tensor_type: Union[None, str, TensorType] = None):
|
| 40 |
+
super().__init__(data)
|
| 41 |
+
self.convert_to_tensors(tensor_type=tensor_type)
|
| 42 |
+
|
| 43 |
+
def convert_to_tensors(self, tensor_type: Optional[Union[str, TensorType]] = None):
|
| 44 |
+
if tensor_type is None:
|
| 45 |
+
return self
|
| 46 |
+
|
| 47 |
+
is_tensor, as_tensor = self._get_is_as_tensor_fns(tensor_type)
|
| 48 |
+
|
| 49 |
+
def converter(value):
|
| 50 |
+
try:
|
| 51 |
+
if not is_tensor(value):
|
| 52 |
+
tensor = as_tensor(value)
|
| 53 |
+
return tensor
|
| 54 |
+
except: # noqa E722
|
| 55 |
+
if key == "overflowing_values":
|
| 56 |
+
raise ValueError("Unable to create tensor returning overflowing values of different lengths. ")
|
| 57 |
+
raise ValueError(
|
| 58 |
+
"Unable to create tensor, you should probably activate padding "
|
| 59 |
+
"with 'padding=True' to have batched tensors with the same length."
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
for key, value in self.items():
|
| 63 |
+
self[key] = recursive_converter(converter, value)
|
| 64 |
+
return self
|
| 65 |
+
|
| 66 |
+
def to(self, *args, **kwargs) -> "MegrezOBatchFeature":
|
| 67 |
+
requires_backends(self, ["torch"])
|
| 68 |
+
import torch
|
| 69 |
+
|
| 70 |
+
def cast_tensor(v):
|
| 71 |
+
# check if v is a floating point
|
| 72 |
+
if torch.is_floating_point(v):
|
| 73 |
+
# cast and send to device
|
| 74 |
+
return v.to(*args, **kwargs)
|
| 75 |
+
elif device is not None:
|
| 76 |
+
return v.to(device=device)
|
| 77 |
+
else:
|
| 78 |
+
return v
|
| 79 |
+
|
| 80 |
+
new_data = {}
|
| 81 |
+
device = kwargs.get("device")
|
| 82 |
+
# Check if the args are a device or a dtype
|
| 83 |
+
if device is None and len(args) > 0:
|
| 84 |
+
# device should be always the first argument
|
| 85 |
+
arg = args[0]
|
| 86 |
+
if is_torch_dtype(arg):
|
| 87 |
+
# The first argument is a dtype
|
| 88 |
+
pass
|
| 89 |
+
elif isinstance(arg, str) or is_torch_device(arg) or isinstance(arg, int):
|
| 90 |
+
device = arg
|
| 91 |
+
else:
|
| 92 |
+
# it's something else
|
| 93 |
+
raise ValueError(f"Attempting to cast a BatchFeature to type {str(arg)}. This is not supported.")
|
| 94 |
+
# We cast only floating point tensors to avoid issues with tokenizers casting `LongTensor` to `FloatTensor`
|
| 95 |
+
for k, v in self.items():
|
| 96 |
+
new_data[k] = recursive_converter(cast_tensor, v)
|
| 97 |
+
self.data = new_data
|
| 98 |
+
return self
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MegrezOImageProcessor(BaseImageProcessor):
|
| 102 |
+
model_input_names = ["pixel_values"]
|
| 103 |
+
|
| 104 |
+
def __init__(self, max_slice_nums=9, scale_resolution=448, patch_size=14, **kwargs):
|
| 105 |
+
super().__init__(**kwargs)
|
| 106 |
+
self.max_slice_nums = max_slice_nums
|
| 107 |
+
self.scale_resolution = scale_resolution
|
| 108 |
+
self.patch_size = patch_size
|
| 109 |
+
self.use_image_id = kwargs.pop("use_image_id", False)
|
| 110 |
+
self.image_feature_size = kwargs.pop("image_feature_size", 64)
|
| 111 |
+
self.im_start_token = kwargs.pop("im_start", "<|image_start|>")
|
| 112 |
+
self.im_end_token = kwargs.pop("im_end", "<|image_end|>")
|
| 113 |
+
self.slice_start_token = kwargs.pop("slice_start", "<|slice_start|>")
|
| 114 |
+
self.slice_end_token = kwargs.pop("slice_end", "<|slice_end|>")
|
| 115 |
+
self.unk_token = kwargs.pop("unk", "<|unk|>")
|
| 116 |
+
self.im_id_start = kwargs.pop("im_id_start", "<|image_id_start|>")
|
| 117 |
+
self.im_id_end = kwargs.pop("im_id_end", "<|image_id_end|>")
|
| 118 |
+
self.slice_mode = kwargs.pop("slice_mode", True)
|
| 119 |
+
self.mean = np.array(kwargs.pop("norm_mean", [0.5, 0.5, 0.5]))
|
| 120 |
+
self.std = np.array(kwargs.pop("norm_std", [0.5, 0.5, 0.5]))
|
| 121 |
+
self.version = kwargs.pop("version", 2.0)
|
| 122 |
+
|
| 123 |
+
def ensure_divide(self, length, patch_size):
|
| 124 |
+
return max(round(length / patch_size) * patch_size, patch_size)
|
| 125 |
+
|
| 126 |
+
def find_best_resize(self, original_size, scale_resolution, patch_size, allow_upscale=False):
|
| 127 |
+
width, height = original_size
|
| 128 |
+
if (width * height > scale_resolution * scale_resolution) or allow_upscale:
|
| 129 |
+
r = width / height
|
| 130 |
+
height = int(scale_resolution / math.sqrt(r))
|
| 131 |
+
width = int(height * r)
|
| 132 |
+
best_width = self.ensure_divide(width, patch_size)
|
| 133 |
+
best_height = self.ensure_divide(height, patch_size)
|
| 134 |
+
return (best_width, best_height)
|
| 135 |
+
|
| 136 |
+
def get_refine_size(self, original_size, grid, scale_resolution, patch_size, allow_upscale=False):
|
| 137 |
+
width, height = original_size
|
| 138 |
+
grid_x, grid_y = grid
|
| 139 |
+
|
| 140 |
+
refine_width = self.ensure_divide(width, grid_x)
|
| 141 |
+
refine_height = self.ensure_divide(height, grid_y)
|
| 142 |
+
|
| 143 |
+
grid_width = refine_width / grid_x
|
| 144 |
+
grid_height = refine_height / grid_y
|
| 145 |
+
|
| 146 |
+
best_grid_size = self.find_best_resize(
|
| 147 |
+
(grid_width, grid_height), scale_resolution, patch_size, allow_upscale=allow_upscale
|
| 148 |
+
)
|
| 149 |
+
refine_size = (best_grid_size[0] * grid_x, best_grid_size[1] * grid_y)
|
| 150 |
+
return refine_size
|
| 151 |
+
|
| 152 |
+
def split_to_patches(self, image, grid):
|
| 153 |
+
patches = []
|
| 154 |
+
width, height = image.size
|
| 155 |
+
grid_x = int(width / grid[0])
|
| 156 |
+
grid_y = int(height / grid[1])
|
| 157 |
+
for i in range(0, height, grid_y):
|
| 158 |
+
images = []
|
| 159 |
+
for j in range(0, width, grid_x):
|
| 160 |
+
box = (j, i, j + grid_x, i + grid_y)
|
| 161 |
+
patch = image.crop(box)
|
| 162 |
+
images.append(patch)
|
| 163 |
+
patches.append(images)
|
| 164 |
+
return patches
|
| 165 |
+
|
| 166 |
+
def slice_image(self, image, max_slice_nums=9, scale_resolution=448, patch_size=14, never_split=False):
|
| 167 |
+
original_size = image.size
|
| 168 |
+
source_image = None
|
| 169 |
+
best_grid = self.get_sliced_grid(original_size, max_slice_nums, never_split)
|
| 170 |
+
patches = []
|
| 171 |
+
|
| 172 |
+
if best_grid is None:
|
| 173 |
+
# dont need to slice, upsample
|
| 174 |
+
best_size = self.find_best_resize(original_size, scale_resolution, patch_size, allow_upscale=True)
|
| 175 |
+
source_image = image.resize(best_size, resample=Image.Resampling.BILINEAR)
|
| 176 |
+
else:
|
| 177 |
+
# source image, down-sampling and ensure divided by patch_size
|
| 178 |
+
best_resize = self.find_best_resize(original_size, scale_resolution, patch_size)
|
| 179 |
+
source_image = image.copy().resize(best_resize, resample=Image.Resampling.BILINEAR)
|
| 180 |
+
refine_size = self.get_refine_size(
|
| 181 |
+
original_size, best_grid, scale_resolution, patch_size, allow_upscale=True
|
| 182 |
+
)
|
| 183 |
+
refine_image = image.resize(refine_size, resample=Image.Resampling.BILINEAR)
|
| 184 |
+
patches = self.split_to_patches(refine_image, best_grid)
|
| 185 |
+
|
| 186 |
+
return source_image, patches, best_grid
|
| 187 |
+
|
| 188 |
+
def get_grid_placeholder(self, grid):
|
| 189 |
+
if grid is None:
|
| 190 |
+
return ""
|
| 191 |
+
slice_image_placeholder = (
|
| 192 |
+
self.slice_start_token + self.unk_token * self.image_feature_size + self.slice_end_token
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
cols = grid[0]
|
| 196 |
+
rows = grid[1]
|
| 197 |
+
slices = []
|
| 198 |
+
for i in range(rows):
|
| 199 |
+
lines = []
|
| 200 |
+
for j in range(cols):
|
| 201 |
+
lines.append(slice_image_placeholder)
|
| 202 |
+
slices.append("".join(lines))
|
| 203 |
+
|
| 204 |
+
slice_placeholder = "\n".join(slices)
|
| 205 |
+
return slice_placeholder
|
| 206 |
+
|
| 207 |
+
def get_image_id_placeholder(self, idx=0):
|
| 208 |
+
return f"{self.im_id_start}{idx}{self.im_id_end}"
|
| 209 |
+
|
| 210 |
+
def get_sliced_images(self, image, max_slice_nums=None):
|
| 211 |
+
slice_images = []
|
| 212 |
+
|
| 213 |
+
if not self.slice_mode:
|
| 214 |
+
return [image]
|
| 215 |
+
|
| 216 |
+
max_slice_nums = self.max_slice_nums if max_slice_nums is None else int(max_slice_nums)
|
| 217 |
+
assert max_slice_nums > 0
|
| 218 |
+
source_image, patches, sliced_grid = self.slice_image(
|
| 219 |
+
image, max_slice_nums, self.scale_resolution, self.patch_size # default: 9 # default: 448 # default: 14
|
| 220 |
+
)
|
| 221 |
+
|
| 222 |
+
slice_images.append(source_image)
|
| 223 |
+
if len(patches) > 0:
|
| 224 |
+
for i in range(len(patches)):
|
| 225 |
+
for j in range(len(patches[0])):
|
| 226 |
+
slice_images.append(patches[i][j])
|
| 227 |
+
return slice_images
|
| 228 |
+
|
| 229 |
+
def get_sliced_grid(self, image_size, max_slice_nums, nerver_split=False):
|
| 230 |
+
original_width, original_height = image_size
|
| 231 |
+
log_ratio = math.log(original_width / original_height)
|
| 232 |
+
ratio = original_width * original_height / (self.scale_resolution * self.scale_resolution)
|
| 233 |
+
multiple = min(math.ceil(ratio), max_slice_nums)
|
| 234 |
+
if multiple <= 1 or nerver_split:
|
| 235 |
+
return None
|
| 236 |
+
candidate_split_grids_nums = []
|
| 237 |
+
for i in [multiple - 1, multiple, multiple + 1]:
|
| 238 |
+
if i == 1 or i > max_slice_nums:
|
| 239 |
+
continue
|
| 240 |
+
candidate_split_grids_nums.append(i)
|
| 241 |
+
|
| 242 |
+
candidate_grids = []
|
| 243 |
+
for split_grids_nums in candidate_split_grids_nums:
|
| 244 |
+
m = 1
|
| 245 |
+
while m <= split_grids_nums:
|
| 246 |
+
if split_grids_nums % m == 0:
|
| 247 |
+
candidate_grids.append([m, split_grids_nums // m])
|
| 248 |
+
m += 1
|
| 249 |
+
|
| 250 |
+
best_grid = [1, 1]
|
| 251 |
+
min_error = float("inf")
|
| 252 |
+
for grid in candidate_grids:
|
| 253 |
+
error = abs(log_ratio - math.log(grid[0] / grid[1]))
|
| 254 |
+
if error < min_error:
|
| 255 |
+
best_grid = grid
|
| 256 |
+
min_error = error
|
| 257 |
+
|
| 258 |
+
return best_grid
|
| 259 |
+
|
| 260 |
+
def get_slice_image_placeholder(self, image_size, image_idx=0, max_slice_nums=None, use_image_id=None):
|
| 261 |
+
max_slice_nums = self.max_slice_nums if max_slice_nums is None else int(max_slice_nums)
|
| 262 |
+
assert max_slice_nums > 0
|
| 263 |
+
grid = self.get_sliced_grid(image_size=image_size, max_slice_nums=max_slice_nums)
|
| 264 |
+
|
| 265 |
+
image_placeholder = self.im_start_token + self.unk_token * self.image_feature_size + self.im_end_token
|
| 266 |
+
use_image_id = self.use_image_id if use_image_id is None else bool(use_image_id)
|
| 267 |
+
if use_image_id:
|
| 268 |
+
final_placeholder = self.get_image_id_placeholder(image_idx) + image_placeholder
|
| 269 |
+
else:
|
| 270 |
+
final_placeholder = image_placeholder
|
| 271 |
+
|
| 272 |
+
if self.slice_mode:
|
| 273 |
+
final_placeholder = final_placeholder + self.get_grid_placeholder(grid=grid)
|
| 274 |
+
return final_placeholder
|
| 275 |
+
|
| 276 |
+
def to_pil_image(self, image, rescale=None) -> PIL.Image.Image:
|
| 277 |
+
"""
|
| 278 |
+
Converts `image` to a PIL Image. Optionally rescales it and puts the channel dimension back as the last axis if
|
| 279 |
+
needed.
|
| 280 |
+
Args:
|
| 281 |
+
image (`PIL.Image.Image` or `numpy.ndarray` or `torch.Tensor`):
|
| 282 |
+
The image to convert to the PIL Image format.
|
| 283 |
+
rescale (`bool`, *optional*):
|
| 284 |
+
Whether or not to apply the scaling factor (to make pixel values integers between 0 and 255). Will
|
| 285 |
+
default to `True` if the image type is a floating type, `False` otherwise.
|
| 286 |
+
"""
|
| 287 |
+
if isinstance(image, PIL.Image.Image):
|
| 288 |
+
return image
|
| 289 |
+
if is_torch_tensor(image):
|
| 290 |
+
image = image.numpy()
|
| 291 |
+
|
| 292 |
+
if isinstance(image, np.ndarray):
|
| 293 |
+
if rescale is None:
|
| 294 |
+
# rescale default to the array being of floating type.
|
| 295 |
+
rescale = isinstance(image.flat[0], np.floating)
|
| 296 |
+
# If the channel as been moved to first dim, we put it back at the end.
|
| 297 |
+
if image.ndim == 3 and image.shape[0] in [1, 3]:
|
| 298 |
+
image = image.transpose(1, 2, 0)
|
| 299 |
+
if rescale:
|
| 300 |
+
image = image * 255
|
| 301 |
+
image = image.astype(np.uint8)
|
| 302 |
+
return PIL.Image.fromarray(image)
|
| 303 |
+
return image
|
| 304 |
+
|
| 305 |
+
def reshape_by_patch(self, image):
|
| 306 |
+
"""
|
| 307 |
+
:param image: shape [3, H, W]
|
| 308 |
+
:param patch_size:
|
| 309 |
+
:return: [3, patch_size, HW/patch_size]
|
| 310 |
+
"""
|
| 311 |
+
image = torch.from_numpy(image)
|
| 312 |
+
patch_size = self.patch_size
|
| 313 |
+
patches = torch.nn.functional.unfold(image, (patch_size, patch_size), stride=(patch_size, patch_size))
|
| 314 |
+
|
| 315 |
+
patches = patches.reshape(image.size(0), patch_size, patch_size, -1)
|
| 316 |
+
patches = patches.permute(0, 1, 3, 2).reshape(image.size(0), patch_size, -1)
|
| 317 |
+
return patches.numpy()
|
| 318 |
+
|
| 319 |
+
def preprocess(
|
| 320 |
+
self,
|
| 321 |
+
images: Union[Image.Image, List[Image.Image], List[List[Image.Image]]],
|
| 322 |
+
do_pad: Optional[bool] = True,
|
| 323 |
+
max_slice_nums: int = None,
|
| 324 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 325 |
+
**kwargs,
|
| 326 |
+
) -> MegrezOBatchFeature:
|
| 327 |
+
if isinstance(images, Image.Image):
|
| 328 |
+
images_list = [[images]]
|
| 329 |
+
elif isinstance(images[0], Image.Image):
|
| 330 |
+
images_list = [images]
|
| 331 |
+
else:
|
| 332 |
+
images_list = images
|
| 333 |
+
|
| 334 |
+
new_images_list = []
|
| 335 |
+
image_sizes_list = []
|
| 336 |
+
tgt_sizes_list = []
|
| 337 |
+
|
| 338 |
+
for _images in images_list:
|
| 339 |
+
if _images is None or len(_images) == 0:
|
| 340 |
+
new_images_list.append([])
|
| 341 |
+
image_sizes_list.append([])
|
| 342 |
+
tgt_sizes_list.append([])
|
| 343 |
+
continue
|
| 344 |
+
if not valid_images(_images):
|
| 345 |
+
raise ValueError(
|
| 346 |
+
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
|
| 347 |
+
"torch.Tensor, tf.Tensor or jax.ndarray."
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
_images = [self.to_pil_image(image).convert("RGB") for image in _images]
|
| 351 |
+
input_data_format = infer_channel_dimension_format(np.array(_images[0]))
|
| 352 |
+
|
| 353 |
+
new_images = []
|
| 354 |
+
image_sizes = np.array([image.size for image in _images])
|
| 355 |
+
tgt_sizes = []
|
| 356 |
+
for image in _images:
|
| 357 |
+
image_patches = self.get_sliced_images(image, max_slice_nums)
|
| 358 |
+
image_patches = [to_numpy_array(image).astype(np.float32) for image in image_patches]
|
| 359 |
+
# image_patches = [to_numpy_array(image).astype(np.float32) / 255 for image in image_patches]
|
| 360 |
+
# image_patches = [
|
| 361 |
+
# self.normalize(image=image, mean=self.mean, std=self.std, input_data_format=input_data_format)
|
| 362 |
+
# for image in image_patches
|
| 363 |
+
# ]
|
| 364 |
+
image_patches = [
|
| 365 |
+
to_channel_dimension_format(image, ChannelDimension.FIRST, input_channel_dim=input_data_format)
|
| 366 |
+
for image in image_patches
|
| 367 |
+
]
|
| 368 |
+
for slice_image in image_patches:
|
| 369 |
+
new_images.append(self.reshape_by_patch(slice_image))
|
| 370 |
+
tgt_sizes.append(
|
| 371 |
+
np.array((slice_image.shape[1] // self.patch_size, slice_image.shape[2] // self.patch_size))
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
if tgt_sizes:
|
| 375 |
+
tgt_sizes = np.vstack(tgt_sizes)
|
| 376 |
+
|
| 377 |
+
new_images_list.append(new_images)
|
| 378 |
+
image_sizes_list.append(image_sizes)
|
| 379 |
+
tgt_sizes_list.append(tgt_sizes)
|
| 380 |
+
return MegrezOBatchFeature(
|
| 381 |
+
data={"pixel_values": new_images_list, "image_sizes": image_sizes_list, "tgt_sizes": tgt_sizes_list},
|
| 382 |
+
tensor_type=return_tensors,
|
| 383 |
+
)
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
AutoImageProcessor.register("MegrezOImageProcessor", MegrezOImageProcessor)
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9d76e6ed9bc5489a9d36a86f123c12981721726e0dbba984044c7481d60f527e
|
| 3 |
+
size 4985008432
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ed84f70f0097e2957804a23e49f5f422ee40ac1d0fb4149356bb313f6b5916a9
|
| 3 |
+
size 3033454936
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
modeling_megrezo.py
ADDED
|
@@ -0,0 +1,328 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
# File: modeling_megrezo.py
|
| 3 |
+
# Description: This file contains the implementation of the Megrez-Omni model.
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 8 |
+
from transformers import AutoProcessor
|
| 9 |
+
from transformers import LlamaForCausalLM
|
| 10 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 11 |
+
from transformers.utils import add_start_docstrings
|
| 12 |
+
from transformers.utils import add_start_docstrings_to_model_forward
|
| 13 |
+
from transformers.utils import is_flash_attn_2_available
|
| 14 |
+
from transformers.utils import is_flash_attn_greater_or_equal_2_10
|
| 15 |
+
from transformers.utils import logging
|
| 16 |
+
from transformers.utils import replace_return_docstrings
|
| 17 |
+
|
| 18 |
+
from .audio import AudioEncoder
|
| 19 |
+
from .configuration_megrezo import MegrezOConfig
|
| 20 |
+
from .modeling_navit_siglip import SiglipVisionTransformer
|
| 21 |
+
from .resampler import Resampler
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def insert_audio_embeddings(text_embeddings, inserted_embeddings, inserted_bounds):
|
| 25 |
+
|
| 26 |
+
inserted_bounds = inserted_bounds.long()
|
| 27 |
+
|
| 28 |
+
for idx in range(len(inserted_embeddings)):
|
| 29 |
+
bid = inserted_bounds[idx][0]
|
| 30 |
+
start_id = inserted_bounds[idx][1]
|
| 31 |
+
end_id = inserted_bounds[idx][2]
|
| 32 |
+
embedding = inserted_embeddings[idx]
|
| 33 |
+
text_embeddings[bid, start_id + 1 : end_id] = embedding
|
| 34 |
+
|
| 35 |
+
return text_embeddings
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def insert_image_embeddings(text_embeddings, inserted_embeddings, inserted_bounds):
|
| 39 |
+
|
| 40 |
+
inserted_bounds = inserted_bounds.long()
|
| 41 |
+
for idx in range(len(inserted_embeddings)):
|
| 42 |
+
bid = inserted_bounds[idx][0]
|
| 43 |
+
start_id = inserted_bounds[idx][1]
|
| 44 |
+
end_id = inserted_bounds[idx][2]
|
| 45 |
+
embedding = inserted_embeddings[idx]
|
| 46 |
+
text_embeddings[bid, start_id:end_id] = embedding
|
| 47 |
+
|
| 48 |
+
return text_embeddings
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
MegrezO_START_DOCSTRING = r"""
|
| 52 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 53 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 54 |
+
etc.)
|
| 55 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 56 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 57 |
+
and behavior.
|
| 58 |
+
Parameters:
|
| 59 |
+
config ([`MegrezOConfig`]):
|
| 60 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 61 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 62 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
@add_start_docstrings(
|
| 67 |
+
"The bare MegrezO Model outputting raw hidden-states without any specific head on top.",
|
| 68 |
+
MegrezO_START_DOCSTRING,
|
| 69 |
+
)
|
| 70 |
+
class MegrezOPreTrainedModel(PreTrainedModel):
|
| 71 |
+
base_model_prefix = "model"
|
| 72 |
+
supports_gradient_checkpointing = True
|
| 73 |
+
config_class = MegrezOConfig
|
| 74 |
+
_skip_keys_device_placement = "past_key_values"
|
| 75 |
+
_supports_flash_attn_2 = True
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
class AudioModel(torch.nn.Module):
|
| 79 |
+
|
| 80 |
+
def __init__(self, config: MegrezOConfig):
|
| 81 |
+
super(AudioModel, self).__init__()
|
| 82 |
+
self.config = config
|
| 83 |
+
self.audio = AudioEncoder(**config.audio_config.to_dict())
|
| 84 |
+
|
| 85 |
+
def forward(self, audio_info):
|
| 86 |
+
audios = audio_info["input_audios"]
|
| 87 |
+
input_audio_lengths = audio_info["input_audio_lengths"]
|
| 88 |
+
audio_span_tokens = audio_info["audio_span_tokens"]
|
| 89 |
+
audios_features = self.audio.encode(audios, input_audio_lengths, audio_span_tokens)
|
| 90 |
+
return audios_features
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class VisionModel(torch.nn.Module):
|
| 94 |
+
|
| 95 |
+
def __init__(self, config: MegrezOConfig):
|
| 96 |
+
super(VisionModel, self).__init__()
|
| 97 |
+
self.config = config
|
| 98 |
+
self.vpm = self.init_vision_module()
|
| 99 |
+
self.resampler = self.init_resampler(self.config.hidden_size, self.vpm.embed_dim)
|
| 100 |
+
|
| 101 |
+
def init_vision_module(self):
|
| 102 |
+
if self.config._attn_implementation == "flash_attention_2":
|
| 103 |
+
self.config.vision_config._attn_implementation = "flash_attention_2"
|
| 104 |
+
else:
|
| 105 |
+
# not suport sdpa
|
| 106 |
+
self.config.vision_config._attn_implementation = "eager"
|
| 107 |
+
model = SiglipVisionTransformer(self.config.vision_config)
|
| 108 |
+
if self.config.drop_vision_last_layer:
|
| 109 |
+
model.encoder.layers = model.encoder.layers[:-1]
|
| 110 |
+
|
| 111 |
+
setattr(model, "embed_dim", model.embeddings.embed_dim)
|
| 112 |
+
setattr(model, "patch_size", model.embeddings.patch_size)
|
| 113 |
+
|
| 114 |
+
return model
|
| 115 |
+
|
| 116 |
+
def init_resampler(self, embed_dim, vision_dim):
|
| 117 |
+
return Resampler(
|
| 118 |
+
num_queries=self.config.query_num,
|
| 119 |
+
embed_dim=embed_dim,
|
| 120 |
+
num_heads=embed_dim // 128,
|
| 121 |
+
kv_dim=vision_dim,
|
| 122 |
+
adaptive=True,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
def get_vision_embedding(
|
| 126 |
+
self,
|
| 127 |
+
all_pixel_values: torch.Tensor,
|
| 128 |
+
patch_attention_mask: torch.Tensor,
|
| 129 |
+
tgt_sizes: torch.Tensor,
|
| 130 |
+
):
|
| 131 |
+
B = all_pixel_values.size(0)
|
| 132 |
+
vision_batch_size = self.config.vision_batch_size
|
| 133 |
+
if B > vision_batch_size:
|
| 134 |
+
hs = []
|
| 135 |
+
for i in range(0, B, vision_batch_size):
|
| 136 |
+
start_idx = i
|
| 137 |
+
end_idx = i + vision_batch_size
|
| 138 |
+
tmp_hs = self.vpm(
|
| 139 |
+
all_pixel_values[start_idx:end_idx],
|
| 140 |
+
patch_attention_mask=patch_attention_mask[start_idx:end_idx],
|
| 141 |
+
tgt_sizes=tgt_sizes[start_idx:end_idx],
|
| 142 |
+
).last_hidden_state
|
| 143 |
+
hs.append(tmp_hs)
|
| 144 |
+
vision_embedding = torch.cat(hs, dim=0)
|
| 145 |
+
else:
|
| 146 |
+
vision_embedding = self.vpm(
|
| 147 |
+
all_pixel_values,
|
| 148 |
+
patch_attention_mask=patch_attention_mask,
|
| 149 |
+
tgt_sizes=tgt_sizes,
|
| 150 |
+
).last_hidden_state
|
| 151 |
+
|
| 152 |
+
return vision_embedding
|
| 153 |
+
|
| 154 |
+
def _prepare_vision_input(self, images, patch_attention_mask, tgt_sizes):
|
| 155 |
+
# (TODO) Move to processor
|
| 156 |
+
device = self.vpm.device
|
| 157 |
+
dtype = self.vpm.dtype
|
| 158 |
+
|
| 159 |
+
pixel_values = torch.stack([(image.to(device) - 127.5) / 127.5 for image in images]).type(dtype)
|
| 160 |
+
patch_attention_mask = patch_attention_mask.to(device)
|
| 161 |
+
return pixel_values, patch_attention_mask, tgt_sizes
|
| 162 |
+
|
| 163 |
+
def forward(self, images, tgt_sizes, patch_attention_mask):
|
| 164 |
+
pixel_values, patch_attention_mask, tgt_sizes = self._prepare_vision_input(
|
| 165 |
+
images, patch_attention_mask, tgt_sizes
|
| 166 |
+
)
|
| 167 |
+
embedding = self.get_vision_embedding(pixel_values, patch_attention_mask, tgt_sizes)
|
| 168 |
+
embedding = self.resampler(embedding, tgt_sizes)
|
| 169 |
+
return embedding
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class MegrezO(MegrezOPreTrainedModel):
|
| 173 |
+
|
| 174 |
+
def __init__(self, config):
|
| 175 |
+
super().__init__(config)
|
| 176 |
+
self.llm = LlamaForCausalLM(config)
|
| 177 |
+
self.vision = VisionModel(config)
|
| 178 |
+
self.audio = AudioModel(config)
|
| 179 |
+
self.post_init()
|
| 180 |
+
self.processor = None
|
| 181 |
+
|
| 182 |
+
# Will be set in the training script
|
| 183 |
+
self.tune_vision = False
|
| 184 |
+
self.tune_audio = False
|
| 185 |
+
|
| 186 |
+
def _get_or_init_processor(self):
|
| 187 |
+
|
| 188 |
+
if self.processor is None:
|
| 189 |
+
self.processor = AutoProcessor.from_pretrained(
|
| 190 |
+
self.config._name_or_path,
|
| 191 |
+
trust_remote_code=True,
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
return self.processor
|
| 195 |
+
|
| 196 |
+
def convert_to_device(self, mini_batch):
|
| 197 |
+
for key in mini_batch:
|
| 198 |
+
if isinstance(mini_batch[key], torch.Tensor):
|
| 199 |
+
mini_batch[key] = mini_batch[key].to(self.device)
|
| 200 |
+
if isinstance(mini_batch[key], list):
|
| 201 |
+
return_value = []
|
| 202 |
+
for value in mini_batch[key]:
|
| 203 |
+
if isinstance(value, torch.Tensor):
|
| 204 |
+
value = value.to(self.device)
|
| 205 |
+
return_value.append(value)
|
| 206 |
+
mini_batch[key] = return_value
|
| 207 |
+
|
| 208 |
+
return mini_batch
|
| 209 |
+
|
| 210 |
+
def compose_embeddings(self, mini_batch):
|
| 211 |
+
position_ids = mini_batch["position_ids"]
|
| 212 |
+
input_ids = mini_batch["input_ids"]
|
| 213 |
+
image_encoding = mini_batch.get("image_encoding")
|
| 214 |
+
audio_encoding = mini_batch.get("audio_encoding")
|
| 215 |
+
if position_ids.dtype != torch.int64:
|
| 216 |
+
position_ids = position_ids.long()
|
| 217 |
+
|
| 218 |
+
embeddings_text = self.llm.model.embed_tokens(input_ids)
|
| 219 |
+
input_embeds = embeddings_text
|
| 220 |
+
if image_encoding:
|
| 221 |
+
pixel_values = image_encoding["pixel_values"]
|
| 222 |
+
tgt_sizes = image_encoding["tgt_sizes"]
|
| 223 |
+
patch_attention_mask = image_encoding["patch_attention_mask"]
|
| 224 |
+
bounds_image = image_encoding["image_bounds"]
|
| 225 |
+
embeddings_image = self.vision(pixel_values, tgt_sizes, patch_attention_mask=patch_attention_mask)
|
| 226 |
+
input_embeds = insert_image_embeddings(embeddings_text, embeddings_image, bounds_image)
|
| 227 |
+
elif self.training and self.tune_vision:
|
| 228 |
+
pixel_values = torch.zeros((3, 14, 3584), dtype=torch.float32)
|
| 229 |
+
tgt_sizes = torch.tensor([[16, 16]], dtype=torch.int64)
|
| 230 |
+
patch_attention_mask = torch.ones((3, 14), dtype=torch.float32)
|
| 231 |
+
embeddings_image = self.vision(pixel_values, tgt_sizes, patch_attention_mask=patch_attention_mask)
|
| 232 |
+
input_embeds += embeddings_image[0].sum() * 0.0
|
| 233 |
+
|
| 234 |
+
if audio_encoding:
|
| 235 |
+
embeddings_audio = self.audio(audio_encoding)
|
| 236 |
+
bounds_audio = audio_encoding["audio_bounds"]
|
| 237 |
+
input_embeds = insert_audio_embeddings(embeddings_text, embeddings_audio, bounds_audio)
|
| 238 |
+
elif self.training and self.tune_audio:
|
| 239 |
+
dummy_audio = torch.zeros((1, 128, 3000), dtype=torch.float32)
|
| 240 |
+
dummy_audio_lengths = torch.tensor([[125, 62]], dtype=torch.int32)
|
| 241 |
+
dummy_span_tokens = [64]
|
| 242 |
+
dummy_audio_encoding = [
|
| 243 |
+
{
|
| 244 |
+
"input_audios": dummy_audio,
|
| 245 |
+
"input_audio_lengths": dummy_audio_lengths,
|
| 246 |
+
"audio_span_tokens": dummy_span_tokens,
|
| 247 |
+
}
|
| 248 |
+
]
|
| 249 |
+
embeddings_audio = self.audio(dummy_audio_encoding)
|
| 250 |
+
input_embeds += embeddings_audio[0].sum() * 0.0
|
| 251 |
+
|
| 252 |
+
return input_ids, input_embeds, position_ids
|
| 253 |
+
|
| 254 |
+
def forward(self, data, **kwargs):
|
| 255 |
+
if self.training:
|
| 256 |
+
_, input_embeds, position_ids = self.compose_embeddings(data)
|
| 257 |
+
return self.llm.forward(
|
| 258 |
+
input_ids=None,
|
| 259 |
+
position_ids=position_ids,
|
| 260 |
+
inputs_embeds=input_embeds,
|
| 261 |
+
**kwargs,
|
| 262 |
+
)
|
| 263 |
+
return self.llm.forward(**kwargs)
|
| 264 |
+
|
| 265 |
+
def generate(
|
| 266 |
+
self,
|
| 267 |
+
input_ids,
|
| 268 |
+
position_ids,
|
| 269 |
+
attention_mask,
|
| 270 |
+
image_encoding=None,
|
| 271 |
+
audio_encoding=None,
|
| 272 |
+
**kwargs,
|
| 273 |
+
):
|
| 274 |
+
tokenizer = self._get_or_init_processor().tokenizer
|
| 275 |
+
data = {
|
| 276 |
+
"input_ids": input_ids,
|
| 277 |
+
"position_ids": position_ids,
|
| 278 |
+
"attention_mask": attention_mask,
|
| 279 |
+
"image_encoding": image_encoding,
|
| 280 |
+
"audio_encoding": audio_encoding,
|
| 281 |
+
}
|
| 282 |
+
data = self.convert_to_device(data)
|
| 283 |
+
input_ids, input_embeds, position_ids = self.compose_embeddings(data)
|
| 284 |
+
|
| 285 |
+
output = self.llm.generate(
|
| 286 |
+
inputs_embeds=input_embeds,
|
| 287 |
+
pad_token_id=tokenizer.pad_token_id,
|
| 288 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 289 |
+
**kwargs,
|
| 290 |
+
)
|
| 291 |
+
return output
|
| 292 |
+
|
| 293 |
+
def trim_stop_words(self, response, stop_words):
|
| 294 |
+
if stop_words:
|
| 295 |
+
for stop in stop_words:
|
| 296 |
+
idx = response.find(stop)
|
| 297 |
+
if idx != -1:
|
| 298 |
+
response = response[:idx]
|
| 299 |
+
return response
|
| 300 |
+
|
| 301 |
+
@torch.inference_mode()
|
| 302 |
+
def chat(self, input_msgs, processor=None, sampling=False, **kwargs):
|
| 303 |
+
if processor is None:
|
| 304 |
+
processor = self._get_or_init_processor()
|
| 305 |
+
|
| 306 |
+
if sampling:
|
| 307 |
+
generation_config = {
|
| 308 |
+
"top_p": 0.8,
|
| 309 |
+
"top_k": 100,
|
| 310 |
+
"temperature": 0.7,
|
| 311 |
+
"do_sample": True,
|
| 312 |
+
"repetition_penalty": 1.05,
|
| 313 |
+
}
|
| 314 |
+
else:
|
| 315 |
+
generation_config = {
|
| 316 |
+
"num_beams": 1,
|
| 317 |
+
"repetition_penalty": 1.2,
|
| 318 |
+
}
|
| 319 |
+
|
| 320 |
+
generation_config.update(kwargs)
|
| 321 |
+
if generation_config.get("temperature") == 0:
|
| 322 |
+
generation_config["do_sample"] = False
|
| 323 |
+
|
| 324 |
+
data = processor(input_msgs)
|
| 325 |
+
output_ids = self.generate(**data, **generation_config)
|
| 326 |
+
tokenizer = processor.tokenizer
|
| 327 |
+
answer = tokenizer.decode(output_ids[0])
|
| 328 |
+
return answer
|
modeling_navit_siglip.py
ADDED
|
@@ -0,0 +1,937 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 Google AI and The HuggingFace Team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" PyTorch Siglip model. """
|
| 16 |
+
# Copied from HuggingFaceM4/siglip-so400m-14-980-flash-attn2-navit and add tgt_sizes
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import os
|
| 20 |
+
import math
|
| 21 |
+
import warnings
|
| 22 |
+
from dataclasses import dataclass
|
| 23 |
+
from typing import Any, Optional, Tuple, Union
|
| 24 |
+
|
| 25 |
+
import numpy as np
|
| 26 |
+
import torch
|
| 27 |
+
import torch.nn.functional as F
|
| 28 |
+
import torch.utils.checkpoint
|
| 29 |
+
from torch import nn
|
| 30 |
+
from torch.nn.init import _calculate_fan_in_and_fan_out
|
| 31 |
+
|
| 32 |
+
from transformers.activations import ACT2FN
|
| 33 |
+
from transformers.modeling_attn_mask_utils import _prepare_4d_attention_mask
|
| 34 |
+
from transformers.modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
|
| 35 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 36 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 37 |
+
from transformers.utils import (
|
| 38 |
+
ModelOutput,
|
| 39 |
+
add_start_docstrings,
|
| 40 |
+
add_start_docstrings_to_model_forward,
|
| 41 |
+
is_flash_attn_2_available,
|
| 42 |
+
logging,
|
| 43 |
+
replace_return_docstrings,
|
| 44 |
+
)
|
| 45 |
+
from transformers.utils import logging
|
| 46 |
+
|
| 47 |
+
logger = logging.get_logger(__name__)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class SiglipVisionConfig(PretrainedConfig):
|
| 51 |
+
r"""
|
| 52 |
+
This is the configuration class to store the configuration of a [`SiglipVisionModel`]. It is used to instantiate a
|
| 53 |
+
Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a
|
| 54 |
+
configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip
|
| 55 |
+
[google/siglip-base-patch16-224](https://huggingface.co/google/siglip-base-patch16-224) architecture.
|
| 56 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 57 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 58 |
+
Args:
|
| 59 |
+
hidden_size (`int`, *optional*, defaults to 768):
|
| 60 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 61 |
+
intermediate_size (`int`, *optional*, defaults to 3072):
|
| 62 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 63 |
+
num_hidden_layers (`int`, *optional*, defaults to 12):
|
| 64 |
+
Number of hidden layers in the Transformer encoder.
|
| 65 |
+
num_attention_heads (`int`, *optional*, defaults to 12):
|
| 66 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 67 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 68 |
+
Number of channels in the input images.
|
| 69 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 70 |
+
The size (resolution) of each image.
|
| 71 |
+
patch_size (`int`, *optional*, defaults to 16):
|
| 72 |
+
The size (resolution) of each patch.
|
| 73 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_pytorch_tanh"`):
|
| 74 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 75 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
|
| 76 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 77 |
+
The epsilon used by the layer normalization layers.
|
| 78 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 79 |
+
The dropout ratio for the attention probabilities.
|
| 80 |
+
Example:
|
| 81 |
+
```python
|
| 82 |
+
>>> from transformers import SiglipVisionConfig, SiglipVisionModel
|
| 83 |
+
>>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
|
| 84 |
+
>>> configuration = SiglipVisionConfig()
|
| 85 |
+
>>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
|
| 86 |
+
>>> model = SiglipVisionModel(configuration)
|
| 87 |
+
>>> # Accessing the model configuration
|
| 88 |
+
>>> configuration = model.config
|
| 89 |
+
```"""
|
| 90 |
+
|
| 91 |
+
model_type = "siglip_vision_model"
|
| 92 |
+
|
| 93 |
+
def __init__(
|
| 94 |
+
self,
|
| 95 |
+
hidden_size=768,
|
| 96 |
+
intermediate_size=3072,
|
| 97 |
+
num_hidden_layers=12,
|
| 98 |
+
num_attention_heads=12,
|
| 99 |
+
num_channels=3,
|
| 100 |
+
image_size=224,
|
| 101 |
+
patch_size=16,
|
| 102 |
+
hidden_act="gelu_pytorch_tanh",
|
| 103 |
+
layer_norm_eps=1e-6,
|
| 104 |
+
attention_dropout=0.0,
|
| 105 |
+
**kwargs,
|
| 106 |
+
):
|
| 107 |
+
super().__init__(**kwargs)
|
| 108 |
+
|
| 109 |
+
self.hidden_size = hidden_size
|
| 110 |
+
self.intermediate_size = intermediate_size
|
| 111 |
+
self.num_hidden_layers = num_hidden_layers
|
| 112 |
+
self.num_attention_heads = num_attention_heads
|
| 113 |
+
self.num_channels = num_channels
|
| 114 |
+
self.patch_size = patch_size
|
| 115 |
+
self.image_size = image_size
|
| 116 |
+
self.attention_dropout = attention_dropout
|
| 117 |
+
self.layer_norm_eps = layer_norm_eps
|
| 118 |
+
self.hidden_act = hidden_act
|
| 119 |
+
|
| 120 |
+
@classmethod
|
| 121 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
|
| 122 |
+
cls._set_token_in_kwargs(kwargs)
|
| 123 |
+
|
| 124 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 125 |
+
|
| 126 |
+
# get the vision config dict if we are loading from SiglipConfig
|
| 127 |
+
if config_dict.get("model_type") == "siglip":
|
| 128 |
+
config_dict = config_dict["vision_config"]
|
| 129 |
+
|
| 130 |
+
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
|
| 131 |
+
logger.warning(
|
| 132 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 133 |
+
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return cls.from_dict(config_dict, **kwargs)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
_CHECKPOINT_FOR_DOC = "google/siglip-base-patch16-224"
|
| 140 |
+
|
| 141 |
+
SIGLIP_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 142 |
+
"google/siglip-base-patch16-224",
|
| 143 |
+
# See all SigLIP models at https://huggingface.co/models?filter=siglip
|
| 144 |
+
]
|
| 145 |
+
|
| 146 |
+
if is_flash_attn_2_available():
|
| 147 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 148 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 152 |
+
def _get_unpad_data(attention_mask):
|
| 153 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 154 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 155 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 156 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 157 |
+
return (
|
| 158 |
+
indices,
|
| 159 |
+
cu_seqlens,
|
| 160 |
+
max_seqlen_in_batch,
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def _trunc_normal_(tensor, mean, std, a, b):
|
| 165 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 166 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 167 |
+
def norm_cdf(x):
|
| 168 |
+
# Computes standard normal cumulative distribution function
|
| 169 |
+
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
|
| 170 |
+
|
| 171 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 172 |
+
warnings.warn(
|
| 173 |
+
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 174 |
+
"The distribution of values may be incorrect.",
|
| 175 |
+
stacklevel=2,
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
# Values are generated by using a truncated uniform distribution and
|
| 179 |
+
# then using the inverse CDF for the normal distribution.
|
| 180 |
+
# Get upper and lower cdf values
|
| 181 |
+
l = norm_cdf((a - mean) / std)
|
| 182 |
+
u = norm_cdf((b - mean) / std)
|
| 183 |
+
|
| 184 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 185 |
+
# [2l-1, 2u-1].
|
| 186 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 187 |
+
|
| 188 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 189 |
+
# standard normal
|
| 190 |
+
if tensor.dtype in [torch.float16, torch.bfloat16]:
|
| 191 |
+
# The `erfinv_` op is not (yet?) defined in float16+cpu, bfloat16+gpu
|
| 192 |
+
og_dtype = tensor.dtype
|
| 193 |
+
tensor = tensor.to(torch.float32)
|
| 194 |
+
tensor.erfinv_()
|
| 195 |
+
tensor = tensor.to(og_dtype)
|
| 196 |
+
else:
|
| 197 |
+
tensor.erfinv_()
|
| 198 |
+
|
| 199 |
+
# Transform to proper mean, std
|
| 200 |
+
tensor.mul_(std * math.sqrt(2.0))
|
| 201 |
+
tensor.add_(mean)
|
| 202 |
+
|
| 203 |
+
# Clamp to ensure it's in the proper range
|
| 204 |
+
if tensor.dtype == torch.float16:
|
| 205 |
+
# The `clamp_` op is not (yet?) defined in float16+cpu
|
| 206 |
+
tensor = tensor.to(torch.float32)
|
| 207 |
+
tensor.clamp_(min=a, max=b)
|
| 208 |
+
tensor = tensor.to(torch.float16)
|
| 209 |
+
else:
|
| 210 |
+
tensor.clamp_(min=a, max=b)
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def trunc_normal_tf_(
|
| 214 |
+
tensor: torch.Tensor, mean: float = 0.0, std: float = 1.0, a: float = -2.0, b: float = 2.0
|
| 215 |
+
) -> torch.Tensor:
|
| 216 |
+
"""Fills the input Tensor with values drawn from a truncated
|
| 217 |
+
normal distribution. The values are effectively drawn from the
|
| 218 |
+
normal distribution :math:`\\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 219 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 220 |
+
the bounds. The method used for generating the random values works
|
| 221 |
+
best when :math:`a \\leq \text{mean} \\leq b`.
|
| 222 |
+
NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
|
| 223 |
+
bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
|
| 224 |
+
and the result is subsquently scaled and shifted by the mean and std args.
|
| 225 |
+
Args:
|
| 226 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 227 |
+
mean: the mean of the normal distribution
|
| 228 |
+
std: the standard deviation of the normal distribution
|
| 229 |
+
a: the minimum cutoff value
|
| 230 |
+
b: the maximum cutoff value
|
| 231 |
+
"""
|
| 232 |
+
with torch.no_grad():
|
| 233 |
+
_trunc_normal_(tensor, 0, 1.0, a, b)
|
| 234 |
+
tensor.mul_(std).add_(mean)
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
|
| 238 |
+
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
|
| 239 |
+
if mode == "fan_in":
|
| 240 |
+
denom = fan_in
|
| 241 |
+
elif mode == "fan_out":
|
| 242 |
+
denom = fan_out
|
| 243 |
+
elif mode == "fan_avg":
|
| 244 |
+
denom = (fan_in + fan_out) / 2
|
| 245 |
+
|
| 246 |
+
variance = scale / denom
|
| 247 |
+
|
| 248 |
+
if distribution == "truncated_normal":
|
| 249 |
+
# constant is stddev of standard normal truncated to (-2, 2)
|
| 250 |
+
trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
|
| 251 |
+
elif distribution == "normal":
|
| 252 |
+
with torch.no_grad():
|
| 253 |
+
tensor.normal_(std=math.sqrt(variance))
|
| 254 |
+
elif distribution == "uniform":
|
| 255 |
+
bound = math.sqrt(3 * variance)
|
| 256 |
+
with torch.no_grad():
|
| 257 |
+
tensor.uniform_(-bound, bound)
|
| 258 |
+
else:
|
| 259 |
+
raise ValueError(f"invalid distribution {distribution}")
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
def lecun_normal_(tensor):
|
| 263 |
+
variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def default_flax_embed_init(tensor):
|
| 267 |
+
variance_scaling_(tensor, mode="fan_in", distribution="normal")
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
@dataclass
|
| 271 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPVisionModelOutput with CLIP->Siglip
|
| 272 |
+
class SiglipVisionModelOutput(ModelOutput):
|
| 273 |
+
"""
|
| 274 |
+
Base class for vision model's outputs that also contains image embeddings of the pooling of the last hidden states.
|
| 275 |
+
Args:
|
| 276 |
+
image_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
|
| 277 |
+
The image embeddings obtained by applying the projection layer to the pooler_output.
|
| 278 |
+
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 279 |
+
Sequence of hidden-states at the output of the last layer of the model.
|
| 280 |
+
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
|
| 281 |
+
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
|
| 282 |
+
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
|
| 283 |
+
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
|
| 284 |
+
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
|
| 285 |
+
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
|
| 286 |
+
sequence_length)`.
|
| 287 |
+
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
|
| 288 |
+
heads.
|
| 289 |
+
"""
|
| 290 |
+
|
| 291 |
+
image_embeds: Optional[torch.FloatTensor] = None
|
| 292 |
+
last_hidden_state: Optional[torch.FloatTensor] = None
|
| 293 |
+
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
|
| 294 |
+
attentions: Optional[Tuple[torch.FloatTensor]] = None
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
class SiglipVisionEmbeddings(nn.Module):
|
| 298 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 299 |
+
super().__init__()
|
| 300 |
+
self.config = config
|
| 301 |
+
self.embed_dim = config.hidden_size
|
| 302 |
+
self.image_size = config.image_size
|
| 303 |
+
self.patch_size = config.patch_size
|
| 304 |
+
|
| 305 |
+
self.patch_embedding = nn.Conv2d(
|
| 306 |
+
in_channels=config.num_channels,
|
| 307 |
+
out_channels=self.embed_dim,
|
| 308 |
+
kernel_size=self.patch_size,
|
| 309 |
+
stride=self.patch_size,
|
| 310 |
+
padding="valid",
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
self.num_patches_per_side = self.image_size // self.patch_size
|
| 314 |
+
self.num_patches = self.num_patches_per_side**2
|
| 315 |
+
self.num_positions = self.num_patches
|
| 316 |
+
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
|
| 317 |
+
|
| 318 |
+
def forward(
|
| 319 |
+
self,
|
| 320 |
+
pixel_values: torch.FloatTensor,
|
| 321 |
+
patch_attention_mask: torch.BoolTensor,
|
| 322 |
+
tgt_sizes: Optional[torch.IntTensor] = None,
|
| 323 |
+
) -> torch.Tensor:
|
| 324 |
+
batch_size = pixel_values.size(0)
|
| 325 |
+
|
| 326 |
+
patch_embeds = self.patch_embedding(pixel_values)
|
| 327 |
+
embeddings = patch_embeds.flatten(2).transpose(1, 2)
|
| 328 |
+
|
| 329 |
+
max_im_h, max_im_w = pixel_values.size(2), pixel_values.size(3)
|
| 330 |
+
max_nb_patches_h, max_nb_patches_w = max_im_h // self.patch_size, max_im_w // self.patch_size
|
| 331 |
+
boundaries = torch.arange(1 / self.num_patches_per_side, 1.0, 1 / self.num_patches_per_side)
|
| 332 |
+
position_ids = torch.full(
|
| 333 |
+
size=(
|
| 334 |
+
batch_size,
|
| 335 |
+
max_nb_patches_h * max_nb_patches_w,
|
| 336 |
+
),
|
| 337 |
+
fill_value=0,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
for batch_idx, p_attn_mask in enumerate(patch_attention_mask):
|
| 341 |
+
if tgt_sizes is not None:
|
| 342 |
+
nb_patches_h = tgt_sizes[batch_idx][0]
|
| 343 |
+
nb_patches_w = tgt_sizes[batch_idx][1]
|
| 344 |
+
else:
|
| 345 |
+
nb_patches_h = p_attn_mask[:, 0].sum()
|
| 346 |
+
nb_patches_w = p_attn_mask[0].sum()
|
| 347 |
+
|
| 348 |
+
fractional_coords_h = torch.arange(0, 1 - 1e-6, 1 / nb_patches_h)
|
| 349 |
+
fractional_coords_w = torch.arange(0, 1 - 1e-6, 1 / nb_patches_w)
|
| 350 |
+
|
| 351 |
+
bucket_coords_h = torch.bucketize(fractional_coords_h, boundaries, right=True)
|
| 352 |
+
bucket_coords_w = torch.bucketize(fractional_coords_w, boundaries, right=True)
|
| 353 |
+
|
| 354 |
+
pos_ids = (bucket_coords_h[:, None] * self.num_patches_per_side + bucket_coords_w).flatten()
|
| 355 |
+
position_ids[batch_idx][p_attn_mask.view(-1).cpu()] = pos_ids
|
| 356 |
+
|
| 357 |
+
position_ids = position_ids.to(self.position_embedding.weight.device)
|
| 358 |
+
|
| 359 |
+
embeddings = embeddings + self.position_embedding(position_ids)
|
| 360 |
+
return embeddings
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class SiglipAttention(nn.Module):
|
| 364 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 365 |
+
|
| 366 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPAttention.__init__
|
| 367 |
+
def __init__(self, config):
|
| 368 |
+
super().__init__()
|
| 369 |
+
self.config = config
|
| 370 |
+
self.embed_dim = config.hidden_size
|
| 371 |
+
self.num_heads = config.num_attention_heads
|
| 372 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 373 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 374 |
+
raise ValueError(
|
| 375 |
+
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
|
| 376 |
+
f" {self.num_heads})."
|
| 377 |
+
)
|
| 378 |
+
self.scale = self.head_dim**-0.5
|
| 379 |
+
self.dropout = config.attention_dropout
|
| 380 |
+
|
| 381 |
+
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 382 |
+
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 383 |
+
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 384 |
+
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 385 |
+
|
| 386 |
+
def forward(
|
| 387 |
+
self,
|
| 388 |
+
hidden_states: torch.Tensor,
|
| 389 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 390 |
+
output_attentions: Optional[bool] = False,
|
| 391 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 392 |
+
"""Input shape: Batch x Time x Channel"""
|
| 393 |
+
|
| 394 |
+
batch_size, q_len, _ = hidden_states.size()
|
| 395 |
+
|
| 396 |
+
query_states = self.q_proj(hidden_states)
|
| 397 |
+
key_states = self.k_proj(hidden_states)
|
| 398 |
+
value_states = self.v_proj(hidden_states)
|
| 399 |
+
|
| 400 |
+
query_states = query_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 401 |
+
key_states = key_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 402 |
+
value_states = value_states.view(batch_size, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 403 |
+
|
| 404 |
+
k_v_seq_len = key_states.shape[-2]
|
| 405 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale
|
| 406 |
+
|
| 407 |
+
if attn_weights.size() != (batch_size, self.num_heads, q_len, k_v_seq_len):
|
| 408 |
+
raise ValueError(
|
| 409 |
+
f"Attention weights should be of size {(batch_size, self.num_heads, q_len, k_v_seq_len)}, but is"
|
| 410 |
+
f" {attn_weights.size()}"
|
| 411 |
+
)
|
| 412 |
+
|
| 413 |
+
if attention_mask is not None:
|
| 414 |
+
if attention_mask.size() != (batch_size, 1, q_len, k_v_seq_len):
|
| 415 |
+
raise ValueError(
|
| 416 |
+
f"Attention mask should be of size {(batch_size, 1, q_len, k_v_seq_len)}, but is {attention_mask.size()}"
|
| 417 |
+
)
|
| 418 |
+
attn_weights = attn_weights + attention_mask
|
| 419 |
+
|
| 420 |
+
# upcast attention to fp32
|
| 421 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 422 |
+
attn_weights = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
|
| 423 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 424 |
+
|
| 425 |
+
if attn_output.size() != (batch_size, self.num_heads, q_len, self.head_dim):
|
| 426 |
+
raise ValueError(
|
| 427 |
+
f"`attn_output` should be of size {(batch_size, self.num_heads, q_len, self.head_dim)}, but is"
|
| 428 |
+
f" {attn_output.size()}"
|
| 429 |
+
)
|
| 430 |
+
|
| 431 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 432 |
+
attn_output = attn_output.reshape(batch_size, q_len, self.embed_dim)
|
| 433 |
+
|
| 434 |
+
attn_output = self.out_proj(attn_output)
|
| 435 |
+
|
| 436 |
+
return attn_output, attn_weights
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
class SiglipFlashAttention2(SiglipAttention):
|
| 440 |
+
"""
|
| 441 |
+
Llama flash attention module. This module inherits from `LlamaAttention` as the weights of the module stays
|
| 442 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 443 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 444 |
+
"""
|
| 445 |
+
|
| 446 |
+
def __init__(self, *args, **kwargs):
|
| 447 |
+
super().__init__(*args, **kwargs)
|
| 448 |
+
self.is_causal = False # Hack to make sure we don't use a causal mask
|
| 449 |
+
|
| 450 |
+
def forward(
|
| 451 |
+
self,
|
| 452 |
+
hidden_states: torch.Tensor,
|
| 453 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 454 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 455 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 456 |
+
output_attentions: bool = False,
|
| 457 |
+
use_cache: bool = False,
|
| 458 |
+
**kwargs,
|
| 459 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 460 |
+
output_attentions = False
|
| 461 |
+
|
| 462 |
+
bsz, q_len, _ = hidden_states.size()
|
| 463 |
+
|
| 464 |
+
query_states = self.q_proj(hidden_states)
|
| 465 |
+
key_states = self.k_proj(hidden_states)
|
| 466 |
+
value_states = self.v_proj(hidden_states)
|
| 467 |
+
|
| 468 |
+
# Flash attention requires the input to have the shape
|
| 469 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 470 |
+
# therefore we just need to keep the original shape
|
| 471 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 472 |
+
key_states = key_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 473 |
+
value_states = value_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 474 |
+
|
| 475 |
+
kv_seq_len = key_states.shape[-2]
|
| 476 |
+
if past_key_value is not None:
|
| 477 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 478 |
+
# cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 479 |
+
# query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 480 |
+
|
| 481 |
+
# if past_key_value is not None:
|
| 482 |
+
# cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models
|
| 483 |
+
# key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 484 |
+
|
| 485 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 486 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 487 |
+
query_states = query_states.transpose(1, 2)
|
| 488 |
+
key_states = key_states.transpose(1, 2)
|
| 489 |
+
value_states = value_states.transpose(1, 2)
|
| 490 |
+
|
| 491 |
+
dropout_rate = self.dropout if self.training else 0.0
|
| 492 |
+
|
| 493 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 494 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 495 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 496 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 497 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 498 |
+
|
| 499 |
+
input_dtype = query_states.dtype
|
| 500 |
+
if input_dtype == torch.float32:
|
| 501 |
+
if torch.is_autocast_enabled():
|
| 502 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 503 |
+
# Handle the case where the model is quantized
|
| 504 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 505 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 506 |
+
else:
|
| 507 |
+
target_dtype = self.q_proj.weight.dtype
|
| 508 |
+
|
| 509 |
+
logger.warning_once(
|
| 510 |
+
"The input hidden states seems to be silently casted in float32, this might be related to the fact"
|
| 511 |
+
" you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 512 |
+
f" {target_dtype}."
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
query_states = query_states.to(target_dtype)
|
| 516 |
+
key_states = key_states.to(target_dtype)
|
| 517 |
+
value_states = value_states.to(target_dtype)
|
| 518 |
+
|
| 519 |
+
attn_output = self._flash_attention_forward(
|
| 520 |
+
query_states, key_states, value_states, attention_mask, q_len, dropout=dropout_rate
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
attn_output = attn_output.reshape(bsz, q_len, self.embed_dim).contiguous()
|
| 524 |
+
attn_output = self.out_proj(attn_output)
|
| 525 |
+
|
| 526 |
+
if not output_attentions:
|
| 527 |
+
attn_weights = None
|
| 528 |
+
|
| 529 |
+
return attn_output, attn_weights
|
| 530 |
+
|
| 531 |
+
def _flash_attention_forward(
|
| 532 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 533 |
+
):
|
| 534 |
+
"""
|
| 535 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 536 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 537 |
+
Args:
|
| 538 |
+
query_states (`torch.Tensor`):
|
| 539 |
+
Input query states to be passed to Flash Attention API
|
| 540 |
+
key_states (`torch.Tensor`):
|
| 541 |
+
Input key states to be passed to Flash Attention API
|
| 542 |
+
value_states (`torch.Tensor`):
|
| 543 |
+
Input value states to be passed to Flash Attention API
|
| 544 |
+
attention_mask (`torch.Tensor`):
|
| 545 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 546 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 547 |
+
dropout (`int`, *optional*):
|
| 548 |
+
Attention dropout
|
| 549 |
+
softmax_scale (`float`, *optional*):
|
| 550 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 551 |
+
"""
|
| 552 |
+
|
| 553 |
+
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
|
| 554 |
+
causal = self.is_causal and query_length != 1
|
| 555 |
+
|
| 556 |
+
# Contains at least one padding token in the sequence
|
| 557 |
+
if attention_mask is not None:
|
| 558 |
+
batch_size = query_states.shape[0]
|
| 559 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
|
| 560 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 561 |
+
)
|
| 562 |
+
|
| 563 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 564 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 565 |
+
|
| 566 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 567 |
+
query_states,
|
| 568 |
+
key_states,
|
| 569 |
+
value_states,
|
| 570 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 571 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 572 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 573 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 574 |
+
dropout_p=dropout,
|
| 575 |
+
softmax_scale=softmax_scale,
|
| 576 |
+
causal=causal,
|
| 577 |
+
)
|
| 578 |
+
|
| 579 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 580 |
+
else:
|
| 581 |
+
attn_output = flash_attn_func(
|
| 582 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 583 |
+
)
|
| 584 |
+
|
| 585 |
+
return attn_output
|
| 586 |
+
|
| 587 |
+
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 588 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 589 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 590 |
+
|
| 591 |
+
key_layer = index_first_axis(
|
| 592 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 593 |
+
)
|
| 594 |
+
value_layer = index_first_axis(
|
| 595 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 596 |
+
)
|
| 597 |
+
if query_length == kv_seq_len:
|
| 598 |
+
query_layer = index_first_axis(
|
| 599 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 600 |
+
)
|
| 601 |
+
cu_seqlens_q = cu_seqlens_k
|
| 602 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 603 |
+
indices_q = indices_k
|
| 604 |
+
elif query_length == 1:
|
| 605 |
+
max_seqlen_in_batch_q = 1
|
| 606 |
+
cu_seqlens_q = torch.arange(
|
| 607 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 608 |
+
) # There is a memcpy here, that is very bad.
|
| 609 |
+
indices_q = cu_seqlens_q[:-1]
|
| 610 |
+
query_layer = query_layer.squeeze(1)
|
| 611 |
+
else:
|
| 612 |
+
# The -q_len: slice assumes left padding.
|
| 613 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 614 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 615 |
+
|
| 616 |
+
return (
|
| 617 |
+
query_layer,
|
| 618 |
+
key_layer,
|
| 619 |
+
value_layer,
|
| 620 |
+
indices_q,
|
| 621 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 622 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 623 |
+
)
|
| 624 |
+
|
| 625 |
+
|
| 626 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Siglip
|
| 627 |
+
class SiglipMLP(nn.Module):
|
| 628 |
+
def __init__(self, config):
|
| 629 |
+
super().__init__()
|
| 630 |
+
self.config = config
|
| 631 |
+
self.activation_fn = ACT2FN[config.hidden_act]
|
| 632 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 633 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 634 |
+
|
| 635 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 636 |
+
hidden_states = self.fc1(hidden_states)
|
| 637 |
+
hidden_states = self.activation_fn(hidden_states)
|
| 638 |
+
hidden_states = self.fc2(hidden_states)
|
| 639 |
+
return hidden_states
|
| 640 |
+
|
| 641 |
+
|
| 642 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->Siglip
|
| 643 |
+
class SiglipEncoderLayer(nn.Module):
|
| 644 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 645 |
+
super().__init__()
|
| 646 |
+
self.embed_dim = config.hidden_size
|
| 647 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 648 |
+
self.self_attn = SiglipAttention(config) if not self._use_flash_attention_2 else SiglipFlashAttention2(config)
|
| 649 |
+
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 650 |
+
self.mlp = SiglipMLP(config)
|
| 651 |
+
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 652 |
+
|
| 653 |
+
def forward(
|
| 654 |
+
self,
|
| 655 |
+
hidden_states: torch.Tensor,
|
| 656 |
+
attention_mask: torch.Tensor,
|
| 657 |
+
output_attentions: Optional[bool] = False,
|
| 658 |
+
) -> Tuple[torch.FloatTensor]:
|
| 659 |
+
"""
|
| 660 |
+
Args:
|
| 661 |
+
hidden_states (`torch.FloatTensor`):
|
| 662 |
+
Input to the layer of shape `(batch, seq_len, embed_dim)`.
|
| 663 |
+
attention_mask (`torch.FloatTensor`):
|
| 664 |
+
Attention mask of shape `(batch, 1, q_len, k_v_seq_len)` where padding elements are indicated by very large negative values.
|
| 665 |
+
output_attentions (`bool`, *optional*, defaults to `False`):
|
| 666 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 667 |
+
returned tensors for more detail.
|
| 668 |
+
"""
|
| 669 |
+
residual = hidden_states
|
| 670 |
+
|
| 671 |
+
hidden_states = self.layer_norm1(hidden_states)
|
| 672 |
+
hidden_states, attn_weights = self.self_attn(
|
| 673 |
+
hidden_states=hidden_states,
|
| 674 |
+
attention_mask=attention_mask,
|
| 675 |
+
output_attentions=output_attentions,
|
| 676 |
+
)
|
| 677 |
+
hidden_states = residual + hidden_states
|
| 678 |
+
|
| 679 |
+
residual = hidden_states
|
| 680 |
+
hidden_states = self.layer_norm2(hidden_states)
|
| 681 |
+
hidden_states = self.mlp(hidden_states)
|
| 682 |
+
hidden_states = residual + hidden_states
|
| 683 |
+
|
| 684 |
+
outputs = (hidden_states,)
|
| 685 |
+
|
| 686 |
+
if output_attentions:
|
| 687 |
+
outputs += (attn_weights,)
|
| 688 |
+
|
| 689 |
+
return outputs
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
class SiglipPreTrainedModel(PreTrainedModel):
|
| 693 |
+
"""
|
| 694 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 695 |
+
models.
|
| 696 |
+
"""
|
| 697 |
+
|
| 698 |
+
config_class = SiglipVisionConfig
|
| 699 |
+
base_model_prefix = "siglip"
|
| 700 |
+
supports_gradient_checkpointing = True
|
| 701 |
+
|
| 702 |
+
def _init_weights(self, module):
|
| 703 |
+
"""Initialize the weights"""
|
| 704 |
+
|
| 705 |
+
if isinstance(module, SiglipVisionEmbeddings):
|
| 706 |
+
width = self.config.hidden_size
|
| 707 |
+
nn.init.normal_(module.position_embedding.weight, std=1 / np.sqrt(width))
|
| 708 |
+
elif isinstance(module, nn.Embedding):
|
| 709 |
+
default_flax_embed_init(module.weight)
|
| 710 |
+
elif isinstance(module, SiglipAttention):
|
| 711 |
+
nn.init.normal_(module.q_proj.weight)
|
| 712 |
+
nn.init.normal_(module.k_proj.weight)
|
| 713 |
+
nn.init.normal_(module.v_proj.weight)
|
| 714 |
+
nn.init.normal_(module.out_proj.weight)
|
| 715 |
+
nn.init.zeros_(module.q_proj.bias)
|
| 716 |
+
nn.init.zeros_(module.k_proj.bias)
|
| 717 |
+
nn.init.zeros_(module.v_proj.bias)
|
| 718 |
+
nn.init.zeros_(module.out_proj.bias)
|
| 719 |
+
elif isinstance(module, SiglipMLP):
|
| 720 |
+
nn.init.normal_(module.fc1.weight)
|
| 721 |
+
nn.init.normal_(module.fc2.weight)
|
| 722 |
+
nn.init.normal_(module.fc1.bias, std=1e-6)
|
| 723 |
+
nn.init.normal_(module.fc2.bias, std=1e-6)
|
| 724 |
+
elif isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 725 |
+
lecun_normal_(module.weight)
|
| 726 |
+
if module.bias is not None:
|
| 727 |
+
nn.init.zeros_(module.bias)
|
| 728 |
+
elif isinstance(module, nn.LayerNorm):
|
| 729 |
+
module.bias.data.zero_()
|
| 730 |
+
module.weight.data.fill_(1.0)
|
| 731 |
+
|
| 732 |
+
|
| 733 |
+
SIGLIP_START_DOCSTRING = r"""
|
| 734 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 735 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 736 |
+
etc.)
|
| 737 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 738 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 739 |
+
and behavior.
|
| 740 |
+
Parameters:
|
| 741 |
+
config ([`SiglipVisionConfig`]): Model configuration class with all the parameters of the model.
|
| 742 |
+
Initializing with a config file does not load the weights associated with the model, only the
|
| 743 |
+
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 744 |
+
"""
|
| 745 |
+
|
| 746 |
+
|
| 747 |
+
SIGLIP_VISION_INPUTS_DOCSTRING = r"""
|
| 748 |
+
Args:
|
| 749 |
+
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
|
| 750 |
+
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
|
| 751 |
+
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
|
| 752 |
+
output_attentions (`bool`, *optional*):
|
| 753 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 754 |
+
tensors for more detail.
|
| 755 |
+
output_hidden_states (`bool`, *optional*):
|
| 756 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 757 |
+
more detail.
|
| 758 |
+
return_dict (`bool`, *optional*):
|
| 759 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 760 |
+
"""
|
| 761 |
+
|
| 762 |
+
|
| 763 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->Siglip
|
| 764 |
+
class SiglipEncoder(nn.Module):
|
| 765 |
+
"""
|
| 766 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 767 |
+
[`SiglipEncoderLayer`].
|
| 768 |
+
Args:
|
| 769 |
+
config: SiglipConfig
|
| 770 |
+
"""
|
| 771 |
+
|
| 772 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 773 |
+
super().__init__()
|
| 774 |
+
self.config = config
|
| 775 |
+
self.layers = nn.ModuleList([SiglipEncoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 776 |
+
self.gradient_checkpointing = False
|
| 777 |
+
|
| 778 |
+
# Ignore copy
|
| 779 |
+
def forward(
|
| 780 |
+
self,
|
| 781 |
+
inputs_embeds,
|
| 782 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 783 |
+
output_attentions: Optional[bool] = None,
|
| 784 |
+
output_hidden_states: Optional[bool] = None,
|
| 785 |
+
return_dict: Optional[bool] = None,
|
| 786 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 787 |
+
r"""
|
| 788 |
+
Args:
|
| 789 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 790 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
|
| 791 |
+
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
|
| 792 |
+
than the model's internal embedding lookup matrix.
|
| 793 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 794 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 795 |
+
- 1 for tokens that are **not masked**,
|
| 796 |
+
- 0 for tokens that are **masked**.
|
| 797 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 798 |
+
output_attentions (`bool`, *optional*):
|
| 799 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 800 |
+
returned tensors for more detail.
|
| 801 |
+
output_hidden_states (`bool`, *optional*):
|
| 802 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 803 |
+
for more detail.
|
| 804 |
+
return_dict (`bool`, *optional*):
|
| 805 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 806 |
+
"""
|
| 807 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 808 |
+
output_hidden_states = (
|
| 809 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 810 |
+
)
|
| 811 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 812 |
+
|
| 813 |
+
encoder_states = () if output_hidden_states else None
|
| 814 |
+
all_attentions = () if output_attentions else None
|
| 815 |
+
|
| 816 |
+
hidden_states = inputs_embeds
|
| 817 |
+
for encoder_layer in self.layers:
|
| 818 |
+
if output_hidden_states:
|
| 819 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 820 |
+
if self.gradient_checkpointing and self.training:
|
| 821 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 822 |
+
encoder_layer.__call__,
|
| 823 |
+
hidden_states,
|
| 824 |
+
attention_mask,
|
| 825 |
+
output_attentions,
|
| 826 |
+
)
|
| 827 |
+
else:
|
| 828 |
+
layer_outputs = encoder_layer(
|
| 829 |
+
hidden_states,
|
| 830 |
+
attention_mask,
|
| 831 |
+
output_attentions=output_attentions,
|
| 832 |
+
)
|
| 833 |
+
|
| 834 |
+
hidden_states = layer_outputs[0]
|
| 835 |
+
|
| 836 |
+
if output_attentions:
|
| 837 |
+
all_attentions = all_attentions + (layer_outputs[1],)
|
| 838 |
+
|
| 839 |
+
if output_hidden_states:
|
| 840 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 841 |
+
|
| 842 |
+
if not return_dict:
|
| 843 |
+
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
|
| 844 |
+
return BaseModelOutput(last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions)
|
| 845 |
+
|
| 846 |
+
|
| 847 |
+
@add_start_docstrings("""The vision model from SigLIP without any head or projection on top.""", SIGLIP_START_DOCSTRING)
|
| 848 |
+
class SiglipVisionTransformer(SiglipPreTrainedModel):
|
| 849 |
+
config_class = SiglipVisionConfig
|
| 850 |
+
main_input_name = "pixel_values"
|
| 851 |
+
_supports_flash_attn_2 = True
|
| 852 |
+
|
| 853 |
+
def __init__(self, config: SiglipVisionConfig):
|
| 854 |
+
super().__init__(config)
|
| 855 |
+
self.config = config
|
| 856 |
+
embed_dim = config.hidden_size
|
| 857 |
+
|
| 858 |
+
self.embeddings = SiglipVisionEmbeddings(config)
|
| 859 |
+
self.encoder = SiglipEncoder(config)
|
| 860 |
+
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
|
| 861 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 862 |
+
|
| 863 |
+
# Initialize weights and apply final processing
|
| 864 |
+
self.post_init()
|
| 865 |
+
|
| 866 |
+
def get_input_embeddings(self) -> nn.Module:
|
| 867 |
+
return self.embeddings.patch_embedding
|
| 868 |
+
|
| 869 |
+
@add_start_docstrings_to_model_forward(SIGLIP_VISION_INPUTS_DOCSTRING)
|
| 870 |
+
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=SiglipVisionConfig)
|
| 871 |
+
def forward(
|
| 872 |
+
self,
|
| 873 |
+
pixel_values,
|
| 874 |
+
patch_attention_mask: Optional[torch.BoolTensor] = None,
|
| 875 |
+
tgt_sizes: Optional[torch.IntTensor] = None,
|
| 876 |
+
output_attentions: Optional[bool] = None,
|
| 877 |
+
output_hidden_states: Optional[bool] = None,
|
| 878 |
+
return_dict: Optional[bool] = None,
|
| 879 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 880 |
+
r"""
|
| 881 |
+
Returns:
|
| 882 |
+
"""
|
| 883 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 884 |
+
output_hidden_states = (
|
| 885 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 886 |
+
)
|
| 887 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 888 |
+
|
| 889 |
+
batch_size = pixel_values.size(0)
|
| 890 |
+
if patch_attention_mask is None:
|
| 891 |
+
patch_attention_mask = torch.ones(
|
| 892 |
+
size=(
|
| 893 |
+
batch_size,
|
| 894 |
+
pixel_values.size(2) // self.config.patch_size,
|
| 895 |
+
pixel_values.size(3) // self.config.patch_size,
|
| 896 |
+
),
|
| 897 |
+
dtype=torch.bool,
|
| 898 |
+
device=pixel_values.device,
|
| 899 |
+
)
|
| 900 |
+
|
| 901 |
+
hidden_states = self.embeddings(
|
| 902 |
+
pixel_values=pixel_values, patch_attention_mask=patch_attention_mask, tgt_sizes=tgt_sizes
|
| 903 |
+
)
|
| 904 |
+
|
| 905 |
+
patch_attention_mask = patch_attention_mask.view(batch_size, -1)
|
| 906 |
+
# The call to `_upad_input` in `_flash_attention_forward` is expensive
|
| 907 |
+
# So when the `patch_attention_mask` is full of 1s (i.e. attending to the whole sequence),
|
| 908 |
+
# avoiding passing the attention_mask, which is equivalent to attending to the full sequence
|
| 909 |
+
if not torch.any(~patch_attention_mask):
|
| 910 |
+
attention_mask = None
|
| 911 |
+
else:
|
| 912 |
+
attention_mask = (
|
| 913 |
+
_prepare_4d_attention_mask(patch_attention_mask, hidden_states.dtype)
|
| 914 |
+
if not self._use_flash_attention_2
|
| 915 |
+
else patch_attention_mask
|
| 916 |
+
)
|
| 917 |
+
|
| 918 |
+
encoder_outputs = self.encoder(
|
| 919 |
+
inputs_embeds=hidden_states,
|
| 920 |
+
attention_mask=attention_mask,
|
| 921 |
+
output_attentions=output_attentions,
|
| 922 |
+
output_hidden_states=output_hidden_states,
|
| 923 |
+
return_dict=return_dict,
|
| 924 |
+
)
|
| 925 |
+
|
| 926 |
+
last_hidden_state = encoder_outputs[0]
|
| 927 |
+
last_hidden_state = self.post_layernorm(last_hidden_state)
|
| 928 |
+
|
| 929 |
+
if not return_dict:
|
| 930 |
+
return (last_hidden_state, None) + encoder_outputs[1:]
|
| 931 |
+
|
| 932 |
+
return BaseModelOutputWithPooling(
|
| 933 |
+
last_hidden_state=last_hidden_state,
|
| 934 |
+
pooler_output=None,
|
| 935 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 936 |
+
attentions=encoder_outputs.attentions,
|
| 937 |
+
)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"im_end": "<|image_end|>",
|
| 3 |
+
"im_end_token": "<|image_end|>",
|
| 4 |
+
"im_id_end": "<|image_id_end|>",
|
| 5 |
+
"im_id_start": "<|image_id_start|>",
|
| 6 |
+
"im_start": "<|image_start|>",
|
| 7 |
+
"im_start_token": "<|image_start|>",
|
| 8 |
+
"image_feature_size": 64,
|
| 9 |
+
"image_processor_type": "MegrezOImageProcessor",
|
| 10 |
+
"audio_feature_extractor_type": "WhisperFeatureExtractor",
|
| 11 |
+
"feature_size": 128,
|
| 12 |
+
"max_slice_nums": 9,
|
| 13 |
+
"mean": [
|
| 14 |
+
0.5,
|
| 15 |
+
0.5,
|
| 16 |
+
0.5
|
| 17 |
+
],
|
| 18 |
+
"norm_mean": [
|
| 19 |
+
0.5,
|
| 20 |
+
0.5,
|
| 21 |
+
0.5
|
| 22 |
+
],
|
| 23 |
+
"norm_std": [
|
| 24 |
+
0.5,
|
| 25 |
+
0.5,
|
| 26 |
+
0.5
|
| 27 |
+
],
|
| 28 |
+
"patch_size": 14,
|
| 29 |
+
"processor_class": "MegrezOProcessor",
|
| 30 |
+
"sampling_rate": 16000,
|
| 31 |
+
"scale_resolution": 448,
|
| 32 |
+
"slice_end": "<|slice_end|>",
|
| 33 |
+
"slice_end_token": "<|slice_end|>",
|
| 34 |
+
"slice_mode": true,
|
| 35 |
+
"slice_start": "<|slice_start|>",
|
| 36 |
+
"slice_start_token": "<|slice_start|>",
|
| 37 |
+
"std": [
|
| 38 |
+
0.5,
|
| 39 |
+
0.5,
|
| 40 |
+
0.5
|
| 41 |
+
],
|
| 42 |
+
"unk": "<|unk|>",
|
| 43 |
+
"unk_token": "<|unk|>",
|
| 44 |
+
"pad_token": "<|pad|>",
|
| 45 |
+
"use_image_id": true
|
| 46 |
+
}
|
processing_megrezo.py
ADDED
|
@@ -0,0 +1,587 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- encoding: utf-8 -*-
|
| 2 |
+
# File: processing_megrezo.py
|
| 3 |
+
# Description: None
|
| 4 |
+
|
| 5 |
+
import io
|
| 6 |
+
import re
|
| 7 |
+
import subprocess
|
| 8 |
+
from collections import UserDict
|
| 9 |
+
from typing import List, Literal, Optional, Tuple, Union
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import PIL
|
| 13 |
+
import PIL.Image
|
| 14 |
+
import torch
|
| 15 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 16 |
+
from transformers import TensorType
|
| 17 |
+
from transformers.feature_extraction_utils import BatchFeature
|
| 18 |
+
from transformers.image_utils import ImageInput
|
| 19 |
+
from transformers.processing_utils import ProcessorMixin
|
| 20 |
+
|
| 21 |
+
from .image_processing_megrezo import MegrezOImageProcessor # noqa: F401
|
| 22 |
+
|
| 23 |
+
AudioInput = Union[str, bytes, "np.ndarray", List[str], List[bytes], List["np.ndarray"]]
|
| 24 |
+
ReturnTensorType = Union[str, TensorType]
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class ImageBatchFeature(BatchFeature):
|
| 28 |
+
r"""
|
| 29 |
+
Holds the image features of a batch of images.
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
pixel_values: Union[np.ndarray, torch.Tensor]
|
| 33 |
+
image_sizes: Union[np.ndarray, torch.Tensor]
|
| 34 |
+
tgt_sizes: Union[np.ndarray, torch.Tensor]
|
| 35 |
+
patch_attention_mask: Union[np.ndarray, torch.Tensor]
|
| 36 |
+
image_bounds: Union[np.ndarray, torch.Tensor]
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class AudioBatchFeature(BatchFeature):
|
| 40 |
+
r"""
|
| 41 |
+
Holds the audio features of a batch of audio.
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
input_audios: List[Union[np.ndarray, torch.Tensor]]
|
| 45 |
+
input_audio_lengths: List[Union[np.ndarray, torch.Tensor]]
|
| 46 |
+
audio_span_tokens: List[Union[np.ndarray, torch.Tensor]]
|
| 47 |
+
audio_bounds: Union[np.ndarray, torch.Tensor]
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class ConvContent(UserDict):
|
| 51 |
+
text: Optional[str] = None
|
| 52 |
+
image: Optional[ImageInput] = None
|
| 53 |
+
audio: Optional[Union[str, bytes, List[Union[str, bytes]]]] = None
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class Conversation(UserDict):
|
| 57 |
+
role: Literal["user", "assistant"]
|
| 58 |
+
content: Union[str, dict, ConvContent]
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def load_audio(
|
| 62 |
+
audio: Union[str, bytes],
|
| 63 |
+
sample_rate: int = 16000,
|
| 64 |
+
) -> "np.ndarray":
|
| 65 |
+
"""Load audio from a file path or bytes and return as a numpy array.
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
audio (Union[str, bytes]): path to a audio file or audio bytes.
|
| 69 |
+
sample_rate (int, optional): sample rate. Defaults to 16000.
|
| 70 |
+
|
| 71 |
+
Raises:
|
| 72 |
+
ValueError: if the input audio is neither a path nor bytes.
|
| 73 |
+
|
| 74 |
+
Returns:
|
| 75 |
+
np.ndarray: the audio as a numpy array.
|
| 76 |
+
"""
|
| 77 |
+
if isinstance(audio, str):
|
| 78 |
+
inp = audio
|
| 79 |
+
out = "-"
|
| 80 |
+
cmd_inp = None
|
| 81 |
+
elif isinstance(audio, bytes):
|
| 82 |
+
inp = "pipe:"
|
| 83 |
+
out = "pipe:"
|
| 84 |
+
cmd_inp = audio
|
| 85 |
+
else:
|
| 86 |
+
raise ValueError("input audio must be either a path or bytes")
|
| 87 |
+
|
| 88 |
+
cmd = [
|
| 89 |
+
"ffmpeg",
|
| 90 |
+
"-nostdin",
|
| 91 |
+
"-threads",
|
| 92 |
+
"0",
|
| 93 |
+
"-i",
|
| 94 |
+
inp,
|
| 95 |
+
"-f",
|
| 96 |
+
"s16le",
|
| 97 |
+
"-ac",
|
| 98 |
+
"1",
|
| 99 |
+
"-acodec",
|
| 100 |
+
"pcm_s16le",
|
| 101 |
+
"-ar",
|
| 102 |
+
str(sample_rate),
|
| 103 |
+
out,
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
out = subprocess.check_output(cmd, input=cmd_inp, stderr=subprocess.PIPE)
|
| 107 |
+
arr = np.frombuffer(out, np.int16).flatten().astype(np.float32) / 32768.0
|
| 108 |
+
return arr
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def load_image(
|
| 112 |
+
image: Union[str, bytes, PIL.Image.Image],
|
| 113 |
+
) -> PIL.Image.Image:
|
| 114 |
+
"""Load image from a file path or bytes and return as a PIL image.
|
| 115 |
+
|
| 116 |
+
Args:
|
| 117 |
+
image (Union[str, bytes, PIL.Image.Image]): path to an image file, image bytes or a PIL image.
|
| 118 |
+
|
| 119 |
+
Raises:
|
| 120 |
+
ValueError: if the input image is neither a path nor bytes.
|
| 121 |
+
|
| 122 |
+
Returns:
|
| 123 |
+
PIL.Image.Image: the image as a PIL image.
|
| 124 |
+
"""
|
| 125 |
+
if isinstance(image, PIL.Image.Image):
|
| 126 |
+
return image
|
| 127 |
+
|
| 128 |
+
if isinstance(image, str):
|
| 129 |
+
img = PIL.Image.open(image)
|
| 130 |
+
elif isinstance(image, bytes):
|
| 131 |
+
img = PIL.Image.open(io.BytesIO(image))
|
| 132 |
+
else:
|
| 133 |
+
raise ValueError("input image must be either a path or bytes")
|
| 134 |
+
|
| 135 |
+
return img
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class MegrezOProcessor(ProcessorMixin):
|
| 139 |
+
attributes = ["image_processor", "audio_feature_extractor", "tokenizer"]
|
| 140 |
+
image_processor_class = "AutoImageProcessor"
|
| 141 |
+
audio_feature_extractor_class = "WhisperFeatureExtractor"
|
| 142 |
+
tokenizer_class = "AutoTokenizer"
|
| 143 |
+
|
| 144 |
+
_image_placeholder = r"(<image>./</image>)"
|
| 145 |
+
_audio_placeholder = r"(<audio>./</audio>)"
|
| 146 |
+
|
| 147 |
+
def __init__(self, image_processor=None, audio_feature_extractor=None, tokenizer=None):
|
| 148 |
+
super().__init__(image_processor, audio_feature_extractor, tokenizer)
|
| 149 |
+
self.chat_template = self.tokenizer.chat_template
|
| 150 |
+
|
| 151 |
+
def _parse_and_check_inputs(self, inputs) -> List[Conversation]:
|
| 152 |
+
if not isinstance(inputs, list):
|
| 153 |
+
raise ValueError("inputs must be a list of conversations")
|
| 154 |
+
|
| 155 |
+
conversations = []
|
| 156 |
+
images = []
|
| 157 |
+
audios = []
|
| 158 |
+
|
| 159 |
+
for input in inputs:
|
| 160 |
+
if not isinstance(input, dict) and not isinstance(input, Conversation):
|
| 161 |
+
raise ValueError("each element of inputs must be a dictionary or a Conversation object")
|
| 162 |
+
|
| 163 |
+
role = input.get("role")
|
| 164 |
+
content = input.get("content")
|
| 165 |
+
if role is None or content is None:
|
| 166 |
+
raise ValueError("role and content must be provided in each conversation")
|
| 167 |
+
|
| 168 |
+
if isinstance(content, str):
|
| 169 |
+
content = content
|
| 170 |
+
elif isinstance(content, dict):
|
| 171 |
+
content = ConvContent({**content})
|
| 172 |
+
elif not isinstance(content, ConvContent):
|
| 173 |
+
raise ValueError("content must be a dictionary or a ConvContent object")
|
| 174 |
+
|
| 175 |
+
if not isinstance(content, str):
|
| 176 |
+
if content.get("image") is not None:
|
| 177 |
+
images.extend(content["image"] if isinstance(content["image"], list) else [content["image"]])
|
| 178 |
+
|
| 179 |
+
if content.get("audio") is not None:
|
| 180 |
+
audios.extend(content["audio"] if isinstance(content["audio"], list) else [content["audio"]])
|
| 181 |
+
|
| 182 |
+
conv = Conversation({"role": role, "content": content})
|
| 183 |
+
conversations.append(conv)
|
| 184 |
+
|
| 185 |
+
return conversations, images, audios
|
| 186 |
+
|
| 187 |
+
def __call__(
|
| 188 |
+
self,
|
| 189 |
+
conversations: List[Conversation],
|
| 190 |
+
apply_chat_template: bool = True,
|
| 191 |
+
max_length: Optional[int] = None,
|
| 192 |
+
return_tensors: ReturnTensorType = TensorType.PYTORCH,
|
| 193 |
+
apply_data_collator: bool = True,
|
| 194 |
+
**kwargs,
|
| 195 |
+
):
|
| 196 |
+
assert return_tensors is TensorType.PYTORCH, "Only PyTorch tensors are supported for now."
|
| 197 |
+
convs, images, audios = self._parse_and_check_inputs(conversations)
|
| 198 |
+
add_generation_prompt = kwargs.pop("add_generation_prompt", True)
|
| 199 |
+
if apply_chat_template:
|
| 200 |
+
prompt = self.tokenizer.apply_chat_template(
|
| 201 |
+
convs,
|
| 202 |
+
tokenize=False,
|
| 203 |
+
add_generation_prompt=add_generation_prompt,
|
| 204 |
+
)
|
| 205 |
+
else: # (TODO) For clarification temporarily. Check whether this needs to be removed.
|
| 206 |
+
prompt = "\n".join([conv["content"] for conv in convs])
|
| 207 |
+
|
| 208 |
+
prompt, multimodal_inputs = self.process_multimodal_inputs(
|
| 209 |
+
prompt,
|
| 210 |
+
images=images,
|
| 211 |
+
audios=audios,
|
| 212 |
+
return_tensors=return_tensors,
|
| 213 |
+
**kwargs,
|
| 214 |
+
)
|
| 215 |
+
text_encodings = self.tokenizer(
|
| 216 |
+
prompt,
|
| 217 |
+
return_tensors=return_tensors,
|
| 218 |
+
max_length=max_length,
|
| 219 |
+
padding=True,
|
| 220 |
+
padding_side="left",
|
| 221 |
+
truncation=True,
|
| 222 |
+
**kwargs,
|
| 223 |
+
)
|
| 224 |
+
|
| 225 |
+
merged = self.merge_encodings(text_encodings, multimodal_inputs)
|
| 226 |
+
|
| 227 |
+
if apply_data_collator:
|
| 228 |
+
return self.data_collator([merged])
|
| 229 |
+
|
| 230 |
+
return merged
|
| 231 |
+
|
| 232 |
+
def merge_encodings(self, text_encodings, multimodal_inputs):
|
| 233 |
+
|
| 234 |
+
result = {
|
| 235 |
+
"image_encoding": None,
|
| 236 |
+
"audio_encoding": None,
|
| 237 |
+
}
|
| 238 |
+
|
| 239 |
+
result["input_ids"] = text_encodings["input_ids"].reshape(-1).to(torch.int32)
|
| 240 |
+
result["attention_mask"] = result["input_ids"].ne(0)
|
| 241 |
+
result["position_ids"] = torch.arange(result["input_ids"].size(0)).long()
|
| 242 |
+
|
| 243 |
+
if "image_encoding" in multimodal_inputs and multimodal_inputs["image_encoding"]:
|
| 244 |
+
result["image_encoding"] = multimodal_inputs["image_encoding"]
|
| 245 |
+
result["image_encoding"]["image_bounds"] = self.compute_bounds_image(result["input_ids"])
|
| 246 |
+
|
| 247 |
+
if "audio_encoding" in multimodal_inputs and multimodal_inputs["audio_encoding"]:
|
| 248 |
+
result["audio_encoding"] = multimodal_inputs["audio_encoding"]
|
| 249 |
+
result["audio_encoding"]["audio_bounds"] = self.compute_bounds_audio(result["input_ids"])
|
| 250 |
+
|
| 251 |
+
return result
|
| 252 |
+
|
| 253 |
+
def compute_bounds_image(self, input_ids: torch.Tensor) -> List[torch.Tensor]:
|
| 254 |
+
image_start_ids = (
|
| 255 |
+
torch.where((input_ids == self.tokenizer.im_start_id) | (input_ids == self.tokenizer.slice_start_id))[0] + 1
|
| 256 |
+
)
|
| 257 |
+
image_end_ids = torch.where(
|
| 258 |
+
(input_ids == self.tokenizer.im_end_id) | (input_ids == self.tokenizer.slice_end_id)
|
| 259 |
+
)[0]
|
| 260 |
+
|
| 261 |
+
valid_image_nums = max(len(image_start_ids), len(image_end_ids))
|
| 262 |
+
bounds_image = torch.hstack(
|
| 263 |
+
[
|
| 264 |
+
image_start_ids[:valid_image_nums].unsqueeze(-1),
|
| 265 |
+
image_end_ids[:valid_image_nums].unsqueeze(-1),
|
| 266 |
+
]
|
| 267 |
+
)
|
| 268 |
+
return bounds_image
|
| 269 |
+
|
| 270 |
+
def compute_bounds_audio(self, input_ids: torch.Tensor) -> torch.Tensor:
|
| 271 |
+
audio_bos_ids = torch.where(input_ids == self.tokenizer.audio_start_id)[0]
|
| 272 |
+
audio_eos_ids = torch.where(input_ids == self.tokenizer.audio_end_id)[0]
|
| 273 |
+
bounds_audio = torch.stack([audio_bos_ids, audio_eos_ids], 1)
|
| 274 |
+
return bounds_audio
|
| 275 |
+
|
| 276 |
+
def process_multimodal_inputs(
|
| 277 |
+
self,
|
| 278 |
+
text: str,
|
| 279 |
+
images: Optional[ImageInput] = None,
|
| 280 |
+
audios: Optional[Union[str, bytes, List[Union[str, bytes]]]] = None,
|
| 281 |
+
return_tensors: ReturnTensorType = TensorType.PYTORCH,
|
| 282 |
+
**kwargs,
|
| 283 |
+
):
|
| 284 |
+
# (NOTE) Only single pair of multimodal input is allowed currently.
|
| 285 |
+
# (TODO) Check whether single multimodal input is allowed.
|
| 286 |
+
if text is None and images is None and audios is None:
|
| 287 |
+
raise ValueError("At least one of text, images or audio must be provided")
|
| 288 |
+
|
| 289 |
+
image_processor_kwargs, audio_feature_extractor_kwargs = {}, {}
|
| 290 |
+
if kwargs:
|
| 291 |
+
image_processor_kwargs = {
|
| 292 |
+
k: v for k, v in kwargs.items() if k in self.image_processor._valid_processor_keys
|
| 293 |
+
}
|
| 294 |
+
audio_feature_extractor_kwargs = {
|
| 295 |
+
k: v for k, v in kwargs.items() if k in self.audio_feature_extractor._valid_processor_keys
|
| 296 |
+
}
|
| 297 |
+
|
| 298 |
+
multimodal_encodings = {
|
| 299 |
+
"image_encoding": None,
|
| 300 |
+
"audio_encoding": None,
|
| 301 |
+
}
|
| 302 |
+
|
| 303 |
+
if images:
|
| 304 |
+
image_encoding = self.process_image(
|
| 305 |
+
images,
|
| 306 |
+
return_tensors=return_tensors,
|
| 307 |
+
**image_processor_kwargs,
|
| 308 |
+
)
|
| 309 |
+
text = self.insert_image_feature_placeholders(text, image_encoding)
|
| 310 |
+
multimodal_encodings["image_encoding"] = image_encoding
|
| 311 |
+
|
| 312 |
+
if audios:
|
| 313 |
+
audio_encoding = self.process_audio(
|
| 314 |
+
audios,
|
| 315 |
+
**audio_feature_extractor_kwargs,
|
| 316 |
+
)
|
| 317 |
+
text = self.insert_audio_feature_placeholders(text, audio_encoding)
|
| 318 |
+
multimodal_encodings["audio_encoding"] = audio_encoding
|
| 319 |
+
|
| 320 |
+
return text, multimodal_encodings
|
| 321 |
+
|
| 322 |
+
def insert_image_feature_placeholders(
|
| 323 |
+
self,
|
| 324 |
+
prompt: str,
|
| 325 |
+
image_features: ImageBatchFeature,
|
| 326 |
+
max_slice_nums: Optional[int] = None,
|
| 327 |
+
use_image_id: Optional[bool] = None,
|
| 328 |
+
) -> List[str]:
|
| 329 |
+
# Check the number of image tags and the number of images.
|
| 330 |
+
img_tags = re.findall(self._image_placeholder, prompt)
|
| 331 |
+
assert len(img_tags) == len(
|
| 332 |
+
image_features.image_sizes
|
| 333 |
+
), f"the number of image tags must match the number of images, got {len(img_tags)} and {len(image_features.image_sizes)}"
|
| 334 |
+
|
| 335 |
+
# Replace image tags with image placeholders.
|
| 336 |
+
text_chunks = prompt.split(self._image_placeholder)
|
| 337 |
+
final_text = ""
|
| 338 |
+
for i in range(len(img_tags)):
|
| 339 |
+
final_text += text_chunks[i] + self.image_processor.get_slice_image_placeholder(
|
| 340 |
+
image_features.image_sizes[i],
|
| 341 |
+
i,
|
| 342 |
+
max_slice_nums,
|
| 343 |
+
use_image_id,
|
| 344 |
+
)
|
| 345 |
+
final_text += text_chunks[-1]
|
| 346 |
+
|
| 347 |
+
return final_text
|
| 348 |
+
|
| 349 |
+
def insert_audio_feature_placeholders(
|
| 350 |
+
self,
|
| 351 |
+
prompt: str,
|
| 352 |
+
audio_features: AudioBatchFeature,
|
| 353 |
+
) -> List[str]:
|
| 354 |
+
# Check the number of audio tags and the number of audios.
|
| 355 |
+
audio_tags = re.findall(self._audio_placeholder, prompt)
|
| 356 |
+
assert len(audio_tags) == len(
|
| 357 |
+
audio_features.input_audios
|
| 358 |
+
), "the number of audio tags must match the number of audios"
|
| 359 |
+
|
| 360 |
+
# Replace audio tags with audio placeholders.
|
| 361 |
+
text_chunks = prompt.split(self._audio_placeholder)
|
| 362 |
+
final_text = ""
|
| 363 |
+
for idx in range(len(audio_features.input_audios)):
|
| 364 |
+
final_text += text_chunks[idx] + (
|
| 365 |
+
self.tokenizer.audio_start
|
| 366 |
+
+ self.tokenizer.unk_token * audio_features.audio_span_tokens[idx]
|
| 367 |
+
+ self.tokenizer.audio_end
|
| 368 |
+
)
|
| 369 |
+
final_text += text_chunks[-1]
|
| 370 |
+
|
| 371 |
+
return final_text
|
| 372 |
+
|
| 373 |
+
def process_audio(
|
| 374 |
+
self,
|
| 375 |
+
audio_input: AudioInput,
|
| 376 |
+
return_tensors: ReturnTensorType = TensorType.PYTORCH,
|
| 377 |
+
**kwargs,
|
| 378 |
+
) -> AudioBatchFeature:
|
| 379 |
+
if isinstance(audio_input, list):
|
| 380 |
+
inputs = [load_audio(x) for x in audio_input]
|
| 381 |
+
elif isinstance(audio_input, (str, bytes, "np.ndarray")):
|
| 382 |
+
inputs = [load_audio(audio_input)]
|
| 383 |
+
else:
|
| 384 |
+
raise ValueError("audio_input must be a path or bytes or a list of paths/bytes")
|
| 385 |
+
|
| 386 |
+
features = self.audio_feature_extractor(
|
| 387 |
+
inputs,
|
| 388 |
+
sampling_rate=self.audio_feature_extractor.sampling_rate,
|
| 389 |
+
return_attention_mask=True,
|
| 390 |
+
return_token_timestamps=True,
|
| 391 |
+
padding="max_length",
|
| 392 |
+
return_tensors=return_tensors,
|
| 393 |
+
**kwargs,
|
| 394 |
+
)
|
| 395 |
+
|
| 396 |
+
input_lengths = features["num_frames"]
|
| 397 |
+
input_lengths = (input_lengths - 1) // 2 + 1
|
| 398 |
+
output_lengths = (input_lengths - 2) // 2 + 1
|
| 399 |
+
input_audio_lengths = torch.stack([input_lengths, output_lengths], dim=1)
|
| 400 |
+
audio_span_tokens = (output_lengths + 2).tolist() # add bos and eos tokens
|
| 401 |
+
|
| 402 |
+
data = {
|
| 403 |
+
"input_audios": features["input_features"],
|
| 404 |
+
"input_audio_lengths": input_audio_lengths,
|
| 405 |
+
"audio_span_tokens": audio_span_tokens,
|
| 406 |
+
}
|
| 407 |
+
|
| 408 |
+
# tensor types are already converted in `self.audio_feature_extractor`.
|
| 409 |
+
return AudioBatchFeature(data={**data})
|
| 410 |
+
|
| 411 |
+
def pad_images(
|
| 412 |
+
self,
|
| 413 |
+
pixel_values_list: List[torch.Tensor],
|
| 414 |
+
tgt_sizes: torch.Tensor,
|
| 415 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 416 |
+
"""Pad images to the same size and return the padded pixel values and patch attention mask.
|
| 417 |
+
|
| 418 |
+
Sliced pataches may have different sizes. We pad them to the same size and return the padded pixel values and corresponding patch attention mask.
|
| 419 |
+
"""
|
| 420 |
+
|
| 421 |
+
all_pixel_values = []
|
| 422 |
+
for pixel_value in pixel_values_list:
|
| 423 |
+
all_pixel_values.append(pixel_value.flatten(end_dim=1).permute(1, 0))
|
| 424 |
+
|
| 425 |
+
max_patches = torch.max(tgt_sizes[:, 0] * tgt_sizes[:, 1])
|
| 426 |
+
all_pixel_values = torch.nn.utils.rnn.pad_sequence(all_pixel_values, batch_first=True, padding_value=0.0)
|
| 427 |
+
B, L, _ = all_pixel_values.shape
|
| 428 |
+
all_pixel_values = all_pixel_values.permute(0, 2, 1).reshape(B, 3, -1, L)
|
| 429 |
+
|
| 430 |
+
patch_attention_mask = torch.zeros((B, 1, max_patches), dtype=torch.bool)
|
| 431 |
+
for i in range(B):
|
| 432 |
+
patch_attention_mask[i, 0, : tgt_sizes[i][0] * tgt_sizes[i][1]] = True
|
| 433 |
+
|
| 434 |
+
return all_pixel_values, patch_attention_mask
|
| 435 |
+
|
| 436 |
+
def process_image(
|
| 437 |
+
self,
|
| 438 |
+
image_input: ImageInput,
|
| 439 |
+
do_pad: bool = True,
|
| 440 |
+
max_slice_nums: Optional[int] = None,
|
| 441 |
+
return_tensors: ReturnTensorType = TensorType.PYTORCH,
|
| 442 |
+
**kwargs,
|
| 443 |
+
) -> ImageBatchFeature:
|
| 444 |
+
if isinstance(image_input, list):
|
| 445 |
+
image_input = [load_image(x) for x in image_input]
|
| 446 |
+
elif isinstance(image_input, (str, bytes, PIL.Image.Image)):
|
| 447 |
+
image_input = [load_image(image_input)]
|
| 448 |
+
else:
|
| 449 |
+
raise ValueError(f"image_input must be a path or bytes or a list of paths/bytes, not: {type(image_input)}")
|
| 450 |
+
|
| 451 |
+
image_features = self.image_processor(
|
| 452 |
+
image_input,
|
| 453 |
+
do_pad=do_pad,
|
| 454 |
+
max_slice_nums=max_slice_nums,
|
| 455 |
+
return_tensors=return_tensors,
|
| 456 |
+
**kwargs,
|
| 457 |
+
)
|
| 458 |
+
|
| 459 |
+
# Multiple images are packed into first element of the list. We unpack them here.
|
| 460 |
+
assert len(image_features.pixel_values) == 1, "images should be packed into one list."
|
| 461 |
+
pixel_values = image_features.pixel_values[0]
|
| 462 |
+
tgt_sizes = image_features.tgt_sizes[0]
|
| 463 |
+
image_sizes = image_features.image_sizes[0]
|
| 464 |
+
|
| 465 |
+
pixel_values, patch_attention_mask = self.pad_images(pixel_values, tgt_sizes)
|
| 466 |
+
|
| 467 |
+
data = {
|
| 468 |
+
"pixel_values": pixel_values,
|
| 469 |
+
"image_sizes": image_sizes,
|
| 470 |
+
"tgt_sizes": tgt_sizes,
|
| 471 |
+
"patch_attention_mask": patch_attention_mask,
|
| 472 |
+
}
|
| 473 |
+
|
| 474 |
+
# tensor types are already converted in `self.image_processor`.
|
| 475 |
+
return ImageBatchFeature(data=data)
|
| 476 |
+
|
| 477 |
+
def data_collator(self, examples, padding_value=0, max_length=4096, collate_labels=False):
|
| 478 |
+
"""Collate data for MegrezO model.
|
| 479 |
+
|
| 480 |
+
Batch data for MegrezO model. This function trims and pads the input_ids, position_ids, and attention_mask tensors. For bounds tensors, it adds batch index to the bounds.
|
| 481 |
+
"""
|
| 482 |
+
# (TODO) Remove this function?
|
| 483 |
+
|
| 484 |
+
def trim_and_pad(seq, batch_first, padding_value):
|
| 485 |
+
return pad_sequence(
|
| 486 |
+
[s[:max_length] for s in seq],
|
| 487 |
+
batch_first=True,
|
| 488 |
+
padding_value=padding_value,
|
| 489 |
+
)
|
| 490 |
+
|
| 491 |
+
input_ids = trim_and_pad(
|
| 492 |
+
[example["input_ids"] for example in examples],
|
| 493 |
+
batch_first=True,
|
| 494 |
+
padding_value=padding_value,
|
| 495 |
+
)
|
| 496 |
+
position_ids = trim_and_pad(
|
| 497 |
+
[example["position_ids"] for example in examples],
|
| 498 |
+
batch_first=True,
|
| 499 |
+
padding_value=padding_value,
|
| 500 |
+
)
|
| 501 |
+
|
| 502 |
+
attention_mask = trim_and_pad(
|
| 503 |
+
[example["attention_mask"] for example in examples],
|
| 504 |
+
batch_first=True,
|
| 505 |
+
padding_value=padding_value,
|
| 506 |
+
)
|
| 507 |
+
|
| 508 |
+
image_encoding_list = {
|
| 509 |
+
"pixel_values": [],
|
| 510 |
+
"image_bounds": [],
|
| 511 |
+
"tgt_sizes": [],
|
| 512 |
+
"patch_attention_mask": [],
|
| 513 |
+
}
|
| 514 |
+
for bid, example in enumerate(examples):
|
| 515 |
+
image_encoding = example.get("image_encoding")
|
| 516 |
+
if not image_encoding:
|
| 517 |
+
continue
|
| 518 |
+
|
| 519 |
+
image_encoding_list["pixel_values"].append(image_encoding["pixel_values"])
|
| 520 |
+
image_encoding_list["tgt_sizes"].append(image_encoding["tgt_sizes"])
|
| 521 |
+
image_encoding_list["patch_attention_mask"].append(image_encoding["patch_attention_mask"])
|
| 522 |
+
|
| 523 |
+
# (TODO) Remove?
|
| 524 |
+
# add batch index to bounds (bid, start, end)
|
| 525 |
+
bounds_with_bid = image_encoding["image_bounds"].clone()
|
| 526 |
+
bounds_with_bid = torch.hstack(
|
| 527 |
+
[
|
| 528 |
+
torch.full((bounds_with_bid.size(0), 1), bid, dtype=bounds_with_bid.dtype),
|
| 529 |
+
bounds_with_bid,
|
| 530 |
+
]
|
| 531 |
+
)
|
| 532 |
+
image_encoding_list["image_bounds"].append(bounds_with_bid)
|
| 533 |
+
|
| 534 |
+
audio_encoding_list = {
|
| 535 |
+
"input_audios": [],
|
| 536 |
+
"input_audio_lengths": [],
|
| 537 |
+
"audio_span_tokens": [],
|
| 538 |
+
"audio_bounds": [],
|
| 539 |
+
}
|
| 540 |
+
for bid, example in enumerate(examples):
|
| 541 |
+
audio_encoding = example.get("audio_encoding")
|
| 542 |
+
if not audio_encoding:
|
| 543 |
+
continue
|
| 544 |
+
|
| 545 |
+
audio_encoding_list["input_audios"].append(audio_encoding["input_audios"])
|
| 546 |
+
audio_encoding_list["input_audio_lengths"].append(audio_encoding["input_audio_lengths"])
|
| 547 |
+
audio_encoding_list["audio_span_tokens"].extend(audio_encoding["audio_span_tokens"])
|
| 548 |
+
bounds_with_bid = audio_encoding["audio_bounds"].clone()
|
| 549 |
+
bounds_with_bid = torch.hstack(
|
| 550 |
+
[
|
| 551 |
+
torch.full((bounds_with_bid.size(0), 1), bid, dtype=bounds_with_bid.dtype),
|
| 552 |
+
bounds_with_bid,
|
| 553 |
+
]
|
| 554 |
+
)
|
| 555 |
+
audio_encoding_list["audio_bounds"].append(bounds_with_bid)
|
| 556 |
+
|
| 557 |
+
result = {
|
| 558 |
+
"input_ids": input_ids,
|
| 559 |
+
"position_ids": position_ids,
|
| 560 |
+
"attention_mask": attention_mask,
|
| 561 |
+
"image_encoding": None,
|
| 562 |
+
"audio_encoding": None,
|
| 563 |
+
}
|
| 564 |
+
|
| 565 |
+
if collate_labels:
|
| 566 |
+
labels = trim_and_pad(
|
| 567 |
+
[example["labels"] for example in examples],
|
| 568 |
+
batch_first=True,
|
| 569 |
+
padding_value=-100,
|
| 570 |
+
)
|
| 571 |
+
result["labels"] = labels
|
| 572 |
+
|
| 573 |
+
if any(image_encoding_list.values()):
|
| 574 |
+
result["image_encoding"] = {
|
| 575 |
+
"pixel_values": torch.vstack(image_encoding_list["pixel_values"]),
|
| 576 |
+
"tgt_sizes": torch.vstack(image_encoding_list["tgt_sizes"]),
|
| 577 |
+
"patch_attention_mask": torch.vstack(image_encoding_list["patch_attention_mask"]),
|
| 578 |
+
"image_bounds": torch.vstack(image_encoding_list["image_bounds"]),
|
| 579 |
+
}
|
| 580 |
+
if any(audio_encoding_list.values()):
|
| 581 |
+
result["audio_encoding"] = {
|
| 582 |
+
"input_audios": torch.vstack(audio_encoding_list["input_audios"]),
|
| 583 |
+
"input_audio_lengths": torch.vstack(audio_encoding_list["input_audio_lengths"]),
|
| 584 |
+
"audio_span_tokens": audio_encoding_list["audio_span_tokens"],
|
| 585 |
+
"audio_bounds": torch.vstack(audio_encoding_list["audio_bounds"]),
|
| 586 |
+
}
|
| 587 |
+
return result
|
processor_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoProcessor": "processing_megrezo.MegrezOProcessor",
|
| 4 |
+
"AutoImageProcessor": "image_processing_megrezo.MegrezOImageProcessor"
|
| 5 |
+
},
|
| 6 |
+
"processor_class": "MegrezOProcessor"
|
| 7 |
+
}
|
resampler.py
ADDED
|
@@ -0,0 +1,783 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
from typing import Optional, Tuple
|
| 3 |
+
import numpy as np
|
| 4 |
+
import warnings
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
from torch import Tensor
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from torch.nn.functional import *
|
| 11 |
+
from torch.nn.modules.activation import *
|
| 12 |
+
from torch.nn.init import trunc_normal_, constant_, xavier_normal_, xavier_uniform_
|
| 13 |
+
|
| 14 |
+
from transformers.integrations import is_deepspeed_zero3_enabled
|
| 15 |
+
|
| 16 |
+
def get_2d_sincos_pos_embed(embed_dim, image_size):
|
| 17 |
+
"""
|
| 18 |
+
image_size: image_size or (image_height, image_width)
|
| 19 |
+
return:
|
| 20 |
+
pos_embed: [image_height, image_width, embed_dim]
|
| 21 |
+
"""
|
| 22 |
+
if isinstance(image_size, int):
|
| 23 |
+
grid_h_size, grid_w_size = image_size, image_size
|
| 24 |
+
else:
|
| 25 |
+
grid_h_size, grid_w_size = image_size[0], image_size[1]
|
| 26 |
+
|
| 27 |
+
grid_h = np.arange(grid_h_size, dtype=np.float32)
|
| 28 |
+
grid_w = np.arange(grid_w_size, dtype=np.float32)
|
| 29 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 30 |
+
grid = np.stack(grid, axis=0)
|
| 31 |
+
|
| 32 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 33 |
+
return pos_embed
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 37 |
+
assert embed_dim % 2 == 0
|
| 38 |
+
|
| 39 |
+
# use half of dimensions to encode grid_h
|
| 40 |
+
emb_h = get_1d_sincos_pos_embed_from_grid_new(embed_dim // 2, grid[0]) # (H, W, D/2)
|
| 41 |
+
emb_w = get_1d_sincos_pos_embed_from_grid_new(embed_dim // 2, grid[1]) # (H, W, D/2)
|
| 42 |
+
|
| 43 |
+
emb = np.concatenate([emb_h, emb_w], axis=-1) # (H, W, D)
|
| 44 |
+
return emb
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_1d_sincos_pos_embed_from_grid_new(embed_dim, pos):
|
| 48 |
+
"""
|
| 49 |
+
embed_dim: output dimension for each position
|
| 50 |
+
pos: a list of positions to be encoded: size (H, W)
|
| 51 |
+
out: (H, W, D)
|
| 52 |
+
"""
|
| 53 |
+
assert embed_dim % 2 == 0
|
| 54 |
+
omega = np.arange(embed_dim // 2, dtype=np.float32)
|
| 55 |
+
omega /= embed_dim / 2.
|
| 56 |
+
omega = 1. / 10000 ** omega # (D/2,)
|
| 57 |
+
|
| 58 |
+
out = np.einsum('hw,d->hwd', pos, omega) # (H, W, D/2), outer product
|
| 59 |
+
|
| 60 |
+
emb_sin = np.sin(out) # (H, W, D/2)
|
| 61 |
+
emb_cos = np.cos(out) # (H, W, D/2)
|
| 62 |
+
|
| 63 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=-1) # (H, W, D)
|
| 64 |
+
return emb
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class Resampler(nn.Module):
|
| 68 |
+
"""
|
| 69 |
+
A 2D perceiver-resampler network with one cross attention layers by
|
| 70 |
+
given learnable queries and 2d sincos pos_emb
|
| 71 |
+
Outputs:
|
| 72 |
+
A tensor with the shape of (batch_size, num_queries, embed_dim)
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def __init__(
|
| 76 |
+
self,
|
| 77 |
+
num_queries,
|
| 78 |
+
embed_dim,
|
| 79 |
+
num_heads,
|
| 80 |
+
kv_dim=None,
|
| 81 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 82 |
+
adaptive=False,
|
| 83 |
+
max_size=(70, 70),
|
| 84 |
+
):
|
| 85 |
+
super().__init__()
|
| 86 |
+
self.num_queries = num_queries
|
| 87 |
+
self.embed_dim = embed_dim
|
| 88 |
+
self.num_heads = num_heads
|
| 89 |
+
self.adaptive = adaptive
|
| 90 |
+
self.max_size = max_size
|
| 91 |
+
|
| 92 |
+
self.query = nn.Parameter(torch.zeros(self.num_queries, embed_dim))
|
| 93 |
+
|
| 94 |
+
if kv_dim is not None and kv_dim != embed_dim:
|
| 95 |
+
self.kv_proj = nn.Linear(kv_dim, embed_dim, bias=False)
|
| 96 |
+
else:
|
| 97 |
+
self.kv_proj = nn.Identity()
|
| 98 |
+
|
| 99 |
+
# Change to nn.MultiheadAttention instead of MultiheadAttention in this file.
|
| 100 |
+
self.attn = nn.MultiheadAttention(embed_dim, num_heads)
|
| 101 |
+
self.ln_q = norm_layer(embed_dim)
|
| 102 |
+
self.ln_kv = norm_layer(embed_dim)
|
| 103 |
+
|
| 104 |
+
self.ln_post = norm_layer(embed_dim)
|
| 105 |
+
self.proj = nn.Parameter((embed_dim ** -0.5) * torch.randn(embed_dim, embed_dim))
|
| 106 |
+
|
| 107 |
+
self._set_2d_pos_cache(self.max_size)
|
| 108 |
+
|
| 109 |
+
def _set_2d_pos_cache(self, max_size, device='cpu'):
|
| 110 |
+
if is_deepspeed_zero3_enabled():
|
| 111 |
+
device='cuda'
|
| 112 |
+
pos_embed = torch.from_numpy(get_2d_sincos_pos_embed(self.embed_dim, max_size)).float().to(device)
|
| 113 |
+
self.register_buffer("pos_embed", pos_embed, persistent=False)
|
| 114 |
+
|
| 115 |
+
def _adjust_pos_cache(self, tgt_sizes, device):
|
| 116 |
+
max_h = torch.max(tgt_sizes[:, 0])
|
| 117 |
+
max_w = torch.max(tgt_sizes[:, 1])
|
| 118 |
+
if max_h > self.max_size[0] or max_w > self.max_size[1]:
|
| 119 |
+
self.max_size = [max(max_h, self.max_size[0]), max(max_w, self.max_size[1])]
|
| 120 |
+
self._set_2d_pos_cache(self.max_size, device)
|
| 121 |
+
|
| 122 |
+
def _init_weights(self, m):
|
| 123 |
+
if isinstance(m, nn.Linear):
|
| 124 |
+
trunc_normal_(m.weight, std=.02)
|
| 125 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 126 |
+
nn.init.constant_(m.bias, 0)
|
| 127 |
+
elif isinstance(m, nn.LayerNorm):
|
| 128 |
+
nn.init.constant_(m.bias, 0)
|
| 129 |
+
nn.init.constant_(m.weight, 1.0)
|
| 130 |
+
|
| 131 |
+
def forward(self, x, tgt_sizes=None):
|
| 132 |
+
assert x.shape[0] == tgt_sizes.shape[0]
|
| 133 |
+
bs = x.shape[0]
|
| 134 |
+
|
| 135 |
+
device = x.device
|
| 136 |
+
dtype = x.dtype
|
| 137 |
+
|
| 138 |
+
patch_len = tgt_sizes[:, 0] * tgt_sizes[:, 1]
|
| 139 |
+
|
| 140 |
+
self._adjust_pos_cache(tgt_sizes, device=device)
|
| 141 |
+
|
| 142 |
+
max_patch_len = torch.max(patch_len)
|
| 143 |
+
key_padding_mask = torch.zeros((bs, max_patch_len), dtype=torch.bool, device=device)
|
| 144 |
+
|
| 145 |
+
pos_embed = []
|
| 146 |
+
for i in range(bs):
|
| 147 |
+
tgt_h, tgt_w = tgt_sizes[i]
|
| 148 |
+
pos_embed.append(self.pos_embed[:tgt_h, :tgt_w, :].reshape((tgt_h * tgt_w, -1)).to(dtype)) # patches * D
|
| 149 |
+
key_padding_mask[i, patch_len[i]:] = True
|
| 150 |
+
|
| 151 |
+
pos_embed = torch.nn.utils.rnn.pad_sequence(
|
| 152 |
+
pos_embed, batch_first=True, padding_value=0.0).permute(1, 0, 2) # BLD => L * B * D
|
| 153 |
+
|
| 154 |
+
x = self.kv_proj(x) # B * L * D
|
| 155 |
+
x = self.ln_kv(x).permute(1, 0, 2) # L * B * D
|
| 156 |
+
|
| 157 |
+
q = self.ln_q(self.query) # Q * D
|
| 158 |
+
|
| 159 |
+
out = self.attn(
|
| 160 |
+
self._repeat(q, bs), # Q * B * D
|
| 161 |
+
x + pos_embed, # L * B * D + L * B * D
|
| 162 |
+
x,
|
| 163 |
+
key_padding_mask=key_padding_mask)[0]
|
| 164 |
+
# out: Q * B * D
|
| 165 |
+
x = out.permute(1, 0, 2) # B * Q * D
|
| 166 |
+
|
| 167 |
+
x = self.ln_post(x)
|
| 168 |
+
x = x @ self.proj
|
| 169 |
+
return x
|
| 170 |
+
|
| 171 |
+
def _repeat(self, query, N: int):
|
| 172 |
+
return query.unsqueeze(1).repeat(1, N, 1)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class MultiheadAttention(nn.MultiheadAttention):
|
| 176 |
+
def __init__(self, embed_dim, num_heads, dropout=0., bias=True, add_bias_kv=False,
|
| 177 |
+
add_zero_attn=False, kdim=None, vdim=None, batch_first=False, device=None, dtype=None):
|
| 178 |
+
super().__init__(embed_dim, num_heads, dropout, bias, add_bias_kv, add_zero_attn, kdim, vdim, batch_first, device, dtype)
|
| 179 |
+
|
| 180 |
+
# rewrite out_proj layer,with nn.Linear
|
| 181 |
+
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias, device=device, dtype=dtype)
|
| 182 |
+
|
| 183 |
+
def forward(
|
| 184 |
+
self,
|
| 185 |
+
query: Tensor,
|
| 186 |
+
key: Tensor,
|
| 187 |
+
value: Tensor,
|
| 188 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 189 |
+
need_weights: bool = True,
|
| 190 |
+
attn_mask: Optional[Tensor] = None,
|
| 191 |
+
average_attn_weights: bool = True,
|
| 192 |
+
is_causal : bool = False) -> Tuple[Tensor, Optional[Tensor]]:
|
| 193 |
+
why_not_fast_path = ''
|
| 194 |
+
if ((attn_mask is not None and torch.is_floating_point(attn_mask))
|
| 195 |
+
or (key_padding_mask is not None) and torch.is_floating_point(key_padding_mask)):
|
| 196 |
+
why_not_fast_path = "floating-point masks are not supported for fast path."
|
| 197 |
+
|
| 198 |
+
is_batched = query.dim() == 3
|
| 199 |
+
|
| 200 |
+
key_padding_mask = _canonical_mask(
|
| 201 |
+
mask=key_padding_mask,
|
| 202 |
+
mask_name="key_padding_mask",
|
| 203 |
+
other_type=F._none_or_dtype(attn_mask),
|
| 204 |
+
other_name="attn_mask",
|
| 205 |
+
target_type=query.dtype
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
attn_mask = _canonical_mask(
|
| 209 |
+
mask=attn_mask,
|
| 210 |
+
mask_name="attn_mask",
|
| 211 |
+
other_type=None,
|
| 212 |
+
other_name="",
|
| 213 |
+
target_type=query.dtype,
|
| 214 |
+
check_other=False,
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
if not is_batched:
|
| 219 |
+
why_not_fast_path = f"input not batched; expected query.dim() of 3 but got {query.dim()}"
|
| 220 |
+
elif query is not key or key is not value:
|
| 221 |
+
# When lifting this restriction, don't forget to either
|
| 222 |
+
# enforce that the dtypes all match or test cases where
|
| 223 |
+
# they don't!
|
| 224 |
+
why_not_fast_path = "non-self attention was used (query, key, and value are not the same Tensor)"
|
| 225 |
+
elif self.in_proj_bias is not None and query.dtype != self.in_proj_bias.dtype:
|
| 226 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_bias ({self.in_proj_bias.dtype}) don't match"
|
| 227 |
+
elif self.in_proj_weight is None:
|
| 228 |
+
why_not_fast_path = "in_proj_weight was None"
|
| 229 |
+
elif query.dtype != self.in_proj_weight.dtype:
|
| 230 |
+
# this case will fail anyway, but at least they'll get a useful error message.
|
| 231 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_weight ({self.in_proj_weight.dtype}) don't match"
|
| 232 |
+
elif self.training:
|
| 233 |
+
why_not_fast_path = "training is enabled"
|
| 234 |
+
elif (self.num_heads % 2) != 0:
|
| 235 |
+
why_not_fast_path = "self.num_heads is not even"
|
| 236 |
+
elif not self.batch_first:
|
| 237 |
+
why_not_fast_path = "batch_first was not True"
|
| 238 |
+
elif self.bias_k is not None:
|
| 239 |
+
why_not_fast_path = "self.bias_k was not None"
|
| 240 |
+
elif self.bias_v is not None:
|
| 241 |
+
why_not_fast_path = "self.bias_v was not None"
|
| 242 |
+
elif self.add_zero_attn:
|
| 243 |
+
why_not_fast_path = "add_zero_attn was enabled"
|
| 244 |
+
elif not self._qkv_same_embed_dim:
|
| 245 |
+
why_not_fast_path = "_qkv_same_embed_dim was not True"
|
| 246 |
+
elif query.is_nested and (key_padding_mask is not None or attn_mask is not None):
|
| 247 |
+
why_not_fast_path = "supplying both src_key_padding_mask and src_mask at the same time \
|
| 248 |
+
is not supported with NestedTensor input"
|
| 249 |
+
elif torch.is_autocast_enabled():
|
| 250 |
+
why_not_fast_path = "autocast is enabled"
|
| 251 |
+
|
| 252 |
+
if not why_not_fast_path:
|
| 253 |
+
tensor_args = (
|
| 254 |
+
query,
|
| 255 |
+
key,
|
| 256 |
+
value,
|
| 257 |
+
self.in_proj_weight,
|
| 258 |
+
self.in_proj_bias,
|
| 259 |
+
self.out_proj.weight,
|
| 260 |
+
self.out_proj.bias,
|
| 261 |
+
)
|
| 262 |
+
# We have to use list comprehensions below because TorchScript does not support
|
| 263 |
+
# generator expressions.
|
| 264 |
+
if torch.overrides.has_torch_function(tensor_args):
|
| 265 |
+
why_not_fast_path = "some Tensor argument has_torch_function"
|
| 266 |
+
elif _is_make_fx_tracing():
|
| 267 |
+
why_not_fast_path = "we are running make_fx tracing"
|
| 268 |
+
elif not all(_check_arg_device(x) for x in tensor_args):
|
| 269 |
+
why_not_fast_path = ("some Tensor argument's device is neither one of "
|
| 270 |
+
f"cpu, cuda or {torch.utils.backend_registration._privateuse1_backend_name}")
|
| 271 |
+
elif torch.is_grad_enabled() and any(_arg_requires_grad(x) for x in tensor_args):
|
| 272 |
+
why_not_fast_path = ("grad is enabled and at least one of query or the "
|
| 273 |
+
"input/output projection weights or biases requires_grad")
|
| 274 |
+
if not why_not_fast_path:
|
| 275 |
+
merged_mask, mask_type = self.merge_masks(attn_mask, key_padding_mask, query)
|
| 276 |
+
|
| 277 |
+
if self.in_proj_bias is not None and self.in_proj_weight is not None:
|
| 278 |
+
return torch._native_multi_head_attention(
|
| 279 |
+
query,
|
| 280 |
+
key,
|
| 281 |
+
value,
|
| 282 |
+
self.embed_dim,
|
| 283 |
+
self.num_heads,
|
| 284 |
+
self.in_proj_weight,
|
| 285 |
+
self.in_proj_bias,
|
| 286 |
+
self.out_proj.weight,
|
| 287 |
+
self.out_proj.bias,
|
| 288 |
+
merged_mask,
|
| 289 |
+
need_weights,
|
| 290 |
+
average_attn_weights,
|
| 291 |
+
mask_type)
|
| 292 |
+
|
| 293 |
+
any_nested = query.is_nested or key.is_nested or value.is_nested
|
| 294 |
+
assert not any_nested, ("MultiheadAttention does not support NestedTensor outside of its fast path. " +
|
| 295 |
+
f"The fast path was not hit because {why_not_fast_path}")
|
| 296 |
+
|
| 297 |
+
if self.batch_first and is_batched:
|
| 298 |
+
# make sure that the transpose op does not affect the "is" property
|
| 299 |
+
if key is value:
|
| 300 |
+
if query is key:
|
| 301 |
+
query = key = value = query.transpose(1, 0)
|
| 302 |
+
else:
|
| 303 |
+
query, key = (x.transpose(1, 0) for x in (query, key))
|
| 304 |
+
value = key
|
| 305 |
+
else:
|
| 306 |
+
query, key, value = (x.transpose(1, 0) for x in (query, key, value))
|
| 307 |
+
|
| 308 |
+
if not self._qkv_same_embed_dim:
|
| 309 |
+
attn_output, attn_output_weights = self.multi_head_attention_forward(
|
| 310 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 311 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 312 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 313 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 314 |
+
training=self.training,
|
| 315 |
+
key_padding_mask=key_padding_mask, need_weights=need_weights,
|
| 316 |
+
attn_mask=attn_mask,
|
| 317 |
+
use_separate_proj_weight=True,
|
| 318 |
+
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
|
| 319 |
+
v_proj_weight=self.v_proj_weight,
|
| 320 |
+
average_attn_weights=average_attn_weights,
|
| 321 |
+
is_causal=is_causal)
|
| 322 |
+
else:
|
| 323 |
+
attn_output, attn_output_weights = self.multi_head_attention_forward(
|
| 324 |
+
query, key, value, self.embed_dim, self.num_heads,
|
| 325 |
+
self.in_proj_weight, self.in_proj_bias,
|
| 326 |
+
self.bias_k, self.bias_v, self.add_zero_attn,
|
| 327 |
+
self.dropout, self.out_proj.weight, self.out_proj.bias,
|
| 328 |
+
training=self.training,
|
| 329 |
+
key_padding_mask=key_padding_mask,
|
| 330 |
+
need_weights=need_weights,
|
| 331 |
+
attn_mask=attn_mask,
|
| 332 |
+
average_attn_weights=average_attn_weights,
|
| 333 |
+
is_causal=is_causal)
|
| 334 |
+
if self.batch_first and is_batched:
|
| 335 |
+
return attn_output.transpose(1, 0), attn_output_weights
|
| 336 |
+
else:
|
| 337 |
+
return attn_output, attn_output_weights
|
| 338 |
+
|
| 339 |
+
def multi_head_attention_forward(
|
| 340 |
+
self,
|
| 341 |
+
query: Tensor,
|
| 342 |
+
key: Tensor,
|
| 343 |
+
value: Tensor,
|
| 344 |
+
embed_dim_to_check: int,
|
| 345 |
+
num_heads: int,
|
| 346 |
+
in_proj_weight: Optional[Tensor],
|
| 347 |
+
in_proj_bias: Optional[Tensor],
|
| 348 |
+
bias_k: Optional[Tensor],
|
| 349 |
+
bias_v: Optional[Tensor],
|
| 350 |
+
add_zero_attn: bool,
|
| 351 |
+
dropout_p: float,
|
| 352 |
+
out_proj_weight: Tensor,
|
| 353 |
+
out_proj_bias: Optional[Tensor],
|
| 354 |
+
training: bool = True,
|
| 355 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 356 |
+
need_weights: bool = True,
|
| 357 |
+
attn_mask: Optional[Tensor] = None,
|
| 358 |
+
use_separate_proj_weight: bool = False,
|
| 359 |
+
q_proj_weight: Optional[Tensor] = None,
|
| 360 |
+
k_proj_weight: Optional[Tensor] = None,
|
| 361 |
+
v_proj_weight: Optional[Tensor] = None,
|
| 362 |
+
static_k: Optional[Tensor] = None,
|
| 363 |
+
static_v: Optional[Tensor] = None,
|
| 364 |
+
average_attn_weights: bool = True,
|
| 365 |
+
is_causal: bool = False,
|
| 366 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 367 |
+
tens_ops = (query, key, value, in_proj_weight, in_proj_bias, bias_k, bias_v, out_proj_weight, out_proj_bias)
|
| 368 |
+
|
| 369 |
+
is_batched = _mha_shape_check(query, key, value, key_padding_mask, attn_mask, num_heads)
|
| 370 |
+
|
| 371 |
+
# For unbatched input, we unsqueeze at the expected batch-dim to pretend that the input
|
| 372 |
+
# is batched, run the computation and before returning squeeze the
|
| 373 |
+
# batch dimension so that the output doesn't carry this temporary batch dimension.
|
| 374 |
+
if not is_batched:
|
| 375 |
+
# unsqueeze if the input is unbatched
|
| 376 |
+
query = query.unsqueeze(1)
|
| 377 |
+
key = key.unsqueeze(1)
|
| 378 |
+
value = value.unsqueeze(1)
|
| 379 |
+
if key_padding_mask is not None:
|
| 380 |
+
key_padding_mask = key_padding_mask.unsqueeze(0)
|
| 381 |
+
|
| 382 |
+
# set up shape vars
|
| 383 |
+
tgt_len, bsz, embed_dim = query.shape
|
| 384 |
+
src_len, _, _ = key.shape
|
| 385 |
+
|
| 386 |
+
key_padding_mask = _canonical_mask(
|
| 387 |
+
mask=key_padding_mask,
|
| 388 |
+
mask_name="key_padding_mask",
|
| 389 |
+
other_type=_none_or_dtype(attn_mask),
|
| 390 |
+
other_name="attn_mask",
|
| 391 |
+
target_type=query.dtype
|
| 392 |
+
)
|
| 393 |
+
|
| 394 |
+
if is_causal and attn_mask is None:
|
| 395 |
+
raise RuntimeError(
|
| 396 |
+
"Need attn_mask if specifying the is_causal hint. "
|
| 397 |
+
"You may use the Transformer module method "
|
| 398 |
+
"`generate_square_subsequent_mask` to create this mask."
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
if is_causal and key_padding_mask is None and not need_weights:
|
| 402 |
+
# when we have a kpm or need weights, we need attn_mask
|
| 403 |
+
# Otherwise, we use the is_causal hint go as is_causal
|
| 404 |
+
# indicator to SDPA.
|
| 405 |
+
attn_mask = None
|
| 406 |
+
else:
|
| 407 |
+
attn_mask = _canonical_mask(
|
| 408 |
+
mask=attn_mask,
|
| 409 |
+
mask_name="attn_mask",
|
| 410 |
+
other_type=None,
|
| 411 |
+
other_name="",
|
| 412 |
+
target_type=query.dtype,
|
| 413 |
+
check_other=False,
|
| 414 |
+
)
|
| 415 |
+
|
| 416 |
+
if key_padding_mask is not None:
|
| 417 |
+
# We have the attn_mask, and use that to merge kpm into it.
|
| 418 |
+
# Turn off use of is_causal hint, as the merged mask is no
|
| 419 |
+
# longer causal.
|
| 420 |
+
is_causal = False
|
| 421 |
+
|
| 422 |
+
assert embed_dim == embed_dim_to_check, \
|
| 423 |
+
f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
|
| 424 |
+
if isinstance(embed_dim, torch.Tensor):
|
| 425 |
+
# embed_dim can be a tensor when JIT tracing
|
| 426 |
+
head_dim = embed_dim.div(num_heads, rounding_mode='trunc')
|
| 427 |
+
else:
|
| 428 |
+
head_dim = embed_dim // num_heads
|
| 429 |
+
assert head_dim * num_heads == embed_dim, f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
|
| 430 |
+
if use_separate_proj_weight:
|
| 431 |
+
# allow MHA to have different embedding dimensions when separate projection weights are used
|
| 432 |
+
assert key.shape[:2] == value.shape[:2], \
|
| 433 |
+
f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
|
| 434 |
+
else:
|
| 435 |
+
assert key.shape == value.shape, f"key shape {key.shape} does not match value shape {value.shape}"
|
| 436 |
+
|
| 437 |
+
#
|
| 438 |
+
# compute in-projection
|
| 439 |
+
#
|
| 440 |
+
if not use_separate_proj_weight:
|
| 441 |
+
assert in_proj_weight is not None, "use_separate_proj_weight is False but in_proj_weight is None"
|
| 442 |
+
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
|
| 443 |
+
else:
|
| 444 |
+
assert q_proj_weight is not None, "use_separate_proj_weight is True but q_proj_weight is None"
|
| 445 |
+
assert k_proj_weight is not None, "use_separate_proj_weight is True but k_proj_weight is None"
|
| 446 |
+
assert v_proj_weight is not None, "use_separate_proj_weight is True but v_proj_weight is None"
|
| 447 |
+
if in_proj_bias is None:
|
| 448 |
+
b_q = b_k = b_v = None
|
| 449 |
+
else:
|
| 450 |
+
b_q, b_k, b_v = in_proj_bias.chunk(3)
|
| 451 |
+
q, k, v = _in_projection(query, key, value, q_proj_weight, k_proj_weight, v_proj_weight, b_q, b_k, b_v)
|
| 452 |
+
|
| 453 |
+
# prep attention mask
|
| 454 |
+
|
| 455 |
+
if attn_mask is not None:
|
| 456 |
+
# ensure attn_mask's dim is 3
|
| 457 |
+
if attn_mask.dim() == 2:
|
| 458 |
+
correct_2d_size = (tgt_len, src_len)
|
| 459 |
+
if attn_mask.shape != correct_2d_size:
|
| 460 |
+
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
|
| 461 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 462 |
+
elif attn_mask.dim() == 3:
|
| 463 |
+
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
|
| 464 |
+
if attn_mask.shape != correct_3d_size:
|
| 465 |
+
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
|
| 466 |
+
else:
|
| 467 |
+
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
|
| 468 |
+
|
| 469 |
+
# add bias along batch dimension (currently second)
|
| 470 |
+
if bias_k is not None and bias_v is not None:
|
| 471 |
+
assert static_k is None, "bias cannot be added to static key."
|
| 472 |
+
assert static_v is None, "bias cannot be added to static value."
|
| 473 |
+
k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
|
| 474 |
+
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
|
| 475 |
+
if attn_mask is not None:
|
| 476 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 477 |
+
if key_padding_mask is not None:
|
| 478 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 479 |
+
else:
|
| 480 |
+
assert bias_k is None
|
| 481 |
+
assert bias_v is None
|
| 482 |
+
|
| 483 |
+
#
|
| 484 |
+
# reshape q, k, v for multihead attention and make em batch first
|
| 485 |
+
#
|
| 486 |
+
q = q.view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
|
| 487 |
+
if static_k is None:
|
| 488 |
+
k = k.view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 489 |
+
else:
|
| 490 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 491 |
+
assert static_k.size(0) == bsz * num_heads, \
|
| 492 |
+
f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
|
| 493 |
+
assert static_k.size(2) == head_dim, \
|
| 494 |
+
f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
|
| 495 |
+
k = static_k
|
| 496 |
+
if static_v is None:
|
| 497 |
+
v = v.view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 498 |
+
else:
|
| 499 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 500 |
+
assert static_v.size(0) == bsz * num_heads, \
|
| 501 |
+
f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
|
| 502 |
+
assert static_v.size(2) == head_dim, \
|
| 503 |
+
f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
|
| 504 |
+
v = static_v
|
| 505 |
+
|
| 506 |
+
# add zero attention along batch dimension (now first)
|
| 507 |
+
if add_zero_attn:
|
| 508 |
+
zero_attn_shape = (bsz * num_heads, 1, head_dim)
|
| 509 |
+
k = torch.cat([k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1)
|
| 510 |
+
v = torch.cat([v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1)
|
| 511 |
+
if attn_mask is not None:
|
| 512 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 513 |
+
if key_padding_mask is not None:
|
| 514 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 515 |
+
|
| 516 |
+
# update source sequence length after adjustments
|
| 517 |
+
src_len = k.size(1)
|
| 518 |
+
|
| 519 |
+
# merge key padding and attention masks
|
| 520 |
+
if key_padding_mask is not None:
|
| 521 |
+
assert key_padding_mask.shape == (bsz, src_len), \
|
| 522 |
+
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
|
| 523 |
+
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
|
| 524 |
+
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
|
| 525 |
+
if attn_mask is None:
|
| 526 |
+
attn_mask = key_padding_mask
|
| 527 |
+
else:
|
| 528 |
+
attn_mask = attn_mask + key_padding_mask
|
| 529 |
+
|
| 530 |
+
# adjust dropout probability
|
| 531 |
+
if not training:
|
| 532 |
+
dropout_p = 0.0
|
| 533 |
+
|
| 534 |
+
#
|
| 535 |
+
# (deep breath) calculate attention and out projection
|
| 536 |
+
#
|
| 537 |
+
|
| 538 |
+
if need_weights:
|
| 539 |
+
B, Nt, E = q.shape
|
| 540 |
+
q_scaled = q / math.sqrt(E)
|
| 541 |
+
|
| 542 |
+
assert not (is_causal and attn_mask is None), "FIXME: is_causal not implemented for need_weights"
|
| 543 |
+
|
| 544 |
+
if attn_mask is not None:
|
| 545 |
+
attn_output_weights = torch.baddbmm(attn_mask, q_scaled, k.transpose(-2, -1))
|
| 546 |
+
else:
|
| 547 |
+
attn_output_weights = torch.bmm(q_scaled, k.transpose(-2, -1))
|
| 548 |
+
attn_output_weights = softmax(attn_output_weights, dim=-1)
|
| 549 |
+
if dropout_p > 0.0:
|
| 550 |
+
attn_output_weights = dropout(attn_output_weights, p=dropout_p)
|
| 551 |
+
|
| 552 |
+
attn_output = torch.bmm(attn_output_weights, v)
|
| 553 |
+
|
| 554 |
+
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
|
| 555 |
+
attn_output = self.out_proj(attn_output)
|
| 556 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 557 |
+
|
| 558 |
+
# optionally average attention weights over heads
|
| 559 |
+
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
|
| 560 |
+
if average_attn_weights:
|
| 561 |
+
attn_output_weights = attn_output_weights.mean(dim=1)
|
| 562 |
+
|
| 563 |
+
if not is_batched:
|
| 564 |
+
# squeeze the output if input was unbatched
|
| 565 |
+
attn_output = attn_output.squeeze(1)
|
| 566 |
+
attn_output_weights = attn_output_weights.squeeze(0)
|
| 567 |
+
return attn_output, attn_output_weights
|
| 568 |
+
else:
|
| 569 |
+
# attn_mask can be either (L,S) or (N*num_heads, L, S)
|
| 570 |
+
# if attn_mask's shape is (1, L, S) we need to unsqueeze to (1, 1, L, S)
|
| 571 |
+
# in order to match the input for SDPA of (N, num_heads, L, S)
|
| 572 |
+
if attn_mask is not None:
|
| 573 |
+
if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
|
| 574 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 575 |
+
else:
|
| 576 |
+
attn_mask = attn_mask.view(bsz, num_heads, -1, src_len)
|
| 577 |
+
|
| 578 |
+
q = q.view(bsz, num_heads, tgt_len, head_dim)
|
| 579 |
+
k = k.view(bsz, num_heads, src_len, head_dim)
|
| 580 |
+
v = v.view(bsz, num_heads, src_len, head_dim)
|
| 581 |
+
|
| 582 |
+
attn_output = F.scaled_dot_product_attention(q, k, v, attn_mask, dropout_p, is_causal)
|
| 583 |
+
attn_output = attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
|
| 584 |
+
|
| 585 |
+
attn_output = self.out_proj(attn_output)
|
| 586 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 587 |
+
if not is_batched:
|
| 588 |
+
# squeeze the output if input was unbatched
|
| 589 |
+
attn_output = attn_output.squeeze(1)
|
| 590 |
+
return attn_output, None
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
def _mha_shape_check(query: Tensor, key: Tensor, value: Tensor,
|
| 594 |
+
key_padding_mask: Optional[Tensor], attn_mask: Optional[Tensor], num_heads: int):
|
| 595 |
+
# Verifies the expected shape for `query, `key`, `value`, `key_padding_mask` and `attn_mask`
|
| 596 |
+
# and returns if the input is batched or not.
|
| 597 |
+
# Raises an error if `query` is not 2-D (unbatched) or 3-D (batched) tensor.
|
| 598 |
+
|
| 599 |
+
# Shape check.
|
| 600 |
+
if query.dim() == 3:
|
| 601 |
+
# Batched Inputs
|
| 602 |
+
is_batched = True
|
| 603 |
+
assert key.dim() == 3 and value.dim() == 3, \
|
| 604 |
+
("For batched (3-D) `query`, expected `key` and `value` to be 3-D"
|
| 605 |
+
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
|
| 606 |
+
if key_padding_mask is not None:
|
| 607 |
+
assert key_padding_mask.dim() == 2, \
|
| 608 |
+
("For batched (3-D) `query`, expected `key_padding_mask` to be `None` or 2-D"
|
| 609 |
+
f" but found {key_padding_mask.dim()}-D tensor instead")
|
| 610 |
+
if attn_mask is not None:
|
| 611 |
+
assert attn_mask.dim() in (2, 3), \
|
| 612 |
+
("For batched (3-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
|
| 613 |
+
f" but found {attn_mask.dim()}-D tensor instead")
|
| 614 |
+
elif query.dim() == 2:
|
| 615 |
+
# Unbatched Inputs
|
| 616 |
+
is_batched = False
|
| 617 |
+
assert key.dim() == 2 and value.dim() == 2, \
|
| 618 |
+
("For unbatched (2-D) `query`, expected `key` and `value` to be 2-D"
|
| 619 |
+
f" but found {key.dim()}-D and {value.dim()}-D tensors respectively")
|
| 620 |
+
|
| 621 |
+
if key_padding_mask is not None:
|
| 622 |
+
assert key_padding_mask.dim() == 1, \
|
| 623 |
+
("For unbatched (2-D) `query`, expected `key_padding_mask` to be `None` or 1-D"
|
| 624 |
+
f" but found {key_padding_mask.dim()}-D tensor instead")
|
| 625 |
+
|
| 626 |
+
if attn_mask is not None:
|
| 627 |
+
assert attn_mask.dim() in (2, 3), \
|
| 628 |
+
("For unbatched (2-D) `query`, expected `attn_mask` to be `None`, 2-D or 3-D"
|
| 629 |
+
f" but found {attn_mask.dim()}-D tensor instead")
|
| 630 |
+
if attn_mask.dim() == 3:
|
| 631 |
+
expected_shape = (num_heads, query.shape[0], key.shape[0])
|
| 632 |
+
assert attn_mask.shape == expected_shape, \
|
| 633 |
+
(f"Expected `attn_mask` shape to be {expected_shape} but got {attn_mask.shape}")
|
| 634 |
+
else:
|
| 635 |
+
raise AssertionError(
|
| 636 |
+
f"query should be unbatched 2D or batched 3D tensor but received {query.dim()}-D query tensor")
|
| 637 |
+
|
| 638 |
+
return is_batched
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
def _canonical_mask(
|
| 642 |
+
mask: Optional[Tensor],
|
| 643 |
+
mask_name: str,
|
| 644 |
+
other_type: Optional[DType],
|
| 645 |
+
other_name: str,
|
| 646 |
+
target_type: DType,
|
| 647 |
+
check_other: bool = True,
|
| 648 |
+
) -> Optional[Tensor]:
|
| 649 |
+
|
| 650 |
+
if mask is not None:
|
| 651 |
+
_mask_dtype = mask.dtype
|
| 652 |
+
_mask_is_float = torch.is_floating_point(mask)
|
| 653 |
+
if _mask_dtype != torch.bool and not _mask_is_float:
|
| 654 |
+
raise AssertionError(
|
| 655 |
+
f"only bool and floating types of {mask_name} are supported")
|
| 656 |
+
if check_other and other_type is not None:
|
| 657 |
+
if _mask_dtype != other_type:
|
| 658 |
+
warnings.warn(
|
| 659 |
+
f"Support for mismatched {mask_name} and {other_name} "
|
| 660 |
+
"is deprecated. Use same type for both instead."
|
| 661 |
+
)
|
| 662 |
+
if not _mask_is_float:
|
| 663 |
+
mask = (
|
| 664 |
+
torch.zeros_like(mask, dtype=target_type)
|
| 665 |
+
.masked_fill_(mask, float("-inf"))
|
| 666 |
+
)
|
| 667 |
+
return mask
|
| 668 |
+
|
| 669 |
+
|
| 670 |
+
def _none_or_dtype(input: Optional[Tensor]) -> Optional[DType]:
|
| 671 |
+
if input is None:
|
| 672 |
+
return None
|
| 673 |
+
elif isinstance(input, torch.Tensor):
|
| 674 |
+
return input.dtype
|
| 675 |
+
raise RuntimeError("input to _none_or_dtype() must be None or torch.Tensor")
|
| 676 |
+
|
| 677 |
+
def _in_projection_packed(
|
| 678 |
+
q: Tensor,
|
| 679 |
+
k: Tensor,
|
| 680 |
+
v: Tensor,
|
| 681 |
+
w: Tensor,
|
| 682 |
+
b: Optional[Tensor] = None,
|
| 683 |
+
) -> List[Tensor]:
|
| 684 |
+
r"""
|
| 685 |
+
Performs the in-projection step of the attention operation, using packed weights.
|
| 686 |
+
Output is a triple containing projection tensors for query, key and value.
|
| 687 |
+
Args:
|
| 688 |
+
q, k, v: query, key and value tensors to be projected. For self-attention,
|
| 689 |
+
these are typically the same tensor; for encoder-decoder attention,
|
| 690 |
+
k and v are typically the same tensor. (We take advantage of these
|
| 691 |
+
identities for performance if they are present.) Regardless, q, k and v
|
| 692 |
+
must share a common embedding dimension; otherwise their shapes may vary.
|
| 693 |
+
w: projection weights for q, k and v, packed into a single tensor. Weights
|
| 694 |
+
are packed along dimension 0, in q, k, v order.
|
| 695 |
+
b: optional projection biases for q, k and v, packed into a single tensor
|
| 696 |
+
in q, k, v order.
|
| 697 |
+
Shape:
|
| 698 |
+
Inputs:
|
| 699 |
+
- q: :math:`(..., E)` where E is the embedding dimension
|
| 700 |
+
- k: :math:`(..., E)` where E is the embedding dimension
|
| 701 |
+
- v: :math:`(..., E)` where E is the embedding dimension
|
| 702 |
+
- w: :math:`(E * 3, E)` where E is the embedding dimension
|
| 703 |
+
- b: :math:`E * 3` where E is the embedding dimension
|
| 704 |
+
Output:
|
| 705 |
+
- in output list :math:`[q', k', v']`, each output tensor will have the
|
| 706 |
+
same shape as the corresponding input tensor.
|
| 707 |
+
"""
|
| 708 |
+
E = q.size(-1)
|
| 709 |
+
if k is v:
|
| 710 |
+
if q is k:
|
| 711 |
+
# self-attention
|
| 712 |
+
proj = linear(q, w, b)
|
| 713 |
+
# reshape to 3, E and not E, 3 is deliberate for better memory coalescing and keeping same order as chunk()
|
| 714 |
+
proj = proj.unflatten(-1, (3, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
|
| 715 |
+
return proj[0], proj[1], proj[2]
|
| 716 |
+
else:
|
| 717 |
+
# encoder-decoder attention
|
| 718 |
+
w_q, w_kv = w.split([E, E * 2])
|
| 719 |
+
if b is None:
|
| 720 |
+
b_q = b_kv = None
|
| 721 |
+
else:
|
| 722 |
+
b_q, b_kv = b.split([E, E * 2])
|
| 723 |
+
q_proj = linear(q, w_q, b_q)
|
| 724 |
+
kv_proj = linear(k, w_kv, b_kv)
|
| 725 |
+
# reshape to 2, E and not E, 2 is deliberate for better memory coalescing and keeping same order as chunk()
|
| 726 |
+
kv_proj = kv_proj.unflatten(-1, (2, E)).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
|
| 727 |
+
return (q_proj, kv_proj[0], kv_proj[1])
|
| 728 |
+
else:
|
| 729 |
+
w_q, w_k, w_v = w.chunk(3)
|
| 730 |
+
if b is None:
|
| 731 |
+
b_q = b_k = b_v = None
|
| 732 |
+
else:
|
| 733 |
+
b_q, b_k, b_v = b.chunk(3)
|
| 734 |
+
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
|
| 735 |
+
|
| 736 |
+
|
| 737 |
+
def _in_projection(
|
| 738 |
+
q: Tensor,
|
| 739 |
+
k: Tensor,
|
| 740 |
+
v: Tensor,
|
| 741 |
+
w_q: Tensor,
|
| 742 |
+
w_k: Tensor,
|
| 743 |
+
w_v: Tensor,
|
| 744 |
+
b_q: Optional[Tensor] = None,
|
| 745 |
+
b_k: Optional[Tensor] = None,
|
| 746 |
+
b_v: Optional[Tensor] = None,
|
| 747 |
+
) -> Tuple[Tensor, Tensor, Tensor]:
|
| 748 |
+
r"""
|
| 749 |
+
Performs the in-projection step of the attention operation. This is simply
|
| 750 |
+
a triple of linear projections, with shape constraints on the weights which
|
| 751 |
+
ensure embedding dimension uniformity in the projected outputs.
|
| 752 |
+
Output is a triple containing projection tensors for query, key and value.
|
| 753 |
+
Args:
|
| 754 |
+
q, k, v: query, key and value tensors to be projected.
|
| 755 |
+
w_q, w_k, w_v: weights for q, k and v, respectively.
|
| 756 |
+
b_q, b_k, b_v: optional biases for q, k and v, respectively.
|
| 757 |
+
Shape:
|
| 758 |
+
Inputs:
|
| 759 |
+
- q: :math:`(Qdims..., Eq)` where Eq is the query embedding dimension and Qdims are any
|
| 760 |
+
number of leading dimensions.
|
| 761 |
+
- k: :math:`(Kdims..., Ek)` where Ek is the key embedding dimension and Kdims are any
|
| 762 |
+
number of leading dimensions.
|
| 763 |
+
- v: :math:`(Vdims..., Ev)` where Ev is the value embedding dimension and Vdims are any
|
| 764 |
+
number of leading dimensions.
|
| 765 |
+
- w_q: :math:`(Eq, Eq)`
|
| 766 |
+
- w_k: :math:`(Eq, Ek)`
|
| 767 |
+
- w_v: :math:`(Eq, Ev)`
|
| 768 |
+
- b_q: :math:`(Eq)`
|
| 769 |
+
- b_k: :math:`(Eq)`
|
| 770 |
+
- b_v: :math:`(Eq)`
|
| 771 |
+
Output: in output triple :math:`(q', k', v')`,
|
| 772 |
+
- q': :math:`[Qdims..., Eq]`
|
| 773 |
+
- k': :math:`[Kdims..., Eq]`
|
| 774 |
+
- v': :math:`[Vdims..., Eq]`
|
| 775 |
+
"""
|
| 776 |
+
Eq, Ek, Ev = q.size(-1), k.size(-1), v.size(-1)
|
| 777 |
+
assert w_q.shape == (Eq, Eq), f"expecting query weights shape of {(Eq, Eq)}, but got {w_q.shape}"
|
| 778 |
+
assert w_k.shape == (Eq, Ek), f"expecting key weights shape of {(Eq, Ek)}, but got {w_k.shape}"
|
| 779 |
+
assert w_v.shape == (Eq, Ev), f"expecting value weights shape of {(Eq, Ev)}, but got {w_v.shape}"
|
| 780 |
+
assert b_q is None or b_q.shape == (Eq,), f"expecting query bias shape of {(Eq,)}, but got {b_q.shape}"
|
| 781 |
+
assert b_k is None or b_k.shape == (Eq,), f"expecting key bias shape of {(Eq,)}, but got {b_k.shape}"
|
| 782 |
+
assert b_v is None or b_v.shape == (Eq,), f"expecting value bias shape of {(Eq,)}, but got {b_v.shape}"
|
| 783 |
+
return linear(q, w_q, b_q), linear(k, w_k, b_k), linear(v, w_v, b_v)
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"eos_token": "<|turn_end|>",
|
| 3 |
+
"unk_token": {
|
| 4 |
+
"content": "<|unk|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false
|
| 9 |
+
}
|
| 10 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"120000": {
|
| 7 |
+
"content": "<|eos|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": false,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"120001": {
|
| 15 |
+
"content": "<|unk|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": false,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": true
|
| 21 |
+
},
|
| 22 |
+
"120002": {
|
| 23 |
+
"content": "<|pad|>",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": false,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": true
|
| 29 |
+
},
|
| 30 |
+
"120003": {
|
| 31 |
+
"content": "<|role_start|>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": true
|
| 37 |
+
},
|
| 38 |
+
"120004": {
|
| 39 |
+
"content": "<|role_end|>",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": false,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": true
|
| 45 |
+
},
|
| 46 |
+
"120005": {
|
| 47 |
+
"content": "<|turn_end|>",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": false,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": true
|
| 53 |
+
},
|
| 54 |
+
"120006": {
|
| 55 |
+
"content": "<|code_start|>",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": false,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": true
|
| 61 |
+
},
|
| 62 |
+
"120007": {
|
| 63 |
+
"content": "<|code_end|>",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": false,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": true
|
| 69 |
+
},
|
| 70 |
+
"120008": {
|
| 71 |
+
"content": "<|commit_start|>",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": false,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": true
|
| 77 |
+
},
|
| 78 |
+
"120009": {
|
| 79 |
+
"content": "<|commit_end|>",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": false,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": true
|
| 85 |
+
},
|
| 86 |
+
"120010": {
|
| 87 |
+
"content": "<|diff_start|>",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": false,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": true
|
| 93 |
+
},
|
| 94 |
+
"120011": {
|
| 95 |
+
"content": "<|diff_end|>",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": false,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": true
|
| 101 |
+
},
|
| 102 |
+
"120012": {
|
| 103 |
+
"content": "<|code_execution_start|>",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": false,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": true
|
| 109 |
+
},
|
| 110 |
+
"120013": {
|
| 111 |
+
"content": "<|code_execution_end|>",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": false,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": true
|
| 117 |
+
},
|
| 118 |
+
"120014": {
|
| 119 |
+
"content": "<|image_start|>",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": false,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": true
|
| 125 |
+
},
|
| 126 |
+
"120015": {
|
| 127 |
+
"content": "<|image_end|>",
|
| 128 |
+
"lstrip": false,
|
| 129 |
+
"normalized": false,
|
| 130 |
+
"rstrip": false,
|
| 131 |
+
"single_word": false,
|
| 132 |
+
"special": true
|
| 133 |
+
},
|
| 134 |
+
"120016": {
|
| 135 |
+
"content": "<|image_pad|>",
|
| 136 |
+
"lstrip": false,
|
| 137 |
+
"normalized": false,
|
| 138 |
+
"rstrip": false,
|
| 139 |
+
"single_word": false,
|
| 140 |
+
"special": true
|
| 141 |
+
},
|
| 142 |
+
"120017": {
|
| 143 |
+
"content": "<|video_start|>",
|
| 144 |
+
"lstrip": false,
|
| 145 |
+
"normalized": false,
|
| 146 |
+
"rstrip": false,
|
| 147 |
+
"single_word": false,
|
| 148 |
+
"special": true
|
| 149 |
+
},
|
| 150 |
+
"120018": {
|
| 151 |
+
"content": "<|video_end|>",
|
| 152 |
+
"lstrip": false,
|
| 153 |
+
"normalized": false,
|
| 154 |
+
"rstrip": false,
|
| 155 |
+
"single_word": false,
|
| 156 |
+
"special": true
|
| 157 |
+
},
|
| 158 |
+
"120019": {
|
| 159 |
+
"content": "<|video_pad|>",
|
| 160 |
+
"lstrip": false,
|
| 161 |
+
"normalized": false,
|
| 162 |
+
"rstrip": false,
|
| 163 |
+
"single_word": false,
|
| 164 |
+
"special": true
|
| 165 |
+
},
|
| 166 |
+
"120020": {
|
| 167 |
+
"content": "<|audio_start|>",
|
| 168 |
+
"lstrip": false,
|
| 169 |
+
"normalized": false,
|
| 170 |
+
"rstrip": false,
|
| 171 |
+
"single_word": false,
|
| 172 |
+
"special": true
|
| 173 |
+
},
|
| 174 |
+
"120021": {
|
| 175 |
+
"content": "<|audio_end|>",
|
| 176 |
+
"lstrip": false,
|
| 177 |
+
"normalized": false,
|
| 178 |
+
"rstrip": false,
|
| 179 |
+
"single_word": false,
|
| 180 |
+
"special": true
|
| 181 |
+
},
|
| 182 |
+
"120022": {
|
| 183 |
+
"content": "<|audio_pad|>",
|
| 184 |
+
"lstrip": false,
|
| 185 |
+
"normalized": false,
|
| 186 |
+
"rstrip": false,
|
| 187 |
+
"single_word": false,
|
| 188 |
+
"special": true
|
| 189 |
+
},
|
| 190 |
+
"120023": {
|
| 191 |
+
"content": "<|function_start|>",
|
| 192 |
+
"lstrip": false,
|
| 193 |
+
"normalized": false,
|
| 194 |
+
"rstrip": false,
|
| 195 |
+
"single_word": false,
|
| 196 |
+
"special": true
|
| 197 |
+
},
|
| 198 |
+
"120024": {
|
| 199 |
+
"content": "<|function_end|>",
|
| 200 |
+
"lstrip": false,
|
| 201 |
+
"normalized": false,
|
| 202 |
+
"rstrip": false,
|
| 203 |
+
"single_word": false,
|
| 204 |
+
"special": true
|
| 205 |
+
},
|
| 206 |
+
"120025": {
|
| 207 |
+
"content": "<|slice_start|>",
|
| 208 |
+
"lstrip": false,
|
| 209 |
+
"normalized": false,
|
| 210 |
+
"rstrip": false,
|
| 211 |
+
"single_word": false,
|
| 212 |
+
"special": true
|
| 213 |
+
},
|
| 214 |
+
"120026": {
|
| 215 |
+
"content": "<|slice_end|>",
|
| 216 |
+
"lstrip": false,
|
| 217 |
+
"normalized": false,
|
| 218 |
+
"rstrip": false,
|
| 219 |
+
"single_word": false,
|
| 220 |
+
"special": true
|
| 221 |
+
},
|
| 222 |
+
"120027": {
|
| 223 |
+
"content": "<|image_id_start|>",
|
| 224 |
+
"lstrip": false,
|
| 225 |
+
"normalized": false,
|
| 226 |
+
"rstrip": false,
|
| 227 |
+
"single_word": false,
|
| 228 |
+
"special": true
|
| 229 |
+
},
|
| 230 |
+
"120028": {
|
| 231 |
+
"content": "<|image_id_end|>",
|
| 232 |
+
"lstrip": false,
|
| 233 |
+
"normalized": false,
|
| 234 |
+
"rstrip": false,
|
| 235 |
+
"single_word": false,
|
| 236 |
+
"special": true
|
| 237 |
+
}
|
| 238 |
+
},
|
| 239 |
+
"auto_map": {
|
| 240 |
+
"AutoProcessor": "processing_megrezo.MegrezOProcessor",
|
| 241 |
+
"AutoTokenizer": [
|
| 242 |
+
"tokenizer_wrapper.LlamaTokenizerWrapper",
|
| 243 |
+
null
|
| 244 |
+
]
|
| 245 |
+
},
|
| 246 |
+
"bos_token": null,
|
| 247 |
+
"chat_template": "{% set audio_count = namespace(value=0) %}{% for message in messages %}{% if loop.first and message['role'] != 'system' %}<|role_start|>system<|role_end|>你是Megrez-3B-Instruct,将针对用户的问题给出详细的、积极的回答。<|turn_end|>{% endif %}<|role_start|>{{ message['role'] }}<|role_end|>{% if message['content'] is string %}{{ message['content'] }}{% else %}{% if 'image' in message['content'] %}{% if message['content']['image'] is sequence and message['content']['image'] is not string %}{% for image in message['content']['image'] %}(<image>./</image>)\n{% endfor %}{% else %}(<image>./</image>)\n{% endif %}{% endif %}{% if 'audio' in message['content'] %}{% if message['content']['audio'] is sequence and message['content']['audio'] is not string %}{% for audio in message['content']['audio'] %}{% set audio_count.value = audio_count.value + 1 %}Audio {{ audio_count.value }}: (<audio>./</audio>)\n{% endfor %}{% else %}{% set audio_count.value = audio_count.value + 1 %}Audio {{ audio_count.value }}: (<audio>./</audio>)\n{% endif %}{% endif %}{% if 'text' in message['content'] and message['content']['text'] %}{{ message['content']['text'] }}{% endif %}{% endif %}<|turn_end|>{% endfor %}{% if add_generation_prompt %}<|role_start|>assistant<|role_end|>{% endif %}",
|
| 248 |
+
"clean_up_tokenization_spaces": true,
|
| 249 |
+
"eos_token": "<|turn_end|>",
|
| 250 |
+
"legacy": true,
|
| 251 |
+
"model_max_length": 4096,
|
| 252 |
+
"processor_class": "MegrezOProcessor",
|
| 253 |
+
"tokenizer_class": "LlamaTokenizerWrapper",
|
| 254 |
+
"unk_token": "<|unk|>",
|
| 255 |
+
"pad_token": "<|pad|>",
|
| 256 |
+
"use_default_system_prompt": false
|
| 257 |
+
}
|
tokenizer_wrapper.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import LlamaTokenizerFast
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class LlamaTokenizerWrapper(LlamaTokenizerFast):
|
| 5 |
+
def __init__(self, **kwargs):
|
| 6 |
+
super().__init__(**kwargs)
|
| 7 |
+
|
| 8 |
+
self.im_start = "<|image_start|>"
|
| 9 |
+
self.im_end = "<|image_end|>"
|
| 10 |
+
self.ref_start = "<|ref_start>|"
|
| 11 |
+
self.ref_end = "<|ref_end|>"
|
| 12 |
+
self.box_start = "<|box_start|>"
|
| 13 |
+
self.box_end = "<|box_end|>"
|
| 14 |
+
self.quad_start = "<|quad_start>"
|
| 15 |
+
self.quad_end = "<|quad_end|>"
|
| 16 |
+
self.point_start = "<|point_start|>"
|
| 17 |
+
self.point_end = "<|point_end|>"
|
| 18 |
+
self.slice_start = "<|slice_start|>"
|
| 19 |
+
self.slice_end = "<|slice_end|>"
|
| 20 |
+
self.audio_start = "<|audio_start|>"
|
| 21 |
+
self.audio_end = "<|audio_end|>"
|
| 22 |
+
self.eos_token = "<|turn_end|>"
|
| 23 |
+
self.pad_token = "<|pad|>"
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def eos_id(self):
|
| 27 |
+
return self.eos_token_id
|
| 28 |
+
|
| 29 |
+
@property
|
| 30 |
+
def unk_id(self):
|
| 31 |
+
return self.unk_token_id
|
| 32 |
+
|
| 33 |
+
@property
|
| 34 |
+
def im_start_id(self):
|
| 35 |
+
return self.encode(self.im_start, add_special_tokens=False)[0]
|
| 36 |
+
|
| 37 |
+
@property
|
| 38 |
+
def im_end_id(self):
|
| 39 |
+
return self.encode(self.im_end, add_special_tokens=False)[0]
|
| 40 |
+
|
| 41 |
+
@property
|
| 42 |
+
def slice_start_id(self):
|
| 43 |
+
return self.encode(self.slice_start, add_special_tokens=False)[0]
|
| 44 |
+
|
| 45 |
+
@property
|
| 46 |
+
def slice_end_id(self):
|
| 47 |
+
return self.encode(self.slice_end, add_special_tokens=False)[0]
|
| 48 |
+
|
| 49 |
+
@property
|
| 50 |
+
def audio_start_id(self):
|
| 51 |
+
return self.encode(self.audio_start, add_special_tokens=False)[0]
|
| 52 |
+
|
| 53 |
+
@property
|
| 54 |
+
def audio_end_id(self):
|
| 55 |
+
return self.encode(self.audio_end, add_special_tokens=False)[0]
|
| 56 |
+
|
| 57 |
+
@property
|
| 58 |
+
def eos_token_id(self):
|
| 59 |
+
return self.encode(self.eos_token, add_special_tokens=False)[0]
|
| 60 |
+
|
| 61 |
+
@property
|
| 62 |
+
def pad_token_id(self):
|
| 63 |
+
return self.encode(self.eos_token, add_special_tokens=False)[0]
|