
models batch 1
Browse files- lidm_dynamic/config.json +52 -0
- lidm_dynamic/config.yaml +105 -0
- lidm_dynamic/diffusion_pytorch_model.safetensors +3 -0
- lvdm/config.json +44 -0
- lvdm/config.yaml +121 -0
- lvdm/diffusion_pytorch_model.safetensors +3 -0
- regression_dynamic/best.pt +3 -0
- reidentification_dynamic/config.json +24 -0
- reidentification_dynamic/privacy_results.png +0 -0
- reidentification_dynamic/reidentification_dynamic_best_network.pth +3 -0
- vae/config.json +31 -0
- vae/diffusion_pytorch_model.safetensors +3 -0
lidm_dynamic/config.json
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNet2DModel",
|
| 3 |
+
"_diffusers_version": "0.27.2",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"add_attention": true,
|
| 6 |
+
"attention_head_dim": 8,
|
| 7 |
+
"attn_norm_num_groups": null,
|
| 8 |
+
"block_out_channels": [
|
| 9 |
+
128,
|
| 10 |
+
256,
|
| 11 |
+
256,
|
| 12 |
+
512
|
| 13 |
+
],
|
| 14 |
+
"center_input_sample": false,
|
| 15 |
+
"class_embed_type": null,
|
| 16 |
+
"decay": 0.9999,
|
| 17 |
+
"down_block_types": [
|
| 18 |
+
"AttnDownBlock2D",
|
| 19 |
+
"AttnDownBlock2D",
|
| 20 |
+
"AttnDownBlock2D",
|
| 21 |
+
"DownBlock2D"
|
| 22 |
+
],
|
| 23 |
+
"downsample_padding": 1,
|
| 24 |
+
"downsample_type": "resnet",
|
| 25 |
+
"dropout": 0.0,
|
| 26 |
+
"flip_sin_to_cos": true,
|
| 27 |
+
"freq_shift": 0,
|
| 28 |
+
"in_channels": 4,
|
| 29 |
+
"inv_gamma": 1.0,
|
| 30 |
+
"layers_per_block": 2,
|
| 31 |
+
"mid_block_scale_factor": 1,
|
| 32 |
+
"min_decay": 0.0,
|
| 33 |
+
"norm_eps": 1e-05,
|
| 34 |
+
"norm_num_groups": 32,
|
| 35 |
+
"num_class_embeds": null,
|
| 36 |
+
"num_train_timesteps": null,
|
| 37 |
+
"optimization_step": 100,
|
| 38 |
+
"out_channels": 4,
|
| 39 |
+
"power": 0.6666666666666666,
|
| 40 |
+
"resnet_time_scale_shift": "default",
|
| 41 |
+
"sample_size": 14,
|
| 42 |
+
"time_embedding_type": "positional",
|
| 43 |
+
"up_block_types": [
|
| 44 |
+
"UpBlock2D",
|
| 45 |
+
"AttnUpBlock2D",
|
| 46 |
+
"AttnUpBlock2D",
|
| 47 |
+
"AttnUpBlock2D"
|
| 48 |
+
],
|
| 49 |
+
"update_after_step": 0,
|
| 50 |
+
"upsample_type": "resnet",
|
| 51 |
+
"use_ema_warmup": false
|
| 52 |
+
}
|
lidm_dynamic/config.yaml
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb_group: lidm
|
| 2 |
+
output_dir: experiments/lidm_dynamic
|
| 3 |
+
pretrained_model_name_or_path: null
|
| 4 |
+
vae_path: models/vae
|
| 5 |
+
globals:
|
| 6 |
+
target_fps: 32
|
| 7 |
+
target_nframes: 64
|
| 8 |
+
outputs:
|
| 9 |
+
- image
|
| 10 |
+
datasets:
|
| 11 |
+
- name: Latent
|
| 12 |
+
active: true
|
| 13 |
+
params:
|
| 14 |
+
root: data/latents/dynamic
|
| 15 |
+
target_fps: ${globals.target_fps}
|
| 16 |
+
target_nframes: ${globals.target_nframes}
|
| 17 |
+
target_resolution: 14
|
| 18 |
+
outputs: ${globals.outputs}
|
| 19 |
+
unet:
|
| 20 |
+
_class_name: UNet2DModel
|
| 21 |
+
sample_size: 14
|
| 22 |
+
in_channels: 4
|
| 23 |
+
out_channels: 4
|
| 24 |
+
center_input_sample: false
|
| 25 |
+
time_embedding_type: positional
|
| 26 |
+
freq_shift: 0
|
| 27 |
+
flip_sin_to_cos: true
|
| 28 |
+
down_block_types:
|
| 29 |
+
- AttnDownBlock2D
|
| 30 |
+
- AttnDownBlock2D
|
| 31 |
+
- AttnDownBlock2D
|
| 32 |
+
- DownBlock2D
|
| 33 |
+
up_block_types:
|
| 34 |
+
- UpBlock2D
|
| 35 |
+
- AttnUpBlock2D
|
| 36 |
+
- AttnUpBlock2D
|
| 37 |
+
- AttnUpBlock2D
|
| 38 |
+
block_out_channels:
|
| 39 |
+
- 128
|
| 40 |
+
- 256
|
| 41 |
+
- 256
|
| 42 |
+
- 512
|
| 43 |
+
layers_per_block: 2
|
| 44 |
+
mid_block_scale_factor: 1
|
| 45 |
+
downsample_padding: 1
|
| 46 |
+
downsample_type: resnet
|
| 47 |
+
upsample_type: resnet
|
| 48 |
+
dropout: 0.0
|
| 49 |
+
act_fn: silu
|
| 50 |
+
attention_head_dim: 8
|
| 51 |
+
norm_num_groups: 32
|
| 52 |
+
attn_norm_num_groups: null
|
| 53 |
+
norm_eps: 1.0e-05
|
| 54 |
+
resnet_time_scale_shift: default
|
| 55 |
+
class_embed_type: null
|
| 56 |
+
num_class_embeds: null
|
| 57 |
+
noise_scheduler:
|
| 58 |
+
_class_name: DDPMScheduler
|
| 59 |
+
num_train_timesteps: 1000
|
| 60 |
+
beta_start: 0.0001
|
| 61 |
+
beta_end: 0.02
|
| 62 |
+
beta_schedule: linear
|
| 63 |
+
variance_type: fixed_small
|
| 64 |
+
clip_sample: true
|
| 65 |
+
clip_sample_range: 4.0
|
| 66 |
+
prediction_type: v_prediction
|
| 67 |
+
thresholding: false
|
| 68 |
+
dynamic_thresholding_ratio: 0.995
|
| 69 |
+
sample_max_value: 1.0
|
| 70 |
+
timestep_spacing: leading
|
| 71 |
+
steps_offset: 0
|
| 72 |
+
train_batch_size: 256
|
| 73 |
+
dataloader_num_workers: 16
|
| 74 |
+
max_train_steps: 500000
|
| 75 |
+
learning_rate: 0.0003
|
| 76 |
+
lr_warmup_steps: 500
|
| 77 |
+
scale_lr: false
|
| 78 |
+
lr_scheduler: constant
|
| 79 |
+
use_8bit_adam: false
|
| 80 |
+
gradient_accumulation_steps: 1
|
| 81 |
+
noise_offset: 0.0
|
| 82 |
+
gradient_checkpointing: false
|
| 83 |
+
use_ema: true
|
| 84 |
+
enable_xformers_memory_efficient_attention: false
|
| 85 |
+
allow_tf32: true
|
| 86 |
+
adam_beta1: 0.9
|
| 87 |
+
adam_beta2: 0.999
|
| 88 |
+
adam_weight_decay: 0.01
|
| 89 |
+
adam_epsilon: 1.0e-08
|
| 90 |
+
max_grad_norm: 1.0
|
| 91 |
+
logging_dir: logs
|
| 92 |
+
mixed_precision: fp16
|
| 93 |
+
validation_timesteps: 128
|
| 94 |
+
validation_fps: ${globals.target_fps}
|
| 95 |
+
validation_frames: ${globals.target_nframes}
|
| 96 |
+
validation_count: 4
|
| 97 |
+
validation_guidance: 1.0
|
| 98 |
+
validation_steps: 2500
|
| 99 |
+
report_to: wandb
|
| 100 |
+
checkpointing_steps: 100
|
| 101 |
+
checkpoints_total_limit: 100
|
| 102 |
+
resume_from_checkpoint: null
|
| 103 |
+
tracker_project_name: echosyn
|
| 104 |
+
seed: 42
|
| 105 |
+
num_train_epochs: 250000
|
lidm_dynamic/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6c337bfad7278d2507f10c9bb3d61055ed15032f87d4cb9951abfae8ed3fa87e
|
| 3 |
+
size 294245640
|
lvdm/config.json
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "UNetSpatioTemporalConditionModel",
|
| 3 |
+
"_diffusers_version": "0.27.2",
|
| 4 |
+
"addition_time_embed_dim": 1,
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
256,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"cross_attention_dim": 1,
|
| 12 |
+
"decay": 0.9999,
|
| 13 |
+
"down_block_types": [
|
| 14 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 15 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 16 |
+
"CrossAttnDownBlockSpatioTemporal",
|
| 17 |
+
"DownBlockSpatioTemporal"
|
| 18 |
+
],
|
| 19 |
+
"in_channels": 8,
|
| 20 |
+
"inv_gamma": 1.0,
|
| 21 |
+
"layers_per_block": 2,
|
| 22 |
+
"min_decay": 0.0,
|
| 23 |
+
"num_attention_heads": [
|
| 24 |
+
8,
|
| 25 |
+
16,
|
| 26 |
+
16,
|
| 27 |
+
32
|
| 28 |
+
],
|
| 29 |
+
"num_frames": 64,
|
| 30 |
+
"optimization_step": 60000,
|
| 31 |
+
"out_channels": 4,
|
| 32 |
+
"power": 0.6666666666666666,
|
| 33 |
+
"projection_class_embeddings_input_dim": 1,
|
| 34 |
+
"sample_size": 14,
|
| 35 |
+
"transformer_layers_per_block": 1,
|
| 36 |
+
"up_block_types": [
|
| 37 |
+
"UpBlockSpatioTemporal",
|
| 38 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 39 |
+
"CrossAttnUpBlockSpatioTemporal",
|
| 40 |
+
"CrossAttnUpBlockSpatioTemporal"
|
| 41 |
+
],
|
| 42 |
+
"update_after_step": 0,
|
| 43 |
+
"use_ema_warmup": false
|
| 44 |
+
}
|
lvdm/config.yaml
ADDED
|
@@ -0,0 +1,121 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb_group: lvdm
|
| 2 |
+
output_dir: experiments/lvdm
|
| 3 |
+
pretrained_model_name_or_path: null
|
| 4 |
+
vae_path: models/vae
|
| 5 |
+
globals:
|
| 6 |
+
target_fps: 32
|
| 7 |
+
target_nframes: 64
|
| 8 |
+
outputs:
|
| 9 |
+
- video
|
| 10 |
+
- lvef
|
| 11 |
+
- image
|
| 12 |
+
datasets:
|
| 13 |
+
- name: Latent
|
| 14 |
+
active: true
|
| 15 |
+
params:
|
| 16 |
+
root: data/latents/dynamic
|
| 17 |
+
target_fps: ${globals.target_fps}
|
| 18 |
+
target_nframes: ${globals.target_nframes}
|
| 19 |
+
target_resolution: 14
|
| 20 |
+
outputs: ${globals.outputs}
|
| 21 |
+
- name: Latent
|
| 22 |
+
active: true
|
| 23 |
+
params:
|
| 24 |
+
root: data/latents/ped_a4c
|
| 25 |
+
target_fps: ${globals.target_fps}
|
| 26 |
+
target_nframes: ${globals.target_nframes}
|
| 27 |
+
target_resolution: 14
|
| 28 |
+
outputs: ${globals.outputs}
|
| 29 |
+
- name: Latent
|
| 30 |
+
active: true
|
| 31 |
+
params:
|
| 32 |
+
root: data/latents/ped_psax
|
| 33 |
+
target_fps: ${globals.target_fps}
|
| 34 |
+
target_nframes: ${globals.target_nframes}
|
| 35 |
+
target_resolution: 14
|
| 36 |
+
outputs: ${globals.outputs}
|
| 37 |
+
unet:
|
| 38 |
+
_class_name: UNetSpatioTemporalConditionModel
|
| 39 |
+
addition_time_embed_dim: 1
|
| 40 |
+
block_out_channels:
|
| 41 |
+
- 128
|
| 42 |
+
- 256
|
| 43 |
+
- 256
|
| 44 |
+
- 512
|
| 45 |
+
cross_attention_dim: 1
|
| 46 |
+
down_block_types:
|
| 47 |
+
- CrossAttnDownBlockSpatioTemporal
|
| 48 |
+
- CrossAttnDownBlockSpatioTemporal
|
| 49 |
+
- CrossAttnDownBlockSpatioTemporal
|
| 50 |
+
- DownBlockSpatioTemporal
|
| 51 |
+
in_channels: 8
|
| 52 |
+
layers_per_block: 2
|
| 53 |
+
num_attention_heads:
|
| 54 |
+
- 8
|
| 55 |
+
- 16
|
| 56 |
+
- 16
|
| 57 |
+
- 32
|
| 58 |
+
num_frames: ${globals.target_nframes}
|
| 59 |
+
out_channels: 4
|
| 60 |
+
projection_class_embeddings_input_dim: 1
|
| 61 |
+
sample_size: 14
|
| 62 |
+
transformer_layers_per_block: 1
|
| 63 |
+
up_block_types:
|
| 64 |
+
- UpBlockSpatioTemporal
|
| 65 |
+
- CrossAttnUpBlockSpatioTemporal
|
| 66 |
+
- CrossAttnUpBlockSpatioTemporal
|
| 67 |
+
- CrossAttnUpBlockSpatioTemporal
|
| 68 |
+
noise_scheduler:
|
| 69 |
+
_class_name: DDPMScheduler
|
| 70 |
+
num_train_timesteps: 1000
|
| 71 |
+
beta_start: 0.0001
|
| 72 |
+
beta_end: 0.02
|
| 73 |
+
beta_schedule: linear
|
| 74 |
+
variance_type: fixed_small
|
| 75 |
+
clip_sample: true
|
| 76 |
+
clip_sample_range: 4.0
|
| 77 |
+
prediction_type: v_prediction
|
| 78 |
+
thresholding: false
|
| 79 |
+
dynamic_thresholding_ratio: 0.995
|
| 80 |
+
sample_max_value: 1.0
|
| 81 |
+
timestep_spacing: leading
|
| 82 |
+
steps_offset: 0
|
| 83 |
+
train_batch_size: 16
|
| 84 |
+
dataloader_num_workers: 16
|
| 85 |
+
max_train_steps: 500000
|
| 86 |
+
learning_rate: 0.0001
|
| 87 |
+
lr_warmup_steps: 500
|
| 88 |
+
scale_lr: false
|
| 89 |
+
lr_scheduler: constant
|
| 90 |
+
use_8bit_adam: false
|
| 91 |
+
gradient_accumulation_steps: 1
|
| 92 |
+
noise_offset: 0.1
|
| 93 |
+
drop_conditionning: 0.1
|
| 94 |
+
gradient_checkpointing: false
|
| 95 |
+
use_ema: true
|
| 96 |
+
enable_xformers_memory_efficient_attention: false
|
| 97 |
+
allow_tf32: true
|
| 98 |
+
adam_beta1: 0.9
|
| 99 |
+
adam_beta2: 0.999
|
| 100 |
+
adam_weight_decay: 0.01
|
| 101 |
+
adam_epsilon: 1.0e-08
|
| 102 |
+
max_grad_norm: 1.0
|
| 103 |
+
logging_dir: logs
|
| 104 |
+
mixed_precision: fp16
|
| 105 |
+
validation_timesteps: 128
|
| 106 |
+
validation_fps: ${globals.target_fps}
|
| 107 |
+
validation_frames: ${globals.target_nframes}
|
| 108 |
+
validation_lvefs:
|
| 109 |
+
- 0.0
|
| 110 |
+
- 0.4
|
| 111 |
+
- 0.7
|
| 112 |
+
- 1.0
|
| 113 |
+
validation_guidance: 1.0
|
| 114 |
+
validation_steps: 1500
|
| 115 |
+
report_to: wandb
|
| 116 |
+
checkpointing_steps: 10000
|
| 117 |
+
checkpoints_total_limit: 100
|
| 118 |
+
resume_from_checkpoint: null
|
| 119 |
+
tracker_project_name: echosyn
|
| 120 |
+
seed: 42
|
| 121 |
+
num_train_epochs: 893
|
lvdm/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:db1526dbff74ea98cdac06ba63c1d18294d34775d87511d5323ce6e4cc7c1bf4
|
| 3 |
+
size 575506960
|
regression_dynamic/best.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5cb136834dde9cac1bdbc7904c49572c0d2df356e20750205bb7225b6fcfb271
|
| 3 |
+
size 250601638
|
reidentification_dynamic/config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"experiment_description": "reidentification_dynamic",
|
| 3 |
+
"resumption": false,
|
| 4 |
+
"resumption_count": null,
|
| 5 |
+
"previous_experiment": null,
|
| 6 |
+
"image_path": "data/latents/dynamic/FileList.csv",
|
| 7 |
+
"siamese_architecture": "ResNet-50",
|
| 8 |
+
"data_handling": "balanced",
|
| 9 |
+
"num_workers": 16,
|
| 10 |
+
"pin_memory": true,
|
| 11 |
+
"n_channels": 4,
|
| 12 |
+
"n_features": 128,
|
| 13 |
+
"image_size": 14,
|
| 14 |
+
"loss": "BCEWithLogitsLoss",
|
| 15 |
+
"optimizer": "Adam",
|
| 16 |
+
"learning_rate": 0.0001,
|
| 17 |
+
"batch_size": 128,
|
| 18 |
+
"max_epochs": 1000,
|
| 19 |
+
"early_stopping": 50,
|
| 20 |
+
"transform": "pmone",
|
| 21 |
+
"n_samples_train": 7465,
|
| 22 |
+
"n_samples_val": 1288,
|
| 23 |
+
"n_samples_test": 1277
|
| 24 |
+
}
|
reidentification_dynamic/privacy_results.png
ADDED
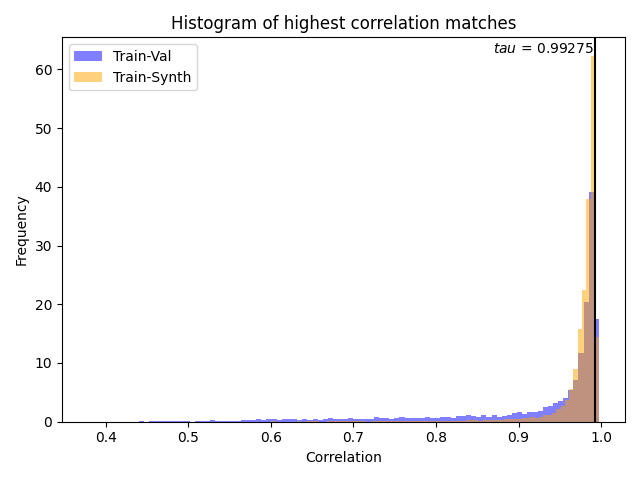
|
reidentification_dynamic/reidentification_dynamic_best_network.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0f462dc5b237d1b2f5a42c35297c6d72b77d07ac3a12b44b1058a204cf95cacb
|
| 3 |
+
size 95425186
|
vae/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.23.1",
|
| 4 |
+
"act_fn": "silu",
|
| 5 |
+
"block_out_channels": [
|
| 6 |
+
128,
|
| 7 |
+
256,
|
| 8 |
+
256,
|
| 9 |
+
512
|
| 10 |
+
],
|
| 11 |
+
"down_block_types": [
|
| 12 |
+
"DownEncoderBlock2D",
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D"
|
| 16 |
+
],
|
| 17 |
+
"force_upcast": true,
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 512,
|
| 24 |
+
"scaling_factor": 0.18215,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
]
|
| 31 |
+
}
|
vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ba0be1555511d1e145bfda156062aab744c6f7fc12e930c78c3640baf8183d5b
|
| 3 |
+
size 249675844
|